Vocal Modulation Features in the Prediction of
advertisement

Vocal Modulation Features in the Prediction of
Major Depressive Disorder Severity
by
Rachelle L. Horwitz
B.S. Electrical and Computer Engineering
B.S. Biomedical Engineering
Worcester Polytechnic Institute, 2008
OF TECHNOLOGY
5 20
2RSEP
LIBRARIES
SUBMITTED TO THE DEPARTMENT OF ELECTRICAL ENGINEERING AND
COMPUTER SCIENCE IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE
DEGREE OF
MASTER OF SCIENCE IN ELECTR!CAL ENGINEERING AND COMPUTER SCIENCE
AT THE
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
SEPTEMBER 2014
0 Massachusetts Institute of Technology. All rights reserved.
The author hereby grants to MIT permission to reproduce
and to distribute publicly paper and electronic
copies of this thesis document in whole or in part
in any medium now known or hereafter created.
Signature of Author..
Signature redacted
Department of Electrical Engineering and Computer Science
August 12, 2014
C1
e
bd.
y.
if
Signature redacted
--------
....................
Thomas F. Quatieri, Ph.D.
Senior Member of Technical Staff, MIT Lincoln Laboratory
Faculty of the Harvard-MIT SHBT Program
Thesis Supervisor
Signature redacted
Accepted by...................................
........
de
i P D
Leslie Kolodziejski, Ph.D.
Professor of Electrical Engineering and Computer Science
Chairman, Committee for Graduate Students
1
Vocal Modulation Features in the Prediction of Major Depressive Disorder Severity
by Rachelle L. Horwitz
Submitted to the Department of Electrical Engineering and Computer Science
August 12 2014
In Partial Fulfillment of the Requirements for the Degree of Master of Science in Electrical
Engineering and Computer Science
ABSTRACT
This tiesis deyelops a model of vocal modulations up to 50 Hz in sustained vowels as a basis for
biomarkers of neurological disease, particularly Major Depressive Disorder (MDD). Two model
components contribute to amplitude modulation (AM): AM from respiratory muscles and from
interaction between formants and frequency modulation in the fundamental frequency harmonics. Based
on the modulation model, we test three methods to extract the envelope of the third formant from which
features are extracted using sustained vowels from the 2013 AudioNisual Emotion Challenge. Using a
Gaussian-Mixture-Model-based predictor, we evaluate performance of each feature in predicting subjects'
Beck MDD severity score by the root mean square error (RMSE), mean absolute error (MAE), and
Spearman correlation between the actual Beck score and predicted score. Our lowest MAE and RMSE
values are 8.46 and 10.32, respectively (Spearman correlation=0.487, p<0.001), relative to the mean
MAE of 10.05 and mean RMSE of 11.86.
Thesis Supervisor: Thomas F. Quatieri
Title: Senior Member of Technical Staff, MIT Lincoln Laboratory; Faculty of the Harvard-MIT SHBT
Program
2
Acknowledgements
First and foremost, I would like to thank my thesis supervisor, The Legendary Tom Quatieri, for the time
he has spent over the past two years providing guidance, and sharing his enthusiasm and vast expertise in
speech signal processing. He encouraged me to take several steps back and see the forest from the trees,
and for that, I am a better researcher. I would also like to thank the following colleagues at MIT Lincoln
Laboratory: Daryush Mehta, Jim Williamson, Brian Helfer, and Elizabeth Godoy. Daryush wrote the code
to extract the formants, aided me with some of the signal processing, and provided me with
encouragement and advice throughout the thesis. I appreciate his time and effort in helping me fully
explore some of the technical difficulties I had encountered, and provide sound advice. Jim wrote the
code for the Gaussian Mixture Model and for the cross-correlation features, which he and Brian took the
time to explain to me and help me to incorporate into my thesis. Elizabeth Godoy wrote the code for one
of the techniques to extract the envelope, and provided additional insights into processing speech data.
I would like to thank my parents, Marshall and Susan Horwitz, for all the encouragement they provided
throughout this process. I enjoyed being able to talk to my mom, a speech pathologist, about the nontechnical aspects of my thesis.
My classmates, Sonam Dilwali, Koeun Lim, Jordan Whitlock, and Nate Zuk, were also excellent
resources of both knowledge and support. I'm particularly grateful to Nate for allowing me to explain the
details of the signal processing to him.
Finally, I would like to thank my fianc6, Rob Martin. Although he would prefer to spend his free time
writing code for his game engine, he now knows all about the source-filter theory of speech, Fourier
transforms, demodulation, and Gaussian Mixture Models! Rob, I'm looking forward to spending the rest
of my life with you.
3
4
Table of Contents
Chapter 1
Introduction ...............................................................................................................................
7
Thesis Outline ..................................................................................................................................
8
12 Contributions ...................................................................................................................................
Chapter 2 Background .............................................................................................................................
8
10
2.1 Acoustics of Vocal Modulations and Vibrato ............................................................................
2.1.1 FM in Vocal Modulations...................................................................................................
2.1.2 AM in Vocal M odulations ...................................................................................................
2.1.3 Periodicity in Vocal Tremor ................................................................................................
2.2 Physiology of Vocal Tremor .....................................................................................................
2.3 Prior Work on Modulation Features of Vocal Tremor ..............................................................
2.4 Conclusions....................................................................................................................................
Chapter 3 Relationship between Perceived Amount of Vocal Modulation and MDD........................
3.1 Experimental Set-Up .................................................................................................................
3.2 Results............................................................................................................................................
3.3 Conclusions....................................................................................................................................22
Chapter 4 M odel ......................................................................................................................................
10
11
11
14
15
16
19
20
20
21
1.1
4.1
M otivation for the M odel and Processing .................................................................................
23
23
4.1.1
Motivation for an AM and FM Model During a Sustained Vowel .................
23
4.1.2
M otivation for Processing the Output of the M odel...........................................................
25
42
Implementation of the M odel .....................................................................................................
25
4.3
Envelope Component Estimation ..............................................................................................
27
4.3.1
4.3.2
4.3.3
4.3.4
Stockham 's method ............................................................................................................
Hilbert-Stockham Method ..................................................................................................
Nonlinear, Iterative Envelope (NLIE) -Stockham M ethod...............................................
Comparison of the Three Processing M ethods ...................................................................
4.4 Conclusions....................................................................................................................................
Chapter 5 Feature Extraction ...............................................................................................................
5.1 The AVEC Database......................................................................................................................50
5.2 Pre-Processing ...............................................................................................................................
5.3 Frequency Domain-Based Features ...........................................................................................
5.3.1 Average of the STFT M agnitude of the Log-Envelope......................................................
5.3.2 Variance of the M agnitude of the STFT of the Log-Envelope..........................................
5.3.3 Coefficient of Variation (CV) of the Magnitude of the STFT of the Log-Envelope ......
5.3.4 Unnormalized Energy in the Frequency Band Corresponding to the AM due to the
Respiratory M uscles............................................................................................................................55
5.3.5 Ratios of Energy in Various Frequency Bands...................................................................
5.4
Time Domain Features ...............................................................................................................
27
35
42
47
48
50
51
52
52
54
54
56
57
5.5 Conclusions....................................................................................................................................60
Chapter 6 Regression and Prediction Using the AVEC MDD Database ............................................
61
Bookmark not defined.
6.1.1 Introduction..............................................................................Error!
6.1.2
Training and Testing Procedure.........................................................................................
62 Average STFT Magnitude of the NLIE-Stockham and Hilbert-Stockham Envelopes .............
6.2.1 NLIE-Stockham Envelope with a Maximum Frequency of 20 Hz .....................................
6.2.2 Hilbert-Stockham Envelope, with a Maximum Frequency of 20 Hz .................................
6.2.3 Stockham Envelope, with a Maximum Frequency of 20 Hz...............................................
6.2.4 NLIE-Stockham Envelope, With a Maximum Frequency of 50 Hz ................
6.2.5 Hilbert-Stockham Envelope with a Maximum Frequency of 50 Hz ..................................
6.3 Variance of the M agnitude of the STFT of the Log-Envelope.................................................
6.3.1 NLIE-Stockham ......................................................................................................................
5
63
63
64
66
68
70
73
76
76
6.3.2
Hilbert-Stockham ....................................................................................................................
77
6.4 Coefficient of Variation (CV) of the Magnitude of the STFT of the Log-Envelope ................. 78
78
6.4.1 NLIE-Stockham ......................................................................................................................
6.4.2 Hilbert-Stockham ....................................................................................................................
80
82
65 Unnormalized Energy in the Low Frequency Band ..................................................................
65.1 NLIE-Stockham ..................................................................................................
..... 82
65.2 Hilbert-Stockham ...............................................................................................................
85
6.6 Energy Ratio ..................................................................................................................................
86
6.7 Time-Dom ain Features ...............................................................................................................
88
6.7.1 Eigenvalues and Summary Statistic from NLIE Envelope.................................................
89
6.7.2 Eigenvalues and Summary Statistic from Hilbert Envelope ..................................................
92
6.8 Conclusions....................................................................................................................................
94
Chapter 7 Conclusions and Future Work..............................................................................................
95
7.1 Improvement to the Underlying M odel ......................................................................................
96
7.2 Implementation of the M odel ....................................................................................................
97
7.3 Envelope Extraction.......................................................................................................................
97
74 N e-Processing the Envelopes.....................................................................................................
98
7.5 Features..........................................................................................................................................98
Appendix A : Subjectively Rating Vocal Modulation...............................................................................
100
Appendix B: Beck Depression Inventory .................................................................................................
103
Appendix C: Derivation of Equations for AM, FM, and FM-and-AM .....................................
104
......
..............
Appendix D: Model of the Vocal Tract .. .................Bibliography..............................................................................................................................................
112
113
6
Chapter 1 Introduction
Vocalizations are not constant, even during the phonation of a sustained vowel. Commonly studied
modulations are jitter and shimmer, which are cycle-to-cycle variations in the amplitude and frequency of
the fundamental frequency (fo), respectively. While the fundamental period ranges between approximately
3 and 20ms, other modulations occur on longer timescales. In this thesis, modulations up to 50 Hz will be
investigated. The modulations under investigation in this range can be periodic, quasi-periodic, or
irregular. Vocal tremor is a characteristic of many pathologies, some of which are due to anatomical or
functional abnormalities (e.g. reflux laryngitis and laryngeal web) while others are neurological in origin
(e.g. Parkinson's disease). Perceptually, vocal tremor is similar to vibrato, or perceptually salient
undulations in a singing voice, because both contain amplitude and frequency modulation [1][2][3]. Vocal
tremor can arise from modulations in the respiratory system, the larynx (vocal folds), or vocal tract cavity.
Although there have been some studies that describe the perceptual characteristics of vocal tremor [2] and
quantitative features of tremor have been proposed [41, the relationship between severity of tremor and its
quantitative characteristics has yet to be adequately explored. Often thought to be periodic in nature,
vocal tremor can be quasi-periodic or irregular. [2]. Furthermore, there has been no attempt to separate
out the effects of the three possible physiological origins of tremor on vocal amplitude and frequency
modulation.
Since the focus of this thesis is on vocal modulations that occur in the time range of vocal tremor, but will
not be limited to modulations that are periodic or quasi-periodic, for the remainder of this thesis, we use
the term "vocal modulation" as a generalization of tremor. This describes modulations in voice that can
be periodic, quasi-periodic, or irregular, and may be less perceptually salient than true vocal tremor.
Technically, rhythm, jitter, and shimmer are also vocal modulations, but they are beyond the scope of this
thesis. The rhythm of running speech is not investigated because this thesis focuses on sustained vowels.
Jitter and shimmer are not investigated because they occur on a shorter timescale than the focus of this
thesis.
Differences in vocal modulation may be present in Major Depressive Disorder (MDD), a common mood
disorder characterized by emotional, cognitive, and/or somatic abnormalities such as melancholia,
feelings of guilt, and sleep abnormalities [5]. Numerous studies have shown that MDD causes changes in
voice [6][7][8][9][10][11][12][13]. This thesis aims to apply vocal modulation features toward predicting
subjects' MDD, under the hypothesis that subjects with more severe MDD have more erratic modulation
in their voices.
7
1.1 Thesis Outline
This thesis contains six chapters. Chapter 2 provides the background for the thesis. It discusses previous
work that characterizes the acoustics and physiology of vocal tremor, as well as prior work where
modulation features are used to predict the severity of patients' Major Depressive Disorder (MDD).
Chapter 3 discusses the perceptual origins of our main hypothesis: there is a relationship between the
regularity of vocal modulation in a sustained vowel and the severity of a patient's MDD. Chapter 4
introduces our model of vocal modulation, as well as three demodulation methods. Chapter 5 describes
the features we extract from a database of sustained /a/ vowels. We use the features from Chapter 5 to
predict the severity of the subjects' MDD, as detailed in Chapter 6. We summarize our findings and
outline future work in Chapter 7.
1.2 Contributions
This thesis accomplishes the following:
1. We create a model of vocal modulation that incorporates contributions from both the muscles of
respiration and the laryngeal muscles. The modulation model is developed in the context of a
sustained vowel, assuming that two components contribute to amplitude modulation (AM): 1) AM
from the respiratory muscles, and 2) AM from interaction between formants and the FM from the
fundamental frequency harmonics, i.e., a mapping of FM to AM. Modulation from both components
is incorporated into the envelope of the waveform. This novel approach allows us to explore the
contributions from each source of modulation independently.
2. We test the separability of the modulation from the two sources by implementing three envelope
extraction techniques. The first technique is Stockham's method, where the logarithm of the
magnitude of the signal is extracted [14]. The second technique involves computing the logarithm of
the magnitude of the Hilbert envelope, and is called the Hilbert-Stockham method. The third method
uses a nonlinear, iterative envelope (NLIE) estimation method, combined with the Stockham
approach, referred to as the NLIE-Stockham method [15].
We find that the Hilbert-Stockham
envelope and the nonlinear, iterative method enable improved separability compared to the Stockham
envelope.
3. We extract frequency- and time-domain features that capture the modulation characteristics of the
envelopes of the speech signals, and use those features to predict the severity of a patient's MDD. By
estimating the mean Beck depression severity score of all patients from each session, the baseline
mean average error (MAE) is 10.05, and the root mean square error (RMSE) is 11.86. In contrast,
using our extracted modulation features, we obtain a decrease of 1.59 points in the MAE, from 10.05
8
to 8.46, and a decrease of 1.54 points in the RMSE, from 11.86 to 10.32. The Spearman correlation
between the actual and predicted MDD severity scores is 0.487 (p<0.001).
4. Our modulation model provides a framework to study other neurological disorders that affect vocal
features. This may aid us in uncovering unseen abnormalities in the nervous systems of patients with
various neurological disorders, as well as providing a foundation for early detection and monitoring
of such disorders.
9
Chapter 2 Background
In the early 1960s, Brown and Simonson [14][15] studied patients with essential vocal tremor and
reported qualitative characteristics associated with it. Essential tremor is a neurological disease of
unknown etiology that causes involuntary movements in the upper body, most notably the hands and
head, but may also cause vocal tremor. Brown and Simonson [15] noted the following:
"The speech symptom common to all of these patients was a disorder of the respiratory-phonatory phase of motor speech. The
dysphonia, characterized by rhythmic alterations of pitch, and, particularly, of loudness of vowels and continuant consonants in
each word, resulted in tremulous, quavering speech. Short phonated sounds could be uttered without impairment, but tremor
appeared when the patients made the indicated sounds of longer duration. It was most apparent when patients were asked to hold
a sound such as 'ah' as long as possible."
This chapter aims to provide background on the acoustics and physiology of vocal modulations, and
review modulation features that have been used in Major Depressive Disorder (MDD) severity prediction.
2.1
Acoustics of Vocal Modulations and Vibrato
Parameters to characterize vocal vibrato have been outlined by Sundberg [1]. The same parameters have
also been used to characterize vocal tremor [16][17][2][4]. He describes vibrato in terms of four
parameters relating to frequency or amplitude modulation: the rate, extent, regularity, and similarity to a
pure sinusoid. The first two are depicted Figure 1 [1].
RATE= I/PERIOD
EE
z
j//'
XTENT
0
U-
0
liME
(msl
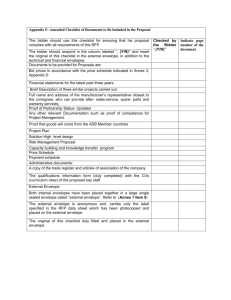
Figure 1: Vibrato period, rate, and extent [1].
In Figure 1, the vertical axis is the deviation from the mean frequency. The rate refers to the number of
periods per second, and the extent refers to difference between the peak value and the mean value of the
frequency. The regularity refers to the differences in the cycle-to-cycle variations in the frequency, and is
also known as jitter [1].
The two types of modulation that have been explored are frequency modulation (FM) and amplitude
modulation (AM). The remainder of this sub-section discusses both.
10
2.1.1
FM in Vocal Modulations
FM in the fundamental frequency (fo) occurs by changing the rate at which the vocal folds adduct and
abduct, but it can also result from AM originating subglottally. An increase in the fundamental frequency
of 0.5-6 Hz/cm H 20 of subglottal pressure has been predicted based on stress-strain curves derived from
fundamental frequency and length measurements on human subjects [18]. Therefore, a change in the
fundamental frequency would be predicted to occur as a result of subglottal changes in AM.
Numerous frequencies of FM have been reported. Winholtz and Ramig [16] created the "Vocal
Demodulator" by demodulating
fo and obtained both an amplitude contour and a frequency contour of fo,
measuring both the amplitude and frequency of each of the contours. They tested the Vocal Demodulator
on subjects with vocal tremor due to Parkinson's disease, essential tremor, spasmodic dysphonia, and
spinal muscular atrophy. They reported variations in fo between 4 Hz and 6.9 Hz. Other studies have
reported different frequencies at which FM occurs [16]. Aronson et al. [19] reported that when patients
with amyotrophic lateral sclerosis (ALS) utter a sustained vowel, peaks in the spectrum of fo range from
1.1 Hz to 23.9 Hz. Their results from control subjects are similar: spectral peaks were observed between
1.1 Hz and 25 Hz. However, the extents of the spectral peaks of the FM were different between the ALS
patients and the controls: compared to a spectral amplitude of 6.9-134.8 mV in the controls' peaks due to
FM, the ALS patients' spectral amplitudes for the FM in their vowels ranged between 17.7 and 637 mV
[19]. Kreiman et al. claim lower frequencies in the FM of fo: they state that the range is between 2 and 12
Hz for both normal and pathological phonation [2].
2.1.2
AM in Vocal Modulations
Unlike FM in an acoustic signal, the origins of AM are more complicated. AM in an acoustic signal
originates from at least one of three different sources: the fo variation itself, oscillations in subglottal
pressure, and/or the vocal tract shape [1].
Acoustic theory explains how fo variation over time can cause AM, assuming that the voice source and
formant frequencies are constant [20]. In the frequency domain, when voicing is present, the glottis
produces multiples of the fundamental frequency, the harmonics, as shown in the top panel of Figure 2.
These are represented by the magnitude of the source spectrum, IS(f) |.
11
IS(f)|~hl1~~nnr
)s I
W
3
1
4
6
S
ITV)i
IR(flj
Frequency (kHz)
Figure 2: Spectra of the source IS(f)l, vocal tract transfer function (VTTF) IT(f)l, radiation characteristic
IR(f)I, and output Ip/J)I (modified from [211).
The shape of the vocal tract has a transfer function, T(f), that varies, depending on the sound produced,
as shown in the second panel of Figure 2. The formants are the peaks in IT(f)|. The third panel shows
the radiation characteristic. The output, which is the sound pressure P at a given distance r, denoted by
P(f), is equal to the product of each of the three quantities:
Pr(f) = S(f)T(f)R(f).
Consequently, the output is a harmonic series of filtered glottal pulses at various amplitudes.
One source of AM is the interaction between the changing harmonics of fo and the formants. The
observed amplitude of the formants depends on fo because the spacing of the fundamental frequency
determines where the vocal tract transfer function (VTTF) is "sampled" by the glottal pulse. If the VTTF
is sampled near its peaks, the formants appear louder; if it is sampled away from its peaks, the formants
appear quieter. Thus, if fo changes and a harmonic of fo becomes closer to the first peak of the VTTF, the
first formant will be louder; the opposite happens if a frequency changes and a harmonic becomes farther
away from the peak of the VTTF. Therefore, AM can be a secondary effect of FM [20]. Both cases are
illustrated in Figure 3 (modified from [1]).
12
Mean FO =100 Hz
Mean FO = 100 Hz
5
10
Case A: Mean FO = 100Hz
40-
PT 110
30-
U. 100
0.1
20
0.2
0.3
0.4
Intensity of Formant
-35
/
10
0
-101
.
Mean FO = 104.1 Hz
30
0
50
CO
Case B: Mean FO = 104.1Hz
40
110
30
100
20
0
10
S 40-
3%
Mean FO
=
107 Hz
so
0.4
0.2
0.3
0.3
0.1
0.2
Mean FO = 107 Hz
0.4
0.1
0.4
_ 110
40-
cc 30
I
0.1
35
-10
.E
0.4
Intensity of Formant
0
Case C: Mean FO = 107Hz
0.1
0.2
0.3
Mean FO = 104.1 Hz
U. 100
0
20
0.2
0.3
Intensity of Formant
10
0
-1',--
200
300
400
500
Frequency (Hz)
600
3003
/
0.1
0.2
Time (sec)
0.3
1
0.4
Figure 3: Relationship between frequency and amplitude modulation (modified from [11). In each of the
figures in the left column, the peak of a hypothetical VTTF is at 415 Hz (ignoring other formants). Each of
the stems in the plots represents a harmonic off,, which varies sinusoidally about a mean, shown in the red
plots in the right-hand column. The harmonics of the mean fo are the black stems, the minimum of each
harmonic is shown in green, and the maximum of each harmonic is magenta. In Case A,f, = 100Hz at the
first time instant, moves sinusoidally up to 103 Hz, and then down to 97 Hz, as shown in the top panel of the
right-hand column. In the left-hand column of Case A, the mean harmonic closest to the peak of the VTTF is
at 400 Hz (black stem). As it increases to 412 Hz (magenta stem), the intensity increases. When it decreases,
the opposite occurs. As a result, the intensity of the formant moves in phase with the harmonic when the
location of the harmonic is on the increasing side of the peak of the VTTF. In Case C, when the mean
harmonic is on the decreasing side of the peak of the VTTF (here, it is 428 Hz), the intensity of the formant
moves out of phase with the motion of the harmonic. In Case B, when the maximum and minimum harmonics
nearest to the peak of the VTTF are on opposite sides of the peak of the VTTF, the intensity of the formant
varies with twice the frequency off,.
In Case A of Figure 3, when
fo
increases by a few Hz, the spacing becomes larger, and the second
harmonic becomes closer to the first formant. Therefore, as the frequency increases, the energy also
increases. In Case C, an increase of a few Hz of the fundamental frequency will push the third harmonic
13
farther away from the peak of the VTTF (in this case, the second harmonic will also be pushed closer to
the peak of the VTTF, but the difference seen in the third harmonic will be greater than the second). In
Case B, the harmonic of fo might also oscillate symmetrically about peak of the VTTF, causing the
amplitude modulation to be twice the frequency of the frequency modulation [1].
A second source of AM originates from oscillations in subglottal pressure. In certain types of vocal
modulation, oscillations in the subglottal pressure cause the voice source to vary in amplitude.
Consequently, although the frequencies of the harmonics of fo remain fixed, the amplitudes of the
harmonics change together over time, causing AM [1].
A third type of AM occurs when the shape of the vocal tract changes. For example, the tongue and
pharynx can move. When this occurs, the formants of the vocal tract change, and AM occurs, for
example, when the harmonics are fixed and the formants move through the harmonics. In a sense, this is
the "converse" of the cases illustrated in Figure 3.
In addition to FM causing AM, AM has been predicted to cause FM. Experimentally, changes info with a
1cm H 2 0 increase in pressure range between 1-10 Hz, and the amount of fo change per unit pressure
increase differs based on the vocal register. An increase info of 0.5-6 Hz/cm H 20 of subglottal pressure
has been predicted based on stress-strain curves derived from fo and length measurements on human
subjects [18]. Therefore, a change info would also be predicted to occur as a result of AM.
Like the frequencies of FM in vocal tremor, the frequencies of AM are also a source of debate. Aronson
et al. [191 report that patients with ALS and controls had similar ranges of peaks in their spectra from the
AM: 1.1 Hz to 25 Hz and 1.1 Hz to 24 Hz, respectively. Winholtz and Ramig [16] report AM rates
between 4.5 Hz and 12.6 Hz.
2.1.3
Periodicity in Vocal Tremor
Kreiman et al. tested whether vocal tremor is periodic or irregular by creating two models of tremor and
asking expert listeners to rate the similarity of the synthesized waveforms to the true voice samples. The
first model consisted of an FM source in which fo was modulated by a sine wave, while fo in the second
model was modulated by an irregular waveform. Based on the ratings of the expert listeners, they found
that in general, both tremor models provided "excellent" matches to the original voices. This suggests that
vocal tremor can be periodic or irregular.
14
One of the shortcomings of this paper is that it does not address AM; it only addresses FM. Kreiman et
al. argue that they did not address AM because most AM is an artifact of FM. Given that FM info causes
AM, it is possible that the listeners were using AM cues from frequency modulation, as described earlier
in this section.
2.2
Physiology of Vocal Tremor
Rhythmic changes in the movements of the muscles of the larynx, respiratory muscles, and muscles of the
supraglottal vocal tract might be responsible for producing modulations in pitch, loudness, or both. Our
focus in this thesis is on the muscles of the larynx and the respiratory muscles.
The larynx is the organ that is responsible for producing voicing, which occurs when the vocal folds
adduct and abduct. Changing the length of the vocal folds changes the pitch. The muscle responsible for
vocal fold lengthening is the cricothyroid muscle, while the thyroarytenoid (TA) muscles shorten the
vocal folds. The posterior cricoarytenoid (PCA) muscle abducts the vocal folds, while the interarytenoid
(IA) and lateral cricoarytenoid (LCA) muscles adduct the vocal folds.
When the cricothyroid muscle contracts, the vocal folds lengthen. This increases the tension of the vocal
folds, which increases their rate of vibration. This is measured as an increase in fo. The opposite occurs
when the TA muscles contract: the vocal folds shorten, decreasing the tension of the vocal folds, resulting
in a decrease info [22] [23]. Whenfo changes, its harmonics change, resulting in modulations in amplitude
by formant sampling as described in Section 2.1.
Respiratory tremor is also thought to cause modulations in fo and intensity. The lungs provide the air
pressure to the larynx during expiration. When tremor affects the chest wall, the motion of the chest wall
is modulated, causing modulations in the glottal flow and therefore in the pressure. Lester and Story [24]
simulated respiratory tremor in healthy adults by mechanically compressing subjects' chest walls, and
found that modulations offo and intensity occurred.
The muscles of the supraglottal vocal tract can also be affected by tremor. These muscles modulate the
length and width of the various parts of the vocal tract. When the shape of the vocal tract changes, the
resonant frequencies, or formants, also change. Therefore, tremor in the vocal tract would be expected to
change the formant frequencies. As the formant frequencies change, the harmonics of fo will "sample"
them at different locations, so the intensity of the voice signal would also be expected to change [22].
15
2.3
Prior Work on Modulation Features of Vocal Tremor
Many studies have measured both the amplitude and frequency modulation of vocal tremor in the voice
signal. This section aims to describe the methodology and results of relevant experiments.
Vocal Demodulator: The Vocal Demodulator, developed by Winholtz and Ramig, [16] was created to
quantify the amplitude and frequency modulation components of vocal tremor. The envelope of the entire
signal is extracted, and the frequency and amplitude of that signal are analyzed. A similar procedure is
performed, but for the frequency contour of fo. Next, spectral analysis is performed on the frequency and
amplitude contours. The amplitude level and frequency levels were measured over 0.5-second intervals
based on full-wave rectification of the demodulated signals. The following equation was used to compute
the amplitude modulation level:
Vmax - Vmiin
Amplitude Modulation Level (%) =
Vmax + Vmin
where V, is the maximum voltage measured in the amplitude envelope of the signal, and V,,1,, is the
minimum voltage measured in the amplitude envelope of the signal. The following equation was used to
compute the frequency modulation level:
Frequency ModulationLevel (%) = fOdeviation - o
fo
where fod,, is the peak-to-peak variation info when thefo contour is taken, andfw... is the meanfo in
the signal.
To test the Vocal Demodulator, the authors recorded the /a/ vowel from individuals with vocal tremor,
individuals without a history of neurological or phonatory disorders, and singers who sang with vibrato.
To investigate the rate of modulation in AM and FM, they used six target frequencies: 3 Hz, 6 Hz, 9 Hz,
12 Hz, 15 Hz, and 18 Hz and correlated those frequencies with the demodulated frequencies from the
subjects. To verify their measurements for the level of amplitude and frequency modulation, they again
performed correlations. The target levels they used were 5%, 10%, 15%, 20%, and 25% for amplitude
modulation, and 1%, 2.5%, 7.5%, and 10% for frequency modulation. When they compared the groups of
subjects, they found that the AM and FM rates of modulation were higher within the tremor and control
subjects than within the vibrato group, the median levels and ranges of AM were significantly larger
within the tremor and vibrato groups than within the control group, the median extents of FM in the
tremor and vibrato groups were higher than in the control groups, and the range of FM was largest for the
tremor group [16].
16
Multi-Dimensional Voice Program: Currently, the Multi-Dimensional Voice Program (MDVP) is a
clinical tool that can be used to measure vocal tremor. It provides the following measurements, which are
similar to the measurements provided by Winholtz and Ramig [16]:
1) Fatr (Frequency of amplitude tremor, measured in): frequency of the strongest low-frequency AM
component within a specified range
2) Fftr (Frequency of frequency tremor, measured in Hz): frequency of the strongest low-frequency
FO-modulating component within a specified range
3) ATrI (Amplitude tremor intensity index, measured in %): average ratio of the strongest lowfrequency AM component to the amplitude of the signal, within a specified range
absATrI -A
ATrI=100*
A
where absATrI represents the absolute tremor intensity in Pascals, and A represents the mean
amplitude in Pascals
4) FTrI (Frequency tremor intensity index, measured in %): average ratio of the strongest lowfrequency fo-modulating component to the meanfo of the signal, within a specified range.
absFTrl - f
-
FTrI = 100 *
Jo
where absFTrI represents the absolute tremor intensity in Hz, and o represents the meanfo, also in Hz
[4][25].
Two other measurements have been proposed by Bruckl [4]
1) Frequency tremor power index (FTrP)
*
FTrP = FTrJ
FTrF
FTrF + 1
where FTrF is the frequency of the tremor frequency, measured in Hz, and
2) Amplitude tremor power index (ATrP)
*
ATrP = FTrI
ATrF
ATrF + 1
where ATrF is the frequency of the tremor amplitude, measured in Hz
The power indices are smaller for lower frequencies, and greater for higher frequencies; a lower index
results if the frequency of the tremor is lower.
17
Praat Software Tool: Br(IckI [4] provides code that runs in an acoustic analysis program called Praat
[26], which computes the autocorrelation of the amplitude and frequency contours to determine the
tremor frequency. FTrI and ATrI are subsequently computed based on the mean maximum and mean
minimum of the contours, and the other four measurements are computed based on FTrI, ATrI, and the
frequencies of the tremor. Bruckl validated the algorithm on sounds with given parameters [4]. Some of
the drawbacks associated with this algorithm are the inherent limitations of Praat's pitch estimator, and
the irregularities in vocal tremor, noted by Kreiman et al. [2], which are not taken into account by
Bruckl's algorithm.
AM-FM Decomposition Algorithm: Another method has been proposed to extract vocal tremor.
Although not yet tested on a population with vocal tremor, the method proposed by Pantazis et al. [27]
uses an AM-FM decomposition algorithm. The advantage of this method is that it adapts to nonstationary
signals. Their method can also be used to analyze any frequency component of the speech signal, not
only the first harmonic. Their method works by first demodulating the signal using the AM-FM
decomposition algorithm, subtracting out modulations less than 2 Hz using a smoothing filter, and then
estimating the modulation frequency and modulation level, which are time-varying attributes. Pantazis et
al. [28] validated the method on normophonic subjects, but it has yet to be tested on pathological subjects.
Modulation Spectrogram: Using various techniques to reduce the dimensionality of the modulation
spectrogram [30], Cummins et al. [29] classified various levels of depression in both the two-class case
and the five-class case, both with and without log-mean subtraction [31] in attempt to isolate the
dynamics of the supraglottal vocal tract. The modulation spectrogram is the Fourier transform of the
temporal trajectory of each frequency channel in the spectrogram [29]. It is defined by:
N-I
M-1
x[n, m]e-j(en+wm)
X(6, W) =
n=O m=O
where x[n, m] is a short term speech segment, n is the frame index, m is the time index, o is the acoustic
frequency, and 0 is the modulation frequency [29].
To classify the MDD severity of the subjects, Cummins et al. partitioned the data into two classes, and
then into five classes. When partitioning the data into two classes, the first class contained sessions with
utterances from patients who were not depressed, mildly depressed, or moderately depressed. The second
class contained patients who were moderately-severely depressed, severely depressed, and very severely
depressed. The classes in the 5-class case were the following: normal, mild depression, moderate
18
depression, severe depression, and very severe depression. The best classifications Cummins et al.
obtained using Gaussian Mixture Models (GMMs) were 66.9% for the two-class case, and 36.4% for the
5-class case, suggesting that there is a link between the modulation characteristics and the depressed
voice. The modulation spectrogram in this case was derived with the use of 24-element gammatone filter
bank using a 35-subject depression database. The spectral analysis of the temporal envelope of each filter
bank output was used as a basis for modulation features at short and long time scales. This modulation
characterization reflects the various sources of tremor discussed above but makes no attempt to represent
individual components or origins of AM and FM. This system also analyzed only the phrase "pa-ta-ka."
2.4
Conclusions
Vocal tremor can be due to at least one of three sources: (1) interactions between the harmonics offo and
the formants, (2) oscillations in subglottal pressure, and (3) movement of the formants through the
harmonics. The rate and depth of both AM and FM can be used to characterize the modulation [1],
although the modulation can be irregular [2]. The modulation spectrogram has aided in classification of
the severity of MDD [29]. Therefore, it is possible that other modulation characteristics can further aid in
the prediction of a patient's MDD severity.
19
Chapter 3 Relationship between Perceived Amount of Vocal Modulation and
MDD
Cummins et al. [29] showed that features extracted from the modulation spectrogram aided in classifying
MDD. When classifying depressed and non-depressed subjects, the highest percentage of correct
classification they achieved was 66.9%. Our goal is to further motivate the hypothesis that the modulation
characteristics of more depressed individuals are different from the modulation characteristics of less
depressed individuals.
3.1
Experimental Set-Up
Seven employees in MIT-Lincoln Laboratory's Bioengineering Systems and Technology group listened
to and visually inspected the spectrograms and waveforms of 25 randomly selected /a/ vowels at a
comfortable loudness level, selected from the training set of the Audio/Visual Depression and Emotion
Challenge (AVEC 2013)[32] that is described in Section 5.1. For each vowel, the raters evaluated the
following vocal characteristics:
1) Aurally perceived vocal modulation. The raters listened to the recording without viewing the
spectrogram or waveform. They rated the vocal modulation on a scale from 1-5, where 1
indicated very little or no vocal modulation, and 5 indicated severe vocal modulation. Examples
of recordings with miniscule/absent modulation and significant modulation were provided for
reference.
2) Visually perceived sub-harmonics. The raters viewed the spectrogram to evaluate the presence of
sub-harmonics, rating between 1 and 5. (See Appendix A for details regarding the process used to
rate the sub-harmonics.)
3) Visually perceived FM. The raters viewed the spectrogram to evaluate the amount of change in
the harmonics of the fundamental frequency. (See Appendix A for details regarding the process
used to rate the FM).
4) Visually perceived AM. The raters viewed the waveform to evaluate the amount of AM. See
Appendix A for details regarding the process used to rate AM.
The raters were instructed to perform one task on all of the recordings before proceeding to the next task.
This was necessary to reduce bias. If raters had performed all four tasks on one recording before
proceeding to the next recording, it is possible that their judgments could have been influenced by prior
evaluations of the same recording. For example, if raters had heard a large amount of vocal modulation
but did not visually perceive a large amount of FM in the same recording, they could have been
unintentionally biased by their previous assessment of the vowel and indicated the presence of a greater
20
amount of FM than they otherwise would have indicated if they had viewed the FM without hearing the
utterance.
3.2
Results
The results suggest that both AM and FM characteristics may be useful in predicting patient's Beck
scores. The Beck Depression Inventory is commonly used to assess the severity of depression, and is
described further in Appendix B. The scores from each of the raters were combined and the Spearman
correlation between each of the subjective ratings and the Beck score was computed. The results are
shown in Table 1.
Table 1: Spearman p values (and p-values in parentheses) among Beck score, aurally-perceived modulation
severity, visually perceived sub-harmonics, visually perceived FM, and visually perceived AM. Statistically
significant correlations, accounting for the Bonferroni correction, are displayed in blue font.
Beck Score
Sub-
Severity
Harmonics
Modulation
0.018
(p=0.809)
0.262
Severity
(p<
Beck Score
0.235
(p=0.00178)
AM
FM
Modulation
9.001)
SubHarmonics
0.265
(p<0.001)
0.324
0.268
(p<0.001)
0.345
(p<0.001)
(p<0.001)
0.140
0.284
(p=0.0 6 4 0)
(p<0.001)
0.280
FM
(p<0.001)
Accounting for the Bonferroni correction, and assuming a desired significance level of 0.05, the Beck
score has a statistically significant correlation with the aural perception of modulation severity, and the
visual perceptions of AM and FM. The Spearman correlation between the Beck score and aurally
perceived vocal modulation is weak but statistically significant: p=0.235 (p=0.00178). There is also a
statistically significant correlation between visually perceived FM and Beck score (p =0.265 p<0.001),
and between visually perceived AM and Beck score (p=0.268, p<0.001).
21
In addition to the Spearman correlations between each of the perceptual ratings and the Beck score, there
are also statistically significant correlations among the perceptual ratings. The greatest of these are the
correlation between visually perceived AM and aurally perceived modulation severity (p=0.3455
p<0.00001), and between visually perceived FM and aurally perceived modulation severity (p=0.324
p<0.0001). There are also statistically significant correlations between visually perceived sub-harmonics
and visually perceived AM (p =0.284 p=0.0001), visually perceived AM and visually perceived FM
(p=0.280 p=0.0002), and visually perceived sub-harmonics and aurally perceived vocal modulation
severity (p=0.262, p=0.005).
3.3 Conclusions
The presence of visually perceived FM and visually perceived AM is expected because it is consistent
with Sundberg [1]. The presence of statistically significant correlations between visually perceived FM
and aurally perceived modulation severity, visually perceived AM and aurally perceived modulation
severity, aurally perceived modulation severity and Beck score, visually perceived FM and Beck score,
and visually perceived AM and Beck score, indicate that attempting to characterize the FM and AM in the
sustained vowels may lead to improved automated Beck score prediction.
22
Chapter 4 Model
In this chapter, we propose a model for vocal modulation based on the source-filter theory of speech [21].
The premise of the model is that in the frequency domain, AM and FM can be separated in a signal by
viewing the logarithm the signal's envelope, whereby FM is mapped to an AM contribution.
Subsequently, the AM and FM contributions can be used to obtain features to predict the MDD severity
of the subjects. To simplify the model, only a single rate and extent of modulation for both AM and FM
are represented, although this can be generalized to multiple rates and extents. For example, the AM in
the model occurs at a single frequency of 4 Hz, and the FM in the model occurs at a single rate of
modulation of 7 Hz. Several assumptions are also made based on the anatomy and physiology of speech
production, as well as prior research on the acoustics and physiology of vocal tremor and vibrato. One of
the assumptions is that the frequency of the AM is lower than the frequency of the FM, where AM arises
from respiratory muscles and FM arises from laryngeal muscles.
To test the model, three envelope types are analyzed: the Stockham envelope, Hilbert-Stockham
envelope, and Nonlinear, Iterative Envelope (NLIE). Three test signals are created and the three envelope
types are extracted from each. The first signal type consists of a source with both AM and FM as inputs to
a synthetic vocal tract. The second signal type consists of a source with AM only, and a third with FM
only.
4.1
4.1.1
Motivation for the Model and Processing
Motivation for an AM and FM Model During a Sustained Vowel
As noted in Chapter 2, the anatomical structures that can contribute to modulation in a sustained vowel
are the muscles of respiration, extrinsic and intrinsic laryngeal muscles, and supraglottal vocal tract. All
are involved during the utterance of a vowel: the muscles of respiration act as pressure sources, forcing air
through the glottis [21]. If the subglottal pressure exceeds a threshold, the vocal folds oscillate, and
phonation occurs [33][34].
The supraglottal vocal tract adds "color" to the sound by introducing
formants. Oscillations in any of the structures throughout the vocal tract can cause AM and/or FM. To
apply constraints to the model, the following were assumed in the AM-FM model:
1. The muscles of respiration are responsible for AM only [24].
As the subglottal pressure increases, in general, the amplitude of the vibration of the vocal
folds also increases [18], resulting in an increase sound intensity [35]. An increase in
subglottal pressure has been theorized to produce an increase info by 2-6 Hz/cm H 20 [18] and
23
has been experimentally shown to produce both intensity and fundamental frequency
increases under the simulated condition of respiratory-induced vocal tremor [24], as
discussed in Chapter 2. However, for simplicity, the model assumes that the muscles of
respiration produce AM only.
The frequency of the AM from the muscles of respiration is assumed to be around 5 Hz, as
this is the frequency used by Farinella et al. [36] and Lester and Story [24] when determining
the relationship between respiratory oscillation and perception of vocal tremor.
2. The AM component contributed by the respiratory muscles is slower than the FM
component contributed by the intrinsic and extrinsic muscles of the larynx.
This is
assumed because air from the lungs is expelled over time as the vowel is held. There is some
auditory feedback that occurs: when the subjects hear themselves sounding quieter, they
increasing by increasing the loudness of the phonation. This is assumed to be slower than the
AM due to the interaction between the harmonics offo and the formants.
3. The extrinsic and intrinsic muscles of the larynx are responsible for FM in the 2-12 Hz
region.
Although the muscles involved with vibrato have been identified, the muscles involved in
vocal tremor have not, and may be different from those in vibrato [37]. Shipp et al. [38]
found that while vibrato can be mediated by either the abdominal muscles or by the larynx,
mainly from the cricothyroid muscle, the latter source of vibrato appears to be more common.
The sources of vibrato are assumed to be mutually exclusive [38], and it is assumed that these
observations carry over to vocal modulation in a held vowel as well. The frequency of the
AM and FM from the muscles in this region is hypothesized to occur in the 2-12 Hz region; a
range of frequencies of vocal tremor proposed by Kreiman et al. [2].
4. The formants are constant. In the simulated /a/ vowel, the vocal tract and thus the formants
are assumed to be constant.
5. As the pitch changes, AM also occurs from the resonance-harmonics interaction. This is
described in Chapter 2.
24
4.1.2
Motivation for Processing the Output of the Model
The goal is to be able to separate the envelope e[n], of a speech signal, into two components: the
envelope due to AM, eA[n], and the envelope due to the resonance-harmonics interaction, eF[n]. In the
case of vocal modulation, both eA[n] and eF [n] are assumed to be slowly-varying relative to the formants,
and are assumed to be the only elements in the envelope e [n]:
e[n] = eA[n]eF[n].
Linear system analysis can be applied to multiplicative signals where one signal is slowly-varying and the
other is quickly-varying. This is accomplished by taking the natural logarithm of the magnitude of the
signals, resulting in the sum of the logarithms [39]. According to Stockham [39], an approach to model
an acoustic signal, y[n], is to let it be the product of a slowly-varying envelope, e[n], where e[n] > 0,
and a quickly-varying signal, v[n]:
y[n] = e[n]v[n].
(2)
If the natural logarithm of the magnitude of both sides is taken, the logarithm of the composite signal
becomes the sum of the logarithm of the magnitudes of e[n] and v[n]:
log(|y[n]|) = log(|e[n]|) + log (Iv[n]|).
(3)
Since the Fourier transform is a linear operation, the Fourier transform of log(|y[n]|) is a linear
combination of the Fourier transform of each component in Eq. 3. One of the goals of this thesis is to
separate e[n] from a vowel into its AM and FM components, eA[n] and eF[n] (Eq. 1). Stockham's
technique provides a basis for this to be accomplished.
4.2
Implementation of the Model
For illustration, eA [n] is chosen to be sinusoidal, with a given depth of modulation (aa) and rate of
modulation (fa). The AM envelope from the respiratory muscles, eA[n], multiplies a source harmonic
signal, the FM of which is produced by the intrinsic and extrinsic muscles of the larynx. The FM is more
generally non-sinusoidal, but a sinusoidal FM signal is also used here for illustration.
In the model of a vowel with both frequency modulation and amplitude modulation, five inputs are
required:
1)
Fundamental frequency,fo
2)
Rate of FM, ff
25
3)
Depth of FM, af
4)
Rate of AM, fa
5)
Depth of AM, aa
This FM source signal is denoted by PF [n]. The result of the multiplication is the FM- and AM-pulse
train, PAF[n]
PAF [n] = eA[n]pF[n].
(4)
The FM-and-AM pulse train, PAF [n], is then convolved with the vocal tract. The impulse response of the
vocal tract, h[n], is configured to model the /a/ vowel. This vowel is chosen for two reasons: the third
formant is far from the first and second formants, and it is the vowel that is uttered in the AVEC database
from which features are derived, as described in Chapters 5 and 6. The output of the vocal tract is XAF [n].
A block diagram of the model is depicted in Figure 4.
Harmonic
synthesizer
Figure 4: Model. The FM parameters are the fundamental frequency (f4), rate of FM (ff), depth of FM (af),
and AM envelope (eA[n]). The output of the model is xA[n]. The AM envelope eA[n] requires two inputs: a
rate (f,) and an extent (a,) of modulation.
The AM from the respiratory muscles, eA [n], is expressed by the following, where aa is the depth of AM
and fa is the rate of the AM:
eA [n] = +
Cos(21r
n).
(5)
Substituting Eq. 5. Into Eq. 4 and using the derivation for the FM described Appendix C, PAF[n] is
expressed as:
PAF n =
+
CoS
COS (2rkfon/fs + afk si nfs6)
21 n)]
The AM-and-FM-modulated signal PAF [n] is then input to the vocal tract, h, [n]. The equations used to
model the vocal tract are described in Appendix D.
26
For example, Figure 5 shows the output from the vocal tract,
XAF
[n], with parameters f0=200 Hz,
ff=7 cycles/sec2 , af=10 Hz, aa=0. 2 , and a1 =4 Hz. The formant frequencies in this example are 820,
1220, and 2810 Hz, and the formant bandwidths are 125, 125, and 250 Hz.
xAF
in time domain
30
.20
10
.80
E
5-10
-20
-30
-0
0.5
1
1.5
2
2.5
3
Time
Figure 5: x[n] in the time domain, with f 0=200 Hz, f.=7 cycles/sec', a,=10 Hz, a.=0.2, and a,=4 Hz. The
formants are 820 Hz, 1220 Hz, and 2810 Hz, with bandwidths of 125 Hz, 125 Hz, and 250 Hz.
There is clearly a slow envelope component at 4 Hz, which results from the respiratory muscles (eA [n])
and a higher frequency envelope component, resulting from the interaction between the harmonics and
the formants (eF[n]). However, when a 1-second window Hamming window is applied to XAF[n] to
reduce the spectral sidelobes, and the mean of the magnitude of the Short-Time Fourier Transform
(STFT) is computed, it is clear that demodulation needs to occur in order to extract the frequency content
of the envelope.
Three processing methods to obtain the envelope were explored: the Stockham-only method, the HilbertStockham method, and nonlinear iterative envelope (NLIE) method. The next section details each of
them.
4.3
Envelope Component Estimation
The first processing scheme is a direct application of Stockham's method for estimation of FM and AM
signals, with the exception that a bandpass filter is used immediately after the synthesis of the /a/ vowel.
4.3.1
Stockham's method
In a speech waveform, the majority of the energy is concentrated around harmonics of fo when the
frequencies of the harmonics are near a formant frequency. The purpose of the bandpass filter is to isolate
the spectral region where FM is accentuated around the third formant. We chose to isolate the third
27
formant instead of one of the first two formants because the multiple of the modulated fo through the
third formant has a greater depth of FM than the multiple of the modulated fo through one of the two
lower formants, as described in Chapter 2.
Figure 6: Block diagram of Stockham's method and envelope generation. The turquoise box denotes the
model. In the mathematical description, the purple boxes, H,(J) and Hb(f), are combined to form H(f). The
time-domain signal that is the output from Stockham's method is log(Ibj[n]1).
A block diagram for the method is detailed in Figure 6.Here, the vocal tract and bandpass filter can be
multiplied together to create a new filter to replace the individual filters. Let this filter be H (f), where
H (f) = HV(f)Hb (f).
(7)
The rapidly-varying component of the speech signal, v[n], is composed of the convolution of two
components, )5[n] and h[n]:
v[n] = P[n] * h[n].
(8)
Since the envelope of the signal is e[nJ, p[n] is a series of impulses that, when convolved with h[n], yield
a signal that has a flat amplitude. In other words,
P[n] * h[n] ~
PAF[f*l[n](9)
e[n]
Since PAF [n] is implicitly flat, the spacing of the impulses of P[n] is equivalent to the spacing of the
impulses in PAF [n], but the amplitude of the pulses is different: the pulses in PAF [n] have the same
amplitude, but in )[n], the amplitudes of the pulses are different.
Based on Figure 6, bAF[n] can be expressed by:
bAFIn]
= PAF In] *
Substituting Eq. 10 into Eq. 9, Eq. 11 is obtained:
28
h[n].
(10)
e[n](P[n]
bAF[n]
*
(11)
h[n]).
Figure 7 displays bAF[n] in the time domain whenf0 =200 Hz, aa=0.2,fa=4, and a=10, andf1 =7.
7
bAF[n]fo= 2 00 Hz, aa=0. 2, fa=4 aI=1 0, ff=
0.3
0.
E
-0.1
-0.3
-
0
0.5
1
2
1.5
Time (sec)
2.5
3
Figure 7: bA,[n] in the time domain when f,=200 Hz, a.=02,fa=4, a=10, andfj=7. The formant parameters are
the same as in Figure 5 and Figure 6.
Compared to Figure 5, where it was difficult to discern the 7 Hz FM, this faster frequency component in
the envelope of bAF [n], is seen in Figure 7 more clearly. Stockham's method provides an approach to
separate the fast-moving component from the 4 Hz component.
Taking the logarithm of the magnitude of both sides of Eq. 11 and knowing that e[n] > 0,
log (IbAF[n]I) = log(Ie[n]I) + log (IP[n] * h[n]).
(12)
Substituting Eq. 11 into Eq. 12 and taking the Fourier transform of both sides,
Fflog (IbAF[n])} = Fflog(eA[n]I)} + F{log(|eF[n]I)} + Fflog (|p[n] * h[n]I)}.
The spectrum of log (IbAF[n]|) is shown in Figure 8.
(13)
This is obtained by removing DC from
log (IbAF[n]), applying a Hamming window to the entire 3-second signal, and then taking the Fourier
transform. It is necessary to remove the DC component because the DC component is often sufficiently
large for its spectral sidelobes to obfuscate the low frequency components. Thus, unless otherwise
specified, all Fourier transforms in this chapter are plotted after removing DC from the signal and
applying a single Hamming window to the entire length of the 3-second signal.
29
DFT of log(IbAi). 1=200Hz, aa=0.2, f,=4, a =10, f =7, DC removed
16000
14000
120DO
10000
8000
6000
FM from
harmonics (7Hz
between
impulses)
4000
2000
00
Inn
Envelope
relon,
from
log(e(n)
9W
Frsq. (W)
*Fast-movlng region, from
log(InJI)
Figure 8: Frequency components in the log-envelope. Green arrow: envelope region. Purple arrow: fast
moving region.
The envelope region primarily consists of components belonging to the log-envelope, log (I e [n] |). This
contains components from both log (I eA [n] 1) and log (I eF [n] |). The "fast-moving" region corresponds to
the frequency components belonging to log(Iv[n] 1) = log(Ip [n] * h[n] 1). The impulses have the greatest
amplitude at around 200 Hz, 400 Hz, and 600 Hz because the pitch of the signal is 200 Hz. The FM of
each of the harmonics in the original signal can be represented by a Bessel function representation [40].
Each of the individual impulses is spaced 7 Hz apart because the rate of the FM is 7 cycles/sec2 . This
explains some of the variation in the magnitudes of each of the impulses in the "fast-moving" region. The
other component that contributes to the magnitude of each of the impulses is the overall envelope in the
frequency domain, denoted by the blue dashed lines in Figure 8 and is due to formant shaping.
Figure 9 shows the regions to which eA [n], the AM due to the respiratory muscles, and eF [n], the AM
due to the interaction between the harmonics and the formants, map within the envelope region.
30
.
......
....
DFT of log(IbAFI). f0=200Hz, a,=0.2, fa=4, a,=10, ff =7, DC removed
5000
4000
3000
2000
1000
LJ I
0
AM due to
10
20
Freq (Hz)
30
40
50
AM due to FM
respiratory
muaces
Figure 9: Components of envelope: AM due to respiratory muscles ("AM region") and AM due to FM ("FM
region"). The peaks represent the locations off. andf Since it is assumed thatf,<f the lower frequencies are
assumed to be due to the AM, and the higher frequencies are assumed to be due to the AM. (There is some
overlap due to a harmonic of the AM, but that becomes negligible after the first harmonic.)
The first major peak is at 4 Hz, which corresponds to the frequency of the AM. The next peak is at 7 Hz,
which is the rate at which the FM changes (ff). The next large peaks are harmonics of the 7 Hz because
the AM due to FM is not a pure sinusoid.
Log-FM-and-AM Envelope as a Sum of the Log-FM Envelope and the Log-AM Envelope: Figure 10
depicts the block diagram used to show that the log-FM-and-AM envelope is the sum of the log-FM and
log-AM envelopes for the "true" low frequencies, defined as the spectra of log (I eA [n]l) and
log (IeF[n] 1). The difference between Figure 10 and Figure 6 is that in Figure 6, the FM and AM are
multiplicative, while in Figure 10, the envelopes are processed individually and then added.
31
bn
Harmonic
stntsiar
F)Ie
Harmonic
r
+o[nI)+Iog(14n)j)
b.[n]
log(+b
lol()
Figure 10: Block diagram for log-FM envelope plus log-AM envelope by using Stockham's method.
Following the same process as described earlier in this chapter, and letting Eq. 7 define H(f), it follows
that:
Fflog (IbAF[n])} = F~log(|eA[n]j)} + Fflog(JeFn]|)} + 2F[Iog (IP[n] * h[n]|)}.
(14)
We are ignoring the last term of Eq. 14 because we are primarily interested in the envelopes. When
viewed on a frequency scale from 0 to 50 Hz, the Fourier transforms of log (I eA [n] 1) and log (I eF [n] 1)
are visible. This is depicted in Figure 11.
32
Fourier transform of log(IbA[n] 0f=200Hz, aa=0. 2 , fa= 4 , af=10, ff=7
6000-
40002000-
0
0
'
5
^
10
15
20
25
30
35
40
Fourier transform of log(IbF[n]I)f 0=200Hz, aa=0. , fa=4, af=10, ff=
1500
I
I
50
45
2
I
I
I
I
30
35
40
45
7
1000500-
0*
0
5
10
15
20
25
50
Fourier transform of log(IbA[n])+Iog(IbF[n]), and Fourier transform of log(IbAF[n]1)
000__
F.T. of log(l[n]I) + log(IbF[n]1)
___ F.T. of Iog(I F[n]1)
400020000
5
10
15
20
25
30
35
40
45
50
Figure 11: Comparison of Fourier transform of log-FM-and-AM, and Fourier transform of log-FM plus logFM envelopes. Top plot: Fourier transform of log(IbA[n]I), the log-AM envelope. Middle plot: Fourier
transform of log(Ib,[n]1), the log-FM envelope. Bottom plot: Fourier transform of log(lbA[nll) + Fourier
transform of log(Ib,[n]I) (red), and the Fourier transform of log(lbA,[n]I) (green). Observe that they are
approximately the same. The parameters used in these plots are the same as those used in Figure 7, Figure 8,
and Figure 9.
Figure 11 depicts the Fourier transform of the log-AM envelope (top plot), derived by following the top
branch of Figure 10, the Fourier transform log-FM envelope (middle plot), derived by following the
bottom branch of Figure 10, and the Fourier transform of the sum of the log-AM and log-FM plots (the
sum of the top and middle plots, shown in red in the bottom plot), and the Fourier transform of the logFM-and-AM envelope, shown in green in the bottom plot. The two signals closely follow each other,
supporting the conclusion that the log-envelopes can be summed together to form the combined log-FMand-AM envelope.
Results from Stockham's Method: Figure 12 compares bAF[n] and the DFT of log (IbAF[n]I) when the
parameters chosen forfo, aa,fa, af, andff are modified.
33
7
2
bAFnl, f 0=200Hz, aa=0. . fa=4, at=10, f,=
DFT of log(lbIAF). f0=200
. aa0.2, f=4 af=10, f =7
5
Baseline
0
- 0 .5
0
2
2.5
0.5
1
1.5
3
bAF[nJ, f0 =200Hz, aa=0. 2 , f,=4, a,=10, f,=13
O.5
-J
0
20
40
60
80
100
DFT of log(Ib A), fo=200Hz, aa=0.2, fa=4, at=10, f,= 13
500
ff increased
to 5Hz/sec
0
-0.5
0
0.5
1
1.5
2
2.5
3
bAF[n, fo=200Hz, aa=0.2, fa=2.5, a,=10, f,=7
so
100
20
40
60
0
DFT of log(Ib ), f0=200Hz, a,=0.2, f,=2.5, a,=10, f,=7
0.5
fa decreased
to 2.5Hz
0
0
0.5
1
1.5
2.5
2
4
bAgJn f0 = 9OHz, aj0.2, fa= , a,=10, f,=7
3
20
DFT
0.5
40
0
80
100
of log(lb AF ), fonI90Hz, a a=0.2, f a =4 a=10, f,=7
0
f. decreased
to 190Hz
0
-0.5
0
0.5
1
1.5
2
2.5
bAn), fo=200Hz, aa=0.2, fa=4, a,=20, f,=7
3
%
20
40
60
80
100
DFT of log(IbA,), f,=200Hz, a,=0.2, f =4, a,=20, f =7
05
-0.5
o
a, increased
o.s
1
1.5
2
2.5
Time (s)
3
0
0
to 20Hz
20
60
Freq (Hz)
40
80
100
Figure 12: Comparison of bAF[n] and DFT of log(Ib[nJi) when the formants are 820 Hz, 1220 Hz, and 2810
Hz, their bandwidths are 125 Hz, 125 Hz, and 250 Hz, respectively, and the bandpass filter is set to formant 3,
with corner frequencies at 2810 Hz 250 Hz. Before taking the DFT, DC was removed from the signal and a
Hamming window was applied. Left column: bA[n]. Right column: DFT of log(IbF[nJI) on a frequency scale
from 0 to 50 Hz. First row: contains the same figures as shown earlier in this section; they are present for
reference.f,=200 Hz, aa=0.2,fa=4 Hz, aj=10 Hz,f1 =7 cycles/sec 2 . Second row: ff is increased from 7 cycles/sec2
to 13 cycles/sec2 . Third row: fa is decreased from 4 Hz to 2.5 Hz. Fourth row: fo is decreased from 200 Hz to
190 Hz. Fifth row: af is increased from 10 Hz to 20 Hz.
Although not visible in the spectra in Figure 12 due to the limits on the frequency axis, all instances of
bAF [n] contain two envelope components: a slow envelope and a fast envelope. In all cases, the frequency
of the slow envelope corresponds to the frequency of the AM from the muscles of respiration, which is fa.
In the first, second, and fourth columns, fa is 4 Hz, but in the third column, it slows to 3 Hz. When ff is
increased from 7 cycles/sec2 to 13 cycles/sec2 , as shown in the change from the first row of Figure 12 to
the second, the higher-frequency component of the envelope appears to increase as well. In the third row,
when fa is changed from 4 Hz to 2.5 Hz, the frequency of the slow envelope decreases from 4 Hz to 2.5
Hz, as expected. When the modulation parameters are kept constant but fo is decreased from 200 Hz to
190 Hz, the frequency components due to the AM from the respiratory muscles remains the same, but the
frequency components due to the interaction between the FM and AM change in amplitude; they are at
the same locations (although the peak at 14 Hz is attenuated). This is expected because the harmonics of
fo that are closest to the third formant are now at different frequencies. Increasing the depth of the FM,
af, keeps the locations of the harmonics of the FM at multiples of 7 Hz, but the harmonics with the
greatest energy have a higher frequency.
34
..........
....
....
..
......
The spectra of log (IbAF[n]1) contain peaks at the AM and FM frequencies and harmonics of those
frequencies, but they also contain some high-frequency artifact in between. This artifact is a byproduct of
taking the magnitude of bAF[nI. The negative time-domain components are flipped about the time axis,
which introduces an additional high-frequency component. Previous studies that used the envelope of a
signal to study dysphonic speech used the Hilbert transform to obtain the envelope [41], so the
combination of the Hilbert transform and Stockham's method was explored next.
4.3.2
Hilbert-Stockham Method
In communications signals and in dysphonic speech, incoherent envelope detection is performed by
bandpass filtering around the carrier frequency. The resulting signal is then transformed to a Hilbert
envelope by performing the Hilbert transform on the bandpassed signal and then taking the magnitude
[41]. In this thesis, the logarithm of the magnitude is taken in an effort to further separate the fast-moving
component from e [n].
Description of Hilbert-Stockham Method: Figure 13 shows the block diagram for the processing
method using both the Hilbert transform and Stockham's method.
GIf I.o(n log
PY0fl
syog(ze
Fltr
1og(ljynlj)+fs(jydnjL)
k%()
synd~zerG(f)
Figure 13: Block diagram representing the model (turquoise box) and processing when the Hilbert transform
and Stockham's method were both used. The Hilbert transform of the bandpassed signal, bA[n], is taken,
resulting in yA[n]. The log of the magnitude OfYAFl1 is subsequently taken.
Note that the only difference between this processing method and the previous method is that the Hilbert
transform is taken prior to taking the magnitude of the time-domain signal.
35
From the block diagram in Figure 13 and Eq. 11, YAF[n], the Hilbert transform of bAF[n], is obtained as:
YAFIn]
e[n](ft[n] * h[n])
*
g[n]
(15)
where g[n] is the Hilbert operator. Since only the magnitude is important in this case, the following
approximation can be made [42]:
YAF[n %te[n]P[n] * (h[n] * g[n])
(16)
Letting h[n] = h[n] * g [n], the Hilbert transform of h[n], then:
YAF[fl-
(e[n]&[]) * h[n]
(17)
Using the same approximation that- was used to obtain Eq. 16 from Eq. 15, it follows that:
YAF [n] oze[n](Pi[n] * h [n])
(18)
Substituting Eq. 8, letting f[n] be the Hilbert transform of v[n], and with e[n] > 0:
IYAF[lI
e[n]It~nhI
(19)
Figure 14 compares bAF [n] to its Hilbert transform, YAF[n], over two timescales, when a bandpass filter is
applied around the third formant.
36
Comparison of bAF and yAF over entire waveform
0.4
__
0.2
bAF
__yAF
0
-0.2
1
0.5
0
1.5
Time (sec)
3
2.5
2
Comparison of bAF and yAF over segment of waveform
0.4__bA
0.2
_
A
-0.2
-0..5
0.55
0.6
Time (sec)
0.65
0.7
.
Figure 14: Comparison of b[n] (blue) and yAF[n] (red).f,=200Hz, aa=0.2,f=.4OA Hz, a,=10 Hz,f=7 cycles/sec 2
The first through third formant frequencies are 820 Hz, 1220 Hz, and 2810 Hz, and the bandwidths are 125
Hz, 125 Hz, and 250 Hz, respectively. Top: bA[n] and yA[n], plotted over the entire 3 second duration of the
waveforms. Bottom: bA[n] and yA[n], plotted between times 04 and 0.7 seconds.
In the bottom plot of Figure 14, YAF [n] appears be the envelope of bAF [n]. It preserves the envelope of
the AM from the respiratory muscles and the AM due to the interaction between the formant and the
harmonics. In contrast, when the magnitude of bAF [n] is taken, the negative samples become positive,
resulting in more high-frequency artifact.
To separate the different sources of AM from the Hilbert envelope, Stockham's method is once again
utilized. Taking the log of the magnitude of both sides of Eq. 19, with eA[n]
0 and eF[n]
0, and
substituting e [n] = eA [n]eF [n], the following is obtained:
log(IyAF [n] 1) = log(eA [n]) + log(eF[n]) + log (I91n]I)
(20)
Taking the Fourier transform of both sides,
F{log(IyAF[n] |)) = Fflog (eA [n])} + F{log (eA [n])} + F{log (IV[n]1))
(21)
The envelope region of the Fourier transform of log (IYAF [n] ) is shown in Figure 15. As a result of the
smoothing from the Hilbert envelope, there is less low-amplitude, high-frequency artifact between the
peaks at 4 Hz, 7 Hz, 8 Hz, 14 Hz, 21 Hz, 28 Hz, etc. Therefore, this processing method might yield
37
features that are more strongly correlated with vocal modulation than Stockham's method without the
Hilbert transform.
DFT of log(lyAFI), f,=200Hz, a,=0.2, fa=4, af=1 0, ff=7 , DC removed
rnnn
500o
4000
3000
2000
100 o
I
0
10
20
30
40
50
Freq (Hz)
AM due to
AM due to FM
respiratory
muscles
Figure 15: Spectrum of log(yA,[n]I), showing the regions where there is AM due to the muscles of respiration
and AM due to the interaction between the formants and harmonics of the fundamental.
However, if the Fourier transform of log (IyAF[n]I) is taken by removing DC and applying a Hamming
window, and then viewed over a wider frequency range, it is clear that many high frequency components
remain in the Hilbert envelope. This is shown in Figure 16.
38
....
...
.......
......
...............
I...........
...
..............
...............
...
...
.............
.
................
...... ...........................
.........
....
Fourier Transform of log(IbAF
x14
1. 51-
0.
0
K 10o
2000
4000
6000
8000
10000
12000
10000
12000
Fourier Transform of Iog(yAF)
4
1.5
1
-l
0.5
00
2000
4000
6000
8000
Freq (Hz)
Figure 16: Comparison of the spectra of of log(IbAF[nlI) and of log(lyA,[n]I). log(yAF[n]I) is nearly a lowpassed
version of log(IbA[n]I).
There is a considerable amount of energy at around 5800 Hz in the plot of the spectrum of
log ( bAF[In] 1) in Figure 16. This occurs because bAF n] contains both positive and negative values. When
IbAF [n] I is obtained, the negative components become positive, effectively doubling the frequency of the
fastest component in the signal, which is formant 3. The third formant is 2810 Hz, so twice the third
formant frequency yields 5620 Hz, which is consistent with the top plot in Figure 16.
Log-FM-and-AM Envelope as a Sum of the Log-FM Envelope and the Log-AM Envelope: Similar to
Stockham's method without the Hilbert transform, the demonstration that the log-FM-and-AM envelope
is the sum of the log-FM and log-AM envelopes, is based on Figure 17.
39
Harmonic
synthesizer
b,[n]
G(f)
yF~
e
andpass
Filter
Harmonic
synthesizer
bayA[
logt)
by
+I[n]
)
log(+yF[n] 1e1n]),
G(f)
1
og()
andpass
Filter
Figure 17: Block diagram for log-FM envelope plus log-AM envelope by using the Hilbert-Stockham method.
Following the same process as described in Section 4.3, and letting Eq. 7 define H(f):
Fflog(IyAF [n]|1)} = F~log (eA [n])} + F~log (eA [n])} + 2F[Iog (I
[n]|}
(22)
Since it is only the envelopes that are of interest, the last term of Eq. 22 is ignored. When viewed on a
frequency scale from 0 to 50 Hz, the Fourier transforms of log (IeA[n] |) and log (IeF[n] 1) are visible.
This is depicted in Figure 18.
40
..
. ...............
....
..
--- ......
1111 ..........
_
Fourier transform of Iog(IyA[n]I) f0=200Hz, aa=0. 2 , fa=4, af=10, f = 7
10000
-
5000
0
0
10
5
15
20
25
35
30
2
45
40
4
Fourier transform of Iog(IyFLn]I) f0 =200Hz, aa=0. , fa= , af=10, f =
50
7
2000
-
1000
0
A
OL
10
5
15
20
- L --- -A-_IA
35
30
25
40
-_
45
Al
50
Fourier transform of log(lyA[n])+1-og(IyF[n]), and Fourier transform of Iog(yAF[n]I)
10000[
F.T. of Iog(IA[n]I) + log(IyF
~__ F.T. of log(I F[n]1)
___
-
5000
0
0
A5
-\
10
A
15
A
20
A
25
Freq (Hz)
-N\
I
30
35
40
45
50
Figure 18: Comparison of Fourier transform of log-FM-and-AM, and Fourier transform of log-FM plus logFM envelopes, obtained using the Hilbert-Stockham method. Top plot: Fourier transform of log(lyA[n]I) , the
log-AM envelope. Middle plot: Fourier transform of log(Iy,[n]I), the log-FM envelope. Bottom plot: Fourier
transform of log(IyA[nJI) + Fourier transform of log(ly,[n]I) (red), and the Fourier transform of log(yAF[nI)
(green). Observe that they are approximately the same.
Much like the Stockham method without the Hilbert transform, the Fourier transform of the log-FM-andAM envelope is very similar to the sum of the Fourier transform of the log-AM envelope and the log-FM
envelope.
Results from Hilbert Transform and Stockham's Method: Figure 19 shows the resulting signal when
the Hilbert transform is taken before taking the magnitude and then taking the logarithm for a number of
different FM parameters.
41
yAF[n]
DFT of 1og(YAF) f0=200Hz, a,=0.2, fa=4, a,=10, f,= 7
fo=200Hz, aa=0.2, fa=4, af=10, ff=7
ROOC
L I
J
1
4000-A
2000-
n5v
0.2
yAF[]
19
2
0
3
UiikdIIikh
0.5
1
1.5
2
2.5
25
1
yAF n] fo=200Hz, aa=0.2, fa= . , a=10, ff=
0.
A
10
20
A
A
30
40
50
DFT of log(IYAF), t0=200Hz, aa=0. 2 , fa=4 , af=10, ff=1 3
fo20Hz, a=0.2, fa=4, a,=10, ff=13
4000
2000
0
o
A
3
[J
,, A
10
_0
DFT of
7
log(IyAF)'
-
20
A
-
O.4r
30
40
f0=200Hz, aa=0.2, fa=2.5, af=10,
50
ff=7
-
6000
4000-
0.
-
2000A
0
0.4 1
0.5
1
1.5
yAF 1[] f0 =190Hz,
2
2.5
3
7
10
A - A.
20
30
A
40
A
50
DFT of Iog(yAF), f0=19OHz, aa=0.2, fa=4, a=10, ff=7
6000--
a=0.2, f,=4, a,=10, f,=7
4000-
0.1
2000-.
1.5
0
Time (s)
A
10
A
A
20
Freq (F-
30
40
50
Figure 19: Comparison of yA.[n] and DFT of log(lyAF[nI) when the formants are 820 Hz, 1220 Hz, and 2810
Hz, their bandwidths are 125 Hz, 125 Hz, and 250 Hz, respectively, and the bandpass filter is set to formant 3,
with corner frequencies at 2810 Hz * 250 Hz. Before taking the DFT, DC was removed from the signal and a
Hamming window was applied. The first column plots YAF[nl, and the second column plots the DFT of
log(lyA,[n]I) on a frequency scale from 0 to 50 Hz. The first row of contains the same figures as shown earlier
in this section; they are present for reference. In the second row, ff is increased from 7 cycles/sec 2 to 13
cycles/sec 2 . In the third row,fa is decreased from 4 Hz to 2.5 Hz. In the fourth row,f, is decreased from 200
Hz to 190 Hz.
The pattern is identical to what was seen in the method without the Hilbert transform, except the Hilbert
transform appears to remove some of the high-frequency artifact. Therefore, using the Hilbert method
might provide better results when extracting features to detect depression.
4.3.3
Nonlinear, Iterative Envelope (NLIE) -Stockham Method
Based on [43], we applied a nonlinear, iterative algorithm to estimate the envelope of a signal*.
Description of the NLIE-Stockham Method: Similar to the two other processing methods, the first step
is to bandpass the output from the vocal tract, resulting in bAF [n]. Then, the NLIE is obtained by
convolving IbAF[n] I with an equally-weighted moving average filter of length 2.5ms. For each point
along the length of IbAF [n]l, the maximum between IbAF [n] I and the convolution is kept. Then, the
* The code for the NLIE envelope was written by Dr. Elizabeth Godoy, a Technical Staff member at MIT-Lincoln
Laboratory, Human Language Systems and Technology Group.
42
process repeats 150 times. The resulting signal is called
magnitude of
ZAF[n]
ZAF
[n]. Finally, the natural logarithm of the
is taken because it is desirable for the natural logarithm of the AM from the
respiratory muscles and the AM from the resonance-harmonics interaction to be additive. This process is
illustrated in Figure 20.
Harmonic
synthesizer
bAF[n]
ZA
[n]
I|I
xNLUE
log()
Bandpass
Fifter
Figure 20: NLIE-Stockham method. The "NLIE" box represents the nonlinear, iterative envelope
computation. The output from the envelope is called ZAFl.
It is important to note that with the parameters used for the NLIE, which are an equally-weighted moving
average filter length of 2.5 ms and a number of iterations set to 150, the envelope does not contain the
fast-moving component of the signal, v[n], that was seen in the other two processing methods.
43
bAF[n] and
0.4
1AA
A.
Ak
v,
~Y
ZAF[n]
over entire waveform
h
.A
rn
0.2
0
-0.2
-0.4
0
0.5
1
I
1.5
Time (sec)
2
2.5
3
bAF[n] and ZAF[n] over a segment of the waveform
0.4
0.2
0
-0.2
0.5
IIP,
0.55
'!II!IfT!IIII'
II
0.6
0.65
0.7
0.75
Time (sec)
0.8
0.85
I '1I
0.9
Figure 21: bA[n] and ZAF[n]. The blue line represents bA[n] and the magenta line represents ZAF[f.
Figure 21 displays bAF[n] and the envelope output from the NLIE, over two timescales. The NLIE
appears to perform very well at estimating the envelope in the time domain. Compared to the Hilbert
envelope in Figure 14, the NLIE appears to be an envelope of the Hilbert envelope, removing additional
high frequencies that are present in the Hilbert envelope, thus removing artifacts that are not components
of the "true envelope" of the speech waveform.
The frequency domain representation of the magnitude of the log of the envelope is shown in Figure 22.
There is a clear peak at 4 Hz, corresponding to the rate of the AM from the muscles of respiration, and
also clear peaks at 7 Hz and its harmonics.
44
Fourier Transform of log(IVI)
6000
4Hz
50001
4000
3000
7Hz
2000
14Hz
28Hz
21Hz
1000
'SHz
UO
10
20
30
40
50
Freq (Hz)
Figure 22: Fourier transform of log(z 4[nJI)
Log- FM-and-AM Envelope as a Sum of the Log-FM Envelope and the Log-AM Envelope: Similar
to Stockham's method and the Hilbert-Stockham method, the verification that the log-FM-and-AM
envelope is the sum of the log-FM and log-AM envelopes with the NLIE-Stockham method is based on
Figure 23.
.nUE
Harmonic
synthesizer
Ulo(
zlIn
FftW
Harmonc
synthesizer
Iog(IznnhI)+Iog(IzrInJ
bAn) NUE znl
NE-;01
t
Figure 23: NLIE-Stockham method for log-FM-and-AM envelope, and log-FM plus log-AM envelope.
When viewed on a frequency scale from 0 to 50 Hz, the Fourier transforms of log (leA [n]I) and
log (IeF[n] 1), derived from Stockham's method, are visible. This is depicted in Figure 24.
45
Fourier transform of Iog(lzA[n]1) fo=200Hz, aa=0. 2 , fa=4, a,=10, ff=7
10000
-
5000
0
A
5
10
15
20
25
30
35
40
45
50
Fourier transform of log(IzF[n]1) f=200Hz, aa=0. 2 , fa=4, aj=10, f =7
40C 0
20C 00
5
10
15
20
25
30
35
40
45
50
Fourier transform of Iog(IzA[n])+Iog(lzF[n]), and Fourier transform of Iog(IzAF[n]1)
1 00C 0I
____ F.T. of Iog(IzA[n]I) + Iog(IzFnil)
F.T. of Iog('zF[n]l)
500 0___
%
5
10
15
20
25
Freq (Hz)
30
35
40
45
50
,
Figure 24: Comparison of Fourier transform of log-FM-and-AM, and Fourier transform of log-FM plus logFM envelopes, obtained using the NLIE and Stockham methods. Top plot: Fourier transform of log(IzA[n]I)
the log-AM envelope. Middle plot: Fourier transform of log(IzF[nJI), the log-FM envelope. Bottom plot:
Fourier transform of log(IzA[n]I) + Fourier Transform of log(lz,[n]I) (red), and the Fourier Transform of
log(IzAF[n]I) (green). Note that they are approximately the same.
As in the Stockham's method and the Hilbert-Stockham method, when the NLIE-Stockham method is
applied, the Fourier transform of the log-FM-and-AM envelope is very similar to the sum of the Fourier
transform of the log-AM envelope and the log-FM envelope.
Results from the NLIE-Stockham Method: Figure 25 shows the resulting signal when the NLIE is
extracted before taking the magnitude and then taking the log of the envelope. Similar to the two previous
methods, the main component of the AM from the respiratory muscles, located at 4 Hz, is present, as well
as the harmonics of the 7 Hz FM component.
46
7
2
4
zAF[n], f 0=200Hz, aa=0. , fa= ' a,=10, ft=
0.4
0.2
DFT of log(lzAF ) f0 =200Hz, aa=0.2, fa=4, af=10, f,=7
10000
5000
0
0.5
2
2.5
1.5
1
zAF[n], f0=200Hz, aa=0.2, f a=4, a=10, f =13
50
40
20
30
10
0
DFT of log(lzAF) f 0=200Hz, a a=0.2, f a=4, a,=10, ff=13
0.4
10000
0.2
5000
0
0.5
1
1.5
2
2.5
zAF[n], f 0=200Hz, aa=0. 2 , fa=2.5, af=10, f=7
50
40
20
30
10
0
DFT of log(lzAF ), f 0=20OHz, aa=0.2, fa=2.5, a,=10, f,= 7
10000
0.4
0.2
0
A
500:1
AA
A
0
0.5
1.5
2
2.5
1
zAF [n] f0=190Hz, aa=0.2, fa=4' a=10, ff =7
0.4
0.2
0
10
DFT of log(lz AF 1)
10000
20
F
30
40
50
(=190Hz,
aa=0.2, fa=4, a=10, f,=7
5000-
0
0.5
1
1.5
2
2.5
0(
10
20
30
40
50
Freq (Hz)
Time (s)
Figure 25: Comparison of y,,[n] and DFT of log(IzA[n]I) when the formants are 820 Hz, 1220 Hz, and 2810
Hz, their bandwidths are 125 Hz, 125 Hz, and 250 Hz, respectively, and the bandpass filter is set to formant 3,
with corner frequencies at 2810 Hz 250 Hz. Before taking the DFT, DC was removed from the signal and a
Hamming window was applied. The first column plots zA[n], and the second column plots the DFT of
log(IzA[n]I) on a frequency scale from 0 to 50 Hz. The first row of contains the same figures as shown earlier
in this section; they are present for reference. In the second row, ff is increased from 7 cycles/sec2 to 13
cycles/sec2 . In the third row,f, is decreased from 4 Hz to 2.5 Hz. In the fourth row,fo is decreased from 200
Hz to 190 Hz.
4.3A
Comparison of the Three Processing Methods
Figure 26 displays the three processing methods when used on four different sets of modulation
parameters. The sets of modulation parameters displayed are the same as those used in the previous parts
of this section.
47
Comparison of Fourier Transform of log(bAFI), IOg(IyAF'), and log(ZAF) fo= 2 0 0 Hz, a,=0.2, fa=4 , a,=10, ff= 7
400 0 200 0-
U
Stockham_
-Hilbert and Stockham
NUE and Stockham
oL~
5
10
15
20
_&Al
25
log(IbAFI),
Comparison of Fourier Transform of
30
A__
_6A
40
35
45
A
A
50
aa=0.2,fa=4, af=10, ff=13
,og(IyAFI)
and Iog(IZAFI f 0=20OHz,
40002000-
0
5
10
15
20
Comparison of Fourier Transform of log(IbAFI),
4000
25
30
35
40
45
50
Iog(IyAFI), and log(IZAFI), fo=200Hz, aa=0. 2 , fa=2.5, a=10, f,=7
--
2000
-
:L1k
1
1.
-
2A,A0 A
1og(IyAFI),
and Iog(IZA
Comparison of Fourier Transform of log(IbAFI),
I
I
I
A0
A
f0=19OHz, aa=0. 2 , fa=4, af=10, f,=7
II
I-
4000-
A
0
5
10
15
20
25
Freq (Hz)
30
35
40
A
-
2000
45
50
Figure 26: Comparison of the three different processing methods for the four different parameter
combinations used.
Ideally, there would be peaks only at 4 Hz, 7 Hz, and multiples of 7 Hz. Based on these plots, the
processing method with the greatest peaks and least amount of high-frequency artifact is the NLIEStockham method. This occurs because the NLIE-Stockham method is finding the envelope of the Hilbert
envelope, removing the component of the Hilbert envelope that represents the pitch period. Therefore, it
is hypothesized that this method will prove to be most useful when deriving features from the waveforms
in the AVEC database.
4.4
Conclusions
The Stockham, Hilbert-Stockham, and NLIE-Stockham methods were successful in demodulating
synthetic FM-and-AM signals. Due to the least amount of high-frequency artifact in the NLIE-Stockham
envelope, it is hypothesized that features extracted from this envelope will be able to best predict
48
subjects' MDD severity. In the next section, we will extract features from the three methods for
comparison.
49
Chapter 5 Feature Extraction
The purpose of this chapter is to describe the features that are will be used in Chapter 6 to predict
depression ratings. Motivated by the perceptual task described in Chapter 3, the model described in
Chapter 4, the theory of motor incoordination in MDD [12], and finding that spectrotemporal information
at low frequencies (up to 25 Hz) can be used to predict Hamilton Depression (HAM-D) scores [29],
various features from each of the speech signals were extracted and used for prediction. The features are
used to test the hypothesis that individuals with MDD have more erratic modulation in their voices, where
"modulation" is reflected by each of the features.
The model of Chapter 4 predicts that many of the features can be found in the low-frequency band of the
logarithm (log) of the envelope of the acoustic speech signal. The features can be outlined as follows:
1) Frequency domain-based features
a. Mean of the magnitude of the STFT of the log-envelope
b. Variance of the magnitude of the STFT of the log-envelope
c. Coefficient of variation of the STFT of the log-envelope
d. Amount of unnormalized energy in the low-frequency region
e. Ratio of energy in low-frequency region to energy in high-frequency region
2) Time domain-based features: eigenvalues of cross-correlations among envelopes containing
different frequencies
Prior to extracting the features, the waveforms must be pre-processed. The purpose of the pre-processing
step is to extract the frequency band of interest. Since the Hilbert-Stockham and NLIE envelopes
appeared to contain less high-frequency artifact than the Stockham envelope when they were tested on the
model, both the Hilbert-Stockham and NLIE-Stockham envelopes were used.
This chapter is outlined as follows: Section 5.1 describes the database used. Section 5.2 describes the preprocessing that is common to both the frequency domain-based features and the time domain-based
features. Section 5.3 details each of the frequency domain-based features, while Section 5.4 details the
time domain-based features.
5.1
The AVEC Database
The 2013 Audio/Visual Emotion Challenge (AVEC) database is used for feature extraction and
classification/regression. The AVEC 2013 challenge contains a subset of an audio-visual depression
50
language corpus that includes 340 video recordings of 292 subjects performing a human-computer
interaction task while being recorded by a webcam and a microphone and wearing a headset. The 16-bit
audio was recorded using a laptop's sound card at a sampling rate of 41 kHz or 32kHz. The video was
recorded using a variety of codecs and frame rates, and was re-sampled to a uniform 30 frames-persecond. For the challenge, the recordings were split into three partitions, 50 recordings each: a training,
development, and test set. Recording lengths fall between 20-50 minutes with a 25-minute mean value.
The mean age is 31.5 years, with a standard deviation of 12.3 years over a range of 18 to 63 years. The
recordings took place in different quiet environments [32]. Subjects were required to utter the /a/ vowel at
a comfortable sound level for part of the task. That /a/ vowel from the training and development sets was
the portion of the recordings used for this thesis in feature extraction and classification/regression. Since 3
of the 100 recordings training and development sets did not contain the /a/ vowel at a comfortable level, 1
contained a recording of the subject laughing during the utterance, 9 were too short, and 1 was too quiet, a
total of 87 /a/ vowels was used.
The subjects' MDD severity ratings were scored using the self-reported Beck assessment, described in
Appendix B. Low Beck scores correspond to little/absent MDD, while high Beck scores correspond to
severe MDD. The scores are rated on a scale between 0 and 63. Among the 87 vowels extracted from the
AVEC database, the Beck scores varied between 0 and 45.
5.2
Pre-Processing
The purpose of the pre-processing is to extract the NLIE-Stockham and Hilbert-Stockham envelopes from
the 87 raw waveforms. The recordings sampled at 41.8 kHz are downsampled to 32 kHz to standardize
the sampling rates of all of the recordings. Next, the middle 3 seconds of each /a/ vowel are extracted to
standardize the number of windows and window lengths used among different sessions when the Fourier
transform is taken. Using a Kalman-based autoregressive moving average framework [44], the formants
of each of the waveforms are computed. A bandpass filter at the center of the third formant is applied for
the same reasons as described in Chapter 4: the frequency of the third formant is significantly away from
the first and second formants, and the greatest amount of modulation of the harmonics of fo is expected to
occur within the third formant. For each of the waveforms, the bandwidth of the bandpass filter is set to
250 Hz on each side of the formant. The result is two envelopes per waveform: the NLIE-Stockham
envelope and the Hilbert-Stockham envelope. Finally, the NLIE-Stockham and Hilbert-Stockham
envelopes are computed (denoted by eL[n] = log (Ie[n] 1) and referred to as the general log-envelope).
51
The NLIE and Hilbert envelopes, without taking the log of the magnitude of the envelope, are denoted by
e [n].
5.3
Frequency Domain-Based Features
This section details each of the frequency domain-based features. Our model and the findings of
Cummins et al. [29] serve as the motivation for this type of feature: these features are derived from the
low-frequency (<20 Hz to <50 Hz) content in the log-envelope of the waveform. The definition of "low
frequency" needed to be established empirically.
To compute the STFT over the middle three seconds, the Hilbert-Stockham and NLIE-Stockham
envelope are segmented into 5 sections, each with a length of 1 second, and with an overlap of ; second.
The DC value of each segment is removed. A 1-second Hamming window is applied to each segment of
the envelope, with an overlap of 0.5 seconds from the previous window. It is necessary to remove the DC
value prior to taking the STFT because the in the frequency domain, the energy from the mainlobe at DC
often leaks into the frequencies of interest. A 262,144-point FFT is applied when the Fourier transform is
computed. The large number of points was necessary because of the desired resolution in the lowfrequency region of the signal.
5.3.1
Average of the STFT Magnitude of the Log-Envelope
These features are motivated by Cummins [29], who used spectrotemporal information from utterances of
"pa-ta-ka" to predict subjects' clinically assessed HAM-D scores. The data used by Cummins et al.
originated from a database different from AVEC. Although it is difficult to extract physiological meaning
from the average STFT magnitude of the log-envelope, this set of features can lay the groundwork for
features that provide physiological meaning.
The STFT magnitude of log(Ie[n]|) at time n, denoted by IEL(n,f)|, is given by Eq. 23:
IEL(n,f)| =
IXO=- 00 log(le[m]|) w[n -
m]e
2
"fm".
(23)
where w[n - m] is the analysis window. Its length is N, and it is nonzero only over the interval
[0, N, - 1]. A single 3-second window is not applied to the signal because the signal is time-variant;
"noise" appears in the STFT if the window is too long. If the window is too short, the frequency
resolution suffers [30]. The STFT is taken over P windows, and the result is averaged. Assuming each
52
STFT is computed at times that are multiples of N,12,
f, is the
sampling frequency, and p is an integer
representing the multiple of N/2, then the time point at which the STFT is taken can be expressed as:
pNw
n =
2
,.
Therefore, the mean of the magnitude of the STFT of log(|e[n] 1),| EL(f)I, is computed as:
lE!p __
|ELUf)J =
S, f).
(24)
In this case, w[n - m] is 1-second Hamming window, and the STFT is taken at
-second intervals of
log(Ie[n] 1). There is a total of P=5 STFTs computed.
As an example, Figure 27 shows the magnitude of the STFT of the NLIE envelope for each of the
windows, as well as the mean STFT magnitude (dark black line).
223_1: Beck score=0
3000
2500
2000
1500M
1500
11000
-Window
1
-Window
2
Window 3
- Window 4
-Wndow
ndow 5
322_1: Beck score=0
2282: Beck score=0
2500
2500
2000
2000
1000
1015
1000
1000
20
500
500
Soo
10
1500
50
500
0
228_2: Beck score=1
2000
0
10
0
20
231_1: Beck score=32
218_1: Beck score=31
10
20
0
10
20
237_2 : Beck score=34
234_1 : Beck score=31
4000
2000
4000
5000
3000
1500
3000
4000
2000
1000
2000
1000
500
1000
3000
2000
c0
10
Freq (Hz)
20
0
10
Freq (Hz)
20
1000
0
10
Freq (Hz)
20
0
10
Freq (Hz)
20
Figure 27: Mean STFT magnitude of NLIE-Stockham envelope for subjects with low Beck scores (top) and
high Beck scores (bottom), when the frequencies of the envelope range between 0 and 20 Hz. Five 1-second
windows over the middle 3 seconds of each vowel are used in the computation of the STFTs. The delay
between each window is 0.5 sec. All subjects uttering the waveforms shown in this figure are female.
A more periodic, less erratic structure is apparent in the average of the STFT magnitude of the logenvelope in two of the less depressed subjects (228_2 and 322_1) than in the four depressed subjects.
However, this observation does not generally hold. As an ensemble, it is difficult to detect patterns from
the waveforms that could be used for classifying the subjects with low Beck scores (top row) from
subjects with high Beck scores (bottom row). Consequently, each of the 164 frequency samples between
53
0 and 20 Hz are input to a dimensionality reduction scheme prior to Beck score prediction. These
processes are described in Chapter 6.
5.3.2
Variance of the Magnitude of the STFT of the Log-Envelope
Motivated by the hypothesis of motor incoordination in MDD [12], it is hypothesized that there is greater
variance over time in the spectrum of a depressed subject.
var(IEL(
This variance is computed as
FFs,fil) as p varies from 1 to 5, over each of the different segments of the signal. In other
words, for all of the windows from one subject from Figure 27, the variance of the magnitude of the
STFT of log(Ie[n] |) is computed. The result is shown in Figure 28.
2231 Beck sCore=O
x
8.
7 io5
2282 BeCk score=O
x
4
6
32.5
4 -
23
2
1
6
3.5
5
3
1431.5
2
0.5
1
0
5
10
15
20
12 218_1: Beck score=31
10
5
_0
.
105
10
15
20
231_1: BeCk score=32
6
.
10,
10
15
20
0
x10e
24-1 Beck score=31
10
5
10
15
20
2372: Beck score=34
2.5
2.5
2-
2.
6
1.5
4
1
2
0.5
1.5
4
2
0
5
0
1x
3
S6
228_2 Beck sCore=1
4
3221 Beck sCOre=O
0.5
5
10
Freq (Hz)
15
20
0
5
10
Freq (Hz)
15
20
0
5
10
Fmq (Hz)
15
20
0r5 101520
Freq (Hz)
Figure 28: Variance of the STFT magnitude of NLIE-Stockham envelope for subjects with low Beck scores
(top) and high Beck scores (bottom), when the frequencies of the envelope used in classification and
regression ranged between 0 and 20 Hz. Five 1-second windows over the middle 3 seconds of each vowel were
used in the STFTs. Each window was delayed by 0.5 seconds from the previous. All subjects uttering the
waveforms shown in this figure are female. The utterances are the same as those shown in Figure 27.
It is difficult to discern a pattern that would classify the depressed subjects from those who are not
depressed. Therefore, each of the 164 frequency samples between 0 and 20 Hz is reduced in
dimensionality prior to Beck score prediction.
5.3.3
Coefficient of Variation (CV) of the Magnitude of the STFT of the Log-Envelope
The coefficient of variation (i.e. the variance normalized by the mean) is also used as a feature. This
measurement is similar to variance of IEL(n, f)l, but this is hypothesized to yield improved prediction
54
because it improves normalization to the mean of the FFT up to 20 Hz. The features from 0 to 20 Hz for
females with low Beck scores and high Beck scores are shown in Figure 29.
223 1 : Beck score=0
1
-1
228 2: Beck score=0
-1
0.8
322 1 : Beck score=0
-1
228 2: Beck score=1
0.8
0.8
0.8
0.6
0.6
0.6
0.4
0.4
0.4
0.2
0.2
0.2
8 0.6000
0.4
0.2;
10
20
00
10
231_1: Beck score=32
218_1: Beck score=31
0.8
0
20
1.5
0.6
10
20
_0
10
20
237_2: Beck score=34
234_1: Beck score=31
0.8
1.2
0.6
1
0.8
> 0.4
0.4
0
0.6
0.5.
0.2
0.2
0
10
Freq (Hz)
20
00
10
Freq (Hz)
20
00
0.4
10
Freq (Hz)
20
0.20
10
Freq (Hz)
20
Figure 29: CV of the STFT magnitude of NLIE-Stockham envelope for subjects with low Beck scores (top)
and high Beck scores (bottom), when the frequencies of the envelope used in classification and regression
ranged between 0 and 20 Hz. Five 1-second windows over the middle 3 seconds of each vowel were used in the
STFTs. Each window was delayed by 0.5 seconds from the previous.
Similar to the mean of the STFT magnitude of the log-envelope, it is difficult to determine a pattern that
would classify the patients into a depressed and non-depressed category.
5.3.4
Unnormalized Energy in the Frequency Band Corresponding to the AM due to the
Respiratory Muscles
Motivated by the model and the hypothesis that patients with MDD have more erratic modulation in their
voices, the unnormalized energy in a low-frequency band of IEL(f)I is computed over frequencies from 0
Hz to an upper limit, denoted by f.. The computation is provided below as:
Eamax IEL (f)12.
This low-frequency unnormalized energy approximates the energy in the AM region, IEAL(f)|, but
without taking the normalization over the frequency range into account. The ideal "low-frequency range"
is tested empirically by varying the upper limit from 1 Hz to 12 Hz in steps of 1 Hz.
55
5.3.5
Ratios of Energy in Various Frequency Bands
Based on the hypothesis that there might be different ratios of energy in various frequency bands as put
forth by the model, ratios between the energy in the IEAL (f) region to the energy in the
IEFL(f)
region
are computed. One of the challenges of this feature is that the frequency regions of the AM due to the
muscles of respiration, and the AM due to the interaction between the formants and the harmonics, are
unknown. To resolve this, numerous different ranges are tested. In all cases, it is assumed that any
frequency up to f.
is a frequency region where AM due to the muscles of respiration could occur.
However, both the lower and upper frequency bounds on IEFL(f)I are unknown, so both bounds are
varied.
There are three forms of the energy ratio feature. Unlike the other features, the average STFT magnitude
is computed for frequencies up to 50 Hz. This is to ensure that the maximum frequency of the FM is
captured.
In each case,
* |EAL(f) I is the mean of the magnitude of the short-time Fourier transform of log(IeA[n] 1).
*
IEFL(f) I is the mean of the magnitude of the short-time Fourier transform of log(I eF[n]
* f.
).
is the highest frequency at which IEALfI occurs. This is varied from 1 Hz to 12 Hz in steps
of 1 Hz.
* ff is the lowest frequency at which
IEFL (f)
occurs. This is varied from 4 Hz to 16 Hz in steps of
1 Hz.
fj be the highest frequency at which IEFL(f)I occurs. This is varied from 20 Hz to 50 Hz in steps
of 5 Hz.
Therefore, for each of the three types of ratio features, 12x13x7 = 1092 combinations of frequency
region bounds are tested. The three forms of the energy ratio features are the following:
1) The ratio of the energy in the IEFL(f)| region to the energy in the IEAL(f) I region:
' f"1l IEPL(f)1
fff
1Efamax
IEALWI
2
famax -fzo
2) The ratio of the energy in the IEAL(f) region to the energy in the IEFL (f) I region:
T1
fa.,
1
EfamaxIEfI
=0o1ALf)1
ff2ff I
3) The difference between the energy in the
Z ff2
IEFL W!
56
IEFLCJ)1 2
den
i
e
()
g
I region and the energy in the IEAL C!) I region:
U2
5A
12
Zffr 2tr|F
ff f=ffi IEFL(f)12
Eamax | E.g f 2
f =0~oIALf
2
Time Domain Features
The time-domain features are the eigenvalues from time-delayed autocorrelation matrices of various
segments of the following envelope grades, performed on both the Hilbert and NLIE envelopes:
1) A lowpass filtered version of the Hilbert or NLIE envelope of each waveform. The cutoff
frequency of the filter is set to 25 Hz, the upper range of the modulation frequency studied by
Cummins [29]. This envelope is called thefine (F) envelope.
2) A lowpass filtered version of the fine envelope. Since Lester and Story compressed subjects'
chest walls at a rate of 5 Hz in their study of respiratory tremor [24], we set the cutoff frequency
of the lowpass filter at 5 Hz. In this thesis, the lowpass filtered version of the fine envelope is
called the coarse (C) envelope.
3) The difference between the fine envelope and the coarse envelope (FMC)
4) The log of the fine envelope (LF)
5) The log of the coarse envelope (LC)
6) The difference between LF and LC (LFMLC)
After computing the 6 envelope grades from both the Hilbert and NLIE envelopes, the features are
extracted. The procedure is described in detail in the context of epileptic seizure prediction [12].
Williamson et al. [45] also used the procedure on the first three formants of the AVEC database and
found that subjects with higher Beck scores exhibited less "coordination" in the formants.
The first step in the procedure is to z-score the envelope grade, which sets the mean of the envelope grade
to 0 and the variance of the envelope grade to 1. The z-scored envelope grade is then separated into five
segments, and the mean from each segment is removed. The final correlation matrix has 25 (5x5) blocks,
where each block contains a subset of the correlation coefficients between the two segments correlated
against each other, as shown in Table 2.
57
Table 2: Structure of the correlation matrix from which the eigenvalues are calculated. Since there are 5
segments, each of the 25 blocks of the whole correlation matrix contains a subset of the correlation
coefficients between two segments.
...
,R
...
...
,
R
.
.
...
..
R1,1
The cross-correlation of each combination of the 5 segments is computed. To reduce the dimensionality
of the cross-correlation matrix, the result of each cross-correlation is downsampled by sampling multiples
of 16 points (0.5 ms). This is called the delay. Thirty points, or taps, of each cross-correlation are then
sampled. The result is that each block is a cross-correlation matrix of size 30x30.
The values of 5 for the number of segments, 16 for the delay, and 30 for the number of taps, were chosen
because these are similar to the values chosen by Williamson et al. [12], when they extracted features
from the formants on the same database. For the envelope grades in this thesis, we attempted using 3, 4,
and 5 segments; 25 and 30 for the number of taps; and 4, 8, and 16 for the number of delays. After
obtaining the eigenvalues and summary statistic for each combination, we computed the Spearman
correlation between each eigenvalue, and the patients' Beck scores. We looked for the combination of
(number of delays, number of segments, number of taps) that produced the eigenvalues most strongly
correlated with the patients' Beck scores.
Once the final matrix is built for each envelope grade, its eigenvalues and a summary statistic are
computed. The eigenvalues are ordered from largest to smallest, and the summary statistic is computed
by taking the log of the trace of the covariance matrix. While the eigenvalues capture only frequency and
phase-related information, the summary statistic contains information about both the entropy of the 5
segments and their relative amplitudes.
58
Since not all of the eigenvalues and summary statistics are useful, Spearman correlations between each
feature (i.e. eigenvalues and summary statistic) and the Beck depression scores are computed, and are
used to predict the effectiveness of each feature in predicting Beck scores. As an example, the results of
the correlations between each of the features from the 6 grades of the Hilbert envelopes are shown in
Figure 30.
Correlation Between Beck Score and Features from LC
Correlation Between Beck Score and Features from C
0.2
8
0.2
0
8
0
-0.2 1
-0.2
-0.4
-0.4
0
50
100
50
150
Feature Number
100
150
Correlation Between Beck Score and Features from LF Grade
Correlation Between Beck Score and Features from F
0.2
0.2.2
8
9
o
8
0-
[0.2
-0.2-
-0.4
-0.4100
50
50
150
8
150
Correlation Between Beck Score and Features from LFMLC Grade
Correlation Between Beck Score and Features from FMC
C
100
0.2
0.2
0
8
0
1 -0.2
-0.2F
-0.4
-0.4
0
50
Feature Number
100
0
150
50
Feature Number
100
150
Figure 30: Spearman correlations between each feature and Beck score, computed for each envelope grade
from the NLIE envelope. The horizontal axis in each plot represents the feature index. The features are
ordered from largest eigenvalue to smallest eigenvalue, with the last feature being the summary statistic (i.e.
feature number 1 represents the correlation between the largest eigenvalue and the Beck scores, etc.). Top
left: Spearman correlation between Beck scores and features from the C grade of the Hilbert envelope. Top
right: Spearman correlation between Beck scores and features from the LC grade of the Hilbert envelope.
Middle left: Spearman correlation between Beck scores and features from the fine grade of the Hilbert
envelope. Middle right: Spearman correlation between Beck scores and features from the log(fine) grade of
the Hilbert envelope. Bottom left: Spearman correlation between Beck scores and features from the finecoarse grade. Bottom right: Spearman correlation between Beck scores and log(fme)-log(coarse) grade.
All of the features in Figure 30 are extracted using the optimal delays, taps, and segments, discussed in
Section 5.4. The correlations for each of the grades in Figure 30 follow the same pattern: the larger
absolute-value eigenvalues generally have a negative correlation with the Beck scores.
59
After the correlations between each of the eigenvalues and Beck score are computed, the indices of the
strongest-correlated eigenvalues are used in Beck score prediction.
5.5
Conclusions
Two principal types of features were introduced in the prediction of a patient's Beck depression score:
features extracted from the spectrum of the envelope or log-envelope, and features extracted from the
time-domain representation of the envelope. These extracted features are input to the predictor of the
Beck depression score, described in Chapter 6.
60
Chapter 6 Regression and Prediction Using the AVEC MDD Database
This chapter describes the regression and prediction procedure and then discusses the results we obtain
using the features from Chapter 5.
6.1
Regression and Prediction Procedure
6.1.1
Gaussian Mixture Model as a Foundation
As a basis for prediction, the type of classifier we use is a Gaussian Mixture Model (GMM). This is a
standard classifier and has demonstrated to be effective in predicting a patient's MDD severity [29][45].
As described in [12], instead of training the GMM using Expectation-Maximization with two classes:
depressed and not depressed, a different technique, called Gaussian Staircase Regression (GSR), is used.
GSR uses multiple data partitions to create a GMM for Class 1 and Class 2. The features from the 87
vowels are partitioned into seven bins based on the Beck score associated with each vowel. Vowels
corresponding to a Beck score of 0-4 are in the first (least depressed) bin, 5-11 are in the second, 12-19 in
the third, 20-26 in the fourth, 27-34 in the fifth, 35-41 in the sixth, and 241 in the seventh, representing
the most depressed subjects. Figure 31 displays the distribution of the partition bins.
0.25
0.2-
d 0.15-
0.10.
0.05-
0 -
1
2
3
4
5
Parition Bins
6
7
Figure 31: Distribution of partition bins.
Therefore, the GMM is formed from an ensemble of Gaussian classifiers that are trained from the
multiple partitions. This is depicted in Figure 32.
61
A
Class 2
Class 1
Beck score
Figure 32: Illustration of the score segmentation in the Gaussian Staircase Method.
In the first partition, Class 1 contains data corresponding to Beck scores between 0 and 4, and Class 2
contains data corresponding to Beck scores above 4. A Gaussian classifier for the first partition is
produced, where one Gaussian represents the features corresponding to Beck scores between 0 and 4, and
a second Gaussian represents the features corresponding to Beck scores above 4. In the second partition,
Class 1 contains data corresponding to Beck scores between 0 and 11, and Class 2 contains data
corresponding to Beck scores above 11. A second Gaussian classifier follows that partition, with one
Gaussian for Class 1, and one Gaussian for Class 2. Since there are 6 partitions, there are 12 Gaussians
that form the GMM. The advantage of Gaussian Staircase method is improved resolution for Class 1
among lower Beck scores, and better resolution for Class 2 among higher Beck scores. This allows for a
test statistic that tends to smoothly increase as the Beck score increases. The Gaussian densities used full
covariance matrices. A constant called the Gaussian regularization factor (GRF) was added to the
diagonal of the covariance matrix to prevent overfitting the data.
Since some of the subjects appear more than once, the means in the Gaussian model can be adapted
toward the mean for the subject. This process has been called feature adaptation.If a subject utters the /a/
vowels in two sessions, feature adaptation is performed on the second session. The mixing weights are
computed as n/O.5+n, where n is the number of sessions in which the features from the subject have been
evaluated (i.e. if feature adaptation is being performed, n=2) The factor of 0.5 is chosen because it was
used by Williamson et al [12]. The purpose of feature adaptation is to smooth the features extracted from
a subject, and is similar to the Universal Background Model [46], a widely used technique in speaker
recognition.
62
6.1.2
Training and Testing Procedure
Leave-one-out cross-validation is performed on each of the 87 waveforms: one waveform for testing and
86 for training. Some subjects performed the test during two separate sessions. In those scenarios, only
the session being tested is left out (i.e. data from the patient under test is in the training set).
A common problem is the presence of too many features from a particular feature type. For example, this
occurs when the average STFT magnitude and variance of the STFT7 magnitude are being tested. In each
case, there are over 100 features, where each feature corresponds to the average STFT magnitude or
variance of the STFT magnitude at a particular frequency. There are over 100 features when frequencies
up to 20 Hz are under test, and each feature may be weakly correlated with the Beck scores. Principal
component analysis (PCA) is required to reduce the dimensionality of the feature matrix. Prior to PCA,
the size of the feature matrix is 87xN, where N is the number of features (over 100 in the case of the
average STFT magnitude and variance of the STFT magnitude). PCA can be performed to reduce the
dimensionality of the matrix to 87xK, where K<N, and the K components account for the largest amount
of variance in the data.
Without utilizing machine learning, the baseline mean absolute error (MAE) and root mean square error
(RMSE) were computed. The baseline MAE is 10.05 and the baseline RMSE is 11.86. In the context of
the Beck scores, if s is the actual Beck score for subject i and 9 is the predicted Beck score for subject i,
then the MAE is defined as follows:
|E - sil.
MA1E=
The RMSE is defined as follows:
RMSE=
6.2
87
Average STFT Magnitude of the NLIE-Stockham and Hilbert-Stockham
Envelopes
We compute the average STFT magnitude of the NLIE-Stockham envelope, including frequencies up to
both 20 Hz and 50 Hz. The upper limit of 20 Hz is chosen because most of the energy in the NLIEStockham envelope is contained below 20 Hz. A second upper limit to test is set to 50 Hz because this is
half of the average assumed fundamental frequency for a male.
63
6.2.1
NLIE-Stockham Envelope with a Maximum Frequency of 20 Hz
Values for the Gaussian regularization factor (GRF) are varied from 0.1 to 1.5 in steps of 0.1, while the
number of PCA components is also varied from 2 to 7 components. This is executed without feature
adaptation and subsequently with feature adaptation. The features from the STFT are taken from
frequencies between 0 and 20 Hz.
RMSEs Without Feature Adapt.
MAEs Without Feature Adapt.
12.5
7
7
6
9.6
6
9.5
12
9.4
4
11.5
3
2
4
9.3
3
9.2
21
9.1
GRF
GRF
Spearman p Without Feature Adapt.
Spearman p Without Feature Adapt.
7
0.42
7
6
0.4
6
5
0.38
5
0.36
4
2
2
0.3
U.51
3
3
0.32
2
5
4
0.34
3
X 104
U.5
1.5
GRF
1
15
GRF
Figure 33: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude of the NLIEStockham envelope, with a maximum frequency of 20 Hz, without feature adaptation. In all plots, unless
otherwise noted, the GRF is varied from 0.1 to 1.5, and K, the number of PCA components, is varied from 2
to 7. For all plots except the bottom left, a cooler color indicates a lower value, which is desirable. Top left:
RMSEs when using the average STFT magnitude feature on the NLIE-Stockham envelope, up to 20 Hz,
without feature adaptation, while varying the number of PCA components from 2 to 7 and simultaneously
varying the GRF from 0.1 to 1.5. Top right: MAEs on the same data. Bottom left: Spearman p values. Bottom
right: Spearman p's.
The results obtained using this strategy are displayed in Figure 33. The lowest RMSE and lowest MAE
occur at different (GRF, K) coordinates, where K is the dimensionality of PCA components used and the
GRF is the Gaussian Regularization Factor, described in Section 6.1. The lowest RMSE, 11.07, occurs at
(GRF, K) coordinates of (1.5, 7) (p=0.41, p<0.001). However, the lowest MAE, 9.01, occurs at (0.5, 5)
(p=0.363, p<0.001). The greatest Spearman correlation, 0.430, occurs at (0.1, 2). At that point, the RMSE
is 11.28 and the MAE is 9.15, both of which are slightly lower than baseline.
64
The same procedure is executed again, except feature adaption is performed. Figure 34 shows the
RMSEs, MAEs, Spearman p, and Spearman p-values between the predicted Beck score and actual Beck
score when the number of PCA components and the GRF were varied.
RMSEs With Feature Adapt.
MAEs With Feature Adapt.
6
11.6
7
11.4
6
9.2
4
8.8
3
10.8
2
2
0.5
1
1.5
10.6
GRF
GRF
Spearman p With Feature Adapt.
7
6
4
Spearman p With Feature Adapt.
.46
14
.44
6
.042
5
12
10
.4
4
.38
3
x104
7
r
3
2
.36
2
.34
1
0.5
0.5
1.5
GRF
1
15
GRF
Figure 34: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude of the NLIEStockham envelope, with a maximum frequency 20 Hz, with feature adaptation.
The lowest RMSE, lowest MAE, and highest Spearman correlations are 10.58, 8.52, and 0.477 (p<0.001),
respectively. Unlike the case without feature adaptation, all of these extrema occur at (0.1, 2). These
coordinates are the same as those in the case without feature adaptation where the highest Spearman
correlation was found. Compared to the baseline RMSE of 11.86, the RMSE from the average STFT
magnitude of the NLIE-Stockham envelope, using frequencies up to 20 Hz, with 2 PCA components a
GRF of 0.1, predicts a patient's Beck score more than one point more accurately than the baseline RMSE.
The baseline MAE is 10.05. Similar to the RMSE, the lowest MAE from this feature, 8.52, predicts a
subject's Beck depression score more than a point more accurately than baseline. At (0.1, 2), the actual
Beck score, predicted Beck score, and line of best fit are shown in Figure 35.
65
Predicted vs. Actual Beck Score, Energy in Frequencies from 0 to 12Hz, No Adaptation
-.
...........
-.-.
..
.
45
40
35
30
Cl,
25
0T
20
-
.0
1
1
0
5
VO
5
10
15
20
25
Beck Score
30
35
40
45
50
Figure 35: Predicted score vs. Beck score from the average STFT magnitude with a maximum frequency of
20 Hz feature, using feature adaptation, when GRF=0.1 and K=2 (p=0 A77, p=0.001). Red line shows line of
best fit.
6.2.2
Hilbert-Stockham Envelope, with a Maximum Frequency of 20 Hz
The procedure described in Section 6.2.1 is used to obtain the RMSEs, MAEs, and Spearman correlations
on the Hilbert-Stockham envelopes: the GRF and K values are varied from 0.1 to 1.5 and from 2 to 7,
respectively. Cross-validation shows that when feature adaptation is not performed, regardless of the
parameters used when computing the average of the STFT magnitude of the Hilbert-Stockham envelope,
the RMSE and MAE are higher than those achieved when guessing. The complete results for the HilbertStockham envelope up to 20 Hz, without feature adaptation, are shown in Figure 36.
66
RMSEs Without Feature Adapt.
MAEs Without Feature Adapt.
11
13
6
12.8
12.6
4
10.6
3
10.4
2
1 2.4
GRF
Spearman p Without Feature Adaot.
7
6
10.8
5
GRF
Spearman p Without Feature Adapt.
0.2
7
0.8
6
.1 5
0.6
5
5
.1
4
3
4
0.4
3
.05
0.2
2
2
GRF
GRF
Figure 36: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude, with a maximum
frequency of 20 Hz, of the Hilbert-Stockham envelope, without feature adaptation.
Observe that in Figure 36, none of the RMSEs are below the baseline value of 11.86, and none of the
MAEs are below the baseline value of 10.05. However, when feature adaptation is performed, the HilbertStockham envelope performs marginally better than guessing under certain combination of (GRF, K). The
results are shown in Figure 37.
67
RMSEs With Feature Adapt.
MAEs With Feature Adapt
106
7
12.8
6
12.6
5
12.4
5
10.2
4
12.2
4
10
3
9.8
7
104
12
3
18
2
U .D
2
9.6
1 .0
GRF
GRF
Spearman p With Feature Adapt.
Spearman p With Feature Adapt.
7
7
.2
6
0.8
6
5
0.15
5
4
.1
4
3
.05
3
2
0.6
0.4
0.2
2
0.5
1
1.5
0.5
GRF
1
1,5
GRF
Figure 37: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude of the HilbertStockham envelope, using a maximum frequency of 20 Hz, with feature adaptation. Top right: MAEs.
Bottom left: Spearman p's. Bottom right: Spearman p's.
Although the average STFT magnitude of the Hilbert-Stockham envelope, using a maximum frequency of
20 Hz, does not accurately predict subjects' Beck scores without feature adaptation, there is a marginal
gain when feature adaptation is performed.
6.2.3
Stockham Envelope, with a Maximum Frequency of 20 Hz
We also attempt to predict MDD severity using the average STFT magnitude of the Stockham envelope
up to 20 Hz. The results without feature adaptation are shown in Figure 38.
68
RMSEs Without Feature Adapt.
MAEs Without Feature Adapt
7
11.2
7
11
10'8
12.8
4
4
12.6
3
10.6
3
2
104
2
GRF
Spearman p Without Feature Adapt.
2
Spearman p Without Feature Adapt.
7
7
08
S15
6
0,6
5
4
4
0.05
3
0
2
0.4
0.2
2
GRF
GRF
Figure 38: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude of the Stockham
envelope, with a maximum frequency of 20 Hz, without feature adaptation.
Compared to the NLIE-Stockham envelope, the Hilbert-Stockham and Stockham envelopes perform
poorly. The NLIE-Stockham envelope shows an improvement in the predicted Beck score relative to
baseline, whereas the Hilbert-Stockham and Stockham envelopes are less accurate than baseline unless
feature adaptation is performed.
Table 3 summarizes the results from all envelopes, without and without feature adaptation, and compares
them to baseline. Some cells in the table contain "N/A" because the classifier performed less accurately
than baseline.
Table 3: Comparison of results from NLIE-Stockham (N-S), Hilbert-Stockham (H-S), and Stockham
envelopes, using the average STFT magnitude up to 20 Hz. The values inside the parentheses indicate the
(GRF, K) values. The lowest MAE, RMSE, and p-value, and highest Spearman correlation, are in blue font.
Lowest
RMSE
MAE at
Lowest
RMSE
11.86
11.07
Baseline
N-S w/o
Feat.
Adapt.
H-S w/o
Feat.
Spearman
p at
lowest
RMSE
N/A
(GRF,
K) at
lowest
RMSE
N/A
Highest
Spearman
p
Spearman
p at
highest p
10.05
Spearman
p at
lowest
RMSE
N/A
N/A
9.08
0.402
<0.001
(1.5,7)
0.430
MAE at
highest
p
N/A
RMSE
at
highest
p
N/A
N/A
(GRFK)
at
highest
p
N/A
<0.001
11.28
9.15
(0.1,2)
N/A
N/A
N/A
N/A
I
12.30
I
_
__
10.47
_
I
_
__
_
N/A
N/A
I_____
N/A
IIIII
69
(1.5,2)
Adapt
Stockham
w/o Feat.
Adapt.
N-S w/
Feat.
Adapt.
H-S w/
Feat.
Adapt.
Stockham
w/ Feat.
Adapt. 1
12.30
10.46
N/A
N/A
N/A
(0.1,2)
N/A
N/A
N/A
N/A
10.58
8.52
0.477
<0.001
(0.1,2)
0.477
<0.001
10.58
8.52
(0.1,2)
11.62
9.63
0.245
0.0223
(0.4,2)
0.247
0.0212
11.62
9.66
(0.5,2)
0.237
0.0274
1_1_1_1
11.65
9.59
(0.3,2)
11.64
9.61
_
0.234
1
0.0294
1
(0.4,2)
1
1
Table 3 indicates that features extracted from the NLIE-Stockham perform more accurately than those
from either the Hilbert-Stockham or Stockham envelopes.
Spearman correlations and p-values are not
provided when the RMSE and MAE are higher than baseline because the correlation between the
predicted Beck score and actual Beck score is no longer meaningful when that occurs.
6.2.4
NLIE-Stockham Envelope, With a Maximum Frequency of 50 Hz
Since the exact range of frequencies in e[n] is unknown, the average STFT magnitude up to 50 Hz is also
computed, and the same procedure as outlined in Section 6.1.1 is performed. Without performing feature
adaptation, the MAEs, RMSEs, and Spearman correlations are shown in Figure 39.
70
RMSEs Without Feature Adopt
MAEs Without Feature Adopt
7
12.5
6
7
10.2
0
10
12
5
4
4
3
1.5
9.6
3
94
2
2
GRF
GRF
Spearman p Without Feature Adapt.
7A7
Spearman p Without Feature Adapt
.4
6
5
0.15
4
03
7
0
6
0.015
5
00001
Y4
3
3
1
0.5
151.5
0,005
2.25
GRF
GRF
Figure 39: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude of NLIE-Stockham
envelope, up to 50 Hz, without feature adaptation. Top left: RMSEs. Top right: MAEs. Bottom left:
Spearman p's. Bottom right: Spearman p's.
The lowest MAE achieved is 9.20, which occurs at (0.2, 2) and has a corresponding Spearman correlation
between the actual Beck score and predicted Beck score of 0.421 (p<0.001). The lowest RMSE is 11.17,
which occurs at (0.1, 2) and has a Spearman correlation of 0.423 (p<0.001). The (GRF, K) coordinates at
which the highest Spearman correlation occurs is (0.1, 2), the same coordinates at which the lowest MAE
occurs. At (0.1, 2), the Spearman correlation is 0.425 (p<0.001).
Although the MAE and RMSE values are not as low as those found when the upper limit on the
frequency range is 20 Hz, when feature adaptation is performed, the MAE and RMSE are lower. Figure
40 displays the results when feature adaptation is performed.
71
RMSEs With Feature Adapt
MAEs With Feature Adapt.
711.4
9.2
6
11.26
5
119
4
10.8
4
3
10,6
3
2
10.4
2
8,8
8.6
1
0.50.5
GRF
15
GRF
Spearman p With Feature Adapt.
Spearman p With Feature Adapt.
7
x104
7
6
0 AS
5
046
0442
4
3
2
0.5
1
63
4
A
3
0 38
2
1.5
1
0.5
GRF
1
1.
GRF
Figure 40: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude of the log-envelope
from NLIE-Stockham envelope, up to 50 Hz, with feature adaptation. In all plots, the GRF is varied from 0.1
to 1.5 and K, the number of PCA components, is varied from 2 to 7. For all plots except the bottom left, a
cooler color indicates a lower value, which is desirable. Top left: RMSEs. Top right: MAEs. Bottom left:
Spearman p's. Bottom right: Spearman p's.
The lowest MAE achieved is 8.46, which occurs at (0.2, 2), and has a corresponding Spearman
correlation of 0.487 (p<0.001). This is more than 1.5 points lower than baseline. The lowest RMSE
achieved is 10.32, which also occurs at (0.2, 2) and has a corresponding Spearman correlation of 0.487
(p<0.001). The highest Spearman correlation is 0.512, at (0.1, 4) (p<0.001). Figure 41 shows the
predicted Beck score versus actual Beck score using the average STFT magnitude of NLIE-Stockham
envelope, up to 50 Hz, with feature adaptation, at (0.2, 2).
72
Predicted vs. Actual Beck Score, Average STFT, With Adaptation
45
40
35
0
8 30
a.
0.
0
25
0
20
'
00O n8
15
n
5
10
15
20
25
Beck Score
30
35
40
45
50
Figure 41: Predicted Beck score vs. actual Beck score from the average STFT magnitude of NLIE-Stockham
up to 50 Hz features, using feature adaptation, when GRF=0.2 and K=2 (p=0A87, p<0.001). Red line shows
line of best fit.
Figure 41 shows the correlation between predicted and actual Beck scores, and the line of best fit. This is
the strongest correlation obtained of all features.
6.2.5
Hilbert-Stockham Envelope with a Maximum Frequency of 50 Hz
We also investigate the average STFT magnitude of the Hilbert-Stockham envelope, using frequencies up
to 50 Hz. Figure 42 shows the results when feature adaptation is not performed.
73
RMSEs Without Feature Adapt.
MAEs Without Feature Adaot.
13.4
7
13.2
6
13
7
11
6
10.8
5
12.8
5
4
12.6
4
3
12.4
3
2
12.2
2
0.5
1
10.6
10.4
10.2
15
1 .o
U.,
GRF
GRF
Spearman p Without Feature Adapt.
Spearman p WIthout Feature Adapt.
7
7
.2
0.8
015
5
0.6
01
4
4
3
0 05
3
2
0
2
GRF
04
02
GRF
Figure 42: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude, with a maximum
frequency of 50 Hz, of the Hilbert-Stockham envelope, without feature adaptation.
Even when frequencies up to 50 Hz are included in the Hilbert-Stockham envelope STFT, the classifier
performs less accurately than baseline when feature adaptation is not performed.
When feature adaptation is performed, there are some (GRF, K) combinations that produce RMSEs and
MAEs that are more accurate than baseline. However, the MAEs and RMSEs are not as low as those
produced by the average STFT magnitude on the NLIE-Stockham envelope up to 50 Hz. The results
when feature adaptation is performed are shown in Figure 43.
74
MAEs With Feature Adapt.
RMSEs With Feature Adapt.
13
7
10.2
6
12.5
12
5
10
4
9'8
3
9.6
2
GRF
GRF
Spearman p With Feature Adapt.
Spearman p With Feature Adapt.
0 25
1
7
06
6
05
0.25
5
04
015
4
03
01
3
0,2
01
21
0.05
0.5
i
U.S
.
11.5
u.5
15
1
GRF
GRF
Figure 43: RMSEs, MAEs, and Spearman correlations of the average STFT magnitude, with a maximum
Frequency of 50 Hz, of the Hilbert-Stockham envelope, with feature adaptation.
The features derived from the Hilbert-Stockham envelope never predict the subjects' Beck scores as
accurately as the features derived from the NLIE-Stockham envelope. Table 4 summarizes the results
from the average STFT magnitude, with a maximum frequency of 50 Hz, extracted from the NLIEStockham and Hilbert-Stockham envelopes.
Table 4: Comparison of results from NLIE-Stockham (N-S) and Hilbert-Stockham (H-S) envelopes, using the
average STFT magnitude with a maximum frequency of 50 Hz. The values inside the parentheses indicate the
(GRF, K) values. The lowest MAE, RMSE, and p-value, and highest Spearman correlation, are in blue font.
Baseline
N-S w/o
Feat.
Adapt.
H-S w/o
Feat.
Adapt
N-S w/
Feat.
Adapt.
H-S w/
Feat.
Adapt.
MAE at
highest
p
(GRFK)
at
highest
N/A
N/A
N/A
<0.001
11.17
9.26
(0.1,2)
N/A
N/A
N/A
N/A
N/A
0.518
<0.001
10.57
8.58
(0.1,4)
Spearman
p at
lowest
RMSE
N/A
(GRF,
K) at
lowest
RMSE
N/A
Highest
Spearman
p
Spearman
p at
highest p
RMSE
at
highest
10.05
Spearman
p at
lowest
RMSE
N/A
N/A
N/A
11.17
9.26
0.425
<0.001
(0.1,2)
0.425
12.02
10.24
N/A
N/A
(1.5,4)
10.32
8.46
0.487
<0.001
(0.2,2)
11.48
9.45
Lowest
RMSE
MAE at
Lowest
RMSE
11.86
I
I
I
75
I
P
I
(1.5,5)
9.45
11.48
0.007
0.287
(1.5,5)
0.007
0.287
I
P
I
I
I
The average STFT magnitude, with a maximum frequency of 50 Hz, of the NLIE-Stockham envelope,
with feature adaptation, most accurately predicts the subjects' Beck scores. This remains true even when
considering the features derived from the average STFT magnitude, with a maximum frequency of 20 Hz,
of the NLIE-Stockham envelope.
Variance of the Magnitude of the STFT of the Log-Envelope
6.3
6.3.1
NLIE-Stockham
Figure 45 shows the RMSEs, MAEs, Spearman p, and Spearman p-values between the predicted Beck
score and actual Beck score when the number of PCA components and the GRF are varied, and when
feature adaptation is performed. The only feature used is the variance of the STFT magnitude of the
NLIE-Stockham envelope, using frequencies between 0 and 20 Hz.
RMSEs Without Feature Adapt.
MAEs Without Feature Adapt.
7
-
4
3
2
9.8
11.8
9.7
11 7
1
0.5
96
15
GRF
GRF
Spearman p Without Feature Adapt.
S pearman p Without Feature Adapt.
02
7
03
015I
0.1
4,
02
3
0 05
2
0 15
GRF
GRF
Figure 44: RMSEs, MAEs, and Spearman correlations of the variance of the STFT magnitude of the
envelope, with a maximum frequency of 20 Hz, from NLIE-Stockham, without feature adaptation.
The lowest RMSE, 11.67, occurs at (0.1, 3). The value of 11.67 is only marginally lower than baseline.
The lowest MAE was at GRF=0.1, K=2, and the value of the MAE is 9.60. Again, it is only marginally
lower than baseline. The highest Spearman correlation, 0.341 (p=0.001) occurs at (0.1, 3).
76
The experiments with Ks and GRFs are also performed using feature adaptation. The results are shown in
Figure 45.
RMSEs With Feature Adapt.
MAEs With Feature Adapt.
7
7
11.6
6
1 155
4
9.6
9.5
4
11.45
11.5
3
9.4
3
111.45
1.35
26
5
9.7
1
0.5
9.3
2
15
5
GRF
0.5
1
15
GRF
Spearman p With Feature Adapt.
Spearman p With Feature Adapt.
7
7
0.1
T oe
03
006
4
4
0 25
3
0 04
3
02
2
0.5
1
0,02
2
15
05
GRF
1
1.5
GRF
Figure 45: RMSEs, MAEs, and Spearman correlations of the variance of the STFT magnitude of the envelope
from NLIE-Stockham (up to 20Hz) with feature adaptation.
Both the RMSE and MAE reach a minimum at (0.2, 6), and their values are 11.33 and 9.32, respectively.
Similar to the case without feature adaptation, this is only a marginal gain over baseline.
6.3.2
Hilbert-Stockham
Similar to the mean STFT feature of the Hilbert-Stockham envelope, the variance of the HilbertStockham envelope does not produce meaningful results. Without feature adaptation, the lowest RMSE
achieved is 11.90, which is slightly worse than baseline. The best MAE is 9.98, which is less than a tenth
of a point better than baseline. Further, there is no correlation between the actual Beck score and the
predicted Beck score.
The results are not improved when feature adaptation is performed. The best RMSE is 11.81, which is
0.05 points more accurate than baseline. However, again, there is no correlation between the predicted
77
Beck score and the actual Beck score. The lowest MAE achieved is 9.88, which is less than 0.20 points
better than baseline.
It can be concluded that with the parameters used, the variance of the STFT magnitude of the HilbertStockham envelope is not helpful in predicting a subject's Beck score. It is possible that different window
lengths might be useful, but we darnot find this result when each-window is 1 second long and applied at
half-second delays along the 3-second signal.
64
6.4.1
Coefficient of Variation (CV) of the Magnitude of the STFT of the LogEnvelope
NLIE-Stockham
When the number of PCA components and GRF are varied in the same manner as when testing the mean
magnitude of the STFT of the log-envelope and the variance, the classifier often performs worse than
guessing. Figure 46 illustrates the results when feature adaptation is not performed.
78
RMSEs Without Feature Adapt.
MAEs Without Feature Adapt.
10.5
12.4
12.3
10.4
12.2
10.3
12.1
10.2
12
101
11.9
11.8
10
K
K
Spearman p Without Feature Adapt.
Spearman p WIthout Feature Adapt.
08
0
0.05
06
0.1
0.4
0.15
0.2
0.2
K
K
Figure 46: RMSEs, MAEs, and Spearman correlations of the coefficient of variation of the STFT magnitude
of the envelope from NLIE-Stockham (up to 20 Hz) without feature adaptation - RMSEs, MAEs, Spearman
correlations.
For most (GRF, K) combinations, the classifier performs less accurately than baseline. The lowest MAE
is 9.99, which occurs at (1.5, 3). At those coordinates, the RMSE is 11.89, which is slightly less accurate
than baseline. There is no statistically significant correlation between the predicted Beck score and the
actual Beck score (p=-0.103, p=0.342). The lowest RMSE is 11.74, which occurs at (0.3, 5). At those
(GRF, K) coordinates, the MAE is 10.14, which is worse than guessing. Again, there is no statistically
significant correlation between the predicted Beck score and the actual Beck score (p=0.006, p=0.953).
When feature adaptation is performed, the MDD severity is predicted even less accurately, as shown in
Figure 47. The RMSE never reaches a value below baseline; thus, the coefficient of variation feature
performs less accurately than baseline.
79
RMSEs With Feature Adapt.
MAEs Wfth Feature Adapt
123
10,6
12.2
10.5
LL
121
0
5
104
12
103
11.9
1
0.5
K
15
K
Spearman p With Feature Adapt.
Spearman p With Feature Adapt.
7
7
6
6
0.8
0.6
0.1
4
0.4
4
0.2
3
2
3
0,2
2
03
0.5
K
1
15
K
Figure 47: RMSEs, MAEs, and Spearman correlations of the coefficient of variation of the STFT magnitude
of the NLIE-Stockham envelope, with frequencies up to 20 Hz, with feature adaptation.
With the poor Spearman correlations, RMSEs, and MAEs, it can be concluded that with the parameters
used, the CV of the NLIE-Stockham envelope is not a satisfactory feature for predicting subjects' Beck
scores. It is possible that if a different signal processing method were used, or if different window lengths
in the STFT were used, this could be a useful feature. Further experiments need to be performed before
this feature is determined to be unhelpful in predicting subjects' Beck scores.
6.4.2
Hilbert-Stockham
Similar to the CV feature extracted from the NLIE-Stockham envelope, and the mean STFT magnitude
and variance from the Hilbert-Stockham envelope, the predictor performs less accurately than baseline in
many cases. There is no correlation between the predicted Beck score and actual Beck score, both with
and without feature adaptation. The results are displayed in Figure 48 and Figure 49 for the cases without
feature adaptation and with feature adaptation, respectively.
80
RMSEs Without Feature Adant.
7
MAEs Without Feature Adact.
11.6
13.5
6
5
11.4
13
11
0 4
10.8
12.5
3
10 6
2
10 4
K
K
Spearman p Without Feature Adapt.
Spearman p Without Feature Adapt.
7
6
0.1
08
5
02
06
03
04
4
3
0,2
04
2
K
K
Figure 48: RMSEs, MAEs, and Spearman correlations of the coefficient of variation of the STFT magnitude
of the Hilbert-Stockham envelope, with frequencies up to 20 Hz, without feature adaptation.
81
RMSEs With Feature Adapt.
MAEs With Feature Adapt.
13
11.2
125
4
41
3
10
2
2
12
05
1
104
1
05
15
K
15
K
Spearman p With Feature Adapt.
Spearman p With Feature Adapt
7
7
5
0.05
5
4
5
0
4
04
3
0.15
3
2
02
2
0.5
1
0,8
06
0.2
0.5
is
K
1
15
K
Figure 49: RMSEs, MAEs, and Spearman correlations of the coefficient of variation of the STFT magnitude
of the Hilbert-Stockham envelope, with frequencies up to 20 Hz, with feature adaptation.
Based on these results, using the CV of the STFT magnitude of the Hilbert-Stockham envelope with the
parameters we chose does not aid in predicting subjects' MDD severity.
6.5
Unnormalized Energy in the Low Frequency Band
The feature explored in this section is the unnormalized energy hypothesized to lie in the frequency band
of the AM due to the muscles of respiration. The GRF is varied from 0.1 to 1.5 in steps of 0.1, and the
upper frequency limit, denoted by
f.,
is varied from 1 Hz to 12 Hz. Unlike the previous features, a
single value for each session is generated, so the number of PCA components does not need to be varied.
6.5.1
NLIE-Stockham
Figure 50 shows the RMSEs, MAEs, and Spearman correlations for the low-frequency feature when there
is no feature adaptation, as the GRF is varied from 0.1 to 1 and the upper frequency limit is varied from 1
Hz to 12 Hz.
82
MAEs Without Feature Adapt.
RMSEs Without Feature Adapt.
12
12
12
10
10
10
%8
9.6
6~9.4
4
4
2
29
0.2
0-4
0.6
0.8
9.2
0.2
1
04
0.6
0.8
1
GRF
GRF
Spearman p Without Feature Adapt.
Spearman p Without Feature Adapt.
0412
12
08
10
10
02
4
O6
4
0.2
02
04
0.6
GRF
0.8
1
04
0,2
0.2
0.4
0.6
0.8
1
GRF
Figure 50: RMSEs, MAEs, and Spearman correlations of the unnormalized energy in low frequency region of
the NLIE-Stockham envelope, no feature adaptation. The horizontal axis is the GRF, but the vertical axis is
now the upper frequency limit, f...
The lowest RMSE achieved is 10.73, which occurs whenf.,,, is 12 Hz and when the GRF is 1. At (1,12),
the MAE is 9.11. Both of these values are improvements over baseline. However, the lowest MAE occurs
when f,,.
is 11 Hz and the GRF is 0.1. At (0.1, 11), the MAE is 8.95, 1.1 points below baseline and the
RMSE is 10.91, 0.95 points below baseline. It is interesting that the RMSEs and MAEs improve as f"'.
increases. If there were a clear boundary between the AM region due to the respiratory muscles and the
AM region due to the interaction between the harmonics and the formants, it would be expected that there
would be little energy in that region. As a result, as fan, were increased, there would be a local minimum
in the RMSE and MAE, and then the RMSE and MAE would once again increase. However, this pattern
is not seen.
Regardless, the highest Spearman correlation is achieved at (1, 12), which is the same as the point where
the RMSE is the lowest. At those values of the GRF and upper frequency bound on IEFL[n]l, the
Spearman correlation is 0.466, and p<0.001. The plot showing the predicted Beck score and actual Beck
score is displayed in Figure 51. The correlation between the predicted score and actual score is one of the
higher correlations obtained.
83
Predicted vs. Actual Beck Score, Energy in Frequencies from 0 to 12Hz, No Adaptation
50
45
40
35
a)
0
C.
C',
'R
30
25
V0
0 0
5
10
15
20
25
Beck Score
30
35
40
45
50
Figure 51: Predicted score vs. Beck score using the energy in frequencies from 0 to 12 Hz feature from the
NLIE-Stockham envelope, using feature adaptation. Red line shows line of best fit. Here, the GRF is set to 1.
The results from the same features but with feature adaptation are shown in Figure 52. When the GRF and
K are varied and when the features are adapted toward the means for the subjects, the lowest RMSE
achieved is 10.86. This occurs at the point (1,11). Interestingly, this is higher than the RMSE achieved
without feature adaptation. The lowest MAE is 8.94, which is more than a point lower than baseline. This
occurs at the point (0.3,11). The highest Spearman correlation is 0.476, and this occurs at the point (0.9,
12).
84
MAEs With Feature Adant.
RMSEs With Feature Adapt.
12
12
12
10
11.8
10
10
9.8
8
911.6
0.2
04
0.6
0.8
0.2
1
04
0.6
0.8
1
GRF
GRF
Spearman p With Feature Adapt.
Spearman p With Feature Adapt.
12
04
10
03
6
16
100
4
12
4
02
0.2
04
0.6
0.8
0.2
1
0.4
0.6
08
1
GRF
GRF
Figure 52: RMSEs, MAEs, and Spearman correlations of the low frequency of the NLIE-Stockham envelope,
with feature adaptation. The horizontal axis is the GRF, but the vertical axis is now the upper frequency
limit,f..
There are some slight performance improvements achieved with regard to the MAE and RMSE by using
the energy in the low frequency region. Compared to a baseline value of 11.86, the lowest RMSE is
10.73. This occurs when f.
12 Hz and when the GRF is 1. Feature adaptation is not used. This is an
improvement of 1.1 points on the Beck scale. The classifier was usually guessing a mid-range Beck score.
One of the disadvantages of simply computing the energy in the low-frequency range is that it is likely to
be correlated with the overall sound intensity level of the signal. To remove dependence on this intensity
level, an estimate of the ratio of AM from the respiratory muscles to the AM from the harmonicsformants interaction is computed.
6.5.2
Hilbert-Stockham
Similar to the previous features computed with the Hilbert-Stockham envelope, there are no statistically
significant correlations seen when the unnormalized energy in frequencies up to 12 Hz are computed.
85
6.6
Energy Ratio
Since frequency-domain features extracted from the Hilbert-Stockham envelope do not perform as
accurately as the NLIE-Stockham envelope, the energy ratio features are computed only for the NLIEStockham envelope. The energy ratios lead to a slight improvement in the MAEs and RMSEs, even when
all 3 types of features and 1,092 frequency ranges are attempted. In each case, the GRF is set to 0.2 to
reduce computation time. The lowest MAE for each type of feature and each frequency range is shown in
Figure 53.
Lowest MAE for Each Energy Ratio Feature, No Adaptation
-
10
9.78
9.58.95
9
F/A
A/F
F-A
Lowest MAE for Each Energy Ratio Feature, With Adaptation
109.5-
10.00
9.28
8.95
9F/A
A/F
F-A
Figure 53: Lowest MAEs. Baseline is 10.05. Top: Lowest MAEs for each energy ratio feature, over all 1,092
frequency ranges tested, when feature adaptation was not performed. Bottom: lowest MAEs for the same
features and frequency ranges, but when feature adaptation was performed. The bottom axes of both bar
graphs indicate which type of feature to which the numbers correspond. F/A means the IEFL(f) region to the
energy in the IEL(f) region; A/F is the ratio of the energy in the IEA(f)l region to the energy in the IEFL(J)I
region; F-A is the difference between the two regions.
The feature with the lowest MAE is the difference between frequency regions (F-A). The MAE for the
F-A feature is 8.95 when feature adaptation is not performed, and 8.94 when feature adaptation is
performed. These MAEs are approximately 1.1 points better than baseline, which is 10.05. The lowest
MAE for the F-A feature achieved, both with and without performing feature adaptation, occurs when the
values for (f,,,,
ff, fp) were (11 Hz, 16 Hz, 50 Hz). This is interesting because 16 Hz is the highest
to the upper limit onf
.
threshold for ff1 that is tested, and 50Hz is the lowest threshold for fa that was tested, while 11 Hz is close
86
Lowest RMSE for Each Energy Ratio Feature, No Adaptation
12-
1 7
11.75
1111.81
11.510.91
11 10.5
F/A
A/F
F-A
Lowest RMSE for Each Energy Ratio Feature, With Adaptation
-
1211.81
11.511
11.21
10.91
11
F/A
A/F
F-A
Figure 54: Lowest RMSEs. Baseline is 11.86. Top: Lowest RMSEs for each energy ratio feature, over all
1,092 frequency ranges tested, when feature adaptation was not performed. Bottom: lowest RMSEs for the
same features and frequency ranges, but when feature adaptation was performed. The bottom axes of both
bar graphs indicate the type of feature to which the numbers correspond. F/A means the IEFL(f)l region to the
energy in the IEA(f) region; A/F is the ratio of the energy in the IEAL(f)1 region to the energy in the IE.(f)l
region; F-A is the difference between the two regions.
Figure 54 displays the lowest RMSE for each type of feature and each frequency range. The difference
between the frequency regions again also yields the lowest RMSEs both with and without feature
adaptation. However, the decreases in the RMSE are less than 1 point. In the case without feature
adaptation, the lowest RMSE, 10.91, occurs when the values for (fa,,,f,fp~fp)were (12 Hz, 16 Hz, 5 OHz).
When feature adaptation is performed, the lowest RMSE achieved, 11.00, occurs when the values for
(f,,,.,
fp, fp) are (11 Hz, 16 Hz, 50 Hz). Those values are identical to the values that produce the lowest
MAE.
Without performing feature adaptation on the log-energy difference feature group, the highest Spearman
correlations between the actual and predicted scores also occur when the values for (f.,
ff, ff) were (12
Hz, 16 Hz, 50 Hz). At those frequency thresholds, the Spearman correlation is 0.450 (p<0.001). This is
consistent with the frequency thresholds that that yielded the lowest RMSE without feature adaptation.
87
The actual Beck scores and predicted Beck scores, along with the line of best fit, are shown for the logenergy difference feature without performing feature adaptation, in Figure 55.
Predicted vs. Actual Beck Score, Energy in Frequencies from 0 to 12Hz, No Adaptation
50
0
0
5
10
15
20
25
Beck Score
30
35
40
45
Figure 55: Predicted score vs. Beck score for the energy difference feature, when the values for
are (12Hz, 16Hz, 50Hz) and no feature adaptation is performed. Red line shows line of best fit.
50
(fa,,..,fflfp)
The correlation obtained between the predicted score and Beck score with the energy difference feature,
without feature adaptation, is 0.16 lower than that obtained from the unnormalized energy feature. Thus,
it seems likely that the majority of the correlation in the energy difference feature is due to the energy
below 12 Hz.
Overall, the log-energy difference feature appears to be promising. Most variations reveal that taking the
log-energy between 0 and 12 Hz and the log-energy between 16 and 50Hz provide the most accurate
Beck score predictions. If the assumption that the AM due to the respiratory muscles is at a lower
frequency than the AM due to the interaction between the formants and the harmonics is true, it appears
that a reasonable estimate at which the AM due to the respiratory muscles occurs is between 0 and 12 Hz,
and the interaction between the formants and harmonics of the fundamental occurs between 16 Hz and 50
Hz. However, it is possible that there is some in the regions, because the maximum fa,,a tested is 12 Hz,
and the minimum and maximum ff1 and fa tested respectively, are 16 Hz and 50 Hz.
6.7
Time-Domain Features
This sub-section presents the results obtained when predicting subjects' Becks scores based on the time
domain features described in Section 5.4.
88
The correlation between each of the features from the envelope grade and the Beck scores allows us to
identify the eigenvalues that are the most likely to predict the patients' Beck scores. We perform the
regression/prediction step 43 times for each envelope grade, gradually increasing the number of features
used from 1 to 151. If there are more than five features used, PCA is performed and the data is flattened
to five dimensions. For example, during the first run of the GMM on the coarse grade, we use only the
feature that has the strongest correlation with the Beck scores. In the case of the coarse grade from the
NLIE envelope, this is the third eigenvalue. During the second run, we use the features with the strongest
and second-strongest Spearman correlations. For the coarse grade from the NLIE envelope, this is these
are the third and seventh eigenvalues. The GRF is set to 0.2 because this is the value used by Williamson
et al. [12].
6.7.1
Eigenvalues and Summary Statistic from NLIE Envelope
Table 5 summarizes the results from the NLIE envelope at each of the six grades when feature adaptation
was not performed. The lowest RMSE, 11.00, occurs when the LFMLC grade is used. This is an
improvement of approximately one point on the Beck scale. When the RMSE is 11.00, the Spearman
correlation is 0.380 (p<0.001), and the 590, 13", 9*, and 6' largest eigenvalues are input to the GMM. It
is not surprising that the LFMLC feature yields the lowest RMSE and highest Spearman correlation
because we had been hypothesized that the differences in the frequency content would aid in Beck score
prediction.
Table 5: Summary of results from NLIE envelope at each grade, without feature adaptation. C denotes the
coarse envelope, F denotes the fine envelope, FMC denotes the fine minus coarse envelope, LC denotes the log
of the coarse envelope, LF denotes the log of the fine envelope, and LFMLC denotes the log of the fine
envelope minus the log of the coarse envelope.
Envelope
Grade
Lowest
RMSE
MAE at
Lowest
RMSE
Spearman
p at lowest
RMSE
Spearman
p at lowest
RMSE
Eigenvalue
Indices at
lowest
RMSE
NLIE
NLIE
NLIE
C
F
FMC
11.33
11.54
11.38
9.12
9.46
9.09
0.367
0.296
0.371
<0.001
0.005
3,7
3
<0.001
1,57,40,
50,...
There is a
total of 110
eigenvalues
used in
NLIE
NLIE
NLIE
LC
LF
LFMLC
11.44
11.60
11.00
9.27
9.39
8.86
0.339
0.274
0.380
0.001
0.010
<0.001
PCA.
89
3,7,17
9,23,3,5
59,13,9,60
Figure 56 illustrates the predicted vs. actual Beck scores using the
5 9 th,
13t, 9t, and 6" eigenvalues from
the LFMLC grade of the NLIE envelope. Each grade has its own set of eigenvalues that are the most
strongly correlated with the Beck scores. All grades except the difference grades contain the third largest
eigenvalue as one of the three eigenvalues that is most strongly correlated with the Beck scores. It is
interesting that this eigenvalue index does not appear in the difference grades. Since the lowest RMSEs
are still close to baseline, it is not appropriate to draw a conclusion about the significance of the third
largest eigenvalue.
Predicted vs. Actual Beck Score, NLIE, LFMLC, No Feature Adaptation
50
40
q
-.-.--.--
--.-.-
-0--
a)830- -
-
--
-
20 -- 0
1
0
0
5
10
15
20
25
Beck Score
30
35
40
45
50
Figure 56: Predicted vs. actual Beck score using the LFMLC grade from the NLIE feature, without feature
adaptation.
The same experiments are also performed with feature adaptation. The results from those experiments are
shown in Table 6. For this case, the features that lead to the lowest RMSE are the 5 features that result
from performing PCA on 110 of the eigenvalues from the correlation matrix. The lowest RMSE is 10.66,
more than a full point lower than the baseline of 11.86. The corresponding MAE is 8.49, more than 1.5
points below the baseline value of 10.05. However, the RMSE, MAE, and Spearman correlation achieved
by the LFMLC grade are also competitive. Figure 57 shows the predicted versus actual Beck score when
PCA on 110 eigenvalues from the FMC grade is performed.
90
Table 6: Summary of results from the NLIE envelope at each grade, with feature adaptation.
Envelope
NLIE
NLIE
NLIE
Grade
C
F
FMC
Lowest
RMSE
11.28
11.28
10.66
MAE at
Lowest
RMSE
9.07
9.31
8.49
Spearman
p at lowest
RMSE
Spearman
p at lowest
RMSE
Eigenvalue
Indices at
lowest
RMSE
0.349
0.298
0.465
0.001
0.005
<0.001
3,7
3, 9,12
1,57,40,...
There is a
total of 110
eigenvalues
used in
PCA.
NLIE
NLIE
NLIE
LC
LF
LFMLC
11.44
11.41
10.78
9.34
9.31
8.67
0.377
0.299
0.420
<0.001
0.005
<0.001
3
9
59, 13,9...
There is a
total of 110
eigenvalues
used in
PCA.
The Spearman correlation between the actual and predicted Beck scores in Figure 57 is 0.420 (p<0.001).
This is the strongest correlation observed among the time-domain features, yet it is not as strong as the
highest Spearman correlation achieved by the frequency-domain feature with the lowest RMSE.
91
Predicted vs. Actual Beck Score, NLIE, FMC, PCA on 110 Eigenvalues, With Feature Adaptation
45
40
35
(D
8 30
C',
25
0
24
0
00
.00
0
0
0
-
Oo
5
0
5
10
15
20
25
Beck Score
30
35
40
45
50
Figure 57: Predicted vs. actual Beck score using the FMC grade from the NLIE feature, with feature
adaptation.
6.7.2
Eigenvalues and Summary Statistic from Hilbert Envelope
The same procedure is performed on the grades derived from the Hilbert envelope. Table 7 illustrates the
results. Similar to the NLIE envelope, the lowest RMSE is achieved when the LFMLC envelope is used.
The RMSE from the Hilbert envelope-derived LFMLC is lower than the RMSE from the NLIE envelopederived RMSE. Here, it is 10.89, approximately a tenth of a point lower than the RMSE from the NLIE
envelope-derived LFMLC grade, and almost a point lower than the baseline RMSE of 11.86. This is
unexpected because the frequency-domain features from the NLIE-Stockham envelope were able to
predict subjects' Beck scores than frequency-domain features from the Hilbert-Stockhlam envelope. The
eigenvalues used to derive the lowest RMSE from the Hilbert LFMLC grade are the 65t, 66h, and 15t
largest eigenvalues. It is surprising that the eigenvalues from the LFMLC grade most strongly correlated
with the Beck score are much smaller in absolute value than the eigenvalues. The significance of this has
yet to be explored.
92
Table 7: Summary of Results from Hilbert Envelope at each grade, without feature adaptation.
Envelope
Grade
Lowest
RMSE
MAE at
Lowest
RMSE
Spearman
p at lowest
RMSE
Spearman
p at lowest
RMSE
Eigenvalue
Indices at
lowest
RMSE
Hilbert
Hilbert
Hilbert
Hilbert
Hilbert
Hilbert
C
F
FMC
LC
LF
LFMLC
11.37
11.32
11.28
11.53
11.23
10.89
9.35
9.38
9.29
9.32
9.21
8.72
0.299
0.338
0.361
0.269
0.332
0.388
0.005
0.001
0.001
0.012
0.002
<0.001
3,7,43
3
13
17,2,43
4,5
65,66, 15
The same experiments are also performed
with feature adaptation. The results from those experiments are
shown in Table 8.
Table 8: Summary of results from Hilbert envelope at each grade, with feature adaptation.
Envelope
Grade
Lowest
RMSE
MAE at
Lowest
RMSE
Spearman
p at lowest
RMSE
Spearman
p at lowest
RMSE
Eigenvalue
Indices at
lowest
RMSE
Hilbert
Hilbert
Hilbert
Hilbert
Hilbert
Hilbert
C
F
FMC
LC
LF
LFMLC
11.49
11.33
11.21
11.50
11.19
10.81
9.46
9.43
9.13
9.40
9.15
8.72
0.363
0.358
0.377
0.300
0.356
0.448
0.001
0.001
0.000
0.005
0.001
0.000
3
3
13,31, 16
17,2
4,5
65,66
The results are very similar to those obtained from the Hilbert envelope without feature adaptation.
Again, the grade that best predicts subjects' Beck scores is the LFMLC. Unlike the case without feature
adaptation, where three eigenvalues of the cross-correlation matrix are used, only two eigenvalues are
used with feature adaptation. The lowest RMSE is 0.08 points lower than without feature adaptation, and
the MAE is exactly the same.
93
6.8
Conclusions
Using two types of envelope extraction methods, the Hilbert-Stockham and NLIE-Stockham, we tested
seven types of features extracted from the envelopes of the AVEC held vowels: the mean STFT of the
envelope, variance of the STFT of the envelope, covariance of the STFT of the envelope, energy in the
low frequency band, difference in energy between two frequency bands, and eigenvalues from the
correlation matrices of various grades extracted from the envelopes. Of all of the features tested, the
features that most accurately predicted the subjects' Beck scores are the average STFT magnitude of the
NLIE-Stockham envelope reduced by PCA, where frequencies up to 50 Hz are extracted, and the
eigenvalues from the correlation matrix of the FMC grade, also computed from the NLIE-Stockham
envelope. In the first case, when feature adaptation is performed, the GRF is set to 0.2, and 2 components
from PCA are input to the GMM, the RMSE is 10.32, the MAE is 8.46, and the Spearman correlation is
0.487 (p<0.001). This represents decreases in error of approximately 1.5 points for both the RMSE and
MAE. When PCA is performed on 110 eigenvalues from the cross-correlation matrix of the FMC grade
of the NLIE envelope, the MAE is 8.49, the RMSE is 10.66, and the Spearman correlation is 0.465
(p<0.001). These features are fairly consistent with the hypothesis that subjects with MDD have different
modulation patterns in their held vowel than subjects without MDD.
94
Chapter 7 Conclusions and Future Work
In this thesis, we proposed a model of vocal modulation as a basis for developing biomarkers of
neurological disease and, in particular, Major Depressive Disorder (MDD). The modulation model was
developed in the context of a sustained vowel, assuming that two components contribute to amplitude
modulation (AM): AM from the respiratory muscles and AM from interaction between formants and the
FM from the fundamental frequency harmonics, i.e., from a mapping of FM to AM. This model was
motivated by the perceptual task of Chapter 3, the hypothesis of motor incoordination in MDD [12], and
the finding that spectrotemporal information at low frequencies (up to 25 Hz) can be used to predict MDD
severity [29]. The two AM components were represented in the model as multiplicative contributions to
the speech signal's envelope. We explored the separability of the modulation contributions by
implementing three envelope extraction techniques: (1) Stockham's method, where the logarithm of the
magnitude of the signal is extracted [39], (2) computing the logarithm of the magnitude of the Hilbert
envelope, referred to as the Hilbert-Stockham envelope and (3) a nonlinear, iterative envelope (NLIE)
estimation method [43], combined with the Stockham approach, referred to as the NLIE-Stockham
method. We found that the Hilbert-Stockham and the NLIE-Stockham estimation methods enable
improved separability compared to the Stockham envelope.
With these envelope estimation approaches as a basis, we derived frequency-domain and time-domain
features from bandpass-filtered speech signals, and predicted the subjects' Beck scores using a GMM.
Bandpass filters were centered around the 3' formant to accentuate the envelope contribution from the
fundamental frequency FM. The frequency-domain features were the following: the average STFT
magnitude of the logarithm of the envelope, the variance of the STFT magnitude of the logarithm of the
envelope, the coefficient of variation of the STFT of the logarithm of the envelope, the unnormalized
energy in a low-frequency band, and the difference in the energy in two frequency bands. The timedomain features were the eigenvalues of the cross-correlation matrix of the envelope over five time
segments.
For the frequency-domain features, the most accurate Beck score prediction was a decrease of 1.54 points
from baseline (from 11.86 to 10.32) in the RMSE, and a decrease of 1.59 (from 10.05 to 8.46) in the
MAE. The corresponding Spearman correlation between the predicted Beck score and actual Beck score
was 0.487 (p<0.001). We accomplished this by performing PCA on the average STFT magnitude of the
NLIE-Stockham envelope, reducing the dimensionality to 2 components, and performing feature
adaptation. For the time-domain features, the most accurate Beck score prediction was a decrease of 1.20
points from baseline (from 11.86 to 10.66) in the RMSE, and a decrease of 1.56 (from 10.05 to 8.49) in
95
the MAE. The Spearman correlation between the actual Beck score and predicted Beck score was 0.465
(p<0.001). The time-domain features that produced these results were obtained by pre-processing the
acoustic signal, creating a sampled correlation matrix, computing the eigenvalues of the matrix,
performing PCA on 110 of the eigenvalues to yield 5 features, and performing feature adaptation, as
described in Sections 54 and 6.7. Together, the features are fairly consistent with the hypothesis that the
modulation patterns of the sustained vowels uttered by subjects with MDD are different from those
uttered by subjects without MDD.
The thesis modeling and prediction methodologies provide a foundation for future work. This includes
improvement to the underlying model, implementation of the model, the pre-processing methods, and the
feature extraction methods. Application to other neurological disorders such as ALS, Parkinson's disease,
and early dementia is another rich area, as well as further investigation of other MDD speech types and
conditions such as running speech with more emotional content or under fatigue.
7.1
Improvement to the Underlying Model
The assumptions underlying the model are overly simplistic. These include: (1) frequency of the AM
from the respiratory muscles is less than the AM due to the interaction between the harmonics of the
fundamental and the formants, (2) there is no relationship between amplitude and change in fundamental
frequency, (3) the frequency and bandwidth of the formant remain constant through the duration of the
vowel. This section describes the limitations in each of these assumptions.
A literature review did not reveal modulation frequencies associated with the muscles of respiration
during a held vowel, but it was assumed that such frequencies are lower than the frequencies at which the
harmonics and formants interact. To ascertain our assumption, respiration modulation frequencies during
a held vowel would need to be measured, and the bandwidth, shape, and magnitude of the formants would
need to be known. Further, the coordination of the various muscles of respiration would need to be
measured. We assumed that the incoordination would occur between the muscles of respiration and the
interaction between the harmonics of the pitch and the formants, but another possible source of
incoordination is within the muscles of respiration themselves.
To further improve our model we should add the possibility that the vocal folds can introduce AM as well
as FM; currently we assume FM only as revealed in pitch modulation. Moreover, we may want to exploit
96
a possible relationship between the amplitude and fundamental frequency modulation in this production
component, as described by Titze [18].
The model also assumes that the formants are held constant throughout the duration of the vowel. When
we viewed the spectrograms, this appeared to be mostly true, although there were some instances where
the formants appeared to move by approximately 100 Hz. A small movement in the frequency location or
bandwidth of the formant can cause different modulation patterns as the harmonics of the fundamental
frequency move through the formant.
7.2
Implementation of the Model
The implementation of the model could be improved by introducing a time-varying depth of modulation
and frequency of modulation of both the AM and FM to represent a more erratic modulation condition,
and by modeling each opening/closure of the vocal folds as a glottal pulse instead of an impulse. We
have hypothesized in this thesis that the depressed voice is characterized by erratic modulation, yet in our
model, we implemented a single, time-invariant depth and frequency of modulation for both AM and FM.
In addition, modeling each opening/closure of the vocal folds as a glottal pulse instead of an impulse will
introduce low-frequency weighting. This time-varying low- frequency weighting might interfere with the
frequencies at which the AM and FM occur, therefore complicating the challenge of identifying the
frequencies in the AM and FM.
7.3
Envelope Extraction
Three methods of envelope extraction were explored in this thesis: Stockham, Hilbert-Stockham, and
NLIE-Stockham. A fourth method of extracting the envelope that could have been performed is bandpassing the Hilbert envelope a second time, passing only the frequencies at which the fundamental
frequency is expected to occur. The Hilbert transform would then again be performed a second time, and
the magnitude and logarithm of that envelope taken. This might offer an improvement over the HilbertStockham method because the Hilbert-Stockham envelope also has a clear envelope component. Thus
band-passing and computing the Hilbert transform envelope as a second application on the Hilbert
envelope might the envelope extraction. Alternatively, a fifth method that uses a novel non-linear
demodulation algorithm based on complex optimization, and allows different temporal resolutions, should
be considered [47].
97
74
Pre-Processing the Envelopes
Due to limited signal duration, the STFT of each envelope was computed over 1-second windows, shifted
at half-second delays over the middle 3 seconds of each speech waveform. Other window lengths could
be tested when computing the STFT. In addition, we might focus our processing at different formants and
more generally different bands. Using multiple bands and later fusing results may lead to more robust
estimators.
The frequency-domain features in this thesis mainly explored the middle three seconds. In the future, we
could also explore the features extracted from the envelopes of the onset and offset of each vowel. It is
possible that psychomotor retardation and/or psychomotor agitation may affect the rise time of the
vowel's envelope, and the time constant of the offset, assuming the offset of the envelope is roughly
exponential.
7.5
Features
Additional features that could be tested involve using the features extracted from the Multi-Dimensional
Voice Program (MDVP), applying the cross-correlation and covariance features to the time-domain
envelope after application of a gammatone filter bank to the envelope, performing the cross-correlation
and covariance features to the envelope spectra in the frequency domain, and developing features that
relate the modulation in the envelope to the DC component of the envelope. As described in Chapter 2,
MDVP outputs features that quantify the depths and rates of modulation. These features could be directly
input to the GMM. Alternatively, the features from MDVP could be extracted at different times
throughout the waveform, and the relationships among those features at different times could be explored.
Applying a gammatone filter bank to the original signal or to its envelope (thus further generalizing the
filtering described in Section 7.3), and computing the cross-correlation and covariance features would be
similar to the process used by Williamson et al. [12] on the formants. However, the features extracted
from the gammatone filter bank would reveal information about the envelopes instead of the formants.
Computing the eigenvalues of the correlation and covariance matrices of the spectrum of the envelopes
may also be features that differentiate depressed from control subjects. The difference between these
features and the features described in Sections 5.4 and 6.7 are that the cross-correlations and covariances
would be performed on signals in the frequency domain.
98
Another class of features that could be computed relates the modulation to the DC component. In this
thesis, we removed the DC component when computing the STFT because the spectral sidelobes of the
component at DC were too large relative to the low frequency components of the envelope. By measuring
the ratio of the energy of the low frequency components and comparing it to the energy at DC, we would
create another class of features.
99
Appendix A: Subjectively Rating Vocal Modulation
Members of MIT Lincoln Laboratory were asked to rate the amount of vocal modulation in 25 held /a/
vowels. For the listening section, raters listened to each of the waveforms. Before they began the test,
they were provided aurally with examples of significant vocal modulation and little/no modulation. They
were told to rate each waveform using the following rating scheme:
1
2
3
4
5
-
very little/no vocal modulation
mild/moderate vocal modulation
moderate vocal modulation
moderate/severe vocal modulation
severe vocal modulation
The objective of the second task was to visually rate the presence of sub-harmonics from spectrograms.
As an example, Figure 58 contains two waveforms: one with sub-harmonics, and one without subharmonics.
1400 Hz
Distinct sub-harmonics
5.90 Time (sec)
1400
0 Hz
No visible sub-harmonics
5.92 Time (sec)
Figure 58: Sub-harmonics in a held vowel. Top spectrogram: /a/ vowel with a region with faint subharmonics, and two regions where there are clearly sub-harmonics. Bottom spectrogram: /a/ vowel with no
sub-harmonics present.
The raters were instructed to avoid listening to the waveforms from the AVEC database. The rating scale
used was:
1 - no sub-harmonics present
100
2
3
4
5
-
sub-harmonics appear once and last < 0.15 sec/unclear sub-harmonics
sub-harmonics appear once and last >0.15 seconds
clear sub-harmonics appear 2 or 3 times and last >0.15 seconds
clear sub-harmonics appear more than 3 times and occur throughout the spectrogram
The third task consisted of rating the amount of FM in each of the waveforms while viewing 7-10
harmonics on the spectrogram. Examples are illustrated in Figure 59.
Significant amount off0 modulation
0W4w
Time (sec)
6.93
P-ASW-
n*
Time (sec)
Relatively flat fo modulation
4.31
Figure 59: FM in a held vowel. Top spectrogram: /a/ vowel with region containing significant amounts of
FM. Bottom spectrogram: /a/ vowel with little FM.
The rating scale was:
1 - nearly constant frequency
2 - mild FM
3 - moderate FM
4 - moderate/severe FM
5 - severe FM
Finally, the raters evaluated the AM in each of the waveforms by viewing the waveforms in the time
domain.
101
--+
4wiw
- 7*
r i r i
Relatively little AM
71,1
Time (sec)
4.31
1
Time (sec)
Significant amount of AM
6.94
Figure 60: AM in a held vowel. Top spectrogram: /a/ vowel with relatively little AM. Bottom spectrogram: /a/
vowel with a significant amount of AM.
Figure 60 illustrates the range of AM seen in the waveforms. The rating scale used was:
1 - nearly constant amplitude
2 - mild AM
3 - moderate AM
4 - moderate/severe AM
5 - severe AM
102
Appendix B: Beck Depression Inventory
The self-reported Beck Depression Inventory rates the following symptoms of depression:
1) Sadness
2) Pessimism
3) Past failure
4) Loss of pleasure
5) Guilty feelings
6) Punishment feelings
7) Self-dislike
8) Self-criticalness
9) Suicidal thoughts
10) Crying
11) Agitation
12) Loss of interest
13) Indecisiveness
14) Worthlessness
15) Loss of energy
16) Change in sleeping
17) Irritability
18) Change in appetite
19) Concentration difficulty
20) Tiredness or fatigue
21) Loss of interest in sex
Each symptom is rated on a scale between 0 and 3 and then all 21 scores are summed. Thus, each
subject's depression is rated on a scale between 0 and 63[48][49].
103
Appendix C: Derivation of Equations for AM, FM, and FM-and-AM
In Figure 4, the AM- and FM-modulated pulse train from the glottis, PAF [n], is the product of the AM
envelope and cosine of a function of the FM, summed over all harmonics of fo. In other words, PAF [n] can
be expressed as:
PAF [
= eA[n]X.1COS(Pk[n]).
A]
(25)
where
K is the number of harmonics
k is the index of the harmonic
eA [n] is the envelope of the AM, described in Chapter 4, and
Pk [n] is a phase function of the FM signal, described later in this appendix.
eA[n]
+ !- cos
21rn
.
As discussed in Chapter 4, the AM envelope, eA [n], is assumed to originate from the muscles of
respiration. It shapes the harmonics of fo, which originate from the opening and closing of the vocal folds.
The equation for eA [n] is assumed to be sinusoidal:
It assumes the muscles of respiration control both the AM extent and AM rate.
If there is AM but no FM in the source signal, the model appears as shown in Figure 61.
Harmonic
syntheszer
Figure 61: Model with AM-only input signal. eA[n] is the AM envelope that shapes the harmonics from the
harmonic synthesizer. The output from the harmonic synthesizer is an AM pulse train, denoted pA[n], which
is sent through the vocal tract, H,(). The output from the vocal tract is xA[n], an AM signal.
If the depth of AM, aa, is set to 0.2 and the frequency of the AM, fa, is 4 Hz, eA [n] appears as shown in
Figure 62. The depth of modulation is constrained to 0 < aa ! 1.
104
AM envelope eA[n], fo=200Hz, aa=0. 2 , fa=4
0.6-0.5 -0.4 -M
V
0.30.20.1-
00
0.5
1
1.5
Time (sec)
2
2.5
3
Figure 62: AM envelope, eA[n], when a =0.2 andf.=4 Hz.
The AM envelope, eA [n], is passed through a harmonic synthesizer, which is modeled as a sum of
sinusoids [30] . The output of the harmonic synthesizer when only AM is present, pA [n], represents the
opening and closing of the vocal folds shaped by the AM envelope, and approximates a series of
impulses. The equation for pA [n] is given in Eq. 26:
PA[fl] = eA[n] {..cos(27rk(fO/fs)n)
where fs is the sampling rate. Figure 63 displays plots of pA [n] are over two timescales. In those plots, the
AM depth and rate are 0.2 and 4 Hz, respectively, as example values.
105
(26)
pA [n], f=200Hz, aa=0.2, fa=4, Displayed over 3 sec
10 VVVVVVV-'i
0.
E
5
0
0
0.5
PA
1
1.5
Time (sec)
2
2.5
3
4
f0=20OHz, aa=0. 2 , fa= , Displayed over 0.2 sec
15
10a&
5-
E
d
0i44
0.15
0.2
Time (sec)
0.25
0.3
Figure 63: AM from respiratory muscles shaping glottal impulses. Upper plot: AM signal over a 3-second
signal. Lower plot: 0.2 seconds of the signal, showing each of the impulses.
The upper plot of Figure 63 displays pA[n] over a 3-second signal. It is difficult to discern the individual
impulses because they are spaced 50 ms apart. However, the shaping of the impulses at a rate of 4 Hz is
visible. The lower plot of Figure 63 is a zoomed-in view of pA [n], from 0.1 seconds to 0.3 seconds. The
AM shaping of the impulses is clearly visible.
When pA [n] is passed through the vocal tract transfer function, bandpass filtered to isolate formant 3
(F3), and Hilbert transformed, as depicted in the bottom branch of Figure 17, the resulting signals appear
as shown in Figure 64.
106
Entire pA[n] waveform, f0=200Hz, aa=0. 2 , fa= 4
PA[n] over 0.2 sec
20
20
10
10 -
bA[n
bA[n]
10
0
-10
o
0.5
1
1.5
2
2.5
.1
3
0.15
20
0
0
-20
-40
0.5
1
1.5
2
4
2.5
.1
0.15
0.5
0.5
0
0
0.5
1
1.5
2
2.5
3
B.1
0.5
0
0
0
0.5
1
1.5
Time (sec)
2
0.2
0.25
0.3
0.15
0'2
0.25
0. 3
bA[n] and YA[n] over 0.2 sec
Entire bA [n] and yA[n] waveforms
0.5
-0.5
0.3
bA[n] over 0.2 sec
Entire bA[n] waveform
0
0.25
20
-20
-0.5
0.2
xA[n] over 0.2 sec
Entire xA[n] waveform,
2.5
3
-.
5.1
0.15
0.2
Time (sec)
0.25
0. 3
Figure 64: First row: pA[n], the AM source signal. Second row: xA[n], the output from the vocal tract when
pA[n] is the input, Third row: bA[n], the F3-bandpass-filtered waveform when xA[n] is the input. Fourth row:
yA[n], the Hilbert transform of bA[n]. The left column shows each of the entire 3-second waveforms; the right
column shows 0.2 seconds of the waveform to depict activity in higher frequencies. The first three formant
frequencies are 820 Hz, 1220 Hz, and 2810 Hz, with bandwidths of 125 Hz, 125 Hz, and 250 Hz, respectively.
The center frequency of the bandpass filter is 2810Hz and bandwidth is 250Hz.
The first row illustrates PA [n], and is identical to the graphs in Figure 63. The output of the model, xA [n],
occurs when pA [n] is input to the vocal tract. In this case, fo is 200 Hz, and the three formants are 820 Hz,
1220 Hz, and 2810 Hz, forming the /a/ vowel. The bandwidths are 125, 125, and 250 Hz for formants 1-3,
respectively. The second row in Figure 64 displays the output from the vocal tract, xA [n] on the same two
timescales. Over the three-second signal, only the slow AM from the respiratory muscles is visible. When
zoomed into the first 0.2 seconds of the synthetic vowel, higher frequency components are visible. xA [n]
is then input to a bandpass filter that passes only F3. The result, bA [n], is shown over the two timescales
in the third row of Figure 64. It is much smaller in amplitude than xA[n] because there is less energy in
the third formant than in the first two formants Finally, the Hilbert transform of bA[n] is taken, and the
result, yA [n], is displayed in the bottom row of Figure 64. The period of the Hilbert transform
approximately traces each pitch period.
Figure 65 illustrates the block diagram for the FM-only model. The extent, rate, and center frequency are
specified to generate the FM signal, which represents the instantaneous frequency. Harmonics of that
signal are generated and added together.
107
Figure 65: FM-only model. #k[n] represents the phase of the FM and described later in this chapter.
The following equation describes vibrato, which is the frequency modulation in the signal. The source of
the FM described in this chapter is assumed to be from the laryngeal muscles. Letting r[n] be the vibrato
as a function of time, af be the extent of the frequency modulation (or FM index), and ff be the rate of
the vibrato, r[n] can be expressed as:
r[n] = af cos (2rffn/fs).
The instantaneous frequency for the k* harmonic,
(27)
k [n], can be expressed as:
Dk[n] = k2 0 [n]
(28)
where J2 [n] is the instantaneous frequency. The instantaneous frequency is a function of r[n]. The
instantaneous frequency is the fundamental frequency offset by r[n]:
120 [n] = fo + r[n].
(29)
Substituting Eq. 27 into Eq. 29, the following expression for 12 k[n] is obtained:
=
k(f0 + afcos (21rfn/fs)).
(30)
The phase qrj [n] is the integral of the frequency of the kth harmonic (modified from [30]):
*fjnk [] da.
(31)
Pk [n]
f
Substituting Eq. 30 into Eq. 31, Eq. 32 is obtained:
k
=
nf
0
+ afkcos (27rffalfs))do.
(32)
Therefore,
(33)
k[n]= + afk sin(27fl/fs)
fs
27rff
When the sum of the cosine of
muscles, PF[n], is obtained:
kk
PF~n
[n] is taken over all harmonics, the pure-FM output from the laryngeal
= PFK=1
COS (27kfon/fs
108
+=af k sin(
f
I
(34)
The 3-second harmonic FM signal generated using fo=200 Hz, af=l0 Hz, and ff=7 cycles/sec 2 is shown
in Figure 66. The bottom panel of Figure 66 shows the same signal, but zoomed into a range of times
from 0.1 second to 0.3 seconds.
7
pF [' f 0=200Hz, af=1 0, ff= , Displayed over 3 sec
E
AU0
0.5
1
1.5
2
2.5
Time (sec)
7
PF ], f0=200Hz, af=10, f,= , Displayed over 0.2 sec
3
-
10
E)
in
'6.1
I
I
0.12
0.14
I
I
0.16
0.18
I
0.2
Time (sec)
I
I
0.22
0.24
I
0.26
I
0.28
0.3
Figure 66: pF[n] over two timescales. Top: pF[n] over 3 seconds. Bottom: p,[n] between times 0.1 and 0.3
seconds
In the bottom panel of Figure 66, the changes in frequency are visually imperceptible; the purpose is to
show that a series of impulses is obtained. Figure 67 illustrates the instantaneous frequency of the same 2second FM signal, as well as the spectrogram of the signal.
Instantaneous Frequency of p[n1, f0=200Hz, af=1 0, ff= 7
210
205
195
10
'4I
0
0.5
-M
1
1.5
2
2.5
3
2
2.5
3
Spectrogram of pF[n
15
g10
0
0.5
1
1.5
Time (sec)
Figure 67: Top plot: instantaneous frequency of pF[n]. Bottom plot: spectrogram of pF[n] from 0 to 2000 Hz.
The upper plot of Figure 67 shows the instantaneous frequency of the fundamental frequency of the signal
created when the center fundamental frequency is 200 Hz, the frequency index (af) is 10 Hz, and the rate
of frequency change (ff) is 7 cycles/sec 2 , and the signal is 2 seconds long. The lower plot is the
109
spectrogram of the FM-only signal with the same parameters, but after the first 10 harmonics are
included. As k increases, the extent of the frequency also increases, but the rate at which the frequency
changes remains constant at 7 cycles/sec2 . The harmonic centered at 2 kHz reaches a maximum frequency
of 2100 Hz and a minimum frequency of 1900 Hz, with an extent of 100 Hz.
When pF[n] is passed through the vocal tract, bandpass filtered to formant 3, and Hilbert transformed, as
depicted in the top branch of Figure 17, the resulting signals appear as shown in Figure 68.
Entire pFJn] waveform, fo=200Hz, a1=1 0, ff=7
pF[n] over 0.2 sec
10.
0
0.5
1
1.5
2
2.5
_.1___.
__
0.15
3
Entire xF[n] waveform
0.25
0 3
0.25
0.3
0.25
0.3
xFJn] over 0.2 sec
50
50
o
0.2
.____
0.5
1
1.5
2
2.5
-5.1
3
0.15
Entire bF[n] waveform
0.2
bF[n] over 0.2 sec
1
0
0
0.5
1
1.5
2
2.5
3
t.1
Entire bF[n] and YF[n] waveforms
0.5
1
1.5
Time (sec)
2
2.5
0.2
bF[n] and YF[n] over 0.2 sec
11111flii lII~
0
0.15
1.
0
6.1
3
0.15
0.2
Time (sec)
0.25
0.3
Figure 68: First row: PF[n], the AM source signal. Second row: xF[n], the output from the vocal tract when
PF[n] is the input, Third row: b,[n], the formant 3-bandpass-filtered waveform when x,[n] is the input Fourth
row: yF[n], the Hilbert transform of bF[n], plotted on top of b,[n] The left column shows each of the entire 3second waveforms; the right column shows 0.2 seconds of the waveform to depict activity in higher
frequencies. The formants are 820 Hz, 1220 Hz, and 2810 Hzwith bandwidths of 125 Hz, 125 Hz, and 250 Hz.
The bandpass filter is set to formant 3, with a center frequency of 2810 Hz and bandwidth of 250 Hz.
The top plots illustrate PF[n],which is identical to the graphs in Figure 66. The output of the model,
XF [n], occurs when pF [n] is put through the vocal tract. In this case, the fundamental frequency is 200 Hz
for a female, and the three formants are 820 Hz, 1220 Hz, and 2810 Hz, forming the /a/ vowel. The
bandwidths are 125, 125, and 250 Hz for formants 1-3, respectively. The second row in Figure 68 shows
XF [n] on the same two timescales. Although there was no AM as an input to the model, it appears as
though there is AM! This occurs because the harmonics of the fundamental interact with the formants, as
discussed in Chapter 4. When zoomed into the first 0.2 seconds of the synthetic vowel, higher frequency
components are visible, but the AM from the interaction between the harmonics and the formants is still
present. The AM-only XF [n] is then passed through a bandpass filter that only filters out formant 3. The
result, bF[n], is shown over the two timescales in the third row of Figure 68. There is still AM due to FM
present, although the shape of the envelope appears to be different. This is because there is only one
formant with which the harmonics can interact, instead of three. Finally, the Hilbert transform of bF [n] is
110
taken, and the result, yF[n], is shown in the bottom row of Figure 68. The period of the Hilbert transform
approximately traces out the fundamental frequency, and the envelope is still present.
111
Appendix D: Model of the Vocal Tract
The vocal tract transfer function, H,(f), shapes the pulse train PAF[n] by utilizing three all-pole filters in
series, as described in [50], one for each of the three formants. Letting i be the index of the formant, the
equation for H,(f) is given in Eq. 35 (modified from [50]):
H,(Z) = 1=(i)-2
i=I1-aC)Z- y(j)z- 2
In Eq. 35, f(i), a(i), and y(i) are given by the following, where B(i) is the 3-dB bandwidth of the
formant i and F(i) is the formant frequency of forinant i (also modified from [50]).
y(i) = -exp (-2nB(i)/f5)
a(i) = 2 cos(27rF(i)/fs) exp (7rB(i)/fs)
f(i) = 1 - a(i) - y(i).
112
(35)
Bibliography
[1] J. Sundberg, "Acoustic and psychoacoustic aspects of vocal vibrato," Vibrato, pp. 35-62, 1995.
[2] J. Kreiman, B. Gabelman, and B. R. Gerratt, "Perception of vocal tremor," J. Speech Lang. Hear.
Res., vol. 46, pp. 203-214, Feb. 2003.
[3] L. A. Ramig and T. Shipp, "Comparative measures of vocal tremor and vocal vibrato," J. Voice, vol.
1,no. 2, pp. 162-167,1987.
[4] M. Bruckl, "Vocal Tremor Measurement Based on Autocorrelation of Contours," in 13th Annual
Conference of the InternationalSpeech CommunicationAssociation, Portland, OR, 2012, pp. 715-
718.
[5] D. J. Kupfer, E. Frank, and M. L. Phillips, "Major Depressive Disorder: New Clinical,
Neurobiological, and Treatment Perspectives," The Lancet, vol. 379, no. 9820, pp. 1045-1055, Mar.
2012.
[6] S. S. Newman and V. G. Mather, "Analysis of Spoken Language of Patients with Affective
Disorder," Am. J. Psychiatry, vol. 94, pp. 913-942, 1938.
[7] A. Nilsonne, J. Sundberg, S. Ternstrom, and A. Askenfelt, "Measuring the Rate of Change of Voice
Fundamental Frequency in Fluent Speech During Mental Depression," J. Acoust. Soc. Am., vol. 83,
no.2, pp.716-728, 1988.
[8] J. C. Mundt, "Voice Acoustic Measures of Depression Severity and Treatment Response Collected
Via Interactive Voice Response (IVR) Technology," J. Neurolinguistics,vol. 20, no. 1, pp. 50-64,
Jan.2007.
[9] A. C. Trevino, T. F. Quatieri, and N. Malyska, "Phonologically-based biomarkers for major
depressive disorder," EURASIP J. Adv. Signal Process., vol. 2011, no. 1, pp. 1-18, 2011.
[101E. Moore, M. Clements, J. Peifer, and L. Weisser, "Analysis of Prosodic Variation in Speech for
Clinical Depression," in Engineeringin Medicine and Biology Society, 2003. Proceedingsof the 25th
Annual InternationalConference of the IEEE, Cancun, Mexico, 2003, vol. 3, pp. 2925-2928.
[11]R. Horwitz, T. F. Quatieri, B. S. Helfer, B. Yu, J. R. Williamson, and J. C. Mundt, "On the Relative
Importance of Vocal Source, System, and Prosody in Human Depression," presented at the 2013
IEEE International Conference on Body Sensor Networks, Cambridge, MA, 2013, pp. 1-6.
[12]J. R. Williamson, T. F. Quatieri, B. S. Helfer, R. Horwitz, B. Yu, and D. D. Mehta, "Vocal
biomarkers of depression based on motor incoordination," in Proceedingsof the 3rd ACM
internationalworkshop on Audio/visual emotion challenge, 2013, pp. 41-48.
[13]N. Cummins, J. Epps, V. Sethu, M. Breakspear, and R. Goecke, "Modeling spectral variability for the
classification of depressed speech.," in Interspeech, Lyon, France, 2013, pp.857-861.
[14]J. R. Brown and J. Simonson, "Organic voice tremor," Trans. Am. Neurol. Assoc., no. 87, pp. 179180, 1962.
[15]J. R. Brown and J. Simonson, "Organic voice tremor: A tremor of phonation," Neurology, vol. 13, pp.
520-525, 1963.
[161W. S. Winholtz and L. 0. Ramig, "Vocal tremor analysis with the vocal demodulator," J. Speech
Lang. Hear. Res., vol. 35, no. 3, pp. 562-573, 1992.
[17]L. A. Ramig, I. R. Titze, R. C. Scherer, and Ringel, Steven P., "Acoustic analysis of voices of
patients with neurologic disease: rationale and preliminary data," Ann. Otol. Rhinol. Laryngol., vol.
97, no. 2 (pt 1), pp. 164-172, Apr. 1988.
[18]I. R. Titze, "On the relation between subglottal pressure and fundamental frequency in phonation," J.
Acoust. Soc. Am., vol. 85, no. 2, Feb. 1989.
[19]A. Aronson, W. S. Winholtz, L. 0. Ramig, and S. R. Sibler, "Rapid voice tremor, or 'flutter,' in
amyotrphic lateral sclerosis," Ann. Otol. Rhinol. Laryngol., vol. 101, pp. 511-518, 1992.
[20]Y. Horii, "Acoustic analysis of vocal vibrato: a theoretical interpretation of data," J. Voice, vol. 3, no.
1, pp. 36-43, 1989.
[21]K. N. Stevens, Acoustic Phonetics.Cambridge, MA: MIT Press, 1998.
113
[22]R. A. Lester, J. Barkmeier-Kraemer, and B. H. Story, "Physiologic and Acoustic Patterns of Essential
Vocal Tremor," J. Voice, vol. 27, no. 4, pp. 422-432, Jul. 2013.
[23] P. MacKinnon and1J. Morris, Oxford Textbook of FunctionalAnatomy: Head and Neck, vol. 3.
.
Oxford University Press, 1990.
[24]R. A. Lester and B. H. Story, "Acoustic characteristics of simulated respiratory-induced vocal
tremor," Am. J. Speech Lang. Pathol.,vol. 22, pp. 205-211, May 2013.
[25]Multi-DimensionalVoice Program.KayPENTAX.
[26]P. Boersma and D. Weenink, Praat.
[27]Y. Pantazis, M. Koutsogiannaki, and Y. Stylianou, "A novel method for the extraction of vocal
tremor," in Models and analysis of vocal emissionsfor biomedicalapplications:6th international
workshop, Firenze, Italy, 2009.
[28]Y. Pantazis, 0. Rosec, and Y. Stylianou, "Adaptive AM-FM Signal Decomposition With Application
to Speech Analysis," IEEE Trans. Audio Speech Lang. Process.,vol. 19, no. 2, pp. 290-300, Feb.
2011.
[29]N. Cummins, J. Epps, and E. Ambikairajah, "Spectro-temporal analysis of speech affected by
depression and psychomotor retardation," in Acoustics, Speech and Signal Processing(ICASSP),
2013 IEEE InternationalConference on, Vancouver, Canada, 2013, pp. 7542-7546.
[30]T. F. Quatieri, Discrete-Time Speech Signal Processing:Principlesand Practice.Upper Saddle
River, NJ: Prentice Hall, 2002.
[31]A. Ivanov and X. Chen, "Modulation Spectrum Analysis for Speaker Personality Trait Recognition.,"
presented at the InterSpeech 2012, Portland, OR, 2012.
[32]M. Valstar, F. Eyben, S. Schnieder, B. Schuller, B. Jiang, R. Cowie, K. Smith, S. Bilakhia, and M.
Pantic, "AVEC 2013 - The Continuous AudioNisual Emotion and Depression Recognition
Challenge," in Proceedingsof the 3rd ACM InternationalWorkshop on Audio/Visual Emotion
Challenge, Barcelona, Spain, 2013, pp. 3-10.
[3311. R. Titze, "The physics of small-amplitude oscillation of the vocal folds," J. Acoust. Soc. Am., vol.
83, no. 4, pp. 1536-1552, Apr. 1988.
[3411. R. Titze, "Phonation threshold pressure: A missing link in glottal aerodynamics," J. Acoust. Soc.
Am., vol. 91, no.5, pp. 2926-2935, May 1992.
[35]R. L. Plant and R. M. Younger, "The interrelationship of subglottic air pressure, fundamental
frequency, and vocal intensity during speech," J. Voice, vol. 14, no. 2, pp. 170-177, 2000.
[361K. A. Farinella, T. J. Hixon, B. H. Story, and P. J. Jones, "Listener Perception of Respiratory-Induced
Vocal Tremor," Am. J. Speech Lang. Pathol.,vol. 15, no. 1, pp. 72-84, Feb. 2006.
[37]C. Dromey and M. E. Smith,, "Vocal Tremor and Vibrato in the Same Person: Acoustic and
Electromyographic Differences," J. Voice, vol. 22, no. 5, pp. 541-545, Sep. 2008.
[38]T. Shipp, E. T. Doherty, and S. Haglund, "Physiologic factors in vocal vibrato production," J. Voice,
vol. 4, no. 4, pp. 300-304, 1990.
[39]T. G. Stockham, "The Applicaiton of Generalized Linearity to Automatic Gain Control," IEEE
Trans. Audio Electroacoustics,vol. AU-16, no.2, pp. 267-270, Jun. 1968.
[40]T. F. Quatieri and R. J. McAulay, "Audio Signal Processing Based on Sinusoidal
Analysis/Synthesis," in Applications of DigitalSignal Processingot Audio and Acoustics, Boston:
Kluwer Academic Publishers, 1998, pp. 343-413.
[41]N. Malyska, T. F. Quatieri, and D. Sturim, "Automatic Dysphonia Recognition Using Biologically
Inspired Amplitude-Modulation Features.," presented at the Proceedings of the ICASSP, Prague,
2005, pp.873-876.
[42]T. F. Quatieri, "Phase Estimation with Applicaiton to Speech Analysis-Synthesis," Ph.D. thesis,
Massachusetts Institute of Technology, Cambridge, MA, 1979.
[43]A. Robel and X. Rodet, "Efficient Spectral Envelope Estimation and Its Application to Pitch Shifting
and Envelope Preservation," in Proceedingsof the 8th InternationalConference on DigitalAudio
Effects, Madrid, Spain, 2005, pp. DAFX1-DAFX6.
114
[44]D. D. Mehta, D. Rudoy, and P. J. Wolfe, "Kalman-based autoregressive moving average modeling
and inferance for formant and antiformatn tracking," J. Acoust. Soc. Am., vol. 132, no. 3, pp. 1732-
1746, Sep. 2012.
[45]J. R. Williamson, D. W. Bliss, and D. W. Browne, "Epileptic seizure prediction using the
spatiotemporal correlation structure of intracranial EEG," in Acoustics, Speech and Signal Processing
(ICASSP), 2011 IEEE InternationalConference on, 2011, pp. 665-668.
[46]D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, "Speaker Verification Using Adapted Gaussian
Mixture Models," Digit. Signal Process., vol. 10, no. 1-3, pp. 19-41, Jan. 2000.
[471G. Sell and M. Slaney, "Solving demodulation as an optimization problem," Audio Speech Lang.
Process.IEEE Trans. On, vol. 18, no. 8, pp. 2051-2066, 2010.
[48]A. T. Beck, R. A. Steer, R. Ball, and W. F. Ranieri, "Comparison of Beck Depression Inventories -IA
and -II in Psychiatric Outpatients," J. Pers. Assess., vol. 67, no. 3, pp. 588-597, 1996.
[49]K. L. Smarr and A. L. Keefer, "Measures of depression and depressive symptoms: Beck Depression
Inventory-II (BDI-II), Center for Epidemiologic Studies Depression Scale (CES-D), Geriatric
Depression Scale (GDS), Hospital Anxiety and Depression Scale (HADS), and Patient Health
Questionna," Arthritis Care Res., vol. 63, no. S11, pp. S454-S466, Nov. 2011.
[50]D. Klatt, "Software for a cascade/parallel formant synthesizer," J. Acoust. Soc. Am., vol. 67, no. 3,
pp. 971-995, Mar. 1980.
115