Document

Before we start ADALINE
Test the response of your Hebb and Perceptron on this following noisy version
Exercise pp98 2.6(d)
ADALINE
ADAPTIVE LINEAR NEURON
Typically uses bipolar (1, -1) activations for its input signal and its target output
The weights are adjustable, has bias whose activation is always 1
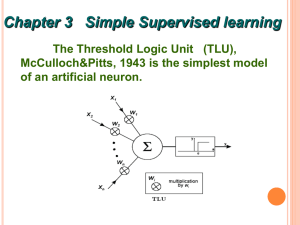
Input Unit
Output Unit
1 b
:
X
1 w
1 w
2
Y
X n
Architecture of an ADALINE
ADALINE
In general ADALINE can be trained using the delta rule also known as least mean squares ( LMS ) or Widrow-Hoff rule
The delta rule can also be used for single layer nets with several output units
ADALINE – a special one - only one output unit
ADALINE
Activation of the unit
Is the net input with identity function
The learning rule minimizes the mean squares error between the activation and the target value
Allows the net to continue learning on all training patterns, even after the correct output value is generated
ADALINE
After training, if the net is being used for pattern classification in which the desired output is either a +1 or a -1, a threshold function is applied to the net input to obtain the activation
If net_input ≥ 0 then activation = 1
Else activation = -1
Step 0:
Step 1:
The Algorithm
Initialize all weights and bias:
(small random values are usually used0
Set learning rate (0 < ≤ 1)
= 0
While stopping condition is false, do steps 2-6.
Step2:For each bipolar training pair s:t, do steps 3-5
Step 3. Set activations for input units:
i = 1, …, n: x i
= s i
Step 4.Compute net input to output unit:
NET = y_in = b + x i w i
;
Step 5.
Step 6.
The Algorithm
Update weights and bias i = 1, …, n else w i
(new) = w i
(old) + b(new) = b(old) +
(t
(t – y_in)x
– y_in) i w i
(new) = w i
(old) b(new) = b(old)
Test stopping condition:
If the largest weight change that occurred in Step
2 is smaller than a specified tolerance, then stop; otherwise continue.
Setting the learning rate
Common to take a small value for = 0.1 initially
If too large, the learning process will not converge
If too small learning will be extremely slow
For single neuron, a practical range is
0.1 ≤ n ≤ 1.0
Application
After training, an ADALINE unit can be used to classify input patterns. If the target values are bivalent (binary or bipolar), a step function can be applied as activation function for the output unit
Step 0:
Step 1:
Initialize all weights
For each bipolar input vector x, do steps 2-4
Step 2. Set activations for input units to x
Step 3. Compute net input to output unit: net = y_in = b + x i w i
;
Step 4. Apply the activation function
f(y_in)
1
-1 if y_in ≥ 0; if y_in < 0.
Example 1
ADALINE for AND function: binary input, bipolar targets
(x1 x2 t)
(1 1 1)
(1 0 -1)
(0 1 -1)
(0 0 -1)
Delta rule in ADALINE is designed to find weights that minimize the total error
Associated target for pattern p
4
E = (x
1 p=1
(p) w
1
+ x
2
(p)w
2
+ w
0
– t(p)) 2
Net input to the output unit for pattern p
Example 1
ADALINE for AND function: binary input, bipolar targets
Delta rule in ADALINE is designed to find weights that minimize the total error
Weights that minimize this error are w
1
= 1, w
2
= 1, w
0
= -3/2
Separating lines x
1
+ x
2
– 3/2 = 0
Example 2
ADALINE for AND function: bipolar input, bipolar targets
(x1 x2 t)
(1 1 1)
(1 -1 -1)
(-1 1 -1)
(-1 -1 -1)
Delta rule in ADALINE is designed to find weights that minimize the total error
Associated target for pattern p
4
E = (x
1 p=1
(p) w
1
+ x
2
(p)w
2
+ w
0
– t(p)) 2
Net input to the output unit for pattern p
Example 2
ADALINE for AND function: bipolar input, bipolar targets
Weights that minimize this error are w
1
1/2
= 1/2, w
2
= 1/2, w
0
= -
Separating lines 1/2x
1
+1/2 x
2
– 1/2 = 0
Example
Example 3: ADALINE for AND NOT function: bipolar input, bipolar targets
Example 4: ADALINE for OR function: bipolar input, bipolar targets
Derivations
Delta rule for single output unit
The delta rule changes the weights of the connections to minimize the difference between input and output unit
By reducing the error for each pattern one at a time
The delta rule for Ith weight(for each pattern) is
w
I
= (t – y_in)x
I
Derivations
The squared error for a particular training pattern is
E = (t – y_in) 2 .
E : function of all weights w i
, I = 1, …, n
The gradient of E is the vector consisting of the partial derivatives of E with respect to each of the weights
The gradient gives the direction of most rapid increase in E
Opposite direction gives the most rapid decrease in the error
The error can be reduced by adjusting the weight w
I direction of -
E
w
I in the
Derivations
Since y_in = x i w i
,
E
w
I
= -2(t – y_in) y_in
w
I
= -2(t – y_in)x
I
The local error will be reduced most rapidly by adjusting the weights according to the delta rule
w
I
= (t – y_in)x
I
Derivations
Delta rule for multiple output unit
The delta rule for Ith weight(for each pattern) is
w
IJ
= (t – y_in
J
)x
I
Derivations
The squared error for a particular training pattern is
E = m j=1
(t j
– y_in j
) 2 .
E : function of all weights w i
, I = 1, …, n
The error can be reduced by adjusting the weight w the direction of
I
E
w
IJ
=
w
I m
j=1
(t j
– y_in j
) 2 in
=
w
I
(t
J
– y_in
J
) 2
Continued pp 88
Exercise
http://www.neural-networks-at-yourfingertips.com/adaline.html
Adaline Network Simulator
MADALINE
MANY ADAPTIVE LINEAR NEURON
1
1 b
1 X
1 b
3
Z
1 w
11 w
12 w
21 w
22
Z
2 v
1 v
2 b
2 X
2
Y
Architecture of an MADALINE with two hidden ADALINES and one output ADALINE
1
MADALINE
Derivation of delta rule for several outputs shows no change in the training process with several combination of ADALINEs
The outputs of two hidden ADALINES, z
1 determined by signal from input units X
1 and z
2 and X
2 are
Each output signal is the result of applying a threshold function to the unit’s net input
y is the non-linear function of the input vector (x
1
, x
2
)
MADALINE
Why we need hidden units???
The use of hidden units Z1 and Z2 give the net
Computational capabilities not found in single layer nets
But…complicate the training process
Two algorithms
MRI – only weights for hidden ADALINES are adjusted, the weights for output unit are fixed
MRII – provides methods for adjusting all weights in the net
ALGORITHM: MRI
1
X
1
X
2 w
11 w
12 w
21 w
22 b
1
Z
1 b
2
Z
2
1
1 v
1 b
3 v
2
Y
The weights v1 and v2 and bias b3 that feed into the output unit Y are determined so that the response of unit Y is 1 if the signal it receives from either Z1 or Z2 (or both) is 1 and is -1 if both Z1 and Z2 send a signal of -1. The unit Y performs the logic function OR on the signals it receives from Z1 and Z2
Set v
1
= ½, v
2
= ½ and b
3
= ½ see example 2.19 the OR function
1
X
X
2 w
11
2 w
1 w
21 w
22
ALGORITHM:
MRI
1 b
1
Z
1
1 v
1 b
3 v
2
Y x1 x2 t
1 1 -1
1 -1 1
-1 1 1
-1 -1 -1
Set = 0.5
Weights into
Z
1 w
11 w
21 b
1
.05 .2 .3
Z
2
1 b
2
Z
2 w
12 w
22 b
2 v
1
Y v
2 b
.1 .2 .15 .5 .5 .5
3
Set v
1
= ½, v
2
= ½ and b
3
= ½ see example 2.19 the OR function
Step 0: Initialize all weights and bias: w i
= 0 (i= 1 to n), b=0
Set learning rate (0 < ≤ 1)
= 0
Step 1: While stopping condition is false, do steps 2-8.
Step2: For each bipolar training pair s:t, do
Step 3.
Set activations for input units: steps 3-7 x i
= s i
Step 4 .Compute net input to each hidden ADALINE unit: f(x)
1 z_in z_in
1
2
= b
= b
1
2
+ x
+ x
1
2 w w
11
12
+ x
+ x
2
2 w w
21
22
;
;
Step 5. Determine output of each hidden ADALINE z
1 z
2
= f(z_in1)
= f(z_in2)
Step 6 . Determine output of net:
y_in = b
3
+ z
1 v
1
+ z
2 v
2
X
1
X
2 w
11 w
12 w
21 w
22 b
1
1 b
2
1
-1
Z
1
Z
2 if x ≥ 0 if x < 0
1 v
1 b
3 v
2
Y
The Algorithm
Step 7.
Update weights and bias if an error occurred for this pattern
If t = y, no weight updates are performed otherwise;
If t = 1, then update weights on Z
J closest to 0,
, the unit whose net input is w iJ
(new) = w iJ b
J
(new) = b
J
(old) +
(old) +
(1 – z_in)x i
(1 – z_in
J
)
If t = -1, then update weights on all units Z
K input,
, that have positive net w ik
(new) = w ik b k
(new) = b k
(old) +
(old) +
(-1 – z_in)x i
(-1 – z_in k
)
Step 8.
Test stopping condition:
Of weight changes have stopped(or reached an acceptable level), or if a specified maximum number of weight update iterations (Step 2) have been performed, then stop; otherwise continue