Lecture 7 µ σ µ µ
advertisement

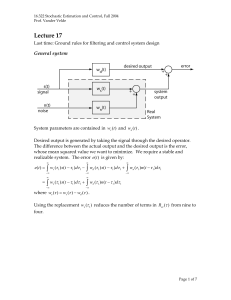
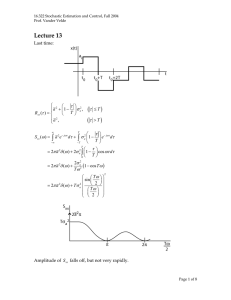
16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde Lecture 7 Last time: Moments of the Poisson distribution from its generating function. G ( s ) = e µ ( s −1) dG = µ e µ ( s −1) ds d 2G = µ 2e µ ( s −1) 2 ds dG =µ X= ds s =1 X2 = d 2G ds 2 + s =1 dG ds s =1 = µ2 + µ σ2 = X2 − X2 = µ2 + µ − µ2 =µ =X Example: Using telescope to measure intensity of an object Photon flux Î photoelectron flux. The number of photoelectrons are Poisson distributed. During an observation we cause N photoelectron emissions. N is the measure of the signal. S = N = λt σ N2 = µ = λ t λt S = = λt σN λt 2 1⎛ S ⎞ t= ⎜ ⎟ λ ⎝σN ⎠ For signal-to-noise ratio of 10, require N = 100 photoelectrons. All this follows from the property that the variance is equal to the mean. This is an unbounded experiment, whereas the binomial distribution is for n number of trials. 9/30/2004 9:55 AM Page 1 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde 3. The Poisson Approximation to the Binomial Distribution The binomial distribution, like the Poisson, is that of a random variable taking only positive integral values. Since it involves factorials, the binomial distribution is not very convenient for numerical application. We shall show under what conditions the Poisson expression serves as a good approximation to the binomial expression – and thus may be used for convenience. b( k ) = n! p k (1 − p ) n −k k !( n − k )! Consider a large number of trials, n, with small probability of success in each, p, such that the mean of the distribution, np, is of moderate magnitude. Define µ ≡ np with n large and p small p= µ n Recalling: n ! ~ 2π n n+ 1 2 −n e ⎛ µ⎞ e − µ = lim ⎜ 1 − ⎟ n →∞ n⎠ ⎝ Stirling's formula n n! µk b( k ) = k !( n − k )! n k ≈ = ≈ µk ⎛ µ⎞ ⎜1 − ⎟ n⎠ ⎝ 2π n n+ k! 2π ( n − k ) µk n k! n n+ 1 2 n+ n −k 1 2 −n n+ e 1 2 e− n+k n k 1 2 −n e ⎛ k⎞ ⎜1 − ⎟ ⎝ n⎠ n −k + 1 2 ek ⎛ µ⎞ ⎜1 − ⎟ n⎠ ⎝ ⎛ µ⎞ ⎜1 − ⎟ n⎠ ⎝ n −k n −k µ k e− µ as n becomes large relative to k k ! e − k ek 1 = µ k e− µ k! The relative error in this approximation is of order of magnitude (k − µ )2 Rel. Error ~ n 9/30/2004 9:55 AM Page 2 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde However, for values of k much smaller or larger than µ , the probability becomes small. The Normal Distribution Outline: 1. Describe the common use of the normal distribution 2. The practical employment of the Central Limit Therorem 3. Relation to tabulated functions Normal distribution function Normal error function Complementary error function 1. Describe the common use of the normal distribution Normally distributed variables appear repeatedly in physical situations. • Voltage across the plate of a vacuum tube • Radar angle tracking noise • Atmospheric gust velocity • Wave height in the open sea 2. The practical employment of the Central Limit Therorem X i (i = 1, 2,..., n ) are independent random variables. Define the sum of these Xi as n S = ∑ Xi i =1 n S = ∑ Xi i =1 n σ S = ∑ σ X2 2 i =1 i Then under the condition lim n →∞ β =0 σ S3 n β = ∑βX i =1 i βX = ( Xi − Xi ) 3 i 9/30/2004 9:55 AM Page 3 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde the limiting distribution of S is the normal distribution. Note that this is true for any distributions of the Xi. These are sufficient conditions under which the theorem can be proved. It is not clear that they are necessary. Notice that each of the noises mentioned earlier depend on the accumulated effect of a great many small causes e.g., voltage across plate: electrons traveling from cathode to plate. It is convenient to work with the characteristic function since we are dealing with the sum of independent variables. Normal probability density function: 1 − e 2π f ( x) = ( x − m )2 2σ 2 Normal probability distribution function: x F ( x) = − 1 e 2π σ ∫ −∞ ( u − m )2 2σ 2 du x −m = 2 σ ∫ −∞ v − 1 e 2 dv 2π σ Where: m= X v= dv = u−m σ 1 σ du This integral with the integrand normalized is tabulated. It is called the normal probability function and symbolized with Φ . 9/30/2004 9:55 AM Page 4 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde 2 x 1 − v2 Φ( x) = ∫ e dv π 2 −∞ This is a different x. Note the relationship between this and the quantity x previous defined. We use x again here as this is how Φ is usually written. Not only this function but also its first several derivatives which appear in analytic work are tabulated. 3. Relation to tabulated functions Even more generally available are the closely related functions: Error function: x 2 − u2 erf ( x ) = ∫ e du π 0 Complementary error function: ∞ 2 − u2 cerf ( x ) = ∫ e du π Φ( x) = x 1⎡ ⎛ x ⎞⎤ 1 + erf ⎜ ⎟⎥ ⎢ 2⎣ ⎝ 2 ⎠⎦ 1 φ (t ) = 2π σ 1 = 2π ∞ ∫e jtx e − ( x − m )2 2σ 2 dx −∞ ∞ ∫e jt ( m +σ y ) e − y2 2 dy , where y = −∞ x−m σ 2 ∞ y − 1 e jtm ∫ (cos ( tσ y ) + j sin ( tσ y ))e 2 dy = 2π −∞ 2 ∞ y − 2 jtm e ∫ cos ( tσ y ) e 2 dy = 2π −∞ − = t 2σ 2 2 2 jtm π e e 2π 2 ⎛ t 2σ 2 ⎞ ⎜⎜ jtm − ⎟ 2 ⎟⎠ ⎝ =e Differentiation of this form will yield correctly the first 2 moments of the distribution. 9/30/2004 9:55 AM Page 5 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde Most important property of normal variables: any linear combination (weighted sum) of normal variables, whether independent or not, is another normal variable. Note that for zero mean variables x2 − 2 1 f ( x) = e 2σ 2π σ φ (t ) = e − σ 2t 2 2 Both are Gaussian forms. The Normal Approximation to the Binomial Distribution The binomial distribution deals with the outcomes of n independent trials of an experiment. Thus if n is large, we should expect the binomial distribution to be well approximated by the normal distribution. The approximation is given by the normal distribution having the same mean and variance. Thus − 1 b( k , n , p ) ≈ e 2π npq ( k − np )2 2 npq ( k − np )3 ( npq) 2 The relative fit is good near the mean if npq is large and degenerates in the tails where the probability itself is small. Relative error is of the order of The Normal Approximation to the Poisson Distribution Also the Poisson distribution depends on the outcomes of independent events. If there are enough of them, 9/30/2004 9:55 AM Page 6 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde − 1 P(k , µ ) ≈ e 2πµ ( k − µ )2 2µ Relative error is of the order of (k − µ )3 µ2 The relative fit is subject to the same behavior as the binomial approximation. Interpretation of a continuous distribution approximating a discrete one: The value of the normal density function at any k approximates the value of the discrete distribution for that value of k. Think of spreading the area of each impulse over a unit interval. Then the height of each rectangle is the probability that the corresponding value of k will be taken. The normal curve approximates this step-wise function. Note that in summing the probabilities for values of k in some interval, the approximating normal curve should be integrated over that interval plus ½ on each end to get all the probability associated with those values of k. P ( N1 ≤ X ≤ N 2 ) = N2 + N2 ∑ P(k , µ ) ≈ ∫ k = N1 1 2 1 N1 − 2 N2 ∑ P(k ) k = N1 − 1 e 2πµ ( x − µ )2 2µ dx 1 1 ⎛ ⎞ ⎛ ⎞ ⎜ N2 + 2 − µ ⎟ ⎜ N1 − 2 − µ ⎟ = Φ⎜ ⎟−Φ⎜ ⎟ µ µ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ⎝ ⎠ Multidimensional Normal Distribution Probability density function: 1 ⎡ 1 ⎤ f ( x) = exp ⎢ − ( x − X )Τ M −1 ( x − X ) ⎥ n ⎣ 2 ⎦ 2π 2 M ( ) 9/30/2004 9:55 AM Page 7 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde Assuming zero mean, which is often the case: 1 ⎡ 1 ⎤ f ( x) = exp ⎢ − x Τ M −1 x ⎥ n ⎣ 2 ⎦ ( 2π ) 2 M For zero mean variables: contours of constant probability density are given by: x T M −1 x = c 2 Not expressed in principal coordinates if the Xi are correlated. Need to know the rudimentary properties of eigenvalues and eigenvectors. M is symmetric and full rank. Mvi = λi vi ⎧1, i = j vi T v j = δ ij = ⎨ ⎩0, i ≠ j This probability density function can be better visualized in terms of its principal coordinates. These coordinates are defined by the directions of the eigenvectors of the covariance matrix. The appropriate transformation is y = Vx ⎡ ← v1T → ⎤ ⎢ ⎥ V =⎢ M ⎥ ⎢ ← vnT → ⎥ ⎣ ⎦ Thus yi is the component of x in the direction vi . (In terms of the new variable y , the contours of constant probability density are) 9/30/2004 9:55 AM Page 8 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde x T M −1 x = y TV −T M −1V −1 y = y T Y −1 y Y −1 = V −T M −1V −1 Y = VMV T ⎡↑ ↑ ⎤ ⎢ ⎥ = VM ⎢ v1 ... vn ⎥ ⎢↓ ↓ ⎥ ⎣ ⎦ ⎡← v1T → ⎤ ⎡ ↑ ↑ ⎤ ⎥ ⎢ ⎥⎢ = ⎢ ... ⎥ ⎢λ1v1 ... λn vn ⎥ ⎢← v1T → ⎥ ⎢ ↓ ↓ ⎥⎦ ⎣ ⎦⎣ ⎡λ1 ⎤ ⎢ ⎥ O = ⎢ ⎥ λn ⎥⎦ ⎢⎣ Y is the covariance matrix for the random variable Y = VX , so the λi are the variance of the Yi. ⎡1 ⎤ ⎢λ ⎥ 1 ⎢ ⎥ Y −1 = ⎢ O ⎥ ⎢ 1⎥ ⎢ ⎥ λn ⎦⎥ ⎣⎢ ⎡1 ⎤ ⎢λ ⎥ 1 ⎢ ⎥ 2 yT ⎢ O ⎥y=c ⎢ 1⎥ ⎢ ⎥ λn ⎦⎥ ⎣⎢ y T Y −1 y = y12 λ1 + y22 λ2 + ... + yn2 λn = c2 These are the principal coordinate with intercepts at yi = ± c λi with λi the standard deviation of yi. Note that two random variables, each having a normal distribution singly, do not necessarily have a binormal joint distribution. However, if the random variables are independent and normally distributed, their joint distribution is clearly a multidimensional normal distribution. 9/30/2004 9:55 AM Page 9 of 10 16.322 Stochastic Estimation and Control, Fall 2004 Prof. Vander Velde Two dimensional case- continued: mij = X i X j f 2 ( x1 , x2 ) = 1 2π m11m22 − m12 2 ⎡ m x 2 − 2m12 x1 x2 + m11 x2 2 ⎤ exp ⎢ − 22 1 ⎥ 2(m11m22 − m12 2 ) ⎣ ⎦ m11 = σ 12 m22 = σ 22 m12 = µ12 ρ12 = µ12 σ xσ y In terms of these symbols: 2 ⎡ ⎛ x ⎞2 ⎛ x1 ⎞ ⎛ x2 ⎞ ⎛ x2 ⎞ ⎤ 1 ⎢ ⎜ ⎟ − 2 ρ12 ⎜ ⎟ ⎜ ⎟ + ⎜ ⎟ ⎥ σ 1 ⎝ σ1 ⎠ ⎝ σ 2 ⎠ ⎝ σ 2 ⎠ ⎥ exp ⎢ − ⎝ 1 ⎠ f 2 ( x1 , x2 ) = ⎢ ⎥ 2 2(1 − ρ12 2 ) 2πσ 1σ 2 1 − ρ12 ⎢ ⎥ ⎢⎣ ⎥⎦ Note that if a set of random variables having the multidimensional normal distribution is uncorrelated, they are independent. This is not true in general. 9/30/2004 9:55 AM Page 10 of 10