An introduction to data assimilation Eric Blayo University of Grenoble and INRIA
advertisement
An introduction
to data assimilation
Eric Blayo
University of Grenoble and INRIA
Data assimilation, the science of compromises
Context characterizing a (complex) system and/or forecasting its
evolution, given several heterogeneous and uncertain
sources of information
Widely used for geophysical fluids (meteorology, oceanography,
atmospheric chemistry. . . ), but also in other numerous
domains (e.g. glaciology, nuclear energy, medicine,
agriculture planning. . . )
Closely linked to inverse methods, control theory, estimation theory,
filtering. . .
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
2/61
Data assimilation, the science of compromises
Numerous possible aims:
I
Forecast: estimation of the present state (initial condition)
I
Model tuning: parameter estimation
I
Inverse modeling: estimation of parameter fields
I
Data analysis: re-analysis (model = interpolation operator)
I
OSSE: optimization of observing systems
I
...
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
3/61
Data assimilation, the science of compromises
Its application to Earth sciences generally raises a number of difficulties,
some of them being rather specific:
I
non linearities
I
huge dimensions
I
poor knowledge of error statistics
I
non reproducibility (each experiment is unique)
I
operational forecast (computations must be performed in a limited
time)
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
4/61
Objectives for these two lectures
I
introduce data assimilation from several points of view
I
give an overview of the main methods
I
detail the basic ones and highlight their pros and cons
I
introduce some current research problems
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
5/61
Objectives for these two lectures
I
introduce data assimilation from several points of view
I
give an overview of the main methods
I
detail the basic ones and highlight their pros and cons
I
introduce some current research problems
Outline
1. Data assimilation for dummies: a simple model problem
2. Generalization: linear estimation theory, variational and sequential
approaches
3. Variational algorithms - Adjoint techniques
4. Reduced order Kalman filters
5. Some current research tracks
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
5/61
Some references
1. Blayo E. and M. Nodet, 2012: Introduction à l’assimilation de données variationnelle. Lecture notes for
UJF Master course on data assimilation.
https://team.inria.fr/moise/files/2012/03/Methodes-Inverses-Var-M2-math-2009.pdf
2. Bocquet M., 2014 : Introduction aux principes et méthodes de l’assimilation de données en géophysique.
Lecture notes for ENSTA - ENPC data assimilation course.
http://cerea.enpc.fr/HomePages/bocquet/Doc/assim-mb.pdf
3. Bocquet M., E. Cosme and E. Blayo (Eds.), 2014: Advanced Data Assimilation for Geosciences.
Oxford University Press.
4. Bouttier F. and P. Courtier, 1999: Data assimilation, concepts and methods. Meteorological training
course lecture series ECMWF, European Center for Medium range Weather Forecast, Reading, UK.
http://www.ecmwf.int/newsevents/training/rcourse notes/DATA ASSIMILATION/
ASSIM CONCEPTS/Assim concepts21.html
5. Cohn S., 1997: An introduction to estimation theory. Journal of the Meteorological Society of Japan, 75,
257-288.
6. Daley R., 1993: Atmospheric data analysis. Cambridge University Press.
7. Evensen G., 2009: Data assimilation, the ensemble Kalman filter. Springer.
8. Kalnay E., 2003: Atmospheric modeling, data assimilation and predictability. Cambridge University Press.
9. Lahoz W., B. Khattatov and R. Menard (Eds.), 2010: Data assimilation. Springer.
10. Rodgers C., 2000: Inverse methods for atmospheric sounding. World Scientific, Series on Atmospheric
Oceanic and Planetary Physics.
11. Tarantola A., 2005: Inverse problem theory and methods for model parameter estimation. SIAM.
http://www.ipgp.fr/~tarantola/Files/Professional/Books/InverseProblemTheory.pdf
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
6/61
A simple but fundamental
example
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
7/61
Model problem: least squares approach
Two different available measurements of a single quantity. Which
estimation for its true value ? −→ least squares approach
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
8/61
Model problem: least squares approach
Two different available measurements of a single quantity. Which
estimation for its true value ? −→ least squares approach
Example 2 obs y1 = 19◦ C and y2 = 21◦ C of the (unknown) present
temperature x .
I
Let J(x ) =
I
Minx J(x )
1
2
(x − y1 )2 + (x − y2 )2
−→ x̂ =
y1 + y2
= 20◦ C
2
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
8/61
Model problem: least squares approach
Observation operator
If 6= units: y1 = 66.2◦ F and y2 = 69.8◦ F
9
x + 32
5
1
I Let J(x ) =
(H(x ) − y1 )2 + (H(x ) − y2 )2
2
I
Let H(x ) =
I
Minx J(x )
◦
−→ x̂ = 20 C
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
9/61
Model problem: least squares approach
Observation operator
If 6= units: y1 = 66.2◦ F and y2 = 69.8◦ F
9
x + 32
5
1
I Let J(x ) =
(H(x ) − y1 )2 + (H(x ) − y2 )2
2
I
Let H(x ) =
I
Minx J(x )
◦
−→ x̂ = 20 C
Drawback # 1: if observation units are inhomogeneous
y1 = 66.2◦ F and y2 = 21◦ C
1
I J(x ) =
(H(x ) − y1 )2 + (x − y2 )2
−→ x̂ = 19.47◦ C !!
2
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
9/61
Model problem: least squares approach
Observation operator
If 6= units: y1 = 66.2◦ F and y2 = 69.8◦ F
9
x + 32
5
1
I Let J(x ) =
(H(x ) − y1 )2 + (H(x ) − y2 )2
2
I
Let H(x ) =
I
Minx J(x )
◦
−→ x̂ = 20 C
Drawback # 1: if observation units are inhomogeneous
y1 = 66.2◦ F and y2 = 21◦ C
1
I J(x ) =
(H(x ) − y1 )2 + (x − y2 )2
−→ x̂ = 19.47◦ C !!
2
Drawback # 2: if observation accuracies are inhomogeneous
2y1 + y2
If y1 is twice more accurate than y2 , one should obtain x̂ =
= 19.67◦ C
3
"
#
2 2
1
x − y1
x − y2
−→ J should be J(x ) =
+
2
1/2
1
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
9/61
Model problem: statistical approach
Reformulation in a probabilistic framework:
I
the goal is to estimate a scalar value x
I
yi is a realization of a random variable Yi
I
One is looking for an estimator (i.e. a r.v.) X̂ that is
I
linear: X̂ = α1 Y1 + α2 Y2
I
unbiased: E (X̂ ) = x
I
of minimal variance: Var(X̂ ) minimum
−→ BLUE
(in order to be simple)
(it seems reasonable)
(optimal accuracy)
(Best Linear Unbiased Estimator)
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
10/61
Model problem: statistical approach
Let Yi = x + εi
with
Hypotheses
I
E (εi ) = 0
(i = 1, 2)
σi2
I
Var(εi ) =
I
Cov(ε1 , ε2 ) = 0
(i = 1, 2)
E. Blayo - An introduction to data assimilation
unbiased measurement devices
known accuracies
independent measurement errors
Ecole GDR Egrin 2014
11/61
Reminder: covariance of two random variables
Let X and Y two random variables.
Covariance: Cov(X , Y )
Cov(X , X )
= E [(X − E (X )) (Y − E (Y ))]
= E (XY ) − E (X )E (Y )
= Var(X )
Linear correlation coefficient: ρ(X , Y ) =
Cov(X , Y )
σX σY
Property: X and Y independent =⇒ Cov(X , Y ) = 0
The reciprocal is generally false.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
12/61
Model problem: statistical approach
Let Yi = x + εi
with
Hypotheses
I
E (εi ) = 0
(i = 1, 2)
σi2
I
Var(εi ) =
I
Cov(ε1 , ε2 ) = 0
(i = 1, 2)
E. Blayo - An introduction to data assimilation
unbiased measurement devices
known accuracies
independent measurement errors
Ecole GDR Egrin 2014
13/61
Model problem: statistical approach
Let Yi = x + εi
with
Hypotheses
I
E (εi ) = 0
(i = 1, 2)
σi2
I
Var(εi ) =
I
Cov(ε1 , ε2 ) = 0
unbiased measurement devices
(i = 1, 2)
known accuracies
independent measurement errors
Then, since X̂ = α1 Y1 + α2 Y2 = (α1 + α2 )x + α1 ε1 + α2 ε2 :
I
E (X̂ ) = (α1 + α2 )x + α1 E (ε1 ) + α2 E (ε2 )
E. Blayo - An introduction to data assimilation
=⇒ α1 + α2 = 1
Ecole GDR Egrin 2014
13/61
Model problem: statistical approach
Let Yi = x + εi
with
Hypotheses
I
E (εi ) = 0
(i = 1, 2)
σi2
I
Var(εi ) =
I
Cov(ε1 , ε2 ) = 0
unbiased measurement devices
(i = 1, 2)
known accuracies
independent measurement errors
Then, since X̂ = α1 Y1 + α2 Y2 = (α1 + α2 )x + α1 ε1 + α2 ε2 :
E (X̂ ) = (α1 + α2 )x + α1 E (ε1 ) + α2 E (ε2 ) =⇒ α1 + α2 = 1
h
i
I Var(X̂ ) = E (X̂ − x )2 = E (α1 ε1 + α2 ε2 )2 = α2 σ 2 + (1 − α1 )2 σ 2
1 1
2
I
∂
σ2
= 0 =⇒ α1 = 2 2 2
∂α1
σ1 + σ2
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
13/61
Model problem: statistical approach
In summary:
BLUE
1
Y1 +
σ2
X̂ = 1
1
+
σ12
Its accuracy:
h
i−1
1
1
= 2+ 2
Var(X̂ )
σ1
σ2
E. Blayo - An introduction to data assimilation
1
Y2
σ22
1
σ22
accuracies are added
go to general case
Ecole GDR Egrin 2014
14/61
Model problem: statistical approach
In summary:
BLUE
1
Y1 +
σ2
X̂ = 1
1
+
σ12
Its accuracy:
h
i−1
1
1
= 2+ 2
Var(X̂ )
σ1
σ2
1
Y2
σ22
1
σ22
accuracies are added
go to general case
Remarks:
I The hypothesis Cov(ε1 , ε2 ) = 0 is not compulsory at all.
Cov(ε1 , ε2 ) = c −→ αi =
I
σj2 −c
σ12 +σ22 −2c
Statistical hypotheses on the two first moments of ε1 , ε2 lead to
statistical results on the two first moments of X̂ .
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
14/61
Model problem: statistical approach
Variational equivalence
This is equivalent to the problem:
1
Minimize J(x ) =
2
E. Blayo - An introduction to data assimilation
(x − y2 )2
(x − y1 )2
+
σ12
σ22
Ecole GDR Egrin 2014
15/61
Model problem: statistical approach
Variational equivalence
This is equivalent to the problem:
1
Minimize J(x ) =
2
(x − y2 )2
(x − y1 )2
+
σ12
σ22
Remarks:
I
This answers the previous problems of sensitivity to inhomogeneous
units and insensitivity to inhomogeneous accuracies
I
This gives a rationale for choosing the norm for defining J
I
1
1
−1
J 00 (x̂ ) = 2 + 2 = [Var(x̂ )]
| {z }
| {z }
σ1
σ2
accuracy
convexity
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
15/61
Model problem
Alternative formulation: background + observation
If one considers that y1 is a prior (or background) estimate xb for x , and
y2 = y is an independent observation, then:
J(x ) =
and
1 (x − xb )2
1 (x − y )2
+
2
2
σ2
σ2
| {z o }
|
{z b }
Jo
Jb
1
1
xb + 2 y
2
σo
σ
σ2
x̂ = b
= xb + 2 b 2 (y − xb )
1
1
σ + σ | {z }
+ 2
| b {z o} innovation
σo
σb2
gain
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
16/61
Model problem
Interpretation
If the background error and the observation
error are uncorrelated: E (e o e b ) = 0, then
one can show that the estimation error and
the innovation are uncorrelated:
E (e a (Y − Xb )) = 0
→ orthogonal projection for the scalar product < Z1 , Z2 >= E (Z1 Z2 )
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
17/61
Model problem: Bayesian approach
One can also consider x as a realization of a r.v. X , and be interested in
the pdf p(X |Y ).
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
18/61
Reminder: Bayes theorem
Let A and B two events.
Conditional probability: P(A|B) =
P(A ∩ B)
P(B)
Example:
P(heart card ∩ red card)
8/32
1
=
=
2
P(red card)
16/32
P(heart card | red card) =
Bayes theorem: P(A|B) =
P(B|A) P(A)
P(B)
Thus, if X and Y are two random variables:
P(X = x | Y = y ) =
E. Blayo - An introduction to data assimilation
P(Y = y | X = x ) P(X = x )
P(Y = y )
Ecole GDR Egrin 2014
19/61
Model problem: Bayesian approach
One can also consider x as a realization of a r.v. X , and be interested in
the pdf p(X |Y ).
Several optimality criteria
I
minimum variance: X̂MV such that the spread around it is minimal
−→ X̂MV = E (X |Y )
I
maximum a posteriori: most probable value of X given Y
|Y )
=0
−→ X̂MAP such that ∂p(X
∂X
I
maximum likelihood: X̂ML that maximizes p(Y |X )
I
Based on the Bayes rule:
P(Y = y | X = x ) P(X = x )
P(X = x | Y = y ) =
P(Y = y )
I
requires additional hypotheses on prior pdf for X and for Y |X
I
In the Gaussian case, these estimations coincide with the BLUE
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
20/61
Model problem: Bayesian approach
Back to our example: observations y1 and y2 of an unknown value x .
The simplest approach: maximum likelihood (no prior on X )
Hypotheses:
I
Yi ,→ N (X , σi2 )
unbiased, known accuracies + known pdf
I
Cov(Y1 , Y2 ) = 0
independent measurement errors
Likelihood function:
L(x ) = dP(Y1 = y1 and Y2 = y2 | X = x )
One is looking for x̂ML = Argmax L(x )
E. Blayo - An introduction to data assimilation
maximum likelihood estimation
Ecole GDR Egrin 2014
21/61
Model problem: Bayesian approach
L(x ) =
2
Y
dP(Yi = yi | X = x ) =
i=1
2
Y
i=1
√
(y −x )
− i 2
1
e 2σi
2π σi
2
Argmax L(x ) = Argmin (− ln L(x ))
1 (x − y1 )2
(x − y2 )2
= Argmin
+
2
σ12
σ22
Hence
x̂ML
1
y1 +
σ12
=
1
+
σ12
1
y2
σ22
1
σ22
E. Blayo - An introduction to data assimilation
BLUE again
(because of Gaussian hypothesis)
Ecole GDR Egrin 2014
22/61
Model problem: synthesis
Data assimilation methods are often split into two families: variational
methods and statistical methods.
I
Variational methods: minimization of a cost function (least squares
approach)
I
Statistical methods: algebraic computation of the BLUE (with
hypotheses on the first two moments), or approximation of pdfs (with
hypotheses on the pdfs) and computation of the MAP estimator
I
There are strong links between those approaches, depending on the
case (linear ? Gaussian ?)
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
23/61
Model problem: synthesis
Data assimilation methods are often split into two families: variational
methods and statistical methods.
I
Variational methods: minimization of a cost function (least squares
approach)
I
Statistical methods: algebraic computation of the BLUE (with
hypotheses on the first two moments), or approximation of pdfs (with
hypotheses on the pdfs) and computation of the MAP estimator
I
There are strong links between those approaches, depending on the
case (linear ? Gaussian ?)
Theorem
If you have understood this previous stuff, you have (almost) understood
everything on data assimilation.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
23/61
Generalization:
variational approach
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
24/61
Generalization: arbitrary number of unknowns and observations
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
25/61
Generalization: arbitrary number of unknowns and observations
A simple example of observation operator
x1
x2
If x =
x3
x4
and y =
2
an observation of x1 +x
2
an observation of x4
then
H(x) = Hx
E. Blayo - An introduction to data assimilation
1
with H =
2
0
1
2
0
0
0
Ecole GDR Egrin 2014
0
1
26/61
Generalization: arbitrary number of unknowns and observations
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
Cost function: J(x) =
1
kH(x) − yk2
2
E. Blayo - An introduction to data assimilation
with k.k to be chosen.
Ecole GDR Egrin 2014
27/61
Reminder: norms and scalar products
u1
u = ... ∈ IRn
un
Euclidian norm: kuk2 = uT u =
n
X
ui2
i=1
Associated scalar product: (u, v) = uT v =
n
X
u i vi
i=1
Generalized norm: let M a symmetric positive definite matrix
n X
n
X
2
T
M-norm: kukM = u M u =
mij ui uj
i=1 j=1
Associated scalar product: (u, v)M = uT M v =
n X
n
X
mij ui vj
i=1 j=1
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
28/61
Generalization: arbitrary number of unknowns and observations
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
Cost function: J(x) =
1
kH(x) − yk2
2
E. Blayo - An introduction to data assimilation
with k.k to be chosen.
Ecole GDR Egrin 2014
29/61
Generalization: arbitrary number of unknowns and observations
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
Cost function: J(x) =
1
kH(x) − yk2
2
with k.k to be chosen.
Remark
(Intuitive) necessary (but not sufficient) condition for the existence of a
unique minimum:
p≥n
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
29/61
Formalism “background value + new observations”
z=
xb
y
←− background
←− new observations
The cost function becomes:
J(x) =
1
kx − xb k2b
2
|
{z
}
Jb
E. Blayo - An introduction to data assimilation
+
1
kH(x) − yk2o
2
|
{z
}
Jo
Ecole GDR Egrin 2014
30/61
Formalism “background value + new observations”
z=
xb
y
←− background
←− new observations
The cost function becomes:
J(x) =
1
kx − xb k2b
2
|
{z
}
Jb
+
1
kH(x) − yk2o
2
|
{z
}
Jo
The necessary condition for the existence of a unique minimum (p ≥ n)
is automatically fulfilled.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
30/61
If the problem is time dependent
I
Observations are distributed in time: y = y(t)
I
The observation cost function becomes:
Jo (x) =
N
1 X
kHi (x(ti )) − y(ti )k2o
2 i=0
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
31/61
If the problem is time dependent
I
Observations are distributed in time: y = y(t)
I
The observation cost function becomes:
Jo (x) =
I
N
1 X
kHi (x(ti )) − y(ti )k2o
2 i=0
dx
= M(x) with
dt
x(t = 0) = x0 . Then J is often no longer minimized w.r.t. x, but
w.r.t. x0 only, or to some other parameters.
There is a model describing the evolution of x:
N
N
1 X
1 X
2
Jo (x0 ) =
kHi (x(ti )) − y(ti )ko =
kHi (M0→ti (x0 )) − y(ti )k2o
2 i=0
2 i=0
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
31/61
If the problem is time dependent
J(x0 ) =
1
kx0 − x0b k2b
2
|
{z
}
background term Jb
E. Blayo - An introduction to data assimilation
+
N
1 X
kHi (x(ti )) − y(ti )k2o
2 i=0
|
{z
}
observation term Jo
Ecole GDR Egrin 2014
32/61
Uniqueness of the minimum ?
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
I
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
If H and M are linear then Jo is quadratic.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
33/61
Uniqueness of the minimum ?
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
I
If H and M are linear then Jo is quadratic.
I
However it generally does not have a unique minimum, since the
number of observations is generally less than the size of x0 (the
problem is underdetermined: p < n).
Example: let (x1t , x2t ) = (1, 1) and y = 1.1 an observation of 21 (x1 + x2 ).
Jo (x1 , x2 ) =
1
2
x1 + x2
− 1.1
2
E. Blayo - An introduction to data assimilation
2
Ecole GDR Egrin 2014
33/61
Uniqueness of the minimum ?
N
1
1 X
2
J(x0 ) = Jb (x0 ) + Jo (x0 ) = kx0 − xb kb +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
I
If H and M are linear then Jo is quadratic.
I
However it generally does not have a unique minimum, since the
number of observations is generally less than the size of x0 (the
problem is underdetermined).
I
Adding Jb makes the problem of minimizing J = Jo + Jb well posed.
Example: let (x1t , x2t ) = (1, 1) and y = 1.1 an observation of 21 (x1 + x2 ). Let (x1b , x2b ) = (0.9, 1.05)
J(x1 , x2 ) =
1
2
|
2
x1 + x2
1
(x1 − 0.9)2 + (x2 − 1.05)2
− 1.1 +
2
2
{z
}
{z
} |
Jo
Jb
−→ (x1∗ , x2∗ ) = (0.94166..., 1.09166...)
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
34/61
Uniqueness of the minimum ?
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
I
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
If H and/or M are nonlinear then Jo is no longer quadratic.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
35/61
Uniqueness of the minimum ?
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
I
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
If H and/or M are nonlinear then Jo is no longer quadratic.
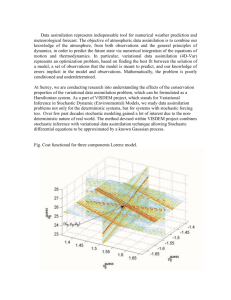
Example: the Lorenz system (1963)
dx
= α(y − x )
dt
dy
= βx − y − xz
dt
dz = −γz + xy
dt
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
35/61
http://www.chaos-math.org
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
36/61
Uniqueness of the minimum ?
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
I If H and/or M are nonlinear then Jo is no longer quadratic.
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
Example: the Lorenz system (1963)
dx
= α(y − x )
dt
dy
= βx − y − xz
dt
dz = −γz + xy
dt
Jo (y0 ) =
N
1 X
2
(x (ti ) − xobs (ti )) dt
2 i=0
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
37/61
Uniqueness of the minimum ?
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
I
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
If H and/or M are nonlinear then Jo is no longer quadratic.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
38/61
Uniqueness of the minimum ?
J(x0 ) = Jb (x0 ) + Jo (x0 ) =
N
1
1 X
kx0 − xb k2b +
kHi (M0→ti (x0 )) − y(ti )k2o
2
2 i=0
I
If H and/or M are nonlinear then Jo is no longer quadratic.
I
Adding Jb makes it “more quadratic” (Jb is a regularization term),
but J = Jo + Jb may however have several local minima.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
38/61
A fundamental remark before going into minimization
aspects
Once J is defined (i.e. once all the ingredients are chosen: control
variables, norms, observations. . . ), the problem is entirely defined. Hence
its solution.
The “physical” (i.e. the most important) part of data
assimilation lies in the definition of J.
The rest of the job, i.e. minimizing J, is “only” technical work.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
39/61
Minimum of a quadratic function in finite dimension
Theorem: Generalized (or Moore-Penrose) inverse
Let M a p × n matrix, with rank n, and b ∈ IRp .
(hence p ≥ n)
Let J(x) = kMx − bk2 = (Mx − b)T (Mx − b).
J is minimum for x̂ = M+ b , where M+ = (MT M)−1 MT
(generalized, or Moore-Penrose, inverse).
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
40/61
Minimum of a quadratic function in finite dimension
Theorem: Generalized (or Moore-Penrose) inverse
Let M a p × n matrix, with rank n, and b ∈ IRp .
(hence p ≥ n)
Let J(x) = kMx − bk2 = (Mx − b)T (Mx − b).
J is minimum for x̂ = M+ b , where M+ = (MT M)−1 MT
(generalized, or Moore-Penrose, inverse).
Corollary: with a generalized norm
Let N a p × p symmetric definite positive matrix.
Let J1 (x) = kMx − bk2N = (Mx − b)T N (Mx − b).
J1 is minimum for x̂ = (MT NM)−1 MT N b.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
40/61
Link with data assimilation
In the case of a linear, time independent, data assimilation problem:
Jo (x) =
1
1
kHx − yk2o = (Hx − y)T R−1 (Hx − y)
2
2
Optimal estimation in the linear case: Jo only
minn Jo (x)
x∈IR
−→
x̂ = (HT R−1 H)−1 HT R−1 y
go to statistical approach
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
41/61
Link with data assimilation
With the formalism “background value + new observations”:
J(x)
= Jb (x) + Jo (x)
1
1
kx − xb k2b +
kH(x) − yk2o
=
2
2
1
1
=
(x − xb )T B−1 (x − xb ) + (Hx − y)T R−1 (Hx − y)
2
2
= (Mx − b)T N (Mx − b) = kMx − bk2N
In
xb
B−1 0
with M =
b=
N=
H
y
0
R−1
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
42/61
Link with data assimilation
With the formalism “background value + new observations”:
J(x)
= Jb (x) + Jo (x)
1
1
kx − xb k2b +
kH(x) − yk2o
=
2
2
1
1
=
(x − xb )T B−1 (x − xb ) + (Hx − y)T R−1 (Hx − y)
2
2
= (Mx − b)T N (Mx − b) = kMx − bk2N
In
xb
B−1 0
with M =
b=
N=
H
y
0
R−1
Optimal estimation in the linear case: Jb + Jo
x̂ = xb + (B−1 + HT R−1 H)−1 HT R−1
(y − Hxb )
|
{z
}
| {z }
gain matrix
innovation vector
Remark: The gain matrix also reads BHT (HBHT + R)−1
(Sherman-Morrison-Woodbury formula)
E. Blayo - An introduction to data assimilation
go to statistical approach
Ecole GDR Egrin 2014
42/61
Remark
Given the size of n and p, it is generally impossible to handle explicitly H,
B and R. So the direct computation of the gain matrix is impossible.
even in the linear case (for which we have an explicit expression for x̂),
the computation of x̂ is performed using an optimization algorithm.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
43/61
Generalization:
statistical approach
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
44/61
Generalization: statistical approach
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
45/61
Generalization: statistical approach
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
Statistical framework:
I
y is a realization of a random vector Y
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
45/61
Reminder: random vectors and covariance matrices
X1
Random vector: X = ... where each Xi is a random variable
Xn
Covariance matrix:
C = (Cov(Xi , Xj ))1≤i,j≤n = E [X − E (X)][X − E (X)]T
on the diagonal: Cii = Var(Xi )
Property: A covariance matrix is symmetric positive semidefinite.
(definite if the r.v. are linearly independent)
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
46/61
Generalization: statistical approach
x1
To be estimated: x = ... ∈ IRn
xn
y1
Observations: y = ... ∈ IRp
yp
Observation operator: y ≡ H(x), with H : IRn −→ IRp
Statistical framework:
I
y is a realization of a random vector Y
I
One is looking for the BLUE, i.e. a r.v. X̂ that is
I
linear: X̂ = AY with size(A) = (n, p)
I
unbiased: E (X̂) = x
I
of minimal variance:
n
X
Var(X̂) =
Var(X̂i ) = Tr(Cov(X̂)) minimum
i=1
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
47/61
Generalization: statistical approach
Hypotheses
I
Linear observation operator: H(x) = Hx
I
Let Y = Hx + ε
I
I
with ε random vector in IRp
E (ε) = 0
Cov(ε) = E (εεT ) = R
E. Blayo - An introduction to data assimilation
unbiased measurement devices
known accuracies and covariances
Ecole GDR Egrin 2014
48/61
Generalization: statistical approach
Hypotheses
I
Linear observation operator: H(x) = Hx
I
Let Y = Hx + ε
I
I
with ε random vector in IRp
E (ε) = 0
Cov(ε) = E (εεT ) = R
unbiased measurement devices
known accuracies and covariances
BLUE:
I
linear: X̂ = AY
with A(n, p)
I
unbiased: E (X̂) = E (AHx + Aε) = AHx + AE (ε) = AHx
So: E (X̂) = x ⇐⇒ AH = In .
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
48/61
Generalization: statistical approach
Hypotheses
I
Linear observation operator: H(x) = Hx
I
Let Y = Hx + ε
I
I
with ε random vector in IRp
E (ε) = 0
Cov(ε) = E (εεT ) = R
unbiased measurement devices
known accuracies and covariances
BLUE:
I
linear: X̂ = AY
with A(n, p)
I
unbiased: E (X̂) = E (AHx + Aε) = AHx + AE (ε) = AHx
So: E (X̂) = x ⇐⇒ AH = In .
Remark:
AH = In =⇒ ker H = {0} =⇒ rank(H) = n
Since size(H) = (p, n), this implies n ≤ p (again !)
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
48/61
BLUE:
I
minimal variance: min Tr(Cov(X̂))
X̂ = AY = AHx + Aε = x + Aε
Cov(X̂) = E [X̂ − E (X̂)][X̂ − E (X̂)]T
= AE (εεT )AT = ARAT
Find A that minimizes Tr(ARAT ) under the constraint AH = In
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
49/61
BLUE:
I
minimal variance: min Tr(Cov(X̂))
X̂ = AY = AHx + Aε = x + Aε
Cov(X̂) = E [X̂ − E (X̂)][X̂ − E (X̂)]T
= AE (εεT )AT = ARAT
Find A that minimizes Tr(ARAT ) under the constraint AH = In
Gauss-Markov theorem
A = (HT R−1 H)−1 HT R−1
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
49/61
BLUE:
I
minimal variance: min Tr(Cov(X̂))
X̂ = AY = AHx + Aε = x + Aε
Cov(X̂) = E [X̂ − E (X̂)][X̂ − E (X̂)]T
= AE (εεT )AT = ARAT
Find A that minimizes Tr(ARAT ) under the constraint AH = In
Gauss-Markov theorem
A = (HT R−1 H)−1 HT R−1
This also leads to
Cov(X̂) = (HT R−1 H)−1
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
49/61
Link with the variational approach
Statistical approach: BLUE
X̂ = (HT R−1 H)−1 HT R−1 Y
with Cov(X̂) = (HT R−1 H)−1
go to variational approach
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
50/61
Link with the variational approach
Statistical approach: BLUE
X̂ = (HT R−1 H)−1 HT R−1 Y
with Cov(X̂) = (HT R−1 H)−1
go to variational approach
Variational approach in the linear case
Jo (x) =
1
1
kHx − yk2o = (Hx − y)T R−1 (Hx − y)
2
2
minn Jo (x)
x∈IR
−→
E. Blayo - An introduction to data assimilation
x̂ = (HT R−1 H)−1 HT R−1 y
Ecole GDR Egrin 2014
50/61
Link with the variational approach
Statistical approach: BLUE
X̂ = (HT R−1 H)−1 HT R−1 Y
with Cov(X̂) = (HT R−1 H)−1
go to variational approach
Variational approach in the linear case
Jo (x) =
1
1
kHx − yk2o = (Hx − y)T R−1 (Hx − y)
2
2
minn Jo (x)
x∈IR
−→
x̂ = (HT R−1 H)−1 HT R−1 y
Remarks
The statistical approach rationalizes the choice of the norm in the
variational approach.
h
i−1
I Cov(X̂)
= HT R−1 H = Hess(Jo )
| {z }
{z
}
|
convexity
accuracy
I
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
50/61
Statistical approach: formalism “background value + new
observations”
Z=
Let Xb = x + εb
and
Xb
Y
←− background
←− new observations
Y = Hx + εo
Hypotheses:
I
E (εb ) = 0
unbiased background
I
E (εo ) = 0
unbiased measurement devices
I
Cov(εb , εo ) = 0
I
Cov(εb ) = B et Cov(εo ) = R
independent background and observation errors
known accuracies and covariances
This is again the general BLUE framework, with
Xb
In
εb
B 0
Z=
=
x+
and Cov(ε) =
Y
H
εo
0 R
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
51/61
Statistical approach: formalism “background value + new
observations”
Statistical approach: BLUE
X̂ = Xb + (B−1 + HT R−1 H)−1 HT R−1 (Y − HXb )
{z
} | {z }
|
gain matrix
innovation vector
h
i−1
with Cov(X̂)
= B−1 + HT R−1 H
accuracies are added
go to model problem
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
52/61
Link with the variational approach
Statistical approach: BLUE
X̂ = Xb + (B−1 + HT R−1 H)−1 HT R−1 (Y − HXb )
with Cov(X̂) = (B−1 + HT R−1 H)−1
E. Blayo - An introduction to data assimilation
go to variational approach
Ecole GDR Egrin 2014
53/61
Link with the variational approach
Statistical approach: BLUE
X̂ = Xb + (B−1 + HT R−1 H)−1 HT R−1 (Y − HXb )
with Cov(X̂) = (B−1 + HT R−1 H)−1
go to variational approach
Variational approach in the linear case
1
1
kx − xb k2b +
kH(x) − yk2o
2
2
1
1
(x − xb )T B−1 (x − xb ) + (Hx − y)T R−1 (Hx − y)
=
2
2
minn J(x) −→
x̂ = xb + (B−1 + HT R−1 H)−1 HT R−1 (y − Hxb )
x∈IR
J(x)
=
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
53/61
Link with the variational approach
Statistical approach: BLUE
X̂ = Xb + (B−1 + HT R−1 H)−1 HT R−1 (Y − HXb )
with Cov(X̂) = (B−1 + HT R−1 H)−1
go to variational approach
Variational approach in the linear case
1
1
kx − xb k2b +
kH(x) − yk2o
2
2
1
1
(x − xb )T B−1 (x − xb ) + (Hx − y)T R−1 (Hx − y)
=
2
2
minn J(x) −→
x̂ = xb + (B−1 + HT R−1 H)−1 HT R−1 (y − Hxb )
x∈IR
J(x)
=
Same remarks as previously
I The statistical approach rationalizes the choice of the norms for Jo and Jb
in the variational approach.
h
i−1
I Cov(X̂)
= B−1 + HT R−1 H = Hess(J)
| {z }
{z
}
|
convexity
accuracy
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
53/61
If the problem is time dependent
Dynamical system: xt (tk+1 ) = M(tk , tk+1 )xt (tk ) + e(tk )
I
xt (tk ) true state at time tk
I
M(tk , tk+1 ) model assumed linear between tk and tk+1
I
e(tk ) model error at time tk
At every observation time tk , we have an observation yk and a model
forecast xf (tk ). The BLUE can be applied:
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
54/61
If the problem is time dependent
xt (tk+1 ) = M(tk , tk+1 ) xt (tk ) + e(tk )
Hypotheses
I
e(tk ) is unbiased, with covariance matrix Qk
I
e(tk ) and e(tl ) are independent (k 6= l)
I
Unbiased observation yk , with error covariance matrix Rk
I
e(tk ) and analysis error xa (tk ) − xt (tk ) are independent
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
55/61
If the problem is time dependent
Kalman filter (Kalman and Bucy, 1961)
Initialization:
xa (t0 )
Pa (t0 )
= x0
= P0
approximate initial state
error covariance matrix
Step k: (prediction - correction, or forecast - analysis)
xf (tk+1 )
Pf (tk+1 )
=
=
xa (tk+1 ) =
Kk+1 =
Pa (tk+1 ) =
where exponents
M(tk , tk+1 ) xa (tk )
Forecast
M(tk , tk+1 )Pa (tk )MT (tk , tk+1 ) + Qk
xf (tk+1 ) + Kk+1 yk+1 − Hk+1 xf (tk+1 )
−1
f
T
Pf (tk+1 )HT
k+1 Hk+1 P (tk+1 )Hk+1 + Rk+1
Pf (tk+1 ) − Kk+1 Hk+1 Pf (tk+1 )
f
and
a
BLUE
stand respectively for forecast and analysis.
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
56/61
If the problem is time dependent
Equivalence with the variational approach
If Hk and M(tk , tk+1 ) are linear, and if the model is perfect (ek = 0),
then the Kalman filter and the variational method minimizing
J(x) =
N
1
1 X
(x − x0 )T P−1
(Hk M(t0 , tk )x − yk )T R−1
0 (x − x0 ) +
k (Hk M(t0 , tk )x − yk )
2
2 k=0
lead to the same solution at t = tN .
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
57/61
In summary
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
58/61
In summary
variational approach least squares minimization (non dimensional terms)
no particular hypothesis
either for stationary or time dependent problems
If M and H are linear, the cost function is quadratic:
a unique solution if p ≥ n
I Adding a background term ensures this property.
I If things are non linear, the approach is still valid.
Possibly several minima
I
I
I
statistical approach
hypotheses on the first two moments
time independent + H linear + p ≥ n: BLUE (first
two moments)
I time dependent + M and H linear: Kalman filter
(based on the BLUE)
I
I
I
hypotheses on the pdfs: Bayesian approach (pdf) +
ML or MAP estimator
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
59/61
In summary
The statistical approach gives a rationale for the choice of the norms, and
gives an estimation of the uncertainty.
time independent problems if H is linear, the variational and the
statistical approaches lead to the same solution (provided
k.kb is based on B−1 and k.ko is based on R−1 )
time dependent problems if H and M are linear, if the model is perfect,
both approaches lead to the same solution at final time.
4D-Var
E. Blayo - An introduction to data assimilation
Kalman filter
Ecole GDR Egrin 2014
60/61
Common main methodological difficulties
I
Non linearities: J non quadratic / what about Kalman filter ?
I
Huge dimensions [x] = O(106 − 109 ): minimization of J /
management of huge matrices
I
Poorly known error statistics: choice of the norms / B, R, Q
I
Scientific computing issues (data management, code efficiency,
parallelization...)
−→ NEXT LECTURE
E. Blayo - An introduction to data assimilation
Ecole GDR Egrin 2014
61/61
 0
0
advertisement






Download
advertisement
Add this document to collection(s)
You can add this document to your study collection(s)
Sign in Available only to authorized usersAdd this document to saved
You can add this document to your saved list
Sign in Available only to authorized users