algebra 1 and statistics…
advertisement

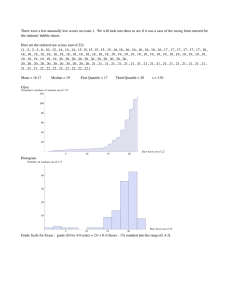
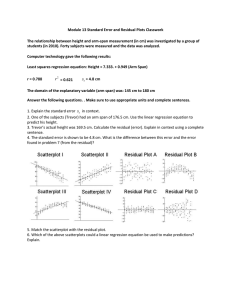
algebra 1 and statistics… teacher reference: descriptive statistics and analyses UNIT 3 – S.ID.A.1, S.ID.A.2, S.ID.A.3 Quantitative and Categorical Variables Quantitative Variable: takes numerical values for which arithmetic operations such as adding and averaging make sense. Examples: cholesterol levels, salaries, numerical test grades, etc. Categorical Variable: places an individual into one of several groups or categories. Examples: car color, gender, zip code, drink size, etc. Quantitative Variables Discrete: A finite number of values between two numbers on a number line. These are counting numbers. Examples: number of siblings, number of states visited, shoe size, number of pets. Continuous: An infinite number of values between two numbers on a number line. These are measurements. Examples: height, weight, temperature, number of ounces in a Starbucks coffee. Distribution – Center Median (M): The midpoint of a distribution, the number such that half the observations are smaller and the other half are larger. How to find the median of a distribution 1. Arrange all observations in order of size, from smallest to largest. 2. If the number of observations (n) is odd, the median M is the center observation in the ordered list. 3. If the number of observations (n) is even, the median M is the mean of the two center observations in the ordered list. Mean (x-bar Ë): The arithmetic average. How to find the mean of a distribution 1. Add all observations in the distribution. 2. Divide the sum by the number of observations, n. xi x n Distribution – Spread Interquartile Range (IQR): IQR = Q3 – Q1 First Quartile (Q1): The median of the observations whose position in the ordered list is to the left of the location of the overall median. Third Quartile (Q3): The median of the observations whose position in the ordered list is to the right of the location of the overall median. Standard Deviation (s): The square root of the average of the squares of the deviations of the observations from their mean. In plain terms, it tells us the average amount the data varies from the mean. If the deviations from the mean are small, we will have a small standard deviation. x i x s n 1 2 Outlier: Any individual observation that falls outside the overall pattern of the graph. Outlier Rule: Any value that falls outside the range: Q1 – 1.5(IQR) and Q3 + 1.5(IQR). UNIT 3 – S.ID.B.5, S.ID.B.6 Two-way Frequency Table Two-way Table: Describes two categorical variables, the row variable (pass/fail) and the column variable (gender). pass fail male 84 11 female 92 6 Relative Frequency: Converting frequency into proportions or percents. Marginal Distribution: Row and column totals. Two-way relative frequency table with marginal distribution by gender: pass fail total male female 0.884 0.939 0.116 0.061 1.0 1.0 Conditional Relative Frequency: A distribution referring to only people who satisfy a given condition. Example: What percent of male students passed? 88.4% UNIT 3 – S.ID.C.7, S.ID.C.8, S.ID.C.9 Residual: The difference between an observed value of the response variable and the value predicted by the regression line. residual = observed y – predicted y A residual plot is a scatterplot of the regression residuals against the independent variable (x-values). Residual plots help us assess the fit of a regression line. If the regression line captures the overall relationship between x and y, the residuals should have no systematic pattern. A curved pattern in a residual plot shows that the relationship between x and y is non-linear. Rate of Change Slope in context of a problem: for each increase in the x-value, on average, the y-value will increase (or decrease if the slope is negative) by the slope. Intercept It is the predicted value of y when x = 0. Sometimes the y-intercept does not have any meaning in the context of the data. Linear Model We fit the best fitting line using least squares regression. This model is where a is the slope of the model and b is the y-intercept. Using Technology In order to display the correlation coefficient on the TI-84, go into CATELOG, select DIAGNOSTIC ON, and enter twice. To retrieve the regression line on the TI-84, go into STAT, 4:LinReg(ax+b), and hit enter twice. Understanding Data as Linear Models Activity 1. Which variable is the explanatory variable and which is the response variable? Explain your reasoning. explanatory variable: car weight – we believe the weight of a car explains the gas mileage response variable: gas mileage – we believe how much gas a car uses is a response (or depends) on the weight of the car. 2. Use this data to make a scatterplot. gas mileage 35 25 15 3000 4000 car weight 5000 3. Find the linear regression equation and graph this on your plot. y = -0.0065x + 49.57 4. What is the rate of change for this line? In context of the data, describe the rate of change. rate of change = slope = -0.0065 For each increase in car weight (in pounds), on average, fuel mileage will decrease by 0.0065 mpg. 5. What is the correlation coefficient? In context of the data, describe the correlation coefficient. correlation coefficient = r = -0.935 There is a strong, negative, linear relationship between car weight and fuel efficiency. 6. A Smart Car weighs about 1,600 pounds. Showing your rationale, predict its gas mileage. prediction: -0.0065(1600) + 49.57 = 39.2 We would expect a Smart Car to get about 39.2 mpg. 7. What is the residual value for a car weighing 3489 pounds? observed y: 28 mpg predicted y: 26.9 mpg residual = observed y – predicted y = 28 mpg – 26.9 mpg = 1.1 mpg 8. Find the residual value for each of the car weights. Car Weight in Pounds 3489 3955 3345 3085 4915 4159 4289 3992 Gas Mileage Residual MPG Value (highway) 28 1.06 25 1.08 27 -0.87 29 -0.56 18 0.31 21 -1.60 20 -1.75 26 2.32 Which car weight has the largest residual value? Show this on your scatterplot. Which car weigh has the smallest residual value? Show this on your scatterplot. largest x=3992 smallest x=4915 Describe what a residual value from your data means. A residual value is the vertical (y) distance an observation point is from the prediction (regression) line. The larger the residual value, the further from the prediction line the point is located. Positive residuals are found with points above the regression line. Because there is no clear pattern in the residual plot, we can conclude a linear model is the best fit for our data, mpg vs. car weight residual 9. Use your car weights and residual values to make a residual plot. Analyze your residual plot. weight Correlation does not equal causation! 10. Examine this data and describe the correlation. There is a VERY strong, positive, linear relationship between our puppy’s weight and Alaska’s snowshoe price. Discuss the moral of this example, “be careful what you infer from your statistical analysis.” BE SURE YOUR RELATIONSHIP MAKES SENSE! What other variables could be involved in this relationship? If our puppy was born at the beginning of snowshoe season, it would make sense that the weight and price would increase together. Representations of Data Activity 1. Find the minimum, quartile 1, median, quartile 3, and maximum for the weights of the players. Use this information to construct a boxplot. 165 220 310 2. Find the minimum, quartile 1, median, quartile 3, and maximum for the heights of the players. Use this information to construct a boxplot. 71 78 90 3. Find the minimum, quartile 1, median, quartile 3, and maximum for the heights of all the players except for Yao Ming. Use this information to construct a boxplot. 71 78 86 4. Compare the boxplots from Questions 2 and 3. How has the plot changed? 71 78 90 The right “whisker” and the box got smaller when we removed Ming’s height. This changes the spread of our data. 5. Did the minimum or the maximum change? Why or why not? Be sure to relate your reasons to the data you used to construct your plot. The minimum stayed the same, but the maximum changed because we removed the largest (maximum) observation. 6. Did the median change? Why or why not? Be sure to relate your reasons to the data you used to construct your plot. The median stayed the same because the middle observation did not change. 7. Did the upper or lower quartile change? Why or why not? Be sure to relate your reasons to the data you used to construct your plot. Because we only removed the largest observation, the lower half of the data did not change (nor did the lower quartile)… however, the upper half changed slightly because we removed one of the data points. The max and upper quartile changed. Relative, Joint, and Marginal Frequencies Activity 1. Divide the numbers in the frequency table by the total to obtain relative frequencies as decimals. Record the results in the table below. preferred food at game hot dogs hamburgers pizza total frequency 0.45 0.3 0.25 1.0 2. How can you check to see if you have accurately converted frequencies to relative frequencies? If the sum of the relative frequencies is 1 (or 100%), then we have correctly converted. 3. Explain why the number in the total column of a relative frequency table is always 1 or 100%. If the total column is more than 100%, then we have too much frequency in at least one category. If the total column is less than 100%, then we have too little frequency in at least one column. The total has to account for all (100%) of the observations. 4. What does the data tell us about the most preferred food to eat at a baseball game? Hot dogs, because that category has the largest relative frequency at 45%. 5. Fill in the missing marginal frequencies (the entries in the row and column total). 6. Highlight the joint frequencies (entries in the body of the table). 7. Find the grand total, which is the sum of the row totals as well as the sum of the column totals. Write the grand total in the lower-right corner of the two-way table. child teenager adult total hotdogs 8 5 5 18 hamburgers 1 3 8 12 pizza 2 5 3 10 total 11 13 16 40 8. Where have you seen the row totals before? They were from Carla’s original table, without considering the age of the respondent. 9. In terms of Carla’s survey, what does the grand total represent? It is the total amount of people that Carla selected for her survey. 10. What does the data tell us about the preference of food for children at a baseball game? Most children prefer to eat hotdogs at baseball games. 11. How does this compare with the adults? The majority of adults polled prefer hamburgers while at baseball games. 12. Make a relative frequency table for each age group (row variable). child teenager adult hotdogs 0.73 0.385 0.31 hamburgers 0.09 0.23 0.5 pizza 0.18 0.385 0.19 total 1 1 1 13. What is the conditional probability that a child will choose pizza? 18% 14. What is the conditional probability that an adult will choose hotdogs? 31%