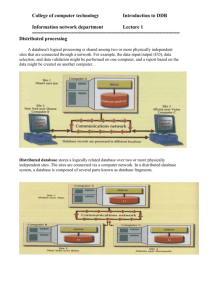
Lecture 1 - Introduction Database • A structured set of data held in a computer, especially one that is accessible in various ways. • An electronic system that allows data to be easily accessed, manipulated and updated. • It is used by an organization as a method of storing, managing and retrieving information. Modern databases are managed using a database management system (DBMS). • Examples include: ORACLE, SQL Server, MySQL, Microsoft Access and MongoDB. Relational database • A database structured to recognize relations between stored items of information. • A set of formally described tables from which data can be accessed or reassembled in many different ways without having to reorganize the database tables. • The standard user and application programming interface (API) of a relational database is the Structured Query Language (SQL). SQL query language • A programming language designed to manage data stored in relational databases. • SQL operates through simple, declarative statements. • This keeps data accurate and secure, and it helps maintain the integrity of databases, regardless of size. Big data • Big Data is a phrase used to refer to a massive volume of both structured and unstructured data that is so large it is difficult to process using traditional database and software techniques. • In most enterprise scenarios the volume of data is too big or it moves too fast or it exceeds current processing capacity. • The data set is very large and may be analysed computationally to reveal patterns, trends, and associations, especially relating to human behaviour and interactions. – The volume of available data is huge – The data keeps growing at a staggering rate – Data comes from a variety of sources in different formats. Distributed Database Systems • A distributed system is a collection of independant computers which are interconnected through a network. A distributed database • A database that consists of two or more files located in different sites either on the same network or on entirely different networks. • Portions of the database are stored in multiple physical locations and processing is distributed among multiple database nodes. Features • Databases in the collection are logically interrelated with each other. Often they represent a single logical database. • Data is physically stored across multiple sites. Data in each site can be managed by a DBMS independent of the other sites. • The processors in the sites are connected via a network. They do not have any multiprocessor configuration. Distributed database management system • DDBMS: The software that manages the DDB and provides a mechanism that makes the distribution transparent to the user. • DDBS = DDB + DDBMS Promises of DDBMS • Transparency: – To what extent should the distributed system appear to the user as a single system? – Distributed systems should be perceived by users and application programmers as a whole rather than as a collection of cooperating components. • Reliability / Availability - If one component is down, yet the system continues to be operational • Performance – tasks execute efficiently independently of the location of invocation or of participating resources • Scalability- Allowing database processing systems to cope with volume, veracity, velocity and variety aspects that big data brings into the system. - The cost of putting together a system of smaller computers is much less than the cost of a single machine with equivelant power. Transparencies in DDBMS • Distribution Transparency Allows user to perceive database as single, logical entity. – – – – Fragmentation Transparency Location Transparency Replication Transparency Local Mapping Transparency If DDBMS exhibits distribution transparency, user does not need to know: – Data is fragmented (fragmentation transparency), – Location of data items (location transparency), – Replication of fragments (replication transparency). • Naming transparency • Objects should be uniquely identifiable throughout their life regardless of their system of origin and current location. • Each item in a DDB must have a unique name. • This type of transparency allows for local autonomy. Concurrency Transparency • All transactions must execute independently and be logically consistent with results obtained if transactions executed one at a time, in some arbitrary serial order. Transaction Transparency • Ensures that all distributed transactions maintain distributed database’s integrity and consistency. • Distributed transaction accesses data stored at more than one location. • Each transaction is divided into number of sub-transactions, one for each site that has to be accessed. • DDBMS must ensure the indivisibility of both the global transaction and each subtransactions. Distributed DBMS environment Factors Encouraging DDBMS • • • • • Distributed Nature of Organizational Units − Most organizations in the current times are subdivided into multiple units that are physically distributed over the globe. Each unit requires its own set of local data. Thus, the overall database of the organization becomes distributed. Need for Sharing of Data − The multiple organizational units often need to communicate with each other and share their data and resources. This demands common databases or replicated databases that should be used in a synchronized manner. Support for Both OLTP and OLAP − Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) work upon diversified systems which may have common data. Distributed database systems aid both these processing by providing synchronized data. Database Recovery − One of the common techniques used in DDBMS is replication of data across different sites. Replication of data automatically helps in data recovery if database in any site is damaged. Users can access data from other sites while the damaged site is being reconstructed. Thus, database failure may become almost inconspicuous to users. Support for Multiple Application Software − Most organizations use a variety of application software each with its specific database support. DDBMS provides a uniform functionality for using the same data among different platforms. Advantages of Distributed Databases Following are the advantages of distributed databases over centralized databases. • Modular Development − If the system needs to be expanded to new locations or new units, in centralized database systems, the action requires substantial efforts and disruption in the existing functioning. However, in distributed databases, the work simply requires adding new computers and local data to the new site and finally connecting them to the distributed system, with no interruption in current functions. • More Reliable − In case of database failures, the total system of centralized databases comes to a halt. However, in distributed systems, when a component fails, the functioning of the system continues may be at a reduced performance. Hence DDBMS is more reliable. • Better Response − If data is distributed in an efficient manner, then user requests can be met from local data itself, thus providing faster response. On the other hand, in centralized systems, all queries have to pass through the central computer for processing, which increases the response time. • Lower Communication Cost − In distributed database systems, if data is located locally where it is mostly used, then the communication costs for data manipulation can be minimized. This is not feasible in centralized systems. Complications introduced by distribution • Replication of data – A distributed database can be designed so that the entire database, or portions of it, reside at different sites of a computer network. – It is not essential that every site on the network contain the database; it is only essential that there be more than one site where the database resides. – The possible duplication of data items is mainly due to reliability and efficiency considerations. – Consequently, the distributed database system is responsible for (1) choosing one of the stored copies of the requested data for access in case of retrievals, and (2) making sure that the effect of an update is reflected on each and every copy of that data item. • • Second, if some sites fail (e.g., by either hardware or software malfunction), or if some communication links fail (making some of the sites unreachable) while an update is being executed, the system must make sure that the effects will be reflected on the data residing at the failing or unreachable sites as soon as the system can recover from the failure. The third point is that since each site cannot have instantaneous information on the actions currently being carried out at the other sites, the synchronization of transactions on multiple sites is considerably harder than for a centralized system. • Need for complex and expensive software − DDBMS demands complex and often expensive software to provide data transparency and co-ordination across the several sites. • Processing overhead − Even simple operations may require a large number of communications and additional calculations to provide uniformity in data across the sites. • Data integrity − The need for updating data in multiple sites pose problems of data integrity. • Overheads for improper data distribution − Responsiveness of queries is largely dependent upon proper data distribution. Improper data distribution often leads to very slow response to user requests. Definition • A parallel system is one in which multiple processors have direct access to shared memory. Why use parallel computing? • Fundamental limits on single processor speed (High-end CPU is expensive / rises sharply ) • Disparity between CPU & memory speeds (Moore's Law) • Distributed data communications – Many processors working together (Save time – wall clock time) – Solve larger problems – larger than one processor’s CPU and memory can handle • Need for very large scale computing platforms Why use parallel computing • Solve larger problems – larger than one processor’s CPU and memory can handle. • Provide concurrency – do multiple things at the same time: online access to databases, search engine. • Taking advantage of non-local resources – using computing resources on a wide area network, or even internet (grid computing). • Cost saving – using multiple “cheap” computing resources instead of a high-end CPU. • Overcoming memory constraints – for large problems, using memories of multiple computers may overcome the memory constraint obstacle. Parallel Databases • Typical system properties - Fast interconnect - Homogeneous software (and even hardware) • Typical goals - High performance - Transparency • Typical system properties - Geographical distribution - Heterogeneity and autonomy • Typical goals - Data sharing - Disconnected operation capabilities Some commercial distributed relational databases • • • • • • • • • • • • • Teradata Database Exadata Greenplum Actian Matrix Exasol Amazon Redshift SAP HANA Sybase IQ Microsoft Pdw Netezza (company) 1010data Vertica Database Splice Machine - The Hadoop RDBMS Some Distributed Database Open Source Projects • • • • • • • • • • • • • • • • • • • Tidb Cockroach Qix Shardingsphere Clickhouse Foundationdb Arangodb Awesome Bigdata Rqlite Talent Plan Citus Yugabyte Db Dynomite Awesome Blockchains Lindb Radon Pegasus Presto Paxosstore • • • • • • • • • • • • • • • • • • • Eventql Dble Olric Corfudb Ghostdb Awesome Distributed Systems Elasticell Raft 3box Catena Js Gryadka Hibari Aviondb Degdb degdb Bitconch Core Dbtester Mysql Notes • • • • • • • • • • • Vectorsql Justindb Herddb Scalardb Blockchain.lite.rb Py Swirld Antsdb Dble Docs Cn Zanredisdb Interference Scalardl