Descriptive Statistics: Variability - Range, IQR, SD
advertisement

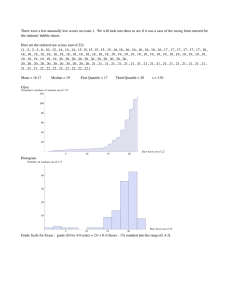
Descriptive Statistics: Variability Week 14 Descriptive Statistics • Statistics used to describe the distribution of, and relationship among, variables • Before we evaluate our hypothesis, we want to know what the variables look like • Three types of DS: central tendency and variability • Central tendency: the most common value (nominal variables) or the value around which cases tend to center (quantitative variables) • Skewness: The extent to which cases are clustered more at one or the other end of the distribution of a quantitative variable rather than in a symmetric pattern around its center. • Variability: the extent to which cases are spread out through the distribution or clustered in just one location Variability • • • • • • Just using central tendency to describe a variable can be misleading Example: Comparing average income in Town A and Town B Mean income for both = $50 Three possible incomes: $0, $50, and $100 Each town has 20 individuals Town A: 20 people have an income of $50. • (20 x 50)/20=$50 • Town B: 10 people have an income of $0, 10 people have an income of $100. • [(10x0) + (10x100)]/20= $50 • One community equal wealth distribution, the other has extreme income inequality • Taking only a central tendency measurement would mislead one to believe the financial situation in both towns is similar Variability Variability • Variability: how the data are spread out across a variable’s distribution • Variable must be interval or ratio (some would argue ordinal, too) • NOT for nominal (cannot order, so the “spread” is meaningless because categories can be placed anywhere along the x-axis) • Central tendency: where the data cluster • Variability: how spread out the data are from the center Variability: Four Measures • Range • Interquartile Range • Variance • Standard Deviation Range • Order all the observations • Highest value-lowest value • Drawback: influenced by outliers Interquartile Range (IQR) • IQR: The range in a distribution between the end of the first quartile and the beginning of the third quartile • In other words, where the middle 50% of the data are • Quartiles: the points in a distribution corresponding to the first 25% of cases (1st quartile), the first 50% of cases (second quartile=median), and the first 75% of cases (third quartile) • 4th quartile not used (100% of all the cases, which is not helpful) • Avoids problem of outliers because arranges cases in order (like the median) and finds the values at each one of these quartiles • Position matters, not the actual value of the observation (like the median) Calculating the IQR • IQR: third quartile value -first quartile value • Visualization: box and whisker plot • Draw a number line from the minimum to maximum values • Calculate Median (Q2). Draw a line through that point • Take median of lower half of data and upper half of data (Q1 & Q3). Draw lines through those points • Connect Q1 and Q3 with a box around that data • Draw lines above the number line from end of the boxes to the minimum and maximum values (“whiskers”) Variance • The average squared distance of each observation from the mean • Larger the variance, the further the data from the mean • Find the mean. Set aside. • For each value: subtract the mean. Then square the result. This is the squared difference of that value from the mean • Take all the squared differences you calculate, add them up, and divide by the number of squared differences you have (the mean of the squared differences) Why “squared” distance and not just distance? Standard Deviation • Another metric for how spread out the data are • Square root of the variance • Low standard deviation: data are close to the mean, not spread out much • High standard deviation: data are spread out far away from the mean Order of Operations • PEMDAS • Parentheses, exponents, multiplication, division, addition, subtraction 1: Find the mean 2: subtract mean from • Work “inward to outward” each value • Example: standard deviation 3: square each new value (original value-mean) 4. Add up all of the new values 6. Take the square root of the number you get in step 5 5. Divide the sum of all the new values by the total number of new values (take the mean) Next time… • Standard deviation, normal distribution, and making sense of what it is and why it’s useful • Standard deviations and calculating sampling error and relationship to the population we care about • Calculating confidence intervals (“margins of error” in polling)