Regression Hypothesis Tests & Confidence Intervals Solutions
advertisement

Chapter 5
Regression with a Single Regressor:
Hypothesis Tests and Confidence Intervals
Solutions to Exercises
1
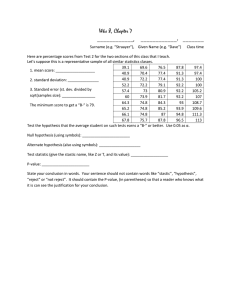
(a) The 95% confidence interval for β1 is {−5.82 ± 1.96 × 2.21}, that is −10.152 ≤ β1 ≤ −1.4884.
(b) Calculate the t-statistic:
t act =
βˆ 1 − 0 −5.82
=
= −2.6335.
SE( βˆ 1) 2.21
The p-value for the test H0 : β1 = 0 vs. H1 : β1 ≠ 0 is
p-value = 2Φ( −|t act |) = 2Φ (−2.6335) = 2 × 0.0042 = 0.0084.
The p-value is less than 0.01, so we can reject the null hypothesis at the 5% significance level,
and also at the 1% significance level.
(c) The t-statistic is
t act =
βˆ 1 − (−5.6) 0.22
=
= 0.10
SE( βˆ 1)
2.21
The p-value for the test H0 : β1 = −5.6 vs. H1 : β1 ≠ −5.6 is
p-value = 2Φ (−|t act |) = 2Φ (−0.10) = 0.92
The p-value is larger than 0.10, so we cannot reject the null hypothesis at the 10%, 5% or 1%
significance level. Because β1 = −5.6 is not rejected at the 5% level, this value is contained in
the 95% confidence interval.
(d) The 99% confidence interval for β0 is {520.4 ± 2.58 × 20.4}, that is, 467.7 ≤ β 0 ≤ 573.0.
2.
(a) The estimated gender gap equals $2.12/hour.
(b) The hypothesis testing for the gender gap is H0 : β1 = 0 vs. H1 : β1 ≠ 0. With a t-statistic
t act =
βˆ 1 − 0 2.12
=
= 5.89,
SE ( βˆ 1) 0.36
the p-value for the test is
p-value = 2Φ( −|t act |) = 2Φ (−5.89) = 2 × 0.0000 = 0.000 (to four decimal places)
The p-value is less than 0.01, so we can reject the null hypothesis that there is no gender gap at a
1% significance level.
Solutions to Exercises in Chapter 5
(c) The 95% confidence interval for the gender gap β1 is {2.12 ± 1.96 × 0.36}, that is,
1.41 ≤ β1 ≤ 2.83.
(d) The sample average wage of women is βˆ0 = $12.52/hour. The sample average wage of men is
βˆ 0 + βˆ 1 = $12.52 + $2.12 = $14.64/hour.
(e) The binary variable regression model relating wages to gender can be written as either
Wage = β 0 + β1 Male + ui ,
or
Wage = γ 0 + γ 1Female + vi .
In the first regression equation, Male equals 1 for men and 0 for women; β 0 is the population
mean of wages for women and β 0 + β1 is the population mean of wages for men. In the second
regression equation, Female equals 1 for women and 0 for men; γ 0 is the population mean of
wages for men and γ 0 + γ 1 is the population mean of wages for women. We have the following
relationship for the coefficients in the two regression equations:
γ 0 = β 0 + β1 ,
γ 0 + γ 1 = β0 .
Given the coefficient estimates β̂ 0 and β̂ 1 , we have
γˆ 0 = βˆ 0 + βˆ 1 = 14.64,
γˆ 1 = βˆ 0 − γˆ 0 = − βˆ 1 = −2.12.
Due to the relationship among coefficient estimates, for each individual observation, the OLS
residual is the same under the two regression equations: uˆ i = vˆ i. Thus the sum of squared
residuals, SSR = ∑ i =1 uˆ i2, is the same under the two regressions. This implies that both
n
2
SER = ( SSR
and R 2 = 1 − SSR
are unchanged.
TSS
n −1 )
1
·
In summary, in regressing Wages on Female, we will get
Wages = 14.64 − 2.12 Female,
R 2 = 0.06, SER = 4.2.
3.
The 99% confidence interval is 1.5 × {3.94 ± 2.58 × 0.31) or 4.71 lbs ≤ WeightGain ≤ 7.11 lbs.
4.
(a) −3.13 + 1.47 × 16 = $20.39 per hour
(b) The wage is expected to increase from $14.51 to $17.45 or by $2.94 per hour.
(c) The increase in wages for college education is β1 × 4. Thus, the counselor’s assertion is that
− 2.50
β1 = 10/4 = 2.50. The t-statistic for this null hypothesis is t = 1.470.07
− 14.71, which has a
p-value of 0.00. Thus, the counselor’s assertion can be rejected at the 1% significance level. A
95% confidence for β1 × 4 is 4 × (1.47 ± 1.97 × 0.07) or $5.33 ≤ Gain ≤ $6.43.
29
30
Stock/Watson - Introduction to Econometrics - Second Edition
5
(a) The estimated gain from being in a small class is 13.9 points. This is equal to approximately 1/5
of the standard deviation in test scores, a moderate increase.
(b) The t-statistic is t act = 13.9
= 5.56, which has a p-value of 0.00. Thus the null hypothesis is
2.5
rejected at the 5% (and 1%) level.
(c) 13.9 ± 2.58 × 2.5 = 13.9 ± 6.45.
6.
(a) The question asks whether the variability in test scores in large classes is the same as the
variability in small classes. It is hard to say. On the one hand, teachers in small classes might able
so spend more time bringing all of the students along, reducing the poor performance of
particularly unprepared students. On the other hand, most of the variability in test scores might be
beyond the control of the teacher.
(b) The formula in 5.3 is valid for heteroskesdasticity or homoskedasticity; thus inferences are valid
in either case.
7.
3.2
= 2.13 with a p-value of 0.03; since the p-value is less than 0.05, the null
(a) The t-statistic is 1.5
hypothesis is rejected at the 5% level.
(b) 3.2 ± 1.96 × 1.5 = 3.2 ± 2.94
(c) Yes. If Y and X are independent, then β1 = 0; but this null hypothesis was rejected at the 5% level
in part (a).
(d) β1 would be rejected at the 5% level in 5% of the samples; 95% of the confidence intervals would
contain the value β1 = 0.
8.
(a) 43.2 ± 2.05 × 10.2 or 43.2 ± 20.91, where 2.05 is the 5% two-sided critical value from the t28
distribution.
(b) The t-statistic is t act = 61.57.4− 55 = 0.88, which is less (in absolute value) than the critical value of
20.5. Thus, the null hypothesis is not rejected at the 5% level.
(c) The one sided 5% critical value is 1.70; tact is less than this critical value, so that the null
hypothesis is not rejected at the 5% level.
9.
(a) β =
1 1
X n
(Y1 + Y2 +
L + Y ) so that it is linear function of Y , Y , …, Y .
n
1
2
n
(b) E(Yi|X1, …, Xn) = β1Xi, thus
E ( β |X1 ,
K, X ) = E X1 1n (Y + Y + L + Y )|X , K, X )
11
=
β (X + L + X ) = β
Xn
n
1
1
2
n
1
n
1
n
1
10. Let n0 denote the number of observation with X = 0 and n1 denote the number of observations with
X = 1; note that
∑
n
i =1
( X i − X )2
Y = n1 Y1 +
n
n0
n
Y0
∑
=∑
n
i =1
X i = n1 ; X = n1| n;
n
i =1
X i2 − nX 2 = n1 −
1
n1
n12
n
∑
n
i =1
(
X iYi = Y1 ;
= n1 1 −
n1
n
)=
n1n0
n
; n1Y1 + n0Y0 = ∑ i =1Yi , so that
n
Solutions to Exercises in Chapter 5
From the least squares formula
∑ ( X − X )(Yi − Y ) ∑i=1 Xi (Yi − Y ) ∑i=1 XiYi − Yn1
= n
=
βˆ1 = i=1 n i
∑i=1 ( Xi − X )2
∑i=1 ( Xi − X )2
n1n0 |n
n
=
n
n
n
n
n
n
(Y1 − Y ) = Y − 1 Y1 − 0 Y0 = Y1 − Y0
n0
n0
n
n
n
n n + n0
n
and βˆ0 = Y − βˆ1 X = 0 Y0 + 1 Y1 − (Y1 − Y0 ) 1 = 1
Y0 = Y0
n
n
n
n
11. Using the results from 5.10, βˆ0 = Ym and βˆ1 = Yw − Ym . From Chapter 3, SE(Ym ) =
SE(Yw − Ym ) =
sm2
nm
Sm
nm
and
s2
+ nww . Plugging in the numbers βˆ0 = 523.1 and SE ( βˆ0 ) = 6.22; βˆ1 = −38.0 and
SE( βˆ1 ) = 7.65.
12. Equation (4.22) gives
σ β2ˆ =
0
var (H i ui )
( )
n E H
2
i
2
, where H i = 1 −
µx
( )
E X i2
Xi .
Using the facts that E (ui | X i ) = 0 and var (ui | X i ) = σ u2 (homoskedasticity), we have
i
E (Hi ui ) = E u −
=0−
µx
( )
2
i
E X
i i
X u = E (ui ) −
µx
( )
E Xi2
E [ Xi E (ui |Xi )]
µx
× 0 = 0,
E ( Xi2 )
and
i
E [(Hi ui ) ] = E u −
2
µx
E Xi2
2
i i
Xu
2
i
2
µ
µx
2
2 2
x
= E u − 2 2 Xiui + 2 Xi ui
E Xi
E Xi
2
µ 2 2
µ
x
= E u − 2 x E Xi E ui2|Xi +
E Xi E ui |Xi
2
2
E Xi
E Xi
2
i
2
µ 2
µ
x
= σ u2 − 2 x 2 µxσ u2 +
E Xi σ u2
E Xi
E Xi2
µ2
= 1 − x 2 σ u2 .
E Xi
Because E ( H i ui ) = 0, var ( H i ui ) = E[( H i ui )2 ], so
31
32
Stock/Watson - Introduction to Econometrics - Second Edition
µ x2
var (H i ui ) = E[( H i ui )2 ] = 1 −
E X i2
( )
σ u2 .
We can also get
( )= E
E H
2
i
1−
µx
( )
E Xi2
2
i
X
= E 1− 2
µx
( )
E Xi2
2
µ
x
Xi +
E Xi2
( )
Xi2
2
µ
µ2
µ2
x
=1− 2 x 2 +
E Xi2 = 1− x 2 .
E ( Xi ) E ( Xi2 )
E ( Xi )
( )
Thus
σ β2ˆ =
0
=
13. (a)
(b)
(c)
(d)
14. (a)
var (Hiui )
nE H 2 2
i
( )
E ( Xi2 )σ u2
(
µx2 2
1 −
σ
E Xi2 u
σ u2
=
=
2
µx2
µx2
n 1 −
n 1 −
E Xi2
E Xi2
( )
( )
( )
E ( X )σ
=
.
2
i
)
2
u
nσ X2
n[E Xi2 − µ x2 ]
Yes
Yes
They would be unchanged
(a) is unchanged; (b) is no longer true as the errors are not conditionally homosckesdastic.
X
From Exercise (4.11), βˆ = ∑ aiYi where ai = n i 2 . Since the weights depend only on Xi but
∑ j=1 X j
not on Yi , β̂ is a linear function of Y.
E( βˆ | X1,
(b)
K, X ) = β + ∑
n
Var ( βˆ |X1,
(c)
n
i=1
K, X ) = ∑
Xi E(ui | X1,
∑in=1 X 2j
n
i=1
K, X ) = β since E(u |X , K, X ) = 0
n
i
Xi 2Var (ui | X1,
n
∑in=1 X 2j
2
K, X ) =
n
1
n
σ2
∑in=1 X 2j
(d) This follows the proof in the appendix.
15. Because the samples are independent, βˆm,1 and βˆw,1 are independent. Thus
var ( βˆm,1 − βˆw,1 ) = var ( βˆm,1 ) + var( βˆw,1 ). Var ( βˆm ,1 ) is consistently estimated as [SE ( βˆm ,1 )]2 and
Var (βˆ ) is consistently estimated as [SE ( βˆ )]2 , so that var( βˆ − βˆ ) is consistently estimated
w ,1
w ,1
m ,1
w ,1
by [SE ( βˆm,1 )] + [SE ( βˆw,1 )] , and the result follows by noting the SE is the square root of the
estimated variance.
2
2