Repeated-Measures ANOVA
advertisement

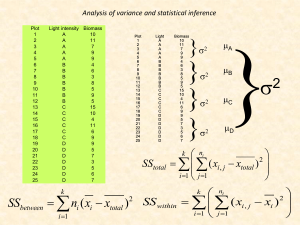
REPEATED-MEASURES ANOVA Old and New One-Way ANOVA looks at differences between different samples exposed to different manipulations (or different samples that may come from different groups) within a single factor. That is, 1 factor, k levels k separate groups are compared. NEW: Often, we can answer the same research questions looking at just 1 sample that is exposed to different manipulations within a factor. That is, 1 factor, k levels 1 sample is compared across k conditions. Multiple measurements for each sample. That is, a single sample is measured on the same dependent variable once for each condition (level) within a factor. Investigate development over time (Quazi-Independent: time 1, time 2, time 3) Chart learning (manipulate different levels of practice) (Independent: 1 hour, 4 hours, 7 hours) Compare different priming effects in a LDT (Independent: Forward, backward, no-prime, non-word) Simply examine performance under different conditions with the same individuals. (Independent: suspect, equal, detective, audio format) Extending t-tests T-test ANOVA cousin Comparing two Comparing more than two independent samples? Independent-samples t-test! independent samples within a single factor? One-way ANOVA! Comparing the dependent Comparing the dependent measures of a single sample under two different conditions? measures of a single sample under more than two different conditions? Related- (or dependent- or Repeated-Measures paired-) sample t-test! ANOVA! R-M ANOVA Like the Related-samples t, repeated measures ANOVA is more powerful because we eliminate individual differences from the equation. In a One-way ANOVA, the F-ratio is calculated using the variance from three sources: F = Treatment(group) Effect + Individual differences + Experimenter error/Individual differences + Experimenter error. The denominator represents “random” error and we do not know how much was from ID and EE. This is error we expect from chance. Why R-M ANOVA is COOL… With a Repeated-Measure ANOVA, we can measure and eliminate the variability due to individual differences!!!! So, the F ratio is conceptually calculated using the variance from two sources: F = Treatment(group) Effect + Experimenter error/ Experimenter error. The denominator represents truly random error that we cannot directly measure…the leftovers. This is error we expect just from chance. What does this mean for our F-value? R-M vs. One-Way: Power All else being equal, Repeated-Measures ANOVAs will be more powerful because they have a smaller error term bigger Fs. Let me demonstrate, if you will. Assume treatment variance = 10, experimental- error variance = 1, and individual difference variance = 1000. In a One-Way ANOVA, F conceptually = (10 + 1 + 1000)/(1 + 1000) = 1.01 In a Repeated-Measures ANOVA, F conceptually = (10 + 1)/(1) = 11 What is a R-M ANOVA doing? Again, SStotal = SSbetween + Sswithin Difference: We break the SSwithin into two parts: SSwithin/error = SSsubjects/individual differences + SSerror To get SSerror we subtract SSsubjects from SSwithin/error. This time, we truly have SSerror , or random variability. Other than breaking the SSwithin into two components and subtracting out SSsubjects, repeated measures ANOVA is similar to OneWay ANOVA. Let’s learn through example. A Priming Experiment! 10 participants engage in an LDT, within which they are exposed to 4 different types of word pairs. RT to click Word or Non-Word recorded and averaged for each pair type. Forward-Prime pairs (e.g., baby-stork) Backward-Prime pairs (e.g., stork-baby) Unrelated Pairs (e.g., glass-apple) Non-Word Pairs (e.g., door-blug) Hypotheses For the overall RM ANOVA: Ho: µf = µb = µu= µn Ha: At least one treatment mean is different from another. Specifically: Ho: µf < µb Ho: µf and µb < µu and µn Ho: µu < µn The Data Part Forward Backward Unrelated Nonword Sum Part. 1 .2 .1 .4 .7 1.4 2 .5 .3 .8 .9 2.5 3 .4 .3 .6 .8 2.1 ƩF2= 1.36 4 .4 .2 .8 .9 2.3 ƩB2= .58 5 .6 .4 .8 .8 2.6 ƩU2= 3.82 6 .3 .3 .5 .8 1.9 ƩN2= 6.63 7 .1 .1 .5 .7 1.4 ƩP2= 385 8 .2 .1 .6 .9 1.8 ƩXt2= 12.39 9 .3 .2 .4 .7 1.6 10 .4 .2 .6 .9 2.1 Ʃ 3.4 2.2 6 8.1 19.7 All = 19.7 Formula for SStotal Ian’s SSt = X 2 TOT ( X TOT ) 2 N TOT Remember, this is the sum of the squared deviations from the grand mean. So, SStotal = 12.39– (19.72/40) = 12.39 – 9.70225 = 2.68775 Importantly, SStotal = SSwithin/error + SSbetween The Data Part Forward Backward Unrelated Nonword Sum Part. 1 .2 .1 .4 .7 1.4 2 .5 .3 .8 .9 2.5 3 .4 .3 .6 .8 2.1 ƩF2= 1.36 4 .4 .2 .8 .9 2.3 ƩB2= .58 5 .6 .4 .8 .8 2.6 ƩU2= 3.82 6 .3 .3 .5 .8 1.9 ƩN2= 6.63 7 .1 .1 .5 .7 1.4 ƩP2= 385 8 .2 .1 .6 .9 1.8 ƩXt2= 12.39 9 .3 .2 .4 .7 1.6 10 .4 .2 .6 .9 2.1 Ʃ 3.4 2.2 6 8.1 19.7 All = 19.7 Within-Groups Sum of Squares: SSwithin/error SSwithin/error = the sum of each SS with each group/condition. Measures variability within each condition, then adds them together. ( X 1 2 ( X 1 ) n1 2 ) ( X 2 2 ( X 2 ) n2 2 ) ... ( X k 2 ( X k ) 2 ) nk So, SSwithin/error = (1.36– ([3.4]2/10)) + (.58– ([2.2]2/10)) + (3.82– ([6]2/10) + (6.63– ([8.1]2/10) = (1.36– 1.156) + (.58– .484) + (3.82– 3.6) + (6.63– 6.561) = .204+ .096+ .22+ .069= .589 The Data Part Forward Backward Unrelated Nonword Sum Part. 1 .2 .1 .4 .7 1.4 2 .5 .3 .8 .9 2.5 3 .4 .3 .6 .8 2.1 ƩF2= 1.36 4 .4 .2 .8 .9 2.3 ƩB2= .58 5 .6 .4 .8 .8 2.6 ƩU2= 3.82 6 .3 .3 .5 .8 1.9 ƩN2= 6.63 7 .1 .1 .5 .7 1.4 ƩP2= 385 8 .2 .1 .6 .9 1.8 ƩXt2= 12.39 9 .3 .2 .4 .7 1.6 10 .4 .2 .6 .9 2.1 Ʃ 3.4 2.2 6 8.1 19.7 All = 19.7 Breaking up SSwithin/error We must find SSSUBJECTS and subtract that from total within variance to get SSERROR SSSUBJECTS = K is generic for the number of conditions, as usual. SSSUBJECTS = (1.42/4 +2.52/4 +2.12/4 +2.32/4 +2.62/4 +1.92/4 +1.42/4 +1.82/4 +1.62/4 +2.12/4 +) – 19.72/40 = .49+1.5625+1.1025+1.3225+1.69+.9025+.49+.81+.6 4+1.1025) -9.70225 = 10.1125-9.70225 =.41025 Now for SSerror SSerror = SSwithin/error – SSsubjects SSerror = .589 - .41025 = .17875 or .179 Weeeeeeeeee! We have pure randomness! The Data Part Forward Backward Unrelated Nonword Sum Part. 1 .2 .1 .4 .7 1.4 2 .5 .3 .8 .9 2.5 3 .4 .3 .6 .8 2.1 ƩF2= 1.36 4 .4 .2 .8 .9 2.3 ƩB2= .58 5 .6 .4 .8 .8 2.6 ƩU2= 3.82 6 .3 .3 .5 .8 1.9 ƩN2= 6.63 7 .1 .1 .5 .7 1.4 ƩP2= 385 8 .2 .1 .6 .9 1.8 ƩXt2= 12.39 9 .3 .2 .4 .7 1.6 10 .4 .2 .6 .9 2.1 Ʃ 3.4 2.2 6 8.1 19.7 All = 19.7 SSbetween-group: The (same) Formula: ( X 1 ) 2 n1 ( X 2 ) n2 2 ... ( X k ) nk 2 ( X TOT ) 2 N TOT So = SSbetween = [((3.4)2/10) + ((2.2)2/10) + ((6)2/10) + ((8.1)2/10)] – 19.72/40 = (1.156+ .484+ 3.6+ 6.561) – 9.70225 = 11.801 – 9.70225 = 2.09875 or 2.099 Getting Variance from SS Need? …DEGREES OF FREEDOM! K=4 Ntotal = total number of scores = 40 (4x10) DfTOTAL = Ntotal – 1 = 39 DfBETWEEN/GROUP = k – 1 = 3 Dfwithin/error= N – K = 40 – 4 = 36 Dfsubjects = s-1 = 10-1 (where s is the # of subjects) = 9 Dferror = (k-1)(s-1) = (3)(9) = 27 OR Dfwithin/error - Dfsubjects = 36 – 9 = 27 Mean Squared (deviations from the mean) We want to find the average squared deviations from the mean for each type of variability. To get an average, you divide by n in some form (or k which is n of groups) and do a little correction with “-1.” That is, you use df. MSbetween/group = MSwithin/error = SS between df between SS ERROR df ERROR = 2.099/3 = .7 = .179/27 = .007 How do we interpret these MS MS error is an estimate of population variance. Or, variability due to ___________? F? F = MSMS BET = .7/.007 = 105.671 ERROR (looks like it should be 100, but there were rounding issues due to very small numbers. OK, what is Fcrit? Do we reject the Null?? Pros and Cons Advantages Each participant serves as own control. Do not need as many participants as one-way. Why? More power, smaller error term. Great for investigating trends and changes. Disadvantages Practice effects (learning) Carry-over effects (bias) Demand characteristics (more exposure, more time to think about meaning of the experiment). Control Counterbalancing Time (greater spacing…but still have implicit memory). Cover Stories Sphericity Levels of our IV are not independent same participants are in each level (condition). Our conditions are dependent, or related. We want to make sure all conditions are equally related to one another, or equally dependent. We look at the variance of the differences between every pair of conditions, and assume these variances are the same. If these variances are equal, we have Sphericity More Sphericity Testing for Sphericity Mauchly’s test Significant, no sphericity, NS… Sphericity! If no sphericity, we must engage in a correction of the F-ratio. Actually, we alter the degrees of freedom associated with the F-ratio. Four types of correction (see book) Estimate sphericity from 0 (no sphericity) to 1 (sphericity) Greenhouse-Geiser (1/k-1) Huynh-Feldt MANOVA (assumes measures are independent) non-parametric, rank-based Friedman test (one-factor only) Symmetry Effect Sizes The issue is not entirely settled. Still some debate and uncertainty on how to best measure effect sizes given the different possible error terms. ω2 = See book for equation. Specific tests Can use Tukey post-hoc for exploration Can use planned comparisons if you have a priori predictions. Sphericity not an issue Contrast Formula Same as one way, except error term is different Contrasts Some in SPSS: Difference: Each level of a factor is compared to the mean of the previous level Helmert: Each level of a factor is compared to the mean of the next level Polynomial: orthogonal polynomial contrasts Simple: Each level of a factor is compared to the last level Specific: GLM forward backward unrelate nonword /WSFACTOR = prime 4 special (1 1 1 1 -1 -1 1 1 -1 1 0 0 0 0 -1 1) 2+ Within Factors Set up. Have participants run on tread mill for 30min. Within-subject factors: Factor A Measure Fatigue every 10min, 3 time points. Factor B Do this once after drinking water, and again (different day) after drinking new sports drink. 3 (time) x 2 (drink) within-subject design. Much is the same, much different… We have 2 factors (A and B) and an interaction between A and B. These are within-subjects factors All participants go through all the levels of each factor. Again, we will want to find SS for the factors and interaction, and eventually the respective MS as well. Again, this will be very similar to a one-way ANOVA. Like a 1-factor RM ANOVA, we will also compute SSsubject so we can find SSerror. What is very different? Again, we can parse up SS w/e into SSsubject and SSerror. NEW: We will do this for each F we calculate. For each F, we will calculate: SS Effect ; SS Subject (within that effect) ; and SS Error What IS SSError for each effect? (We will follow the logic of factorial ANOVAS) What are the SSErrors now? Lets start with main effects. Looking at Factor A, we have Variability due to Factor A: SSFactor A Variability due to individual differences. How do we measure that? By looking at the variability due to a main effect of Participant (i.e., Subject): SSSubject (within Factor A) Variability just due to error. How do we calculate that!?!?!? Think about the idea that we actually have 2 factors here, Factor A and Subject. The Error is in the INTERACTIONS with “Subject.” For FFactor A (Time) SSAS is the overall variability looking at Factor A and Subjects in Factor A (collapsing across Drink). To find SSerror for the FFactor A (Time) Calculate: SSAS; SSFactor A ; SSSubject (within Factor A) SSerror is: SSAS - (SSFactor A + SSSubject (within Factor A)) That is, SSerror for FFactor A (Time)is SS A*subj !!!!!! Which measures variability within factor A due to the different participants (i.e., error) The Same for Factor B. For FFactor B (Drink) SSAS is the overall variability looking at Factor B and Subjects in Factor B (collapsing across Time). To find SSerror for the FFactor B (Drink) Calculate: SSBS; SSFactor B ; SSSubject (within Factor B) SSerror is: SSBS - (SSFactor B + SSSubject (within Factor B)) That is, SSerror for FFactor B (Drink)is SS B*subj !!!!!! SS B*subj: Which measures variability within factor B due to the different participants (i.e., error) Similar for AxB Interaction For FAxB SSBetween groups is the overall variability due to Factor A, Factor B, and Subjects. To find SSerror for the FAxB Calculate: SSBetween; SSFactor A ; SSFactor B ; SSSubject SSerror is: SSBetween - (SSFactor A + SSFactor B + SSSubject) That is, SSerror for FAxB is SS A*B*subj !!!!!! SS A*B*subj: measures variability within the AxB interaction due to the different participants (i.e., error) We are finely chopping SSW/E SSSub (A) SSSub (B) SSSub (AxB) Getting to F Factor A (Time) SSA = 91.2; dfA = (kA – 1) = 3 – 1 = 2 SSError(A*S) = 16.467; dfError(A*S) = (kA – 1)(s – 1) = (3- 1)(10-1) = 18 So, MSA = 91.2/ 2 = 45.6 So, MSError(A*S) = 16.467/ 18 = .915 FA = 45.6/.915 = 49.846 Snapshot of other Fs Factor B (Drink) dfB = (kB – 1) = 2 – 1 = 1 dfError(B*S) = (kB – 1)(s – 1) = (2-1)(10-1) = 9 AxB (Time x Drink) dfAxB = (kA – 1)(kB – 1) = 2 x 1= 2 dfError(A*B*S) = (kA – 1)(kB – 1)(s – 1) = 2 x 1 x 9 = 18 Use SS’s to calculate the respective MSeffect and MSerror for the other main effect and the Interaction F-values.