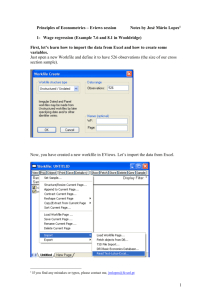
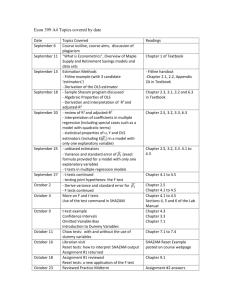
Lecture 18: Heteroskedasticity BUEC 333 Professor David Jacks
advertisement

Lecture 18: Heteroskedasticity BUEC 333 Professor David Jacks 1 Three assumptions necessary for unbiasedness: 1.) correct specification; 2.) zero mean error term; 3.) exogeneity of independent variables. Three assumptions necessary for efficiency: 4.) no perfect collinearity; 5.) no serial correlation; 6.) homoskedasticity. Violatin’ the classical assumptions 2 Since heteroskedasticity (SC) violates 6.) and this implies that OLS is not BLUE, we want to know: 1.) What is the nature of the problem? 2.) What are the consequence of the problem? 3.) How is the problem diagnosed? 4.) What remedies for the problem are available? We now consider these in turn… Violatin’ the classical assumptions 3 Recall what homoskedasticity actually refers to: all error terms have the same variance; that is, Var(εi) = σ2 for all i = 1, 2, 3,…, n. Heteroskedasticity occurs when different observations’ error terms (εi) have different values for their variances; that is, Var(εi) = σi2. Heteroskedasticity 4 Heteroskedasticity most often occurs in crosssectional (CS) data, but is also present in TS data. CS data: data where observations are for the same time periods (e.g., a particular day, month, or year) but are for different observational units (e.g., countries, firms, individuals, or provinces). Heteroskedasticity 5 This also suggest that when modeling salaries, a $1 million error for Jaromir Jagr (who earned $10.3 million that year) is “small.” But a $1 million error is huge for someone like Brent Sopel (who earned $226,050). We might then expect players who played many games and who scored many points to have larger salary Heteroskedasticity 6 Just as in the case of SC, there are two basic types of heteroskedasticity: pure and impure. Pure heteroskedasticity arises if the model is correctly specified, but the errors themselves are heteroskedastic. Example: the true DGP is Yi = β0 + β1X1i + εi and we estimate a univariate regression model accordingly Pure heteroskedasticity 7 Not surprisingly, there are many ways to characterize the heteroskedastic variance term, σi2. Simplest specification: discrete heteroskedasiticity Pure heteroskedasticity 8 A more common specification is to assume that the error variance is proportional to variable Z which may or may not be one of the included independent variables. In this case, Var(εi) = σi2 = σ2 Zi2 with each observation’s error being drawn from its own distribution with zero mean and variance σ2 Zi2. Pure heteroskedasticity 9 Pure heteroskedasticity 10 Pure heteroskedasticity 11 Just like impure SC, impure heteroskedasticity can arise if the model is mis-specified, and the specification error induces heteroskedasticity. For example, suppose the DGP is Yi 0 1 X 1i 2 X 2i i Instead, we estimate Yi 0 1 X 1i where: 1.) i* 2 X 2i i 2.) i is a classical error term, but X 2i has a * i Impure heteroskedasticity via omitted variables 12 Both forms of heteroskedasticity violate Assumption 6 of the CLRM, and hence OLS is not the BLUE. What more can we say? 1.) OLS estimates remain unbiased…but only if the problem is with pure heteroskedasticity. Consequences of heteroskedasticity 13 OLS estimates, however, will be biased if the problem is with impure heteroskedasticity brought about by correlated omitted variables. Impure heteroskedasticity represents violation of Assumption 1. In this case, the heteroskedasticity problem is of secondary importance Consequences of heteroskedasticity 14 2.) Even if unbiased, the sampling variance of the OLS estimator is inflated. OLS may attribute systematic variation in the dependent variable to the independent variables, even though this is really due to the error term. Because positive “mistakes” of this kind are as likely as negative ones, the estimator remains Consequences of heteroskedasticity 15 3.) Because of #2 above, the estimated value of the sampling variance—and consequently, the calculated standard error—is wrong. By not accounting for this extra sampling variation, we get a skewed sense of how spread out our OLS estimates really are. Generally speaking, this works in the direction of OLS providing us with a sense of “too much” Consequences of heteroskedasticity 16 Many formal tests available which make assumptions about the particular form of the heteroskedasticity. But even before proceeding along these lines, we should think hard about possible omitted variables as possible source of apparent heteroskedasticity. We should also make a habit of always looking at Testing for heteroskedasticity 17 Of the tests available, by far the most useful is the White test. Its usefulness is derived from its generality: it is designed to test for heteroskedasticity of an unknown form Its generality also explains its popularity: this is has been the standard for statistical packages (including Eviews) for the past 30 years. The White test for heteroskedasticity 18 We can think of the White test as being composed of three steps: 1.) Estimate a regression model of interest, call this Equation 1, and collect the residuals. Suppose our population regression model is: Equation 1: Yi 0 1 X 1i 2 X 2i i We will then estimate the following: The White test for heteroskedasticity 19 2.) Now, calculate the squared residuals. Run an auxiliary regression (Equation 2 ) of the squared residuals on the original independent variables, their squared terms, and their cross products (implies hetero. can depend in very general ways on all of the variables in our model). In our example, Equation 2 is: ei2 0 1 X 1i 2 X 2i 3 X 12i 4 X 22i 5 X 1i X 2i ui The White test for heteroskedasticity 20 3.) Finally, test overall significance of Equation 2. Our test statistic: n * R the sample size * R 2 2 2 2 Under the null of no heteroskedasticity, this test statistic has a χ2 distribution with k* degrees of freedom Critical values of χ2 found in standard sources, and standard reasoning applies: if calculated value of test statistic exceeds critical value, reject the null. The White test for heteroskedasticity 21 Let’s return to our NHL data and suppose that salaries are a function of age and points. . reg salary age points Source SS df MS Model Residual 5.5423e+14 5.2403e+14 2 643 2.7711e+14 8.1498e+11 Total 1.0783e+15 645 1.6717e+12 salary Coef. age points _cons 56254.93 39941.76 -1148843 Std. Err. 8934.183 1711.216 237466.9 The White test in action t 6.30 23.34 -4.84 Number of obs F( 2, 643) Prob > F R-squared Adj R-squared Root MSE = = = = = = 646 340.03 0.0000 0.5140 0.5125 9.0e+05 P>|t| [95% Conf. Interval] 0.000 0.000 0.000 38711.23 36581.51 -1615148 73798.63 43302 -682538.9 22 6000000 4000000 0 2000000 Residuals -2000000 0 50 100 150 Points The White test in action 23 4.00e+13 ei2 3.00e+13 2.00e+13 0 1.00e+13 0 50 100 150 Points The White test in action 24 Source SS df MS Model Residual 1.8395e+27 2.4183e+27 5 640 3.6789e+26 3.7786e+24 Total 4.2578e+27 645 6.6012e+24 ei2 Coef. age points square_of_~e square_of_~s age_times_~s _cons -4.28e+11 -1.55e+08 9.16e+09 1.62e+09 -1.93e+09 5.23e+12 Std. Err. 2.30e+11 2.77e+10 4.22e+09 1.18e+08 9.98e+08 3.11e+12 t -1.86 -0.01 2.17 13.75 -1.93 1.68 Number of obs F( 5, 640) Prob > F R-squared Adj R-squared Root MSE P>|t| 0.063 0.996 0.030 0.000 0.054 0.093 = = = = = = 646 97.36 0.0000 0.4320 0.4276 1.9e+12 [95% Conf. Interval] -8.80e+11 -5.45e+10 8.76e+08 1.39e+09 -3.89e+09 -8.81e+11 2.40e+10 5.42e+10 1.75e+10 1.85e+09 3.22e+07 1.13e+13 Here: 0.05 Critical value of 11.07 2 5 The White test in action 25 If evidence of pure heteroskedasticity—whether through a formal test or just by looking at residual plots—you have several options available to you: 1.) Use OLS and “fix” the standard errors. We know OLS is unbiased in this case but the usual formulas for the standard errors is wrong Remedies for heteroskedastic errors 26 Just as in the case of serial correlation, we can get consistent estimates of the standard errors using Newey-West standard errors. What consistency means: estimators get arbitrarily close to their true value (in a probabilistic sense) when the sample size goes to infinity. If you know the source of the heteroskedasticity: Remedies for heteroskedastic errors 27 Heteroskedasticity as a very common problem in econometrics. At best, heteroskedasticity presents problems related to the efficiency of OLS estimators. At worst, heteroskedasticity presents problems related to both the bias and efficiency of OLS estimators. Conclusion 28