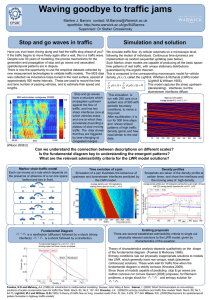
What Does Physics Bias: A Comparison of Model Priors for... Jonathan Scholz and Martin Levihn and Charles L. Isbell
advertisement

What Does Physics Bias: A Comparison of Model Priors for Robot Manipulation
Jonathan Scholz and Martin Levihn and Charles L. Isbell
Robotics and Intelligent Machines, Georgia Institute of Technology
2. GenPhys Overview
N
(φi)i=1
Let Φ =
denote a full assignment to the relevant physical
parameters for all N objects. The GenPhys transition model is:
st+1 = f (st, at; Φ̃) + ,
2
∼ N(0, σ )
π(s)
(1)
Φ
We place priors on components of Φ, e.g.:
Parameter
Distribution
mass m
log Normal(µm, σm2 )
2
friction µ truncated Normal(µf , σf , af , bf )
I We use MCMC to estimate Φ from observation history h:
I
f (s, a; Φ̃)
g(s; Γ)
P(h|Φ, σ) =
=
n
Y
t=1
n
Y
t=1
I
0
P(st|Φ, σ, st, at)
1
√ exp
σ 2π
0
−(st
− f (st, at; Φ̃))
2σ 2
2
∼ π(st)
∼ P(st+1|st, at)
Transitions sampled from model posterior:
∗
I
Effect of Sample Bias
!
I
LWR appears sensitive to online sample bias
I
Confirmed by testing maximum reward vs.
True-Model agent averaged over 20 episodes:
Max Reward
Online
Unbiased
LWR (p = 2.54E − 20) (p = 0.05)
Phys
(p = 0.30)
(p = 0.26)
LWR Online
LWR Unbiased
GenPhys Online
GenPhys Unbiased
1200
−2
−4
6
−6
∗
True Model
GenPhys
LWR
LR
This representation can simulate pushing tasks
with hinged or furniture-like objects:
0
500
1000
Time
1500
2000
−8
True Model
GenPhys
LWR
LR
0
200
400
600
800
1000
Time
Phys > LWR > LR on low-dimensional problem
I GenPhys scales to high-dimensional problems, but LWR
diverges for practical horizons
I Unstable performance observed for regression-based agents,
due to model inaccuracies
I
(b) Living Room
(c) Pendulum
7. Conclusion
Compared max reward over 50 steps using
online vs. unbiased training sets
800
4
φ := {m} ∪ {Jd } ∪ {Jw}
(a) Cart
400
2
Overall, the parameters φ for single body are
defined as the set:
Φ, σ ∼
P(Φ, σ|h)
2
∼
N(0, σ )
st+1 = f (st, at; Φ̃) + 6. Bias and Generalization
I
1. Distance: Jd = {a, b, ax, ay, bx, by}
2. Anisotropic friction: Jw = {x, y, θ, µx, µy}
I
Online Performance: Multiple Bodies
−10
I
Online Performance: Single Body
−2
Used Eq. 2 for unnormalized density p(x), and a
multi-variate Gaussian for proposal q(y|x)
I Likelihood evaluated on a Gaussian centered at
prediction from Eq. 1:
(
n
X
a
0
V(s) =
R(s, a) + γ max
V(s
)
0
s0
s
i=1
Compared with Linear (LR) & Locally-Weighted (LWR)
−4
p(y)q(y|x)
P(θt+1 = y|θt = x) = min
,1
p(x)q(x|y)
GenPhys compatible with Model-based
Monte-Carlo (“Sparse-Sampling”):
Example Parametrization
I Implemented GenPhys prior with mass and 2
constraints:
I
Reward
Φ̃
ot+1
5. Online Performance
Planning with a stochastic-physics model
I
g(s; Γ)
Figure : GP model in terms of state st, observation ot, and action at. Latent variables Γ
(appearance) and Φ (dynamics) parameterize time-series, with Γ and s assumed to be
observable. Φ̃ denotes set of all dynamics-related parameters.
4. GenPhys: Generative Physics-Based Model Prior
Model Inference
I Defined MCMC algorithm for inference on Φ:
mass
mesh geometry color
friction
collision shapes textures
velocity constraints
...
...
...
st+1
st
ot
(2)
Γ
π(s)
Γ
P(Φ, σ|h) ∝ P(h|Φ, σ)P(Φ)P(σ)
Φ
−12
Main idea:
We formalize object manipulation as
a Bayesian Reinforcement Learning problem,
and introduce a physics-based model prior.
at+1
at
−14
I
Log−Reward
Motivation:
We are interested in robot manipulation in
uncertain environments. Robots need to learn
object dynamics quickly to be useful. However
data is expensive to acquire, and is biased by
the robot’s current knowledge and abilities.
3. Assumptions of the GenPhys Graphical Model
0
1. Introduction
1600
2000
Number of Pretrain Samples
http://www.robotics.gatech.edu/
Figure : Max reward vs. True model for priors
(LWR,GenPhys) and conditions (online,unbiased).
Interaction between model and cond. significant
(p = 1.8E − 8, df = 19).
We presented a novel approach to robot manipulation using
I Example of generalization for a situated agent:
physics-based Bayesian Reinforcement Learning, and
compared it to traditional regression-based alternatives. Our
results confirm that this inductive bias can make both
quantitative and qualitative differences in the performance for
online
learning
scenarios.
(a)
(b)
(c)
(d)
Figure : (a) Initial configuration (b) Expected outcome: table Future Work
I Implement gradient-based MCMC methods for faster GenPhys
has lower mass and offers lowest-cost manipulation plan.
(c) Actual behavior: table rotates in place. Robot updates
inference
beliefs to reflect high probability of revolute constraint. (d)
I Combine GenPhys and Gaussian-Process Regression into
Based on the new information the robot decides to move
single
generative
model
for
robustness
to
unmodelled
effects
the couch.
{jkscholz,levihn,isbell}@gatech.edu