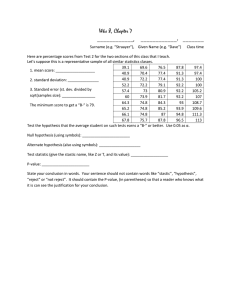
Practice Problems Summation Notation 2-8+9+0 = -15
advertisement

Practice Problems Summation Notation 2-8+9+0 = -15 [(14*-2)+(2*0)+(-8*0)+(9*-1)+(0*10)+(5*6)+(-3*7)]= -28 Then a new vector is created: = [(19-2),(19+0),(19+0),(19-1),(19+10),(19+6),(19+7)] Then a new vector is created: = [(17-2),(17+0),(17+0),(17-1),(17+10),(17+6),(17+7)] -2+0+0-1+10+6+7 = 20 [(-2+14*-2)+(0+2*0)+(0+-8*0)+(-1+9*-1)+(10+0*10)+(6+5*6)+(73*7)] = -8 = [(-2+14*-2),(0+2*0),(0+-8*0),(-1+9*-1),(10+0*10),(6+5*6),(73*7)] I1 I2 I3 J1 30 17 -2 J2 10 -1 0 J3 12 10 27 J4 47 9 5 30+10+12+47+17-1+10+9-2+0+27+5 = 164 17-1-2+0 = 14 Z-Scores P(-1≤z≤1) = .68 This is the probability lies in the middle 2 standard deviations of the distribution (-1,1) P(z≥4) = ~0 Look at the “smaller portion” column in z-table. P(-3.5≤z) = .0002 Look at the “smaller portion” column in z-table. P(-3.5≤z≥2.5) = 0.9997674 This can be obtained by taking the larger portion from the z table. P(-1≤z or z≥2) = .1587 + .0228 = .1815 This can be done by taking the right 50% of the distribution plus the “mean to z” column value. Or, you can just take the “larger value,” which is .9772 P(-1≥z or z≥-2) = P(-1≥z≥-2) The probability of z being between -1 and -2 This can be computed by taking the “mean to z” for each For -2 the mean to z is .4778, for -1 the mean to z is .3413 we can get the p-value by taking the difference between the two: .4778-.3414 = .1364 See the graph below: Report the p-value for the following: P(z≥1)= .1587 Look at the smaller portion. P(-1≤z≤2) Since this crosses the middle of the distribution we can take two mean to z values and add them: .34+.4772 = .8172 The average systolic blood pressure in the United States is 124 with a standard deviation of 16. My blood pressure is 155. Should I be concerned that my blood pressure is excessively high? Why or why not? z = (155-124)/16 = 1.9375 p = .0262 I am definitely concerned! (Not real data so I am really OK) At what point would my blood pressure be so I that I should begin worrying? Provide a real-world explanation. Using an alpha of .05, our critical value would be 1.65 sd’s and X=1.65*16+124 (x=z*sd+mu; reverse our standardization) X=150.4 Chi-Squares Psychopathology is reported to have the highest probability of manifestation between 15 and 25. I have collected a random sample of 100 undergraduates at Loyola. 7 persons meet criteria major depressive disorder, 2 persons meet criteria for schizophrenia, and 15 persons meet criteria for alcohol abuse. I want to know if my frequencies (or proportions) match those of the population with regard to these specific disorders: .04, .01, .05 respectively. What test should I use and why? Chi-square goodness of fit test should be used. We are only interested in one variable and want to see if our observed frequencies match with those theoretical expected values. Analyze these data and report the chi-square statistic and associated p-value. Major Dep. Schizophrenia Alcohol Abuse Observed 7 2 15 Expected .04*100 = 4 .01*100 = 1 .05*100 = 5 [(7-4)^2/4] + [(2-1)^2/1] + [(15-5)^2/5] = 23.25 df = k-1 = 3-1 = 2 p < .000001 (χ2(2) = 23.25, p < .05) What assumptions are we making with this test? Are you concerned any assumptions may be violated? Why or why not? We are assuming these data are independent, normally distributed. I get concerned about these data because I don’t know if some of these students met criteria for multiple disorders (e.g. alcohol abuse and depression). If that was the case and some of these cases were counted multiple times, we have violated the assumption of independence. I would also feel a lot better about these data if there were more observations in each of the cells and the expected values were higher for this sample; a bigger sample would help out here. For example, there were only 2 persons found who met criteria for schizophrenia. What if I know that there are expected differences between genders and the conditional distribution of each of these disorders? How would I test this – what test should be used? We would need to have a chi-square test of association to examine the relationship between these two variables. Analyze these data and report the expected values, chi-square statistic and p-value. Give a real world interpretation of the results. EXPECTED VALUES COMPUTED AND PLACED IN PARANTHESES Males Females Total MDD Schizophrenia Substance Abuse 11 [(14*15)/24] = (8.75) Total 2 [(14*7)/24] = (4.083333) 5 [(10*7)/24] = (2.916667) 7 1 [(14*2)/24] = (4.083333) 1 [(10*2)/24] = (0.8333333) 4 [(10*15)/24] = (6.25) 10 2 15 24 14 (OBSERVED-EXPECTED)^2/EXPECTED Males Females Total MDD Schizophrenia 1.062925 2.694403 7 2.328231 0.03333335 2 Substance Abuse 0.5785714 .81 15 Total 14 10 24 CHI-SQUARE = [(2-4.083333)^2/4.083333] + [(1-4.083333)^2/4.083333] + [(118.75)^2/8.75] + [(5-2.196667)^2/2.916667] + [(10.8333333)^2/0.8333333]+[(4-6.25)^2/6.25] = 7.507464 df = (3-1)*(2-1) = 2 p = 0.02 (χ2(2) = 7.507464, p < .05) Comment on the model assumptions and whether or not you think it is plausible that they were violated. We are assuming these data are independent, normally distributed. I get concerned about these data because I don’t know if some of these students met criteria for multiple disorders (e.g. alcohol abuse and depression). Adding the dimension of gender does not exacerbate this concern but it does thin out the cell frequencies even more. Notice that only 4/6 of the expected values are greater than 5. Compute an effect size of your choice for these data (the chisquare test of association). I am computing two different ones (note, you cannot compute phi for these data). C = sqrt(7.507464/(7.507464+24)) = .49 Phi_C = sqrt(7.507464/(24*(2-1))) = .55 This is a moderately large effect size! [New Wentworth Example] Wentworth has a propensity for jumping up on the kitchen table. While I was brainstorming solutions to this problem, I wondered if he is more likely to jump on the table after he was given catnip (maybe we should cut down on the catnip). I randomly chose 15 days in the month when I would give him some catnip and record whether or not he jumped on the table afterwards. On the other days, I observed his regular activity without giving him any catnip and recorded whether or not he jumped on the table. Here is what the data look like: Catnip Jump 11 Not Jump 4 No Catnip 8 7 Compute the odds ratio for this data and interpret. OR = (11*7)/(8*4) = 2.40625 The odds of Wentworth jumping on the table given he had catnip are 2.40625 (141%) times the odds of Wentworth jumping on the table given he did not have catnip. There is strong evidence of an association between catnip and Wentworth jumping on the table. Or… OR = (8*4)/(11*7) = 0.4155844 The odds of Wentworth jumping on the table given that he did not have any catnip are 0.4155844 (42%) times the odds of Wentworth jumping on the table given that Wentworth did have catnip. Compute the risk ratio for this data, interpret. Catnip Jump 11 Not Jump 4 Total 15 No Catnip Total 8 19 7 11 15 30 RiskCatnip = (11/15) = 0.7333333 RiskNoCatnip = (8/15) = 0.5333333 RR = .7333/.5333 = 1.375023 The risk of Wentworth jumping on the table given he had catnip are 1.37 (37%) times the risk of him jumping on the table given he did not have catnip. Two psychiatrists are conducting an epidemiological study of bipolar disorders. They are required to diagnose persons in the study has having bipolar I, bipolar II, or other. Both doctors rate all 37 individuals in the study. The following table provides their ratings. Compute Cohen’s Kappa and interpret its meaning for these data. Doctor 2 Doctor 1 Bipolar I Bipolar II Other Total Bipolar I 5 9 2 16 Bipolar II 8 7 1 16 Other 4 1 0 5 Total 17 17 3 37 Doctor 2 Bipolar I Doctor 1 Bipolar II Other Total Bipolar I 5 9 (7.351351) 2 16 Bipolar II 8 7 (7.351351) 1 16 Other 4 1 0 5 (0.4054054) Total 17 17 3 37 First compute the expected values (we are only interested in the diagonals) BP I = 16*17/37 = 7.351351 BP II = 16*17/37 = 7.351351 Other = 5*3/37 = 0.4054054 Compute K K = ((5+7+0)-(7.351351+7.351351+0.4054054))/(37(7.351351+7.351351+0.4054054)) = -0.1419753 A negative K indicates that the two doctors are agreeing less than chance would have predicted. Or, we could say these two doctors are disagreeing more than chance would have predicted. Substantively this means these two doctors are likely using different criteria in making these diagnoses. School district X collects test anxiety data on all if its 5000 students. A teacher in that school is interested in knowing how his students compare to the whole district in terms of test anxiety. The mean and sd of the district are 25 and 15 respectively. The teacher’s classroom mean test anxiety score is 19 for his 33 students. What are the null and alternative hypotheses? H0: Mean(classroom) = Mean(District) (The teacher’s classroom is no different than the district) H1: Mean(Classroom) ≠ Mean(District) (The teacher’s classroom is different than the district) Given the information provided, what test should you use, why? Since the population parameters are known, we can simply use a Z-test for this problem. Conduct the analysis and interpret the results. We want the difference between the population and sample means. Z = (19-25)/(15/sqrt(33)) = -2.297825 P = .011 Based on this test statistic I would reject the null hypothesis that these two groups (classroom and district) are equal and say that the mean test anxiety for this teacher’s classroom is significantly less than the mean of the district. Suppose this teacher was still not satisfied and decided he wanted to lower his student’s test anxiety even further. He heard about applied relaxation training at a conference he recently attended. His student’s test anxiety was measured at the beginning of the school year (where the mean was 19). He will implement his intervention for 2 months and measure his students’ anxiety again in order to see if their anxiety lowered even further. The mean difference (time1-time2) and sd of the mean difference are 1.25 and 1.07 respectively. What are the null and alternative hypotheses? H0: Mean(time1) = Mean(time2) (There is no difference between time 1 (pretest) and time 2 (posttest) – no evidence of a treatment effect.) H1: Mean(time1) ≠ Mean(time2) (The mean level of test anxiety at time 2 is less than time 1 (before the treatment was implemented)) NOTE: I have specified a non-directional two-tailed hypothesis test but you could make an argument here for a one-tailed (directional) test if you are only interested in know if there is improvement in test scores. Remember that the two-tailed test is more conservative. What test would be most appropriate to answer this teacher’s question? This is a dependent sample since the same students are being measured multiple times and being compared to themselves. We would want to use a dependent samples t-test. Conduct the analysis and interpret the results. t = (1.25-0)/(1.07/sqrt(33)) = 6.710938 df = 32 p < .0001 Based on this test statistic I would reject the null hypothesis that the two testing times are equal. There is some evidence of a treatment effect based on these data. Suppose this same teacher had an end-year goal of getting his students mean test anxiety score down to 16.5 and their actual end-of-year score was 17.93 (sd=12). How could this teacher examine whether or not he may have met his goal? How can he test the difference between his observed mean and his goal mean for statistical significance? The teacher could use a one-sample t-test comparing the observed mean of 17.93 with the theoretical (goal) mean of 16.5. What are the null and alternative hypotheses? H0: mean(observed) = mean(theoretical) H1: mean(observed) ≠ mean(theoretical) Conduct the analysis and interpret the results. t = (17.93-16.5)/(12/sqrt(33)) df = 32 p = .25 Based on these data I would retain the null hypothesis that the theoretical mean and the observed mean are equal. This teacher should be reasonably pleased with his results – 16.5 is just as plausible as 17.93 to be the true end-year value of test anxiety. Some practice from the book # 7.6 x<-c(40,58,72,73,76,78,52,72,84,70,72) t.test(x,mu=50) # One Sample t-test #data: x #t = 4.6426, df = 10, p-value = 0.0009184 #alternative hypothesis: true mean is not equal to 50 #95 percent confidence interval: # 59.31385 76.50433 #sample estimates: #mean of x # 67.90909 #Or... t<-(mean(x)-50)/(sd(x)/sqrt(length(x))) t # [1] 4.642561 1-pt(t,length(x)-1) # [1] 0.0004592003 # 7.7 # 7.7 One could argue a one-tailed test is appropriate because #the # researcher may only be interested in whether the students are # "greater than" the average and does not care whether or not they # are less than average. # 7.10 (applied to 7.6) CI.U<-mean(x)+(sd(x)/sqrt(length(x)))*2.228 CI.L<-mean(x)-(sd(x)/sqrt(length(x)))*2.228 # 7.16 # (tx1 = 12 hours before surgery) # (tx2 = 10 minutes before surgery) tx1<c(10,6.5,8,12,5,11.5,5,3.5,7.5,5.8,4.7,8,7,17,8.8,17,15,4.4,2) tx2<c(6.5,14,13.5,18,14.5,9,18,42,7.5,6,25,12,52,20,16,15,11.5,2.5,2 ) t.test(tx1,tx2,paired=T) # Paired t-test # data: tx1 and tx2 # t = -2.4827, df = 18, p-value = 0.02313 # alternative hypothesis: true difference in means is not equal to 0 # 95 percent confidence interval: # -14.216028 -1.183972 # sample estimates: # mean of the differences -7.7 # Endorphin levels are significantly higher at 10 minutes prior # to surgery. # 7.17 We use a dependent samples test because we are comparing two # observations (different times) from the same set of individuals. # 7.18 SE<-sqrt(var(tx1-tx2)) CI.L = -7.7 - 2.110*13.51916/sqrt(19) CI.U = -7.7 + 2.110*13.51916/sqrt(19) The distributions above were drawn from the same population. Use what you know about the central limit theorem to explain what you see. The four distributions above share the same mean (50) but their variance are clearly different. The first graph is the widest, indicating that the distribution of sample means must be repeated draws of small sample sizes. The last one is very thin (low variance) indicating that it must be a sampling distribution of large sample sizes (relative to the other three). True/False – Explain your answers As alpha increase so does statistical power____T_____ As we increase alpha our type II error rate will fall. That is to say that we will be less strict about determining statistical significance and will be rejecting the null more often (but making more type I errors). If a research finding shows a strong effect (association or difference) one can also expect to have a large type II error probability ____F______ The larger the effect, the more likely one will correctly reject the null hypothesis (i.e. the conclusion is more clear the larger the effect size). An effect size of .8 (from a two-independent samples t-test) will always mean the test has strong statistical power____F_____ All things being equal, yes, a .8 effect size will have more power than a smaller effect size. However, it is possible that statistical assumptions were violated in the process thus reducing its power. It is also possible that the sample is small, making it less likely to reject the null hypothesis than perhaps smaller effect sizes. One way for me to boost power is to collect more data_____T_____ Increasing the sample size is the best way for a researcher to boost power. I carried out a program evaluation of a school district’s new after school program to prevent truancy. There were 500 students who participated in the program and 488 who were evaluated but did not participate in the program. The mean levels of truancy for the experimental group and control group were 17.58 (sd=5.1) and 21.2 (sd=4.3) respectively. What test should be used? Two-independent samples t-test. Compute the test statistic and effect size for this data. Sp2=((500-1)*5.1^2+(488-1)*4.3^2)/(500+488-2) = 22.29576 t=( 22.29576-17.58)/sqrt((22.29576/500)+( 22.29576/488)) = 15.69484 df=500+488-2 = 986 tc = 1.96 I would reject the null hypothesis that the experimental and control group are equal in their levels of truancy after the program implementation. Conduct a power analysis and interpret the results. nh = 2*500*488/(500+488) = 494 d = (21.2-17.58)/ 22.81703 = 0.1586534 delta = 0.1586534*sqrt(494/2) = 2.49 power ≈ .71 using a two-tailed alpha of .05 The following is output from a regression analysis. I am predicting cultural trauma with age. Interpret the results. ################################################################ Call: lm(formula = trauma ~ age) Residuals: Min 1Q -2.65410 -0.62412 Median 0.01143 3Q 0.63711 Max 2.97065 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 18.53400 0.61876 29.95 <2e-16 *** age 0.32573 0.03083 10.57 <2e-16 *** --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.9681 on 998 degrees of freedom Multiple R-squared: 0.1006, Adjusted R-squared: 0.09972 F-statistic: 111.7 on 1 and 998 DF, p-value: < 2.2e-16 ################################################################ This analysis shows a significantly strong relationship between age and cultural trauma (b=.32, p<.05). For each year increase in age there is a .32 unit increase in cultural trauma. R2adj = .09972 indicating roughly 9% of the variance in cultural trauma is accounted for by age. The overall model is significant (F=111.7, p<.05) and the RMSE=.9681 indicating adequate model quality. Write the regression equation. Predict someone’s level of cultural trauma when they are 15 years old. Say their actual score was 20, what is the error (or residual)? For the same output above, manually reproduce the intercept and slope parameter estimates. r = .32 Mean SD Age 20.04793 0.993616 Trauma 25.06418 1.020315 r = .32 N = 1000 sxy = .32*0.993616*1.020315 = 0.3244164 b = 0.3244164/ 0.993616^2 = 0.3285925 a = 25.06418 - 0.3285925*20.04793 = 18.47658 Manually test the statistical significance of the slope estimate you reproduced. sb = 0.9681/(0.993616*sqrt(1000-1)) = 0.03082612 t = (0.32441640)/0.03082612 = 10.52 tc = 1.96 We would reject the null hypothesis that b=0. Perhaps I am interested in knowing whether or not males and females significantly differ in their levels of cultural trauma. I conduct a t-test in R. Show me how to manually produce the ttest results below. The sd for males (0) is 1.03 and the sd for females (1) is 1.02. Two Sample t-test data: cultural trauma by gender t = 1.0073, df = 998, p-value = 0.314 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.06132259 0.19068238 sample estimates: mean in males (group 0) mean in females (group 1) 25.03901 24.97433 t = (24.97433-25.03901)/((1.03^2+1.02^2)/2) = -0.06156189 df = 998 tc = 1.96 My recalculation of the output confirms that we should retain the null hypothesis that males and females are equal in their levels of cultural trauma. Based on the following information about cultural trauma and age, compute the covariance estimate. Mean SD Age 20.04793 0.993616 Trauma 25.06418 1.020315 r = .32 N = 1000 sxy = .32*0.993616*1.020315 = 0.3244164 Compute the adjusted correlation (radj) for these data and compare it to r. radj = sqrt(1-(((1-.32^2)*(1000-1))/998)) = 0.3185916 [NOT MUCH DIFFERENT THAN r]