Clone Wrapper Detection Technique: Clones Family Tree Ontology Moses Lesiba Gadebe
advertisement

2012 International Conference on Computer and Software Modeling (ICCSM 2012)
IPCSIT vol. 54 (2012) © (2012) IACSIT Press, Singapore
DOI: 10.7763/IPCSIT.2012.V54.05
Clone Wrapper Detection Technique: Clones Family Tree Ontology
Moses Lesiba Gadebe1 and George Enson Ditsa 2
1
Graduate student, Department of Computer Science, Tshwane University of Technology, South Africa
2
Professor, Department of Computer Science, Tshwane University of Technology, South Africa
Abstract. Code clone is a code portion in one source code that is similar or identical to another source code.
Current clone code detection techniques detect, refactor, remove and redirect clones without being archived
in the Discoverable Digital Clone Library (DDCL). This paper introduces Clone Wrapper Detection
Technique (CWDT) that detects and wraps commonly used structural clones into a DDCL and extract
metadata of each clone to induce Family Tree Ontology of related class clones. In order to evaluate the
usefulness of CWDT, we conducted preliminary experiments on large open source software including Java
Development Kit (JDK), Apache and JConnector projects. The preliminary results show a great number of
structural reusable and sharable Type1, Type2 and Type3 clones detected from large system software. And
also the results of the experiments show a significant reduction in clone detection time.
Keywords: Code Clones, Family Tree, Ontology, Vectors, Matrix, Detection techniques, discoverable
library
1. Introduction
The software engineering community is faced with deadline dilemma because of three important
business constraints - time, budget and change [1] [2]. Developers take an easy way-out by repeatedly
copying and pasting their proven and tested artifact source codes. Reusing source codes in a primitive way
of copy and paste (“code cloning”) is aggravated by the fact that developers do not document their completed
application source code in a conceptual model to afford other developers to reuse their existing source codes
[3][4].
Currently clone detection tools detect clones based on the specific portion of source code fragments (e.g.
declaration, statements, loop block, method block and class block) and report clone pairs or clones classes as
static indexed HTML text files [5]. Ontology provides vigorous metadata schema to provide a vocabulary to
explicitly define axioms, which provide concepts in a family tree hierarchy in a specific domain of interest.
These enable digital libraries to store/archive reusable knowledge family tree concepts to be shared,
communicated and be discoverable over the network [6] [7].
This study proposed clone wrapper detection technique (CWDT) to detect and wrap structural code
clones into a DDCL. The proposed CWDT extracts and transforms each input methods/functions of a
structural (class begin-block) source code into rectangular method matrix aggregated into class column
vector granularity. Finally CWDT extracts the metadata of each archived structural clones to induce
interlinked Family Tree Ontology (FTO). The CWDT technique prototype is developed using Java and JDT
Abstract Syntax Tree.
Preliminary experiments were conducted on large scale of system software to evaluate the usefulness of
CWDT. The preliminary results shows that the CWDT is cost effective on memory and processor usage in
detecting real, reusable and sharable Type1, Type2 and Type3 structural clones, moreover is accurate and
can scale in large system software. The rest of this paper is organized as follows: Section 2 reviews the
Corresponding author. Tel.: + 27734773972;fax: +2712382 9525
E-mail address :gadebeml@tut.ac.za
20
related literature for the study; Section 3 details the research methodology; Section 4 presents
implementation and evaluation of the technique. Section 5 outlines some contributions of the study; and
lastly, Section 6 presents the conclusion and future work.
2. Literature Review
Currently object orientation programming is the dominant software paradigm in software engineering. It
offers reuse of existing source code through mechanism such as composition, inheritance, and polymorphism
[6]. However, due to tight schedules imposed by marketing teams, developers use primitive reuse of
previously tested and proven source code to meet the demand of software applications and tight schedules
[1]. This eventually leads to code clones scattering in systems and thus promoting clones in business
services within organizations with no record of these duplications resulting high costs of maintenance and
low return on investments.
2.1. Basic Concepts of Clone Detection
The primitive reuse of existing code is called “code cloning” and the removal of clones from the
application is called “code refactoring”. Any sequence of code line is called “code fragments”. Code
fragments can be of specific “granularity”, for example, they can be variables declaration that can be block
of codes - loop statement, selection statement, function definition and class. Two similar code fragments
form a “clone pairs”. If more than two code fragments are similar they are called “clone class” or “clone
group” [5] and [8]. Code clones can be literally simplified into four types [8]:-Type 1: Identical or exact
copy without modification after pasting; -Type 2: Nearly Identical – syntactical identical copy. In some areas
of the codes such as variable names, method name or class name are changed without changing the syntax; Type 3: Gapped – copied fragments are improved by adding or deleting some statements.-Type 4: Semantic
– partly similar to other fragments. They are not intentionally copied and pasted; are created by different
programmers accidentally implementing the same semantic kind of logic.
2.2. Related Work AST and Metric
Baxter et al. [9], proposed an abstract syntax tree (AST) which parses code fragment tokens into AST,
and then executes hashing on AST subtrees. All sub-trees of the same length are grouped into a cluster
based on similarity of the hashes. Lastly, subtrees in a cluster are compared based on granularity similarity
threshold and all subtrees that meet thresholds are passed on to post-processing phase to determine a parent
of a clone until a set of parents is found. The AST operations to build all AST subtress are relatively costly
and slow. As a follow up on AST, Koschke [8] proposed a suffix trees to find clones on AST. Their
approach is built on the string-based algorithm implemented by Ukkonen [10], which is based on the AST
tokens. The technique managed to find syntactic clones (identical and nearly identical clones) in a linear
time and space, but could not detect similar and gapped clones.
Yang et al. [11] proposed a transformation technique which maps tree structured data into numerical
vector with a standard L1 lower edit distance. The mapping technique maintains the original tree structure
by generating an equivalent numeric multi-dimension vector. The tree edit distance can be lower by the L1
distance of the corresponding vectors. Jiang et al [11] proposed a detection tool similar to Yang [12] called
DECKARD - an efficient algorithm to detect similar subtrees. Their algorithm is based on a novel numerical
characteristics vector clone in a Euclidean space . The algorithm clusters these numerical vectors in the
Euclidean distance metrics. Subtrees with vectors in the same cluster are considered similar.
2.3. Motivation
Most clone detection techniques produce indexed static HTML files depicting the clones and their
locations. Also there is limited evidence that clones detected are stored for future reuse [5]. Hence this study
proposed Clone Wrapper Detection Technique to detect and store code clones into a Discoverable Digital
Clone Library and then filter the stored clones metadata based on abstraction to hierarchically induce Clone
Family Tree Ontology, which is based on Inheritance and Composition as formalized using Ontology Web
Language (OWL).
21
2.4. Ontologies and Ontology Engineering
Currently software engineers use traditional Entity Relational Diagrams (ERD) and structured analysis to
conceptualize the phenomena; recently they converged to Unified Modeling Language (UML) to model
objects of information system [6]. The ERD and UML are both static and off-line building blocks for the
analysis and design, whereas Ontology can be used at design and on runtime of information system. More
importantly Ontology provides vigorous metadata schema to explicitly define concepts in an specific domain
to help people and machines to share, reuse, search, discover and communicate concisely [13][14].
2.4.1
Formal Definition of Ontology
Ontology structure is five tuple defined as
>, where:
is a set, whose elements are called entities (concepts).
is a set, whose elements are attributes of each entity
is a set, whose elements are relations that exists between entities i.e.
defines other relationship that can exist between entities.
is a set of lexical reference terms/nouns/entities to define the scope of entities in a domain.
Object Orientation Programming Languages (OOPL) source codes can be reversed-engineered and
mapped into ontology to provide metadata to present real world objects currently represented in UML and
ERD notations [6].
The object orientation resource ontology (ORO) is introduced as
to re-engineer OOPL into ontology. Where OC is a set of object resource
classes, OA is a set of attributes/functions in object resource class, OR is called object resource taxonomy
(relation) that is
is-a
and OP is a set of object resource in a class. Ontology and Object Oriented
Java (OOJ) have obvious but rarely noted parallel: Java class makes a hierarchy from java.lang.Object class
viewed as a well elaborated ontology. Also a class constructs corresponds to Ontology entity class, where
Java single and multiple inheritance (is-a) and composition (has-a) are standard in ontology [8] [14].
2.5. Research Questions Addressed
What is an effective way to detect and archive reusable and sharable clones?
How can code clones be made available for reuse and sharability?
3. Research Methodology
3.1. Overview of our technique
This study proposed clone detection process portrayed in Figure 1 to develop Clone Wrapper Detection
Technique (CWDT) algorithm to detect clones, wrap/store and extract structural clone’s metadata to induce
reusable and sharable Family Tree Ontology
Fig. 1: Generic Clone Detection Process.
3.2. Algorithm Description
22
This section detailed technical description of CWDT algorithms incorporating generic clone detection
process presented in Figure 1.
Rows
(m_statements
Pre-processing process: This process presents Method Matrix Generator (MMG) function (see Algorithm
1 below). The MMG partition each structural (class block) source code methods into rectangular matrix of
statements by tokens simplified to
, as comparison units to capture methods structural body statements,
which is stored in class vector. The comparison unit, capture corresponding numerical occurrence count
values either 1, 0 of relevant and irrelevant tokens in matrix entry
. For example if a method contains
three statements with varying token size (suppose one of three statements contain five tokens greater than
other two statements) the resulted rectangular matrix is A[3 Statements By 5 tokens] of corresponding
method token node patterns of m_statements by n_tokens array as shown by Figure 2 below.
Columns (n_tokens))
Fig. 2:
Algorithm Listing 1: Method Matrix Generator
The MMG accepts structural source code and configuration delimiter file (e.g Wage.java source code
and configuration file depicted in Table 2 and Table 3 in Appendix 1) in line 3 and 4. MMG loop through all
methods in the input source code from line 10 to 30. Then tokenize each statement into tokens based on
delimiter symbols in the configuration file in line 12. Each token is compared against symbols in a
configuration file, to determine whether is relevant or not. All tokens are relevant in exception of delimiters
in configuration file. This process is performed between line 16 and 20. If a tokens exist in the configuration
otherwise 1 is stored. All rectangular matrixes for each class are stored in
file 0 is stored in matrix entry
class vector in line 29 and returned in line 31. Table 2, in Appendix 1 depicts the results of the
as A=[ ]m_statments * n_tokens of mapped occurrence count values.
i. Transformation Process: This process aggregates each method of rectangular matrix
A=[ ]m_statments*n_tokens of class vector into a reduced class column vector (CCV). System of linear
transformation equation is used to transpose each rectangular matrix into a reduced singular column vector.
Where matrix m_statement by n_tokens give a raise to a real numbers
into a system
linear equation Ax=b: where A is a single entry element, x is the scalar variable value and b is product of
scalar multiplication see Figure 3, below.
Fig. 3: Systematic Linear equation
23
Elementary row operation is performed to solve the multiple linear equations, to reduce the rectangular
matrix based on a product of scalar multiplication. Each matrix entry (
is multiplied with a given scalar
value ( ), then all scalar products for each row are added as method hash code based on (E.q.1) below.
E.q.1
The method hash code equation (E.q.1) is translated into Column Vector Generation (CVG) function
given in Algorithm 2 below. The CVG function accepts the column vector of metrics
A=[ ]m_statement*n_token in line 3. Then calculates a sum of scalar product by traversing each
method_matrix(row,column) value as multiplied by a scalar row value, plus a parity row value in line 10. In
line 13 all the computed method hash codes are stored in a reduced class column vector (CCV) as shown in
Appendix 1, transformation process column in Table 1.
Algorithm Listing 2: Column Vector Generator
ii. Matching Process: We illustrate our intersection comparison process with an Algorithm 3 below. Two sets
of class column vector (CCV) are inputs in line 3 and line 4. Where x is an element of CCV1, given as
CCV1= {702, 31, 13,834}, and y is an entry element of CCV2 given as CCV2= {14, 31, 13,834} of
transformed source codes Wages.java and Salary.java as depicted in Table 1 and Table 2 in Appendix 1.
Algorithm Listing 3: Intersection Comparison.
The intersection comparison algorithm adds all common method hash code values in line 10 to line18.
Every element
in CCV1 is compared against each element
of CCV2 in line 12. If two elements are
equal, an intersection sum is computed by adding a common value
to the intersection sum in line 13.
Then a minimum intersection entry (MinIE) of method hash codes is determined in line 20. If MinIE is met,
an edit distance (ED) is computed in 22 based on equation E.q.2 below.
E.q.2
The ED is compared against a given similarity threshold K in line 23 to line 26. If the similarity
threshold is achieved both Class Column Vectors CCV1 and CCV2 original source codes (Wages and Salary)
are wrapped/stored in a Discoverable Digital Clone Library in line 24 and line 25.
iii. Filtering/Post-Processing: In this last process we extract knowledge of Object Oriented Java (OOJ)
source code metadata to induce Clone Family Tree Ontology (CFTO). This study proposed extraction and
mapping rules based on abstraction process, listed in Table 1.
24
Table 1: Extraction Rules
As you recall from literature review OOJ is four tuple
. OC defines the entity
encapsulating both properties and behaviors defined by OA, that are hierarchically related to each other,
indicated by OR. Belonging to axiom defined as OP. Where ontology O is five tuple:
>.
We map extraction rules from Table 1, into ontology to conceptualize clones metadata into CFTO. Rules
(R1, R2, R3 and R4 in Table 1) are mapped into equation E.q.3 based on Cartesian product function.
E.q.3
Where: - DO is domain x existing in ontology of specific domain of interests.
. Then
elements of
is set of properties as
is a set of taxonomy relationships (“is-a”) which belongs to
set of data types (either Primitive or Reference data types (“has-a”)) that belongs to
: Is a
.
is an entity
belonging to axiom in domain of interest. A: is axiom (set of reference entities) containing as a
member
comprising of
member
.
: Element of:
as elements.
comprises of
: is containing as member, axiom A contains as a
,
and
as elements.
Rule Mapping R1 (see equation E.q.4 below):
A class is a blueprint from which objects/entities are created from; that intimately encapsulate data
members and method as an object/entity. Entity contains properties and behavior
declared as
data
type.
E.q.4
Case Study 1: Class Player below (Figure 4) contains private property name of type String, with a pair of
public setters and getters methods to expose the properties to the public domain.
Fig. 5: Owl source code Player 1.
Fig. 4: OOJ Metadata of class Player
OWL Engineering rule R1 mapping: The <owl:class> tag defines class Player in line 1 in Figure 5 above,
whereas <owl:DatatypeProperty> defines variables in line 2 to line 3 declared as String data type using tag
25
<rdfs:range>. Both setName and getName methods are declared using <owl:ObjectProperty> tag as shown
in line 5 and line 8. Line 11 default java.lang.Object is represented as Thing, using <rdfs:subclass> tag.
Rule Mapping R2 (equation E.q.5):
Class A is composite of class B if and only if class B contains as attribute object of class type A referred
to us as “has-a” relationship. Entity contains a property or behavior
declared as class type
data
type.
E.q.5
Case Study 2: Class PrecessOlypianList (Figure 6 below) contains olympianList array and getPlayer
Fig. 6: OOJ Metadata ProcessOlympianList
Fig. 7: Owl source code ProcessOlypainList.
ethod of type Player data type as depicted below in Figure 4.
Owl Representation from rule R2: The concept “ProcessOlypianList” is defined using <owl:class> tag
(in Figure 7 above). The <owl:ObjectProperty> tag in line 2 defines the reference olympianList array of type
Player, defined in line 3 using <rdfs:range> tag. Each method in a class is transformed using
<owl:ObjectProperty> as shown in line 6 to 9 where getPlayer method of type Player defined as composition
relation (”has-a”). The <rdf:domain> in line 6 defines the scope of the method showing that the method
belongs to ProcessOlympianList and is of type Player, defined as <rdfs:range> tag in line 7 and 8.
Rule Mapping R3 and R4 (equation E.q.6)
Rule R3 and R4 are mapped as hierarchy taxonomy of existing entities in a domain. We map inheritance
rule (also referred as “is-a”), where an Object Oriented Java (OOJ) class inherits from one direct super class
and implements variant of multiple (sister classes) interfaces. Hierarchy taxonomy
is an existing relation
in entity .
E.q.6
Case Study 3: Class Ball inherits from direct superclass Circle, and also implements the abstract methods
of interfaces Bounceable and Rollable. Below are OOJ classes in Figure 8 and the corresponding OWL
source code in Figure 9
Fig. 9: Owl source code Ball.
Fig. 8: OOJ Metadata of class Ball (R3 and R4)
Owl Representation from rule R3 and R4: In Figure 9, the <owl:class> tag in line 1 defines the
class/concept “Ball” as a subclass of Circle that is Bounceable and Rollable, defined in line 8 to 10 using
<owl:subClassOf> tag.. Also the Ball overrides inherited bounce and rolls methods in line 2 to 7 using
<owl:ObjectProperty> tag.
4. Implementation and Evaluation
On writing of this paper Clone Wrapper Detection Technique (CWDT) prototype was implemented and
preliminary experiments were conducted. The prototype firstly partition input source code into comparison
26
units. Secondly it produce corresponding rectangular matrix of m_statements by n_tokens. Thirdly, all the
corresponding rectangular matrices are aggregated into Class Column Vector (CCV) as granularity needed
by intersection comparison to detect reusable and discoverable structural clones. Prototype allows users to
select minimum intersection entry (MinEI) and similarity threshold both known as similarity query.
4.1. Judgement of clones
Two CCVs are judged as Type 1 and Type 2 if edit distance is 100%. Type 3 is clones with additional
methods, if the threshold is between 75% and 90% a taken as type 3. We use exact match to identify clone
Type 1 and Type 2, which have high probability to be real clones.
4.2. Experiments Setup
In this research paper CWDT was evaluated by conducting a series of similarity queries on Java open
source projects as our subjects in our case study (see Table 2 below).
Table 2: Experiments corpus
The experiments were designed to address research question (RQ) “What is an effective way to detect
and archive reusable and Discoverable clones”. To address RQ we distributed it into four sub questions (SQ)
as follows: SQ1 (Detectability) How many Type1, Type2 and Type3 reusable clones can be detected by the
CWDT? - SQ2 (Accuracy) How Accurate is the CWDT in terms of precision versus recall? - SQ3
(Scalability): How does the CWDT scale in terms of time versus line of code (LOC) size? - And SQ4
(Sharability and Reusable) How can code clones be made available for reuse and Discoverable?
Similarity queries, threshold (K) and the minimum intersection entry (MinIE) are varied as shown in
table 3 below.
Similarity Query
Table 3: Similarity Query.
Threshold (K)
Q1
Q2
Q3
Q4
Q5
Q6
4.2.1
70
70
80
80
90
90
MinIE
0.4
0.6
0.4
0.6
0.4
0.6
SQ1: Detectability
The CWDT was applied to evaluate the detectability by performing a series of queries on the each corpus
subjects (as shown Table 2 above). In this research paper similarity Q3 and Q5 were selected as highest
ranked similarity queries. Researchers [5][9][12] indicates that high similarity threshold can reduce number
of false positives clones and also can produce a great number of high quality clones.
Table 4: Clones Results.
After running CWDT based on similarity query Q3 and Q5, we found 1095 relevant files out of 7227
files. A total of 259 clones at ratio 23% found at similarity Q3, then when we raise similarity query to Q5
we found 206 clones at ratio 18.81% within a declared ratio of 17% and 20% of Roy et al.[5].
4.2.2. SQ2: Accuracy
The next SQ is “How Accurate is the CWDT terms of precision versus recall?” on the JDK subjects.
27
Fig. 4.1 Precision Recall
4.2.3. SQ3: Scalability
In this section we measure the time spent to detect clones. Experiments were conducted on 32 bit with
2.4 GHz Intel core i5 processor, with 4.00 GB RAM on Windows 7 operating system. The results show that
CWDT can scale in different corpus subjects to detect clones.
Fig. 4.2: Time Spent for CWDT detection
4.2.4. SQ4: Sharability and Reusable
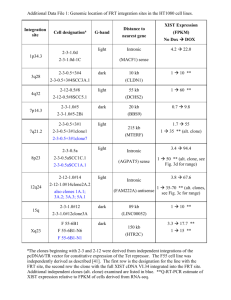
In this section the results of the CWDT object clones metadata relationship is depicted using Protégé
ontology viewer tool in Appendix 2 (Protégé1). The hierarchical taxonomy of the corpus subject JDK based
on the similarity query Q5 is chosen, where clone objects EventObject family tree are hierarchically
portrayed. The Clone Family Tree Ontology snapshot, display the inheritance relationship existing between
the objects clone, which descent from ancestor Thing or Object in ontology. This illustration confirms that
our CWDT can detect reusable and sharable structural clones.
4.3. Discussion
We discuss the limitation of our clone wrapper and threats to validity of experiments.
4.3.1. Limitation of CWDT
Since our CWDT use rectangular matrix to represent parsed method as a multi-dimensional array of
m_statements by n_tokens, as aggregated to class column vectors as granularity. It can only detect
object/class clones from object oriented programming languages (Java, C++, C#) and procedural languages.
Any other level of granularity cannot be detected by our technique. Due to fact that it depends on the
syntactic it cannot detect semantic clone (type 4). When CWDT is applied on a low similarity query
produces number of false positives and false negatives clones. However CWDT can detect quality type1, 2
and 3.
4.3.2. Validity of the results
We used three open source projects as subjects of case study, which do not represent all large evolving
system software. Thus we cannot generalize the results of our CWDT across different large projects. Also we
did not compare CWDT with state-of-art clone detection tools such as Deckard, CloneDR, CCFinder.
However the results of our experiments can be used as the basis to compare CWDT with in terms of
detectability, accuracy and scalability.
5. Contributions
A systematic clone wrapper detection technique can be used by software engineers and maintenance
programmers to detect, reuse and share structural clones within intranet network [7][13][14]. The technique
improves traceability of structural clones based on their URL. Re-coding legacy applications into semantic
web it takes years and effort to be converted. Also to extract to induce Family Tree conceptual
documentation can take a lot more effort. Hence our study plays an important role to provide extraction tool
to extract commonly used objects that are reusable, sharable and searchable, without losing their core
business knowledge. To prevent recurring clones a discoverable and sharable digital library can be used to
allow software developers, to create new software by inheriting, composing existing tested and trusted clones.
28
6. Conclusion and Future work
Our proposed CWDT is language independent; it depends on the syntactic of the input source code. It
can detect reusable and sharable type1 and type2 clones with a low frequency of type 3 clones. Our
preliminary results of our study show that CWDT is accurate and effective to detect high quality clones on a
higher similarity query. The result reveals that CWDT is efficient and cost effective in terms of memory
usage and time to detect clones. We expect in the future to advance CWDT to detect clone type 3 and type 4
at high frequency rate.
7. References
[1]. Borland. A Borland Vision and Solution Strategy Paper: The transformation of software development into an
accelerated yet disciplined approach that aligns people, process and technology to maximize the business value of
software. Available at:
http://www.borland.com/resources/en/pdf/white_papers/borland_software_delivery_optimization_exec_white_pap
er.pdf. 2005.
[2]. G. Di Lucca, A. M. Di Penta, and A.R. Fasolino. An Approach to Identify Duplicated Web Pages. 2002.
[3]. G. Ganapathy and S.Sarayaraj. To generate the ontology from Java Source code: Owl creation. International
Journal of advanced Science and Applications. 2011, 2 (2):111-116.
[4]. ,D.C. Rine. and N. Nada. An empirical study of a software reuse reference model. Information and Software
Technology. 2000, 42 (1): 47-65.
[5]. K. Roy, J. R. Cordy and R. Koschke. Comparison and Evaluation of Code Clone Detection Techniques and Tools:
A Qualitative Approach. Science of Computing Programming. 2009
[6]. V. Devedžić. Understanding Ontological Engineering. Communications of the ACM. April 2002, 45(4):136-144.
[7]. I. Keivanloo, L. Roostapour, P. Schugerl, and J. Rilling.Semantic web-based source code search. In Proceedings of
2010, 6th Intl.Workshop on Semantic Web Enabled Software Engineering.
[8]. K. Koschke, R. Falke and P. Frenzel. Clone Detection Using Abstract Syntax Suffix Trees. In Proceedings of the
13th Working Conference on Reverse Engineering WCRE 2006: 253-262.
[9]. I. Baxter, A. Yahin, L. Moura, M. Sant and L.Bier. Clone Detection Using Abstract Syntax Trees. In Proceedings
of the International Conference on Software Maintenance.1998.
[10]. E. Ukkonen. On-line contruction of suffix trees. Algorithmic. 1995, 14 (3):249-260
[11]. R.Yang, P. Kalnis and A.K.H. Tung. Similarity Evaluation of Tree-structured Data. SIGMOD 2005 ACM 159593-060-4/05/06.
[12]. L. Jiang, G. Misherghi, Z.Su and S. Gloudu. Deckard: Scalable and accurate Tree-based Detection of Code Clone.
In proceedings of the 29th International Conference On Software Engineering ICSE. 2007. Pp.96-105.
[13]. T.R. Gruber. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. International
Workshop of Formal Ontology. March 1993. Available as a Technical Report KSL. Knowledge Systems
Laboratory, Stanford University.
[14]. Y. Wand and R. Weber. On the deep structure of information systems, Information Systems Journal. 1995, 5 (3):
203-23.
8. APPENDIX 1
Table 1: Salary Transformed source code
29
Table 2: Wages Transformed source code
Table 3: Configuration Delimiter file (Symbol ~ is not counted, separates symbols in configuration file)
9. APPENDIX 2:
CWDT Extraction Results
Pretege1 Owl Viz Tab: Object Clone EventObject Clone Family Tree Ontology
30