State space models Rob J Hyndman 1: Exponential smoothing
advertisement

Rob J Hyndman
State space models
1: Exponential smoothing
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
2
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
3
State space perspective
Observed data: y1 , . . . , yT .
Unobserved state: x1 , . . . , xT .
Forecast ŷT +h|T = E(yT +h |xT ).
The “forecast variance” is Var(yT +h |xT ).
A prediction interval or “interval
forecast” is a range of values of yT +h
with high probability.
State space models
1: Exponential smoothing
4
State space perspective
Observed data: y1 , . . . , yT .
Unobserved state: x1 , . . . , xT .
Forecast ŷT +h|T = E(yT +h |xT ).
The “forecast variance” is Var(yT +h |xT ).
A prediction interval or “interval
forecast” is a range of values of yT +h
with high probability.
State space models
1: Exponential smoothing
4
State space perspective
Observed data: y1 , . . . , yT .
Unobserved state: x1 , . . . , xT .
Forecast ŷT +h|T = E(yT +h |xT ).
The “forecast variance” is Var(yT +h |xT ).
A prediction interval or “interval
forecast” is a range of values of yT +h
with high probability.
State space models
1: Exponential smoothing
4
State space perspective
Observed data: y1 , . . . , yT .
Unobserved state: x1 , . . . , xT .
Forecast ŷT +h|T = E(yT +h |xT ).
The “forecast variance” is Var(yT +h |xT ).
A prediction interval or “interval
forecast” is a range of values of yT +h
with high probability.
State space models
1: Exponential smoothing
4
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
5
Simple Exponential Smoothing
Component form
Forecast equation
Smoothing equation
ŷt+h|t = `t
`t = αyt + (1 − α)`t−1
`1 = αy1 + (1 − α)`0
State space models
1: Exponential smoothing
6
Simple Exponential Smoothing
Component form
Forecast equation
Smoothing equation
ŷt+h|t = `t
`t = αyt + (1 − α)`t−1
`1 = αy1 + (1 − α)`0
State space models
1: Exponential smoothing
6
Simple Exponential Smoothing
Component form
Forecast equation
Smoothing equation
ŷt+h|t = `t
`t = αyt + (1 − α)`t−1
`1 = αy1 + (1 − α)`0
`2 = αy2 + (1 − α)`1 = αy2 + α(1 − α)y1 + (1 − α)2 `0
State space models
1: Exponential smoothing
6
Simple Exponential Smoothing
Component form
Forecast equation
Smoothing equation
ŷt+h|t = `t
`t = αyt + (1 − α)`t−1
`1 = αy1 + (1 − α)`0
`2 = αy2 + (1 − α)`1 = αy2 + α(1 − α)y1 + (1 − α)2 `0
`3 = αy3 + (1 − α)`2 =
2
X
α(1 − α)j y3−j + (1 − α)3 `0
j=0
State space models
1: Exponential smoothing
6
Simple Exponential Smoothing
Component form
Forecast equation
ŷt+h|t = `t
Smoothing equation
`t = αyt + (1 − α)`t−1
`1 = αy1 + (1 − α)`0
`2 = αy2 + (1 − α)`1 = αy2 + α(1 − α)y1 + (1 − α)2 `0
`3 = αy3 + (1 − α)`2 =
2
X
α(1 − α)j y3−j + (1 − α)3 `0
j=0
..
.
`t =
t −1
X
α(1 − α)j yt−j + (1 − α)t `0
j=0
State space models
1: Exponential smoothing
6
Simple Exponential Smoothing
Forecast equation
ŷt+h|t =
t
X
α(1 − α)t−j yj + (1 − α)t `0 ,
(0 ≤ α ≤ 1)
j=1
Observation
Weights assigned to observations for:
α = 0.2
α = 0.4
α = 0.6
α = 0.8
yt
yt−1
yt−2
yt−3
yt−4
yt−5
0.2
0.16
0.128
0.1024
(0.2)(0.8)4
(0.2)(0.8)5
0.8
0.16
0.032
0.0064
(0.8)(0.2)4
(0.8)(0.2)5
0.4
0.24
0.144
0.0864
(0.4)(0.6)4
(0.4)(0.6)5
Limiting cases: α → 1,
State space models
0.6
0.24
0.096
0.0384
(0.6)(0.4)4
(0.6)(0.4)5
α → 0.
1: Exponential smoothing
7
Simple Exponential Smoothing
Forecast equation
ŷt+h|t =
t
X
α(1 − α)t−j yj + (1 − α)t `0 ,
(0 ≤ α ≤ 1)
j=1
Observation
Weights assigned to observations for:
α = 0.2
α = 0.4
α = 0.6
α = 0.8
yt
yt−1
yt−2
yt−3
yt−4
yt−5
0.2
0.16
0.128
0.1024
(0.2)(0.8)4
(0.2)(0.8)5
0.8
0.16
0.032
0.0064
(0.8)(0.2)4
(0.8)(0.2)5
0.4
0.24
0.144
0.0864
(0.4)(0.6)4
(0.4)(0.6)5
Limiting cases: α → 1,
State space models
0.6
0.24
0.096
0.0384
(0.6)(0.4)4
(0.6)(0.4)5
α → 0.
1: Exponential smoothing
7
Simple Exponential Smoothing
Forecast equation
ŷt+h|t =
t
X
α(1 − α)t−j yj + (1 − α)t `0 ,
(0 ≤ α ≤ 1)
j=1
Observation
Weights assigned to observations for:
α = 0.2
α = 0.4
α = 0.6
α = 0.8
yt
yt−1
yt−2
yt−3
yt−4
yt−5
0.2
0.16
0.128
0.1024
(0.2)(0.8)4
(0.2)(0.8)5
0.8
0.16
0.032
0.0064
(0.8)(0.2)4
(0.8)(0.2)5
0.4
0.24
0.144
0.0864
(0.4)(0.6)4
(0.4)(0.6)5
Limiting cases: α → 1,
State space models
0.6
0.24
0.096
0.0384
(0.6)(0.4)4
(0.6)(0.4)5
α → 0.
1: Exponential smoothing
7
Simple Exponential Smoothing
Component form
Forecast equation
ŷt+h|t = `t
Smoothing equation
`t = αyt + (1 − α)`t−1
State space form
Observation equation
State equation
yt = `t−1 + et
`t = `t−1 + αet
et = yt − `t−1 = yt − ŷt|t−1 for t = 1, . . . , T, the one-step
within-sample forecast error at time t.
`t is an unobserved “state”.
Need to estimate α and `0 .
State space models
1: Exponential smoothing
8
Simple Exponential Smoothing
Component form
Forecast equation
ŷt+h|t = `t
Smoothing equation
`t = αyt + (1 − α)`t−1
State space form
Observation equation
State equation
yt = `t−1 + et
`t = `t−1 + αet
et = yt − `t−1 = yt − ŷt|t−1 for t = 1, . . . , T, the one-step
within-sample forecast error at time t.
`t is an unobserved “state”.
Need to estimate α and `0 .
State space models
1: Exponential smoothing
8
Simple Exponential Smoothing
Component form
Forecast equation
ŷt+h|t = `t
Smoothing equation
`t = αyt + (1 − α)`t−1
State space form
Observation equation
State equation
yt = `t−1 + et
`t = `t−1 + αet
et = yt − `t−1 = yt − ŷt|t−1 for t = 1, . . . , T, the one-step
within-sample forecast error at time t.
`t is an unobserved “state”.
Need to estimate α and `0 .
State space models
1: Exponential smoothing
8
Simple Exponential Smoothing
Component form
Forecast equation
ŷt+h|t = `t
Smoothing equation
`t = αyt + (1 − α)`t−1
State space form
Observation equation
State equation
yt = `t−1 + et
`t = `t−1 + αet
et = yt − `t−1 = yt − ŷt|t−1 for t = 1, . . . , T, the one-step
within-sample forecast error at time t.
`t is an unobserved “state”.
Need to estimate α and `0 .
State space models
1: Exponential smoothing
8
SES in R
library(fpp)
fit <- ses(oil, h=3)
plot(fit)
summary(fit)
State space models
1: Exponential smoothing
9
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
10
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
Trend
`t = αyt + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
Two smoothing parameters α and β ∗
(0 ≤ α, β ∗ ≤ 1).
`t level: weighted average between yt one-step
ahead forecast for time t, (`t−1 + bt−1 = ŷt|t−1 )
bt trend (slope): weighted average of (`t − `t−1 )
and bt−1 , current and previous estimate of the
trend.
State space models
1: Exponential smoothing
11
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
Trend
`t = αyt + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
Two smoothing parameters α and β ∗
(0 ≤ α, β ∗ ≤ 1).
`t level: weighted average between yt one-step
ahead forecast for time t, (`t−1 + bt−1 = ŷt|t−1 )
bt trend (slope): weighted average of (`t − `t−1 )
and bt−1 , current and previous estimate of the
trend.
State space models
1: Exponential smoothing
11
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
Trend
`t = αyt + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
Two smoothing parameters α and β ∗
(0 ≤ α, β ∗ ≤ 1).
`t level: weighted average between yt one-step
ahead forecast for time t, (`t−1 + bt−1 = ŷt|t−1 )
bt trend (slope): weighted average of (`t − `t−1 )
and bt−1 , current and previous estimate of the
trend.
State space models
1: Exponential smoothing
11
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
Trend
`t = αyt + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
Two smoothing parameters α and β ∗
(0 ≤ α, β ∗ ≤ 1).
`t level: weighted average between yt one-step
ahead forecast for time t, (`t−1 + bt−1 = ŷt|t−1 )
bt trend (slope): weighted average of (`t − `t−1 )
and bt−1 , current and previous estimate of the
trend.
State space models
1: Exponential smoothing
11
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
`t = αyt + (1 − α)(`t−1 + bt−1 )
Trend
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
State space form
Observation equation
State equations
yt = `t−1 + bt−1 + et
`t = `t−1 + bt−1 + αet
bt = bt−1 + β et
β = αβ ∗
et = yt − (`t−1 + bt−1 ) = yt − ŷt|t−1
Need to estimate α, β, `0 , b0 .
State space models
1: Exponential smoothing
12
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
`t = αyt + (1 − α)(`t−1 + bt−1 )
Trend
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
State space form
Observation equation
State equations
yt = `t−1 + bt−1 + et
`t = `t−1 + bt−1 + αet
bt = bt−1 + β et
β = αβ ∗
et = yt − (`t−1 + bt−1 ) = yt − ŷt|t−1
Need to estimate α, β, `0 , b0 .
State space models
1: Exponential smoothing
12
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
`t = αyt + (1 − α)(`t−1 + bt−1 )
Trend
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
State space form
Observation equation
State equations
yt = `t−1 + bt−1 + et
`t = `t−1 + bt−1 + αet
bt = bt−1 + β et
β = αβ ∗
et = yt − (`t−1 + bt−1 ) = yt − ŷt|t−1
Need to estimate α, β, `0 , b0 .
State space models
1: Exponential smoothing
12
Holt’s linear trend
Component form
Forecast
ŷt+h|t = `t + hbt
Level
`t = αyt + (1 − α)(`t−1 + bt−1 )
Trend
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1 ,
State space form
Observation equation
State equations
yt = `t−1 + bt−1 + et
`t = `t−1 + bt−1 + αet
bt = bt−1 + β et
β = αβ ∗
et = yt − (`t−1 + bt−1 ) = yt − ŷt|t−1
Need to estimate α, β, `0 , b0 .
State space models
1: Exponential smoothing
12
Holt’s method in R
fit2 <- holt(ausair, h=5)
plot(fit2)
summary(fit2)
State space models
1: Exponential smoothing
13
Exponential trend
Level and trend are multiplied rather than added:
Component form
ŷt+h|t = `t bht
`t = αyt + (1 − α)(`t−1 bt−1 )
`t
+ (1 − β ∗ )bt−1
bt = β ∗
` t −1
State space form
Observation equation
State equations
State space models
yt = (`t−1 bt−1 ) + et
`t = `t−1 bt−1 + αet
bt = bt−1 + β et /`t−1
1: Exponential smoothing
14
Trend methods in R
fit3 <- holt(air, h=5, exponential=TRUE)
plot(fit3)
summary(fit3)
State space models
1: Exponential smoothing
15
Additive damped trend
Component form
ŷt+h|t = `t + (φ + φ2 + · · · + φh )bt
`t = αyt + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1 .
State space form
Observation equation
State equations
yt = `t−1 + φbt−1 + et
`t = `t−1 + φbt−1 + αet
bt = φbt−1 + β et
Damping parameter 0 < φ < 1.
If φ = 1, identical to Holt’s linear trend.
As h → ∞, ŷT +h|T → `T + φbT /(1 − φ).
Short-run forecasts trended, long-run forecasts constant.
State space models
1: Exponential smoothing
16
Additive damped trend
Component form
ŷt+h|t = `t + (φ + φ2 + · · · + φh )bt
`t = αyt + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1 .
State space form
Observation equation
State equations
yt = `t−1 + φbt−1 + et
`t = `t−1 + φbt−1 + αet
bt = φbt−1 + β et
Damping parameter 0 < φ < 1.
If φ = 1, identical to Holt’s linear trend.
As h → ∞, ŷT +h|T → `T + φbT /(1 − φ).
Short-run forecasts trended, long-run forecasts constant.
State space models
1: Exponential smoothing
16
Additive damped trend
Component form
ŷt+h|t = `t + (φ + φ2 + · · · + φh )bt
`t = αyt + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1 .
State space form
Observation equation
State equations
yt = `t−1 + φbt−1 + et
`t = `t−1 + φbt−1 + αet
bt = φbt−1 + β et
Damping parameter 0 < φ < 1.
If φ = 1, identical to Holt’s linear trend.
As h → ∞, ŷT +h|T → `T + φbT /(1 − φ).
Short-run forecasts trended, long-run forecasts constant.
State space models
1: Exponential smoothing
16
Additive damped trend
Component form
ŷt+h|t = `t + (φ + φ2 + · · · + φh )bt
`t = αyt + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1 .
State space form
Observation equation
State equations
yt = `t−1 + φbt−1 + et
`t = `t−1 + φbt−1 + αet
bt = φbt−1 + β et
Damping parameter 0 < φ < 1.
If φ = 1, identical to Holt’s linear trend.
As h → ∞, ŷT +h|T → `T + φbT /(1 − φ).
Short-run forecasts trended, long-run forecasts constant.
State space models
1: Exponential smoothing
16
Additive damped trend
Component form
ŷt+h|t = `t + (φ + φ2 + · · · + φh )bt
`t = αyt + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1 .
State space form
Observation equation
State equations
yt = `t−1 + φbt−1 + et
`t = `t−1 + φbt−1 + αet
bt = φbt−1 + β et
Damping parameter 0 < φ < 1.
If φ = 1, identical to Holt’s linear trend.
As h → ∞, ŷT +h|T → `T + φbT /(1 − φ).
Short-run forecasts trended, long-run forecasts constant.
State space models
1: Exponential smoothing
16
Trend methods in R
fit4 <- holt(air, h=5, damped=TRUE)
plot(fit4)
summary(fit4)
State space models
1: Exponential smoothing
17
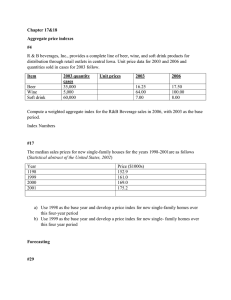
Example: Sheep in Asia
Forecasts from Holt's method with exponential trend
Data
SES
Holt's
Exponential
Additive Damped
Multiplicative Damped
450
●
●
●
●
400
●
● ●
●
●
● ● ●
● ●
●
●
●
●
●
●
350
●
●
●
●
● ●
●
●
●
300
Livestock, sheep in Asia (millions)
●
●
●
●
● ●
●
● ●
●
●
●
●
1970
●
●
1980
State space models
1990
2000
1: Exponential smoothing
2010
18
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
19
Holt-Winters additive method
Holt and Winters extended Holt’s method to capture
seasonality.
Component form
ŷt+h|t = `t + hbt + st−m+h+m
`t = α(yt − st−m ) + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
st = γ(yt − `t−1 − bt−1 ) + (1 − γ)st−m ,
h+
m = b(h − 1) mod mc + 1 - the largest integer not
greater than (h − 1) mod m. Ensures estimates
from the final year are used for forecasting.
Parameters: 0 ≤ α ≤ 1, 0 ≤ β ∗ ≤ 1, 0 ≤ γ ≤ 1 − α
and m = period of seasonality (e.g. m=4 for
quarterly data).
State space models
1: Exponential smoothing
20
Holt-Winters additive method
Holt and Winters extended Holt’s method to capture
seasonality.
Component form
ŷt+h|t = `t + hbt + st−m+h+m
`t = α(yt − st−m ) + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
st = γ(yt − `t−1 − bt−1 ) + (1 − γ)st−m ,
h+
m = b(h − 1) mod mc + 1 - the largest integer not
greater than (h − 1) mod m. Ensures estimates
from the final year are used for forecasting.
Parameters: 0 ≤ α ≤ 1, 0 ≤ β ∗ ≤ 1, 0 ≤ γ ≤ 1 − α
and m = period of seasonality (e.g. m=4 for
quarterly data).
State space models
1: Exponential smoothing
20
Holt-Winters additive method
Holt and Winters extended Holt’s method to capture
seasonality.
Component form
ŷt+h|t = `t + hbt + st−m+h+m
`t = α(yt − st−m ) + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
st = γ(yt − `t−1 − bt−1 ) + (1 − γ)st−m ,
h+
m = b(h − 1) mod mc + 1 - the largest integer not
greater than (h − 1) mod m. Ensures estimates
from the final year are used for forecasting.
Parameters: 0 ≤ α ≤ 1, 0 ≤ β ∗ ≤ 1, 0 ≤ γ ≤ 1 − α
and m = period of seasonality (e.g. m=4 for
quarterly data).
State space models
1: Exponential smoothing
20
Holt-Winters additive method
Component form
ŷt+h|t = `t + hbt + st−m+h+m
`t = α(yt − st−m ) + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
st = γ(yt − `t−1 − bt−1 ) + (1 − γ)st−m ,
State space form
yt = `t−1 + bt−1 + st−m + et
` t = ` t −1 + b t −1 + α e t
bt = bt−1 + β et
st = st −m + γ e t .
State space models
1: Exponential smoothing
21
Holt-Winters multiplicative
Component form
ŷt+h|t = (`t + hbt )st−m+h+m .
yt
`t = α
+ (1 − α)(`t−1 + bt−1 )
st−m
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
yt
st = γ
+ (1 − γ)st−m
(`t−1 + bt−1 )
State space form
yt = (`t−1 + bt−1 )st−m + et
`t = `t−1 + bt−1 + αet /st−m
bt = bt−1 + β et /st−m
st = st−m + γ et /(`t−1 + bt−1 ).
State space models
1: Exponential smoothing
22
Seasonal methods in R
aus1 <- hw(austourists)
aus2 <- hw(austourists, seasonal="mult")
plot(aus1)
plot(aus2)
summary(aus1)
summary(aus2)
State space models
1: Exponential smoothing
23
Holt-Winters damped method
Often the single most accurate forecasting method for
seasonal data:
ŷt+h|t = [`t + (φ + φ2 + · · · + φh )bt ]st−m+h+m
`t = α(yt /st−m ) + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1
yt
+ (1 − γ)st−m
st = γ
(`t−1 + φbt−1 )
State space form
yt = (`t−1 + φbt−1 )st−m + et
`t = `t−1 + φbt−1 + αet /st−m
bt = φbt−1 + β et /st−m
st = st−m + γ et /(`t−1 + φbt−1 ).
State space models
1: Exponential smoothing
24
Seasonal methods in R
aus3 <- hw(austourists, seasonal="mult",
damped=TRUE)
summary(aus3)
plot(aus3)
State space models
1: Exponential smoothing
25
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
26
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
Simple exponential smoothing
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
A,N:
Simple exponential smoothing
Holt’s linear method
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
A,N:
Ad ,N:
Simple exponential smoothing
Holt’s linear method
Additive damped trend method
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
A,N:
Ad ,N:
M,N:
Simple exponential smoothing
Holt’s linear method
Additive damped trend method
Exponential trend method
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
A,N:
Ad ,N:
M,N:
Md ,N:
Simple exponential smoothing
Holt’s linear method
Additive damped trend method
Exponential trend method
Multiplicative damped trend method
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
A,N:
Ad ,N:
M,N:
Md ,N:
A,A:
Simple exponential smoothing
Holt’s linear method
Additive damped trend method
Exponential trend method
Multiplicative damped trend method
Additive Holt-Winters’ method
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
N,N:
A,N:
Ad ,N:
M,N:
Md ,N:
A,A:
A,M:
Simple exponential smoothing
Holt’s linear method
Additive damped trend method
Exponential trend method
Multiplicative damped trend method
Additive Holt-Winters’ method
Multiplicative Holt-Winters’ method
State space models
1: Exponential smoothing
27
Exponential smoothing methods
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
There are 15 separate exponential smoothing methods.
State space models
1: Exponential smoothing
27
Component form
Trend
Seasonal
A
N
7/ exponential smoothing
145
M
ŷt+h|t = `t
ŷt+h|t = `t + st−m+h+m
ŷt+h|t = `t st−m+h+m
N
`t = αyt + (1 − α)`t−1
`t = α(yt − st−m ) + (1 − α)`t−1
st = γ(yt − `t−1 ) + (1 − γ)st−m
`t = α(yt /st−m ) + (1 − α)`t−1
st = γ(yt /`t−1 ) + (1 − γ)st−m
A
`t = αyt + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
`t = α(yt − st−m ) + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
st = γ(yt − `t−1 − bt−1 ) + (1 − γ)st−m
`t = α(yt /st−m ) + (1 − α)(`t−1 + bt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )bt−1
st = γ(yt /(`t−1 − bt−1 )) + (1 − γ)st−m
Ad
`t = αyt + (1 − α)(`t−1 + φbt−1 ) `t = α(yt − st−m ) + (1 − α)(`t−1 + φbt−1 ) `t = α(yt /st−m ) + (1 − α)(`t−1 + φbt−1 )
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1 bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1
bt = β ∗ (`t − `t−1 ) + (1 − β ∗ )φbt−1
st = γ(yt − `t−1 − φbt−1 ) + (1 − γ)st−m
st = γ(yt /(`t−1 − φbt−1 )) + (1 − γ)st−m
ŷt+h|t = `t bth
ŷt+h|t = `t bth + st−m+h+m
ŷt+h|t = `t bth st−m+h+m
M
`t = αyt + (1 − α)`t−1 bt−1
bt = β ∗ (`t /`t−1 ) + (1 − β ∗ )bt−1
`t = α(yt − st−m ) + (1 − α)`t−1 bt−1
bt = β ∗ (`t /`t−1 ) + (1 − β ∗ )bt−1
st = γ(yt − `t−1 bt−1 ) + (1 − γ)st−m
`t = α(yt /st−m ) + (1 − α)`t−1 bt−1
bt = β ∗ (`t /`t−1 ) + (1 − β ∗ )bt−1
st = γ(yt /(`t−1 bt−1 )) + (1 − γ)st−m
ŷt+h|t = `t + hbt
ŷt+h|t = `t + φh bt
φh
ŷt+h|t = `t bt
Md
φ
`t = αyt + (1 − α)`t−1 bt−1
φ
∗
bt = β (`t /`t−1 ) + (1 − β ∗ )bt−1
State space models
ŷt+h|t = `t + hbt + st−m+h+m
ŷt+h|t = `t + φh bt + st−m+h+m
φ
ŷt+h|t = (`t + hbt )st−m+h+m
ŷt+h|t = (`t + φh bt )st−m+h+m
φ
ŷt+h|t = `t bt h st−m+h+m
φ
φ
`t = α(yt − st−m ) + (1 − α)`t−1 bt−1
`t = α(yt /st−m ) + (1 − α)`t−1 bt−1
φ
φ
∗
∗
∗
∗
bt = β (`t /`t−1 ) + (1 − β )bt−1
bt = β (`t /`t−1 ) + (1 − β )bt−1
φ
φ
st = γ(yt − `t−1 bt−1 ) + (1 − γ)st−m
st = γ(yt /(`t−1 bt−1 )) + (1 − γ)st−m
1: Exponential smoothing
28
ŷt+h|t = `t bt h + st−m+h+m
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
29
Methods V Models
Exponential smoothing methods
Algorithms that return point forecasts.
Innovations state space models
Generate same point forecasts but can also
generate forecast intervals.
A stochastic (or random) data generating
process that can generate an entire forecast
distribution.
Allow for “proper” model selection.
State space models
1: Exponential smoothing
30
Methods V Models
Exponential smoothing methods
Algorithms that return point forecasts.
Innovations state space models
Generate same point forecasts but can also
generate forecast intervals.
A stochastic (or random) data generating
process that can generate an entire forecast
distribution.
Allow for “proper” model selection.
State space models
1: Exponential smoothing
30
Methods V Models
Exponential smoothing methods
Algorithms that return point forecasts.
Innovations state space models
Generate same point forecasts but can also
generate forecast intervals.
A stochastic (or random) data generating
process that can generate an entire forecast
distribution.
Allow for “proper” model selection.
State space models
1: Exponential smoothing
30
Methods V Models
Exponential smoothing methods
Algorithms that return point forecasts.
Innovations state space models
Generate same point forecasts but can also
generate forecast intervals.
A stochastic (or random) data generating
process that can generate an entire forecast
distribution.
Allow for “proper” model selection.
State space models
1: Exponential smoothing
30
Methods V Models
Exponential smoothing methods
Algorithms that return point forecasts.
Innovations state space models
Generate same point forecasts but can also
generate forecast intervals.
A stochastic (or random) data generating
process that can generate an entire forecast
distribution.
Allow for “proper” model selection.
State space models
1: Exponential smoothing
30
ETS models
Each model has an observation equation and
transition equations, one for each state (level,
trend, seasonal), i.e., state space models.
Two models for each method: one with additive
and one with multiplicative errors, i.e., in total
30 models.
ETS(Error,Trend,Seasonal):
Error= {A, M}
Trend = {N, A, Ad , M, Md }
Seasonal = {N, A, M}.
State space models
1: Exponential smoothing
31
ETS models
Each model has an observation equation and
transition equations, one for each state (level,
trend, seasonal), i.e., state space models.
Two models for each method: one with additive
and one with multiplicative errors, i.e., in total
30 models.
ETS(Error,Trend,Seasonal):
Error= {A, M}
Trend = {N, A, Ad , M, Md }
Seasonal = {N, A, M}.
State space models
1: Exponential smoothing
31
ETS models
Each model has an observation equation and
transition equations, one for each state (level,
trend, seasonal), i.e., state space models.
Two models for each method: one with additive
and one with multiplicative errors, i.e., in total
30 models.
ETS(Error,Trend,Seasonal):
Error= {A, M}
Trend = {N, A, Ad , M, Md }
Seasonal = {N, A, M}.
State space models
1: Exponential smoothing
31
ETS models
Each model has an observation equation and
transition equations, one for each state (level,
trend, seasonal), i.e., state space models.
Two models for each method: one with additive
and one with multiplicative errors, i.e., in total
30 models.
ETS(Error,Trend,Seasonal):
Error= {A, M}
Trend = {N, A, Ad , M, Md }
Seasonal = {N, A, M}.
State space models
1: Exponential smoothing
31
ETS models
Each model has an observation equation and
transition equations, one for each state (level,
trend, seasonal), i.e., state space models.
Two models for each method: one with additive
and one with multiplicative errors, i.e., in total
30 models.
ETS(Error,Trend,Seasonal):
Error= {A, M}
Trend = {N, A, Ad , M, Md }
Seasonal = {N, A, M}.
State space models
1: Exponential smoothing
31
ETS models
Each model has an observation equation and
transition equations, one for each state (level,
trend, seasonal), i.e., state space models.
Two models for each method: one with additive
and one with multiplicative errors, i.e., in total
30 models.
ETS(Error,Trend,Seasonal):
Error= {A, M}
Trend = {N, A, Ad , M, Md }
Seasonal = {N, A, M}.
State space models
1: Exponential smoothing
31
Exponential smoothing methods
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
Trend
Component
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
Exponential smoothing methods
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
Trend
Component
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
Exponential smoothing methods
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
Trend
Component
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
↑
Trend
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
Exponential smoothing methods
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
Trend
Component
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
↑ -
Trend Seasonal
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
Exponential smoothing methods
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
Trend
Component
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
% ↑ -
Error Trend Seasonal
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
Exponential smoothing methods
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
Trend
Component
N
(None)
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
(Multiplicative)
M,N
M,A
M,M
Md
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
% ↑ -
Error Trend Seasonal
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
Exponential smoothing methods
Innovations state space models
Seasonal Component
Trend
N
A
M
å AllComponent
ETS models can (None)
be written
in innovations
(Additive)
(Multiplicative)
N
state
(None) space form.
N,N
N,A
N,M
A
(Additive)
A,N
A,A
A,M
å Additive
and multiplicative
versions
give
the
Ad
(Additive damped)
Ad ,N
Ad ,A
Ad ,M
M
Md
same
point forecastsM,N
but different
prediction
(Multiplicative)
M,A
M,M
intervals.
(Multiplicative damped)
Md ,N
Md ,A
Md ,M
General notation
E T S : ExponenTial Smoothing
% ↑ -
Error Trend Seasonal
Examples:
A,N,N:
A,A,N:
M,A,M:
Simple exponential smoothing with additive errors
Holt’s linear method with additive errors
Multiplicative Holt-Winters’ method with multiplicative errors
State space models
1: Exponential smoothing
32
ETS(A,N,N)
Observation equation
State equation
yt = `t−1 + εt ,
`t = `t−1 + αεt
et = yt − ŷt|t−1 = εt
Assume εt ∼ NID(0, σ 2 )
“innovations” or “single source of error”
because same error process, εt .
State space models
1: Exponential smoothing
33
ETS(A,N,N)
Observation equation
State equation
yt = `t−1 + εt ,
`t = `t−1 + αεt
et = yt − ŷt|t−1 = εt
Assume εt ∼ NID(0, σ 2 )
“innovations” or “single source of error”
because same error process, εt .
State space models
1: Exponential smoothing
33
ETS(A,N,N)
Observation equation
State equation
yt = `t−1 + εt ,
`t = `t−1 + αεt
et = yt − ŷt|t−1 = εt
Assume εt ∼ NID(0, σ 2 )
“innovations” or “single source of error”
because same error process, εt .
State space models
1: Exponential smoothing
33
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
ETS(M,N,N)
SES with multiplicative errors.
Specify relative errors εt =
yt −ŷt|t−1
ŷt|t−1
∼ NID(0, σ 2 )
Substituting ŷt|t−1 = `t−1 gives:
yt = `t−1 + `t−1 εt
et = yt − ŷt|t−1 = `t−1 εt
Observation equation
State equation
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
Models with additive and multiplicative errors
with the same parameters generate the same
point forecasts but different prediction
intervals.
State space models
1: Exponential smoothing
34
Holt’s linear method
ETS(A,A,N)
yt = `t−1 + bt−1 + εt
`t = `t−1 + bt−1 + αεt
bt = bt−1 + βεt
ETS(M,A,N)
yt = (`t−1 + bt−1 )(1 + εt )
`t = (`t−1 + bt−1 )(1 + αεt )
bt = bt−1 + β(`t−1 + bt−1 )εt
State space models
1: Exponential smoothing
35
Holt’s linear method
ETS(A,A,N)
yt = `t−1 + bt−1 + εt
`t = `t−1 + bt−1 + αεt
bt = bt−1 + βεt
ETS(M,A,N)
yt = (`t−1 + bt−1 )(1 + εt )
`t = (`t−1 + bt−1 )(1 + αεt )
bt = bt−1 + β(`t−1 + bt−1 )εt
State space models
1: Exponential smoothing
35
ETS(A,A,A)
Holt-Winters additive method with additive errors.
Forecast equation ŷt+h|t = `t + hbt + st−m+h+m
Observation equation
State equations
yt = `t−1 + bt−1 + st−m + εt
`t = `t−1 + bt−1 + αεt
bt = bt−1 + βεt
st = st−m + γεt
Forecast errors: εt = yt − ŷt|t−1
h+
m = b(h − 1) mod mc + 1.
State space models
1: Exponential smoothing
36
Additive error models
ADDITIVE ERROR MODELS
Trend
Seasonal
A
N
N
M
yt = `t−1 + εt
`t = `t−1 + αεt
yt = `t−1 + st−m + εt
`t = `t−1 + αεt
st = st−m + γεt
yt = `t−1 st−m + εt
`t = `t−1 + αεt /st−m
st = st−m + γεt /`t−1
A
yt = `t−1 + bt−1 + εt
`t = `t−1 + bt−1 + αεt
bt = bt−1 + βεt
yt = `t−1 + bt−1 + st−m + εt
`t = `t−1 + bt−1 + αεt
bt = bt−1 + βεt
st = st−m + γεt
yt = (`t−1 + bt−1 )st−m + εt
`t = `t−1 + bt−1 + αεt /st−m
bt = bt−1 + βεt /st−m
st = st−m + γεt /(`t−1 + bt−1 )
Ad
yt = `t−1 + φbt−1 + εt
`t = `t−1 + φbt−1 + αεt
bt = φbt−1 + βεt
yt = `t−1 + φbt−1 + st−m + εt
`t = `t−1 + φbt−1 + αεt
bt = φbt−1 + βεt
st = st−m + γεt
yt = (`t−1 + φbt−1 )st−m + εt
`t = `t−1 + φbt−1 + αεt /st−m
bt = φbt−1 + βεt /st−m
st = st−m + γεt /(`t−1 + φbt−1 )
M
yt = `t−1 bt−1 + εt
`t = `t−1 bt−1 + αεt
bt = bt−1 + βεt /`t−1
yt = `t−1 bt−1 + st−m + εt
`t = `t−1 bt−1 + αεt
bt = bt−1 + βεt /`t−1
st = st−m + γεt
yt = `t−1 bt−1 st−m + εt
`t = `t−1 bt−1 + αεt /st−m
bt = bt−1 + βεt /(st−m `t−1 )
st = st−m + γεt /(`t−1 bt−1 )
φ
Md
φ
φ
yt = `t−1 bt−1 + εt
φ
`t = `t−1 bt−1 + αεt
yt = `t−1 bt−1 + st−m + εt
φ
`t = `t−1 bt−1 + αεt
yt = `t−1 bt−1 st−m + εt
φ
`t = `t−1 bt−1 + αεt /st−m
bt = bt−1 + βεt /`t−1
bt = bt−1 + βεt /`t−1
st = st−m + γεt
bt = bt−1 + βεt /(st−m `t−1 )
φ
st = st−m + γεt /(`t−1 bt−1 )
φ
MULTIPLICATIVE ERROR MODELS
State space models
φ
φ
1: Exponential smoothing
37
bt = bt−1 + βεt /`t−1
bt = bt−1 + βεt /`t−1
bt = bt−1 + βεt /(st−m `t−1 )
st = st−m + γεt
st = st−m + γεt /(`t−1 bt−1 )
φ
Multiplicative error models
MULTIPLICATIVE ERROR MODELS
Trend
Seasonal
A
N
N
M
yt = `t−1 (1 + εt )
`t = `t−1 (1 + αεt )
yt = (`t−1 + st−m )(1 + εt )
`t = `t−1 + α(`t−1 + st−m )εt
st = st−m + γ(`t−1 + st−m )εt
yt = `t−1 st−m (1 + εt )
`t = `t−1 (1 + αεt )
st = st−m (1 + γεt )
A
yt = (`t−1 + bt−1 )(1 + εt )
`t = (`t−1 + bt−1 )(1 + αεt )
bt = bt−1 + β(`t−1 + bt−1 )εt
yt = (`t−1 + bt−1 + st−m )(1 + εt )
`t = `t−1 + bt−1 + α(`t−1 + bt−1 + st−m )εt
bt = bt−1 + β(`t−1 + bt−1 + st−m )εt
st = st−m + γ(`t−1 + bt−1 + st−m )εt
yt = (`t−1 + bt−1 )st−m (1 + εt )
`t = (`t−1 + bt−1 )(1 + αεt )
bt = bt−1 + β(`t−1 + bt−1 )εt
st = st−m (1 + γεt )
Ad
yt = (`t−1 + φbt−1 )(1 + εt )
`t = (`t−1 + φbt−1 )(1 + αεt )
bt = φbt−1 + β(`t−1 + φbt−1 )εt
yt = (`t−1 + φbt−1 + st−m )(1 + εt )
`t = `t−1 + φbt−1 + α(`t−1 + φbt−1 + st−m )εt
bt = φbt−1 + β(`t−1 + φbt−1 + st−m )εt
st = st−m + γ(`t−1 + φbt−1 + st−m )εt
yt = (`t−1 + φbt−1 )st−m (1 + εt )
`t = (`t−1 + φbt−1 )(1 + αεt )
bt = φbt−1 + β(`t−1 + φbt−1 )εt
st = st−m (1 + γεt )
M
yt = `t−1 bt−1 (1 + εt )
`t = `t−1 bt−1 (1 + αεt )
bt = bt−1 (1 + βεt )
yt = (`t−1 bt−1 + st−m )(1 + εt )
`t = `t−1 bt−1 + α(`t−1 bt−1 + st−m )εt
bt = bt−1 + β(`t−1 bt−1 + st−m )εt /`t−1
st = st−m + γ(`t−1 bt−1 + st−m )εt
yt = `t−1 bt−1 st−m (1 + εt )
`t = `t−1 bt−1 (1 + αεt )
bt = bt−1 (1 + βεt )
st = st−m (1 + γεt )
φ
yt = `t−1 bt−1 (1 + εt )
Md
φ
`t = `t−1 bt−1 (1 + αεt )
φ
bt = bt−1 (1 + βεt )
State space models
φ
yt = (`t−1 bt−1 + st−m )(1 + εt )
φ
φ
φ
`t = `t−1 bt−1 + α(`t−1 bt−1 + st−m )εt
φ
φ
bt = bt−1 + β(`t−1 bt−1 + st−m )εt /`t−1
φ
st = st−m + γ(`t−1 bt−1 + st−m )εt
yt = `t−1 bt−1 st−m (1 + εt )
φ
`t = `t−1 bt−1 (1 + αεt )
φ
bt = bt−1 (1 + βεt )
st = st−m (1 + γεt )
Table 7.10: State space equations
for smoothing
each of the models in the ETS38
1: Exponential
Innovations state space models
iid
Let xt = (`t , bt , st , st−1 , . . . , st−m+1 ) and εt ∼ N(0, σ 2 ).
yt
= h(xt−1 ) + k (xt−1 )εt
| {z }
µt
|
{z
et
}
xt = f (xt−1 ) + g(xt−1 )εt
Additive errors:
k (x) = 1.
yt = µ t + ε t .
Multiplicative errors:
k (xt−1 ) = µt .
yt = µt (1 + εt ).
εt = (yt − µt )/µt is relative error.
State space models
1: Exponential smoothing
39
Innovations state space models
All the methods can be written in this state
space form.
The only difference between the additive error
and multiplicative error models is in the
observation equation.
Additive and multiplicative versions give the
same point forecasts.
State space models
1: Exponential smoothing
40
Innovations state space models
All the methods can be written in this state
space form.
The only difference between the additive error
and multiplicative error models is in the
observation equation.
Additive and multiplicative versions give the
same point forecasts.
State space models
1: Exponential smoothing
40
Innovations state space models
All the methods can be written in this state
space form.
The only difference between the additive error
and multiplicative error models is in the
observation equation.
Additive and multiplicative versions give the
same point forecasts.
State space models
1: Exponential smoothing
40
Some unstable models
Some of the combinations of (Error, Trend,
Seasonal) can lead to numerical difficulties; see
equations with division by a state.
These are: ETS(M,M,A), ETS(M,Md ,A),
ETS(A,N,M), ETS(A,A,M), ETS(A,Ad ,M),
ETS(A,M,N), ETS(A,M,A), ETS(A,M,M),
ETS(A,Md ,N), ETS(A,Md ,A), and ETS(A,Md ,M).
Models with multiplicative errors are useful for
strictly positive data – but are not numerically
stable with data containing zeros or negative
values. In that case only the six fully additive
models will be applied.
State space models
1: Exponential smoothing
41
Some unstable models
Some of the combinations of (Error, Trend,
Seasonal) can lead to numerical difficulties; see
equations with division by a state.
These are: ETS(M,M,A), ETS(M,Md ,A),
ETS(A,N,M), ETS(A,A,M), ETS(A,Ad ,M),
ETS(A,M,N), ETS(A,M,A), ETS(A,M,M),
ETS(A,Md ,N), ETS(A,Md ,A), and ETS(A,Md ,M).
Models with multiplicative errors are useful for
strictly positive data – but are not numerically
stable with data containing zeros or negative
values. In that case only the six fully additive
models will be applied.
State space models
1: Exponential smoothing
41
Some unstable models
Some of the combinations of (Error, Trend,
Seasonal) can lead to numerical difficulties; see
equations with division by a state.
These are: ETS(M,M,A), ETS(M,Md ,A),
ETS(A,N,M), ETS(A,A,M), ETS(A,Ad ,M),
ETS(A,M,N), ETS(A,M,A), ETS(A,M,M),
ETS(A,Md ,N), ETS(A,Md ,A), and ETS(A,Md ,M).
Models with multiplicative errors are useful for
strictly positive data – but are not numerically
stable with data containing zeros or negative
values. In that case only the six fully additive
models will be applied.
State space models
1: Exponential smoothing
41
Exponential smoothing models
Additive Error
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
A,N,N
A
(Additive)
Ad
(Additive damped)
M
(Multiplicative)
Md
(Multiplicative damped)
A,N,A
A,N,M
A,A,N
A,A,A
A,A,M
A,Ad ,N
A,Ad ,A
A,Ad ,M
A,M,N
A,M,A
A,M,M
A,Md ,N
A,Md ,A
A,Md ,M
Multiplicative Error
Trend
Component
Seasonal Component
N
A
M
(None)
(Additive) (Multiplicative)
N
(None)
M,N,N
A
(Additive)
M,A,N
M,A,A
M,A,M
Ad
(Additive damped)
M,Ad ,N
M,Ad ,A
M,Ad ,M
M
(Multiplicative)
M,M,N
M,M,A
M,M,M
Md
(Multiplicative damped)
M,Md ,N
M,Md ,A
M,Md ,M
State space models
M,N,A
M,N,M
1: Exponential smoothing
42
Innovations state space models
Estimation
∗
X
n
L (θ, x0 ) = n log
t =1
n
X
ε /k (xt−1 ) + 2
log |k (xt−1 )|
2
t
2
t =1
= −2 log(Likelihood) + constant
Estimate parameters θ = (α, β, γ, φ) and initial
states x0 = (`0 , b0 , s0 , s−1 , . . . , s−m+1 ) by
minimizing L∗ .
State space models
1: Exponential smoothing
43
Innovations state space models
Estimation
∗
X
n
L (θ, x0 ) = n log
t =1
n
X
ε /k (xt−1 ) + 2
log |k (xt−1 )|
2
t
2
t =1
= −2 log(Likelihood) + constant
Estimate parameters θ = (α, β, γ, φ) and initial
states x0 = (`0 , b0 , s0 , s−1 , . . . , s−m+1 ) by
minimizing L∗ .
State space models
1: Exponential smoothing
43
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Parameter restrictions
Usual region
Traditional restrictions in the methods
0 < α, β ∗ , γ ∗ , φ < 1 — equations interpreted as
weighted averages.
In models we set β = αβ ∗ and γ = (1 − α)γ ∗ therefore
0 < α < 1, 0 < β < α and 0 < γ < 1 − α.
0.8 < φ < 0.98 — to prevent numerical difficulties.
Admissible region
To prevent observations in the distant past having a
continuing effect on current forecasts.
Usually (but not always) less restrictive than the
usual region.
For example for ETS(A,N,N):
usual 0 < α < 1 — admissible is 0 < α < 2.
State space models
1: Exponential smoothing
44
Model selection
Akaike’s Information Criterion
AIC = −2 log(L) + 2k
where L is the likelihood and k is the number of
parameters initial states estimated in the model.
Corrected AIC
AICc = AIC +
2(k + 1)(k + 2)
T−k
which is the AIC corrected (for small sample bias).
Bayesian Information Criterion
BIC = AIC + k (log(T ) − 2).
State space models
1: Exponential smoothing
45
Model selection
Akaike’s Information Criterion
AIC = −2 log(L) + 2k
where L is the likelihood and k is the number of
parameters initial states estimated in the model.
Corrected AIC
AICc = AIC +
2(k + 1)(k + 2)
T−k
which is the AIC corrected (for small sample bias).
Bayesian Information Criterion
BIC = AIC + k (log(T ) − 2).
State space models
1: Exponential smoothing
45
Model selection
Akaike’s Information Criterion
AIC = −2 log(L) + 2k
where L is the likelihood and k is the number of
parameters initial states estimated in the model.
Corrected AIC
AICc = AIC +
2(k + 1)(k + 2)
T−k
which is the AIC corrected (for small sample bias).
Bayesian Information Criterion
BIC = AIC + k (log(T ) − 2).
State space models
1: Exponential smoothing
45
Automatic forecasting
From Hyndman et al. (IJF, 2002):
Apply each model that is appropriate to the
data. Optimize parameters and initial values
using MLE (or some other criterion).
Select best method using AIC:
AIC = −2 log(Likelihood) + 2p
where p = # parameters.
Produce forecasts using best method.
Obtain prediction intervals using underlying
state space model.
Method performed very well in M3 competition.
State space models
1: Exponential smoothing
46
Automatic forecasting
From Hyndman et al. (IJF, 2002):
Apply each model that is appropriate to the
data. Optimize parameters and initial values
using MLE (or some other criterion).
Select best method using AIC:
AIC = −2 log(Likelihood) + 2p
where p = # parameters.
Produce forecasts using best method.
Obtain prediction intervals using underlying
state space model.
Method performed very well in M3 competition.
State space models
1: Exponential smoothing
46
Automatic forecasting
From Hyndman et al. (IJF, 2002):
Apply each model that is appropriate to the
data. Optimize parameters and initial values
using MLE (or some other criterion).
Select best method using AIC:
AIC = −2 log(Likelihood) + 2p
where p = # parameters.
Produce forecasts using best method.
Obtain prediction intervals using underlying
state space model.
Method performed very well in M3 competition.
State space models
1: Exponential smoothing
46
Automatic forecasting
From Hyndman et al. (IJF, 2002):
Apply each model that is appropriate to the
data. Optimize parameters and initial values
using MLE (or some other criterion).
Select best method using AIC:
AIC = −2 log(Likelihood) + 2p
where p = # parameters.
Produce forecasts using best method.
Obtain prediction intervals using underlying
state space model.
Method performed very well in M3 competition.
State space models
1: Exponential smoothing
46
Automatic forecasting
From Hyndman et al. (IJF, 2002):
Apply each model that is appropriate to the
data. Optimize parameters and initial values
using MLE (or some other criterion).
Select best method using AIC:
AIC = −2 log(Likelihood) + 2p
where p = # parameters.
Produce forecasts using best method.
Obtain prediction intervals using underlying
state space model.
Method performed very well in M3 competition.
State space models
1: Exponential smoothing
46
Forecasting with ETS models
Point forecasts obtained by iterating equations
for t = T + 1, . . . , T + h, setting εt = 0 for t > T.
Not the same as E(yt+h |xt ) unless trend and
seasonality are both additive.
Point forecasts for ETS(A,x,y) are identical to
ETS(M,x,y) if the parameters are the same.
Prediction intervals will differ between models
with additive and multiplicative methods.
Exact PI available for many models.
Otherwise, simulate future sample paths,
conditional on last estimate of states, and
obtain PI from percentiles of simulated paths.
State space models
1: Exponential smoothing
47
Forecasting with ETS models
Point forecasts obtained by iterating equations
for t = T + 1, . . . , T + h, setting εt = 0 for t > T.
Not the same as E(yt+h |xt ) unless trend and
seasonality are both additive.
Point forecasts for ETS(A,x,y) are identical to
ETS(M,x,y) if the parameters are the same.
Prediction intervals will differ between models
with additive and multiplicative methods.
Exact PI available for many models.
Otherwise, simulate future sample paths,
conditional on last estimate of states, and
obtain PI from percentiles of simulated paths.
State space models
1: Exponential smoothing
47
Forecasting with ETS models
Point forecasts obtained by iterating equations
for t = T + 1, . . . , T + h, setting εt = 0 for t > T.
Not the same as E(yt+h |xt ) unless trend and
seasonality are both additive.
Point forecasts for ETS(A,x,y) are identical to
ETS(M,x,y) if the parameters are the same.
Prediction intervals will differ between models
with additive and multiplicative methods.
Exact PI available for many models.
Otherwise, simulate future sample paths,
conditional on last estimate of states, and
obtain PI from percentiles of simulated paths.
State space models
1: Exponential smoothing
47
Forecasting with ETS models
Point forecasts obtained by iterating equations
for t = T + 1, . . . , T + h, setting εt = 0 for t > T.
Not the same as E(yt+h |xt ) unless trend and
seasonality are both additive.
Point forecasts for ETS(A,x,y) are identical to
ETS(M,x,y) if the parameters are the same.
Prediction intervals will differ between models
with additive and multiplicative methods.
Exact PI available for many models.
Otherwise, simulate future sample paths,
conditional on last estimate of states, and
obtain PI from percentiles of simulated paths.
State space models
1: Exponential smoothing
47
Forecasting with ETS models
Point forecasts obtained by iterating equations
for t = T + 1, . . . , T + h, setting εt = 0 for t > T.
Not the same as E(yt+h |xt ) unless trend and
seasonality are both additive.
Point forecasts for ETS(A,x,y) are identical to
ETS(M,x,y) if the parameters are the same.
Prediction intervals will differ between models
with additive and multiplicative methods.
Exact PI available for many models.
Otherwise, simulate future sample paths,
conditional on last estimate of states, and
obtain PI from percentiles of simulated paths.
State space models
1: Exponential smoothing
47
Forecasting with ETS models
Point forecasts obtained by iterating equations
for t = T + 1, . . . , T + h, setting εt = 0 for t > T.
Not the same as E(yt+h |xt ) unless trend and
seasonality are both additive.
Point forecasts for ETS(A,x,y) are identical to
ETS(M,x,y) if the parameters are the same.
Prediction intervals will differ between models
with additive and multiplicative methods.
Exact PI available for many models.
Otherwise, simulate future sample paths,
conditional on last estimate of states, and
obtain PI from percentiles of simulated paths.
State space models
1: Exponential smoothing
47
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Point forecasts: iterate the equations for
t = T + 1, T + 2, . . . , T + h and set all εt = 0 for t > T.
For example, for ETS(M,A,N):
yT +1 = (`T + bT )(1 + εT +1 )
Therefore ŷT +1|T = `T + bT
yT +2 = (`T +1 + bT +1 )(1 + εT +1 ) =
[(`T + bT )(1 + αεT +1 ) + bT + β(`T + bT )εT +1 ] (1 + εT +1 )
Therefore ŷT +2|T = `T + 2bT and so on.
Identical forecast with Holt’s linear method and
ETS(A,A,N). So the point forecasts obtained from the
method and from the two models that underly the
method are identical (assuming the same parameter
values are used).
State space models
1: Exponential smoothing
48
Forecasting with ETS models
Prediction intervals: cannot be generated using
the methods.
The prediction intervals will differ between
models with additive and multiplicative
methods.
Exact formulae for some models.
More general to simulate future sample paths,
conditional on the last estimate of the states,
and to obtain prediction intervals from the
percentiles of these simulated future paths.
Options are available in R using the forecast
function in the forecast package.
State space models
1: Exponential smoothing
49
Forecasting with ETS models
Prediction intervals: cannot be generated using
the methods.
The prediction intervals will differ between
models with additive and multiplicative
methods.
Exact formulae for some models.
More general to simulate future sample paths,
conditional on the last estimate of the states,
and to obtain prediction intervals from the
percentiles of these simulated future paths.
Options are available in R using the forecast
function in the forecast package.
State space models
1: Exponential smoothing
49
Forecasting with ETS models
Prediction intervals: cannot be generated using
the methods.
The prediction intervals will differ between
models with additive and multiplicative
methods.
Exact formulae for some models.
More general to simulate future sample paths,
conditional on the last estimate of the states,
and to obtain prediction intervals from the
percentiles of these simulated future paths.
Options are available in R using the forecast
function in the forecast package.
State space models
1: Exponential smoothing
49
Forecasting with ETS models
Prediction intervals: cannot be generated using
the methods.
The prediction intervals will differ between
models with additive and multiplicative
methods.
Exact formulae for some models.
More general to simulate future sample paths,
conditional on the last estimate of the states,
and to obtain prediction intervals from the
percentiles of these simulated future paths.
Options are available in R using the forecast
function in the forecast package.
State space models
1: Exponential smoothing
49
Outline
1 The state space perspective
2 Simple exponential smoothing
3 Trend methods
4 Seasonal methods
5 Taxonomy of exponential smoothing
methods
6 Innovations state space models
7 ETS in R
State space models
1: Exponential smoothing
50
Exponential smoothing
1.2
1.0
0.8
0.6
0.4
Total scripts (millions)
1.4
1.6
Forecasts from ETS(M,Md,M)
1995
2000
2005
2010
Year
State space models
1: Exponential smoothing
51
Exponential smoothing
1.2
0.6
0.8
1.0
library(forecast)
fit <- ets(h02)
fcast <- forecast(fit)
plot(fcast)
0.4
Total scripts (millions)
1.4
1.6
Forecasts from ETS(M,Md,M)
1995
2000
2005
2010
Year
State space models
1: Exponential smoothing
52
Exponential smoothing
> fit
ETS(M,Md,M)
Smoothing parameters:
alpha = 0.3318
beta = 4e-04
gamma = 1e-04
phi
= 0.9695
Initial states:
l = 0.4003
b = 1.0233
s = 0.8575 0.8183 0.7559 0.7627 0.6873 1.2884
1.3456 1.1867 1.1653 1.1033 1.0398 0.9893
sigma:
0.0651
AIC
AICc
-121.97999 -118.68967
State space models
BIC
-65.57195
1: Exponential smoothing
53
The ets() function in R
ets(y, model="ZZZ", damped=NULL,
alpha=NULL, beta=NULL,
gamma=NULL, phi=NULL,
additive.only=FALSE,
lambda=NULL
lower=c(rep(0.0001,3),0.80),
upper=c(rep(0.9999,3),0.98),
opt.crit=c("lik","amse","mse","sigma"),
nmse=3,
bounds=c("both","usual","admissible"),
ic=c("aic","aicc","bic"), restrict=TRUE)
State space models
1: Exponential smoothing
54
The ets() function in R
y
The time series to be forecast.
model
use the ETS classification and notation: “N” for none,
“A” for additive, “M” for multiplicative, or “Z” for
automatic selection. Default ZZZ all components are
selected using the information criterion.
damped
If damped=TRUE, then a damped trend will be used
(either Ad or Md ).
damped=FALSE, then a non-damped trend will used.
If damped=NULL (the default), then either a damped
or a non-damped trend will be selected according to
the information criterion chosen.
State space models
1: Exponential smoothing
55
The ets() function in R
y
The time series to be forecast.
model
use the ETS classification and notation: “N” for none,
“A” for additive, “M” for multiplicative, or “Z” for
automatic selection. Default ZZZ all components are
selected using the information criterion.
damped
If damped=TRUE, then a damped trend will be used
(either Ad or Md ).
damped=FALSE, then a non-damped trend will used.
If damped=NULL (the default), then either a damped
or a non-damped trend will be selected according to
the information criterion chosen.
State space models
1: Exponential smoothing
55
The ets() function in R
y
The time series to be forecast.
model
use the ETS classification and notation: “N” for none,
“A” for additive, “M” for multiplicative, or “Z” for
automatic selection. Default ZZZ all components are
selected using the information criterion.
damped
If damped=TRUE, then a damped trend will be used
(either Ad or Md ).
damped=FALSE, then a non-damped trend will used.
If damped=NULL (the default), then either a damped
or a non-damped trend will be selected according to
the information criterion chosen.
State space models
1: Exponential smoothing
55
The ets() function in R
y
The time series to be forecast.
model
use the ETS classification and notation: “N” for none,
“A” for additive, “M” for multiplicative, or “Z” for
automatic selection. Default ZZZ all components are
selected using the information criterion.
damped
If damped=TRUE, then a damped trend will be used
(either Ad or Md ).
damped=FALSE, then a non-damped trend will used.
If damped=NULL (the default), then either a damped
or a non-damped trend will be selected according to
the information criterion chosen.
State space models
1: Exponential smoothing
55
The ets() function in R
y
The time series to be forecast.
model
use the ETS classification and notation: “N” for none,
“A” for additive, “M” for multiplicative, or “Z” for
automatic selection. Default ZZZ all components are
selected using the information criterion.
damped
If damped=TRUE, then a damped trend will be used
(either Ad or Md ).
damped=FALSE, then a non-damped trend will used.
If damped=NULL (the default), then either a damped
or a non-damped trend will be selected according to
the information criterion chosen.
State space models
1: Exponential smoothing
55
The ets() function in R
y
The time series to be forecast.
model
use the ETS classification and notation: “N” for none,
“A” for additive, “M” for multiplicative, or “Z” for
automatic selection. Default ZZZ all components are
selected using the information criterion.
damped
If damped=TRUE, then a damped trend will be used
(either Ad or Md ).
damped=FALSE, then a non-damped trend will used.
If damped=NULL (the default), then either a damped
or a non-damped trend will be selected according to
the information criterion chosen.
State space models
1: Exponential smoothing
55
The ets() function in R
alpha, beta, gamma, phi
The values of the smoothing parameters can be
specified using these arguments. If they are set to
NULL (the default value for each of them), the
parameters are estimated.
additive.only
Only models with additive components will be
considered if additive.only=TRUE. Otherwise all
models will be considered.
lambda
Box-Cox transformation parameter. It will be ignored
if lambda=NULL (the default value). Otherwise, the
time series will be transformed before the model is
estimated. When lambda is not NULL,
additive.only is set to TRUE.
State space models
1: Exponential smoothing
56
The ets() function in R
alpha, beta, gamma, phi
The values of the smoothing parameters can be
specified using these arguments. If they are set to
NULL (the default value for each of them), the
parameters are estimated.
additive.only
Only models with additive components will be
considered if additive.only=TRUE. Otherwise all
models will be considered.
lambda
Box-Cox transformation parameter. It will be ignored
if lambda=NULL (the default value). Otherwise, the
time series will be transformed before the model is
estimated. When lambda is not NULL,
additive.only is set to TRUE.
State space models
1: Exponential smoothing
56
The ets() function in R
alpha, beta, gamma, phi
The values of the smoothing parameters can be
specified using these arguments. If they are set to
NULL (the default value for each of them), the
parameters are estimated.
additive.only
Only models with additive components will be
considered if additive.only=TRUE. Otherwise all
models will be considered.
lambda
Box-Cox transformation parameter. It will be ignored
if lambda=NULL (the default value). Otherwise, the
time series will be transformed before the model is
estimated. When lambda is not NULL,
additive.only is set to TRUE.
State space models
1: Exponential smoothing
56
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The ets() function in R
lower,upper bounds for the parameter estimates of
α, β , γ and φ.
opt.crit=lik (default) optimisation criterion used
for estimation.
bounds Constraints on the parameters.
usual region – "bounds=usual";
admissible region – "bounds=admissible";
"bounds=both" (the default) requires the
parameters to satisfy both sets of constraints.
ic=aic (the default) information criterion to be used
in selecting models.
restrict=TRUE (the default) models that cause
numerical difficulties are not considered in model
selection.
State space models
1: Exponential smoothing
57
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
forecast(object,
h=ifelse(object$m>1, 2*object$m, 10),
level=c(80,95), fan=FALSE,
simulate=FALSE, bootstrap=FALSE,
npaths=5000, PI=TRUE, lambda=object$lambda, ..
object: the object returned by the ets() function.
h: the number of periods to be forecast.
level: the confidence level for the prediction
intervals.
fan: if fan=TRUE, suitable for fan plots.
simulate
If simulate=TRUE, prediction intervals generated
via simulation rather than analytic formulae.
Even if simulate=FALSE simulation will be used if
there are no algebraic formulae exist.
State space models
1: Exponential smoothing
58
The forecast() function in R
bootstrap: If bootstrap=TRUE and simulate=TRUE,
then the simulated prediction intervals use
re-sampled errors rather than normally distributed
errors.
npaths: The number of sample paths used in
computing simulated prediction intervals.
PI: If PI=TRUE, then prediction intervals are
produced; otherwise only point forecasts are
calculated. If PI=FALSE, then level, fan, simulate,
bootstrap and npaths are all ignored.
lambda: The Box-Cox transformation parameter. This
is ignored if lambda=NULL. Otherwise, forecasts are
back-transformed via an inverse Box-Cox
transformation.
State space models
1: Exponential smoothing
59
The forecast() function in R
bootstrap: If bootstrap=TRUE and simulate=TRUE,
then the simulated prediction intervals use
re-sampled errors rather than normally distributed
errors.
npaths: The number of sample paths used in
computing simulated prediction intervals.
PI: If PI=TRUE, then prediction intervals are
produced; otherwise only point forecasts are
calculated. If PI=FALSE, then level, fan, simulate,
bootstrap and npaths are all ignored.
lambda: The Box-Cox transformation parameter. This
is ignored if lambda=NULL. Otherwise, forecasts are
back-transformed via an inverse Box-Cox
transformation.
State space models
1: Exponential smoothing
59
The forecast() function in R
bootstrap: If bootstrap=TRUE and simulate=TRUE,
then the simulated prediction intervals use
re-sampled errors rather than normally distributed
errors.
npaths: The number of sample paths used in
computing simulated prediction intervals.
PI: If PI=TRUE, then prediction intervals are
produced; otherwise only point forecasts are
calculated. If PI=FALSE, then level, fan, simulate,
bootstrap and npaths are all ignored.
lambda: The Box-Cox transformation parameter. This
is ignored if lambda=NULL. Otherwise, forecasts are
back-transformed via an inverse Box-Cox
transformation.
State space models
1: Exponential smoothing
59
The forecast() function in R
bootstrap: If bootstrap=TRUE and simulate=TRUE,
then the simulated prediction intervals use
re-sampled errors rather than normally distributed
errors.
npaths: The number of sample paths used in
computing simulated prediction intervals.
PI: If PI=TRUE, then prediction intervals are
produced; otherwise only point forecasts are
calculated. If PI=FALSE, then level, fan, simulate,
bootstrap and npaths are all ignored.
lambda: The Box-Cox transformation parameter. This
is ignored if lambda=NULL. Otherwise, forecasts are
back-transformed via an inverse Box-Cox
transformation.
State space models
1: Exponential smoothing
59