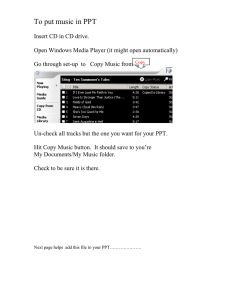
15-213 Memory System Performance March 21, 2000 Topics
advertisement

15-213
Memory System Performance
March 21, 2000
Topics
• Impact of cache parameters
• Impact of memory reference patterns
– memory mountain range
– matrix multiply
class19.ppt
Basic Cache Organization
Address space (N = 2n bytes)
Cache (C = S x E x B bytes)
E lines/set
Address
(n = t + s + b bits)
t
s
S = 2s sets
b
B
Valid bit tag
1 bit t bits
class19.ppt
data
B = 2b bytes (line size)
–2–
Cache line
(cache block)
CS 213 S’00
Multi-Level Caches
Options: separate data and instruction caches, or a unified cache
Processor
TLB
regs
L1 Dcache
L1 Icache
size:
speed:
$/Mbyte:
line size:
200 B
2 ns
L2
Cache
8-64 KB
2 ns
1-4MB SRAM
4 ns
$100/MB
8B
32 B
32 B
larger, slower, cheaper
Memory
disk
128 MB DRAM
60 ns
$1.50/MB
8 KB
9 GB
8 ms
$0.05/MB
larger line size, higher associativity, more likely to write back
class19.ppt
–3–
CS 213 S’00
Cache Performance Metrics
Miss Rate
• fraction of memory references not found in cache
(misses/references)
• Typical numbers:
3-10% for L1
can be quite small (e.g., < 1%) for L2, depending on size, etc.
Hit Time
• time to deliver a line in the cache to the processor (includes time
to determine whether the line is in the cache)
• Typical numbers:
1 clock cycle for L1
3-8 clock cycles for L2
Miss Penalty
• additional time required because of a miss
– Typically 25-100 cycles for main memory
class19.ppt
–4–
CS 213 S’00
Impact of Cache and Line Size
Cache Size
• impact on miss rate:
– larger is better
• impact on hit time:
– smaller is faster
Line Size
• impact on miss rate:
– big lines can help exploit spatial locality (if it exists)
– however, for a given cache size, bigger lines means that there are
fewer of them (which can hurt the miss rate)
• impact on miss penalty:
– given a fixed amount of bandwidth, larger lines means longer
transfer times (and hence larger miss penalties)
class19.ppt
–5–
CS 213 S’00
Impact of Associativity
• Direct mapped, set associative, or fully associative?
Total Cache Size (tags+data):
• Higher associativity requires more tag bits, LRU state machine
bits
• Additional read/write logic, multiplexers (MUXs)
Miss Rate:
• Higher associativity (generally) decreases miss rate
Hit Time:
• Higher associativity increases hit time
– direct mapped is the fastest
Miss Penalty:
• Higher associativity may require additional delays to select victim
– in practice, this decision is often overlapped with other parts of
the miss
class19.ppt
–6–
CS 213 S’00
Impact of Write Strategy
• Write through or write back?
Advantages of Write Through:
• Read misses are cheaper.
– Why?
• Simpler to implement.
– uses a write buffer to pipeline writes
Advantages of Write Back:
• Reduced traffic to memory
– especially if bus used to connect multiple processors or I/O
devices
• Individual writes performed at the processor rate
class19.ppt
–7–
CS 213 S’00
Qualitative Cache Performance Model
Compulsory (aka “Cold”) Misses:
• first access to a memory line (which is not in the cache already)
– since lines are only brought into the cache on demand, this is
guaranteed to be a cache miss
• changing the cache size or configuration does not help
Capacity Misses:
• active portion of memory exceeds the cache size
• the only thing that really helps is increasing the cache size
Conflict Misses:
• active portion of address space fits in cache, but too many lines map
to the same cache entry
• increased associativity and better replacement policies can potentially
help
class19.ppt
–8–
CS 213 S’00
Measuring Memory Bandwidth
int data[MAXSIZE];
int test(int size, int stride)
{
int result = 0;
int wsize = size/sizeof(int);
for (i = 0; i < wsize; i+= stride)
result += data[i];
return result;
}
Stride (words)
Size (bytes)
class19.ppt
–9–
CS 213 S’00
Measuring Memory Bandwidth (cont.)
Stride (words)
Size (bytes)
Measurement
• Time repeated calls to test
– If size sufficiently small, then can hold array in cache
Characteristics of Computation
• Stresses read bandwidth of system
• Increasing stride yields decreased spatial locality
– On average will get stride*4/B accesses / cache block
• Increasing size increases size of “working set”
class19.ppt
– 10 –
CS 213 S’00
Alpha Memory Mountain Range
DEC Alpha 21164
466 MHz
8 KB (L1)
96 KB (L2)
2 M (L3)
600
500
400
L1 Resident
300
200
100
16m
s13
s11
L3 Resident
Data Set
s15
class19.ppt
s9
Stride
s7
s5
s3
0
8m
4m
2m
1024k
512k
256k
128k
64k
32k
16k
8k
4k
2k
1k
.5k
L2 Resident
s1
MB/s
– 11 –
Main Memory Resident
CS 213 S’00
Effects Seen in Mountain Range
Cache Capacity
• See sudden drops as increase working set size
Cache Block Effects
• Performance degrades as increase stride
– Less spatial locality
• Levels off
– When reach single access per line
class19.ppt
– 12 –
CS 213 S’00
Alpha Cache Sizes
600
500
400
300
200
100
0
16m
8m
4m
2m
1024k 512k 256k 128k
64k
32k
16k
8k
4k
2k
1k
• MB/s for stride = 16
Ranges
.5k – 8k
16k – 64k
128k
256k – 2m
4m – 16m
class19.ppt
Running in
Running in
Indistinct
Running in
Running in
L1 (High overhead for small data set)
L2.
cutoff (Since cache is 96KB)
L3.
main memory
– 13 –
CS 213 S’00
.5k
Alpha Line Size Effects
600
500
16m
1024k
32k
8k
400
300
200
100
0
s1
s2
s4
s8
s16
Observed Phenomenon
• As double stride, decrease accesses/block by 2
• Until reaches point where just 1 access / block
• Line size at transition from downward slope to horizontal line
– Sometimes indistinct
class19.ppt
– 14 –
CS 213 S’00
Alpha Line Sizes
600
500
16m
1024k
32k
8k
400
300
200
100
0
s1
s2
s4
s8
s16
Measurements
8k
32k
1024k
16m
Entire array L1 resident. Effectively flat (except for overhead)
Shows that L1 line size = 32B
Shows that L2 line size = 32B
L3 line size = 64?
class19.ppt
– 15 –
CS 213 S’00
Xeon Memory Mountain Range
Pentium III Xeon
550 MHz
16 KB (L1)
512 KB (L2)
1200
1000
800
MB/s
600
L1 Resident
400
16m
s13
s11
L2 Resident
Data Set
s15
class19.ppt
s9
Stride
s7
s5
s3
s1
0
8m
4m
2m
1024k
512k
256k
128k
64k
32k
16k
8k
4k
2k
1k
.5k
200
Main Memory Resident
– 16 –
CS 213 S’00
Xeon Cache Sizes
1000
900
800
700
600
500
400
300
200
100
0
16m
8m
4m
2m
1024k 512k 256k 128k
64k
32k
16k
8k
4k
2k
1k
.5k
• MB/s for stride = 16
Ranges
.5k – 16k
32k – 256k
512k
1m – 16m
class19.ppt
Running
Running
Running
Running
in
in
in
in
L1. (Overhead at high end)
L2.
main memory (but L2 supposed to be 512K!)
main memory
– 17 –
CS 213 S’00
Xeon Line Sizes
1200
1000
800
16m
600
256k
400
4k
200
0
s1
s2
s4
s8
s16
Measurements
4k
Entire array L1 resident. Effectively flat (except for overhead)
256k Shows that L1 line size = 32B
16m Shows that L2 line size = 32B
class19.ppt
– 18 –
CS 213 S’00
Interactions Between Program & Cache
Major Cache Effects to Consider
• Total cache size
– Try to keep heavily used data in cache closest to processor
Variable sum
• Line size
held in register
– Exploit spatial locality
/* ijk */
Example Application
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
sum = 0.0;
for (k=0; k<n; k++)
sum += a[i][k] * b[k][j];
c[i][j] = sum;
}
}
• Multiply N x N matrices
• O(N3) total operations
• Accesses
– N reads per source element
– N values summed per destination
» but may be able to hold in register
class19.ppt
– 19 –
CS 213 S’00
Matrix Mult. Performance: Sparc20
20
18
16
mflops (d.p.)
14
12
10
8
175
200
6
4
50
75
100
ikj
kij
ijk
jik
jki
kji
2
0
125
150
matrix size (n)
• As matrices grow in size, they eventually exceed cache capacity
• Different loop orderings give different performance
– cache effects
– whether or not we can accumulate partial sums in registers
class19.ppt
– 20 –
CS 213 S’00
Miss Rate Analysis for Matrix Multiply
Assume:
• Line size = 32B (big enough for 4 64-bit words)
• Matrix dimension (N) is very large
– Approximate 1/N as 0.0
• Cache is not even big enough to hold multiple rows
Analysis Method:
• Look at access pattern of inner loop
k
i
j
k
A
class19.ppt
j
i
C
B
– 21 –
CS 213 S’00
Layout of Arrays in Memory
C arrays allocated in row-major order
• each row in contiguous memory locations
Stepping through columns in one row:
for (i = 0; i < N; i++)
sum += a[0][i];
• accesses successive elements
• if line size (B) > 8 bytes, exploit spatial
locality
– compulsory miss rate = 8 bytes / B
Stepping through rows in one column:
for (i = 0; i < n; i++)
sum += a[i][0];
• accesses distant elements
• no spatial locality!
– compulsory miss rate = 1 (i.e. 100%)
Memory Layout
0x80000
0x80008
0x80010
0x80018
a[0][0]
a[0][1]
a[0][2]
a[0][3]
• • •
0x807F8
0x80800
0x80808
0x80810
0x80818
a[0][255]
a[1][0]
a[1][1]
a[1][2]
a[1][3]
• • •
0x80FF8
a[1][255]
• • •
• • •
0xFFFF8 a[255][255]
class19.ppt
– 22 –
CS 213 S’00
Matrix Multiplication (ijk)
/* ijk */
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
sum = 0.0;
for (k=0; k<n; k++)
sum += a[i][k] * b[k][j];
c[i][j] = sum;
}
}
Inner loop:
(*,j)
(i,*)
A
B
Row-wise
Columnwise
Misses per Inner Loop Iteration:
A
0.25
class19.ppt
B
1.0
(i,j)
C
Fixed
C
0.0
– 23 –
CS 213 S’00
Matrix Multiplication (jik)
/* jik */
for (j=0; j<n; j++) {
for (i=0; i<n; i++) {
sum = 0.0;
for (k=0; k<n; k++)
sum += a[i][k] * b[k][j];
c[i][j] = sum
}
}
Misses per Inner Loop Iteration:
A
0.25
class19.ppt
B
1.0
C
0.0
– 24 –
Inner loop:
(*,j)
(i,j)
(i,*)
A
B
Row-wise
Columnwise
C
Fixed
CS 213 S’00
Matrix Multiplication (kij)
/* kij */
for (k=0; k<n; k++) {
for (i=0; i<n; i++) {
r = a[i][k];
for (j=0; j<n; j++)
c[i][j] += r * b[k][j];
}
}
Inner loop:
(i,k)
A
Fixed
(k,*)
B
class19.ppt
B
0.25
C
0.25
– 25 –
C
Row-wise Row-wise
Misses per Inner Loop Iteration:
A
0.0
(i,*)
CS 213 S’00
Matrix Multiplication (ikj)
/* ikj */
for (i=0; i<n; i++) {
for (k=0; k<n; k++) {
r = a[i][k];
for (j=0; j<n; j++)
c[i][j] += r * b[k][j];
}
}
Inner loop:
(i,k)
A
Fixed
(k,*)
B
class19.ppt
B
0.25
C
0.25
– 26 –
C
Row-wise Row-wise
Misses per Inner Loop Iteration:
A
0.0
(i,*)
CS 213 S’00
Matrix Multiplication (jki)
/* jki */
for (j=0; j<n; j++) {
for (k=0; k<n; k++) {
r = b[k][j];
for (i=0; i<n; i++)
c[i][j] += a[i][k] * r;
}
}
Inner loop:
(*,k)
A
Column wise
Misses per Inner Loop Iteration:
A
1.0
class19.ppt
B
0.0
(k,j)
(*,j)
B
Fixed
C
Columnwise
C
1.0
– 27 –
CS 213 S’00
Matrix Multiplication (kji)
/* kji */
for (k=0; k<n; k++) {
for (j=0; j<n; j++) {
r = b[k][j];
for (i=0; i<n; i++)
c[i][j] += a[i][k] * r;
}
}
Misses per Inner Loop Iteration:
A
1.0
class19.ppt
B
0.0
Inner loop:
(*,k)
A
Columnwise
(k,j)
B
Fixed
C
1.0
– 28 –
CS 213 S’00
(*,j)
C
Columnwise
Summary of Matrix Multiplication
ijk (& jik):
• 2 loads, 0 stores
kij (& ikj):
• 2 loads, 1 store
• misses/iter = 1.25 • misses/iter = 0.5
for (i=0; i<n; i++) {
for (k=0; k<n; k++) {
for (j=0; j<n; j++) {
jki (& kji):
• 2 loads, 1 store
• misses/iter = 2.0
for (j=0; j<n; j++) {
for (i=0; i<n; i++) {
for (k=0; k<n; k++) {
sum = 0.0;
r = a[i][k];
r = b[k][j];
for (k=0; k<n; k++)
for (j=0; j<n; j++)
for (i=0; i<n; i++)
sum += a[i][k] * b[k][j];
c[i][j] += r * b[k][j];
c[i][j] = sum;
}
c[i][j] += a[i][k] * r;
}
}
}
}
}
class19.ppt
– 29 –
CS 213 S’00
Matrix Mult. Performance: DEC5000
3
mflops (d.p.)
2.5
kij
ijk
jik
1.5
0.5
0
ikj
2
1
jki
kji
(misses/iter = 0.5)
(misses/iter = 1.25)
50
75
class19.ppt
100
125
150
matrix size (n)
175
– 30 –
200
(misses/iter = 2.0)
CS 213 S’00
Matrix Mult. Performance: Sparc20
Multiple columns of B fit in cache
20
mflops (d.p.)
18
16
14
12
8
6
kij
ijk
jik
jki
kji
(misses/iter = 0.5)
(misses/iter = 1.25)
2
0
ikj
10
4
50
75
class19.ppt
100
125
150
matrix size (n)
175
– 31 –
200
(misses/iter = 2.0)
CS 213 S’00
Matrix Mult. Performance: Alpha 21164
Too big for L1 Cache
Too big for L2 Cache
160
mflops (d.p.)
140
120
ijk
ikj
jik
jki
kij
kji
(misses/iter = 0.5)
100
80
60
40
20
(misses/iter = 1.25)
0
(misses/iter = 2.0)
matrix size (n)
class19.ppt
– 32 –
CS 213 S’00
Matrix Mult.: Pentium III Xeon
90
80
70
ijk
ikj
jik
jki
kij
kji
50
40
30
20
(misses/iter
= 0.5 or
1.25)
(misses/iter
= 2.0)
10
10
0
12
5
15
0
17
5
20
0
22
5
25
0
27
5
30
0
32
5
35
0
37
5
40
0
42
5
45
0
47
5
50
0
75
50
0
25
MFlops (d.p.)
60
class19.ppt
Matrix Size (n)
– 33 –
CS 213 S’00
Blocked Matrix Multiplication
• “Block” (in this context) does not mean “cache block”
- instead, it means a sub-block within the matrix
Example: N = 8; sub-block size = 4
A11 A12
A21 A22
B11 B12
X
B21 B22
=
C11 C12
C21 C22
Key idea: Sub-blocks (i.e., Axy) can be treated just like scalars.
C11 = A11B11 + A12B21
C21 = A21B11 + A22B21
class19.ppt
C12 = A11B12 + A12B22
C22 = A21B12 + A22B22
– 34 –
CS 213 S’00
Blocked Matrix Multiply (bijk)
for (jj=0; jj<n; jj+=bsize) {
for (i=0; i<n; i++)
for (j=jj; j < min(jj+bsize,n); j++)
c[i][j] = 0.0;
for (kk=0; kk<n; kk+=bsize) {
for (i=0; i<n; i++) {
for (j=jj; j < min(jj+bsize,n); j++) {
sum = 0.0
for (k=kk; k < min(kk+bsize,n); k++) {
sum += a[i][k] * b[k][j];
}
c[i][j] += sum;
}
}
}
}
class19.ppt
– 35 –
CS 213 S’00
Blocked Matrix Multiply Analysis
• Innermost loop pair multiplies a 1 X bsize sliver of A by a bsize X
bsize block of B and accumulates into 1 X bsize sliver of C
• Loop over i steps through n row slivers of A & C, using same B
for (i=0; i<n; i++) {
for (j=jj; j < min(jj+bsize,n); j++) {
sum = 0.0
for (k=kk; k < min(kk+bsize,n); k++) {
sum += a[i][k] * b[k][j];
}
c[i][j] += sum;
Innermost
}
kk
jj
jj
Loop Pair
i
A
class19.ppt
kk
i
B
C
Update successive
row sliver accessed
elements of sliver
bsize times
block reused n
times in succession
– 36 –
CS 213 S’00
Blocked Matrix Mult. Perf: DEC5000
3
mflops (d.p.)
2.5
2
1.5
1
125
150
175
200
bijk
bikj
ikj
ijk
0.5
0
50
class19.ppt
75
100
matrix size (n)
– 37 –
CS 213 S’00
Blocked Matrix Mult. Perf: Sparc20
20
mflops (d.p.)
18
16
14
12
75
100
125
150
175
200
bijk
bikj
ikj
ijk
10
8
6
4
2
0
50
class19.ppt
matrix size (n)
– 38 –
CS 213 S’00
Blocked Matrix Mult. Perf: Alpha 21164
160
140
mflops (d.p.)
120
100
bijk
bikj
80
ijk
ikj
60
40
20
500
475
450
425
400
375
350
325
300
275
250
225
200
175
150
125
100
75
50
0
matrix size (n)
class19.ppt
– 39 –
CS 213 S’00
90
Blocked Matrix Mult. : Xeon
80
70
ijk
ikj
bijk
bikj
50
40
30
20
10
10
0
12
5
15
0
17
5
20
0
22
5
25
0
27
5
30
0
32
5
35
0
37
5
40
0
42
5
45
0
47
5
50
0
75
0
50
MFlops (d.p.)
60
class19.ppt
Matrix Size (n)
– 40 –
CS 213 S’00