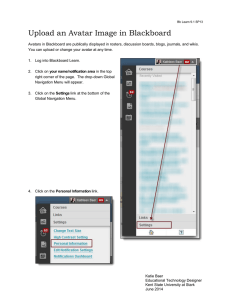
IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 27, NO. 11, NOVEMBER 2021 4129 Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User Perception in 3D Asymmetric Telepresence Kevin Yu , Gleb Gorbachev , Ulrich Eck, Frieder Pankratz, Nassir Navab, Daniel Roth Fig. 1: User with both avatar conditions investigated in the study. Left: The local user of the asymmetric telepresence system was wearing an AR display to interact with the remote user (who was present via VR). Center: In the point-cloud reconstruction based avatar condition (PCR), the local user was represented by the avatar resulting from RGB-D based point cloud reconstruction, which occluded upper parts of the face. Right: In the 3D virtual character based avatar condition (3DVC), the local users point cloud representation was masked and exchanged with a personalized virtual character driven by body, face, and gaze motion tracking. Abstract—A 3D Telepresence system allows users to interact with each other in a virtual, mixed, or augmented reality (VR, MR, AR) environment, creating a shared space for collaboration and communication. There are two main methods for representing users within these 3D environments. Users can be represented either as point cloud reconstruction-based avatars that resemble a physical user or as virtual character-based avatars controlled by tracking the users’ body motion. This work compares both techniques to identify the differences between user representations and their fit in the reconstructed environments regarding the perceived presence, uncanny valley factors, and behavior impression. Our study uses an asymmetric VR/AR teleconsultation system that allows a remote user to join a local scene using VR. The local user observes the remote user with an AR head-mounted display, leading to facial occlusions in the 3D reconstruction. Participants perform a warm-up interaction task followed by a goal-directed collaborative puzzle task, pursuing a common goal. The local user was represented either as a point cloud reconstruction or as a virtual character-based avatar, in which case the point cloud reconstruction of the local user was masked. Our results show that the point cloud reconstruction-based avatar was superior to the virtual character avatar regarding perceived co-presence, social presence, behavioral impression, and humanness. Further, we found that the task type partly affected the perception. The point cloud reconstruction-based approach led to higher usability ratings, while objective performance measures showed no significant difference. We conclude that despite partly missing facial information, the point cloud-based reconstruction resulted in better conveyance of the user behavior and a more coherent fit into the simulation context. Index Terms—Telepresence, Avatars, Augmented Reality, Mixed Reality, Virtual Reality, Collaboration, Embodiment Kevin Yu and Gleb Gorbachev contributed equally Kevin Yu is with Research group MITI, Technical University of Munich. E-mail: kevin.yu@tum.de •• Gleb Gorbachev is with Computer Aided Medical Procedures, Technical University of Munich. E-mail: gleb.gorbachev@tum.de • Ulrich Eck is with Computer Aided Medical Procedures, Technical University of Munich. E-mail: ulrich.eck@tum.de • Frieder Pankratz is with the Institute for Emergency Medicine, Ludwig Maximilian University. E-mail: frieder.pankratz@med.uni-muenchen.de • Nassir Navab is Chair of Computer Aided Medical Procedures, Technical University of Munich. E-mail: nassir.navab@tum.de • Daniel Roth is Professor for Human-Centered Computing and Extended Reality, Friedrich-Alexander University (FAU) Erlangen-Nuremberg. E-mail: d.roth@fau.de Manuscript received 15 Mar. 2021; revised 11 June 2021; accepted 2 July 2021. Date of publication 27 Aug. 2021; date of current version 1 Oct. 2021. Digital Object Identifier no. 10.1109/TVCG.2021.3106480 1077-2626 © 2021 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. See https://www.ieee.org/publications/rights/index.html for more information. 4130 1 IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 27, NO. 11, NOVEMBER 2021 I NTRODUCTION Telepresence [42], “the experience of presence in an environment by means of a communication medium” [66] is the foundation to create new forms of Virtual & Augmented Reality (VR/AR) communication and collaboration. It opens pathways for remote guidance and teleconsultation [49, 59, 81], collaborative group meetings and group work [5] and supernatural interaction types with multiple participants [2, 15, 23, 54]. A central aspect of telepresence systems is user embodiment, i.e., the representation of users to others and themselves in the environment [6], which has been the subject of present and past research on telepresence and remote collaboration (e.g., [5, 7, 34, 40, 43, 46, 53, 62, 64]). Avatars are defined as virtual characters driven by human behavior [3]. By presenting an avatar as a virtual surrogate of a user’s physical body in Virtual Reality (VR), the users can gain a sense of embodiment within the virtual environment [60]. Simultaneously, the user’s behavior can be influenced by the embodiment with an atypical representation that contrasts with one’s personality or physiology [26, 65, 76, 78, 79]. The discussion on which level of conveyance on non-verbal behaviour matches the same or better rate as in face-to-face meetings resulted in much research [18, 56]. Non-verbal behaviour, even subtle ones, can be perceived by a person and contribute significantly to the feeling of social closeness [68]. A visually and kinematically satisfying representation of the participants in the shared environment promotes communication and immersion. However, even a static and abstract representation in cartoon or shapes can create a sense of co-presence in a telepresence scenario, and it was pragmatically argued that any representation may be better than no representation [43]. Two main approaches to avatar representation have been presented in the past: i) 3D point cloud reconstruction based avatar representations of users using RGB-D sensing (e.g., [5, 16, 37, 40, 44]), ii) 3D virtual character based representations that are animated based on motion tracking of users (e.g., [2, 7, 49, 53, 57, 64]. Further research proposed a combination of both techniques (e.g., [63, 69]); for a review and summaries see [32, 54]. Prior research has investigated different forms of avatar representations [57], their impact on social interaction [20, 31, 33], and compared point-cloud based avatars to partially personalized (3D-scanned head) avatars with limited expression animations in a general fashion [17]. However, the aspect of non-verbal cues, in particular, the importance of gaze and facial expression for a personalized animated avatar representation, has not been investigated and compared against a 360° real-time capture point cloud representation of a user. The question remains from existing work, if a 3D authored, personalized high-fidelity avatar with a high degree of freedom in expression realism would better convey information and perceived presence than a realistic but potentially noisy or incomplete point cloud representation for tasks during real-time teleconsultation. 1.1 Contribution To tackle this gap, we present a deeper investigation into the comparison of point cloud representations vs. personalized, 3d authored, expression-rich avatar representations for asymmetric teleconsultation systems. In such systems, local users typically equip an Augmented Reality (AR) head-mounted display, which inherently occludes a large area of the upper face that is substantially responsible for conveying meaning and intentions during communication. During our comparative user study between point-cloud representation (PCR) and 3D virtualcharacter-based avatars (3DVC), we analyze both on performing two tasks, a social interaction and a goal-oriented task. Based on the results, we derive the importance of facial expression in such setups. We developed a sophisticated telepresence system and pipeline to compare both avatar representations by masking the point cloud and substitute it by the 3DVC avatar within the point cloud environment. The social interaction task (a 20 questions game) promotes verbal face-to-face communication. During the goal-oriented task, participants solve a puzzle that pairs can only clear in time through cooperative, goal-focused collaboration. Based on the results of our user study, we observe that the PCR representation was superior with regard to copresence, social presence measures, humanness, and behavior impression. A further finding suggests that the task type impacts the perception of telepresence. The observed data are essential for future developments as they guide further research and the understanding of avatar representations in teleconsultation systems. 2 R ELATED W ORK We split the related work into two categories and present similar or previous work on (i) collaborative telepresence systems and (ii) user representation and avatars. 2.1 Collaborative Telepresence Systems Collaborative telepresence systems have been developed using a variety of approaches. Avatar-mediated telepresence uses prepared realistic or abstracted 3D models capable of replicating essential factors for mediating non-verbal communication (e.g. [18,56,58,61]). Telepresence based on point clouds and real-time reconstruction (e.g. [5, 40, 44, 47, 67, 69]) captures users together with their environment and creates a shared environment. Such created avatars can be optimized further for network transmission depending on the view of the receiving end [30]. Other variants specialize on teleconsultation by using an asymmetric approach [49, 63], or create group-to-group telepresence experience using dynamic displays [45]. A 3D virtual avatar that is created in advance can be used within reconstruction-based telepresence (e.g. [27, 75] to allow a remote user to embody a virtual being. An extensive review on telepresence systems can be found in [21]. In this work, we use a telepresence system similar to the latter category of combining avatars with the point cloud based real-time reconstruction of the environment. Unlike related work in this category, we focus on the comparison of two fundamental methods on representing the user, rather than on the telepresence system. Further, we use articulated avatars with functioning body movement, facial expression, and fine motor movements of hands and fingers while most telepresence systems use an abstracted avatar. 2.2 User Representation and Avatars Different methods to represent users in VR and 3D telepresence have been investigated with respect to body ownership and social presence in previous research, ranging from partial [19] or simplified virtual characters over high-fidelity, personalized avatars [35, 41] to real-time reconstructed point clouds [10, 29] or surface meshes of the actual person. While Kondo et al. [28] found that invisible avatars with minimal visualization (gloves and socks) can create a sense of body ownership in virtual environments, Waltemate et al. [74] showed that detailed customized avatars can greatly enhance body ownership and self-perceived co-presence. Yoon et al. [80] showed that cartoon and realistic user representation in an AR telepresence setup do not impact social presence; however, a significant drop of social presence has been measured by hiding parts of the avatar. Few works analyse the effect of multi-scale avatars [48, 49] an asymmetric telepresence scenario. Walker et al. [73] show in an empirical study that human-sized avatar imposing more influence on the remote user than a miniature-version and is connected to the subjective satisfaction of task outcome. Consequently, we design avatars used in this work to be exact the same height as the users. Gamelin et al. [17] presented a collaborative system in which they compare a number of measures including presence, visual fidelity, and kinematic fidelity between a point cloud representation and an avatar based on 3D reconstruction. 3D reconstructed avatar scores higher in visual fidelity due to lack of artifacts that interfere with the perception of this representation, while the point cloud representation scores much higher in kinematic fidelity. Point cloud representation was only captured from a single depth camera perspective and the personalized avatar had neither facial nor finger animation. We see this as a foundation of our work but we substantially extend it in complexity, involving a real-time captured environment with both live-captured user in point cloud and the addition of novel facial expression and finger tracking technology for the animation of an avatar. Wu et al. [77] compared depth-sensor-based avatar animation against a controller-based Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. YU ET AL.: Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User... animation system and deducted that full body tracking with hand gestures increased virtual body ownership and improved the overall user experience. Non-verbal behavior was also rated higher in the situation with complete body tracking. Albeit RGB-D cameras were used for body tracking, the option for a point cloud representation was not investigated. The portrayed avateering method would have benefited from the addition of facial tracking capabilities and improved body tracking, therefore, providing valuable insights about the possible improvements and techniques. Lombardi et al. [38] and later Chu et al. [12] present methods to generate hyper-realistic faces that are driven by the inbuilt VR cameras. They discuss the difficulties of the traditional morph-able 3D models and their results in testing the Uncanny Valley Effect. This effect can be seen in the comparisons between point cloud representations and character modeled avatars. The solution towards higher realism expressions is presented using similar facial trackers and the inclusion of Modular Codec Avatars that utilize view-dependent neural networks to achieve realistic facial animations. 2.3 Summary 3D telepresence benefits greatly from advances in wearable virtual and mixed reality headsets and manifold methods of avatar representations studied in previous works. However, such wearable display and sensing devices occlude parts of the users face (in the case of head-mounted display (HMD) based VR or AR), preventing external optical sensors from capturing non-verbal cues such as gaze direction, lower and upper facial expressions. Without the employment of offline reconstructed or 3D modeled avatars, for instance, while using a real-time captured point cloud of the user, no communicative cues can be acquired from the upper face without additional effort. Further, while [17] compared single RGB-D sensor-based avatar reconstructions, there have not been any comparisons with multi-user avatar reconstructions based on multisensor RGB-D imaging. 3 S TUDY H YPOTHESES Our study aims to investigate the differences between a point-cloud representation and virtual character user representations for the local user, observed by a remote VR user. We hypothesize • (H1): the task type influences the perception of presence aspects. As we assumed that users during a verbal interaction task would focus more on the other person than compared to a collaborative assembly task, there may be greater social connectedness in the verbal interaction task. From previous works, we derive further hypotheses to guide our research. Following previous work Gamelin et al. [17] we assumed that • (H2): Point-cloud avatars show better kinematic fidelity and perform better at collaborative tasks. Following their argumentation that higher fidelity virtual character avatars could have been superior, we argue that • (H3): Integrating facial and hand animation enhances social presence perception for virtual character avatars in comparison to point cloud avatars since it may allow a more complete conveyance of non-verbal communication cues based on facial expressions and gestures, specifically considering the upper facial occlusions in asymmetric VR/AR telepresence systems. Finally, • (H4): character-based avatars will be perceived as less human and more eerie than point cloud avatars since the real-time animation based on few anchor points from motion tracking would not portray all facets of coarse and subliminal aspects of human behaviour. 4 M ETHODS We conducted a user study using an asymmetric AR/VR telepresence system, to highlight the differences of user representation methods in consideration of the task context, regarding both, subjective and objective aspects. Users were asked to perform two tasks, a verbal and social collaboration task as well as a functional and goal directed collaboration task. We were specifically interested in investigating both, the effect of the avatar type as well as the effect of the task type, assuming there would be different exposure between functional tasks 4131 and verbal (social) interactive tasks as used in [17]. In the next sections, we describe our system and study in more detail. 4.1 Design The study is a two-factor (Avatar Type × Task Type) repeated-measures within-subjects experiment. Participants pairs were asked to perform a warm-up task (20 questions game) as well as a functional task before switching the role between remote guide and local user, so that each participant performed all tasks in both roles. The local user was either represented as a 3D virtual character based - 3DVC avatar, or as a 3D point cloud based reconstruction - PCR avatar. 4.2 Telepresence System We present our multi-faceted telepresence system consisting of (i) realtime room-sized scene reconstruction based on point clouds, (ii) avatar creation, and (iii) multi-modal sensor fusion for character animation. 4.2.1 Scene Capture via Point Cloud Similar to previous approaches [40, 59, 75, 81] we use multiple RGBD sensors to reconstruct a local scene. Our system consists of four hardware synchronized RGB-D cameras (Microsoft Kinect Azure [4] - see [70] for a comparison to previous sensors) that are connected to dedicated capture nodes (MSI Trident 3, 16GB RAM, RTX 2060 GPU) to capture a local scene from multiple viewpoints. Each capture node acquires color and depth images from the attached camera, compresses the images using Nvidia hardware encoders on the GPU, and serves them as real-time streaming protocol (RTSP) endpoints [50]. Human poses are also tracked using the Azure Kinect bodytracking library and transmitted via network. A VR graphics workstation (Core I7, 64GB RAM, RTX 2080Ti) consumes image streams from all capture nodes, feeds them into the real-time reconstruction and visualization component, and displays the reconstructed remote scene on an HTC Vive Pro Eye head-mounted display. To meet the performance and latency requirements, all image processing and network components are implemented as a distributed, multi-threaded data-flow system in C++ and CUDA. Measurements are time-stamped, stored in ring-buffers, and temporally aligned with a window-based matching algorithm to ensure consistent reconstruction. All participating computers are connected via a 1GBit network and synchronized via precision time protocol [1] to allow for accurate frame synchronization after network transmission. The sensor extrinsic parameters are calibrated using 2D-3D pose estimation from 2D correspondences on infrared images detected from a calibration wand with reflective spheres. The reconstructed environment, the local avatar, and the user interface are displayed to the remote user in VR using Unity3D. We integrated the data-flow engine as native Unity3D to achieve low-latency, high-throughput streaming. The reconstruction system uses depth images, extrinsic and intrinsic parameters as input, unprojects them into point clouds, registers them into a global reference frame, and transforms them into textured-surface meshes using a shader pipeline. The spatial registration between the local (HoloLens, AR) and the remote (HTC VIVE, VR) environments is accomplished via a multi-modal registration target consisting of infrared-reflective spheres and a fiducial marker, so that the HoloLens tracking information can be correlated with the reconstructed environment. 4.2.2 Personalized Virtual Character Avatars The avatars of the participants were created using Character Creator 3 (Reallusion [51]) with the Headshot plugin. Virtual characters were created using a single portrait photograph of the participant’s face. Avatars resulting from the procedure are rigged with desired blendshapes for facial animations, matching hair and eye color, and dressed in a resembling way to the participant’s attire. Ethnicity, gender, and body measures were additionally accounted for and included for the most resemblance to the participant’s look on the day of the study. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. 4132 IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 27, NO. 11, NOVEMBER 2021 Fig. 2: The telepresence system used in the study. (a) First person and (b) third person view of the local user. (c) Mixed reality capture in the shared environment using a HoloLens 2. (d) First person and (e) external view of the remote user in the 3DVC condition. A remote participant is immersed in a 3D reconstructed local scene, and can interact with a local participant. While the scene is displayed to the remote participant rendering the local participant either as point cloud avatar or virtual character-based avatar by masking the respective point cloud, the remote user is always represented as virtual character based avatar. Fig. 3: Motion tracking and avatar animation of the remote user for the 3DVC condition. Left: Five pose trackers are attached to the waist, arm and legs of the user. The dominant hand holds the VR stylus. Right: A VR head-mounted display with integrated eye-tracker and an lip capture extension animates facial expression of the virtual avatar. Strategies for puzzle annotations were different, some annotated drawings in the air (as seen in c), whereas others annotated correct placements on the puzzle table. 4.2.3 Remote User Avatar There are several methods to animate an avatar representation based on the user’s pose. In the case of a remote expert avatar, inverse kinematics approach was selected due to the compatibility of the tracking systems with the HMD worn by the participant, see Figure 3. We used five HTC VIVE trackers attached to the waist, lower arms, and ankles of the remote user (VR) as seen in Figure 3. The tracking latency is minimal and does not appear to show perceivable latency. The resulting data is processed by kinematic human pose solvers with no additional perceivable latency as a sequential list of muscle values to establish the corresponding body pose. The body pose is then applied to the 3DVC avatar model using the HumanTrait Unity3D animation module. Finger motions were limited to the predefined gestures based on the interaction with the stylus: base (muscle values of zero), idle (resting hand state) and a VR stylus grabbing posture. Finally, to assist the self-body image, inverse kinematics of the dominant hand working with the VR stylus were adjusted and fused from the pure wrist tracking to aid accurate hand location based on the controller’s position. The facial expressions of a character avatar were controlled through the use of blendshapes. Facial expression retargeting was split into upper and lower facial animations. Upper facial animations were controlled by the inbuilt eyetracking of the VIVE Pro Eye VR HMD. This camera module, enabled through the collaboration with Tobii Eye Tracking (HTC VIVE Pro eye with Tobii [71]), delivers eye tracking information and furthermore eyebrow and eyelid motion predictions. Eye tracking information is converted through the use of the Tobii SDK into gaze directions that are remapped onto the avatar eye muscle movements. The eye muscle motions were clamped in up-down and left-right motion directions to limit the eye rotations to biologically-allowed ranges. Additionally, the lower facial animation is controlled by a separate HTC lipsync facial tracker prototype (now announced as “Facial Tracker”) mounted on the front of the VIVE Pro Eye VR HMD as seen in Figure 3. The module was mounted in front of the participant’s mouth with the use of a designed 3D-printed headset mount that allowed for correct viewing angle for the IR camera of the lip tracker. Up to 38 distinct facial movements can be derived from the lipsync tracker and are retargeted to the 3DVC blendshapes similar to upper facial animations, which allowed the 3DVC to portray facial expressions of the remote expert. Finally, the body motions, upper and lower facial expressions, as well as eye motion muscle values are synchronized via Unity UNet networking as human pose to all clients in the simulation using a distributed server-client architecture. 4.2.4 Local User Avatar Similar to the remote expert, local user animation is split into several important directions: body motion, facial expression motion, and finger/hand tracking motion. These techniques vary in implementation compared to the remote user; however, they inhibit similarities in network synchronization and remote avatar retargeting. Local user embodiment implementation follows two variations as discussed before: PCR and 3DVC. PCR Representation The PCR representation (see Figure 4, right) equals the overall reconstruction of the environment. Similar to the environment, the local user is reconstructed fusing the calibrated point clouds from multiple RGB-D sensors and thus multiple camera views. The data is then transformed into a textured-surface mesh representing the avatar. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. YU ET AL.: Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User... 3DVC Body Tracking To realize the 3DVC avatar representation (see Figure 4, left) we utilized an optimally oriented Azure Kinect camera with the Microsoft Body Tracking SDK to animate the avatar of the local user during the respective experimental condition. Unlike wearable trackers, such pose estimation does not require the attachment of additional devices onto the user’s body. In our study, we deploy this body tracking method for the local user and combine it with the optical see-through HMD HoloLens 2 capabilities of eye tracking and hand-tracking. Hand tracking provided by HoloLens 2 HMD provides an additional kinematic feature to animate the 3DVC. A global pose that includes positions and rotations of the finger and wrist joints can be deducted from the HandTracking MRTK module. Local rotations are calculated and transformed into muscle movements that are applied to the avatar representation. Wrist joint is treated at the highest hierarchy element that proximal finger phalanges are related to, and using the alignment relationship between AR and VR worlds, this joint is transformed to provide locally accurate muscle value to the avatar’s hand movement. Knowledge of the global hands’ poses derived from the HMD’s hand tracking, permits for accuracy improvement of avatar’s wrist position, which otherwise depends on the Kinects capability of finding the hand location based on the thumb, palm and handtip positions. The HoloLens 2 eye tracking was used to track and replicate eye motions. Lower facial expressions was reproduced by using speech-toanimation (SALSA LipSync). To exchange the PCR avatar with the 3DVC avatar, point cloud masking was implemented on the basis of Kinect Azure body tracking to correctly detect and remove the point cloud belonging to the user and replace it with the relevant avatar representation. The masking region was slightly dilated to compensate for the possible artifacts corresponding to quick movements and unexpected or simply poor boundaries. Additional masking of the table region was applied to prohibit surface deformations in the 3DVC condition, to avoid artifacts. Finally, verbal communication was established via voice over IP. Participants used headphones and built in- and external microphones in order to communicate. A comparison and close up view of the two avatar conditions is depicted in Figure 4. Latency Assessment We assessed body movement latency by frame counting of the climax of repetitive body movements (clapping) using a high-speed camera capturing both, the original motion and the displayed motion at the Unity (remote) client with a Eizo EV2735 screen (approx. 35 ms input lag). Body movements were replicated within M = 566.30 ms (SD = 41.14 ms) for the 3DVC condition, and within M = 502, 31 ms (SD = 23.23 ms) for the PCR condition. The data was assessed with 45 samples and full network transmission as present in the actual study. Note that this latency values consider the latency of the telepresence system, therefore the transmission and replication of the local scene and local user movements to the remote VR simulation. The VR simulation as such (i.e., movements of the VR user in the simulation and camera/perspective motion) was rendered in with regular, and thus little and negligible latency. 4.3 Task Description The study is conducted using a set of two tasks. In order to evaluate the effect of a missing facial expression from PCR, we chose tasks in (1) a verbal communication and (2) a task-oriented collaboration. Based on the combination of both tasks, we anticipate to draw conclusion on the importance of facial animations for avatar representations. 4.3.1 20 Question Game The first task was the popular “20 Questions Game”, in which one person asks his or her peers up to 20 questions that can only be answered by yes or no to find a specific item that only that person does not know. During the study, this game is played uni-directional with the local user deciding on an item while the remote user asks questions. The participants positioned themselves facing each other inside the virtual space and had no additional helping materials. The remote users saw the real-time reconstructed point cloud environment and the local 4133 Fig. 4: Close-up view on both conditions from the perspective of the remote user in VR. Left: local user embodied as 3D virtual character avatar (3DVC). Right: local user embodied as point cloud based representation (PCR). Fig. 5: Illustration of the 20 Question warm-up task. Users had direct face-to-face exposure without object attention/distraction. user either visualized using 3DVC or PCR. If remote users looked down toward their own body or at their arms, they could see their own personalized avatar animated through inverse kinematics. User presentations of both participants were visualized in the same spatial relationship to each other and the room in VR and AR. 4.3.2 Collaborative Puzzle Solving The second task is a puzzle in which they arrange uncommon symbols and shapes in a given order, orientation, and color (as seen in Figure 6) in front of the local user. The remote user can draw 3D sketches in the air, visible by both users, to describe the symbols. We chose colors for this task such that protanopia and deuteranopia color-blindnesses (red-green weakness) would not affect the outcome. Each of both tasks is limited to eight minutes. This intends to restrain fatigue from influencing the result of the study. Both participants take on the roles of a local user and a remote user. The participants positioned themselves on each side of the table. We installed an RGB-D camera behind the location of the remote user, as seen in Figure 2(c) to improve the captured quality from the perspective of the remote user. The local user can see the avatar of the remote user and virtual annotations visualized in-situ inside the room but has no information regarding the final configuration of the puzzle. The remote user can see a virtual floating image of the desired puzzle configuration, as seen in Figure 6, next to the user representation of the local user, but is unable to see the remaining puzzle pieces in the designated area on the table marked with a red line. Remote users are represented using their personalized avatar equally to the previous task. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. 4134 IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 27, NO. 11, NOVEMBER 2021 Fig. 6: The four puzzles used for the puzzle task. The puzzles were pseudo randomly assigned for each trial in balanced fashion. Each puzzle included the same tiles in different arrangements. experimental conditions, all devices are disinfected, and participants switched their roles and repeated the study once more. COVID-19 measures: Experimenters wore masks during the experiment and kept distance to the participants. Participants wore masks except for the time of the task and were placed in remote rooms. Equipment and surfaces were carefully disinfected after each trial block, disinfectant was provided, and exchange devices were prepared for the participant switch. Rooms were sufficiently ventilated. Previous visits to risk areas and any symptoms or contact with infected persons were strict exclusion criteria. Participants were clarified of these conditions upfront, and all participants consented. The study was conducted in accordance with the local COVID-19 regulations with necessary precautions and in accordance with the declaration of Helsinki. 4.5 Measures This study aims to determine if and how different user representations affect the completion of shared tasks. In addition to the quality of the task completion, we also measure perception of presence (including copresence, telepresence, and social presence) between users, kinematic fidelity and perception of the user representation. Participants have no knowledge of the expected outcomes; however, are briefed of their roles in the teleconsultation scenario. 4.5.1 Objective Performance Measures To assess potential impacts on user performance, we measured the time on task during the puzzle task with a maximum time cap of 8 minutes. Further, we evaluated the correct placement of symbol, shape, and color tiles, compared to the instruction template by the study director visible for the remote participant. The number of errors was counted and analyzed. Fig. 7: Study procedure. After initial instructions and pre-study questionnaires, both users performed both roles in repetitions, one time where the local participant was represented by a point cloud reconstructed avatar, and one time where the local participant was represented by a virtual character based avatar. Each pair performed four trials of each task. Avatar questionnaires include questions on presence, eeriness, behaviour, and visual coherence of avatars during the tasks. 4.4 Procedure The study was conducted in pairs. The procedure is illustrated in Figure 7. We welcomed each participant separately and guided them to separate rooms. The first phase of the study is led by an initial demographics questionnaire and followed by vision tests, including the Ishihara test for color-blindness [24] and a Landolt-C vision acuity test. Each participant was randomly assigned to a role of either local user or remote user. Remote users interact from within virtual reality. To animate their digital representation, i.e. the avatar, users get five VIVE trackers, which they attach to their waist, arms, and legs. (see Figure 3). In their dominant hand, they use a VR stylus (Logitech VR Ink) to create 3D freehand annotations within the shared environment. Local users wore an optical see-through head-mounted display (Microsoft HoloLens 2) which allowed them to see the avatar of the remote users and their annotations. The participants were allowed to familiarize themselves with the devices for a maximum of 10 minutes. Once they felt confident, we continued explaining their role and task in the upcoming task (as described in section 4.3. A questionnaire was employed after finishing each task (both 20 question game and puzzle) as further described in section 4.5.2. Once they finished all tasks of both 4.5.2 Subjective Measures After each task, participants were asked to complete questionnaires to assess copresence, telepresence, and social presence using the measure from Nowak & Biocca [43], self-location using the measure by Vorderer et al. [72], as well as uncanniness and eeriness perception toward the AR participant’s avatar using the measure by Ho & MacDorman [22] with 7-point Likert type scales (see the sources for the respective anchors). In addition, we adapted a behavior impression measure from [55] and asked the VR remote participant after each task how natural (“The displayed behavior was natural”), realistic (“The displayed behavior was realistic”), and how synchronous (“All displayed behavior was synchronous/in natural rhythm”) she/*/he perceived the behavior of the other participant with a 7-point scale. The scores were then aggregated to a measure for behavior impression. For assessing the perceived visual coherence of the avatars in the point cloud reconstruction, we added questions on a 7-point Likert scale regarding to what extent (not at all - extremely) the avatar “fit with the environment”, “disturb the perception of the environment clues”, “complement the environment”, and “present artifacts that disturbed the collaboration”. In addition, we asked the users to respond to the system usability scale (SUS) [9] with a 7-point scale [14] and the fast motion sickness scale (FMSS) [25] with a sliding scale from 1-100 after each study condition. Additional comment fields were provided to allow participants to describe two positive and negative aspects on the method of the user representation. 4.6 Participants In total, N = 24 participants (Mage = 23.83, SDage = 2.31) were recruited via mailing lists and campus announcements. Of those, 18 were students, mainly from STEM fields. 8 participants were female, 16 male. Participants stated to spend time with digital media (PC, mobile phone, etc.) for about 59.79 hours per week (SD = 21.30). 21 participants noted to have used VR systems before, and 13 participants noted to have used AR systems before. The average amount of previous VR usage was M = 6.04 times, ranging between 0 and 40, excluding a single outlier participant with 300 times. The majority of participants had between 1 and 20 previous experiences and a regular use of M = 0.33 h per week with VR. The average amount of AR usage was M = 1.04 Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. YU ET AL.: Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User... Table 1: Comparisons for Avatar Type as perceived by the remote participant. Note. Descriptive statistics depict M ± SEM. Dependent Variable PCR Avatar 3DVC Avatar F(1, 23) p η p2 Self-perc. Copresence Perc. other’s Copresence Telepresence Social Presence Self-location Behavior Impression Humanness Eeriness Visual Coherence 5.27±.15 5.23±.19 5.28±.20 4.75±.20 5.31±.22 5.07±.19 4.82±.22 3.75±.10 4.91±.09 4.91±.18 4.95±.19 5.12±.20 4.02±.22 5.15±.21 3.96±.29 3.05±.23 3.82±.16 4.68±.10 11.34 11.85 1.79 15.18 2.05 24.35 32.00 .35 1.21 .003 .002 .194 .001 .166 <001 <.001 .560 .276 .330 .340 .072 .398 .082 .514 .582 .015 .030 Table 2: Comparisons for Task Type as perceived by the remote participant. Note. Descriptive statistics depict M ± SEM. Dependent Variable 20 Q Task Puzzle Task F(1, 23) p η p2 Self-perc. Copresence Perc. other’s Copresence Telepresence Social Presence Self-Location Behavior Impression Humanness Eeriness Visual Coherence 4.98±.15 4.91±.16 4.79±.22 4.09±.21 4.90±.22 4.40±.21 3.91±.18 3.78±.12 4.65±.10 5.19±.17 5.26±.21 5.61±.18 4.67±.18 5.56±.21 4.63±.26 3.96±.19 3.79±.13 4.94±.09 5.15 10.36 56.70 26.33 29.60 1.67 0.84 .001 2.23 .033 .004 <.001 <.001 <.001 .209 .774 .979 .133 .183 .311 .711 .534 .563 .068 .004 .000 .050 times, ranging between 0 and 5, excluding outlier participants once with 100 and once with 300 times. However, no participant stated any regular use AR per week. Five participant pairs knew each other before. To avoid any bias from visual impairments, we assessed a Landolt C-Test (EN ISO 8596) for acuity and a Color blindness test for color deficiency. One participant was partly color blind and one participant had slightly inferior acuity. All other participants had normal or corrected-to-normal vision regarding acuity. Given our trials and the color scheme used in the tasks, we found that all participants were capable of performing the experiment. 5 R ESULTS 5.1 Objective Performance Results A Shapiro Wilk test showed that data was not normally distributed within the sample. Wilcoxon signed-rank tests showed no significant effects for time (z = −1.338, p = .181, r = .202) or error assessments (z = −.754, p = .451, r = .114) of the puzzle tasks when comparing those measures for point-cloud based avatar vs. the virtual character-based avatar. On average, participants needed M = 400 s (SD = 103.30 s, Median = 437.0) to complete the puzzle when the local expert was represented as virtual character based avatar, and M = 370 s (SD = 82.12 s, Mdn = 376.0) when the local participant was represented as point cloud reconstructed avatar. Errors were similarly distributed with a mean of M = 1.27 (SD = 1.75, Mdn = 1) errors in the virtual character based avatar condition, and M = .91 (SD = 1.37, Mdn = 0) errors in the point cloud condition. 5.2 Subjective Results We performed two-way (Avatar Type × Task Type) repeated measures ANOVAs to assess the subjective results. Sphericity could be assumed for all subjective data, assessed by Maulchy’s test of sphericity. Table 1 depicts the ANOVA results and descriptive statistics for Avatar Type and Table 2 the results for Task Type for the presence and behavior impression measures. 5.2.1 Presence An ANOVA for self-perceived copresence showed a significant main effect for Avatar Type (p = .003). The self-perceived copresence by 4135 the remote expert was significantly greater with the PCR Avatar in comparison to the 3DVC Avatar. In addition, the task type significantly influenced the overall perception of the self-perceived copresence by the remote VR participant, which was greater in the puzzle task (p = .033). Similarly, the perceived other’s copresence was rated greater by the VR remote participant with the PCR avatar in comparison to the 3DVC avatar, and greater when performing the puzzle task. There was no significant effect of the avatar type on telepresence. However, as expected, the participants in the remote user role perceived significantly higher telepresence in the puzzle task (p < .001). Similarly to the copresence measures, social presence was increased with the PCR avatar, compared to the 3DVC avatar p = .001. In addition, it was also affected by the task type. It seems that due to the coordinated interaction and active collaboration, participants perceived a higher degree of social presence (p < .001) in the puzzle task, compared to the 20 questions task. Participants in the remote user role perceived significantly greater self-location from the puzzle task, as compared to the 20 questions task (p < .001), which was expected, given that there were higher degrees of interaction in the environment. The avatar type of the interaction partner did not affect the self-location rating. No further main or interaction effects were observed for the presence measures. 5.2.2 Behavior Impression, Humanness, Eeriness, Coherence We analyzed the measures for behavior impression by aggregating the scores of the impression questions. ANOVA revealed that there was a significant impact of the avatar type on the perception of the behavior. Participants had a more realistic and naturalistic impression of the PCR avatar (p < .001), potentially due to tracking artefacts. Furthermore, the perceived humanness was rated significantly higher with the PCR avatar (p < .001), whereas there was no significant effect on eeriness from neither of the avatar representations in comparison. Neither the behavioral impression, nor the humanness or eeriness perception were affected by the task type (ps >= .209). No further main or interaction effects were observed. This includes that no significance can be observed for visual coherence in correlation to task type and conditions. 5.2.3 System Usability The system usability score was assessed as a combined measure after both tasks for each avatar type. Data was normally distributed, assessed by Shapiro-Wilk test. The system usability score [9], assessed with a 7-point scale [14] and normalized to result in responses between 0 and 100, showed a significant effect for Avatar Type; t = 2.19, p = .039. The system that used the PCR avatar resulted in an above average score of M = 72.08 (SE = 2.85), whereas the 3DVC avatar based system resulted in a lower score of M = 68.61 (SE = 2.96), which was however still above average according to the SUS rating. 5.2.4 Motion Sickness The data resulting from the FMSS [25] was not normally distributed, as evaluated by a Shapiro Wilk test. A Wilcoxon signed rank test showed no significant differences between the conditions for the remote VR participant (p = .204). The Mdn for both conditions was 1. Overall, four users rated their motion sickness perception minor (above 15), with the highest ratings being 21 and 22. Therefore, no severe sickness effects or significant differences of these effects between the conditions were observed in the study. 5.2.5 Qualitative Comments The qualitative comments collected from the users substantiated our quantitative findings. For the PCR representation users stated, for example, that the PCR avatar “looks more like a person, and moves more naturally”, that it “was very natural and realistic and human like”, that it “looks a little bit less realistic but feels more alive”. One user preferred the PCR avatar “because it seemed more like a real person”. But the users also stated obvious issues like “facial expressions sometimes were not clear and a bit messed up” in the PCR avatar, or that there was “no sense of eye contact -graphics didn’t seem organic-”, Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. 4136 IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 27, NO. 11, NOVEMBER 2021 Fig. 8: Results of the subjective assessments in comparison per avatar and task. Red lines within the box plots depict the median value while black circles depict mean values. Top and bottom edges visualize 25th and 75th percentile. or that “unemotional facial expression made it seem scary”. Overall, these impressions were similar across users. Regarding the 3DVC avatar the participants stated that “avatar wasn’t very life like and thus hard to connect to”. However, participants also mentioned that the “Person seemed more stable (like less popping in and out of little points as with the point cloud) ” and that the 3DVC avatar “felt more real to interact with person, avatar had good proportions”. Regarding potential tracking artefacts, comments were also mentioning “the avatar of the other person can be slightly distracting (if body parts are facing in a strange direction)”. Moreover, 7 participants stated PCR avatar looks more natural while 4 participants preferred the 3DVC avatar since its gestures were clear and free of artefacts of the point cloud. 8 participants stated that the point cloud has low resolution or is noisy. Latter two statements are summarized with “[it was] easier to focus on the person in the environment (kind of like if you take a picture and the background is blurry but the person is in focus)”. 6 D ISCUSSION We investigated the impact of local user avatar representations in an asymmetric telepresence system. In our study, we compared two different representation types, a point cloud based representation (PCR) and a virtual character based representation (3DVC) driven by kinematic tracking. Both avatar types were based on Kinect Azure RGB-Depth sensing (PCR) and body pose tracking in combination with eye tracking and hand tracking from the HoloLens 2 as well as speech to animation (3DVC). H1: We found that overall, the point cloud representation was superior to the virtual character based representation, with regard to presence aspects, behavior impression, and humanness. Further, it seems that the task type plays a role in the perception of perceived copresence, social presence, and self-location. However, contrary the anticipation in hypothesis, the collaborative puzzle task contributed more to perceived presence measures compared to the verbal task. H2: Our results are partly in line with previous findings on point cloud comparisons [17]. However, we could not confirm the hypothe- sized improved collaborative task performance, as suggested by prior work. There was no significant difference in collaborative performance in the puzzle task. H3: Further, as interpreted from the prior research [8, 17], the potentially improved behavioral realism by the transmission of facial behaviors in the 3DVC avatar, compared to missing gaze cues with the PCR avatar, did not improve the overall behavior impression, nor the social presence aspects. In contrast, both measures led to higher ratings with the PCR avatar. We interpret the reason for this in the yet not sufficiently convincing tracking and replication of the 3DVC, based on the RGB-depth sensor based body tracking, in combination with speech to animation and gaze as well as hand tracking, performed by the HoloLens 2. Previous research suggests that tracking artefacts and tracking fidelity strongly impact the perception of related aspects, such as embodiment [13, 55]. We can therefore not confirm that “any image is better than no image” [43] with regard to the behavioral fidelity transmitted. It seems that the level of realism, robustness and naturalness of the behavior displayed plays an important role regarding the perceived copresence, social presence, and humanness. Regenbrecht et al. [52] theorize that visually coherent avatar and environment representations are relevant for the perceived presence. This suggests that a cause for lower perceived presence on 3DVC could be its unnatural fit inside the point cloud. However, we can neither confirm nor deny this theory, since participants did not perceive a significant difference on environmental fit of conditions within the point cloud. Based on the observation, we assume, visual coherence was perceived similar between conditions. Li et al. [36] argued that user representations which are not perceived as “real” deliver lower social presence and behaviour impressions. This explanation co-aligns with our observations, therefore, consider 3DVC not as a real person while considering PCR as real. Placing our conditions into the context of the work of Li et al., 3DVC is perceived less physically present and acting more as an embodiment compared to PCR, and therefore, showed lower social presence. While we assume the same holds true for the coherence between the behaviors transmitted, our study design does not allow to draw any conclusions in that regard. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. YU ET AL.: Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User... H4: The perceived eeriness was not significantly greater with the 3DVC avatar, which we interpret to be because we utilized human pose solvers and limited the gaze behavior to human boundaries similar to previous work [53]. Hence our findings only partially support hypothesis. While the 3DVC avatar was perceived less human, we did not find significant differences in the perception of eeriness, which is why we conclude that the 3DVC avatar was not perceived particularly eerie. Nevertheless, we believe that tracking artefacts played a role in the perceptual ratings. A related work from Choi et al. [11], to part, supports this assumption. They interpreted that artefact prone locomotion types may benefit from not showing the respective body parts, as “glide motion showed a notably increased naturalness score in head-to-knee visibility, presumably because the foot sliding artifacts became less visible” [p.8]. Therefore, future work should investigate more robust tracking approaches, such as with pose fusion systems drawing information from multiple cameras. Another interpretation of our findings is, that the level of coherence may have partially affected the perception of the remote participants judging the presented avatar. For example, Mac Dorman and Chattopadhyay [39] argue that decreasing consistency in human realism in avatar images results in an increase in the perception of uncanny valley categories. A similar aspect could be argued for our study, while the 3DVC avatar was not entirely out of consistency with the environment, it is clear that the PCR avatar was exactly fitting the style and presentation of the environment reconstruction, as the same system was used for the avatar and for the environment. 6.1 Limitations Our study shows some limitations. First, the warm-up task was not strictly defined in length and could be ended quickly, when the participants had the correct guess, or end at a maximum time of 8 minutes. We picked this task specifically, as most participants could potentially relate to the game and “warm up” their collaboration. However, future work may consider using a task that results in stronger bonding or emotion elicitation. Second, our personalization was not utilizing photogrammetry scanning [74], but rather single portrait images and approximated facial reconstruction and standardized clothes, which the participants were asked to wear. We can thus not blindly generalize our found effects to avatars, created from full photogrammetry setups or even more abstract avatars. For future studies, we will let participants rank the similarity of the avatars with their perceived self, to further be able to draw conclusions. Third, we did not use sophisticated pose fusion algorithms to fuse the avatar poses from multiple cameras. In our pilot studies, we found that the approaches using fusion methods, Kalman filters, or alike, introduced large additional parts of latency, which is why we prioritized a comparability between the two systems in this regard. Finally, the order of tasks was fixed in our experiment, i.e., the warm-up task was always performed before the collaborative puzzle task. This was an experimental consideration due to the fact that we first wanted to expose the participants to the full avatars without any focus, before asking them to perform collaborative task actions. Future research should identify further means of comparisons for task and context types, such as different social interaction tasks and context modifications. 6.2 Future Work In future work, we aim to improve the overall tracking fidelity by using additional marker-based systems with the local participant for a better ground truth assessment, and/or multi-modal sensor fusion. In addition, other avatar types may be investigated, that are either more abstract or blend in better with the reconstruction. Further, one potential approach could be to also improve the PCR avatar by using generative adversarial networks in order to generate the occluded face from lower face motion or voice, according to image templates [12]. However, the latter may require the introduction of additional sensing, such as stretch sensing, additional cameras, or EMG. Finally, we aim to investigate affective and emotional situations, assuming that these may suffer most from the limited possibilities to transmit facial displays in asymmetric systems. 7 4137 C ONCLUSION In this paper, we presented a comparison between two representations for a local user in an asymmetric VR/AR telepresence system, namely a point-cloud reconstruction based avatar representation, and a virtual character based avatar representation. Our results indicate that the point-cloud based reconstruction that visualized the local user’s avatar as 3D mesh, calculated from point cloud input, was beneficial with regards to copresence, social presence, and humanness aspects. This approach scored higher in system usability, whereas there was no performance increase. We further found indications that presence aspects were task dependent. We conclude that the personalized virtual character surrogates of the local user representation are inferior with regards to fidelity and environment coherence. Future investigations may improve tracking fidelity and robustness, and investigate hybrid solutions for the reconstruction of upper facial cues for a HMD wearing local participant. ACKNOWLEDGMENTS The authors wish to thank Andreas Keller for his help in carrying out the user study. This work was supported by the German Federal Ministry of Education and Research (BMBF) as part of the project ArtekMed (Grant No. 16SV8092) R EFERENCES [1] IEEE 1588-2008 - IEEE Standard for a Precision Clock Synchronization Protocol for Networked Measurement and Control Systems. https://standards.ieee.org/standard/1588-2008.html. [2] J. N. Bailenson, A. C. Beall, J. Loomis, J. Blascovich, and M. Turk. Transformed social interaction: Decoupling representation from behavior and form in collaborative virtual environments. PRESENCE: Teleoperators and Virtual Environments, 13(4):428–441, 2004. [3] J. N. Bailenson and J. Blascovich. Avatars. Encyclopedia of HumanComputer Interaction, pp. 64–68, 2004. [4] C. S. Bamji, S. Mehta, B. Thompson, T. Elkhatib, S. Wurster, O. Akkaya, A. Payne, J. Godbaz, M. Fenton, V. Rajasekaran, L. Prather, S. Nagaraja, V. Mogallapu, D. Snow, R. McCauley, M. Mukadam, I. Agi, S. McCarthy, Z. Xu, T. Perry, W. Qian, V. Chan, P. Adepu, G. Ali, M. Ahmed, A. Mukherjee, S. Nayak, D. Gampell, S. Acharya, L. Kordus, and P. O’Connor. Impixel 65nm Bsi 320mhz Demodulated Tof Image Sensor with 3µm Global Shutter Pixels and Analog Binning. In 2018 IEEE International Solid - State Circuits Conference - (ISSCC), pp. 94–96, 2018. doi: 10.1109/ISSCC.2018.8310200 [5] S. Beck, A. Kunert, A. Kulik, and B. Froehlich. Immersive Group-toGroup Telepresence. IEEE transactions on visualization and computer graphics, 19(4):616–625, 2013. [6] S. Benford, J. Bowers, L. E. Fahlén, C. Greenhalgh, and D. Snowdon. User embodiment in collaborative virtual environments. In Proceedings of the SIGCHI conference on Human factors in computing systems, pp. 242–249, 1995. [7] G. Bente, S. Rüggenberg, N. C. Krämer, and F. Eschenburg. Avatarmediated Networking: Increasing Social Presence and Interpersonal Trust in Net-based Collaborations. Human communication research, 34(2):287– 318, 2008. [8] J. Blascovich. Social influence within immersive virtual environments. In The social life of avatars, pp. 127–145. Springer, 2002. [9] J. Brooke. SUS: A Quick and Dirty Usability. Usability evaluation in industry, 189, 1996. [10] S. Cho, S.-w. Kim, J. Lee, J. Ahn, and J. Han. Effects of Volumetric Capture Avatars on Social Presence in Immersive Virtual Environments. In 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 26–34. IEEE, 2020. [11] Y. Choi, J. Lee, and S. Lee. Effects of Locomotion Style and Body Visibility of a Telepresence Avatar. In 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 1–9, 2020. doi: 10.1109/VR46266.2020 .00017 [12] H. Chu, S. Ma, F. De la Torre, S. Fidler, and Y. Sheikh. Expressive telepresence via modular codec avatars. In European Conference on Computer Vision, pp. 330–345. Springer, 2020. [13] J. C. Eubanks, A. G. Moore, P. A. Fishwick, and R. P. McMahan. The Effects of Body Tracking Fidelity on Embodiment of an Inverse-Kinematic Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. 4138 [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL. 27, NO. 11, NOVEMBER 2021 Avatar for Male Participants. In 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 54–63. IEEE, 2020. K. Finstad. Response interpolation and scale sensitivity: Evidence against 5-point scales. Journal of usability studies, 5(3):104–110, 2010. R. Fribourg, N. Ogawa, L. Hoyet, F. Argelaguet, T. Narumi, M. Hirose, and A. Lécuyer. Virtual co-embodiment: Evaluation of the sense of agency while sharing the control of a virtual body among two individuals. IEEE Transactions on Visualization and Computer Graphics, 2020. H. Fuchs, G. Bishop, K. Arthur, L. McMillan, R. Bajcsy, S. Lee, H. Farid, and T. Kanade. Virtual Space Teleconferencing Using a Sea of Cameras. In Proc. First International Conference on Medical Robotics and Computer Assisted Surgery, vol. 26, 1994. G. Gamelin, A. Chellali, S. Cheikh, A. Ricca, C. Dumas, and S. Otmane. Point-cloud Avatars to Improve Spatial Communication in Immersive Collaborative Virtual Environments. Personal and Ubiquitous Computing, pp. 1–18, 2020. M. Garau, M. Slater, V. Vinayagamoorthy, A. Brogni, A. Steed, and M. A. Sasse. The Impact of Avatar Realism and Eye Gaze Control on Perceived Quality of Communication in a Shared Immersive Virtual Environment. In Proceedings of the SIGCHI conference on Human factors in computing systems, pp. 529–536, 2003. J. Grubert, L. Witzani, E. Ofek, M. Pahud, M. Kranz, and P. O. Kristensson. Effects of Hand Representations for Typing in Virtual Reality. In 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 151–158. IEEE, 2018. F. Herrera, S. Y. Oh, and J. N. Bailenson. Effect of behavioral realism on social interactions inside collaborative virtual environments. PRESENCE: Virtual and Augmented Reality, 27(2):163–182, 2020. D. M. Hilty, K. Randhawa, M. M. Maheu, A. J. McKean, R. Pantera, M. C. Mishkind, et al. A Review of Telepresence, Virtual Reality, and Augmented Reality Applied to Clinical Care. Journal of Technology in Behavioral Science, pp. 1–28, 2020. C.-C. Ho and K. F. MacDorman. Revisiting the Uncanny Valley Theory: Developing and Validating an Alternative to the Godspeed Indices. Computers in Human Behavior, 26(6):1508–1518, 2010. J. Hollan and S. Stornetta. Beyond being there. In Proceedings of the SIGCHI conference on Human factors in computing systems, pp. 119–125, 1992. S. Ishihara et al. Tests for Color Blindness. American Journal of Ophthalmology, 1(5):376, 1918. B. Keshavarz and H. Hecht. Validating an Efficient Method to Quantify Motion Sickness. Human factors, 53(4):415–426, 2011. K. Kilteni, J.-M. Normand, M. V. Sanchez-Vives, and M. Slater. Extending Body Space in Immersive Virtual Reality: A Very Long Arm Illusion. PloS one, 7(7):e40867, 2012. J. Kolkmeier, E. Harmsen, S. Giesselink, D. Reidsma, M. Theune, and D. Heylen. With a little help from a holographic friend: The openimpress mixed reality telepresence toolkit for remote collaboration systems. In Proceedings of the 24th ACM Symposium on Virtual Reality Software and Technology, pp. 1–11, 2018. R. Kondo, M. Sugimoto, K. Minamizawa, T. Hoshi, M. Inami, and M. Kitazaki. Illusory Body Ownership of an Invisible Body Interpolated Between Virtual Hands and Feet via Visual-motor Synchronicity. Scientific reports, 8(1):1–8, 2018. M. Kowalski, J. Naruniec, and M. Daniluk. Livescan3d: A Fast and Inexpensive 3d Data Acquisition System for Multiple Kinect V2 Sensors. In 2015 international conference on 3D vision, pp. 318–325. IEEE, 2015. A. Kreskowski, S. Beck, and B. Froehlich. Output-Sensitive Avatar Representations for Immersive Telepresence. IEEE Transactions on Visualization and Computer Graphics, 2020. C. O. Kruzic, D. Kruzic, F. Herrera, and J. Bailenson. Facial expressions contribute more than body movements to conversational outcomes in avatar-mediated virtual environments. Scientific Reports, 10(1):1–23, 2020. P. Ladwig and C. Geiger. A Literature Review on Collaboration in Mixed Reality. In International Conference on Remote Engineering and Virtual Instrumentation, pp. 591–600. Springer, 2018. M. Latoschik, D. Roth, D. Gall, J. Achenbach, T. Waltemate, and M. Botsch. The Effect of Avatar Realism in Immersive Social Virtual Realities. In Proceedings of ACM Symposium on Virtual Reality Software and Technology, pp. 39:1–39:10. Gothenburg, Sweden, 2017. doi: 10. 1145/3139131.3139156 M. E. Latoschik, F. Kern, J.-P. Stauffert, A. Bartl, M. Botsch, and J.-L. [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] Lugrin. Not Alone Here?! Scalability and User Experience of Embodied Ambient Crowds in Distributed Social Virtual Reality. IEEE transactions on visualization and computer graphics, 25(5):2134–2144, 2019. T.-Y. Lee, P.-H. Lin, and T.-H. Yang. Photo-realistic 3d Head Modeling Using Multi-view Images. In International Conference on Computational Science and Its Applications, pp. 713–720. Springer, 2004. J. Li. The Benefit of Being Physically Present: A Survey of Experimental Works Comparing Copresent Robots, Telepresent Robots and Virtual Agents. International Journal of Human-Computer Studies, 77:23–37, 2015. R. Li, K. Olszewski, Y. Xiu, S. Saito, Z. Huang, and H. Li. Volumetric Human Teleportation. In ACM SIGGRAPH 2020 Real-Time Live!, SIGGRAPH ’20. Association for Computing Machinery, New York, NY, USA, 2020. doi: 10.1145/3407662.3407756 S. Lombardi, J. Saragih, T. Simon, and Y. Sheikh. Deep appearance models for face rendering. K. F. MacDorman and D. Chattopadhyay. Reducing Consistency in Human Realism Increases the Uncanny Valley Effect; Increasing Category Uncertainty Does Not. Cognition, 146:190–205, 2016. A. Maimone and H. Fuchs. A First Look at a Telepresence System with Room-sized Real-time 3d Capture and Life-sized Tracked Display Wall. Proceedings of ICAT 2011, to appear, pp. 4–9, 2011. A. Mao, H. Zhang, Y. Liu, Y. Zheng, G. Li, and G. Han. Easy and Fast Reconstruction of a 3D Avatar with an RGB-D Sensor. Sensors, 17(5):1113, 2017. M. Minsky. Telepresence. 1980. K. L. Nowak and F. Biocca. The Effect of the Agency and Anthropomorphism on Users’ Sense of Telepresence, Copresence, and Social Presence in Virtual Environments. Presence: Teleoperators & Virtual Environments, 12(5):481–494, 2003. S. Orts-Escolano, C. Rhemann, S. Fanello, W. Chang, A. Kowdle, Y. Degtyarev, D. Kim, P. L. Davidson, S. Khamis, M. Dou, et al. Holoportation: Virtual 3d Teleportation in Real-time. In Proceedings of the 29th annual symposium on user interface software and technology, pp. 741–754, 2016. K. Otsuka. MMSpace: Kinetically-augmented Telepresence for Small Group-to-group Conversations. In 2016 IEEE Virtual Reality (VR), pp. 19–28. IEEE, 2016. Y. Pan and A. Steed. A comparison of avatar, video, and robot-mediated interaction on users’ trust in expertise. Frontiers in Robotics and AI, 3:12, 2016. T. Pejsa, J. Kantor, H. Benko, E. Ofek, and A. Wilson. Room2room: Enabling Life-size Telepresence in a Projected Augmented Reality Environment. In Proceedings of the 19th ACM conference on computer-supported cooperative work & social computing, pp. 1716–1725, 2016. T. Piumsomboon, G. A. Lee, B. Ens, B. H. Thomas, and M. Billinghurst. Superman vs Giant: A Study on Spatial Perception for a Multi-scale Mixed Reality Flying Telepresence Interface. IEEE transactions on visualization and computer graphics, 24(11):2974–2982, 2018. T. Piumsomboon, G. A. Lee, J. D. Hart, B. Ens, R. W. Lindeman, B. H. Thomas, and M. Billinghurst. Mini-me: An Adaptive Avatar for Mixed Reality Remote Collaboration. In Proceedings of the 2018 CHI conference on human factors in computing systems, pp. 1–13, 2018. A. Rao, R. Lanphier, M. Stiemerling, H. Schulzrinne, and M. Westerlund. Real-Time Streaming Protocol Version 2.0. https://tools.ietf.org/html/rfc7826. Reallusion. https://www.reallusion.com/ - Reallusion Animation Software. H. Regenbrecht, K. Meng, A. Reepen, S. Beck, and T. Langlotz. Mixed Voxel Reality: Presence and Embodiment in Low Fidelity, Visually Coherent, Mixed Reality Environments. In 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 90–99. IEEE, 2017. D. Roth, G. Bente, P. Kullmann, D. Mal, C. F. Purps, K. Vogeley, and M. E. Latoschik. Technologies for Social Augmentations in User-Embodied Virtual Reality. In 25th ACM Symposium on Virtual Reality Software and Technology, VRST’19, pp. 1–12. ACM, New York, NY, USA, 2019. doi: 10.1145/3359996.3364269 D. Roth, C. Kleinbeck, T. Feigl, C. Mutschler, and M. E. Latoschik. Beyond replication: Augmenting social behaviors in multi-user virtual realities. In 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 215–222. IEEE, 2018. D. Roth and M. E. Latoschik. Construction of the Virtual Embodiment Questionnaire (VEQ). IEEE Transactions on Visualization and Computer Graphics, 26(12):3546–3556, 2020. doi: 10.1109/TVCG.2020.3023603 D. Roth, J.-L. Lugrin, D. Galakhov, A. Hofmann, G. Bente, M. E. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply. YU ET AL.: Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User... [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] Latoschik, and A. Fuhrmann. Avatar Realism and Social Interaction Quality in Virtual Reality. In 2016 IEEE Virtual Reality (VR), pp. 277–278. IEEE, 2016. D. Roth, K. Waldow, M. E. Latoschik, A. Fuhrmann, and G. Bente. Socially Immersive Avatar-based Communication. In 2017 IEEE Virtual Reality (VR), pp. 259–260. IEEE, Los Angeles, USA, 2017. doi: 10. 1109/VR.2017.7892275 D. Roth, K. Waldow, M. E. Latoschik, A. Fuhrmann, and G. Bente. Socially Immersive Avatar-based Communication. In 2017 IEEE Virtual Reality (VR), pp. 259–260. IEEE, 2017. D. Roth, K. Yu, F. Pankratz, G. Gorbachev, A. Keller, M. Lazarovic, D. Wilhelm, S. Weidert, N. Navab, and U. Eck. Real-time Mixed Reality Teleconsultation for Intensive Care Units in Pandemic Situations. In IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR), 2021. M. Slater, B. Spanlang, M. V. Sanchez-Vives, and O. Blanke. First Person Experience of Body Transfer in Virtual Reality. PloS one, 5(5):e10564, 2010. M. Slater and A. Steed. Meeting People Virtually: Experiments in Shared Virtual Environments. In The social life of avatars, pp. 146–171. Springer, 2002. H. J. Smith and M. Neff. Communication Behavior in Embodied Virtual Reality. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems - CHI ’18, pp. 1–12. ACM Press, Montreal QC, Canada, 2018. doi: 10.1145/3173574.3173863 A. Steed, W. Steptoe, W. Oyekoya, F. Pece, T. Weyrich, J. Kautz, D. Friedman, A. Peer, M. Solazzi, F. Tecchia, et al. Beaming: An Asymmetric Telepresence System. IEEE computer graphics and applications, 32(6):10– 17, 2012. W. Steptoe, O. Oyekoya, A. Murgia, R. Wolff, J. Rae, E. Guimaraes, D. Roberts, and A. Steed. Eye tracking for avatar eye gaze control during object-focused multiparty interaction in immersive collaborative virtual environments. In Virtual Reality Conference, 2009. VR 2009. IEEE, pp. 83–90. IEEE, 2009. doi: 10.1109/VR.2009.4811003 W. Steptoe, A. Steed, and M. Slater. Human Tails: Ownership and Control of Extended Humanoid Avatars. IEEE transactions on visualization and computer graphics, 19(4):583–590, 2013. J. Steuer. Defining virtual reality: Dimensions determining telepresence. Journal of communication, 42(4):73–93, 1992. P. Stotko, S. Krumpen, M. B. Hullin, M. Weinmann, and R. Klein. Slamcast: Large-scale, Real-time 3D Reconstruction and Streaming for Immersive Multi-client Live Telepresence. IEEE transactions on visualization and computer graphics, 25(5):2102–2112, 2019. B. Tarr, M. Slater, and E. Cohen. Synchrony and Social Connection in Immersive Virtual Reality. Scientific reports, 8(1):1–8, 2018. B. Thoravi Kumaravel, F. Anderson, G. Fitzmaurice, B. Hartmann, and T. Grossman. Loki: Facilitating Remote Instruction of Physical Tasks Using Bi-directional Mixed-Reality Telepresence. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, pp. 161–174, 2019. M. Tölgyessy, M. Dekan, L. Chovanec, and P. Hubinskỳ. Evaluation of the Azure Kinect and Its Comparison to Kinect V1 and Kinect V2. Sensors, 21(2):413, 2021. VIVE. https://vr.tobii.com/integrations/htc-vive-pro-eye/ - VIVE Pro Eye with Tobii Eye Tracking. P. Vorderer, W. Wirth, F. R. Gouveia, F. Biocca, T. Saari, L. Jäncke, S. Böcking, H. Schramm, A. Gysbers, T. Hartmann, et al. MEC Spatial Presence Questionnaire. Retrieved Sept, 18:2015, 2004. M. E. Walker, D. Szafir, and I. Rae. The Influence of Size in Augmented Reality Telepresence Avatars. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 538–546. IEEE, 2019. T. Waltemate, D. Gall, D. Roth, M. Botsch, and M. E. Latoschik. The Impact of Avatar Personalization and Immersion on Virtual Body Ownership, Presence, and Emotional Response. IEEE transactions on visualization and computer graphics, 24(4):1643–1652, 2018. N. Weibel, D. Gasques, J. Johnson, T. Sharkey, Z. R. Xu, X. Zhang, E. Zavala, M. Yip, and K. Davis. ARTEMIS: Mixed-Reality Environment for Immersive Surgical Telementoring. In Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, pp. 1–4, 2020. A. S. Won, J. N. Bailenson, and J. Lanier. Appearance and Task Success in Novel Avatars. Presence: Teleoperators and Virtual Environments, 24(4):335–346, 2015. Y. Wu, Y. Wang, S. Jung, S. Hoermann, and R. W. Lindeman. Exploring the use of a robust depth-sensor-based avatar control system and its effects [78] [79] [80] [81] 4139 on communication behaviors. In 25th ACM Symposium on Virtual Reality Software and Technology, pp. 1–9. ACM, 2019. doi: 10.1145/3359996. 3364267 N. Yee and J. N. Bailenson. The Proteus effect: The effect of transformed self-representation on behavior. Human communication research, 33(3):271–290, 2007. N. Yee, N. Ducheneaut, and J. Ellis. The Tyranny of Embodiment. Artifact: Journal of Design Practice, 2(2):88–93, 2008. B. Yoon, H.-i. Kim, G. A. Lee, M. Billinghurst, and W. Woo. The Effect of Avatar Appearance on Social Presence in an Augmented Reality Remote Collaboration. In 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 547–556. IEEE, 2019. K. Yu, A. Winkler, F. Pankratz, M. Lazarovici, D. Wilhelm, U. Eck, D. Roth, and N. Navab. Magnoramas: Magnifying Dioramas for Precise Annotations in Asymmetric 3D Teleconsultation. In IEEE Conference on Virtual Reality and 3D User Interfaces (IEEE VR), 2021. Authorized licensed use limited to: TU Ilmenau. Downloaded on November 16,2022 at 18:23:56 UTC from IEEE Xplore. Restrictions apply.