EE382A Lecture 7: Dynamic Scheduling
advertisement

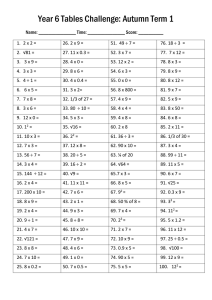
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a EE382A – Autumn 2009 Lecture 7- 1 John P Shen Announcements • Project proposal due on Wed 10/14 – 2-3 2 3 pages submitted through email – – – – – List the group members Describe the topic including why it is important and your thesis Describe the methodology you will use (experiments (experiments, tools tools, machines) Statement of expected results Few key references to related work EE382A – Autumn 2009 Lecture 7- 2 John P Shen What Limits ILP INSTRUCTION PROCESSING CONSTRAINTS Resource C R Contention t ti (Structural Dependences) C d D Code Dependences d Control Dependences (RAW) True T D Dependences d (WAR) Anti-Dependences EE382A – Autumn 2009 Lecture 7- 3 Data Dependences St Storage Conflicts C fli t Output Dependences (WAW) John P Shen The Reason for WAW and WAR: Register Recycling COMPILER REGISTER ALLOCATION CODE GENERATION REG. ALLOCATION Single Assignment Assignment, Symbolic Reg Reg. Map Symbolic Reg. to Physical Reg. Maximize a e Reuse euse o of Reg. eg INSTRUCTION LOOPS 9 $34: 10 11 12 13 14 15 16 17 18 19 20 21 22 mul addu mull addu lw mul addu mul addu lw mul addu dd addu ble EE382A – Autumn 2009 $14 $15, $24 $24, $25, $11, $12, $13,, $ $14, $15, $24, $25, $10 $10, $9, $9, $7, 40 $4, $14 $9 $9, 4 $15, $24 0($25) $9, 40 $$5,, $ $12 $8, 4 $13, $14 0($15) $11, $24 $10 $25 $10, $9, 1 10, $34 For (k=1;k<= 10; k++) t += a [i] [k] * b [k] [j] ; Reuse Same Set of Reg. in each Iteration Overlapped Execution of different Iterations Lecture 7- 4 John P Shen Resolving False Dependences • • • (1) R4 ← R3 + 1 Must Prevent (2) from completing before (1) is dispatched (2) R3 ← R5 + 1 (1) R3 ← R3 + R5 • • • • • • ← R3 Must Prevent (2) from completing before (1) completes (2) R3 ← R5 + 1 Stalling: delay dispatching (or write back) of the later instruction Copy Operands: Copy not-yet-used operand to prevent being overwritten ((WAR)) Register Renaming: use a different register (WAW & WAR) EE382A – Autumn 2009 Lecture 7- 5 John P Shen Register Renaming: The Idea • Anti and output dependences are false dependences • The dependence is on name/location rather than data • Given unlimited number of registers, anti and output dependences can always be eliminated r3 ← r1 op r2 r5 ← r3 op r4 r3 ← r6 op r7 Original Renamed r1 ← r2 / r3 r4 ← r1 * r5 r1 ← r3 + r6 r3 ← r1 - r4 EE382A – Autumn 2009 r1 ← r2 / r3 r4 ← r1 * r5 r8 ← r3 + r6 r9 ← r8 - r4 Lecture 7- 6 John P Shen Register Renaming Technique Register Renaming Resolves: Anti-Dependences Output Dependences Architected A i Registers R1 R2 • • • Rn Physical i Registers P1 P2 • • • Pn • • • Pn + k EE382A – Autumn 2009 : Design of Redundant Registers Number: One Multiple Allocation: Fixed for Each Register Pooled for all Regsiters Location: Attached to Register File (Centralized) Attached to functional units (Distributed) Lecture 7- 7 John P Shen Integrating Map Tables with the ARF EE382A – Autumn 2009 Lecture 7- 8 John P Shen Register Renaming Operations • At Decode/Dispatch: for each instruction handled in parallel 1 Source Read: Check availability of source operands 1. 2. Destination Allocate: Map destination register to new physical register • Stall if no register available – Note: N t mustt have h enough h ports t tto any map tables t bl • At finish: 3. Register g Update: p update p p physical y register g • At Complete/Commit: for each instruction handled in parallel 3. Register Update: update architectural register – Copy C ffrom RRF/ROB to t ARF & deallocate d ll t RRF entry; t OR – Upgrade physical location and deallocate register with old value • • It is now safe to do that Question: can we allocate later or deallocate earlier? EE382A – Autumn 2009 Lecture 7- 9 John P Shen Renaming Operation EE382A – Autumn 2009 Lecture 7- 10 John P Shen Renaming Buffer Options 1. Unified/merged register file – MIPS R10K, Alpha 21264 – Registers change role architecture to renamed 2. Rename register g file ((RRF)) – PA 8500,, PPC 620 – – Holds new values until they are committed to ARF Extra data transfer… 3. Renaming in the ROB – Pentium III Note: can have a single scheme or separate for integer/FP EE382A – Autumn 2009 Lecture 7- 11 John P Shen Unified Register File: Physical Register FSM EE382A – Autumn 2009 Lecture 7- 12 John P Shen Register Renaming in the IBM RS6000 FPU … <= R7 (actual last use) … Fload R7 <= Mem[] FPU Register Renaming OP T S1 S2 S3 FAD 3 2 1 O P T S1 S2 S3 FAD 3 2 1 head Free List tail 32 33 34 35 36 37 38 39 R7: R32 Map table 32 x 6 Free when Fload R7 commits Pending Target Return Queue 7 Simplified FPU Register Model head h d release tail Incoming FPU instructions pass through a renaming table prior to decode The 32 architectural registers are remapped to 40 physical registers y register g names are used within the FPU Physical Complex control logic maintains active register mapping EE382A – Autumn 2009 Lecture 7- 13 John P Shen Renaming Difficulties: Wide Instruction Issue • Need many ports in RFs and mapping tables • Instruction dependences during dispatching/issuing/committing – Must handle dependencies across instructions – E.g. add R1←R2+R3; sub R6←R1+R5 – Implementation: use comparators, multiplexors, counters • Comparators: discover RAW dependencies • Multiplexors: generate right physical address (old or new allocation) physical y registers g allocated • Counters: determine number of p EE382A – Autumn 2009 Lecture 7- 14 John P Shen Renaming Difficulties: Mispredictions & Exceptions • If exception/misprediction occurs, register mapping must be precise • Separate RRF: consider all RRF entries free • g consider all ROB entries free ROB renaming: • Unified RF: restore precise mapping – Single map: traverse ROB to undo mapping (history file approach) • ROB mustt remember b old ld mapping… i – Two maps: architectural and future register map • On exception, copy architectural map into future map… – Checkpointing: Ch k i ti kkeep regular l check h k points i t off map, restore t when h needed d d • When do we make a checkpoint? On every instruction? On every branch? • What are the trade-offs? • We’ll W ’ll revisit i it thi this approach h llater t on… EE382A – Autumn 2009 Lecture 7- 15 John P Shen “Dataflow Engine” for Dynamic Execution Reg. Write Back Dispatch Buffer - Read register or - Assign A i register i t tag t - Advance instructions to reservation stations Dispatch Reg. File Allocate Reorder Buffer entries - Monitor reg. tag - Receive R i d data t being forwarded - Issue when all operands ready Reservation Stations Branch Integer g g Integer Compl. Buffer (Reorder Buff.) Complete EE382A – Autumn 2009 Ren. Reg. Lecture 7- 16 Float.Point Load/ Store Forwarding results to Res. Sta. & rename registers Managed as a queue; Maintains sequential order of all Instructions in flight (“takeoff” = dispatching; “landing” = completion) John P Shen Historical Background • Dynamic or Data-flow Scheduling: – Scheduling hardware allows instructions to be executed as soon as its source operands are ready and a FU is available – Assuming renaming, only limited by RAW and structural hazards • First proposal: Tomasulo’s algorithm in IBM 360/91 FPU (1967) – 1 instruction per cycle, distributed implementation, imprecise exceptions… • We will talk directly about modern implementations – Read the original in the textbook – Differences: renaming, precise exceptions, multiple instructions per cycle, … EE382A – Autumn 2009 Lecture 7- 17 John P Shen Steps in Dynamic Execution (1) • Fetch instruction (in-order, speculative) – I-cache I cache access access, predictions predictions, insert in a fetch buffer • DISPATCH ((in-order,, speculative) p ) – Read operands from Register File (ARF) and/or Rename Register File (RRF) • RRF mayy return a readyy value or a Tag g for a p physical y location – Allocate new RRF entry (rename destination register) for destination – Allocate Reorder Buffer (ROB) entry – Advance instruction to appropriate entry in the scheduling hardware • Typical name for centralized: issue queue or instruction window • Typical name for distributed: reservation stations EE382A – Autumn 2009 Lecture 7- 18 John P Shen Steps in Dynamic Execution (2) • ISSUE & EXECUTE (out-of-order, speculative) – Scheduler entry monitors result bus for rename register Tag(s) • Find out if source operand becomes ready – When all operands ready, issue instruction into Functional Unit (FU) and deallocate scheduler entry (wake (wake-up up & select) • Subject to structural hazards & priorities – When execution finishes, broadcast result to waiting scheduler entries and RRF entry • COMMIT/RETIRE/GRADUATE (in-order, non-speculative) – When ready to commit result into “in-order” state (head of the ROB): • Update architectural register from RRF entry, deallocate RRF entry, and if it is a store instruction, advance it to Store Buffer • Deallocate ROB entry and instruction is considered architecturally completed • Update predictors based on instruction result EE382A – Autumn 2009 Lecture 7- 19 John P Shen Centralized Instruction Window or Issue Queue Implementation + info for executing instruction (e.g. opcode, ROB entry, entry RRF entry) EE382A – Autumn 2009 Lecture 7- 20 John P Shen Instruction Window Source Operand Options • Option (a): read at dispatch and keep in the window • Option (b): read at issue EE382A – Autumn 2009 Lecture 7- 21 John P Shen ROB Implementation EE382A – Autumn 2009 Lecture 7- 22 John P Shen Example: MIPS R10000 circa 1996 EE382A – Autumn 2009 Lecture 7- 23 John P Shen R10000 Design Choices • Register Renaming – – – – • Map table lookup + dependency check on simultaneous dispatches Unified physical register file 4-deep branch stack to backup the map table on branch predictions Sequential (4 (4-at-a-time) at a time) back-tracking back tracking to recover from exceptions Instruction Queues – S Separate t 16-entry 16 t floating fl ti point i t and d iinteger t iinstruction t ti queues – Prioritized, dataflow-ordered scheduling • Reorder Buffer – One per outstanding instruction, FIFO ordered – Stores PC, logical destination number, old physical destination number Why not current physical destination number? EE382A – Autumn 2009 Lecture 7- 24 John P Shen R10000 Block Diagram EE382A – Autumn 2009 Lecture 7- 25 John P Shen R10000 Instruction Fetch and Branch EE382A – Autumn 2009 Lecture 7- 26 John P Shen R10000 Register Renaming EE382A – Autumn 2009 Lecture 7- 27 John P Shen R10000 Pipelines EE382A – Autumn 2009 Lecture 7- 28 John P Shen R10000 Integer Queue EE382A – Autumn 2009 Lecture 7- 29 John P Shen Priority/Select Logic • • Tree of arbiters that works in 2 phases First phase – Request signals are propagated up the tree. Only ready instructions send requests – This in turn raises the ready signal of its parent arbiter cell. At the root cell one or more of the input request signals will be high if there are one or more instructions that are ready. – The root cell grants the functional unit to one of its children by raising one of its grant outputs. • Second phase p – Grant signal is propagated down the tree to the instruction that is selected – The enable signal to the root cell is g whenever the functional unit is high ready to execute an instruction. EE382A – Autumn 2009 Lecture 7- 30 John P Shen Priority/Select Logic Issues • Selection is easier if the priority depends on instruction location – Older instructions are at the bottom of window and receive priority • This creates an issue of compacting/collapsing: p g p g – As instructions depart, compress remaining towards the bottom – Younger instructions will be inserted towards the top (lower priority) • Compacting the window is not easy! – Its complexity can affect performance (clock frequency) – Often implemented in some restricted form • E.g. split window into two parts, allow compaction from 2nd half towards 1st • Trade-off between window utilization and compaction p simplicity p y EE382A – Autumn 2009 Lecture 7- 31 John P Shen Wake-up and Select Latency • Assume a result becomes available in cycle i – When you can start executing an instruction that waits for it? • Ideal solution: in cycle i+1 – Back to back executing, just like with 5-stage pipeline – Requirement: the following have to work in one cycle • Distribute result tag to the window & detect that instruction becomes read • Select instruction for execution & forward its info/operands to FU – May stress clock cycle in wide processor • Alternative: split wake-up and select in separate cycles – Simpler hardware hardware, faster clock cycle – Lower IPC (dependencies cost one extra cycle) EE382A – Autumn 2009 Lecture 7- 32 John P Shen Result Forwarding (Common Data Bus – CDB) • Common data bus: used to broadcast results of FUs • B d Broadcast t destinations d ti ti – RF or RRF or ROB, depending on the renaming scheme – Instruction window • May need result or tag for the result • Number of CDBs – Best case, case 1 per functional unit – Can have less, but now we may have structural hazard • Notes: – CDBs can be slow as they go across large chip area – Broadcast tag early EE382A – Autumn 2009 Lecture 7- 33 John P Shen Dynamic Scheduling Implementation Cost • To support N-way dispatch into IW per cycle – Nx2 simultaneous lookups into the rename map (or associative search) – N simultaneous write ports into the IW and the ROB • To support N-way issue per cycle (assuming read at issue) – 1 prioritized associative lookup of N entries – N read ports into the IW – Nx2 read ports into the RF • To support N-way finish per cycle – N write ports into the RF and the ROB – Nx2 associative lookup and write in IW • To support N-way retire per cycle – N read ports in the ROB – N ports t into i t the th RF (potentially) ( t ti ll ) EE382A – Autumn 2009 Lecture 7- 34 John P Shen Instruction Window Alternatives • Single vs. multiple buffers (trade-offs?) – Single centralized window – Single centralized window with static alignment for different FUs – Separate integer – FP – LSU windows – Separate buffers for each FU • Aka, reservation stations (see Tomasulo algorithm) • Management policies to keep in mind – Random access or FIFO • In-order vs out-of-order within each queue – Age Age-prioritized prioritized or criticality-based criticality based – Value vs. tag only – When to deallocate • Reservation stations for Ld/St units are more complicated EE382A – Autumn 2009 Lecture 7- 35 John P Shen MIPS R10000 EE382A – Autumn 2009 Lecture 7- 36 John P Shen