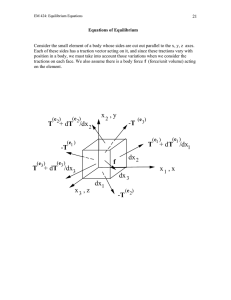
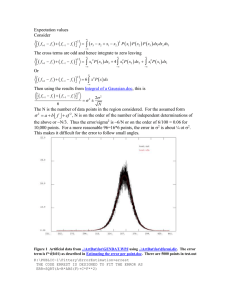
8.1
advertisement

8.1
After adding slack variables, the decision variable vector and the
1
x = (x1 , x2 , x3 , s1 , s2 , s3 )> and A = 2
6
LHS constraint matrix are:
1 2 1 0 0
3 4 0 1 0 .
6 2 0 0 1
The objective function vector is c = (8, 9, 5, 0, 0, 0)> . The initial BFS and basis are
x0 = (0, 0, 0, 2, 3, 8)> ,
B 0 = {s1 , s2 , s3 }.
Iteration 1: First, we compute simplex directions for every nonbasic variable. For x1 , we solve Adx1 = 0,
i.e.,
1 + dxs11 = 0
2 + dxs21 = 0
6 + dxs31 = 0
so dx1 = (1, 0, 0, −1, −2, −6)> . Similar calculations show that
dx2 = (0, 1, 0, −1, −3, −6)> ,
dx3 = (0, 0, 1, −2, −4, −2)> .
The reduced costs are
c̄x1 = c> dx1 = 8,
c̄x2 = c> dx2 = 9,
c̄x3 = c> dx3 = 5
so we choose x2 as our entering variable. To calculate step size, we use the minimum ratio test:
3
8
2
xj
,
,
: dj < 0 = min
= min{2, 1, 4/3} = 1.
λmax = min
−dj
−(−1) −(−3) −(−6)
Thus s2 is our leaving variable, and the new solution and basis are
x1 = (0, 1, 0, 1, 0, 2)> ,
B 1 = {x2 , s1 , s3 }.
Iteration 2: Again, we compute simplex directions for each of the nonbasic variables. We see that the
directions are
dx1 = (1, −2/3, 0, −1/3, 0, −2)> ,
dx3 = (0, −4/3, 1, −2/3, 0, 6)> ,
ds2 = (0, −1/3, 0, 1/3, 1, 2)> .
The reduced costs are
c̄x1 = c> dx1 = 2,
c̄x3 = c> dx3 = −7,
c̄s2 = c> ds2 = −3.
The entering variable is x1 . The step size is λmax = 1. The leaving variable is s3 . The new solution and
basis are
x2 = (1, 1/3, 0, 2/3, 0, 0)> ,
B 2 = {x1 , x2 , s1 }.
Iteration 3: Again, we compute simplex directions for each nonbasic variable. The directions are
dx3 = (3, −10/3, 1, −5/3, 0, 0)> ,
ds2 = (1, −1, 0, 0, 1, 0)> ,
ds3 = (−1/2, 1/3, 0, 1/6, 0, 1).
The reduced costs are
c̄x3 = c> dx3 = −1,
c̄s2 = c> ds2 = −1,
c̄s3 = c> ds3 = −1
Because none of the simplex directions are improving, the solution x2 is optimal.
1