Chapter 2 Course Notes
advertisement

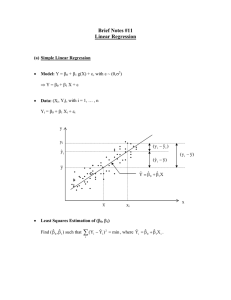
Inference in Simple Linear
Regression
KNNL – Chapter 2
Least Squares Estimate of b1
Note the following results:
n
X
n
i 1
n
i 1
i
n
n
n
X Xi X Xi nX Xi n
Xi X
i 1
2
n
i 1
i 1
i 1
n
n
b1
XY
i i
X
i 1
n
i 1
n
i
n
n
Xi Xi 0
i 1
i 1
n
n
i 1
i 1
X i2 X 2 X i X X i2 n X 2 X X i X i2 n X 2n X
2
n
Xi
n
n
2
X i2 n X X i2 n i 1
n
i 1
i 1
i 1
n
i 1
2
2
2
n
X
i
n
n
i 1
2
Xi
Xi X Xi
n
i 1
i 1
2
n
X Y
i 1
2
i
i
i 1
n
n
X
i
n
2
X i i 1
n
i 1
X X
where: ki i
SS XX
2
X
n
i 1
i
X Yi Y
X
n
i 1
n
Note: ki 0
i 1
i
X
n
2
n
1 n
n
X i X kiYi
X i X Yi Y
SS XX i 1
i 1
i 1
n
ki X i
i 1
i 1
X
i
X Xi
SS XX
n
1
1 k 2
SS XX
i 1
2
i
X
n
i 1
i X
2
SS XX
1
2
SS XX
SS XX
Sampling Distribution of b1 – Normal Error Model
Note the following results assuming independent Normal Random Variables:
Y1 ,..., Yn ~ N i ,
2
i
U aiYi ~ N U , U2
n
where:
i 1
n
n
U E U ai i
U ai2 i2
2
U
i 1
2
i 1
Simple linear regression model with normal and independent errors:
Yi ~ N b 0 b1 X i , 2
n
b1 kiYi
i 1
X X
where: ki i
SS XX
n
with: ki 0
i 1
n
n
n
i 1
i 1
i 1
n
ki X i 1
i 1
n
2
k
i
i 1
1
SS XX
b1 E b1 ki b 0 b1 X i b 0 ki b1 ki X i b 0 (0) b1 (1) b1
2
b1 k k
b1 ~ N b1 ,
SS
SS
i 1
i 1
XX
XX
s2
MSE
2
2
2
In practice unknown sb1 s b1
SS XX SS XX
n
2
b1
2
n
2
i
2
i
2
2
i
2
Sampling Distribution of (b1-b1)/s{b1}
2
b1 ~ N b1 ,
SS XX
b1 b1
2 SS XX
n 2 s 2 n 2 MSE ~ 2
2
2
n2
b1 b1
~ N 0,1
b1
b b
also: 1 1 and
b1
b b
b1 b1
1
1
2
SS XX
SS XX b1 b1
2
s
SS XX
n 2 s n 2
2
n 2 s2
2
independent
b1 b1
s s SS XX
b1 b1
Pr t / 2; n 2
t 1 / 2 ; n 2 1
s b1
b1 b1
Pr t 1 / 2 ; n 2
t 1 / 2 ; n 2 1
s SS XX
b1 b1
~ t n 2
s b1
(1-)100% Confidence Interval for b1
b1 b1
~ t n 2
s b1
s
SS XX
s b1
b1 b1
Pr t n 2;1 / 2
t n 2;1 / 2 1
s b1
Pr b t n 2;1 / 2 s b b b t n 2;1 / 2 s b 1
Pr b t n 2;1 / 2 s b b b t n 2;1 / 2 s b 1
Pr t n 2;1 / 2 s b1 b1 b1 t n 2;1 / 2 s b1 1
1
1
1
1
1
1
1
1
1
1
1 100% Confidence Interval for b1 b1 t n 2;1 / 2 s b1
Test of Hypothesis for b1
2-sided test: H 0 : b1 b10
Test Statistic: t*
b1 b10
s b1
H A : b1 b10
(Almost always b10 0)
Note: if b10 0 t*
b1
s b1
Decision Rule: t * t n 2;1 / 2 Reject H 0 otherwise Fail to Reject
P-value: 2Pr t n 2 t *
Upper-tail test: H 0 : b1 b10
H A : b1 b10
Decision Rule: t* t n 2;1 Reject H 0 otherwise Fail to Reject
P-value: Pr t n 2 t *
Lower-tail test: H 0 : b1 b10
H A : b1 b10
Decision Rule: t* t n 2;1 Reject H 0 otherwise Fail to Reject
P-value: Pr t n 2 t *
Inference Concerning b0
n
b0 Y b1 X
X
n
1
where: Y Yi
i 1 n
and b1
i
X
SS XX
i 1
Y
i
b Y b X Y X b 2 X Y , b
1
X X
1 X X
Aside: Y , b Y ,
Y
n
SS
n SS
E b0 E Y b1 X b 0 b1 X b1 X b 0
2
2
2
2
0
2
1
1
n
1
2 b0 2
n
i 1
i
n
i
i 1
i
XX
2
1
X
Y X 2 b1 2
n SS XX
2
2
1
X
b0 ~ N b 0 , 2
n SS XX
1
i 1
i
XX
2
0
2
2
1
1
X
X
Estimated Standard Error: s b0 s
MSE
n SS XX
n SS XX
b0 b 0
~ t n 2 1 100% CI for b 0 b0 t n 2;1 / 2 s b0
s b0
Test Statistic for testing H 0 : b 0 b 00
H A : b 0 b 00 : t*
b0 b 00
s b0
Reject H 0 if t * t n 2;1 / 2
Interval Estimation of E{Yh} = b0+b1Xh
Goal:Estimate population mean when X X h :
Parameter: E Yh b 0 b1 X h
^
Estimator: Y h b0 b1 X h Y b1 X b1 X h Y b1 X h X
^
E Y h b 0 b1 X h
^
Yh
2
2
n
X
^
s Yh s
h
2
Y b1 X h X
X
2
SS XX
1 X
n
1 100%
Y b X
2
1
Xh X
21
n
SS XX
2
h X
SS XX
2
2
2
h X
Xh X
1
MSE
n
SS XX
Y X
2
Note: Y , b1 0
2
CI for E Yh b 0 b1 X h : Y h t n 2;1 / 2 s Y h
^
^
h X
2
2
b1
Prediction Interval forYh(new) when X=Xh
Goal: Predict a new (future) observation when X X h :
Target: Yh (new) b 0 b1 X h + (new)
^
Prediction: Y h b0 b1 X h
^
Prediction Error: Yh (new) Y h
2 pred 2 Yh (new) Y h 2 Yh (new) 2 Y h
^
Xh X
1
2
1
n
SS XX
s pred s
1 100%
2
1 X
1
n
^
h X
SS XX
^
Xh X
2
21
n
SS XX
2
Note: Yh (new) , Y h 0
2
Xh X
1
MSE 1
n
SS XX
2
Prediction Interval for Yh (new) : Y h t n 2;1 / 2 s pred
^
Confidence Band for Regression Line
Goal:Simultaneously Estimate population mean for all X values (not extrapolating) :
Parameter: E Yh b 0 b1 X h
^
Estimator: Y h b0 b1 X h Y b1 X b1 X h Y b1 X h X
^
E Y h b 0 b1 X h
^
2
Yh
^
s Yh
Xh X
21
n
SS XX
Xh X
1
s
n
SS XX
1 100%
2
2
Xh X
1
MSE
n
SS XX
^
2
^
CI for E Yh b 0 b1 X h : Y h Ws Y h
W 2 F 1 ; 2, n 2
This can be used for any number of specific X levels, simultaneously
Analysis of Variance Approach to Regression
Deviation of ith observation from the Mean: Yi Y
n
Total Sum of Squares: SSTO Yi Y
i 1
2
^
Deviation of i observation from the Regression Line: Yi Y i
th
Error Sum of Squares: SSE Yi Y i
i 1
n
^
2
^
Deviation of i fitted value from the Mean: Y i Y
th
Regression Sum of Squares: SSR Y i Y
i 1
n
^
2
Total Deviations (Data from Mean)
600
500
Y
400
Y
300
Yhat
Ybar
200
100
0
0
20
40
60
80
X
100
120
140
Deviations (Data - Fitted Values)
600
500
Y
400
300
Y
Yhat
200
100
0
0
20
40
60
80
X
100
120
140
Deviations (Fitted Values - Mean)
600
500
Y
400
300
Yhat
Ybar
200
100
0
0
20
40
60
80
X
100
120
140
ANOVA Partitioning - I
^
^
Yi Y Yi Y i Y i Y
Y Y
2
i
2
2
^
^
Yi Y i Y i Y 2 Yi Y i Y i Y
^
^
2
2
^
^
Yi Y Y i Y Yi Y i 2 Yi Y i Y i Y
i 1
i 1
i 1
i 1
Note(from normal equations, Chapter 1, Slide 5):
n
2
n
^
n
^
n
^
^
^
^
Yi Y i Y i Y ei Y i Y ei Y i Y ei 0 0 0
i 1
i 1
i 1
i 1
n
n
n
2
Y i Y Yi Y i
i 1
i 1
i 1
SSTO SSR SSE
n
Yi Y
2
n
^
n
^
n
2
ANOVA Partitioning
Note useful result regarding SSR :
2
SSR Y i Y b0 b1 X i Y
i 1
i 1
n
n
^
b1 X i b1 X
i 1
2
n
b
2
1
X
n
i 1
i X
2
Y b X b X Y
2
n
i 1
1
1
i
2
b12 SS XX
Degrees of Freedom associated with each sum of squares:
n
Total: SSTO Yi Y
i 1
^
Error: SSE Yi Y i
i 1
n
2
df TO = n 1 (One parameter estimated)
2
df E n 2 (Two parameters estimated)
2
^
Regression: SSR Y i Y df R 2 1 1
i 1
(Fitted equation has 2 parameters, mean removes 1)
n
df TO =df R df E
Note: Mean Squares are Sums of Squares divided by degrees of freedom
Analysis of Variance Table
Source
SS
^
Regression Y i Y
i 1
n
Error
^
Y
Y
i
i
i 1
Total
Y Y
E{MS }
1
SSR
MSR
1
b
2
n 2 MSE
2
2
2
1
X
n
i 1
i
X
2
SSE
2
n2
n 1
i
i 1
MS
2
n
n
df
Note:
SSE
2
SSE
SSE
2
~ n 2 E 2 n 2 E
E MSE
n 2
2
MSR SSR b
2
1
SS XX
n
i 1
Xi X
2
E MSR SS XX E b12 SS XX 2 b1 E b1
n
2
2
2
2
b1 b1 X i X
SS
i 1
XX
2
2
F-Test for H0:b1=0 vs HA:b1≠0
H 0 : b1 0 H A : b1 0
Test Statistic: F *
MSR
MSE
Reject H 0 if F * F 1 ;1, n 2
*
Reject H 0 for large F since
E MSR
E MSE
b
2
2
1
X
n
i 1
i
X
(See below for why)
2
2
Sampling Distribution of F * Under H 0 : b1 0 (Cochran's Theorem, p. 70):
1) SSR SSE SSTO
2)
SSE
2
~ 2 n 2
df R df E 1 (n 2) n 1 dfTO
SSR
2
~ 2 1
SSE SSR
, 2 independent
2
2
1 1
*
3) F 2
~ F 1, n 2
n 2 n 2
SSR
2 1
MSR
F*
~ F 1, n 2
SSE
MSE
2 n 2
Comments on F-Test
1)
2)
SSE
~ 2 n 2 regardless of whether or not b1 0, when b1 0 :
2
SSR
2
~ non-central 2 1
SSE SSR
, 2 independent regardless
2
SSR
2 1
MSR
3)
F*
~ non-central F 1, n 2
SSE
MSE
n
2
2
4) F-test and t-test are equivalent for H 0 : b1 0 H A : b1 0 :
SSR 1
2
b1
b SS XX
b
b
*
F
2
t*
MSE
SSE n 2
MSE SS XX s b1 s b1
2
1
2
1
2
1
2
Critical Value for F * F 1 ;1, n 2 t 1 2; n 2 Critical Value for t *
2
General Linear Test – Very Flexible Method
1) Fit the Full/Unrestricted Model (No restrictions on b 0 , b1
^
Compute b1 , b0 by least squares and Y i F b0 b1 X i
2
^
Error sum of squares for Full Model: SSE F Yi Y i F df F n 2
i 1
2) Fit the Reduced/Restricted Model (Restriction(s) on b 0 , and/or b1
n
H 0 : b 0 b 00 and/or b1 b10
^
Estimate any unspecified parameters by least squares with restriction(s) and obtain Y i R
^
Error sum of squares for Reduced Model: SSE R Yi Y i R
i 1
n
df R n (# of unrestricted b s
SSE ( R) SSE ( F ) df R df F
3) Compute Test Statistic: F
SSE ( F ) df F
*
4) Reject H 0 if F * F 1 ; df R df F , df F
2
Example 1 – H0: b1 = 0
SS XY
SS XX
Full (Unrestricted) Model: b1
b0 Y b1 X
2
^
Y i F b0 b1 X i SSE F Yi Y i F SSE df F n 2
i 1
n
^
Reduced (Restricted) Model: b1 b1 0 b0 Y b1 X Y
^
Y i R b0 (0) X i Y
2
SSE R Yi Y i R Yi Y
i 1
i 1
n
^
n
2
SSTO df R n 1 (only 1 "free" parameter: b 0
SSE ( R) SSE ( F ) df R df F SSTO SSE (n 1) (n 2)
Test Statistic: F
SSE n 2
SSE ( F ) df F
*
SSR 1 MSR = F *
SSE n 2 MSE
Reject H 0 if F * F 1 ;1, n 2
(The ANOVA F -test)
Descriptive Measures of Linear Association
Coefficient of Determination (Proportionate Reduction in Error):
^
Ignoring Predictor (Setting b1 0) : Y i Y
"Error SS" = SSTO
^
Accounting for Predictor: Y i b0 b1 X i
"Error SS" = SSE
Difference: Portion "accounted" by X : SSTO SSE SSR
R2
SSR
SSE
1
SSTO
SSTO
0 R2 1
Note: See plots on slides 12-14
Coefficient of Correlation (Often used when both X and Y are random):
r R2
SS XY
SS XX SSYY
1 r 1
1) r and b1 are of the same sign
2) r (but not b1 ) is not changed by linear transformations of Y and/or X
Correlation Models – Y1,Y2 Bivariate Normal
Y1 , Y2
2 Characteristics (Random) observed on Experimental Unit
Joint Density (at specific pairs of values y1 , y2 ) :
f y1 , y2
1
2 1 2
1
exp
2
1 122
2 1 12
where 12 is the correlation between Y1 , Y2
2
y 2
y
y
y
1
1
1
1
2
2
2
2
2 12
1
1
2
2
12
12
1 2
12 Y1 , Y2 E Y1 1 Y2 2
Marginal Densities:
f1 y1
1 y 2
1
f y1 , y2 dy2
exp 1 1 Y1 ~ N 1 , 12
2 1
2 1
Conditional Densities Y1 | Y2 y2 &
f y1 | y2
f y1 , y2
f 2 y2
where: 1|2 1 2 12
1
2
1
2 1|2
Y2 ~ N 2 , 22
Y2 | Y1 y1
1 y b y 2
12 2
exp 1 1|2
2
1|2
b12 12
1
2
1|22 12 1 122
2
Y1 | Y2 y2 ~ N 1 12 1 y2 2 , 12 1 122 N 1|2 b12 y2 , 1|2
2
Inferences on Correlation Coefficients
Parameter: 12
Y1 , Y2
12
Y1 Y2 1 2
Point (maximum likelihood) Estimator (aka Pearson product-moment correlation coefficient):
X
n
r12
i 1
X
n
i 1
i
i
X Yi Y
X
Y Y
2 n
i 1
2
SS XY
SS XX SSYY
1 r12 1
i
Testing H 0 : 12 0 vs H A : 12 0 :
r12 n 2
Test Statistic:
t*
Reject H 0 if
t * t 1 2 ; n 2
1 r122
For 1-sided tests:
H A : 12 0 : Reject H 0 if t * t 1 ; n 2
H A : 12 0 : Reject H 0 if t * t 1 ; n 2
This test is mathematically equivalent to t-test for H 0 : b1 0
Confidence Interval for 12
Problem: When 12 0, sampling distribution of r12 is messy
1 1 r12
Fisher's z transformation: z ' ln
2 1 r12
1
For large n (typically at least 25): z ' ~ N ,
n
3
approx
1 1 12
ln
2 1 12
Compute an approximate 1 100% CI for and transform back for :
1 100% CI for :
z ' z 1 2
1
n3
e 2 1
After computing CI for , use identity 12 2
e 1
Spearman Rank Correlation Coefficient
When data are not normal, and no transformations are normal:
Spearman's Rank Correlation Method:
1) Rank Y11 ,..., Yn1 from 1 to n (smallest to largest) and label: R11 ,..., Rn1
2) Rank Y12 ,..., Yn 2 from 1 to n (smallest to largest) and label: R12 ,..., Rn 2
3) Compute Spearman's rank correlation coefficient:
R
n
rS
i1
i 1
R
n
i 1
i1
R1 Ri 2 R 2
R1
R
2 n
i 1
i2
R2
2
To Test: H 0 : No Association Between Y1 , Y2 vs H A : Association Exists
Test Statistic: t
*
rS n 2
1 rS2
Reject H 0 if t * t 1 2 ; n 2