What is a probability density function ? Parameters and Moments of
advertisement

What is a probability density function ?
Parameters and Moments of a probability density function I
Definition
Definition
A random variable is a variable whose value is determined by the outcome of a
A parameter, θ , is a function of the probability density function (p.d.f.) f e.g.:
random experiment. A random variable is said discrete if its values are countable,
θ = t( f )
or continuous otherwise.
Definition
Definition
A moment of order n is a parameter of the probability density function (p.d.f.) f ,
The probability density function (p.d.f.) f of a random variable X gives a natural
defined as:
θ=
description of the distribution of X and allows probabilities associated with X to
be computed:
P (a < X < b) =
Zb
f ( x) dx
a
∀(a, b) a < b
Parameters and Moments of a probability density function II
R
x n f ( x) dx
raw moment
R
Central moments are also defined using the first raw moment µ = x f ( x) dx:
θ=
Z
( x − µ)n f ( x) dx
central moments (n > 1)
Parameters and Moments of a probability density function III
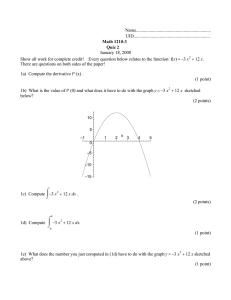
Exercise. Compute the mean and variance of the following distributions:
if θ is the mean
1
θ = E f ( x) =
Z+∞
−∞
Dirac distribution
f ( x) = δ( x − 6)
x f ( x) dx = µ f
2
The normal distribution
1
1
( x − 1)2
f ( x) = p exp −
8
2 2π
if θ is the variance
3
2
θ = E f [( x − µ f ) ] =
Z+∞
−∞
2
( x − µ f ) f ( x)
f ( x) = 0.2 δ( x − 1) + 0.8 δ( x − 6)
dx = σ2f
4
f ( x) = 0.2 N (µ=1,σ=2) + 0.8 N (µ=6,σ=1)
1 also noted N (µ = 1, σ = 2)
Estimation fˆ of a density function f
Non-Parametric estimation: Empirical p.d.f.
Lets assume that we have a set of samples or observations { x i } i=1,··· ,n of the
Definition
We can differentiate two approaches to estimate the p.d.f. f ( x):
The empirical density function fˆ(.) is computed using a set of samples { x i } i=1,··· ,n
random variable X.
parametric
non-parametric
Today we focus on non-parametric approaches
such that:
fˆ( x) =
1
n
where δ(·) is the Dirac delta function.
Pn
i =1 δ( x − x i )
Non-Parametric estimation: Histograms I
Non-Parametric estimation: Kernel density I
Definition
Definition (Histogram)
The kernel estimator of a probability density function is defined as:
³x−x ´
n
1 X
i
k
fˆ( x) =
nh i=1
h
Lets consider a set of observations { x i } i=1,··· ,n of the random variable X. A
histogram defined as:
1
(no. of x i in the same bin as x)
fˆ( x) =
nh
is an estimate of the probability density function f . Note that we need to specify
h is called the bandwidth, and k(·) is the kernel function which satisfies:
Z+∞
k( x) dx = 1
−∞
the origin x0 and a bin width h to define the bins of the histogram to be
[ x0 + mh, x0 + ( m + 1) h] with m ∈ Z.
Example (kernels)
Exercise: Propose a procedure to compute the histogram of a grey-level image.
Exercise
k ( x) =
(
1/2
0
if | x| < 1
otherwise
Estimates of parameters I
Definition
Consider the observations {94; 197; 16; 38; 99; 141; 23} of a r.v. X .
1
Draw their empirical p.d.f , their histogram, their kernel distribution with a
gaussian kernel.
2
Compare and comment those different estimates of the p.d.f.
An estimate θ̂ of the parameter θ = t( f ) is a function of the estimated p.d.f. fˆ or
the sample x = { x i }, e.g.:
θ̂ = t( fˆ)
or also written θ̂ = s(x).
The Plug-in estimate θ̂ = t( fˆ) is computed using the empirical p.d.f..
Estimates of parameters II
Example: Difference between θ and θ̂ I
Plug-in estimate of the mean
Computing the mean knowing f
Lets assume we know the p.d.f. f :
θ̂
= t( fˆ)
=
R+∞
x fˆ( x) dx
=
R+∞
1 Pn
=
1
n
−∞
−∞
f ( x) = 0.2 N (µ=1,σ=2) + 0.8 N (µ=6,σ=1)
x
n
i =1 δ( x − x i ) dx
Pn
i =1 x i
= s(x) = x
Exercise: compute the plug-in estimate of the variance.
0.035
0.03
Then the mean is computed:
µ f = E f ( x)
=
R+∞
−∞
0.025
0.02
x f ( x) dx
= 0.2 · 1 + 0.8 · 6
0.015
0.01
0.005
0
−10
=5
−5
0
5
10
15
20
Example: Difference between θ and θ̂ II
Accuracy of arbituary estimates θ̂ I
Estimating the mean knowing the observations x
7.0411
5.2546
7.4199
4.1230
3.6790
−3.8635
−
0.1864
−1.0138
6.9523
6.5975
6.1559
4.5010
5.5741
6.6439
6.0919
7.3199
5.3602
7.0912
4.9585
4.7654
4.8397
7.3937
5.3677
3.8914
0.3509
2.5731
2.7004
4.9794
5.3073
6.3495
5.8950
4.7860
5.5139
4.5224
7.1912
5.1305
6.4120
7.0766
5.9042
6.4668
5.3156
4.3376
6.7028
5.2323
1.4197
−0.7367
2.1487
0.1518
4.7191
7.2762
5.7591
5.4382
5.8869
5.5028
6.4181
6.8719
6.0721
5.9750
5.9273
6.1983
6.7719
4.4010
6.2003
5.5942
1.7585
0.5627
2.3513
2.8683
5.4374
5.9453
5.2173
4.8893
7.2756
4.5672
7.2248
5.2686
5.2740
6.6091
6.5762
4.3450
We can compute an estimate θ̂ of a parameter θ from an observation sample
From the samples, the mean can be
Observations x = ( x1 , · · · , x100 ) :
7.0616
5.1724
7.5707
7.1479
2.4476
1.6379
1.4833
1.6269
4.6108
4.6993
4.9980
7.2940
5.8449
5.8718
8.4153
5.8055
7.2329
7.2135
5.3702
5.3261
x = ( x1 , x2 , · · · , xn ). But
computed:
x
=
P100
x
i =1 i
100
= 4.9970
how accurate is θ̂ compared to the real value θ ?
Our attention is focused on questions concerning the probability distribution of θ̂ .
For instance we would like to know about
its standard error
its confidence interval
etc.
In this course, only the concept of standard error is introduced.
Accuracy of arbituary estimates θ̂ II
Accuracy of arbituary estimates θ̂ III
Definition
Suppose now that f is unknown and that only the random sample x = ( x1 , · · · , xn )
The standard error is the standard deviation of a statistic θ̂ . As such, it measures
is known. As µ f and σ f are unknown, we can use the previous formula to
the precision of an estimate of the statistic of a population distribution.
compute a plug-in estimate of the standard error.
se(θ̂ ) =
q
Definition
var f [θ̂ ]
The estimated standard error of the estimator θ̂ is defined as:
ˆ θ̂ ) = se fˆ (θ̂ ) = [var fˆ (θ̂ )]1/2
se(
Standard error of x
We have:
Then
£
¤
E f ( x − µ f )2 =
Pn
i =1 E f
¤
£
( x i − µ f )2
n2
=
σ2f
n
Estimated standard error of x
σ̂
ˆ x) = p
se(
n
σf
se f ( x) = [var f ( x)]1/2 = p
n
Example on the mouse data
Example on the mouse data
Mean and Standard error for both groups
Data (Treatment group)
Data (Control group)
94; 197; 16; 38; 99; 141; 23
52; 104; 146; 10; 51; 30; 40; 27; 46
Table: The mouse data [Efron]. 16 mice assigned to a treatment group (7) or a control
group (9). Survival in days following a test surgery.
Did the treatment prolong survival ?
x
ˆ
se
Treatment
86.86
25.24
Control
56.22
14.14
Conclusion at first glance
It seems that mice having the treatment survive d = 86.86 − 56.22 = 30.63 days
more than the mice from the control group.
Example on the mouse data
Stantard error of the difference d = xT reat − xCont
xT reat and xCont are independent, so the standard error of their difference is
q
ˆ 2T reat + se
ˆ 2Cont = 28.93. We see that:
se
ˆ d) =
se(
30.63
d
=
= 1.05
ˆ d ) 28.93
se(
This shows that this is an insignificant result as it could easily have arised by
chance (i.e. if the test was reproduced, it is likely possible to measure datasets
giving d = 0!).
Therefore, we can not conclude with certainty that the treatment improves the
survival of the mice.