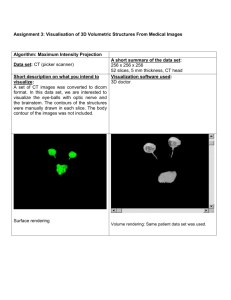
Meshing with Grids: Toward functional abstractions for grid-based visualization Rita Borgo David Duke
advertisement

Meshing with Grids: Toward functional abstractions for grid-based visualization Rita Borgo∗ David Duke† University of Leeds University of Leeds Malcolm Wallace‡ University of York Colin Runciman§ University of York Abstract A challenge for grid computing is finding abstractions that separate concerns about what a grid application must achieve from the specific resources on which it might be deployed. One approach, taken by a range of toolkits and APIs, is to add further layers of abstraction above the raw machine and network, allowing explicit interaction with grid services. The developers’ view, however, remains that of a stateful von Neumann machine, and the interleaving of grid services with domain computations adds complexity to systems. An alternative is to replace this tower of abstraction with a new kind of programming structure, one that abstracts away from complexities of control and location while at the same time adapting to local resources. This paper reports early results from a project exploring the use of functional language technologies for computationally demanding problems in data visualization over the grid. Advances in functional language technology mean that pure languages such as Haskell are now feasible for scientific applications, bringing opportunities and challenges. The opportunities are the powerful types of ‘glue’ that higher order programming and lazy evaluation make possible. The challenge is that structures that work well within stateful computation are not necessarily appropriate in the functional world. This paper reports initial results on developing functional approaches to an archetypal visualization task, isosurfacing, that are a preliminary step towards implementing such algorithms on a polytypic grid. 1 Introduction Distribution and parallelism are inherent properties of grid computing environment, and grid programming requires attitude and skills that go beyond that of traditional sequential or even parallel and distributed programming. Programmers need to cope not only with sharing of resources but to handle computation in an environment characterised by heterogeneous and dynamic resources. Resources allocated to a program may vary between executions, and in some cases may change during execution. Managing this complexity ideally requires a combination of run-time support systems and high level abstraction that allow the programmer to separate cleanly applications concerns and grid interfaces. Building such layers of service abstraction is an approach that has served computing well in the past, giving developers reusable domain-independent blocks for building an application. For example middleware and libraries such as Globus, OpenGL, and VTK are likewise abstractions that provide high-level access to lower-level services (HPC tasks, graphical rendering, and visualization, respectively). Data visualization is an application domain that has a close affinity with grid computing for two reasons: large scale datasets are challenging computational problem, and visualization is frequently an important component of grid computing applications. A number of architectures have been proposed and developed for data visualization, including spreadsheets, relational databases, spray-rendering, scene graphs, and pipelines. They provide a layer of application-oriented services on 1 which problem-specific visualization tools can be constructed. Although some of these architectures can be used in a grid environment (e.g. Cactus [1]) this is by explicit use of low-level services. Of the approaches explored to date, the pipeline model has found the most widespread use. It underlies the implementation of well-known systems such as AVS, SCIRun, and also serves as a conceptual model for visualization workflow as VTK [16],. For the pipeline model, services provide the capability to organize visualization operations within a dataflow-like network. Some pipelined systems extend the basic model with demand-driven evaluation and streaming of dataset chunks, again frozen into the service layer. Streaming [12] is an enrichment to the basic model that allows a pipeline to pass datasets in chunks. For scientific data, such chunks are usually spatially contiguous subsets of the full extent. Some algorithms, for example Marching Cubes [14], can operate on individual chunks in isolation. Others require access to the full dataset, for example surface reconstruction: the dataset may be passed as a sequence of chunks, with algorithms working downstream and upstream on different sequencesof the pipeline. However, this layered approach fixes design decisions associated with the services, without regard for the operations that are implemented in terms of those services. Pipeline services provide a lazy, dataflow-like model, but client operations are defined as a separate layer of stateful computation. While pipeline capabilities have advanced, both the services and the algorithms that use those services continue to be implemented using imperative languages, usually C or C++. The underlying computational model Figure 1: (a) Marching cubes applied to a 2D dataset (e.g. marching squares) and extracted isocontour; (b) Marching cubes applied to a 3D dataset and extracted isosurface.) is call-by-value parameter-passing, yet the way to access services from an application is conceptually callby-need. In contrast, non-strict functional languages such as Haskell [7] use a call-by-need evaluation strategy in which function arguments are only evaluated to the extent they are demanded (if at all). Apart from closely matching the pipeline model, this strategy also provides a ‘new kind of glue’ [8] for assembling programs from components. Recent work on functional languages has produced new forms of generic programming including polytypic functions (GH [3]) and typegeneric frameworks (SYB [10]). In Generic Haskell (GH), a polytypic function captures a family of polymorphic functions in a single, inductive, and typed definition. Instances of the family for specific types can be generated automatically by the GH compiler. In a grid context, polytypic definitions may support single functions that capture patterns of computation over a family of data representations. This paper sets out initial findings on work aimed at using functional technologies for data visualization over the grid. Implementations of ‘lazy’ functional languages have advanced significantly over the last decade. They now have well-developed interfaces to low-level services such as graphics and I/O. In this paper we take surfacing as an archetypal visualization task. We illustrate how pipelining and demand-driven evaluation become naturally integrated within the expression of an algorithm. The resulting implementations have a pattern of space utilization quite different to their imperative counterparts, occupying an intermediate point between purely in-core and out-of-core approaches. Section 2 revisits the basic marching cubes algorithm for surface extraction, using the lazy functional language Haskell [7]. Through a series of refinements, we show how pipelining and demand-driven evaluation allow the use of memoization to improve performance. Section 2.5, on evaluation, gives particular attention to the space performance of our implementation. The lazy streaming approach set out here features low memory residency, even with larger datasets. Section 3 discusses related research. The work reported here is a first step in a much larger programme of work, and in Section 4 we summarize the achievement to date. 2 Marching Cubes, Functionally Without giving a full tutorial on Haskell, we need to introduce some key aspects of functional languages, for which we use the classic Marching Cubes algorithm as an exemplar. Marching Cubes is a technique widely used in the visualization field to represent 3D scalar fields in terms of approximating polygonal surfaces. Given a scalar field F and a constant value c then the locus of points x, with x ∈ R 3 , that satisfies the equation F (x) = c represents an isosurface of value c. Given a threshold value c the marching cube algorithm proceeds through the scalar field, testing the corner of each voxel (or cube) in the scalar field as being either above or below the threshold. If one or more corners of the cube have values less than the threshold, and one or more have values greater than this value, the voxel must contribute some component of the isosurface. Locating which edges of the cube are intersected by the isosurface, it is possible to determine the polygons that must be created to represent the part of isosurface that is intersected by the voxel. The result of the marching cubes algorithm is a smooth surface that approximates the isosurface that is constant along a given threshold. Figure 1 represents the algorithm for the 2D and 3D case respectively. Examples of 2D scalar fields are temperature, pressure and humidity in a meteorologichal context, examples of 3D scalar fields can be taken from the medical field lik eCT scans of human skull or body parts. We first implement it in the standard fashion, iterating through an array of sample values, then refine the implementation into suite lazily streaming variations. These illustrate two of the main benefits of laziness – on-demand processing (permitting fine-grained pipelining of input and output data), and automatic sharing of already-computed results. In the following section we introduce some of the early results presented in more detail in [5] we then exploit how our approach can interestingly suit within the grid context. 2.1 Ordinary, array-based algorithm. First, we explore a straightforward representation of the dataset as a three-dimensional array of sample values. type XYZ = (Int,Int,Int) type Num a => Dataset a = Array XYZ a These type definitions declare synonyms for the actual array representation. Concrete type names are capitalised, for instance the Array index domain type is XYZ. The type variable (lower-case a) in the range of the array indicates that the type of the samples themselves is generic (polymorphic). The predicate Num a constrains the polymorphism: samples must have arithmetic operations defined over them. Thus, we can reuse the algorithm with bytes, signed words, floats, complex numbers, and so on, without change. isosurface :: Num a => a -> Dataset a -> [Triangle b] This type declaration (signature) of the Marching Cubes isosurface function shows that it takes two arguments, a threshold value and the dataset, and computes from them a sequence of triangles approximating the surface. The triangles can be fed directly into e.g. OpenGL for rendering. The full visualization pipeline can be written:1 pipeline t = mapper view . normalize . isosurface t . reader Here the dot . operator means pipelined composition of functions. The last function in the chain is applied to some input (a filename), and its results are fed back to the previous function, whose results are fed back, and so on. Since this operator is the essence of the pipeline model, let’s look briefly at its definition: (.) :: (b->c) -> (a->b) -> a -> c (f . g) x = f (g x) Dot takes two functions as arguments, with a third argument being the initial data. The result of applying the second function to the data is used as the argument to the first function. The type signature should help to make this clear - each type variable, a, b, and c, stands for any arbitrary (polymorphic) type, where for instance each occurrence of a must be the same, but a and b may be different. Longer chains of these compositions can be built up, as we have already seen in the earlier definition of pipeline. Dot is our first example of higher-order function. From the very name “functional language” one can surely guess that functions are important. Indeed, passing functions as arguments, and receiving functions as results, comes entirely naturally. A function that receives or returns a function is called higher-order. Shortly, we will need another common higher-order function, map, which takes a function f and applies it to every element of a sequence: map :: (a->b) -> [a] -> [b] map f [] = [] map f (x:xs) = f x : map f xs 1 Our Haskell implementation is actually built directly on the HOpenGL binding, so the mapping phase is implemented slightly differently, via a function that is invoked as the GL display callback. This definition uses pattern-matching to distinguish the empty sequence [], from a non-empty sequence whose initial element is x, with the remainder of the sequence denoted by xs. Colon : is used both in patternmatching, and to construct a new list. Now to the algorithm itself. We assume the classic table, either hard-coded or generated by the Haskell compiler from some specification. Full details of these tables are not vital to the presentation and are omitted; see [14] for example. Marching Cubes iterates through the dataset from the origin. At every cell it considers whether each of the eight vertices is below or above the threshold, treating this 8-tuple of Booleans as a byte-index into the case table. Having selected from the table which edges have the surface passing through them, we then interpolate the position of the cut point on each edge, and group these points into threes as triangles, adding in the absolute position of the cell on the underlying grid. isosurface threshold sampleArray = concat [ mcube threshold lookup (i,j,k) | k <- [1 .. ksz-1] , j <- [1 .. jsz-1] , i <- [1 .. isz-1] ] where (isz,jsz,ksz) = rangeSize sampleArray lookup (x,y,z) = eightFrom sampleArray (x,y,z) In Haskell, application of a function to arguments is by juxtaposition so in the definition of isosurface, the arguments are threshold and sampleArray. The standard array function rangeSize extracts the maximum co-ordinates of the grid. The larger expression in square brackets is a list comprehension2 , and denotes the sequence of all applications of the function mcube to some arguments, where the variables (i,j,k) range over (or are drawn from) the given enumerations. The enumerators are separated from the main expression by a vertical bar, and the evaluation order causes the final variable i to vary most rapidly. This detail is of interest mainly to ensure good cache behaviour, if the array is stored with x-dimension first. The comprehension can be viewed as equivalent to nested loops in imperative languages. The result of computing mcube over any single cell is a sequence of triangles. These per-cube sequences are concatenated into a single global sequence, by the standard function concat. Now we look more closely at the data structure representing an individual cell. For a regular cubic grid, this is just an 8-tuple of values from the full array. type Cell a = (a,a,a,a,a,a,a,a) eightFrom :: Array XYZ a -> XYZ -> Cell a eightFrom arr (x,y,z) = ( arr!(x,y,z), arr!(x+1,y,z) 2 It bears similarities to Zermelo-Frankel (ZF) set comprehensions in mathematics. , arr!(x+1,y+1,z), arr!(x,y+1,z) , arr!(x,y,z+1), arr!(x+1,y,z+1) , arr!(x+1,y+1,z+1), arr!(x,y+1,z+1) ) Finally, to the definition of mcube: mcube :: a -> (XYZ->Cell a) -> XYZ -> [Triangle b] mcube thresh lookup (x,y,z) = group3 (map (interpolate thresh cell (x,y,z)) (mcCaseTable ! bools)) where cell = lookup (x,y,z) bools = toByte (map8 (>thresh) cell) The cell of vertex sample values is found using the lookup function that has been passed in. We derive an 8-tuple of booleans by comparing each sample with the threshold (map8 is a higher-order function like map, only over a fixed-size tuple rather than an arbitrary sequence), then convert the 8 booleans to a byte (bools) to index into the classic case table (mcCaseTable). The result of indexing the table is the sequence of edges cut by the surface. Using map, we perform the interpolation calculation for every one of those edges, and finally group those interpolated points into triples as the vertices of triangles to be rendered. The linear interpolation is standard: interpolate :: Num a => a -> Cell a -> XYZ -> Edge -> TriangleVertex interpolate thresh cell (x,y,z) edge = case edge of 0 -> (x+interp, y, z) 1 -> (x+1, y+interp, z) ... 11 -> (x, y+1, z+interp) where interp = (thresh - a) / (b - a) (a,b) = selectEdgeVertices edge cell Although interpolate takes four arguments, it was initially applied to only three in mcube. This illustrates another important higher-order technique: a function of n arguments can be partially applied to its first k arguments; the result is a specialised function of n − k arguments, with the already-supplied values ‘frozen in’. 2.2 Factoring Common Design Patterns The implementation outlined so far is a naive and quite straightforward “functional translation” of the traditional marching cubes algorithm. As for the original C implementation sections where improvements can be made are easy to spot: (1) the entire dataset is assumed to be loaded in memory; (2) common behaviours like threshold comparison and interpolant computation are not factored out and shared between adjoining cells; (3) and ambiguous cell configurations are not considered. The ideal solution to the listed issues would intuitively be an implementation of the algorithm that would take care of all the three kind of problems simultaneously. However often ideal solutions are taylored to specific resources of computation, policy not affordable in a multi-facet environment like the grid. Experience shows how to one holistic solution it is often preferable an amenable suite of solutions capable to efficiently provide optimal trade-offs between results and available computational power: different implementations for different environments. However the ability to swap between different versions of the same algorithms involves evincing crucial patterns of behaviour within the algorithm itself. Exploiting the abstraction and expression power of Haskell in the context of the marching cubes algorithm, we have outlined several different implementations that in turn take care of memory issues, when the entire dataset cannot be loaded in memory, and sharing of computation, when the same computation is carried on the same data more than once. 2.2.1 Stream based algorithm When dealing with large dataset the monolithic array data structure presented so far is not feasible; it simply may not fit in core memory. A solution is to separate traversal and processing of data. For its inner structure the marching cube algorithm only ever needs at any one moment, a small partition of the whole dataset: a single point and 7 of its neighbours suffices, making up a unit cube of sample values. If we compare this with a typical array or file storage format for regular grids (essentially a linear sequence of samples), then the unit cube is entirely contained within a “window” of the file, corresponding to exactly one plane + line + sample of the volume. The ideal solution is to slide this window over the file, constructing one unit cube on each iteration, and dropping the previous unit cube. Figure 2 illustrates the idea. Figure 2: Sliding a window over a grid Following this idea our first implementation provides a streamed version of the algorithm as follow: isosurfaceS :: (Ord a, Int a, Fract b) => a -> Dataset a -> [Triangle b] isosurfaceS thresh (D size samples) = concat (zipWith2 (mcubeS thresh) (cellStream samples) allXYZ ) where cellStream = disContinuities size . mkStream size allXYZ = [XYZ i j k | k <- [0 .. ksz-2] , j <- [0 .. jsz-2] byte stream, before it is tupled up into cells, rather than , i <- [0 .. isz-2]] after. (XYZ isz jsz ksz) = size isosurfaceT :: (Ord a, Int a, Fract b) => a -> Dataset a -> [Triangle b] mcubeS :: (Ord a, Int a, Fract b) => a -> Cell a -> XYZ -> [Triangle b] isosurfaceT thresh (D size samples) = concat (zipWith3 (mcubeT thresh) mcubeS thresh cell xyz = (cellStream samples) group3 (map (interpolate thresh cell xyz) (idxStream samples) allXYZ ) (mcCaseTable ! byte)) where where cellStream = disContinuities size . byte = toByte (mapCell (>thresh) cell) mkStream size Haskell allows us to read data out of a file in this idxStream = map toByte . cellStream . streamed fashion using lazy file I/O. The content of the map (>thresh) file appears to the program as a sequence of bytes, exallXYZ = [XYZ i j k | k <- [0 .. ksz-2] tended on-demand one byte at a time.3 As for dropping , j <- [0 .. jsz-2] data after it has been consumed, Haskell is a garbage, i <- [0 .. isz-2]] collected language, so when a datum is no longer ref(XYZ isz jsz ksz) = size erenced by the computation, the memory storing it is recycled automatically. mcubeT :: (Int a, Fract b) => a -> Cell a The datatype representing the dataset is constructed -> Byte -> XYZ -> [Triangle b] from a lazy sequence of samples, stored along with the mcubeT thresh cell index xyz = bounds of the grid: group3 (map (interpolate thresh cell xyz) (mcCaseTable ! index)) data Num a => Dataset a = D XYZ [a] Taking the notion of sharing-by-construction one The sliding window of eight point values (cell) is step further, we now memoize the interpolation of extracted from the lazy stream of samples as follows: edges. Recall that, in the result of the mcCaseTable, 8 copies of the datastream are laid side-by-side, one the sequence of edges through which the isosurface value from each of the 8 is then repeatedly sliced off passes may have repeats, because the same edge beand glued together into a cell. We refer to [5] for a longs to more than one triangle of the approximated surmore detailed description of the code. Table 2 shows face. But in general, an edge that is incident on the isothe memory performances of our streamed implemen- surface is also common to four separate cells, and we tation. would like to share the interpolation calculation with The advantage of call-by-need over call-by-name is those cells too. So, just as the threshold calculation was that although the evaluation of an item might be de- performed at an outer level, on the original datastream, layed until it is needed, it is never repeated, no mat- something similar can be done here building 12-tuple of ter how often the value is used. If we want to share a possible edges, one entry for each cube edge, adding a computation between different parts of the program, we per-edge description of how to compute the interpolajust arrange for the shared value to be constructed in tion one place, by one expression, rather than constructing it multiple times which leads to multiple evaluations. type CellEdge a = (a,a,a,a,a,a,a,a,a,a,a,a) In the streaming version of marching cubes presented so far, we can see that the reading of sample values isosurfaceI :: (Ord a, Int a, Fract b) => from file is shared and performed only once. However, a -> Dataset a -> [Triangle b] by construction, comparison against the threshold value isosurfaceI thresh (D size samples) = (in mcubeS) is performed eight times for every sample, concat (zipWith3 mcubeI because on each occasion, the sample is at a different (edgeStream samples) vertex position in the cell. Depending on the compu(idxStream samples) allXYZ ) tational power available it is sometime worth to allow where for redundant computations rather than to increase the edgeStream = disContinuities size . complexity of the algorithm or adding extra structure mkCellEdges thresh size at memory expenses. However such a conclusion can cellStream = disContinuities size . be often achieved only after a performance comparison mkStream size of both solutions. For what concerns algorithm comidxStream = map toByte . cellStream . plexity in our implementation it does not represents an map (>thresh) issue, to compute the comparison only once per sample, allXYZ = [XYZ i j k | k <- [0 .. ksz-2] we just need to do the thresholding against the original , j <- [0 .. jsz-2] , i <- [0 .. isz-2]] 3 For efficiency, the underlying system may choose to hold (XYZ isz jsz ksz) = size variable-size buffers for the file, but crucially, that buffering can be tuned to match available resources of memory, disc, and processor. mcubeI :: Num a => CellEdge a -> Byte -> XYZ -> [Triangle a] mcubeI edges index xyz = group3 (map (selectEdge edges xyz) (mcCaseTable ! index)) This per-edge implementation guarantees that an interpolated vertices is computed only once and therefore no replication of the same value are present. When dealing with slow graphics hardware the possibility to reduce the amount of information sent to be rendered (i.e. duplicated primitives like vertices, edges or faces) is worth to be prosecuted. Up to now we have built three different version of the same algorithm able to cope with the previously marked issues. Each version represents an independent and ready to execute program and at the same time as the flexibility to be merged with with its siblings to generate a unique optimized solution. We still miss one point worth of noting, it is well-known that in the original marching cubes, ambiguous cases can occur, and several efforts have been carried on in literature to enhance and generalize the original method to assure topological correctness of the result. Within the available solutions we adopted the approach proposed in [2, 13]. 2.3 Functional Patterns following defines a class of algorithm that given a cell intersected by the contour (isosurface in 3D) follows it walking along its neighbours until the starting point (the surface border) is reached. In our Haskell implementation we have split the contour following algorithm into two main functions: (1) Traverse Seeds: which given a Seed Set and a threshold value, searches the seeds sets for all the cells that constitute a seed for the given value. (2) Grow Contour: which given a Seed grows the contour following the contour path through cells adjacent to the seed. The function signature are expressed as follows: traverseSeeds:: Dataset a -> a -> [Seed a] -> [Triangle b] growContour:: Dataset a -> a -> Seed a -> [Triangle b] Our implementation of the Contour Tracking algorithm is built on top of the marching cube implementation, first the Seed data is introduced to define an arbitrary type of cell (in the regular case either a cube or a tetra) while growContour employs at its interior alternatively mcube or mtetra to extract the complete isosurface according to the seed (cell) kind. 2.4 Observations. The approach presented so far has several interesting aspects. The availability of a suite of polymorphic versions of the same algorithm allows to choose between the more suitable ones for the type of resources available. Figures from Tables 3 and 4 show how performance can change between platforms with similar comisosurface:: a -> Dataset a -> [Triangle b] putational power but different architectures. Moreover mcube:: a -> Cell a -> Format -> Dataset a through polymorphic types (sec 2.1) functions can be -> [Triangle b] defined independent of the datatypes available on a specific architecture; type predicates allow developers to We pushed the abstraction a step further generalizset out the minimum requirements that particular types ing the interface to other surface fitting techniques in must satisfy. Beyond the scope of this paper, polytypism the means of marching tetrahedra and contour tracking. [9], also known as structural polymorphism on types, Both algorithm fall within the aforementioned specifihas the capability to abstract over data organisation and cation. The marching tetrahedra algorithm is closely traversal, e.g. a polytypic marching cubes could be aprelated to marching cubes except that the fundamental plied to other kinds of dataset organization like irregsampling structure is a tetrahedron instead of a cube. ular grids. The employment of a functional language Extension of the marching cubes code presented so far, like Haskell makes the construction of such a suite easy to the marching tetrahedra technique keeps unchanged to achieve. Its abstraction power outlines common rethe isosurface signature while the marching tetrahedra cursive patterns quite easily. If we consider the class of itself looks as follow. surface fitting techniques presented the emerging pattern is the one made up of a set of Cells (the Dataset) mtetra :: (Num a, Int a, Fract b) => a -> a threshold value and a fitting technique. The fitting TetraGrid a -> Cell a -> technique itself (marching cubes, marching tetrahedra, XYZ -> trilinear interpolation) appears strictly dependent on the [ Triangle b ] Cell kind (cube or tetrahedra) up to a generic and commtetra thresh g cell lookup = prehensive definition that culminates in the Seed definigroup3 map interpolate g ((!)mtCaseTable tion. The generic pattern can be then specified accord(caseIndex lookup cell thr)) ing to the kind of Dataset (Cell) and within each imThe interpolation function remains unchanged plementation further qualified with respect to specific as well while mcCaseTable is substituted with computational issues. At the same time the intrinsic mtCaseTable table containing the possible configura- property of the language where each function is indetion of the interpolant within a tetrahedral cell. Contour pendent of the other ease the process of merging pieces Occurrence of the same computational pattern are easily evinceable from the signature of each implemented function. The creation of a gluing interface for the suite of algorithm version is straightforward: Table 1: Dataset Statistics. size wndw surface (b) neghip 64×64×64 4,16 131,634 hAtom 128×128×128 16,51 134,952 statueLeg 341×341×93 116,62 553,554 aneurism 256×256×256 65,79 1,098,582 skull 256×256×256 65,79 18,415,053 stent8 512×512×174 262,65 8,082,312 vertebra8 512×512×512 262,65 197,497,908 dataset of code coming from different implementations but defined by logically equivalent signatures. In our testing phase for example we have noticed how the best performance on both machine were achieved by a marching cubes implementation which included both the streaming and sharing of the threshold computation. 2.5 Time and Space Profiles Performance numbers are given for all the presented versions of marching cubes written in Haskell, over a range of sizes of dataset (all taken from volvis.org). The relevant characteristics of the datasets are summarised in Table 1, where the streaming window size is calculated as one plane+line+1. Tables 3 and 4 give the absolute time taken to compute an isosurface at threshold value 20 for every dataset, on two different platforms, a 3.0GHz Dell Xeon and a 2.3GHz Macintosh G5 respectively, compiled with the ghc compiler and -O2 optimization. Table 2 shows the peak live memory usage of each version of the algorithm, as determined by heap profiling. dataset neghip hydrogen statueLeg aneurism skull stent8 vertebra8 Table 2: Memory Usage memory (MB) array stream. VTK 0.270 0.142 1.4 2.10 0.550 3.0 11.0 3.72 15.9 17.0 2.10 28.1 17.0 2.13 185.3 46.0 8.35 119.1 137.0 8.35 1,300.9 On the Intel platform the array-based version struggles to maintain acceptable performance as the size of the array gets larger. We suspect that the problem is memory management costs: (1) The data array itself is large: its plain unoptimised representation in Haskell uses pointers, and so it is already of the order of 5– 9× larger than the original file alone, depending on machine architecture. (2) The garbage collection strategy used by the compiler’s runtime system means that there is a switch from copying GC to compacting GC at larger sizes, which changes the cost model. (3) The compiler’s memory allocator in general uses blocksizes up to a maximum of a couple of megabytes. A single array value that spans multiple blocks will im- Table 3: Time Performance - Intel time (s) dataset array stream. VTK neghip 1.09 0.44 0.06 hydrogen 16.7 3.47 0.21 275.0 17.9 1.09 statueLeg 619.7 28.1 1.73 aneurism skull 626.4 30.1 28.6 4530.0 79.7 13.1 stent8 vertebra8 6530.0 277.8 269.2 Table 4: Time Performance - PowerPC time (s) dataset array stream. VTK neghip 1.088 0.852 0.29 hydrogen 8.638 6.694 0.51 48.78 34.54 2.78 statueLeg aneurism 72.98 54.44 5.69 skull 79.50 57.19 79.03 stent8 287.5 154.9 33.17 517.1 755.0 vertebra8 703.0 pose extra administrative burden. In contrast, the time performance of the streaming version scales linearly with the size of dataset outperforming VTK (see Table 4). It can also be seen that the memory performance is exactly proportional to the size of the sliding window (plane+line+1). The streaming version has memory overheads too, mainly in storing and retrieving intermediate (possibly unevaluated) structures. However, the ability to stream datasets in a natural fashion makes this approach much more scalable to large problem sets. Comparing the haskell implementations with implementations in other languages something interesting appears. If we consider the figures obtained by running the algorithm on a Mac paltforms the streaming Haskell version is actually faster than VTK for the larger surfaces generated by skull and vertebra8. Moving to a different platform the panorama changes “apparently” in favour of the VTK implementation. However surprisingly the Haskell implementation appears to be still competitive. The interesting aspect worth noting is the speed-up gained by VTK which is much bigger than the one of the Haskell implementation, in proportion to the increase in computational power due to a faster processor. We suspect that such a difference resides in the compiler-generated code which could easily be better optimized for an Intel architecture rather than for a PowerPC. 3 Related Work The difficulties of working with large volumes of data have prompted a number of researchers to consider whether approaches based on lazy or eager evaluation strategies would be most appropriate. While call-byneed is implicit in lazy functional languages, several in the kind of data defining the sample points, and several of the simple functions used to make the final application are eminently reusable in other visualization algorithms (for example mkStream). Our next step is to explore how type-based abstraction, e.g. polytypic programming, can be used to make the algorithm independent of the specific mesh organization; we would like the one expression of marching cubes to apply both to regular and irregular meshes. Acknowledgement The work reported in this paper was funded by the UK Engineering and Physical Sciences Research Council. References Figure 3: Functionally surfaced dataset coloured to show age of triangles in stream generated by the streaming marching cubes Haskell implementation over the neghip dataset. efforts have explored more ad hoc provision of lazy evaluation in imperative implementations of visualization systems e.g. [11],[4]. In [15] Moran et al. use a coarse-grained form of lazy evaluation for working with large time-series datasets. The fine-grained approach inherent in Haskell not only delays evaluation until it is needed, but also evaluates objects piecewise. This behaviour is of particular interest in graphics and computational geometry, where order of declaration and computation may differ. Properties of our fine-grained streaming approach also match requirements for data streaming from [12], we refer for a more detailed disscussion on this topic to [5]. 4 Conclusion Our purely functional reconstruction of the marching cubes algorithm makes two important contributions. First, it shows how functional abstractions and data representations can be used to factor algorithms in new ways, in this case by replacing monolithic arrays with a stream-based window, and composing the overall algorithm itself from a collection of (functional) pipelines. This is important in the context of grid computing, because a stream- based approach may be more suitable for distribution than one that relies on a monolithic structure. It is also important for visualization, as streaming occupies an important niche between fully in-core and fully out-of-core methods, and the functional approach is novel in that the flow of data is managed on a need-driven basis, without the programmer resorting to explicit control over buffering. Second, the functional reconstruction shows that elegance and abstraction need not be sacrificed to improve performance; the functional implementation is polymorphic [1] G. Allen, T. Dramlitsch, I. Foster, N.T. Karonis, M. Ripeanu, E. Seidel, and B. Toonen. Supporting efficient execution in heterogeneous distributed computing environments with cactus and globus. In Supercomputing ’01: Proc. of the 2001 ACM/IEEE conference on Supercomputing, pages 52–52, 2001. [2] E. Chernyaev. Marching cubes 33: Construction of topologically correct isosurfaces. Technical report, 1995. [3] D. Clarke, R. Hinze, J. Jeuring, A. oh, and J. de Wit. The generic haskell user’s guide, 2001. [4] M. Cox and D. Ellsworth. Application-controlled demand paging for out-of-core visualization. In Proceedings of Visualization ’97, pages 235–ff. IEEE Computer Society Press, 1997. [5] D. Duke, M. Wallace, R. Borgo, and C. Runciman. Fine-grained visualization pipelines and lazy functional languages. IEEE Transaction on Visualization and Computer Graphics, 12(5), 2006. [6] R.B. Haber and D. McNabb. Visualization idioms: A conceptual model for scientific visualization systems. In Visualization in Scientific Computing. IEEE Computer Society Press, 1990. [7] Haskell: A purely functional language. http://www.haskell.org, Last visited 27-03-2006. [8] J. Hughes. Why functional programming matters. Computer Journal, 32(2):98–107, 1989. See also http://www.cs.chalmers.se/ rjmh/Papers/whyfp.html. [9] Johan Jeuring and Patrik Jansson. Polytypic programming. In J. Launchbury, E. Meijer, and T. Sheard, editors, Tutorial Text 2nd Int. School on Advanced Functional Programming, Olympia, WA, USA, 26–30 Aug 1996, volume 1129, pages 68– 114. Springer-Verlag, 1996. [10] R. Lämmel and S. Peyton Jones. Scrap your boilerplate: a practical design pattern for generic programming. ACM SIGPLAN Notices, 38(3):26–37, 2003. Proceedings of the ACM SIGPLAN Workshop on Types in Language Design and Implementation (TLDI 2003). [11] D.A. Lane. UFAT: a particle tracer for time-dependent flow fields. In Proceedings of Visualization ’94, pages 257–264. IEEE Computer Society Press, 1994. [12] C.C. Law, W.J. Schroeder, K.M. Martin, and J. Temkin. A multi-threaded streaming pipeline architecture for large structured data sets. In Proceedings of Visualization ’99, pages 225– 232. IEEE Computer Society Press, 1999. [13] T. Lewiner, H. Lopes, A.W. Vieira, and G. Tavares. Efficient implementation of marching cubes’ cases with topological guarantees. Journal of Graphics Tools, 8(2):1–15, 2003. [14] W.E. Lorensen and H.E. Cline. Marching cubes: A high resolution 3d surface construction algorithm. In Proceedings of SIGGRAPH’87, pages 163–169. ACM Press, 1987. [15] P.J. Moran and C. Henze. Large field visualization with demand-driven calculation. In Proceedings of Visualization’99, pages 27–33. IEEE Computer Society Press, 1999. [16] W. Schroeder, K. Martin, and B. Lorensen. The Visualization Toolkit: An Object-Oriented Approach to 3D Graphics. Prentice Hall, second edition, 1998.