Slides - UCL Computer Science
advertisement

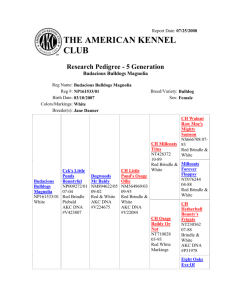
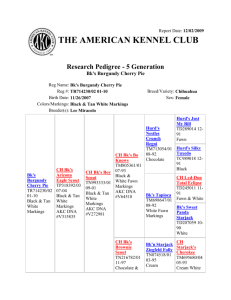
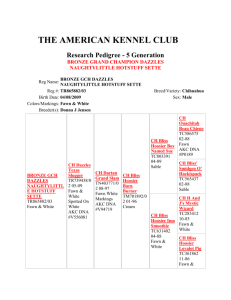
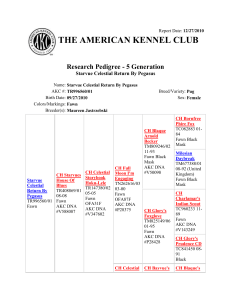
FAWN: Fast Array of Wimpy Nodes Developed By D. G. Andersen, J. Franklin, M. Kaminsky, A. Phanishayee, L. Tan, V. Vasudevan Presented by Peter O. Oliha Chengyu Zheng UCL Computer Science COMPM038/COMPGZ06 Motivation • Can we reduce energy use by a factor of ten? • Still serve the same workloads. • Avoid increasing capital cost. Power Consumption and Computing • High amount of energy is required for large amounts of data processing • “Energy consumption by data centers could nearly double ...(by 2011) to more than 100 billion kWh, representing a $7.4 billion annual electricity cost” [EPA Report 2007] FAWN System • FAWN-KV is a key/value store with per-node datastore built on flash storage. • Desires to reduce energy consumption • Each node: Single core 500MHz AMD processor, 256MB RAM, 4GB CompactFlash device FAWN -Components •FAWN –Flash –FAWN-DS •Log structured data store –FAWN-KV • Key/value system • Put()/get() interface FAWN Approach: Why use “wimpy” nodes •Match CPU-I/O processing times •Using wimpy processors reduce I/O-induced idle cycle while maintaining high performance •Fast CPU’s consumes more power •Spends longer time idle, so less utilization FAWN Approach: Why use Flash Storage •Fast Random Reads –<<1ms upto 175 times faster than random reads on magnetic disks •Efficient I/O –Consumes less than 1W even under heavy load •Slow Random writes –influences design of the FAWN-DS •Suitable for desired workload; random-access, read-intensive. FAWN-DS: Datastore Functions: Lookup, store ,delete, merge, split, compact Designed specifically for flash characteristics –Sequential writes, single-random-access reads FAWN-DS: Store, Delete Store: -Appends an entry to the log -Updates hash table entry to point to the offset within the data log -Set valid bit to 1 - If the key written already exists, the old value is now orphaned. Delete: -Invalidates hash entry corresponding to the key -Clears the valid bit -Writes “delete entry” at the end of the file -Delete operations are not applied immediately to avoid random writes. -Deletes are carried out on compact operations FAWN-DS: Maintenance Split, Merge, Compact Split & Merge Parses the Data log sequentially Splits single DS into two, one for each key range Merge writes every log entry from one DS to the other Compact Cleans up entries to the data store It Skips Entries outside data store key range Orphaned entries Delete entries corresponding to the above Writes all other valid entries to the output data store FAWN-KV: The key-value system Client Front-end Services client requests through standard put/get interface. Passes request to the back-end Back-end Satisfies requests using its FAWN-DS Replies front-end FAWN-KV: Consistent hashing •Consistent hashing used to organize FAWN-KV virtual ID’s (similar to Chord DHT) •Uses 160-bit circular ID space •Does not use DHT routing FAWN-KV: Replication and Consistency •Items stored at successor and R-1 virtual ID’s •Put()’s are successful when writes are completed on all virtual nodes. •Get()s are directly routed to the tail of the chain FAWN-KV: Joins and Leaves •Joins occur in 2 phases –Datastore pre-copy •New node gets data from current tail –Chain insertion, log flush •Leaves –Replicas must merge key range owned by departed node –Add a new replica to replace departed node: equivalent to a join FAWN-KV: Failure Detection • Nodes are assumed to be fail-stop • Each front-end exchanges heartbeat messages with nodes FAWN: Evaluation 1. Individual Node Performance 2. FAWN-KV 21-Node System •Single core 500MHz AMD processors, 256MB RAM, 4GB CompactFlash device •Workload targets small objects that are readintensive( 256 byte and 1KB) FAWN: Single Node Lookup and Write Speed • 80% lookup Speed of raw flash systems • Insert rate 23.2MB/s(~24Kentries/s) is 96% write Speed of raw Flash Systems FAWN: Read-intensive vs. Write-intensive workload FAWN: Semi-Random Writes FAWN: System Power Consumption •Measurements shown at peak performance FAWN: Node Joins and Power •Measurements shown at max and low loads •Joins take longer to complete at max load FAWN: Splits and Query Latency •For purely get() workloads •Split increases query latency FAWN Nodes vs. Conventional Nodes •Traditional systems still have sub-optimal efficiency. TCO: FAWN vs. Traditional Architecture FAWN: When to use FAWN? •FAWN-Based system can provide lower cost per (GB, QueryRate) Related Work • JouleSort: energy efficiency benchmark developed for disk-based low-power CPU. • CEMS, AmdahlBlades, Microblades: advocates low-cost, low-power components as building blocks for Datacenter systems • IRAM Project: CPU's and memory into a single unit. IRAM-based CPU could use quarter of the power of conventional system for same workload. • Dynamo: distributed hashtable structure providing availability to certain workloads Future Work • Consider more failure scenarios • Management node replication • Use in computationally intensive/large dataset workloads • Decrease impact of split on query latency FAWN: Conclusion •Fast and efficient processing of random readintensive workloads. • More work done with less power •FAWN-DS balances read/write throughput •FAWN-KV balances workload while maintaining replication and consistency •Splits and Joins affect latency at high workload •Can it be used for computational intensive workloads?