Statistics Lecture Notes: Sampling, Experiments, and Analysis
advertisement

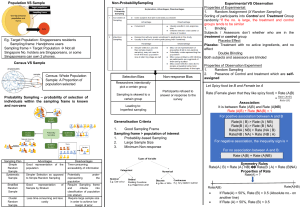
Non-ProbabilitySampling Population VS Sample Experimental VS Observation Properties of Experimental: 1. Random Assignment (X Random Sampling) Sorting of participants into Control and Treatment Group randomly.*If the no. is large, the treatment and control groups tends to be similar 1. Binding Subjects / Assessors don’t whether who are in the treatment or control group Placebo Effect Placebo: Treatment with no active ingredients, and no effect Double Blinding Both subjects and assessors are blinded Eg. Target Population: Singaporeans residents Sampling frame: Handphone users Sampling frame > Target Population → Not all Singapore No. holders are Singaporeans, or some Singaporeans can own 2 phones. Census VS Sample Census: Whole Population Sample: A Proportion of population selected Probability Sampling – probability of selection of individuals within the sampling frame is known and non-zero Selection Bias Non-response Bias Researchers intentionally pick a certain group Sampling is skewed to a certain group Properties of Observation Experiment 1. Random Sampling 2. Presence of Control and treatment which are selfassigned Let Spicy food be B and Female be A Participants refused to answer or response to the survey Rate (Female given that they like spicy food) = Rate (A|B) = 𝑅𝑎𝑡𝑒 (𝐴∩𝐵) 𝑅𝑎𝑡𝑒 (𝐵) Association: It is between Rate (A|B) and Rate (A|NB) Rate (A|B) + Rate (NA|B) = 1 Leading to: Imperfect sampling For positive association between A and B Generalisation Criteria Rate(A | B) > Rate (A | NB) Rate(B | A) > Rate (B | NA) Rate(NA | NB) > Rate (NA | B) Rate(NB | NA) > Rate (NB | A) 1. Good Sampling Frame Sampling frame > population of interest 1. Probability-based Sampling 2. Large Sample Size 3. Minimum Non-response For negative association, the inequality sign is < For no association between A and B: Rate (A|B) = Rate (A|NB) Sampling Plan Simple Random Sample Systematic Sample Advantages Good representation of the population Disadvantages Time-consuming; accessibility of information Simpler Selection as opposed to Simple Random Sampling Potentially underrepresenting the population Require Sampling frame and criteria into classification of population into stratum Require large sample size in order to achieve low margin of error Stratified Random Sample Good representation Sample by Stratum of Cluster Random Sample Less time-consuming and less costly Symmetry Rules Rate(A | B) < Rate (A | NB) Rate(B | A) < Rate (B|NA) Properties of Rate Rate(A) = ? Rate(A|B) • • Rate(A|NB) If Rate(A) = 50%, Rate (B) = 0.5 (Absolute no.- on another line) If Rate (A) > 50%, Rate (B) < 0.5 Simpson’s Paradox Simpson’s Paradox is a phenomenon in which a trend appears in more than half of the groups of data but disappears or reverses when the groups are combined. Confidence Interval Correlation (r) • • • r is not affected by Interchanging x and y Adding/ subtracting a constant number to all values Multiplying / Dividing positive no to all variable A regression equation is for the average population, not directed to a specific person. ∴ The regression equation cannot determine anything for a person Confounders Therefore, the size of the stone is a confounders. Co-founders must have association with the 2 variables Presence of a Simpson’s Paradox → Confounder present BUT Having a confounder ≠ Have Simpson’s Paradox Distribution Curve Identifying Outlier High outlier: > Q3 +1.5 x IQR Low outlier: < Q3 -1.5 x IQR How big numerical outliers affect mean, median and standard deviation? • Mean will increase greatly • Median and IQR will remain approximately the same • Standard deviation will decrease greatly (no matter what type of outlier If many samples are taken, 95% of the time, the sample mean will fall within the population mean. Variance 𝑠2 = • • • Spread Range log 𝑒 𝑦 = 1.33 𝑦 = ⅇ0.33 Probability Rule A and B are mutually exclusive = P(A∩B) / P(A and B) = 0 P(A∪B) / P(A or B) = P(A) + P(B) A and B are independent: P(A∩B) = P(A) × P(B) P(B | A) = P(B) P(A| B) = P(A) 𝑥,ҧ 𝜎 2 ▪ Greater Variation → Fatter bell shape Greater number of participants → Narrower confidence interval 𝑥ҧ = mean 𝜎 = standard deviation p-value < Value of significance → reject H0 The stronger the r value = the point are closer to the best fit line 𝑠 𝑅𝑖𝑠𝑒 m= 𝑠𝑦 𝑟 m= 𝑅𝑢𝑛 𝑥 x is used to predict y 2 𝑛−1 If the variance of x is zero, then xi = x for all i ranging from 1 to n. If all the values of x in the data set are multiplied by 2, then the variance is multiplied by 4. Adding/ subtracting a constant to x will not change variance For “at least as extreme” questions, 1. Extreme value must include the sample value that is stated In the question 2. Inequality follow the H1 definition 1. 2. Properties of Mean, Median Adding a constant (+/-) → change mean by that constant value. Multiply by constant → mean multiply by constant Normal Distribution ▪ Regression 𝑥𝑖 − 𝑥ҧ p-value = how likely is the data going to occur under H0 1. 2. Properties of Standard Deviation& IQR Adding a constant (+/-) won’t change mean by that constant value. Multiply by constant (+/-) → mean multiply by |constant|