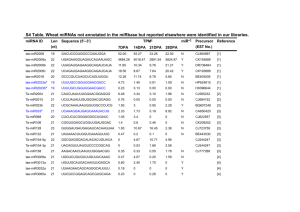
Sequence Determinants of Pri-miRNA Processing
advertisement

Sequence Determinants of Pri-miRNA Processing by Vincent C. Auyeung B.S., Biology California Institute of Technology, 2005 SUBMITTED TO THE DEPARTMENT OF BIOLOGY IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY AT THE MASSACHUSETTS INSTITUTE OF TECHNOLOGY JUNE 2012 © 2012 Massachusetts Institute of Technology All rights reserved Signature of Author: ____________________________________________________________ Vincent C. Auyeung Department of Biology May 21, 2012 Certified by: ___________________________________________________________________ David P. Bartel Professor of Biology Thesis Supervisor Accepted by: __________________________________________________________________ Robert T. Sauer Professor of Biology Chair, Biology Graduate Committee 1 Sequence determinants of pri-miRNA processing by Vincent C. Auyeung Submitted to the Department of Biology on May 21, 2012 in partial fulfillment of the requirements for the degree of Doctor of Philosophy MicroRNAs (miRNAs) are short RNAs that regulate many processes in physiology and pathology by guiding the repression of target messenger RNAs. For classification purposes, miRNAs are defined as ~22 nt RNAs that are produced by the cleavage of endogenously transcribed hairpins. From a cellular perspective, however, miRNAs are the functional products of a multistep maturation pathway, and are thus defined by the ability of their precursors to enter this pathway. The cellular distinction between miRNA precursors and other hairpins is made in the first step of maturation, when the primary miRNA transcript (pri-miRNA) is cleaved by the Microprocessor, a complex containing Drosha, an RNase III enzyme, and an RNA-binding partner DGCR8. However, it is unclear how the Microprocessor distinguishes between these hairpins and authentic pri-miRNAs. In fact, C. elegans pri-miRNAs are not processed in human cells, illustrating the complexity of pri-miRNA recognition and processing. To systematically explore sequence determinants of pri-miRNA recognition, hundreds of billions of variants of human pri-miRNAs were generated, and millions of variants that were functional Microprocessor substrates were selected in vitro and sequenced. Analysis of the successful sequences revealed multiple determinants of pri-miRNA binding and cleavage, including hairpin secondary structure and primary sequence preferences in the terminal loop and flanking the hairpin. One of these determinants, a CNNC motif downstream of the Drosha cleavage site, is enriched in pri-miRNAs throughout bilaterian animals. Addition of the primary sequence motifs to C. elegans pri-miRNAs promoted their efficient processing in human cells, underscoring the importance of these determinants. The identification and characterization of specific motifs greatly expands the understanding of the features that cells use to recognize pri-miRNAs, and opens the door to future studies of pri-miRNA recognition in humans and other bilaterian animals. In addition, the approach is applicable to the exploration of a variety of functional RNA elements that have so far resisted functional dissection, including long noncoding RNAs and messenger RNA localization signals. Thesis Advisor: David P. Bartel Title: Professor 3 4 Acknowledgements Many individuals have contributed to the work described here, and to my professional and personal development. Of course, none of this would have been possible without the support and guidance of Dave Bartel. I have admired and benefited from his willingness to pursue any approach and master any technique, as long as it moves us closer to answering interesting scientific questions. Beyond that, Dave is an excellent personal and professional role model. One of the greatest things about Dave has been his ability to recruit a group of fantastic scientists to work in his lab. The atmosphere of the lab is incredibly open, with people regularly speaking to each other throughout the day to exchange ideas and advice. I have also benefited from members’ backgrounds in in diverse disciplines, including developmental biology, cancer biology, computational biology, plant biology, biochemistry, and genetics. I am inspired by the lab members’ ability to creatively combine different experimental approaches and ways of thinking to address a variety of scientific problems. The work described in Chapter 2 relied on the critical contributions of David Shechner and Igor Ulitsky. The circularized-substrate cleavage selection was born of a nighttime brainstorming session with David Shechner, and was just one of his ideas among many good ones. Igor Ulitsky performed most of the conservation analysis described in Chapter 2. I am always amazed by his ability to quickly grasp the biological question and apply his vast computational expertise to finding the answer, all the while maintaining a great sense of humor. I am grateful to the people who listened to my constant stream of stupid ideas and considered them critically: Calvin Jan, J. Graham Ruby, Olivia Rissland, David Weinberg, and Igor Ulitsky. Our conversations have taught me to take idle musings, strengthen their intellectual foundations, and operationalize them into productive experiments. I have particularly benefited from the wisdom of Calvin Jan; without Calvin, I would have wandered around the wildernesses of science much longer than I did. Over the years I have also gained from mentors and role models my research and medical careers. My thesis committee, Phillip Sharp and Uttam RajBhandary, have been with me nearly every step of my research training. On the medical side, I have benefited from the advice and guidance of Richard Mitchell. On a personal level, many people have helped keep me sane over the past few years. My baymates Ines Anna Drinnenberg and David Garcia have helped maintain an “atmosphere” in the bay to make spending hours at the bench that much more palatable. I’ve shared good times in lab and out of lab with Laura Resteghini, Sue-Jean Hong, Huili Guo, Stephen Eichhorn, Igor Ulitsky, Alena Shkumatava, Christine Mayr, Andrew Grimson, Calvin Jan, Olivia Rissland, David Shechner, J. Graham Ruby, and Noah Spies. My other Boston friends have kept things in perspective for me while I was immersed in research; Evgeniy Kreydin, Xavier Rios, and Takahiro Soda deserve special thanks. Others have kept me physically active, like the many graduate students and postdocs who played for the Biograds intramural tennis team, which I had the privilege of organizing. Our consistent losing record never stopped us from loving the game. David Garcia, Calvin Jan, James Patridge, Dave Kenezevic, and Eveline Stein have cycled thousands of miles with me, giving me a chance to see a slice of Massachusetts up close and to get some vitamin D in the process. No set of acknowledgements would be complete without mentioning the support and patience of my parents, Marianna and Michael, my brother William, and my sister Wendy. And, most importantly, Joanne. Thank you for everything. 5 6 Table of Contents Chapter 1. What defines a miRNA?...................................................................................... 9 Chapter 2. Beyond secondary structure: primary-sequence determinants license pri-miRNA hairpins for processing..................................................................... 59 Chapter 3. Future directions................................................................................................. 121 Appendix 1. Experimental protocols........................................................................................ 161 Appendix 2. Statistical methods.............................................................................................. 225 Appendix 3. Mammalian microRNAs: experimental evaluation of novel and previously annotated genes.................................................................................. 235 7 8 Chapter 1. What defines a miRNA? Contents Introduction ................................................................................................................................... 10 Understanding the cellular definition of an animal miRNA ......................................................... 13 The biogenesis of miRNAs ........................................................................................................... 15 Known determinants of pri-miRNA processing ........................................................................... 16 General preferences of the Microprocessor .......................................................................... 17 Regulation of cleavage in subsets of animal pri-miRNAs .................................................... 20 Plant pri-miRNA processing: DCL1..................................................................................... 23 Determinants of canonical biogenesis downstream of the Microprocessor.................................. 24 Specificity of nuclear export mediated by exportin-5........................................................... 24 Specificity of cleavage by Dicer ........................................................................................... 25 Specificity of loading into Argonaute ................................................................................... 28 Regulation of biogenesis in subsets of animal pre-miRNAs ................................................ 30 Finding additional biogenesis determinants in pri-miRNAs ........................................................ 31 Substrate specificity in RNase III family proteins ........................................................................ 33 Eubacterial RNase III ............................................................................................................ 33 Yeast RNase III: Rnt1p and Pac1 ......................................................................................... 35 An exhaustive, quantitative approach to defining pri-miRNAs.................................................... 39 9 Introduction The microRNA (miRNA) field began with the cloning of the nematode gene lin-4 and the realization that it formed Watson–Crick base pairs with the 3′ untranslated region of the lin-14 messenger RNA (mRNA). Both genes had previously been identified as key regulators of developmental timing in the nematode Caenorhabditis elegans, although the molecular mechanism linking the two genes was unknown. Extensive effort to clone and sequence these two genes revealed that lin-4 was a tiny RNA that did not encode a protein (Lee et al., 1993). The realization that lin-4 was complementary to portions of the lin-14 mRNA led to the hypothesis that the genetic relationship between lin-4 and lin-14 was mediated by the physical relationship between regulator RNA and target mRNA (Lee et al., 1993; Wightman et al., 1993). This type of interaction had never been described in animals, and even among prokaryotic regulatory RNAs lin-4 was exceptional: four times smaller than any other noncoding regulatory RNA known at that time (Ruvkun et al., 2004). Still, this regulatory scheme seemed likely to be idiosyncratic (Ruvkun et al., 2004); both examples were from one pathway from one rapidlyevolving nematode. As it turns out, lin-4 is the founding member of a much larger class of regulatory RNAs in animals. Several years later, a second small regulatory RNA, let-7, was identified and shown to regulate lin-14 and other developmental timing genes by binding to their 3′ untranslated regions (Reinhart et al., 2000), and was conserved across bilaterian animals (Pasquinelli et al., 2000). The initial trickle of small RNA discovery became a torrent when three groups described the existence of a large number of tiny RNAs, ranging from 21 to 24 nucleotides (nt) long (Lagos-Quintana et al., 2001; Lau et al., 2001; Lee and Ambros, 2001). These RNAs were found in multiple bilaterian animal species (Drosophila melanogaster, Caenorhabditis elegans, and humans); were both diverse and individually abundant; and were often conserved between all three species, spanning hundreds of millions of years of evolution. In recognition of their small size, these RNAs were called “microRNAs” (miRNAs). In the past decade, both the number of miRNAs and the catalog of their biological functions have blossomed. Extensive miRNA discovery efforts in animals have identified hundreds of miRNA families in animals and plants, and each family can have many individual miRNA members in each species (Bartel, 2004). For perspective, miRNAs account for over 2% of predicted mammalian genes, and the number of annotated human miRNA families in 10 miRBase (Griffiths-Jones et al., 2006) is comparable to the number of human protein tyrosine kinases annotated by the Gene Ontology Consortium (Ashburner et al., 2000). Like lin-4, miRNAs recognize their targets by base pairing to sites in the mRNA; in plants, the target pairing occurs throughout the length of the miRNA, while in animals target pairing to ~6–8 nt at the 5′ end of the miRNA, termed “seed” pairing, is nearly always necessary and often sufficient for repression (Bartel, 2009). Supplemental elements also contribute to target site efficacy in animals, including the local nucleotide content, position of the target site in the mRNA 3′ untranslated region (3′ UTR), thermodynamic stability of seed pairing, the abundance of target sites in the cell, and proximity of the target site to other miRNA sites (Doench and Sharp, 2004; Grimson et al., 2007; Saetrom et al., 2007; Ui-Tei et al., 2008; Arvey et al., 2010; Garcia et al., 2011). The mechanism by which miRNAs repress target mRNAs varies between plants and animals, in accordance to the targeting mechanism. In plants, this extensive pairing guides cleavage of the target mRNA (Llave et al., 2002; Tang et al., 2003; Jones-Rhoades et al., 2006). Although animal miRNAs also guide cleavage of some targets, their limited pairing with most miRNA targets is insufficient to support target-site cleavage (Yekta et al., 2004; Shin et al., 2010). Instead, miRNA targeting results in mRNA destabilization and/or inhibition of translation. Which mode of target gene repression predominates depends on time; recent transcriptome- and proteome-wide studies indicate that steady-state repressive effects are mostly explained by mRNA destabilization (Baek et al., 2008; Hendrickson et al., 2009; Guo et al., 2010), while similar studies in the fish embryo show that translational repression can dominate for a brief period immediately after induction of miRNA expression (Bazzini et al., 2012). Regardless of mechanism, the magnitude of effects is generally modest but nevertheless significant. Despite the subtlety of their effect, the animal miRNAs are critical regulators of the transcriptome. After all, each miRNA can have hundreds of conserved targets, and >60% of mammalian mRNAs have been under selective pressure to maintain at least one target site (Friedman et al., 2009), while other mRNAs have been under selective pressure to avoid targeting by coexpressed miRNAs (Farh et al., 2005; Stark et al., 2005). As a class, the miRNAs are essential for normal mammalian development, since mutations that ablate miRNA biogenesis are lethal in mammals (Bernstein et al., 2003; Babiarz et al., 2008). Individual miRNAs have 11 been implicated in a spectrum of biological processes. A particular theme has been spatiotemporal control in development, consistent with the roles of lin-4 and let-7 in developmental timing in C. elegans. For example, the mammalian miRNA miR-155 regulates the differentiation of helper T cells in the immune system, and loss of miR-155 impairs the formation of germinal centers, which are important for effective antibody responses (Thai et al., 2007). By contrast, sustained overexpression of this miRNA perturbs the early differentiation of hematopoietic cells, and ultimately causes the inappropriate proliferation of the myeloid cell compartment in mice (O'Connell et al., 2008). In human cancer, miRNAs are often located at or near sites of genomic damage and have reduced levels, suggesting that the disruption of miRNA regulation is a common feature of cancer (Calin et al., 2004b; Lu et al., 2005). Consistent with this view, a general reduction in miRNA levels by inhibition of biogenesis promotes oncogenic transformation in mice (Kumar et al., 2007). In fact, the disruption of a single miRNA–target relationship between let-7 and the oncogene HMGA2 is enough to promote oncogenic transformation, and disruptions of this relationship occur frequently in human cancers (Mayr et al., 2007). More broadly, miRNAs comprise just one class of molecule in a larger paradigm of biological regulation by small noncoding RNAs. This paradigm emerged from a collection of mysterious observations in plants, animals, and fungi. In plants and fungi, separate efforts to overexpress genes unexpectedly caused silencing of both the exogenously introduced gene and endogenous genes with the same sequence (Napoli et al., 1990; van der Krol et al., 1990; Romano and Macino, 1992). In animals, antisense nucleic acids had been used to inhibit endogenous gene expression, presumably by forming duplexes with the target mRNA (Izant and Weintraub, 1984), although the method was curiously successful when either sense or antisense RNAs were injected (Fire et al., 1991; Guo and Kemphues, 1995). It was later discovered that the efficacy of inhibition could be enhanced over 100-fold in C. elegans when both sense and antisense RNAs were injected (Fire et al., 1998). These observations, disparate in method, goals, and even phylogenetic kingdom, likely had a single commonality: the intentional or unintentional introduction of double-stranded RNA (dsRNA) (Montgomery and Fire, 1998). In plants, induction of post-transcriptional gene silencing by dsRNA caused the accumulation of smaller, ~25 nt RNA fragments (Hamilton and Baulcombe, 1999). In animals, the dsRNA was later shown to be processed into small, 21-22 nt fragments (Hammond et al., 2000; Zamore et al., 12 2000), and these fragments are the active species that mediate silencing (Elbashir et al., 2001a; Elbashir et al., 2001b). Since then, thousands of studies have used artificial dsRNA or the small active species to silence genes of interest, a technique called RNA interference (RNAi). Yet the use of RNAi as a tool belies the importance of the many forms of endogenous silencing, each mediated by distinct small RNAs (Ketting, 2011). With the exception of PIWI-interacting RNAs, the various small RNAs are derived from paired RNA, including transcribed hairpins with long stems, dual sense and antisense transcripts from a genomic locus, and duplexes synthesized by RNA-dependent RNA polymerases. They have a variety of evolutionarily-conserved biological functions, including the regulation of gene expression by degrading messages, repressing translation, or modifying chromatin; and the defense against viruses and other invasive genetic elements by cleaving gene products or the genomes themselves. These small RNAs and their diverse biological functions are interconnected by a web of related biogenesis and effector mechanisms, including those mediated by the RNase III and Argonaute protein families, leading to the view that RNAi is ancient and pervasive. It is ironic that the herald of this paradigm, lin-4, was once thought to be an oddity of nematode development. Understanding the cellular definition of an animal miRNA To study the common properties of miRNAs, it is crucial to distinguish those RNAs that belong to the miRNA class from others. Accordingly, a set of criteria was adopted for classifying small RNAs as miRNAs (Ambros et al., 2003). One set of criteria relates to size and expression: miRNAs should be ~22 nt RNAs, and thus detectable in cellular RNA by methods such as small RNA blotting or cDNA sequencing (Ambros et al., 2003). The second relates to origin: miRNAs should be derived from the stem region of relatively regular hairpins, without large internal loops or bulges; ideally, the pairing in the hairpin should be conserved, and the hairpin should be cleaved by an RNase III enzyme called Dicer (discussed below) (Ambros et al., 2003). Although these criteria are useful for human minds to classify certain small RNAs as miRNAs, they do not answer an important question: what is a miRNA to the cell? Since miRNAs are derived from precursor RNAs much longer than the mature miRNA, cells must somehow recognize certain RNA species as miRNA precursors, as distinct from precursors of 13 pri-miRNA pri-miRNA Unstructured terminal loop (? >10 nt) Recognition and binding (Microprocessor) ~1 helical turn Stem Watson–Crick pairing (~ 3 helical turns) Downstream unstructured sequence (> 20 nt) Upstream unstructured sequence (>20 nt) Basal stem junction Cleavage (Microprocessor) pre-miRNA Nuclear-cytosolic export (Exportin 5) Stem Watson–Crick pairing 3′ overhang (2-8 nt) P OH Unstructured terminal loop (? >14 nt) 3′ overhang (2 nt) 5′ phosphate 3′ hydroxyl 3′ hydroxyl OH Cleavage (Dicer) p Central stem mismatches OH 5′ phosphate Argonaute loading (RISC loading complex) P P Weaker pairing stability OH ~2 helical turns Stem Watson–Crick pairing (~ 2 helical turns) P OH other RNA species, and process the miRNA precursors accordingly. Thus, from the cellular perspective, miRNAs are defined by the ability of their precursors to enter a specific biogenesis pathway; the miRNAs themselves are simply the functional products of this pathway. To understand the cellular definition of an animal miRNA, we must therefore consider their biogenesis and the specificity of each step in the pathway for particular RNAs (Figure 1). The biogenesis of miRNAs In the canonical pathway of miRNA biogenesis, primary miRNA transcripts (primiRNAs) are synthesized by RNA polymerase II (Lee et al., 2004a) as noncoding transcripts, or as embedded sequences within introns of protein-coding “host” genes. While still in the nucleus, the pri-miRNA is cleaved (Lee et al., 2002). This cleavage is carried out by the “Microprocessor,” a large protein complex composed of Drosha, an RNase III enzyme, and a protein cofactor DGCR8, called Pasha and Psh-1 in Drosophila melanogaster and C. elegans, respectively (Lee et al., 2003; Denli et al., 2004; Gregory et al., 2004; Han et al., 2004; Landthaler et al., 2004). DGCR8 is thought to recognize the junction between the miRNA hairpin and flanking single strand RNA, positioning Drosha to cleave approximately one helical turn above the junction (Han et al., 2006; Yeom et al., 2006). The resulting hairpin is termed the precursor miRNA (pre-miRNA), and consists of a ~2-turn stem with a characteristic 2 nt 3′overhang. This distinctive hairpin is exported from the nucleus to the cytosol by exportin-5 (Yi et al., 2003; Bohnsack et al., 2004; Lund et al., 2004); in species where there is no exportin-5 ortholog, the pre-miRNA presumably makes use of exportin-t instead (Murphy et al., 2008). In the cytosol, the pre-miRNA is cleaved by a complex of proteins containing another RNase III enzyme called Dicer (Grishok et al., 2001; Hutvagner et al., 2001; Ketting et al., 2001). For most miRNAs, one strand is preferentially loaded into an Argonaute family member based on the thermodynamic stability of the Dicer product (Khvorova et al., 2003; Schwarz et al., 2003). The mature miRNA strand and its Argonaute protein partner form the core of the silencing complex (Liu et al., 2004; Meister et al., 2004). Figure 1. Summary of the biogenesis of miRNAs and determinants in intermediate RNA species. For each intermediate along the path to maturity, determinants are shown that promote the processing of that intermediate. 15 The vast majority of annotated miRNAs mature through the canonical pathway, based on their dependencies on DGCR8/Pasha and Dicer (Calabrese et al., 2007; Wang et al., 2007; Babiarz et al., 2008). However, several miRNAs make use of alternative pathways which bypass various steps of the canonical pathway. For the miRNA introns, or “mirtrons,” one or both ends of the pre-miRNA are established by the spliceosome during intron excision (Okamura et al., 2007; Ruby et al., 2007a). For many mitrons, the debranched introns have all the features of a canonical pre-miRNA, including a 2 nt 3′-overhang, and they are exported, diced, and loaded like canonical pre-miRNAs (Okamura et al., 2007; Ruby et al., 2007a). In other mirtrons, the 3′ splice sites are downstream of the pre-miRNA ends; in these cases, the intron 3′ end is trimmed by the exosome before dicing (Flynt et al., 2010). Endogenous short hairpin RNAs also bypass Microprocessor cleavage. Although not well-studied as a class, these noncanonical miRNAs are probably derived from short transcription units that intrinsically produce a hairpin with the features of a pre-miRNA (Babiarz et al., 2008). A third alternative pathway bypasses Dicer. Like canonical miRNAs, the primary transcript of mir-451 is cleaved by the Microprocessor and the pre-miRNA is exported to the cytosol; however, unlike canonical pre-miRNAs, pre-mir-451 is cleaved by Argonaute 2 (Ago2) (Cheloufi et al., 2010; Cifuentes et al., 2010). Known determinants of pri-miRNA processing Two parallel lines of investigation converged on the early identification of Drosha in animals. One was incidental; the drosha locus in Drosophila melantogaster was encountered during genomic analysis of the rnh1 locus encoding RNase H1 amid questions about the role of RNase H proteins in animal biology. Microdeletions in a region adjacent to rnh1 caused lethality, and sequencing of this region revealed an open reading frame predicted to produce a 153 kDa protein with homology to the endonuclease domain of bacterial and yeast RNase III proteins (Filippov et al., 2000). Named Drosha, the the novel protein contained two tandem endonuclease domains instead of just one, and gene database searching revealed highly related homologues with tandem RNase III domains in the genomes of both C. elegans and humans (Filippov et al., 2000). Thanks to the growing power of large sequence databases, it was already known that two classes of RNase III enzymes were present in animals (Mian, 1997); Drosha was one type, while the other helicase-like (Rotondo and Frendewey, 1996) and would later be named Dicer (discussed below). At the same time, a separate group interested in mammalian 16 RNase III proteins used a phage cDNA clone library to build the full-length cDNA of a human protein containing RNase III domains (Wu et al., 2000). This protein degraded long dsRNA, albeit much more poorly than the E. coli RNase III. Importantly, the protein was nuclearlocalized, and it was believed to mediate rRNA processing, based on the functions of RNase III in yeast and bacteria (Wu et al., 2000). Because of its localization, the protein was named RNASEN, the human nuclear RNase III, but is now called Drosha like its ecdysozoan orthologs. The proteins remained unassociated with RNA interference and the biogenesis of miRNAs until two observations were made: first, that the initial post-transcriptional event of miRNA biogenesis was the cleavage of pri-miRNAs in the basal hairpin stem, an activity that was localized to the nucleus (Lee et al., 2002); and second, that the pre-miRNA product of this first cleavage had 2 nt 3′-overhangs, precisely the expected product of staggered cleavage by RNase III enzymes (Lee et al., 2003). Indeed, immunoprecipitated human Drosha (i.e., RNASEN) accurately excised pre-miRNAs from longer primary transcripts (Lee et al., 2003). In human and Drosophila lysates, Drosha and pri-miRNA cleavage activity fractionates with a ~600 kDa complex which has been called the Microprocessor (Denli et al., 2004; Gregory et al., 2004). In this complex, Drosha is tightly associated with a binding partner called Pasha in Drosophila and C. elegans, and DGCR8 in humans, which are homologues of each other (Denli et al., 2004; Gregory et al., 2004). DGCR8/Pasha is required for Microprocessor cleavage activity both in vitro and in vivo (Denli et al., 2004; Gregory et al., 2004), and recombinant human Drosha and DGCR8 are together sufficient to reconstitute the pri-miRNA cleavage in vitro (Gregory et al., 2004). DGCR8/Pasha contains two double-strand RNA binding domains (dsRBDs), and the presence of at least one is required to support pri-miRNA cleavage by the Microprocessor (Yeom et al., 2006). Thus, DGCR8/Pasha probably contributes significantly to pri-miRNA binding and recognition, since Drosha itself contains just one dsRBD (Lee et al., 2003). The functions of Drosha and Pasha/DGCR8 are so entwined that the Drosha protein is unstable in the absence of DGCR8, and Drosha regulates DGCR8 levels by cleaving a hairpin in the 5′ untranslated region of the DGCR8 mRNA (Han et al., 2009). General preferences of the Microprocessor Given its role as the gateway to the canonical miRNA biogenesis pathway, the Microprocessor and its substrate preferences have been subjected to intense scrutiny. Minimal 17 substrates for the Microprocessor in vitro are composed of the pre-miRNA hairpin flanked by at least 20-50 nt of genomic sequence; the determinants in these segments are necessary and sufficient to support at least minimal cleavage by the Microprocessor in vitro (Lee et al., 2003) and expression of the mature miRNA in vivo (Chen et al., 2004). This region is important in part because of Watson–Crick base pairing that extends basally to the pre-miRNA hairpin. Mutations that abolish base pairing impair cleavage, while mutations that preserve base pairing preserve cleavage, albeit at reduced efficiency (Lee et al., 2003). This pairing is consistent with the observation that C. elegans, Drosophila, and human pri-miRNAs strongly tend to have base pairing that extends beyond the pre-miRNA hairpin (Lim et al., 2003b; Han et al., 2006). Beyond the stem, a length of unstructured RNA flanking the stem is required for pri-miRNA processing, since the Microprocessor does not cleave substrates lacking flanking RNA (Zeng and Cullen, 2005; Han et al., 2006). The Microprocessor is thought to recognize the flank-stem junction, and uses the junction to guide cleavage approximately one helical turn above the base (Han et al., 2006). Consistent with this model, mutations that shorten or lengthen the base of the stem shift Microprocessor cleavage site accordingly, at least in vitro (Han et al., 2006). The structural basis of Microprocessor binding to the stem-flank junction is poorly understood. It was initially suggested that DGCR8 was responsible for junction recognition (Han et al., 2006), but substrate affinity studies with the DGCR8 dsRBDs have not consistently demonstrated that the dsRBDs can distinguish between hairpins and hairpins with flanking RNA (Sohn et al., 2007). It is worth noting that binding affinities measured in this study were in the 2–4 µM range, far higher than expected, suggesting that physiological binding of the dsRBDs to pri-miRNAs may require the presence of other domains in DGCR8, or a functional complex between DGCR8, Drosha, and perhaps other proteins in the Microprocessor complex. Others have suggested that DGCR8 binding to the pri-miRNA is cooperative, and that DGCR8 monomers can bind to multiple regions of the pri-miRNA (Faller et al., 2010). Whether this multimerization contributes to substrate specificity is unclear. The apical stem and terminal loop also contribute to recognition of pri-miRNAs by the Microprocessor, although their importance has been debated. Earlier in the characterization of the Microprocessor, it was suggested that the Drosha cleavage site was established by a molecular ruler two turns away from the loop (Zeng et al., 2005). This model was unsatisfying because it failed to accurately predict the Drosha cleavage site based on the thermodynamically 18 predicted stem terminus; by contrast, basal stem length robustly predicts cleavage site, even in artificial substrates that have no loop at all (Han et al., 2006). As a consequence, loop-based measurement is not widely accepted as the mechanism of cleavage site selection. Nevertheless, shortening of either the terminal loop or the apical stem impairs binding to DGCR8 and cleavage by the Microprocessor (Zeng et al., 2005; Han et al., 2006; Zhang and Zeng, 2010). The optimal length of the loop has not been determined, but the optimal length of the apical stem appears to be ~2 helical turns above the Microprocessor cleavage site. Thus the optimal structure of a primiRNA is a ~3-turn hairpin (one turn between the base and the cleavage site, and two turns between the cleavage site and the loop) flanked on each side by some length of unstructured RNA (Figure 1). Existing studies of Microprocessor preferences also hint at the existence of other, less well-defined sequence or structural determinants. First, sequence analysis of miRNA hairpins demonstrates a propensity for these hairpins to contain internal loops that are reasonably symmetric (Lim et al., 2003b; Han et al., 2006; Warf et al., 2011). These could contribute somehow to enhance binding and cleavage by the Microprocessor, although an early study of the hsa-mir-30a pri-miRNA suggested that its internal loops were dispensable (Lee et al., 2003). Alternatively, central internal loops could inhibit inappropriate or non-productive binding or cleavage in the apical stem, one helical turn from the stem-loop junction, thus biasing the Microprocessor to cleave at the appropriate location (Han et al., 2006). Central loops or bulges could also facilitate miRNA biogenesis downstream of the Microprocessor, particularly at the step of loading into Argonaute (discussed below). Second, a number of stem and loop mutations that impair Drosha processing in vitro have been described (Zeng et al., 2005; Gottwein et al., 2006), along with some single nucleotide polymorphisms (SNPs) thought to impair in vivo processing (Duan et al., 2007; Sun et al., 2009). The significance of these mutations in the hairpin is unclear. One view is that these mutations could be altering critical sequence motifs that are recognized by the Microprocessor or auxiliary recognition proteins, although such motifs were not delineated in the studies. Another view is that such mutations could substantially change the pri-miRNA folding landscape, biasing the ensemble of folding isoforms away from the optimal structure and thus preventing proper cleavage (P. Dallaire, personal communication). differentiate between these two models. 19 Additional investigation is needed to Finally, the lengths of upstream and downstream RNA required for pri-miRNA processing in vivo (Chen et al., 2004) are not fully explained by the stem-flank junction model for pri-miRNA cleavage, since just a few flanking nucleotides are sufficient for cleavage site determination in artificial substrates (Han et al., 2006). It is possible that additional primary sequence or structural determinants could reside in the RNA sequence flanking the stem. Indeed, a SNP downstream of the hsa-mir-16-1 pri-miRNA impairs its processing in cell lines, and is associated with B-cell chronic lymphocytic leukemia in humans (Calin et al., 2002; Calin et al., 2005). It is tempting to speculate that this SNP has affected recognition of a motif downstream of the pri-miRNA hairpin, although no specific motifs were identified in those studies. Regulation of cleavage in subsets of animal pri-miRNAs Several mechanisms for the dynamic regulation of pri-miRNA cleavage have been described. These mechanisms are typically mediated by individual proteins, and may only affect a subset of miRNAs at specific times. Most described regulatory mechanisms are thought to mildly enhance pri-miRNA cleavage by the Microprocessor, while the remaining ones sequester the pri-miRNA or induce its active degradation without necessarily inhibiting the activity of the Microprocessor per se. Some regulators of pri-miRNA cleavage appear to depend on binding to the pri-miRNA terminal loop. One example is the heterogeneous nuclear ribonucleoprotein A1 (hnRNPA1), a highly abundant protein thought to function in general mRNA metabolism, including splicing, mRNA export, and regulation of stability (Dreyfuss et al., 1993). A transcriptome-wide study of hnRNPA1 binding sites by crosslinking and immunoprecipitation incidentally found binding sites in the terminal loop of hsa-mir-18a; of note, there were no observed binding events to other terminal loops in the mir-17~92 cluster of miRNAs, of which mir-18a is a member (Guil and Caceres, 2007). Binding of hnRNPA1 is thought to promote Microprocessor cleavage of the mir-18a pri-miRNA by altering the conformation of the mid-stem (Michlewski et al., 2008), based on changes in RNase V1 accessibility, although it is not clear whether this is the consequence of stem melting or is actually due to occlusion of the RNase V1 cleavage sites by hnRNPA1 binding. This study noted that miRNA loops are generally more conserved than nearby sequence (although considerably less conserved than the mature miRNA and the miRNA* strand), suggesting that other proteins may also have conserved binding sites in many 20 pri-miRNAs (Michlewski et al., 2008). Nonetheless, the role of hnRNPA1 in pri-miRNA cleavage may not be straightforward; its binding to the let-7a pri-miRNA appears to antagonize cleavage by the Microprocessor (Michlewski and Caceres, 2010). How hnRNPA1 enhances processing in some pri-miRNAs but represses processing in others is not clear. Similarly, an RNA-binding protein that plays multiple roles in RNA metabolism, the KHtype splicing regulatory protein (KSRP), appears to bind the terminal loop of the let-7a primiRNA and enhance its cleavage by both the Microprocessor and Dicer (Trabucchi et al., 2010). KSRP may also regulate other miRNAs, based on reductions in the mature miRNA levels after KSRP knockdown. It has also been suggested that KSRP may compete with hnRNPA1 for binding to the let-7a terminal loop, and that the relative expression levels of these antagonistic proteins may dynamically establish the processing efficiency for let-7a (Michlewski and Caceres, 2010). The cleavage of a subset of pri-miRNAs is thought to be regulated by extracellular signals. Signaling through the transforming growth factor β (TGFβ) pathway upregulates mature miR-21 by increasing processing of the mir-21 pri-miRNA (Davis et al., 2008). The effector proteins downstream of TGFβ are the Smad proteins, which trimerize and act as transcription factors. TGFβ signaling appears to induce the association of both SMAD proteins and the helicase p68 with the hsa-mir-21 pri-miRNA, which results in enhanced cleavage by the Microprocessor (Davis et al., 2008). This effect of TGFβ signaling does not depend on Smad4, which is usually a necessary cofactor in trimeric Smad complexes that regulate transcription (Davis et al., 2008). Many miRNAs appear to be regulated by TGFβ signaling, and appear to have the common sequence motif 5′−CAGAC−3′ 3′−GUCUG−5′ in the mid-stem adjacent to the Microprocessor cleavage site (Davis et al., 2010). This motif, when grafted onto non-regulated pri-miRNAs, is sufficient to confer TGFβ regulation (Davis et al., 2010). Oddly, this is nearly exactly the 5′−AGAC−3′ canonical Smad binding element 3′− TCTG−5′ in DNA which the Smad MH1 domain recognizes by inserting a β-sheet “hairpin” into the major groove (Shi et al., 1998). The MH1 domain is also thought to mediate binding to pri-miRNAs (Davis et al., 2010), but it is not clear whether the domain is capable of inserting into the deeper and narrower major groove of the presumably Aform pri-miRNA stem. The Smad proteins are not the only transcription factor proteins proposed to bind primiRNAs and regulate their cleavage. The transcription factor All1 has been suggested to 21 enhance Microprocessor cleavage, but its association with the Microprocessor is DNAdependent (Nakamura et al., 2007), raising the possibility that the Microprocessor could be regulated by recruitment to sites of active transcription. Two other examples are the DEAD-box helicases p68 and p72, which are multifunctional DEAD-box helicases that, among other things, activate transcription in collaboration with other transcriptional regulators like p53 and steroid receptors. The mouse knockouts of these proteins resulted in reductions in the mature levels of a handful of mature miRNAs (Fukuda et al., 2007). The ability of Drosha to crosslink to these primiRNAs is impaired in the absence of these helicases, and antibodies against the helicases inhibit processing in vitro (Fukuda et al., 2007). It is not clear how these proteins promote cleavage by the Microprocessor, and how the effect is restricted to a subset of pri-miRNAs. Nevertheless, the association of these helicases with the critical DNA damage response regulator p53 instigated an analysis of the effect of p53 activation and loss-of-function on miRNA levels. Activation of p53 by doxorubicin increased the expression of a subset of mature miRNAs without affecting pri-miRNA levels, and this effect was dependent on p68 and p72 (Suzuki et al., 2009). Addition of p53 also enhanced pri-miRNA cleavage by the Microprocessor for some of these miRNAs (Suzuki et al., 2009). As with p68 and p72, the mechanism of p53-mediated enhancement of pri-miRNA cleavage and how the effect is restricted to a few pri-miRNAs remain to be elucidated. Further study could also shed light on whether different p53 mutations affect the levels of subsets of mature miRNAs, and whether these effects contribute to the pathophysiology of cancer. Cleavage of pri-miRNAs can also be regulated by “anti-determinants” that inhibit cleavage or stimulate degradation of the pri-miRNA. One of the earliest examples was the regulation of let-7 family members by binding of Lin28A to the pri-miRNA terminal loop; this binding was mediated by a specific motif which may be present in other pri-miRNAs (Newman et al., 2008; Piskounova et al., 2008; Nam et al., 2011) . Binding was thought to inhibit cleavage of let-7 pri-miRNAs, and this negative regulation helped maintain the pluripotent state in embryonic stem cells (Viswanathan et al., 2008). This mechanism was controversial because Lin-28A is largely localized to the cytosol in embryonic stem cells, and later work demonstrated that Lin-28A could induce the 3′ terminal polyuridylation of the let-7 pre-miRNA and subsequent degradation (discussed below). Recently, however, it has been shown that a closely related paralog, Lin-28B, also inhibits biogenesis of let-7 family members, but is localized to the 22 nucleus and does not appear to interact with terminyl uridyl transferases (Piskounova et al., 2011). In particular Lin-28B localizes to nucleoli, where there is little Microprocessor localization, leading to the model that Lin-28B sequesters let-7 pri-miRNAs to a location where it is inaccessible to the Microprocessor. Another example of negative regulation is ADAR1-mediated RNA editing, which causes the active degradation of some pri-miRNAs. ADAR1, an adenosine deaminase, catalyzes the conversion of adenosine to inosine in dsRNA. Editing can be highly specific, with editing of some adenosines but not others within the same substrate, although the contextual determinants that specify the edited adenosines are not well understood (Nishikura, 2010). A-to-I editing is detectable in human and mouse precursor and mature miRNAs, and is confined to brainexpressed miRNAs, consistent with the tissue expression pattern of ADAR1 (Blow et al., 2006; Landgraf et al., 2007; Kawahara et al., 2008; Chiang et al., 2010). The significance of mature miRNA editing is unclear, although the editing has a propensity to occur in the miRNA seed, opening the possibility that editing alters the target profile of the mature miRNA (Chiang et al., 2010). By contrast, the editing of two pri-miRNAs, mir-142 and mir-151, induces the degradation of the pri-miRNAs by TudorSN (Yang et al., 2006). Thus A-to-I editing may inhibit the processing of a subset of miRNAs in a tissue-specific manner. In summary, several regulatory paradigms have been described that influence the cleavage of subsets of pri-miRNAs. Since these regulatory schemes affect only subsets of primiRNAs, it seems unlikely that they, either individually or in aggregate, could explain how the Microprocessor recognizes pri-miRNAs. Nevertheless, these studies add nuance to our understanding of how processing can be sensitive to cell type, gene expression state, and extracellular signals, and could provide insight into how the dysregulation of pri-miRNA processing could contribute to human disease. Plant pri-miRNA processing: DCL1 Like the animal miRNAs, plant miRNA biogenesis depends on an RNase III protein. CARPEL FACTORY (CAF) was identified in a genetic screen for abnormal flower development (Jacobsen et al., 1999), and encodes an RNase III protein. Its developmental phenotypes and homology homology to the animal Dicer proteins inspired experiments that demonstrated its importance in miRNA biogenesis (Park et al., 2002; Reinhart et al., 2002). CAF was later 23 renamed DICER-LIKE1 (DCL1) in recognition of its sequence and functional homology (Schauer et al., 2002). DCL1 has functions in plants equivalent to those of both Drosha and Dicer in animals (Park et al., 2002; Reinhart et al., 2002; Kurihara and Watanabe, 2004). Like the animal Microprocessor, DCL1 and its partners SERRATE and HYPONASTIC LEAVES (HYL1) appear to recognize junctions between unstructured RNA in internal loops and base paired stems; the cleavage site is typically 15 bp above the junction (Dong et al., 2008; Mateos et al., 2010; Song et al., 2010). However, no additional determinants have been identified that might shed light on how the DCL1 complex distinguishes the appropriate loop-stem junction corresponding to the pri-miRNA cleavage site from other loop-stem junctions in the pri-miRNA, much less how DCL1 distinguishes pri-miRNAs from other structured RNAs. One study partially-randomized pri-miRNA sequences, expressed the sequences in plants, and selected functional molecules based on the miRNA overexpression phenotype (Mateos et al., 2010). In principle, this approach could explore the DCL1 cleavage determinants in great detail, but, in practice, the low numbers of variants that could be tested limited the study’s ability to find determinants other than the 15 bp basal stem. Determinants of canonical biogenesis downstream of the Microprocessor Specificity of nuclear export mediated by exportin-5 The product of Microprocessor cleavage, called the pre-miRNA, is exported from the nucleus by exportin-5 in animals (Yi et al., 2003; Bohnsack et al., 2004; Lund et al., 2004), and by the homologous protein HASTY in Arabidopsis (Park et al., 2005). Initially characterized due to its sequence homology to other karyopherin β proteins, exportin-5 was at first thought to recognize and export dsRBD containing proteins (Brownawell and Macara, 2002). It was soon shown to export tRNAs and the adenovirus VA1 RNA, both RNAs that contain helices with 3′ overhangs (Bohnsack et al., 2002; Calado et al., 2002; Gwizdek et al., 2003). In fact, short artificial helices with single-stranded 3′-overhangs are sufficient for exportin-5 recognition and RanGTP-mediated nuclear export (Gwizdek et al., 2003). A crystal structure of exportin-5 in complex with a pre-miRNA stem explains this preference: the protein is shaped like a mitt with a positively charged “palm” that partially wraps the helix, with a positively-charged tunnel at the 24 base of the mitt that accommodates the 3′-overhang (Okada et al., 2009). This tunnel is oriented in such a way that threading a 2 nt 5′-overhang through it results in a steric clash between the 3′ end and the protein (Okada et al., 2009), explaining the specificity for 3′-overhangs. Importantly, all protein–RNA contacts are mediated through the phosphate backbone (Okada et al., 2009), consistent with the view that exportin-5 substrates are defined by their end structure rather than by sequence. Since RNase III family proteins produce 2 nt 3′-overhangs, exportin-5 is theoretically capable of exporting any product of Drosha cleavage, and seems unlikely to impose additional constraints on miRNA maturation. Specificity of cleavage by Dicer The identification of Dicer emerged from studies of animal RNA interference (RNAi), a phenomenon where the introduction of exogenous dsRNA derived from the sequences of a protein-coding gene induced post-transcriptional silencing of that gene (Fire et al., 1998). Although the dsRNA used to induce RNAi was hundreds of nucleotides long, studies of RNAi using a Drosophila in vitro lysate system revealed that the long dsRNA was cleaved at regular, 21–22 nt intervals (Zamore et al., 2000). Fractionation of the lysate showed that these short fragments were associated with target mRNA cleavage activity (Hammond et al., 2000). These observations led to the view that the long dsRNA is actually a precursor molecule, and the small fragments derived from it are the active species that guide and induce target mRNA cleavage. This view was later strengthened by the demonstration that synthetic 21–22 nt fragments were sufficient to induce mRNA cleavage in the Drosophila lysate and post-transcriptional gene silencing in mammalian cells (Elbashir et al., 2001a; Elbashir et al., 2001b; Nykanen et al., 2001). Given that the RNase III family of enzymes was known to cleave dsRNA into discretelysized products, it seemed likely that the dsRNA-cleaving enzyme would contain an RNase III domain (Bass, 2000). At that time, the only animal RNase III enzyme that had been described was Drosha (discussed previously), but analysis of the then-newly available Drosophila melanogaster and C. elegans genomes picked up three additional, unnamed proteins containing tandem RNase III domains, one in C. elegans and two in Drosophila (Bernstein et al., 2001). The Drosophila and human enzymes were sufficient to produce the ~22 nt active fragments from long dsRNA, and were named “Dicer” accordingly (Bernstein et al., 2001). Consistent with its 25 role in generating the active RNAi-inducing species, loss of Dicer in Drosophila cells and C. elegans abolished RNAi (Bernstein et al., 2001; Knight and Bass, 2001). This characterization of the RNAi phenomenon dovetailed with studies of miRNA biogenesis when Dicer was shown to be necessary for the maturation of lin-4 and let-7 (Grishok et al., 2001; Hutvagner et al., 2001; Ketting et al., 2001). In Drosophila, Dicer proteins are functionally specialized; Dicer-1 (Dcr-1) cleaves pre-miRNA hairpins, while Dicer-2 (Dcr-2) processes long dsRNA into siRNAs (Lee et al., 2004b). Like Drosha, Dicer requires the association of dsRBD-containing partners for full activity. Drosophila Dicer-1 (Dcr-1) is associated with Loquacious (Loqs) (Forstemann et al., 2005; Jiang et al., 2005; Saito et al., 2005), while Dicer-2 (Dcr-2) is associated with R2D2 (Liu et al., 2003) and additionally depends on isoforms of Loqs for some substrates (Czech et al., 2008; Okamura et al., 2008; Hartig et al., 2009; Zhou et al., 2009). In mammals, Dicer is associated with the TAR-element binding protein (TRBP) (Chendrimada et al., 2005; Haase et al., 2005) and another related protein called PACT (Lee et al., 2006). In humans, TRBP does not appear to be required for Dicer cleavage of pre-miRNAs (Chendrimada et al., 2005), although its presence enhances Dicer catalysis of pre-miRNAs and long dsRNA (Chakravarthy et al., 2010). Similarly, Drosophila Dicer2 processes dsRNA efficiently without R2D2 (Liu et al., 2003). By contrast, the association of Drosophila Dcr-1 with Loqs is required for processing of the premiRNAs in flies (Forstemann et al., 2005; Jiang et al., 2005; Saito et al., 2005), although some pre-miRNAs may not depend on Loqs (Liu et al., 2007). No canonical set of substrate binding preferences have been ascribed to the individual Dicer binding partners, but the Dicer binding partners can assist in restricting the specificity of Dicer paralogs to specific substrates (Cenik et al., 2011). The principal determinant of Dicer cleavage is the structure of the dsRNA ends. Human Dicer preferentially cleaves from the ends of a dsRNA, suggesting that the phase of dsRNA cleavage products is set by successive cleavage from the ends (Zhang et al., 2002). Based on systematic mutagenesis of Dicer, a model for substrate recognition was developed where the Dicer PAZ domain binds the duplex ends and positions the RNase III domains to cleave the dsRNA helix (Zhang et al., 2004); once the PAZ domain is positioned, the three-dimensional organization of domains in Dicer proteins of different organisms sets the length of Dicer products (Lau et al., 2012). The PAZ domain has a specific preferences for 3′ overhangs at the 26 end of the duplex; a 2 nt overhang with a free 3′-OH is the optimal structure, consistent with crystal structures of the PAZ domain in complex with a duplex RNA (Ma et al., 2004). In fact, the recognition of this end structure resides entirely in the PAZ domain: swapping the PAZ domain for the RNA binding domain of the spliceosomal protein U1A converts Dicer’s preference for 2 nt 3′-overhangs to a preference for the U1 RNA loop (MacRae et al., 2007). Consistent with the binding of its PAZ domain, Dicer cleavage of hairpins with 3′-overhangs is more efficient than cleavage of substrates with blunt ends (Vermeulen et al., 2005). The nucleotide identities of the overhanging bases influence binding affinity to the PAZ domain and Dicer cleavage efficiency, but their contribution is small relative to that of the 2 nt 3′-overhang (Ma et al., 2004; Vermeulen et al., 2005). Whether the 5′-phosphate or the 3′-OH in the overhang is more important for defining the cleavage site is currently debated. Based on the crystal structure of Giardia Dicer, it was believed that Dicer measured its cleavage site from the 3′-OH of the overhang (Macrae et al., 2006; MacRae et al., 2007). However, it has been recently proposed that the human Dicer primarily measures from the 5′-phosphate, and uses measurement from the 3′-OH as a backup mechanism, explaining why Dicer cleavage sites are preserved in 3′ uridylated pre-miRNAs (Park et al., 2011). Either way, pre-miRNAs with 2 nt 3′-overhangs are optimal substrates, since 5′ or 3′ single-stranded RNA extensions reduce cleavage efficiency, even when the cleavage site per se is unaffected (Park et al., 2011). Thus Dicer and its PAZ domain have evolved to recognize substrates produced by other RNase III cleavage events, consistent with its role in biogenesis downstream of Drosha and exportin-5. In addition to the overhang structure, the Drosophila Dcr1-Loqs complex appears to prefer pre-miRNA-like hairpins with ~22 bp stems capped by a 14 nt loop over substrates with longer stems and/or shorter loops (Miyoshi et al., 2010; Tsutsumi et al., 2011). Recognition of pre-miRNA loops depends on the Dcr-1 helicase domain, consistent with a structural model based on electron microscopy that localizes the Dicer helicase domains to the pre-miRNA apical stem and loop (Lau et al., 2012). Similarly, human Dicer cleavage is moderately impaired when the pre-miRNA contains an unusually small loop or short stem (Zhang and Zeng, 2010). This preference may contribute to the propensity of pri-miRNA hairpins to be ~3 helical turns long. One possible model is that the Microprocessor has an intrinsic preference for 3-turn helices with appropriately-sized terminal loops (Zeng et al., 2005; Gottwein et al., 2006; Zhang and Zeng, 27 2010). Dicer then reinforces this structural requirement by preferentially cleaving pre-miRNAs with ~2 helical turns and the same terminal loop, corresponding to the Microprocessor cleavage product. To the extent that Dicer has primary sequence preferences in the pre-miRNA stem, they are likely to pale beside the structural determinants. Short hairpin RNAs (shRNAs) have been used extensively to repress the expression of target genes. In most experimental systems, shRNAs are transcribed by RNA polymerase III to produce hairpins similar in structure to premiRNAs, which are cleaved by Dicer and ultimately induce repression of target mRNAs (Brummelkamp et al., 2002; Paddison et al., 2002). Libraries consisting of hundreds of thousands of artificial shRNAs have been generated for the purpose of performing loss-offunction genetic screens in mammalian cells; the sequences of the shRNA stems are very diverse, since it is these sequences which specify targets for cleavage by Argonaute2 within the RNA-induced silencing complex. Despite the sequence diversity of the library, most examined shRNAs are cleaved by Dicer and repress target gene expression (Moffat et al., 2006), demonstrating that Dicer cleaves many hairpins with different sequences but identical structures. Specificity of loading into Argonaute Argonaute family proteins form the core of the effector complex that represses targets in a variety of RNA-induced silencing pathways, including the miRNA pathways in both animals and plants. The founding member of the family, Arabidopsis AGO1, was identified genetically in a screen for mutants that cause altered leaf morphology (Bohmert et al., 1998). At the same time, genetic studies of C. elegans RNAi identified an Argonaute homolog, rde-1, which was required for RNAi. RNAi seemed similar to a plant phenomenon called post-transcriptional gene silencing (PTGS), in which the introduction of exogenous transgenes appeared to silence endogenous genes with the same sequence. This led to the hypothesis that Arabidopsis AGO1 might be related to PTGS; indeed, AGO1 mutants were defective in PTGS (Fagard et al., 2000). Meanwhile, studies of RNAi in extracts had shown the existence of a nuclease activity that specifically cleaved target mRNAs, and the protein complex that contained the activity was called the RNA Induced Silencing Complex (RISC) (Tuschl et al., 1999; Hammond et al., 2000; Zamore et al., 2000). When RISC was fractionated, a human Argonaute homolog, Argonaute2 28 (Ago2), copurified with the nuclease activity (Hammond et al., 2001), and purified Ago2 carried out small RNA guided target cleavage (Liu et al., 2004; Meister et al., 2004; Rivas et al., 2005). Within a given animal or plant species, many Argonaute homologs can be present, which may be associated with different small RNAs derived from various biogenesis pathways (Ketting, 2011). For example, the 27 Argonaute superfamily members in C. elegans associate with Piwi-associated RNAs, endogenously derived siRNAs, exogenously derived siRNAs, and other small RNAs; of the 27, only ALG-1 and ALG-2 associate with miRNAs (Grishok et al., 2001). In Drosophila, miRNAs primarily associate with Ago1 (Caudy et al., 2002; Miyoshi et al., 2009), while in mammals miRNAs are associated with Ago1, Ago2, Ago3, and Ago4 (Liu et al., 2004; Meister et al., 2004). Given the plethora of small RNAs and their sorting into different Argonautes, it is understandable that the Argonaute-loading process inspects Dicer cleavage products for specific features. Among miRNA-associated Argonautes in animals, Drosophila Ago1 and its loading are best understood. One principal determinant is stem secondary structure: Ago1 prefers RNA duplexes with central mismatches, particularly at positions 9-10 of the loaded strand (Forstemann et al., 2007; Tomari et al., 2007; Kawamata et al., 2009). Likewise, central mismatches drive small RNAs into C. elegans ALG-1 (Steiner et al., 2007). Two other determinants relate to strand selection: of the two strands in the Dicer cleavage product, only one strand is preferentially loaded into Ago1. The 5′ end of the loaded strand is usually derived from the less thermodynamically stable end of the duplex (Schwarz et al., 2003), and the 5′ nucleotide of the loaded strand is usually U (Czech et al., 2009; Okamura et al., 2009; Ghildiyal et al., 2010; Seitz et al., 2011). Finally, loading requires a 5′ phosphate, consistent with the products of Dicer cleavage (Kawamata et al., 2011). The sorting of small RNAs between Ago1 and Ago2 blurs the distinction between miRNAs and other small RNAs in flies. On one hand, only Drosophila Ago1 is capable of mediating targeting using the miRNA seed, which is the basis of most miRNA targeting in animals; Ago2 efficiently cleaves its targets but requires nearly perfect matches, which is atypical of metazoan miRNA target sites (Forstemann et al., 2007; Bartel, 2009). Thus RNA species that are predominantly loaded into Ago2 might not be considered proper miRNAs. On the other hand, there are hairpins (such as dme-mir-277) encoded in the Drosophila genome that are processed by the Microprocessor and Dcr-1/Loqs, but the Dcr-1 products are sorted primarily 29 into Ago2 due to extensive pairing (Tomari et al., 2007). Even when the miRNA strand is selectively loaded into Ago1, the miRNA* strand is often loaded into Ago2 (Czech et al., 2009; Okamura et al., 2009; Ghildiyal et al., 2010). Thus, different small RNA species can be derived from the same precursor molecules but come to rest in different maturation endpoints. From a biogenesis standpoint, it seems that sorting preferences are not really requirements for miRNA authenticity; instead, one might view them as different ways for the cell to utilize the RNA precursors that enter the miRNA biogenesis pathway. Ago loading preferences in vertebrates are less well studied, but are likely to be similar to those of Drosophila Ago1. Like Drosophila Ago1, loading of mammalian Ago proteins is more efficient when the duplex contains central mismatches (Yoda et al., 2010). Mammalian Ago proteins prefer 5′ U or A nucleotides, since mammalian miRNAs and functional shRNAs tend to start with U or A (Bartel, 2004; Fellmann et al., 2011); structurally, this preference is mediated by contacts between the Ago MID domain and A and U bases at the 5′ end (Frank et al., 2010). The 5′ end of the loaded strand is usually derived from the less thermodynamically stable end of the duplex (Khvorova et al., 2003). No evidence of significant miRNA sorting between Ago proteins has been found to date (Liu et al., 2004; Meister et al., 2004; Wang et al., 2012). Regulation of biogenesis in subsets of animal pre-miRNAs In addition to positive determinants that promote miRNA biogenesis, it is possible in principle to evolve “anti-determinants” that induce the active elimination of RNA species that are not authentic pre-miRNAs. There are no convincing examples of this paradigm in the literature, but individual miRNAs can be dynamically regulated by the active degradation of the pre-miRNA. This regulation does not help the cell define miRNAs as a class, but does help control the levels of specific miRNAs in response to internal or external cues. One example is the ADAR1-mediated editing of pre-mir-151, which inhibits its cleavage by Dicer (Kawahara et al., 2007). Another, well-studied example is the regulation of let-7 by Lin-28A. Lin-28A binds two specific motifs in the pre-miRNA loops of let-7 family members (Newman et al., 2008; Piskounova et al., 2008; Nam et al., 2011) and recruits a terminal uridyl transferase to add uridines to the 3′ end of the pre-miRNA (Heo et al., 2008; Hagan et al., 2009; Heo et al., 2009; Lehrbach et al., 2009). Uridylation inhibits Dicer processing of the pre-miRNA and recruits an unknown nuclease to degrade the pre-miRNA (Heo et al., 2008; Hagan et al., 2009; Heo et al., 30 2009; Lehrbach et al., 2009). Although Lin-28A regulation was thought to be exclusive to let-7 family members, several other pre-miRNAs have part of the Lin-28 binding motif in their loops, and the presence of the partial motif correlates with evidence of uridylation, albeit less than that of pre-let-7 (Heo et al., 2009). Analysis of mature miRNA sequences has shown that terminal uridylation of mature miRNAs is 3-fold more common in miRNAs derived from the pre-miRNA 3′ arm, suggesting that regulation by uridylation may occur surprisingly frequently (Chiang et al., 2010). Indeed, this is likely to be an underestimate of regulation by polyuridylation, since polyuridylated pre-miRNAs are both less likely to be Dicer processed and more likely to be degraded. The proteins that mediate this putative regulation have not been identified to date, and it is possible that proteins other than Lin-28 can recruit terminal uridyl transferases to premiRNAs. Finding additional biogenesis determinants in pri-miRNAs In summary, the substrate specificity of each successive step in miRNA biogenesis is largely dictated by the biochemistry of the previous step. This observation is not surprising, since these steps are joined in a contiguous maturation pathway, but it does reinforce the notion that authentic miRNA precursors are primarily defined at the first step of biogenesis, when primiRNAs are recognized and cleaved by the Microprocessor. Given the broad substrate specificity of the Microprocessor, it is not understood how the complex differentiates between miRNA structures and other hairpins. On an intellectual level, hairpins are common motifs in structured RNAs, and other RNAs may stochastically assemble into secondary structures that contain hairpins. Indeed, a genome wide-search found some 11 million hairpins in the human genome (Bentwich et al., 2005). To the extent that they are transcribed and functionally important, inappropriate cleavage of many of these structures by Drosha is surely detrimental to the cell. On a practical level, attempts to predict pri-miRNAs based on canonical secondary structure produce many false-positives, which must be eliminated using additional criteria, such as evolutionary conservation or experimental evaluation (Lim et al., 2003a; Lim et al., 2003b; Bentwich et al., 2005; Berezikov et al., 2006; Chiang et al., 2010). Of course, the Microprocessor has no direct way of assessing the conservation of a pri-miRNA substrate, so our inability to predict pri-miRNAs from the sequence of a single genome illustrates our poor understanding of how the Microprocessor recognizes its substrates. 31 The mystery of how Drosha can distinguish pri-miRNAs from other hairpins is part of a recurrent mystery of how an enzyme with minimal apparent preferences can distinguish its authentic substrates from other, superficially similar substrates. For example, questions about the substrate specificity of E. coli RNase III emerged early in the investigation of this enzyme. Polyoma virus dsRNA could be cleaved exhaustively to produce 11-13 nt fragments (Robertson and Dunn, 1975), suggesting that RNase III lacked strong nucleotide preferences. It seemed that RNase III was a general dsRNA endonuclease, at least in vitro, yet it did not seem possible that an enzyme with few if any discernible substrate preferences (other than secondary structure) could function in vivo. Indeed, Hugh D. Robertson and John J. Dunn concluded their 1975 paper on this note: “In conclusion, we can expect the specific sites in cellular RNAs which are processed by RNase III to have substantial double helical structure; to be greater than 20 base pairs in length; to contain 5′-phosphate and 3′-hydroxyl endgroups after cleavage; and to contain, in all probability, at least one further characteristic feature, either a common sequence or an additional structural element, to differentiate them from the many regions of potential secondary structure now thought to reside at frequent intervals in biological RNA sequence.” (Robertson and Dunn, 1975) Just as investigators studying RNase III in the 1970s recognized that the enzyme had to have additional determinants for substrate recognition, it is virtually certain that the Microprocessor recognizes pri-miRNA features beyond the common hairpin structure. I will describe the known specificity determinants in two classes of RNase III enzymes: the eubacterial RNase III enzymes, including the eponymous E. coli RNase III; and the yeast RNase III enzymes Rnt1p and Pac1. Considering these enzymes will provide inspiration about the location and nature of additional determinants that might define pri-miRNAs, and review experimental approaches that have been successful for defining substrate specificity in other recognition paradigms. 32 Substrate specificity in RNase III family proteins RNase III family proteins have evolved to have divergent cellular roles and substrates, so the specific preferences of individual RNase III family members may not translate well to the Microprocessor. However, it is reasonable to believe that the locations and types of preferences may overlap despite evolutionary divergence. Indeed, Cα superposition analysis shows considerable overlap of the structures of Mycobacterium tuberculosis RNase III, Aquifex aeolicus RNase III, the two endonuclease domains of Giardia intestinalis Dicer, and Sacchromyces castellii Dcr-1 (Akey and Berger, 2005; Gan et al., 2006; Macrae et al., 2006; Weinberg et al., 2011). Thus, even though the different classes of RNase III proteins may have their own idiosyncratic modes of recognition, the preferences of the endonuclease domains themselves could be relatively well-preserved. Eubacterial RNase III The founding member of the RNase III family, the Escherichia coli RNase III, was first identified as an enzyme which specifically caused dsRNA to become soluble in trichloroacetic acid (Robertson et al., 1967) in a Mg2+-dependent manner (Robertson et al., 1968), although it did not have a known biological function at that time. Several years later, another group determined that the conversion of the T7 phage early transcript from a ~7 kb primary transcript into five distinct mRNAs depended on a post-transcriptional “sizing factor” which had chromatographic qualities comparable to that of RNase III (Dunn and Studier, 1973b). Indeed, processing of the T7 early RNA was defective in an RNase III deficient E. coli strain, and purified RNase III was sufficient to generate the five messenger RNA products from in vitro transcribed T7 early RNA (Dunn and Studier, 1973a). Furthermore, the RNase III deficient strain had delayed production of 16S and 23S ribosomal RNA (rRNA) from a larger RNA species; as with the T7 early transcript, treatment of this larger RNA with purified RNase III generated products the same size as the 16S and 23S rRNAs (Dunn and Studier, 1973a). Consistent with the dsRNA cleavage activity of RNase III, these cleavage sites were later shown to reside in regions of contiguous pairing between RNA separated by thousands of nucleotides (Young and Steitz, 1978; Bram et al., 1980). This work was followed by the characterization of other RNase III cleavage sites, including ones in other phage RNAs (Hughes et al., 1987; Daniels et al., 1988) and E. coli mRNAs (Barry et al., 1980; Regnier and Portier, 1986; Portier et al., 33 1987; Regnier and Grunberg-Manago, 1989), including the mRNA encoding RNase III itself (Bardwell et al., 1989). RNase III also regulates other RNAs through binding without cleavage (Altuvia et al., 1987). Efforts to study the RNase III substrate specificity centered on comparative analysis of the known RNase III cleavage sites. The observation that cleavage sites in the T7 early transcript were at least superficially related to each other led to the view that RNase III could be a restriction endonuclease for RNA: an enzyme which preferentially cleaved dsRNA with a specific consensus sequence at or near the cleavage site (Robertson, 1982). However, this model eroded as more RNase III cleavage sites were characterized; in particular, lack of significant homology between the 16S and 23S rRNA cleavage sites and the T7 early transcript sites demonstrated that any consensus sequence was, at best, degenerate, if it existed at all. Nevertheless, aggregation of sequences flanking characterized cleavage sites resulted in the identification of a common motif: 5′−CUUN NN|−3′ 3′−GAAN|NN −5′ where N denotes any nucleotide and “|” marks the RNase III cleavage sites (Daniels et al., 1988), along with additional preferences further from the cleavage site (Krinke and Wulff, 1990). However, studies of T7 R1.1 variants that had altered nucleotide identities but retained Watson–Crick base-pairing showed nearly identical cleavage rates compared to wildtype (Chelladurai et al., 1991). Instead, it has been argued that RNase III preferences in this region (“proximal box”) and a second region 5 bp further away from the cleavage site (“distal box”) are driven by disfavored base pairs or “antideterminants.” Substitution of the T7 R1.1 base pairs with these disfavored base pairs results in considerable inhibition of cleavage (Zhang and Nicholson, 1997). On a practical front, it is difficult to tell whether the observed inhibition by antideterminants is due to truly inhibitory base pairs, or if the inhibition simply represents the difference between substrates with the most optimal base pairs and those with the least optimal base pairs. Indeed, a more recent analysis of determinants of RNase III cleavage has pushed the pendulum back towards the concept of a consensus sequence. In this study, RNase III preferred preferred 5′−AG−3′ 3′−UU−5′ 5′−CWUW NN|−3′ 3′−GWAW|NN −5′ in the proximal box, and in the distal box; shifting these motifs in a dsRNA context was sufficient to correspondingly shift the cleavage site (Pertzev and Nicholson, 2006). X-ray crystal structures of Aquifex aeolicus RNase III in complex with model RNA have revealed RNA-protein contacts in the proximal and distal boxes, and additional contacts between the two in a region termed the “middle box” (Figure 2A and 2B) (Gan et al., 2006; Gan et al., 34 2008). The study identified four RNA binding motifs (RBMs). RBMs 1 and 2 occur in the double strand RNA binding domain (dsRBD) and contact the proximal and middle boxes, respectively. RBM1 forms 8 contacts to the ribose 2′-OH or the backbone phosphates along the proximal box and at the cleavage site, explaining the specificity for A-form helical RNA, but only makes one base contact in the proximal box (Gan et al., 2006; Gan et al., 2008). Likewise, RBM2 forms a contact to a 2′-OH and a base in the middle box (Gan et al., 2006; Gan et al., 2008). RBMs 2 and 3 occur in the RNase III domain, and contact the cleavage site and proximal box, and the distal box, respectively. RBM3 extends into the contacts the two bases immediately adjacent to the cleavage site, which could translate into base identity preferences at the cleavage site (Gan et al., 2006; Gan et al., 2008). Interestingly, although RBM4 protrudes into the minor groove, it did not appear to make any contacts to the bases in the distal box (Gan et al., 2006; Gan et al., 2008). Overall, the structures explain the specificity of RNase III for dsRNA, but do not really address the weak preferences for (or against) individual base pairs. The substrate regions where RNase III has base pair preferences could be important in the recognition of pri-miRNAs (Figure 2C). Most RNase III contacts with RNA bases occur in the dsRBDs; since the dsRBDs in different RNase III family proteins contact different parts of the substrate RNA relative to the cleavage site, it is difficult to know where the dsRBDs of Drosha and DGCR8 bind the pri-miRNA. Thus, in drawing parallels between RNase III and the Microprocessor, the most relevant analogy is between the endonuclease domains in RNase III and Drosha, corresponding to RBM3 and RBM4. The RBM3 of Drosha may contact the two bases adjacent to the cleavage site (Gan et al., 2006; Gan et al., 2008), which may translate into a specific nucleotide preference near its cleavage site. Likewise, RBM4 would be situated on the 3p side of the basal stem, and extends into the minor groove on that side, corresponding to the distal box of RNase III substrates. Although RBM4 did not make base contacts in the distal box, it is possible that the RBM4 of Drosha could do so. Yeast RNase III: Rnt1p and Pac1 The RNase III family member with the most defined substrate preferences is Rnt1p. The gene encoding this protein was sequenced in the process of exploring Saccharomyces cerevisiae genome adjacent to a spliceosome factor CUS1. Consistent with its homology with E. coli RNase III and the Schizosaccharomyces pombe gene pac1, Rnt1p cleaved dsRNA in vitro and 35 A RNase III domain RNase III domain dsRBD domain dsRBD domain dsRBD domain RNase III domain B dsRBD domain C Bacterial RNAse III substrate RNase III domain Microprocessor pri-miRNA substrate pre-miRNA RBM2 P9 P7 “Proximal” box P6 P4 RBM1 P3 P2 RBM3 P1 P10 RBM4 (dsRBD) (RNase III) P9 P3 P2 RBM3 -1 -4 +2 -5 +3 -6 +4 -8 +6 -9 +7 -11 +9 -12 +10 Cleavage site RBM3 “Proximal” box +1 RBM2 (dsRBD) RBM4 (RNase III) “Distal” box +1 -4 +2 -5 +3 -6 +4 -8 +6 -9 +7 -11 +9 -12 +10 Cleavage site RBM4 -13 4 -1 +1 6 3’ 7 8 +1 5’ +1 “Mid” box RBM1 “Distal” box (dsRBD) RBM3 P4 P1 -1 (RNase III) “Distal” box (dsRBD) P10 “Proximal” box RBM4 “Proximal” box (RNase III) 5’ “Mid” box “Distal” box 3’ 5’ 3’ disruption of RNT1 impaired the removal of both 5′ and 3′ external transcribed spacers (ETS) in pre-rRNA (Elela et al., 1996). Correspondingly, purified Rnt1p cleaved the 5′ ETS at the A0 cleavage site, and cleaved in the 3′ ETS at a site 21 nt downstream of the 3′ end of mature 28S rRNA (Elela et al., 1996). Intriguingly, selection of the A0 site had been previously shown to be dependent on U3 snoRNA binding upstream (Beltrame and Tollervey, 1995), suggesting some interaction between snoRNAs and Rnt1p, although U3 binding is dispensable for actual cleavage (Elela et al., 1996). Despite the superficial similarity to eubacterial rRNA processing, the actual substrate preferences of Rnt1p are considerably more defined. Further characterization of the RNT1 disrupted strain demonstrated accumulation of many snoRNA precursors (of both H/ACA and C/D snoRNAs), all of which contained an internal or terminal tetraloop with the degenerate motif AGNN (Chanfreau et al., 1998). Analysis of an expanded catalog of Rnt1p substrate sequences, including a panel of snoRNAs, the U1, U2, U4, and U5 small nucleolar RNAs (snRNAs), and the 3′ ETS cleavage site invariably showed the presence of an (U/A)GNN tetraloop (nearly always AGNN), situated 13-16 base pairs from the Rnt1p cleavage site (Figure 2) (Chanfreau et al., 2000). Mutation of the A and G nucleotides either severely impaired or completely abolished cleavage, and changing the tetraloop position shifted the Rnt1p cleavage site accordingly, demonstrating that the AGNN tetraloop is required for both substrate recognition and cleavage site selection (Chanfreau et al., 2000). NMR structure analysis of AGNN tetraloops shows that the tetraloop has a distinct conformation notable for a syn conformation in the G nucleotide, allowing the base to stack with the first base of the tetraloop and hydrogen bond to the phosphate in ApG (Figure 2A) (Wu et al., 2001). The syn conformation causes a backbone turn at the GpN junction (Wu et al., 2001). The structure is stabilized by non-Watson–Crick base pairs between the first and last bases in the Figure 2. Specificity determinants in substrates of eubacterial RNase III. (A) Structural basis of RNase III recognition of substrates. Structure information was taken from PDB 2EZ6. (B) Locations of published specificity determinants, correlated with protein motifs in the RNase III dsRBD and RNase III endonuclease domain. The proximal, middle, and distal boxes are shaded in gray, outlined with the color of the corresponding region in (A). (C) Inference of potential specificity determinants in pri-miRNAs. The location of determinants is aligned based on the cleavage site of RNase III and Drosha. 37 tetraloop (Wu et al., 2001) and the adjacent Watson–Crick pairs of the hairpin helix, consistent with the necessity of these nearby pairs in what has been termed the “binding and stability box” (Lamontagne et al., 2003). The conformation was conserved between the AGAA, AGUU, and UGAA tetraloops, but was lost when G was mutated to C to form an ACAA tetraloop (Butcher et al., 1997; Wu et al., 2001). This opens the possibility that the apparent nucleotide preferences of Rnt1p actually translate into an RNA conformation preference, which is most easily (or exclusively) adopted in this specific nucleotide context. Indeed, an NMR structure of the Rnt1p dsRBD in complex with AGAA tetraloop (Figure 3A) is remarkable for its lack of base-specific contacts; instead, the α1 helix of the dsRBD contacts tetraloop backbone and the minor groove formed by its conformation (Wu et al., 2004). In order to distinguish the AGNN tetraloop from dsRNA, the Rnt1p α1 helix is oriented differently from α1 helices in other dsRBDs (Wu et al., 2004). Other contacts between the hairpin-tetraloop structure include the α1 helix extending into the minor groove of the apical stem region, the β3α2 loop resting superficially along stem major groove, and the β1β2 loop reaching into the minor groove one turn away from the loop (Wu et al., 2004). These contacts may explain why Rnt1p prefers certain Watson–Crick pairs in the binding and stability box (Lamontagne et al., 2003). The lack of base-specific contacts suggests that these preferences may also be conformational in nature. Even though a structure of the full-length Rnt1p protein is not available at present, it is very likely that the position of the dsRBD relative to the endonuclease domain in Rnt1p is quite different from that of other RNase III family members. The uniqueness of the Rnt1p dsRBD position and its unique conformation compared to other dsRBDs makes it difficult to draw significant parallels between the substrate recognition of Rnt1p and that of the Microprocessor. In fact, the other well-characterized yeast RNase III, Pac1, has no discernible preference for AGNN tetraloops, and instead resembles E. coli RNase III in its relatively relaxed substrate specificity (Figure 3B) (Rotondo and Frendewey, 1996). However, it is worth noting that, in C. elegans, trans-splicing between SL1 and cel-let-7 has been reported to be required for the processing of the pri-miRNA; it was argued that SL1 trans-splicing could alter the predicted structure of the let-7 pri-miRNA (Bracht et al., 2004). Intriguingly, NMR studies of the donated portion of the SL1 RNA have demonstrated the presence of an AGUU tetraloop structure above a buckled A:U pair (Greenbaum et al., 1996). Although the reported G is in a syn conformation, the base is oriented in the opposite direction as the G in the yeast AGNN tetraloops. It has been 38 argued that the difference is due to a misassigned resonance peak in the SL1 structure (Wu et al., 2001). Thus, it is tempting to speculate that AGNN tetraloop recognition plays a role in nematode pri-miRNA processing, and that SL1 trans-splicing is important to pri-let-7a processing because it brings an AGNN tetraloop into proximity with the Drosha cleavage site. Regions recognized by the endonuclease domains of yeast RNase III proteins are more likely to be relevant to pri-miRNA processing. For Rnt1p, changes to the base pairs immediately flanking the cleavage site alter the cleavage rate without affecting binding affinity (Lamontagne et al., 2003). This suggests that Rnt1p substrate affinity is driven primarily by the dsRBD. It may be more useful to consider Pac1, which has a preference for an internal loop near the cleavage site in a region analogous to the E. coli proximal box; the position of this loop may guide the Pac1 cleavage site (Figure 3B) (Lamontagne and Elela, 2004). Although it is not known whether this internal loop preference is read by the Pac1 dsRBD or the endonuclease domain, its positioning relative to the cleavage site suggests that the internal loop might be an endonuclease domain preference. If so, this observation reinforces the idea that RNase III domains may have substrate preferences in a common region relative to the cleavage site, although the specific preferences have diverged (Figure 3C). An exhaustive, quantitative approach to defining pri-miRNAs It is likely that the Microprocessor has substrate preferences beyond secondary structure, but no such recognition paradigm has emerged despite many published studies with individual pri-miRNA variants. When one compares studies of the Microprocessor and studies of bacterial RNase III, it is apparent that Microprocessor studies are missing two things that were critical to elucidating RNase III substrate determinants. First, pri-miRNA cleavage must be measured quantitatively. Nearly all published primiRNA cleavage experiments thus far have been non-quantitative; typical read-outs are “cleaved” or “uncleaved.” But these qualitative experiments will not suffice to elucidate the determinants that distinguish pri-miRNA hairpins from other hairpins. For bacterial RNase III, several determinants contribute relatively subtly to differences in binding affinity and cleavage rate; together, the presence of these determinants (or the absence of anti-determinants, if they indeed exist) define the RNase III substrate. The distinguishing features of pri-miRNA hairpins 39 A Minor groove Major groove dsRBD domain Minor groove dsRBD domain A A B G A dsRBD domain S. cerevisiae Rnt1p substrate 3’ C S. pombe Pac1p substrate 5’ 3’ Microprocessor pri-miRNA substrate 5’ pre-miRNA P1 P1 P1 -1 -1 -1 Cleavage site +2 dsRBD G -11 +9 -12 +10 RNase III (?) -13 8 A N +3 6 +14 N +2 +1 +13 -16 -5 -6 +1 -15 RNase III (?) Cleavage site 7 +12 +3 AGNN tetraloop +11 -14 +2 +1 4 -1 dsRBD -13 -5 -6 Cleavage site “Binding and stability” box +3 +1 +1 +1 5’ 3’ may individually contribute just the difference between moderate and maximal cleavage efficiency. Indeed, many mutations introduced into pri-miRNA substrates alter cleavage efficiency without completely abolishing cleavage, but these substrates are often lumped into the “cleaved” category, masking the potential contribution of additional determinants. For example, mutations in the basal stem that shift the Microprocessor cleavage site also reduce the overall efficiency of cleavage (Han et al., 2006), suggesting either that the mutations perturb an important sequence or that the new cleavage site is somehow in a suboptimal context. Either way, it is clear that our understanding of recognition and cleavage is incomplete. Second, studies must use large sets of variants derived from individual pri-miRNAs, enabling a more precise understanding of what specific sequence motifs or structural features are important to recognition by the Microprocessor. For example, conclusions about the optimal apical stem length for cleavage were primarily based on deletions or mutations that abolished base pairing (Zeng et al., 2005; Han et al., 2006; Zhang and Zeng, 2010). Based on these experiments, it is extremely difficult to tell whether recognition by the Microprocessor was impaired because stem length per se was important, or because a specific recognition determinant resides in this region and had been deleted or mutated. The approach of mutating away base pairs is even more prone to misinterpretation, since at least three mechanisms could be in play: stem length, loop or unstructured RNA length, and primary sequence. Similarly, studies of the flanking RNA sequence were largely based on deletions (Lee et al., 2003; Zeng and Cullen, 2005), and the results are compatible with the idea that additional, subtle determinants reside in the flanking RNA. By contrast, studies of the proximal, mid, and distal boxes in the substrates of bacterial RNase III systematically tested most or all possible Watson– Crick base pairs at the interrogated positions (Pertzev and Nicholson, 2006). Similarly detailed studies will be needed to make significant progress in understanding the cleavage of pri- Figure 3. Specificity determinants in substrates of yeast RNase III enzymes Rnt1p and Pac1. (A) Structural basis of Rnt1p recognition of the AGNN tetraloop. Structure information was taken from PDB 1T4L. (B) Locations of published specificity determinants, correlated with protein motifs where information is available. Recognition boxes for Rnt1p and Pac1 are shown. (C) Inference of potential specificity determinants in pri-miRNAs. The location of determinants is aligned based on the cleavage sites of Rnt1p, Pac1, and Drosha. 41 miRNAs. In seeking large sets of pri-miRNA variants, it will probably not be sufficient to gather collections of the pri-miRNAs encoded in animal genomes and derive determinants from their common sequences. Many groups have attempted to use sequence analysis and computational learning models to analyze pri-miRNAs for predictive determinants, largely for the purpose of computationally predicting novel pri-miRNAs (Grad et al., 2003; Lim et al., 2003a; Lim et al., 2003b; Bentwich et al., 2005; Nam et al., 2005; Berezikov et al., 2006). The resulting algorithms perform surprisingly poorly unless conservation or experimental data are taken into account (Lim et al., 2003a; Lim et al., 2003b; Ruby et al., 2006; Ruby et al., 2007b; Stark et al., 2007; Chiang et al., 2010). Others have attempted to quantify the Microprocessor cleavage of 250 pri-miRNAs, in the hope that measured cleavage efficiencies would offer an extra dimension of information that straight sequence analysis of pri-miRNAs may have lacked. This study was not much more successful than comparative sequence analysis: it found that conserved pri-miRNAs were processed more efficiently than less conserved pri-miRNAs, and that the general structural features defined previously were correlated with cleavage efficiency (Feng et al., 2011). The success of these studies was likely limited by the small number of “true positive” hairpins in the training sets, and their wide sequence and structural divergence. In particular, sequence and structural divergence severely hampers alignment, which in turn limits the power of computational analysis to discover short or degenerate motifs. What is needed is an experimental system that systematically generates a large number of related hairpin substrates, and quantifies the cleavage of these hairpins. These hairpins must be sufficiently divergent to sample suboptimal pri-miRNA sequences and structures, but sufficiently similar to enable computational sequence analysis. In the following chapters I will describe such an experimental and computational approach. Hundreds of billions of pri-miRNA variants were generated, each related to one of four human pri-miRNAs. Of these variants, millions of functional variants cleaved by the Microprocessor were sequenced. Computational analysis of the successful variants revealed a panel of important determinants of pri-miRNA recognition, and quantified the relative contribution of these determinants. Together, these evolutionarilyconserved features define the majority of authentic human pri-miRNAs. The elucidation of these features greatly expands the understanding of what pri-miRNAs are, and how the cell recognizes the correct hairpins to process into mature miRNAs. 42 Bibliography and References Cited Akey, D.L., and Berger, J.M. (2005). Structure of the nuclease domain of ribonuclease III from M. tuberculosis at 2.1 A. Protein Sci 14, 2744-2750. Altuvia, S., Locker-Giladi, H., Koby, S., Ben-Nun, O., and Oppenheim, A.B. (1987). RNase III stimulates the translation of the cIII gene of bacteriophage lambda. Proc Natl Acad Sci U S A 84, 6511-6515. Ambros, V., Bartel, B., Bartel, D.P., Burge, C.B., Carrington, J.C., Chen, X., Dreyfuss, G., Eddy, S.R., Griffiths-Jones, S., Marshall, M., et al. (2003). A uniform system for microRNA annotation. RNA 9, 277-279. Arvey, A., Larsson, E., Sander, C., Leslie, C.S., and Marks, D.S. (2010). Target mRNA abundance dilutes microRNA and siRNA activity. Mol Syst Biol 6, 363. Ashburner, M., Ball, C.A., Blake, J.A., Botstein, D., Butler, H., Cherry, J.M., Davis, A.P., Dolinski, K., Dwight, S.S., Eppig, J.T., et al. (2000). Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet 25, 25-29. Babiarz, J.E., Ruby, J.G., Wang, Y., Bartel, D.P., and Blelloch, R. (2008). Mouse ES cells express endogenous shRNAs, siRNAs, and other Microprocessor-independent, Dicerdependent small RNAs. Genes Dev 22, 2773-2785. Baek, D., Villen, J., Shin, C., Camargo, F.D., Gygi, S.P., and Bartel, D.P. (2008). The impact of microRNAs on protein output. Nature 455, 64-71. Bardwell, J.C., Regnier, P., Chen, S.M., Nakamura, Y., Grunberg-Manago, M., and Court, D.L. (1989). Autoregulation of RNase III operon by mRNA processing. EMBO J 8, 3401-3407. Barry, G., Squires, C., and Squires, C.L. (1980). Attenuation and processing of RNA from the rplJL--rpoBC transcription unit of Escherichia coli. Proc Natl Acad Sci U S A 77, 33313335. Bartel, D.P. (2004). MicroRNAs: genomics, biogenesis, mechanism, and function. Cell 116, 281297. Bartel, D.P. (2009). MicroRNAs: target recognition and regulatory functions. Cell 136, 215-233. Bass, B.L. (2000). Double-stranded RNA as a template for gene silencing. Cell 101, 235-238. Bazzini, A.A., Lee, M.T., and Giraldez, A.J. (2012). Ribosome profiling shows that miR-430 reduces translation before causing mRNA decay in zebrafish. Science 336, 233-237. Beltrame, M., and Tollervey, D. (1995). Base pairing between U3 and the pre-ribosomal RNA is required for 18S rRNA synthesis. EMBO J 14, 4350-4356. Bentwich, I., Avniel, A., Karov, Y., Aharonov, R., Gilad, S., Barad, O., Barzilai, A., Einat, P., Einav, U., Meiri, E., et al. (2005). Identification of hundreds of conserved and nonconserved human microRNAs. Nat Genet 37, 766-770. Berezikov, E., van Tetering, G., Verheul, M., van de Belt, J., van Laake, L., Vos, J., Verloop, R., van de Wetering, M., Guryev, V., Takada, S., et al. (2006). Many novel mammalian microRNA candidates identified by extensive cloning and RAKE analysis. Genome Res 16, 1289-1298. Bernstein, E., Caudy, A.A., Hammond, S.M., and Hannon, G.J. (2001). Role for a bidentate ribonuclease in the initiation step of RNA interference. Nature 409, 363-366. Bernstein, E., Kim, S.Y., Carmell, M.A., Murchison, E.P., Alcorn, H., Li, M.Z., Mills, A.A., Elledge, S.J., Anderson, K.V., and Hannon, G.J. (2003). Dicer is essential for mouse development. Nat Genet 35, 215-217. 43 Blow, M.J., Grocock, R.J., van Dongen, S., Enright, A.J., Dicks, E., Futreal, P.A., Wooster, R., and Stratton, M.R. (2006). RNA editing of human microRNAs. Genome Biol 7, R27. Bohmert, K., Camus, I., Bellini, C., Bouchez, D., Caboche, M., and Benning, C. (1998). AGO1 defines a novel locus of Arabidopsis controlling leaf development. EMBO J 17, 170-180. Bohnsack, M.T., Czaplinski, K., and Gorlich, D. (2004). Exportin 5 is a RanGTP-dependent dsRNA-binding protein that mediates nuclear export of pre-miRNAs. RNA 10, 185-191. Bohnsack, M.T., Regener, K., Schwappach, B., Saffrich, R., Paraskeva, E., Hartmann, E., and Gorlich, D. (2002). Exp5 exports eEF1A via tRNA from nuclei and synergizes with other transport pathways to confine translation to the cytoplasm. EMBO J 21, 6205-6215. Bracht, J., Hunter, S., Eachus, R., Weeks, P., and Pasquinelli, A.E. (2004). Trans-splicing and polyadenylation of let-7 microRNA primary transcripts. RNA 10, 1586-1594. Bram, R.J., Young, R.A., and Steitz, J.A. (1980). The ribonuclease III site flanking 23S sequences in the 30S ribosomal precursor RNA of E. coli. Cell 19, 393-401. Brownawell, A.M., and Macara, I.G. (2002). Exportin-5, a novel karyopherin, mediates nuclear export of double-stranded RNA binding proteins. J Cell Biol 156, 53-64. Brummelkamp, T.R., Bernards, R., and Agami, R. (2002). A system for stable expression of short interfering RNAs in mammalian cells. Science 296, 550-553. Butcher, S.E., Dieckmann, T., and Feigon, J. (1997). Solution structure of the conserved 16 Slike ribosomal RNA UGAA tetraloop. J Mol Biol 268, 348-358. Calabrese, J.M., Seila, A.C., Yeo, G.W., and Sharp, P.A. (2007). RNA sequence analysis defines Dicer's role in mouse embryonic stem cells. Proc Natl Acad Sci U S A 104, 18097-18102. Calado, A., Treichel, N., Muller, E.C., Otto, A., and Kutay, U. (2002). Exportin-5-mediated nuclear export of eukaryotic elongation factor 1A and tRNA. EMBO J 21, 6216-6224. Calin, G.A., Dumitru, C.D., Shimizu, M., Bichi, R., Zupo, S., Noch, E., Aldler, H., Rattan, S., Keating, M., Rai, K., et al. (2002). Frequent deletions and down-regulation of micro- RNA genes miR15 and miR16 at 13q14 in chronic lymphocytic leukemia. Proc Natl Acad Sci U S A 99, 15524-15529. Calin, G.A., Ferracin, M., Cimmino, A., Di Leva, G., Shimizu, M., Wojcik, S.E., Iorio, M.V., Visone, R., Sever, N.I., Fabbri, M., et al. (2005). A MicroRNA signature associated with prognosis and progression in chronic lymphocytic leukemia. N Engl J Med 353, 1793-1801. Calin, G.A., Sevignani, C., Dumitru, C.D., Hyslop, T., Noch, E., Yendamuri, S., Shimizu, M., Rattan, S., Bullrich, F., Negrini, M., et al. (2004). Human microRNA genes are frequently located at fragile sites and genomic regions involved in cancers. Proc Natl Acad Sci U S A 101, 2999-3004. Caudy, A.A., Myers, M., Hannon, G.J., and Hammond, S.M. (2002). Fragile X-related protein and VIG associate with the RNA interference machinery. Genes Dev 16, 2491-2496. Cenik, E.S., Fukunaga, R., Lu, G., Dutcher, R., Wang, Y., Tanaka Hall, T.M., and Zamore, P.D. (2011). Phosphate and R2D2 restrict the substrate specificity of Dicer-2, an ATP-driven ribonuclease. Mol Cell 42, 172-184. Chakravarthy, S., Sternberg, S.H., Kellenberger, C.A., and Doudna, J.A. (2010). Substratespecific kinetics of Dicer-catalyzed RNA processing. J Mol Biol 404, 392-402. Chanfreau, G., Buckle, M., and Jacquier, A. (2000). Recognition of a conserved class of RNA tetraloops by Saccharomyces cerevisiae RNase III. Proc Natl Acad Sci U S A 97, 3142-3147. Chanfreau, G., Legrain, P., and Jacquier, A. (1998). Yeast RNase III as a key processing enzyme in small nucleolar RNAs metabolism. J Mol Biol 284, 975-988. 44 Chelladurai, B.S., Li, H., and Nicholson, A.W. (1991). A conserved sequence element in ribonuclease III processing signals is not required for accurate in vitro enzymatic cleavage. Nucleic Acids Res 19, 1759-1766. Cheloufi, S., Dos Santos, C.O., Chong, M.M., and Hannon, G.J. (2010). A dicer-independent miRNA biogenesis pathway that requires Ago catalysis. Nature 465, 584-589. Chen, C.Z., Li, L., Lodish, H.F., and Bartel, D.P. (2004). MicroRNAs modulate hematopoietic lineage differentiation. Science 303, 83-86. Chendrimada, T.P., Gregory, R.I., Kumaraswamy, E., Norman, J., Cooch, N., Nishikura, K., and Shiekhattar, R. (2005). TRBP recruits the Dicer complex to Ago2 for microRNA processing and gene silencing. Nature 436, 740-744. Chiang, H.R., Schoenfeld, L.W., Ruby, J.G., Auyeung, V.C., Spies, N., Baek, D., Johnston, W.K., Russ, C., Luo, S., Babiarz, J.E., et al. (2010). Mammalian microRNAs: experimental evaluation of novel and previously annotated genes. Genes Dev 24, 992-1009. Cifuentes, D., Xue, H., Taylor, D.W., Patnode, H., Mishima, Y., Cheloufi, S., Ma, E., Mane, S., Hannon, G.J., Lawson, N.D., et al. (2010). A novel miRNA processing pathway independent of Dicer requires Argonaute2 catalytic activity. Science 328, 1694-1698. Czech, B., Malone, C.D., Zhou, R., Stark, A., Schlingeheyde, C., Dus, M., Perrimon, N., Kellis, M., Wohlschlegel, J.A., Sachidanandam, R., et al. (2008). An endogenous small interfering RNA pathway in Drosophila. Nature 453, 798-802. Czech, B., Zhou, R., Erlich, Y., Brennecke, J., Binari, R., Villalta, C., Gordon, A., Perrimon, N., and Hannon, G.J. (2009). Hierarchical rules for Argonaute loading in Drosophila. Mol Cell 36, 445-456. Daniels, D.L., Subbarao, M.N., Blattner, F.R., and Lozeron, H.A. (1988). Q-mediated late gene transcription of bacteriophage lambda: RNA start point and RNase III processing sites in vivo. Virology 167, 568-577. Davis, B.N., Hilyard, A.C., Lagna, G., and Hata, A. (2008). SMAD proteins control DROSHAmediated microRNA maturation. Nature 454, 56-61. Davis, B.N., Hilyard, A.C., Nguyen, P.H., Lagna, G., and Hata, A. (2010). Smad proteins bind a conserved RNA sequence to promote microRNA maturation by Drosha. Mol Cell 39, 373384. Denli, A.M., Tops, B.B., Plasterk, R.H., Ketting, R.F., and Hannon, G.J. (2004). Processing of primary microRNAs by the Microprocessor complex. Nature 432, 231-235. Doench, J.G., and Sharp, P.A. (2004). Specificity of microRNA target selection in translational repression. Genes Dev 18, 504-511. Dong, Z., Han, M.H., and Fedoroff, N. (2008). The RNA-binding proteins HYL1 and SE promote accurate in vitro processing of pri-miRNA by DCL1. Proc Natl Acad Sci U S A 105, 9970-9975. Dreyfuss, G., Matunis, M.J., Pinol-Roma, S., and Burd, C.G. (1993). hnRNP proteins and the biogenesis of mRNA. Annu Rev Biochem 62, 289-321. Duan, R., Pak, C., and Jin, P. (2007). Single nucleotide polymorphism associated with mature miR-125a alters the processing of pri-miRNA. Hum Mol Genet 16, 1124-1131. Dunn, J.J., and Studier, F.W. (1973a). T7 early RNAs and Escherichia coli ribosomal RNAs are cut from large precursor RNAs in vivo by ribonuclease 3. Proc Natl Acad Sci U S A 70, 3296-3300. Dunn, J.J., and Studier, F.W. (1973b). T7 early RNAs are generated by site-specific cleavages. Proc Natl Acad Sci U S A 70, 1559-1563. 45 Elbashir, S.M., Harborth, J., Lendeckel, W., Yalcin, A., Weber, K., and Tuschl, T. (2001a). Duplexes of 21-nucleotide RNAs mediate RNA interference in cultured mammalian cells. Nature 411, 494-498. Elbashir, S.M., Lendeckel, W., and Tuschl, T. (2001b). RNA interference is mediated by 21- and 22-nucleotide RNAs. Genes Dev 15, 188-200. Elela, S.A., Igel, H., and Ares, M., Jr. (1996). RNase III cleaves eukaryotic preribosomal RNA at a U3 snoRNP-dependent site. Cell 85, 115-124. Fagard, M., Boutet, S., Morel, J.B., Bellini, C., and Vaucheret, H. (2000). AGO1, QDE-2, and RDE-1 are related proteins required for post-transcriptional gene silencing in plants, quelling in fungi, and RNA interference in animals. Proc Natl Acad Sci U S A 97, 11650-11654. Faller, M., Toso, D., Matsunaga, M., Atanasov, I., Senturia, R., Chen, Y., Zhou, Z.H., and Guo, F. (2010). DGCR8 recognizes primary transcripts of microRNAs through highly cooperative binding and formation of higher-order structures. RNA 16, 1570-1583. Farh, K.K., Grimson, A., Jan, C., Lewis, B.P., Johnston, W.K., Lim, L.P., Burge, C.B., and Bartel, D.P. (2005). The widespread impact of mammalian MicroRNAs on mRNA repression and evolution. Science 310, 1817-1821. Fellmann, C., Zuber, J., McJunkin, K., Chang, K., Malone, C.D., Dickins, R.A., Xu, Q., Hengartner, M.O., Elledge, S.J., Hannon, G.J., et al. (2011). Functional identification of optimized RNAi triggers using a massively parallel sensor assay. Mol Cell 41, 733-746. Feng, Y., Zhang, X., Song, Q., Li, T., and Zeng, Y. (2011). Drosha processing controls the specificity and efficiency of global microRNA expression. Biochim Biophys Acta 1809, 700707. Filippov, V., Solovyev, V., Filippova, M., and Gill, S.S. (2000). A novel type of RNase III family proteins in eukaryotes. Gene 245, 213-221. Fire, A., Albertson, D., Harrison, S.W., and Moerman, D.G. (1991). Production of antisense RNA leads to effective and specific inhibition of gene expression in C. elegans muscle. Development 113, 503-514. Fire, A., Xu, S., Montgomery, M.K., Kostas, S.A., Driver, S.E., and Mello, C.C. (1998). Potent and specific genetic interference by double-stranded RNA in Caenorhabditis elegans. Nature 391, 806-811. Flynt, A.S., Greimann, J.C., Chung, W.J., Lima, C.D., and Lai, E.C. (2010). MicroRNA biogenesis via splicing and exosome-mediated trimming in Drosophila. Mol Cell 38, 900907. Forstemann, K., Horwich, M.D., Wee, L., Tomari, Y., and Zamore, P.D. (2007). Drosophila microRNAs are sorted into functionally distinct argonaute complexes after production by dicer-1. Cell 130, 287-297. Forstemann, K., Tomari, Y., Du, T., Vagin, V.V., Denli, A.M., Bratu, D.P., Klattenhoff, C., Theurkauf, W.E., and Zamore, P.D. (2005). Normal microRNA maturation and germ-line stem cell maintenance requires Loquacious, a double-stranded RNA-binding domain protein. PLoS Biol 3, e236. Frank, F., Sonenberg, N., and Nagar, B. (2010). Structural basis for 5'-nucleotide base-specific recognition of guide RNA by human AGO2. Nature 465, 818-822. Friedman, R.C., Farh, K.K., Burge, C.B., and Bartel, D.P. (2009). Most mammalian mRNAs are conserved targets of microRNAs. Genome Res 19, 92-105. Fukuda, T., Yamagata, K., Fujiyama, S., Matsumoto, T., Koshida, I., Yoshimura, K., Mihara, M., Naitou, M., Endoh, H., Nakamura, T., et al. (2007). DEAD-box RNA helicase subunits of the 46 Drosha complex are required for processing of rRNA and a subset of microRNAs. Nat Cell Biol 9, 604-611. Gan, J., Shaw, G., Tropea, J.E., Waugh, D.S., Court, D.L., and Ji, X. (2008). A stepwise model for double-stranded RNA processing by ribonuclease III. Mol Microbiol 67, 143-154. Gan, J., Tropea, J.E., Austin, B.P., Court, D.L., Waugh, D.S., and Ji, X. (2006). Structural insight into the mechanism of double-stranded RNA processing by ribonuclease III. Cell 124, 355366. Garcia, D.M., Baek, D., Shin, C., Bell, G.W., Grimson, A., and Bartel, D.P. (2011). Weak seedpairing stability and high target-site abundance decrease the proficiency of lsy-6 and other microRNAs. Nat Struct Mol Biol 18, 1139-1146. Ghildiyal, M., Xu, J., Seitz, H., Weng, Z., and Zamore, P.D. (2010). Sorting of Drosophila small silencing RNAs partitions microRNA* strands into the RNA interference pathway. RNA 16, 43-56. Gottwein, E., Cai, X., and Cullen, B.R. (2006). A novel assay for viral microRNA function identifies a single nucleotide polymorphism that affects Drosha processing. J Virol 80, 53215326. Grad, Y., Aach, J., Hayes, G.D., Reinhart, B.J., Church, G.M., Ruvkun, G., and Kim, J. (2003). Computational and experimental identification of C. elegans microRNAs. Mol Cell 11, 12531263. Greenbaum, N.L., Radhakrishnan, I., Patel, D.J., and Hirsh, D. (1996). Solution structure of the donor site of a trans-splicing RNA. Structure 4, 725-733. Gregory, R.I., Yan, K.P., Amuthan, G., Chendrimada, T., Doratotaj, B., Cooch, N., and Shiekhattar, R. (2004). The Microprocessor complex mediates the genesis of microRNAs. Nature 432, 235-240. Griffiths-Jones, S., Grocock, R.J., van Dongen, S., Bateman, A., and Enright, A.J. (2006). miRBase: microRNA sequences, targets and gene nomenclature. Nucleic Acids Res 34, D140-144. Grimson, A., Farh, K.K., Johnston, W.K., Garrett-Engele, P., Lim, L.P., and Bartel, D.P. (2007). MicroRNA targeting specificity in mammals: determinants beyond seed pairing. Mol Cell 27, 91-105. Grishok, A., Pasquinelli, A.E., Conte, D., Li, N., Parrish, S., Ha, I., Baillie, D.L., Fire, A., Ruvkun, G., and Mello, C.C. (2001). Genes and mechanisms related to RNA interference regulate expression of the small temporal RNAs that control C. elegans developmental timing. Cell 106, 23-34. Guil, S., and Caceres, J.F. (2007). The multifunctional RNA-binding protein hnRNP A1 is required for processing of miR-18a. Nat Struct Mol Biol 14, 591-596. Guo, H., Ingolia, N.T., Weissman, J.S., and Bartel, D.P. (2010). Mammalian microRNAs predominantly act to decrease target mRNA levels. Nature 466, 835-840. Guo, S., and Kemphues, K.J. (1995). par-1, a gene required for establishing polarity in C. elegans embryos, encodes a putative Ser/Thr kinase that is asymmetrically distributed. Cell 81, 611-620. Gwizdek, C., Ossareh-Nazari, B., Brownawell, A.M., Doglio, A., Bertrand, E., Macara, I.G., and Dargemont, C. (2003). Exportin-5 mediates nuclear export of minihelix-containing RNAs. J Biol Chem 278, 5505-5508. 47 Haase, A.D., Jaskiewicz, L., Zhang, H., Laine, S., Sack, R., Gatignol, A., and Filipowicz, W. (2005). TRBP, a regulator of cellular PKR and HIV-1 virus expression, interacts with Dicer and functions in RNA silencing. EMBO Rep 6, 961-967. Hagan, J.P., Piskounova, E., and Gregory, R.I. (2009). Lin28 recruits the TUTase Zcchc11 to inhibit let-7 maturation in mouse embryonic stem cells. Nat Struct Mol Biol 16, 1021-1025. Hamilton, A.J., and Baulcombe, D.C. (1999). A species of small antisense RNA in posttranscriptional gene silencing in plants. Science 286, 950-952. Hammond, S.M., Bernstein, E., Beach, D., and Hannon, G.J. (2000). An RNA-directed nuclease mediates post-transcriptional gene silencing in Drosophila cells. Nature 404, 293-296. Hammond, S.M., Boettcher, S., Caudy, A.A., Kobayashi, R., and Hannon, G.J. (2001). Argonaute2, a link between genetic and biochemical analyses of RNAi. Science 293, 11461150. Han, J., Lee, Y., Yeom, K.H., Kim, Y.K., Jin, H., and Kim, V.N. (2004). The Drosha-DGCR8 complex in primary microRNA processing. Genes Dev 18, 3016-3027. Han, J., Lee, Y., Yeom, K.H., Nam, J.W., Heo, I., Rhee, J.K., Sohn, S.Y., Cho, Y., Zhang, B.T., and Kim, V.N. (2006). Molecular basis for the recognition of primary microRNAs by the Drosha-DGCR8 complex. Cell 125, 887-901. Han, J., Pedersen, J.S., Kwon, S.C., Belair, C.D., Kim, Y.K., Yeom, K.H., Yang, W.Y., Haussler, D., Blelloch, R., and Kim, V.N. (2009). Posttranscriptional crossregulation between Drosha and DGCR8. Cell 136, 75-84. Hartig, J.V., Esslinger, S., Bottcher, R., Saito, K., and Forstemann, K. (2009). Endo-siRNAs depend on a new isoform of loquacious and target artificially introduced, high-copy sequences. EMBO J 28, 2932-2944. Hendrickson, D.G., Hogan, D.J., McCullough, H.L., Myers, J.W., Herschlag, D., Ferrell, J.E., and Brown, P.O. (2009). Concordant regulation of translation and mRNA abundance for hundreds of targets of a human microRNA. PLoS Biol 7, e1000238. Heo, I., Joo, C., Cho, J., Ha, M., Han, J., and Kim, V.N. (2008). Lin28 mediates the terminal uridylation of let-7 precursor MicroRNA. Mol Cell 32, 276-284. Heo, I., Joo, C., Kim, Y.K., Ha, M., Yoon, M.J., Cho, J., Yeom, K.H., Han, J., and Kim, V.N. (2009). TUT4 in concert with Lin28 suppresses microRNA biogenesis through premicroRNA uridylation. Cell 138, 696-708. Hughes, J.A., Brown, L.R., and Ferro, A.J. (1987). Nucleotide sequence and analysis of the coliphage T3 S-adenosylmethionine hydrolase gene and its surrounding ribonuclease III processing sites. Nucleic Acids Res 15, 717-729. Hutvagner, G., McLachlan, J., Pasquinelli, A.E., Balint, E., Tuschl, T., and Zamore, P.D. (2001). A cellular function for the RNA-interference enzyme Dicer in the maturation of the let-7 small temporal RNA. Science 293, 834-838. Izant, J.G., and Weintraub, H. (1984). Inhibition of thymidine kinase gene expression by antisense RNA: a molecular approach to genetic analysis. Cell 36, 1007-1015. Jacobsen, S.E., Running, M.P., and Meyerowitz, E.M. (1999). Disruption of an RNA helicase/RNAse III gene in Arabidopsis causes unregulated cell division in floral meristems. Development 126, 5231-5243. Jiang, F., Ye, X., Liu, X., Fincher, L., McKearin, D., and Liu, Q. (2005). Dicer-1 and R3D1-L catalyze microRNA maturation in Drosophila. Genes Dev 19, 1674-1679. Jones-Rhoades, M.W., Bartel, D.P., and Bartel, B. (2006). MicroRNAS and their regulatory roles in plants. Annu Rev Plant Biol 57, 19-53. 48 Kawahara, Y., Megraw, M., Kreider, E., Iizasa, H., Valente, L., Hatzigeorgiou, A.G., and Nishikura, K. (2008). Frequency and fate of microRNA editing in human brain. Nucleic Acids Res 36, 5270-5280. Kawahara, Y., Zinshteyn, B., Chendrimada, T.P., Shiekhattar, R., and Nishikura, K. (2007). RNA editing of the microRNA-151 precursor blocks cleavage by the Dicer-TRBP complex. EMBO Rep 8, 763-769. Kawamata, T., Seitz, H., and Tomari, Y. (2009). Structural determinants of miRNAs for RISC loading and slicer-independent unwinding. Nat Struct Mol Biol 16, 953-960. Kawamata, T., Yoda, M., and Tomari, Y. (2011). Multilayer checkpoints for microRNA authenticity during RISC assembly. EMBO Rep 12, 944-949. Ketting, R.F. (2011). The many faces of RNAi. Dev Cell 20, 148-161. Ketting, R.F., Fischer, S.E., Bernstein, E., Sijen, T., Hannon, G.J., and Plasterk, R.H. (2001). Dicer functions in RNA interference and in synthesis of small RNA involved in developmental timing in C. elegans. Genes Dev 15, 2654-2659. Khvorova, A., Reynolds, A., and Jayasena, S.D. (2003). Functional siRNAs and miRNAs exhibit strand bias. Cell 115, 209-216. Knight, S.W., and Bass, B.L. (2001). A role for the RNase III enzyme DCR-1 in RNA interference and germ line development in Caenorhabditis elegans. Science 293, 2269-2271. Krinke, L., and Wulff, D.L. (1990). The cleavage specificity of RNase III. Nucleic Acids Res 18, 4809-4815. Kumar, M.S., Lu, J., Mercer, K.L., Golub, T.R., and Jacks, T. (2007). Impaired microRNA processing enhances cellular transformation and tumorigenesis. Nat Genet 39, 673-677. Kurihara, Y., and Watanabe, Y. (2004). Arabidopsis micro-RNA biogenesis through Dicer-like 1 protein functions. Proc Natl Acad Sci U S A 101, 12753-12758. Lagos-Quintana, M., Rauhut, R., Lendeckel, W., and Tuschl, T. (2001). Identification of novel genes coding for small expressed RNAs. Science 294, 853-858. Lamontagne, B., and Elela, S.A. (2004). Evaluation of the RNA determinants for bacterial and yeast RNase III binding and cleavage. J Biol Chem 279, 2231-2241. Lamontagne, B., Ghazal, G., Lebars, I., Yoshizawa, S., Fourmy, D., and Elela, S.A. (2003). Sequence dependence of substrate recognition and cleavage by yeast RNase III. J Mol Biol 327, 985-1000. Landgraf, P., Rusu, M., Sheridan, R., Sewer, A., Iovino, N., Aravin, A., Pfeffer, S., Rice, A., Kamphorst, A.O., Landthaler, M., et al. (2007). A mammalian microRNA expression atlas based on small RNA library sequencing. Cell 129, 1401-1414. Landthaler, M., Yalcin, A., and Tuschl, T. (2004). The human DiGeorge syndrome critical region gene 8 and Its D. melanogaster homolog are required for miRNA biogenesis. Curr Biol 14, 2162-2167. Lau, N.C., Lim, L.P., Weinstein, E.G., and Bartel, D.P. (2001). An abundant class of tiny RNAs with probable regulatory roles in Caenorhabditis elegans. Science 294, 858-862. Lau, P.W., Guiley, K.Z., De, N., Potter, C.S., Carragher, B., and MacRae, I.J. (2012). The molecular architecture of human Dicer. Nat Struct Mol Biol 19, 436-440. Lee, R.C., and Ambros, V. (2001). An extensive class of small RNAs in Caenorhabditis elegans. Science 294, 862-864. Lee, R.C., Feinbaum, R.L., and Ambros, V. (1993). The C. elegans heterochronic gene lin-4 encodes small RNAs with antisense complementarity to lin-14. Cell 75, 843-854. 49 Lee, Y., Ahn, C., Han, J., Choi, H., Kim, J., Yim, J., Lee, J., Provost, P., Radmark, O., Kim, S., et al. (2003). The nuclear RNase III Drosha initiates microRNA processing. Nature 425, 415419. Lee, Y., Hur, I., Park, S.Y., Kim, Y.K., Suh, M.R., and Kim, V.N. (2006). The role of PACT in the RNA silencing pathway. EMBO J 25, 522-532. Lee, Y., Jeon, K., Lee, J.T., Kim, S., and Kim, V.N. (2002). MicroRNA maturation: stepwise processing and subcellular localization. EMBO J 21, 4663-4670. Lee, Y., Kim, M., Han, J., Yeom, K.H., Lee, S., Baek, S.H., and Kim, V.N. (2004a). MicroRNA genes are transcribed by RNA polymerase II. EMBO J 23, 4051-4060. Lee, Y.S., Nakahara, K., Pham, J.W., Kim, K., He, Z., Sontheimer, E.J., and Carthew, R.W. (2004b). Distinct roles for Drosophila Dicer-1 and Dicer-2 in the siRNA/miRNA silencing pathways. Cell 117, 69-81. Lehrbach, N.J., Armisen, J., Lightfoot, H.L., Murfitt, K.J., Bugaut, A., Balasubramanian, S., and Miska, E.A. (2009). LIN-28 and the poly(U) polymerase PUP-2 regulate let-7 microRNA processing in Caenorhabditis elegans. Nat Struct Mol Biol 16, 1016-1020. Lim, L.P., Glasner, M.E., Yekta, S., Burge, C.B., and Bartel, D.P. (2003a). Vertebrate microRNA genes. Science 299, 1540. Lim, L.P., Lau, N.C., Weinstein, E.G., Abdelhakim, A., Yekta, S., Rhoades, M.W., Burge, C.B., and Bartel, D.P. (2003b). The microRNAs of Caenorhabditis elegans. Genes Dev 17, 9911008. Liu, J., Carmell, M.A., Rivas, F.V., Marsden, C.G., Thomson, J.M., Song, J.J., Hammond, S.M., Joshua-Tor, L., and Hannon, G.J. (2004). Argonaute2 is the catalytic engine of mammalian RNAi. Science 305, 1437-1441. Liu, Q., Rand, T.A., Kalidas, S., Du, F., Kim, H.E., Smith, D.P., and Wang, X. (2003). R2D2, a bridge between the initiation and effector steps of the Drosophila RNAi pathway. Science 301, 1921-1925. Liu, X., Park, J.K., Jiang, F., Liu, Y., McKearin, D., and Liu, Q. (2007). Dicer-1, but not Loquacious, is critical for assembly of miRNA-induced silencing complexes. RNA 13, 23242329. Llave, C., Xie, Z., Kasschau, K.D., and Carrington, J.C. (2002). Cleavage of Scarecrow-like mRNA targets directed by a class of Arabidopsis miRNA. Science 297, 2053-2056. Lu, J., Getz, G., Miska, E.A., Alvarez-Saavedra, E., Lamb, J., Peck, D., Sweet-Cordero, A., Ebert, B.L., Mak, R.H., Ferrando, A.A., et al. (2005). MicroRNA expression profiles classify human cancers. Nature 435, 834-838. Lund, E., Guttinger, S., Calado, A., Dahlberg, J.E., and Kutay, U. (2004). Nuclear export of microRNA precursors. Science 303, 95-98. Ma, J.B., Ye, K., and Patel, D.J. (2004). Structural basis for overhang-specific small interfering RNA recognition by the PAZ domain. Nature 429, 318-322. MacRae, I.J., Zhou, K., and Doudna, J.A. (2007). Structural determinants of RNA recognition and cleavage by Dicer. Nat Struct Mol Biol 14, 934-940. Macrae, I.J., Zhou, K., Li, F., Repic, A., Brooks, A.N., Cande, W.Z., Adams, P.D., and Doudna, J.A. (2006). Structural basis for double-stranded RNA processing by Dicer. Science 311, 195-198. Mateos, J.L., Bologna, N.G., Chorostecki, U., and Palatnik, J.F. (2010). Identification of microRNA processing determinants by random mutagenesis of Arabidopsis MIR172a precursor. Curr Biol 20, 49-54. 50 Mayr, C., Hemann, M.T., and Bartel, D.P. (2007). Disrupting the pairing between let-7 and Hmga2 enhances oncogenic transformation. Science 315, 1576-1579. Meister, G., Landthaler, M., Patkaniowska, A., Dorsett, Y., Teng, G., and Tuschl, T. (2004). Human Argonaute2 mediates RNA cleavage targeted by miRNAs and siRNAs. Mol Cell 15, 185-197. Mian, I.S. (1997). Comparative sequence analysis of ribonucleases HII, III, II PH and D. Nucleic Acids Res 25, 3187-3195. Michlewski, G., and Caceres, J.F. (2010). Antagonistic role of hnRNP A1 and KSRP in the regulation of let-7a biogenesis. Nat Struct Mol Biol 17, 1011-1018. Michlewski, G., Guil, S., Semple, C.A., and Caceres, J.F. (2008). Posttranscriptional regulation of miRNAs harboring conserved terminal loops. Mol Cell 32, 383-393. Miyoshi, K., Miyoshi, T., and Siomi, H. (2010). Many ways to generate microRNA-like small RNAs: non-canonical pathways for microRNA production. Mol Genet Genomics 284, 95103. Miyoshi, K., Okada, T.N., Siomi, H., and Siomi, M.C. (2009). Characterization of the miRNARISC loading complex and miRNA-RISC formed in the Drosophila miRNA pathway. RNA 15, 1282-1291. Moffat, J., Grueneberg, D.A., Yang, X., Kim, S.Y., Kloepfer, A.M., Hinkle, G., Piqani, B., Eisenhaure, T.M., Luo, B., Grenier, J.K., et al. (2006). A lentiviral RNAi library for human and mouse genes applied to an arrayed viral high-content screen. Cell 124, 1283-1298. Montgomery, M.K., and Fire, A. (1998). Double-stranded RNA as a mediator in sequencespecific genetic silencing and co-suppression. Trends Genet 14, 255-258. Murphy, D., Dancis, B., and Brown, J.R. (2008). The evolution of core proteins involved in microRNA biogenesis. BMC Evol Biol 8, 92. Nakamura, T., Canaani, E., and Croce, C.M. (2007). Oncogenic All1 fusion proteins target Drosha-mediated microRNA processing. Proc Natl Acad Sci U S A 104, 10980-10985. Nam, J.W., Shin, K.R., Han, J., Lee, Y., Kim, V.N., and Zhang, B.T. (2005). Human microRNA prediction through a probabilistic co-learning model of sequence and structure. Nucleic Acids Res 33, 3570-3581. Nam, Y., Chen, C., Gregory, R.I., Chou, J.J., and Sliz, P. (2011). Molecular Basis for Interaction of let-7 MicroRNAs with Lin28. Cell. Napoli, C., Lemieux, C., and Jorgensen, R. (1990). Introduction of a Chimeric Chalcone Synthase Gene into Petunia Results in Reversible Co-Suppression of Homologous Genes in trans. Plant Cell 2, 279-289. Newman, M.A., Thomson, J.M., and Hammond, S.M. (2008). Lin-28 interaction with the Let-7 precursor loop mediates regulated microRNA processing. RNA 14, 1539-1549. Nishikura, K. (2010). Functions and regulation of RNA editing by ADAR deaminases. Annu Rev Biochem 79, 321-349. Nykanen, A., Haley, B., and Zamore, P.D. (2001). ATP requirements and small interfering RNA structure in the RNA interference pathway. Cell 107, 309-321. O'Connell, R.M., Rao, D.S., Chaudhuri, A.A., Boldin, M.P., Taganov, K.D., Nicoll, J., Paquette, R.L., and Baltimore, D. (2008). Sustained expression of microRNA-155 in hematopoietic stem cells causes a myeloproliferative disorder. J Exp Med 205, 585-594. Okada, C., Yamashita, E., Lee, S.J., Shibata, S., Katahira, J., Nakagawa, A., Yoneda, Y., and Tsukihara, T. (2009). A high-resolution structure of the pre-microRNA nuclear export machinery. Science 326, 1275-1279. 51 Okamura, K., Chung, W.J., Ruby, J.G., Guo, H., Bartel, D.P., and Lai, E.C. (2008). The Drosophila hairpin RNA pathway generates endogenous short interfering RNAs. Nature 453, 803-806. Okamura, K., Hagen, J.W., Duan, H., Tyler, D.M., and Lai, E.C. (2007). The mirtron pathway generates microRNA-class regulatory RNAs in Drosophila. Cell 130, 89-100. Okamura, K., Liu, N., and Lai, E.C. (2009). Distinct mechanisms for microRNA strand selection by Drosophila Argonautes. Mol Cell 36, 431-444. Paddison, P.J., Caudy, A.A., Bernstein, E., Hannon, G.J., and Conklin, D.S. (2002). Short hairpin RNAs (shRNAs) induce sequence-specific silencing in mammalian cells. Genes Dev 16, 948-958. Park, J.E., Heo, I., Tian, Y., Simanshu, D.K., Chang, H., Jee, D., Patel, D.J., and Kim, V.N. (2011). Dicer recognizes the 5' end of RNA for efficient and accurate processing. Nature 475, 201-205. Park, M.Y., Wu, G., Gonzalez-Sulser, A., Vaucheret, H., and Poethig, R.S. (2005). Nuclear processing and export of microRNAs in Arabidopsis. Proc Natl Acad Sci U S A 102, 36913696. Park, W., Li, J., Song, R., Messing, J., and Chen, X. (2002). CARPEL FACTORY, a Dicer homolog, and HEN1, a novel protein, act in microRNA metabolism in Arabidopsis thaliana. Curr Biol 12, 1484-1495. Pasquinelli, A.E., Reinhart, B.J., Slack, F., Martindale, M.Q., Kuroda, M.I., Maller, B., Hayward, D.C., Ball, E.E., Degnan, B., Muller, P., et al. (2000). Conservation of the sequence and temporal expression of let-7 heterochronic regulatory RNA. Nature 408, 86-89. Pertzev, A.V., and Nicholson, A.W. (2006). Characterization of RNA sequence determinants and antideterminants of processing reactivity for a minimal substrate of Escherichia coli ribonuclease III. Nucleic Acids Res 34, 3708-3721. Piskounova, E., Polytarchou, C., Thornton, J.E., LaPierre, R.J., Pothoulakis, C., Hagan, J.P., Iliopoulos, D., and Gregory, R.I. (2011). Lin28A and Lin28B inhibit let-7 microRNA biogenesis by distinct mechanisms. Cell 147, 1066-1079. Piskounova, E., Viswanathan, S.R., Janas, M., LaPierre, R.J., Daley, G.Q., Sliz, P., and Gregory, R.I. (2008). Determinants of microRNA processing inhibition by the developmentally regulated RNA-binding protein Lin28. J Biol Chem 283, 21310-21314. Portier, C., Dondon, L., Grunberg-Manago, M., and Regnier, P. (1987). The first step in the functional inactivation of the Escherichia coli polynucleotide phosphorylase messenger is a ribonuclease III processing at the 5' end. EMBO J 6, 2165-2170. Regnier, P., and Grunberg-Manago, M. (1989). Cleavage by RNase III in the transcripts of the met Y-nus-A-infB operon of Escherichia coli releases the tRNA and initiates the decay of the downstream mRNA. J Mol Biol 210, 293-302. Regnier, P., and Portier, C. (1986). Initiation, attenuation and RNase III processing of transcripts from the Escherichia coli operon encoding ribosomal protein S15 and polynucleotide phosphorylase. J Mol Biol 187, 23-32. Reinhart, B.J., Slack, F.J., Basson, M., Pasquinelli, A.E., Bettinger, J.C., Rougvie, A.E., Horvitz, H.R., and Ruvkun, G. (2000). The 21-nucleotide let-7 RNA regulates developmental timing in Caenorhabditis elegans. Nature 403, 901-906. Reinhart, B.J., Weinstein, E.G., Rhoades, M.W., Bartel, B., and Bartel, D.P. (2002). MicroRNAs in plants. Genes Dev 16, 1616-1626. 52 Rivas, F.V., Tolia, N.H., Song, J.J., Aragon, J.P., Liu, J., Hannon, G.J., and Joshua-Tor, L. (2005). Purified Argonaute2 and an siRNA form recombinant human RISC. Nat Struct Mol Biol 12, 340-349. Robertson, H.D. (1982). Escherichia coli ribonuclease III cleavage sites. Cell 30, 669-672. Robertson, H.D., and Dunn, J.J. (1975). Ribonucleic acid processing activity of Escherichia coli ribonuclease III. J Biol Chem 250, 3050-3056. Robertson, H.D., Webster, R.E., and Zinder, N.D. (1967). A nuclease specific for doublestranded RNA. Virology 32, 718-719. Robertson, H.D., Webster, R.E., and Zinder, N.D. (1968). Purification and properties of ribonuclease III from Escherichia coli. J Biol Chem 243, 82-91. Romano, N., and Macino, G. (1992). Quelling: transient inactivation of gene expression in Neurospora crassa by transformation with homologous sequences. Mol Microbiol 6, 33433353. Rotondo, G., and Frendewey, D. (1996). Purification and characterization of the Pac1 ribonuclease of Schizosaccharomyces pombe. Nucleic Acids Res 24, 2377-2386. Ruby, J.G., Jan, C., Player, C., Axtell, M.J., Lee, W., Nusbaum, C., Ge, H., and Bartel, D.P. (2006). Large-scale sequencing reveals 21U-RNAs and additional microRNAs and endogenous siRNAs in C. elegans. Cell 127, 1193-1207. Ruby, J.G., Jan, C.H., and Bartel, D.P. (2007a). Intronic microRNA precursors that bypass Drosha processing. Nature 448, 83-86. Ruby, J.G., Stark, A., Johnston, W.K., Kellis, M., Bartel, D.P., and Lai, E.C. (2007b). Evolution, biogenesis, expression, and target predictions of a substantially expanded set of Drosophila microRNAs. Genome Res 17, 1850-1864. Ruvkun, G., Wightman, B., and Ha, I. (2004). The 20 years it took to recognize the importance of tiny RNAs. Cell 116, S93-96, 92 p following S96. Saetrom, P., Heale, B.S., Snove, O., Jr., Aagaard, L., Alluin, J., and Rossi, J.J. (2007). Distance constraints between microRNA target sites dictate efficacy and cooperativity. Nucleic Acids Res 35, 2333-2342. Saito, K., Ishizuka, A., Siomi, H., and Siomi, M.C. (2005). Processing of pre-microRNAs by the Dicer-1-Loquacious complex in Drosophila cells. PLoS Biol 3, e235. Schauer, S.E., Jacobsen, S.E., Meinke, D.W., and Ray, A. (2002). DICER-LIKE1: blind men and elephants in Arabidopsis development. Trends Plant Sci 7, 487-491. Schwarz, D.S., Hutvagner, G., Du, T., Xu, Z., Aronin, N., and Zamore, P.D. (2003). Asymmetry in the assembly of the RNAi enzyme complex. Cell 115, 199-208. Seitz, H., Tushir, J.S., and Zamore, P.D. (2011). A 5'-uridine amplifies miRNA/miRNA* asymmetry in Drosophila by promoting RNA-induced silencing complex formation. Silence 2, 4. Shi, Y., Wang, Y.F., Jayaraman, L., Yang, H., Massague, J., and Pavletich, N.P. (1998). Crystal structure of a Smad MH1 domain bound to DNA: insights on DNA binding in TGF-beta signaling. Cell 94, 585-594. Shin, C., Nam, J.W., Farh, K.K., Chiang, H.R., Shkumatava, A., and Bartel, D.P. (2010). Expanding the microRNA targeting code: functional sites with centered pairing. Mol Cell 38, 789-802. Sohn, S.Y., Bae, W.J., Kim, J.J., Yeom, K.H., Kim, V.N., and Cho, Y. (2007). Crystal structure of human DGCR8 core. Nat Struct Mol Biol 14, 847-853. 53 Song, L., Axtell, M.J., and Fedoroff, N.V. (2010). RNA secondary structural determinants of miRNA precursor processing in Arabidopsis. Curr Biol 20, 37-41. Stark, A., Brennecke, J., Bushati, N., Russell, R.B., and Cohen, S.M. (2005). Animal MicroRNAs confer robustness to gene expression and have a significant impact on 3'UTR evolution. Cell 123, 1133-1146. Stark, A., Kheradpour, P., Parts, L., Brennecke, J., Hodges, E., Hannon, G.J., and Kellis, M. (2007). Systematic discovery and characterization of fly microRNAs using 12 Drosophila genomes. Genome Res 17, 1865-1879. Steiner, F.A., Hoogstrate, S.W., Okihara, K.L., Thijssen, K.L., Ketting, R.F., Plasterk, R.H., and Sijen, T. (2007). Structural features of small RNA precursors determine Argonaute loading in Caenorhabditis elegans. Nat Struct Mol Biol 14, 927-933. Sun, G., Yan, J., Noltner, K., Feng, J., Li, H., Sarkis, D.A., Sommer, S.S., and Rossi, J.J. (2009). SNPs in human miRNA genes affect biogenesis and function. RNA 15, 1640-1651. Suzuki, H.I., Yamagata, K., Sugimoto, K., Iwamoto, T., Kato, S., and Miyazono, K. (2009). Modulation of microRNA processing by p53. Nature 460, 529-533. Tang, G., Reinhart, B.J., Bartel, D.P., and Zamore, P.D. (2003). A biochemical framework for RNA silencing in plants. Genes Dev 17, 49-63. Thai, T.H., Calado, D.P., Casola, S., Ansel, K.M., Xiao, C., Xue, Y., Murphy, A., Frendewey, D., Valenzuela, D., Kutok, J.L., et al. (2007). Regulation of the germinal center response by microRNA-155. Science 316, 604-608. Tomari, Y., Du, T., and Zamore, P.D. (2007). Sorting of Drosophila small silencing RNAs. Cell 130, 299-308. Trabucchi, M., Briata, P., Filipowicz, W., Ramos, A., Gherzi, R., and Rosenfeld, M.G. (2010). KSRP promotes the maturation of a group of miRNA precursors. Adv Exp Med Biol 700, 36-42. Tsutsumi, A., Kawamata, T., Izumi, N., Seitz, H., and Tomari, Y. (2011). Recognition of the premiRNA structure by Drosophila Dicer-1. Nat Struct Mol Biol 18, 1153-1158. Tuschl, T., Zamore, P.D., Lehmann, R., Bartel, D.P., and Sharp, P.A. (1999). Targeted mRNA degradation by double-stranded RNA in vitro. Genes Dev 13, 3191-3197. Ui-Tei, K., Naito, Y., Nishi, K., Juni, A., and Saigo, K. (2008). Thermodynamic stability and Watson-Crick base pairing in the seed duplex are major determinants of the efficiency of the siRNA-based off-target effect. Nucleic Acids Res 36, 7100-7109. van der Krol, A.R., Mur, L.A., Beld, M., Mol, J.N., and Stuitje, A.R. (1990). Flavonoid genes in petunia: addition of a limited number of gene copies may lead to a suppression of gene expression. Plant Cell 2, 291-299. Vermeulen, A., Behlen, L., Reynolds, A., Wolfson, A., Marshall, W.S., Karpilow, J., and Khvorova, A. (2005). The contributions of dsRNA structure to Dicer specificity and efficiency. RNA 11, 674-682. Viswanathan, S.R., Daley, G.Q., and Gregory, R.I. (2008). Selective blockade of microRNA processing by Lin28. Science 320, 97-100. Wang, D., Zhang, Z., O'Loughlin, E., Lee, T., Houel, S., O'Carroll, D., Tarakhovsky, A., Ahn, N.G., and Yi, R. (2012). Quantitative functions of Argonaute proteins in mammalian development. Genes Dev 26, 693-704. Wang, Y., Medvid, R., Melton, C., Jaenisch, R., and Blelloch, R. (2007). DGCR8 is essential for microRNA biogenesis and silencing of embryonic stem cell self-renewal. Nat Genet 39, 380385. 54 Warf, M.B., Johnson, W.E., and Bass, B.L. (2011). Improved annotation of C. elegans microRNAs by deep sequencing reveals structures associated with processing by Drosha and Dicer. RNA 17, 563-577. Weinberg, D.E., Nakanishi, K., Patel, D.J., and Bartel, D.P. (2011). The inside-out mechanism of Dicers from budding yeasts. Cell 146, 262-276. Wightman, B., Ha, I., and Ruvkun, G. (1993). Posttranscriptional regulation of the heterochronic gene lin-14 by lin-4 mediates temporal pattern formation in C. elegans. Cell 75, 855-862. Wu, H., Henras, A., Chanfreau, G., and Feigon, J. (2004). Structural basis for recognition of the AGNN tetraloop RNA fold by the double-stranded RNA-binding domain of Rnt1p RNase III. Proc Natl Acad Sci U S A 101, 8307-8312. Wu, H., Xu, H., Miraglia, L.J., and Crooke, S.T. (2000). Human RNase III is a 160-kDa protein involved in preribosomal RNA processing. J Biol Chem 275, 36957-36965. Wu, H., Yang, P.K., Butcher, S.E., Kang, S., Chanfreau, G., and Feigon, J. (2001). A novel family of RNA tetraloop structure forms the recognition site for Saccharomyces cerevisiae RNase III. EMBO J 20, 7240-7249. Yang, W., Chendrimada, T.P., Wang, Q., Higuchi, M., Seeburg, P.H., Shiekhattar, R., and Nishikura, K. (2006). Modulation of microRNA processing and expression through RNA editing by ADAR deaminases. Nat Struct Mol Biol 13, 13-21. Yekta, S., Shih, I.H., and Bartel, D.P. (2004). MicroRNA-directed cleavage of HOXB8 mRNA. Science 304, 594-596. Yeom, K.H., Lee, Y., Han, J., Suh, M.R., and Kim, V.N. (2006). Characterization of DGCR8/Pasha, the essential cofactor for Drosha in primary miRNA processing. Nucleic Acids Res 34, 4622-4629. Yi, R., Qin, Y., Macara, I.G., and Cullen, B.R. (2003). Exportin-5 mediates the nuclear export of pre-microRNAs and short hairpin RNAs. Genes Dev 17, 3011-3016. Yoda, M., Kawamata, T., Paroo, Z., Ye, X., Iwasaki, S., Liu, Q., and Tomari, Y. (2010). ATPdependent human RISC assembly pathways. Nat Struct Mol Biol 17, 17-23. Young, R.A., and Steitz, J.A. (1978). Complementary sequences 1700 nucleotides apart form a ribonuclease III cleavage site in Escherichia coli ribosomal precursor RNA. Proc Natl Acad Sci U S A 75, 3593-3597. Zamore, P.D., Tuschl, T., Sharp, P.A., and Bartel, D.P. (2000). RNAi: double-stranded RNA directs the ATP-dependent cleavage of mRNA at 21 to 23 nucleotide intervals. Cell 101, 2533. Zeng, Y., and Cullen, B.R. (2005). Efficient processing of primary microRNA hairpins by Drosha requires flanking nonstructured RNA sequences. J Biol Chem 280, 27595-27603. Zeng, Y., Yi, R., and Cullen, B.R. (2005). Recognition and cleavage of primary microRNA precursors by the nuclear processing enzyme Drosha. EMBO J 24, 138-148. Zhang, H., Kolb, F.A., Brondani, V., Billy, E., and Filipowicz, W. (2002). Human Dicer preferentially cleaves dsRNAs at their termini without a requirement for ATP. EMBO J 21, 5875-5885. Zhang, H., Kolb, F.A., Jaskiewicz, L., Westhof, E., and Filipowicz, W. (2004). Single processing center models for human Dicer and bacterial RNase III. Cell 118, 57-68. Zhang, K., and Nicholson, A.W. (1997). Regulation of ribonuclease III processing by doublehelical sequence antideterminants. Proc Natl Acad Sci U S A 94, 13437-13441. Zhang, X., and Zeng, Y. (2010). The terminal loop region controls microRNA processing by Drosha and Dicer. Nucleic Acids Res 38, 7689-7697. 55 Zhou, R., Czech, B., Brennecke, J., Sachidanandam, R., Wohlschlegel, J.A., Perrimon, N., and Hannon, G.J. (2009). Processing of Drosophila endo-siRNAs depends on a specific Loquacious isoform. RNA 15, 1886-1895. 56 57 58 Chapter 2. Beyond secondary structure: primary-sequence determinants license pri-miRNA hairpins for processing Contents Summary ........................................................................................................................................61 Introduction ....................................................................................................................................61 Results ............................................................................................................................................63 Existence of auxiliary elements for efficient pri-miRNA processing ................................... 63 Functional substrates from large libraries of pri-miRNA variants. ...................................... 66 Importance of an 11 bp basal stem flanked by ≥ 5 unstructured nucleotides ....................... 70 A basal UG motif enhances processing ................................................................................ 73 The broadly conserved CNNC motif enhances processing .................................................. 75 Loop and apical stem elements can enhance processing ...................................................... 79 Rescue of C. elegans miRNA expression in human cells ..................................................... 81 Discussion ......................................................................................................................................83 Experimental Procedures ...............................................................................................................85 Ectopic pri-miRNA expression in HEK293 cells and S2 cells ............................................. 85 Whole-cell lysate with overexpressed Microprocessor complex.......................................... 86 Competitive binding and cleavage assays............................................................................. 87 Synthesis of pools of pri-miRNA variants ............................................................................ 87 In vitro selection and high-throughput sequencing ............................................................... 88 Sequence analysis ................................................................................................................. 89 Positional enrichments of sequence motifs ........................................................................... 91 59 pri-miRNA collections .......................................................................................................... 91 Accession Numbers .............................................................................................................. 92 Acknowledgements ............................................................................................................... 92 Supplemental Materials .................................................................................................................99 Supplemental Figures............................................................................................................ 99 Supplemental Table S1: Oligonucleotides used in the in vitro selections .......................... 112 Supplemental Table S2. Pri-miRNA collections ............................................................... 116 60 Summary To use microRNAs to down-regulate mRNA targets, cells must first process these ~22 nt RNAs from primary transcripts (pri-miRNAs). These transcripts form RNA hairpins important for processing, but additional unknown determinants must distinguish pri-miRNAs from the many other hairpin-containing transcripts expressed in each cell. Illustrating the complexity of this recognition, we show that most Caenorhabditis elegans pri-miRNAs lack determinants required for processing in human cells. To find these determinants, we generated >1011 variants of four human pri-miRNAs, sequenced millions that retained function and compared them with the starting variants. Our results confirmed the importance of pairing in the stem and revealed three primary-sequence determinants, including a CNNC motif found downstream of most primiRNA hairpins in bilaterian animals but not in nematodes. Adding this and other determinants to C. elegans pri-miRNAs imparted efficient processing in human cells, further illustrating the importance of primary-sequence determinants for distinguishing pri-miRNAs from other hairpincontaining transcripts. Introduction MicroRNAs (miRNAs) are ~22 nt RNAs that pair to the mRNAs of protein-coding genes to direct the post-transcriptional repression of these mRNAs (Bartel, 2004, 2009). In animals, miRNAs are processed from hairpin-containing primary transcripts (pri-miRNAs) that undergo successive cleavage steps before yielding the functional small RNA. In the canonical pathway, pri-miRNAs are first cleaved in the nucleus by the Microprocessor, a protein complex containing an RNase III enzyme Drosha and its cofactor DGCR8 (called Pasha and Psh-1 in Drosophila melanogaster and C. elegans, respectively) (Lee et al., 2003; Denli et al., 2004; Gregory et al., 2004; Han et al., 2004; Landthaler et al., 2004). The liberated portion of the hairpin, termed the pre-miRNA, is exported to the cytosol (Lee et al., 2002; Yi et al., 2003; Bohnsack et al., 2004; Lund et al., 2004), where it is cleaved by the RNase III enzyme Dicer (Grishok et al., 2001; Hutvagner et al., 2001; Ketting et al., 2001) approximately two helical turns from the base of the hairpin to remove the loop (Lee et al., 2004a) and generate two ~22 nt strands that pair to each other with 2 nt 3′ overhangs (Lim et al., 2003b). One strand of each duplex is loaded into an Argonaute protein to form the core of the silencing complex, whereas the other strand is discarded (Khvorova et al., 2003; Schwarz et al., 2003; Liu et al., 2004; Meister et al., 2004). 61 Noncanonical pathways also contribute to the miRNA repertoire of animal cells. For example, mirtron miRNA precursors are excised from the primary transcript by the spliceosome rather than Drosha; after debranching, the excised mirtron folds into a hairpin that enters the canonical pathway at the step of export to the cytoplasm (Okamura et al., 2007; Ruby et al., 2007a). Tailed mirtrons and endogenous small-hairpin RNAs (shRNAs) are other types of noncanonical precursors that bypass Microprocessor cleavage (Babiarz et al., 2008), and miR451 is unusual in bypassing Dicer cleavage (Cheloufi et al., 2010; Cifuentes et al., 2010). A long-standing mystery of canonical miRNA biogenesis has been how the animal cell determines which of its many hairpin-containing transcripts are recognized by the Microprocessor to enter the miRNA pathway. Determinants of subsequent Dicer cleavage are better understood (Zhang et al., 2004; Macrae et al., 2006; Park et al., 2011), as illustrated by both the success in designing artificial Dicer substrates that bypass Drosha processing (Brummelkamp et al., 2002; Paddison et al., 2002) and the success in accurately predicting mirtrons from a single genomic sequence, without considering evolutionary conservation (Chung et al., 2011). With regard to Microprocessor recognition, sequences within 40 nt upstream and 40 nt downstream of the pre-miRNA hairpin are required for ectopic miRNA expression (Chen et al., 2004), which is consistent with the observation that these flanking sequences tend to pair to each other to extend the stem another turn of the helix beyond the site of cleavage (Lim et al., 2003b). The pairing within this helical extension and a lack of pairing immediately following the last pair of the basal stem is required for productive Microprocessor recognition, as illustrated by in vitro studies demonstrating that the human Microprocessor complex can cleave artificial sequences that form perfectly paired stems flanked by single-strand RNA (ssRNA) (Han et al., 2006). However, these known structural determinants cannot fully explain the specificity of Microprocessor cleavage. Many cellular transcripts have paired regions flanked by ssRNA, and most of these are not endogenous substrates of the Microprocessor. Indeed, attempts to predict canonical miRNA hairpins from genomic sequence yield thousands or millions of false-positive predictions, which must be eliminated using additional criteria, such as analysis of conservation or experimental evaluation (Lim et al., 2003a; Lim et al., 2003b; Bentwich et al., 2005; Berezikov et al., 2006; Chiang et al., 2010), illustrating a large gap in our understanding of how the Microprocessor distinguishes between bona fide pri-miRNA substrates and other transcribed hairpins. 62 In this study, we found that transcripts that enter the miRNA pathway in C. elegans failed to do so in human cells. Thus, the definition of a pri-miRNA in one species differs from that in another, which adds a new dimension to the mystery of pri-miRNA recognition. To elucidate sequence and structural features of human pri-miRNAs, we generated >1011 variants of four human pri-miRNA sequences and sequenced millions that were cleaved by the human Microprocessor complex. Comparison of the cleaved variants with the initial pool of variants revealed sequence and structural features important for Microprocessor recognition and cleavage. These features were evolutionarily conserved in non-nematode lineages and sufficient to increase the processing efficiency of C. elegans hairpins in human cells. Results Existence of auxiliary elements for efficient pri-miRNA processing To examine whether miRNA processing features are shared across animals, we ectopically expressed C. elegans, D. melanogaster and human pri-miRNAs in human cells and compared the yields of mature miRNA. For each miRNA investigated, the hairpin and ~100 nt of flanking genomic sequence were expressed upstream of the human mir-1-1 pri-miRNA on a bicistronic transcript under control of the CMV promoter (Figure S1A). Cells transfected with each vector were harvested and pooled, and small RNAs were sequenced. As reported previously, most human miRNAs were efficiently expressed (Chiang et al., 2010), as were four of nine tested Drosophila miRNAs (Figure 1A). However, the tested C. elegans miRNAs were less efficiently expressed in HEK293 cells (Figure 1A, p = 1.4×10–5, Wilcoxon rank-sum test). Likewise, in Drosophila S2 cells, C. elegans miRNAs were expressed less efficiently than were human miRNAs (p = 0.024). These results indicated that most nematode pri-miRNAs are missing determinants required for proper processing by human or insect cells. To isolate the processing defect, we probed for processing intermediates. For each inefficiently expressed miRNA examined, the primary transcript was present (Figure S1A and S1B), but no pre-miRNA or mature miRNA was detected (Figure 1B). These results suggested that C. elegans pri-miRNAs are not productively recognized as substrates of the Microprocessor in the first step of miRNA maturation. To assay directly for binding to the human Microprocessor 63 – + – + – + – + D P22 P1 –1 –51 –41 1.00 0.09 1.00 –31 –21 –11 5p position 0.08 1.00 +1 –13 +11 –1 0.09 1.00 0.8 0.7 0.6 0.5 0.33 P1 cel-mir-235 cel-mir-60 cel-mir-59 cel-mir-50 cel-mir-46 600 400 200 0 0 Fly Worm C Nitrocellulose filtration Reference Basal stem 1 0.9 P11 P21 P31 P41 P51 pre-miRNA position 0.5 1 11 hsa-mir-1-1 hsa-mir-128-1 hsa-mir-205 cel-lin-4 cel-lsy-6 cel-mir-40 cel-mir-50 cel-mir-230 cel-mir-240 293 cells 21 31 41 3p position cel-mir-50 + 0.07 1151 6752 2777 4919 10362 3037 3271 5024 3705 4171 499 1000 cel-mir-40 – 1.00 800 cel-lsy-6 + cel-mir-44 Human cel-lin-4 hsa-mir-1-1 – cel-lsy-6 Microprocessor Average BLS + 0.13 Query miRNA: hsa-mir-122 – 1.00 Query + 0.21 Reference – 1.00 DroshaTN DGCR8 1.65 Query 1.00 hsa-mir-1-1 hsa-mir-17 hsa-mir-18a hsa-mir-19a hsa-mir-20a hsa-mir-19b-1 hsa-mir-92a-1 hsa-mir-122 hsa-mir-125a hsa-mir-128-1 hsa-mir-133a-1 hsa-mir-138-2 hsa-mir-142 hsa-mir-205 dme-mir-2a-1 dme-mir-4 dme-mir-5 dme-mir-34 dme-mir-92a dme-mir-125 dme-mir-286 dme-mir-279 dme-mir-281-1 cel-mir-2 cel-lin-4 cel-lsy-6 cel-mir-34 cel-mir-40 cel-mir-43 cel-mir-44 cel-mir-46 cel-mir-50 cel-mir-59 cel-mir-60 cel-mir-124 cel-mir-235 cel-mir-240 Normalized hairpin reads A 30 25 20 S2 cells 15 10 5 Human 1 Basal stem 0.9 0.8 0.7 0.6 51 Worm B pre-miRNA 70 mature miRNA 20 15 fmol cognate control 750 300 Microprocessor, we established a competitive-binding assay that compared the ability of different pri-miRNAs to bind catalytically-deficient Drosha and DGCR8 (Figure 1C). Whereas human pri-mir-122 bound the Microprocessor somewhat better than did human pri-mir-125a, all seven tested C. elegans pri-miRNAs bound worse (Figure 1C). Thus, most C. elegans primiRNAs are missing some of the determinants needed for efficient recognition and processing by the Microprocessor complex. As a result, many transcripts recognized as pri-miRNAs in C. elegans cells are not recognized as pri-miRNAs by human cells. Known features of C. elegans and human pri-miRNAs appear largely similar, as illustrated by the accuracy of an algorithm trained on C. elegans pri-miRNA features in predicting most miRNA genes conserved in human, mouse and fish (Lim et al., 2003a). Nonetheless, the poor specificity of this algorithm when predicting non-conserved miRNAs supports the idea that unknown features also exist and help the cell define authentic pri-miRNAs. To look for clues regarding previously unknown features that might be required for human primiRNA recognition, we analyzed the sequence immediately flanking human pre-miRNAs for conservation in other vertebrates. In a meta-analysis of human pri-miRNAs conserved in other Figure 1. The existence of auxiliary elements that specify human pri-miRNA transcripts. (A) Processing of human, fly, and worm pri-miRNAs in human HEK293T cells and Drosophila S2 cells. Cells were transfected with plasmids expressing the indicated pri-miRNA hairpins with ~100 flanking genomic nucleotides on each side of each hairpin, and total RNA was pooled for small-RNA sequencing. Graphs plot the small RNA reads derived from the indicated pri-miRNAs. (B) Attempted detection of pre-miRNA and mature miRNA production in HEK293T cells. RNA blots of total RNA isolated from cells transfected with the indicated pri-miRNA were probed for the cognate miRNA. Blots also included lanes with 15 fmol in vitro transcribed standards derived from the corresponding pri-miRNAs (pri-RNA controls). (C) Relative binding of C. elegans and human pri-miRNAs to the Microprocessor. In the competitive binding assay (left, schematic), radiolabeled query pri-miRNA was mixed with the radiolabeled shorter reference pri-miRNA (human mir-125a) and incubated with immunopurified, catalytically impaired Drosha (Drosha-TN) and DGCR8 in conditions of RNA excess. Bound RNA was isolated on nitrocellulose filters and eluted for analysis on a denaturing gel. Phosphorimaging (right) indicated the relative amounts of query and reference RNA in the input (–) and bound to the Microprocessor (+). Numbers below each lane indicate the ratio of bound query miRNA relative to bound reference RNA, normalized to the input ratio. (D) Nucleotide conservation of human pri-miRNAs conserved to mouse. At each position, the average branch-length score (BLS) is plotted, in which each BLS indicates the phylogenetic branch lengths of all the aligned mammalian species in which the ancestral identity was preserved, divided by the branch lengths of all the species in which the miRNA is preserved. Positions are numbered based on the inferred Drosha cleavage site (inset); negative indices are upstream of the 5p Drosha cleavage site, indices with “P” count from the 5′ end of the pre-miRNA, and positive indices are downstream of the 3p Drosha cleavage site. 65 mammals, residues extending 13 nt upstream of the 5p Drosha cleavage site (i.e., the site corresponding to the 5′ end of the pre-miRNA) and 11 nt downstream of the 3p Drosha cleavage site were conserved above background, consistent with the importance of the ~11 bp basal stem for pri-miRNA processing (Figure 1D). Upstream of the hairpin, conservation dropped rapidly with distance from the cleavage site, with just a few nucleotides immediately flanking the basal stem conserved above background. Conservation also dropped on the 3p side of the pre-miRNA, but not quite as rapidly in the region 15–25 nt from the cleavage site (Figure 1D). This asymmetry in the conservation drop-off hinted at potential determinants downstream of the hairpin. However, the overall weakness of the conservation signal beyond the basal stem suggested that any determinants in these flanking regions might either be at variable distances from the hairpin or present in some subsets of miRNAs but not others, making them difficult to identify using only comparative sequence analyses. Functional substrates from large libraries of pri-miRNA variants. To identify sequence and structural features important for Microprocessor recognition and cleavage, we generated >1011 variants of a pri-miRNA, sequenced millions that retained function and compared these sequences to those of the initial pool of variants (Figure 2A). At each variable nucleotide position, most molecules had the wild-type residue, and a minority had the other three alternatives. This approach resembled classical in vitro selection approaches, particularly those that started with degenerate libraries with the goal of characterizing nucleic acids known to function as ligands and substrates (Ellington and Szostak, 1990; Bartel et al., 1991; Breaker et al., 1994), except we did not perform multiple rounds of selection. Instead, we collected the variants that were cleaved by the Microprocessor and then directly prepared them for high-throughput sequencing. Similar strategies have been used for DNA-binding and ribozyme experiments (Zykovich et al., 2009; Jolma et al., 2010; Pitt and Ferre-D'Amare, 2010; Slattery et al., 2011). Because the differences from the starting pool were from a single round of cleavage, and because both the starting pool and the selected pool were subject to the same number of transcription, reverse-transcription and amplification steps, any differences observed between the two pools were subject to neither the compounding effects of multiple rounds nor the confounding effects of amplification biases. Moreover, because in each sample millions of molecules were sequenced, the differences were not influenced by stochastic sampling of small 66 numbers. Thus, compared to the results of classical approaches, enrichment or depletion of a residue was a more direct reflection of its contribution to biochemical specificity. To query sequence and structural determinants at the base of the hairpin and flanking the hairpin, pools of variants were constructed in which residues >8 nt upstream of the 5p Drosha cleavage site or >8 nt downstream of the 3p cleavage site were varied while the remaining hairpin residues were not varied. Suspecting that different pri-miRNAs might use different determinants, four different pools were constructed, based on the pri-miRNAs of human mir125a, mir-16-1, mir-30a, and mir-223, respectively. Each pool was produced by in vitro transcription of a DNA template constructed using degenerate oligonucleotides in which variable positions had non-wild-type residues introduced at a frequency of 21%. For example, at a variable position in which the wild-type residue was an A, 79% of the pool molecules would have an A, whereas 7% would have a C, 7% would have a G, and 7% would have a U. The other key design element was that, borrowing from a strategy used to identify variants of RNAcleaving ribozymes (Pan and Uhlenbeck, 1992), each variant was circularized (Figure 2A). Without circularization, some variable nucleotides would have resided in the upstream cleavage product, whereas others would have resided in a separate downstream product, making it impossible to reconstruct the starting variant from the sequenced products. With circularization, all the variable nucleotides resided in a single product, the sequence of which revealed the starting variant, thereby enabling a full analysis of sequence interdependencies and covariation. In vitro cleavage of circularized pri-miRNA variants was carried out in whole-cell lysate of HEK293T cells overexpressing Drosha and DGCR8. Very little pri-miRNA cleavage occurred in lysate from cells not overexpressing the proteins, which indicated that the dominant pri-miRNA cleavage activity depended on overexpressed Drosha or DGCR8 (Figure 2B). At a time in which the lysate cleaved linear and circularized pri-mir-125a nearly to completion, much of the pool of pri-mir-125a variants remained uncleaved, which indicated that substitutions in the basal stem and flanking regions can attenuate Microprocessor cleavage in vitro (Figure 2C). Analogous results were obtained with pools of variants based on the other three pri-miRNAs (data not shown). Variants that were cleaved by the Microprocessor were recovered by gel purification, ligated to sequencing adaptors, and prepared for high-throughput, paired-end sequencing (Figure 2A). Sequence analyses were restricted to products cleaved at the wild-type processing sites, 67 –0.4 5p Position 25 27 29 31 33 35 37 39 41 43 45 25 27 29 31 33 35 37 39 41 43 45 25 27 29 31 33 3p Position 45 C U 47 43 A G 45 41 +1 43 39 37 Stem-loop 41 39 0.4 35 –9 33 –1 31 0.6 29 0.8 27 25 23 21 19 17 15 13 293T Transfection 37 13 9 11 Drosha DGCR8 B 35 23 23 23 9 11 21 0 21 –0.2 21 0.2 19 0.4 19 0.6 19 0.8 17 hsa-mir-223 17 0 17 –0.2 15 0.2 15 0.4 13 0.6 15 0.8 13 hsa-mir-30a 9 0 11 0.2 9 hsa-mir-125a 11 Drosha DGCR8 Mock Circular pri-miRNA substrate (pool of variants) –9 –11 –13 –15 –17 –19 –21 –23 –25 –27 Nonfunctional variants –29 1 –31 Information content (bits) Drosha DGCR8 –33 1.2 –35 –0.4 –37 1 –39 1.2 –41 –0.4 –43 1 –45 1.2 –47 –51 –49 –47 –45 –43 –41 –39 –37 –35 –33 –31 –29 –27 –25 –23 –21 –19 –17 –15 –13 –11 –9 –0.4 –49 –47 –45 –43 –41 –39 –37 –35 –33 –31 –29 –27 –25 –23 –21 –19 –17 –15 –13 –11 –9 Information content (bits) 1 –49 –47 –45 –43 –41 –39 –37 –35 –33 –31 –29 –27 –25 –23 –21 –19 –17 –15 –13 –11 –9 Information content (bits) 1.2 –49 Information content (bits) A C pri-mir-125a WT WT Pool Topology Linear Circ. Circ. Functional variants Splint-ligated product Library for paired-end sequencing D +9 Invariant residues –14 +12 –0.2 hsa-mir-16-1 0.8 0.6 0.4 0.2 –0.2 0 which were inferred from the dominant reads in small-RNA sequencing data (Landgraf et al., 2007; Bar et al., 2008; Chiang et al., 2010; Witten et al., 2010), except for miR-16-1* and miR223, which appear to undergo post-cleavage 3′-end trimming (Han et al., 2011). Because product ligation and computational analysis both selected for cleavage at the wild-type site, nucleotide changes that altered the site of Microprocessor cleavage were not distinguished from those that abolished cleavage. At each variant position, we compared the odds of each nucleotide in the properly cleaved pool to the odds of that nucleotide in the starting pool. These odds ratios were used to calculate the information content of each nucleotide possibility at each variant position—the greater the information content, the more favorable the influence on Microprocessor recognition and cleavage, with positive values indicating a favorable influence and negative values indicating a disruptive influence. Information content was chosen as the metric for displaying enrichment or depletion in the cleaved pool because it effectively indicated the relative influence of the nucleotide, regardless of whether it was the wild-type possibility or one of the other three possibilities. Some positions had substantial enrichment of one or more nucleotide possibilities, with corresponding depletion of the others (Figure 2D). To validate the influence of representative positions on recognition and cleavage, pri-mir-125a mutants were tested in the competitivecleavage assay, comparing cleavage to that of wild-type pri-mir-125a (Figure S2A and B). The Figure 2. In vitro selection for functional pri-miRNA variants. (A) Schematic of the selection in which variable sequences (red) flanked the Drosha cleavage site. PrimiRNA variants were circularized by ligation and incubated in whole-cell lysate from HEK293T cells overexpressing Drosha and DGCR8. Cleaved variants were gel-purified, ligated to adaptors, reverse transcribed and amplified for high-throughput sequencing. (B) Cleavage of linear hsa-let-7a in whole-cell lysate from HEK293T cells (mock) and whole-cell lysate from HEK293T cells transfected with plasmids expressing Drosha and DGCR8. Incubations were for 90 minutes. Body-labeled reactants and products were resolved on a denaturing polyacrylamide gel and visualized by phosphorimaging. (C) Cleavage of linear and circular pri-mir-125a (WT linear and WT circ., respectively) and a pool of circular hsa-mir-125a variants (pool). RNAs were incubated for 5 minutes in the extracts supplemented with Drosha and DGCR8 and analyzed as in (B). The WT linear RNA was 5′ endlabeled; the other RNAs were body-labeled. (D) Enrichment and depletion at variable residues in functional pri-miRNA variants. At each varied position (inset, red inner line), information content was calculated for each residue (green, cyan, black, and red for A, C, G, and U, respectively). 69 results of changing specific residues closely matched those predicted from analysis of sequenced variants, thereby confirming that the calculated relative cleavage faithfully reflected the influence on Microprocessor recognition and cleavage in vitro. The effects of these changes were also confirmed in HEK293T cells (Figure S2C). Importance of an 11 bp basal stem flanked by ≥ 5 unstructured nucleotides For all four miRNAs, some of the variable residues with the greatest influence fell within the basal stem (Figure 2D). The high information content at these paired positions could be due to either the importance of primary sequence or the need to pair to the nucleotide on the other arm of the hairpin, or both. To distinguish between these possibilities, we examined covariation matrices, generated by calculating the odds of each pair of nucleotide identities at each predicted base pair, relative to the odds of those identities in the initial pool. These matrices showed overall preference for Watson–Crick geometry at each of these basal pairs, with the G:U wobble being the most frequently preferred non-Watson–Crick alternative (Figure 3A, S3A). For example, the most favored alternatives to the C:G pair at positions –11 and +9 of mir-125a are the G:C and U:A pairs, and to a lesser extent the A:U, G:U and U:G pairs (Figure 3A). In fact, Watson–Crick pairing was strongly preferred even if it did not occur in the wild-type sequence. For example, the wild-type A:C pair at positions –12 and +10 of mir-30a was disfavored, whereas the four Watson–Crick pairs were most strongly favored (Figure 3A). Similarly, the bulged A at position +10 of mir-223 was preferentially incorporated into an alternative continuous helix (Fig. S3A–B). Layered on top of the overall preference for Watson–Crick pairing were primarysequence preferences specific to each basal pair. For example, at positions –11 and +9 the C:G pair was strongly favored over the A:U alternative. The primary-sequence preference was most acute at position –13. At this position the preference for a G was often stronger than the preference for Watson–Crick pairing, in that the G:U wobble and sometimes the G:A or G:G mismatches were less disruptive than were the other three Watson–Crick alternatives (Figure 3A). We conclude that primary-sequence features supplement and sometimes supersede structural features important for basal-stem recognition. 70 Using the same covariation analysis, we screened for evidence of Watson–Crick pairing between all possible pairs of varied positions. For each of these >3000 possible pairs, the degree of Watson–Crick preference was evaluated using a scoring metric that compared the average odds of Watson–Crick pairs to that of non-Watson–Crick alternatives. In each case, the highestscoring pairs were those of the basal stem (Fig. S3C). In the case of mir-223, the highest scoring pairs also included the alternative pairs that incorporated the bulged A at +10 into a contiguous helix. For each pri-miRNA, we inspected the next four highest-scoring pairs, and in each case, the covariation matrix did not appear consistent with Watson–Crick pairing (data not shown). These results indicate that in the sequence flanking the pre-miRNA, Watson–Crick pairing important for Microprocessor recognition and cleavage is restricted to the basal stem. The Microprocessor recognizes the junction between the miRNA hairpin and flanking ssRNA, and thereby positions the active site to cleave approximately one helical turn (11 bp of A-form RNA) from the base of the duplex (Han et al., 2006; Yeom et al., 2006). To examine whether a specific number of pairs was preferred in the basal stem, we calculated the relative cleavage of different stem-length variants, normalizing to that of an 8 bp stem. Invariant mismatches within symmetric internal loops (e.g., the A:C mismatch at positions –6 and +4 of mir-30a) were assumed to be non-canonical pairs that stacked within the stem to contribute to its length, whereas mismatches at varied positions were assumed to disrupt further pairing and thereby terminate the inferred basal stem. For all four pri-miRNAs, an 11 bp basal stem was optimal (Figure 3B), consistent with the single-turn measurement for cleavage-site selection. Indeed, an 11 bp basal stem was preferred for mir-223, even though the wild-type sequence was predicted to form a 12 bp stem (Figures 3A and S3A). For most pri-miRNAs, however, the efficiency of the 12-pair stem approached that of the 11-pair stem (Figure 3B). This tolerance of a twelfth pair hinted at the influence of other features, such as the G at position –13, in overriding the single-turn measurement to specify the precise site of cleavage. The model for single-turn measurement also posits that the nucleotides immediately flanking the basal stem are unstructured (Han et al., 2006; Yeom et al., 2006). To test this part of the model, we used RNAfold (Hofacker and Stadler, 2006) to predict the minimum free-energy structure of all sequenced miRNA variants in the selected pools and the initial pools. For each sequence with wild-type predicted pairing in the stem, the number of nucleotides between the base of the stem and the most proximal two consecutive structured bases was recorded. 71 −0.2 −0.4 −0.6 −0.8 −1 Relative cleavage Timepoint 2 U 0.34 –1.02 –0.04 Position 10 C G U A –1.48 –1.18 –1.20 –0.23 C –1.11 –1.60 G –0.54 U –0.15 –1.50 –0.40 –0.76 1.17 –1.14 0.17 –0.41 –0.16 Position 11 C G U A –0.50 –0.93 –0.58 –0.22 C –0.98 –1.61 –0.40 –1.02 G –0.35 U –1 U C C-G +1 G-U U-A G A A G C-G G-U A-U –11 C-G +9 –12 U-A +10 –13 G-C +11 U C A A A U C A 0.36 –0.85 –0.30 –0.48 0.81 –0.27 hsa-mir-16-1 Wildtype basal stem 0.04 –0.04 –0.74 –0.28 –0.30 hsa-mir-125a A –4.17 –3.5 –3.45 –0.39 C –3.29 –3.72 2.5 –2.45 G –2.85 0.41 –2.6 0.14 U 0.09 A –2.04 –0.67 –1.06 0.35 C –1.25 –1.83 1.03 –0.95 G –0.22 0.7 0.39 U 0.74 0.15 –1.44 –0.03 –0.04 Position 11 C G U Pair 11 A A –1.12 –2.05 –1.23 –0.93 C –1.51 –3.12 –0.69 –1.65 G 0.32 U –0.57 –1.7 –0.71 –1.22 0.74 hsa-mir-30a Wildtype basal stem –0.16 0.37 hsa-mir-30a 64 32 32 32 16 16 16 16 8 8 8 8 4 4 4 4 2 2 2 2 1 1 1 9 10 11 12 13 Basal stem pairs 8 9 10 11 12 13 Basal stem pairs 8 Position 9 C G U A –3.34 –3.01 –3.07 –0.98 C –2.18 –2.93 2.64 G –0.98 0.13 G –1.60 U –1.66 –3.63 –1.98 –1.88 –2.18 –1.29 –0.08 1 9 10 11 12 13 Basal stem pairs 2.01 –0.51 –0.21 hsa-mir-223 64 32 8 A –1 C U –0.27 –2.72 –1.74 –1.82 A G-U +1 C-G Position 10 G-C Pair 10 A C G U A C A –0.92 –0.65 –0.22 1.63 G-U U-A C 0.18 –1.45 2.39 –0.14 G-C G 0.00 1.57 0.58 0.99 A-U U 1.63 –1.00 1.38 0.48 –11 C-G +9 C +10 –12 A –13 G-C +11 U U Position 11 Pair 11 A U C C G U G G A –1.80 –2.40 –1.15 –0.96 U G C –2.37 –2.92 –0.95 –2.17 –2.16 –0.66 –1.29 Position 10 C G U Pair 10 A hsa-mir-16-1 64 Position –11 –0.90 1.14 –0.90 Position –11 G Pair 11 A 64 Timepoint 1 –0.95 –1.27 Pair 10 A hsa-mir-125a Wildtype basal stem B –1.37 –1.22 –1.35 –0.03 Pair 9 pre-miRNA Position –12 0 A C Position 9 C G U A Position –13 0.2 –1 G G A-U +1 U-G C-G U C C G U U G-C A-U –11 C-G +9 –12 C-G +10 –13 G-C +11 U C U C G C U A Pair 9 pre-miRNA Position –12 0.4 Odds ratio (log2) 0.6 Position –11 0.8 Position –12 1 Position 9 C G U A Position –13 Pair 9 pre-miRNA Position –13 A 8 9 10 11 12 13 Basal stem pairs C 1 hsa-mir-125a 0.8 0.2 0 −0.2 −0.4 3p unstructured nucleotides 0.4 Odds ratio (log2) 0.6 −0.6 −0.8 5 10 10 8 8 6 6 5 4 0 0 0 2 4 6 8 10 12 5 10 5p unstructured nucleotides 0 10 6 5 4 0 10 8 5 4 2 2 0 12 10 10 10 hsa-mir-223 hsa-mir-30a hsa-mir-16-1 12 12 2 0 0 2 4 6 8 10 12 5 10 5p unstructured nucleotides 0 0 0 0 2 4 6 8 10 12 5 10 5p unstructured nucleotides 0 0 5 10 5p unstructured nucleotides −1 Timepoint 1 Timepoint 2 16 Relative cleavage D hsa-mir-125a 16 hsa-mir-16-1 16 hsa-mir-30a 16 8 8 8 8 4 4 4 4 2 2 2 2 1 0 2 4 6 8 10 12 14 16 18 20 Flanking unstructured nucleotides 1 0 2 4 6 8 10 12 14 16 18 20 Flanking unstructured nucleotides 1 0 2 4 6 8 10 12 14 16 18 20 Flanking unstructured nucleotides 1 hsa-mir-223 0 2 4 6 8 10 12 14 16 18 20 Flanking unstructured nucleotides Although at best this metric was a rough estimate of the size of the unstructured region flanking the base of the helix, we observed a clear correlation between the number of flanking unstructured nucleotides and enrichment in the selection (Figure 3C). Pairing was tolerated in one flank, provided that the other flank contained at least 5–7 unstructured bases, a result consistent with the observation that pri-miRNAs are cleaved with partial efficiency when only one flanking segment is present (Zeng and Cullen, 2005; Han et al., 2006). When summing the flanking unstructured bases from both sides, the optimum plateaued at ~9–18 nt, depending on the pre-miRNA (Figure 3D). A basal UG motif enhances processing Among the nucleotides upstream of the stem-loop, the most striking enrichment was for a U at position –14 (Figure 2D). This U immediately preceded the position that, as mentioned above, displayed a strong primary-sequence preference for a G, either when paired with a C at position +11 to form the most basal Watson–Crick pair of the helix or when partnered with a wobble or mismatch. The U and G at positions –14 and –13 both appeared to contribute independently to recognition; variants with either a U or a G were enriched over variants with neither, and variants containing both were even more enriched (Figure 4A). For mir-223, the UG at positions –14 and –13 was preferred (Figure 2D), even though wild-type mir-223 has a UG at Figure 3. Basal stem secondary structure in functional pri-miRNA variants. (A) Predicted basal secondary structure and covariation matrices for mir-125a, mir-16-1, and mir-30a. For each pair of positions, joint nucleotide distributions were tabulated from sequencing data and the odds ratio calculated. Favored pairs have positive odds ratios and are colored red, whereas disfavored pairs have negative odds ratios and are colored blue, with color intensity indicating magnitudes, according to the key (left). (B) Relative cleavage of variants with different stem lengths. The number of contiguous Watson–Crick pairs was counted, and the relative cleavage calculated, normalized to the 8 bp stem. (C) Enrichment for unstructured nucleotides flanking the basal stem. Predicted folds of variant sequences were generated, and the subset of sequences with wild-type basal stem pairing were classified based on the distance to the nearest structured consecutive nucleotides upstream of position –13 and the nearest structured consecutive nucleotides downstream of position +11. Enrichment (red) and depletion (blue) of different unstructured lengths for the selected variants are colored according the key (left). Black indicates that the sequencing data were insufficient to calculate enrichment values. (D) Relative cleavage of variants with numbers of total unstructured nucleotides flanking the basal stem. Unstructured lengths upstream and downstream calculated in (C) were summed, and the relative cleavage calculated, normalized to zero unstructured nucleotides. 73 4 4 2 2 2 2 1 1 1 1 0.5 0.5 0.5 0.5 0 4 –15 –4 –13 –11 5p Position –17 0.6 0 T G T T G A C A –4 –15 –13 –11 5p Position C hsa-mir-223 chrX 65,238,719–65,238,726 (+) 4 0 C A A T G T C A A –17 C –15 –13 –11 5p Position G C C T G C A G T –4 –17 –15 –13 –11 5p Position U 0.5 0.4 Frequency –17 G(–13) only hsa-mir-30a chr6 72,113,329–72,113,336 (–) 0 T G T T G C C A –4 No (–14) motif hsa-mir-16-1 chr13 50,623,097–50,623,104 (–) 4 0.3 0.2 0.1 0.0 –19 –17 –15 –13 –11 –9 Position D Human UG Position 24% miRNAs with positioned UG PhyloP vertebrate conservation 4 UG(–14) UG(–14) G(–13) only U(–14) only hsa-mir-125a chr19 52,196,503–52,196,510 (+) 16% 8% 0% H. sapiens * D. rerio * C. intestinalis * A. gambiae D. melanogaster D. pulex C. elegans C. briggsae P. pacificus C. teleta * L. gigantea S. mediterranea N. vectensis Chordates Arthropods Nematodes Ecdysozoans B UG(–14) 4 U(–14) only 4 G(–13) only 8 U(–14) only 8 Timepoint 2 No (–14) motif 8 Timepoint 1 8 UG(–14) hsa-mir-223 16 G(–13) only hsa-mir-30a 16 No (–14) motif Relative cleavage hsa-mir-16-1 16 U(–14) only hsa-mir-125a 16 No (–14) motif A Lophotrochozoans –22 –20 –18 –16 –14 –12 –10 –8 Position –6 –4 –2 Drosha cleavage site positions –15 and –14, respectively. The –14 preference was also observed among variants of mir-125a selected for Microprocessor binding rather than for Microprocessor cleavage (Figure S4B), which indicated that this preference was due at least in part to increased binding affinity to the Microprocessor. We refer to this dinucleotide motif as the basal UG. The basal UG was conserved in vertebrate orthologs of mir-16-1 and mir-30a (Figure 4B). The motif was also enriched in other mammalian pri-miRNAs, as illustrated by the sequence composition of human pri-miRNAs conserved to mouse, which show clear preferences for U at position –14 and G at position –13 (Figure 4C). Enrichment was also observed in primiRNAs of zebrafish (D. rerio) and sea squirt (C. intestinalis) but only sporadically in more distantly related lineages, suggesting that recognition of the UG motif emerged in a common ancestor of the chordates (Figure 4C). The broadly conserved CNNC motif enhances processing Examination of nucleotides preferred in the 3′ flanking sequence revealed a strong preference for a pair of C residues, separated by two intervening nucleotides, located 17–18 nt downstream of the Drosha cleavage site in mir-16-1, mir-30a, and mir-223 (Figure 2D). The two C residues of this CNNC motif (in which N signifies any nucleotide) seemed to act synergistically, in that variants that retained neither C residue were not disfavored much more than those that retained one (Figure 5A). As expected, the C residues enriched in the active variants were also conserved in vertebrate orthologs of these three pri-miRNAs (Figure 5B). Figure 4. Enrichment and conservation of the basal UG motif. (A) Relative cleavage of variants with a full UG motif, a partial motif, and no motif. Relative cleavage values were normalized to that of variants with no motif. (B) PhyloP conservation across 30 vertebrate species in the region of the basal UG motif (red letters) for the four selected miRNAs. Bars extending beyond the scale of the graph are truncated (red). Nucleotides predicted to be paired in the wildtype basal stem are shaded. (C) Frequencies of A, C, G, and U (green, cyan, black, and red, respectively) at the indicated positions of human pri-miRNAs conserved to mouse. Analysis was of 202 pri-miRNAs, each representing a unique miRNA paralog family (Table S2). (D) Enrichment for the UG dinucleotide in the pri-miRNAs of representative animals with sequenced genomes (Table S2). For each species, pri-miRNA sequences were aligned according to the predicted Drosha cleavage site, and upstream UG occurrences tabulated. Species with a statistically –5 significant enrichment at position –14 are indicated (asterisks, empirical p-value < 10 ). 75 2 1 1 1 1 0.5 0.5 0.5 0.5 C Signal / background 0 15 17 19 21 3p Position -4 23 Human miRNAs (conserved to mouse) NNNNN NNNN NNN NN 15 17 19 21 3p Position 6 5 5 4 3 2 1 4 7 10 13 16 19 22 25 28 Position -4 23 4 1 0 A C T C T A C A G D. melanogaster miRNAs CNNC 2 0 4 4 A C C A C A C A C 15 17 19 21 3p Position -4 23 C. elegans miRNAs 7 10 13 16 19 22 25 28 Position 15 17 19 21 3p Position 23 S. mediterranea miRNAs 12 10 6 0 T A C C A G C T C 14 8 0 D 0 G A C T T C A A G 2 1 4 4 3 1 1 chrX 65,238,816–65,238,824 (+) 4 2 1 4 7 10 13 16 19 22 25 28 Position 0 1 4 7 10 13 16 19 22 25 28 Position Human CNNC window H. sapiens D. rerio C. intestinalis A. gambiae D. melanogaster D. pulex C. elegans C. briggsae P. pacificus C. teleta L. gigantea S. mediterranea N. vectensis * * * * * * Chordates Arthropods Nematodes * * * 1 3 Drosha cleavage site Lophotrochozoans 5 7 9 11 13 15 Position 17 19 21 23 25 27 29 miRNAs with positioned CNNC PhyloP Vertebrate Conservation -4 chr6 72,113,234–72,113,242 (–) chr13 50,623,097–50,623,105 (–) 4 0 C(18) only CNNC C(19) only C(16) only Neither C Relative cleavage chr19 52,196,597–52,196,605 (+) CNNC 2 C(21) Only 2 CNNC 2 C(20) Only 4 C(17) Only 4 Neither C 4 CNNC 4 C(21) only 8 Neither C 8 Timepoint 2 B 3 hsa-mir-223 8 8 4 hsa-mir-30a C(18) Only hsa-mir-16-1 Timepoint 1 Neither C hsa-mir-125a Ecdysozoans A 30% 20% 10% 0% The mir-125a pri-miRNA also had four C residues in the vicinity (positions 16–21), which gave rise to a CNNC at position 16 and the possibility of creating a CNNC at positions 17 or 18 (by changing A20 to a C or changing A18 to a C, respectively). However, neither C of the CNNC at position 16 was preferred in the selection, nor were either of the single-nucleotide changes that could create a CNNC, and the position 16 CNNC was not conserved in vertebrate orthologs (Figure 2D, Figure 5A and 5B). These results indicate that unidentified sequence features present in mir-16-1, mir-30a, and mir-223 but absent in the mir-125a pri-miRNA are required for the CNNC to exert its effect in increasing Microprocessor cleavage efficiency. For the three pri-miRNAs in which the CNNC motif was effective, its position fell in a small window 17–18 nt downstream of the Drosha cleavage site. In variants in which neither wild-type C was present, an alternative CNNC was strongly preferred one or two nucleotide registers downstream, which further indicated that a CNNC motif within a small range of positions can contribute to pri-miRNA recognition (Figure S5A). Analyses of the 3′ regions of conserved human pri-miRNAs revealed that of the 64 possible dinucleotide motifs with 0–3 intervening nucleotides, CNNC was most highly enriched (Figure 5C). Moreover, enrichment was limited a small range of positions 16–18 nt downstream of the Drosha cleavage site, peaking at positions 17 and 18, which matched the positions of the motifs originally found within mir-16-1, mir-30a, and mir-223. These results suggest that the CNNC motif enhances recognition and cleavage of many human pri-miRNAs. Analyses of miRNAs in non-mammalian species indicated strong, position-specific Figure 5. Enrichment and conservation of the downstream CNNC motif. (A) Relative cleavage of variants with a full CNNC motif, a partial motif, and no motif. Relative cleavage values were normalized to that of variants with no motif. (B) PhyloP conservation across 30 vertebrate species in the region of the downstream CNNC motif (blue letters) for the four selected miRNAs. Bars extending beyond the scale of the graph are truncated (red). (C) Comparison of CNNC enrichment to that of 63 other spaced dinucleotide motifs. Pri-miRNAs sequences from each species (Table S2) were aligned according to the predicted Drosha cleavage site, and the occurrences of each spaced dinucleotide motif tabulated. Occurrences were normalized to those expected by chance, based on the nucleotide composition downstream of primiRNAs in each species. (D) Enrichment of the CNNC motif in the pri-miRNAs of representative bilaterian animals (Table S2). For each species, pri-miRNA sequences were aligned as in (C) and downstream CNNC occurrences tabulated. Species with a statistically significant enrichment at positions 16, 17, or 18 are marked –4 with an asterisk (empirical p-value < 10 ). 77 A Linear pri-miRNA substrate (pool of variants) ppp Drosha DGCR8 Functional variants ppp Nonfunctional variants Library for single-end sequencing 0.4 0.2 0 −0.2 A –0.69 –0.79 –1.03 0.52 C –0.96 –0.97 0.62 G –0.14 0.63 –0.76 0.28 U −0.6 −0.8 A Pair 18 0.49 0.19 –0.76 –0.64 Pair 17 −0.4 Position P43 C G U 0.30 Position P42 C G U A –0.93 –1.29 –0.72 0.22 C –0.98 –1.58 1.03 –1.00 G –0.7 U 0.33 –1.02 –0.2 –0.62 0.55 –0.4 –0.25 A Position P41 C G U A –0.88 –0.54 –0.49 0.51 C –1.03 –1.09 0.45 –1.05 G –0.62 0.88 –0.03 –0.28 U 0.87 –0.67 –0.29 –0.82 Pair 19 A A –1.3 –1.38 –1.77 0.26 –0.9 –1.33 0.31 –0.91 G –1.27 19 21 23 25 Apical stem pairs Pair 20 Position P40 C G U C U 17 19 21 23 25 Apical stem pairs Position P22 0.6 17 hsa-mir-223 64 32 16 8 4 2 1 0.5 0.25 0.125 1.4 –1.16 –0.37 Position P39 C G U A –1.17 –0.93 –1.23 C –0.63 –0.88 0.81 –1.02 G –0.96 0.39 –0.73 –0.23 U 0.98 –0.93 –0.13 –1.04 Pair 21 0.27 –1.32 –0.91 –0.83 A A 0.10 Position P38 C G U A –1.24 –1.35 –1.06 0.12 C –1.11 –1.23 0.47 –0.94 G –0.77 U 1.1 –0.94 –0.08 0.16 –1.01 –0.16 –0.37 −1 D hsa-mir-30a 2 1 Timepoint 2 Mature miRNA P20 P22 P24 P26 P28 P30 0.5 E 4 0 A AG CT G T GAAG chr6 –4 72,113,290–72,113,300 (–) F H. sapiens D. rerio C. intestinalis A. gambii D. melanogaster D. pulex C. elegans C. briggsae P. pacificus C. teleta L. gigantea S. mediterranea N. vectensis Human UGU/GUG window * * * * * * * Position miRNAs with positioned UGU/GUG Timepoint 1 P20 P21 P22 P23 P24 P25 P26 P27 P28 P29 P30 P31 G A-U P23 G-C P38 P22 U-A P39 P21 G-C P40 P20 U-A P41 P19 C-G P42 P18 C-G P43 15th Pair A-U A | U | U-G U-A hsa-mir-125a C-G C-G pre-miRNA C U A-U G-C A-U G-U U-G C-G C-G C A P1 U-G C C P62 0.8 A Odds ratio (WT base) A G G Position P18 G Pair 16 1 C 19 21 23 25 Apical stem pairs Position P20 UCC A C A G 17 19 21 23 Apical stem pairs hsa-mir-30a 64 32 16 8 4 2 1 0.5 0.25 0.125 Position P21 15 hsa-mir-16-1 64 32 16 8 4 2 1 0.5 0.25 0.125 Position P23 hsa-mir-125a Position P19 C 64 32 16 8 4 2 1 0.5 0.25 0.125 Timepoint 2 Odds ratio (log2) Relative cleavage Timepoint 1 PhyloP vertebrate conservation B 20% 15% 10% 5% 0% enrichment of the CNNC motif in chordates, arthropods and lophotrochozoans (Figure 5D). Indeed the CNNC motif was the most enriched dinucleotide motif in the downstream region of both Drosophila and planarian pri-miRNAs (Figure 5C). Positional enrichment of CNNC was not observed in sea anemone (Nematostella vectensis), suggesting that usage of motif for primiRNA recognition emerged after the divergence of bilaterians, around the time of the evolution of the core bilaterian miRNAs (Sempere et al., 2006; Grimson et al., 2008). Interestingly, enrichment was also absent in nematodes (Figure 5C and D), suggesting an isolated loss of this mode of recognition in the nematode but not the arthropod branch of the ecdysozoans. The contributions of basal sequence and structure motifs were confirmed in HEK293T cells (Figure S5C). Mutation of the basal UG and CNNC motifs each reduced accumulation of mature miR-30a; mutation of both together reduced accumulation ~8-fold relative to wild type. Loop and apical stem elements can enhance processing In addition to the basal stem and flanking regions, another potential location for features required for processing is in the pri-miRNA loop and apical stem. Indeed, this part of the premiRNA has been the region most intensively studied as potentially harboring determinants of pri-miRNA recognition. Point mutations in this region abolish cleavage (Zeng et al., 2005; Gottwein et al., 2006) and this region contains binding sites for proteins reported to modulate Figure 6. Identification of the apical pairing features and the UGUG motif. (A) Schematic of the in vitro selection for functional pri-miRNA variants with partially-randomized sequences in the apical stem and terminal loop. Linear pri-miRNA variants substrates were incubated in whole-cell lysate from HEK293T cells overexpressing Drosha and DGCR8. Cleaved pre-miRNA variants were gel-purified, reverse transcribed, and amplified for high-throughput sequencing. (B) Relative cleavage of variants with different apical stem lengths. The number of contiguous Watson– Crick pairs was counted and the relative cleavage calculated, normalized to that of the 15 bp stem. (C) Predicted secondary structure and covariation matrices for the apical stem of mir-125a. Otherwise, as in Figure 3A. (D) Relative cleavage of variants with the apical UGUG motif beginning at the indicated positions, normalized to variants without the motif. Nucleotides of the mature miRNA are shaded in yellow. (E) Conservation of the region centered on the apical UGUG of mir-30a. Otherwise, as in Figure 4B. (F) Enrichment for UGU or GUG trinucleotides in the terminal loops of metazoan pri-miRNAs (Table S2). For each species, pri-miRNA sequences were aligned according to the predicted Drosha cleavage site and occurrences of loop UGU or GUG trinucleotides tabulated. Species with –5 statistically significant enrichment are marked with an asterisk (empirical p-value < 10 ). 79 pri-miRNA processing (Guil and Caceres, 2007; Michlewski et al., 2008; Viswanathan et al., 2008; Trabucchi et al., 2009). Moreover, the distance from the junction of the terminal loop and apical stem was reported to determine the Microprocessor cleavage site of hsa-mir-30a (Zeng et al., 2005), although the terminal loop is dispensable for processing of hsa-mir-16-1 (Han et al., 2006). To find processing determinants in this region, we partially randomized the loop and apical stem sequences of each of the four pri-miRNAs, incubated each pool of variants with Microprocessor-containing extract, gel-purified the pre-miRNA cleavage products, and prepared them for high-throughput sequencing (Figure 6A). Comparison to sequences of the starting pools showed that pairing at the apical portion of the stem contributed to pri-miRNA recognition and processing for some miRNAs, although the preferred structures differed for different primiRNAs, as might have been suspected based on the different conclusions drawn previously from studies of different pri-miRNAs (Zeng et al., 2005; Han et al., 2006). For mir-125a, 22 bp above the 5p Drosha cleavage site was strongly preferred; longer stems were tolerated, whereas shorter stems were disfavored (Figure 5B). Watson–Crick pairing throughout the apical stem was supported by analysis of covariation (Figure 6C). A 22-pair apical stem was also preferred, albeit more weakly, in mir-30a (Figure 6B, Figure S6B). By contrast, no preference for apical pairing was observed in the stems of mir-16-1 and mir-223 (Figure 6B, Figure S6C). Indeed, lengthening of the mir-16-1 apical stem at the expense of loop size was detrimental (Figure 5B), which was consistent with a previous report (Zhang and Zeng, 2010). Because several loop-binding protein regulators of miRNA processing have been reported, we looked for evidence of primary-sequence motifs in the loops. Overall, enrichment was weaker than that observed for flanking residues, particularly for mir-16-1, which showed almost no primary-sequence enrichment throughout the variable region (Figure S6A). The best candidate for a loop-binding motif was observed only in mir-30a, in which the wild-type UGUG at positions P24–27 was preferred (Figure S6A). This motif overlapped a region of vertebrate conservation that included the last base of the most commonly sequenced isoform of mature miR-30a (Figure 6D). Human and zebrafish miRNAs were enriched in UGU or GUG in this region of the loop (empirical p < 10-5 for each species), as were the arthropods and one of three lophotrochozoans examined (empirical p < 10-5 for each) (Figure 6E). However, the lack of 80 enrichment in several other representative species raises the question of whether the usage of this motif arose independently in multiple lineages or was ancestral and lost multiple times. Rescue of C. elegans miRNA expression in human cells The primary-sequence motifs found in this study are absent in nematode clade, either because an ancestral mode of recognition was lost (e.g., downstream CNNC), or because the use of a particular motif is an innovation more recent than the divergence of the vertebrate lineage from nematodes (e.g., basal UG). Using our newly acquired knowledge of pri-miRNA recognition, we tested whether missing primary-sequence motifs might account for the failure of C. elegans pri-miRNAs to be processed in human cells. We focused on the basal UG and the flanking CNNC motifs because these were implicated in three of the four human pri-miRNAs analyzed in detail and thus seemed most likely to function in a variety of pri-miRNA contexts. These motifs were systematically added to cel-mir-44 in the context of the bicistronic vector, after first disrupting the predicted pairing between positions –14 and +12 and substituting the G:C pair at positions –13 and +11 (Figure 7A, construct mir44.1). These changes, which were expected to simultaneously enhance processing by shortening the basal stem to its optimal length and inhibit processing by replacing the fortuitous G at position –13, had a marginal net effect on production of mature miR-44 in human HEK293T cells (Figure 7A). Adding a basal UG (construct mir44.3) enhanced production of mature miR-44 by 5-fold (8-fold over the wildtype), primarily from restoring the G at –13 (Figure 7A). Adding a CNNC 17 nt downstream of the cleavage site (mir44.4) enhanced production another 8-fold, thereby yielding a 64-fold increase over wildtype (Figure 7A). Likewise, converting the wild-type, asymmetrically bulged stem of cel-mir-50 to a regular, 11-pair stem and adding the basal UG and CNNC motifs enhanced expression of mature miR-50 by 31-fold (Figure S7A), while adding the basal UG and CNNC motifs to cel-mir-40 enhanced expression of mature miR-40 by 5-fold (Figure S7B). We conclude that primary-sequence motifs discovered in this study enable human cells to distinguish pri-miRNAs hairpins from other hairpins and that the absence of these motifs in C. elegans primiRNAs helps to explain why human cells do not regard these transcripts as pri-miRNAs. 81 A mir44.wt UGAAA- Query pri-miRNA ? ? Gppp U GU --- AA GGCCAA CUGGAUGUG CUC UGGUCAUA GACG UC \ CCGGUU GACUUACAC GAG AUCAGUAU UUGU AG C CGU C A -AC CA CA UUUUGA hsa-mir-1-1 TK pA mir44.1 UG(–14) CNNC WT -14 Mismatch -14 Mismatch -14 Mismatch -14 Mismatch AG AC CG UG UG None None None None CNNC(+17) 4 cel-miR-44-3p hsa-miR-1 128 mir44.2 UGAAA- C AAU U - GU -- -- AA AG GAA GGCCAA CUGGAUGUG CUC UGGUCAUA GACG UC | UC CUU CCGGUU GACUUACAC GAG AUCAGUAU UUGU AG C UUUUGA U CGU C A -AC CA CA mir44.3 UGAAA- U AAU U - GU -- -- 64 miR-44-3p expression Basal Stem 3 20- A AAU U GU --- AA AG CAA GGCCAA CUGGAUGUG CUC UGGUCAUA GACG UC | UC GUU CCGGUU GACUUACAC GAG AUCAGUAU UUGU AG C UUUUGA C CGU C A -AC CA CA mir44.wt mir44.1 mir44.2 mir44.3 mir44.4 2 30- UGAAA- Construct wt 1 70605040- cel-miR-44-3p probe binding site AAAAA mir-44 mutant CMV Promoter AAU AGAGAA UCUCUU Control pri-miRNA AA AG GAA GGCCAA CUGGAUGUG CUC UGGUCAUA GACG UC | UC CUU CCGGUU GACUUACAC GAG AUCAGUAU UUGU AG C UUUUGA U CGU C A -AC CA CA 32 16 8 4 2 1 0.5 wt 1 2 3 4 B G UG Apical stem structure –1 5p Arm +1 3p Arm Basal stem structure CNNC Other loop positions Other loop positions Apical stem 0 Basal stem 0 Loop GUG 0 Apical stem 0.1 0 CNNC 0.1 Other basal positions 0.1 UG 0.2 0.1 Basal stem 0.2 UG 0.2 CNNC Other basal positions apical stem Other loop positions 0.3 0.2 Basal stem 0.4 0.3 Other loop positions 0.4 0.3 Apical stem 0.4 0.3 UG 0.4 Other basal positions hsa-mir-223 0.5 CNNC hsa-mir-30a 0.5 Other basal positions hsa-mir-16-1 0.5 UG hsa-mir-125a 0.5 Basal stem C Average information (bits/nt) UG D UG(–14) 1.3% 17% 7.4% 9.9% 33% 4.5% 2.5% 5.0% 0.6% 0.1% Loop GUG(P22–P24) CNNC(16–17) No motif E 2.2% 76% 79% 8.2% 0.7% 6.6% 4.7% 12% 9.3% 9.9% 21% Human pri-miRNAs 65% Chance 5.6% 1.9% 5.6% C. elegans pri-miRNAs 7.9% 0.5% 4.7% Chance Discussion We find that secondary structure is generally inadequate on its own to specify pri-miRNA hairpins: Primary-sequence features, including the basal UG, the CNNC and the apical GUG motifs, also contribute to efficient processing in human cells (Figure 7B). Complicating the story (and perhaps explaining why these primary-sequence features had not been observed earlier), different pri-miRNAs differentially benefit from the different motifs (Figure 7C). Among human pri-miRNAs, these motifs were nonetheless highly enriched over chance expectation, with 79% of the conserved human miRNAs containing at least one of the three motifs (Figure 7D). The motifs were not enriched in C. elegans pri-miRNAs (Figure 7E), and when added to the C. elegans pri-miRNAs, the motifs conferred more efficient processing in mammalian cells (Figure 7A and Figure S7). These experiments that added mammalian features to C. elegans miRNAs also showed the benefit of disrupting pairing normally present at positions –14 and +12 of the C. elegans miRNAs (Figure 7A and Figure S7). The presence of pairing that is inhibitory to mammalian processing suggests that measurement from the base of the helix might also differ in nematodes. We conclude that despite the many broadly conserved features of miRNAs, some Figure 7. Structural and primary-sequence features important for human pri-miRNA processing. (A) Processing enhancement from addition of human pri-miRNA motifs to C. elegans mir-44. Changes that sequentially introduce the listed features were incorporated into mir-44 within the bicistronic expression vector (left). Secondary structures are shown for mutations predicted to affect the wildtype basal stem (middle) with the annotated Drosha cleavage sites (purple arrowheads). After transfection into HEK293T cells, accumulation of miR-44-3p was assessed on an RNA blot, normalizing to the expression of the hsa-miR-1 control, and increased miR-44-3p expression is plotted (geometric mean ± standard error, n = 3, right). (B) Summary of human pri-miRNA recognition determinants. (C) Contributions of individual motifs to in vitro processing. For each pri-miRNA, average information content per nucleotide is plotted for the indicated features and positions. (D) Enrichment of primary-sequence motifs in human pri-miRNAs conserved to mouse (Table S2). Human pri-miRNAs were classified based on whether they had the basal UG, an apical GUG or UGU, or the flanking CNNC motif (left). Expectations by chance (right) were estimated based on the nucleotide composition of human pri-miRNAs upstream of the Drosha cleavage site, in the premiRNA, and downstream of the cleavage site for the basal UG, apical GUG or UGU, and flanking CNNC motifs, respectively. (E) A search for human primary-sequence motifs in C. elegans pri-miRNAs conserved in other nematodes (Table S2). Pri-miRNA sequences were analyzed as in (D); the smaller Venn diagrams reflect the smaller number of analyzed miRNAs. 83 primary-sequence features and some secondary-structure features differ in mammals and nematodes, which implies that important aspects of pri-miRNA biogenesis differ in different metazoan lineages. About a fifth of human pri-miRNAs lack all three newly identified primary-sequence determinants (Figure 7D). These are attractive subjects for further study, in that the combinatorial approach implemented here presumably would identify additional unique determinants used by these pri-miRNAs. Sequence and structural determinants probably also exist at the Microprocessor cleavage site and the middle of pri-miRNA stem, regions that were inaccessible to our approach as implemented. Indeed, point mutations that disrupt pairing in the middle of the stem dramatically impair processing (Gottwein et al., 2006; Duan et al., 2007; Jazdzewski et al., 2008; Sun et al., 2009), and although the cleavage site has not been directly implicated in processing in human miRNAs, the Drosha cleavage sites of C. elegans miRNAs are enriched for symmetric internal loops, which presumably reflect preferences at the level of pri-miRNA processing, nuclear export, dicing, or loading (Warf et al., 2011). Also hinting at the possibility of additional primary-sequence preferences within the stem are results from bacterial RNase III, which avoids specific base-pair identities in the “proximal box” and the “distal box” (Zhang and Nicholson, 1997), and fungal Rnt1 and Pac1, which are also influenced by similarly positioned motifs (Lamontagne and Elela, 2004). The proximal box is adjacent to the cleavage site, and the distal box is 8 bp away from the cleavage site, but nonetheless in a region not interrogated in our experiments. Although more needs to be learned about the recognition of pri-miRNAs for processing, the emerging picture is that of a modular phenomenon in which each module contributes modestly to overall discrimination, and different pri-miRNAs depend on any individual module to varying degrees. Our results quantify the relative importance of each module for each primiRNA (Figure 7C). Pairing within the basal stem was crucial, as expected from previous analyses (Lim et al., 2003b; Han et al., 2006). In addition, all four miRNAs made use of the basal UG motif, which provided as much or more information content per nucleotide as the basal stem nucleotides. For the three miRNAs that used a CNNC motif, the motif information content per nucleotide was comparable to that of the basal stem nucleotides. Compared to these motifs, other flanking nucleotides contributed very little to the selection information content. 84 Apical and terminal loop elements were less important than the basal motifs (Figure 7C). We detected significant contributions only in pri-mir-125a, in which the apical stem nucleotides were as important as the basal stem nucleotides, and in pri-mir-30a, in which the loop UGUG motif contributed some information, albeit less than any of the three basal motifs. Together, both basal and apical motifs described here explained 61–78% of the nucleotide enrichment observed in the selected sequences. The remaining information content was diffusely distributed among the other partially-randomized positions. Although some of this remaining enrichment could have reflected small beneficial contributions of flanking bases, we suspect that most reflected avoidance of detrimental alternative structures. A better understanding of features important for miRNA biogenesis will aid in interpreting human mutations that affect mature miRNA levels. For example, loss of mir-16-1 expression associated with chronic lymphocytic leukemia (CLL) is typically due to deletions spanning the intron that contains both hsa-mir-15a and hsa-mir-16-1 (Calin et al., 2002). However, in a study of 75 CLL patients, two had tumors that retain the pri-miRNA hairpins and instead carry a germline C>T single-nucleotide polymorphism (SNP) downstream of the mir-161 hairpin (Calin et al., 2005). This SNP lowers overexpression of miR-16-1 in HEK293 cells, and in both patients heterozygosity for the SNP was lost in the tumor, which suggests that it was a driver mutation (Calin et al., 2005). This SNP corresponds to the C at +18, the first C in the mir-16-1 CNNC motif, which explains why this mutation flanking the hairpin lowers miR-16 accumulation and leads to CLL: it affects pri-miRNA processing by disrupting the mir-16-1 CNNC motif. Discovery of additional motifs for pri-miRNA recognition and processing and identification of proteins that recognize these motifs may lead to improved diagnostic and therapeutic tools in cancer and other diseases in which miRNAs are dysregulated. Experimental Procedures Ectopic pri-miRNA expression in HEK293 cells and S2 cells A genomic fragment corresponding to the human mir-1-1 hairpin and flanking sequences was amplified and cloned into both pcDNA3.2/V5-DEST (Invitrogen) and pMT-DEST (Invitrogen) expression plasmids. Query pri-miRNA sequences were cloned into these plasmids using the Gateway system (Invitrogen), such that they were transcriptionally fused upstream of 85 mir-1-1. Expression plasmids and pMAX-GFP were co-transfected into HEK293 cells using Lipofectamine 2000 (Invitrogen) and co-transfected into S2 cells using Cellfectin (Invitrogen) according to manufacturer’s instructions. After 36–48 h, total RNA was collected by addition of Tri-Reagent (Ambion) according to manufacturer’s instructions. RNA blots for detecting mature and pre-miRNAs were as described. Ribonuclease protection assays were performed with the RPA III kit (Invitrogen) according to manufacturer’s instructions. For detection of expression by sequencing, total RNA from individual transfections was combined and libraries for small-RNA sequencing prepared as described (Chiang et al., 2010). Sequencing reads were mapped to a miRNA hairpin collection composed of the miRBaseannotated hairpins of miRNAs endogenously expressed in the cell line and the miRBaseannotated hairpins of the transfected miRNAs. Reads were included if they perfectly matched a hairpin in this library and excluded if they matched more than one hairpin corresponding to a transfected miRNA. Read counts were normalized to the total reads matching a set of endogenous hairpins that had no transfected counterparts. For each expressed pri-miRNA hairpin, number of reads reported is the number obtained after subtracting the number observed in a normalized, mock-transfected control library. Whole-cell lysate with overexpressed Microprocessor complex Microprocessor lysates were prepared as described (Lee and Kim, 2007), with minor modifications. HEK293T cells were transfected with a mixture of pCK-Drosha-FLAG (Lee and Kim, 2007) pFLAG-HA-DGCR8 (Landthaler et al., 2004), and a transfection-control plasmid pMAX-GFP (Amaxa) using Lipofectamine 2000 (Invitrogen) according to the manufacturer’s instructions. For catalytically-inactive Microprocessor lysates, pCK-DroshaTN-FLAG replaced the wild-type Drosha plasmid (Han et al., 2009). After 72 h, cells were harvested by rinsing the monolayer in phosphate buffered saline (PBS, 137 mM NaCl, 2.7 mM KCl, 1.5 mM KH2PO4, 8 mM Na2HP04, [pH 7.4]). Cells were pelleted, resuspended in sonication buffer (100 mM KCl, 0.2 mM EDTA, 20 mM Tris-Cl pH 8.0, and 0.7 µl/ml 2-mercaptoethanol) supplemented with mini-EDTA Free Protease Inhibitor tablets (Roche), and sonicated. The sonication lysate was cleared by centrifugation and cell lysis was confirmed by the liberation of GFP into the supernatant. The supernatant was distributed into single-use aliquots, and stored in liquidnitrogen vapor phase. 86 Competitive binding and cleavage assays The competitive binding assay was based on that of Bartel et al. (1991). T7-transcribed ~200 nt pri-miRNA substrates were gel-purified, treated with calf intestinal phosphatase (NEB), extracted in Tri-Reagent (Invitrogen), and 5′ end-labeled by phosphorylation using T4 Polynucleotide Kinase (NEB) and γ-[32P]-ATP. Reference substrates were the same, except for a 10–25 nt difference in length, which enabled separation on denaturing gels. Complexes containing Drosha-TN and DGCR8 were immunopurified as described (Lee and Kim, 2007; Han et al., 2009). Competitor and reference RNAs were mixed and incubated with immunoprecipitated Drosha-TN and DGCR8 for 15-30 min [final concentrations, 250 nM each RNA, 100 mM KCl, 1 mM MgCl2, 0.2 mM EDTA, 20 mM Tris-Cl (pH 8.0), 0.7 µl/ml 2mercaptoethanol and 300 ng/µl yeast total RNA (Ambion)]. RNA-protein complexes were filtered on Immobilon-NC nitrocellulose filter discs (Millipore), washed with at least 10 reaction volumes of sonication buffer. RNA was eluted from the membrane by incubating in elution buffer (300 mM NaCl, 8M urea, and 25 mM EDTA) for 10 min at 85ºC, ethanol precipitated and resolved on a denaturing 5% polyacrylamide gel. For competitive cleavage, 5′ end-labeled query and reference pri-miRNA substrates were mixed and incubated in whole-cell lysate from HEK293T cells overexpressing Drosha and DGCR8 [final concentrations, 50 nM each RNA, 100 mM KCl, 1 mM MgCl2, 0.2 mM EDTA, 20 mM Tris-Cl (pH 8.0), 0.7 µl/ml 2-mercaptoethanol, 300 ng/µl yeast total RNA, 10 nM Microprocessor complex (concentration estimated exploiting the single-turnover behavior of the Microprocessor when cleaving linear pri-miR-125a)]. After incubation for 30 seconds at 37ºC the reaction was stopped by addition of Tri-Reagent (Ambion) with mixing. Extracted RNA was precipitated with isopropanol, then resuspended and resolved on a denaturing 5% polyacrylamide gel. Synthesis of pools of pri-miRNA variants Linear pri-miRNA variants for the apical stem and loop selections were transcribed by T7 RNA polymerase from oligonucleotide templates (Table S1) that were synthesized using nucleoside phosphoramidite mixtures such that they varied at specified positions (IDT). The transcription reaction included α-[32P]-UTP to body-label the product. Pri-miRNA pools were gel-purified on urea-polyacrylamide gels before use. 87 For circular pri-miRNA variants, body-labeled linear precursors were transcribed by T7 RNA polymerase from synthetic oligonucleotide templates (Table S1). Each transcript ended with a minimal HDV ribozyme (Schurer et al., 2002) that co-transcriptionally self-cleaved at a defined position to produce a homogenous 3′ end. After treatment with TurboDNAse (Ambion), transcripts were gel-purified, treated with calf intestinal phosphatase (NEB) to remove the 5′ triphosphate, extracted with Tri-Reagent, precipitated with isopropanol, and treated with T4 polynucleotide kinase (NEB) to remove the 2′-3′ cyclic phosphate as described (Guo et al., 2010). After ethanol precipitation, the transcripts were 5′ phosphorylated with T4 polynucleotide kinase, diluted, and ligated using T4 RNA ligase 1 (NEB). Circularized pri-miRNAs were purified from linear species on denaturing polyacrylamide gels. In vitro selection and high-throughput sequencing Pools of variants were incubated in HEK293T whole-cell lysate overexpressing FLAGtagged Drosha and FLAG-HA-tagged DGCR8 (Lee and Kim, 2007). At one or two time points (for circularized pri-miRNA variants, 1 minute for mir-125a, 1 and 4 minutes for mir-16-1, 1 and 5 minutes for mir-30a, and 3 and 15 minutes for mir-223; for apical stem and loop variants, 5 seconds and 15 seconds for mir-125a, 15 seconds and 2 minutes for mir-16-1, 30 seconds and 2 minutes for mir-30a, and 30 seconds and 2 minutes for mir-223) reactions were stopped by addition of Tri-Reagent (Ambion) with mixing, and cleaved products were purified from denaturing gels. Cleavage products of circularized pri-miRNA variants were splint-ligated (Moore, 1999) to oligonucleotide adaptors containing barcode sequences, reverse transcribed, and amplified. To sequence the initial pools, a sample of phosphorylated, uncircularized RNA was reverse transcribed and amplified. Amplicons from the initial pools and the cleaved products were pooled for Illumina paired-end sequencing (75 nt reads per end). Pre-miRNA cleavage products of linear pri-miRNA variants were reverse transcribed, amplified. To sequence the initial pools, a sample of the pool was taken before cleavage, reverse transcribed, and amplified. Amplicons from the initial pools and cleaved pre-miRNA products were pooled for Illumina single-read sequencing (54 nt reads) 88 Sequence analysis High-throughput sequencing reads were divided into individual experimental groups according to constant sequences specific to each pri-miRNA, and further divided based on barcode. After filtering for sequencing quality, discarding any sequences that had an error rate ≥0.1 (phred score ≤10) at any variant position, the sequencing error averaged <0.001 per variant position (average phred score >30). We also discarded sequences in which the length of a partially randomized region differed from that of the wildtype, thereby eliminating many sequences with insertions or deletions. Libraries were collapsed so that sequences that appeared multiple times with the same bar code were considered just once in the analysis (although in retrospect this precaution was not required because there was no group of dominant, multi-copy sequences that would have biased the analysis). To calculate the information content at each position, we used the data from the initial pool sequences and the product sequences to calculate the relative cleavage of each base versus the other three bases. For example, for the A residue, the three relative cleavage values are given below, where P(N) is estimated by the frequency of a base in the initial pool, and P(N|cleavage) is estimated by the frequency of that base in the product sequences. 𝑃(cleavage|𝐶) 𝑃(𝐶|cleavage) 𝑃(𝐶) = � 𝑃(cleavage|𝐴) 𝑃(𝐴|cleavage) 𝑃(𝐴) 𝑃(cleavage|𝐺) 𝑃(𝐺|cleavage) 𝑃(𝐺) = � 𝑃(cleavage|𝐴) 𝑃(𝐴|cleavage) 𝑃(𝐴) 𝑃(cleavage|𝑈) 𝑃(𝑈|cleavage) 𝑃(𝑈) = � 𝑃(cleavage|𝐴) 𝑃(𝐴|cleavage) 𝑃(𝐴) We then used Bayes’ Theorem (Pitman, 1993) to infer the nucleotide composition that would have resulted after selection from a pool of variants in which there was an equal probability of an A, C, G, or U at this position. For example, the formula to infer the frequency of A at a particular position after selection from such a pool was 89 𝑃(cleavage|𝐶) 𝑃inferred A = 𝑃(𝐴|cleavage) = �1 + 𝑃(cleavage|𝐴) + 𝑃(cleavage|𝐺) + 𝑃(cleavage|𝑈) � 𝑃(cleavage|𝐴) 𝑃(cleavage|𝐴) −1 The inferred post-selection distribution was then used to calculate information content scores for each nucleotide at each position. For example, the information content for A at a particular position was calculated as 𝐼𝐴 = 𝑃inferred A × [𝑙𝑜𝑔2 (𝑃inferred A ) + 2] If results from two time points were available, information content values were averaged. For evaluating motifs, we calculated a relative cleavage value based on the frequencies of the motif in the reference and selected pools [P(motifi) and P(motifi)|cleavage), respectively], and the frequencies of a reference motif in the reference and selected pools [P(motifref) and P(motifref)|cleavage), respectively]. Relative cleavage = 𝑃(motif𝑖 |cleavage) 𝑃(motif𝑖 ) � 𝑃(motifref |cleavage) 𝑃(motifref ) We also used an odds ratio score to calculate the enrichment for particular motifs by using the frequency of the motif in the reference and selected pools [P(motifi) and P(motifi)|cleavage), respectively]. Odds ratio = 𝑃(motif𝑖 |cleavage) 𝑃(motif𝑖 ) � 1 − 𝑃(motif𝑖 |cleavage) 1 − 𝑃(motif𝑖 ) If two timepoints were available, the geometric mean of the ratios was reported, unless noted otherwise. To screen for specifically for Watson–Crick pairing between all possible combinations of randomized positions, we used a scoring metric to compare the geometric average of odds ratios for Watson–Crick pairing to that of odds ratios for non-Watson–Crick pairs. 90 Pairing score = � � Watson–Crick 1/4 Odds ratio� −� � non−Watson–Crick 1/12 Odds ratio� Positional enrichments of sequence motifs Enrichment of a motif at a set of positions relative to the cleavage site was computed by generating 100,000 cohorts of miRNAs in which the upstream, downstream and pre-miRNA sequences were independently shuffled. An empirical P-value was computed by comparing the number of miRNAs that contained at least one match to the motif in the window to the number of matches in each of the random cohorts. pri-miRNA collections A list of representative pri-miRNAs used for analyses is provided (Table S2). Coordinates of miRNA loci in miRBase version 17 (Kozomara and Griffiths-Jones, 2011) were used to extract the sequences of the annotated hairpin and 200 genomic bases flanking each side. miRBase hairpin sequences and flanking genomic sequences (20 nt on each side) were folded using RNAFold (Hofacker and Stadler, 2006). The Microprocessor cleavage site was inferred using the mature sequences annotated in miRBase. Only hairpins for which the predicted folding and the annotated mature sequences could be reconciled as a 2 nt 3′ overhang were carried forward for analysis. For hairpins in miRBase-annotated miRNA families, a single representative was chosen to represent the family in each species. For human, D. melanogaster, and C. elegans, the family member with the most conserved pre-miRNA sequence was chosen. For other species, the representative was chosen at random. Whole-genome alignments and phylogenetic trees were obtained from the UCSC genome browser (Fujita et al., 2011). Conservation of a pre-miRNA was defined as the average conservation across the pre-miRNA, and the conservation of a base was defined as the ratio between the total branch length of the species that contained the same base as the reference sequence and the total branch length of the species that had an aligned base at that position. 91 Accession Numbers Sequencing data have been deposited into the Short Read Archive (SRA, accession number SRA051323). Acknowledgements This work was done in collaboration with Igor Ulitsky, who carried out much of the evolutionary conservation analysis. I thank D. Shechner for help with circularized-substrate selections; C. Jan, O. Rissland, D. Weinberg, J. Ruby, J. Nam, and V.N. Kim for valuable discussions; and L. Schoenfeld and J. Lassar for technical assistance This work was supported by NIH grant GM067031 (to D.P.B.). 92 Bibliography and References Cited Babiarz, J.E., Ruby, J.G., Wang, Y., Bartel, D.P., and Blelloch, R. (2008). Mouse ES cells express endogenous shRNAs, siRNAs, and other Microprocessor-independent, Dicerdependent small RNAs. Genes Dev 22, 2773-2785. Bar, M., Wyman, S.K., Fritz, B.R., Qi, J., Garg, K.S., Parkin, R.K., Kroh, E.M., Bendoraite, A., Mitchell, P.S., Nelson, A.M., et al. (2008). MicroRNA discovery and profiling in human embryonic stem cells by deep sequencing of small RNA libraries. Stem Cells 26, 2496-2505. Bartel, D.P. (2004). MicroRNAs: genomics, biogenesis, mechanism, and function. Cell 116, 281297. Bartel, D.P. (2009). MicroRNAs: target recognition and regulatory functions. Cell 136, 215-233. Bartel, D.P., Zapp, M.L., Green, M.R., and Szostak, J.W. (1991). HIV-1 Rev regulation involves recognition of non-Watson-Crick base pairs in viral RNA. Cell 67, 529-536. Bentwich, I., Avniel, A., Karov, Y., Aharonov, R., Gilad, S., Barad, O., Barzilai, A., Einat, P., Einav, U., Meiri, E., et al. (2005). Identification of hundreds of conserved and nonconserved human microRNAs. Nat Genet 37, 766-770. Berezikov, E., van Tetering, G., Verheul, M., van de Belt, J., van Laake, L., Vos, J., Verloop, R., van de Wetering, M., Guryev, V., Takada, S., et al. (2006). Many novel mammalian microRNA candidates identified by extensive cloning and RAKE analysis. Genome Res 16, 1289-1298. Bohnsack, M.T., Czaplinski, K., and Gorlich, D. (2004). Exportin 5 is a RanGTP-dependent dsRNA-binding protein that mediates nuclear export of pre-miRNAs. RNA 10, 185-191. Breaker, R.R., Banerji, A., and Joyce, G.F. (1994). Continuous in vitro evolution of bacteriophage RNA polymerase promoters. Biochemistry 33, 11980-11986. Brummelkamp, T.R., Bernards, R., and Agami, R. (2002). A system for stable expression of short interfering RNAs in mammalian cells. Science 296, 550-553. Calin, G.A., Dumitru, C.D., Shimizu, M., Bichi, R., Zupo, S., Noch, E., Aldler, H., Rattan, S., Keating, M., Rai, K., et al. (2002). Frequent deletions and down-regulation of micro- RNA genes miR15 and miR16 at 13q14 in chronic lymphocytic leukemia. Proc Natl Acad Sci U S A 99, 15524-15529. Calin, G.A., Ferracin, M., Cimmino, A., Di Leva, G., Shimizu, M., Wojcik, S.E., Iorio, M.V., Visone, R., Sever, N.I., Fabbri, M., et al. (2005). A MicroRNA signature associated with prognosis and progression in chronic lymphocytic leukemia. N Engl J Med 353, 1793-1801. Cheloufi, S., Dos Santos, C.O., Chong, M.M., and Hannon, G.J. (2010). A dicer-independent miRNA biogenesis pathway that requires Ago catalysis. Nature 465, 584-589. Chen, C.Z., Li, L., Lodish, H.F., and Bartel, D.P. (2004). MicroRNAs modulate hematopoietic lineage differentiation. Science 303, 83-86. Chiang, H.R., Schoenfeld, L.W., Ruby, J.G., Auyeung, V.C., Spies, N., Baek, D., Johnston, W.K., Russ, C., Luo, S., Babiarz, J.E., et al. (2010). Mammalian microRNAs: experimental evaluation of novel and previously annotated genes. Genes Dev 24, 992-1009. Chung, W.J., Agius, P., Westholm, J.O., Chen, M., Okamura, K., Robine, N., Leslie, C.S., and Lai, E.C. (2011). Computational and experimental identification of mirtrons in Drosophila melanogaster and Caenorhabditis elegans. Genome Res 21, 286-300. Cifuentes, D., Xue, H., Taylor, D.W., Patnode, H., Mishima, Y., Cheloufi, S., Ma, E., Mane, S., Hannon, G.J., Lawson, N.D., et al. (2010). A novel miRNA processing pathway independent of Dicer requires Argonaute2 catalytic activity. Science 328, 1694-1698. 93 Denli, A.M., Tops, B.B., Plasterk, R.H., Ketting, R.F., and Hannon, G.J. (2004). Processing of primary microRNAs by the Microprocessor complex. Nature 432, 231-235. Duan, R., Pak, C., and Jin, P. (2007). Single nucleotide polymorphism associated with mature miR-125a alters the processing of pri-miRNA. Hum Mol Genet 16, 1124-1131. Ellington, A.D., and Szostak, J.W. (1990). In vitro selection of RNA molecules that bind specific ligands. Nature 346, 818-822. Fujita, P.A., Rhead, B., Zweig, A.S., Hinrichs, A.S., Karolchik, D., Cline, M.S., Goldman, M., Barber, G.P., Clawson, H., Coelho, A., et al. (2011). The UCSC Genome Browser database: update 2011. Nucleic Acids Res 39, D876-882. Gottwein, E., Cai, X., and Cullen, B.R. (2006). A novel assay for viral microRNA function identifies a single nucleotide polymorphism that affects Drosha processing. J Virol 80, 53215326. Gregory, R.I., Yan, K.P., Amuthan, G., Chendrimada, T., Doratotaj, B., Cooch, N., and Shiekhattar, R. (2004). The Microprocessor complex mediates the genesis of microRNAs. Nature 432, 235-240. Grimson, A., Srivastava, M., Fahey, B., Woodcroft, B.J., Chiang, H.R., King, N., Degnan, B.M., Rokhsar, D.S., and Bartel, D.P. (2008). Early origins and evolution of microRNAs and Piwiinteracting RNAs in animals. Nature 455, 1193-1197. Grishok, A., Pasquinelli, A.E., Conte, D., Li, N., Parrish, S., Ha, I., Baillie, D.L., Fire, A., Ruvkun, G., and Mello, C.C. (2001). Genes and mechanisms related to RNA interference regulate expression of the small temporal RNAs that control C. elegans developmental timing. Cell 106, 23-34. Guil, S., and Caceres, J.F. (2007). The multifunctional RNA-binding protein hnRNP A1 is required for processing of miR-18a. Nat Struct Mol Biol 14, 591-596. Guo, H., Ingolia, N.T., Weissman, J.S., and Bartel, D.P. (2010). Mammalian microRNAs predominantly act to decrease target mRNA levels. Nature 466, 835-840. Han, B.W., Hung, J.H., Weng, Z., Zamore, P.D., and Ameres, S.L. (2011). The 3′-to-5′ Exoribonuclease Nibbler Shapes the 3′ Ends of MicroRNAs Bound to Drosophila Argonaute1. Curr Biol. Han, J., Lee, Y., Yeom, K.H., Kim, Y.K., Jin, H., and Kim, V.N. (2004). The Drosha-DGCR8 complex in primary microRNA processing. Genes Dev 18, 3016-3027. Han, J., Lee, Y., Yeom, K.H., Nam, J.W., Heo, I., Rhee, J.K., Sohn, S.Y., Cho, Y., Zhang, B.T., and Kim, V.N. (2006). Molecular basis for the recognition of primary microRNAs by the Drosha-DGCR8 complex. Cell 125, 887-901. Han, J., Pedersen, J.S., Kwon, S.C., Belair, C.D., Kim, Y.K., Yeom, K.H., Yang, W.Y., Haussler, D., Blelloch, R., and Kim, V.N. (2009). Posttranscriptional crossregulation between Drosha and DGCR8. Cell 136, 75-84. Hofacker, I.L., and Stadler, P.F. (2006). Memory efficient folding algorithms for circular RNA secondary structures. Bioinformatics 22, 1172-1176. Hutvagner, G., McLachlan, J., Pasquinelli, A.E., Balint, E., Tuschl, T., and Zamore, P.D. (2001). A cellular function for the RNA-interference enzyme Dicer in the maturation of the let-7 small temporal RNA. Science 293, 834-838. Jazdzewski, K., Murray, E.L., Franssila, K., Jarzab, B., Schoenberg, D.R., and de la Chapelle, A. (2008). Common SNP in pre-miR-146a decreases mature miR expression and predisposes to papillary thyroid carcinoma. Proc Natl Acad Sci U S A 105, 7269-7274. 94 Jolma, A., Kivioja, T., Toivonen, J., Cheng, L., Wei, G., Enge, M., Taipale, M., Vaquerizas, J.M., Yan, J., Sillanpaa, M.J., et al. (2010). Multiplexed massively parallel SELEX for characterization of human transcription factor binding specificities. Genome Res 20, 861873. Ketting, R.F., Fischer, S.E., Bernstein, E., Sijen, T., Hannon, G.J., and Plasterk, R.H. (2001). Dicer functions in RNA interference and in synthesis of small RNA involved in developmental timing in C. elegans. Genes Dev 15, 2654-2659. Khvorova, A., Reynolds, A., and Jayasena, S.D. (2003). Functional siRNAs and miRNAs exhibit strand bias. Cell 115, 209-216. Kozomara, A., and Griffiths-Jones, S. (2011). miRBase: integrating microRNA annotation and deep-sequencing data. Nucleic Acids Res 39, D152-157. Lamontagne, B., and Elela, S.A. (2004). Evaluation of the RNA determinants for bacterial and yeast RNase III binding and cleavage. J Biol Chem 279, 2231-2241. Landgraf, P., Rusu, M., Sheridan, R., Sewer, A., Iovino, N., Aravin, A., Pfeffer, S., Rice, A., Kamphorst, A.O., Landthaler, M., et al. (2007). A mammalian microRNA expression atlas based on small RNA library sequencing. Cell 129, 1401-1414. Landthaler, M., Yalcin, A., and Tuschl, T. (2004). The human DiGeorge syndrome critical region gene 8 and Its D. melanogaster homolog are required for miRNA biogenesis. Curr Biol 14, 2162-2167. Lee, Y., Ahn, C., Han, J., Choi, H., Kim, J., Yim, J., Lee, J., Provost, P., Radmark, O., Kim, S., et al. (2003). The nuclear RNase III Drosha initiates microRNA processing. Nature 425, 415419. Lee, Y., Jeon, K., Lee, J.T., Kim, S., and Kim, V.N. (2002). MicroRNA maturation: stepwise processing and subcellular localization. EMBO J 21, 4663-4670. Lee, Y., Kim, M., Han, J., Yeom, K.H., Lee, S., Baek, S.H., and Kim, V.N. (2004). MicroRNA genes are transcribed by RNA polymerase II. EMBO J 23, 4051-4060. Lee, Y., and Kim, V.N. (2007). In vitro and in vivo assays for the activity of Drosha complex. Methods Enzymol 427, 89-106. Lim, L.P., Glasner, M.E., Yekta, S., Burge, C.B., and Bartel, D.P. (2003a). Vertebrate microRNA genes. Science 299, 1540. Lim, L.P., Lau, N.C., Weinstein, E.G., Abdelhakim, A., Yekta, S., Rhoades, M.W., Burge, C.B., and Bartel, D.P. (2003b). The microRNAs of Caenorhabditis elegans. Genes Dev 17, 9911008. Liu, J., Carmell, M.A., Rivas, F.V., Marsden, C.G., Thomson, J.M., Song, J.J., Hammond, S.M., Joshua-Tor, L., and Hannon, G.J. (2004). Argonaute2 is the catalytic engine of mammalian RNAi. Science 305, 1437-1441. Lund, E., Guttinger, S., Calado, A., Dahlberg, J.E., and Kutay, U. (2004). Nuclear export of microRNA precursors. Science 303, 95-98. Macrae, I.J., Zhou, K., Li, F., Repic, A., Brooks, A.N., Cande, W.Z., Adams, P.D., and Doudna, J.A. (2006). Structural basis for double-stranded RNA processing by Dicer. Science 311, 195-198. Meister, G., Landthaler, M., Patkaniowska, A., Dorsett, Y., Teng, G., and Tuschl, T. (2004). Human Argonaute2 mediates RNA cleavage targeted by miRNAs and siRNAs. Mol Cell 15, 185-197. Michlewski, G., Guil, S., Semple, C.A., and Caceres, J.F. (2008). Posttranscriptional regulation of miRNAs harboring conserved terminal loops. Mol Cell 32, 383-393. 95 Moore, M.J. (1999). Joining RNA molecules with T4 DNA ligase. Methods Mol Biol 118, 1119. Okamura, K., Hagen, J.W., Duan, H., Tyler, D.M., and Lai, E.C. (2007). The mirtron pathway generates microRNA-class regulatory RNAs in Drosophila. Cell 130, 89-100. Paddison, P.J., Caudy, A.A., Bernstein, E., Hannon, G.J., and Conklin, D.S. (2002). Short hairpin RNAs (shRNAs) induce sequence-specific silencing in mammalian cells. Genes Dev 16, 948-958. Pan, T., and Uhlenbeck, O.C. (1992). In vitro selection of RNAs that undergo autolytic cleavage with Pb2+. Biochemistry 31, 3887-3895. Park, J.E., Heo, I., Tian, Y., Simanshu, D.K., Chang, H., Jee, D., Patel, D.J., and Kim, V.N. (2011). Dicer recognizes the 5′ end of RNA for efficient and accurate processing. Nature 475, 201-205. Pitman, J. (1993). Probability (New York, Springer-Verlag). Pitt, J.N., and Ferre-D'Amare, A.R. (2010). Rapid construction of empirical RNA fitness landscapes. Science 330, 376-379. Ruby, J.G., Jan, C.H., and Bartel, D.P. (2007). Intronic microRNA precursors that bypass Drosha processing. Nature 448, 83-86. Schurer, H., Lang, K., Schuster, J., and Morl, M. (2002). A universal method to produce in vitro transcripts with homogeneous 3′ ends. Nucleic Acids Res 30, e56. Schwarz, D.S., Hutvagner, G., Du, T., Xu, Z., Aronin, N., and Zamore, P.D. (2003). Asymmetry in the assembly of the RNAi enzyme complex. Cell 115, 199-208. Sempere, L.F., Cole, C.N., McPeek, M.A., and Peterson, K.J. (2006). The phylogenetic distribution of metazoan microRNAs: insights into evolutionary complexity and constraint. J Exp Zool B Mol Dev Evol 306, 575-588. Slattery, M., Riley, T., Liu, P., Abe, N., Gomez-Alcala, P., Dror, I., Zhou, T., Rohs, R., Honig, B., Bussemaker, H.J., et al. (2011). Cofactor binding evokes latent differences in DNA binding specificity between Hox proteins. Cell 147, 1270-1282. Sun, G., Yan, J., Noltner, K., Feng, J., Li, H., Sarkis, D.A., Sommer, S.S., and Rossi, J.J. (2009). SNPs in human miRNA genes affect biogenesis and function. RNA 15, 1640-1651. Trabucchi, M., Briata, P., Garcia-Mayoral, M., Haase, A.D., Filipowicz, W., Ramos, A., Gherzi, R., and Rosenfeld, M.G. (2009). The RNA-binding protein KSRP promotes the biogenesis of a subset of microRNAs. Nature 459, 1010-1014. Viswanathan, S.R., Daley, G.Q., and Gregory, R.I. (2008). Selective blockade of microRNA processing by Lin28. Science 320, 97-100. Warf, M.B., Johnson, W.E., and Bass, B.L. (2011). Improved annotation of C. elegans microRNAs by deep sequencing reveals structures associated with processing by Drosha and Dicer. RNA 17, 563-577. Witten, D., Tibshirani, R., Gu, S.G., Fire, A., and Lui, W.O. (2010). Ultra-high throughput sequencing-based small RNA discovery and discrete statistical biomarker analysis in a collection of cervical tumours and matched controls. BMC Biol 8, 58. Yeom, K.H., Lee, Y., Han, J., Suh, M.R., and Kim, V.N. (2006). Characterization of DGCR8/Pasha, the essential cofactor for Drosha in primary miRNA processing. Nucleic Acids Res 34, 4622-4629. Yi, R., Qin, Y., Macara, I.G., and Cullen, B.R. (2003). Exportin-5 mediates the nuclear export of pre-microRNAs and short hairpin RNAs. Genes Dev 17, 3011-3016. 96 Zeng, Y., and Cullen, B.R. (2005). Efficient processing of primary microRNA hairpins by Drosha requires flanking nonstructured RNA sequences. J Biol Chem 280, 27595-27603. Zeng, Y., Yi, R., and Cullen, B.R. (2005). Recognition and cleavage of primary microRNA precursors by the nuclear processing enzyme Drosha. EMBO J 24, 138-148. Zhang, H., Kolb, F.A., Jaskiewicz, L., Westhof, E., and Filipowicz, W. (2004). Single processing center models for human Dicer and bacterial RNase III. Cell 118, 57-68. Zhang, K., and Nicholson, A.W. (1997). Regulation of ribonuclease III processing by doublehelical sequence antideterminants. Proc Natl Acad Sci U S A 94, 13437-13441. Zhang, X., and Zeng, Y. (2010). The terminal loop region controls microRNA processing by Drosha and Dicer. Nucleic Acids Res 38, 7689-7697. Zykovich, A., Korf, I., and Segal, D.J. (2009). Bind-n-Seq: high-throughput analysis of in vitro protein-DNA interactions using massively parallel sequencing. Nucleic Acids Res 37, e151. 97 0.0 cel-lsy-6 X cel-mir-50 Query pri-miRNA cel-mir-40 B cel-lin-4 Unprocessed pri-miRNA X Gppp hsa-mir-1-1 11 oc (o n m k1 ly) oc lin k2 -4 ls y6 m ir4 m 0 ir5 m 0 ir2 le 40 t-7 m ir1 m ir2 m ir3 m 4 ir4 m 3/4 ir- 4 4 m 6 ir5 m 9 ir6 m 0 ir1 m 24 ir23 5 ir- m m CMV Promoter Relative pri-miRNA ir1 ir2a m -1 ir2 le 86 t-7 /4 /5 m ir3 m 4 ir9 m 2 ir12 m 5 ir2 m 79 ir2 le 81 t-7 m a ir9 m 2a ir2 m 05 ir1 m 7~ ir- 20 1 m 25 ir- a 1 m 28 ir- -1 1 m 38 ir- -2 1 m 22 ir1 m 33 ir- a14 1 2 m m A Control pri-miRNA hsa-mir-1-1 AAAAA dme miRNAs miR-1 mature miR-1-1 pre U6 snRNA Glu tRNA 2.5 2.0 1.5 1.0 0.5 TK pA cel miRNAs miR-1 mature miR-1-1 pre U6 snRNA Glu tRNA hsa miRNAs Supplemental Materials Supplemental Figures Figure S1. Human, fly, and worm pri-miRNA transcription in human cells, related to Figure 1. (A) Schematic of HEK293 overexpression system and detection of miR-1-1 processing products. HEK293 cells were individually transfected with plasmids bearing a human, D. melanogaster, or C. elegans pri-miRNAs transcriptionally fused to human pri-mir-1-1. Mature miR-1 and pre-miR-1-1 derived from the transcriptional fusion were detected by RNA blot. Results from vectors in which let-7 and mir-1 were the query pri-miRNAs are shown. However, results from these let-7 and mir-1 vectors are not shown in Figure 1A because the corresponding mature miRNAs were indistinguishable from those of other transfected vectors after total RNA was pooled for small-RNA sequencing. (B) Direct detection of C. elegans pri-miRNA transcription. Selected human and C. elegans pri-miRNAs were detected by a ribonuclease protection assay and signals were normalized to that of neomycin phosphotransferase mRNA expressed from the same plasmid. 99 A Basal Stem mir125.wt (Wildtype) mir125.1 mir125.2 UCU GCCAG CUAGG CGGUC GGU CCAACC UGC pre-miRNA CAUGAA UCU GCCAG CUAGG CGGUC GGU CCAACC UGC pre-miRNA CAUGCC UCU GCCAG CUAGG CGGUC GGU CCAACC UGC pre-miRNA UCU GGGCCAG CUAGG CCCGGUC GGU CCAA UGC pre-miRNA mir125.4 CAUGUUA UCU CCAG CUAGG GGUC GGU CCAACCC UGC pre-miRNA mir125.5 CAUGUUAA UCU CAG CUAGG GUC GGU CCAACCCG UGC pre-miRNA mir125.6 CAUGUUAAG UCU AG CUAGG UC GGU CCAACCCGG UGC pre-miRNA mir125.3 B CAUGUU CAUG Control miRNA (WT mir-125a) C Query miRNA *P ? *P ? 1 CMV Promoter 3 4 5 AAAAA mir-125a mutant wt 2 Control miRNA ? Gppp mir-125a mutants 1 2 3 hsa-mir-1-1 4 5 TK pA 6 605040- Competitive Cleavage Prediction from mir-125a selection (1 mM Mg) wt ? 6 30- 1 hsa-miR-125a 20- hsa-miR-1 0.25 0.125 0.0625 0.03125 1 Relative expression Relative Cleavage 0.5 0.5 0.25 wt 1 2 3 4 5 6 Figure S2. Confirmation of hsa-mir-125a selection results in vitro and in HEK293T cells, related to Figure 2. (A) Predicted basal stem secondary structure of mir-125a variants tested in the experiment. (B) Competitive cleavage of individual mir-125a variants, relative to wildtype mir-125a. Variants were mixed with a reference wildtype mir-125a, which was longer at its 5′ end, and incubated in whole-cell lysate from HEK293T cells overexpressing Drosha and DGCR8. Cleavage products were separated on denaturing gels, and the ratio of wildtype and variant products quantified (blue, geometric mean ± standard error, n = 3), together with the relative cleavage inferred from the selection experiment (gray). (C) Evaluation of mir-125a variants in HEK293T cells. Variants were transcriptionally fused to pri-mir-1-1 as in Figure S1A and expressed in HEK293T cells. Accumulation of mature miR-125a was quantified by RNA blot and normalized to the level of mature miR-1 (geometric mean ± standard error, n = 3). 101 A Position 12 C G A 0.29 C –1.14 –1.57 0.99 Pair 12 A 0.1 –0.2 1.65 U –0.32 –0.06 –1.85 –0.16 –0.02 –0.08 –0.64 –0.97 –0.78 A 1.48 Position 13 C G 0.06 0.54 U –0.67 C 1.03 –0.34 –1.01 –1.11 G 0.99 –0.94 –0.04 –1.31 U 1.79 1.61 1.48 Position –12 A –1.82 –1.77 –0.91 0.24 C –1.99 –2.18 0.69 –1.51 G –0.94 1.00 –1.41 0.23 U 0.47 –0.21 0.12 –0.13 hsa-mir-223 Wildtype basal stem –1 C U C-G +1 G-U C-G A C C-G C-G G-C –10 U-A +8 –11 G-C +9 –12 N-N +10 –13 N-N +11 –14 N-N +12 N +13 –15 N N N N N N N N N B hsa-mir-125a 1024 256 256 64 64 16 1 0 0.5 1 0 Threshold score hsa-mir-30a 1024 256 256 64 64 16 16 4 4 1 0 0.5 Threshold score 1 1 0 C –1.25 –0.83 1.62 –0.89 G –0.51 1.74 –0.16 0.78 U 0.86 –0.27 0.35 –0.37 A Position 11 C G U A –1.36 –1.00 –1.21 –0.05 C –1.58 G –1.44 0.75 U –0.48 –1.51 –1.25 –0.81 A –1.10 –0.14 0.68 –1.63 Position 12 C G A –0.59 –0.53 0.47 0.2 U –1.08 C –0.71 G –1.03 –1.11 –0.34 –1.59 U 0.64 –0.70 –0.11 –1.25 0.76 1.82 0.13 Timepoint 2 2 1 9 10 11 12 Basal stem pairs 0.5 1 Threshold score hsa-mir-223 1024 0.8 Timepoint 1 4 1 U –0.15 4 16 Basal stem 4 0.55 8 hsa-mir-16-1 1024 Position 10 C G hsa-mir-223 Alternative pairs 16 0.5 C –0.48 Pair 12 0.73 A A Pair 11 hsa-mir-223 Alternative basal stem Relative cleavage G U Position –14 A U C-G +1 G-U C-G A C C-G C-G G-C –10 U-A +8 –11 G-C +9 | A +10 –12 A-U +11 –13 C-G +12 –14 G-C +13 U U C U C A U C Candidate pairs Position –13 Pair 11 –1 C 0.45 U Position –13 1.93 A Pair 10 Position –14 0.23 Position –11 1.26 Candidate pairs Position –12 U pre-miRNA Pair 9 1 –0.21 –0.21 Odds ratio (log2) –2.23 0.49 Position 9 C G 0.8 1.64 –1.69 –1.19 –0.98 0.6 1.73 –0.9 1.67 0.4 –1.22 –1.08 U 0.2 –1.24 C G –1.32 0 0.69 0.00 −0.2 –2.26 –1.79 –1.39 –1.22 –1.78 0.22 –1.47 pre-miRNA U A C G −0.4 Position 11 C G U –2.44 –0.59 –2.89 0.33 −0.6 A Position 8 C G −0.8 Pair 10 A A −1 Position –10 Pair 8 0.5 Threshold score 1 13 Figure S3. Analysis of mir-223 basal stem structure, related to Figure 3. (A) Wild-type (left) and alternative (right) basal stem structures for hsa-mir-223. In the wild-type basal stem, the A at +10 is predicted to be bulged, whereas some variants are predicted to have an alternative structure in which the nucleotide at +10 is Watson–Crick paired within a contiguous helix. Covariation matrices for both conformations were calculated as in Figure 3A. (B) Relative cleavage of variants with different lengths of the alternative basal stem. Cleavage values were calculated as in Figure 3B and normalized to the 9 bp stem. (C) Screen for Watson–Crick pairs involving any two varied positions. A Watson–Crick-pairing score was calculated for each of the >3000 possible pairs of varied positions in each of the four pri-miRNAs. The number of Watson–Crick candidates is plotted as a function of threshold score, in which a pair is considered a Watson–Crick candidate if its score exceeds the threshold. The number of pairs corresponding to the basal stem is shown (dashed line). 103 A Linear pri-miRNA substrate (pool of variants) ppp DroshaTN DGCR8 ppp ppp Nonfunctional variants Functional variants Nitrocellulose filtration X Library preparation for paired-end sequencing B 1 A 0.8 G hsa-mir-125a C U –1 0.4 0 +1 –14 +12 Invariant residues 0.2 43 45 45 41 39 37 Stem-loop –1 Cleavage selection 0.8 35 33 31 29 27 25 23 21 19 17 15 13 –15 –17 –19 –21 –23 –25 –27 –29 –31 hsa-mir-125a 1 43 1.2 –33 –35 –37 –39 –41 –43 –45 –47 –49 –0.2 –0.4 –9 0.6 +1 +9 –14 +12 0.4 Invariant residues 0.2 0 41 39 37 35 33 31 29 27 25 23 21 19 17 15 13 9 11 –9 –11 –13 –15 –17 –19 –21 –23 –25 –27 –29 –31 –33 –35 –37 –39 –41 –43 –45 –47 –0.4 –49 –0.2 –51 Information content (bits) Stem-loop TN binding selection Round 1 0.6 –51 Information content (bits) 1.2 Figure S4. Selection for Microprocessor-binding variants of hsa-mir-125a, related to Figure 4. (A) Schematic of the in vitro selection. Linear, partially-randomized variants of mir-125a were incubated with immunopurified DGCR8 and catalytically-inactive Drosha (DroshaTN). Bound variants were recovered by nitrocellulose filtration, reverse-transcribed, and amplified for high-throughput sequencing. (B) Information content after one round of selection for Microprocessor binding. Information content was calculated as in Figure 2D. Information content after one round of cleavage selection (Figure 2D) is reproduced here for comparison. The nucleotides varied in the initial pools are shown for each selection (insets, red inner lines). 105 A Timepoint 1 Odds ratio of CNNC Timepoint 2 hsa-mir-16-1 16 16 8 8 4 4 2 2 1 1 0.5 0.5 Odds ratio of CNNC 0.25 hsa-mir-30a Odds ratio of CNNC 14 15 16 17 18 19 20 21 0.25 8 8 4 4 2 2 1 1 0.5 0.5 0.25 hsa-mir-223 Sequences without wildtype CNNC All Sequences 14 15 16 17 18 19 20 21 0.25 8 8 4 4 2 2 1 1 0.5 0.5 0.25 14 15 16 17 18 19 20 21 0.25 NA NA 14 15 16 17 18 19 20 21 NA NA NA NA ? ? Position Control pri-miRNA Gppp mir-30a mutant CMV Promoter Construct Basal Stem mir30.wt mir30.1 mir30.2 mir30.3 mir30.4 mir30.5 mir30.6 mir30.7 WT –12 Paired WT WT WT WT WT 7-pair stem mir30.wt AAAAA hsa-mir-1-1 TK pA UG(–14) CNNC(+17) UG UG AG UG UG UG AG UG CNNC CNNC CNNC CNNU UNNC UNNU UNNU CNNC hsa-miR-30a probe binding site UGUU A A A UC GUGAAG G CAGUG GCG CUGUAAACAUCC GACUGGAAGCU C C GUCAU CGU GACGUUUGUAGG CUGACUUUCGG C GGCU C C C -GUAGACA mir30.1 UGUU A A UC UGUGAAG GCCAGUG GCG CUGUAAACAUCC GACUGGAAGC C CGGUCAU CGU GACGUUUGUAGG CUGACUUUCG C C C -GGUAGACA GGCU mir30.7 UGUUCCGC NA 14 15 16 17 18 19 20 21 A A UC UGUGAAG GUG GCG CUGUAAACAUCC GACUGGAAGC C CAU CGU GACGUUUGUAGG CUGACUUUCG C GGCUCCGU C C -GGUAGACA wt 1 70605040- 2 3 4 5 6 7 30hsa-miR-30a 20hsa-miR-1-1 hsa-miR-30a expression Query pri-miRNA NA 14 15 16 17 18 19 20 21 Position B NA 2 1 0.5 0.25 0.125 0.063 0.031 wt 1 2 3 4 5 6 7 Figure S5. Contribution of the CNNC motif in vitro and in HEK293T cells, related to Figure 5. (A) CNNC odds ratios at alternative positions. Odds ratios were calculated for CNNC dinucleotides starting at the indicated of positions downstream of the Drosha cleavage site. Plotted are odds ratios for all sequences (left) and for sequences that lack both wild-type C residues (right). (B) Contributions of basal features, including the CNNC motif, to the accumulation of hsa-miR-30a in HEK293T cells. The listed variants of hsa-mir-30a were transcriptionally fused to hsa-mir-1-1 (left). Predicted secondary structures for variants with non-wild-type structure are shown (center), with the annotated Drosha cleavage sites (purple arrowheads). The accumulation of miR-30a was quantified by RNA blot, normalized to miR-1 (right, geometric mean ± standard error, n = 3). 107 B Pair 18 P1 0.8 CCA 0.6 G 0.4 A 0.2 A G 0 U G P24 U-G P40 P23 C-G P41 P22 G-C P42 P21 A-U P43 P20 A-U P44 17th Pair G-U G-C U-A C-G A-U G-C C | U | hsa-mir-30a C-G pre-miRNA C-G U-A A-U C-G A-U A-U A-U U-G G-C P1 U-A G C P63 0.4 0.2 0 P44 P42 P40 P38 P36 P34 P32 P30 P28 P26 P24 P22 -0.2 0.8 0.6 0.4 0.2 0 P44 P42 P40 P38 P36 P34 P32 P30 P28 P26 -0.4 P24 -0.2 P22 hsa-mir-30a 1 P20 Information content (bits) 1.2 0.11 C –0.11 –0.1 –0.54 –0.15 G 0.11 –0.05 –0.08 –0.24 U 0 0.27 –0.05 –0.21 A Position P43 C G U Position P21 0.05 –0.31 0.03 C 0.06 –0.29 –0.17 G 0.3 0.23 0.14 0.24 U 0.39 0.5 –0.02 –0.06 A Candidate pairs Position P24 0.2 0 0.5 Threshold score A –0.12 0.22 0.4 C –0.32 –0.54 –0.01 –0.41 0.2 G –0.28 0.15 0.01 0.42 0 U 0.18 –0.14 0.08 –0.41 −0.2 A Position P41 C G U A –0.48 –0.41 –0.7 0.54 C –0.49 –0.66 0.47 –0.61 G –0.04 0.37 -0.06 0.44 U 0.44 –0.29 0.07 –0.13 A A –0.61 −0.6 −0.8 −1 Position P40 C G U –0.5 –0.66 0.04 C –0.42 –0.41 –0.07 –0.66 G –0.17 –0.06 –0.49 –0.11 U 0.03 –0.21 0.32 –0.09 P46 P44 P42 P40 P38 P36 P34 P32 P28 P26 P24 P30 hsa-mir-16-1 Apical Stem 0 0.6 –0.25 -0.2 hsa-mir-125a 256 128 64 32 16 8 4 2 1 0.8 Position P42 C G U –0.41 Pair 21 0.4 -0.4 C 1 −0.4 0.6 P22 Information content (bits) hsa-mir-223 0.16 –0.13 Pair 22 0.8 –0.13 –0.15 1.2 1 –0.04 A Pair 20 Position P22 0.6 Position P44 C G U A Pair 19 Position P23 P42 P40 P38 P36 P34 P32 P30 P28 P26 P24 P22 P20 0.8 P20 Information content (bits) 1 -0.4 A G 1.2 hsa-mir-16-1 C G A U -0.2 -0.4 Position P20 1 P18 hsa-mir-125a Information content (bits) 1.2 A Odds ratio (log2) A 1 128 64 32 16 8 4 2 1 0 0.5 Threshold score hsa-mir-30a 1 128 64 32 16 8 4 2 1 0 0.5 Threshold score hsa-mir-223 1 128 64 32 16 8 4 2 1 0 0.5 Threshold score 1 Figure S6. Primary-sequence and structural elements in the apical stem and terminal loop, related to Figure 6. (A) Enrichment and depletion at variable residues in pri-miRNA variants selected from a pool with varied nucleotide identities in the apical stem and loop. At each varied position (inset, red inner line), information content was calculated for each residue (green, cyan, black, and red for A, C, G, and U, respectively), as in Figure 2D. (B) Apical stem secondary structure of mir-30a. Predicted secondary structure and covariation matrices for were calculated as in Figure 3A. (C) Screen for Watson–Crick pairs involving any to varied positions of the apical stem and loop. A Watson–Crick pairing score was calculated as in Figure S3C for each of the >275 possible pairs of varied positions in each of the four pri-miRNAs. The number of pairs corresponding to the apical stem is shown (dashed line). 109 A Query pri-miRNA ? Control pri-miRNA ? Gppp CMV Promoter mir-50 mutant AAAAA hsa-mir-1-1 TK pA Construct Basal Stem UG(–14) CNNC mir50.wt WT UG None mir50.1 11-pair stem AC None mir50.2 11-pair stem UC None 40- mir50.3 11-pair stem UC CNNC(+19) 30- mir50.4 11-pair stem UC CNNC(+18) mir50.5 11-pair stem UC CNNC(+17) mir50.6 11-pair stem UC CNNC(+16) mir50.7 11-pair stem UC CNNC(+15) mir50.8 11-pair stem UG None mir50.9 11-pair stem UG CNNC(+18) wt 1 3 4 5 6 7 8 9 cel-miR-50 20- CUG C UCU G UUC UAUU CCUG CCCGCCGGCCG UGAUAUGUCUGGUAU UGGGUUU AAC \ GUAA GGAC GGGCGGCCGGC GCUAUGCAGAUUAUA GCCCAAG UUG C UCG U G A C-CGA cel-miR-50 relative expression hsa-miR-1 cel-miR-50 Probe Binding Site mir50.wt 2 706050- 64 32 16 8 4 2 0 0.5 0.25 wt 1 2 3 4 5 6 7 8 9 mir50.2 CUGUAUUCCUC UCU G UUC CCCCGCCGGCCG UGAUAUGUCUGGUAU UGGGUUU AAC \ GGGGCGGCCGGC GCUAUGCAGAUUAUA GCCCAAG UUG C UCGGUAAU--AC A C-CGA Query pri-miRNA ? Control pri-miRNA ? Gppp CMV Promoter mir-40 mutant AAAAA hsa-mir-1-1 TK pA Construct Basal Stem UG(–14) CNNC mir40.wt WT CC None None mir40.1 (mutant) UG mir40.2 WT reverted UG None mir40.3 WT reverted UG CNNC(+16) mir40.4 WT reverted UG CNNC(+17) mir40.5 WT reverted UG CNNC(+18) mir40.6 WT reverted UG CNNC(+19) mir40.7 WT reverted UG CNNC(+20) mir40.wt GUCUC CCU- -C G A A A AUC CCUGU CCGCACCU AGU GAUGUAUGCC UG UGAUA GAU \ GGACA GGCGUGGA UCG CUACAUGUGG GC ACUAU CUA A ACGU UG A A - C C AAG CGAA GUUU A---- cel-miR-40 Probe Binding Site mir40.1 GUCUC CCU- G -C G A A A AUC U UGU CCGCACCU AGU GAUGUAUGCC UG UGAUA GAU \ G ACA GGCGUGGA UCG CUACAUGUGG GC ACUAU CUA A ACGU G UG A A - C C AAG CGAA GUUU A---mir40.2 GUCUC CCU- -C G A A A AUC UGUGU CCGCACCU AGU GAUGUAUGCC UG UGAUA GAU \ ACACA GGCGUGGA UCG CUACAUGUGG GC ACUAU CUA A ACGU UG A A - C C AAG A---- CGAA GUUU 706050- wt 1 2 3 4 5 6 7 4030cel-miR-40 20hsa-miR-1 cel-miR-40 relative expression B 8 4 2 1 0.5 wt 1 2 3 4 5 6 7 Figure S7. Rescue of C. elegans pri-miRNA processing in human cells, related to Figure 7. (A) Effects of adding human pri-miRNA motifs to C. elegans mir-50. Changes that introduced the listed features were incorporated into mir-50 within the bicistronic expression vector (left). Secondary structures are shown for changes that were predicted to affect the wild-type basal stem (middle), with the annotated Drosha cleavage sites (purple arrowheads). After transfection into HEK293T cells, accumulation of miR-50 was assessed on an RNA blot, normalizing to the accumulation of the miR-1 control, and increased miR-50 expression is plotted (geometric mean ± standard error, n = 3, right). (B) Effects of adding human pri-miRNA motifs to C. elegans mir-40, otherwise as in (A). 111 Supplemental Table S1: Oligonucleotides used in the in vitro selections Related to the Experimental Procedures. Degenerate and conventional oligonucleotides were commercially synthesized (IDT). Oligonucleotides are DNA unless otherwise noted. HDV 5′ Polishing Primer hsa-mir-125a circular selection CTTCTCCCTTAGCCTACCGAAGTAGCCCAGG Note: Underlined bases were degenerate. S125circ.004 T7 Adaptor CAGAGATGCATAATACGACTCACTATAGGGTCACAG S125circ.001a Left arm S125circ.003 HDV adaptor GACTCACTATAGGGTCACAGGTGAGGTTCTTGGGAGCCTGGCGTCTGGCCCA ACCACACACCTGGGGAATTGCTGGCCTGACTTCTGACCCCTGACTCCT TCCTCACAGGTTAAAGGGTCTCAGGGACCTAGAGACTGGCAACATGGTGTGC GGTGGCCCGGTAGACCCTGGGGTGGGGGTATGAGGAGTCAGGGGTCAG CTTCTCCCTTAGCCTACCGAAGTAGCCCAGGTCGGACCGCGAGGAGGTGGAG ATGCCATGCCGACCCTGGATGTCCTCACAGGTTAAAGG S125circ.006 3p Arm Splint AGACGCCAAGATCGGA S125circ.007 5p Arm Splint ACGTGTACCCTAGAGA S125circ.009 Ref RT TGGATGTCCTCACAGGTTAAAGGGTCTCAGGGACCTAG S125circ.014 Ref-II Fwd Primer S125circ.015 Ref-II Rev Primer CTTTCCCTACACGACGCTCTTCCGATCTCAGGTGAGGTTCTTGGGAGCCTGG C GCATTCCTGCTGAACCGCTCTTCCGATCTTTAAAGGGTCTCAGGGACCTAGA G hsa-mir-16-1 circular selection Note: Underlined bases were degenerate. S16-1circ.004 T7 Adaptor S16-1circ.003 HDV Adaptor CAGAGATGCATAATACGACTCACTATACTAAAATTATCTCCAGTATTAACTG TGC ATACTAAAATTATCTCCAGTATTAACTGTGCTGCTGAAGTAAGGTTGACCAT ACTCTACAGTTGTGTTTTAATGTATATTAATGTTGCTTAATTAAGGAC ACCCAATCTTAACGCCAATATTTACGTGCTGCTAAGGCACTGCTGACATTGC TATCATAAGAGCTATGAATAAAAAGAAATATGTCCTTAATTAAGCAAC GCCTACCGAAGTAGCCCAGGTCGGACCGCGAGGAGGTGGAGATGCCATGCCG ACCCAATCTTAACGCCAATATTTAC S16-1circ.006 3p Arm Splint AACCTTACAGATCGGA S16-1circ.006b 3p Arm Splint Variant AACCTTACTAGATCGGA S16-1circ.007 5p Arm Splint ACGTGTACAGGCACTG S16-1circ.009 Ref RT Primer AATCTTAACGCCAATATTTACGTGCTGCTAAGGC S16-1circ.010 Ref Fwd Primer CTTTCCCTACACGACGCTCTTCCGATCTTCCAGTATTAACTGTGCTGCTGA S16-1circ.011 Ref Rev Primer GCATTCCTGCTGAACCGCTCTTCCGATCTCCAATATTTACGTGCTGCTA hsa-mir-30a circular selection Note: Underlined bases were degenerate. S30acirc.004 T7 Adaptor CAGAGATGCATAATACGACTCACTATAGCCACAGATGGGCTTTCAGTCGG S30acirc.001a Left Arm S30a.003 HDV Adaptor CTATAGCCACAGATGGGCTTTCAGTCGGATGTTTGCAGCTGCCTACTGCCTC GGACTTCAAGGGGCTACTTTAGGAGCAATTATCTTGTTAATTAAGGTT CGACCCTTCACAGCTTCCAGTCGAGGATGTTTACAGTCGCTCACTGTCAACA GCAATATACCTTCTTTAGCCTTCTGTTGGGTTAACCTTAATTAACAAG GCCTACCGAAGTAGCCCAGGTCGGACCGCGAGGAGGTGGAGATGCCATGCCG ACCCTTCACAGCTTCCAGTCGAGG S30acirc.006 3p Arm Splint AGTAGGCAAGATCGGA S30acirc.007 5p Arm Splint ACGTGTACGTCGCTCA S125circ.002a Right arm S16-1circ.001a Left Arm S16-1circ.002a Right Arm S30acirc.002a Right Arm 112 S30acirc.009 Ref RT Primer CCGATCTTTCCAGTCGAGGATGTTTACAGTCGC S30acirc.010 Ref Fwd Primer S30acirc.011 Ref Rev Primer CTTTCCCTACACGACGCTCTTCCGATCTGGGCTTTCAGTCGGATGTTTGCAG CTGC GCATTCCTGCTGAACCGCTCTTCCGATCTTTCCAGTCGAGGATGTTTACAGT CGC hsa-mir-223 circular selection Note: Underlined bases were degenerate. S223circ.004 T7 Adaptor CAGAGATGCATAATACGACTCACTATAGGTAGAGTGTCAGTTTGTC S223circ.001a Left Arm S223.003 HDV Adaptor ACTATAGGTAGAGTGTCAGTTTGTCAAATACCCCAAGTGCGGCACATGCTTA CCAGCTCTAGGCCAGGGCAGATGGGATATGACGAATTTAATTAAGATC ACATGGAGTGTCCAACTCAGCTTGTCAAATACACGGAGCGTGGCACTGCAGG AGGCCAGGCCAAGAGCTTCTGTGGGGAAGTGAGATCTTAATTAAATTC CTTCTCCCTTAGCCTACCGAAGTAGCCCAGGTCGGACCGCGAGGAGGTGGAG ATGCCATGCCGACCCACATGGAGTGTCCAACTCAGC S223circ.006 3p Arm Splint GCCGCACTAGATCGGA S223circ.007 5p Arm Splint ACGTGTACGAGCGTGG S223circ.009 Ref RT Primer ACATGGAGTGTCCAACTCAGCTTGTCAAATACAC S223circ.010 Ref Fwd Primer S223circ.011 Ref Rev Primer CTTTCCCTACACGACGCTCTTCCGATCTGTCAGTTTGTCAAATACCCCAAGT G GCATTCCTGCTGAACCGCTCTTCCGATCTACTCAGCTTGTCAAATACACGGA GC Common oligonucleotides for circular cleavage selection Note: “p” indicates a phosphate and lowercase letters denote RNA S0circ.005 3p Arm Adaptor S0circ.007B.007.A 5p Arm Adaptor, CAT barcode S0circ.007B.007.B 5p Arm Adaptor, ATG barcode S0circ.007B.007.C 5p Arm Adaptor, TGA barcode S0circ.007B.007.D 5p Arm Adaptor, TAG barcode S0circ.008 RT Primer (-1) GAGATCTACACTCTTTCCCTACACGACGCTCTuccgaucu S0.001 Solexa Fwd Seq S0.002 Solexa Rev Seq, -1 short AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTC CGATCT CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTC TTCCGATC hsa-mir-125a binding selection Note: Underlined bases were degenerate. S0.003 T7-fwdSeq CAGAGATGCATAATACGACTCACTATAGGACACGACGCTCTTCCGATCT S125.001 Left arm S125.002 Right arm ACGCTCTTCCGATCTCCCCAGGGTCTACCGGGCCACCGCACACCATGTTGCC AGTCTCTAGGTCCCTGAGACCCTTTAACCTGTGAGGACATCCAGGGTC AGGAGTCAGGGGTCAGAAGTCAGGCCAGCAATTCCCCAGGTGTGTGGTTGGG CCAGACGCCAGGCTCCCAAGAACCTCACCTGTGACCCTGGATGTCCTC S125.003 RT primer TATGAGGAGTCAGGGGTCAG S125.005.A Solexa Reverse, barcoded CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTC TTCCGATCTCATTATGAGGAGTCAGGGGTCAG CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTC TTCCGATCTATGTATGAGGAGTCAGGGGTCAG CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTC TTCCGATCTTGATATGAGGAGTCAGGGGTCAG CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTC TTCCGATCTTAGTATGAGGAGTCAGGGGTCAG S223circ.002a Right Arm S125.005.B Solexa Reverse, barcoded S125.005.C Solexa Reverse, barcoded S125.005.D Solexa Reverse, barcoded p-guacacguaugaGATCGGAAGAGCGGTTCAGCAGGAATGC p-guacacgucauaGATCGGAAGAGCGGTTCAGCAGGAATGC p-guacacguucaaGATCGGAAGAGCGGTTCAGCAGGAATGC p-guacacgucuaaGATCGGAAGAGCGGTTCAGCAGGAATGC GCATTCCTGCTGAACCGCTCTTCCGATC 113 hsa-mir-125a loop and apical selection Note: Underlined bases were degenerate. S125loop.001a Central S125loop.002 Left Arm ACCATGTTGCCAGTCTCTAGGTCCCTGAGACCCTTTAACCTGTGAGGACATC CAGGGTCACAGGTGAGGTTCTTGGGAGCCTGGCGTCTGGCCCAACCAC CAGAGATGCATAATACGACTCACTATAgCCCCCACCCCAGGGTCTACCGGGC CACCGCACACCATGTTGCCAGTCTCTAGG S125loop.003 Right Arm GGTCAGAAGTCAGGCCAGCAATTCCCCAGGTGTGTGGTTGGGCCAGACGCCA S125loop.004 RT Primer GGCATAGGCTCCCAAGAACCTC S125loop.005 Init. PCR Fwd GACGATCTCCCTGAGACCCTTTAA S125loop.005a Init. PCR Fwd, barcoded GACGATCgaTCCCTGAGACCCTTTAA S125loop.005b Init. PCR Fwd, barcoded GACGATCctTCCCTGAGACCCTTTAA S125loop.006 Solexa-R Adaptor CAAGCAGAAGACGGCATACGAGGCTCCCAAGAACCTC S125loop.007 Solexa-Seq Adaptor AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCTCC CTGAGACCCTTTAA AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCgaT CCCTGAGACCCTTTAA S125loop.007a Solexa-Seq Adaptor, barcoded S125loop.007b Solexa-Seq Adaptor, barcoded AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCctT CCCTGAGACCCTTTAA hsa-mir-16-1 loop and apical selection Note: Underlined bases were degenerate. S16-1loop.001a Central S16-1loop.003 Right Arm GCAATGTCAGCAGTGCCTTAGCAGCACGTAAATATTGGCGTTAAGATTCTAA AATTATCTCCAGTATTAACTGTGCTGCTGAAGTAAGGTTGACCATAC CAGAGATGCATAATACGACTCACTATAgATATTTCTTTTTATTCATAGCTCT TATGATAGCAATGTCAGCAGTGCCTTAG AACATTAATATACATTAAAACACAACTGTAGAGTATGGTCAACCTTACTTCA G S16-1loop.004 RT Primer GACGGCATATTCAGCAGCACAGTTAATAC S16-1loop.005 Init. PCR Fwd CCGACGATCTAGCAGCACGTAAATATT S16-1loop.005a Init. PCR Fwd, Barcoded CCGACGATCgaTAGCAGCACGTAAATATT S16-1loop.005b Init. PCR Fwd, Barcoded CCGACGATCctTAGCAGCACGTAAATATT S16-1loop.006 Solexa-R Adaptor CAAGCAGAAGACGGCATACGATTCAGCAGCACAGTTAATAC S16-1loop.007 Solexa-Seq Adaptor AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCTAG CAGCACGTAAATATT AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCgaT AGCAGCACGTAAATATT S16-1loop.002 Left Arm S16-1loop.007a Solexa-Seq Adaptor, barcoded S16-1loop.007b Solexa-Seq Adaptor, barcoded AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCctT AGCAGCACGTAAATATT hsa-mir-30a loop and apical selection Note: Underlined bases were degenerate. S30aloop.001a Central S30aloop.003 Right Arm GCTGTTGACAGTGAGCGACTGTAAACATCCTCGACTGGAAGCTGTGAAGCCA CAGATGGGCTTTCAGTCGGATGTTTGCAGCTGCCTACTGCCTCGGAC CAGAGATGCATAATACGACTCACTATAGGTTAACCCAACAGAAGGCTAAAGA AGGTATATTGCTGTTGACAGTGAGCGACTGTAAACATC GTAAACAAGATAATTGCTCCTAAAGTAGCCCCTTGAAGTCCGAGGCAGTAGG CAGCTGCAAACATC S30aloop.004 RT Primer GACGGCATAGCTGCAAACATCCGACTGA S30aloop.005 Init. PCR Fwd CCGACGATCTGTAAACATCCTCGACTG S30aloop.005a Init. PCR Fwd, Barcoded CCGACGATCgaTGTAAACATCCTCGACTG S30aloop.005b Init. PCR Fwd, Barcoded CCGACGATCctTGTAAACATCCTCGACTG S30aloop.006 Solexa-R Adaptor CAAGCAGAAGACGGCATACGAGCTGCAAACATCCGACTGA S30aloop.007 Solexa-Seq Adaptor AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCTGT AAACATCCTCGACTG AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCgaT GTAAACATCCTCGACTG S30aloop.002 Left Arm S30aloop.007a Solexa-Seq Adaptor, barcoded 114 S30aloop.007b Solexa-Seq Adaptor, barcoded AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCctT GTAAACATCCTCGACTG hsa-mir-223 loop and apical selection Note: Underlined bases were degenerate. S223loop.001a Central S223loop.003 Right Arm TCCTGCAGTGCCACGCTCCGTGTATTTGACAAGCTGAGTTGGACACTCCATG TGGTAGAGTGTCAGTTTGTCAAATACCCCAAGTGCGGCACATGCTTAC CAGAGATGCATAATACGACTCACTATAGATCTCACTTCCCCACAGAAGCTCT TGGCCTGGCCTCCTGCAGTGCCACGCTCCGTGTATTTGACAAGCTGAG ATTCGTCATATCCCATCTGCCCTGGCCTAGAGCTGGTAAGCATGTGCCGCAC TTGGGGTATTTGACAAAC S223loop.004 RT Primer GACGGCATATGGGGTATTTGACAAAC S223loop.005 Init. PCR Fwd CCGACGATCCGTGTATTTGACAAGCTGA S223loop.005a Init. PCR Fwd, Barcoded CCGACGATCgaCGTGTATTTGACAAGCTGA S223loop.005b Init. PCR Fwd, Barcoded CCGACGATCctCGTGTATTTGACAAGCTGA S223loop.006 Solexa-R Adaptor CAAGCAGAAGACGGCATACGATGGGGTATTTGACAAAC S223loop.007 Solexa-Seq Adaptor AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCCGT GTATTTGACAAGCTGA AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCgaC GTGTATTTGACAAGCTGA S223loop.002 Left Arm S223loop.007a Solexa-Seq Adaptor, barcoded S223loop.007b Solexa-Seq Adaptor, barcoded AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCctC GTGTATTTGACAAGCTGA 115 Supplemental Table S2. Pri-miRNA collections Related to the Experimental Procedures. Pri-miRNAs used in phylogenetic analyses were chosen as described in the Experimental Procedures. H. sapiens D. rerio hsa-mir-455, hsa-mir-451, hsa-mir-452, hsa-mir-181b-1, hsa-mir-568, hsa-mir-302a, hsa-mir-7-1, hsa-mir-19a, hsa-mir-708, hsa-mir-219-2, hsa-mir-28, hsa-mir-431, hsa-mir-301a, hsa-mir-432, hsa-mir-21, hsa-mir-433, hsa-mir-22, hsa-mir-574, hsamir-598, hsa-mir-599, hsa-mir-101-1, hsa-mir-592, hsa-mir-18a, hsa-mir-590, hsamir-3960, hsa-mir-449a, hsa-mir-320a, hsa-mir-1306, hsa-mir-125b-1, hsa-mir-31, hsa-mir-32, hsa-mir-216a, hsa-mir-1193, hsa-mir-582, hsa-mir-212, hsa-mir-376a-1, hsa-mir-214, hsa-mir-210, hsa-mir-215, hsa-mir-217, hsa-mir-129-2, hsa-mir-124-2, hsa-mir-412, hsa-mir-411, hsa-mir-224, hsa-mir-328, hsa-mir-222, hsa-mir-325, hsa-mir-223, hsa-mir-326, hsa-mir-718, hsa-mir-324, hsa-mir-1912, hsa-mir-711, hsa-mir-425, hsa-mir-424, hsa-mir-423, hsa-mir-1277, hsa-mir-200a, hsa-mir-615, hsa-mir-96, hsa-mir-105-1, hsa-mir-802, hsa-mir-337, hsa-mir-24-1, hsa-mir-338, hsa-mir-339, hsa-mir-335, hsa-mir-330, hsa-mir-331, hsa-mir-744, hsa-mir-218-1, hsa-mir-135a-2, hsa-mir-202, hsa-mir-203, hsa-mir-551b, hsa-mir-199a-2, hsa-mir345, hsa-mir-346, hsa-mir-204, hsa-mir-205, hsa-mir-342, hsa-let-7a-1, hsa-mir340, hsa-mir-544, hsa-mir-542, hsa-mir-541, hsa-mir-138-1, hsa-mir-33a, hsa-mir1298, hsa-mir-760, hsa-mir-668, hsa-mir-764, hsa-mir-150, hsa-mir-761, hsa-mir23b, hsa-mir-762, hsa-mir-664, hsa-mir-767, hsa-mir-665, hsa-mir-9-2, hsa-mir-3652, hsa-mir-149, hsa-mir-107, hsa-mir-142, hsa-mir-144, hsa-mir-1249, hsa-mir-143, hsa-mir-1247, hsa-mir-145, hsa-mir-140, hsa-mir-193b, hsa-mir-652, hsa-mir-653, hsa-mir-654, hsa-mir-759, hsa-mir-139, hsa-mir-153-2, hsa-mir-137, hsa-mir-136, hsa-mir-134, hsa-mir-196a-2, hsa-mir-1264, hsa-mir-194-1, hsa-mir-127, hsa-mir126, hsa-mir-122, hsa-mir-505, hsa-mir-506, hsa-mir-1251, hsa-mir-770, hsa-mir503, hsa-mir-504, hsa-mir-10b, hsa-mir-1-2, hsa-mir-133a-1, hsa-mir-128-2, hsamir-99a, hsa-mir-486, hsa-mir-147b, hsa-mir-489, hsa-mir-488, hsa-mir-208a, hsamir-483, hsa-mir-485, hsa-mir-484, hsa-mir-384, hsa-mir-383, hsa-mir-191, hsa-mir190, hsa-mir-185, hsa-mir-186, hsa-mir-187, hsa-mir-188, hsa-mir-27b, hsa-mir892b, hsa-mir-490, hsa-mir-374c, hsa-mir-491, hsa-mir-3074, hsa-mir-146a, hsamir-375, hsa-mir-184, hsa-mir-500b, hsa-mir-378, hsa-mir-183, hsa-mir-182, hsamir-30c-1, hsa-mir-15b, hsa-mir-367, hsa-mir-362, hsa-mir-361, hsa-mir-363, hsamir-370, hsa-mir-1224, hsa-mir-371, hsa-mir-29a, hsa-mir-92a-1, hsa-mir-2861, hsa-mir-496, hsa-mir-670, hsa-mir-26a-1, hsa-mir-495, hsa-mir-148a, hsa-mir-493, hsa-mir-671, hsa-mir-499, hsa-mir-676, hsa-mir-675, hsa-mir-497, hsa-mir-875, hsa-mir-876, hsa-mir-877, hsa-mir-155, hsa-mir-450a-2, hsa-mir-297, hsa-mir-3064, hsa-mir-298, hsa-mir-296, hsa-mir-3065, hsa-mir-34a, hsa-mir-873, hsa-mir-299, hsa-mir-874 dre-let-7f, dre-mir-100-2, dre-mir-101b, dre-mir-107, dre-mir-10d, dre-mir-122, dremir-124-2, dre-mir-125b-1, dre-mir-126b, dre-mir-128-1, dre-mir-129-2, dre-mir-1322, dre-mir-133a-2, dre-mir-135b, dre-mir-137-2, dre-mir-1388, dre-mir-139, dre-mir140, dre-mir-142b, dre-mir-145, dre-mir-146b-1, dre-mir-148, dre-mir-153a, dre-mir155, dre-mir-15c, dre-mir-1788, dre-mir-181b-1, dre-mir-182, dre-mir-183, dre-mir184, dre-mir-187, dre-mir-190, dre-mir-192, dre-mir-193a-1, dre-mir-194a, dre-mir196a-2, dre-mir-199-3, dre-mir-19b, dre-mir-202, dre-mir-203a, dre-mir-204-2, dremir-206-2, dre-mir-20a, dre-mir-210, dre-mir-21-1, dre-mir-214, dre-mir-216a-1, dremir-2188, dre-mir-218a-1, dre-mir-219-3, dre-mir-222, dre-mir-223, dre-mir-22a, dre-mir-23a-3, dre-mir-24-1, dre-mir-26a-3, dre-mir-27a, dre-mir-29b-3, dre-mir301c, dre-mir-30a, dre-mir-31, dre-mir-338-1, dre-mir-34, dre-mir-363, dre-mir-3652, dre-mir-375-2, dre-mir-429, dre-mir-430c-3, dre-mir-451, dre-mir-454b, dre-mir455, dre-mir-456, dre-mir-458, dre-mir-460, dre-mir-489, dre-mir-499, dre-mir-736, dre-mir-7b, dre-mir-92a-1, dre-mir-9-3, dre-mir-96 116 C. intestinalis A. gambiae D. melanogaster cin-mir-4003b, cin-mir-4001a-2, cin-mir-4092, cin-mir-4001a-1, cin-mir-4091, cinmir-4094, cin-mir-4093, cin-mir-4098, cin-mir-196, cin-mir-4097, cin-mir-4099, cinmir-4219, cin-mir-4003d, cin-mir-4003c, cin-mir-4217, cin-mir-4090, cin-mir-4207, cin-mir-4209, cin-mir-4208, cin-mir-4213, cin-mir-4214, cin-mir-4215, cin-mir-4216, cin-mir-4006a-1, cin-mir-4212, cin-mir-4014-1, cin-mir-4006a-3, cin-mir-4006a-2, cin-mir-4010-1, cin-mir-4001d, cin-mir-4001c, cin-mir-4001h, cin-mir-4001g, cin-mir4001f, cin-mir-4001e, cin-mir-4001i, cin-mir-1502c, cin-mir-1502b, cin-mir-1502d, cin-mir-4013a, cin-mir-4013b, cin-mir-4120, cin-mir-4123, cin-mir-4124, cin-mir4121, cin-mir-4122, cin-mir-4127, cin-mir-4128, cin-mir-4118, cin-let-7f, cin-mir4000d, cin-mir-4000e, cin-mir-4000f, cin-mir-4000g, cin-mir-15, cin-mir-375, cin-mir4000c, cin-mir-4110, cin-mir-4112, cin-mir-219, cin-mir-4113, cin-mir-4114, cin-mir4115, cin-mir-4116, cin-mir-4011a, cin-mir-4011b, cin-mir-4000i, cin-mir-4000h, cinmir-4002, cin-mir-29, cin-mir-200, cin-mir-4007, cin-mir-4004, cin-mir-4106, cin-mir4103, cin-mir-4101, cin-mir-367, cin-mir-4100, cin-mir-4201, cin-mir-31, cin-mir4077d, cin-mir-4077c, cin-mir-4205, cin-mir-34, cin-mir-4203, cin-mir-124-1, cin-mir3598, cin-mir-3599, cin-mir-92c, cin-mir-92a, cin-mir-4159, cin-mir-4158, cin-mir4157, cin-mir-4156, cin-mir-4155, cin-mir-92e, cin-mir-4154, cin-mir-4153, cin-mir4019, cin-mir-4169, cin-mir-4166, cin-mir-4165, cin-mir-4021, cin-mir-4022, cin-mir4025, cin-mir-4178a, cin-mir-4163, cin-mir-4024, cin-mir-126, cin-mir-4012-2, cinmir-125, cin-mir-4026, cin-mir-4029, cin-mir-4028, cin-mir-3575, cin-mir-4020b, cinmir-4129, cin-mir-4134, cin-mir-4031, cin-mir-4133, cin-mir-4030, cin-mir-4132, cinmir-4139, cin-mir-135, cin-mir-133, cin-mir-4137, cin-mir-4136, cin-mir-4039, cinmir-4038, cin-mir-4037, cin-mir-4131, cin-mir-4036, cin-mir-4130, cin-mir-4035, cinmir-4034, cin-mir-4033, cin-mir-4041, cin-mir-4144, cin-mir-4143, cin-mir-4146, cinmir-4043, cin-mir-141, cin-mir-4145, cin-mir-4009b, cin-mir-4147, cin-mir-4009a, cin-mir-4009c, cin-mir-4049, cin-mir-4048, cin-mir-4140, cin-mir-4045, cin-mir-4044, cin-mir-4142, cin-mir-4047, cin-mir-4046, cin-mir-4141, cin-mir-4057, cin-mir-4196, cin-mir-7, cin-mir-4197, cin-mir-4055, cin-mir-4194, cin-mir-4195, cin-mir-4056, cinmir-4192, cin-mir-4001b-2, cin-mir-4193, cin-mir-4190, cin-mir-4059, cin-mir-9, cinmir-4001b-1, cin-mir-4008b, cin-mir-4008c, cin-mir-4050, cin-mir-4008a, cin-mir155, cin-mir-4053, cin-mir-153, cin-mir-4054, cin-mir-4198, cin-mir-4051, cin-mir-1, cin-mir-4052, cin-mir-1473, cin-mir-96, cin-mir-4066, cin-mir-4067, cin-mir-4068, cin-mir-4069, cin-let-7a-2, cin-mir-4060, cin-mir-4061, cin-mir-4062, cin-mir-4063, cin-mir-4064, cin-mir-4065, cin-mir-132-2, cin-mir-4171, cin-mir-4014-2, cin-mir4174, cin-mir-4079, cin-mir-4006f, cin-mir-4172, cin-mir-4078, cin-mir-4006g, cinmir-4173, cin-mir-4006d, cin-mir-4076, cin-mir-4006e, cin-mir-4179, cin-mir-4073, cin-mir-4006b, cin-mir-4176, cin-mir-4074, cin-mir-4006c, cin-mir-4177, cin-mir4071, cin-mir-4072, cin-mir-4070, cin-mir-182, cin-mir-1497, cin-mir-4017-2, cin-mir4018b, cin-mir-281, cin-mir-4180, cin-mir-4181, cin-mir-4015-1, cin-mir-4088, cinmir-4183, cin-mir-4089, cin-mir-4185, cin-mir-4186, cin-mir-4084, cin-mir-4005a, cin-mir-183, cin-mir-4085, cin-mir-4086, cin-mir-4005c, cin-mir-4087, cin-mir-40162, cin-mir-4081, cin-mir-4083 aga-mir-9a, aga-mir-1000, aga-mir-957, aga-mir-100, aga-mir-iab-4, aga-mir-275, aga-mir-965-1, aga-mir-278, aga-mir-279, aga-mir-276, aga-mir-277, aga-mir-993, aga-mir-1, aga-mir-8, aga-mir-305, aga-mir-996, aga-mir-137, aga-mir-10, aga-mir11, aga-mir-929, aga-mir-12, aga-mir-927, aga-mir-14, aga-mir-283, aga-mir-286, aga-mir-375-2, aga-mir-281, aga-mir-282, aga-mir-309, aga-mir-308, aga-mir-307, aga-bantam, aga-mir-1890, aga-mir-315, aga-mir-981, aga-let-7, aga-mir-87, agamir-184, aga-mir-219, aga-mir-2-1, aga-mir-1891, aga-mir-124, aga-mir-125, agamir-190, aga-mir-210, aga-mir-988, aga-mir-989, aga-mir-317, aga-mir-970, agamir-34, aga-mir-92b, aga-mir-263, aga-mir-1175 dme-mir-31a, dme-mir-932, dme-mir-8, dme-mir-5, dme-mir-4, dme-mir-7, dme-mir125, dme-mir-1, dme-mir-124, dme-mir-3, dme-mir-318, dme-mir-219, dme-mir-316, dme-mir-317, dme-mir-34, dme-mir-33, dme-mir-193, dme-mir-190, dme-mir-281-2, dme-mir-92a, dme-mir-210, dme-mir-315, dme-mir-314, dme-mir-313, dme-mir-312, dme-mir-305, dme-mir-306, dme-mir-308, dme-mir-375, dme-mir-959, dme-mir-958, 117 C. elegans C. briggsae P. pacificus dme-mir-184, dme-mir-957, dme-mir-955, dme-mir-100, dme-mir-2494, dme-mir304, dme-mir-303, dme-mir-969, dme-mir-965, dme-mir-9a, dme-mir-968, dme-mir967, dme-mir-961, dme-mir-962, dme-mir-276a, dme-mir-963, dme-mir-964, dmemir-960, dme-mir-2489, dme-mir-307b, dme-mir-263a, dme-mir-971, dme-mir-970, dme-mir-975, dme-mir-976, dme-mir-977, dme-mir-978, dme-bantam, dme-mir307a, dme-mir-1001, dme-mir-1002, dme-mir-1003, dme-mir-1005, dme-mir-1006, dme-mir-6-3, dme-mir-982, dme-mir-981, dme-mir-980, dme-mir-986, dme-mir1000, dme-mir-989, dme-mir-987, dme-mir-988, dme-mir-iab-4, dme-mir-iab-8, dme-mir-252, dme-mir-2a-2, dme-mir-1012, dme-mir-1013, dme-mir-1010, dme-mir995, dme-mir-1011, dme-mir-994, dme-mir-87, dme-mir-996, dme-mir-991, dmemir-993, dme-mir-992, dme-let-7, dme-mir-288, dme-mir-289, dme-mir-999, dmemir-286, dme-mir-284, dme-mir-285, dme-mir-282, dme-mir-283, dme-mir-280, dme-mir-927, dme-mir-929, dme-mir-279, dme-mir-11, dme-mir-275, dme-mir-12, dme-mir-277, dme-mir-14, dme-mir-278, dme-mir-133, dme-mir-10, dme-mir-274, dme-mir-137, dme-mir-983-2 cel-mir-2208b, cel-mir-237, cel-mir-90, cel-mir-238, cel-mir-55, cel-mir-233, cel-mir58, cel-mir-234, cel-mir-57, cel-mir-239a, cel-mir-235, cel-mir-236, cel-mir-59, celmir-2209b, cel-mir-230, cel-mir-231, cel-mir-232, cel-mir-50, cel-mir-52, cel-mir-51, cel-mir-4922-1, cel-lin-4, cel-mir-2214, cel-mir-67, cel-mir-65, cel-mir-248, cel-mir249, cel-mir-246, cel-mir-247, cel-mir-244, cel-mir-245, cel-mir-240, cel-mir-241, cel-mir-63, cel-mir-62, cel-mir-790, cel-mir-61, cel-mir-791, cel-mir-60, cel-mir-7892, cel-mir-2, cel-mir-4812, cel-mir-1, cel-mir-788, cel-mir-787, cel-mir-786, cel-mir785, cel-mir-71, cel-mir-255, cel-mir-72, cel-mir-35, cel-mir-73, cel-mir-38, cel-mir353, cel-mir-74, cel-mir-259, cel-mir-392, cel-mir-34, cel-mir-70, cel-mir-79, cel-mir358, cel-mir-359, cel-mir-250, cel-mir-354, cel-mir-75, cel-mir-251, cel-mir-355, celmir-76, cel-mir-252, cel-mir-356, cel-mir-77, cel-mir-253, cel-mir-357, cel-mir-254, cel-let-7, cel-mir-1822, cel-lsy-6, cel-mir-39, cel-mir-124, cel-mir-84, cel-mir-268, cel-mir-49, cel-mir-85, cel-mir-269, cel-mir-48, cel-mir-82, cel-mir-83, cel-mir-46, cel-mir-80, cel-mir-360, cel-mir-44, cel-mir-43, cel-mir-42, cel-mir-228, cel-mir-86, cel-mir-87 cbr-let-7, cbr-mir-238, cbr-mir-236, cbr-mir-237, cbr-mir-234, cbr-mir-87, cbr-mir235, cbr-mir-233, cbr-mir-47, cbr-mir-48, cbr-mir-49, cbr-mir-43, cbr-mir-124, cbrmir-42, cbr-mir-83, cbr-mir-242, cbr-mir-239b, cbr-mir-84, cbr-mir-241, cbr-mir-85, cbr-mir-240, cbr-mir-86, cbr-mir-80, cbr-mir-81, cbr-mir-248, cbr-mir-249, cbr-mir232-1, cbr-mir-35b-6, cbr-mir-244, cbr-mir-245, cbr-mir-76, cbr-mir-246, cbr-mir791, cbr-mir-39, cbr-mir-73b, cbr-mir-34, cbr-mir-789, cbr-mir-786, cbr-mir-787, cbrmir-784, cbr-mir-785, cbr-mir-357-1, cbr-mir-74, cbr-mir-251, cbr-mir-250, cbr-mir72, cbr-mir-253, cbr-mir-392, cbr-mir-252, cbr-mir-70, cbr-mir-71, cbr-mir-90b, cbrmir-67, cbr-mir-359, cbr-mir-255, cbr-mir-358, cbr-mir-254, cbr-mir-355, cbr-mir-353, cbr-mir-259, cbr-mir-354, cbr-mir-360, cbr-mir-45-2, cbr-mir-790-1, cbr-mir-2222-2, cbr-mir-60, cbr-mir-61, cbr-mir-1822, cbr-mir-57, cbr-mir-55, cbr-mir-228, cbr-mir-58, cbr-mir-1, cbr-mir-268, cbr-mir-54a, cbr-mir-77-2, cbr-lsy-6, cbr-mir-52, cbr-mir-35d, cbr-mir-231, cbr-mir-50, cbr-mir-230 ppc-mir-2265, ppc-mir-2266, ppc-mir-2235-1, ppc-mir-2267, ppc-mir-2268, ppc-mir2269, ppc-mir-279, ppc-mir-72, ppc-mir-71, ppc-mir-63b, ppc-mir-67, ppc-mir-65, ppc-mir-2239-1, ppc-mir-993, ppc-mir-2271, ppc-mir-236, ppc-mir-2270, ppc-mir2233, ppc-mir-2273, ppc-mir-234, ppc-mir-2272, ppc-mir-2234a, ppc-mir-232, ppcmir-2274, ppc-lin-4, ppc-mir-2237b, ppc-mir-1, ppc-mir-2, ppc-mir-86, ppc-mir-55a, ppc-mir-55b, ppc-mir-81, ppc-mir-124, ppc-mir-79, ppc-mir-2253b, ppc-mir-2247, ppc-mir-2248, ppc-mir-2249, ppc-let-7, ppc-mir-2243, ppc-mir-252, ppc-mir-2244, ppc-mir-38, ppc-mir-2245, ppc-mir-37, ppc-mir-2246, ppc-mir-312, ppc-mir-2241a-2, ppc-mir-45, ppc-mir-46, ppc-mir-2240c, ppc-mir-2250, ppc-mir-2236a, ppc-mir2236b, ppc-mir-87, ppc-mir-2258, ppc-mir-2259, ppc-mir-2256, ppc-mir-240, ppcmir-84b, ppc-mir-2255, ppc-mir-2234b, ppc-mir-242, ppc-mir-2242-2, ppc-mir-22321, ppc-mir-2238a-2, ppc-mir-56, ppc-mir-42b, ppc-mir-42a, ppc-mir-2264, ppc-mir2263, ppc-mir-2262, ppc-mir-2261, ppc-mir-239-2 118 C. teleta L. gigantea S. mediterranea N. vectensis cte-mir-1999, cte-mir-87a, cte-mir-1997, cte-mir-1998, cte-mir-1991, cte-mir-124, cte-mir-1992, cte-mir-1993, cte-mir-1994, cte-mir-193, cte-mir-277b, cte-mir-216b, cte-mir-12, cte-mir-750, cte-mir-1989, cte-mir-216c, cte-mir-2694, cte-mir-137, ctemir-1987, cte-mir-2693, cte-mir-2692, cte-mir-2691, cte-mir-133, cte-mir-2690, ctemir-2686b, cte-mir-2699, cte-mir-2686c, cte-mir-2695, cte-mir-2696, cte-mir-29b, cte-mir-92c, cte-mir-92b, cte-mir-153, cte-mir-219, cte-mir-277a, cte-mir-210, ctemir-210b, cte-mir-71, cte-mir-182, cte-mir-1175, cte-mir-1996b, cte-mir-1996a, ctemir-281, cte-mir-981, cte-mir-278, cte-mir-279, cte-mir-67, cte-mir-2001, cte-mir375, cte-mir-2000, cte-mir-7, cte-mir-1, cte-mir-9, cte-mir-8, cte-mir-2703, cte-mir2706, cte-mir-993, cte-mir-2705, cte-mir-2708, cte-mir-2707, cte-mir-996, cte-mir2709, cte-mir-365, cte-mir-2700, cte-mir-2702, cte-mir-317, cte-mir-2687, cte-mir1990c, cte-mir-2g, cte-mir-2685, cte-mir-2f, cte-mir-2e, cte-mir-315, cte-mir-1990b, cte-mir-2d, cte-mir-2c, cte-mir-2689, cte-mir-2688, cte-mir-2719, cte-mir-2718, ctemir-2717, cte-mir-252b, cte-mir-2716, cte-mir-2714, cte-mir-2713, cte-mir-2712, ctemir-2711, cte-mir-2710, cte-mir-184b, cte-mir-31, cte-let-7, cte-bantam, cte-mir-10b, cte-mir-10a, cte-mir-10d, cte-mir-10c, cte-mir-745a, cte-mir-745b, cte-mir-242, ctemir-2721, cte-mir-33, cte-mir-34, cte-mir-2720, cte-mir-36 lgi-mir-31, lgi-mir-34, lgi-mir-33, lgi-mir-2001, lgi-mir-745b, lgi-mir-252, lgi-let-7, lgimir-87, lgi-mir-981, lgi-mir-193, lgi-mir-216a, lgi-mir-2c, lgi-mir-317, lgi-mir-1, lgi-mir315, lgi-mir-124, lgi-mir-745a, lgi-mir-96a, lgi-mir-96b, lgi-mir-71, lgi-mir-2d, lgi-mir182, lgi-mir-184, lgi-mir-183, lgi-mir-375, lgi-mir-8, lgi-mir-10, lgi-mir-9, lgi-mir-7, lgimir-12, lgi-mir-1993, lgi-mir-137, lgi-mir-133, lgi-mir-281, lgi-mir-1990, lgi-mir-1992, lgi-mir-1991, lgi-mir-92, lgi-mir-67, lgi-mir-29, lgi-mir-242, lgi-mir-1985, lgi-mir-279, lgi-mir-1984, lgi-mir-278, lgi-mir-1989, lgi-mir-1994b, lgi-mir-1988, lgi-mir-750, lgimir-1986, lgi-mir-252b, lgi-mir-100, lgi-mir-1175 sme-mir-1175, sme-mir-1a, sme-mir-1c, sme-mir-1b, sme-mir-71c, sme-mir-125a, sme-mir-125b, sme-mir-61b, sme-mir-61a, sme-mir-2156b, sme-mir-2156a, smemir-92, sme-lin-4, sme-mir-7d, sme-mir-7c, sme-mir-7b, sme-mir-7a, sme-mir-745, sme-mir-31a, sme-mir-10b, sme-mir-10a, sme-mir-190b, sme-mir-190a, sme-mir12, sme-mir-2150, sme-mir-8b, sme-mir-13, sme-mir-8a, sme-mir-2152, sme-mir2151, sme-mir-2153, sme-mir-2155, sme-mir-1993, sme-mir-2158, sme-mir-1992, sme-mir-2157, sme-mir-278, sme-mir-2159, sme-mir-96b, sme-mir-315, sme-mir9b, sme-mir-281, sme-mir-2154-1, sme-mir-2149, sme-mir-2148, sme-mir-2200, sme-mir-2201, sme-mir-2202, sme-let-7d, sme-mir-124e, sme-mir-277d, sme-mir2203, sme-mir-124d, sme-mir-277c, sme-let-7c, sme-mir-2204, sme-mir-31b-2, sme-mir-277b, sme-mir-2205, sme-mir-277a, sme-mir-2206, sme-mir-2147b, smemir-2e, sme-mir-2f, sme-mir-2177, sme-mir-2b, sme-mir-2178, sme-mir-2179, smemir-36c, sme-mir-2173, sme-mir-36b, sme-mir-36a, sme-mir-2175, sme-mir-2176, sme-mir-2170, sme-mir-2171, sme-mir-2172, sme-bantam-a, sme-mir-133a, smemir-133b, sme-mir-2168, sme-mir-2169, sme-mir-2166, sme-mir-2167, sme-mir2164, sme-mir-2165, sme-mir-2162, sme-mir-2163, sme-mir-2161, sme-mir-67, sme-mir-748, sme-mir-749, sme-mir-746, sme-mir-87d, sme-mir-747, sme-mir-87b, sme-mir-87c, sme-mir-219, sme-mir-87a, sme-mir-752, sme-mir-751, sme-mir-750, sme-mir-756, sme-mir-755, sme-mir-79, sme-mir-76, sme-mir-753b, sme-mir-184, sme-mir-2160-1, sme-mir-216, sme-mir-754c-1, sme-mir-2181, sme-let-7b, nve-mir-2049, nve-mir-2023, nve-mir-2022, nve-mir-2047, nve-mir-2048, nve-mir100, nve-mir-2041, nve-mir-2042, nve-mir-2029, nve-mir-2028, nve-mir-2046, nvemir-2027, nve-mir-2026, nve-mir-2044, nve-mir-2025, nve-mir-2040a-1, nve-mir2024a-3, nve-mir-2033, nve-mir-2034, nve-mir-2031, nve-mir-2030, nve-mir-2050, nve-mir-2035-2, nve-mir-2037, nve-mir-2036, nve-mir-2039, nve-mir-2043b, nvemir-2032b-2 119 120 Chapter 3. Future directions Contents Overview ..................................................................................................................................... 122 Expanding the understanding of human Microprocessor substrates........................................... 122 Recognition of human pri-miRNAs without known motifs ............................................... 122 Dynamics of pri-miRNA recognition in different cellular contexts ................................... 123 Recognition of non-miRNA substrates of Drosha and DGCR8/Pasha............................... 127 Defining nematode pri-miRNAs ................................................................................................. 128 Gaining insight into mechanisms of pri-miRNA recognition ..................................................... 132 Applying selection approaches to stubborn questions in RNA biology ..................................... 136 121 Overview In Chapter 2, in vitro selection of partially-randomized pri-miRNAs and high-throughput sequencing of the functional variants confirmed the importance of secondary structure and revealed three novel and conserved primary sequence determinants. These experiments provided a detailed perspective on the substrate specificity of the human Microprocessor, and, correspondingly, the features that define most conserved human pri-miRNAs. The results in Chapter 2 also inspire several additional questions related to the Microprocessor and the biological definition of a pri-miRNA. I will discuss some attractive avenues of further investigation, ranging from a wider search for determinants in human Microprocessor substrates to the application of in vitro and in vivo selection strategies to find functional elements in other RNAs that have resisted detailed characterization. Expanding the understanding of human Microprocessor substrates Recognition of human pri-miRNAs without known motifs The three recognition motifs identified in Chapter 2 are generally utilized by conserved human pri-miRNAs, with 79% having one or more motifs. Despite the success of the study, the motifs that define the remaining 21% are still unknown. Many of these pri-miRNAs are conserved across vertebrates, and three are conserved across bilaterian animals, suggesting that they have distinct, evolutionarily-conserved processing motifs that were simply not present in the four pri-miRNAs studied (Figure 1A). Partial-randomization and selection of these pri-miRNAs will therefore expand the catalog of pri-miRNA recognition motifs, and perhaps uncover additional determinants that are deeply conserved in bilaterian animals. Some of these pri-miRNAs are located in clusters of miRNAs, including hsa-mir-15b, hsa-mir-24-1, and hsa-mir-200a, and other members of these clusters have the downstream CNNC motif. These pri-miRNAs may simply use separate processing motifs that have not been discovered yet (Figure 1B), but an intriguing possibility is that the processing of clustered primiRNAs is somehow coordinated, and that a single positioned CNNC instance in the cluster is sufficient to recruit the Microprocessor to process the cluster hairpins (Figure 1C). Consistent with this idea, the ~600 kDa Microprocessor complex has been suggested to consist of multiple 122 functional Drosha and DGCR8 units (Han et al., 2004; Sohn et al., 2007), and a single complex could be capable of simultaneously cleaving multiple pri-miRNAs in a cluster. At the same time, clustered miRNAs could interact at a tertiary level to promote or inhibit joint processing by the Microprocessor (Chakraborty et al., 2012). This question could be addressed by computationally analyzing clustered pri-miRNAs and determining whether the probability that any individual member has a processing motif is dependent on the presence or absence of processing motifs in other cluster members. Suggestive results could be followed by in vitro and in vivo studies of the processing of clustered miRNAs. Dynamics of pri-miRNA recognition in different cellular contexts Processing motifs may exist that are dependent on cell identity or cell state, and may not have been identified in Chapter 2 because the lysate used for pri-miRNA cleavage was derived from a single cell line (HEK293T) under standard culture conditions. Such conditional motifs, and the proteins that recognize them, are likely to help regulate levels of pri-miRNA processing and may play important, dynamic roles during physiological changes such as during development or in response to extracellular signals; or during pathological changes, such as oncogenic transformation. For example, the regulation and dysregulation of miRNAs has a crucial role in oncogenesis, primary tumor growth, and distant metastasis (Garzon et al., 2009). On a cellular and molecular level, studies have demonstrated the importance of miRNAs as both tumor suppressors and oncogenes (Zhang et al., 2007). Indeed, many highly-expressed miRNAs overlap with regions that are genomically unstable in cancer, including deletions, duplications, translocations, or losses of heterozygozity (Calin et al., 2005). At an epidemiological level, miRNA expression patterns are highly correlated with both cancer type (Lu et al., 2005) and clinical course (Calin et al., 2004a; Yanaihara et al., 2006), and thus are of both diagnostic and prognostic value. In particular, pri-miRNA processing is dysregulated in cancer. For example, a SNP in the hsa-mir-16-1 locus severely impairs the processing of mir-16-1 by the Microprocessor. Mir16-1 has been shown to be frequently deleted in chronic lymphoid leukemia (CLL) (Calin et al., 2002), leading to dysregulation of the key apoptosis factor BCL2 (Cimmino et al., 2005). Correspondingly, the SNP identified in mir-16-1 that impairs processing was found in two CLL 123 patients, one meeting the criteria for familial CLL, and was associated with loss of heterozygozity in both (Calin et al., 2005). More broadly, as discussed in Chapter 1, several oncogenic and tumor-suppressor proteins have been shown to interact with pri-miRNAs and regulate their cleavage by the Microprocessor complex, including p53 (Suzuki et al., 2009), Smad family members (Davis et al., 2008; Davis et al., 2010; Hata and Davis, 2011), and Lin-28 [reviewed in (Viswanathan and Daley, 2010)]. In most cases, the RNA motifs that these proteins recognize and bind are poorly understood. Identification of conditional motifs will require two expansions to the in vitro selection approach described in Chapter 2 (Figure 1D). First, a more extensive panel of pri-miRNAs must be examined, preferably ones for which there is evidence of dynamic processing and important function in physiology or pathology. For example, four pri-miRNAs might be fertile ground for additional study: hsa-mir-206, hsa-mir-199a-2, hsa-mir-155, and hsa-let-7e. SNPs have been identified in cancer samples for all four of these miRNAs, and these polymorphisms may be responsible for inhibited or enhanced miRNA processing in specific cells or tissues (Calin et al., 2005; Wu et al., 2008). mir-206 is a tumor suppressor miRNA that is downregulated in metastatic subsets of the human breast cancer cell line MDA-MB-231 and the human lung cancer line LM2; restoration of miR-206 expression decreases the colonization capacity of these cells (Tavazoie et al., 2008). mir-199a has been implicated in the regulation of the SWI/SNF complex, and hence may be both a tumor suppressor and an oncogenic miRNA, depending on the tumor (Sakurai et al., 2011). Likewise, miR-155, the major product of the BIC locus, is an oncogenic miRNA activated in human and bird B-lymphomas (Tam et al., 1997; Eis et al., 2005), and its overexpression is sufficient to cause lymphoproliferation (Costinean et al., 2006) and myeloproliferation (O'Connell et al., 2008) disorders in mice. Finally, the let-7 family of miRNAs is a well-studied class of tumor-suppressor miRNAs that have been implicated in a variety of oncologic settings in both molecular and epidemiological studies [reviewed in (Viswanathan and Daley, 2010)]. The second expansion is the preparation and use of lysates from different cell lines or tissues, in order to maximize opportunity to detect cancer or cell-type specific motifs. For example, one might use four readily-available cell lines: HeLa, derived from a cervical carcinoma; Huh7, derived from a hepatocellular carcinoma; MCF7, derived from a breast carcinoma; and K562, derived from a chronic myelogenous leukemia. These lines divide rapidly 124 and are efficiently transfected using cationic lipids, making them suitable for medium-scale preparation of lysates containing the Microprocessor complex and any auxiliary proteins expressed in those cells. These lysates would be used to cleave the expanded panel of partiallyrandomized miRNA substrates. As in Chapter 2, any novel motifs should be confirmed by in vitro and in vivo analysis. High-throughput sequencing of the selected pri-miRNA variants is likely to reveal a variety of sequence and structural features important to processing. Some of these elements will recur in selections from all four cell lines and 293T cells, suggesting that these elements are important for general recognition of pri-miRNAs for cleavage. In contrast, other features could be present in some selections but not others; such motifs are of special interest. For example, some motifs may only be observable in the four human cancer lines, and not in the 293T transformed embryonic line; or in some cancer lines, but not others. This heterogeneity suggests that the utilization of such features is dependent on the cellular milieu, including the expression and/or activity of unknown proteins that may dynamically regulate miRNA processing. Variable motifs may therefore be binding sites for such proteins. In addition to novel motif discovery, the in vitro selection will also provide data on the effect of cancer SNPs previously identified in the four example miRNAs described above. These polymorphisms will be represented millions of times in the proposed selection pool, in addition to the billions of variants mutated at other positions. Analysis of the selected variants will provide quantitative data on the cleavage efficiency of pri-miRNAs with mutations that mimic cancer SNPs. For let-7e, where the specific polymorphism is already known to impair processing of the pri-miRNA (Wu et al., 2008), further study would help define the complete sequence or structural motif that is mutated in prostate cancer. For mir-206, mir-199a-2, and mir-155, detailed studies of processing motifs would help establish whether the cancer polymorphisms affect pri-miRNA processing, in addition to helping define the affected motif. To the extent that novel elements enhance miRNA biogenesis, this study will also aid efforts towards miRNA-based cancer gene therapy. Several approaches are based on stably reconstituting expression of tumor suppressor miRNAs to inhibit tumor growth or metastasis (Esquela-Kerscher et al., 2008; Kumar et al., 2008; Kota et al., 2009; Aigner, 2011), while others are attempting to stably express miRNA-derived hairpins engineered to downregulate specific oncogenes (Wang et al., 2009). In both cases, highly efficient miRNA processing will be critical 125 A Mammalian >1 known motif 79% No known motifs 21% hsa-mir-302a hsa-mir-320a hsa-mir-325 hsa-mir-326 hsa-mir-328 hsa-mir-335 hsa-mir-337 hsa-mir-383 hsa-mir-384 hsa-mir-423 hsa-mir-484 hsa-mir-486 hsa-mir-505 hsa-mir-568 hsa-mir-582 Human pri-miRNAs B hsa-mir-653 hsa-mir-654 hsa-mir-664 hsa-mir-665 hsa-mir-668 hsa-mir-676 hsa-mir-711 hsa-mir-718 hsa-mir-759 hsa-mir-764 hsa-mir-767 hsa-mir-877 hsa-mir-1193 hsa-mir-1251 hsa-mir-1912 hsa-mir-2861 Vertebrate Bilaterian hsa-mir-15b hsa-mir-24-1 hsa-mir-143 hsa-mir-155 hsa-mir-181b-1 hsa-mir-214 hsa-mir-223 hsa-mir-301a hsa-mir-153-2 hsa-mir-200a hsa-mir-216a C Microprocessor CNNC D ??? Partially randomized pri-miRNA sequences mir-206 let-7 family mir-199a-2 mir-155 In vitro selection HeLa Huh7 MCF7 K562 Lysate overexpressing Drosha and DGCR8 Unselected reference pools High-throughput sequencing Novel motif discovery to the efficacy of the therapy, and these efforts will be able to use the miRNA processing motifs identified in this study. In addition, if cancer-specific or tissue-specific motifs are identified, gene therapy platforms could use this information to maximize therapeutic miRNA expression specifically in cancer cells. Recognition of non-miRNA substrates of Drosha and DGCR8/Pasha Several groups have recently described substrates of Drosha and DGCR8/Pasha that are not processed into mature miRNAs, at least not efficiently. Instead, these substrates are mRNAs, and cleavage destabilizes the target messages. The best-described example of this is DGCR8 in humans; its mRNA contains two hairpins, one in the 5′ untranslated region and another in the beginning of the coding region, which are cleaved by Drosha (Han et al., 2009). Since the DGCR8 protein helps stabilize Drosha, the cleavage of DGCR8 would in turn lead to destabilization of Drosha. Thus, the activity of the Drosha-DGCR8 complex is self-limiting (Han et al., 2009). Two mature miRNAs, hsa-mir-3618 and hsa-mir-1306 have been annotated that are derived from the DGCR8 hairpins, but the importance of these miRNAs is unclear; the fact that mature miRNAs can be produced might be considered good illustrations of how the specificity of the processing machinery downstream of the Microprocessor is largely dependent on the biochemistry of the previous steps (Chapter 1). DGCR8 is not the only mRNA target of Drosha cleavage. A microarray comparison of gene expression after Drosha knockdown to expression after Dicer knockdown revealed Figure 1. Open questions in the recognition of human pri-miRNAs (A) How does the Microprocessor recognize pri-miRNAs without known primary sequence determinants? Among conserved human pri-miRNA families, 21% do not have any of the three primary sequence determinants elucidated in Chapter 2. The representatives of these human pri-miRNA families are listed, classified by their conservation. (B) To what degree is the recognition of individual pri-miRNAs biochemically independent from the recognition of other pri-miRNAs in a cluster? One model is that recognition of clustered pri-miRNAs is distinct, implying that pri-miRNAs in the cluster that do not have apparent primary sequence determinants utilize other motifs that have yet to be discovered. (C) To what degree is the recognition of clustered pri-miRNAs coordinated? In contrast to (B), sequence determinants in one pri-miRNA could be sufficient to recruit the Microprocessor to the cluster, so that multiple pri-miRNAs are dependent on a single set of determinants for processing. (D) To what extent is the use of individual recognition determinants conditional on cell state or identity? Performing in vitro selection on additional pri-miRNAs in cell lysates derived from a panel of cancer cell lines could identify motifs that are differentially utilized in different cellular environments. 127 hundreds of mRNAs upregulated after Drosha knockdown but not after Dicer knockdown, suggesting that Drosha could be directly regulating these mRNAs (Han et al., 2009). Similar results were obtained with Dicer knockout and Drosha knockout cell lines in mice (Chong et al., 2010), and an analogous experiment in Drosophila S2 cells similar found hundreds of genes upregulated by Drosha knockdown but not Dicer knockdown (Kadener et al., 2009). Thus Drosha could cleave many mRNAs as a mechanism for directly regulating of gene expression. There are several open questions in the direct cleavage of mRNAs. First, are hairpins in mRNA targets recognized in the same manner as pri-miRNA hairpins? A glance at the DGCR8 hairpins indicates that the upstream hairpin does not have any of the three motifs identified in Chapter 2, while the downstream hairpin has both the loop GUG and the downstream CNNC. A more systematic analysis is needed to determine whether mRNA cleavage substrates have the same propensity as pri-miRNAs to have one or more processing motifs. Second, is the DroshaDGCR8 complex that cleaves mRNA hairpins the same as the Microprocessor complex that cleaves pri-miRNAs? Cleavage of mRNA hairpins has the same core protein requirements (Drosha and Pasha/DGCR8), but it would be interesting to know whether the ~600 kDa Microprocessor complex isolated by gel filtration (Gregory et al., 2004) is fully competent to cleave these hairpins, or if a distinct complex of Drosha, Pasha/DGCR8, and other unidentified proteins is utilized instead. If these hairpins use processing motifs distinct from those of primiRNAs, it would be reasonable to hypothesize that the proteins that recognize those motifs are members of a distinct Drosha-DGCR8 complex. Finally, is Drosha-DGCR8 cleavage of individual mRNAs regulated in a dynamic manner? From a teleological standpoint, constitutive cleavage of the DGCR8 mRNA is comprehensible, since this negative feedback makes the activity of Drosha and DGCR8 self-limiting. However, it is not obvious why Drosha and DGCR8 would constitutively cleave hundreds of other putative mRNA targets. As with primiRNA processing, perhaps Drosha and DGCR8 cleavage of individual mRNAs is dynamically regulated. Defining nematode pri-miRNAs As described in Chapter 2, a species barrier exists between C. elegans pri-miRNAs and human pri-miRNAs, leading to poor processing of C. elegans pri-miRNAs in human cells. In Chapter 2, I described the discovery of additional motifs that promote efficient pri-miRNAs 128 processing in humans, which are absent in C. elegans and other nematode pri-miRNAs. The lack of human processing motifs in nematode pri-miRNAs explains why the nematode pri-miRNAs are poorly processed in human cells, and the species barrier can be bridged by adding the human processing motifs to nematode pri-miRNAs. Although this work has improved the understanding of human pri-miRNA processing, nematode processing continues to be poorly understood. In fact, pri-miRNA processing in nematodes may be unique among bilaterian animals: the downstream CNNC motif described in Chapter 2 is conserved in pri-miRNAs throughout bilaterian animals, but is strikingly absent in nematodes. One interpretation is that mechanisms of pri-miRNA recognition have generally diverged in nematodes from recognition in other bilaterian animals. In fact, pri-miRNA processing would not be alone in this divergence. Nematodes have 2-3 fold higher substitution rates in their 18S ribosomal sequences than other metazoan animals (Aguinaldo et al., 1997), and, among nematodes, the evolution of the C. elegans 18S ribosomal sequence is particularly fast (Holterman et al., 2006). Rapid evolution is reflected in protein coding genes as well; the nematodes have lost several homeobox (Hox) genes compared to the Hox clusters in other animals, and there are high substitution rates in the retained Hox genes (Aboobaker and Blaxter, 2003). Again, even among nematodes, C. elegans and its close relatives have evolved more rapidly, with more Hox gene losses and even a unique expansion of the posterior Hox genes (Aboobaker and Blaxter, 2003). The approach used in Chapter 2 to detail the processing motifs of human pri-miRNAs used a cell lysate to cleave pri-miRNA variants in vitro. This approach can be applied to nematode pri-miRNAs, with some considerations for biological and practical differences between C. elegans and other model animals. One example of a biological difference that could impinge on pri-miRNA processing studies is trans-splicing. C. elegans is unique among the model animals in that some 70% of pre-messenger RNA transcripts are spliced in trans to 22 nt leader exons called SL1 and SL2 (Blumenthal, 2005). Since the splice leaders RNAs form the 5′ end of the mature mRNA, splice leaders provide the methylguanosine cap, and trans-splicing serves to physically excise individual mRNAs from polycistronic transcripts. In many transcripts, SL1 and SL2 form almost the entirety of the 5′ untranslated region in the mature mRNA, and may play a role in efficient translational initiation (Blumenthal, 2005). 129 In a similar way, trans-splicing may play a critical role in pri-miRNA processing. The processing of the cel-let-7 pri-miRNA is thought to be dependent on trans-splicing to SL1, which occurs 41 nt upstream of the 5p cleavage site (Bracht et al., 2004). The degree to which trans-splicing occurs and is important in other pri-miRNAs is not clear, although analysis of whole-transcriptome sequencing in C. elegans suggests that trans splicing to pri-miRNAs may be relatively common (J.-W. Nam, personal communication). This poses an inconvenience for the synthesis of pri-miRNA substrates for in vitro studies. For Drosophila and humans, primiRNA substrates have been inferred by simply examining the sequence of the corresponding genome. By contrast, it will be necessary to determine the 5′ ends of the C. elegans pri-miRNAs by examining transcriptome sequencing data when possible, or by direct experimental approaches like amplification and sequencing of cDNA ends (e.g., 5′-RACE). When trans-splicing to cel-let-7 was characterized, it was suggested that the SL1 exon changed the optimal overall secondary structure of the pri-miRNA, presumably converting a nonfunctional substrate into a recognizable pri-miRNA substrate (Bracht et al., 2004). However, computationally-predicted folding (and changes in folding) is notoriously difficult to interpret when RNAs are hundreds of nucleotides long. To the extent that trans-splicing is generally important in pri-miRNA processing, it seems unlikely that the SL1 sequence optimizes the folding of all these divergent RNAs. An alternative possibility is that the SL1 exon contains a processing motif that marks nearby hairpins as bona-fide pri-miRNAs. For example, the SL1 exon contains an AGUU tetraloop (Greenbaum et al., 1996), and the structure of this tetraloop is thought to be very similar to the AGNN tetraloops recognized by the S. cerevisae RNase III protein Rnt1p (Wu et al., 2001). Perhaps one of the dsRBDs in the C. elegans Microprocessor complex has convergently evolved to recognize the AGNN tetraloop in SL1, and this recognition serves to recruit the nematode Microprocessor to pri-miRNAs. If the AGUU tetraloop in SL1 is important, it should be easy to see enrichment of the SL1 stem and tetraloop after in vitro selection. On a practical level, C. elegans has been a difficult platform for biochemistry. Since no C. elegans cell line is currently available, whole animals would have to be raised and used to make cell-free lysates, including their protease- and nuclease-rich gastrointestinal tracts. Nevertheless, lysates derived from C. elegans larvae have been used to study miRNA turnover, indicating that lysates with cytosolic activities and probably nuclear activities can be successfully 130 prepared (Chatterjee and Grosshans, 2009). In addition, a cell-free system from the parasitic nematode Ascaris lumbricoides was developed to study transcription and co-transcriptional events, including capping (Maroney et al., 1990) and trans-splicing (Hannon et al., 1990). Recently, this technique was adapted to generate splicing-competent extracts in C. elegans (Lasda et al., 2010). It is reasonable to believe that either of these extracts from C. elegans could also be competent for pri-miRNA processing. Regardless of the mechanism of pri-miRNA recognition in nematodes, the divergence from other animals is an opportunity to explore the co-evolution of an enzyme complex and its substrates. At first glance, an enzyme with multiple substrates seems likely to evolve its substrate preferences very slowly, since any significant change would cause the enzyme to lose the capacity to catalyze the reaction on many (perhaps most) of its substrates. To the extent that the enzyme activity on these substrates is important, changes to enzyme specificity would surely be detrimental, and thus the enzyme would be subjected to strong purifying selection. For example, the 3′ splice site consensus sequence YAG recognized by the U2AF complex is conserved in canonical U2-dependent splice sites in animals, plants, and fungi (Sharp and Burge, 1997; Spingola et al., 1999), perhaps because any alteration to the specificity of U2AF would negatively affect thousands of 3′ splice sites. By contrast, proteins that interact with just one binding partner may be capable of much more rapid evolution in their binding specificities. One of the best-studied examples of this is the abalone sperm enzyme lysin, which specifically binds the egg vitelline protein VERL and induces a conformational change that opens a pore for sperm heads to access the egg membrane. VERL and lysin are among the most rapidly evolving proteins in the abalone genome, perhaps because there is evolutionary pressure to continuously change sperm-egg specificity, particularly in organisms with external fertilization (Swanson and Vacquier, 2002). It is reasonable to believe that this rapid evolution would be severely impeded if VERL had to simultaneously maintain critical interactions with dozens or hundreds of ligands. Nevertheless, Microprocessor specificity does appear to have evolved in nematodes. One potential path to altered enzyme specificity is duplication and sub- or neofunctionalization; the redundancy allows one duplicate to evolve, while the other maintains the biologically important substrate interactions. Over time, substrates could then co-evolve to be recognized by one or both duplicates. For example, a functionally distinct spliceosome with different snRNPs, including U12 in place of U2, tends to utilize 3′ splice sites that have an AC rather than AG 131 (Tarn and Steitz, 1996). In worms and other animals, there could be variant Microprocessor complexes that would have allowed the substrate specificity of the complex to change over evolutionary time. Another potential path is modularity in the substrate, where multiple recognition motifs collaborate to distinguish true substrates from other substrates, even though each individual motif contributes relatively little to recognition. In this scenario, if the enzyme or enzyme complex alters its specificity for any one of the motifs, overall recognition is not significantly impacted; over time, the specificity for all the motifs could change quite considerably. For example, the rapid evolution of VERL is likely facilitated by the presence of 22 tandem repeats of the VERL binding domain, since variations in one repeat will not be too detrimental to lysin binding; in time, the overall VERL-lysin interaction can change dramatically, resulting in speciation (Swanson and Vacquier, 2002). Likewise, recognition of human pri-miRNAs appears to be modular, and it would be reasonable to suppose that recognition of nematode pri-miRNAs is also modular, although the modules themselves have diverged between the two lineages. Once the recognition motifs have been determined in C. elegans, phylogenetic analysis of pri-miRNA sequences across the nematode clade could permit a reconstruction of the evolutionary history of pri-miRNA recognition. For example, it is possible that the less rapidlyevolving members of the nematode clade might continue to use the downstream CNNC motif, while gaining recognition elements that are used throughout the nematode clade. C. elegans might use the common nematode elements, and may have gained additional elements specific to the rhabditid subclade, in lieu of the CNNC motif. If the members of the Microprocessor complex are elucidated that recognize these putative motifs, it may even be possible to correlate the evolutionary history of pri-miRNA motifs with the history of individual Microprocessor components. The next section will describe possible strategies for finding protein components of the Microprocessor that recognize pri-miRNA motifs. Gaining insight into mechanisms of pri-miRNA recognition Each sequence or structural preference found in the selection corresponds to a protein component of the Microprocessor that recognizes and binds to the motif, or to an RNA structure whose formation is dependent upon the motif. What proteins bind the motifs identified in Chapter 2, and any additional motifs that might be identified in pri-miRNAs? Given a functional 132 RNA motif, it is possible to specifically incorporate a photoreactive nucleoside analog in the motif, crosslink the nucleoside to a bound protein, and identify the proteins by mass spectrometry. This technique of incorporating a photoreactive nucleoside at a specific site in a long RNA substrate was initially used to identify spliceosome proteins that recognize the 5′ splice site motif (Wyatt et al., 1992). For snoRNAs and tRNAs, structured RNAs with multiple important motifs and protein interactions, this form of site-specific crosslinking has provided physical maps of the functional elements of the ribonucleoprotein complex relative to the substrate RNA (Mishima and Steitz, 1995; Cahill et al., 2002). The classic site-specific crosslinking protocol (Sontheimer, 1994) can be adapted to purify protein/pri-miRNA complexes and identify the peptide components by mass spectrometry. For example, to identify proteins bound to the CNNC motif, a pri-miRNA substrate could be assembled by splint ligation of three RNA fragments: a synthetic RNA oligonucleotide with a 4-thiouridine moiety in the CNNC motif, a synthetic RNA oligonucleotide with a 3′ biotin modification, and an RNA that includes the 5p flank and the hairpin (Figure 2A). This substrate would be crosslinked to candidate proteins in the Microprocessor-containing lysate described in Chapter 2, and covalently-linked protein-RNA complexes purified by binding to streptavidincoated beads (Figure 2B). As in the classic protocol, RNase T1 or another suitable RNase would be used to digest away the RNA substrate; in the proposed protocol, RNase digestion would additionally serve to elute the protein-RNA complexes from the streptavidin-coated beads. The peptides in the eluted protein-RNA complex would then be identified by mass spectrometry. Nearly all pri-miRNA motifs should be amenable to this crosslinking approach. However, one potential pitfall is that, for certain motifs, bound proteins may not be efficiently crosslinked; the 4-thiouridine moiety can only be crosslinked to peptide moieties within a few angstroms (Sontheimer, 1994). This spatial specificity is advantageous for identifying only those proteins which are directly bound to the motif. However, for some direct binding interactions, it is possible that the thio group may be too distant from a reactive amino acid to crosslink efficiently. An alternative strategy could use 5′-[(4-azidophenacyl)thio]-uridine, a photoreactive uridine analog whose reactive moiety is about 10 angstroms distant from the base, and is thus more likely to react with nearby amino acids (Hanna, 1989). Additionally, one could attempt to co-precipitate the bound protein with biotinylated pri-miRNA without crosslinking. Binding of biotinylated, wildtype pri-miRNA molecules would be carried out in the presence of competing 133 A Splint ligation s s p CUUC Bio GApCUUC Bio p B Crosslinking ? s s Bio GApCUUC Bio Binding to solid support ? s GApCUUC Bio Streptavidin-coated bead GApCUUC Aggressive washing Elution by RNAse T1 Elution by RNAse T1 ? s GApCUUC Peptide identification by mass spectrometry Bio pri-miRNA molecules in which the motif has been mutated. This approach would selectively coprecipitate proteins whose binding depends on the motif; these proteins can then be identified by either mass spectrometry or Western blot. In any of these approaches, the contributions of the candidate proteins should be delineated by in vitro and in vivo processing assays after loss-offunction or gain-of-function of the candidate proteins. The identification of proteins that recognize pri-miRNA processing motifs has implications for the regulation and dysregulation of miRNA processing in physiology and pathology. As discussed above, processing motifs may be mutated in cancer, as the CNNC motif is mutated in human chronic lymphoid leukemia. The proteins that recognize these motifs may themselves be dysregulated in cancer, and may be possible to infer the nature of this dysregulation based on the regulated miRNA (tumor-suppressor or oncogene) and the type of motif (promoting or inhibiting Microprocessor cleavage). For example, proteins that enhance processing of a tumor-suppressor miRNA may themselves be tumor suppressors. One instance of this is found in the biogenesis of let-7, a family of tumor-suppressor miRNAs that target key oncogenes such as c-MYC, and HMGA2 (Mayr et al., 2007; Chang et al., 2008). Lin-28A protein inhibits Microprocessor cleavage of let-7 family pri-miRNAs and thus reduces mature levels of this key tumor-suppresor miRNA (Piskounova et al., 2011). Correspondingly, both isoforms of Lin-28 are upregulated in cancer samples, particularly in samples from advanced malignancy (Viswanathan et al., 2009). It could be possible to characterize the functional roles of identified proteins by analyzing analyze publicly-available databases on cancer gene expression, mutations, clinical course, and drug sensitivity (Cowin et al., 2010). For example, candidate proteins could be cross-referenced against protein-coding genes known to be mutated in cancer (Futreal et al., 2004). Data on the Figure 2. Proposed strategy for identifying proteins that bind identified pri-miRNA sequence determinants. Identification of CNNC-binding proteins is shown as an example. (A) Assembly of a biotinylated pri-miRNA substrate containing a 4-thiouridine moiety specifically incorporated in the CNNC motif. Three synthetic RNAs would be assembled into a pri-miRNA 32 substrate by splint ligation. The red “p” denotes a P phosphate. (B) Purification of crosslinked RNA-protein complexes. The assembled pri-miRNA would be incubated in whole-cell lysate. Proteins that bind in close proximity to the 4-thiouridine moiety would be crosslinked to the biotinylated pri-miRNA by 365 nm ultraviolet light. Crosslinked complexes would be purified by streptavidin bead binding with aggressive washing, and released by RNase T1 digestion of the pri-miRNA. Protein components of the complex would be identified by massspectrometry. 135 NCI-60 cancer cell lines would be particularly appealing for analysis, since many types of data are available for all 60 lines, including protein-coding gene expression data (Ross et al., 2000; Liu et al., 2010) and miRNA expression data (Blower et al., 2007; Liu et al., 2010; Sokilde et al., 2011). For proteins that have not been characterized in the literature, gene expression clustering analysis may help reveal the molecular pathways that impinge on the candidate proteins and thus on miRNA biogenesis. Identifying the proteins that bind processing motifs and characterizing their effects on miRNA biogenesis would open new avenues of investigation and may lead to opportunities for the development of diagnostic tools or novel therapeutics. At a basic level, identifying proteins that bind pri-miRNAs and regulate their biogenesis would expand the catalog of proteins comprise the Microprocessor complex, and shed light on the mechanisms by which the activity of the complex can be regulated. In addition, since little is known of the structure of the Microprocessor, determination of which proteins bind to various parts of the pri-miRNA would yield a schematic of the three-dimensional structure of the Microprocessor, albeit at low spatial resolution. From a regulatory pathway standpoint, classification of previously uncharacterized proteins as miRNA regulators may give insight into novel oncogenic or tumor suppressing regulatory pathways. On an epidemiological level, the expression levels of identified proteins may be useful as biomarkers for tumor progression and prognosis, as is the case for Drosha, Dicer, and Lin-28 (Merritt et al., 2008; Viswanathan et al., 2009). To the extent that identified proteins are mutated in cancer, the proposed work may also aid the interpretation of loci identified in cancer genome efforts. On a therapeutic level, these proteins may also be novel drug targets for regulating miRNA levels. Applying selection approaches to stubborn questions in RNA biology The availability of hundreds of organismal genomes has made it possible to identify and characterize functional elements, including those in functional RNAs, simply by computationally analyzing sequence data. The power of comparative sequence analysis is illustrated by some of the original work to identify Dicer: knowing that the precursors of small interfering RNAs were double-stranded and that RNase III enzymes in other organisms cleaved RNA duplexes, investigators simply searched the D. melanogaster and C. elegans genomes for sequences that 136 would code for proteins resembling RNase III (Bernstein et al., 2001). Computational analysis can even provide powerful evidence for biological importance when actual function is unknown, since conservation of nucleic acid or protein sequence over a long evolutionary timespan is ipso facto evidence for purifying selection. However, computational analysis of genomic sequence data is limited when functional sequence elements are degenerate, as motifs for RNA–protein binding tend to be. The study of pri-miRNA determinants described in Chapter 2 was situated just beyond the limits of computational analysis, given the relatively unsuccessful efforts to find determinants by comparing individual pri-miRNAs to their orthologs, or by comparing pri-miRNAs to other primiRNAs in the same species. In fact, the determinants identified by in vitro selection are composed of just two or three informative nucleotides, which are generally too short to be found by multiple-sequence alignment or de novo motif discovery algorithms. In particular, discovery of the CNNC motif by pure computational analysis was probably complicated because it is a “spaced” motif, where two informative nucleotides are separated by less informative nucleotides, and the CNNC position can vary across a narrow range of positions relative to the Drosha cleavage site. Even when subtle enrichment signals were detected in pure sequence analysis, it was often difficult to interpret their significance, since the sequence data was not intrinsically rooted in pri-miRNA processing. These difficulties were overcome by generating hundreds of billions of sequence variants, selecting in vitro for those that were functional in a specific biochemical context, and coupling the in vitro selection to high-throughput sequencing. This approach is not limited to the identification of motifs in pri-miRNAs; it can be applied to the study of any functional nucleic acid, and is uniquely suited to study RNA species which have not been amenable to computational analysis either because of extensive divergence that impairs evolutionary conservation analysis, or because the elements to be found are too subtle to be detected above noise by computational algorithms. application is the study of long noncoding RNAs (lncRNAs). One potentially fertile These RNAs are important regulators of gene expression, but studies of lncRNAs have been hampered by diversity in both sequence and regulatory mechanism (Wang and Chang, 2011). When blocks of sequence conservation can be found, the sequences have been shown to be important for the function of the lncRNA and for normal vertebrate development (Ulitsky et al., 2011). 137 A Incubation with immunopurified PRC2 Nitrocellulose filtration Pool of partially-randomized lncRNA variants High-throughput sequencing ?? Pool of selected lncRNA variants B Novel motifs that define PRC2 binding High-throughput plasmid sequencing Poly-A signals Barcode Reporter ORF Database mapping barcodes to lncRNA variant sequences Enhancer-like lncRNA A AAAA In vivo expression of reporter mRNA AAA A AAA AAAA A AAA High-throughput barcode sequencing AAAA Plasmid pool of partially-randomized lncRNA variants A AAA AAAA ?? Novel motifs that promote lncRNA function C Model ORF Putative zipcode region Soma compartment In vivo expression of model mRNA Poly-A signal Plasmid pool of partially-randomized 3’ UTR variants High-throughput sequencing NGF-containing axon compartment A AAAA AAA A ?? AAAA AAA AAAA Novel motifs that regulate mRNA localization However, the vast majority of lncRNAs are poorly conserved at the sequence level, even when the presence of a noncoding transcript is conserved in syntenic regions of the genome in other organisms (Wang and Chang, 2011). In vitro and in vivo selection techniques, coupled with high throughput sequencing, could rapidly identify and characterize the functional elements in such lncRNAs. For example, many lncRNAs are probably molecular scaffolds that assist in the assembly of chromatin-regulation complexes in specific genomic regions. The best-studied example of this is the recruitment of polycomb repressive complex 2 (PRC2) to the HOXD locus by the lncRNA HOTAIR (Rinn et al., 2007). In fact, up to 20% of the annotated lncRNAs in mammalian genomes may bind PRC2, although some of these may be interacting nonspecifically (Khalil et al., 2009; Guttman et al., 2011). The region of HOTAIR that binds PRC2 components has been isolated to a 300 nt region that is thought to have some secondary structure, but the importance of this structure or any potential primary sequence elements is unclear (Tsai et al., 2010). A relatively straightforward approach to studying this region would be to partially randomize the 300 nt region and select for variants that retain binding to immunopurified PRC2 complexes, followed by sequencing of those variants (Figure 3A). This approach resembles that first used to define the HIV Rev-binding site (Bartel et al., 1991). Any motifs that are found in HOTAIR might directly translate to some of the hundreds of other lncRNAs that are thought to bind PRC2, thus defining a functional domain in many lncRNAs with a single experiment. Another set of lncRNAs that could be studied by in vivo selection and sequencing are the enhancer-like lncRNAs that promote the expression of nearby protein-coding genes, including a Figure 3. Possible selection strategies to study three functional RNAs. (A) Scheme for identifying motifs that specify binding substrates of PRC2. Variants of lncRNAs that bind the immunopurified PRC2 complex would be isolated by nitrocellulose filtration and sequenced. (B) Scheme for mapping functional elements in enhancer-like lncRNAs. The enhancer lncRNA sequences would be partially randomized and cloned into an expression plasmid with a nearby reporter mRNA containing a random barcode. An initial sequencing run would associate the sequence of the enhancer-lncRNA variants with the reporter barcode. Successful variants would promote the transcription of the reporter mRNA, including the barcode, and would be identified by sequencing the barcode. (C) Scheme for identifying and characterizing zipcode motifs that promote the localization of mRNAs to axon terminals. Variant 3′ UTR sequences corresponding to a putative zipcode region would be cloned into a plasmid downstream of a model localized protein-coding sequence. Neurons expressing these variants would be grown in a compartmentalized chamber that permits easy separation of axons from the neuronal soma. Successful variants would be isolated from the axon compartment and sequenced. 139 set of transcription factors that are master regulators of hematopoiesis (Orom et al., 2010). The enhancement function of these lncRNAs is dependent on the lncRNA molecule, as opposed to the act of transcription, but the important elements in the lncRNA are unclear. Since the enhancing effects of the lncRNAs can be recapitulated in a plasmid-based reporter gene system, the lncRNAs could be partially randomized and cloned into a reporter plasmid, and functional variants could be selected on the basis of reporter expression. The randomization, selection, and sequencing would be carried out following a strategy developed to study DNA enhancer elements (Patwardhan et al., 2012). This strategy uses a two-step approach to selection and sequencing. In the first step, the plasmid pool is sequenced to determine the sequence of the partially randomized region, which is correlated to a barcode sequence located in the reporter transcript. In the second step, plasmids are transfected into cells, where functional DNA enhancer elements drive the transcription of the reporter mRNA, including the barcode. These barcoded mRNAs are reverse transcribed and sequenced to determine which variants successfully promoted transcription. For enhancer-like lncRNAs, the strategy would be identical, except the partially-randomized DNA enhancer sequence would be replaced by the partially-randomized lncRNA sequence (Figure 3B). Another potentially fertile application of selection and high-throughput sequencing is the study of “zipcode” elements that specify the localization of mRNAs. Dynamic mRNA transport is an important component of many biological processes, such as the formation of spatial gradients in developmental syncytia and polarized cells, local regulation at the leading edge of migrating cells, and the specification of cell identity in daughter cells after mitosis (Meignin and Davis, 2010). The regulated localization of mRNAs is particularly important in neurons, where transported mRNAs play important roles in the growth and migration of new dendrites and axons, and in the maintenance of functional synaptic terminals (Jung et al., 2012). The bestcharacterized zipcode is a bipartite element in the 3′ UTR of the β-actin mRNA, consisting of two 6 nt motifs separated by a 15 nt spacer; this spacer is thought to allow the zipcode region to loop around the zipcode-binding protein (ZBP1) so that the two motifs can be simultaneously recognized by a pair of KH domains (Patel et al., 2012). However, this zipcode is present in just a fraction of synapse-localized mRNAs; for the rest, neither the zipcodes nor the proteins that recognize them are known. For example, the mRNA of the chaperone protein calreticulin is localized to axon terminals, and two 100 nt conserved regions in the 3′ UTR are individually 140 sufficient to drive mRNA transport, but the actual motifs and the proteins that bind them are unknown (Vuppalanchi et al., 2010). Since the 3′ UTR is sufficient to drive mRNA transport, a relatively simple selection approach could be undertaken where a pool of variant 3′ UTRs would be cloned into an expression plasmid downstream of a reporter mRNA; the plasmid pool would be transfected into neurons grown in a compartmentalized culture system that permits easy separation of axon terminals from the neuron soma (Campenot et al., 2009). Successful 3′ UTR variants would be transported into the axon terminals, collected by the compartmentalized culture system, amplified and sequenced (Figure 3C). Once the specific zipcode motifs have been delineated, the proteins that bind the zipcode and recruit the mRNA to transport granules would be identified by candidate testing or by site-specific crosslinking, as described above. These three applications illustrate the diversity of questions that could be addressed by the careful design of a selection experiment, coupled to a high-throughput sequencing of the selected variants. This type of strategy is becoming increasingly attractive as the cost of sequencing falls, and the capacity increases to generate long, high-quality sequences. More broadly, prospects are excellent for approaches that combine experimental savvy with the power of computational analysis to crack stubborn but critical problems in biology. 141 Bibliography and References Cited Aboobaker, A., and Blaxter, M. (2003). Hox gene evolution in nematodes: novelty conserved. Curr Opin Genet Dev 13, 593-598. Aguinaldo, A.M., Turbeville, J.M., Linford, L.S., Rivera, M.C., Garey, J.R., Raff, R.A., and Lake, J.A. (1997). Evidence for a clade of nematodes, arthropods and other moulting animals. Nature 387, 489-493. Aigner, A. (2011). MicroRNAs (miRNAs) in cancer invasion and metastasis: therapeutic approaches based on metastasis-related miRNAs. J Mol Med (Berl) 89, 445-457. Akey, D.L., and Berger, J.M. (2005). Structure of the nuclease domain of ribonuclease III from M. tuberculosis at 2.1 A. Protein Sci 14, 2744-2750. Altuvia, S., Locker-Giladi, H., Koby, S., Ben-Nun, O., and Oppenheim, A.B. (1987). RNase III stimulates the translation of the cIII gene of bacteriophage lambda. Proc Natl Acad Sci U S A 84, 6511-6515. Ambros, V., Bartel, B., Bartel, D.P., Burge, C.B., Carrington, J.C., Chen, X., Dreyfuss, G., Eddy, S.R., Griffiths-Jones, S., Marshall, M., et al. (2003). A uniform system for microRNA annotation. RNA 9, 277-279. Arvey, A., Larsson, E., Sander, C., Leslie, C.S., and Marks, D.S. (2010). Target mRNA abundance dilutes microRNA and siRNA activity. Mol Syst Biol 6, 363. Ashburner, M., Ball, C.A., Blake, J.A., Botstein, D., Butler, H., Cherry, J.M., Davis, A.P., Dolinski, K., Dwight, S.S., Eppig, J.T., et al. (2000). Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet 25, 25-29. Babiarz, J.E., Ruby, J.G., Wang, Y., Bartel, D.P., and Blelloch, R. (2008). Mouse ES cells express endogenous shRNAs, siRNAs, and other Microprocessor-independent, Dicerdependent small RNAs. Genes Dev 22, 2773-2785. Baek, D., Villen, J., Shin, C., Camargo, F.D., Gygi, S.P., and Bartel, D.P. (2008). The impact of microRNAs on protein output. Nature 455, 64-71. Bar, M., Wyman, S.K., Fritz, B.R., Qi, J., Garg, K.S., Parkin, R.K., Kroh, E.M., Bendoraite, A., Mitchell, P.S., Nelson, A.M., et al. (2008). MicroRNA discovery and profiling in human embryonic stem cells by deep sequencing of small RNA libraries. Stem Cells 26, 2496-2505. Bardwell, J.C., Regnier, P., Chen, S.M., Nakamura, Y., Grunberg-Manago, M., and Court, D.L. (1989). Autoregulation of RNase III operon by mRNA processing. EMBO J 8, 3401-3407. Barry, G., Squires, C., and Squires, C.L. (1980). Attenuation and processing of RNA from the rplJL--rpoBC transcription unit of Escherichia coli. Proc Natl Acad Sci U S A 77, 33313335. Bartel, D.P. (2004). MicroRNAs: genomics, biogenesis, mechanism, and function. Cell 116, 281297. Bartel, D.P. (2009). MicroRNAs: target recognition and regulatory functions. Cell 136, 215-233. Bartel, D.P., Zapp, M.L., Green, M.R., and Szostak, J.W. (1991). HIV-1 Rev regulation involves recognition of non-Watson-Crick base pairs in viral RNA. Cell 67, 529-536. Bass, B.L. (2000). Double-stranded RNA as a template for gene silencing. Cell 101, 235-238. Bazzini, A.A., Lee, M.T., and Giraldez, A.J. (2012). Ribosome profiling shows that miR-430 reduces translation before causing mRNA decay in zebrafish. Science 336, 233-237. Beltrame, M., and Tollervey, D. (1995). Base pairing between U3 and the pre-ribosomal RNA is required for 18S rRNA synthesis. EMBO J 14, 4350-4356. 142 Bentwich, I., Avniel, A., Karov, Y., Aharonov, R., Gilad, S., Barad, O., Barzilai, A., Einat, P., Einav, U., Meiri, E., et al. (2005). Identification of hundreds of conserved and nonconserved human microRNAs. Nat Genet 37, 766-770. Berezikov, E., van Tetering, G., Verheul, M., van de Belt, J., van Laake, L., Vos, J., Verloop, R., van de Wetering, M., Guryev, V., Takada, S., et al. (2006). Many novel mammalian microRNA candidates identified by extensive cloning and RAKE analysis. Genome Res 16, 1289-1298. Bernstein, E., Caudy, A.A., Hammond, S.M., and Hannon, G.J. (2001). Role for a bidentate ribonuclease in the initiation step of RNA interference. Nature 409, 363-366. Bernstein, E., Kim, S.Y., Carmell, M.A., Murchison, E.P., Alcorn, H., Li, M.Z., Mills, A.A., Elledge, S.J., Anderson, K.V., and Hannon, G.J. (2003). Dicer is essential for mouse development. Nat Genet 35, 215-217. Blow, M.J., Grocock, R.J., van Dongen, S., Enright, A.J., Dicks, E., Futreal, P.A., Wooster, R., and Stratton, M.R. (2006). RNA editing of human microRNAs. Genome Biol 7, R27. Blower, P.E., Verducci, J.S., Lin, S., Zhou, J., Chung, J.H., Dai, Z., Liu, C.G., Reinhold, W., Lorenzi, P.L., Kaldjian, E.P., et al. (2007). MicroRNA expression profiles for the NCI-60 cancer cell panel. Mol Cancer Ther 6, 1483-1491. Blumenthal, T. (2005). Trans-splicing and operons. WormBook, 1-9. Bohmert, K., Camus, I., Bellini, C., Bouchez, D., Caboche, M., and Benning, C. (1998). AGO1 defines a novel locus of Arabidopsis controlling leaf development. EMBO J 17, 170-180. Bohnsack, M.T., Czaplinski, K., and Gorlich, D. (2004). Exportin 5 is a RanGTP-dependent dsRNA-binding protein that mediates nuclear export of pre-miRNAs. RNA 10, 185-191. Bohnsack, M.T., Regener, K., Schwappach, B., Saffrich, R., Paraskeva, E., Hartmann, E., and Gorlich, D. (2002). Exp5 exports eEF1A via tRNA from nuclei and synergizes with other transport pathways to confine translation to the cytoplasm. EMBO J 21, 6205-6215. Bracht, J., Hunter, S., Eachus, R., Weeks, P., and Pasquinelli, A.E. (2004). Trans-splicing and polyadenylation of let-7 microRNA primary transcripts. RNA 10, 1586-1594. Bram, R.J., Young, R.A., and Steitz, J.A. (1980). The ribonuclease III site flanking 23S sequences in the 30S ribosomal precursor RNA of E. coli. Cell 19, 393-401. Breaker, R.R., Banerji, A., and Joyce, G.F. (1994). Continuous in vitro evolution of bacteriophage RNA polymerase promoters. Biochemistry 33, 11980-11986. Brownawell, A.M., and Macara, I.G. (2002). Exportin-5, a novel karyopherin, mediates nuclear export of double-stranded RNA binding proteins. J Cell Biol 156, 53-64. Brummelkamp, T.R., Bernards, R., and Agami, R. (2002). A system for stable expression of short interfering RNAs in mammalian cells. Science 296, 550-553. Butcher, S.E., Dieckmann, T., and Feigon, J. (1997). Solution structure of the conserved 16 Slike ribosomal RNA UGAA tetraloop. J Mol Biol 268, 348-358. Cahill, N.M., Friend, K., Speckmann, W., Li, Z.H., Terns, R.M., Terns, M.P., and Steitz, J.A. (2002). Site-specific cross-linking analyses reveal an asymmetric protein distribution for a box C/D snoRNP. EMBO J 21, 3816-3828. Calabrese, J.M., Seila, A.C., Yeo, G.W., and Sharp, P.A. (2007). RNA sequence analysis defines Dicer's role in mouse embryonic stem cells. Proc Natl Acad Sci U S A 104, 18097-18102. Calado, A., Treichel, N., Muller, E.C., Otto, A., and Kutay, U. (2002). Exportin-5-mediated nuclear export of eukaryotic elongation factor 1A and tRNA. EMBO J 21, 6216-6224. Calin, G.A., Dumitru, C.D., Shimizu, M., Bichi, R., Zupo, S., Noch, E., Aldler, H., Rattan, S., Keating, M., Rai, K., et al. (2002). Frequent deletions and down-regulation of micro- RNA 143 genes miR15 and miR16 at 13q14 in chronic lymphocytic leukemia. Proc Natl Acad Sci U S A 99, 15524-15529. Calin, G.A., Ferracin, M., Cimmino, A., Di Leva, G., Shimizu, M., Wojcik, S.E., Iorio, M.V., Visone, R., Sever, N.I., Fabbri, M., et al. (2005). A MicroRNA signature associated with prognosis and progression in chronic lymphocytic leukemia. N Engl J Med 353, 1793-1801. Calin, G.A., Liu, C.G., Sevignani, C., Ferracin, M., Felli, N., Dumitru, C.D., Shimizu, M., Cimmino, A., Zupo, S., Dono, M., et al. (2004a). MicroRNA profiling reveals distinct signatures in B cell chronic lymphocytic leukemias. Proc Natl Acad Sci U S A 101, 1175511760. Calin, G.A., Sevignani, C., Dumitru, C.D., Hyslop, T., Noch, E., Yendamuri, S., Shimizu, M., Rattan, S., Bullrich, F., Negrini, M., et al. (2004b). Human microRNA genes are frequently located at fragile sites and genomic regions involved in cancers. Proc Natl Acad Sci U S A 101, 2999-3004. Campenot, R.B., Lund, K., and Mok, S.A. (2009). Production of compartmented cultures of rat sympathetic neurons. Nat Protoc 4, 1869-1887. Caudy, A.A., Myers, M., Hannon, G.J., and Hammond, S.M. (2002). Fragile X-related protein and VIG associate with the RNA interference machinery. Genes Dev 16, 2491-2496. Cenik, E.S., Fukunaga, R., Lu, G., Dutcher, R., Wang, Y., Tanaka Hall, T.M., and Zamore, P.D. (2011). Phosphate and R2D2 restrict the substrate specificity of Dicer-2, an ATP-driven ribonuclease. Mol Cell 42, 172-184. Chakraborty, S., Mehtab, S., Patwardhan, A., and Krishnan, Y. (2012). Pri-miR-17-92a transcript folds into a tertiary structure and autoregulates its processing. RNA 18, 1014-1028. Chakravarthy, S., Sternberg, S.H., Kellenberger, C.A., and Doudna, J.A. (2010). Substratespecific kinetics of Dicer-catalyzed RNA processing. J Mol Biol 404, 392-402. Chanfreau, G., Buckle, M., and Jacquier, A. (2000). Recognition of a conserved class of RNA tetraloops by Saccharomyces cerevisiae RNase III. Proc Natl Acad Sci U S A 97, 3142-3147. Chanfreau, G., Legrain, P., and Jacquier, A. (1998). Yeast RNase III as a key processing enzyme in small nucleolar RNAs metabolism. J Mol Biol 284, 975-988. Chang, T.C., Yu, D., Lee, Y.S., Wentzel, E.A., Arking, D.E., West, K.M., Dang, C.V., ThomasTikhonenko, A., and Mendell, J.T. (2008). Widespread microRNA repression by Myc contributes to tumorigenesis. Nat Genet 40, 43-50. Chatterjee, S., and Grosshans, H. (2009). Active turnover modulates mature microRNA activity in Caenorhabditis elegans. Nature 461, 546-549. Chelladurai, B.S., Li, H., and Nicholson, A.W. (1991). A conserved sequence element in ribonuclease III processing signals is not required for accurate in vitro enzymatic cleavage. Nucleic Acids Res 19, 1759-1766. Cheloufi, S., Dos Santos, C.O., Chong, M.M., and Hannon, G.J. (2010). A dicer-independent miRNA biogenesis pathway that requires Ago catalysis. Nature 465, 584-589. Chen, C.Z., Li, L., Lodish, H.F., and Bartel, D.P. (2004). MicroRNAs modulate hematopoietic lineage differentiation. Science 303, 83-86. Chendrimada, T.P., Gregory, R.I., Kumaraswamy, E., Norman, J., Cooch, N., Nishikura, K., and Shiekhattar, R. (2005). TRBP recruits the Dicer complex to Ago2 for microRNA processing and gene silencing. Nature 436, 740-744. Chiang, H.R., Schoenfeld, L.W., Ruby, J.G., Auyeung, V.C., Spies, N., Baek, D., Johnston, W.K., Russ, C., Luo, S., Babiarz, J.E., et al. (2010). Mammalian microRNAs: experimental evaluation of novel and previously annotated genes. Genes Dev 24, 992-1009. 144 Chong, M.M., Zhang, G., Cheloufi, S., Neubert, T.A., Hannon, G.J., and Littman, D.R. (2010). Canonical and alternate functions of the microRNA biogenesis machinery. Genes Dev 24, 1951-1960. Chung, W.J., Agius, P., Westholm, J.O., Chen, M., Okamura, K., Robine, N., Leslie, C.S., and Lai, E.C. (2011). Computational and experimental identification of mirtrons in Drosophila melanogaster and Caenorhabditis elegans. Genome Res 21, 286-300. Cifuentes, D., Xue, H., Taylor, D.W., Patnode, H., Mishima, Y., Cheloufi, S., Ma, E., Mane, S., Hannon, G.J., Lawson, N.D., et al. (2010). A novel miRNA processing pathway independent of Dicer requires Argonaute2 catalytic activity. Science 328, 1694-1698. Cimmino, A., Calin, G.A., Fabbri, M., Iorio, M.V., Ferracin, M., Shimizu, M., Wojcik, S.E., Aqeilan, R.I., Zupo, S., Dono, M., et al. (2005). miR-15 and miR-16 induce apoptosis by targeting BCL2. Proc Natl Acad Sci U S A 102, 13944-13949. Costinean, S., Zanesi, N., Pekarsky, Y., Tili, E., Volinia, S., Heerema, N., and Croce, C.M. (2006). Pre-B cell proliferation and lymphoblastic leukemia/high-grade lymphoma in E(mu)miR155 transgenic mice. Proc Natl Acad Sci U S A 103, 7024-7029. Cowin, P.A., Anglesio, M., Etemadmoghadam, D., and Bowtell, D.D. (2010). Profiling the cancer genome. Annu Rev Genomics Hum Genet 11, 133-159. Czech, B., Malone, C.D., Zhou, R., Stark, A., Schlingeheyde, C., Dus, M., Perrimon, N., Kellis, M., Wohlschlegel, J.A., Sachidanandam, R., et al. (2008). An endogenous small interfering RNA pathway in Drosophila. Nature 453, 798-802. Czech, B., Zhou, R., Erlich, Y., Brennecke, J., Binari, R., Villalta, C., Gordon, A., Perrimon, N., and Hannon, G.J. (2009). Hierarchical rules for Argonaute loading in Drosophila. Mol Cell 36, 445-456. Daniels, D.L., Subbarao, M.N., Blattner, F.R., and Lozeron, H.A. (1988). Q-mediated late gene transcription of bacteriophage lambda: RNA start point and RNase III processing sites in vivo. Virology 167, 568-577. Davis, B.N., Hilyard, A.C., Lagna, G., and Hata, A. (2008). SMAD proteins control DROSHAmediated microRNA maturation. Nature 454, 56-61. Davis, B.N., Hilyard, A.C., Nguyen, P.H., Lagna, G., and Hata, A. (2010). Smad proteins bind a conserved RNA sequence to promote microRNA maturation by Drosha. Mol Cell 39, 373384. Denli, A.M., Tops, B.B., Plasterk, R.H., Ketting, R.F., and Hannon, G.J. (2004). Processing of primary microRNAs by the Microprocessor complex. Nature 432, 231-235. Doench, J.G., and Sharp, P.A. (2004). Specificity of microRNA target selection in translational repression. Genes Dev 18, 504-511. Dong, Z., Han, M.H., and Fedoroff, N. (2008). The RNA-binding proteins HYL1 and SE promote accurate in vitro processing of pri-miRNA by DCL1. Proc Natl Acad Sci U S A 105, 9970-9975. Dreyfuss, G., Matunis, M.J., Pinol-Roma, S., and Burd, C.G. (1993). hnRNP proteins and the biogenesis of mRNA. Annu Rev Biochem 62, 289-321. Duan, R., Pak, C., and Jin, P. (2007). Single nucleotide polymorphism associated with mature miR-125a alters the processing of pri-miRNA. Hum Mol Genet 16, 1124-1131. Dunn, J.J., and Studier, F.W. (1973a). T7 early RNAs and Escherichia coli ribosomal RNAs are cut from large precursor RNAs in vivo by ribonuclease 3. Proc Natl Acad Sci U S A 70, 3296-3300. 145 Dunn, J.J., and Studier, F.W. (1973b). T7 early RNAs are generated by site-specific cleavages. Proc Natl Acad Sci U S A 70, 1559-1563. Eis, P.S., Tam, W., Sun, L., Chadburn, A., Li, Z., Gomez, M.F., Lund, E., and Dahlberg, J.E. (2005). Accumulation of miR-155 and BIC RNA in human B cell lymphomas. Proc Natl Acad Sci U S A 102, 3627-3632. Elbashir, S.M., Harborth, J., Lendeckel, W., Yalcin, A., Weber, K., and Tuschl, T. (2001a). Duplexes of 21-nucleotide RNAs mediate RNA interference in cultured mammalian cells. Nature 411, 494-498. Elbashir, S.M., Lendeckel, W., and Tuschl, T. (2001b). RNA interference is mediated by 21- and 22-nucleotide RNAs. Genes Dev 15, 188-200. Elela, S.A., Igel, H., and Ares, M., Jr. (1996). RNase III cleaves eukaryotic preribosomal RNA at a U3 snoRNP-dependent site. Cell 85, 115-124. Ellington, A.D., and Szostak, J.W. (1990). In vitro selection of RNA molecules that bind specific ligands. Nature 346, 818-822. Esquela-Kerscher, A., Trang, P., Wiggins, J.F., Patrawala, L., Cheng, A., Ford, L., Weidhaas, J.B., Brown, D., Bader, A.G., and Slack, F.J. (2008). The let-7 microRNA reduces tumor growth in mouse models of lung cancer. Cell Cycle 7, 759-764. Fagard, M., Boutet, S., Morel, J.B., Bellini, C., and Vaucheret, H. (2000). AGO1, QDE-2, and RDE-1 are related proteins required for post-transcriptional gene silencing in plants, quelling in fungi, and RNA interference in animals. Proc Natl Acad Sci U S A 97, 11650-11654. Faller, M., Toso, D., Matsunaga, M., Atanasov, I., Senturia, R., Chen, Y., Zhou, Z.H., and Guo, F. (2010). DGCR8 recognizes primary transcripts of microRNAs through highly cooperative binding and formation of higher-order structures. RNA 16, 1570-1583. Farh, K.K., Grimson, A., Jan, C., Lewis, B.P., Johnston, W.K., Lim, L.P., Burge, C.B., and Bartel, D.P. (2005). The widespread impact of mammalian MicroRNAs on mRNA repression and evolution. Science 310, 1817-1821. Fellmann, C., Zuber, J., McJunkin, K., Chang, K., Malone, C.D., Dickins, R.A., Xu, Q., Hengartner, M.O., Elledge, S.J., Hannon, G.J., et al. (2011). Functional identification of optimized RNAi triggers using a massively parallel sensor assay. Mol Cell 41, 733-746. Feng, Y., Zhang, X., Song, Q., Li, T., and Zeng, Y. (2011). Drosha processing controls the specificity and efficiency of global microRNA expression. Biochim Biophys Acta 1809, 700707. Filippov, V., Solovyev, V., Filippova, M., and Gill, S.S. (2000). A novel type of RNase III family proteins in eukaryotes. Gene 245, 213-221. Fire, A., Albertson, D., Harrison, S.W., and Moerman, D.G. (1991). Production of antisense RNA leads to effective and specific inhibition of gene expression in C. elegans muscle. Development 113, 503-514. Fire, A., Xu, S., Montgomery, M.K., Kostas, S.A., Driver, S.E., and Mello, C.C. (1998). Potent and specific genetic interference by double-stranded RNA in Caenorhabditis elegans. Nature 391, 806-811. Flynt, A.S., Greimann, J.C., Chung, W.J., Lima, C.D., and Lai, E.C. (2010). MicroRNA biogenesis via splicing and exosome-mediated trimming in Drosophila. Mol Cell 38, 900907. Forstemann, K., Horwich, M.D., Wee, L., Tomari, Y., and Zamore, P.D. (2007). Drosophila microRNAs are sorted into functionally distinct argonaute complexes after production by dicer-1. Cell 130, 287-297. 146 Forstemann, K., Tomari, Y., Du, T., Vagin, V.V., Denli, A.M., Bratu, D.P., Klattenhoff, C., Theurkauf, W.E., and Zamore, P.D. (2005). Normal microRNA maturation and germ-line stem cell maintenance requires Loquacious, a double-stranded RNA-binding domain protein. PLoS Biol 3, e236. Frank, F., Sonenberg, N., and Nagar, B. (2010). Structural basis for 5'-nucleotide base-specific recognition of guide RNA by human AGO2. Nature 465, 818-822. Friedman, R.C., Farh, K.K., Burge, C.B., and Bartel, D.P. (2009). Most mammalian mRNAs are conserved targets of microRNAs. Genome Res 19, 92-105. Fujita, P.A., Rhead, B., Zweig, A.S., Hinrichs, A.S., Karolchik, D., Cline, M.S., Goldman, M., Barber, G.P., Clawson, H., Coelho, A., et al. (2011). The UCSC Genome Browser database: update 2011. Nucleic Acids Res 39, D876-882. Fukuda, T., Yamagata, K., Fujiyama, S., Matsumoto, T., Koshida, I., Yoshimura, K., Mihara, M., Naitou, M., Endoh, H., Nakamura, T., et al. (2007). DEAD-box RNA helicase subunits of the Drosha complex are required for processing of rRNA and a subset of microRNAs. Nat Cell Biol 9, 604-611. Futreal, P.A., Coin, L., Marshall, M., Down, T., Hubbard, T., Wooster, R., Rahman, N., and Stratton, M.R. (2004). A census of human cancer genes. Nat Rev Cancer 4, 177-183. Gan, J., Shaw, G., Tropea, J.E., Waugh, D.S., Court, D.L., and Ji, X. (2008). A stepwise model for double-stranded RNA processing by ribonuclease III. Mol Microbiol 67, 143-154. Gan, J., Tropea, J.E., Austin, B.P., Court, D.L., Waugh, D.S., and Ji, X. (2006). Structural insight into the mechanism of double-stranded RNA processing by ribonuclease III. Cell 124, 355366. Garcia, D.M., Baek, D., Shin, C., Bell, G.W., Grimson, A., and Bartel, D.P. (2011). Weak seedpairing stability and high target-site abundance decrease the proficiency of lsy-6 and other microRNAs. Nat Struct Mol Biol 18, 1139-1146. Garzon, R., Calin, G.A., and Croce, C.M. (2009). MicroRNAs in Cancer. Annu Rev Med 60, 167-179. Ghildiyal, M., Xu, J., Seitz, H., Weng, Z., and Zamore, P.D. (2010). Sorting of Drosophila small silencing RNAs partitions microRNA* strands into the RNA interference pathway. RNA 16, 43-56. Gottwein, E., Cai, X., and Cullen, B.R. (2006). A novel assay for viral microRNA function identifies a single nucleotide polymorphism that affects Drosha processing. J Virol 80, 53215326. Grad, Y., Aach, J., Hayes, G.D., Reinhart, B.J., Church, G.M., Ruvkun, G., and Kim, J. (2003). Computational and experimental identification of C. elegans microRNAs. Mol Cell 11, 12531263. Greenbaum, N.L., Radhakrishnan, I., Patel, D.J., and Hirsh, D. (1996). Solution structure of the donor site of a trans-splicing RNA. Structure 4, 725-733. Gregory, R.I., Yan, K.P., Amuthan, G., Chendrimada, T., Doratotaj, B., Cooch, N., and Shiekhattar, R. (2004). The Microprocessor complex mediates the genesis of microRNAs. Nature 432, 235-240. Griffiths-Jones, S., Grocock, R.J., van Dongen, S., Bateman, A., and Enright, A.J. (2006). miRBase: microRNA sequences, targets and gene nomenclature. Nucleic Acids Res 34, D140-144. 147 Grimson, A., Farh, K.K., Johnston, W.K., Garrett-Engele, P., Lim, L.P., and Bartel, D.P. (2007). MicroRNA targeting specificity in mammals: determinants beyond seed pairing. Mol Cell 27, 91-105. Grimson, A., Srivastava, M., Fahey, B., Woodcroft, B.J., Chiang, H.R., King, N., Degnan, B.M., Rokhsar, D.S., and Bartel, D.P. (2008). Early origins and evolution of microRNAs and Piwiinteracting RNAs in animals. Nature 455, 1193-1197. Grishok, A., Pasquinelli, A.E., Conte, D., Li, N., Parrish, S., Ha, I., Baillie, D.L., Fire, A., Ruvkun, G., and Mello, C.C. (2001). Genes and mechanisms related to RNA interference regulate expression of the small temporal RNAs that control C. elegans developmental timing. Cell 106, 23-34. Guil, S., and Caceres, J.F. (2007). The multifunctional RNA-binding protein hnRNP A1 is required for processing of miR-18a. Nat Struct Mol Biol 14, 591-596. Guo, H., Ingolia, N.T., Weissman, J.S., and Bartel, D.P. (2010). Mammalian microRNAs predominantly act to decrease target mRNA levels. Nature 466, 835-840. Guo, S., and Kemphues, K.J. (1995). par-1, a gene required for establishing polarity in C. elegans embryos, encodes a putative Ser/Thr kinase that is asymmetrically distributed. Cell 81, 611-620. Guttman, M., Donaghey, J., Carey, B.W., Garber, M., Grenier, J.K., Munson, G., Young, G., Lucas, A.B., Ach, R., Bruhn, L., et al. (2011). lincRNAs act in the circuitry controlling pluripotency and differentiation. Nature 477, 295-300. Gwizdek, C., Ossareh-Nazari, B., Brownawell, A.M., Doglio, A., Bertrand, E., Macara, I.G., and Dargemont, C. (2003). Exportin-5 mediates nuclear export of minihelix-containing RNAs. J Biol Chem 278, 5505-5508. Haase, A.D., Jaskiewicz, L., Zhang, H., Laine, S., Sack, R., Gatignol, A., and Filipowicz, W. (2005). TRBP, a regulator of cellular PKR and HIV-1 virus expression, interacts with Dicer and functions in RNA silencing. EMBO Rep 6, 961-967. Hagan, J.P., Piskounova, E., and Gregory, R.I. (2009). Lin28 recruits the TUTase Zcchc11 to inhibit let-7 maturation in mouse embryonic stem cells. Nat Struct Mol Biol 16, 1021-1025. Hamilton, A.J., and Baulcombe, D.C. (1999). A species of small antisense RNA in posttranscriptional gene silencing in plants. Science 286, 950-952. Hammond, S.M., Bernstein, E., Beach, D., and Hannon, G.J. (2000). An RNA-directed nuclease mediates post-transcriptional gene silencing in Drosophila cells. Nature 404, 293-296. Hammond, S.M., Boettcher, S., Caudy, A.A., Kobayashi, R., and Hannon, G.J. (2001). Argonaute2, a link between genetic and biochemical analyses of RNAi. Science 293, 11461150. Han, B.W., Hung, J.H., Weng, Z., Zamore, P.D., and Ameres, S.L. (2011). The 3'-to-5' Exoribonuclease Nibbler Shapes the 3' Ends of MicroRNAs Bound to Drosophila Argonaute1. Curr Biol. Han, J., Lee, Y., Yeom, K.H., Kim, Y.K., Jin, H., and Kim, V.N. (2004). The Drosha-DGCR8 complex in primary microRNA processing. Genes Dev 18, 3016-3027. Han, J., Lee, Y., Yeom, K.H., Nam, J.W., Heo, I., Rhee, J.K., Sohn, S.Y., Cho, Y., Zhang, B.T., and Kim, V.N. (2006). Molecular basis for the recognition of primary microRNAs by the Drosha-DGCR8 complex. Cell 125, 887-901. Han, J., Pedersen, J.S., Kwon, S.C., Belair, C.D., Kim, Y.K., Yeom, K.H., Yang, W.Y., Haussler, D., Blelloch, R., and Kim, V.N. (2009). Posttranscriptional crossregulation between Drosha and DGCR8. Cell 136, 75-84. 148 Hanna, M.M. (1989). Photoaffinity cross-linking methods for studying RNA-protein interactions. Methods Enzymol 180, 383-409. Hannon, G.J., Maroney, P.A., Denker, J.A., and Nilsen, T.W. (1990). Trans splicing of nematode pre-messenger RNA in vitro. Cell 61, 1247-1255. Hartig, J.V., Esslinger, S., Bottcher, R., Saito, K., and Forstemann, K. (2009). Endo-siRNAs depend on a new isoform of loquacious and target artificially introduced, high-copy sequences. EMBO J 28, 2932-2944. Hata, A., and Davis, B.N. (2011). Regulation of pri-miRNA Processing Through Smads. Adv Exp Med Biol 700, 15-27. Hendrickson, D.G., Hogan, D.J., McCullough, H.L., Myers, J.W., Herschlag, D., Ferrell, J.E., and Brown, P.O. (2009). Concordant regulation of translation and mRNA abundance for hundreds of targets of a human microRNA. PLoS Biol 7, e1000238. Heo, I., Joo, C., Cho, J., Ha, M., Han, J., and Kim, V.N. (2008). Lin28 mediates the terminal uridylation of let-7 precursor MicroRNA. Mol Cell 32, 276-284. Heo, I., Joo, C., Kim, Y.K., Ha, M., Yoon, M.J., Cho, J., Yeom, K.H., Han, J., and Kim, V.N. (2009). TUT4 in concert with Lin28 suppresses microRNA biogenesis through premicroRNA uridylation. Cell 138, 696-708. Hofacker, I.L., and Stadler, P.F. (2006). Memory efficient folding algorithms for circular RNA secondary structures. Bioinformatics 22, 1172-1176. Holterman, M., van der Wurff, A., van den Elsen, S., van Megen, H., Bongers, T., Holovachov, O., Bakker, J., and Helder, J. (2006). Phylum-wide analysis of SSU rDNA reveals deep phylogenetic relationships among nematodes and accelerated evolution toward crown Clades. Mol Biol Evol 23, 1792-1800. Hughes, J.A., Brown, L.R., and Ferro, A.J. (1987). Nucleotide sequence and analysis of the coliphage T3 S-adenosylmethionine hydrolase gene and its surrounding ribonuclease III processing sites. Nucleic Acids Res 15, 717-729. Hutvagner, G., McLachlan, J., Pasquinelli, A.E., Balint, E., Tuschl, T., and Zamore, P.D. (2001). A cellular function for the RNA-interference enzyme Dicer in the maturation of the let-7 small temporal RNA. Science 293, 834-838. Izant, J.G., and Weintraub, H. (1984). Inhibition of thymidine kinase gene expression by antisense RNA: a molecular approach to genetic analysis. Cell 36, 1007-1015. Jacobsen, S.E., Running, M.P., and Meyerowitz, E.M. (1999). Disruption of an RNA helicase/RNAse III gene in Arabidopsis causes unregulated cell division in floral meristems. Development 126, 5231-5243. Jazdzewski, K., Murray, E.L., Franssila, K., Jarzab, B., Schoenberg, D.R., and de la Chapelle, A. (2008). Common SNP in pre-miR-146a decreases mature miR expression and predisposes to papillary thyroid carcinoma. Proc Natl Acad Sci U S A 105, 7269-7274. Jiang, F., Ye, X., Liu, X., Fincher, L., McKearin, D., and Liu, Q. (2005). Dicer-1 and R3D1-L catalyze microRNA maturation in Drosophila. Genes Dev 19, 1674-1679. Jolma, A., Kivioja, T., Toivonen, J., Cheng, L., Wei, G., Enge, M., Taipale, M., Vaquerizas, J.M., Yan, J., Sillanpaa, M.J., et al. (2010). Multiplexed massively parallel SELEX for characterization of human transcription factor binding specificities. Genome Res 20, 861873. Jones-Rhoades, M.W., Bartel, D.P., and Bartel, B. (2006). MicroRNAS and their regulatory roles in plants. Annu Rev Plant Biol 57, 19-53. 149 Jung, H., Yoon, B.C., and Holt, C.E. (2012). Axonal mRNA localization and local protein synthesis in nervous system assembly, maintenance and repair. Nat Rev Neurosci 13, 308324. Kadener, S., Rodriguez, J., Abruzzi, K.C., Khodor, Y.L., Sugino, K., Marr, M.T., 2nd, Nelson, S., and Rosbash, M. (2009). Genome-wide identification of targets of the droshapasha/DGCR8 complex. RNA 15, 537-545. Kawahara, Y., Megraw, M., Kreider, E., Iizasa, H., Valente, L., Hatzigeorgiou, A.G., and Nishikura, K. (2008). Frequency and fate of microRNA editing in human brain. Nucleic Acids Res 36, 5270-5280. Kawahara, Y., Zinshteyn, B., Chendrimada, T.P., Shiekhattar, R., and Nishikura, K. (2007). RNA editing of the microRNA-151 precursor blocks cleavage by the Dicer-TRBP complex. EMBO Rep 8, 763-769. Kawamata, T., Seitz, H., and Tomari, Y. (2009). Structural determinants of miRNAs for RISC loading and slicer-independent unwinding. Nat Struct Mol Biol 16, 953-960. Kawamata, T., Yoda, M., and Tomari, Y. (2011). Multilayer checkpoints for microRNA authenticity during RISC assembly. EMBO Rep 12, 944-949. Ketting, R.F. (2011). The many faces of RNAi. Dev Cell 20, 148-161. Ketting, R.F., Fischer, S.E., Bernstein, E., Sijen, T., Hannon, G.J., and Plasterk, R.H. (2001). Dicer functions in RNA interference and in synthesis of small RNA involved in developmental timing in C. elegans. Genes Dev 15, 2654-2659. Khalil, A.M., Guttman, M., Huarte, M., Garber, M., Raj, A., Rivea Morales, D., Thomas, K., Presser, A., Bernstein, B.E., van Oudenaarden, A., et al. (2009). Many human large intergenic noncoding RNAs associate with chromatin-modifying complexes and affect gene expression. Proc Natl Acad Sci U S A 106, 11667-11672. Khvorova, A., Reynolds, A., and Jayasena, S.D. (2003). Functional siRNAs and miRNAs exhibit strand bias. Cell 115, 209-216. Knight, S.W., and Bass, B.L. (2001). A role for the RNase III enzyme DCR-1 in RNA interference and germ line development in Caenorhabditis elegans. Science 293, 2269-2271. Kota, J., Chivukula, R.R., O'Donnell, K.A., Wentzel, E.A., Montgomery, C.L., Hwang, H.W., Chang, T.C., Vivekanandan, P., Torbenson, M., Clark, K.R., et al. (2009). Therapeutic microRNA delivery suppresses tumorigenesis in a murine liver cancer model. Cell 137, 1005-1017. Kozomara, A., and Griffiths-Jones, S. (2011). miRBase: integrating microRNA annotation and deep-sequencing data. Nucleic Acids Res 39, D152-157. Krinke, L., and Wulff, D.L. (1990). The cleavage specificity of RNase III. Nucleic Acids Res 18, 4809-4815. Kumar, M.S., Erkeland, S.J., Pester, R.E., Chen, C.Y., Ebert, M.S., Sharp, P.A., and Jacks, T. (2008). Suppression of non-small cell lung tumor development by the let-7 microRNA family. Proc Natl Acad Sci U S A 105, 3903-3908. Kumar, M.S., Lu, J., Mercer, K.L., Golub, T.R., and Jacks, T. (2007). Impaired microRNA processing enhances cellular transformation and tumorigenesis. Nat Genet 39, 673-677. Kurihara, Y., and Watanabe, Y. (2004). Arabidopsis micro-RNA biogenesis through Dicer-like 1 protein functions. Proc Natl Acad Sci U S A 101, 12753-12758. Lagos-Quintana, M., Rauhut, R., Lendeckel, W., and Tuschl, T. (2001). Identification of novel genes coding for small expressed RNAs. Science 294, 853-858. 150 Lamontagne, B., and Elela, S.A. (2004). Evaluation of the RNA determinants for bacterial and yeast RNase III binding and cleavage. J Biol Chem 279, 2231-2241. Lamontagne, B., Ghazal, G., Lebars, I., Yoshizawa, S., Fourmy, D., and Elela, S.A. (2003). Sequence dependence of substrate recognition and cleavage by yeast RNase III. J Mol Biol 327, 985-1000. Landgraf, P., Rusu, M., Sheridan, R., Sewer, A., Iovino, N., Aravin, A., Pfeffer, S., Rice, A., Kamphorst, A.O., Landthaler, M., et al. (2007). A mammalian microRNA expression atlas based on small RNA library sequencing. Cell 129, 1401-1414. Landthaler, M., Yalcin, A., and Tuschl, T. (2004). The human DiGeorge syndrome critical region gene 8 and Its D. melanogaster homolog are required for miRNA biogenesis. Curr Biol 14, 2162-2167. Lasda, E.L., Allen, M.A., and Blumenthal, T. (2010). Polycistronic pre-mRNA processing in vitro: snRNP and pre-mRNA role reversal in trans-splicing. Genes Dev 24, 1645-1658. Lau, N.C., Lim, L.P., Weinstein, E.G., and Bartel, D.P. (2001). An abundant class of tiny RNAs with probable regulatory roles in Caenorhabditis elegans. Science 294, 858-862. Lau, P.W., Guiley, K.Z., De, N., Potter, C.S., Carragher, B., and MacRae, I.J. (2012). The molecular architecture of human Dicer. Nat Struct Mol Biol 19, 436-440. Lee, R.C., and Ambros, V. (2001). An extensive class of small RNAs in Caenorhabditis elegans. Science 294, 862-864. Lee, R.C., Feinbaum, R.L., and Ambros, V. (1993). The C. elegans heterochronic gene lin-4 encodes small RNAs with antisense complementarity to lin-14. Cell 75, 843-854. Lee, Y., Ahn, C., Han, J., Choi, H., Kim, J., Yim, J., Lee, J., Provost, P., Radmark, O., Kim, S., et al. (2003). The nuclear RNase III Drosha initiates microRNA processing. Nature 425, 415419. Lee, Y., Hur, I., Park, S.Y., Kim, Y.K., Suh, M.R., and Kim, V.N. (2006). The role of PACT in the RNA silencing pathway. EMBO J 25, 522-532. Lee, Y., Jeon, K., Lee, J.T., Kim, S., and Kim, V.N. (2002). MicroRNA maturation: stepwise processing and subcellular localization. EMBO J 21, 4663-4670. Lee, Y., Kim, M., Han, J., Yeom, K.H., Lee, S., Baek, S.H., and Kim, V.N. (2004a). MicroRNA genes are transcribed by RNA polymerase II. EMBO J 23, 4051-4060. Lee, Y., and Kim, V.N. (2007). In vitro and in vivo assays for the activity of Drosha complex. Methods Enzymol 427, 89-106. Lee, Y.S., Nakahara, K., Pham, J.W., Kim, K., He, Z., Sontheimer, E.J., and Carthew, R.W. (2004b). Distinct roles for Drosophila Dicer-1 and Dicer-2 in the siRNA/miRNA silencing pathways. Cell 117, 69-81. Lehrbach, N.J., Armisen, J., Lightfoot, H.L., Murfitt, K.J., Bugaut, A., Balasubramanian, S., and Miska, E.A. (2009). LIN-28 and the poly(U) polymerase PUP-2 regulate let-7 microRNA processing in Caenorhabditis elegans. Nat Struct Mol Biol 16, 1016-1020. Lim, L.P., Glasner, M.E., Yekta, S., Burge, C.B., and Bartel, D.P. (2003a). Vertebrate microRNA genes. Science 299, 1540. Lim, L.P., Lau, N.C., Weinstein, E.G., Abdelhakim, A., Yekta, S., Rhoades, M.W., Burge, C.B., and Bartel, D.P. (2003b). The microRNAs of Caenorhabditis elegans. Genes Dev 17, 9911008. Liu, H., D'Andrade, P., Fulmer-Smentek, S., Lorenzi, P., Kohn, K.W., Weinstein, J.N., Pommier, Y., and Reinhold, W.C. (2010). mRNA and microRNA expression profiles of the NCI-60 integrated with drug activities. Mol Cancer Ther 9, 1080-1091. 151 Liu, J., Carmell, M.A., Rivas, F.V., Marsden, C.G., Thomson, J.M., Song, J.J., Hammond, S.M., Joshua-Tor, L., and Hannon, G.J. (2004). Argonaute2 is the catalytic engine of mammalian RNAi. Science 305, 1437-1441. Liu, Q., Rand, T.A., Kalidas, S., Du, F., Kim, H.E., Smith, D.P., and Wang, X. (2003). R2D2, a bridge between the initiation and effector steps of the Drosophila RNAi pathway. Science 301, 1921-1925. Liu, X., Park, J.K., Jiang, F., Liu, Y., McKearin, D., and Liu, Q. (2007). Dicer-1, but not Loquacious, is critical for assembly of miRNA-induced silencing complexes. RNA 13, 23242329. Llave, C., Xie, Z., Kasschau, K.D., and Carrington, J.C. (2002). Cleavage of Scarecrow-like mRNA targets directed by a class of Arabidopsis miRNA. Science 297, 2053-2056. Lu, J., Getz, G., Miska, E.A., Alvarez-Saavedra, E., Lamb, J., Peck, D., Sweet-Cordero, A., Ebert, B.L., Mak, R.H., Ferrando, A.A., et al. (2005). MicroRNA expression profiles classify human cancers. Nature 435, 834-838. Lund, E., Guttinger, S., Calado, A., Dahlberg, J.E., and Kutay, U. (2004). Nuclear export of microRNA precursors. Science 303, 95-98. Ma, J.B., Ye, K., and Patel, D.J. (2004). Structural basis for overhang-specific small interfering RNA recognition by the PAZ domain. Nature 429, 318-322. MacRae, I.J., Zhou, K., and Doudna, J.A. (2007). Structural determinants of RNA recognition and cleavage by Dicer. Nat Struct Mol Biol 14, 934-940. Macrae, I.J., Zhou, K., Li, F., Repic, A., Brooks, A.N., Cande, W.Z., Adams, P.D., and Doudna, J.A. (2006). Structural basis for double-stranded RNA processing by Dicer. Science 311, 195-198. Maroney, P.A., Hannon, G.J., and Nilsen, T.W. (1990). Transcription and cap trimethylation of a nematode spliced leader RNA in a cell-free system. Proc Natl Acad Sci U S A 87, 709-713. Mateos, J.L., Bologna, N.G., Chorostecki, U., and Palatnik, J.F. (2010). Identification of microRNA processing determinants by random mutagenesis of Arabidopsis MIR172a precursor. Curr Biol 20, 49-54. Mayr, C., Hemann, M.T., and Bartel, D.P. (2007). Disrupting the pairing between let-7 and Hmga2 enhances oncogenic transformation. Science 315, 1576-1579. Meignin, C., and Davis, I. (2010). Transmitting the message: intracellular mRNA localization. Curr Opin Cell Biol 22, 112-119. Meister, G., Landthaler, M., Patkaniowska, A., Dorsett, Y., Teng, G., and Tuschl, T. (2004). Human Argonaute2 mediates RNA cleavage targeted by miRNAs and siRNAs. Mol Cell 15, 185-197. Merritt, W.M., Lin, Y.G., Han, L.Y., Kamat, A.A., Spannuth, W.A., Schmandt, R., Urbauer, D., Pennacchio, L.A., Cheng, J.F., Nick, A.M., et al. (2008). Dicer, Drosha, and outcomes in patients with ovarian cancer. N Engl J Med 359, 2641-2650. Mian, I.S. (1997). Comparative sequence analysis of ribonucleases HII, III, II PH and D. Nucleic Acids Res 25, 3187-3195. Michlewski, G., and Caceres, J.F. (2010). Antagonistic role of hnRNP A1 and KSRP in the regulation of let-7a biogenesis. Nat Struct Mol Biol 17, 1011-1018. Michlewski, G., Guil, S., Semple, C.A., and Caceres, J.F. (2008). Posttranscriptional regulation of miRNAs harboring conserved terminal loops. Mol Cell 32, 383-393. 152 Mishima, Y., and Steitz, J.A. (1995). Site-specific crosslinking of 4-thiouridine-modified human tRNA(3Lys) to reverse transcriptase from human immunodeficiency virus type I. EMBO J 14, 2679-2687. Miyoshi, K., Miyoshi, T., and Siomi, H. (2010). Many ways to generate microRNA-like small RNAs: non-canonical pathways for microRNA production. Mol Genet Genomics 284, 95103. Miyoshi, K., Okada, T.N., Siomi, H., and Siomi, M.C. (2009). Characterization of the miRNARISC loading complex and miRNA-RISC formed in the Drosophila miRNA pathway. RNA 15, 1282-1291. Moffat, J., Grueneberg, D.A., Yang, X., Kim, S.Y., Kloepfer, A.M., Hinkle, G., Piqani, B., Eisenhaure, T.M., Luo, B., Grenier, J.K., et al. (2006). A lentiviral RNAi library for human and mouse genes applied to an arrayed viral high-content screen. Cell 124, 1283-1298. Montgomery, M.K., and Fire, A. (1998). Double-stranded RNA as a mediator in sequencespecific genetic silencing and co-suppression. Trends Genet 14, 255-258. Moore, M.J. (1999). Joining RNA molecules with T4 DNA ligase. Methods Mol Biol 118, 1119. Murphy, D., Dancis, B., and Brown, J.R. (2008). The evolution of core proteins involved in microRNA biogenesis. BMC Evol Biol 8, 92. Nakamura, T., Canaani, E., and Croce, C.M. (2007). Oncogenic All1 fusion proteins target Drosha-mediated microRNA processing. Proc Natl Acad Sci U S A 104, 10980-10985. Nam, J.W., Shin, K.R., Han, J., Lee, Y., Kim, V.N., and Zhang, B.T. (2005). Human microRNA prediction through a probabilistic co-learning model of sequence and structure. Nucleic Acids Res 33, 3570-3581. Nam, Y., Chen, C., Gregory, R.I., Chou, J.J., and Sliz, P. (2011). Molecular Basis for Interaction of let-7 MicroRNAs with Lin28. Cell. Napoli, C., Lemieux, C., and Jorgensen, R. (1990). Introduction of a Chimeric Chalcone Synthase Gene into Petunia Results in Reversible Co-Suppression of Homologous Genes in trans. Plant Cell 2, 279-289. Newman, M.A., Thomson, J.M., and Hammond, S.M. (2008). Lin-28 interaction with the Let-7 precursor loop mediates regulated microRNA processing. RNA 14, 1539-1549. Nishikura, K. (2010). Functions and regulation of RNA editing by ADAR deaminases. Annu Rev Biochem 79, 321-349. Nykanen, A., Haley, B., and Zamore, P.D. (2001). ATP requirements and small interfering RNA structure in the RNA interference pathway. Cell 107, 309-321. O'Connell, R.M., Rao, D.S., Chaudhuri, A.A., Boldin, M.P., Taganov, K.D., Nicoll, J., Paquette, R.L., and Baltimore, D. (2008). Sustained expression of microRNA-155 in hematopoietic stem cells causes a myeloproliferative disorder. J Exp Med 205, 585-594. Okada, C., Yamashita, E., Lee, S.J., Shibata, S., Katahira, J., Nakagawa, A., Yoneda, Y., and Tsukihara, T. (2009). A high-resolution structure of the pre-microRNA nuclear export machinery. Science 326, 1275-1279. Okamura, K., Chung, W.J., Ruby, J.G., Guo, H., Bartel, D.P., and Lai, E.C. (2008). The Drosophila hairpin RNA pathway generates endogenous short interfering RNAs. Nature 453, 803-806. Okamura, K., Hagen, J.W., Duan, H., Tyler, D.M., and Lai, E.C. (2007). The mirtron pathway generates microRNA-class regulatory RNAs in Drosophila. Cell 130, 89-100. 153 Okamura, K., Liu, N., and Lai, E.C. (2009). Distinct mechanisms for microRNA strand selection by Drosophila Argonautes. Mol Cell 36, 431-444. Orom, U.A., Derrien, T., Beringer, M., Gumireddy, K., Gardini, A., Bussotti, G., Lai, F., Zytnicki, M., Notredame, C., Huang, Q., et al. (2010). Long noncoding RNAs with enhancerlike function in human cells. Cell 143, 46-58. Paddison, P.J., Caudy, A.A., Bernstein, E., Hannon, G.J., and Conklin, D.S. (2002). Short hairpin RNAs (shRNAs) induce sequence-specific silencing in mammalian cells. Genes Dev 16, 948-958. Pan, T., and Uhlenbeck, O.C. (1992). In vitro selection of RNAs that undergo autolytic cleavage with Pb2+. Biochemistry 31, 3887-3895. Park, J.E., Heo, I., Tian, Y., Simanshu, D.K., Chang, H., Jee, D., Patel, D.J., and Kim, V.N. (2011). Dicer recognizes the 5' end of RNA for efficient and accurate processing. Nature 475, 201-205. Park, M.Y., Wu, G., Gonzalez-Sulser, A., Vaucheret, H., and Poethig, R.S. (2005). Nuclear processing and export of microRNAs in Arabidopsis. Proc Natl Acad Sci U S A 102, 36913696. Park, W., Li, J., Song, R., Messing, J., and Chen, X. (2002). CARPEL FACTORY, a Dicer homolog, and HEN1, a novel protein, act in microRNA metabolism in Arabidopsis thaliana. Curr Biol 12, 1484-1495. Pasquinelli, A.E., Reinhart, B.J., Slack, F., Martindale, M.Q., Kuroda, M.I., Maller, B., Hayward, D.C., Ball, E.E., Degnan, B., Muller, P., et al. (2000). Conservation of the sequence and temporal expression of let-7 heterochronic regulatory RNA. Nature 408, 86-89. Patel, V.L., Mitra, S., Harris, R., Buxbaum, A.R., Lionnet, T., Brenowitz, M., Girvin, M., Levy, M., Almo, S.C., Singer, R.H., et al. (2012). Spatial arrangement of an RNA zipcode identifies mRNAs under post-transcriptional control. Genes Dev 26, 43-53. Patwardhan, R.P., Hiatt, J.B., Witten, D.M., Kim, M.J., Smith, R.P., May, D., Lee, C., Andrie, J.M., Lee, S.I., Cooper, G.M., et al. (2012). Massively parallel functional dissection of mammalian enhancers in vivo. Nat Biotechnol 30, 265-270. Pertzev, A.V., and Nicholson, A.W. (2006). Characterization of RNA sequence determinants and antideterminants of processing reactivity for a minimal substrate of Escherichia coli ribonuclease III. Nucleic Acids Res 34, 3708-3721. Piskounova, E., Polytarchou, C., Thornton, J.E., LaPierre, R.J., Pothoulakis, C., Hagan, J.P., Iliopoulos, D., and Gregory, R.I. (2011). Lin28A and Lin28B inhibit let-7 microRNA biogenesis by distinct mechanisms. Cell 147, 1066-1079. Piskounova, E., Viswanathan, S.R., Janas, M., LaPierre, R.J., Daley, G.Q., Sliz, P., and Gregory, R.I. (2008). Determinants of microRNA processing inhibition by the developmentally regulated RNA-binding protein Lin28. J Biol Chem 283, 21310-21314. Pitman, J. (1993). Probability (New York, Springer-Verlag). Pitt, J.N., and Ferre-D'Amare, A.R. (2010). Rapid construction of empirical RNA fitness landscapes. Science 330, 376-379. Portier, C., Dondon, L., Grunberg-Manago, M., and Regnier, P. (1987). The first step in the functional inactivation of the Escherichia coli polynucleotide phosphorylase messenger is a ribonuclease III processing at the 5' end. EMBO J 6, 2165-2170. Regnier, P., and Grunberg-Manago, M. (1989). Cleavage by RNase III in the transcripts of the met Y-nus-A-infB operon of Escherichia coli releases the tRNA and initiates the decay of the downstream mRNA. J Mol Biol 210, 293-302. 154 Regnier, P., and Portier, C. (1986). Initiation, attenuation and RNase III processing of transcripts from the Escherichia coli operon encoding ribosomal protein S15 and polynucleotide phosphorylase. J Mol Biol 187, 23-32. Reinhart, B.J., Slack, F.J., Basson, M., Pasquinelli, A.E., Bettinger, J.C., Rougvie, A.E., Horvitz, H.R., and Ruvkun, G. (2000). The 21-nucleotide let-7 RNA regulates developmental timing in Caenorhabditis elegans. Nature 403, 901-906. Reinhart, B.J., Weinstein, E.G., Rhoades, M.W., Bartel, B., and Bartel, D.P. (2002). MicroRNAs in plants. Genes Dev 16, 1616-1626. Rinn, J.L., Kertesz, M., Wang, J.K., Squazzo, S.L., Xu, X., Brugmann, S.A., Goodnough, L.H., Helms, J.A., Farnham, P.J., Segal, E., et al. (2007). Functional demarcation of active and silent chromatin domains in human HOX loci by noncoding RNAs. Cell 129, 1311-1323. Rivas, F.V., Tolia, N.H., Song, J.J., Aragon, J.P., Liu, J., Hannon, G.J., and Joshua-Tor, L. (2005). Purified Argonaute2 and an siRNA form recombinant human RISC. Nat Struct Mol Biol 12, 340-349. Robertson, H.D. (1982). Escherichia coli ribonuclease III cleavage sites. Cell 30, 669-672. Robertson, H.D., and Dunn, J.J. (1975). Ribonucleic acid processing activity of Escherichia coli ribonuclease III. J Biol Chem 250, 3050-3056. Robertson, H.D., Webster, R.E., and Zinder, N.D. (1967). A nuclease specific for doublestranded RNA. Virology 32, 718-719. Robertson, H.D., Webster, R.E., and Zinder, N.D. (1968). Purification and properties of ribonuclease III from Escherichia coli. J Biol Chem 243, 82-91. Romano, N., and Macino, G. (1992). Quelling: transient inactivation of gene expression in Neurospora crassa by transformation with homologous sequences. Mol Microbiol 6, 33433353. Ross, D.T., Scherf, U., Eisen, M.B., Perou, C.M., Rees, C., Spellman, P., Iyer, V., Jeffrey, S.S., Van de Rijn, M., Waltham, M., et al. (2000). Systematic variation in gene expression patterns in human cancer cell lines. Nat Genet 24, 227-235. Rotondo, G., and Frendewey, D. (1996). Purification and characterization of the Pac1 ribonuclease of Schizosaccharomyces pombe. Nucleic Acids Res 24, 2377-2386. Ruby, J.G., Jan, C., Player, C., Axtell, M.J., Lee, W., Nusbaum, C., Ge, H., and Bartel, D.P. (2006). Large-scale sequencing reveals 21U-RNAs and additional microRNAs and endogenous siRNAs in C. elegans. Cell 127, 1193-1207. Ruby, J.G., Jan, C.H., and Bartel, D.P. (2007a). Intronic microRNA precursors that bypass Drosha processing. Nature 448, 83-86. Ruby, J.G., Stark, A., Johnston, W.K., Kellis, M., Bartel, D.P., and Lai, E.C. (2007b). Evolution, biogenesis, expression, and target predictions of a substantially expanded set of Drosophila microRNAs. Genome Res 17, 1850-1864. Ruvkun, G., Wightman, B., and Ha, I. (2004). The 20 years it took to recognize the importance of tiny RNAs. Cell 116, S93-96, 92 p following S96. Saetrom, P., Heale, B.S., Snove, O., Jr., Aagaard, L., Alluin, J., and Rossi, J.J. (2007). Distance constraints between microRNA target sites dictate efficacy and cooperativity. Nucleic Acids Res 35, 2333-2342. Saito, K., Ishizuka, A., Siomi, H., and Siomi, M.C. (2005). Processing of pre-microRNAs by the Dicer-1-Loquacious complex in Drosophila cells. PLoS Biol 3, e235. Sakurai, K., Furukawa, C., Haraguchi, T., Inada, K., Shiogama, K., Tagawa, T., Fujita, S., Ueno, Y., Ogata, A., Ito, M., et al. (2011). MicroRNAs miR-199a-5p and -3p target the Brm 155 subunit of SWI/SNF to generate a double-negative feedback loop in a variety of human cancers. Cancer Res 71, 1680-1689. Schauer, S.E., Jacobsen, S.E., Meinke, D.W., and Ray, A. (2002). DICER-LIKE1: blind men and elephants in Arabidopsis development. Trends Plant Sci 7, 487-491. Schurer, H., Lang, K., Schuster, J., and Morl, M. (2002). A universal method to produce in vitro transcripts with homogeneous 3' ends. Nucleic Acids Res 30, e56. Schwarz, D.S., Hutvagner, G., Du, T., Xu, Z., Aronin, N., and Zamore, P.D. (2003). Asymmetry in the assembly of the RNAi enzyme complex. Cell 115, 199-208. Seitz, H., Tushir, J.S., and Zamore, P.D. (2011). A 5'-uridine amplifies miRNA/miRNA* asymmetry in Drosophila by promoting RNA-induced silencing complex formation. Silence 2, 4. Sempere, L.F., Cole, C.N., McPeek, M.A., and Peterson, K.J. (2006). The phylogenetic distribution of metazoan microRNAs: insights into evolutionary complexity and constraint. J Exp Zool B Mol Dev Evol 306, 575-588. Sharp, P.A., and Burge, C.B. (1997). Classification of introns: U2-type or U12-type. Cell 91, 875-879. Shi, Y., Wang, Y.F., Jayaraman, L., Yang, H., Massague, J., and Pavletich, N.P. (1998). Crystal structure of a Smad MH1 domain bound to DNA: insights on DNA binding in TGF-beta signaling. Cell 94, 585-594. Shin, C., Nam, J.W., Farh, K.K., Chiang, H.R., Shkumatava, A., and Bartel, D.P. (2010). Expanding the microRNA targeting code: functional sites with centered pairing. Mol Cell 38, 789-802. Slattery, M., Riley, T., Liu, P., Abe, N., Gomez-Alcala, P., Dror, I., Zhou, T., Rohs, R., Honig, B., Bussemaker, H.J., et al. (2011). Cofactor binding evokes latent differences in DNA binding specificity between Hox proteins. Cell 147, 1270-1282. Sohn, S.Y., Bae, W.J., Kim, J.J., Yeom, K.H., Kim, V.N., and Cho, Y. (2007). Crystal structure of human DGCR8 core. Nat Struct Mol Biol 14, 847-853. Sokilde, R., Kaczkowski, B., Podolska, A., Cirera, S., Gorodkin, J., Moller, S., and Litman, T. (2011). Global microRNA analysis of the NCI-60 cancer cell panel. Mol Cancer Ther 10, 375-384. Song, L., Axtell, M.J., and Fedoroff, N.V. (2010). RNA secondary structural determinants of miRNA precursor processing in Arabidopsis. Curr Biol 20, 37-41. Sontheimer, E.J. (1994). Site-specific RNA crosslinking with 4-thiouridine. Mol Biol Rep 20, 35-44. Spingola, M., Grate, L., Haussler, D., and Ares, M., Jr. (1999). Genome-wide bioinformatic and molecular analysis of introns in Saccharomyces cerevisiae. RNA 5, 221-234. Stark, A., Brennecke, J., Bushati, N., Russell, R.B., and Cohen, S.M. (2005). Animal MicroRNAs confer robustness to gene expression and have a significant impact on 3'UTR evolution. Cell 123, 1133-1146. Stark, A., Kheradpour, P., Parts, L., Brennecke, J., Hodges, E., Hannon, G.J., and Kellis, M. (2007). Systematic discovery and characterization of fly microRNAs using 12 Drosophila genomes. Genome Res 17, 1865-1879. Steiner, F.A., Hoogstrate, S.W., Okihara, K.L., Thijssen, K.L., Ketting, R.F., Plasterk, R.H., and Sijen, T. (2007). Structural features of small RNA precursors determine Argonaute loading in Caenorhabditis elegans. Nat Struct Mol Biol 14, 927-933. 156 Sun, G., Yan, J., Noltner, K., Feng, J., Li, H., Sarkis, D.A., Sommer, S.S., and Rossi, J.J. (2009). SNPs in human miRNA genes affect biogenesis and function. RNA 15, 1640-1651. Suzuki, H.I., Yamagata, K., Sugimoto, K., Iwamoto, T., Kato, S., and Miyazono, K. (2009). Modulation of microRNA processing by p53. Nature 460, 529-533. Swanson, W.J., and Vacquier, V.D. (2002). The rapid evolution of reproductive proteins. Nat Rev Genet 3, 137-144. Tam, W., Ben-Yehuda, D., and Hayward, W.S. (1997). bic, a novel gene activated by proviral insertions in avian leukosis virus-induced lymphomas, is likely to function through its noncoding RNA. Mol Cell Biol 17, 1490-1502. Tang, G., Reinhart, B.J., Bartel, D.P., and Zamore, P.D. (2003). A biochemical framework for RNA silencing in plants. Genes Dev 17, 49-63. Tarn, W.Y., and Steitz, J.A. (1996). A novel spliceosome containing U11, U12, and U5 snRNPs excises a minor class (AT-AC) intron in vitro. Cell 84, 801-811. Tavazoie, S.F., Alarcon, C., Oskarsson, T., Padua, D., Wang, Q., Bos, P.D., Gerald, W.L., and Massague, J. (2008). Endogenous human microRNAs that suppress breast cancer metastasis. Nature 451, 147-152. Thai, T.H., Calado, D.P., Casola, S., Ansel, K.M., Xiao, C., Xue, Y., Murphy, A., Frendewey, D., Valenzuela, D., Kutok, J.L., et al. (2007). Regulation of the germinal center response by microRNA-155. Science 316, 604-608. Tomari, Y., Du, T., and Zamore, P.D. (2007). Sorting of Drosophila small silencing RNAs. Cell 130, 299-308. Trabucchi, M., Briata, P., Filipowicz, W., Ramos, A., Gherzi, R., and Rosenfeld, M.G. (2010). KSRP promotes the maturation of a group of miRNA precursors. Adv Exp Med Biol 700, 36-42. Trabucchi, M., Briata, P., Garcia-Mayoral, M., Haase, A.D., Filipowicz, W., Ramos, A., Gherzi, R., and Rosenfeld, M.G. (2009). The RNA-binding protein KSRP promotes the biogenesis of a subset of microRNAs. Nature 459, 1010-1014. Tsai, M.C., Manor, O., Wan, Y., Mosammaparast, N., Wang, J.K., Lan, F., Shi, Y., Segal, E., and Chang, H.Y. (2010). Long noncoding RNA as modular scaffold of histone modification complexes. Science 329, 689-693. Tsutsumi, A., Kawamata, T., Izumi, N., Seitz, H., and Tomari, Y. (2011). Recognition of the premiRNA structure by Drosophila Dicer-1. Nat Struct Mol Biol 18, 1153-1158. Tuschl, T., Zamore, P.D., Lehmann, R., Bartel, D.P., and Sharp, P.A. (1999). Targeted mRNA degradation by double-stranded RNA in vitro. Genes Dev 13, 3191-3197. Ui-Tei, K., Naito, Y., Nishi, K., Juni, A., and Saigo, K. (2008). Thermodynamic stability and Watson-Crick base pairing in the seed duplex are major determinants of the efficiency of the siRNA-based off-target effect. Nucleic Acids Res 36, 7100-7109. Ulitsky, I., Shkumatava, A., Jan, C.H., Sive, H., and Bartel, D.P. (2011). Conserved function of lincRNAs in vertebrate embryonic development despite rapid sequence evolution. Cell 147, 1537-1550. van der Krol, A.R., Mur, L.A., Beld, M., Mol, J.N., and Stuitje, A.R. (1990). Flavonoid genes in petunia: addition of a limited number of gene copies may lead to a suppression of gene expression. Plant Cell 2, 291-299. Vermeulen, A., Behlen, L., Reynolds, A., Wolfson, A., Marshall, W.S., Karpilow, J., and Khvorova, A. (2005). The contributions of dsRNA structure to Dicer specificity and efficiency. RNA 11, 674-682. 157 Viswanathan, S.R., and Daley, G.Q. (2010). Lin28: A microRNA regulator with a macro role. Cell 140, 445-449. Viswanathan, S.R., Daley, G.Q., and Gregory, R.I. (2008). Selective blockade of microRNA processing by Lin28. Science 320, 97-100. Viswanathan, S.R., Powers, J.T., Einhorn, W., Hoshida, Y., Ng, T.L., Toffanin, S., O'Sullivan, M., Lu, J., Phillips, L.A., Lockhart, V.L., et al. (2009). Lin28 promotes transformation and is associated with advanced human malignancies. Nat Genet 41, 843-848. Vuppalanchi, D., Coleman, J., Yoo, S., Merianda, T.T., Yadhati, A.G., Hossain, J., Blesch, A., Willis, D.E., and Twiss, J.L. (2010). Conserved 3'-untranslated region sequences direct subcellular localization of chaperone protein mRNAs in neurons. J Biol Chem 285, 1802518038. Wang, D., Zhang, Z., O'Loughlin, E., Lee, T., Houel, S., O'Carroll, D., Tarakhovsky, A., Ahn, N.G., and Yi, R. (2012). Quantitative functions of Argonaute proteins in mammalian development. Genes Dev 26, 693-704. Wang, K.C., and Chang, H.Y. (2011). Molecular mechanisms of long noncoding RNAs. Mol Cell 43, 904-914. Wang, S.L., Yao, H.H., and Qin, Z.H. (2009). Strategies for short hairpin RNA delivery in cancer gene therapy. Expert Opin Biol Ther 9, 1357-1368. Wang, Y., Medvid, R., Melton, C., Jaenisch, R., and Blelloch, R. (2007). DGCR8 is essential for microRNA biogenesis and silencing of embryonic stem cell self-renewal. Nat Genet 39, 380385. Warf, M.B., Johnson, W.E., and Bass, B.L. (2011). Improved annotation of C. elegans microRNAs by deep sequencing reveals structures associated with processing by Drosha and Dicer. RNA 17, 563-577. Weinberg, D.E., Nakanishi, K., Patel, D.J., and Bartel, D.P. (2011). The inside-out mechanism of Dicers from budding yeasts. Cell 146, 262-276. Wightman, B., Ha, I., and Ruvkun, G. (1993). Posttranscriptional regulation of the heterochronic gene lin-14 by lin-4 mediates temporal pattern formation in C. elegans. Cell 75, 855-862. Witten, D., Tibshirani, R., Gu, S.G., Fire, A., and Lui, W.O. (2010). Ultra-high throughput sequencing-based small RNA discovery and discrete statistical biomarker analysis in a collection of cervical tumours and matched controls. BMC Biol 8, 58. Wu, H., Henras, A., Chanfreau, G., and Feigon, J. (2004). Structural basis for recognition of the AGNN tetraloop RNA fold by the double-stranded RNA-binding domain of Rnt1p RNase III. Proc Natl Acad Sci U S A 101, 8307-8312. Wu, H., Xu, H., Miraglia, L.J., and Crooke, S.T. (2000). Human RNase III is a 160-kDa protein involved in preribosomal RNA processing. J Biol Chem 275, 36957-36965. Wu, H., Yang, P.K., Butcher, S.E., Kang, S., Chanfreau, G., and Feigon, J. (2001). A novel family of RNA tetraloop structure forms the recognition site for Saccharomyces cerevisiae RNase III. EMBO J 20, 7240-7249. Wu, M., Jolicoeur, N., Li, Z., Zhang, L., Fortin, Y., L'Abbe, D., Yu, Z., and Shen, S.H. (2008). Genetic variations of microRNAs in human cancer and their effects on the expression of miRNAs. Carcinogenesis 29, 1710-1716. Wyatt, J.R., Sontheimer, E.J., and Steitz, J.A. (1992). Site-specific cross-linking of mammalian U5 snRNP to the 5' splice site before the first step of pre-mRNA splicing. Genes Dev 6, 2542-2553. 158 Yanaihara, N., Caplen, N., Bowman, E., Seike, M., Kumamoto, K., Yi, M., Stephens, R.M., Okamoto, A., Yokota, J., Tanaka, T., et al. (2006). Unique microRNA molecular profiles in lung cancer diagnosis and prognosis. Cancer Cell 9, 189-198. Yang, W., Chendrimada, T.P., Wang, Q., Higuchi, M., Seeburg, P.H., Shiekhattar, R., and Nishikura, K. (2006). Modulation of microRNA processing and expression through RNA editing by ADAR deaminases. Nat Struct Mol Biol 13, 13-21. Yekta, S., Shih, I.H., and Bartel, D.P. (2004). MicroRNA-directed cleavage of HOXB8 mRNA. Science 304, 594-596. Yeom, K.H., Lee, Y., Han, J., Suh, M.R., and Kim, V.N. (2006). Characterization of DGCR8/Pasha, the essential cofactor for Drosha in primary miRNA processing. Nucleic Acids Res 34, 4622-4629. Yi, R., Qin, Y., Macara, I.G., and Cullen, B.R. (2003). Exportin-5 mediates the nuclear export of pre-microRNAs and short hairpin RNAs. Genes Dev 17, 3011-3016. Yoda, M., Kawamata, T., Paroo, Z., Ye, X., Iwasaki, S., Liu, Q., and Tomari, Y. (2010). ATPdependent human RISC assembly pathways. Nat Struct Mol Biol 17, 17-23. Young, R.A., and Steitz, J.A. (1978). Complementary sequences 1700 nucleotides apart form a ribonuclease III cleavage site in Escherichia coli ribosomal precursor RNA. Proc Natl Acad Sci U S A 75, 3593-3597. Zamore, P.D., Tuschl, T., Sharp, P.A., and Bartel, D.P. (2000). RNAi: double-stranded RNA directs the ATP-dependent cleavage of mRNA at 21 to 23 nucleotide intervals. Cell 101, 2533. Zeng, Y., and Cullen, B.R. (2005). Efficient processing of primary microRNA hairpins by Drosha requires flanking nonstructured RNA sequences. J Biol Chem 280, 27595-27603. Zeng, Y., Yi, R., and Cullen, B.R. (2005). Recognition and cleavage of primary microRNA precursors by the nuclear processing enzyme Drosha. EMBO J 24, 138-148. Zhang, B., Pan, X., Cobb, G.P., and Anderson, T.A. (2007). microRNAs as oncogenes and tumor suppressors. Dev Biol 302, 1-12. Zhang, H., Kolb, F.A., Brondani, V., Billy, E., and Filipowicz, W. (2002). Human Dicer preferentially cleaves dsRNAs at their termini without a requirement for ATP. EMBO J 21, 5875-5885. Zhang, H., Kolb, F.A., Jaskiewicz, L., Westhof, E., and Filipowicz, W. (2004). Single processing center models for human Dicer and bacterial RNase III. Cell 118, 57-68. Zhang, K., and Nicholson, A.W. (1997). Regulation of ribonuclease III processing by doublehelical sequence antideterminants. Proc Natl Acad Sci U S A 94, 13437-13441. Zhang, X., and Zeng, Y. (2010). The terminal loop region controls microRNA processing by Drosha and Dicer. Nucleic Acids Res 38, 7689-7697. Zhou, R., Czech, B., Brennecke, J., Sachidanandam, R., Wohlschlegel, J.A., Perrimon, N., and Hannon, G.J. (2009). Processing of Drosophila endo-siRNAs depends on a specific Loquacious isoform. RNA 15, 1886-1895. Zykovich, A., Korf, I., and Segal, D.J. (2009). Bind-n-Seq: high-throughput analysis of in vitro protein-DNA interactions using massively parallel sequencing. Nucleic Acids Res 37, e151. 159 160 Appendix 1. Experimental protocols Contents In Vitro Cleavage Selection for Functional pri-miRNAs ............................................................164 Preparation of Drosha/DGCR8 Overexpression Lysate ..................................................... 164 Overview ................................................................................................................... 164 Cell culture and transfection ..................................................................................... 164 Lysate preparation ..................................................................................................... 165 Assay for microprocessor activity ............................................................................ 165 In vitro cleavage selection of circular pri-miRNA substrates ............................................. 168 Overview ................................................................................................................... 168 Assembly of partially-randomized, circular pri-miRNA substrate ........................... 169 Selection of functional variants from circular pri-miRNA pool ............................... 174 Library preparation for Illumina high-throughput sequencing ................................. 175 In vitro cleavage selection of linear pri-miRNA substrates ................................................ 184 Overview ................................................................................................................... 184 Assembly of linear, partially-randomized, pri-miRNA substrate ............................. 185 Selection of functional variants from linear pri-miRNA pool .................................. 187 Library preparation for Illumina high-throughput sequencing ................................. 188 In Vitro Binding Selection for Functional pri-miRNAs ..............................................................191 Preparation of immunopurified Drosha-TN/DGCR8 ......................................................... 191 Overview ................................................................................................................... 191 Cell culture and transfection ..................................................................................... 191 161 Lysate preparation ..................................................................................................... 192 Immunoprecipitation with anti-FLAG beads ............................................................ 192 In vitro binding selection of linear pri-miRNA substrates.................................................. 194 Overview ................................................................................................................... 194 Assembly of linear, partially-randomized, pri-miRNA substrate ............................. 195 Selection of functional variants from linear pri-miRNA pool .................................. 197 PCR amplification for downstream applications ...................................................... 200 Identification of Motif-Binding Proteins by Site-Specific Crosslinking .....................................203 Overview ............................................................................................................................. 203 Assembly of 4-thiouridine containing RNA substrate ........................................................ 204 RNA-protein crosslinking and complex analysis ............................................................... 205 Optimization of 365 nm UV dose ............................................................................. 205 Large-scale purification of crosslinked complexes for analysis ............................... 207 Candidate protein testing by immunoprecipitation of crosslinked complexes ......... 209 Supplement 1: Standard Protocols ...............................................................................................211 Crush-and-soak technique for acrylamide gel extraction ................................................... 211 T7 transcription (“Midi” scale) ........................................................................................... 212 Phosphorylation of nucleic acid 5′ Ends ............................................................................. 213 Cold ........................................................................................................................... 213 Hot............................................................................................................................. 213 Dephosphorylation of nucleic acid 5′ ends ......................................................................... 214 Dephosphorylation of 2′-3′ cyclic phosphates and 3′ phosphates ....................................... 214 Splint ligation of RNA ........................................................................................................ 215 Using T4 RNA Ligase 2 (RNL2) .............................................................................. 215 Partial hydrolysis of RNA................................................................................................... 216 162 Supplement 2: Standard Reagents ...............................................................................................217 Buffers................................................................................................................................. 217 Commercial products .......................................................................................................... 219 163 In Vitro Cleavage Selection for Functional pri-miRNAs Preparation of Drosha/DGCR8 Overexpression Lysate Overview 293T cells are transiently transfected with plasmids encoding C-terminal FLAG tagged human Drosha and N-terminal FLAG-HA tagged human DGCR8. Cells are harvested and sonicated. After centrifuge clearing of precipitates and insoluble material, the whole-cell lysate is stored in single-use aliquots. This protocol is modified from Lee and Kim, Meth. Enz. 427 (2007), with additional input from Jinju Han and V. Narry Kim. Plasmids: • • • pMAX-GFP (transfection marker) pFLAG-HA-DGCR8 (courtesy of T. Tuschl) pCK-Drosha-FLAG (courtesy of V. Narry Kim) Cell culture and transfection Maintain 293T cells under standard conditions. We use Dulbecco’s Modified Eagle Medium (DMEM) supplemented to 10% Fetal Bovine Serum. To transfect cells, start with three 15-cm dishes at 90-100% confluence. Split all of these cells into eight 15-cm dishes the day before transfection. Use 15 ml media per plate. The day after splitting (18-24 hours later), begin transfection. Assemble Lipofectamine dilution in one 50 ml Falcon tube: 720 µl Lipofectamine 2000 24 ml Opti-mem I Serum-Free Media Incubate at room temperature for 5 min. Meanwhile, assemble plasmid mixture in another 50 ml Falcon tube: 24 µg pMAX-GFP 60 µg pCK-Drosha-FLAG 60 µg pFLAG-HA-DGCR8 24 ml Opti-mem I Serum-Free Media Add plasmid mixture to Lipofectamine dilution, and gently invert twice to mix. complexes to form by incubating at room temperature for 20-30 min. Allow After complexes have formed, add 6 ml of mixture dropwise to each 15-cm dish. Rock plate gently 1-2 times to ensure even dispersal of transfection complexes. 164 12-24 hours after transfection, check for expression of GFP. At this relatively early point, 50%75% of cells will already be expressing GFP. Split all the transfected cells into twenty 15-cm dishes. Allow cells to grow for 48 hr. After this period, cells should be at or just past confluence. Frequently, with a successful transfection containing pMAX-GFP, the monolayer is faintly green in room lighting. Cells are now ready for harvesting. Lysate preparation Harvest overexpressing cells by removing media and pipetting PBS onto the monolayer. Due to the poor adherence of 293T cells, this is typically enough to dislodge the monolayer. Collect PBS suspension of cells, and keep on ice. Pellet PBS suspension by centrifugation. This pellet should be green from GFP in the cells; there should be little or no visible fluorescence in the supernatant. Prepare 1X Sonic Buffer + protease inhibitors by dissolving a Mini EDTA-Free Protease Inhibitor tablet in 10 ml of 1X Sonic Buffer. Keep on ice. Resuspend cell pellet in 10 ml of 1X Sonic Buffer + protease inhibitors. Prepare sonicator for use. We use a Branson Sonifier 250 at 50% duty cycle and output level 4. Clean the probe by sonicating RNase-ZAP solution for 10 pulses (approximately 20 seconds at 50% duty cycle), then sonicating deionized water for 10 pulses. Lyse 293T cells by sonicating for 10 pulses. Clear the lysate once by centrifuging lysate at 3500 x g for 15 min. If lysis is successful, the pellet should be yellow and perhaps light-green, while the supernatant is green. Collect supernatant. Clear supernatant once more by centrifuging at 3500 x g for 15 min. Collect supernatant. This is the cleared whole-cell extract. Aliquot whole-cell extract into single-use aliquots and store aliquots in liquid nitrogen vapor. Assay for microprocessor activity We assess Microprocessor activity by cleavage of a model miRNA substrate, pri-mir-125a. Cleavage of this substrate appears to be essentially complete at 10 minutes, and shows features consistent with a single-turnover reaction. Accordingly, we use this substrate to estimate a functional concentration of Microprocessor complex. 165 Synthesis of pri-mir-125a reference substrate Amplify a runoff template for T7 transcription by PCR using standard protocols. Human genomic DNA or a mir-125a expression plasmid can be used as a template for this reaction. T7::mir-125a Forward Primer: TAATACGACTCACTATAggTCTCTGACCCCCACCCCAGGG mir-125a Reverse Primer ATGAGGAGTCAGGGGTCAGAAGTCAGGCCAGC See Appendix I for a T7 transcription protocol using the PCR product as a template. The expected product is below (underlined region is the pre-miRNA product). Pri-mir-125a reference (187 nt) ggUCUCUGACCCCCACCCCAGGGUCUACCGGGCCACCGCACACCAUGUUGCCAGUCUCUAGGUCC CUGAGACCCUUUAACCUGUGAGGACAUCCAGGGUCACAGGUGAGGUUCUUGGGAGCCUGGCGUCU GGCCCAACCACACACCUGGGGAAUUGCUGGCCUGACUUCUGACCCCUGACUCCUCAU After purification on urea-polyacrylamide, dephosphorylate the 5′-triphosphorylated substrate RNA using CIP, according to the standard protocol in Appendix I. After the reaction is complete, phenol extract the reaction and ethanol precipitate the product; resuspend in deionized water. 5′-label the substrate using γ-[32P]-ATP and T4 Polynucleotide Kinase, as described in Appendix I. After the reaction is complete, run over a size-exclusion column such as G-25 or P-30 to remove unincorporated ATP. Purify again on urea-polyacrylamide. After resuspension, measure concentration of hot substrate or dilute into a known concentration of cold substrate. We typically maintain substrates at 1 µM or greater to minimize concentration changes due to tube wall adsorption. Titration-timecourse assay for microprocessor activity Set up a titration of the whole-cell lysate for estimating the effective concentration of Microprocessor complex: 10X Cleavage Buffer (5 mM Mg) Microprocessor Lysate 1X Sonic Buffer 1 µM pri-mir-125a Ref. Substrate 1% Rxn 10 µl 1 µl 80 µl 10 µl 100 µl 5% Rxn 10 µl 5 µl 75 µl 10 µl 100 µl 10% Rxn 10 µl 10 µl 70 µl 10 µl 100 µl 20% Rxn 10 µl 20 µl 50 µl 10 µl 100 µl 50% Rxn 10 µl 50 µl 30 µl 10 µl 100 µl Before adding substrate, prewarm the reaction mixture to 37º. Be sure to add the substrate last, as addition of the substrate marks timepoint “0.” After addition of substrate, withdraw 20 µl of 166 the reaction at 0 min, 1 min, 3 min, 9 min, and 27 min. Each 20 µl timepoint should be immediately mixed with at least 100 µl ice-cold Tri-Reagent to stop the reaction. After extraction from Tri-Reagent and precipitation, load and run a 10% Urea-polyacrylamide gel. Labeled Decade markers can be used as a size ladder. The expected product size is 61 nt. Measure the fraction of substrate cleaved at each time point to estimate the concentration of active enzyme. Results from a representative experiment is shown below. Since the initial substrate concentration was 100 nM, the Microprocessor appears to cleave hsa-mir-125a with burst kinetics. We have used this behavior to estimate the concentration of Microprocessor at about 75 nM. 50 45 40 nM Product 35 30 1% Lysate 25 5% Lysate 20 10% Lysate 15 20% Lysate 10 50% Lysate 5 0 0 5 10 15 20 Time (min) 167 25 30 In vitro cleavage selection of circular pri-miRNA substrates Overview The goal of this selection is to explore Microprocessor cleavage determinants in sequences flanking the pre-miRNA hairpin. The overall strategy is to generate a large pool of variant molecules and subject this pool to Microprocessor cleavage. Products of cleavage are recovered and sequenced by high-throughput sequencing to detect motifs that are enriched in the product (Microprocessor-cleaved) population, relative to the original pool. A major hindrance to this strategy is that after cleavage of linear pri-miRNA substrates, there are two flanking RNA products, a 5p (upstream) product, and a 3p (downstream) product. We would like to clone and sequence both products, maintaining the relationship between upstream fragment and downstream fragment for any given partially-randomized RNA molecule. For example, the basal stem of a pri-miRNA hairpin involves pairing between bases in the 5p product and complementary bases in the 3p product. To detect evidence of covariation, we must recover and sequence both bases from the 5p and 3p product of the same substrate molecule. We have accomplished this by circularizing pri-miRNA substrates, and isolating linearized products for high-throughput sequencing. 168 Assembly of partially-randomized, circular pri-miRNA substrate The overall strategy is summarized in the following diagram. A T7 template corresponding to the desired RNA is assembled by PCR, then transcribed. An HDV ribozyme is included in the sequence to homogenize the 3′ ends; self-cleavage occurs in the transcription reaction. After gel purification, the 5′ and 3′ ends are treated to produce ligatable ends. The circularization is achieved using T4 RNA Ligase 1. Template assembly by PCR Templates for T7 transcription are assembled from synthetic oligonucleotides. IDT will synthesize long oligos with both constant sequence and partially randomized positions (for a price). In addition to the pri-miRNA sequence (both constant and partially-randomized), sequence corresponding to the HDV ribozyme is also added to the template amplicon. By way of example, oligonucleotide sequences are provided for the constant (unrandomized) C125circ template. However, the clonal pool (composed many copies of the wildtype miRNA sequence) should be prepared in parallel with the partially randomized pool (composed of a few copies of many variant sequences). C125circ.001a Left arm GACTCACTATAGGGTCACAGGTGAGGTTCTTGGGAGCCTGGCGTCTGGCCCAACCACACACCTGGGGAATT GCTGGCCTGACTTCTGACCCCTGACTCCT 169 C125circ.002a Right arm (ordering orientation) TCCTCACAGGTTAAAGGGTCTCAGGGACCTAGAGACTGGCAACATGGTGTGCGGTGGCCCGGTAGACCCTG GGGTGGGGGTATGAGGAGTCAGGGGTCAG C125circ.003 HDV adaptor CTTCTCCCTTAGCCTACCGAAGTAGCCCAGGTCGGACCGCGAGGAGGTGGAGATGCCATGCCGACCCTGGA TGTCCTCACAGGTTAAAGG C125circ.004 T7 Adaptor CAGAGATGCATAATACGACTCACTATAGGGTCACAG HDV 5′ Polishing Primer CTTCTCCCTTAGCCTACCGAAGTAGCCCAGG First, PAGE-purify long primers. In general, primers longer than 60 nt are difficult even for commercial operations to synthesize, and should be purified before use. Resuspend purified oligos to 100 µM where possible. An initial primer extension between the left and right primers is used to generate a small amount of template for PCR. Assemble the following reaction: 15 µl 15 µl 270 µl 40 µl 40 µl 20 µl 400 µl Left Arm oligo (100 µM) Right Arm oligo (100 µM) H2O 10X “House” PCR Buffer 10X “House” dNTP Mix “House” Taq Perform a primer extension using the program “L/R Ext.” 30 sec (ramp) 1 min 1 min (hold) 95°C Ramp to 37°C at 0.1°C/sec 37°C 72°C Repeat for 5 total cycles 10°C Without purifying or concentrating the primer extension, assemble the following reaction: 30 µl 355 µl 5 µl 5 µl 50 µl 50 µl 5 µl 500 µl Primer extension reaction H2O C125circ.003 HDV Adaptor (100 µM) C125circ.004 T7 Adaptor (100 µM) 10X “House” PCR Buffer 10X “House” dNTP Mix “House” Taq 170 Perform an initial PCR amplification using the program “L/R PCR.” Note that the annealing temperature is based on the amount of homology between the T7 adaptor and the left arm oligo, and the amount of homology between the HDV adaptor and the right arm oligo. 30 sec 30 sec 30 sec 30 sec (hold) 95°C 95°C 45°C or appropriate annealing temp. 72°C Repeat for 4 total cycles 10°C Perform a second PCR amplification to “polish” the template for use. Frequently, the long HDV oligo has internal lesions that prevent T7 RNA polymerase from proceeding through the template. Incomplete transcripts will not have intact HDV ribozyme sequences, and will not self-cleave to the correct size. A few additional rounds of PCR will selectively amplify molecules that have fewer lesions. 50 µl 335 µl 5 µl 5 µl 50 µl 50 µl 5 µl 500 µl Initial PCR reaction H2O HDV Polish Primer (100 µM) C125circ.004 T7 Adaptor (100 µM) 10X “House” PCR Buffer 10X “House” dNTP Mix “House” Taq Repeat L/R PCR program. The annealing temperature may be raised based on the melting temperatures of the HDV Polish Primer and the T7 Adaptor. Ethanol precipitate the reaction and resuspend in 50 µl H2O. Transcription of linear pri-miRNA pool Use T7 RNA Polymerase to transcribe the template prepared in the previous step. A 200 µl reaction scale should be sufficient for most applications, but more is always possible. 25 µl 85 µl 20 µl 40 µl 10 µl 10 µl 10 µl 200 µl Concentrated template pool H2O 10X “House” T7 Buffer 5X “House” NTP Mix DTT (100 mM) Fresh α-[32P]-UTP “House” T7 RNA Polymerase Incubate 37º x 2-3 hr 171 Add 5 µl Turbo DNAse (Ambion) Incubate 37º x 30 min Add 1/20 volume 500 mM EDTA Add 1/10 volume 3M NaCl Add 1 volume 100% ethanol Final: T7 reaction mixture with whatever NTP/Salt/Mg/PPi is present ~25 mM EDTA ~75 mM NaCl (supplemental) 50% ethanol Incubate at least 15 min in -20 Spin 15 min at 4º After precipitation, the reaction should be purified on a 5% Urea-polyacrylamide gel with an appropriate size marker. The expected products are (1) a full-length transcript that has not been self-cleaved; (2) the mature, self-cleaved transcript, and (3) the HDV ribozyme RNA after liberation from the rest of the transcript. Cut out and elute the mature, self-cleaved transcript. This is the linear pri-miRNA pool. For the C125circ primers given above, the expected product sequence is given below. The S125circ partially randomized transcript was twin to this sequence, except that positions colored red were partially randomized at 79% wildtype (indicated base) and 7% each of the other three bases. These positions comprise the basal miRNA stem and 35-45 nt of flanking sequence. ppp-5′GGGTCACAGGTGAGGTTCTTGGGAGCCTGGCGTCTGGCCCAACCACACACCTGGGGAATTGCTGG CCTGACTTCTGACCCCTGACTCCTCATACCCCCACCCCAGGGTCTACCGGGCCACCGCACACCAT GTTGCCAGTCTCTAGGTCCCTGAGACCCTTTAACCTGTGAGGACATCCA-[2′-3′ cyclic phosphate] Treatment of transcript ends for ligation After transcription and self-cleavage, the pool molecules have a 5′ triphosphate and a 2′-3′ cyclic phosphate. The goal of this phase is to convert these ends to a 5′ monophosphate and a 3′-OH, which are the substrates of T4 RNA Ligase 1. First, the triphosphate is removed using Calf Intestinal Phosphatase or Alkaline Phosphatase (CIP). Assemble the following reaction. It is often convenient to reconstitute the pellet from gel extraction directly in the appropriate amount of water. 172 (pellet) 50 µl 6 µl 4 µl 60 µl Linear pri-miRNA pool from previous H2O NEBuffer 3 CIP Incubate at 37°C x 1 hr Phenol-extract the reaction and precipitate. It is often convenient to directly resuspend the pellet in the next reaction’s buffer. Next, the 2′-3′ cyclic phosphate is removed using T4 Polynucleotide Kinase, which has this activity in addition to its kinase activity, in keeping with its role in repairing cleaved tRNA anticodon loops. Assemble the following: (pellet) 50 µl 120 µl 10 µl 180 µl First dephosphorylation from above H2O 1.5X MES Dephosphorylation Buffer T4 PNK Incubate at 37°C x 6 hr Since PNK is also used to 5′ phosphorylate the RNA, it is not necessary to phenol extract. Instead, ethanol precipitate the reaction and resuspend it in the phosphorylation reaction mix. Note: T4 DNA Ligase buffer from NEB is equivalent to T4 PNK Buffer supplemented with 1 mM ATP (final). If using PNK buffer, supplement the reaction to 1 mM ATP (final). (pellet) 170 µl 20 µl 10 µl 200 µl Dephosphorylated pri-miRNA pool H2O T4 DNA Ligase Buffer T4 PNK Incubate at 37°C x 1 hr Phenol-extract the reaction and precipitate. Resuspend in 340 µl H2O. Half will be used directly for circularization. Circularization of pri-miRNA pool using T4 RNA Ligase 1 Consistent with its role in repairing cleaved tRNA anticodon loops, T4 RNA Ligase 1 is reasonably good at ligating single stranded RNA ends that are held close to each other by double-stranded RNA. This is the design of the circularization strategy. Assemble the following reaction: 170 µl Phosphorylated pri-miRNA pool Heat to 85°C x 1 min and cool to room temperature 20 µl T4 RNA Ligase 1 Buffer 10 µl T4 RNA Ligase 1 200 µl Incubate at 37°C x 2 hr 173 Purify the ligation product on a 5% urea-polyacrylamide gel along with an appropriate size ladder. It is frequently convenient to include a small amount of the phosphorylated pri-miRNA pool as a reference. The circularized RNA runs slightly higher than its linearized form. The apparent linear RNA from the ligation lane is a mixture of unligated RNA and nicked circular RNA. Based on experiments using hot 5′ phosphorylated RNA, it appears that much of the apparently linear RNA is actually nicked circularized RNA, suggesting that the ligation reaction is relatively efficient, but that hydrolysis occurs during the reaction for reasons not clear. The nicked RNA does not appear to accumulate with time, indicating that its occurrence is not due to contaminating activity. If desired, the circular nature of the substrate can be verified by two methods. First, cleave the substrate with the Microprocessor to verify that two products form, corresponding to the premiRNA and a single molecule with the flanking sequence. Second, perform a partial hydrolysis time course from 30 sec to 10 min, and compare the products with the uncut circular substrate and the phosphorylated, unligated, linear substrate. At early time points, hydrolysis of the circular substrate should produce a product at the size of the unligated linear substrate. Further hydrolysis will produce a smear of degradation products. Selection of functional variants from circular pri-miRNA pool Cleavage timecourse of clonal wildtype pool and partially-randomized pool This experiment serves three purposes: (1) verification that the circularized pri-miRNA substrates are cleavage competent circular molecules, (2) estimation of the overall contribution of flanking RNA sequence by comparing the cleavage of the partially-randomized pool to the cleavage of wildtype pri-miRNA, and (3) optimization of cleavage timing for the actual selection. Assemble the following reaction, assuming 1 µM stock solutions of RNA and 50 nM Microprocessor complex in whole-cell lysate. As concentrations from different substrate and protein preps vary, volumes should be adjusted to match these final concentrations. 39 µl 50 µl 10 µl 1 µl 100 µl 1X Sonic Buffer Microprocessor Lysate 10X Cleavage/Binding Buffer (1 mM Mg) Circularized clonal or randomized pool (1 µM) Prior to addition of the RNA substrate, the reaction mixture should be prewarmed at 37º. After addition of substrate, withdraw 10 µl at the following times: 0 min, 20 sec, 40 sec, 1 min, 2 min, 4 min, 6 min, 8 min, 10 min, and 12 min. Each timepoint should be mixed immediately with 100 µl of ice-cold Tri-Reagent to stop the reaction. After extraction from Tri-Reagent, run the reactions on an 8% urea-polyacrylamide gel and estimate the amount of cleavage at each timepoint for both the clonal (wildtype) substrate and 174 the partially-randomized pool. For miRNAs where the flanking sequence contributes to recognition and cleavage, the clonal (wildtype) substrate is cleaved 4-5 fold more rapidly than the partially randomized pool. For miRNAs studied so far, this ratio appears to be constant for most early time points (between 20 sec and 6 min). When this is the case, we have selected a timepoint where ~1% of the partially randomized pool and used this timepoint for selection. In some situations, to achieve 1% cleavage it was necessary to adjust the ratio between Microprocessor complex and partially-randomized pool substrate. Selection of functional variants from partially-randomized circular pri-miRNA pool Using conditions optimized in the previous experiment, perform a selection for functional, Microprocessor-cleaved variants in the partially-randomized circular pri-miRNA pool. The reaction should be scaled such that ~100 fmol of cleaved product can be obtained. This corresponds to a selection for 6x1010 product molecules. After accounting for yield losses in library preparation, ~108 to 109 molecules will be available for sequencing; as of early 2012, a single lane of Illumina HiSeq is capable of producing upwards of 108 sequences. Thus, this scale is the minimum scale needed to fully leverage the current sequencing capacity. A target of 100 fmol product requires a moderately large cleavage reaction. For example, for cleavage conditions using a (typical) final reaction concentration of 10 nM pri-miRNA pool, a 1000 µl cleavage reaction will use a total of 10,000 fmol substrate. Cleavage of 1% of this amount yields 100 fmol of product for library prepation for high-throughput sequencing. After performing the selection reaction under optimized conditions, phenol-extract the reaction and precipitate it. The precipitate should be resuspended in the minimum amount of water needed to fully dissolve the pellet, and the resulting nucleic acid should separated on a 5% ureapolyacrylamide gel. Cut out the band corresponding to the flanking, partially-randomized RNA. For the S125circ example given above, the product is expected to be 119 nt. Since yield is valuable, it is advisable to use the crush-and-soak technique to purify this band (see Standard Protocols). Resuspend in 20 µl water. Library preparation for Illumina high-throughput sequencing Library preparation from the selected pool The goal of this phase is to ligate adaptors to the ends of the product sequence; these adaptors will permit amplification of the variant molecules, and contain some necessary sequence for the current (Feb. 2012) Illumina paired-end sequencing technology. We use splint ligation to assist in ligation of adaptors to the correct arm. Because both T4 RNA Ligase 2 and T4 DNA Ligase are highly sensitive to gaps or overhangs in the substrate, the splint ligation is highly selective for defined ends. In general, we have designed splints corresponding to the MirBase annotated cleavage site, which in turn is usually based on the observed ends by deep-sequencing mature miRNAs and their * species. However, recent work by the Zamore lab has suggested that the 3p arm cleavage site annotations may be incorrect, and this view is supported by our experience with splint ligation. Instead, we recommend that the 5p splint be designed according to the 175 annotated 5p arm cleavage, and the 3p arm splint be designed against an inferred cleavage site that leaves a 2-nt overhang. 176 3p Arm 5p Arm p-uggcgucu---------------------ucucuagg-OH S125circ.006 3p Arm Splint (ordering orientation) AGACGCCAAGATCGGA S125circ.007 5p Arm Splint ACGTGTACCCTAGAGA S125circ.006 3p Arm Splint (ordering orientation) AGACGCCAAGATCGGA S125circ.005 3p Arm Adaptor S125circ.007.A 5p Arm Adaptor, CAT barcode GAGATCTACACTCTTTCCCTACACGACGCTCTuccgaucuuggcgucu---------------------ucucuagg guacacguaugaGATCGGAAGAGCGGTTCAGCAGGAATGC S125circ.007 5p Arm Splint ACGTGTACCCTAGAGA (Splints do not cross-hybridize) S0.002 Solexa Rev Seq, -1 short CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATC S125circ.008 RT Primer (-1) GCATTCCTGCTGAACCGCTCTTCCGATC S0.001 Solexa Fwd Seq AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT GAGATCTACACTCTTTCCCTACACGACGCTCTuccgaucuuggcgucu---------------------ucucuaggguacacguaugaGATCGGAAGAGCGGTTCAGCAGGAATGC On a sequence level, this is the strategy for ligating and amplifying the S125circ product. The same adaptors can be used for other miRNA products, provided that a new splint is designed. Due to the circular permutation of the substrate, the 5p arm of the miRNA is at the 3′ end, and the 3p arm of the miRNA is at the 5′ end. To avoid confusion, this protocol will continue to use the 5p and 3p arm convention relative to the miRNA sequence. By way of example, after cleavage and gel purification, the desired product from S125circ selection is as follows. “NNNN” denotes partially randomized sequence in the S125circ. p-TGGCGTCTNNNNNNNNNNNNN-------------------------------NNNNNNNNNNNNNTCTCTAGG-OH There are several features of note. First, as noted above, due to circular permutation, the 5p arm basal stem sequence (TCTCTAGG) is at the 3′ end of the product molecule, while the 3p arm basal stem sequence (TGGCGTCT) is at the 5p end of the product. In the intact circular substrate, the pre-miRNA sequence joined these two ends to form a closed circle. Second, the partially randomized pool was designed such that eight unrandomized nucleotides cap the product. This will serve as the splint binding site during ligation. Third, since this product was generated by Drosha (RNase III) cleavage, it has a 5′ phosphate and 3′-OH and is therefore ready for ligation. Molecules in the product pool that were generated by other endonuclease activities, such as metal cation or base catalyzed hydrolysis and cleavage by RNase A or RNase T1, would have a 5-hydroxyls and 3′ phosphates (or cyclic 2′-3′ phosphates) and are therefore unligatable. Thus the splint ligation approach also selects for true products of Microprocessor activity, rather than unintended endonucleolytic degradation products. First, ligate adaptors to the 5p side. The following sequences were used to ligate the S125circ product pool. Note lowercase letters are RNA sequence. Also, the adaptors are synthetically 5′phosphorylated at the time of synthesis; this service can be requested from most oligo synthesis facilities. Finally, four separate adaptors were synthesized, each with a slight sequence variation. This provides the opportunity to do up to four selections using the same parent miRNA pool, and sequence the selections in the same Illumina lane (provided that each selection library uses a different adaptor barcode). Three nucleotides were used for the barcode, so in principle one could design a total of 43 or 64 barcodes. S125circ.007 5p Arm Splint ACGTGTACCCTAGAGA S125circ.007.A 5p Arm Adaptor, CAT barcode p-guacacguaugaGATCGGAAGAGCGGTTCAGCAGGAATGC S125circ.007.B 5p Arm Adaptor, ATG barcode p-guacacgucauaGATCGGAAGAGCGGTTCAGCAGGAATGC S125circ.007.C 5p Arm Adaptor, TGA barcode p-guacacguucaaGATCGGAAGAGCGGTTCAGCAGGAATGC S125circ.007.D 5p Arm Adaptor, TAG barcode p-guacacgucuaaGATCGGAAGAGCGGTTCAGCAGGAATGC 178 Assemble the ligation reaction. 1.2 µl 5 µl 1.0 µl 0.8 µl 8 µl 5p Arm Adaptor (100 µM) Gel-purified selection product 5p Arm Splint (100 µM) H2O Heat to 85º for 5 min, then air cool to room temperature +1 µl +1 µl 10 µl 10X DNA Ligase Buffer T4 DNA Ligase Incubate at 25º x overnight. Due to the short splint, do not incubate at 37º. Add 0.5 µl Turbo DNAse and incubate at 37º x 10 min to degrade the splint. After the reaction is complete, gel purify the product on a 5% urea-polyacrylamide gel using appropriate size markers. Yield may range from 10-50%, depending on the amount of product available, and the fraction of product with the desired ends. Cut out the band, elute using the crush-and-soak method, precipitate, and resuspend in 10 µl H2O. Next, ligate adaptors to the 3p arm side. The following sequences were used to ligate the S125circ product pool. Note lowercase letters are RNA sequence. Do not phosphorylate adaptors, (a) because it is not necessary, and (b) phosphorylation may make certain side products possible. S125circ.005 3p Arm Adaptor Do not phosphorylate. GAGATCTACACTCTTTCCCTACACGACGCTCTuccgaucu S125circ.006 3p Arm Splint AGACGCCAAGATCGGA Assemble the 3p arm ligation reaction. 1.2 µl 5 µl 1.0 µl 0.8 µl 8 µl 3p Arm Adaptor (100 µM) Gel-purified 5p ligation product 3p Arm Splint (100 µM) H2O Heat to 85º for 5 min, then air cool to room temperature +1 µl +1 µl 10 µl 10X DNA Ligase Buffer T4 DNA Ligase Incubate at 25º x overnight. Due to the short splint, do not incubate at 37º. 179 Add 0.5 µl Turbo DNAse and incubate at 37º x 10 min to degrade the splint. After the reaction is complete, gel purify the product on a 5% urea-polyacrylamide gel using appropriate size markers. Yield may range from 10-50%, depending on the amount of product available, and the fraction of product with the desired ends. Cut out the band, elute using the crush-and-soak method, precipitate, and resuspend in 10 µl H2O. Reverse transcribe the ligated product. Since the product is partially-randomized, the reverse transcription will be primed from the 5p arm ligation adaptor. Note that reverse transcriptase appears to be error-prone in the first few nucleotides after the primer; ideally, one or more nucleotides of constant sequence should be included before a critical sequence (e.g. the barcode) is encountered. For our selections, we used this primer. S125circ.008 RT Primer (-1) GCATTCCTGCTGAACCGCTCTTCCGATC Assemble the RT reaction: 5 µl 3p Ligation Product 5 µl H2O 6.25 µl 10X “House” dNTP Mix 0.3 µl RT primer 16.55 µl Heat to 85º for 5 min, then air cool to room temperature +5 µl +1.25 µl +2 µl ~25 µl 5X First Strand Buffer 100 mM DTT Superscript III Incubate at 55º x 2hr Base hydrolyze the RT reaction by adding 5 µl 1N NaOH and heating to 85º x 10 min. Add 25 µl of 1M HEPES-NaOH pH 7.0 and desalt over a P30 column. PCR amplify the cDNA of the selected pool. The primers hybridize to the cDNA and add the remaining sequences necessary for Illumina paired-end sequencing. It is crucial to use PAGE or some other technique to purify the primers. The sequences are: S0.001 Solexa Fwd Seq GAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT S0.002 Solexa Rev Seq, -1 short CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATC 180 Assemble the following reaction: 38 µl 0.5 µl 0.5 µl 5 µl 5 µl 1 µl 50 µl Desalted RT reaction S0.001 Solexa Fwd Primer (100 µM) S0.002 Solexa Rev Primer -1 (100 µM) 10X “House” dNTP 10X “House” Taq Buffer “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 62°C 72°C Repeat for 10 total cycles 10°C Use the following program. (hold) After 10 cycles are complete, withdraw 5 µl of the reaction and run on a 1.5% agarose gel. If product is visible, stop and purify the product. If no product is visible, amplify another 3 cycles and withdraw a second aliquot. If still no product is visible, amplify another 3 cycles and withdraw a third aliquot. If no product is visible after this stage (16 total cycles), it is likely that one must repeat the selection at a larger scale, taking greater care to preserve yield. If product is visible at any point, stop and purify. Use a 10% formamide-acrylamide gel and stain with Sybr Gold. After elution, precipitation, and resuspension, the purified DNA is ready for Illumina sequencing. Library preparation from the reference (uncleaved) pool To discover contributing sequence elements, we need to determine whether the sequences in the selected pool deviate in abundance from expectation. To minimize bias, we directly sample the unselected pool by amplifying the unselected pool RNA and preparing high-throughput sequencing libraries. Since no cleavage has occurred, the ligation-RT-amplification approach taken for the selected is neither necessary nor possible. Instead, the uncircularized, phosphorylated pool (before circularization ligation) is directly reverse transcribed, amplified, and sequenced. For the unselected S125circ pool, the reverse transcription primer was: S125circ.009 Ref RT TGGATGTCCTCACAGGTTAAAGGGTCTCAGGGACCTAG 181 Assemble the following reaction: 0.5 µl Phosphorylated, uncircularized pool RNA 9.5 µl H2O 6.25 µl 10X “House” dNTP Mix 0.3 µl RT primer 16.55 µl Heat to 85º for 5 min, then air cool to room temperature +5 µl +1.25 µl +2 µl ~25 µl 5X First Strand Buffer 100 mM DTT Superscript III Incubate at 55º x 2hr Base hydrolyze the RT reaction by adding 5 µl 1N NaOH and heating to 85º x 10 min. Add 25 µl of 1M HEPES-NaOH pH 7.0 and desalt over a P30 column. We will add the Illumina sequences needed for sequencing by PCR, in two stages. The primers for the first stage amplification of S125circ are as follows. S125circ.014 Ref-II Fwd Primer CTTTCCCTACACGACGCTCTTCCGATCTCAGGTGAGGTTCTTGGGAGCCTGGC S125circ.015 Ref-II Rev Primer GCATTCCTGCTGAACCGCTCTTCCGATCTTTAAAGGGTCTCAGGGACCTAGAG Assemble the following reaction: 38 µl 0.5 µl 0.5 µl 5 µl 5 µl 1 µl 50 µl Desalted RT reaction S125circ.014 Fwd (100 µM) S125circ.015 Rev (100 µM) 10X “House” dNTP 10X “House” Taq Buffer “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 55°C 72°C Repeat for 3 total cycles 10°C Use the following program. (hold) Polish the pool for Illumina sequencing using the following primers (second stage): 182 S0.001 Solexa Fwd Seq GAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT S0.002 Solexa Rev Seq, -1 short CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATC Assemble the following reaction: 5 µl 0.5 µl 0.5 µl 5 µl 5 µl 33 µl 1 µl 50 µl Stage 1 PCR Reaction S0.001 Solexa Fwd (100 µM) S0.002 Solexa Rev (100 µM) 10X “House” dNTP 10X “House” Taq Buffer H2O “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 55°C 72°C Repeat for 8 total cycles 10°C Use the following program. (hold) Run a 5 µl aliquot on a 1.5% agarose gel. If no product is visible, amplify an additional 3 cycles. When product is faintly visible on agarose, run the remaining reaction on a 10% formamideacrylamide gel and stain with Sybr Gold. After elution, precipitation, and resuspension, the purified DNA is ready for Illumina sequencing. 183 In vitro cleavage selection of linear pri-miRNA substrates Overview The goal of this selection is to explore Microprocessor cleavage determinants the stem-loop region (what will µltimately be the pre-miRNA). The overall strategy is to generate a large pool of variant molecules and subject this pool to Microprocessor cleavage. Products of cleavage are recovered and sequenced by high-throughput sequencing to detect motifs that are enriched in the product (Microprocessor-cleaved) population, relative to the original pool. For RNA motifs flanking the pre-miRNA, a major hindrance to this strategy was that after cleavage of linear pri-miRNA substrates, there will be three products: (1) the pre-miRNA, (2) a 5p (upstream) product, and (3) a 3p (downstream) product. By contrast, motifs in the loop and apical stem are relatively easy to explore, since the entire partially randomized region is contained within a single product molecule, which can be recovered and sequenced. We would like to generate a large number of variants, recover the variants that are cleaved by the Microprocessor, and sequence the successful variants. 184 Assembly of linear, partially-randomized, pri-miRNA substrate Template assembly by PCR Templates for T7 transcription are assembled from synthetic oligonucleotides. IDT will synthesize long oligos with both constant sequence and partially randomized positions (for a price). By way of example, oligonucleotide sequences are provided for the constant (unrandomized) C125loop template. However, the clonal pool (composed many copies of the wildtype miRNA sequence) should be prepared in parallel with the partially randomized pool (composed of a few copies of many variant sequences). Oligos for the clonal pool are the same as oligos for the randomized pool, except that nucleotides in red were partially randomized to 79% wildtype base and 7% chance of each nonwildtype base. S125loop.001a Central ACCATGTTGCCAGTCTCTAGGTCCCTGAGACCCTTTAACCTGTGAGGACATCCAGGGTCACAGGT GAGGTTCTTGGGAGCCTGGCGTCTGGCCCAACCAC S125loop.002 Left Arm CAGAGATGCATAATACGACTCACTATAgCCCCCACCCCAGGGTCTACCGGGCCACCGCACACCAT GTTGCCAGTCTCTAGG S125loop.003 Right Arm GGTCAGAAGTCAGGCCAGCAATTCCCCAGGTGTGTGGTTGGGCCAGACGCCA First, PAGE-purify long primers. In general, primers longer than 60 nt are difficult even for commercial operations to synthesize, and should be purified before use. Resuspend purified oligos to 100 µM where possible. The T7 template can be generated by a single PCR reaction. In the first cycle, the “Central” oligo acts as a template for an initial primer extension by the “Right Arm” oligo. In the second cycle, the extended “Right Arm” DNA acts a template for a second primer extension by the “Left Arm.” After two cycles, the reaction should proceed as a normal PCR. Assemble the following: 370 µl 0.3 µl 10 µl 10 µl 50 µl 50 µl 10 µl 500 µl H2O S125loop.001a (100 µM) S125loop.002 (100 µM) S125loop.003 (100 µM) 10X “House” PCR Buffer 10X “House” dNTP Mix “House” Taq 185 Use this program: 30 sec 30 sec 30 sec 30 sec (hold) 95°C 95°C 52°C or appropriate annealing temp. 72°C Repeat for 4 total cycles 10°C Ethanol precipitate the reaction and resuspend in 50 µl H2O. Transcription of linear pri-miRNA pool Use T7 RNA Polymerase to transcribe the template prepared in the previous step. A 200 µl reaction scale should be sufficient for most applications, but more is always possible. 25 µl 195 µl 40 µl 80 µl 20 µl 20 µl 20 µl 400 µl Concentrated template pool H2O 10X “House” T7 Buffer 5X “House” NTP Mix DTT (100 mM) Fresh α-[32P]-UTP “House” T7 RNA Polymerase Incubate 37º x 2-3 hr Add 5 µl Turbo DNAse (Ambion) Incubate 37º x 30 min Add 1/20 volume 500 mM EDTA Add 1/10 volume 3M NaCl Add 1 volume 100% ethanol Final: T7 reaction mixture with whatever NTP/Salt/Mg/PPi is present ~25 mM EDTA ~75 mM NaCl (supplemental) 50% ethanol Incubate at least 15 min in -20 Spin 15 min at 4º After precipitation, the reaction should be purified on a 5% Urea-polyacrylamide gel with an appropriate size marker. Cut out and elute the mature, self-cleaved transcript. This is the linear pri-miRNA pool. 186 For the C125loop primers given above, the expected product sequence is given below. The S125loop partially randomized transcript was twin to this sequence, except that positions colored red were partially randomized at 79% wildtype (indicated base) and 7% each of the other three bases. These positions comprise the apical miRNA stem and the loop. ppp-5′gCCCCCACCCCAGGGTCTACCGGGCCACCGCACACCATGTTGCCAGTCTCTAGGTCCCTGAGACCCTTTA ACCTGTGAGGACATCCAGGGTCACAGGTGAGGTTCTTGGGAGCCTGGCGTCTGGCCCAACCACACACCTG GGGAATTGCTGGCCTGACTTCTGACC-3′-OH Selection of functional variants from linear pri-miRNA pool Cleavage timecourse of clonal wildtype pool and partially-randomized pool This experiment serves three purposes: (1) verification that the linear pri-miRNA substrates are cleavage competent molecules, (2) estimation of the overall contribution of apical stem and/or loop RNA sequence by comparing the cleavage of the partially-randomized pool to the cleavage of wildtype pri-miRNA, and (3) optimization of cleavage timing for the actual selection. Assemble the following reaction, assuming 1 µM stock solutions of RNA and 50 nM Microprocessor complex in whole-cell lysate. As concentrations from different substrate and protein preps vary, volumes should be adjusted to match these final concentrations. 39 µl 50 µl 10 µl 1 µl 100 µl 1X Sonic Buffer Microprocessor Lysate 10X Cleavage/Binding Buffer (1 mM Mg) Linear clonal or randomized pool (1 µM) Prior to addition of the RNA substrate, the reaction mixture should be prewarmed at 37º. After addition of substrate, withdraw 10 µl at the following times: 0 min, 20 sec, 40 sec, 1 min, 2 min, 4 min, 6 min, 8 min, 10 min, and 12 min. Each timepoint should be mixed immediately with 100 µl of ice-cold Tri-Reagent to stop the reaction. After extraction from Tri-Reagent, run the reactions on an 10% urea-polyacrylamide gel and estimate the amount of cleavage at each timepoint for both the clonal (wildtype) substrate and the partially-randomized pool. For selection (next section), we have previously selected timepoints where ~1% of the partially randomized pool and used this timepoint for selection. In some situations, to achieve 1% cleavage it was necessary to adjust the ratio between Microprocessor complex and partially-randomized pool substrate. Selection of functional variants from partially-randomized linear pri-miRNA pool Using conditions optimized in the previous experiment, perform a selection for functional, Microprocessor-cleaved variants in the partially-randomized linear pri-miRNA pool. The reaction should be scaled such that ~10 fmol of cleaved product can be obtained. This 187 corresponds to a selection for 6x109 product molecules. There is very little loss in the library preparation, so essentially all of these molecules will be available for sequencing. A target of 10 fmol product requires just a small cleavage reaction. For example, for cleavage conditions using a (typical) final reaction concentration of 10 nM pri-miRNA pool, a 100 µl cleavage reaction will use a total of 1,000 fmol substrate. Cleavage of 1% of this amount yields 10 fmol of product for library prepation for high-throughput sequencing. After performing the selection reaction under optimized conditions, phenol-extract the reaction and precipitate it. The precipitate should be resuspended in the minimum amount of water needed to fully dissolve the pellet, and the resulting nucleic acid should separated on a 10% ureapolyacrylamide gel. Cut out the band corresponding to the pre-miRNA. For the S125loop example given above, the product is expected to be 60 nt. Since yield is valuable, it is advisable to use the crush-and-soak technique to purify this band (see Standard Protocols). Resuspend in 20 µl water. Library preparation for Illumina high-throughput sequencing Library preparation from the selected pool and reference pool The goal of this phase is to add adaptors to the ends of the product sequence; these adaptors will permit amplification of the variant molecules, and contain some necessary sequence for the current (Feb. 2012) Illumina paired-end sequencing technology. We use PCR with long primers to achieve this. Reverse transcribe the pre-miRNA product, or the reference pool RNA. Note that reverse transcriptase appears to be error-prone in the first few nucleotides after the primer; ideally, one or more nucleotides of constant sequence should be included before a critical sequence (e.g. randomized sequence) is encountered. For our selections, we used this primer. S125loop.004 RT Primer GGCATAGGCTCCCAAGAACCTC Assemble the RT reaction: 10 µl Pre-miRNA product or reference pool 6.25 µl 10X “House” dNTP Mix 0.3 µl RT primer 16.55 µl Heat to 85º for 5 min, then air cool to room temperature +5 µl +1.25 µl +2 µl ~25 µl 5X First Strand Buffer 100 mM DTT Superscript III Incubate at 55º x 2hr 188 Base hydrolyze the RT reaction by adding 5 µl 1N NaOH and heating to 85º x 10 min. Add 25 µl of 1M HEPES-NaOH pH 7.0 and desalt over a P30 column. PCR amplify the cDNA of the selected pool. The primers hybridize to the cDNA and will add (1) a short barcode, and (2) part of the sequence needed for Illumina single-end sequencing. It is crucial to use PAGE or some other technique to purify the primers. The reverse primer will be the RT primer used above. The forward primers vary (each contains a different barcode, or no barcode at all). We used: S125loop.005 Init. PCR Fwd GACGATCTCCCTGAGACCCTTTAA S125loop.005a Init. PCR Fwd, barcoded GACGATCgaTCCCTGAGACCCTTTAA S125loop.005b Init. PCR Fwd, barcoded GACGATCctTCCCTGAGACCCTTTAA Assemble the following reaction: 20 µl 1 µl 1 µl 10 µl 10 µl 57 µl 1 µl 100 µl Desalted RT reaction S125loop.005 Series Primer (100 µM) S125loop.004 RT Primer (100 µM) 10X “House” dNTP 10X “House” Taq Buffer H2O “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 50°C 72°C Repeat for 5 total cycles 10°C Use the following program. (hold) Without purifying the PCR reaction, assemble the second-stage PCR, which adds the remaining sequences necessary for Illumina single-end sequencing. The primers used are specific to the barcode used in the initial reaction, i.e. if 005a was used for the first reaction, 007a should be used for the second reaction. It is essential to purify these primers to get optimal sequencing results. S125loop.006corr Solexa-R Adaptor CAAGCAGAAGACGGCATACGAGGCTCCCAAGAACCTC 189 S125loop.007 Solexa-Seq Adaptor AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCTCCCTGAGACCCTTTAA S125loop.007a Solexa-Seq Adaptor, barcoded AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCgaTCCCTGAGACCCTTTAA S125loop.007b Solexa-Seq Adaptor, barcoded AATGATACGGCGACCACCGACAGGTTCAGAGTTCTACAGTCCGACGATCctTCCCTGAGACCCTTTAA Assemble the following reaction: 20 µl 2 µl 2 µl 20 µl 20 µl 2 µl 100 µl Initial PCR Reaction S125loop.007 Series Primer (100 µM) S125loop.006corr R. Primer (100 µM) 10X “House” dNTP 10X “House” Taq Buffer “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 55°C 72°C Repeat for 5 total cycles 10°C Use the following program. (hold) Run a 5 µl aliquot on a 1.5% agarose gel. If no product is visible, amplify an additional 3 cycles. When product is faintly visible on agarose, run the remaining reaction on a 10% formamideacrylamide gel and stain with Sybr Gold. Due to the nature of the PCR-addition approach, there may be four dominant products visible on the gel: (1) Product from the initial PCR reaction, which may be further amplified by the dilute oligos that are still around, at 73-75 bp; (2) products of reactions where only the reverse extended arm has been added, at 85-87 bp; (3) products of reactions where only the forward extended arm has been added, at 115-117 bp; and (4) full-length product for Illumina sequencing, at 127-129 bp. This is the band that should be excised. After elution, precipitation, and resuspension, the purified DNA is ready for Illumina sequencing. 190 In Vitro Binding Selection for Functional pri-miRNAs Preparation of immunopurified Drosha-TN/DGCR8 Overview 293T cells are transiently transfected with plasmids encoding C-terminal FLAG tagged human DroshaTN (a dominant-negative form of Drosha in which the two RNase III domains are mutated), and N-terminal FLAG-HA tagged human DGCR8. Cells are harvested and sonicated. After centrifuge clearing of precipitates and insoluble material, the whole-cell lysate is stored in single-use aliquots. This protocol is modified from Lee and Kim, Meth. Enz. 427 (2007), with additional input from Jinju Han and V. Narry Kim. Plasmids: • • • pMAX-GFP (transfection marker) pFLAG-HA-DGCR8 (courtesy of T. Tuschl) pCK-DroshaTN-FLAG (courtesy of V. Narry Kim) Cell culture and transfection Maintain 293T cells under standard conditions. We use Dulbecco’s Modified Eagle Medium (DMEM) supplemented to 10% Fetal Bovine Serum. To transfect cells, start with three 15-cm dishes at 90-100% confluence. Split all of these cells into eight 15-cm dishes the day before transfection. Use 15 ml media per plate. The day after splitting (18-24 hours later), begin transfection. Assemble Lipofectamine dilution in one 50 ml Falcon tube: 720 µl Lipofectamine 2000 24 ml Opti-mem I Serum-Free Media Incubate at room temperature for 5 min. Meanwhile, assemble plasmid mixture in another 50 ml Falcon tube: 24 µg pMAX-GFP 60 µg pCK-Drosha-FLAG 60 µg pFLAG-HA-DGCR8 24 ml Opti-mem I Serum-Free Media Add plasmid mixture to Lipofectamine dilution, and gently invert twice to mix. complexes to form by incubating at room temperature for 20-30 min. Allow After complexes have formed, add 6 ml of mixture dropwise to each 15-cm dish. Rock plate gently 1-2 times to ensure even dispersal of transfection complexes. 191 12-24 hours after transfection, check for expression of GFP. At this relatively early point, 50%75% of cells will already be expressing GFP. Split all the transfected cells into twenty 15-cm dishes. Allow cells to grow for 48 hr. After this period, cells should be at or just past confluence. Frequently, with a successful transfection containing pMAX-GFP, the monolayer is faintly green in room lighting. Cells are now ready for harvesting. Lysate preparation Harvest overexpressing cells by removing media and pipetting PBS onto the monolayer. Due to the poor adherence of 293T cells, this is typically enough to dislodge the monolayer. Collect PBS suspension of cells, and keep on ice. Pellet PBS suspension by centrifugation. This pellet should be green from GFP in the cells; there should be little or no visible fluorescence in the supernatant. Prepare 1X Sonic Buffer without any reducing agents. Add protease inhibitors by dissolving a Mini EDTA-Free Protease Inhibitor tablet in 10 ml of 1X Sonic Buffer (no reducing agents). Keep on ice. Resuspend cell pellet in 10 ml of 1X Sonic Buffer + protease inhibitors. Prepare sonicator for use. We use a Branson Sonifier 250 at 50% duty cycle and output level 4. Clean the probe by sonicating RNase-ZAP solution for 10 pulses (approximately 20 seconds at 50% duty cycle), then sonicating deionized water for 10 pulses. Lyse 293T cells by sonicating for 10 pulses. Clear the lysate once by centrifuging lysate at 3500 x g for 15 min. If lysis is successful, the pellet should be yellow and perhaps light-green, while the supernatant is green. Collect supernatant. Clear supernatant once more by centrifuging at 3500 x g for 15 min. Collect supernatant. This is the cleared whole-cell extract. Immunoprecipitation with anti-FLAG beads Prepare 100 µl Anti-FLAG agarose or magnetic beads according to manufacturer’s directions. Wash twice more with 1X Sonic Buffer, without reducing agents. Add beads to cleared whole-cell extract. Rotate or agitate at 4º x 4-18hr. 192 Pellet the beads by centrifugation or magnet. Pull off the supernatant and wash 3 times in 1X Sonic Buffer + protease inhibitors, without reducing agents. Each wash should be at least 10fold larger than the volume of the packed beads, and each wash should incubate with the beads at 4º for at least 10 minutes. After the final wash, elute with a combination of FLAG peptide and reducing agent. Prepare the following elution buffer: 1X Sonic Buffer with Protease Inhibitors 0.7 µl/ml 2-mercaptoethanol 50% glycerol 100 ng/ul RNase-free BSA 100 ng/ul Yeast total RNA Use at least 3-fold more than the packed bead volume. Aliquot eluted complex into single-use aliquots and store in the vapor phase of liquid nitrogen. 193 In vitro binding selection of linear pri-miRNA substrates Overview The goal of this selection is to explore Microprocessor cleavage determinants the flanking regions upstream and downstream of the pre-miRNA. The overall strategy is to generate a large pool of variant molecules and subject this pool to a binding reaction with immunopurified Drosha-TN and DGCR8. We would like to generate a large number of variants, recover the variants that are bound by the Microprocessor, and sequence the successful variants. We seek motifs that are enriched in the product (Microprocessor-bound) population, relative to the original pool. Since dominant-negative Drosha with mutations in the RNase III domains is used in this experiment, the pri-miRNA substrate should remain intact after binding. Thus it is possible to simply reverse-transcribe and amplify the bound RNA for Illumina high-throughput sequencing. 194 Assembly of linear, partially-randomized, pri-miRNA substrate Template assembly by PCR Templates for T7 transcription are assembled from synthetic oligonucleotides. IDT will synthesize long oligos with both constant sequence and partially randomized positions (for a price). By way of example, oligonucleotide sequences are provided for the constant (unrandomized) C125 template. However, the clonal pool (composed many copies of the wildtype miRNA sequence) should be prepared in parallel with the partially randomized pool (composed of a few copies of many variant sequences). Oligos for the clonal pool are the same as oligos for the randomized pool, except that nucleotides in red were partially randomized to 79% wildtype base and 7% chance of each nonwildtype base. Note that, on the left arm, 15 nucleotides of nongenomic sequence are included. These are part of the sequences needed for Illumina pairedend sequencing. C125.001 Left Arm acgctcttccgatctCCCCAGGGTCTACCGGGCCACCGCACACCATGTTGCCAGTCTCTAGGTCC CTGAGACCCTTTAACCTGTGAGGACATCCAGGGTC C125.002 Right Arm AGGAGTCAGGGGTCAGAAGTCAGGCCAGCAATTCCCCAGGTGTGTGGTTGGGCCAGACGCCAGGC TCCCAAGAACCTCACCTGTGACCCTGGATGTCCTC First, PAGE-purify long primers. In general, primers longer than 60 nt are difficult even for commercial operations to synthesize, and should be purified before use. Resuspend purified oligos to 100 µM where possible. An initial primer extension between the left and right primers is used to generate a small amount of template for PCR. Assemble the following reaction: 15 µl 15 µl 270 µl 40 µl 40 µl 20 µl 400 µl Left Arm oligo (100 µM) Right Arm oligo (100 µM) H2O 10X “House” PCR Buffer 10X “House” dNTP Mix “House” Taq 195 Perform a primer extension using the program “L/R Ext.” 30 sec (ramp) 1 min 1 min (hold) 95°C Ramp to 37°C at 0.1°C/sec 37°C 72°C Repeat for 5 total cycles 10°C The T7 template can be generated a PCR reaction, using primers that add the T7 promoter, along with two template C residues (so that T7 can initiate with GTP): S0.002 T7-fwdSeq CAGAGATGCATAATACGACTCACTATAggacacgacgctcttccgatct S125.003 RT primer TATGAGGAGTCAGGGGTCAG Without purifying or concentrating the primer extension, assemble the following reaction: 30 µl 355 µl 5 µl 5 µl 50 µl 50 µl 5 µl 500 µl Primer extension reaction H2O S0.002 T7-fwdSeq (100 µM) S125.003 RT Primer (100 µM) 10X “House” PCR Buffer 10X “House” dNTP Mix “House” Taq Perform an initial PCR amplification using the program “L/R PCR.” Note that the annealing temperature is based on the amount of homology between the T7 adaptor and the left arm oligo, and the amount of homology between the RT primer and the right arm oligo. 30 sec 30 sec 30 sec 30 sec (hold) 95°C 95°C 55°C or appropriate annealing temp. 72°C Repeat for 4 total cycles 10°C Ethanol precipitate reaction and resuspend in 50 µl H2O. Transcription of linear pri-miRNA pool Use T7 RNA Polymerase to transcribe the template prepared in the previous step. A 400 µl reaction scale should be sufficient for most applications, but more is always possible. 196 25 µl 195 µl 40 µl 80 µl 20 µl 20 µl 20 µl 400 µl Concentrated template pool H2O 10X “House” T7 Buffer 5X “House” NTP Mix DTT (100 mM) Fresh α-[32P]-UTP “House” T7 RNA Polymerase Incubate 37º x 2-3 hr Add 10 µl Turbo DNAse (Ambion) Incubate 37º x 30 min Add 1/20 volume 500 mM EDTA Add 1/10 volume 3M NaCl Add 1 volume 100% ethanol Final: T7 reaction mixture with whatever NTP/Salt/Mg/PPi is present ~25 mM EDTA ~75 mM NaCl (supplemental) 50% ethanol Incubate at least 15 min in -20 Spin 15 min at 4º After precipitation, the reaction should be purified on a 5% Urea-polyacrylamide gel with an appropriate size marker. Cut out and elute the full-length transcript. This is the linear primiRNA pool. For the C125 primers given above, the expected product sequence is given below. The S125 partially randomized transcript was twin to this sequence, except that positions colored red were partially randomized at 82% wildtype (indicated base) and 6% each of the other three bases. These positions comprise the flanking RNA sequence, up to (but not including) the basal stem. ppp-5′ggacacgacgctcttccgatctCCCCCACCCCAGGGTCTACCGGGCCACCGCACACCATGTTGCCAGTCT CTAGGTCCCTGAGACCCTTTAACCTGTGAGGACATCCAGGGTCACAGGTGAGGTTCTTGGGAGCCTGGCG TCTGGCCCAACCACACACCTGGGGAATTGCTGGCCTGACTTCTGACCCCTGACTCCTCATA-3′-OH Selection of functional variants from linear pri-miRNA pool Trial competitive binding between clonal wildtype RNA and partially-randomized pool This experiment serves to estimate the overall contribution of flanking RNA sequence by comparing the binding of the partially-randomized pool to the binding of wildtype pri-miRNA. 197 First, transcribe a reference pri-miRNA sequence that is 15-20 nt shorter than the pool RNAs. For mir-125a, the following sequence can be ordered from IDT and transcribed using T7 polymerase (see Standard Protocols). The RNA can be body labeled, or 5′ dephosphorylated and 5′ labeled with ATP. See Standard Protocols. TATGAGGAGTCAGGGGTCAGAAGTCAGGCCAGCAATTCCCCAGGTGTGTGGTTGGGCCA GACGCCAGGCTCCCAAGAACCTCACCTGTGACCCTGGATGTCCTCACAGGTTAAAGGGT CTCAGGGACCTAGAGACTGGCAACATGGTGTGCGGTGGCCCGGTAGACCCTGGGGTGGG GGcTATAGTGAGTCGTATTATGCATCTCTG To perform the competitive binding experiment, assemble the following reaction, assuming 5 µM stock solutions of RNA. Although we do not have a measurement of the functional Microprocessor concentration, it is likely to be much less than the concentration of RNA used in the experiment. 20 µl 1.25 µl 1.25 µl 2.5 µl 25 µl DroshaTN/DGCR8 eluate Short Reference pri-miRNA (5 µM) C125 wildtype or S125 pool RNA (5 µM) 10X Cleavage/Binding Buffer (1 mM Mg) Allow binding reaction to proceed at room temperature for 15-30 min. “unbound” sample and store in 1X urea loading dye. Withdraw 0.5 µl Prepare nitrocellulose filters for binding. Place pedestals on vacuum system (we use an older vacuum setup that is totally unlabeled and inherited from David P. Bartel’s younger days; in principle, a new Qiagen vacuum manifold could be used). Wet filters by adding 500 µl 1X Sonic Buffer. Apply binding reaction to the center of a nitrocellulose filter, under vacuum. Wash the filter three times. For each wash, add at least 10-fold more than the reaction volume of 1X Sonic Buffer. Elute protein-RNA complexes from the filter by carefully lifting the filter and placing in a microcentrifuge tube. Add 500 µl 1X VCA Elution Buffer, and heat to 85º x 10 min. Vortex. Withdraw elution buffer and ethanol precipitate by adding 1000 µl 100% ethanol. After precipitation, estimate the number of filter-retained counts in the pellet. Resuspend the pellet in an appropriate amount of 1X urea loading dye. Run an equal counts between the bound and unbound sample (retained above) on a 4% urea-polyacrylamide gel. The gel should be run such that the xylene dye is almost at the bottom of the gel in order to maximize the resolution at ~180 nt. 198 Quantify the ratio of long (pool) RNA to short (reference) RNA, and normalize by the ratio in the input lane. The normalized ratio is an estimate of the relative binding of the long RNA vs. the shorter RNA. Ideally, the relative binding between the reference RNA and C125 (the clonal, wildtype, long RNA) is ~1, while the relative binding between the reference RNA and S125 (the partially-randomized, long RNA) is >1, i.e. binding favors the reference RNA. Selection of functional variants from partially-randomized linear pri-miRNA pool Perform a selection for functional, Microprocessor-binding variants in the partially-randomized linear pri-miRNA pool. Assemble the following reaction: 40 µl 5 µl 5 µl 50 µl DroshaTN/DGCR8 eluate C125 wildtype or S125 pool RNA (5 µM) 10X Cleavage/Binding Buffer (1 mM Mg) Apply binding reaction to the center of a nitrocellulose filter, under vacuum. Wash the filter three times. For each wash, add at least 10-fold more than the reaction volume of 1X Sonic Buffer. Elute protein-RNA complexes from the filter by carefully lifting the filter and placing in a microcentrifuge tube. Add 500 µl 1X VCA Elution Buffer, and add 1 µl Yeast Total RNA to act as a tube-blocking and co-precipitating agent. Heat to 85º x 10 min. Vortex. Withdraw elution buffer and ethanol precipitate by adding 1000 µl 100% ethanol. Resuspend the pellet directly in the following reaction. Reverse transcribe the RNA. For the pri-mir-125 binding selection, the following primer was used: S125.003 RT primer TATGAGGAGTCAGGGGTCAG Assemble the RT reaction. (pellet) Eluted bound RNA 10 µl H2O 6.25 µl 10X “House” dNTP Mix 0.3 µl RT primer 16.55 µl Heat to 85º for 5 min, then air cool to room temperature +5 µl +1.25 µl +2 µl ~25 µl 5X First Strand Buffer 100 mM DTT Superscript III Incubate at 55º x 2hr Base hydrolyze the RT reaction by adding 5 µl 1N NaOH and heating to 85º x 10 min. Add 25 µl of 1M HEPES-NaOH pH 7.0 and desalt over a P30 column. 199 PCR amplification for downstream applications Template preparation for the next round of selection The goal of this phase is to add adaptors to the ends of the product sequence; these adaptors will permit amplification and then transcription of the variant molecules. We use PCR with long primers to achieve this. PCR amplify the cDNA of the selected pool using the same primers used to generate the original T7 template. S0.002 T7-fwdSeq CAGAGATGCATAATACGACTCACTATAggacacgacgctcttccgatct S125.003 RT primer TATGAGGAGTCAGGGGTCAG Assemble the following reaction: 55 µl 4 µl 4 µl 40 µl 40 µl 253 µl 4 µl 400 µl Desalted RT reaction S125.003 RT Primer (100 µM) S0.002 T7-fwdSeq (100 µM) 10X “House” dNTP 10X “House” Taq Buffer H2O “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 55°C 72°C Repeat for 6 total cycles 10°C Use the following program. (hold) Run a 10 µl aliquot on a 1.5% agarose gel. If no product is visible, amplify an additional 3 cycles, and check again; we often get visible product around 10 cycles. When product is faintly visible on agarose. Ethanol precipitate the PCR reaction and resuspend in 50 µl H2O. This reaction can be used for T7 transcription for the next round of selection. Library preparation for Illumina high-throughput sequencing Any selected T7 template pool can be “polished” for Illumina high-throughput sequencing. To sequence the initial pool (Pool 0), the pool RNA should be reverse-transcribed and amplified as 200 above, in order to fully capture any biases that were introduced by reverse transcription and PCR. The “polishing” primers add (1) a short barcode, and (2) part of the sequence needed for Illumina single-end sequencing. It is crucial to use PAGE or some other technique to purify the primers. The reverse primers vary (each contains a different barcode, in blue). We used: S0.001 Solexa Fwd Seq AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT S125.005.A Solexa Reverse Paired-End Sequencing, barcoded CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATCTCATTATGAGG AGTCAGGGGTCAG S125.005.B Solexa Reverse Paired-End Sequencing, barcoded CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATCTATGTATGAGG AGTCAGGGGTCAG S125.005.C Solexa Reverse Paired-End Sequencing, barcoded CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATCTTGATATGAGG AGTCAGGGGTCAG S125.005.D Solexa Reverse Paired-End Sequencing, barcoded CAAGCAGAAGACGGCATACGAGATCGGTCTCGGCATTCCTGCTGAACCGCTCTTCCGATCTTAGTATGAGG AGTCAGGGGTCAG Assemble the following reaction: 0.3 µl 59 µl 1 µl 1 µl 10 µl 10 µl 1 µl 100 µl Pool DNA H2O S125.005 Series Primer (100 µM) S0.001 Solexa Fwd Seq (100 µM) 10X “House” dNTP 10X “House” Taq Buffer “House” Taq 30 sec 30 sec 30 sec 30 sec 95°C 95°C 55°C 72°C Repeat for 4 total cycles 10°C Use the following program. (hold) 201 Ethanol precipitate the PCR reaction and run on a 10% formamide-acrylamide gel. Stain with Sybr Gold and cut out the product. After elution, precipitation, and resuspension, the purified DNA is ready for Illumina sequencing. 202 Identification of Motif-Binding Proteins by Site-Specific Crosslinking Overview This protocol outlines a method to identify proteins bound to a particular RNA motif. Typically, a specific region of RNA is thought to be functionally important, and the underlying assumption of this protocol is that this region provides a sequence-specific binding site for important proteins. Given the motif, a 4-thiouridine (or, in principle, another reactive nucleoside analog) is incorporated in specific positions, preferably at positions known to be important for function. After 365 nm UV-mediated crosslinking of the 4-thiouridine to protein candidates, the covalently-linked protein-RNA complex is subjected to further analysis to characterize the unknown protein. A schematic of this process, in the context of pri-miRNAs, is provided below. Protocol development was heavily influenced by Sontheimer EJ. Site-Specific Crosslinking with 4-thiouridine. Mol. Biol. Rep. (1994). 203 Assembly of 4-thiouridine containing RNA substrate A 4-thiouridine containing substrate must be assembled or synthesized such that the following conditions are met: 1. The 4-thiouridine is incorporated at a position thought to be important for binding of the protein-of-interest. 2. A radioactive phosphate is incorporated at or near the 4-thiouridine site, such that after complete digestion of the RNA by RNase (preferably RNase T1), the fragment of RNA that contains the 4-thiouridine also contains the radioactive phosphate. 3. A biotin moiety is incorporated such that after binding to the protein complex of interest, the piece of RNA that contains the 4-thiouridine also contains the biotin moiety. However, the biotin should be incorporated such that cleavage by RNase (preferably RNase T1) separates the biotin from the 4-thiouridine. We have assembled substrates with these properties by splint ligating together a mix of RNAs containing a particular 4-thiouridine, RNAs containing biotin, and RNAs containing a 5′-32P. RNAs with 4-thiouridine were synthesized commercially by Dharmacon (we have not been able to find a supplier for the (4-S-U)pG suggested by Sontheimer); likewise, RNAs containing 3′ or 5′ biotin were synthesized commercially by Dharmacon or IDT. Other RNAs were synthesized by T7 transcription, where possible. See Supplement 1 for protocols related to splint ligation, 5′ phosphorylation, and T7 transcription. It is essential to perform all operations, to the greatest extent possible, under light-protected conditions. As an example, we have constructed a pri-miRNA substrate that contains a 4-thiouridine in the CNNC motif, located in the 3p flanking region of the pri-miRNA. The first step is to use T7 transcription to synthesize the “left” arm of the substrate, which includes the 5p flanking region of the miRNA, the 5p arm of the hairpin, the loop, the 3p arm, and part of the 3p flanking region. This is the T7 template used for this purpose: CX30.017 (E) T7-L.Arm Template TCCGAGGCAGTAGGCAGCTGCAAACATCCGACTGAAAGCCCATCTGTGGCTTCACAGCTTCCAGT CGAGGATGTTTACAGTCGCTCACTGTCAACAGCAATATACCTTCTTTAGCCTTCTGTTGGGTTAA CCTATAGTGAGTCGTATTATGCATCTCTG The transcription product was gel purified. Next, a 4-thiouridine containing RNA was purchased from Dharmacon: CX30.020RNA CU(4-S-U)CAAGGG This RNA was 5′ phosphorylated with γ-32P-ATP and polynucletide kinase, then ligated to the CX30.017 transcript by splint ligation with T4 RNA Ligase 2 and the following DNA splint from IDT. 204 CX30.029 3p Splint GCTCCTAAAGTAGCCCCTTGAAGTCCGAGGCAGTA Finally, the following RNA was purchased from Dharmacon. CX30.028 3p Biotin Fragment GCTACTTTAGGAGCAATTATC-3′-Biotin This RNA was 5′ phosphorylated with cold ATP and polynucleotide kinase, then ligated to the 017+020 ligation product using T4 RNA Ligase 2 and the same DNA splint (CX30.029). The resulting ligation product looks like this: 5′pppGGTTAACCCAACAGAAGGCTAAAGAAGGTATATTGCTGTTGACAGTGAGCGACTGTAAA CATCCTCGACTGGAAGCTGTGAAGCCACAGATGGGCTTTCAGTCGGATGTTTGCAGCTGCCT ACTGCCTCGGACT(4-S-U)CAAGGGGCTACTTTAGGAGCAATTATC-3′-biotin The product was validated by RNaseH cleavage at various places in the 5p sequence, the hairpin loop, and the 3p sequence. In addition, the ligation product is cleavage-competent in Drosha/DGCR8 overexpressing lysate. RNA-protein crosslinking and complex analysis Optimization of 365 nm UV dose The goal of UV dose optimization is to maximize the amount of crosslinking to proteins of interest, while minimizing other, possibly nonspecific crosslinks. In practice it seems to be difficult to distinguish between the two, so we generally choose a UV dose to achieve crosslinking just shy of maximum. First, assemble a binding reaction under conditions where the putative protein of interest is known to bind the RNA. Presumably, conditions in which the RNA is functional should be appropriate conditions to perform the binding reaction. For the Microprocessor complex and binding to the CNNC motif, we have used the following reaction binding and/or cleavage reaction: 39 µl 50 µl 10 µl 1 µl 100 µl 1X Sonic Buffer Microprocessor Lysate from 293T 10X Cleavage/Binding Buffer (1 mM Mg) 4-S-U containing RNA substrate (1 µM) 205 Prepare a platform for crosslinking. We wrap an aluminum heat block or aluminum tube rack in parafilm, and inverted it so that the binding reaction can be spotted on to a flat, parafilm-covered surface, according to this cross-sectional diagram. The advantage of using aluminum as a solid support is that the block can be preheated or prechilled to a desired temperature, and will reasonably hold this temperature during the crosslinking process. Binding Reaction (20100 ul droplet) Parafilm layer Aluminum block Spot aliquots of the reaction onto the parafilm surface in 20-100 µl volumes, taking care not to puncture the parafilm layer with the pipette tip (if the RNA is radioactive, the aluminum block will adsorb the radioactive RNA and is quite difficult to clean). Place the block with the binding reaction droplets into the crosslinker. We use a Stratagene UV 2400 Stratalinker with 365 nm bulbs. Crosslink the RNA. We use a constant-energy setting rather than a timer for greater consistency, particularly as individual bulbs wear down and become dimmer or fail. For the UV dose titration, a good starting point is to place 5 spots of 20 µl, and expose them to UV in multiple iterations, removing one spot at a time, as described in the following table: NB1: 500 mJ = “5000 x 100 micro Joules” NB2: The maximum setting is about 1000 mJ = “9999 x 100 micro Joules” Cycle 1 2 3 4 5 Setting 500 mJ 500 mJ 1000 mJ 1000 mJ 1000 mJ Total Dose: Spot #1 Spot #2 Spot #3 Spot #4 Spot #5 X X X X X 0 mJ 500 mJ X X X X 500 mJ 500 mJ 500 mJ X X X 1000 mJ 500 mJ 500 mJ 1000 mJ X X 2000 mJ 500 mJ 500 mJ 1000 mJ 1000 mJ 1000 mJ 4000 mJ After each dose, remove the appropriate spot and place in a light-protected (e.g. amber) Eppendorf tube. For each dose, aliquot half the recovered reaction (usually about 80% of the original volume, less for higher doses) into separate tubes. Keep one set of crosslinked reactions at room temperature, which will be a set of undigested controls. 206 For the other set of crosslinked reactions, digest the RNA in a manner such that the RNA is largely degraded, but the hot phosphate label is still associated with the crosslinked RNA-protein complex. For the CNNC crosslinking experiment described as an example, we used RNase T1. We added 0.5 µl high-concentration RNase T1 to each 20 µl reaction and incubated at room temperature for 15 minutes. After RNase digestion, add SDS-PAGE buffer, e.g. Laemmli Buffer, to every sample and boil for 5 minutes. Run the reactions on an appropriate SDS-PAGE gel. For most crosslinking reactions, we have used Invitrogen Novex Nu-Page 4-12% Bis-Tris gels and MOPS buffer. After separation on SDS-PAGE, expose the gel to film or phosphorimager plate. Proteins of interest should be visible as discrete, UV-dependent, RNase-resistant bands. Large-scale purification of crosslinked complexes for analysis The goal of this section is to purify substantial amounts of crosslinked RNA-protein complex using streptavidin-biotin affinity pulldown. The first step is to simply increase the scale of the binding reaction, and crosslink using optimized UV dosing. If complex is being prepared for mass-spectrometry analysis, it is worth determining whether the mass-spectrometry operator is willing to accept radioactive samples. If not, it will be necessary to prepare a non-radioactive or “cold” 4-thiouridine substrate, and do experiments in parallel with both hot and cold substrates. For the CNNC binding experiment, a 10-fold scale up was sufficient for mass spectrometry, although just barely so. 390 µl 500 µl 100 µl 10 µl 1000 µl 1X Sonic Buffer Microprocessor Lysate from 293T 10X Cleavage/Binding Buffer (1 mM Mg) 4-S-U containing RNA substrate (1 µM) As before, half the binding reaction should be kept at room temperature without exposure to UV light. The other half should be crosslinked using previously optimized conditions. The goal of the purification is to only retain proteins that are covalently linked to the RNA in a UV-dependent manner. Consequently, we purify both crosslinked and uncrosslinked complexes; the uncrosslinked preparation is used as a negative control in downstream analysis experiments. Wash streptavidin beads according to manufacturer’s instructions. Wash twice more with 1X Sonic buffer to equilibrate the beads. Use enough beads so that the binding capacity is in reasonable excess over the amount of RNA used in the binding reaction. For example, in the 10X scale CNNC binding experiment, 10 pmol biotinylated RNA was used. The binding capacity of the beads is 500 pmol/mg, or 0.5 pmol RNA per µl of beads. A reasonable amount to use would therefore be 40 µl of beads (20 pmol capacity). Add beads to binding reactions (uncrosslinked and crosslinked). Incubate at 4º, rotating or agitating, for 15 min. Magnetically pellet the beads and withdraw the unbound supernatant. We 207 routinely keep all purification intermediates, including the unbound supernatant. For radioactive substrates, compare counts on the beads to counts in the supernatant to ensure that most or all counts have been captured on the beads. Additional incubation time is occasionally needed to fully capture the biotinylated RNA. Wash the beads thoroughly. Wash buffers should be at least 10-fold excess over packed bead volume, and beads should be incubated in each wash cycle for at least 15 min at room temperature, agitated or rotated. We have used the following washing pattern: Wash 1: 1X Laemmli buffer Wash 2: 1X VCA-EB (see Standard Reagents) Move beads to fresh light-protected tubes Wash 3: 1X Laemmli buffer Wash 4: 1X VCA-EB After the final wash has been removed, elute the RNA-protein complex from the beads by cleaving the RNA with RNase. We use RNase T1 for our experiments; other RNases can be used subject to the conditions outlined at the beginning of this section. For the 10X scale CNNC complex pulldown, we diluted high-concentration RNase T1 1:25 in 1X Sonic Buffer and added 20 µl of diluted RNase T1 to the beads. Note that small volumes were used in order to preserve our ability to load the sample on to 1.5 mm thick SDS-PAGE gels. Incubate at room temperature, rotating or agitating, for at least 15 min. Magnetically pellet the beads and withdraw the supernatant. If using radioactive substrate, verify that all or nearly all counts are released into the supernatant. This is the eluate containing the RNA-protein complex (and a lot of RNase). We have primarily used the eluate for mass-spectrometry. Check with the mass-spectrometry facility or operator before purifying individual bands for this experiment. We have previously run the sample on 1.5 mm 4-12% Bis-Tris gels using MOPS buffer. Hot and cold complex purifications were carried out in parallel, and run on adjacent lanes in the gel. The radioactive lane was used to mark the gel cutting location for the cold lane, and the cold gel slices submitted for mass spectrometry. We have tried using Invitrogen SilverQuest silver staining to visualize individual protein-RNA complex bands, but this appears to severely impede mass-spectrometric workup. Another approach is to run the eluate on a 1 mm SDS-PAGE gel, transfer to nitrocellulose or PVDF membrane, and Western blot the eluate for candidate proteins. Due to the low amount of protein purified, we have not had much success with this approach. 208 If candidate proteins are available by “educated guess” or from mass-spectrometry results, a more robust approach immunoprecipitate the protein-RNA complex, as suggested by Sontheimer and as described below. Candidate protein testing by immunoprecipitation of crosslinked complexes The goal of this section is to determine whether a protein of interest binds the target RNA site (4thiouridine location). If an antibody is available for immunoprecipitation, a reasonably robust approach is to crosslink the RNA-protein complex, immunoprecipitate the protein, and demonstrate the association of radioactive RNA with the immunoprecipitated protein. Assemble a sufficiently large binding reaction such that immunoprecipitated protein-RNA complex can be easily visualized by phosphorimager or film exposure. You will need enough binding reaction to do immunoprecipitation with the candidate protein’s antibody, as well as an isotype control antibody. For the CNNC motif binding experiment, a 100 µl binding reaction was used (for four total immunoprecipitations). 39 µl 50 µl 10 µl 1 µl 100 µl 1X Sonic Buffer Microprocessor Lysate from 293T 10X Cleavage/Binding Buffer (1 mM Mg) 4-S-U containing RNA substrate (1 µM) Crosslink using optimized crosslinking conditions and recover all droplets. Divide into aliquots. For the CNNC binding experiment, four immunoprecipitations were carried out: (1) Mouse IgG, (2) Anti-FLAG M2 antibody, (3) Anti-Candidate1 antibody, and (4) Anti-Candidate2 antibody. For each immunoprecipitation, add 1 µl high-concentration RNase T1 per 25 µl binding reaction (for other RNases, use an appropriate concentration). The RNase T1 will digest the substrate while the immunoprecipitation is ongoing. For each immunoprecipitation, add an appropriate dilution of antibody for immunoprecipitation. For example, 1:500 (10 µg/ml) anti-FLAG is a typical dilution for immunoprecipitation. Incubate at 4º 1 hour to overnight. Wash Protein A or Protein G agarose beads or magnetic beads according to manufacturer’s instructions. Wash twice more with 1X Sonic Buffer to equilibrate the beads. Add sufficient beads to bind the amount of antibody used in the immunoprecipitation. For example, Sigma Protein G agarose has a binding capacity of 8 mg IgG per ml of beads. Thus 10 µl of beads is usually more than enough to bind the added IgG. Add beads to the immunoprecipitation mixes. Incubate one hour at 4º, agitated or rotating. 209 Pellet beads and pull off supernatant. Wash 2-3 times in 1X Sonic Buffer. If a more aggressive wash is desired, we have previously supplemented Sonic Buffer to 500 mM KCl (final) and 0.1% Tween-20 (final). Elute the RNA-protein complex from the beads by adding 20 µl 1X Laemmli Buffer and boiling beads for 10 minutes. Pellet the beads and carefully pull off the eluate. Beads that carry over may clog pipette tips and make gel loading difficult. Run the eluate on an appropriate SDS-PAGE gel, e.g. 4-12% Bis-Tris with MOPS buffer. Visualize radioactive bands by phosphorimager or film. Candidate proteins that bind the target RNA site will show a radioactive band at or near the expected size of the protein, since the immunoprecipitated protein is covalently linked to the radioactive phosphate in the RNA. If a radioactive band is seen but is not at the target protein size, consider the possibility that the candidate protein is in a complex with another protein and the target RNA, but the candidate protein does not directly bind the RNA (i.e. the candidate protein coprecipitates with the actual binding protein, but is not directly crosslinked to the RNA). 210 Supplement 1: Standard Protocols Crush-and-soak technique for acrylamide gel extraction This technique uses a centrifuge to force a gel slice through a 22-gauge needle hole. This produces an acrylamide gel slurry, and decreases the diffusion distance between RNA molecules and the elution fluid. This technique requires that the gel slice be small enough to fit in a 0.5 ml Sarstedt Eppendorf tube. First, the 0.5 ml tube must be prepared for use. Close the tube cap and stand the tube on its cap. Unpackage a new, unused and sterile 22-gauge needle. Attach this needle to a syringe for convenient handling. Heat the tip of the needle using a Bunsen burner to red hot. Obviously, it is important to handle the plastic portion, and not to overheat (i.e. to avoid melting the plastic and the human parts). Carefully stab the hot needle through the very bottom of the conical portion of the tube (sitting inverted on the bench). For obvious safety reasons, it is critical to avoid holding the tube with one’s hand, as this places the offending hand at needlestick risk. Although this needle is sterile, it is likely that a needlestick with a red-hot needle will be quite painful. After the hole has been created, carefully place the 0.5 ml tube inside a standard 1.5 ml eppendorf tube. Minimize the amount of glove contact with the exterior of the 0.5 ml tube, since this will be in contact with the interior of the 1.5 ml tube. Place the gel slice in 0.5 ml eppendorf tube. Place the entire assembly (gel slice in the 0.5 ml tube; 0.5 ml tube inside the 1.5 ml Eppendorf tube) into a centrifuge. Centrifuge at full speed (~13,000 x g) for 1 min or until the gel slice is spun through the hole. Discard 0.5 ml tube. Suspend the gel particles in 500 µl of 300 mM NaCl solution, and rotate overnight for elution. After elution is complete, filter the slurry through a Costar Spin-X filter. Precipitate the filtrate by adding 1000 µl ethanol, incubating in cold, and centrifuging as usual. 211 T7 transcription (“Midi” scale) Note: 1 µl of 1 µM solution = 1 pmol solute NB1. T7 RNA polymerase requires a double-stranded promoter region. The enzyme will extend on a single-stranded antisense template. If a PCR product is used for runoff transcription, the T7 promoter sense strand oligo should be excluded. NB2. It is crucial that the first incorporated nucleotide be G, i.e. all T7 transcription products will begin with pppG… Minimal T7 promoter sequence and template strand T7 promoter 5′ TAATTACGACTCACTATA 3′ Template strand 3′ ATTAATGCTGAGTGATATCNNNNNNNNNNNNN…NNNNNN 5′ 5 µl 40 µl 80 µl 20 µl 10 µl 500 pmol oligo template 500 pmol T7 promoter sense strand (100 µM) 10 X House T7 Buffer 5X House NTP Mix 100 mM DTT House T7 Enzyme H2O 400 µl Incubate 37º x 2-3 hr Add 10 µl Turbo DNAse (Ambion) Incubate 37º x 30 min Add 1/20 volume 500 mM EDTA Add 1/10 volume 3M NaCl Add 1 volume 100% ethanol Final: T7 reaction mixture with whatever NTP/Salt/Mg/PPi is present ~25 mM EDTA ~75 mM NaCl (supplemental) 50% ethanol Incubate at least 15 min in -20 Spin 15 min at 4º 212 Phosphorylation of nucleic acid 5′ Ends Note: 1 µl of 1 µM solution = 1 pmol solute Cold NB1. For cold phosphorylation, a 1 mM final ATP concentration is used. This is sufficiently higher than Km such that PNK quantitatively phosphorylates the substrate in 15 min, as measured by PAGE shift. NB2. For the 10X Buffer, either supplement NEB 10X PNK buffer to 1 mM ATP (final) or use 10X T4 DNA Ligase Buffer, which has the same buffer composition with 1 mM ATP (final). 1 µl 1 µl Up to 100 pmol 5′ ends 10X NEB T4 DNA Ligase Buffer (Yes, Ligase.) T4 PNK H2O 10 µl Incubate 37º x 30 min Hot NB3. For hot phosphorylation, the hot ATP concentration is limiting and is sub-Km. NB4. NEN/PE ATP is 6000 Ci/mmol, 150 mCi/ml = 2.5e-4 mmol/ml = 25 µM. For quantitative phosphorylation, use less than 25 pmol 5′ ends and be prepared to wait for >1 hr. 1 µl 1 µl 1 µl Up to 25 pmol 5′ ends 6000 Ci/mmol y-ATP 10X NEB T4 PNK Buffer T4 PNK H2O 10 µl Incubate 37º x 60 min 213 Dephosphorylation of nucleic acid 5′ ends Note: 1 µl of 1 µM solution = 1 pmol solute NB1. Unit conditions in typical CIP reactions is sufficient to dephosphorylate recessed 5′ ends. Nevertheless, if significant secondary structure shields the 5′ end, reaction can be carried out at 50º; CIP is quite heat stable. Up to 100 pmol 5′ ends 10X NEBuffer 3 T4 CIP H2O 1 µl 1 µl 10 µl Incubate 37-50º x 60 min Dephosphorylation of 2′-3′ cyclic phosphates and 3′ phosphates NB1. Adapted from Huili Guo’s RNaseq protocol NB2. I have not tested this protocol to strictly define the parameters for RNA concentration. 20 µl 1 µl RNA, preferably in water 1.5X MES dephosphorylation buffer T4 PNK H2O 30 µl Incubate 37º x 6 hrs 214 Splint ligation of RNA Note: 1 µl of 1 µM solution = 1 pmol solute Using T4 RNA Ligase 2 (RNL2) NB1. T4 RNL2 is exceptionally efficient when the concentration of the nicked helical substrate is around 10 µM. Below 10 µM, yield is either low or dominated by side products. NB2. Splint should have 40-50º Tm so that the nicked substrate is stable at 37º. 100 pmol RNA with 5′-P (3p substrate) 100 pmol RNA with 3′-OH (5p substrate) 100 pmol Splint Oligo H2O 8 µl Heat to 85º for 5 min, then air cool to room temperature +1 µl +1 µl 10 µl 10X RNL2 Buffer T4 RNL2 Incubate 37º x 4 hr or at 25º x overnight Optional: add 0.5 µl Turbo DNAse and incubate at 37º x 10 min to degrade the splint. Using T4 DNA Ligase NB3. T4 DNA Ligase was used for the Moore and Sharp ligation protocol. The Km of DNA Ligase is in the low nM range. Although it is less efficient than RNL2 with high concentration of substrates, it is less sensitive to substrate concentration. NB4. Typically a ligation target is at low concentration and the other components are in excess. If this is the case, the splint oligo should be at least higher in concentration than the lower of the two substrates. 1-100 pmol RNA with 5′-P (3p substrate) 1-100 pmol RNA with 3′-OH (5p substrate) 1-100 pmol Splint Oligo. H2O 8 µl Heat to 85º for 5 min, then air cool to room temperature +1 µl +1 µl 10 µl 10X DNA Ligase Buffer T4 DNA Ligase Incubate 37º x 4 hr or at 25º x overnight Optional: add 0.5 µl Turbo DNAse and incubate at 37º x 10 min to degrade the splint. 215 Partial hydrolysis of RNA NB1: Adapted from Huili Guo’s RNaseq protocol 10 µl RNA, preferably in water 2X Fragmentation Buffer H2O 20 µl Incubate 85º x variable time, ranging from 30 sec to 20 min. Individual substrates should be optimized. Chill immediately on ice and neutralize. Neutralization option 1 (Huili Guo): Add 380 µl of 300 mM NaOAc pH 5.2. Neutralization option 2: Add 20 µl of 1M Tris-Cl pH 7.6. Add 360 µl of 300 mM NaCl. Precipitate RNA by adding 1000 µl 100% ethanol. 216 Supplement 2: Standard Reagents Buffers 1X Sonic Buffer Modified from Lee and Kim, Meth. Enz. 427 (2007), with additional input from Jinju Han and V. Narry Kim. Concentrations: 20 mM Tris-Cl pH 8.0 100 mM KCl 0.2 mM EDTA 5 mM DTT (equivalent to 0.7 µl/ml 2-mercaptoethanol); add fresh 10X Drosha Cleavage/Binding Buffer Designed to be added to reactions assembled in 1X Sonic Buffer. Due to large volume of Yeast Total RNA, this buffer requires assembly of 10X Sonic Buffer concentrate. 5 mM Mg version – concentrations at 10X: 1X Sonic Buffer 3 µg/ul Yeast Total RNA (Ambion) 50 mM MgCl 1 mM Mg version – concentrations at 10X: 1X Sonic Buffer 3 µg/ul Yeast Total RNA (Ambion) 10 mM MgCl 1.5X MES dephosphorylation buffer Concentrations at 1.5X: 150 mM MES-NaOH, pH 5.5 15 mM MgCl2 15 mM β-mercaptoethanol (add fresh) 450 mM NaCl 10X “House” T7 Transcription Buffer Concentrations at 10X: 400mM Tris-Cl, pH 7.9 at 20C 25mM Spermidine 260mM MgCl2 217 0.1% Triton X-100 Urea Loading Buffer Concentrations at 2X: 8 M 25 mM EDTA Add bromophenol blue and xylene cyanol FF as needed. Urea 5X “House” NTP Mix Note: From powder, resuspend 1 gram in 2 mls of H2O. Empirically pH with 1M NaOH to pH 7. Can estimate equivalents of NaOH needed based on salt form of the NTP and charge of 3.5 at pH 7. Concentrations at 5X: 40 mM GTP 25 mM CTP 25 mM ATP 10 mM UTP 10X “House” dNTP Mix Concentrations at 10X: 2 mM dATP 2 mM dCTP 2 mM dGTP 2 mM dTTP 10X “House” PCR Buffer Concentrations at 10X: 100 mM TRIS pH 8.3 @20° 500 mM KCl 15 mM MgCl2 0.1% Gelatin 1X VCA Elution Buffer (VCA-EB) Modified from DPB Elution buffer (DPBEB) Concentrations at 1X: 8M Urea 25 mM EDTA 300 mM NaCl 218 2X Fragmentation Buffer Modified from Huili Guo. Concentrations at 2X: 2 mM EDTA 10 mM Na2CO3 90 mM NaHCO3 (Final carbonate buffer pH 9.3) Commercial products γ-[32P]-ATP (NEN/PE) Catalog number: NEG035C001MC Concentration: 6000ci/mmol, 150 mCi/ml α-[32P]-UTP (NEN/PE) Catalog number: BLU007X500UC Concentration: 800Ci/mmol, 10mCi/ml T4 DNA Ligase (NEB) Catalog number M0202 Concentration: 400,000 cohesive end units/ml Storage Temperature: -20°C 10X T4 DNA Ligase Buffer (NEB) Catalog number B0202 Concentrations at 1X: 50 mM Tris-HCl 10 mM MgCl2 10 mM Dithiothreitol 1 mM ATP pH 7.5 @ 25°C Storage Temperature: -20°C T4 RNA Ligase 2 (NEB) Catalog number M0239 Concentration: 10,000 units/ml Storage Temperature: -20°C 219 10X T4 RNA Ligase 2 Buffer (NEB) Concentrations at 1X: 50 mM Tris-HCl 2 mM MgCl2 1 mM DTT 400 µM ATP pH 7.5 @ 25°C T4 Polynucleotide Kinase (NEB) Catalog number M0201 Concentration: 10,000 units/ml Storage Temperature: -20°C 10X T4 Polynucleotide Kinase Buffer (NEB) Concentrations at 1X: 70 mM Tris-HCl 10 mM MgCl2 5 mM Dithiothreitol pH 7.6 @ 25°C Yeast Total RNA (Ambion) Catalog number: AM7118 Concentration: 10 mg/ml Storage Temperature: -20°C Lipofectamine 2000 (Invitrogen) Catalog number: 11668-027 Storage Temperature: 4°C Opti-MEM I Reduced Serum Medium (Invitrogen) Catalog number: 31985-062 Storage Temperature: 4°C Complete Mini EDTA-Free Protease Inhibitor Tablets (Roche) Catalog Number: 1836170001 Storage Temperature: 4°C 220 MicroSpin G-25 Columns (GE) Catalog Number: 28917922 Storage Temperature: Room Temperature Note: G-25 columns have higher overall RNA retention than P-30 columns, and are somewhat less consistent. However, these columns reasonably pass 10-mer RNAs and are therefore useful for preparation of Decade markers Micro Bio-Spin 30 (aka P30) Columns (Bio-Rad) Catalog Number: 732-6250 Storage Temperature: 4°C Note: P-30 columns are highly consistent with low overall RNA retention. The cutoff for this column is somewhere between 10 and 20 nt. Decade Markers (Ambion) Catalog Number: AM7778 Storage Temperature: -20°C Tri-Reagent (Ambion) Catalog Number: AM9738 Storage Temperature: 4°C Turbo DNAse (Ambion) Catalog Number: AM2238 Concentration: 2 units/ul Storage Temperature: -20°C 0.5 ml Microcentrifuge Tube (Sarstedt) Catalog Number: 72.699 Spin-X centrifuge tube filters (Costar / Corning) Catalog Number: 8161 Pore size: 0.22 um Superscript III Reverse Transcriptase (Invitrogen) Catalog Number: 18080044 Concentration: 200 units/ul Storage Temperature: -20°C SYBR Gold nucleic acid stain (Invitrogen) Catalog Number: S11494 221 Concentration: 10,000X Storage Temperature: -20°C Stratalinker 2400 bulbs, 365 nm (Thermo Fisher) Catalog Number: 50125580 RNase T1 (Cloned), a.k.a High-Concentration (Ambion) Catalog Number: AM2280 Concentration: 1000 units/ul Storage Temperature: -20°C Dynabeads MyOne Streptavidin C1 Magnetic Beads (Invitrogen) Catalog Number: 650-02 Concentration: 10 mg/ml Binding Capacity: 500 pmol/mg ssDNA oligo EZview Red Protein G Affinity Gel (Sigma) Catalog Number: E3403 Binding Capacity: 8 mg/ml rabbit IgG EZview Red Anti-FLAG M2 (Sigma) Catalog Number: F2426 Binding Capacity: 0.6 mg tagged bacterial alkaline phosphatase / ml packed slurry Storage Temperature: -20°C Anti-FLAG M2 Magnetic Beads (Sigma) Catalog Number: M8823 Binding Capacity: 0.6 mg tagged bacterial alkaline phosphatase / ml packed slurry Storage Temperature: -20°C Ultrapure BSA (Applied Biosystems) Catalog Number: AM2616 Concentration: 50 mg/ml Storage Temperature: -20°C 3X FLAG Peptide (Sigma) Catalog Number: F4799 Storage Temperature: 4°C (lyophilized) 222 Immobilon-NC Membrane Filters (Millipore) Catalog Number: HATF01300 Pore size: 0.45 um Diameter: 13 mm “Surfactant-Free” 223 224 Appendix 2. Statistical methods Contents Overview ......................................................................................................................................226 Calculation of relative cleavage ...................................................................................................226 Calculation of the odds ratio score...............................................................................................229 Calculation of the Watson–Crick base pairing score ...................................................................230 Calculation of Information Content .............................................................................................231 225 Overview After selection and sequencing, analysis of the data is rooted in measuring frequencies of motifs in the reference pool and the selected pool. Intuitively, these frequencies reflect the preference of the Microprocessor for a given motif: if the Microprocessor prefers the motif, it would be enriched by the selection, and would be present more frequently in the selected pool than in the reference pool. By contrast, a disfavored motif would be depleted by the selection, so that the motif would be present less frequently in the selected pool than in the reference pool. The following discussion formalizes this intuition in order to quantify the relative contribution of different motifs to recognition and cleavage by the Microprocessor. Calculation of relative cleavage For each base at any given position, we know two values based on sequencing of selected and reference pools. We want to estimate the selectivity of the complex for a particular base, or a particular motif. Bayes’ Theorem, written in odds form, can be used to compare one motif to one other motif at that position: 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × = 𝑃(𝑚𝑜𝑡𝑖𝑓𝑗 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑗 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑗 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) (Eq. 1A: Bayesian statement for motifi vs. motifj) The first term is the proportion of motifi to motifj in the initial, unselected pool of sequences, estimated by sequencing the reference pool. The third term is the proportion of motifi to motifj in the selected pool, estimated by sequencing the cleavage/selection product. The middle term describes the relative cleavage of motifi vs. motifj, and is the observed relative cleavage of motifi over motifj, at a particular position. This term is ideally a property of the enzyme cleavage conditions, independent of the distribution of motifs in the initial pool. For every motifi of length n, there are 4n terms that describe its relative cleavage with respect to each of every other possible motifj of length n at that position: 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × = 𝑃(𝑚𝑜𝑡𝑖𝑓1 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓1 ) 𝑃(𝑚𝑜𝑡𝑖𝑓1 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 226 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × = 𝑃(𝑚𝑜𝑡𝑖𝑓2 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓2 ) 𝑃�𝑚𝑜𝑡𝑖𝑓𝑗 �𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒� … 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × = 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) … 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × = 𝑃(𝑚𝑜𝑡𝑖𝑓4𝑛 ) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑚𝑜𝑡𝑖𝑓4𝑛 ) 𝑃(𝑚𝑜𝑡𝑖𝑓4𝑛 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) In practice, however, we rarely consider a single, isolated motif relative to another isolated motif, due to the design of the selection. In addition, the analysis occasionally necessitates comparison of degenerate motifs, e.g. Watson-Crick pairs vs. nonpairs, or wildtype vs. nonwildtype motifs. In these cases, each probability in Eq. 1A must be partitioned and expressed as the sum of those sub-motifs. Let I be a partition of motifi into individual submotifs, and let J be a partition of motifj into submotifs, i.e. 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) = ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐼) and 𝑃�𝑚𝑜𝑡𝑖𝑓𝑗 � = ∑𝐽 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝑗) ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐼) × 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐼) ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐼|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) = ∑𝐽 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐽) × 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐽) ∑𝐽 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓 ∈ 𝐽|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) Factoring, ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼)×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) � 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) � ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) × ∑ 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽)×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽) = 𝑃(𝑚𝑜𝑡𝑖𝑓𝑗 ) � 𝐽 � 𝑃(𝑚𝑜𝑡𝑖𝑓𝑗 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) ∑𝐽 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽) (Eq. 1B: Bayesian statement after partition of motifi and motifj) Thus, the relative cleavage (middle) term is the ratio of the average cleavage of submotifs in I to the average cleavage of submotifs in J, weighted by the frequencies of the individual submotifs in the initial pool. The equation is even more straightforward in three special cases: • Probabilities of cleavage are roughly equal between submotifs. This case is useful in this particular analysis, because each sequence is unique by stipulation. Thus, in order to 227 consider any motif at all, we may reasonably assume that sequences outside the motif contribute equally to cleavage. Similarly, when considering the relative cleavage of Watson-Crick pairs vs. nonpairs, we assume for the sake of argument that individual pairs are equivalent, and that individual nonpairs are equivalent. • Submotifs are approximately equiprobable in the initial pool. This case primarily occurs when comparing motifs composed exclusively of wildtype bases to motifs composed of nonwildtype bases, e.g. CNNC vs. (not-C)NN(not-C). The initial pool was designed such that nonwildtype bases are equiprobable, and sequencing of the initial pool shows nonwildtype bases are indeed nearly equiprobable. Probabilities of cleavage and submotif frequencies are independent. We cannot rely on this case in much of the relevant analysis, since motifs composed of wildtype nucleotides are more frequent in the pool, and are more likely to have higher probabilities of cleavage than nonwildtype motifs, assuming that the wildtype sequence has evolved in nature to optimize cleavage. Nevertheless, in this condition the weighted average converges to the arithmetic average as the number of submotifs increases. combinations of independent cleavage probabilities demonstrates this: 8 4 2 1 0.5 Number of submotifs 228 1048576 65536 4096 256 16 0.25 1 (Weighted average) (arithmetic average) • and A simulation of 2000 submotif frequencies In any of these possibly overlapping situations, the equation collapses to: ∑ 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) 𝐼 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) |𝐼| × ∑ 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽) = 𝐽 𝑃(𝑚𝑜𝑡𝑖𝑓𝑗 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑗 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) |𝐽| (Eq. 1C: Bayesian statement after equipartition of motifi and motifj) and the relative cleavage (middle) term is simply the ratio of (unweighted) average cleavages of the submotifs. Calculation of the odds ratio score The calculation of relative cleavage requires us to nominate a specific reference motif (motifj). In situations where there is no obvious reference motif, and when rapidly screening for enriched motifs, it is convenient to consider a single motif at a time, and simply compare it to the aggregation of all other motifs. We use a score called the “odds ratio.” In principle, our formulation is: 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × 𝑂𝑑𝑑𝑠 𝑅𝑎𝑡𝑖𝑜 = 1 − 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 1 − 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) (Eq. 2A: “Odds Ratio” measure of relative cleavage for motifi over all other motifs) This is a specific case of Eq. 1B, rewritten with the set I as before, and Ic, the complement of I, composed of all submotifs of length n that are not members of set I: ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼)×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) � � 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) ∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) × ∑ 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 = 𝑐 𝑐 )×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 ) 1 − 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) � 𝐼𝑐 � 1 − 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 |𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑐 ∑𝐼𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 ) (Eq. 2A: Reformulation of Eq. 1B for the Odds Ratio) Thus, the odds ratio is the ratio of the average cleavage of submotifs in I to the average cleavage of submotifs in Ic, weighted by the frequencies of the individual submotifs in the initial pool. The odds ratio can be further simplified under the same special conditions as with the relative cleavage measure. One important caveat is that odds ratios cannot strictly be used to compare two motifs. To see why this is so, consider two motifs of length n at the same position, motifi and motifj. 229 𝑂𝑑𝑑𝑠 𝑅𝑎𝑡𝑖𝑜𝑖 = 𝑂𝑑𝑑𝑠 𝑅𝑎𝑡𝑖𝑜𝑗 = �∑𝐼 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼)×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) � ∑ 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼) 𝐼 𝑐 )×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 𝑐 ) ∑ � 𝐼𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 � ∑𝐼𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 𝑐 ) ∑𝐽 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽)×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽) � ∑𝐽 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽) � ∑𝐽𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽𝑐 )×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽𝑐 ) � ∑𝐽𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽𝑐 ) � Because the sets I and J are mutually exclusive, it follows that Ic≠Jc and the denominators are not equal. Therefore, when directly comparing two motifs, the relative cleavage score (Eq. 1B) is superior. However, the Odds Ratio is still useful for considering many motifs at the same time. Since 𝐼 𝑐 = 𝐽𝑐 + 𝐽 − 𝐼 it is intuitive that, as the number of motifs being considered increases, 𝑃(𝑚𝑜𝑡𝑖𝑓𝑖 ) → 0 and 𝑃�𝑚𝑜𝑡𝑖𝑓𝑗 � → 0 ∑𝐽𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽𝑐 )×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽𝑐 ) ∑𝐽𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐽𝑐 ) ∑𝐼𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 𝑐 )×𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 𝑐 ) ∑𝐼𝑐 𝑃(𝑠𝑢𝑏𝑚𝑜𝑡𝑖𝑓∈𝐼 𝑐 ) → and the ability to compare two odds ratio scores improves accordingly. Calculation of the Watson–Crick base pairing score To screen for specifically for Watson–Crick pairing between all possible combinations of randomized positions, we used a scoring metric to compare the geometric average of odds ratios for Watson–Crick pairing to that of odds ratios for non-Watson–Crick pairs. The score has no fundamental meaning, and simply serves to identify position pairs where Watson–Crick nucleotide identities are, on average, more preferred than non-Watson–Crick identities. It is also a useful metric for prioritizing position pairs for followup analysis. Pairing score = � � Watson–Crick 1/4 Odds ratio� 230 −� � non−Watson–Crick 1/12 Odds ratio� Calculation of Information Content To calculate the information content at each position, we use Bayes’ Theorem to infer the distribution of bases after selection from a completely random pool, then calculate an information content score based on the post-selection distribution. We can use Bayes’ Theorem to infer how a distribution of the four bases changes after selection, for any initial pool. Because we are considering all four bases at once, we must consider the relative cleavage of any given base vs. the other three bases. For clarity, the formula is shown for one base, A. According to Bayes’ Theorem for Total Probability: = 𝑃(𝑏𝑎𝑠𝑒 → 𝐴 𝑎𝑓𝑡𝑒𝑟 𝑠𝑒𝑙𝑒𝑐𝑡𝑖𝑜𝑛) = 𝑃(𝑏𝑎𝑠𝑒 → 𝐴|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐴) × 𝑃(𝑏𝑎𝑠𝑒 → 𝐴) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐴) × 𝑃(𝑏𝑎𝑠𝑒 → 𝐴) �+𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐶) × 𝑃(𝑏𝑎𝑠𝑒 → 𝐶) +𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐺) × 𝑃(𝑏𝑎𝑠𝑒 → 𝐺) +𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝑈) × 𝑃(𝑏𝑎𝑠𝑒 → 𝑈) Reorganization shows: 𝑃(𝑏𝑎𝑠𝑒 → 𝐴|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐶) 𝑃(𝑏𝑎𝑠𝑒→𝐶) 𝑃(𝑏𝑎𝑠𝑒→𝐺) × + 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐺) × = �1 + 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐴) 𝑃(𝑏𝑎𝑠𝑒→𝐴) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐴) 𝑃(𝑏𝑎𝑠𝑒→𝐴) 𝑃(𝑏𝑎𝑠𝑒→𝑈) + 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝑈) × � 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐴) 𝑃(𝑏𝑎𝑠𝑒→𝐴) −1 In other words, the new probability depends on the relative cleavage of A vs. the other nucleotides, and the relative abundance of A vs. the other nucleotides in the initial pool. We can calculate the relative cleavage of one base vs. another, e.g. A vs. C, using the selection data and Eq. 1A. 𝑅𝑎𝑡𝑖𝑜 𝑜𝑓 𝐶 𝑡𝑜 𝐴 𝑅𝑒𝑙𝑎𝑡𝑖𝑣𝑒 𝐶𝑙𝑒𝑎𝑣𝑎𝑔𝑒 𝑅𝑎𝑡𝑖𝑜 𝑜𝑓 𝐶 𝑡𝑜 𝐴 × = (𝑝𝑟𝑒 − 𝑠𝑒𝑙𝑒𝑐𝑡𝑖𝑜𝑛) 𝐶 𝑣𝑠. 𝐴 (𝑝𝑜𝑠𝑡 − 𝑠𝑒𝑙𝑒𝑐𝑡𝑖𝑜𝑛) 𝑃(𝑏𝑎𝑠𝑒 → 𝐶) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐶) 𝑃(𝑏𝑎𝑠𝑒 → 𝐶|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) × = 𝑃(𝑏𝑎𝑠𝑒 → 𝐴) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐴) 𝑃(𝑏𝑎𝑠𝑒 → 𝐴|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 231 𝑃(𝑏𝑎𝑠𝑒 → 𝐶|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐶) 𝑃(𝑏𝑎𝑠𝑒 → 𝐴|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) � = 𝑃(𝑏𝑎𝑠𝑒 → 𝐶) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒 → 𝐴) 𝑃(𝑏𝑎𝑠𝑒 → 𝐴) For a totally random initial pool, the bases are equiprobable, i.e. Hence: 𝑃(𝑏𝑎𝑠𝑒 → 𝐴) = 𝑃(𝑏𝑎𝑠𝑒 → 𝐶) = 𝑃(𝑏𝑎𝑠𝑒 → 𝐺) = 𝑃(𝑏𝑎𝑠𝑒 → 𝑈) 𝑃𝑖𝑛𝑓𝑒𝑟𝑟𝑒𝑑 𝐴 = 𝑃(𝑏𝑎𝑠𝑒 → 𝐴|𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐶) = �1 + 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐴) + 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐺) + 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝑈) � 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐴) 𝑃(𝑐𝑙𝑒𝑎𝑣𝑎𝑔𝑒|𝑏𝑎𝑠𝑒→𝐴) −1 This is the inferred fraction of A bases after selection from a random pool. Knowing this fraction, we can calculate the information “contribution” for that base: 𝐼𝐴 = 𝑃𝑖𝑛𝑓𝑒𝑟𝑟𝑒𝑑 𝐴 × �𝑙𝑜𝑔2 �𝑃𝑖𝑛𝑓𝑒𝑟𝑟𝑒𝑑 𝐴 � + 2� And the total information at that position is: 𝐼𝑡𝑜𝑡𝑎𝑙 = 2 + ∑𝑎𝑙𝑙 𝑏𝑎𝑠𝑒𝑠 𝑃𝑖𝑛𝑓𝑒𝑟𝑟𝑒𝑑 × 𝑙𝑜𝑔2 �𝑃𝑖𝑛𝑓𝑒𝑟𝑟𝑒𝑑 � 232 233 234 Appendix 3. Mammalian microRNAs: experimental evaluation of novel and previously annotated genes H. Rosaria Chiang1,2, Lori W. Schoenfeld1,2, J. Graham Ruby3, Vincent C. Auyeung1,2,4, Noah Spies1,2, Daehyun Baek1,2, Wendy K. Johnston1,2, Carsten Russ5, Shujun Luo6, Joshua E. Babiarz7, Robert Blelloch7, Gary P. Schroth6, Chad Nusbaum5, David P. Bartel1,2 1 Whitehead Institute for Biomedical Research, Cambridge, MA 02142, USA 2 Howard Hughes Medical Institute and Department of Biology, Massachusetts Institute of Technology, Cambridge, MA 02139, USA 3 Department of Biochemistry and Biophysics, University of California San Francisco, San Francisco, CA 94158, USA 4 Harvard-MIT Division of Health Sciences and Technology, Cambridge, MA 02139, USA 5 Broad Institute of MIT and Harvard, Cambridge, MA 02141, USA 6 Illumina, Inc., Hayward, CA 94545, USA 7 Institute for Regeneration Medicine, Center for Reproductive Sciences, and Department of Urology, University of California San Francisco, San Francisco, CA 94143, USA Published as: Chiang, et al. Mammalian microRNAs: experimental evaluation of novel and previously annotated genes. Genes and Development. 2010 May 15;24(10):992-1009. Contribution: V.C.A. performed the analysis of RNA editing. 235 Mammalian microRNAs: experimental evaluation of novel and previously annotated genes H. Rosaria Chiang,1,2 Lori W. Schoenfeld,1,2 J. Graham Ruby,1,2,7 Vincent C. Auyeung,1,2,3 Noah Spies,1,2 Daehyun Baek,1,2 Wendy K. Johnston,1,2 Carsten Russ,4 Shujun Luo,5 Joshua E. Babiarz,6 Robert Blelloch,6 Gary P. Schroth,5 Chad Nusbaum,4 and David P. Bartel1,2,8 1 Whitehead Institute for Biomedical Research, Cambridge, Massachusetts 02142, USA; 2Howard Hughes Medical Institute and Department of Biology, Massachusetts Institute of Technology, Cambridge, Massachusetts 02139, USA; 3Harvard-Massachusetts Institute of Technology Division of Health Sciences and Technology, Cambridge, Massachustts 02139, USA; 4Broad Institute of Massachusetts Institute of Technology and Harvard, Cambridge, Massachusetts 02141, USA; 5Illumina, Inc., Hayward, California 94545, USA; 6Institute for Regeneration Medicine, Center for Reproductive Sciences, and Department of Urology, University of California at San Francisco, San Francisco, California 94143, USA MicroRNAs (miRNAs) are small regulatory RNAs that derive from distinctive hairpin transcripts. To learn more about the miRNAs of mammals, we sequenced 60 million small RNAs from mouse brain, ovary, testes, embryonic stem cells, three embryonic stages, and whole newborns. Analysis of these sequences confirmed 398 annotated miRNA genes and identified 108 novel miRNA genes. More than 150 previously annotated miRNAs and hundreds of candidates failed to yield sequenced RNAs with miRNA-like features. Ectopically expressing these previously proposed miRNA hairpins also did not yield small RNAs, whereas ectopically expressing the confirmed and newly identified hairpins usually did yield small RNAs with the classical miRNA features, including dependence on the Drosha endonuclease for processing. These experiments, which suggest that previous estimates of conserved mammalian miRNAs were inflated, provide a substantially revised list of confidently identified murine miRNAs from which to infer the general features of mammalian miRNAs. Our analyses also revealed new aspects of miRNA biogenesis and modification, including tissue-specific strand preferences, sequential Dicer cleavage of a metazoan precursor miRNA (pre-miRNA), consequential 59 heterogeneity, newly identified instances of miRNA editing, and evidence for widespread pre-miRNA uridylation reminiscent of miRNA regulation by Lin28. [Keywords: MicroRNA; miRNA biogenesis; noncoding RNA genes; high-throughput sequencing] Supplemental material is available at http://www.genesdev.org. Received November 11, 2009; revised version accepted March 19, 2010. MicroRNAs (miRNAs) are endogenous ;22-nucleotide (nt) RNAs that post-transcriptionally regulate gene expression (Bartel 2004). miRNAs mature through three intermediates: a primary miRNA transcript (pri-miRNA), a precursor miRNA (pre-miRNA), and a miRNA:miRNA* duplex. RNA Polymerase II transcribes the pri-miRNA, which contains one or more segments that each fold into an imperfect hairpin. For canonical metazoan miRNAs, the RNase III enzyme Drosha together with its partner, the RNA-binding protein DGCR8, recognize the hairpin, and Drosha cleaves both strands ;11 base pairs (bp) from the base of the stem (Han et al. 2006). The cut leaves a 7 Present address: Department of Biochemistry and Biophysics, University of California San Francisco, San Francisco, CA 94158, USA. 8 Corresponding author. E-MAIL dbartel@wi.mit.edu; FAX (617) 258-6768. Article published online ahead of print. Article and publication date are online at http://www.genesdev.org/cgi/doi/10.1101/gad.1884710. 992 59 phosphate and 2-nt 39 overhang (Lee et al. 2003). The liberated pre-miRNA hairpin is then exported to the cytoplasm by Exportin-5 (Yi et al. 2003; Lund et al. 2004). There, the RNase III enzyme Dicer cleaves off the loop of the pre-miRNA, ;22 nt from the Drosha cut (Lee et al. 2003), again leaving a 59 monophosphate and 2-nt 39 overhang. The resulting miRNA:miRNA* duplex, comprised of ;22-nt strands from each arm of the original hairpin, then associates with an Argonaute protein such that the miRNA strand is usually the one that becomes stably incorporated, while the miRNA* strand dissociates and is degraded. In addition to canonical miRNAs, some miRNAs mature through pathways that bypass Drosha/DGCR8 recognition and cleavage. Members of the mirtron subclass of pre-miRNAs are excised as intron lariats from the primiRNA by the spliceosome and, following debranching, fold into Dicer substrates (Okamura et al. 2007; Ruby et al. GENES & DEVELOPMENT 24:992–1009 Ó 2010 by Cold Spring Harbor Laboratory Press ISSN 0890-9369/10; www.genesdev.org 236 Mammalian microRNAs 2007a). For some mirtrons, known as tailed mirtrons, a longer intron is excised such that only one end of the pre-miRNA is generated by the spliceosome, whereas the other end of the pre-miRNA matures through the Droshaindependent trimming of a 59 or 39 tail (Ruby et al. 2007a; Babiarz et al. 2008). Members of another subclass of premiRNAs, called endogenous shRNAs, are suitable Dicer substrates without preprocessing by either Drosha or the spliceosome (Babiarz et al. 2008). Other small silencing RNAs are generated from the sequential processing of long hairpins or long bimolecular duplexes. These small RNAs are classified as endogenous siRNAs rather than miRNAs because they derive from extended duplexes that produce many different small RNA species, whereas miRNAs derive from distinctive hairpins that produce one or two dominant species (Bartel 2004). The first indication of the abundance of miRNA genes came from sequencing small RNAs from mammals, flies, and worms (Lagos-Quintana et al. 2001; Lau et al. 2001; Lee and Ambros 2001). Hundreds of mammalian miRNAs have been identified by Sanger sequencing of cloned small RNA-derived cDNAs (Lagos-Quintana et al. 2001, 2002, 2003; Houbaviy et al. 2003; Berezikov et al. 2006b; Landgraf et al. 2007). Some miRNAs, however, are expressed only in a limited number of cells or through a limited portion of development, and their rarity makes them difficult to detect. Computational methods have been used to identify mammalian miRNAs initially missed by sequencing, and some of these predicted miRNAs have been evaluated experimentally—e.g., by rapid amplification of cDNA ends (RACE) (Lim et al. 2003; Xie et al. 2005), hybridization to RNA blots (Berezikov et al. 2005), microarrays (Bentwich et al. 2005), and RNA-primed array-based Klenow extension (RAKE) (Berezikov et al. 2006b). Each of these experimental methods, however, can yield false positives. Indeed, recent work in invertebrates and plants (Rajagopalan et al. 2006; Ruby et al. 2006, 2007b) has shown that the fraction of erroneously annotated miRNAs can be quite high, depending on the quality of the initial computational predictions. Even when miRNA genes are predicted correctly, the resolution of the prediction is often insufficient to confidently determine the precise 59 end of the mature miRNA. Because miRNAs repress target mRNAs by pairing to the seed sequence, which is defined relative to the position of the miRNA 59 end, singlenucleotide resolution of 59-end annotations is required for useful downstream analysis of their physiological consequences (Bartel 2009). Another approach for finding miRNAs and other small RNAs missed in the early discovery efforts is highthroughput sequencing (Lu et al. 2005). In mammals, high-throughput sequencing methods that have contributed to miRNA discovery efforts have included massively parallel signature sequencing (MPSS) (Mineno et al. 2006), miRNA serial analysis of gene expression (miRAGE) (Cummins et al. 2006), 454 pyrosequencing (Berezikov et al. 2006a, 2007; Calabrese et al. 2007), and Illumina sequencing (Babiarz et al. 2008; Kuchenbauer et al. 2008). Here we use the Illumina sequencing-by-synthesis platform (Seo et al. 2004) for miRNA discovery in mice. Analyses of these reads, combined with experimental evaluation of newly identified miRNAs as well as previous annotations, led us to substantially revise the set of confidently identified murine miRNAs, thereby providing a more accurate picture of the general features of mammalian miRNAs and their abundance in the genome. In addition, our results revealed new aspects of miRNA biogenesis and modification, including tissuespecific strand preferences, sequential Dicer cleavage of a metazoan pre-miRNA, cases of consequential 59 heterogeneity, newly identified instances of miRNA editing, and widespread pre-miRNA uridylation reminiscent of Lin28-like miRNA regulation. Results We sequenced small-RNA libraries from three mouse tissues—brain, ovary, and testes—as well as embryonic day 7.5 (E7.5), E9.5, E12.5, and newborn. Combining these data with data collected similarly from mouse embryonic stem (ES) cells (Babiarz et al. 2008) yielded 28.7 million reads between 16 nt and 27 nt in length that perfectly matched the mouse genome assembly (Supplemental Table 1). Of these reads, 79.3% mapped to miRNA hairpins, and 7.1% mapped to other annotated noncoding RNA genes (Supplemental Table 2). Because the sequencing protocol was selective for RNAs with 59 monophosphate and 39 hydroxyl groups, this dominance of miRNA species was expected (Lau et al. 2001). miRNA gene discovery As when analyzing high-throughput data from invertebrates (Ruby et al. 2006, 2007b; Grimson et al. 2008), we identified miRNA genes in mice by applying the following criteria: (1) expression of the candidate miRNA, with a relatively uniform 59 terminus; (2) pairing characteristics of the predicted hairpin; (3) absence of annotation suggesting non-miRNA biogenesis; (4) absence of proximal reads suggesting that the candidate is a degradation intermediate; and (5) presence of reads corresponding to a miRNA* species with potential to pair to the miRNA candidate with ;2-nt 39 overhangs. Using a low-stringency genomic search strategy that considered the first four criteria, 736 miRNA candidates were identified from the total data set of mouse reads. Manual inspection of these candidates, focusing on all five criteria, narrowed the list to 465 canonical miRNA genes, 377 of which were already annotated in miRBase version 14.0 (GriffithsJones 2004) and 88 of which were novel (Fig. 1A; Supplemental Fig. S1; Supplemental Table 3). We also found 14 mirtrons (including 10 tailed mirtrons), four of which were already annotated, and 16 endogenous shRNAs, six of which were annotated previously (Fig. 1B). When added to the 88 novel canonical miRNA genes, the newly identified mirtons and shRNAs raised the total number of novel genes to 108. Of these 108 genes, 36 appeared to be close paralogs of previously annotated miRNA genes (most of which were paralogs of mir-466, mir-467, or mir-669), producing GENES & DEVELOPMENT 237 993 Chiang et al. Figure 1. Mouse miRNAs and candidates initially identified by high-throughput sequencing. (A) Overlap between previously annotated miRNA hairpins (miRBase version 14.0; green), miRNA candidates identified in the current study, and the subset of these candidates that met our criteria for classification as confidently identified canonical miRNAs (red). Additional considerations increased the number of confidently identified canonical miRNAs to 475. (B) Overlap between previously annotated mirtrons and shRNAs and the mirtrons and shRNAs supported by our study, colored as in A. miRNA reads that were identical to the previously annotated miRNAs, creating ambiguity as to which loci contributed to the sequenced reads. Most of these close paralogs (35 of 36), as well as 14 other novel loci, were clustered with annotated miRNAs. The 72 novel genes with reads distinguishable from those of previously identified genes were expressed at a lower level than the previously annotated genes (median read counts 27 and 8206, respectively), and, compared with previously annotated miRNAs, a higher fraction of these novel miRNAs were located within introns of annotated RefSeq (Pruitt et al. 2005) mRNAs (47% and 26%, respectively). Experimental evaluation of unconfirmed miRNAs Of 564 miRBase-annotated miRNA genes (including four confirmed mirtons and six confirmed shRNAs) that map to mm8 genome assembly, 157 annotated miRNAs did not pass the filters for miRNA candidates (Fig. 1A,B; Supplemental Fig. S1; Supplemental Table 4). Of these 157, 26 mapped to annotated rRNA and tRNA loci, 52 had no reads mapping to them, and another 72 had some reads but in numbers deemed insufficient for confident annotation. The remaining seven either had reads with very heterogeneous 59 ends, which suggested nonspecific degradation of a non-pri-miRNA transcript (mir-464, mir1937a, and mir-1937b); had many reads that mapped well into the loop of the putative hairpin, which were inconsistent with Dicer processing (mir-451, mir-469, and mir805); or did not give a predicted fold with the requisite pairing involving the candidate and predicted miRNA* (mir-484) (Supplemental Fig. S2). For five of these seven, we have no reason to suspect that they might be authentic miRNA genes. Among the remaining two, mir-484 might be regarded as a miRNA candidate because manual refolding was able to generate a hairpin with the requisite pairing, but, even so, this candidate lacked reads for the predicted miRNA*. miR-451 is a noncanonical miRNA generated from an unusual hairpin without production of a miRNA:miRNA* duplex (S Cheloufi and G Hannon, pers comm.). We do not suspect that any other annotated miRNA genes failed to pass our filters for the same reason as mir-451. An additional 20 annotated miRNA hairpins were in our set of candidates but failed the manual inspection because they lacked predicted miRNA* reads even after allowing for alternate hairpin structures. Hundreds of 994 candidates from other miRNA discovery efforts (Xie et al. 2005; Berezikov et al. 2006b) also failed to pass the filters, usually because no reads mapped to them. One of the annotated miRNA genes missing from our data sets was mir-220, which had been predicted computationally using MiRscan as a miRNA gene candidate conserved in humans, mice, and fish, and was supported experimentally using RACE analysis of zebrafish small RNAs (Lim et al. 2003). In contrast, the other 37 miRNAs newly annotated by Lim et al. (2003) were among our confirmed miRNAs. The absence of mir-220 in our data sets might have reflected either very low expression in the sequenced samples or inaccuracy of its annotation. Similarly, mir-207, annotated in a contemporaneous study that cloned novel miRNAs from mouse tissues, was missing from our data set, but another 27 miRNAs annotated from that study were confirmed (Lagos-Quintana et al. 2003). To evaluate whether the missing annotated miRNAs and candidates represented authentic miRNAs, we developed a moderate-throughput assay to examine if their respective hairpins could be processed as miRNAs in cultured cells (Fig. 2A). If these putative miRNAs were missing from our data sets because they were not expressed in the sequenced tissues or stages, we reasoned that they would probably be detected in cells ectopically expressing their respective hairpins, because most authentic miRNAs are processed correctly from heterologous transcripts that include the full hairpin flanked by ;100 nt of genomic sequence on each side of the hairpin (Chen et al. 2004; Voorhoeve et al. 2006). Alternatively, if these putative miRNAs were missing because they were not authentic miRNAs and therefore lacked the features needed for Drosha and Dicer processing, they would not be sequenced from cells ectopically expressing their hairpins. To evaluate many hairpins simultaneously, we transfected pools of hairpin-expressing constructs into HEK293T cells and isolated small RNAs for high-throughput sequencing. The performance of 26 positive controls, chosen from canonical human/mouse miRNAs confirmed by our sequencing from mice, illustrated the value of the assay. For all but one of these controls, miRNA and miRNA* reads were more abundant in the cells ectopically expressing the hairpin than in the cells without the hairpin constructs (Fig. 2B–D; Supplemental Figs. S3, S4). For example, both hsa-miR-193b and mmu-miR-137 (from humans and mice, respectively) were >10 fold overexpressed (Fig. 2B). The positive controls included genes of tissue-specific miRNAs, GENES & DEVELOPMENT 238 Mammalian microRNAs Figure 2. Experimental evaluation of annotated miRNAs and previously proposed candidates. (A) Schematic of the expression vector transfected into HEK293T cells. (B) Examples of the standard ectopic expression assay, transfecting plasmids indicated in the key. Reads from the control transfection (no hairpin plasmid) were from endogenous expression in HEK293T cells. (C) Assay results for annotated human miRNAs and published candidates. Bars are colored as in B; asterisks indicate detectable overexpression ($1 read from both the anticipated miRNA and miRNA*, with miRNA and miRNA* combined expressed more than threefold over endogenous levels). (D) Assay results for unconfirmed annotated mouse miRNAs and published candidates. Mouse controls were selected from miRNAs that were sequenced from our mouse samples. Bars are colored as in B; detectable overexpression is indicated (asterisks). Shown are the results compiled from two experiments (Supplemental Figs. S3, S4). including mir-122 (liver), mir-133 (muscle), mir-223 (neutrophil), and several neuron-specific miRNAs, with the idea that hairpins of tissue-specific miRNAs might require tissue-specific factors for their processing, and therefore might be sensitive to the potential absence of such factors in HEK293T cells. Differences were observed, ranging from ;100 to 10,000 reads above the control transfection (Fig. 2C, hsa-mir-214 and hsa-mir-9-1, respectively), consistent with the idea that factors absent in HEK293T cells might play a role in processing of some miRNAs. Alternatively, some miRNA hairpins might be processed less efficiently in all cell types, perhaps because our vectors might not present the hairpins in an optimal context for processing. Perhaps hsa-mir-192, the control gene that did not overexpress in our assay, lacked crucial processing determinants needed in all cells. In either scenario, the very high sensitivity of highthroughput sequencing enabled miRNAs to be observed from most of the less efficiently processed hairpins. GENES & DEVELOPMENT 239 995 Chiang et al. From the 52 annotated mouse miRNAs that our study did not sequence, 17 miRNAs, including mir-220 and mir207, were tested in the ectopic expression assay. One, mir698, generated a single read corresponding to the annotated miRNA, and the rest failed to generate any reads representing the annotated miRNA (Fig. 2D). From the 72 annotated miRNAs that we could not identify due to insufficient number of reads, 28 were tested, and only four of these were found to be overexpressed (Fig. 2D). The difficulty in overexpressing a canonical control miRNA (hsa-miR-192) illustrates that our ectopic expression assay cannot be used to prove conclusively that a particular hairpin does not represent an authentic miRNA gene. However, the inability to overexpress each of the 17 unsequenced miRNAs, as well as most of the 28 insufficiently sequenced miRNAs, strongly indicated that, overall, these annotations have been faulty, and that our failure to detect previously annotated miRNAs in mouse samples was not merely due to inadequate sequencing coverage. We also tested 10 of the 20 annotated miRNA genes that we identified as candidates but did not confidently classify as miRNA genes because the predicted miRNA* species was not sequenced. Four of seven genes without a miRNA* read and one of three genes with substantially offset miRNA* reads produced the predicted miRNA* species in our ectopic expression assay (Fig. 2D). mir-184 and mir-489, both of which tested positive in this assay, are conserved. mir-184 is conserved throughout mammals, and mir-489 is conserved to chicken, although the miRNA seed, which is highly conserved in mammals and chickens, differs in mice and rats. Thus, these two genes, as well as mir-875, which is a broadly conserved gene without a miRNA* read, were added to our set of confidently identified miRNA genes. Also added were mir-290, mir291a, mir-291b, mir-292, mir-293, mir-294, and mir-295, which were missing in the genome assembly (mm8) used in our analysis because they fall in the region of the genome that is difficult to assemble. Including these 10 genes, plus mir-451, brings the total number of confidently identified miRNA genes to 506, which includes 475 canonical genes. Our sets of confirmed and novel murine miRNAs also provided the opportunity to evaluate results of more recent computational efforts to find miRNAs conserved among mammals. One set of studies predicted miRNAs based on phylogenetic conservation, and then tested these and additional murine-specific hairpins using RAKE and cloning (Berezikov et al. 2005, 2006b). Among the 322 candidates supported by these experiments, 11 were in our sets of miRNAs (two in our confirmed set, and nine in our novel set), and another nine did not satisfy our annotation criteria but had at least one read consistent with the predictions. Another study started with MiRscan predictions conserved in four mammals, and filtered these predictions for potential seed pairing to conserved motifs in 39 untranslated regions (UTRs) (Xie et al. 2005). Of their 144 final candidates, 45 were paralogs of miRNAs already published at the time of prediction. Of the remaining 99 candidates, 27 were in our sets of miRNAs (26 in our confirmed set and one in our novel set), and one did not satisfy our annotation criteria but had three reads 996 consistent with the miRNA* of the predicted miRNA. However, only four of the 27 confirmed miRNA genes (4% of the 99 novel predictions) gave rise to the mature miRNA with the predicted seed, suggesting that filtering MiRscan predictions for potential seed pairing provided little, if any, added benefit. This conclusion concurs with a recent analysis of miRNA targeting: miRNAs that are not conserved beyond mammals do not have enough preferentially conserved sites to place these sites as among the most conserved UTR motifs (Friedman et al. 2009). Therefore, it stands to reason that preferentially conserved UTR motifs would provide little value for predicting such miRNAs. To investigate whether the computational candidates might have been missed because of low expression in tissues and stages from which we sequenced, we included representatives from each study in our ectopic expression assay. We randomly selected 12 Xie et al. (2005) candidates and eight Berezikov et al. (2006b) candidates that our study did not sequence, as well as four human candidates from the Berezikov et al. (2005) set whose mouse orthologs were not sequenced. None generated reads representing the candidate miRNAs (Fig. 2C,D). Taken together, our results raise new questions regarding the authenticity of these candidates, and suggest that previous extrapolation from these candidates, which had suggested that mammals have a surprisingly high number of conserved miRNA genes (as many as 1000) (Berezikov et al. 2005), should be revised accordingly. Experimental evaluation of novel miRNAs and new candidates We also used the ectopic expression assay to evaluate novel miRNAs identified from our sequencing. Of the 25 evaluated hairpins, 18 (72%) generated a significant number of miRNA-like reads in HEK293T cells, indicating that most, although perhaps not all, of our 108 novel annotations represented authentic miRNAs (Fig. 3; Supplemental Figs. S5, S6). These 25 hairpins were selected arbitrarily for evaluation, except for a preference for rare miRNAs; i.e., those that had <10 mature miRNA reads. The rare miRNAs and the higher-abundance miRNAs performed similarly (five of seven and 11 of 14 positives, respectively). To evaluate Drosha and Dicer dependence of the overexpressed hairpins, the experiment was repeated with and without a plasmid encoding a dominant-negative allele of either Drosha or Dicer (Fig. 3A; Han et al. 2009). All but two canonical miRNA controls and most of the novel canonical miRNAs (16 of 17) responded to TNdrosha coexpression (Fig. 3B; Supplemental Fig. S7). Fewer responded to TNdicer, suggesting that this construct was less disruptive of normal miRNA processing (Supplemental Fig. S7). The tested hairpins included several noncanonical miRNA precursors. The level of mmu-miR-1224, an annotated mirtronic miRNA (Berezikov et al. 2007), increased in the presence of TNdrosha, as expected if this pre-miRNA had more access to Exportin-5 and Dicer when the canonical pre-miRNAs were reduced (Grimm GENES & DEVELOPMENT 240 Mammalian microRNAs et al. 2006). Although mmu-miR-1839, an annotated shRNA (Babiarz et al. 2008), did not overexpress, mmumiR-344e and mmu-miR-344f, novel shRNAs, did over- express from our vector, and, as expected for shRNAs, their biogenesis was Drosha-independent (Fig. 3B; Supplemental Figs. S5–S7). Repeating the ectopic expression assay in Dicer knockout and control cells confirmed that mmu-miR-344e biogenesis was Dicer-dependent (data not shown). We also evaluated our candidates that had not satisfied our criteria for confident annotation as miRNAs, usually because they lacked reads representing the predicted miRNA*. We tested three sets of these candidates. One set represented our candidates that lacked predicted miRNA* reads, yet, based on small RNA sequencing results from wild-type and mutant ES cells (Babiarz et al. 2008), appeared DGCR8- and Dicer-dependent. Another set represented candidates that appeared conserved in syntenic regions of other mammalian genomes, and the third set was selected at random from among the remaining candidates. All but one of the 28 tested candidates failed to generate miRNA-like reads, and the processing of the candidate that did generate miRNA-like reads in HEK293T cells was not dependent on Dicer, based on its presence in Dicer knockout ES cells (Babiarz et al. 2008). The results evaluating the novel miRNAs and candidates illustrated the importance of requiring a convincing miRNA* read as a criterion for confident miRNA annotation. Five previously annotated miRNAs that were initially rejected due to lack of a convincing miRNA* read had tested positive in our overexpression assay (Fig. 2D), which indicated that this criterion was too stringent for some of the previously annotated genes. However, the results for the newly identified miRNAs and candidates showed that the presence of a convincing miRNA* read was the primary criterion that distinguished the novel canonical miRNAs (most of which tested positive) from the remaining candidates (nearly all of which tested negative). By requiring a convincing miRNA* read in addition to the other four annotation criteria, our approach accurately distinguished miRNA reads from the millions of other small RNA reads generated by high-throughput sequencing, with relatively few false positives among the novel annotations and few false negatives among the rejected candidates. miRNA expression profiles To compare expression levels of each miRNA in different sequenced samples, we constructed relative miRNA expression profiles (Fig. 4; Supplemental Table 5), and to compare the relative expression of various miRNAs with Figure 3. Experimental evaluation of novel miRNAs and candidates. (A) Examples of assays evaluating Drosha dependence, transfecting plasmids indicated in the key. (B) Assay results for control miRNAs, novel miRNAs, and miRNA candidates. Bars are colored as in A; detectable overexpression (black asterisks), overexpression attempted but not detected (black minus sign), detectable Drosha dependence (orange asterisks), and Drosha dependence assayed but not detected (orange minus sign) are all indicated. Shown are the results compiled from three experiments (Supplemental Figs. S5–S7). GENES & DEVELOPMENT 241 997 Chiang et al. Figure 4. miRNA relative expression profiles. Profiles of mature miRNAs were constructed as described (Ruby et al. 2007b). The relative contribution of each miRNA from each sample and the sum of the normalized reads of all samples are provided (Supplemental Table 5). each other, we generated a table of overall miRNA abundance (Supplemental Table 5). Most miRNAs had substantially stronger expression in some tissues or stages than in others, in agreement with previous observations (Wienholds et al. 2005). We expect that strong tissue- or stage-specific expression preferences inferred from our limited sample set will be revised as more tissues and stages are surveyed. General features of mammalian miRNAs Our analyses of high-throughput sequencing data and subsequent experimental evaluation reshaped the set of known murine miRNAs, setting aside 173 questionable 998 annotations and adding 108 novel miRNA genes to bring the total number of confidently identified murine genes to 506. A majority (60%) of the 506 genes appeared conserved in other mammals (Supplemental Fig. S1; Supplemental Table 6). However, only 15 of the 108 novel miRNA genes were conserved in other mammals, suggesting that the number of nonconserved miRNA genes will soon surpass that of conserved ones as high-throughput sequencing is applied more deeply and more broadly. Five novel miRNAs (mir-3065, mir-3071, mir-3074-1, mir3074-2, and mir-3111) mapped to the antisense strand of previously annotated miRNAs (mir-338, mir-136, mir-24-1, mir-24-2, and mir-374, respectively), which, when added to the previously identified mir-1-2/mir-1-2-as pair, brings GENES & DEVELOPMENT 242 Mammalian microRNAs the total number of sense/antisense miRNA pairs to six. In addition, the mir-486 hairpin has a palindromic sequence, which resulted in the same reads mapping to both the sense (mir-486) and antisense (mir-3107) hairpins. Analysis of the antisense loci of all 498 miRNA genes identified six additional loci that gave rise to some antisense reads resembling miRNAs (antisense loci of mir-21, mir-126, mir-150, mir-337, mir-434, and mir-3073). As more highthroughput data is acquired, these as well as other antisense loci are likely to be annotated as miRNA genes. However, <0.00002 of our miRNA reads corresponded to miRNAs from antisense loci (excluding the reads mapping ambiguously to mir-486/mir-3107), raising the possibility that none of the murine antisense miRNAs have a function comparable with that of miR-iab-as in flies (Bender 2008; Stark et al. 2008; Tyler et al. 2008). Our substantially revised set of miRNA genes provided the opportunity to speak to the general features of 475 canonical miRNAs in mice, with the properties of the 295 conserved genes applying also to the conserved genes of humans and other mammals (Table 1). Most canonical miRNA genes (61%) were clustered in the genome, falling within 50 kb of another miRNA gene, on the same genomic strand. Even when excluding the four known megaclusters (Calabrese et al. 2007), which are on chromosomes 2, 12 (two clusters), and X (with 69, 35, 16, and 18 genes, respectively), a sizable fraction of the remaining genes (153 of 337) were in clusters of two to seven genes. As observed in humans (Baskerville and Bartel 2005), miRNAs from these loci within 50 kb of each other tended to have correlated expression, consistent with their processing from polycistronic pri-miRNA transcripts (Supplemental Fig. S8). In a scenario of one transcript per cluster, the 475 canonical miRNA genes would derive from 245 transcription units. In addition, many miRNA hairpins mapped to introns. Just over a third (38%) of the hairpins fell within introns of annotated mRNAs. Several lines of evidence—including coexpression correlations, chromatin marks, and directed experiments—indicate that miRNAs can be processed from introns (Baskerville and Bartel 2005; Kim and Kim 2007; Marson et al. 2008). In this scenario, as many as 107 Table 1. Properties of canonical miRNAs Total Conserved Nonconserved Hairpins Cluster analysis In clusters In small clusters In large clusters Not in clusters Intron overlap In introns (same strand) Opposite introns Not in introns Arm preferences With miRNA from 59 arm With miRNA from 39 arm With miRNAs from both arms 475 295 180 291 153 138 184 163 129 34 132 128 24 104 52 180 22 273 77 18 200 103 4 73 202 141 137 102 65 39 132 56 76 (44%) of the 245 transcription units could double as premRNAs. Other hairpins were found within transcripts that lacked other annotated functions, falling either within introns or exons, or in transcripts without evidence of splicing. miRNA hairpins are generally thought to each give rise to a single dominant mature guide RNA. This was usually the case for the murine miRNAs, although, as in other species, this result relied on grouping together as a single functional species all the isoforms that share the same 59 terminus. This grouping is justified based on the current understanding of miRNA target recognition, which stipulates that heterogeneity often observed at miRNA 39 termini should have no effect on miRNA target recognition (Bartel 2009). Most mature miRNA reads (97%) were 20–24 nt in length, with 20mer, 21mer, 22mer, 23mer, and 24mer comprising 5%, 19%, 47%, 21%, and 4% of the reads, respectively (Supplemental Fig. S9). Although a single dominant mature species appears to be the most frequent outcome of miRNA biogenesis, some miRNA hairpins give rise to two or more species that each could function to target different sets of mRNAs. This expanded targeting potential arises from multiple mechanisms, including utilization of both strands of the miRNA:miRNA* duplex with similar frequency, 59 heterogeneity, sequential Dicer cleavage, and RNA editing. Addition of untemplated nucleotides to the 39 termini of the miRNAs can also occur, and although not thought to change targeting specificity, these changes could indicate post-transcriptional regulation of miRNA stability. Occurrence of each of these phenomena is described below. miRNAs from both arms, with occasional tissue-specific differences in the preferred arm Most canonical miRNA genes produced one dominant mature miRNA species, from either the 59 or 39 arm of the pre-miRNA hairpin, with an overall tendency to derive from the 59 arm (Table 1), as reported for previously annotated human miRNAs (Hu et al. 2009). Some, however, yielded a similar number of reads from both arms, suggesting that the two species enter the silencing complex with similar frequencies. For these genes, mature species from the 59 and 39 arms were annotated using the -5p and -3p suffixes, as is conventional in such cases (GriffithsJones 2004). Discrimination favoring one arm over the other was less pronounced for both the nonconserved miRNAs and the less highly expressed miRNAs (Fig. 5A), although for the miRNAs with very few reads this trend was likely enhanced by our requirement for a miRNA* read. Overall, the discrimination was high, with the species from the less dominant arm comprising 4.1% of the reads that map to a miRNA or miRNA*. For the 10 most abundant miRNAs (sampling just the most abundant member in cases of repetitive miRNAs), discrimination was even higher, with the less dominant arm comprising only 1.3% of the reads. Nevertheless, the miRNA* species of these more highly expressed miRNAs were sequenced at a median frequency 13-fold greater than that of the median nonconserved miRNA, suggesting that a search for GENES & DEVELOPMENT 243 999 Chiang et al. Figure 5. Reads from both arms of a hairpin, and sequential reads from the same arm. (A) Fraction and abundance of miRNA reads from each miRNA hairpin. To calculate the fraction, the miRNA reads were divided by the total number of miRNA and miRNA* reads, considering on each arm only the major 59 terminus. The dashed lines indicate the median fraction of miRNA reads and the median number of miRNA reads for conserved (red) and nonconserved (blue) miRNAs. (B) Switching of the dominant arm in different samples. For each sample, the fold enrichment of miRNA reads produced from the 59 arm over those produced from the 39 arm and vice versa was calculated. Shown are results for nonrepetitive miRNAs that switch dominant arms, with at least a fivefold differential between two samples. The samples are color-coded (key), and an asterisk indicates samples with statistically significant enrichment of miRNAs produced from one arm over the other (P < 0.05, x2 test). (C) Sequential Dicer cleavage. Predicted secondary structure of mmu-mir-3102 premiRNA (Hofacker et al. 1994). biological function for these miRNA* species might be at least as fruitful as that for the poorly expressed nonconserved miRNAs. If the mature miRNA accumulated preferentially from one arm of the pre-miRNA hairpin, the preferred arm generally remained consistent across the various libraries. For a few miRNAs, however, the preferred arms switched between samples (Fig. 5B), as reported previously using PCR-based miRNA quantification (Ro et al. 2007). For example, miR-142-5p was sequenced more frequently in ovary, testes, and brain, and miR-142-3p was sequenced more frequently in embryonic and newborn samples. These results imply a developmental switch in targeting preferences. A similar arm-switching phenomena has been reported for a sponge miRNA (Grimson et al. 2008), and was observed for 20 other nonrepetitive mouse miRNA genes (Fig. 5B). 1000 Sequential Dicer cleavage of a mirtron hairpin In plants, a few pri-miRNA hairpins with long, continuous RNA duplexes are cleaved sequentially by Dicer to generate two adjacent miRNA:miRNA* duplexes (Kurihara and Watanabe 2004; Rajagopalan et al. 2006). Those precursors bear little resemblance to the shorter, imperfectly base-paired hairpins of metazoan miRNA genes. In mice, similar precursors are found in the form of hairpin siRNA (hp-siRNA) precursors, but their expression appears to be limited to germline tissues and totipotent ES cells, which lack a robust interferon response to intracellular dsRNA (Babiarz et al. 2008; Tam et al. 2008; Watanabe et al. 2008). However, we detected two miRNA:miRNA* duplexes deriving from the mmumir-3102 pre-miRNA hairpin, an apparent mirtron as evidenced by reads mapping to both boundaries of an GENES & DEVELOPMENT 244 Mammalian microRNAs intron (Fig. 5C; Supplemental Table 3). After splicing and debranching, the excised intron was predicted to fold into a 104-nt pre-miRNA hairpin—substantially longer than the average pre-miRNA length of 61 nt (calculated from the set of confirmed miRNAs). Reads from this locus suggested that Dicer cleaved this pre-miRNA twice, with the first cut generating the outer miRNA:miRNA* duplex and the second cut generating the inner miRNA: miRNA* duplex (Fig. 5C). The inner miRNA (miR3102.2-3p) was among a set of proposed miRNA candidates (Berezikov et al. 2006b), but the most frequently sequenced species from this hairpin was the outer miRNA (miR-3102.1) (Fig. 5C). Of the 16 genomes examined, the extended mir-3102 hairpin with both the inner and outer miRNAs appeared conserved only in rats, although the orthologous loci in cows, dogs, and humans also could fold into shorter hairpins, with miR-3102.1 potentially conserved in cows. We suspect that it is more than a coincidence that the single metazoan example of a sequentially diced miRNA is initially processed by the spliceosome rather than by Drosha. One way to explain this observation is that DGCR8/Drosha interacts directly with the loop of primiRNA stem–loops when recognizing its substrates (Zeng et al. 2005), and that the lack of sequentially diced Drosha-dependent miRNA hairpins in animals reflects the limited reach of this complex. 59 Heterogeneity Most conserved miRNAs had very precise 59 processing, with alternative 59 isoforms comprising only 8% of all miRNA reads (Fig. 6A,B). These results, analogous to those observed in worms and flies (Ruby et al. 2006, 2007b), are consistent with the idea that selective pressure to avoid off-targeting acts to optimize precision of the cleavage event that produces the 59 terminus of the dominant species so as to prevent a consequential number of molecules with seed sequences in the wrong register. Moreover, 59 termini of conserved miRNAs were more precise than those of miRNA* reads (4% and 12% offset reads, respectively, excluding those that produce comparable numbers of small RNAs from each arm). For cases in which Dicer produced the 59 terminus of the miRNA, the Dicer cut appeared somewhat more precise than the Drosha cut (5% offset reads for miRNAs on the 39 arm, compared with 7% offset reads for miRNA* on the 59 arm), hinting that features of the pre-miRNA structure may supplement the distance from the Drosha cut as determinants of Dicer cleavage specificity (Ruby et al. 2006, 2007b). A few miRNAs had less uniform 59 termini (Fig. 6A,B). For some miRNAs, 59 heterogeneity has been documented previously (Ruby et al. 2007b; Stark et al. 2007; AzumaMukai et al. 2008; Wu et al. 2009), the most prominent example being hsa-miR-124, a conserved neuronal miRNA for which the 59-shifted isoform was initially annotated as the miRNA and eventually replaced by the more prominent isoform following more extensive sequencing (LagosQuintana et al. 2002; Landgraf et al. 2007). Another pro- minent miRNA with unusually diverse 59 termini was miR-133a. This conserved miRNA, which is highly expressed in heart and muscle, had a second dominant isoform (miR-133a.2) that was shifted 1 nt downstream from the annotated miRNA (miR-133a.1) (Fig. 6C; Supplemental Table 3). To test whether this heterogeneity might be explained by differential processing of the two mir-133a paralogous hairpins, as observed for the two Drosophila mir-2 hairpins (Ruby et al. 2007b), we tested the two mir133a hairpins in our ectopic expression assay. Although mir-133a-1 was somewhat more prone to produce the miR133a.2 isoform, both hairpins produced a substantial amount of both isoforms (Fig. 6C). To investigate the functional consequences of miRNA 59 heterogeneity, we examined published array data showing the responses of mRNAs after deleting either mir-223, a miRNA with substantial heterogeneity, or mir155, a miRNA with little heterogeneity. miR-223 is highly expressed in neutrophils, and analysis of small RNA sequences from isolated neutrophils (Baek et al. 2008) was consistent with our sequencing results (Supplemental Table 3) in showing 59 heterogeneity, with 81% of the reads mapping to the 59 end of the major isoform miRNA and 12% mapping to the 59 end of a second isoform that was shifted by 1 nt in the 39 direction (Fig. 6D). As expected, mRNAs with canonical 7–8mer sites (Bartel 2009) matching the seed of the major isoform were significantly derepressed in the mir-223 deletion mutant (P < 10 12, Kolmogorov–Smirnov [K–S] test, compared with no site distribution). mRNAs with canonical sites matching the minor isoform also showed a significant tendency to be derepressed, albeit to a lesser degree (P = 0.0022 3 10 7, 0.013 3 10 7, and 1.7 3 10 7, for 8mer, 7mer-m8, and 7–8mers combined, respectively) (Fig. 6D). This result could not be attributed to the overlap between sites matching the major and minor isoforms because all mRNAs with a 6mer seed match to the major isoform (ACUGAC) were excluded, and additional analyses ruled out participation of the ‘‘shifted 6mer’’ match (Friedman et al. 2009) to the major isoform (AACUGA) (Supplemental Fig. S10A). Analogous analysis of miR-155 yielded strong evidence for function of the major isoform (Rodriguez et al. 2007) but no sign of function for the minor isoform, which comprised very few (1%) of our miR-155 reads (Fig. 6E; Supplemental Table 3). Taken together, our results show that some miRNAs have alternative 59 miRNA isoforms that are expressed at levels sufficient to direct the repression of a distinct set of endogenous targets and thereby broaden the regulatory impact of the miRNA genes. Therefore, we suggest that, rather than choosing one isoform over the other for annotation as the authentic miRNA, more of these alternative isoforms should be annotated, with the expectation that, for some highly expressed miRNAs, more than one 59 isoform contributes to miRNA function. RNA editing RNA editing in which adenosine is deaminated and thereby converted to inosine (I) has been reported for GENES & DEVELOPMENT 245 1001 Chiang et al. Figure 6. miRNAs with 59 heterogeneity. (A) The distribution of conserved (red) and nonconserved (blue) miRNAs with reads #5 nt offset at their 59 terminus. (B) The fraction of offset reads and abundance of reads for each miRNA hairpin, colored as in A. The dashed lines indicate the median level of reads for conserved (red) and nonconserved (blue) miRNAs. (C) 59 Heterogeneity of miR-133a. Data from mouse heart (Rao et al. 2009) and newborn are mapped to the mir-133a-1 hairpin (top), and data from the ectopic expression assay are mapped to the indicated transfected hairpin (bottom). The lines indicate miR-133a.1 (dark blue) and miR-133a.2 (light blue), and red nucleotides indicate those that differ between mir-133a-1 and mir-133a-2. (D) Effect of losing miR-223 on messages with 39 UTR sites for miR-223 major and minor isoforms. (Top) Small RNA sequencing data from mouse neutrophils (Baek et al. 2008) were mapped to the mir-223 hairpin as in C. For each set of messages with the indicated 39 UTR site for miR-233 (major isoform sites, bottom left; minor isoform sites, bottom right), the fraction that changed at least to the degree indicated following loss of miR-223 is plotted, using data published for neutrophils differentiated in vivo (Baek et al. 2008). (E) Effect of losing miR-155 on messages with 39 UTR sites for miR155 major and minor isoforms, plotted as in D using published data from T cells (Rodriguez et al. 2007). (Top) Sequencing data from our study are mapped to the mir-155 hairpin as in C. The mRNAs with 8mer and 7mer-A1 sites for the minor isoform were excluded from the analysis because these sites overlapped with 7mer-m8 sites for the major isoform. 1002 GENES & DEVELOPMENT 246 Mammalian microRNAs some miRNA precursors (Blow et al. 2006; Landgraf et al. 2007; Kawahara et al. 2008). Because I pairs with C, such edits could change miRNA target recognition. Reasoning that the mammalian adenosine deaminases (ADARs) responsible for A-to-I editing are expressed primarily in the brain, we searched for sequencing reads from the brain that did not match the genome and had as their closest match a mature miRNA or miRNA*. After filtering for mismatches occurring >2 nt from the 39 end, a step taken to avoid considering instances of untemplated 39-terminal addition, only 4% of the reads had single mismatches to the genome (Supplemental Fig. S11A). Moreover, the fraction of sequences with A-to-G changes (indicative of A-to-I editing) was only 0.61%, a fraction resembling that of other mismatches (Supplemental Fig. S11A). This fraction was also similar to that of the A-to-G changes in our synthetic internal standards used for preparing the sequencing libraries. These results indicate that mature edited miRNAs are very rare and difficult to distinguish above the background level of sequencing errors. The low frequency of editing in mature miRNAs was consistent with the findings that edited processed miRNAs are more than fourfold less common in mice relative to humans (Landgraf et al. 2007), and are less common than edited miRNA precursors (Kawahara et al. 2008). The latter observation might be due to rapid degradation or impaired processing, which has been shown for miR-142 (Yang et al. 2006) and miR-151 (Kawahara et al. 2007a). Although editing did not appear to be a widespread phenomenon among all mature miRNAs, editing at specific sites might still be important for a few individual miRNAs. To investigate this possibility, mismatch fractions were calculated as the fraction of reads bearing a particular mismatch over all reads covering that genomic position. For each library, a change was considered significant if the fraction exceeded 5% and at least 10 reads contained the mismatch. Additional filters designed to remove sequencing errors, alignment artifacts, and instances of untemplated nucleotide addition preferentially retained A-to-G changes while removing nearly all other events (Supplemental Fig. S11B). Sixteen A-to-G events passed the filters and subsequent manual examination, all of which occurred only in the brain library (Table 2). Five of these inferred editing sites were also observed in a low-throughput sequencing effort in human brain samples (Kawahara et al. 2008), indicating that editing of some miRNAs is conserved between mammals. Consistent with that study, eight of 16 editing sites occurred in a UAG motif. A separate examination of read alignments with up to three mismatches showed that the vast majority of edited reads were edited at one position, suggesting that either editing of multiple sites in the same RNA molecule is rare, or multiply edited RNAs are degraded more rapidly. A-to-I editing of a seed nucleotide would dramatically affect targeting. In addition to editing in the miR-376 cluster described previously (Kawahara et al. 2007b, 2008), we found another eight miRNAs that are edited within the seed of either the miRNA or the miRNA*. A-to-I editing could also affect miRNA loading, and thereby indirectly affect targeting. Indeed, the editing of miR-540 might Table 2. Inferred A-to-I editing sites in miRNAs miRNA miR-219-2-3p miR-337-3p miR-376a* miR-376b-3p miR-376c miR-378 miR-379* miR-381 miR-411-5p miR-421 miR-467d miR-497 miR-497* miR-540* miR-1251 miR-3099 Position Fraction edited 15 10 4 6 6 16 5 4 5 14 3 2 20 3 6 7 0.064 0.062 0.297 0.501 0.311 0.087 0.095 0.125 0.239 0.054 0.094 0.104 0.699 0.080 0.431 0.209 help explain why the 59 arm is more abundant in the brain than in other tissues, although editing is too infrequent to fully explain the switch in strand bias. Altering Drosha and Dicer processing could also indirectly affect targeting. Analysis of 59 ends showed that seven of 16 instances of editing were associated with a statistically significant (P < 0.05) shift in the 59 nucleotide, presumably due to changes in the Drosha and Dicer cleavage site (Supplemental Fig. S11D). Untemplated nucleotide addition Much more prevalent than editing of internal nucleotides was addition of untemplated nucleotides to miRNA 39 termini. As reported previously for miRNAs in mammals (Landgraf et al. 2007), and also observed for those of worms and flies (Ruby et al. 2006, 2007b), nucleotides most frequently added to murine miRNAs were U and A (Fig. 7A). Addition of C or G was no higher than background, as estimated by monitoring apparent addition to tRNA fragments (Fig. 7A). Possible sources of the background rate could be sequencing error, transcription error, or a low level of biological nucleotide addition. Some miRNAs were much more frequently extended than others (Supplemental Table 7). One very frequently extended miRNA was miR-143, for which the extended reads outnumbered the nonextended ones (196,565 compared with 114,980 reads, respectively). For extension by U, RNAs from the pre-miRNA 39 arm were three times more frequently extended than were those from the 59 arm (Fig. 7A,B, P = 2.3 3 10 4, K–S test). This preference, not observed for the A extension (Fig. 7A,C), suggests that much of the U extension occurs to the pre-miRNA, prior to Dicer cleavage—a state in which the 39 arm but not the 59 arm would be available for extension (Fig. 7D). TUT4-catalyzed poly(U) addition to the let-7 premiRNA, which is specified by Lin28, plays an important role in post-transcriptional repression of let-7 expression (Heo et al. 2008, 2009; Hagan et al. 2009). Our analyses indicating untemplated U extension to many other premiRNAs hint that this type of regulation may not be GENES & DEVELOPMENT 247 1003 Chiang et al. Figure 7. Untemplated nucleotide addition. (A) Untemplated nucleotide addition rate for miRNA and miRNA* reads from the indicated arm. Rates for each miRNA are provided (Supplemental Table 6). As a control, tRNA degradation fragments were analyzed similarly. Numbers of genes analyzed are indicated in parentheses. (B) Distribution of rates for untemplated U addition to RNAs from the 59 arm (blue) and from the 39 arm (red). (C) Distribution of rates for untemplated A addition to RNAs from the 59 arm (blue) and from the 39 arm (red). (D) Schematic of the biogenesis stage in which U could be added to the RNA of only one arm (pre-miRNA, left), and the stage in which U could be added to the RNA of either arm (mature miRNA and miRNA*, right). limited to let-7, but that analogous pathways, presumably using mediators other than Lin28, act to regulate the expression of other murine miRNAs. Discussion The status of miRNA gene discovery in mammals Our current study sets aside nearly a third (173 of 564) of the miRBase version 14.0 gene annotations for lack of convincing evidence that these produce authentic miRNAs. It also adds another 108 novel miRNA loci, raising the question of how many more authentic loci remain undiscovered. This question is difficult to answer. Ever since the recognition that the poorly conserved miRNAs are also the ones expressed at lower levels in mammals, and thus are the most difficult to detect by both computational and experimental methods, we have known that it is impossible to provide a meaningful estimate of the number of mammalian miRNA genes remaining to be discovered (Bartel 2004). The broadly conserved miRNAs are another matter. Only three of the 88 novel canonical miRNAs had recognizable orthologs sequenced in chickens, lizards, frogs, or fish, and these three were antisense to previously annotated broadly conserved miRNA genes. Therefore, apart from miRNAs expressed at very low levels from the antisense strand of known genes, we suspect that the list of broadly conserved miRNA gene families is nearing completion. The current set of murine miRNA genes includes 192 genes that fall into 89 broadly conserved miRNA gene families (Supplemental Table 6). Another 107 miRNA gene families appeared conserved in other mammals (Supplemental Table 6). These were represented by 120 murine genes, including 14 novel 1004 genes. Of these novel genes, 11 were founding members of novel conserved gene families. Some of these were identified with only 11 reads, indicating that additional pan-mammalian gene families remain to be found, although we have no evidence supporting the idea that the number of conserved gene families will rise to the very high levels suggested by some earlier computational studies (Berezikov et al. 2005, 2006b; Xie et al. 2005). For now, we can say that mammals have at least 196 conserved miRNA gene families represented in mice by at least 312 pre-miRNA hairpins (303 canonical and nine noncanonical hairpins) produced from at least 194 unique transcription units. Because a single miRNA hairpin can produce multiple functional isoforms, generated by either 59 processing heterogeneity or utilization of both arms of the miRNA duplex, a single conserved hairpin can produce more than one conserved miRNA isoform. Because the different isoforms have different seed sequences, they fall into different families of mature miRNAs. Thus, the number of conserved families of miRNAs (i.e., mature guide RNAs) will exceed the number of conserved families of genes (i.e., hairpins). Perhaps the best known example of a hairpin with two broadly conserved isoforms is mir-9, for which conserved miRNAs from both arms of the hairpin are readily detected by using in situ hybridization in both zebrafish and marine annelids (Wienholds et al. 2005; Christodoulou et al. 2010). Numerous conserved genes produce more than one miRNA isoform (Figs. 5A, 6A), but for most of these we do not yet know whether production of the alternative isoform is conserved in other species. High-throughput sequencing from other species will help identify many additional conserved GENES & DEVELOPMENT 248 Mammalian microRNAs isoforms. We anticipate that the discovery of multiple conserved isoforms will contribute much more to the future growth in the list of broadly conserved miRNA families than will the discovery of new conserved genes. As expected, the conserved miRNAs tended to be expressed at much higher levels than were the nonconserved ones, with the median read frequency of conserved miRNAs 44-fold greater than that of the nonconserved miRNAs (Figs. 5A, 6B). Therefore, even if many nonconserved miRNA genes remained to be found, these would add little to the number of annotated miRNA molecules in a given cell or tissue, and presumably even less to the impact of miRNAs on gene expression (Bartel 2009). Indeed, even more pressing than the question of how many poorly conserved miRNAs remain undetected is the question of whether any of the known poorly conserved miRNAs have any consequential function in the animal. Most of these poorly conserved miRNAs could have derived from transcripts that fortuitously acquired hairpin regions with features needed for some Drosha/Dicer processing. In this scenario, most of these newly emergent miRNAs will be lost during the course of evolution before ever acquiring the expression levels needed to have a targeting function sufficient for their selective retention in the genome. Consistent with the hypothesis that most of these miRNAs play inconsequential regulatory roles, these miRNAs generally accumulated to much lower levels in our ectopic expression assay, (Fig. 3B, median read frequencies of 58 and 844 for nonconserved and conserved miRNAs, respectively), and they displayed weaker specificity for one arm of the hairpin (Fig. 5A), as would be expected if there was no advantage for the cell to efficiently use their respective hairpins. Nonetheless, some were processed efficiently, and at least a few poorly conserved miRNAs probably have acquired consequential species-specific functions. Although none have known functions, such hairpins are worthy of annotation as miRNA loci (just as protein-coding genes can be annotated before the protein is known to be functional), and as a class these newly emergent miRNAs could provide an important evolutionary substrate for the emergence of new regulatory activities. The major challenge for miRNA gene discovery stems from the difficulty in proving that a nonconserved, poorly expressed candidate is an authentic miRNA, combined with the even greater difficulty in proving that a questionable candidate is not an authentic miRNA. This challenge has become all the more acute as miRNA discovery has reached the point to which nearly all of the novel candidates are both nonconserved and poorly expressed. Our approach of testing pools of candidates in an ectopic expression assay provides useful data for evaluating miRNA authenticity. However, our approach cannot provide conclusive proof for or against the authenticity of a proposed candidate, leaving open the possibility that some of the nonconserved, poorly expressed candidates that we classify as ‘‘confidently identified miRNAs’’ are false positives. When considering the limitations of the current tools for miRNA gene identification, this possi- bility cannot be avoided. Therefore, if any nonconserved, poorly expressed miRNAs are annotated as miRNAs, the resulting list of miRNAs will have to be somewhat fuzzy, with an expectation that some of the annotated genes will not be authentic miRNAs. This expectation should not be viewed as advocating the indiscriminant annotation of all candidates as miRNAs. Our proposal is that miRNA gene discovery efforts should annotate as miRNAs only those novel candidates that both are found in highthoughput sequencing libraries and pass a set of criteria that is sufficiently stringent such that a majority of the novel canonical miRNAs are cleanly processed in a Drosha-dependent manner when using the ectopic expression assay. Although implementing this proposal would not prevent all false positives from entering the databases, it would preserve a higher quality set of miRNAs while eliminating few authentic annotations. Those wanting to take additional measures to avoid false positives could focus on only the subset of miRNAs that both meet these criteria and are conserved in other species. Unknown features required for Drosha/Dicer processing Before learning the results of our experiments, we wondered whether any ectopically overexpressed hairpin of suitable length would be processed as if it were a miRNA, a result that would have rendered our assay too permissive to be of value. In this scenario, most of the specificity that distinguished authentic miRNA genes from other regions of the genome with the potential to produce transcripts that fold into seemingly miRNA-like hairpins would have been a function of whether or not the regions were transcribed. This scenario was not realized, however, and our assay turned out to be informative, which illustrates how much of Drosha/Dicer substrate recognition still remains unknown. Many of the previously proposed miRNA hairpins that had no reads in our mouse samples were indistinguishable from authentic miRNA hairpins with regard to the known determinants for Drosha/Dicer recognition, yet none of these unconfirmed hairpins produced miRNA and miRNA* molecules in our very sensitive assay (Fig. 2C,D). These results showing that major processing specificity determinants still remain undiscovered point to the importance of finding these determinants—efforts that, if successful, will mark the next substantive advance in accurately predicting and annotating metazoan miRNAs. Materials and methods Library preparation Total RNA samples from mouse ovary, testes, and brain were purchased from Ambion, and total RNA from mouse E7.5, E9.5, E12.5, and newborn were obtained from the Chess laboratory. The small RNA cDNA libraries were made as described (Grimson et al. 2008), except for the 39 adaptor ligation, which was 59 adenylated pTCGTATGCCGTCTTCTGCTTGidT. For a detailed protocol, see http://web.wi.mit.edu/bartel/pub/protocols.html. GENES & DEVELOPMENT 249 1005 Chiang et al. miRNA discovery The reads with inserts of 16–27 nt were processed as described (Babiarz et al. 2008). The miRNA candidates were identified using reads matching genomic regions that were not very highly repetitive (reads with <500 genomic matches). Reads from all data sets were combined and grouped by their 59-terminal loci, requiring that each candidate 59 locus pass five criteria listed in the text. (1) To pass the expression criterion, a candidate required $10 normalized reads. (2) To address the hairpin requirement, the secondary structure of the candidate was evaluated by selecting for each 59-terminal locus the most abundant sequence and extending its 59 end by 2 nt to define the range of the potential miRNA/miRNA* duplex. Three genomic windows were extracted with the 59 end extended an additional 10 nt and the 39 end extended either 50 nt, 100 nt, or 150 nt. Three more windows were extracted extending the 39 end by 10 nt and the 59 end another 50 nt, 100 nt, or 150 nt. The secondary structure of each of the six windows was predicted using RNAfold (Hofacker et al. 1994), and the number of hairpin base pairs (denoted using bracket notation) involving the 59-extended miRNA candidate was calculated as the absolute value of ([number of 59-facing brackets] [number of 39-facing brackets]). A candidate with a minimum of 16 bp using at least one of the six genomic windows satisfied the hairpin criteria. (3) The candidates with non-miRNA biogenesis were found by mapping to annotated noncoding RNA loci (rRNA, tRNA, snRNA, and srpRNA). (4) The candidates likely produced by degradation were defined as those failing the 59 homogeneity requirement. A candidate satisfied the 59 homogeneity requirement if at least half of the reads within 30 nt of the candidate 59 end were present within 2 nt of the candidate 59 end and if the candidate 59 end comprised at least half of the reads within 2 nt of the candidate 59 end, or if there was only one other 59 end within 30 nt of the candidate 59 end that had more than half of the reads mapping to the candidate 59 end. (5) Manual inspection of reads mapped to predicted secondary structures identified candidates accompanied by potential miRNA* reads. For 10 previously annotated miRNAs and seven novel miRNAs, a suitable miRNA* read was found only after considering alternative hairpin folds predicted to be suboptimal using mfold (Mathews et al. 1999; Zuker 2003). For the analysis of mir-290, mir-291a, mir-291b, mir-292, mir293, mir-294, and mir-295, which are not present in mm8 genome assembly, we mapped all reads to mm9 genome assembly corresponding to the region [chr7(+): 3,218,627–3,220,842]. For conservation analysis, a candidate was considered broadly conserved if the hairpin structure and the seed sequence were conserved to chickens, fish, frogs, or lizards (galGal3, danRer5, xenTro2, and anoCar1, respectively) in the University of California at Santa Cruz whole-genome alignments (Kuhn et al. 2009). To identify a candidate conserved in mammals, we looked at 12 additional genomes (bosTau3, canFam2, cavPor2, equCab1, hg18, loxAfr1, monDom4, ornAna1, panTro2, ponAbe2, rheMac2, and rn4) and calculated the branch length score from a phylogenetic tree trained on mouse 39 UTR data (Friedman et al. 2009), using the cutoff score of 0.7. A gene was considered to be in a conserved miRNA gene family if the hairpin produced a miRNA with a seed matching that of a conserved miRNA (Supplemental Table 6). Ectopic overexpression assays To generate expression constructs, pre-miRNA hairpins and the surrounding regions were amplified from human genomic DNA (NCI-BL2126) or from mouse BL6 genomic DNA using Pfu Ultra II 1006 polymerase (Stratagene) and primers with Gateway (Invitrogen)compatible ends designed to anneal ;100 nt upstream of and downstream from the miRNA hairpins. PCR products were inserted into Gateway vector pDONR221 and subsequently into pcDNA3.2/V5-DEST, and the resulting plasmids were transformed into DH5-a cells. Positive clones were selected by colony PCR and were sequenced. Clones that did not have a mutation within premiRNA hairpins were selected. Plasmid DNA from the confirmed expression clones was purified for transfection using the Plasmid Mini Kit (Qiagen). For each standard assay, plasmids for up to 10 hairpin expression constructs were mixed in equal amounts to create seven or eight pools of ;1.4 mg of DNA each, with each pool including one to three positive control hairpins. HEK293T cells were cultured in DMEM supplemented with 10% FBS, and were plated in 12-well plates ;24 h prior to transfection to reach ;80%–90% confluency. Each well of cells was transfected with one pool of DNA using Lipofectamine 2000 (Invitrogen). For the standard assays, 145–200 ng of pMaxGFP (Amaxa) was cotransfected with each pool to enable transfection efficiency to be confirmed by GFP expression. Control wells (no hairpin plasmid) were transfected only with 145 ng of pMaxGFP. For the Drosha/Dicer dependency assays, seven to eight hairpin constructs were combined to create six pools of ;400 ng each. Each pool was mixed with 1.2 mg of the pCK-Drosha-Flag(TN) (TNdrosha), pCK-Flag-Dicer(TN) (TNdicer), or pCK-dsRed.T4 (control vector, constructed by replacing the Drosha-coding sequence of TNdrosha with dsRed-coding sequence) and used to transfect one well of HEK293T cells as above. Control wells were transfected with 1.2 mg of either TNdrosha, TNdicer, or control vector. For the dependency assays, each transfection was performed in duplicate wells. Cells from all assays were harvested 39–48 h after transfection. Cells from each treatment were combined, total RNA was extracted using TriReagent (Ambion), and small RNA libraries were prepared for Illumina sequencing. The reads were processed as above, and RNA species were matched to the transfected hairpins. In the standard assay, reads were normalized by the median of the 30 most frequently sequenced endogenous miRNAs. For assays testing Drosha/Dicer dependency, reads were normalized based on the number of reads corresponding to an 18-nt internal standard that had been spiked into equivalent amounts of total RNA prior to beginning library preparation. Reads matching the transfected hairpins were grouped by their 59 termini (59-terminal locus). The locus with the largest number of reads was considered the 59-terminal locus of the mature miRNA produced by the hairpin, and similarly, the most dominant 59 locus on the opposite arm was considered the miRNA*. The normalized miRNA and miRNA* read numbers were summed to calculate the expression level. If an overexpressed hairpin generated mature miRNA with the dominant 59-terminal locus corresponding to the expected locus and at least one read corresponding to the miRNA* with an ;2-nt 39 overhang, it was considered expressed. A hairpin was classified as overexpressed if there were at least threefold more reads in the hairpin transfection than in the control transfection, after adding psuedocounts of five to both. A hairpin was classified as Droshaor Dicer-dependent if the knockdown was at least threefold. Identification of arm-switching miRNAs To determine the read numbers from the 59 and 39 arms, reads from each sample were grouped based on their 59 termini, and the read numbers were tallied for those corresponding to the miRNA or miRNA* 59 terminus. Only samples with five or more reads on either arm were considered. The fold enrichment was calculated as the ratio of 59 and 39 arm reads after adding pseudocounts of one. GENES & DEVELOPMENT 250 Mammalian microRNAs RNA editing analysis Sequencing libraries from individual tissues were combined and mapped to the genome using the Bowtie alignment tool (Langmead et al. 2009). The alignments were filtered for sequences that uniquely aligned to the genome, contained at most one mismatch to the genome, and had 59 ends that mapped to within 1 nt of an annotated miRNA or miRNA* 59 end. The 12 possible mismatch types were then quantified at each position covered by the filtered reads. For example, to screen for A-to-G mismatches indicative of A-to-I editing sites, the editing fraction was calculated as the number of reads containing an A-to-G mismatch at a particular position, divided by the number of filtered reads covering that position. Sites were considered editing candidates if the editing fraction was >5%, had at least 10 A-to-G mismatch reads, and did not occur in the last 2 nt of the corresponding miRNA or miRNA*. Candidate editing sites were then manually examined and discarded if an alternative explanation was more parsimonious. For example, the only nonbrain editing candidate mapped to let-7c-1, but was most likely due to a handful of let-7b reads containing untemplated nucleotide additions that fortuitously matched the let-7c-1 locus. Consistent with this explanation, the putatively edited reads were unusually long and at unusually low abundance. Candidate editing sites were also checked in the Perlegen SNP database (Frazer et al. 2007) and dbSNP; no editing candidates corresponded to known SNPs. Untemplated nucleotide analysis To examine untemplated nucleotide addition, non-genome-mapping reads were filtered for those that matched miRNA or miRNA* sequences but also included a nongenomic poly(N) at the 39 end. The untemplated nucleotide addition rate was calculated as the ratio of reads with the untemplated nucleotide to the sum of the reads with and without the untemplated nucleotide. After excluding miRNAs that map to multiple loci, and any miRNAs or miRNA*s with a genomic T at the position immediately 39 of the annotated sequence, there were 343 miRNA/miRNA* species with untemplated U on the 59 arm and 318 on the 39 arm. Similarly, there were 287 59 arm species with untemplated A on the 59 arm and 324 on the 39 arm. The background tRNA untemplated U addition rate was calculated similarly. A two-sided K–S test was used to assess significant differences in distributions. Accession numbers All small RNA reads are available at the GEO database with accession number GSE20384. Acknowledgments We thank N. Lau and A. Chess for embryonic and newborn total RNA, R. Friedman for calculating branch length scores for the analysis of conservation, A. Marson and N. Hannet for technical advice, and V.N. Kim for TNdrosha and TNdicer plasmids. This work was supported by a grant from the NIH (GM067031) to D.B. References Azuma-Mukai A, Oguri H, Mituyama T, Qian ZR, Asai K, Siomi H, Siomi MC. 2008. Characterization of endogenous human Argonautes and their miRNA partners in RNA silencing. Proc Natl Acad Sci 105: 7964–7969. Babiarz JE, Ruby JG, Wang YM, Bartel DP, Blelloch R. 2008. Mouse ES cells express endogenous shRNAs, siRNAs, and other Microprocessor-independent, Dicer-dependent small RNAs. Genes & Dev 22: 2773–2785. Baek D, Villén J, Shin C, Camargo FD, Gygi SP, Bartel DP. 2008. The impact of microRNAs on protein output. Nature 455: 64–71. Bartel DP. 2004. MicroRNAs: Genomics, biogenesis, mechanism, and function. Cell 116: 281–297. Bartel DP. 2009. MicroRNAs: Target recognition and regulatory functions. Cell 136: 215–233. Baskerville S, Bartel DP. 2005. Microarray profiling of microRNAs reveals frequent coexpression with neighboring miRNAs and host genes. RNA 11: 241–247. Bender W. 2008. MicroRNAs in the Drosophila bithorax complex. Genes & Dev 22: 14–19. Bentwich I, Avniel A, Karov Y, Aharonov R, Gilad S, Barad O, Barzilai A, Einat P, Einav U, Meiri E, et al. 2005. Identification of hundreds of conserved and nonconserved human microRNAs. Nat Genet 37: 766–770. Berezikov E, Guryev V, van de Belt J, Wienholds E, Plasterk RHA, Cuppen E. 2005. Phylogenetic shadowing and computational identification of human microRNA genes. Cell 120: 21–24. Berezikov E, Thuemmler F, van Laake LW, Kondova I, Bontrop R, Cuppen E, Plasterk RHA. 2006a. Diversity of microRNAs in human and chimpanzee brain. Nat Genet 38: 1375–1377. Berezikov E, van Tetering G, Verheul M, van de Belt J, van Laake L, Vos J, Verloop R, van de Wetering M, Guryev V, Takada S, et al. 2006b. Many novel mammalian microRNA candidates identified by extensive cloning and RAKE analysis. Genome Res 16: 1289–1298. Berezikov E, Chung WJ, Willis J, Cuppen E, Lai EC. 2007. Mammalian mirtron genes. Mol Cell 28: 328–336. Blow MJ, Grocock RJ, van Dongen S, Enright AJ, Dicks E, Futreal PA, Wooster R, Stratton MR. 2006. RNA editing of human microRNAs. Genome Biol 7: R27. doi: 10.1186/gb-2006-7-4-r27. Calabrese JM, Seila AC, Yeo GW, Sharp PA. 2007. RNA sequence analysis defines Dicer’s role in mouse embryonic stem cells. Proc Natl Acad Sci 104: 18097–18102. Chen C-Z, Li L, Lodish HF, Bartel DP. 2004. MicroRNAs modulate hematopoietic lineage differentiation. Science 303: 83–86. Christodoulou F, Raible F, Tomer R, Simakov O, Trachana K, Klaus S, Snyman H, Hannon GJ, Bork P, Arendt D. 2010. Ancient animal microRNAs and the evolution of tissue identity. Nature 463: 1084–1088. Cummins JM, He YP, Leary RJ, Pagliarini R, Diaz LA, Sjoblom T, Barad O, Bentwich Z, Szafranska AE, Labourier E, et al. 2006. The colorectal microRNAome. Proc Natl Acad Sci 103: 3687–3692. Frazer KA, Eskin E, Kang HM, Bogue MA, Hinds DA, Beilharz EJ, Gupta RV, Montgomery J, Morenzoni MM, Nilsen GB, et al. 2007. A sequence-based variation map of 8.27 million SNPs in inbred mouse strains. Nature 448: 1050–1053. Friedman RC, Farh KKH, Burge CB, Bartel DP. 2009. Most mammalian mRNAs are conserved targets of microRNAs. Genome Res 19: 92–105. Griffiths-Jones S. 2004. The microRNA registry. Nucleic Acids Res 32: D109–D111. doi: 10.1093/nar/gkh023. Grimm D, Streetz KL, Jopling CL, Storm TA, Pandey K, Davis CR, Marion P, Salazar F, Kay MA. 2006. Fatality in mice due to oversaturation of cellular microRNA/short hairpin RNA pathways. Nature 441: 537–541. Grimson A, Srivastava M, Fahey B, Woodcroft BJ, Chiang HR, King N, Degnan BM, Rokhsar DS, Bartel DP. 2008. Early origins and evolution of microRNAs and Piwi-interacting RNAs in animals. Nature 455: 1193–1197. Hagan JP, Piskounova E, Gregory RI. 2009. Lin28 recruits the TUTase Zcchc11 to inhibit let-7 maturation in mouse embryonic stem cells. Nat Struct Mol Biol 16: 1021–1025. GENES & DEVELOPMENT 251 1007 Chiang et al. Han JJ, Lee Y, Yeom KH, Nam JW, Heo I, Rhee JK, Sohn SY, Cho YJ, Zhang BT, Kim VN. 2006. Molecular basis for the recognition of primary microRNAs by the Drosha–DGCR8 complex. Cell 125: 887–901. Han J, Pedersen JS, Kwon SC, Belair CD, Kim Y-K, Yeom K-H, Yang W-Y, Haussler D, Blelloch R, Kim VN. 2009. Posttranscriptional crossregulation between Drosha and DGCR8. Cell 136: 75–84. Heo I, Joo C, Cho J, Ha M, Han JJ, Kim VN. 2008. Lin28 mediates the terminal uridylation of let-7 precursor microRNA. Mol Cell 32: 276–284. Heo I, Joo C, Kim Y-K, Ha M, Yoon M-J, Cho J, Yeom K-H, Han J, Kim VN. 2009. TUT4 in concert with Lin28 suppresses microRNA biogenesis through pre-microRNA uridylation. Cell 138: 696–708. Hofacker IL, Fontana W, Stadler PF, Bonhoeffer LS, Tacker M, Schuster P. 1994. Fast folding and comparison of rna secondary structures. Monatsh Chem 125: 167–188. Houbaviy HB, Murray MF, Sharp PA. 2003. Embryonic stem cell-specific microRNAs. Dev Cell 5: 351–358. Hu H, Yan Z, Xu Y, Hu H, Menzel C, Zhou Y, Chen W, Khaitovich P. 2009. Sequence features associated with microRNA strand selection in humans and flies. BMC Genomics 10: 413. Kawahara Y, Zinshteyn B, Chendrimada TP, Shiekhattar R, Nishikura K. 2007a. RNA editing of the microRNA-151 precursor blocks cleavage by the Dicer–TRBP complex. EMBO Rep 8: 763–769. Kawahara Y, Zinshteyn B, Sethupathy P, Iizasa H, Hatzigeorgiou AG, Nishikura K. 2007b. Redirection of silencing targets by adenosine-to-inosine editing of miRNAs. Science 315: 1137– 1140. Kawahara Y, Megraw M, Kreider E, Iizasa H, Valente L, Hatzigeorgiou AG, Nishikura K. 2008. Frequency and fate of microRNA editing in human brain. Nucleic Acids Res 36: 5270–5280. Kim Y-K, Kim VN. 2007. Processing of intronic microRNAs. EMBO J 26: 775–783. Kuchenbauer F, Morin RD, Argiropoulos B, Petriv OI, Griffith M, Heuser M, Yung E, Piper J, Delaney A, Prabhu AL, et al. 2008. In-depth characterization of the microRNA transcriptome in a leukemia progression model. Genome Res 18: 1787–1797. Kuhn RM, Karolchik D, Zweig AS, Wang T, Smith KE, Rosenbloom KR, Rhead B, Raney BJ, Pohl A, Pheasant M, et al. 2009. The UCSC Genome Browser Database: Update 2009. Nucleic Acids Res 37: D755–D761. doi: 10.1093/nar/gkn875. Kurihara Y, Watanabe Y. 2004. Arabidopsis micro-RNA biogenesis through Dicer-like 1 protein functions. Proc Natl Acad Sci 101: 12753–12758. Lagos-Quintana M, Rauhut R, Lendeckel W, Tuschl T. 2001. Identification of novel genes coding for small expressed RNAs. Science 294: 853–858. Lagos-Quintana M, Rauhut R, Yalcin A, Meyer J, Lendeckel W, Tuschl T. 2002. Identification of tissue-specific microRNAs from mouse. Curr Biol 12: 735–739. Lagos-Quintana M, Rauhut R, Meyer J, Borkhardt A, Tuschl T. 2003. New microRNAs from mouse and human. Rna 9: 175– 179. Landgraf P, Rusu M, Sheridan R, Sewer A, Iovino N, Aravin A, Pfeffer S, Rice A, Kamphorst AO, Landthaler M, et al. 2007. A mammalian microRNA expression atlas based on small RNA library sequencing. Cell 129: 1401–1414. Langmead B, Trapnell C, Pop M, Salzberg S. 2009. Ultrafast and memory-efficient alignment of short DNA sequences to the human genome. Genome Biol 10: R25. doi: 10.1186/gb-200910-3-r25. 1008 Lau NC, Lim LP, Weinstein EG, Bartel DP. 2001. An abundant class of tiny RNAs with probable regulatory roles in Caenorhabditis elegans. Science 294: 858–862. Lee RC, Ambros V. 2001. An extensive class of small RNAs in Caenorhabditis elegans. Science 294: 862–864. Lee Y, Ahn C, Han JJ, Choi H, Kim J, Yim J, Lee J, Provost P, Radmark O, Kim S, et al. 2003. The nuclear RNase III Drosha initiates microRNA processing. Nature 425: 415–419. Lim LP, Glasner ME, Yekta S, Burge CB, Bartel DP. 2003. Vertebrate microRNA genes. Science 299: 1540. Lu C, Tej SS, Luo S, Haudenschild CD, Meyers BC, Green PJ. 2005. Elucidation of the small RNA component of the transcriptome. Science 309: 1567–1569. Lund E, Guttinger S, Calado A, Dahlberg JE, Kutay U. 2004. Nuclear export of microRNA precursors. Science 303: 95–98. Marson A, Levine SS, Cole MF, Frampton GM, Brambrink T, Johnstone S, Guenther MG, Johnston WK, Wernig M, Newman J, et al. 2008. Connecting microRNA genes to the core transcriptional regulatory circuitry of embryonic stem cells. Cell 134: 521–533. Mathews DH, Sabina J, Zuker M, Turner DH. 1999. Expanded sequence dependence of thermodynamic parameters improves prediction of RNA secondary structure. J Mol Biol 288: 911–940. Mineno J, Okamoto S, Ando T, Sato M, Chono H, Izu H, Takayama M, Asada K, Mirochnitchenko O, Inouye M, et al. 2006. The expression profile of microRNAs in mouse embryos. Nucleic Acids Res 34: 1765–1771. Okamura K, Hagen JW, Duan H, Tyler DM, Lai EC. 2007. The mirtron pathway generates microRNA-class regulatory RNAs in Drosophila. Cell 130: 89–100. Pruitt KD, Tatusova T, Maglott DR. 2005. NCBI Reference Sequence (RefSeq): A curated non-redundant sequence database of genomes, transcripts and proteins. Nucleic Acids Res 33: D501–D504. doi: 10.1093/nar/gki025. Rajagopalan R, Vaucheret H, Trejo J, Bartel DP. 2006. A diverse and evolutionarily fluid set of microRNAs in Arabidopsis thaliana. Genes & Dev 20: 3407–3425. Rao PK, Toyama Y, Chiang HR, Gupta S, Bauer M, Medvid R, Reinhardt F, Liao R, Krieger M, Jaenisch R, et al. 2009. Loss of cardiac microRNA-mediated regulation leads to dilated xardiomyopathy and heart failure. Circ Res 105: 585–594. Ro S, Park C, Young D, Sanders KM, Yan W. 2007. Tissuedependent paired expression of miRNAs. Nucleic Acids Res 35: 5944–5953. Rodriguez A, Vigorito E, Clare S, Warren MV, Couttet P, Soond DR, van Dongen S, Grocock RJ, Das PP, Miska EA, et al. 2007. Requirement of bic/microRNA-155 for normal immune function. Science 316: 608–611. Ruby JG, Jan C, Player C, Axtell MJ, Lee W, Nusbaum C, Ge H, Bartel DP. 2006. Large-scale sequencing reveals 21U-RNAs and additional microRNAs and endogenous siRNAs in C. elegans. Cell 127: 1193–1207. Ruby JG, Jan CH, Bartel DP. 2007a. Intronic microRNA precursors that bypass Drosha processing. Nature 448: 83–86. Ruby JG, Stark A, Johnston WK, Kellis M, Bartel DP, Lai EC. 2007b. Evolution, biogenesis, expression, and target predictions of a substantially expanded set of Drosophila microRNAs. Genome Res 17: 1850–1864. Seo TS, Bai XP, Ruparel H, Li ZM, Turro NJ, Ju JY. 2004. Photocleavable fluorescent nucleotides for DNA sequencing on a chip constructed by site-specific coupling chemistry. Proc Natl Acad Sci 101: 5488–5493. Stark A, Kheradpour P, Parts L, Brennecke J, Hodges E, Hannon GJ, Kellis M. 2007. Systematic discovery and characterization GENES & DEVELOPMENT 252 Mammalian microRNAs of fly microRNAs using 12 Drosophila genomes. Genome Res 17: 1865–1879. Stark A, Bushati N, Jan CH, Kheradpour P, Hodges E, Brennecke J, Bartel DP, Cohen SM, Kellis M. 2008. A single Hox locus in Drosophila produces functional microRNAs from opposite DNA strands. Genes & Dev 22: 8–13. Tam OH, Aravin AA, Stein P, Girard A, Murchison EP, Cheloufi S, Hodges E, Anger M, Sachidanandam R, Schultz RM, et al. 2008. Pseudogene-derived small interfering RNAs regulate gene expression in mouse oocytes. Nature 453: 534–538. Tyler DM, Okamura K, Chung W-J, Hagen JW, Berezikov E, Hannon GJ, Lai EC. 2008. Functionally distinct regulatory RNAs generated by bidirectional transcription and processing of microRNA loci. Genes & Dev 22: 26–36. Voorhoeve PM, le Sage C, Schrier M, Gillis AJM, Stoop H, Nagel R, Liu Y-P, van Duijse J, Drost J, Griekspoor A, et al. 2006. A genetic screen implicates miRNA-372 and miRNA-373 as oncogenes in testicular germ cell tumors. Cell 124: 1169– 1181. Watanabe T, Totoki Y, Toyoda A, Kaneda M, KuramochiMiyagawa S, Obata Y, Chiba H, Kohara Y, Kono T, Nakano T, et al. 2008. Endogenous siRNAs from naturally formed dsRNAs regulate transcripts in mouse oocytes. Nature 453: 539–543. Wienholds E, Kloosterman WP, Miska E, Alvarez-Saavedra E, Berezikov E, de Bruijn E, Horvitz HR, Kauppinen S, Plasterk RHA. 2005. MicroRNA expression in zebrafish embryonic development. Science 309: 310–311. Wu H, Ye C, Ramirez D, Manjunath N. 2009. Alternative processing of primary microRNA transcripts by Drosha generates 59 end variation of mature microRNA. PLoS One 4: e7566. doi: 10.1371/journal.pone.0007566. Xie XH, Lu J, Kulbokas EJ, Golub TR, Mootha V, Lindblad-Toh K, Lander ES, Kellis M. 2005. Systematic discovery of regulatory motifs in human promoters and 39 UTRs by comparison of several mammals. Nature 434: 338–345. Yang W, Chendrimada TP, Wang Q, Higuchi M, Seeburg PH, Shiekhattar R, Nishikura K. 2006. Modulation of microRNA processing and expression through RNA editing by ADAR deaminases. Nat Struct Mol Biol 13: 13–21. Yi R, Qin Y, Macara IG, Cullen BR. 2003. Exportin-5 mediates the nuclear export of pre-microRNAs and short hairpin RNAs. Genes & Dev 17: 3011–3016. Zeng Y, Yi R, Cullen BR. 2005. Recognition and cleavage of primary microRNA precursors by the nuclear processing enzyme Drosha. EMBO J 24: 138–148. Zuker M. 2003. Mfold web server for nucleic acid folding and hybridization prediction. Nucleic Acids Res 31: 3406–3415. GENES & DEVELOPMENT 253 1009 Chiang135681_SuppFig1 Undetected annotated miRNAs (157) Not sequenced (52) Not enough reads (72) Failed other filters (33) DGCR8 & Dicer-dependent (290, 226) DGCR8-dependent (2, 2) Confirmed miRNAs (387) Annotated miRNAs (407) Dicer-dependent (7, 3) Not strongly dependent (3, 3) miRNA candidates not confidently confirmed (20) Cannot determine (85, 49) DGCR8 & Dicer-dependent (37, 0) Total candidates (736) Novel miRNAs (108) Dicer-dependent (1, 0) Not strongly dependent (1, 0) Cannot determine (69, 15) New candidates (329) DGCR8 & Dicer-dependent (45, 0) miRNA candidates (221) Dicer-dependent (5, 0) Not strongly dependent (42, 8) Cannot determine (129, 9) Supplementary Figure 1. Mouse miRNA candidates identified by Illumina sequencing. MicroRNAs that are annotated in miRBase v.14.0 are boxed in green. The miRNA hairpin loci were further categorized by DGCR8- and Dicer-dependency using sequencing data from wild-type an mutant ES cells (Babiarz et al. 2008). The number in parenthesis is the total number of loci in the category. If followed by another number, the second number is the number of conserved loci. A candidate was considered DGCR8- and Dicer-dependent using criteria of a previous study (Babiarz et al. 2008), except that predicted hairpin loci replaced the 100-nt windows, with the read cutoffs scaled to the hairpin lengths. 254 Chiang135681_FigureS3 hsa-mir-124-1 hsa-mir-125a hsa-mir-128-1 hsa-mir-142 hsa-mir-150 hsa-mir-192 hsa-mir-193b hsa-mir-205 hsa-mir-214 hsa-mir-455 hsa-mir-483 hsa-mir-499 hsa-mir-888 hsa-mir-9-1 hsa-mir-220a cand141 cand142 cand181 cand316 mmu-mir-122 mmu-mir-133a-1 mmu-mir-137 mmu-mir-138-1 mmu-mir-139 mmu-mir-153 mmu-mir-208a mmu-mir-216a mmu-mir-217 mmu-mir-223 mmu-mir-224 mmu-mir-375 mmu-mir-105 mmu-mir-207 mmu-mir-220 mmu-mir-327 mmu-mir-343 mmu-mir-453 mmu-mir-568 mmu-mir-654 mmu-mir-678 mmu-mir-680-3 mmu-mir-687 mmu-mir-697 mmu-mir-698 mmu-mir-717 mmu-mir-719 mmu-mir-761 mmu-mir-882 mmu-mir-682 mmu-mir-690 mmu-mir-707 mmu-mir-763 mmu-mirc-niob-MM_28 mmu-mirc-niob-MM_57 mmu-mirc-niob-MM_76 mmu-mirc-niob-MM_155 mmu-mirc-niob-MM_185 mmu-mirc-niob-MM_227 mmu-mirc-niob-MM_290 mmu-mirc-niob-MM_298 MIR90 MIR103 MIR146 MIR165 MIR170 MIR174 MIR181 MIR192 MIR213 MIR223 MIR237 MIR252 ≤1 * * * * * Human miRNA controls * * * * * * * * Lim 2003 Berezikov 2005 * * * * * * * * * Mouse miRNA controls * * Not sequenced Not enough reads Berezikov 2006b Xie 2005 10 100 1000 10000 100000 Reads No hairpin plasmid Hairpin plasmid Supplemental Figure S3. Ectopic-expression assay evaluating unconfirmed annotated miRNAs and predicted miRNAs. Either GFP (red) or miRNA hairpins (blue) were expressed in HEK293T. Asterisk indicates positive results. Results of this experiment were compiled with those of Supplemental Figure S4 to produce Figure 2C and D. 255 Chiang135681_FigureS4 * hsa-mir-193b * mmu-mir-122 Human miRNA control * mmu-mir-133a-1 * mmu-mir-137 * mmu-mir-138-1 * * mmu-mir-139 mmu-mir-153 Mouse miRNA controls * mmu-mir-208a * mmu-mir-216a * mmu-mir-217 * mmu-mir-223 * mmu-mir-224 * mmu-mir-375 mmu-mir-599 mmu-mir-669i * mmu-mir-684-1 mmu-mir-684-2 mmu-mir-685 mmu-mir-688 mmu-mir-690 * mmu-mir-693 mmu-mir-704 mmu-mir-705 mmu-mir-707 mmu-mir-763 mmu-mir-1187 Not enough reads mmu-mir-1192 mmu-mir-1894 mmu-mir-1903 mmu-mir-1904 mmu-mir-1907 mmu-mir-1927 * * mmu-mir-1929 mmu-mir-1936 mmu-mir-1937c mmu-mir-1940 mmu-mir-1959 mmu-mir-1960 mmu-mir-1966 mmu-mir-1970 * mmu-mir-184 mmu-mir-297a-6 mmu-mir-466f-4 * mmu-mir-489 mmu-mir-1191 mmu-mir-1953 No miRNA* * * mmu-mir-1969 mmu-mir-449c * mmu-mir-677 mmu-mir-1944 ≤1 Incorrect miRNA* 10 100 1000 10000 100000 Reads No hairpin plasmid Hairpin plasmid Supplemental Figure S4. Ectopic-expression assay evaluating unconfirmed annotated miRNAs. Either GFP (red) or miRNA hairpins (blue) were expressed in HEK293T. Asterisk indicates positive results. Results of this experiment were compiled with those of Supplemental Figure S3 to produce Figure 2C and D. 256 Chiang135681_FigureS5 * hsa-mir-124-1 hsa-mir-125a hsa-mir-128-1 hsa-mir-142 hsa-mir-150 hsa-mir-192 hsa-mir-193b hsa-mir-205 hsa-mir-214 hsa-mir-455 hsa-mir-483 hsa-mir-499 hsa-mir-888 hsa-mir-9-1 hsa-mir-220a cand141 cand142 cand181 cand316 mmu-mir-122 mmu-mir-133a-1 mmu-mir-137 mmu-mir-138-1 mmu-mir-139 mmu-mir-153 mmu-mir-208a mmu-mir-216a mmu-mir-217 mmu-mir-223 mmu-mir-224 mmu-mir-375 mmu-mir-1941 mmu-mir-1964 mmu-mir-1968 mmu-mir-1912 mmu-mir-3061 mmu-mir-3072 mmu-mir-3073 mmu-mir-3075 mmu-mir-3081 mmu-mir-3089 mmu-mir-3090 mmu-mir-3093 mmu-mir-3095 mmu-mir-3108 mmu-mir-3109 mmu-mir-3110 mmu-mir-344f mmu-mir-3104 noStar-014 noStar-033 noStar-043 noStar-073 noStar-080 noStar-087 noStar-117 noStar-135 noStar-150 noStar-154 noStar-166 wrongStar-016 noStar-149 ≤1 * * * Human miRNA controls * * * * * * * * Lim 2003 Berezikov 2005 * * * * * * * * * * * Mouse miRNA controls * * * * * * * * * Novel miRNAs * * * * * Novel shRNAs * DGCR8- & DCR-dependent candidates Other candidate 10 100 1000 10000 100000 Reads No hairpin plasmid Hairpin plasmid Supplemental Figure S5. Ectopic-expression assay evaluating predicted miRNAs, novel miRNAs, and miRNA candidates. Either GFP (red) or miRNA hairpins (blue) were expressed in HEK293T. Asterisk indicates positive results. Results of this experiment were compiled with those of Supplemental Figures S6 and S7 to produce Figure 3B. 257 Chiang135681_FigureS6 * hsa-mir-124-1 hsa-mir-125a hsa-mir-128-1 hsa-mir-142 hsa-mir-150 hsa-mir-192 hsa-mir-193b hsa-mir-205 hsa-mir-214 hsa-mir-455 hsa-mir-483 hsa-mir-499 hsa-mir-888 hsa-mir-9-1 hsa-mir-220a cand141 cand142 cand181 cand316 mmu-mir-122 mmu-mir-133a-1 mmu-mir-137 mmu-mir-138-1 mmu-mir-139 mmu-mir-153 mmu-mir-208a mmu-mir-216a mmu-mir-217 mmu-mir-223 mmu-mir-224 mmu-mir-375 mmu-mir-1188 mmu-mir-1197 mmu-mir-1933 mmu-mir-1947 mmu-mir-1224 mmu-mir-1839 mmu-mir-509 mmu-mir-3059 mmu-mir-3063 mmu-mir-3065 mmu-mir-3067 mmu-mir-3079 mmu-mir-3086 mmu-mir-3091 mmu-mir-3100 mmu-mir-3112 mmu-mir-344e mmu-mir-3111 noStar-046 noStar-148 wrongStar-017 noStar-020 noStar-034 noStar-054 noStar-056 noStar-068 noStar-093 noStar-122 noStar-126 noStar-160 wrongStar-002 wrongStar-007 wrongStar-009 ≤1 * * * * Human miRNA controls * * * * * * * * Lim 2003 Berezikov 2005 * * * * * * * * * * * Noncanonical controls Early miRBase Novel miRNA * * Mouse miRNA controls * * * * * * * Rare novel miRNAs * * Novel shRNAs Conserved candidates Other candidates * 10 100 1000 10000 100000 Reads No hairpin plasmid Hairpin plasmid Supplemental Figure S6. Ectopic-expression assay evaluating novel miRNAs, miRNA candidates, predicted miRNAs, and an unconfirmed annotated miRNA (mmu-mir-509). Either GFP (red) or miRNA hairpins (blue) were expressed in HEK293T. Asterisk indicates positive results. Results of this experiment were compiled with those of Supplemental Figures S5 and S7 to produce Figure 3B. 258 Chiang135681_FigureS7 Human miRNA control Lim 2003 Mouse miRNA controls Noncanonical controls Early miRBase Novel miRNAs Novel rare miRNAs Novel shRNAs Candidates hsa-mir-193b hsa-mir-220a mmu-mir-122 mmu-mir-133a-2 mmu-mir-137 mmu-mir-138-1 mmu-mir-139 mmu-mir-153 mmu-mir-208a mmu-mir-216a mmu-mir-217 mmu-mir-223 mmu-mir-224 mmu-mir-375 mmu-mir-1933 mmu-mir-1941 mmu-mir-1947 mmu-mir-1964 mmu-mir-1968 mmu-mir-1224 mmu-mir-1839 mmu-mir-509 mmu-mir-1912 mmu-mir-3059 mmu-mir-3061 mmu-mir-3072 mmu-mir-3073 mmu-mir-3075 mmu-mir-3081 mmu-mir-3090 mmu-mir-3095 mmu-mir-3108 mmu-mir-3109 mmu-mir-3110 mmu-mir-3063 mmu-mir-3065 mmu-mir-3079 mmu-mir-3086 mmu-mir-3091 mmu-mir-344e mmu-mir-344f noStar-020 noStar-056 noStar-122 noStar-148 wrongStar-002 wrongStar-009 <=1 10 No hairpin plasmid + no TNdrosha/TNdicer plasmid Hairpin plasmid + no TNdrosha/TNdicer plasmid 100 Reads 1000 No hairpin plasmid + TNdrosha plasmid Hairpin plasmid + TNdrosha plasmid 10000 100000 No hairpin plasmid + TNdicer plasmid Hairpin plasmid + TNdicer plasmid Supplemental Figure S7. Drosha/Dicer-dependent biogenesis of novel miRNAs. The selected hairpins were transfected into HEK293T with a control vector (blue), TNdrosha (red), or TNdicer (green). Similar transfections using the control vector instead of the hairpins are shown in light blue, orange, and light green, respectively. Results of this experiment were compiled with those of Supplemental Figures S5 and S6 to produce Figure 3B. 259 Chiang135681_FigureS8 1 0.8 0.6 Correlation coefficient 0.4 0.2 0 -0.2 -0.4 -0.6 -0.8 -1 10 102 103 104 105 106 107 108 109 Genomic distance Not clustered Clustered Supplemental Figure S8. Correlation of expression and genomic distance. The correlation of expression with clustering was calculated as previously (Baskerville and Bartel 2005), except that miRNAs that mapped to the same pre-mRNA transcript were considered clustered regardless of genomic distance. The clustered miRNAs (red) were more correlated than non-clustered miRNAs (blue). Some miRNA pairs more than 50,000 nt apart were categorized as clustered with each other due to joint proximity to intervening miRNAs, and their correlated expressions supported this clustering method. Other miRNAs that are within 50,000 nt of each other were not considered clustered because one mapped within a pre-mRNA, whereas the other one did not; each of these three pairs of miRNAs were not correlated in expression. Correlated expression observed for many miRNAs located ~130,000 nt apart was due to likely co-expression of two megaclusters on chr12. 260 Chiang135681_FigureS9 A B 12,000,000 350 300 10,000,000 250 miRNAs Reads 8,000,000 6,000,000 200 150 4,000,000 100 2,000,000 50 0 16 17 18 19 20 21 22 23 24 25 26 0 27 miRNA length Conserved 18 19 20 21 22 23 24 25 26 miRNA length Nonconserved Conserved Nonconserved Supplemental Figure S9. The distribution of lengths of conserved (red) and nonconserved (blue) mature miRNAs. (A) Size distribution plotted in terms of number of normalized reads. (B) Size distribution plotted in terms of the dominant read length for each miRNA. 261 Chiang135681_FigureS10 A UCAGUUG UCAGUUC 0.50 8mer 7mer-m8 7mer-A1 6mer No Site 0.25 -0.5 -0.25 0.0 0.25 0.5 Fold Change (log2) 0.75 0.50 8mer 7mer-m8 7mer-A1 6mer No Site 0.25 0.00 -0.75 0.75 Cummulative Fraction 0.75 0.00 -0.75 UCAGUUA 1.00 1.00 Cummulative Fraction Cummulative Fraction 1.00 -0.5 0.5 -0.25 0.0 0.25 Fold Change (log2) 0.75 0.50 0.25 0.00 -0.75 0.75 8mer 7mer-m8 7mer-A1 6mer No Site -0.5 -0.25 0.0 0.25 0.5 Fold Change (log2) 0.75 B AAUGCUU AAUGCUG 0.50 8mer 7mer-m8 7mer-A1 6mer No Site 0.25 -0.5 -0.25 0.0 0.25 0.5 Fold Change (log2) 0.75 1.00 Cummulative Fraction Cummulative Fraction Cummulative Fraction 0.75 0.00 -0.75 AAUGCUC 1.00 1.00 0.75 0.50 8mer 7mer-m8 7mer-A1 6mer No Site 0.25 0.00 -0.75 -0.5 0.5 -0.25 0.0 0.25 Fold Change (log2) 0.75 0.75 0.50 8mer 7mer-m8 7mer-A1 6mer No Site 0.25 0.00 -0.75 -0.5 0.5 -0.25 0.0 0.25 Fold Change (log2) 0.75 Supplemental Figure S10. Controls to ensure that observed mRNA derepression attributed to the minor isoform was not due to overlap of its sites with offset 6mer sites of the major isoform. (A) Lack of statistically significant derepression by the three control motifs that differed from the miR-223 minor site by a single nt at position 8. (B) Same as in A except for the miR-155 minor site. The mRNAs with 8mer and 7mer-A1 sites for the minor isoform were excluded from the analysis because these sites overlapped with 7mer-m8 sites for the major isoform. 262 Chiang135681_FigureS11 Distance from 3’ end of read Mismatch type T>C C>T (1.2%) C>G C>A One mismatch (12%) Distance from 3’ end of read T>C T>G T>A 1-2 nt (2.0%) Perfect match (86%) Brain miRNA-matching sequences Mismatch type 1-2 nt (13%) Perfect match (80%) G>T One mismatch (16%) G>T >2 nt (9.6%) G>C G>A A>T G>C G>A >2 nt (4.0%) A>T A>C A>G (0.32%) Three mismatches (0.92%) Two mismatches (2.0%) C Significant mismatch events Thresholds Fraction edited: >5% Edited reads: >10 250 A>G C>T All others 100 40 50 30 20 0 10 0 Single mismatches Read filters miRNA mature or * Brain – mir-381 chr12(+): 110965025 - 110965112 GTTTGGTACTTAAAGCGAGGTTGCCCTTTGTATATTCGGTTTATTGACATGGAATATACAAGGGCAAGCTCTCTGTGAGTATCAAACC ((((((((((((.((.(((.((((((((.((((((((.(((....)))...)))))))))))))))).))).)).)))))))))))). .............AGCGAGGTTGCCCTTTGTAA....................................................... .............GGCGAGGTTGCCCTTTGTATATT.................................................... .....................................................CTATACAAGGGCAAGCTCTCTGT............ .....................................................ATATACAAGGGCAAGCTCTCTGA............ ......................................................TATACAAGGGCAAGCTCTCTGC............ .......................................................ATGCAAGGGCAAGCTCTCTGT............ ......................................................TATACAAGGGCACGCTCTCTGT............ ......................................................TATACAAGGGCAAGCTCTCTGTT........... ......................................................TATACAAGGGCAAGCTCTCTGA............ ......................................................TATACAGGGGCAAGCTCTCTGT............ ......................................................TATACAAGGGCAAGCTCTCTGTA........... ......................................................TATGCAAGGGCAAGCTCTCTGT............ .............AGCGAGGTTGCCCTTTGTA........................................................ .............AGCGAGGTTGCCCTTTGTAT....................................................... .............AGCGAGGTTGCCCTTTGTATA...................................................... .............AGCGAGGTTGCCCTTTGTATAT..................................................... .............AGCGAGGTTGCCCTTTGTATATT.................................................... .............AGCGAGGTTGCCCTTTGTATATTC................................................... .....................................................ATATACAAGGGCAAGCTCTC............... .....................................................ATATACAAGGGCAAGCTCTCT.............. .....................................................ATATACAAGGGCAAGCTCTCTG............. .....................................................ATATACAAGGGCAAGCTCTCTGT............ ......................................................TATACAAGGGCAAGCTCTC............... ......................................................TATACAAGGGCAAGCTCTCT.............. ......................................................TATACAAGGGCAAGCTCTCTG............. ......................................................TATACAAGGGCAAGCTCTCTGT............ .......................................................ATACAAGGGCAAGCTCTCTG............. .......................................................ATACAAGGGCAAGCTCTCTGT............ 150 Unique alignments A>G (0.61%) 217 Sequences mapped (sequences with at least 5 reads shown) 200 Genome matching A>C Three mismatches (0.65%) Two mismatches (2.9%) B 300 T>G T>A C>T (0.26%) C>G C>A >2 nt from 3’ end Event filter 1mm 1mm 1mm 1mm 1mm 1mm 1mm 1mm 1mm 1mm 1mm 1mm Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Perf. Reads Spiked-in sequence controls Mismatches A 5 7 31 36 37 39 41 100 200 236 260 2054 9 43 19 57 96 32 5 90 57 212 33 407 547 11639 15 239 150 120 90 60 30 miR-337 3p arm (star strand) 24 32 40 p = 3.27e-13 Edited reads Edited reads 16 3000 2500 2000 1500 1000 500 miR-411 5p arm (star strand) GAGATAGTAGACCGTATAGCGTACG 0 CCATTCAGCTCCTATATGATGCCTTT 8 3500 Perfect match reads 180 p < 2.2e-16 300 600 900 1200 900 750 600 450 300 miR-376a 150 5p arm (star strand) AAAAGGTAGATTCTCCTTCTATGAGT Edited reads 210 Perfect match reads D Perfect match reads A>G Rate: 0.125 70 p < 2.2e-16 140 210 280 350 1500 Supplemental Figure S11. RNA editing. (A) An overview of mismatches from the sequences indicated. In the two spiked-in synthetic RNAs of known sequence, mismatches were distributed throughout the length of the sequence, with no preference for A-to-G mismatches. In miRNA-mapping small RNA sequences from brain, mismatches were concentrated in the last 2 nt of the read, probably due to cellular terminal-transferase activity. (B) Loss of most mismatch events after applying filters expected to distinguish editing events from background. Mismatch events were considered significant if a position had at least 10 reads corresponding to a particular mismatch, and these reads accounted for at least 5% of reads covering that position. As successive filters were applied to the genome-mapping reads, the number of significant A-to-G mismatch events remained relatively unaffected, whereas nearly all other mismatch events were eliminated. In particular, C-to-T mismatches were mostly eliminated, indicating that C-to-U RNA editing does not occur to any significant degree in miRNAs. A-to-G mismatch events that passed all filters were considered editing candidates and manually examined to see if other plausible models could explain the mismatches. (C) A display of most abundant perfectly-matching and single-mismatch reads from the mmu-mir-381 locus illustrates that inferred A-to-I editing accounts for essentially all mismatches at the edited position, and the great majority of all mismatched reads mapping to the miRNA or miRNA*. An analogous pattern was found for all 16 miRNAs that passed filters and manual validation. (D) Editing of a miRNA or miRNA* was associated with significantly altered 5' end specificity. In the cases of mmu-mir-337 and mmu-mir-411, edited reads had more homogeneous 5' ends than unedited reads. 263