Introductio
Information
n
to
Management
Computing
COMP 20093
Compiled by:
Compiled by:
Monina D. Barretto
Monina D. Barretto
Rosita E. Canlas
Table of Contents
Message to the Student ..............................................................................................................3
Course Syllabus ..........................................................................................................................4
DATABASE CONCEPTS .........................................................................................................11
DATABASE DEVELOPMENT PROCESS ................................................................................18
RELATIONAL DATA MODEL ..................................................................................................24
Conceptual Data Modeling (Entity-Relationship Model).......................................................33
ERD to Relation Conversion...................................................................................................33
ENHANCED ENTITY-RELATIONSHIP MODEL (EERD) ..........................................................47
RELATIONAL ALGEBRA ........................................................................................................56
SQL – STRUCTURED QUERY LANGUAGE............................................................................73
Page | 2
Message to the Student
This instructional material presents all topics which are based in the course syllabus. It is
presented in a concise, simple manner intended to guide you through the different topics of the
course. Please read the material thoroughly for better understanding of the lessons.
You are encouraged to read additional learning materials available to you. There are suggested
reading materials at the end of each topic.
All course materials, activities which have a need to access the internet are optional. You may
access them only if you can gain access to the net.
The assessments at the end of each module must be answered. They are intended to gauge
your understanding of what you have learned from the lessons.
Your professor should get in touch with you at the start of the semester regarding the
submission of answers to assessment and will give further instructions on how distance learning
will be implemented.
Thank you, God bless, and keep safe.
Page | 3
Course Syllabus
POLYTECHNIC UNIVERSITY OF THE PHILIPPINES
College of Computer and Information Sciences
Department of Computer Science
COURSE TITLE
Information Management
COURSE CODE
COMP20093
CREDIT UNITS
3 units / 5 hours
COURSE PREREQUISITE
COMP 20063
COURSE DESCRIPTION
The course introduces students the basic relational database concepts. During the course, students
will learn how to design databases observing concepts and procedures in relational database
design, document design using entity-relationship diagram, and use SQL to retrieve data and
generate information. Students gain actual experience of database development from analysis of
actual user requirements to implementation and testing of their database design.
Institutional Learning Outcomes
1. Creative and Critical Thinking
Graduates use their imaginative as well
as rational thinking abilities to life
situations in order to push boundaries,
realize possibilities, and deepen their
interdisciplinary
and
general
understanding of the world.
Program Outcomes
Apply knowledge of computing
fundamentals, knowledge of a
computing specialization, and
mathematics, science and domain
knowledge appropriate for the
computing specialization to the
abstraction and conceptualization of
computing models from defined
problems and requirements.
Identify, analyze, formulate, research
literature, and solve complex
computing problems and requirements
reaching substantiated conclusions
using fundamental principles of
mathematics, computing sciences, and
relevant domain disciplines.
Course Outcomes
Apply computing fundamentals and
integrate them to database management
solutions.
Develop database application that will
improve the way of doing things and
will create a positive impact to
stakeholders
Evaluate database needs of a group and
formulate recommendations based on
principles in database design.
Knowledge and understanding of
information security issues in relation
to the design, development and use of
information systems.
2. Effective Communication
Graduates are proficient in the four
macro skills in communication (reading,
Communicate effectively with the
computing community and with
society-at- large about complex
Conduct effective interviews with
stakeholders in connection to the
development of a database application.
Page | 4
writing, listening, and speaking) and are
able to use these skills in solving
problems. Making decisions and
articulating thoughts when engaging
with people in various circumstances.
computing activities by being able to
comprehend and write effective
reports, design documentation, make
effective presentations, and give and
understand clear instructions.
Create project documentation
3. Strong Service Orientation
Graduates exemplify the potentialities
of an efficient, well-rounded and
responsible professional deeply
committed to service excellence.
Design and evaluate solutions for
complex computing problems, and
design and evaluate systems,
components, or processes that meet
specified needs with appropriate
consideration for public health and
safety, cultural, societal, and
environmental considerations.
Perform tasks, depending on the role
assignment
Contribute expertise to other members of
the team.
Solve problems, whether technical and or
non-technical issues that may arise.
4. Community Engagement
Graduates take an active role in the
promotion and fulfillment of various
advocacies (educational, social and
environmental) for the advancement of
community welfare.
Create, select, adapt and apply
appropriate techniques, resources and
modern computing tools to complex
computing activities, with an
understanding of the limitations to
accomplish a common goal.
Develop a database application that will
be relevant to society.
5. Adeptness in the Responsible Use of
Technology
Graduates demonstrate optimized use
of digital learning abilities, including
technical and numerical skills.
An ability to apply mathematical
foundations, algorithmic principles
and computer science theory in the
modeling and design of computer
based systems in a way that
demonstrates comprehension of the
tradeoffs involved in design choices
Design and develop efficiently running
applications
6. Passion to Lifelong Learning
Graduates are enabled to perform and
function in the society by taking
responsibility in their quest to know
more about the world through lifelong
learning.
Recognize the need, and have the
ability, to engage in independent
learning for continual development as
a computing professional.
Make use of all available possible
resources (can be online) to help debug
or troubleshoot problems that could be
encountered during application
development
7.
High Level of Leadership and
Organizational Skills
Graduates are developed to become the
best professionals in their respective
disciplines
by
manifesting
the
appropriate skills and leaderships
qualities.
Function effectively as an individual
and as a member or leader in diverse
teams and in multidisciplinary settings.
Perform the role of a leader and
organize the team so that each member
will be able to maximize his full
potential
8. Sense of Personal and Professional
Ethics
Graduates show desirable attitudes and
behavior either in their personal and
professional circumstances.
An ability to recognize the legal, social,
ethical and professional issues
involved in the utilization of computer
technology and be guided by the
adoption of appropriate, ethical and
legal practices
Design database applications which will
be useful or beneficial to the well-being of
the stakeholders
9. Sense of National and Global
Responsiveness
Graduates’ deep sense of national
compliments the need to live in a global
Function effectively as an individual
and as a member or leader in diverse
teams and in multidisciplinary settings.
Design database applications which will
be useful or beneficial to the broader
segment of the community
Apply computing fundamentals and
integrate them to database management
solutions.
Page | 5
village where one’s culture and other
people culture are respected.
Course Plan
Week
1
1-2
3
Topic
1.
Introduction to the
Course
a. Vision Mission Goals
and Objective of the
University,
and
College.
b. Self-Introduction
c.
Course Overview
d. Grading System
e. Classroom Mgnt
2. Database Concepts
a. Fundamentals
of
Data,
Information,
Database, Metadata
b. Electronic Database
(Components
of
Database
Environment, Range
of
Database
Application)
c. Database Approach
(Advantages of DB
Approach, DB
Development
Process, DB
Models/Architecture)
The Database
Development Process
Database Development
Activities during the
Systems Development Life
Cycle
a.
Enterprise modeling
b.
Conceptual data
modeling
c.
Logical database
design
d.
Physical database
design
e.
Database
implementation
f.
Database
maintenance
Learning Outcomes
a.
b.
c.
a.
b.
c.
a.
b.
c.
d.
Methodology
Resources
Assessment*
Demonstrate a sense of
readiness for the upcoming
semester.
Identify
their
learning
outcomes and expectations
for the course.
Recognize their capacity to
create new understandings
from reflecting on the course
Orientation
SelfIntroduction
Group
Discussions
University
Student
Handbook
College
Manual
Course
Syllabus
Define key terms related to
the database environment
Differentiate a database
approach from a traditional
file processing system
Describe
the
different
database models in the
evolution of DB Systems
Class
Discussion
Reading
Assignment
Slide
Presentation
Quiz
Class
Discussion
Demonstration
& Simulation
Slide
Presentation
Seatwork
Define basic terminologies
Describe
the
different
phases of the life cycle of
system development
Describe
the
different
database
development
activities which goes on in
each phase of the SDLC
Compare the traditional
SDLC with current newer
system
development
methodologies e.g. rapid
application
development
(RAD)
a.
Other system
development
methodologies
4-6
Relational Database
Modeling
a. Design a relational database
applying
principles
of
relational database design
Page | 6
(Properties of Relations,
Integrity Constraints,
Normalization)
b.
c.
d.
e.
7-8
Conceptual Data
Modeling
(Entity-Relationship
Model)
Transform ERD into
Relations
a.
b.
c.
Week
9
MIDTERM
10-11
Enhanced EntityRelationship Diagram
and
using
standard
notations and tools.
Use
normalization
to
decompose relations with
anomalies
into
wellstructured relations.
Design relations in at least
3rd Normal Form.
Implement
Integrity
Constraints
Apply the normalization
process
in
forms
and
business rules and transform
them
into
relations
observing the properties of
relational database.
Group
Discussions
Sample
Forms and
Reports
Design a relational database
applying
principles
of
relational database design
and
using
standard
notations and tools.
Use
Entity
relationship
diagram as data model.
Evaluate database design of
a group and formulate
recommendations based on
principles in database
design. Document both
assessments and
recommendation.
Class
Discussion
Seatwork
Problem
Solving
Data
Modelling
CASE tool
Slide
Presentation
Case Study
Project:
Conceptual Data
Model
Midterm
Examination
a.
b.
c.
Analyze and identify if the
problem
requires
an
Enhanced
EntityRelationship Diagram.
Apply
generalization/specialization
processes for the problem.
Implement constraints in the
EERD.
Class
Discussion
Seatwork
Problem
Solving
Data
Modelling
Slide
Presentation
Hands-on
exercises
11-12
Relational Algebra
Use the basic operators in
relational algebra to understand
the
foundation
of
query
languages in relational database
systems
Class
Discussion
Seatwork
Slide
Presentation
Quiz
13-14
Data manipulation
language
(Basic SQL statements for
data retrieval)
a.
Class
Discussion
Demonstration
Group
Seatwork
Computer
DBMS-SQL
Hands-on
exercises
Quiz
Write DML SQL statements
to generate information
required by the database
users using:
Simple
SELECT
Statement
SELECT
Statement
with WHERE clause
Page | 7
(using
Relational,
Logical and Special
database operators)
14-15
Aggregate Functions
a.
Write DML SQL statements
to generate information
required by the database
users using:
SELECT
Statement
with
Aggregate
functions.
SELECT
Statement
with GROUP BY and
HAVING Clause
Discussion
Demonstration
Group
Seatwork
Computer
DBMS-SQL
Hands-on
exercises
Quiz
16
3.
a.
Write DML SQL statements
to generate information
required by the database
users using multiple tables.
Class
Discussion
Demonstration
Group
Seatwork
Computer
DBMS-SQL
Hands-on
exercises
16-17
18
Complex Retrieval of
Data
(Multiple
relations
handling using WHERE as
join predicate)
PRESENTATION OF
LEARNING OUTPUT
a.
Project
Documentation
Database
Implementation
Project
Presentation
FINAL EXAMINATION
Final
Examination
*May not apply with a different teaching modality (i.e. distance learning)
Suggested Readings and References
REFERENCES
1.
2.
3.
4.
5.
6.
7.
8.
Modern Database Management by J.A. Hoffer, Ramesh Topi , 13th ed, 2019.
Modern Database Management by J.A. Hoffer, Ramesh Topi , 11th ed, 2013.
Fundamentals of Database Systems, Ramez Elmasri and Shamkant B. Navathe, 7th Ed, 2017
Database Systems: Design, Implementation, and Management, Coronel, Carlos & Morris, Steven, 11th Ed,
2015
Introduction to Database Management Systems, 3G e-Learning FZ LLC,2015
Database Systems: A Practical Approach to Design, Implementation, and Management, Connolly, Thomas M.
Begg, Carolyn, 6 th Ed, 2015
SQL Tutorial (https://www.w3schools.com/sql/)
DB2 SQL Workshop Guide, 2002 and other DBMS Guides
Note: Extended readings may be assigned by the professor.
Software/Program Developed Rubrics
CRITERIA
EXCELLENT
96-100
GOOD
86-95
SATISFACTORY
76-85
POOR
60-75
FAILED
Below 60
Page | 8
User Interface
(.15)
Interaction is
natural to the user
and is as specified
Interaction is
acceptable to user
and generally
meets
specifications
Data Types and
Size/Constraints
(.10)
Database design
use appropriate
structures;
Normalization
(.30)
All fields are
logically grouped
in tables
Database design
generally use
appropriate
structures;
1-5% error in
logical field
grouping in
normalization
Relationships
(.10)
-
Correct
primary and
foreign keys
are assigned
in all tables
-
Coding
Correctness and
Efficiency (.10)
-
All queries
correctly
coded
Level of
Complexity
(.10)
-
All queries
coded with
the right
level of
complexity
required
Number of
tables used is
based on
requirement
User interaction
minimally meets
usability and
specifications
User interaction is
incomplete or
ineffective and
does not meet
specifications
6-10% error in
logical field
grouping in
normalization
Few of the
database
structures are
appropriate.
11-15% error in
logical field
grouping in
normalization
Almost all of the
database
structures are
inappropriate.
More than 15%
error in logical
field grouping in
normalization
1-5% error
in assigning
of the right
relational
keys
-
6-10% error
in assigning
of the right
relational
keys
-
11-15% error
in assigning
of the right
relational
keys
-
-
1-10% of
queries have
coding issues
-
11-20% of
queries have
coding issues
-
21-30% of
queries have
coding issues
-
-
1-10% of
queries did
not follow
complexity
requirements
-
11-20% of
queries did
not follow
complexity
requirements
-
21-30% of
queries did
not follow
complexity
requirements
-
Number of
Number of
Number of
tables used is
tables used is
tables used is
90%-80%
89%-70%
79%-60%
based on
based on
based on
requirement
requirement
requirement
*Processing involves use of more advanced SQL commands, views, stored procedures, subquery
-
Scope (.15)
-
User interaction
fails in some
respects but
generally meets
usability and
specifications
Not all database
structures are
appropriate.
-
More than
15% error in
assigning of
the right
relational
keys
More than
30% of
queries have
coding issues
More than
30% of
queries did
not follow
complexity
requirements
Number of
tables used is
less than 60%
based on
requirement
COURSE ASSESSMENT& EVALUATION CRITERIA (GRADING & REQUIREMENTS)*
Assignments / Quizzes / Exercises
Major Requirements
Midterm and Final Exam
Database Application project in collaboration with Advance Programming
GRADING SYSTEM:
FIRST GRADING
= Class Standing (70%): Quizzes, Assignment, Exercises, Project Activities ; Midterm
Examination (30%)
SECOND GRADING
= Class Standing (70%): Quizzes, Assignment, Exercises, Project Activities ; Final Examination
(30%)
FINAL GRADE
= (FIRST GRADING + SECOND GRADING) / 2
*May not apply with a different teaching modality (i.e. distance learning)
Page | 9
Classroom Policy
Aside from what is prescribed in the student handbook, the following are the professor’s additional house rules:
1.
2.
3.
4.
5.
6.
7.
8.
9.
The course is expected to have a minimum of four (4) quizzes.
Assignments and research projects/report works will be given throughout the semester. Such requirements shall be
due as announced in class. Late submission shall be penalized with grade deductions (5% per day) or shall no longer
be accepted, depending on the subject facilitator’s discretion. Assignments and exercises are designed to assist you
in understanding the materials presented in class, and to prepare you for the exams.
Students are required to attend classes regularly, including possible make-up classes. The student will be held liable
for all topics covered and assignments made during his/her absence. The university guidelines on attendance and
tardiness will be implemented.
Any evidence of copying or cheating during any examinations may result in a failing grade from the examination for
all parties involved. Note that other university guidelines shall be used in dealing with this matter.
Students are advised to keep graded work until the semester has ended.
Contents of the syllabus are subject to modification with notification.
Cell phones, radios or other listening devices are not allowed to be used inside lecture and laboratory rooms to
prevent any distractive interruption of the class activity. *
No foods, drinks, cigarettes nor children are allowed inside the lecture and laboratory rooms. *
Withdrawal and dropping from the subject should be done in accordance with existing university policies and
guidelines regarding the matter.
*May not apply with a different teaching modality (i.e. distance learning, non F2F mode)
Consultation Time
Prepared by:
Reviewed by:
Assist. Prof. Monina D. Barretto,
MBA
Assist. Prof. Melvin C. Roxas,MSGITS
Department/Academic Program Head
Faculty Member from the Main
Campus
Prof. Gisela May A. Albano, PhD
Assoc. Prof. Rosita E. Canlas, MIT
Faculty Member from the Main
Campus
Dean, CCIS
Prof. Emanuel C. De Guzman, PhD
VP For Academic Affairs
Page |
10
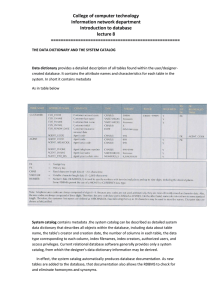
DATABASE CONCEPTS
OVERVIEW
The past decades, we have seen how data and databases have grown in its use and
importance in almost all fields of human life: business, education, government, health, etc. The
benefits derived from using databases to manage data have shown its tremendous contribution
on how data can be best maintained and be made more relevant in terms of providng timely and
accurate information. This module familiarizes the student with the concepts, terminologies,
and the evolution of databases.
LEARNING OUTCOMES:
At the end of this chapter, the student should be able to:
Define key terms related to the database environment
Differentiate a database approach from a traditional file processing system
Describe the different database models in the evolution of DB Systems
COURSE MATERIALS
Data Vs. Information
Data: facts, text, graphics, images, sound, video segments
Information: Data processed to be useful in decision making; actionable
Sample Data
Page |
11
Data in context: Information
coun
t
11
%
41
%
14
%
BIE
BSC
OE
34
%
BSCS
BSIT
Student
9000 Population
0
8000
75000
8000
70000
0
0
7000
60000
0
50000
6000
40000
0
2000
5000 100015000
0 019900 1995 2000 2005 2010 2015 2020 2025
2030
4000
1
2
3
4
5
6
7
8
9
0 199 199 200 200 201
Year
201 202 202 203
5
0
5
0
5
0
5
0
No. Of 3000 0 000150002000040000500006000070000750008
0000
Students10 0
2000
Yea
No. Of
0
r
Students
1000
0 Environment
Components of the Database
0
CASE Tools – computer-aided software engineering
Repository – centralized storehouse of metadata
Database Management System (DBMS) – software for managing the database
Page |
12
Database – storehouse of the data
Application Programs – software using the data
User Interface – text and graphical displays to users
Data Administrators – personnel responsible for maintaining the database
System Developers – personnel responsible for designing databases and software
End Users – people who use the applications and databases
The Database
Central repository of shared data
Data is managed by a controlling agent
Stored in a standardized, convenient form
Requires a Database Management System (DBMS)
Page |
13
Database Management System (DBMS)
is a collection of programs that enables users to create and maintain a database;
a general purpose software system that facilitates the processes of defining, constructing,
manipulating, and sharing databases among various users and applications
Metadata
Descriptions of the properties or characteristics of the data, including data types, field
sizes, allowable values, and documentation
The metadata is stored in a repository.
Traditional File Processing
File processing system where data are stored
organization.
for each individual application in an
Each department or area within an organization has its own set of files, often creating data
redundancy and data isolation.
There is no overall map, plan, or model guided application growth.
Page |
14
Example of an old file processing system :
Pine Valley Furniture Company
Duplicate Data
Disadvantages of Traditional File Processing
Duplication of Data
Program Data Dependence
Inefficient use of storage space
Data integrity may be compromised
Excessive program maintenance
Lengthy development of program
Limited Data Sharing – no centralized storage of data
The Database Approach
An approach where data are logically stored in databases, managed by a database
management system.
A database is designed using data models which define the nature and relationships
among data.
Page |
15
The effectiveness and efficiency of a database is directly associated with the structure of
the database
Advantages of the Database Approach
Planned data redundancy
o Minimal data duplication
o Improved data consistency
Program data independence
o Allows data to evolve without changing the application programs
o Reduced program maintenance
Improved data sharing
Increased productivity of application development
Enforcement of standards
Improved data quality
Improved data accessibility and responsiveness
Improved decision support
Range of Database Applications
Personal Databases - supports one user
Workgroup Databases (less than 25 users) – supported by two-tier client/server databases
Department/Division Databases (between 25 to 100 users) – supported by multitier
client/server databases
Enterprise Databases – scope is entire organization
Evolution of Database Systems
1960s – Experimental proof-of-concept
1970 - 1990 - Hierarchical, Network
1980 – present – Relational
1990 – present – Object-Oriented
1990 – present – Object-Relational
2000 – present – Not only SQL (NoSQL)
Evolution of Database Systems
1970 - 1990 - Hierarchical
Hierarchical -data model in which the data is organized into a tree-like structure; confined
to up to ‘one to many relationship’
1970 - 1990 - Network
Network -much like the hierarchical model except that it permitted many
relationship
to many
1980 – present - Relational
Page |
16
Relational (RDB) – establish the relationships between entities by means of common fields
included in a file, called a relation
1990 – present – Object-oriented
Object-oriented (OODB) – subscribes to a model with information represented by objects
; encapsulates both data and behavior
1990 – present – Object-relational
Object-relational (ORDB) – provide a middle ground between relational databases and
object oriented databases
References / Reading Materials
Modern Database Management 11th Ed by Hoffer, Ramesh, Ropi
Assessment:
1.
2.
3.
4.
5.
Explain 3 advantages of a database approach
Differentiate data from information
Research on differences between a relational and an object oriented database system
Differentiate a repository from a database
What can be found in a metadata. Give 5.
Page |
17
DATABASE DEVELOPMENT PROCESS
OVERVIEW
The development of an application is done by undergoing certain phases. This chapter
discusses what are being done in each phase including the deliverables for each phase. The
database activities in each phase are also explained including the database outputs. Towards
the end of this chapter, the traditional system development methodology is compared with
newer rapid development methods.
LEARNING OUTCOMES:
At the end of this chapter, the student should be able to:
Define basic terminologies
Describe the different phases of the life cycle of system development
Describe the different database development activities which goes on in each phase of
the SDLC
Compare the traditional SDLC with current newer system development methodologies e.g.
rapid application development (RAD)
COURSE MATERIALS
System Development Life Cycle
Page |
18
PLANNING
Purpose: To develop a preliminary understandingof a business situation and how information
systems might help solve a problem or make an opportunity possible.
Deliverable: A written request to study the possible changes to an existing system or the
development
of a new system that addresses an information systems solution to the business problems or
opportunities.
ANALYSIS
Deliverable: A written request to study the possible changes to an existing system or the
development of a new system that addresses an information systems solution to the business
problems or opportunities.
Deliverable: A written request to study the possible changes to an existing system or the
development of a new system that addresses an information systems solution to the business
problems or opportunities.
DESIGN
Purpose: To elicit and structure all information requirements; to develop all technology and
organizational specifications
Deliverables: Detailed technical specifications of all data, forms, reports, displays, and
processing
rules; program and database structures, technology purchases, physical site plans, and
organizational
redesigns
IMPLEMENTATION
Purpose: To write programs, build data files, test and install the new system, train users, and
finalize documentation
Deliverables: Programs that work accurately and to specifications, documentation, and training
materials
MAINTENANCE
Purpose: To monitor the operation and usefulness of a system, and to repair and enhance the
system
Deliverables: Periodic audits of the system to demonstrate whether the system is accurate and
still meets user's needs
Page |
19
Database Development Activities During the Systems Development Life Cycle (SDLC)
PLANNING
Enterprise Modelling
Analyze current data processing
Analyze the general business functions and their database needs
Justify need for new data and databases in support of business
An enterprise data model establishes the range and general contents of organizational
databases
An Enterprise Data Model is an integrated view of the data produced and consumed across an
entire organization.
A data architectural framework used for integration. It enables the identification of shareable
and/or redundant data across functional and organizational boundaries*
*http://tdan.com/the-enterprise-data-model/5205
Conceptual Data Modeling
Identify scope of database requirements for proposed information system
Analyze overall data requirements for business function(s) supported by database
ANALYSIS
Conceptual Data Modeling
Develop preliminary conceptual data model, including entities and relationships
Compare preliminary conceptual data model with enterprise data model
Develop detailed conceptual data model, including all entities, relationships, attributes,
and business rules
Make conceptual data model consistent with other models of information system
Populate repository with all conceptual database specifications
DATABASE DESIGN
Logical Database Design
Analyze in detail the transactions, forms, displays, and inquiries (database views) required
by the business functions supported by the database
Integrate database views into conceptual data model
Identify
data
integrity
and
security
requirements,
and
populate repository
Physical Database Design and Definition
Define database to DBMS (often generated from repository)
Decide on physical organization of data
Design database processing programs
Page |
20
DATABASE IMPLEMENTATION
Database Implementation
Code and test database processing programs
Complete database documentation and training materials
Install database and convert data from prior systems
DATABASE MAINTENANCE
Database Maintenance
Analyze database and database applications to ensure that evolving information
requirements are met
Tune database for improved performance
Fix errors in database and database applications and recover database when it is
contaminated
Two Approaches to Database and Information Systems Development
System Development Life Cycle (SDLC)
Detailed, well-planned development process
Time-consuming, but comprehensive
Long development cycle
Page |
21
Rapid Application Development (RAD)
Iterative process of rapidly repeating analysis, design, and implementation steps until they
converge on the system the user wants; Utilizes prototyping
Popular RAD method : Agile Software Development
•
•
•
•
Scrum
Kanban
Lean
XP
Agile methods mostly focus on the following key principles:
•
•
•
•
•
Satisfying customers is of foremost importance
Develop projects with inspired contributors
Interactions are best when done in person
Software that works is a measure of progress
Reflect and adapt on an ongoing basis
Core values of Agile are as follows:
•
•
•
•
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
RAD or Agile Software Development should be considered..
When a project involves unpredictable and / or changing requirements
When most of the necessary database structures already exist
Prototyping Database Methodology and the Database Development Process
Page |
22
References / Reading Material:
Modern Database Management, 11th Ed, by Hoffer, Ramesh, Topi
Assessment:
1.
2.
3.
4.
5.
What goes on during the analysis phase of the system development life cycle?
What are the database activities involved during the analysis phase of SDLC?
What are being done during the maintenance phase of SDLC?
How does the maintenance phase help continue the cycle of system development?
Compare the traditional SDLC with the rapid application development methodology of
system development
Activity:
1. Provide an example of an application you are developing from scratch, e.g. retail inventory
system. Prepare your database output in the analysis and design phases of system
development
Page |
23
RELATIONAL DATA MODEL
OVERVIEW
Among the different database management systems, the relational data model is one which is
the most used and most dominant. It has gained popularity because of its simplicity,
robustness, performance, and scalability. Its query language is also easy to use and is almost
compatible with the different types of RDBMS in the market.
LEARNING OUTCOMES:
At the end of this module, the student is expected to :
Design a relational database applying principles of relational database design and using
standard notations and tools.
Use normalization to decompose relations with anomalies into well-structured relations.
Design relations in at least 3rd Normal Form.
Implement Integrity Constraints
Apply the normalization process in forms and business rules and transform them into
relations observing the properties of relational database.
COURSE MATERIALS
Relational Data Model
Represent data in the form of tables
A named, two-dimensional table is called a relation
Each relation consists of named columns and an arbitrary number of unnamed rows
A named column is called an attribute
Each row of a relation corresponds to a record that contains data
Properties of a Relation
1.
2.
3.
4.
5.
It has a unique name
No multivalued attributes are allowed in a relation
Each row is unique
Each attribute has a unique name
The sequence of columns as well as of rows is insignificant
Classification of Attributes
Required vs. Optional Attributes
o Required – must have a value
o Optional – may not have a value
Simple vs. Composite Attributes
o Simple (or atomic) - cannot be broken down into smaller components
Page |
24
o Composite – has meaningful component parts
Single-valued vs. Multivalued Attributes
o Single-valued – attribute which has only one value
o Multivalued Attributes – attribute that may take on more than one value
Stored vs. Derived Attributes
o Stored – value is provided by user
o Derived – value is computed or derived from another attribute/s
Identifier – an attribute or combination of attribute whose value distinguishes instances
of an entity type
o Must not change in value
o Must not be null
o Must be unique
Examples : Classification of Attributes (for a given form for an insurance application)
Required vs. Optional Attributes
o Required – medical condition, attributes pertaining to co-morbidities
o Optional – provincial address
Simple vs. Composite Attributes
o Simple (or atomic) - Age
o Composite – Name, can be broken down into first name, middle and last name
Single-valued vs. Multivalued Attributes
o Single-valued – Birthdate
o Multivalued Attributes – Contact number (may have more than 1 phone number)
Stored vs. Derived Attributes
o Stored – Name
o Derived – Age (can be derived from birthdate)
Identifier – an attribute or combination of attribute whose value distinguishes instances
of an entity type - Account number (assigned by the insurance company)
Relation Employee with the attributes inside the parenthesis, empid, name, depname,
employstatus
EMPLOYEE(EmpID, Name, DeptName, EmployStatus)
Relational Keys
Primary Key – an attribute or a combination of attributes that uniquely identifies each row in a
relation
Composite key – a primary key that consists of more than one attribute
Foreign Key – attribute used to establish the relationship between two tables. A foreign key in a
table/relation always point to the primary key of another table/relation
Page |
25
Cust_ID is a foreign key in ORDER_T. It allows an order to be associated with a particular
customer in the CUSTOMER_T table.
Integrity Constraints - Rules limiting acceptable values and actions, to facilitate maintaining
the accuracy and integrity of data
Domain Constraints – Domain is a set of values that can be assigned to an attribute ; a
domain definition consists of domain name, meaning, data type, size and allowable
values for the domain values
Entity Integrity– ensures that every relation has a valid primary key
Referential Integrity -rule that maintains consistency among the rows of two relations.
The rule states that if there is a foreign key, either each foreign key value must match a
primary key value or the foreign key value must be null.
Database Normalization
Definition
Optimizing table structures
Removing duplicate data entries
Process of efficiently organizing data in the DB.
A technique for producing a set of relations with desirable properties, given the data
requirements of an enterprise.
a formal method that identifies relations based on their primary key and the functional
dependencies among their attributes.
Why Normalize?
Improved speed
More efficient use of space (Eliminate redundant data in a DB)
Ensure data dependencies make sense
Increased data integrity - decreased chance that data can get messed up due to
maintenance
Page |
26
(prevent possible corruption of DB stemming from update anomalies -insertion, deletion,
modification).
Tables that are not normalized are susceptible to experiencing modification anomalies
o Insertion Anomaly - occurs when certain attributes cannot be inserted into
the database without the presence of other attributes
o Update Anomaly - exists when one or more instances of duplicated data is
updated, but not all
o Deletion Anomaly - exists when certain attributes are lost because of
the deletion of other attributes
Terminologies
Functional dependency: Describes the relationship between attributes in a relation.
If A and B are attributes of a relation R, B is functionally dependent on A, if each value of A in R
is associated with exactly one value of B in R.
B is functionally dependent on A
A
B
Example : Given an ISBN, one would know the title of a book, Title is functionally dependent
on ISBN
ISBN
Title
Determinant: attribute or set of attributes on the left hand side of the arrow. ISBN is the
determinant for the given example.
Unnormalized form (UNF): A table that contains one or more repeating groups.
Repeating group: an attribute or group of attributes within a table that occurs with multiple
values for a single occurrence of the nominated key attributes of that table.
Example of a table in unnormalized form (see figure below). ProdID, ProductDescription,
ProdFinish, UnitPrice, OrderedQty are multivalued attributes. They have more than one value
in the table. In this example, 1 order ID (1006) has 3 products (product IDs 7, 5, and 4).
Page |
27
PROCESS OF NORMALIZATION
First normal form (1NF): A relation in which the intersection of each row and column contains one
and only one value, meaning there are no repeating groups.
First normal form (UNF → 1NF): Remove repeating groups:
Enter appropriate data in the empty columns of rows.
Place repeating data along with a copy of the original key attribute in a separate relation.
Identifying a primary key for each of the new relations.
In the UNF example above, below is the table in the 1NF, repeating groups removed, each of
the products are now in different records
Second normal form (1NF -> 2NF): A relation that is in 1NF and with no partial dependencies.
Remove partial functional dependencies.
1NF → 2NF: the partial functionally dependent attributes are removed from the relation by
placing them in a new relation along with a copy of their determinant.
Identify the candidate key for a relation: recognise the attribute (group of attributes) that
uniquely identifies each row in a relation. All of the attributes that are not part of the primary key
(non-primary key attributes) should be functionally dependent on the key.
In the example, the attributes that will uniquely identify each row in the relation is a combination
of order id and prod id. So the PK is a composite key.
Partial functional dependency is when a nonkey attribute is functionally dependent on part (but
not all) of the primary key
Page |
28
In the example above, order date, custid and customer name are nonkey attributes which are
partially dependent on the PK since they are only functionally dependent on part of the PK, the
order ID. So we can break this down into one whole relation (see figure below, ORDER_T).
Likewise, product description, prod finish, unit price are also partially dependent on the PK since
they are only functionally dependent on part of the PK, the prod id. So we can also break this
down into another relation (see figure below, PRODUCT_T).
Full functional dependency: when a nonkey attribute is functionally dependent on the primary key.
In the example above, only the ordered qty is fully dependent on the PK (order id, prod id). So
this is the full functional dependency. (see figure below, ORDER_DETAIL_T).
Primary keys underlined.
Third normal form (3NF): A relation that is in 1NF and 2NF, and in which no non-primary key
attribute is transitively dependent on the primary key. Remove transitive dependencies.
Transitive dependency: A condition where A, B and C are attributes of a relation such that if A
→ B and B → C, then C is transitively dependent on A via B (provided that A is not functionally
dependent on B or C).
2NF → 3NF: the transitively dependent attributes are removed from the relation by placing
them in a new relation along with a copy of their determinant
Page |
29
From the example above, there are no transitive dependencies in tables PRODUCT_T and
ORDER_DETAIL_T. In ORDER_T, customer name and customer address are transitively
dependent on order id via the customer id. This is transitive dependency and should be moved
to a different table.
Page |
30
Reference / Reading Material :
Modern Database Management, 11th Ed
Hoffer , Ramesh, Topi
Assessment
1. Give your own examples (3 examples) of functional dependencies between attributes. Use
line with arrow to show the determinant and the dependent attributes
2. Give you own example (1) of record with multi-valued attributes. Show all attribute names
and give data for each attribute highlighting the multi-valued attributes
3. Give other examples (3) of attributes which can be derived (any record).
4. Explain how domain constraints impose restrictions on data to be input into the
attribute/table/database
5. Explain how normalization can remove redundancy
Page |
31
Activity
Normalization Problem #2
Table of Attributes for ‘Weekly Employee Assignment and Hours Rendered’ (with sample
data)
EmpID
Agency
E1
Emp
Name
Cruz
E2
David
A1
E3
Ramos
A2
A1
Hourly Company Company
Rate
Code
Name
50
C1
Makati Inn
C2
Golden Inn
C3
Shang Inn
45
C1
Makati Inn
C3
Shang Inn
60
C1
Makati Inn
Hours
Rendered
16
24
8
8
32
40
YearWeek
2019-W1
2019-W1
2019-W1
2019-W1
2019-W1
2019-W1
Business Rules
1. An employee can work in several companies per week depending upon where his agency
assigns him.
2. A company may get workers from 1 or more agencies depending on contract with the
agency/ies and the workload which needs to be filled in the company.
Create the following. Make sure to provide name for each table
1. Schema for 1NF
1.1 Underline the PK in the 1NF
1.2 Show partial dependencies (if any) and full dependencies
2. Schema for 2NF
3. Schema for 3NF
3.1 Underline all relational keys in 3NF
3.2 Show relationships between tables using lines with arrow
Page |
32
Conceptual Data Modeling (Entity-Relationship Model)
ERD to Relation Conversion
OVERVIEW
The entity-relationship diagram is a modeling tool used to represent data as entities. It also
represents relationships between entities. The ERD is widely used to model business
problems and is a tool to be able to design databases.
The second part of this chapter discusses how to convert these diagrams to their equivalent
relation.
LEARNING OUTCOMES
After successful completion of this module, the students are expected to:
Design a relational database applying principles of relational database design and using
standard notations and tools.
Use Entity relationship diagram as data model.
Evaluate database design of a group and formulate recommendations based on
principles in database design. Document both assessments and recommendation.
COURSE MATERIALS
Entity-Relationship Model
An entity-relationship model (E-R model) is a detailed, logical representation of the data for an
organization or for a business area. This is done during conceptual data modeling phase.
An E-R model is normally expressed as an entity-relationship diagram (E-R diagram or ERD)
which is a graphical representation of an E-R model
Basic Constructs of an E-R Model
1. Entity
2. Relationship
3. Attribute
Entities - An entity is a person, place, object, event, or concept in the user environment which
the organization wishes to maintain data.
Entity Type - is described just once in a database (using metadata). It is a collection of
entities that share common properties, e.g. EMPLOYEE, STUDENT
Examples: Entities with entity types
Person : EMPLOYEE, STUDENT, PATIENT
Place : STORE, WAREHOUSE, PROVINCE
Page |
33
Object : MACHINE, BUILDING, AUTOMOBILE
Event : SALE, REGISTRATION, RENEWAL
Concept : ACCOUNT, COURSE, WORK CENTER
An entity instance is a single occurrence of an entity type (records, rows)
Attributes - A property or characteristic of an entity type
Examples: attributes of Student, Automobile, Employee entity types
STUDENT
Student_ID, Student_name, Home_Address
AUTOMOBILE Vehicle_ID, Color, Weight
EMPLOYEE
Employee_ID, Employee_name, Employee_Status
Relationship - Association representing an interaction among the entity types
Relationship type - meaningful association between (or among) entity types.
Relationship instance – a relationship between (or among) entity instances
Example:
Relationship Type
Employee
Completes
Course
Relationship Instances
Page |
34
Guidelines in Naming Relationships
1. A relationship name is a verb phrase (such as Assigned_to, Supplies, Sends)
2. Represents action being taken, usually in the present tense
3. Avoid vague names such as Has or Is_related_to. Use descriptive , powerful verb
phrases
Characteristics of Relationships
1. Degree
2. Cardinality
Degree of a Relationship is the number of entity types that participate in it
Unary Relationship
Binary Relationship
Ternary Relationship
One entity
related to
another of the
same entity
type
Entities of two
different types
related to each
other
Entities of three
different types
related to each
Page |
35
Example : Unary Relationships
Example : Binary Relationships
Page |
36
Example : Ternary Relationships
Cardinality of Relationships - Specifies the number of instances of an entity type that can be associated
with the instances of another entity type
One – to – One
o Each entity in the relationship will have exactly one related entity
One – to – Many
o An entity on one side of the relationship can have many related entities, but an
entity on the other side will have a maximum of one related entity
Many – to – Many
o Entities on both sides of the relationship can have many related entities on the
other side
Cardinality Constraints - the number of instances of one entity that can or must be associated
with each instance of another entity.
Page |
37
Minimum Cardinality - Is the minimum number of instances of entity B that may be associated
with each instance of entity A.
If the minimum cardinality is zero (0), participation is optional
If the minimum cardinality is one (1), participation is mandatory
Maximum Cardinality - Is the maximum number of instances of entity B that may be associated
with each instance of entity A
Examples
Page |
38
In the first example, a patient must have one or many history details (visits to the doctor). While in the
second example, an employee may have zero or many projects (check out the cardinality symbols to
determine the symbols to be used)
Example:
This example is optional one. A
person may or may not
(optional) be married. If he is
married, he is married to just
one person
Other Examples
Page |
39
A Customer may submit any number of orders is shown by the optional many cardinality pointing to
Order entity type.
Each order must be submitted by exactly one Customer is shown by the mandatory one cardinality
pointing to Costumer entity type.
An Order must reequest one (or more) Products is shown by the mandatory many cardinality pointing to
Product entity type.
A given Product may not be requested on any Order, or may be requested on one (or more) Orders is
shown by the optional many cardinality pointing to Order entity type.
Strong VS Weak Entities
Strong entity
exist independently of other types of entities
has its own unique identifier
represented with single-line rectangle
Weak entity
dependent on a strong entity…cannot exist on its own
Does not have a unique identifier
represented with double-line rectangle
Strong entity types is one that exists independently of other entity types.
A weak entity is an entity type whose existence depends on some other entity type
Examples:
Strong
EMPLOYEE
ORDER
Weak
DEPENDENT
ORDER_DETAILS
Associative Entity
The presence of one or more attributes on a relationship suggests that the relationship should perhaps be
represented as an entity type.
When to convert a relationship to an associative entity type?
Page |
40
1.
2.
3.
4.
All the relationships for the participating entity types are “many” relationships
The resulting entity type has an independent meaning to end users
The associative entity has one or more attributes in addition to the identifier
The associative entity participates in one or more relationships independent of the entities related in
the associated relationship
The relationship Completes is converted to an associative entity type Certificate. It follows the 4 rules on
converting a relationship to an associative entity type.
Conversion of ER diagram to Relation
1. Map regular entities – Each regular entity in an ERD is transformed into a relation. The name of
the relation is generally the same as the entity type. Each simple attribute of the entity type
becomes an attribute of the relation. The identifuer of the entity type becomes the primary key of
the relation.
Composite attributes – When a regular entity type has a composite attribute, only the simple
components of the composite attribute are included in the new relation
Example
EMPLOYEE
EmpID
EmpName (Surname, First Name, MI)
Birthdate
Employee
EmpID Surname
First Name
MI
Birthdate
Page |
41
Multivalued attributes – When a regular entity type contains a multivalued attribute, two new
relations are created. The first relation contains all of the attributes of the entity type except the
multivalued attribues. The second relation contains two attributes that form the primary key of
the second relation. The first of these attributes is the primary key from the first relation. The
second is the multivalued attribute. The name of the seocnd relation should capture the meaning
of the multivalued attribute.
Example:
EMPLOYEE
EmpID
EmpName (Surname, First Name, MI)
Birthdate
{Skill}
Employee
EmpID Surname
First Name
MI
Birthdate
Employee_skill
EmpID Skill
Employee_skill contains no nonkey attributes. Each row records a particular employee skill.
2. Map weak entity types – For each weak entity type, create a new relation and include all of the
simple attributes as attributes of this relation. The include the primary key of the identifying
relation as a foreign key attribute of this new relation. The primary key of the new relation is the
combination of the primary key of the identifying relation and the partial identifier of the weak
entity type.
Example:
EMPLOYEE
DEPENDENT
EmpID
ExEam
mppN
le:ame
DepName
(Surname, First
Name, MI)
Birthdate
Employee
EmpID EmpName
Dependent
Surnam
e
First_name MI
EmpID
Birthdate
Page |
42
In practice an alternative approach is often used to simplify the primary key of the Dependent relation.
Create a new attribute called Dependent_no which will be used as a surrogate primary key. (see When to
Create a Surrogate Key below)
3. Map binary relationships - the procedure for representing relationships depend on both the
degree of the relatioships and the cardinalities of the relationships. Procedure is given below for
mapping binary one-to-many relationships
Map binary one-to-many relationships – For each binary 1:M relationship, first create a
relation for each of the 2 entity types participating in the relationship (step 1 procedure). Next
include the PK (primary key) attribute (or attributes) of the entity on the one-side of the
relationship as an FK (foreign key) in the relation that is on the many-side of the relationship
Example:
ORDER
CUSTOMER
OrderID
OrderDate
CustID
ExCaumsptN
lea: me
Customer
CustID CustName
Dependent
OrderID
OrderDate CustID
4. Map associative entities - When a data modeler encounters a many-to-many relationship, that
relationship may be modeled as an associative entity in the ERD.
The first step is to create 3 relations, one for each of the 2 participating entity types and the third
for the associative entity.
Example:
PRODUCT
ORDER
OrderID
ExOarmdpelreD
: ate
ORDERLI
NE
OrderedQt
y
ProductID
ProdDesc
ProdPrice
Order
Page |
43
OrderI
D
OrderDate
Dependent
ProductID OrderedQty
OrderID
Product
ProdDesc ProdPrice
ProductI
D
5. Map unary relationships - Unary relationships are also called recursive relationships.
5.1 Unary one-to-many relationships
Example:
EMPLOYEE
EmpID
ExEam
mppN
lea: me
Date of Birth
Is managed by
Manages
Order
EmpID EmpName
DateofBirth
ManagerID
5.2 Unary many-to-many relationships
Example:
ITEM
itemNo
ExItaemm
plDe:es cription
ItemUnit Cost
Quantity
Contains
Page |
44
Item
Page |
45
ItemNo ItemDescriptio ItemUnitCost
n
Component
ItemNo ComponentNo Quantity
When to Create a surrogate Key. A surrogate key is usually created to simplify the key structures. It
should be create when any of the following conditions hold:
1. There is a composite PK, as in the case of DEPENDENT relation shown previously with the 4
component PK
2. The nature PK (i.e. Key used in the organization and recognized in the conceptual data modeling
as the identifier) is inefficient (e.g. it may be very long)
3. The natural PK is recycled or is not guaranteed to be unique over time (e.g. there could be
duplicates , such as with names or titles).
Whenever a surrogate key is created, the natural key is always kept as a nonkey data in the same relation
because the natural key has organizational meaning that to be captured in the database.
Watch
Entity Relationship Diagram Tutorial (Part 1)
https://www.youtube.com/watch?v=QpdhBUYk7Kk
Reference / Reading Material
Chapter 11: Data and Database Administration, Modern Database Management by Hoffer, Ramesh, and
Topi
Assessments/Activities:
For each of the following narratives, draw an ERD diagram which indicates the entities and their
attributes (if noted).Identify and label significant relationships between pairs of entities and identify
the cardinality of the relationship.
Exercise 1
Create a Crow’s Foot ERD for each of the following descriptions. (Note that the word “many” is
meant to mean “more than one” in a database modelling environment).
a) Each of the MegaCo Corporation’s divisions is composed of many departments. Each of the
departments has many employees assigned to it, but each employee works for only one
department. Each department is managed by one employee, and each of these managers can
manage only one department at a time.
Page |
46
b) An airline can be assigned to fly many flights, but each flight is flown by only one airliner.
c) The KwikTite Corporation operates many factories. Each factory is located in a region. Each
region can be “home” to many of KwikTite’s factories. Each factory employs many employees,
but each of these employees is employed by only one factory.
d) An employee may have earned many degrees, and each degree may have been earned by
many employees.
Exercise 2. Create the ERD and the corresponding relations of the ERD.
Pick and Shovel Construction Company is a multi-state building contractor specializing in
medium-priced town homes. Assume that Pick and Shovel’s main entities are its customers,
employees, projects and equipment. A customer can hire the company for more than one project,
and employees sometimes work on more than one project at a time. Equipment, however, is
assigned to only one project at a time. Draw an ERD showing those entities.
Exercise 3 Create ERD and the corresponding relations of the ERD.
Prepare an Entity Relationship Diagram for Patty’s Daycare Centre. For each entity indicate the
primary key by underlining attribute(s) making up primary key and also specify 1 additional
significant attribute. Identify and label significant relationships between pairs of entities and
identify the cardinality of the relationship (either 1:1, 1 : many or many : many).
Patty’s Playschool is a Child Daycare Centre. A parent registers their child or children at the
school using a registration form. A parent can submit more than one registration form. Each room
in the daycare is assigned an age group. For example an infant is under 1 year of age and toddlers
are from 1 to 3 years of age. A child is assigned to a room based on their age and availability of
space. A room may be assigned one or more employees. An employee can only be assigned to
one room. The minimum number of employees required for a room is determined by the number
of children assigned to the room and the child:staff ratio identified by the government. For example
one employee can care for 5 infants or 8 toddlers.
Page |
47
ENHANCED ENTITY-RELATIONSHIP MODEL (EERD)
OVERVIEW
Changes in data complexity and the way data is being used paved the way to the enhancement
of the ERD. The EER (enhance entity relationship) model applied new modeling constructs to
be able to more accurately represent data in its more complex form.
LEARNING OUTCOMES
At the end of this chapter, the student should be able to:
Analyze and identify if the problem requires an Enhanced Entity-Relationship Diagram.
Apply generalization/specialization processes for the problem.
Implement constraints in the EERD.
COURSE MATERIALS
Introduction
The ER model was first introduced in the mid 1970s. It has been suitable for modeling most
common business problems and was widely used.
However, business environment has become more complex, making business data more
complex as well.
To better cope, the enhanced entity relationship (EER) model was introduced.
The EER model is semantically similar to object-oriented data modelling.
EER Modeling Constructs
Supertype - general entity type that has a relationship with one or more subtypes
Subtype - specialized entity types to which the supertype is subdivided; subgrouping of the
entities in an entity type
Example:
EMPLOYEE becomes the supertype of SALARIED and HOURLY subtypes
Page |
48
Attribute Inheritance
Property by which subtype entities inherit values of all attributes and instance of all relationships
of the supertype
When to Use Supertype/Subtype Relationships
1. There are attributes that apply to some (but not all) instances of an entity type
2. The instances of a subtype participate in a relationship unique to that subtype (a
subtype has an attribute unique to that subtype)
Page |
49
Two Processes Used in Developing Supertype/Subtype relationships
1. Generalization – defines more general entity type from a set of more specialized entity
types; bottom up process
2. Specialization - Direct reverse of generalization; top down process
Generalization Example
Entity Types CAR, TRUCK, MOTORCYCLE
Generalization to VEHICLE supertype
Specialization Example
Entity Type PART
Specialization to MANUFACTURED PART and PURCHASED PART subtypes
Page |
50
Constraints in Supertype/Subtype relationships
1. Completeness Constraint – Addresses the question of whether an instance of a
supertype must also be a member of at least one subtype
2. Disjointness Constraint - Addresses whether an instance of a supertype may
simultaneously be a member of two (or more) subtypes
Completeness Constraint
Two Rules
1.1 Total specialization rule – specifies that each entity instance of the supertype must be a
member of some subtype in the relationship
1.2 Partial specialization rule – specifies that an entity instance of the supertype may not belong
to any subtype
Page |
51
Total Specialia on
Page |
52
Disjointness Constraint
Two Rules
2.1 Disjoint Rule – specifies that if an entity instance (of a supertype) is a member of one
subtype, it cannot simultaneously be a member of any other subtype
2.2 Overlap Rule – specifies that an entity instance can simultaneously be a member of two (or
more) subtypes
A subtype discriminator is an attribute of a supertype whose values determine the target
subtype or subtypes
Page |
53
Supertype/subtype hierarchy is a hierarchical arrangement of supertypes and subtypes where
each subtype has only one supertype.
Page |
54
Summary of Supertype/Subtype Hierarchies
1. Attributes are assigned at the highest logical level that is possible in the hierarchy
2. Subtypes that are lower in hierarchy inherit attributes not only from their immediate
supertype, but from all supertypes higher in the hierarchy, up to the root
Reference / Reading Material:
Modern Database Management, 11th Ed, by Hoffer, Ramesh, Topi
Assessment/Actvities:
1. Create and EERD for the following problem.
A company provides offerings to its customers. Offerings are of two types: products and
services. Offerings are identified by an offering ID and description. In addition, products are
described by product name, standard price, and date of first release; services are described
by name of the company’s unit responsible for the services and the conditions of the
service. There are repair, maintenance, and other types of services. A repair service has a
cost while a maintenance service has an hourly rate.
Fortunately, some products never require repair. However, there are many potential repair
services for a product.
2. Map the EERD to a relational data model
Page |
55
3. A University resident has to have an identification ID. A university has 3 types of residents
with their attributes below:
Students - course, status; Faculty – college, class schedule; Administration staff –
department, basic pay
Further , Students is of 2 types, with the following attributes
OU (Open University) – monthly meet; Regular – classroom schedule
Questions
a. What are the common attributes of a regular and an OU student
b. What are all of the attributes that will apply to an OU student
c. What are the common attributes of Faculty, Student, Admin staff
4. Enumeration …Identification
a. Rules of completeness constraint (2 answers)
b. From your answer in letter a, which of the 2 specifies that each entity instance of the
supertype must be a member of some subtype in the relationship
c. Rules of disjointness constraint (2 answers)
d. From your answer in letter c, what rule specifies that an entity instance can
simultaneously be a member of two (or more) subtypes
e. Processes of creating supertype / subtype relationship (2 answers)
f. From your answer in letter e, which is the bottom-up approach
g. It locates target subtypes for an entity
Page |
56
RELATIONAL ALGEBRA
OVERVIEW
This topic discusses the different operations used in a procedural query language. It introduces
the students to concepts which will be applied in SQL programming.
LEARNING OUTCOMES
After successful completion of this module, the students are expected to:
Use the basic operators in relational algebra to understand the foundation of query
languages in relational database systems
COURSE MATERIALS
Relational Algebra Overview
•
•
•
•
•
•
Relational algebra is the basic set of operations for the relational model
These operations enable a user to specify basic retrieval requests (or queries)
The result of an operation is a new relation, which may have been formed from one or
more input relations
– This property makes the algebra “closed” (all objects in relational algebra are
relations)
The algebra operations thus produce new relations
– These can be further manipulated using operations of the same algebra
A sequence of relational algebra operations forms a relational algebra expression
– The result of a relational algebra expression is also a relation that represents the
result of a database query (or retrieval request)
Relational Algebra consists of several groups of operations
– Unary Relational Operations
•
•
•
–
Relational Algebra Operations From Set Theory
•
•
–
SELECT (symbol: s (sigma))
PROJECT (symbol: p (pi))
RENAME (symbol: (rho))
UNION ( È ), INTERSECTION ( Ç ), DIFFERENCE (or MINUS, – )
CARTESIAN PRODUCT ( x )
Binary Relational Operations
•
JOIN (several variations of JOIN exist)
Page |
57
Database State for COMPANY
All examples discussed below refer to the COMPANY database shown here.
Page |
58
Unary Relational Operations: SELECT
•
The SELECT operation (denoted by s (sigma)) is used to select a subset of the tuples from
a relation based on a selection condition.
–
–
–
The selection condition acts as a filter
Keeps only those tuples that satisfy the qualifying condition
Tuples satisfying the condition are selected whereas the other tuples are discarded
(filtered out)
Examples:
–
Select the EMPLOYEE tuples whose department number is 4:
σ DNO = 4 (EMPLOYEE)
–
In general, the select operation is denoted by σ <selection condition>(R) where
Page |
59
the symbol σ (sigma) is used to denote the select operator
the selection condition is a Boolean (conditional) expression specified on
the attributes of relation R
• tuples that make the condition true are selected
– appear in the result of the operation
• tuples that make the condition false are filtered out
– discarded from the result of the operation
–
SELECT Operation Properties
•
•
–
The SELECT operation σ <selection condition>(R) produces a relation S that has the
same schema (same attributes) as R
–
SELECT σ is commutative:
•
–
Because of commutativity property, a cascade (sequence) of SELECT operations
may be applied in any order:
•
–
σ <cond1>( σ <cond2> (σ <cond3> (R)) = σ <cond2> (σ <cond3> (σ <cond1> ( R)))
A cascade of SELECT operations may be replaced by a single selection with a
conjunction of all the conditions:
•
–
σ <condition1>( σ < condition2> (R)) = σ <condition2> (σ < condition1> (R))
σ <cond1>( σ < cond2> (σ <cond3>(R)) = σ <cond1> AND < cond2> AND < cond3>(R)))
The number of tuples in the result of a SELECT is less than (or equal to) the
number of tuples in the input relation R
The following query results refer to this database state
Page |
60
Unary Relational Operations: PROJECT
•
•
•
PROJECT Operation is denoted by p (pi)
This operation keeps certain columns (attributes) from a relation and discards the other columns.
– PROJECT creates a vertical partitioning
• The list of specified columns (attributes) is kept in each tuple
• The other attributes in each tuple are discarded
Example: To list each employee’s first and last name and salary, the following is used:
Π LNAME, FNAME,SALARY(EMPLOYEE)
The general form of the project operation is:
p<attribute list>(R)
– p (pi) is the symbol used to represent the project operation
Page |
61
•
– <attribute list> is the desired list of attributes from relation R.
The project operation removes any duplicate tuples
– This is because the result of the project operation must be a set of tuples
• Mathematical sets do not allow duplicate elements.
•
PROJECT Operation Properties
– The number of tuples in the result of projection p<list>(R) is always less or equal to the
number of tuples in R
• If the list of attributes includes a key of R, then the number of tuples in the result
of PROJECT is equal to the number of tuples in R
– PROJECT is not commutative
• p <list1> (p <list2> (R) ) = p <list1> (R) as long as <list2> contains the attributes in
<list1>
*p used instead of π
Examples of applying SELECT and PROJECT operations
Relational Algebra Expressions
•
•
We may want to apply several relational algebra operations one after the other
– Either we can write the operations as a single relational algebra expression by nesting the
operations, or
– We can apply one operation at a time and create intermediate result relations.
In the latter case, we must give names to the relations that hold the intermediate results.
Single expression versus sequence of relational operations (Example)
•
To retrieve the first name, last name, and salary of all employees who work in department number
5, we must apply a select and a project operation
Page |
62
•
•
We can write a single relational algebra expression as follows:
– pFNAME, LNAME, SALARY(s DNO=5(EMPLOYEE))
OR We can explicitly show the sequence of operations, giving a name to each intermediate
relation:
DEP5_EMPS s DNO=5(EMPLOYEE)
RESULT p FNAME, LNAME, SALARY (DEP5_EMPS)
Unary Relational Operations: RENAME
•
•
The RENAME operator is denoted by (rho)
In some cases, we may want to rename the attributes of a relation or the relation name or both
– Useful when a query requires multiple operations
– Necessary in some cases (see JOIN operation later)
•
The general RENAME operation can be expressed by any of the following forms:
– S (B1, B2, …, Bn )(R) changes both:
• the relation name to S, and
• the column (attribute) names to B1, B1, …..Bn
– S(R) changes:
• the relation name only to S
–
(B1, B2, …, Bn )(R) changes:
• the column (attribute) names only to B1, B1, …..Bn
•
For convenience, we also use a shorthand for renaming attributes in an intermediate relation:
– If we write:
• RESULT p FNAME, LNAME, SALARY (DEP5_EMPS)
• RESULT will have the same attribute names as DEP5_EMPS (same attributes as
EMPLOYEE)
– If we write:
RESULT
• RESULT (F, M, L, S, B, A, SX, SAL, SU, DNO)
(F.M.L.S.B,A,SX,SAL,SU, DNO)(DEP5_EMPS)
• The 10 attributes of DEP5_EMPS are renamed to F, M, L, S, B, A, SX, SAL,
SU, DNO, respectively
Page |
63
Example of applying multiple operations and RENAME
Relational Algebra Operations from Set Theory: UNION
•
•
UNION Operation
– Binary operation, denoted by È
– The result of R È S, is a relation that includes all tuples that are either in R or in S or in
both R and S
– Duplicate tuples are eliminated
– The two operand relations R and S must be “type compatible” (or UNION compatible)
• R and S must have same number of attributes
• Each pair of corresponding attributes must be type compatible (have same or
compatible domains)
Example:
– To retrieve the social security numbers of all employees who either work in department 5
(RESULT1 below) or directly supervise an employee who works in department 5
(RESULT2 below)
– We can use the UNION operation as follows:
DEP5_EMPS sDNO=5 (EMPLOYEE)
RESULT1 p SSN(DEP5_EMPS)
RESULT2(SSN) pSUPERSSN(DEP5_EMPS)
RESULT RESULT1 È RESULT2
–
The union operation produces the tuples that are in either RESULT1 or RESULT2 or
both
Page |
64
Example of the result of a UNION operation
Relational Algebra Operations from Set Theory
•
•
•
Type Compatibility of operands is required for the binary set operation UNION È, (also for
INTERSECTION Ç, and SET DIFFERENCE –, see next slides)
R1(A1, A2, ..., An) and R2(B1, B2, ..., Bn) are type compatible if:
– they have the same number of attributes, and
– the domains of corresponding attributes are type compatible (i.e. dom(Ai)=dom(Bi) for
i=1, 2, ..., n).
The resulting relation for R1ÈR2 (also for R1ÇR2, or R1–R2, see next slides) has the same
attribute names as the first operand relation R1 (by convention)
Relational Algebra Operations from Set Theory: INTERSECTION
•
•
•
INTERSECTION is denoted by Ç
The result of the operation R Ç S, is a relation that includes all tuples that are in both R and S
– The attribute names in the result will be the same as the attribute names in R
The two operand relations R and S must be “type compatible”
Relational Algebra Operations from Set Theory: SET DIFFERENCE
•
•
•
SET DIFFERENCE (also called MINUS or EXCEPT) is denoted by –
The result of R – S, is a relation that includes all tuples that are in R but not in S
– The attribute names in the result will be the same as the attribute names in R
The two operand relations R and S must be “type compatible”
Example to illustrate the result of UNION, INTERSECT, and DIFFERENCE
Page |
65
Some properties of UNION, INTERSECT, and DIFFERENCE
•
Notice that both union and intersection are commutative operations; that is
– R È S = S È R, and R Ç S = S Ç R
• Both union and intersection can be treated as n-ary operations applicable to any number of
relations as both are associative operations; that is
– R È (S È T) = (R È S) È T
– (R Ç S) Ç T = R Ç (S Ç T)
The minus operation is not commutative; that is, in general
– R–S≠S–R
Relational Algebra Operations from Set Theory: CARTESIAN PRODUCT
•
CARTESIAN (or CROSS) PRODUCT Operation
– This operation is used to combine tuples from two relations in a combinatorial fashion.
– Denoted by R(A1, A2, . . ., An) x S(B1, B2, . . ., Bm)
– Result is a relation Q with degree n + m attributes:
• Q(A1, A2, . . ., An, B1, B2, . . ., Bm), in that order.
– The resulting relation state has one tuple for each combination of tuples—one from R and
one from S.
Page |
66
–
–
•
•
•
Hence, if R has nR tuples (denoted as |R| = nR ), and S has nS tuples, then R x S will have
nR * nS tuples.
The two operands do NOT have to be "type compatible”
Generally, CROSS PRODUCT is not a meaningful operation
– Can become meaningful when followed by other operations
Example (not meaningful):
– FEMALE_EMPS s SEX=’F’(EMPLOYEE)
– EMPNAMES p FNAME, LNAME, SSN (FEMALE_EMPS)
– EMP_DEPENDENTS EMPNAMES x DEPENDENT
EMP_DEPENDENTS will contain every combination of EMPNAMES and DEPENDENT
– whether or not they are actually related
Example of applying CARTESIAN PRODUCT
Page |
67
•
•
•
To keep only combinations where the DEPENDENT is related to the EMPLOYEE, we add a
SELECT operation as follows
Example (meaningful):
– FEMALE_EMPS s SEX=’F’(EMPLOYEE)
– EMPNAMES p FNAME, LNAME, SSN (FEMALE_EMPS)
– EMP_DEPENDENTS EMPNAMES x DEPENDENT
– ACTUAL_DEPS s SSN=ESSN(EMP_DEPENDENTS)
– RESULT p FNAME, LNAME, DEPENDENT_NAME (ACTUAL_DEPS)
RESULT will now contain the name of female employees and their dependents
Binary Relational Operations: JOIN
•
JOIN Operation (denoted by )
– The sequence of CARTESIAN PRODECT followed by SELECT is used quite commonly
to identify and select related tuples from two relations
– A special operation, called JOIN combines this sequence into a single operation
– This operation is very important for any relational database with more than a single
relation, because it allows us combine related tuples from various relations
– The general form of a join operation on two relations R(A1, A2, . . ., An) and S(B1, B2, .
. ., Bm) is:
R
<join condition>S
– where R and S can be any relations that result from general relational algebra
expressions.
Example: Suppose that we want to retrieve the name of the manager of each department.
– To get the manager’s name, we need to combine each DEPARTMENT tuple with the
EMPLOYEE tuple whose SSN value matches the MGRSSN value in the department
tuple.
– We do this by using the join
operation.
– DEPT_MGR DEPARTMENT MGRSSN=SSN EMPLOYEE
MGRSSN=SSN is the join condition
– Combines each department record with the employee who manages the department
– The join condition can also be specified as DEPARTMENT.MGRSSN=
EMPLOYEE.SSN
Example of applying the JOIN operation
DEPT_MGR DEPARTMENT
MGRSSN=SSN EMPLOYEE
Page |
68
Some properties of JOIN
•
Consider the following JOIN operation:
– R(A1, A2, . . ., An)
S(B1, B2, . . ., Bm)
R.Ai=S.Bj
– Result is a relation Q with degree n + m attributes:
• Q(A1, A2, . . ., An, B1, B2, . . ., Bm), in that order.
– The resulting relation state has one tuple for each combination of tuples—r from R and s
from S, but only if they satisfy the join condition r[Ai]=s[Bj]
– Hence, if R has nR tuples, and S has nS tuples, then the join result will generally have less
than nR * nS tuples.
– Only related tuples (based on the join condition) will appear in the result
•
The general case of JOIN operation is called a Theta-join: R
S
theta
•
•
•
The join condition is called theta
Theta can be any general boolean expression on the attributes of R and S; for example:
– R.Ai<S.Bj AND (R.Ak=S.Bl OR R.Ap<S.Bq)
Most join conditions involve one or more equality conditions “AND”ed together; for example:
– R.Ai=S.Bj AND R.Ak=S.Bl AND R.Ap=S.Bq
Binary Relational Operations: EQUIJOIN
•
•
•
EQUIJOIN Operation
The most common use of join involves join conditions with equality comparisons only
Such a join, where the only comparison operator used is =, is called an EQUIJOIN.
– In the result of an EQUIJOIN we always have one or more pairs of attributes (whose
names need not be identical) that have identical values in every tuple.
– The JOIN seen in the previous example was an EQUIJOIN.
Binary Relational Operations: NATURAL JOIN Operation
•
NATURAL JOIN Operation
– Another variation of JOIN called NATURAL JOIN — denoted by * — was created to
get rid of the second (superfluous) attribute in an EQUIJOIN condition.
• because one of each pair of attributes with identical values is superfluous
– The standard definition of natural join requires that the two join attributes, or each pair of
corresponding join attributes, have the same name in both relations
If this is not the case, a renaming operation is applied first.
Example of NATURAL JOIN operation
Page |
69
Complete Set of Relational Operations
•
•
The set of operations including SELECT s, PROJECT p , UNION È, DIFFERENCE - ,
RENAME , and CARTESIAN PRODUCT X is called a complete set because any other
relational algebra expression can be expressed by a combination of these five operations.
For example:
– R Ç S = (R È S ) – ((R - S) È (S - R))
– R
<join condition>S = s <join condition> (R X S)
Recap of Relational Algebra Operations
Page |
70
Page |
71
Reference / Reading Material
Fundamentals of Database Systems 7th Ed., Elmasri & Navathe
Assessments:
Consider the relational databases below
A.
LIVES (employee-name, street, city)
employee-name
CANLAS
FABREGAS
FADERA
DE JESUS
street
Matahimik Street
Kaunlaran Street
Brooklyn Street
Yakal Street
city
MAKATI
MANILA
BGC
CALOOCAN
WORKS (employee-name, company-name, salary)
employee-name
CANLAS
FABREGAS
FADERA
DE JESUS
company-name
First Bank Corporation
Good Investment Corp
ABC Insurance Corp
Fortune Book House
salary
10,000.00
25,000.00
73,250.00
45,950.00
LOCATED-IN (company-name, city)
company-name
First Bank Corporation
Good Investment Corp
ABC Insurance Corp
Fortune Book House
city
BGC
MAKATI
MANILA
MAKATI
MANAGES (employee -name, manager-name, position)
employee-name
CANLAS
FABREGAS
FADERA
DE JESUS
manager-name
PAOLO
MICO
MATT
ROI
position
Operation Manager
Production Supervisor
Manufacturing Manager
Marketing Executive
Provide an expression in Relational Algebra
1. List all the names of manager.
2. Find the name of all employees who work for First Bank Corporation.
3. Find the name and the city of all employees who work for First Bank Corporation
4. Give all employees of First Bank Corporation a 10 percent increase.
5. Give all managers a 10 percent increase.
Page |
72
6. Find the name, street, city of all employees who work for First Bank Corporation and earn
more than 10,000.00
7. Find the name of all employees whose salary is more than 25,000.00 and manage by Paolo
8. List the name of all company located in BGC.
9. Find the name of all employees who lived in the same city where he/she worked.
10. List the name of all employees who worked either in First Bank Corporation or Good
Investment Corp or both.
B. Relational Algebra
Perform the following operation using the list of relations below.
A {1 , 3 , 5 , 6 , 7 , 9}
B {0, 2 , 4 , 6 , 7 , 8}
C {0, 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9}
1. A ∩ C =
2. B U A
3. C – B
4. B ∩ C
5. A U C
Page |
73
SQL – STRUCTURED QUERY LANGUAGE
Data Manipulation Language (SELECT), Aggregate Functions, Complex Retrieval of Data
OVERVIEW
This module covers all topics pertaining to introduction to SQL programming. It first gives a
short presentation of the different classifications of SQL commands and then focuses on the
most basic query operation. It then proceeds to discuss aggregate functions and how they are
used with other clauses of the query function. The last part discusses processing of multiple
data by joining relations which is a concept first learned in relational algebra.
LEARNING OUTCOMES
Write DML SQL statements to generate information required by the database users using:
Simple SELECT Statement
SELECT Statement with WHERE clause (using Relational, Logical and Special
database operators)
Write DML SQL statements to generate information required by the database users
using:
SELECT Statement with Aggregate functions.
SELECT Statement with GROUP BY and HAVING Clause
Write DML SQL statements to generate information required by the database users
using multiple tables
COURSE MATERIALS
Classification of SQL commands:
1. Data Definition Language (DDL) – used to create, alter, and drop tables
2. Data Manipulation Language (DML) – core commands of SQL used for updating,
inserting, modifying, and querying the data in the database
3. Data Control Language (DCL) – used to grant or revoke privileges to access the
database or particular objects within the database; used to store or remove transactions
that would affect the database
DML Command For Query Operations
SELECT – allows users to query the data contained in the tables based on certain
criteria
Structure of an SQL Query
SELECT
FROM
Page |
74
WHERE
GROUP BY
HAVING
ORDER BY
SELECT columns
literals
arithmetic expression
scalar or column functions
FROM tables or views
WHERE condition for row selection
ORDER BY sort key
Examples:
SELECT prod_id, prod_desc, prod_finish, standard_price, prod_line_id
FROM Product_T;
Is the same as
SELECT *
FROM Product_T ;
Display prod id and description, finish of those whose finish is red
SELECT prod_id, prod_desc,prod_finish
FROM Product_T
WHERE prod_finish = ‘red’;
Display prod id and description of those whose price is less than 400
SELECT prod_id, prod_desc
FROM Product_T
WHERE standard_price < 400;
Display prod id and description of those whose finish is red. Sort by description
SELECT prod_id, prod_desc
FROM Product_T
WHERE prod_finish = ‘red’
ORDER BY prod_desc;
Display prod id and description of those whose finish is red. Sort by prod_id and price
SELECT prod_id, prod_desc
FROM Product_T
WHERE prod_finish = ‘red’
ORDER BY prod_id, standard_price;
USING BOOLEAN OPERATORS WITH SELECT CLAUSE
Page |
75
AND – joins 2 or more conditions ; only when all conditions are true
OR – joins 2 or more conditions ; when any conditions are true
NOT – negates an expression
If multiple boolean operators are used in an SQL statement, NOT is evaluated first, then
AND, then OR.
SELECT * FROM Product_T
WHERE Standard_Price = 400 AND
Prod_Finish = ‘Ash’ OR Prod_Finish = ‘Red
Using above data, the SELECT statement will output 3 records:
1 record , combination of standard_price = 400 and prof_finish = ‘ash’ - prod_id #3
2 records with prod_finish = ‘red’ - prod_id #s 4 and 5
The WHERE clause may include the IN keyword to specify that a particular column value must
match one of the values in a list
The following programs will generate same output
SELECT
FROM
WHERE
EMP_NAME
EMP_T
DEPTID IN (5, 8, 10);
SELECT
FROM
WHERE
EMP_NAME
EMP_T
DEPTID = 5 OR DEPTID = 8 OR DEPTID = 10;
Any criteria statements can be preceded by a NOT operator in order to invert the results
Using NOT will return all information except the information matching the specified criteria
Examples:
SELECT
EMP_NAME
FROM EMP_T
WHERE
DEPTID NOT IN (5, 8, 10);
Page |
76
SELECT CUST_NAME, STATE
FROM CUSTOMER_T
WHERE STATE NOT IN (‘NY’, ‘CA’)
Using these data, the output of above SQL code will be the cust_name and state of cust_id 2
and 3.
SQL provides a BETWEEN keyword that allows a user to specify a minimum and maximum
value on one line. BETWEEN is inclusive.
The following programs will generate same output
SELECT
FROM
WHERE
EMP_NAME
EMP_T
SALARY BETWEEN 1000 AND 5000;
SELECT
FROM
WHERE
EMP_NAME
EMP_T
SALARY >=1000 AND SALARY <= 5000;
The SQL LIKE keyword allows for searches on partial data values
LIKE can be paired with wildcards to find rows that partially match a string value
The multiple character wildcard is an asterisk (*)
The single character wildcard character is a question mark(?)
The wildcards above are for MS Access. Other RDBMS may have different wildcard symbols .
Examples:
SELECT
emp_name
FROM emp_t
WHERE
joblevel LIKE ‘S*’;
SELECT
emp_name
Page |
77
FROM emp_t
WHERE
Phone
LIKE ‘632-???????’
The first statement will list the names if the joblevel begins with an S. The second code will list
the names if phone begins with ‘632-‘ and is followed by 7 characters
SQL Column Functions
Two types of SQL functions:
1. Column functions - produce a summary row for a set of rows
2. Scalar functions - returns a value for a row based on input argument
Most Common COLUMN FUNCTIONS
SUM() - computes total
AVG() - computes average
MIN() - finds minimum value
MAX() - finds maximum value
COUNT() - determines the total number of rows
Syntax:
SELECT SUM(column name)
FROM table name;
SELECT AVG(column name)
FROM table name;
SELECT MIN(column name)
FROM table name;
SELECT MAX(column name)
FROM table name;
Examples:
Page |
78
SELECT SUM(salary) AS [Total Salary]
FROM employee
Output:
Total Salary
36000
SELECT AVG(tax) AS [Average Tax]
FROM employee
Output:
Average Tax
325
SELECT MIN(tax) AS [Minimum Tax]
FROM employee
Output:
Minimum Tax
200
SELECT COUNT(*) AS [Total Employees]
FROM employee
Output:
Total Employees
4
SELECT AVG(tax), MAX(tax), MIN(tax) FROM EMPLOYEE;
Output:
325 500
200
You may also have an arithmetic operation as argument of the function e.g.
SELECT MAX(tax+sss+otherded)
FROM employee;
Output
750
<- comment : this is the highest total for tax + sss + otherded
How null values are treated in column and row level computations
If a null is part of row level computation, the result will be null.
However, in column level computations, nulls are ignored.
Row level
Row level
Column
Level
Page |
79
SELECT empid, sss, philhealth, pag-ibig, sss+philhealth+pag-ibig <- row level computatation
FROM emp_t
<- sum of sss+philhealth+pag-ibig is 0
SELECT SUM(sss), sum(philhealth),sum(pag-ibig) , sum(sss)+sum(philhealth)+sum(pag-ibig)
FROM emp_t
column level computation, nulls are ignored
Group By clause in SELECT
The GROUP BY clause tells which rows in a table are to be grouped together. It divides a
table into subsets (by groups).
With GROUP BY, a column function results in a single value for each group
GROUP BY does not guarantee a sorted result table. If an ordered result table is required an
appropriate ORDER BY clause must be specified.
It is particularly useful when paired with an aggregate function.
Important Reminder:
If a SELECT clause has COLUMN function and columns not in COLUMN function, all
columns not in COLUMN function must be included in GROUP BY clause
Examples using above data
Compute the average salary for each division.
SELECT AVG(salary)
FROM Employee_T
GROUP BY Division;
Output
6000
4750
3000
Compute the average salary for each division. Include the division.
Output
ISD
6000
FIN
4750
HR
3000
Page | 79
SELECT Division, AVG(salary)
FROM Employee_T
GROUP BY Division;
Sum up the salaries for each job function. Include the job in the output. Output
SELECT Job, SUM(salary)
FROM Employee_T
GROUP BY Job;
MGR
RF
7000
3500
SMR 17000
Group By / Having clause in SELECT
The HAVING clause is a search condition for a group or an aggregate. This is typically
used with the GROUP BY clause.
The HAVING clause tells which groups of information are to be processed based upon a
group qualification criteria rather than rows.
List the average salary which is greater than 5000 for each division. Include the division
SELECT Division, AVG(salary)
FROM Employee_T
GROUP BY Division
HAVING AVG(salary) > 5000 ;
Output
ISD
6000
Only ISD has an average salary greater than 5000 among the 3 divisions.
The WHERE clause is used to filter the rows from a table
Whereas
The HAVING clause is used to filter the grouped result.
Working with Multiple Tables
1. Cartesian Product
2. Joining tables using WHERE clause as join predicate
Cartesian Product
In a cartesian product or cross join, all records from tables are joined with no condition. The
number of output records will be the product of the number of records from all tables being
joined.
Example:
Page |
80
Table 1: Employee
SELECT empname,
deptname FROM
employee, department
Table 2: Department
Output is
3 recprds from employee
table multipled by 2 records
from department table = 6
records
All records from employee
table were paired with all
records in department
table.
Joining tables using WHERE clause as join predicate
The join predicate will join tables depending on a matching condition in the join predicate.
Example:
List the employee name and his corresponding department name
Solution 1: the table names are used as qualifier for deptid attribute in the WHERE clause
SELECT
FROM
WHERE
empname, deptname
Employee , Department
employee.deptid = department.deptid;
If there is a matching deptid from the 2 tables, the records will be joined.
Page |
81
Solution 2: the alias or correlation names are used as qualifier for deptid attribute in the
WHERE clause. The aliases are assigned to each table in the FROM clause, E for employee
and D for department.
SELECT
FROM
WHERE
empname, deptname
Employee AS E, Department AS D
E.deptid = D.deptid;
Solution 3: If the attribute name for department ID is not the same in the 2 tables… Assuming
workdept is the attribute for department id in department table.
SELECT
FROM
WHERE
empname, deptname
Employee, Department
deptid = workdept
Output from the 3 solutions
GENERAL RULE
:
The number of tables minus one (n-1) is USUALLY the LEAST number of join predicates
needed for the query, to ensure that there are no un-linked tables.
So for 2 tables, 1 join predicate is needed, for 3 tables, 2 join predicates, etc. Find the common
attribute, typically the primary key and foreign key, as the attribute to be used in your join
predicate.
Example:
Page |
82
SELECT customer_id, cust_name, name
FROM customer AS c, salesman AS s
WHERE c.salesman_id = s.salesman_id
OR
SELECT customer_id, cust_name, name
FROM customer, salesman
WHERE customer.salesman_id = salesman.salesman_id
Reference / Reading Material
Modern Database Management, 11th Ed, by Hoffer, Ramesh, Topi
Assessments:
Create the SQL code for the following problems
Use below table for the first set of problems
Page |
83
1. Display all records of IT and CS students who got a gwa of 1.75 and above (meaning
1.5, 1.25, 1.00)
2. Display all records of BBF students who got a gwa of 1.75 and CS students who got a
gwa of 1.00
3. Display all records IT students who got a gwa within the range of 1.00 to 1.75. Display
also all records of BBF students.
4. Compute the average gwa per course and display only the averages which are within
1.00 to 1.25 range. Display also the course.
5. Display all student names which begins with ‘Y’
6. Compute the average gwa of IT and CS students only. Display average grades per
course. Display also the course
7. Compute the average gwa for BBF only. Include in the computation gwa which are 1.75
and above. Display only the average if it is 1.25 and above.
8. Display the names which ends with ‘o’ or ‘a’
9. Count how many students got a grade within the range of 3.01 to 5.00.
10. Count how many students there are for each course.
Use the tables below for the next set of questions
11. List the customer id, customer name and all the orders he had placed (order id, purchae
amount, and order date
12. List the customer name and his salesman’s name if they both live in the same city
13. A customer may have many orders in the orders table. Sum up the total purchase of
each customer. Display also the customer’s name, city and grade
14. Display purchases by customers who live in New York if the purchase amount is within
the 500 to 1000 range. Display the customer id, order no, purchase amount and the
order date
15. Display the customer name and his salesman’s name if the salesman has a commission
more than 12%.
Page |
84
16. List all orders made by customers from Paris if the order date was made August of 2012
17. List all the customer names of salesman 5001. List also the name of 5001.
18. Count how many orders each customer made. Display the name of the customer, his
salesman’s name, and the count.
19. Count how many orders each customer made for the year 2012. Display the name of
the customer, his salesman’s name, and the count if the count is more than 100.
20. Display the names of the customers whose purchases amounted to more than 100,000.
Display also the total amount of purchase. Sort in descending order of the total amounts.
Activity: Final Project
Create a small application where you will transform a manual form into a database. The project
will consist of the following parts
1. Title page – name of application with student name
2. Background / Overview of the project and the application being created and business
rules
3. Softcopy of the manual form to be converted
4. Normalization steps for the data to be used. Show 1NF, 1NF, 3NF
5. Entity Relationship Diagram
6. Data dictionary
7. SQL Statements (15 in all)
7.1 simple SQL statements which use IN, WHERE, BETWEEN
7.2 sql statements which use GROUP BY , HAVING, aggregate functions
7.3 sql statements using multiple table processing
Format should be
Requirement :
SQL Code:
Output
8. User Interface
9. Test Data
Page |
85
Page | 86