Lecture 3 - Probability Distribution
Recall
● The only difference between the formula for the actual value and the predicted value is the
residual terms/prediction error
● Least squares prediction function gets the predicted Y value
○ Eg.
● Least squares regression function gets the actual Y value
○ Eg.
Intro to describing populations
● The easiest way to describe a specific population characteristic is to measure the
characteristic of every object in the population
● Given a time series graph, seasonality is a common characteristic.
○ This considers seasonal patterns
○ To get the general pattern, time series data is separated into the trend component,
a seasonal component, and a random component
■ Trend component captures changes in level over time
■ Seasonal component captures cyclical effects due to the time in the year
■ Random component captures influences not described by the trend and
seasonal components
Probability Distribution
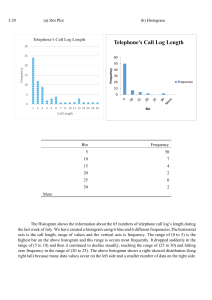
● It is best to visualize probability distribution with the use of a histogram
○ The histogram provides an insight of the range in which the data is most likely to
fall
○ The more bins that are added, the more bars appear and the easier it is to visualize
the probability density curve.
■ The probability density curve is the smooth curve that appears over the
histogram
● At the core, probability distribution provides a framework that describes how probabilities
are distributed over the values of a random variable
○ It allows for predictions and the likelihood of different outcomes
Common measures in probability
● Mean is denoted with the greek letter μ
● The standard deviation is denoted with the greek letter σ
● Before finding the median, lower and upper quartile, the data must be properly organized
from least to greatest before manual calculations
○ Median is simply the middle point of the data set. Median = Q2 = 50th percentile
○ Lower quartile is the 25th percentile
○ Upper quartile is the 75th percentile
○ Eg. given values 7, 2, 4, 2, 20, 17, 11
■ Reorganize: 2, 2, 4, 7, 11, 17, 20
■ Q2 = 7, there are 3 data to right and left
● 2, 2, 4 make up the lower half and 11, 17, 20 make up the upper half
■ Q1 = 2
■ Q3 = 17
■ IQR = Q3 - Q1 = 17-2 = 15
■ Lower Whisker = Q1 - 1.5IQR = 2 - 1.5x15 = -20.5
■ Upper whisker = Q3 + 1.5IQR = 17 + 1.5x15 = 39.5
○ Eg. given values 16, 17, 28, 21, 16, 39, 31, 39
■ Reorganize: 16, 16, 17, 21, 28, 31, 39, 39
■ Q2 = (21+28)/2 = 24.5
● 16, 16, 17, 21 make up the lower half and 28, 31, 39, 39 make up the
upper half
■ Q1 = (16+17)/2 = 16.5
■ Q3 = (31+39)/2 = 35
■ IQR = Q3 - Q1 = 35 - 16.5 = 18.5
■ Lower Whisker = Q1 - 1.5IQR = 16.5 - 1.5x18.5 = -11.25
■ Upper whisker = Q3 + 1.5IQR = 35 + 1.5x18.5 = 62.75
● If mean > median, likely will be skewed to the right
● If mean < median, likely will be skewed left
● If mean = median, bell shaped curve, centered in the middle
Tutorial
● To create histograms in R, use the geom_histogram() function after the ggplot() function
ggplot(dt1, aes(x = RET)) +
geom_histogram( color = "white", fill = "skyblue")
● To create a histogram and make your own bins, it is best to use the following code as a
reference
bin_num <- 15
bin_width <- (max(dt1$RET) - min(dt1$RET))/bin_num
bin_edge <- seq(from = min(dt1$RET), to = max(dt1$RET), by = bin_width)
ggplot(dt1, aes(x = RET)) +
geom_histogram(breaks = bin_edge, color = "white", fill = "skyblue") +
scale_x_continuous(breaks = bin_edge, labels = scales :: percent) +
#tidyverse doesn't have anything to go from decimal to percent
#we use a function from the scales package while staying in the tidyverse by using the :: to
reference
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
#hjust just fixes the anchoring point and makes it clearer
labs(x = "Tesla Monthly Returns", y = "Frequency")
● If you also want to add the probability density curve, add y = after_stat(density) in the first
line inside aes() and also add geom_density(color = "red",linewidth = 1.5)
 0
0