The concept of measurement and attitude scales
advertisement

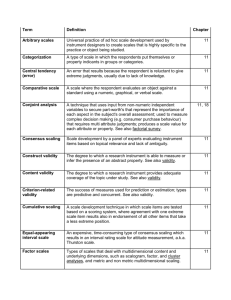
Measurement is the process of assigning numbers or labels to persons, objects or events in accordance with specific rules for representing quantities or qualities of attributes. Rule is a guide, method or command that tells a researcher what to do. Scale is a set of symbol or numbers so constructed that the symbols or numbers can be assigned by a rule to the individuals to whom the scale is applied. Nominal scale is a discrete classification of data, in which data are neither measured nor ordered but subjects are merely allocated to distinct categories (male/female, buyer/non-buyer). Ordinal scale is a scale on which data is shown simply in order of magnitude since there is no standard of measurement of differences. Ordinal numbers are used strictly to indicate rank order. Interval scale is a scale of measurement of data according to which the differences between values can be quantified in absolute but not relative terms and for which any zero is merely arbitrary. Ex : Temperature in Celsius or Fahrenheit. Ratio scale is a scale of measurement of data which permits the comparison of differences of values; a scale having a fixed zero value. Ex : The distances travelled by a projectile. Measurement = Accurate data + Error Random error ? Special error ? ◦ ◦ ◦ ◦ ◦ ◦ ◦ Personality, value, intelligence Temporary mood, fatigue Distractions Variations in the interviewer Sampling of items Lack of clarity Mechanical error The reliability is the degree to which measures are free from random error and, therefore, provide consistent data. The less error there is, the more reliable the observation is. The key question about reliability is : “If we measure some phenomenon over and over again with the same measurement device, will we get the same or highly similar results ? An affirmative answer means that the device is reliable. Test-retest reliability is obtained by repeating the measurement with the same instrument, approximating the original conditions as closely as possible. Equivalent form reliability is the ability of two very similar forms of an instrument to produce closely correlated results. Internal consistency reliability is the ability of an instrument to produce similar results when used on different samples during the same time period to measure phenomenon. Validity is the degree to which what the researcher was trying to measure was actually measured. When Pontiac brought out the Aztec, research told them that the car would sell between 50,000 and 70,000 units annually despite the controversial styling. After selling only 27,000 cars per year, the model was discontinued in 2005. The research measuring instrument was not valid. Face validity is the weakest form of validity. A test can be said to have face validity if it "looks like" it is going to measure what it is supposed to measure. Content validity is the representativeness of the content of the measurement instrument. In other word, an interview which is not speaking about the main subject or main objective has a lack of content validity. Measurement of attitudes relies on less precise scales than those found in the physical sciences. Indeed the mind of the consumer is not directly observable unlike the weight. Unidimensional scales measure only one attribute of a concept, respondent or object. Multidimensional scales measure several dimension of a concept, respondent or object. Graphic rating scale is a measurement scale that include a graphic continuum, anchored by 2 extremes. There are simply to use and considered as interval data. But one disadvantage of this scale is that the extreme anchors tend to force the respondents toward the middle of scale. Itemized rating scale is a measurement scale in which the respondent selects an answer from a limited number or ordered categories. It is also simply to construct and administer. Rank-order scale is a measurement scale in which the respondent compares several items and ranks them. Itemized and graphic scales are considered to be noncomparative scales, in other world the respondent makes a judgment without reference to another object. Place a 1 next to the brand you prefer, then a 2 for the second and so on _ Chevrolet _ BMW _ Toyota _ Ford Paired comparison scale is a measurement scale that ask the respondent to pick one of two objects in set, based on some started criteria. Problem : the respondent select only one object and does not rank. Constant sum scale ask to respondent to divide a given number (100) among several attributes based on their importance to him or her. It is preferred to paired comparison scale but it is preferable to have 10 items or less because the respondent can have difficulties allocating points if there are too many characteristics. The construction of a semantic differential scale begins with determination of a concept to be rated, such as the image of a company, brand or store. The researcher selects opposite pairs of words that could be used to describe the concept. Respondents then rate the concept on a scale (usually 1 to 7) Very useful, reliable and valid for decision making and prediction, it has proved to be statistically robust but it has to be adapted (more researched). Be careful with the halo effect! The semantic differential scale. (BIS) Be careful with the Halo effect ! Indeed the rating of a specific image component may be dominated by the interview’s overall impression of the concept, thus you rate every time the good or bad answer. To counteract the halo effect we should randomly reverse scale adjectives so that all the “good” ones are not placed on one side of the scale. The purchase intent scales are used to measure a respondent’s intention to buy or not buy a product. The ultimate issue for the marketing manager is “Will they buy the product or not ?” Purchase intent is evaluated at each stage of development and demand estimates are refined. It is a good predictor of consumer choice, very easy to construct and we need just a subjective judgment. Example : If a set of final exam answer is available would you : 1/Definitely buy 2/Probably buy 3/Probably not buy 4/Definitely not buy The purchase intent scale. (BIS) For example, based on historical follow-up studies we learnt that : ◦ ◦ ◦ ◦ 63% of the “definitely we will buy” purchase it. 28% of the “probably we will buy” purchase it. 12% of the “probably we will not buy” purchase it. 3% of the “definitely we will not buy” purchase it. ◦ ◦ ◦ ◦ 40% 20% 30% 10% And after our own study we have the result in the following : of of of of “definitely we will buy” “probably we will buy” “probably we will not buy” “definitely we will not buy” So assuming that the sample is representative of the target market we will have : 0,4 x (63%) + 0,2 x (28%) + 0,3 x (12%) + 0,1 x (3%) = 34,7% of the market share Type of scale Most commercial researchers use telephone or internet to save expense. So a rank-order scale can be quickly created whereas developing semantic differential scale is often long and tedious process. We can also consider the respondent preference who usually prefer nominal and ordinal scale because of their simplicity. Balanced VS non-balanced scale The balanced has the same number of positive and negative categories whereas the non-balanced is oriented toward one end. If past research has determined that most opinions are positive, we will use more positive gradients than negative. Number of scale categories If the number of categories is too small (good, fair and poor) the scale is crude and lacks richness. After if we have too many categories we can have a kind of discrimination of some ones. Research has shown that rating scales with either 5 or 7 points are the most reliable. Forced VS non-forced choice If a neutral category is included, it typically attract those who are neutral or those who lack adequate knowledge. Adding a “Don’t know” response is the solution. However this option can attract lazy respondent.