Application layer multicast routing
advertisement

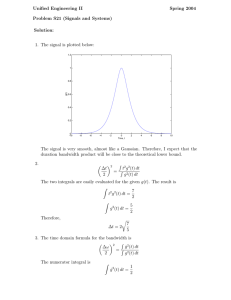
Application layer multicast routing Key: What Is Multicast? Unicast transfer Broadcast transfer Multicast transfer • Unicast – One-to-one – Destination – unique receiver host address • Broadcast – One-to-all – Destination – address of network • Multicast – One-to-many – Multicast group must be identified – Destination – address of group Multicast application examples • Financial services – Delivery of news, stock quotes, financial indices, etc • Remote conferencing/e-learning – Streaming audio and video to many participants (clients, students) – Interactive communication between participants • Data distribution IP Multicast Gatech Stanford CMU Berkeley Routers with multicast support •Highly efficient bandwidth usage Key Architectural Decision: Add support for multicast in IP layer So what is the big issue … 15 years since proposal, but no wide area IP multicast deployment • Scalability (with number of groups) -- Routers maintain per-group state -- Require every group to dynamically obtain a globally unique address from the multicast address space • IP Multicast: best-effort multi-point delivery service -- Providing higher level features such as reliability, congestion control, flow control, and security has shown to be more difficult than in the unicast case • Other issues -- Change in infrastructure -- DOS attacks -- Network management, billing etc. -- works across space, not across time Can we achieve efficient multi-point delivery without IP-layer support? Application layer multicast Gatech Stanford Stan1 Stan2 CMU Berk1 Berkeley Overlay Tree Berk2 Stan1 Gatech Stan2 CMU Berk1 Berk2 Pros and Cons • Scalability – Routers do not maintain per-group state – End systems do, but they participate in very few groups – No need for globally consistent naming, allows application specific naming • Easier to deploy – No infrastructural support • Potentially simplifies support for higher level functionality – Leverage computation and storage of end systems – Leverage solutions for unicast congestion, error and flow control • Efficiency concerns – redundant traffic on physical links – increase in latency due to end-systems Open questions! What are the performance implications of using an overlay? How do end systems with limited topological information cooperate to construct good overlay structures? What metric should the optimization be based on? End-to-end overlay vs. proxy-based overlay? Does high bandwidth data dissemination require special attention? A lot of work has been done to tackle these questions, for eg. Narada, Yoid, Scattercast, ALMI, Overcast, ROMA, NICE, Bullet, Selectcast, Scribe .… Overcast : Motivation • Offering bandwidth-intensive content on demand - primarily video content - necessary to maintain full fidelity • Long-running content availability for multiple clients - data distribution system for businesses • Bandwidth bottlenecks develop as multiple requests are made Key: Line thickness indicates desired bandwidth usage by sending entity What is Overcast? • An application level multicasting system • Provides scalable and reliable single-source multicast • Goals Overlay structured to maximize bandwidth Utilize network topology efficiently - limit repeated usage of physical links No change to existing routers - easy deployment • Draws upon work in content distribution, caching, and server replication Key insight and contribution’s • Add storage to the network fabric for reliability and scalability - use disk-space to time shift multicast distribution - trade-off between disk-space and bandwidth • Contribution’s a simple protocol for forming efficient and scalable distribution trees that dynamically adapt to changes a protocol for maintaining global status at the root of the changing distribution tree System structure The overlay comprises of : • A central source (may be replicated for fault tolerance) • A no of overcast nodes (standard PCs with lot’s of storage) - organized into a distribution tree rooted at the source - bandwidth efficient trees • Final Consumers – members of the multicast group - allows unmodified HTTP clients to join The business model involves a content provider who installs these nodes (proxies) in the fabric and the overlay acts as a data distribution system for businesses Bandwidth Efficient Overlay Trees 1 10 Mb/s R 2 “…three ways of organizing the root and the nodes into a distribution tree.” 1 R R 2 1 2 R 2 1 How Does Overcast Build Bandwidth Efficient Trees? • Goal – maximize bandwidth to root for all nodes • Places a new node as far away from root as possible without sacrificing bandwidth • Additional details – Bandwidth: measured by timing a 10KB download – Hystersis: nodes with bandwidth within 10% of each other considered equal – in case of a tie, choose the closest parent as determined by traceroute • Won’t the results of this algorithm change over time? The node addition algorithm R R 5 10 1 10 3 8 1 2 7 5 2 Physical network substrate 3 Overcast distribution tree But …. • What is the 10 Kb download measuring? TCP begins with a ‘slow start’ Download is over by the time it switches to AIMD Does not give a measure of long-term TCP throughput • Where is the bottleneck bandwidth? Nodes on the edges -- access links (leads to linear trees) Nodes in the core - fat pipes (a 10 Kbps download does not give the bandwidth) - bottleneck due to congestion, which can vary on a short time scale May have been more relevant at the time of the work …. The impact of the child nodes on the bandwidth …. Dynamic Topology • A node periodically reevaluates its position in the tree by measuring the bandwidth been itself and – its parent (baseline) – its grandparent – all its siblings • Node can relocate to become – child of a sibling – sibling of a parent • Inherently tolerant of non-root failures – if the parent dies, a node moves up the ancestry tree Interactions Between Node Adding And Dynamic Topology R 10 R 20 1 R 2 2 1 15 2 Physical network substrate 1 Overcast distribution tree Overcast distribution tree Round 1 Round 2 But …. • What happens when bandwidth keeps fluctuating? 10% hysterisis gap is ineffective given the way the bandwidth is measured Smart choice of bandwidth’s for the network edges in the generated graph. No evaluation in case of bandwidth flux Even if the system does converge, the convergence time is limited by the probes to siblings and ancestors State tracking – the Up/Down protocol • An efficient mechanism is needed to exchange information between nodes – must scale sublinearly in terms of network usage – may scale linearly in terms of storage • Assumes information either – changes slowly (E.g., Health status of nodes) – can be combined efficiently from multiple children into a single description (E.g., Totals from subtrees) • Each node maintains state about all nodes in its subtree Management of information with the Up/Down protocol • Each node periodically contacts its parent • Parents assume a child (and all descendants) has died if the child fails to contact within some interval • During contact, a node reports to its parent – – – – Death certificates Birth certificates Extra information Information propagated from children • Sequence numbers used to prevent race conditions Scaling sublinearly in terms of network usage 1 • A node (and descendants) relocates under a sibling • The sibling must learn about all the node’s descendants – Birth certificates • The sibling passes this information to the (original node’s) parent 1.1 1.2.1 1.2 1.2.2 1.2.2.1 • The parent recognizes no changes and halts further propagation 1.3 1.2.3 No change observed. Propagation halted. Birth certificates for 1.2.2, 1.2.2.1 The client side – how to join a multicast group • Clients join a multicast group through a typical HTTP GET request • Root determines where to connect the client to the multicast tree using – Pathname of URL (multicast group being joined) – Status of Overcast nodes – Location of client* • Root selects “best” server and redirects the client to that server Key: Client joins Content query (multicast join) Query redirect Content delivery R1 R2 1 3 2 4 R3 5 6 Evaluation • Based on simulations with GT-ITM – Five 600-node graphs • 3 transit domains (backbone) • 8 stub networks per domain • 25 nodes per stub – Assigned Bandwidth • 45Mbps, 1.5Mbps, 100Mbps • T3, T1, Fast Ethernet – One node supports 20 clients • (MPEG-1 video) Bandwidth utilization • Backbone – Adds transit nodes first • Random – All nodes chosen randomly • Fraction = Overcast bandwidth/Optimal bandwidth • At full participation – distribution trees are different Discussion (cont.) • Is a tree structure effective for high bandwidth data dissemination? Kostic et. al. differ! Bullet achieves this by distributing data in a disjoint manner to strategic points - the nodes organize as a mesh • For good performance, the content provider will have to manually choose strategically placed nodes in the core which are anyway connected by big fat pipes – so what is the relevance of the provided automation? • What are the reliability semantics? - what if a node is down while a transmission completes – how does the log help, does the node receive the file, does the root know of this? - when is data removed from the storage? • Not suitable for live streams - although the authors were never aiming for this! Discussion (cont.) • What about NAT’s - how can any overcast node be inside a NAT? • In case of a tie in bandwidth measure, why not use latency instead of hop count – leads to a shortest widest kind of selection • Where does the root get the location of client from, when doing server selection? • Simply coupled TCP connections not the best way to realize the bandwidth potential of the topology - May be a problem in case of heterogeneous receivers - ROMA uses loosely coupled connections with fast forward error correction • Seems more like a contribution to smarter content distribution systems than to application level multicasting Bit Torrent does the same thing! Enabling Conferencing Applications on the Internet using an Overlay Multicast Architecture Past Work • Self-organizing protocols – Yoid (ACIRI), Narada (CMU), Scattercast (Berkeley), Overcast (CISCO), Bayeux (Berkeley), … – Construct overlay trees in distributed fashion – Self-improve with more network information • Performance results showed promise, but… – Evaluation conducted in simulation – Did not consider impact of network dynamics on overlay performance Focus of This Paper • Can End System Multicast support real-world applications on the Internet? – Study in context of conferencing applications – Show performance acceptable even in a dynamic and heterogeneous Internet environment • First detailed Internet evaluation to show the feasibility of End System Multicast Enhancements of Overlay Design • Two new issues addressed – Dynamically adapt to changes in network conditions – Optimize overlays for multiple metrics • Latency and bandwidth • Study in the context of the Narada protocol (Sigmetrics 2000) – Techniques presented apply to all self-organizing protocols Optimize Overlays for Dual Metrics Source rate 2 Mbps 60ms, 2Mbps Receiver X Source 30ms, 1Mbps • Prioritize bandwidth over latency • Break tie with shorter latency Adapt to Dynamic Metrics • Adapt overlay trees to changes in network condition – Monitor bandwidth and latency of overlay links • Link measurements can be noisy – Aggressive adaptation may cause overlay instability persistent: react bandwidth transient: do not react raw estimate smoothed estimate discretized estimate time • Capture the long term performance of a link – Exponential smoothing, Metric discretization Evaluation overview Compare performance of their scheme with -- Benchmark (IP Multicast) -- Other overlay schemes that consider fewer network metrics Overlay Scheme Choice of Metrics Bandwidth Bandwidth-Latency Bandwidth-Only Latency-Only Random Latency Three Scenarios Considered Primary Set 1.2 Mbps Primary Set 2.4 Mbps Extended Set 2.4 Mbps (lower) “stress” to overlay schemes (higher) • Does ESM work in different scenarios? • How do different schemes perform under various scenarios? BW, Primary Set, 1.2 Mbps Internet pathology Naïve scheme performs poorly even in a less “stressful” scenario RTT results show similar trend Scenarios Considered Primary Set 1.2 Mbps Primary Set 2.4 Mbps Extended Set 2.4 Mbps (lower) “stress” to overlay schemes (higher) • Does an overlay approach continue to work under a more “stressful” scenario? • Is it sufficient to consider just a single metric? – Bandwidth-Only, Latency-Only BW, Extended Set, 2.4 Mbps no strong correlation between latency and bandwidth Optimizing only for latency has poor bandwidth performance RTT, Extended Set, 2.4Mbps Bandwidth-Only cannot avoid poor latency links or long path length Optimizing only for bandwidth has poor latency performance Discussion • Does a source rate of 2.4 Mbps represent a realistic setting! • Issues not addressed Scalability - how to lower network costs for large sized groups - how to make the tree building algorithm more scalable Extremely dynamic environments - how to achieve shorter time scale adaptation - trade-off between overlay stability and the detection time • Optimizing for 2 dynamic metrics - Optimizing for both bandwidth and latency may be tricky; the discretization and hysterisis combined with the probe latency may affect the granularity of adjustment Discussion (cont) • Is end-system multicast suitable for real time applications? Does provide distribution across time But for applications with timing constraints, it may not be such a good idea! These are some of the most well connected machined on the Internet! • Is the internet a good place for such measurements and comparisons? The authors do a decent job of making the analysis fair and objective On a general note …. • What is the impact of such overlays on the other traffic? • The usefulness of the overlay concept Will they be a success iff nobody uses them? Interaction between multiple independent overlays • What is the motivation for their deployment? Users come in and go out ! Cheating by end hosts • All the ALM’s provide a best effort service! are they comparable? which one provides the best best-effort service