Reading 4.9 just p. 384-386 (stop at pipelined implementation)
MC - Not in the textbook – we’ll get into some
detail in lecture and suggested hw problems
Multi-cycle CPU
Breaking up is hard to do….
Peer Instruction Lecture Materials for Computer Architecture by Dr. Leo Porter is
licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0
Unported License.
Single-Cycle CPU Summary
• Easy, particularly the control
• Which instruction takes the longest? By how much? Why
is that a problem?
• ET = IC * CPI * CT
• What else can we do?
• When does a multi-cycle implementation make sense?
– e.g., 70% of instructions take 75 ns, 30% take 200 ns?
– suppose 20% overhead for extra latches
• Real machines have much more variable instruction
latencies than this.
200 vs. (200*.3+75*.7)*1.2
(60+50)*1.2 ~ 135
You’ve been walking through history
• Someone needed to run a program
You’ve been walking through history
• Someone needed to run a program
• Simple instructions were designed for very simple
hardware (limited transistors)
You’ve been walking through history
• Someone needed to run a program
• Simple instructions were designed for very simple
•
hardware (limited transistors)
Someone wants to run a new program, but not create all
new hardware
You’ve been walking through history
• Someone needed to run a program
• Simple instructions were designed for very simple
•
•
hardware (limited transistors)
Someone wants to run a new program, but not create all
new hardware
More instructions added
LAB!
You’ve been walking through history
• Someone needed to run a program
• Simple instructions were designed for very simple
•
•
•
•
hardware (limited transistors)
Someone wants to run a new program, but not create all
new hardware
More instructions added
More transistors enable more complex hardware
More complex instructions are desired as instruction
memory is limited and costly
The story continues..
Why a Multiple Clock Cycle CPU?
• the problem => single-cycle cpu has a cycle time long
•
•
enough to complete the longest instruction in the machine
the solution => break up execution into smaller tasks, each
task taking a cycle, different instructions requiring
different numbers of cycles or tasks
other advantages => reuse of functional units (e.g., alu,
memory)
• ET = IC * CPI * CT
Breaking Execution Into Clock Cycles
• We will have five execution steps (not all instructions use
all five)
–
–
–
–
–
fetch
decode & register fetch
execute
memory access
write-back
Single Cycle vs. Multi-cycle
CPI
Single Cycle
Multi-cycle
lw
sw
add
r-type
Draw stages and how they get cutup
CT
Cutting up Single Cycle
Draw how we’d most logically cut this up
Then point out wait – if I cut the cycle time, how do I keep
What I’ve done?
Breaking Execution Into Clock Cycles
• Introduces extra registers when:
– signal is computed in one clock cycle and used in another, AND
– the inputs to the functional block that outputs this signal can
change before the signal is written into a state element.
• Significantly complicates control. Why?
• The goal is to balance the amount of work done each cycle.
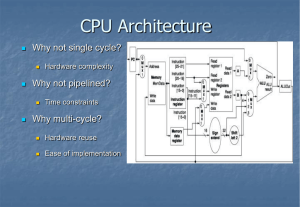
Multicycle datapath
Intermediate latches.
One ALU
One memory (give hint about self-modifying code)
Load word, write RTL below
Multicycle datapath –per
Load
word
cycle
Talk through each – esp. the early branch computation
Summary of execution steps
•We can use Register-Transfer-Language (RTL) to describe these steps
Step
Instruction Fetch
Instruction Decode/
register fetch
Execution, address
computation, branch
completion
Memory access or Rtype completion
Write-back
R-type
Memory
Branch
IR = Mem[PC]
PC = PC + 4
A = Reg[IR[25-21]]
B = Reg[IR[20-16]]
ALUout = PC + (sign-extend(IR[15-0]) << 2)
ALUout = A op B
ALUout = A + if (A==B) then
signPC=ALUout
extend(IR[15-0])
Reg[IR[15-11]] =
memory-data =
ALUout
Mem[ALUout]
or
Mem[ALUout]=
B
Reg[IR[20-16]] =
memory-data
Step
Instruction Fetch
Instruction Decode/
register fetch
Execution, address
computation, branch
completion
Memory access or Rtype completion
Write-back
Selection
R-type
Memory
Branch
IR = Mem[PC]
PC = PC + 4
A = Reg[IR[25-21]]
B = Reg[IR[20-16]]
ALUout = PC + (sign-extend(IR[15-0]) << 2)
ALUout = A op B
ALUout = A + if (A==B) then
signPC=ALUout
extend(IR[15-0])
Reg[IR[15-11]] =
memory-data =
ALUout
Mem[ALUout]
or
Mem[ALUout]=
B
Reg[IR[20-16]] =
memory-data
Peer instruction
Why are the first
Two the same?
Why are the first two stages always the same (best answer)?
A
All instructions do the same thing at the start
B
The instruction is not determined until after the 2nd cycle
C
To decrease the complexity of the control logic
D
Trick question – they aren’t always the same
E
None of the above
Complete Multicycle Datapath
(don’t be intimidated – it all makes sense…)
Complete Multicycle Datapath
R-type – 1st cycle
Draw active path
Complete Multicycle Datapath
R-type – 2nd cycle
Complete Multicycle Datapath
R-type –3rd cycle
Complete Multicycle Datapath
R-type – 4th cycle
Which inst.
does PCWrite
stuck at 1 break?
A. Lw
B. R-type
C. Beq
D. Both A & B
E. A,B,&C
Multicycle Control
• Single-cycle control used combinational logic
• Multi-cycle control uses a Finite State Machine.
• FSM defines a succession of states, transitions between
•
states (based on inputs), and outputs (based on state)
First two states same for every instruction, next state
depends on opcode
Breaking a single cycle processor into stages, hardware
engineers determine these to be the execution time
per stage. The code below is the most commonly
executed code by the company.
Loop: lw r1, 0 (r2)
Isomorphic
add r2, r3, r4
sub r5, r1, r2
beq r5, $zero
IF = 200ps
ID = 50ps
EX = 100ps
M = 200ps
WB = 50ps
Your boss is interested in changing to the MIPS multi-cycle processor. He asks
you whether or not this would be a good idea. You say?
Selection
Good idea?
Reason
A
Yes
CPI stays the same. CT decreases (factor of 4)
B
Yes
CPI increases (factor of 4). CT decreases (factor of 5)
C
No
CPI increases (factor of 4). CT decreases (factor of 3)
D
No
CPI decreases (factor of 5 ). CT increases (factor of 5)
E
No
CPI stays the same. CT stays the same. Complexity increases.
Breaking a single cycle processor into stages, hardware
engineers determine these to be the execution time
per stage. The code below is the most commonly
executed code by the company.
Loop: lw r1, 0 (r2)
add r2, r3, r4
sub r5, r1, r2
beq r5, $zero
IF = 200ps
ID = 200ps
EX = 200ps
M = 200ps
WB = 200ps
Your boss is interested in changing to the MIPS multi-cycle processor. He asks
you whether or not this would be a good idea. You say?
Selection
Good idea?
Reason
A
Yes
CPI stays the same. CT decreases (factor of 4)
B
Yes
CPI increases (factor of 4). CT decreases (factor of 5)
C
No
CPI increases (factor of 4). CT decreases (factor of 3)
D
No
CPI decreases (factor of 5 ). CT increases (factor of 5)
E
No
CPI stays the same. CT stays the same. Complexity increases.
Balanced cycles explanation
Draw single-cycle wasted time
Draw multi-cycle potential wasted
time (200,50,100,200,50)
Multi-cycle Questions
• How many cycles will it take to execute this code?
lw $t2, 0($t3)
lw $t3, 4($t3)
beq $t2, $t3, Label #assume not taken
add $t5, $t2, $t3
sw $t5, 8($t3)
Selection
Number of
Label:
...
Cycles
A
5
B
21
C
22
D
25
E
None of the above
Multi-cycle Questions
• What is going on in cycle 8?
lw $t2, 0($t3)
lw $t3, 4($t3)
beq $t2, $t3, Label
add $t5, $t2, $t3
sw $t5, 8($t3)
Label:
...
#assume not taken
Selection
Number of Cycles
A
PC=PC+4; IR=M[pc]
B
A=R[t3]; B=R[t3]
C
ALUOut=R[t3]+4
D
R[t3]=M[ALUOut]
E
None of the above
Suppose you work on an embedded multi-cycle MIPS processor and
your software team tells you that every program which executes has
to go through memory and zero 1k bytes of data fairly often
(averages 10% of ET). You realize you could just have a single
instruction do this called zero1k (rs) which does:
Remember to ask about
M[rs] = 0 … M[rs+1020] = 0.
single-cycle
Your coworker thinks you are crazy. You reply? Answer - D
Selection Crazy?
Reason
A
Yes
The complexity of such an instruction combined with no
performance gain is silly.
B
Yes
The complexity of such an instruction combined with minimal
performance gain (<5%) is silly.
C
No
The minimal performance gains (<5%) rationalize this simple
instruction.
D
No
The significant performance gains (>5%) rationalize this
complex instruction.
E
Maybe None of the above.
Show code, then cycle
analysis.
Finite State Machine for Control
• Implementation:
• ROM = "Read Only Memory"
ROM Implementation
– values of memory locations are fixed ahead of time
• A ROM can be used to implement a truth table
– if the address is m-bits, we can address 2m entries in the ROM.
– our outputs are the bits of data that the address points to.
m
n
2m is the "height", and n is the "width"
0
1
0
0
0
0
0
0
1
0
1
0
0
1
0
0
1
0
1
0
0
0
0
1
0 0 0
1 1 1
0 1 1
1 1 0
0 0 0
1 0 0
ROM Implementation
• How many inputs are there?
•
6 bits for opcode, 4 bits for state = 10 address lines
(i.e., 210 = 1024 different addresses)
How many outputs are there?
16 datapath-control outputs, 4 state bits = 20 outputs
• ROM is 210 x 20 = 20K bits (and a rather unusual size)
• Rather wasteful, since for lots of the entries, the outputs
are the same
— i.e., opcode is often ignored
Multicycle CPU Key Points
• Performance gain achieved from variable-length
•
•
•
•
instructions
ET = IC * CPI * cycle time
Required very few new state elements
More, and more complex, control signals
Control requires FSM
 0
0