Slides
advertisement

StreamX10: A Stream
Programming Framework on X10
Haitao Wei
2012-06-14
School of Computer Science at Huazhong University of Sci&Tech
Outline
1
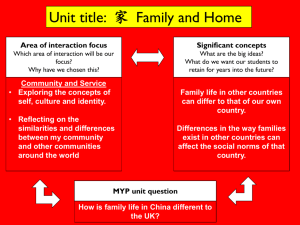
Introduction and Background
2
COStream Programming Language
3
Stream Compilation on X10
4
Experiments
5
Conclusion and Future Work
2
Background and motivition
Stream Programming
A high level programming model that has been
productively applied
Usually, depends on the specific architectures which
makes it difficult to port between different platforms
X10
a productive parallel programming environment
isolates the different architecture details
provides a flexible parallel programming abstract layer
for stream programming
StreamX10:try to make the stream program
portable based on X10
Outline
1
Introduction and Background
2
COStream Programming Language
3
Stream Compilation on X10
4
Experiments
5
Conclusion and Future Work
4
COStream Language
stream
FIFO queue connecting operators
operator
Basic func unit—actor node in stream graph
Multiple inputs and multiple outputs
Window
– like pop,peek,push operations
Init and work function
composite
Connected operators—subgraph of actors
A stream program is composed of
composites
COStream and Stream Graph
Composite Main{
Composite MyOp(output Out ; input In){
graph
stream<int i> S = Source(){
state :{ int x;}
param
stream
attribute:pn
graph
init :{x=0;}
work :{
S[0].i = x;
stream<int j> Out = Averager(In){
operator
work :{
int sum=0,i;
x++;
}
window S:tumbling,count(1);
for(i=0;i<pn;i++)
composite
sum += In[i],j;
Out[0].j = (sum/pn);
}
}
streamit<int j> P = MyOp(S){
window In: sliding,count(10),count(1);
param
Out:tumbling,count(1);
pn:N
}
() as SinkOp = Sink(P){
}
}
state :{int r;}
S
work :{
r = P[0].j;
println(r);
}
window P:tumbling,count(1);
}
}
Source
push=1
peek=10
pop=1
P
Averager
pop=1
Sink
push=1
6
Outline
1
Introduction and Background
2
COStream Programming Language
3
Stream Compilation on X10
4
Experiments
5
Conclusion and Future Work
7
Compilation flow of StreamX10
Phrase
Function
Translates the COStream syntax into abstract syntax tree.
Front-end
Instantiation
Instantiates the composites hierarchically to static flattened
operators.
Constructs static stream graph from flattened operators.
Static Stream Graph
Scheduling
Calculates initialization and steady-state execution orderings of
operators.
Partitioning
Performs partitioning based on X10 parallelism models for load
balance.
Generates X10 code for COStream programs.
Code Generation
The Execution Framework
activity
activity
activity
threads
pool
Place 0
Place 1
Local buffer object
Data flow intra place
Place 2
Global buffer object
Data flow inter place
The node is partitioned between the places
Each node is mapped to an activity
The nodes use the pipeline fashion to exploit the parallelisms
The local and Global FIFO buffer are used
9
Work Partition Inter-place
10
Comp. work=10
1
2
5
Comp. work=10
5
5
2
2
5
5
2
5
Comp. work=10
2
1
10
Speedup:30/10 =3
Communication:2
Objective:Minimized Communication and Load Balance (Using Metis)
10
Global FIFO implementation
push
peek/pop
0
Producer
1 …
copy
n
0
0
1 …
n
1 …
n
copy
Place0
Consumer
Place1
Local Array
DistArray
Each Producer/Consumer has its own local buffer
the producer uses push operation to store the data to the local buffer
The consumer uses peek/pop operation to fetch data from the local
buffer
When the local buffer is full/empty is data will be copied automatically
11
X10 code in the Back-end
//main.x10 control code
public static def main( ) {
...
finish for (p in Place.places())
async at (p) {
switch(p.id){
case 0:
val a_0 = new Source_0(rc);
a_0.run();
break;
case 1:
val a_2 = new MovingAver_2(rc);
a_2.run();
break;
case 2:
val a_1 = new Sink_1(rc);
a_1.run();
break;
default: break;
}
}
…
}
//Source.x10 code
...
def work(){
...
push_Source_0_Sink_1(0).x=x;
x+=1.0;
Define the work function
pushTokens();
popTokens();
}
public def run(){
initWork();//init
Call the work function in
//initSchedule
initial and steady schedule
for(var j:Int=0;j<Source_0_init;j++)
work();
//steadySchedule
for(var i:Int=0;i<RepeatCount;i++)
for(var j:Int=0;j<Source_0_steady;j++)
work();
flush();
}
...
Spawn activities for each node at
place according to the partition
12
Outline
1
Introduction and Background
2
COStream Programming Language
3
Stream Compilation on X10
4
Experiments
5
Conclusion and Future Work
13
Experimental Platform and Benchmarks
Platform
Intel Xeon processor (8 cores ) 2.4 GHZ with 4GB memory
Radhat EL5 with Linux 2.6.18
X10 compiler and runtime used are 2.2.0
Benchmarks
Rewrite 11 benchmarks from StreamIt
14
The throughputs comparison
Throughputs of 4 different configurations (NPLACE*NTHREAD=8)
Normalized to 1 place with 8 threads
10
9
Throughput normalized to 1 place with 8 threads
8
7
• for most benchmarks, CPU utilization increases from 24%
to NTHREADS=8
NPLACES=1,
NPLACES=2, NTHREADS=4
89% ,when places varies from 1 to 4, except for the benchmark
NPLACES=4, NTHREADS=2
with low computation/communication ratio
NPLACES=8, NTHREADS=1
• benefits are little or worse when the number of places increases
from 4 to 8
6
5
4
3
2
1
0
15
Observation and Analysis
The throughput goes up when the number of
places increases. This is because that multiple
places increase the CPU utilization
Multiple places show parallelism but also bring
more communication overhead
Benchmarks with more computation workload like
DES and Serpent_full can still benefit form the
number of places increasing
16
Outline
1
Introduction and Background
2
COStream Programming Language
3
Stream Compilation on X10
4
Experiments
5
Conclusion and Future Work
17
Conclusion
We proposed and implemented StreamX10, a
stream programming language and compilation
system on X10
A raw partitioning optimization is proposed to
exploit the parallelisms based on X10 execution
model
Preliminary experiment is conducted to study the
performance
18
Future Work
How to choose the best configuration (# of places
and # of threads) automatically for each benchmark
How to decrease the thread switching overhead by
mapping multiple nodes to the single activity
19
Acknowledgment
X10 Innovation Award founding support
QiMing Teng, Haibo Lin and David P. Grove
at IBM for their help on this research
20