LINGUISTICA GENERALE E COMPUTAZIONALE - clic
advertisement

LINGUISTICA GENERALE E
COMPUTAZIONALE
DISAMBIGUAZIONE DELLE PARTI DEL
DISCORSO
POS tagging: the problem
• People/NNS continue/VBP to/TO inquire/VB
the/DT reason/NN for/IN the/DT race/NN
for/IN outer/JJ space/NN
• Problem: assign a tag to race
• Requires: tagged corpus
2
Ambiguity in POS tagging
The
man
still
saw
her
AT
NN
NN
NN
PPO
VB
VB
VBD
PP$
RB
3
How hard is POS tagging?
In the Brown corpus,
- 11.5% of word types ambiguous
- 40% of word TOKENS
Number of tags 1
2
Number of
words types
3760 264 61
35340
3
4
5
6
7
12
2
1
4
Frequency + Context
• Both the Brill tagger and HMM-based taggers
achieve good results by combining
– FREQUENCY
• I poured FLOUR/NN into the bowl.
• Peter should FLOUR/VB the baking tray
– Information about CONTEXT
• I saw the new/JJ PLAY/NN in the theater.
• The boy will/MD PLAY/VBP in the garden.
5
The importance of context
• Secretariat/NNP is/VBZ expected/VBN to/TO
race/VB tomorrow/NN
• People/NNS continue/VBP to/TO inquire/VB
the/DT reason/NN for/IN the/DT race/NN
for/IN outer/JJ space/NN
6
TAGGED CORPORA
Choosing a tagset
• The choice of tagset greatly affects the
difficulty of the problem
• Need to strike a balance between
– Getting better information about context (best:
introduce more distinctions)
– Make it possible for classifiers to do their job
(need to minimize distinctions)
8
Some of the best-known Tagsets
• Brown corpus: 87 tags
• Penn Treebank: 45 tags
• Lancaster UCREL C5 (used to tag the BNC): 61
tags
• Lancaster C7: 145 tags
9
Important Penn Treebank tags
10
Verb inflection tags
11
The entire Penn Treebank tagset
12
UCREL C5
13
Tagsets per l’italiano
PAROLE
Si-TAL (Pisa, Venezia, IRST, ....)
TEXTPRO (dopo)
14
Il tagset di SI-TAL
15
POS tags in the Brown corpus
Television/NN has/HVZ yet/RB to/TO work/VB out/RP a/AT
living/RBG arrangement/NN with/IN jazz/NN ,/, which/VDT
comes/VBZ to/IN the/AT medium/NN more/QL as/CS an/AT
uneasy/JJ guest/NN than/CS as/CS a/AT relaxed/VBN
member/NN of/IN the/AT family/NN ./.
16
SGML-based POS in the BNC
<div1 complete=y org=seq>
<head>
<s n=00040> <w NN2>TROUSERS <w VVB>SUIT
</head>
<caption>
<s n=00041> <w EX0>There <w VBZ>is <w PNI>nothing
<w AJ0>masculine <w PRP>about <w DT0>these <w
AJ0>new <w NN1>trouser <w NN2-VVZ>suits <w
PRP>in <w NN1>summer<w POS>'s <w AJ0>soft <w
NN2>pastels<c PUN>.
<s n=00042> <w NP0>Smart <w CJC>and <w
AJ0>acceptable <w PRP>for <w NN1>city <w NN1VVB>wear <w CJC>but <w AJ0>soft <w AV0>enough <w
PRP>for <w AJ0>relaxed <w NN2>days
</caption>
17
Quick test
DoCoMo and Sony are to develop a chip that would let people
pay for goods through their mobiles.
18
POS TAGGED CORPORA IN NLTK
>>> tagged_token =
nltk.tag.str2tuple('fly/NN')
>>> tagged_token
('fly', 'NN')
>>> tagged_token[0]
'fly'
>>> tagged_token[1]
'NN'
>>> nltk.corpus.brown.tagged_words()
[('The', 'AT'), ('Fulton', 'NP-TL'),
('County', 'NN-TL'), ...]
Exploring tagged corpora
• Ch.5, p. 184-189
OTHER POS-TAGGED CORPORA
• NLTK:
• WAC Corpora:
– English: UKWAC
– Italian: ITWAC
POS TAGGING
Markov Model POS tagging
• Again, the problem is to find an `explanation’
with the highest probability:
argmax P ( t1 ..t n | w1 .. w n )
t i T
• As in the lecture on text classification, this can
be ‘turned around’ using Bayes’ Rule:
argmax
P ( w1 .. w n | t1 ..t n ) P ( t1 ..t n )
P ( w1 .. w n )
23
Combining frequency and contextual
information
• As in the case of spelling, this equation can be
simplified:
prior
likelihood
argmax P ( w 1 .. w n | t1 ..t n ) P ( t1 ..t n )
• As we will see, once further simplifications are
applied, this equation will encode both
FREQUENCY and CONTEXT INFORMATION
24
Three further assumptions
• MARKOV assumption: a tag only depends on a
FIXED NUMBER of previous tags (here, assume
bigrams)
– Simplify second factor
• INDEPENDENCE assumption: words are
independent from each other.
• A word’s identity only depends on its own tag
– Simplify first factor
25
The final equations
CONTEXT
FREQUENCY
26
Estimating the probabilities
Can be done using Maximum Likelihood Estimation as
usual, for BOTH probabilities:
27
An example of tagging with Markov
Models :
• Secretariat/NNP is/VBZ expected/VBN to/TO race/VB
tomorrow/NN
• People/NNS continue/VBP to/TO inquire/VB the/DT
reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN
• Problem: assign a tag to race given the subsequences
– to/TO race/???
– the/DT race/???
• Solution: we choose the tag that has the greater of these
probabilities:
– P(VB|TO) P(race|VB)
– P(NN|TO)P(race|NN)
28
Tagging with MMs (2)
• Actual estimates from the Switchboard corpus:
• LEXICAL FREQUENCIES:
– P(race|NN) = .00041
– P(race|VB) = .00003
• CONTEXT:
– P(NN|TO) = .021
– P(VB|TO) = .34
• The probabilities:
– P(VB|TO) P(race|VB) = .00001
– P(NN|TO)P(race|NN) = .000007
29
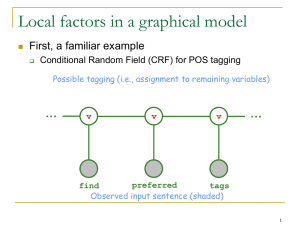
A graphical interpretation of the POS
tagging equations
30
Hidden Markov Models
31
An example
32
Computing the most likely sequence of
tags
• In general, the problem of computing the
most likely sequence t1 .. tn could have
exponential complexity
• It can however be solved in polynomial time
using an example of DYNAMIC
PROGRAMMING: the VITERBI ALGORITHM
(Viterbi, 1967)
• (Also called TRELLIS ALGORITHMs)
33
POS TAGGING IN NLTK
DEFAULT POS TAGGER: nltk.pos_tag
>>> text = nltk.word_tokenize("And now for something
completely different")
>>> nltk.pos_tag(text) [('And', 'CC'), ('now', 'RB'),
('for', 'IN'), ('something', 'NN'), ('completely',
'RB'), ('different', 'JJ')]
TEXTPRO
• The most widely used NLP tool for Italian
• http://textpro.fbk.eu/
• Demo
THE TEXTPRO TAGSET
READINGS
• Bird et al, chapter 5, chapter 6.1