20.106J – Systems Microbiology Lecture 7 Prof. DeLong
advertisement

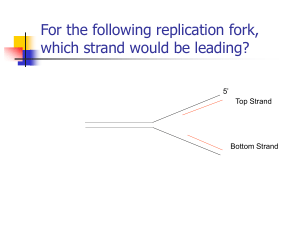
20.106J – Systems Microbiology Lecture 7 Prof. DeLong ¾ Problem set 2 due today. ¾ For next week: we’ll be doing Chapter 8 of Brock ¾ Exam in a week and a half Slide: Central Dogma o Replication, Transcription, Translation o Reverse transcription sometimes Slide: Flow of information o Right now we’re just thinking about information flow within an individual species – how nucleic acid information flow occurs o How you maintain fidelity and copy your DNA for all your daughter cells What we know about DNA: o The four bases o The ring system of the sugar The number of carbons How you tell the difference between DNA and RNA (the lack of oxygen) o The nomenclature of the bases o Alternating linkage (3’ and 5’) o The base pairing (G-C, A-T) –This is how it replicates with such high fidelity. o Anti-parallel (5’ Æ 3’, 3’ Æ 5’) o When the structure was first determined, the pairing was inferred, but the method of replication wasn’t clear It could have been Semiconservative, Conservative, or Random Dispersive. These different methods incorporate the mother strands into the daughter strands in different ways. To determine this, they added 15N labels experimentally – they could predict the densities resulting from each replication method – heavy vs. light The Conclusion, of course, was that it was semiconservative. o The replication process is not simple, and involves a lot of enzymes. Polymerase III can’t just set down on a DNA strand – it needs a DNA primer. That primer is then used to extend the DNA strand. This means that initially it’s not just a DNA strand – it’s a DNARNA hybrid. The DNA polymerase synthesizes 5’ Æ 3’. This means that one strand goes more easily than the other strand. The leading strand goes directly, but the lagging strand develops a lot of smaller fragments – these are called Okazaki fragments (about 1000 bases long). DNA polymerase I (not III) is used on the lagging strand, so that it will eat through the extra primers (polymerase I would stop). An RNA primer is laid down by a primase. The primers have to be removed. Nicks have to be removed by DNA ligase. With a circular DNA, the replication happens circularly (a bubble opens up between the strands, and replication happens there). • This is generally what happens with prokaryotes. • But there are also some that have linear DNA. Regulatory Pathways in prokaryotes – the larger topic of today’s lecture. o The more important means of cell regulation is transcription. Prokaryotic transcription o DNA is more stable than RNA, while RNA can be turned over and used faster than DNA. o The 2’ hydroxy group of RNA is useful here. o RNA polymerase does not need a primer – it just transcribes directly. o Halfway through the sigma factor falls off. o Pribnow box and -35 region. o Some bases are more highly conserved than others. Also, some organisms are more GC-rich than others. o There are different types of sigma factors Sigma 70 – kind of the vanilla flavor – used for “normal” promoters Sigma 32 is used for heat-shock promoters Sigma 54 is used for N limitation promoters o There’s a modularity in how cells can turn on all kinds of different genes. o Strong versus weak promoters. o Initially RNA polymerase binds, the strand is opened up, and transcription begins. o Transcription termination Inverted repeats – these connect to each other, stopping transcription, and they require no extra factors. Row dependent terminations – require extra proteins There are other sorts as well Differences between eukaryotic and prokaryotic transcription o Archaea are very different from bacteria – they do it more like eukaryotes. o Eukaryotes do not have classical operons o Eukaryotic mRNAs are usually sliced, capped, and tailed, in the nucleus o RNA polymerase structure/function differ o Initiation complexes differ o These differences make good targets for antibiotics o Translation – prokaryotes are better in terms of rapid response – transcription and translation happen next to each other – they are coupled. In eukaryotes, one is in the nucleus, the other in the cytoplasm. Overview of Prokaryotic Translation o Slide: simple structure of a prokaryotic gene o Maintaining high enough fidelity for translation is really remarkable o Shine-Dalgarno sequence o The genetic code has been inferred from lots of different experiments – which codons code for which amino acids How this code could have occurred is really remarkable Originally it was assumed to be random, in the 1960s, but this doesn’t seem to be the case, because it seems like there is some order to the groupings. Nobody really knows how it developed yet though. o Transfer RNAs o The early experiments that discovered how this works were really remarkable o The Genetic code is degenerate (meaning that multiple codons can code for the same amino acid). Sometimes there is a bias (in once cell, for example, UUU might be used for phenylalanine more often than UUC is used) Codon families exist. Also codon pairs. o Staying in the correct frame is critical. o The code is not absolutely hard and fast: Recently selenocysteine and pyrrolysine have been dubbed the 21st and 22nd amino acids Previously people had thought that the Selenium in Selenocysteine was added later, but this is incorrect. It has its own codon (UGA – normally nonsense/stop codon!) and transfer RNA. For pyrrolysine, it looks like a similar mechanism, although it’s not yet absolutely hard and fast. (UAG codon) o The tRNA has to be very well matched (very specific covalent bond). o Aminoacyl-tRNA Synthetase recognizes both the amino acid and the tRNA. It’s a two-step reaction. Anticodon loop and acceptor stem of the tRNA are both involved. o Messenger RNAs are very labile – they turn over on the order of minutes in the cells, getting eaten up by nucleases. Other RNAs are more stable. o Drugs that inhibit translation: there are a whole series of antibiotics that inhibit bacterial translation without touching eukaryotic translation. o Initiation 50S 30S Shine-Delgarno o Elongation Movement of ribosome along the strand. After peptide bond formation, there’s a new empty site, and the ribosome moves along so that the chain grows. Incredible that the ribosome can do this with such high fidelity. o Ribozymes are catalytic RNAs