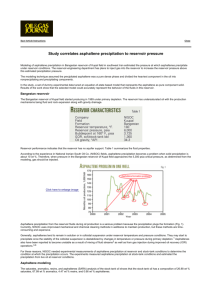
Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 Contents lists available at ScienceDirect Journal of Petroleum Science and Engineering journal homepage: www.elsevier.com/locate/petrol Evolving robust intelligent model based on group method of data handling technique optimized by genetic algorithm to predict asphaltene precipitation T Maryam Sadi∗, Abbas Shahrabadi Research Institute of Petroleum Industry (RIPI), West Blvd. Azadi Sport Complex, P.O. Box: 14665-137, Tehran, Iran A R T I C LE I N FO A B S T R A C T Keywords: Asphaltene precipitation Group method of data handling Genetic algorithm SARA fractions Leverage approach Precipitation of asphaltene during primary production of hydrocarbon reservoirs leads to formation damage and well bore plugging. Therefore, proposing an accurate model to estimate asphaltene precipitation under various operating and thermodynamic conditions are crucial. In this study, a new mathematical model based on the integrating group method of data handling (GMDH) with genetic algorithm has been developed to predict asphaltene precipitation as a function of reservoir pressure and temperature, crude oil API, bubble point pressure, Saturated-Aromatic-Resin-Asphaltene (SARA) fractions and mole percent of non-hydrocarbon gases. Genetic algorithm technique has been applied to optimize the most appropriate network structure of GMDH model. In order to accomplish modeling, asphaltene precipitation of different crude oils from a number of Iranian reservoirs at wide ranges of operating conditions have been measured experimentally and applied for network construction. The accuracy of developed model has been evaluated by both statistical and graphical error analysis techniques. The average absolute relative deviation of the proposed model is 3.65%, which indicates model predictions are in excellent agreement with experimental data. Also, the comparison of developed GMDH model with scaling equation and least squares support vector machine (LSSVM) reveals the superiority of the proposed GMDH structure in prediction of asphaltene precipitation over scaling equation and LSSVM technique. In addition, the Leverage approach has been applied to detect suspected data. The results show that all experimental data are reliable and located within the applicable domain of developed model. Finally, a comprehensive sensitivity analysis based on the relevancy factor has been carried out which shows that percentages of resin and saturated components have the largest direct and inverse impacts on asphaltene precipitation, respectively. 1. Introduction Asphaltene is defined as the heaviest component of crude oil that is insoluble in normal alkanes, but soluble in toluene and benzene (Speight et al., 1985; Subramanian et al., 2016). Asphaltene can be separated from crude oil under certain thermodynamic conditions and precipitates. In the past decades, asphaltene precipitation and deposition which may occur in all components of a production system, has been the major problem in oil industry. Asphaltene usually starters to deposit in surface facilities and then in tubing where the pressure falls below the onset pressure. If the pressure decline continues, this problem will involve the reservoir zone (Zoveidavianpoor et al., 2013). The deposited materials reduce the permeability of the rock and in some cases plug the well bore and tubing which leads to operational problems and decreases the production efficiency. Therefore, asphaltene ∗ precipitation is an unwanted phenomenon to the level that it is called as the cholesterol of oil (Kokal and Sayegh, 1995). To prevent such problems, it is essential to understand the phenomenon and predict it under different conditions. So far, different thermodynamic models have been presented for this purpose. These models are classified in four categories, namely solubility model, solid model, colloid model, and micellization model. Solubility models are based on Flory Huggins (FH) theory in which the stability of asphaltene is expressed in terms of reversible equilibrium of solution. Some investigators used the molecular thermodynamic model of FH with an equation of state to predict asphaltene phase behavior (Hirschberg et al., 1984; Mansoori et al., 1988; Buckley, 1999; Novosad and Costain, 1990; Kokal et al., 1992; Rassamdana et al., 1996). Later, Anderson and Stenby (Andersen and Stenby, 1996) introduced an interaction parameter of oil mixture and asphaltene into Corresponding author. E-mail address: sadim@ripi.ir (M. Sadi). https://doi.org/10.1016/j.petrol.2018.08.041 Received 7 May 2018; Received in revised form 5 August 2018; Accepted 16 August 2018 Available online 18 August 2018 0920-4105/ © 2018 Elsevier B.V. All rights reserved. Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi volume injection data as model inputs. Ansari and Gholami (2015) used support vector regression method optimized by imperialist competitive algorithm to model asphaltene precipitation by considering temperature, solvent molecular weight and dilution rate as input variables. Although several artificial intelligence-based modeling techniques have been applied in the recent literature to solve problems of oil industry, to the best of the authors' knowledge, no research has been performed on the application of group method of data handling (GMDH) technique to model asphaltene precipitation as a function of crude oil properties and reservoir conditions. The GMDH is a self organizing approach introduced by Ivakhnenko (1968) for modeling and identification of complex systems without having prior knowledge about the studied process. The main concept of GMDH technique is identifying the functional structure of polynomial type model by application of feed forward networks based on a quadratic transfer function (Farlow, 1984). Optimization methods are implemented to define the best network structure of GMDH model and calculate the optimal coefficients of transfer functions. Evolutionary optimization techniques such as genetic algorithm and particle swarm optimization can improve the prediction accuracy of GMDH model as reported in the literature (Abbod and Deshpande, 2008; Shaghaghi et al., 2017). Shaghaghi et al. (2017) showed that integrating GMDH with genetic algorithm is more efficient than coupling GMDH by particle swarm optimization. The objective of this work is developing an intelligent model based on the GMDH technique to predict asphaltene precipitation during natural depletion by considering crude oil API, bubble point pressure, reservoir temperature and pressure, SARA fractions and mole percent of non-hydrocarbon gases as input parameters. Due to the advantages of evolutionary optimization methods, genetic algorithm technique is applied to obtain the best functional structure of the proposed model. The asphaltene precipitation of different Iranian crude oils is measured experimentally and used to construct the model structure. Then, the accuracy and reliability of the proposed model is evaluated using various statistical parameters and graphical error analyses. Also, the performance of GMDH model is compared with scaling equation and the published results of LSSVM technique. In addition, Leverage approach is carried out to detect outliers and identify the applicable domain of developed model. Furthermore, a sensitivity analysis is performed to quantify the impact of all input parameters on asphaltene precipitation. the theory of polymeric solution, and improved the previous thermodynamic models. Solid model is a type of thermodynamic models that uses cubic equation of state to predict phase behavior of asphaltene. In these models precipitated asphaltene is treated as a pure solid phase and a cubic equation of state is applied for calculation of equilibria parameters in oil and gas phases. Nghiem et al. (1993) developed a solid model with splitting the heaviest component of crude oil into a precipitating and a non-precipitating (asphaltene) component. All properties of these two parts are the same; the only difference is in their interaction coefficients with light components. The temperature and pressure dependency of asphaltene fugacity was introduced into the solid model of Nghiem by Kohse et al. (2000). This model can be considered as a general method to obtain the fugacity of precipitated asphaltene. Leontarities and Mansoori (Leontaritis and Mansoori, 1987) developed a colloidal dispersion model based on statistical thermodynamic and colloidal science, which was further extended by Park and Mansoori (1988). In this model it is assumed that asphaltenes are dispersed in oil while being absorbed by resin molecules, and the repulsive forces between resin molecules inhibit asphaltene precipitation. Nowadays, after observing reversibility behavior of asphaltene, the colloidal model as an irreversible model is less being used. Later, the irreversibility assumption of asphaltenes was rejected in the proposed model by Victorov and Firoozabadi (1996). They proposed the name of “micells” for aggregates of asphaltene. In this method the Gibbs free energy of the system composed of liquid and precipitate phases is minimized to calculate the composition of equilibrium phase. It should be noted that the micellization model is too complex for computation and its limitation is inability to predict the maximum amount of precipitated asphaltene (Tavakkoli et al., 2009). Due to the complexity of asphaltene behavior, none of the above mentioned models can describe all aspects of asphaltene precipitation. Therefore, using any of these models will cause some deviations from the experimental data. In addition to the thermodynamic models, scaling equation is another technique for modeling asphaltene precipitation. Rassamdana et al. (1996) applied scaling equation approach for the first time to estimate the onset of asphaltene precipitation based on the aggregation and gelation behavior of asphaltene presented by Park and Mansoori (1988). Ashoori et al. (2010) proposed a scaling equation to consider the effect of temperature on the amounts of asphaltene precipitation titration data. Moradi et al. (2012) developed a scaling equation to model asphaltene precipitation under gas injection conditions. Kord and Ayatollahi (2012) considered the effect of pressure in a five parameters scaling equation to predict asphaltene precipitation of live oil due to natural depletion. Behbahani et al. (2013) proposed a new scaling equation to estimate asphaltene precipitation of bottom hole live oil during pressure depletion and gas injection. Recently, intelligent techniques such as support vector machine, neural network and neuro fuzzy, which are based on the empirical data, have been applied for modeling different engineering processes (Abghari and Sadi, 2013; Helmy et al., 2017; Yarveicy et al., 2018; Van and Chon, 2017; Ayatollahi et al., 2016; Sadi, 2017) and prediction of asphaltene precipitation (Alimohammadi et al., 2017; Ahmadi and Golshadi, 2012; Taleghani et al., 2017). Yetilmezsoy et al. (2011) developed an adaptive neuro fuzzy model to simulate water in oil emulsion formation by considering density, viscosity and Saturated-Aromatic-Resin-Asphaltene (SARA) fractions as input variables. Hemmati Sarapardeh et al. (Hemmati Sarapardeh et al., 2013) applied least squares support vector machine (LSSVM) approach to estimate precipitated asphaltene during natural depletion as a function of bubble point pressure, reservoir pressure and temperature, crude oil API, and SARA fractions. Salahshoor et al. (2013) utilized adaptive neuro fuzzy technique to model asphaltene deposition in terms of pressure drop and permeability ratio, by considering time and pore 2. Experimental section 2.1. Experimental set-up and procedure Asphaltene precipitation tests were carried out under the static condition on a number of crude oil samples taken from some oilfields in Iran. These crude oils have been selected in a way to cover wide ranges of crude properties and reservoir conditions. So, it can be said that most Iranian crude oils are in the selected ranges. Gas chromatography techniques based on the ASTM D2887-16a and ASTM D1945-14 (ASTM D2887-16a, 2016; ASTM D1945-14, 2014), differential liberation and constant composition expansion tests (Pedersen et al., 2015) have been implemented to characterize oil composition as well as other properties including the molecular weight, API and bubble point pressure. Moreover, oil samples have been analyzed using SARA test to determine the fractions of asphaltene, aromatic, resin, and saturate as described by the ASTM D3279-12e1 procedure (ASTM D3279-12e1, 2012). Fig. 1 shows a schematic of the experimental set-up implemented in this study to determine the amount of precipitated asphaltene during depressurization of crude oil at reservoir temperature. A visual equilibrium cell is the main part of the experimental set-up. This cell which is mercury-free operates up to a maximum temperature of 400 °F and a maximum pressure of 15000 psia. Other parts of the experimental set-up include a high pressure pump, a 0.2 μm filter paper and holder, transfer vessels for crude oil and 1212 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 1. Schematic of the laboratory apparatus employed for asphaltene precipitation experiments. Filtered oil received at the sampler was flashed and its asphaltene content was measured using the IP 143 standard procedure (IP-143/90, 1985). Weight percentage of the precipitated asphaltene was obtained from the difference between original and filtered crude oil, at each pressure step. Table 1 The ranges and statistical information of experimental data. Variables Minimum Maximum Average Input Parameters Pressure (psia) Temperature (oF) Crude Oil API Bubble Point Pressure (psia) Saturated (%) Aromatic (%) Resin (%) Asphaltene (%) H2S (mol %) CO2 (mol %) N2 (mol %) 715 210 19.85 1608 29.30 30.01 0.49 3.75 0.00 0.47 0.02 5021 260 28.10 2966 47.72 52.09 18.80 13.75 2.97 7.96 0.93 2503 242 22.74 2052 40.27 42.95 8.77 7.99 1.32 3.78 0.31 Target Parameter Precipitated Asphaltene (wt %) 0.02 6.29 1.06 2.2. Experimental data In the present study, the amounts of asphaltene precipitation for 35 different crude oils from a number of oil reservoirs located in south of Iran have been measured experimentally. The measured experimental data were randomly divided into training (75%) and testing (25%) data sets. To partitioning measured data into testing and training subsets, several distributions have been used to avoid the local accumulations of experimental data points in the problem feasible region. Finally, the homogeneous accumulations of data points on the feasible domain are selected as adequate distributions (Eslamimanesh et al., 2012). The training subset (220 data points) was applied to obtain the optimum values of model unknown coefficients and testing subset (73 data points) was utilized for selection of the most appropriate functional structure of model. Table 2 Genetic algorithm parameters. Variable Value Population Size Cross Over Probability Mutation Probability Maximum Generation 100 0.85 0.03 400 3. Model development 3.1. Input variables definition Reliability of a predictive data-based model depends on the comprehensiveness of the empirical data and accurate selection of input variables. As mentioned earlier, a wide range of experimental data which covers many of the Iranian oil reservoir conditions has been applied for model development. To construct the model structure, the effective parameters on the asphaltene precipitation including crude oil properties and reservoir conditions should be considered as input variables. In the previously published paper (Ansari and Gholami, 2015), temperature, molecular weight of solvent and dilution ratio were selected as input variables to estimate the amounts of asphaltene precipitation titration data. In another research (Hemmati Sarapardeh et al., 2013), to predict asphaltene precipitation during natural solvent storage, pressure transducers and gauges. The working temperature in all experiments has been set equal to the corresponding reservoir temperature. Asphaltene precipitation experiments were later conducted at different pressures as follow. First, the equilibrium cell has been cleaned and maintained at reservoir temperature using an oven. Then, 150–200 cc of oil was injected into the cell under high pressure at the single phase condition and brought to equilibrium. The cell pressure was depleted at different pressure intervals; at each step the oil was passed through a 0.2 μm filter paper and then towards a sampler. In order to maintain the sample in a monophasic condition, when it passed through the filter, high pressure helium gas was used to exert a back pressure on the filter downstream. 1213 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 2. Structure of developed GMDH model. The GMDH approach is quite simple and at the same time is a suitable technique for modeling unstructured complex systems (Pazuki and Kakhki, 2013). In this method, the most appropriate polynomial functions are selected by combination of two independent variables in each layer to generate new virtual neurons in the next layer. The formal definition of the problem in GMDH method is to approximate actual value (y) with a polynomial function ( fˆ ) to accurately predict target variable (ŷ). The main objective of GMDH is developing a multilayer network structure comprised of a set of quadratic neurons in different layers to map input variables to a single target. In GMDH technique, the relationship between input and output variables for a network with multiple inputs and single output can be represented by Volterra–Kolmogorov–Gabor (VKG) polynomial (Ivakhnenko, 1971): depletion, reservoir conditions including temperature, pressure and bubble point pressure and crude oil properties such as API and SARA fractions were chosen as input parameters. In the present study, to develop a more comprehensive model, in addition to the aforementioned parameters (temperature, pressure, bubble point pressure, crude oil API and SARA fractions), the amounts of non-hydrocarbon gases including H2S, CO2 and N2 have been considered as model inputs to estimate asphaltene precipitation as output parameter. The ranges and statistical information of experimental data used for model development including input variables and target values are presented in Table 1. 3.2. Group method of data handling The Group Method of Data Handling (GMDH) technique firstly proposed by Ivakhnenko (1968) is a heuristic self organizing method applied for modeling sophisticated non linear systems (Farlow, 1984). m yˆ = a0 + i=1 1214 m m m m m ∑ ai xi + ∑ ∑ aij xi xj + ∑ ∑ ∑ aijk xi xj xk i=1 j=1 i=1 j=1 k=1 (1) Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi to a second order polynomial consisting of only two variables (Onwubolu, 2009): Table 3 Statistical results for the proposed GMDH network. Parameters Value Training Data Set R2 RMSE AARD 0.9981 0.0622 2.9772 Testing Data Set R2 RMSE AARD 0.9965 0.0778 4.7798 Total Data R2 RMSE AARD yˆ = fˆ (x1, x2) = a0 + a1 x1 + a2 x2 + a3 x1 x2 + a4 x12 + a5 x 22 (2) The GMDH structure is constructed using an iterative procedure consists of training and testing steps. During network training, the unknown parameters of quadratic polynomials are calculated by minimizing the errors between experimental data and model predicted values: Nt Minimize ⎛∑ [yˆi − yi ]2 = ⎝ 0.9976 0.0684 3.6502 i=1 Nt ∑ [fˆ (xip , i=1 2 x iq) − yi ] ⎞ ⎠ (3) where Nt is the number of training data points. In testing step, the most appropriate combination of variables is selected using testing data set (Atashrouz et al., 2014). As the algorithm iterates, new middle layers are gradually produced and finally a tree of multilayered quadratic functions is developed as model structure (Amanifard et al., 2008). The detailed descriptions about GMDH technique can be found in the literature (Pazuki and Kakhki, 2013; Ghanadzadeh et al., 2012; Sadi, 2018). 3.3. Genetic algorithm Genetic algorithm (GA), which was first introduced by Holland (1975) and further described by Goldberg (1989), is an adaptive heuristic search algorithm. This evolutionary optimization technique is based on the Darwin's Theory of natural evolution. According to this theory, the less adapted species tend to disappear while the fittest individuals survive and create more offspring. The advantages of evolutionary optimization techniques such as GA are simplicity, flexibility and self-adapt ability which leads to find the global optimum (Fogel et al., 1997). As the first step in GA, a population of possible solutions is generated randomly and then the fitness values of all population members are evaluated by calculating the objective function. After computing the fitness value, a particular group of individuals is selected to generate offspring by the defined genetic operators. Reproduction, cross over and mutation are the main operators applied in GA (Goldberg, 1989). In reproduction step individual pairs are selected on the basis of fitness values and propagate in the next generation as parent members (Sadi et al., 2008). Cross over is a recombination step which creates two new offspring by exchanging information between parents with a predefined rate named as cross over probability. Mutation operator which keeps GA diversity introduces a minor change into the children with a small rate called mutation probability (Goldberg, 1989; Sadi et al., 2008). The above mentioned steps, including parents selection and children production, are repeated during each iteration, until a desired termination criterion such as predefined number of generations is reached. As mentioned earlier, genetic algorithm technique has been applied to calculate optimum values of quadratic functions parameters and obtain the best structure of GMDH model. The objective function is defined as minimization of the differences between GMDH predictions and experimental values: Fig. 3. Comparison between experimental data and model predictions for training data set. Fig. 4. Comparison between experimental data and model predictions for testing data set. n OF = Minimize ∑ (yexpi − ycali )2 i=1 (4) In the above equation, ycal, yexp and n are model prediction, experimental value and number of data points, respectively. The genetic algorithm parameters used to optimize the structure of GMDH model are listed in Table 2. In the above equation, a0, a1, …, aijk and x1, x2, …, xm are the unknown coefficients and input variables, respectively; and m denotes the number of input variables. In most cases, the general equation of VKG series can be simplified 1215 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 5. Experimental data and model predictions versus data points. Fig. 6. Relative differences between GMDH predictions and experimental values. 4. Results and discussion oil have been considered as model input parameters to estimate precipitated asphaltene as target value. To evaluate the reliability and accuracy of the developed GMDH model in predicting asphaltene precipitation, graphical analysis including cross plot, relative error diagram and error histogram in addition to the various statistical parameters such as coefficient of determination (R2), root mean square error (RMSE) and average absolute relative deviation (AARD) have been employed. These statistical 4.1. Model performance evaluation In the present study, the GMDH technique has been utilized to predict precipitated asphaltene due to natural depletion. In the developed model crude oil API, reservoir pressure and temperature, bubble point pressure, SARA fractions, and H2S, CO2 and N2 contents in crude 1216 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 7. Errors histogram for developed GMDH model. 3. Average Absolute Relative Deviation Table 4 Experimental data and predicted values for validation data. Sample No. 1 No. 2 No. 3 API SARA Fractions (%) 31.28 27.86 24.49 P (psia) Asphaltene Precipitation (wt %) Experimental GMDH model Relative Difference (%) Sat: 52.49 Ar: 41.04 Res: 5.48 Asp: 0.99 2000 3000 4000 4500 5000 0.1805 0.2574 0.3699 0.3418 0.2854 0.1793 0.2630 0.3576 0.3400 0.2910 −0.66 2.18 −3.33 −0.53 1.96 Sat: 63.61 Ar: 20.85 Res: 10.54 Asp: 5 1015 1515 2016 2517 3018 3518 0.1009 0.2501 0.4796 0.6608 0.1982 0.0621 0.1006 0.2419 0.5075 0.6279 0.2034 0.0619 −0.30 −3.28 5.82 −4.98 2.62 −0.32 Sat: 58.23 Ar: 29.89 Res: 7.08 Asp: 4.69 1000 1500 2000 3000 5000 0.6700 0.9300 0.8600 0.5600 0.0700 0.6975 0.9613 0.8321 0.5602 0.0698 4.10 3.37 −3.24 0.04 −0.29 Relative Difference (%) = AARD = n ∑i = 1 (yexpi − ycali )2 (5) 2. Root Mean Square Error: RMSE = 1 n n ∑ (yexpi − ycali )2 i=1 yexpi ∗100 (7) The statistical results of the optimum structure of GMDH network are presented in Table 3. These results show the high accuracy of developed GMDH model in prediction of the precipitated asphaltene during natural depletion. As mentioned earlier, graphical error analysis has been done to better evaluation of model performance as shown in Figs. 3–7. The predicted values of asphaltene precipitation during natural depletion for training and testing data sets are plotted against experimental data in Figs. 3 and 4, respectively. The accumulation of data points in close to the diagonal line indicates the robustness and perfect accuracy of the developed model. Therefore, the excellent prediction capability of the proposed model is proven. Moreover, Fig. 5 depicts the model predictions including training and testing subsets and experimental values versus data number. This figure confirms that the developed GMDH model can estimate asphaltene precipitation during natural depletion by high accuracy. In addition, the relative errors between model predictions and experimental data are plotted in Fig. 6. As can be seen, the maximum and average values of relative deviations for training subset are 7.54% and 2.98%, respectively. These values for testing set are 11.51% and 4.78%, respectively. These results reveal that model predictions are in excellent agreement with experimental data, which is another evidence for accuracy of the developed model. Finally, in order to present further authentication of model performance, histogram of errors between predicted and actual values is 1. Coefficient of Determination (R2): n i=1 yexpi − ycali - Eleven variables as model input parameters at input layer. - Five middle layers including five different groups of virtual variables (W1-W12, Z1-Z8, V1-V5, O1-O3 and U1-U2). - A single variable at output layer as target value. Prec Aspcal − Prec Aspexp ∗100 . Prec Aspexp ∑i = 1 (yexpi − yexp )2 n ∑ where yexp is the mean value of experimental data points. The optimal configuration of the proposed GMDH model is shown in Fig. 2. As observed, the developed network structure is as follow: parameters which are a combination of relative and absolute errors are defined as follows: R2 = 1 − 1 n (6) 1217 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 8. Experimental data and predicted values for three samples applied for model validation. Fig. 8. As depicted, asphaltene starts to precipitate at onset pressure which is higher than crude oil bubble pressure. During natural depletion of hydrocarbon reservoir, the pressure decreases gradually and asphaltene precipitation increases up to a maximum value at bubble pressure. Below the crude oil bubble point, the amount of precipitated asphaltene decreases. So, the bubble point pressure plays an important role in asphaltene precipitation. Above the bubble point, by decreasing reservoir pressure, the solubility of asphaltene in crude oil decreases which leads to an increasing in precipitated asphaltene. By decreasing reservoir pressure, the asphaltene solubility reaches to a minimum value at the bubble pressure. Below this point, the solubility of asphaltene in crude oil increases with decrease in reservoir pressure which results in reducing asphaltene precipitation (Wang, 2000). According to this figure and relative differences between predicted values and experimental data reported in Table 4, the developed GMDH model has acceptable reliability in prediction of asphaltene precipitation during natural depletion for different crude oils. Table 5 Experimental data and LSSVM technique results. Sample P (psia) Asphaltene Precipitation (wt %) Relative Difference (%) Experimental LSSVM Technique (Hemmati Sarapardeh et al., 2013) No. 1 2000 3000 4000 4500 5000 0.1805 0.2574 0.3699 0.3418 0.2854 0.181 0.268 0.3529 0.3396 0.296 0.28 4.12 −4.59 −0.64 3.71 No. 2 1015 1515 2016 2517 3018 3518 0.1009 0.2501 0.4796 0.6608 0.1982 0.0621 0.0778 0.302 0.493 0.5199 0.3364 0.0264 −22.89 20.75 2.79 −21.32 69.73 −57.49 No. 3 1000 1500 2000 3000 5000 0.6700 0.9300 0.8600 0.5600 0.0700 0.7152 0.8844 0.9109 0.5584 0.0835 6.75 −4.90 5.92 −0.29 19.29 4.3. Comparison of GMDH model with other techniques In this section, the performance of the proposed GMDH model in prediction of asphaltene precipitation has been firstly compared with a well-known scaling equation. Kord and Ayatollahi (2012) proposed two separate equations to predict asphaltene precipitation at upper and lower the bubble point by considering pressure (P), bubble point pressure (Pb), gas oil ratio (GOR), temperature (T) and asphaltene content of crude oil (Asp) as input parameters: demonstrated in Fig. 7. The bell shape of error distribution indicates the normal behavior of the proposed GMDH model. 4.2. Model validation Y = A∗Ln (X ) + B In this section, to check the validity of the proposed GMDH model, the amounts of precipitated asphaltene for three samples of Iranian crude oils have been extracted from the literature (Hemmati Sarapardeh et al., 2013) and applied as validation data set. It should be noted that these data, have been also employed in the next section to compare the accuracy of the proposed GMDH model with other techniques in prediction of asphaltene precipitation. The information of these data points including crude oil properties, experimental values and model predictions for asphaltene precipitation accompanied by relative differences between predicted and experimental data are reported in Table 4. Also, model predictions and experimental values for precipitated asphaltene of validation data set are plotted versus reservoir pressure in for P < Pb Y = A∗exp (B∗X ) for P > Pb (8) (9) where A and B are the scaling coefficients and X and Y are two new scaling parameters defined as: X= ( (P − Pb) Pb ) GOR z (10) T z" −z ′ Y= AspPer ⎛ P − Pb ⎞ Asp ⎝ Pb ⎠ ⎜ ⎟ (11) where Aspper represents the amount of asphaltene precipitation and z, z' and z” are the adjustable parameters. 1218 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 9. Comparison of the developed GMDH model with scaling equation and LSSVM technique for validation data a. Sample 1, b. Sample 2 and c. Sample 3. amounts of asphaltene precipitation for some experimental data. Three sets of these empirical data have been selected as validation data in the present study and utilized for both validation and comparison purposes. These data sets have been presented in Table 5. The results of GMDH model, scaling equation and LSSVM technique for validation data are compared in Fig. 9a and c. As observed, the In addition to the scaling equation, the results of LSSVM approach, which were previously published (Hemmati Sarapardeh et al., 2013), have been utilized to compare the prediction accuracy of the proposed GMDH model. As mentioned earlier, Hemmati Sarapardeh et al. (Hemmati Sarapardeh et al., 2013) applied LSSVM method to estimate precipitated asphaltene during natural depletion and reported the 1219 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Sarapardeh et al., 2016). The detailed information about Leverage method has been presented in the literature (Mohammadi et al., 2012). The Williams plot of the proposed GMDH model in prediction of the precipitated asphaltene during natural depletion has been illustrated in Fig. 10. As observed, all experimental data are in the ranges of 0 ≤ H ≤ H ∗ = 0.1229 (as critical Leverage value) and − 3 ≤ R ≤ 3 (in the limits of green and red lines). This figure confirms that the measured experimental data are reliable and located within the applicable domain of developed model which consequently leads to a statistically acceptable and correct model. Table 6 The statistical criteria of GMDH model, scaling equation and LSSVM model for validation data. Parameters GMDH model Scaling Equation (Kord and Ayatollahi, 2012) LSSVM model (Hemmati Sarapardeh et al., 2013) R2 RMSE AARD 0.9084 0.0803 23.8133 0.9547 0.0565 15.3416 0.9958 0.0171 2.3060 proposed GMDH model can predict asphaltene precipitation more accurately in comparison to the scaling equation and LSSVM approach. Moreover, the values of statistical parameters including R2, RMSE and AARD for GMDH model, scaling equation and LSSVM technique are reported in Table 6. The calculated R2 for GMDH model, LSSVM technique and scaling equation are 0.9958, 0.9547 and 0.9084, respectively. Also, the value of AARD for the proposed GMDH model is 2.31%, whereas these criteria for LSSVM technique and scaling equation are 15.34% and 23.81%, respectively, which indicate the better performance of GMDH model than both LSSVM approach as an intelligent technique and scaling equation as a regression method. Therefore, based on the results summarized in Table 6, it can be concluded that the developed GMDH model can estimate asphaltene precipitation behavior with more accuracy compared to the scaling equation as well as LSSVM technique. 4.5. Sensitivity analysis A sensitivity analysis based on the relevancy factor has been conducted to quantify the effect of input parameters on asphaltene precipitation in natural depletion. The mathematical definition of relevancy factor (r) is as follow (Chen et al., 2014): r= n ∑i = 1 [(xk, i − xk )( yˆi − yˆ )] n n ∑i = 1 (xk, i − xk )2 ∗ ∑i = 1 (yˆi − yk )2 (12) Where xk, i and xk are the ith and average values of the kth input parameter, respectively; ŷi and ŷ are the ith and average values of the predicted asphaltene precipitation, respectively; and n represents the number of experimental data. The value of relevancy factor ranges from −1 to +1. The higher absolute value of relevancy factor between an input variable and target value implies that input parameter has a greater influence on the model prediction. Also, positive or negative sign of relevancy factor for each input parameter represents the increasing or decreasing impact of that variable on the model target (Ayatollahi et al., 2016). The values of relevancy factor for all input parameters on asphaltene precipitation have been depicted in Fig. 11. It can be observed from this figure that reservoir temperature, bubble point pressure, fractions of asphaltene and resin and H2S and CO2 contents have positive r values, which mean that an increase in these parameters increases the asphaltene precipitation. While API, percentages of saturated and aromatic components and N2 content with negative r values 4.4. Outlier detection The accuracy of applied experimental data has a great effect on the prediction capability of the proposed model (Rousseeuw and Leroy, 1987). Accordingly, various methods have been proposed for identification of the suspected data, among which the Leverage approach is recognized as a reliable algorithm for outlier detection purpose (Hemmati Sarapardeh et al., 2016; Mohammadi et al., 2012). Therefore, this approach has been employed in the present study to detect suspected data and identify the applicable domain of developed GMDH network. In this technique, outliers are defined graphically through calculating Hat matrix (H) and sketching the Williams plot (Hemmati Fig. 10. Detection of the probable outliers and the applicable domain of developed GMDH model. 1220 Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi Fig. 11. Relative effect of input parameters on asphaltene precipitation. Nomenclature have an inverse effect on the asphaltene precipitation, which indicate that by increasing these parameters, asphaltene precipitation decreases during natural depletion. Moreover, this figure shows that the percentages of resin and asphaltene components with positive r values of 0.59 and 0.56, respectively, have the highest direct effect on asphaltene precipitation. Whereas, the percentage of saturated components with a negative r value of −0.48, has the highest reverse impact on asphaltene precipitation. Finally, it can be concluded that all input parameters except percentage of aromatic components by −0.07 r value, have a significant effect on asphaltene precipitation. a A AARD API Ar Asp B CO2 fˆ FH GA GMDH GOR H H∗ H2S LSSVM m n N2 Nt O OF P Pb Prec Asp r R R2 Res RMSE SARA Sat T U V VKG W x xk X y y 5. Conclusion In the present study, GMDH technique has been applied to model asphaltene precipitation during natural depletion as a function of reservoir pressure and temperature, crude oil API, bubble point pressure, SARA fraction and the content of non-hydrocarbon gases in crude oil. For this purpose, the amounts of precipitated asphaltene for 35 different crude oils from a number of Iranian oil reservoirs have been measured experimentally and applied in model development. Genetic algorithm technique has been utilized to optimize the model unknown coefficients and select the most appropriate functional structure of GMDH model. The calculated R2, RMSE and AARD in prediction of asphaltene precipitation were 0.9976, 0.0684 and 3.65%, respectively. These results reveal that the proposed GMDH network can be accurately applied to predict asphaltene precipitation. Also, the comparison of GMDH model with scaling equation and the previously published results of LSSVM technique confirms the better performance of developed GMDH network in prediction of asphaltene precipitation. In addition, an outlier analysis based on Leverage approach has been performed to detect suspected data and identify the applicable domain of developed network. The results of outlier detection reveal that all experimental data are reliable and located within the applicable domain of the proposed GMDH model which consequently leads to an acceptable and correct model. Finally, the sensitivity analysis based on the relevancy factor has been done to evaluate the effect of input variables on asphaltene precipitation. The values of relevancy factor for all input parameters show that the percentages of resin and asphaltene components have the highest direct effect on asphaltene precipitation, while, the percentage of saturated components has the largest reverse impact. Declarations of interest None. 1221 unknown coefficient of polynomial scaling coefficient average absolute relative deviation crude oil API gravity percentage of aromatic components in SARA test percentage of asphaltene components in SARA test scaling coefficient CO2 concentration in crude oil, mol% approximated function Flory Huggins genetic algorithm group method of data handling gas oil ratio, SCF/STB Hat matrix critical Leverage value H2S concentration in crude oil, mol% least squares support vector machine number of input variables number of experimental data points N2 concentration in crude oil, mol% number of training data set fourth middle layer function objective function reservoir pressure, psia bubble point pressure, psia precipitated asphaltene, wt% relevancy factor standardized residual coefficient of determination percentage of resin components in SARA test root mean square error Saturated-Aromatic-Resin-Asphaltene percentage of saturated components in SARA test temperature, oF fifth middle layer function third middle layer function Volterra–Kolmogorov–Gabor first middle layer function input parameter average value of the kth input parameter scaling parameter output value average value of output Journal of Petroleum Science and Engineering 171 (2018) 1211–1222 M. Sadi, A. Shahrabadi ŷ ŷ Y z z' z" Z Subscripts predicted output average value of the predicted output scaling parameter adjustable parameter of scaling equation adjustable parameter of scaling equation adjustable parameter of scaling equation second middle layer function cal exp per model predictions experimental value precipitated Holland, J.H., 1975. Adaptation in Natural and Artificial Systems: an Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. University of Michigan Press. IP-143/90, 1985. Standards for Petroleum and its Products Institute of Petroleum, London, UK 143.1–143.7. Ivakhnenko, A.G., 1968. The group method of data handling: a rival of the method of stochastic approximation. Soviet Automatic Control 13, 43–55. Ivakhnenko, A.G., 1971. Polynomial theory of complex systems. IEEE Transactions on Systems, Man, and Cybernetics 1, 364–378. Kohse, B.F., Nghiem, L.X., Maeda, H., Ohno, K., 2000. Modeling phase behavior including the effect of pressure and temperature on asphaltene precipitation. In: SPE 64465, SPE Asia Pacific Oil and Gas Conference and Exhibition, Brisbance, Australia, 16–18 October. Kokal, S.L., Sayegh, S.G., 1995. Asphaltenes: the Cholesterol of Petroleum, SPE 29787. SPE Middle East Oil Show, Bahrain 11-14 March. Kokal, S.L., Najman, J., Sayegh, S.G., George, A.E., 1992. Measurement and correlation of asphaltene precipitation from heavy oils by gas injection. J. Can. Petrol. Technol. 31, 24–30. Kord, S., Ayatollahi, S., 2012. Asphaltene precipitation in live crude oil during natural depletion: experimental investigation and modeling. Fluid Phase Equil. 336, 63–70. Leontaritis, K.J., Mansoori, G.A., 1987. Asphaltene flocculation during oil production and processing: a thermodynamic colloidal model. In: SPE 16258, SPE International Symposium on Oilfield Chemistry, San Antonio, Texas, USA, 4–6 February. Mansoori, G.A., Jiang, T.S., Kawanaka, S., 1988. Asphaltene deposition and its role in petroleum production and processing. Arabian J. Sci. Eng. 13, 17–34. Mohammadi, A.H., Eslamimanesh, A., Gharagheizi, F., Richon, D., 2012. A novel method for evaluation of asphaltene precipitation titration data. Chem. Eng. Sci. 78, 181–185. Moradi, S., Rashtchian, D., Ghazvini, M.G., Emadi, M.A., Dabir, B., 2012. Experimental investigation and modeling of asphaltene precipitation due to gas injection. Iran. J. Chem. Chem. Eng. (Int. Engl. Ed.) 31, 89–98. Nghiem, L.X., Hassam, M.S., Nutakki, R., George, A.E.D., 1993. Efficient modeling of asphaltene precipitation. In: SPE 26642, SPE Annual Technical Conference and Exhibition, Houston, Texas, USA, 3–6 October. Novosad, Z., Costain, T.G., 1990. Experimental and modeling studies of asphaltene equilibria for a reservoir under CO2 injection. In: SPE 20530, SPE Annual Technical Conference and Exhibition. Louisiana, New Orleans 23-26 September. Onwubolu, G.C., 2009. Hybrid Self Organizing Modeling Systems. Springer, Berlin. Park, S.J., Mansoori, G.A., 1988. Aggregation and deposition of heavy organics in petroleum crudes. Energy Sources 10, 109–125. Pazuki, G., Kakhki, S.S., 2013. A hybrid GMDH neural network to investigate partition coefficients of penicillin G acylase in polymer–salt aqueous two-phase systems. J. Mol. Liq. 188, 131–135. Pedersen, K.S., Christensen, P.L., Shaikh, J.A., 2015. Phase Behavior of Petroleum Reservoir Fluids. CRC Press, Taylor & Francis Group. Rassamdana, H., Dabir, B., Nematy, M., Farhani, M., Sahimi, M., 1996. Asphalt flocculation and deposition: I. The onset of precipitation. AIChE J. 42, 10–22. Rousseeuw, P.J., Leroy, A.M., 1987. Robust Regression and Outlier Detection. John Wiley and Sons, New York, USA. Sadi, M., 2017. Prediction of thermal conductivity and viscosity of ionic liquid-based nanofluids using adaptive neuro fuzzy inference system. Heat Tran. Eng. 38, 1561–1572. Sadi, M., 2018. Determination of heat capacity of ionic liquid based nanofluids using group method of data handling technique. Heat Mass Tran. 54, 49–57. Sadi, M., Dabir, B., Shahrabadi, A., 2008. Multiobjective optimization of polymerization reaction of vinyl acetate by genetic algorithm technique with a new replacement criterion. Polym. Eng. Sci. 48, 853–859. Salahshoor, K., Zakeri, S., Mahdavi, S., Kharrat, R., Khalifeh, M., 2013. Asphaltene deposition prediction using adaptive neuro-fuzzy models based on laboratory measurements. Fluid Phase Equil. 337, 89–99. Shaghaghi, S., Bonakdari, H., Gholami, A., Ebtehaj, I., Zeinolabedini, M., 2017. Comparative analysis of GMDH neural network based on genetic algorithm and particle swarm optimization in stable channel design. Appl. Math. Comput. 313, 271–286. Speight, J.G., Wernick, D.L., Gould, K.A., Overfield, R.E., Rao, B.M.L., Savage, D.W., 1985. Molecular weight and association of asphaltenes: a critical review. Oil & Gas Science and Technology - Rev. IFP 40, 51–61. Subramanian, S., Simon, S., Sjöblom, J., 2016. Asphaltene precipitation models: a review. J. Dispersion Sci. Technol. 37, 1027–1049. Taleghani, M.S., Dehaghani, A.H.S., Shafiee, M.E., 2017. Modeling of precipitated asphaltene using the ANFIS approach. Petrol. Sci. Technol. 35, 235–241. Tavakkoli, M., Masihi, M., Kharrat, R., Ghazanfari, M.H., 2009. Thermodynamlic modeling of asphaltene precipitation for heavy crude: a comparative study of thermodynamic micellization model and solid model. In: Canadian International Petroleum Conference and 60th Annual Technical Meeting of the Petroleum Society (CIPC 2009), Calgary, Alberta, Canada, 16-18 June. Van, S.L., Chon, B.H., 2017. Evaluating the critical performances of a CO2–enhanced oil recovery process using artificial neural network models. J. Petrol. Sci. Eng. 157, 207–222. Victorov, A.I., Firoozabadi, A., 1996. Thermodynamic micellizatin model of asphaltene precipitation from petroleum fluids. AIChE J. 42, 1753–1764. Wang, S., 2000. Simulation of Asphaltene Deposition in Petroleum Reservoirs during Primary Oil Recovery. PhD. Thesis. The University of Oklahoma, USA. Yarveicy, H., Ghiasi, M.M., Mohammadi, A.H., 2018. Performance evaluation of the machine learning approaches in modeling of CO2 equilibrium absorption in Piperazine aqueous solution. J. Mol. Liq. 255, 375–383. Yetilmezsoy, K., Fingas, M., Fieldhouse, B., 2011. An adaptive neuro-fuzzy approach for modeling of water-in-oil emulsion formation. Colloid. Surface. Physicochem. Eng. Aspect. 389, 50–62. Zoveidavianpoor, M., Samsuri, A., Shadizadeh, S.R., 2013. The clean up of asphaltene deposits in oil wells. Energy Sources, Part A Recovery, Util. Environ. Eff. 35, 22–31. References Abbod, M., Deshpande, K., 2008. Using intelligent optimization methods to improve the group method of data handling in time series prediction. In: International Conference on Computational Science, Krakow, Poland, 23-25 June. Abghari, S.Z., Sadi, M., 2013. Application of adaptive neuro-fuzzy inference system for the prediction of the yield distribution of the main products in the steam cracking of atmospheric gasoil. Journal of the Taiwan Institute of Chemical Engineers 44, 365–376. Ahmadi, M.A., Golshadi, M., 2012. Neural network based swarm concept for prediction asphaltene precipitation due to natural depletion. J. Petrol. Sci. Eng. 98–99, 40–49. Alimohammadi, S., Sayyad Amin, J., Nikooee, E., 2017. Estimation of asphaltene precipitation in light, medium and heavy oils: experimental study and neural network modeling. Neural Comput. Appl. 28, 679–694. Amanifard, N., Nariman Zadeh, N., Farahani, M.H., Khalkhali, A., 2008. Modeling of multiple short-length-scale stall cells in an axial compressor using evolved GMDH neural networks. Energy Convers. Manag. 49, 2588–2594. Andersen, S.I., Stenby, E.H., 1996. Thermodynamics of asphaltene precipitation and dissolution investigation of temperature and solvent effects. Fuel Sci. Technol. Int. 14, 261–287. Ansari, H.R., Gholami, A., 2015. Robust method based on optimized support vector regression for modeling of asphaltene precipitation. J. Petrol. Sci. Eng. 201–205. Ashoori, S., Abedini, A., Abedini, R., Nasheghi, K.Q., 2010. Comparison of scaling equation with neural network model for prediction of asphaltene precipitation. J. Petrol. Sci. Eng. 72, 186–194. ASTM D1945-14, 2014. Standard Test Method for Analysis of Natural Gas by Gas Chromatography. ASTM International, West Conshohocken, PA. www.astm.org. ASTM D2887-16a, 2016. Standard Test Method for Boiling Range Distribution of Petroleum Fractions by Gas Chromatography. ASTM International, West Conshohocken, PA. www.astm.org. ASTM D3279-12e1, 2012. Standard Test Method for N-Heptane Insolubles. ASTM International, West Conshohocken, PA. www.astm.org. Atashrouz, S., Pazuki, G., Alimoradi, Y., 2014. Estimation of the viscosity of nine nanofluids using a hybrid GMDH-type neural network system. Fluid Phase Equil. 372, 43–48. Ayatollahi, S., Hemmati Sarapardeh, A., Roham, M., Hajirezaie, S., 2016. A rigorous approach for determining interfacial tension and minimum miscibility pressure in parafin-CO2 systems: application to gas injection processes. Journal of the Taiwan Institute of Chemical Engineers 63, 107–115. Behbahani, T.J., Ghotbi, C., Taghikhani, V., Shahrabadi, A., 2013. A modified scaling equation based on properties of bottom hole live oil for asphaltene precipitation estimation under pressure depletion and gas injection conditions. Fluid Phase Equil. 358, 212–219. Buckley, J.S., 1999. Predicting the onset of asphaltene precipitation from refractive index measurements. Energy Fuels 13, 328–332. Chen, G., Fu, K., Liang, Z., Sema, T., Li, C., Tontiwachwuthikul, P., Idem, R., 2014. The genetic algorithm based back propagation neural network for MMP prediction in CO2-EOR process. Fuel 126, 202–212. Eslamimanesh, A., Gharagheizi, F., Illbeigi, M., Mohammadi, A.H., Fazlali, A., Richon, D., 2012. Phase equilibrium modeling of clathrate hydrates of methane, carbon dioxide, nitrogen, and hydrogen + water soluble organic promoters using support vector machine algorithm. Fluid Phase Equil. 316, 34–45. Farlow, S.J., 1984. Self Organizing Methods in Modeling: GMDH Type Algorithms. Marcel Dekker, New York, USA. Fogel, D.B., 1997. The advantages of evolutionary computation. In: Lundh, D., Olsson, B., Narayanan, A. (Eds.), Bio-computing and Emergent Computation. World Scientific Press, Singapore. Ghanadzadeh, H., Ganji, M., Fallahi, S., 2012. Mathematical model of liquid–liquid equilibrium for a ternary system using the GMDH-type neural network and genetic algorithm. Applied Mathematical Modeling 36, 4096–4105. Goldberg, D.E., 1989. Genetic Algorithms in Search, Optimization and Machine Learning. Addison-Wesley, USA. Helmy, T., Hossain, M.I., Adbulraheem, A., Rahman, S.M., Rafiul Hassan, Md, Khoukhi, A., Elshafei, M., 2017. Prediction of non-hydrocarbon gas components in separator by using hybrid computational intelligence models. Neural Comput. Appl. 28, 635–649. Hemmati Sarapardeh, A., Yeganeh Marand, R.A., Naseri, A., Safiabadi, A., Gharagheizi, F., Kashkouli, P.I., Mohammadi, A.H., 2013. Asphaltene precipitation due to natural depletion of reservoir: determination using a SARA fraction based intelligent model. Fluid Phase Equil. 354, 177–184. Hemmati Sarapardeh, A., Ameli, F., Dabir, B., Ahmadi, M., Mohammadi, A.H., 2016. On the evaluation of asphaltene precipitation titration data: modeling and data assessment. Fluid Phase Equil. 415, 88–100. Hirschberg, A., de Jong, L.N.G., Schipper, B.A., Meijer, J.G., 1984. Influence of temperature and pressure on asphaltene flocculation. Soc. Petrol. Eng. J. 24, 283–293. 1222