TCP Performance Improvement over Heterogeneous Networks David Lecumberri
advertisement

TCP Performance Improvement over
Heterogeneous Networks
by
David Lecumberri
B.S., Telecommunications Engineering
Universidad Pdiblica de Navarra, 1997
B.S., Electrical Engineering
Institut National Polytechnique de Grenoble, 1996
Submitted to the Department of Electrical Engineering and Computer Science
in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Electrical Engineering
and Computer Science
at the
Massachusetts Institute of Technology
June 2000
@ 2000 David Lecumberri. All rights reserved.
The author hereby grants to MIT permission to reproduce and to distribute
publicly paper and electronic copies of this thesis document in whole or in part.
Signature of Author:
______________
Department of Electricaf'Engineering aniqbomputer Science
March 10, 2000
Certified by
-.
Kai-Yeung Siu
Associate Professor of Mechanical Engineering
TbP.-cicZimprvisor
Accepted by
Aithur C. Smith
Chairman, Committee on Graduate Students
Department of Electrical Engineering and Computer Science
ASSACHUSETTS INSTITUTE
OF TECHNOLOGY
JUN 2 2 2000
LIBRARIES
ENG
-A
2
TCP Performance Improvement over
Heterogeneous Networks
by
David Lecumberri
Submitted to the Department of Electrical Engineering and Computer Science
on March 10 th 2000 in Partial Fulfillment of the Requirements for the Degree
of Master of Science in Electrical Engineering and Computer Science
Abstract
TCP/IP is one of the most popular protocol suites that are in use today. However, the desire and
availability of increased bandwidth and differentiated applications have shown that the operation
of current TCP implementations can have limitations.
In this work, we address some of these limitations, in particular those derived from the TCP
window size, the presence of traffic in asymmetric networks, and the optimization of TCP over
high speed flow switching networks. We propose different solutions that will lead to improved
performance, either by introducing software modules that optimize packet handling, or by
proposing slight modifications to current TCP implementations. We implement three of these
solutions, showing results that demonstrate how they improve TCP performance.
Thesis Supervisor: Kai-Yeung Siu
Title: Associate Professor of Mechanical Engineering
3
Acknowledgements
I wish to thank Professor Kai-Yeung Siu for allowing me to become part of his
research group for over almost two years, and for his constant support and insights for this work.
Also, my officemates made my work much more enjoyable and valuable. My special gratitude to
Paolo for his friendship and his guidance over what it means to do research at MIT. I also want
to thank Mike Patrick and Whay Lee for his support, help and enthusiasm for large parts of this
work. Working with all of them has been one of my best experiences and I hope to be able to
repeat it in the future.
To "la Caixa Fellowship Program" for the financial support for my studies at MIT, andto Josep-Anton Monfort and Anne Klarich for taking care of their fellows so well.
To all my friends in Boston, that helped me enjoy living here, and to all those in the
distance that helped me appreciate what is to be far from the ones we love, my deep gratitude.
To my parents, because none of this would have been possible without them. And last, but not
least, my love and gratitude to Maria, for always being there for me and for her constant love
and support during the good and the hard times.
4
Index
INTRODUCTION
7
TCP main characteristics
7
SOME ADVERSE EFFECTS IN TCP
13
The effect of the receiver window size
TCP in asymmetric networks.
Flow switching in high-speed networks.
13
15
17
PRELIMINARY ANALYSIS
21
Test scenario in asymmetric networks
The effect of the receiver window size
The effect of cross traffic
Some possible solutions
21
23
24
31
ACK Suppression (AS) at CM
Window modification at CMTS or CM
ACK arrival estimation at CMTS
ACK reconstruction (AR) at CMTS
TCP with high-speed flow switching.
Mode switching
The recovery phase
32
32
32
33
33
36
37
IMPLEMENTATION OF SOLUTIONS PROPOSED
43
Window size modifier (WM)
ACK suppression (AS)
WM and AS Implementation Details
43
46
47
Window Modifier Operation
ACK Suppression operation
Interface description
Operation details
48
49
49
50
High Performance TCP
Basic algorithms
57
57
DESCRIPTION OF RESULTS
61
Window Modifier
ACK Suppression
High Performance TCP and high speed flow switching
61
64
66
CONCLUSIONS AND FUTURE WORK
73
REFERENCES
75
5
6
Introduction
Introduction
TCP/IP or Transport Control Protocol/Internet Protocol is one of the most popular protocol
suites that are in use today. Since is inception in the early 70's [1], it has been the base upon
which the Internet and many other network implementations have been deployed. Its reliability
and robustness have made of it almost the de facto standard in network interconnection.
However, the desire and availability of increased bandwidth and differentiated applications have
shown that the operation of current TCP implementations can have limitations. The popularity of
the Internet has lead to a variety of scenarios and configurations that present new challenges to
the versatility that TCP/IP has demonstrated in the past. It is an enormous challenge to adapt
TCP/IP to the increasing demands for high bandwidth in the network backbone, as well as to
provide good performance for residential access, both at high and low bandwidth.
We are interested in analyzing some of the scenarios that might lead to a poor TCP performance.
These are situations to which TCP is confronted everyday. They lead to different problems that
we could consider independently and which are not mutually exclusive, i.e. they can be
experienced simultaneously and will have little or no interaction. There are a number of causes
that would lead to this poor performance and we will address in this work a number of them. We
will first describe the most relevant characteristics of TCP. Then we will describe the scenarios
in which we are interested in evaluating TCP performance, pointing out the adverse effects that
can be experienced. We will then outline the solutions that we intend to develop in order to relief
some of these bad effects of TCP performance. Finally, we will implement some of these
solutions and we will discuss the results obtained.
TCP main characteristics
TCP is a very complex protocol and we do not aim at explaining it here in all detail, since the
full specifications are readily available in the literature ([1], [12], [18], [24], [27]). However, we
will try to describe its main characteristics in order to argue later how they affect the
7
Introduction
performance under the different scenarios that we are going to analyze. First, let us mention that
there are a number of functions that a lossless protocol has to implement in order to be correct
and functional. They can be divided into two main categories:
*
Flow control and Recovery: Flow control in the function that ensures that the flow of
information between the two ends occurs in a controlled manner. It has to ensure that the
sender will not transmit data faster than the receiver can process it. It also has to guarantee
that the information is processed in the correct order, and that packet loss in the network is
detected and solved. Recovery is the designation of the mechanism that a protocol uses to
recover from packet loss (being it due to network congestion or to isolated losses) and to
ensure that this loss will be remedied, usually by retransmission.
*
Congestion control: This is the mechanism by which a protocol reacts to network
conditions, namely congestion. The congestion control mechanism can be implemented in
many places, but when it is implemented within the protocol, it provides reactions to
indications of network congestion by adapting the transmission rate to the new conditions.
Flow control in TCP is achieved through a sliding window mechanism. The concept of sliding
window has been around for a very long time and in order to understand it we have to imagine
the packets that that connection has to send as aligned in a sequence. In order to provide lossless
communication, a TCP sender has to keep a copy of any packet sent until it has a confirmation
that the other end has correctly received that packet. TCP packets with a special flag, called ACK
packets, offer that confirmation, carrying the sequence number of the next packet that the
receiver is waiting for. This implicitly indicates that any packet with a lower sequence number
has been correctly received. Each sender maintains a window of packets that correspond to those
that could have been sent (but are not yet acknowledged) at a given point of time. When new
packets are acknowledged, we say that the window slides, allowing more packets to be sent. The
position of the window on the aligned sequence of packets therefore depends on the number of
packets that have been acknowledged by the receiver at the other end. The size of the window
8
Introduction
sndUna
sndnxt
sndcwnd
Figure 1: The TCP sliding window scheme
itself varies in time according to a series of algorithms and heuristics that have been developed
over time and we will describe later on this introduction. They aim to ensure that the buffering
space required at the sender is kept at a minimum, and that recovery from error can be achieved
with the less possible disturbance to the ongoing transmission.
In order to ensure that this sliding window mechanism is effectively implemented, each TCP
sender maintains a number of window parameters about a given connection. The most relevant
for our purpose are shown in Figure 1 and are the following:
" snduna: this is a pointer to the first packet that was sent but has not yet been
acknowledged.
*
sndnxt: this is a pointer to the next packet that will be send whenever the window
mechanism allows it.
*
sndcwnd: this is the window size value that TCP is using at the moment.
snduna is updated every time an ACK packet is received, and is set to the packet whose
sequence number is demanded by the ACK. The maximum number of packets that can be
outstanding (i.e. sent but not yet acknowledged) is given by sndcwnd. Therefore, sndnxt
can advance over the stream of packets until its value is greater than snduna + sndcwnd. In
this case, we say that the window is exhausted, and no other packet can be sent until we receive a
new ACK that would increase snduna (and therefore, slide the window).
9
Introduction
The maximum throughput that a TCP connection can achieve will depend on the network state at
that particular time, but it will be bounded, among other things, by the maximum TCP window
size (sometimes called socket size). The window size value is responsible for the congestion
control mechanism in the sense that while there is no congestion in the network, the window size
will steadily grow until it experiences some packet loss. Each end of the connection maintains a
maximum value for this window. On the sender side, different control algorithms ([2], [3], [23],
[18]) determine the window size and this value varies depending on the losses detected and the
frequency at which ACKs are received. The window size usually starts with a small value and
grows exponentially during the slow start phase and it is steadily increased during the congestion
avoidance phase. On the receiver side, it is usually a fixed value and its unique purpose it to not
overflow the receiver's buffers, rather than react to network congestion or losses. The effective
socket size at which the TCP connection will work is the minimum between the sender window
size and the receiver window size. In most of the practical realizations of a TCP connection, the
sender window is the actual value that will bound the maximum window size and will be
determined by the slow start and congestion avoidance phases.
Let us describe how TCP performs the three key requirements for a lossless transport protocol:
*
Flow control: In regular TCP, flow control is implemented in the receiver window. The
receiver, depending on its buffer population, can modify this value. Its purpose is to ensure
that packets received out of order of after a loss will not overflow the receiver.
*
Congestion control: it is implemented also through the window settings, but in this case, on
the sender. TCP takes a conservative approach (congestion avoidance) through which it
slowly grows the window provided it does not experience losses. This mechanism is aimed at
avoiding network congestion, since whenever it sees losses, it will shrink this window.
" Recovery: TCP recognizes losses in the network through repeated ACK sequence numbers.
When a packet is lost, the destination will keep sending ACKs with that packet's sequence
10
Introduction
number, allowing the source to know that this packet did not arrive. Early implementations of
TCP (Tahoe) did not distinguish between isolated losses (due to a transient error) and losses
due to congestion, and therefore were too sensible to lossy links. In successive flavors of
TCP (Reno) a new mechanism called fast recovery was devised, targeted at solving isolated
losses (i.e. usually not due to congestion) without slowing down TCP throughput.
In the TCP version we are going to work with, TCP Reno (probably the most widely accepted)
the recovery information in implied from the ACK sequence number. When the sender receives
three consecutive repeated ACKs, the fast recovery phase starts: the demanded packet is
retransmitted, the window is halved, but it is increased by the number of repeated ACKs received
so far, thus allowing transmission of further packets. This mechanism tries to cope with a single
isolated loss. If the losses persist (the the sender will experience a timeout, then the window is
shrunk to one, and every outstanding packet (starting from snduna) is retransmitted.
11
Introduction
This page intentionally left blank
12
Some adverse effects in TCP
Some Adverse Effects in TCP
The effect of the receiver window size
One of the characteristics of sliding window protocols like TCP is that they have to wait for
acknowledgements of previously transmitted packets in order to slide its window and transmit
new ones. A basic theoretical limit is that such a protocol cannot send more data that what it is
contained in a full window, before receiving an ACK for any packet on this window. Therefore,
for TCP to be working at the maximum rate at which it can transmit and not being limited by the
window size, we need to ensure that the roundtrip time is less that the time it would take to
transmit a full window.
In figure 2, we depict the theoretical limitation that the receiver window size can place in a TCP
connection. For each roundtrip time in the horizontal axis, and for a given maximum window
value, we can find the maximum throughput that a connection can achieve, regardless of the
maximum speed of the bottleneck link. Let us give a quick example: assume the roundtrip time
is 100 ms (a value quite common in the actual Internet). As an example, if the maximum window
size is 8760 bytes (generally the value that Microsoft Windows uses by default), we find that:
Maximum throughput =
window size (bytes) 8,760
- 87.6 Kbytes/sec.
roundtrip time (sec.)
0.1
=max
That is the maximum throughput that we can expect and in some cases it will introduce an
artificial limitation to our connection. Traditionally, before the popularity of the public Internet,
users could be placed in two main categories: Local LAN users and modem users. For users that
are sitting in a LAN and want to access local resources, the window size is not generally an
issue, since the roundtrip time is very small (on the order of some milliseconds) and ACK for
packets within a window come back before the full window is exhausted. For users accessing a
network from a modem, the speeds of the telephone line (56 kbps) itself are the bottleneck, so
13
Some adverse effects in TCP
TCP Window Limitation
" 8760
17560
35040
100000
xD-S-L)_-m-d---m,
c-
-_-_
--- - -
- --------- -- -- ---- -- F -ne
e A-es
-
10000
'A
0.
.0
1000
(U
~~iij
-------------------------------------------------------
LAN
_____
F' f1 _ - _-
-I -L-L
D
20
40
~
-
~
-
-
~
-
~
_
_
-
-
-
_
_-
_
-__
__
-
_
__
-
_I
----- -- -
I
------------------
60
80
100
120
140
160
180
200
Roundtrip time (ms)
Figure 2: The theoretical window limitation in TCP
the window size is again not an issue. But with the popularity of the Internet and the ability to
access remote sites, together with new access methods, such as cable modem or xDSL at much
faster rates, users start to get concerned about the influence of an ill-chosen maximum window
size. This is not a problem if we are accessing the Internet from a modem, but if our connection
can run at some Mbps, then we are clearly unnecessarily limiting the speed.
As a solution, we will explore an algorithm whose main purpose is to break the limitation of not
properly tuned receive windows. Because of the sliding window nature of TCP, we can only
send a window worth of data every roundtrip time from the source to the destination. The main
idea of this modification is splitting the roundtrip time in two components, from the source up to
a switch close to the destination and from this switch to the destination. By doing this we will
14
Some adverse effects in TCP
keep the limitation of the small receiver window on the destination only in the switch-destination
system.
In order to do this, we will install a Window Modifier (WM) at the switch, which will modify the
value of the receive window advertised by the destination by a value configurable at the switch.
Modifying the advertised window size has been explored in previous research [5], but with a
focus on traffic management and limitation. We intend to implement this mechanism and
demonstrate how this approach improves TCP performance.
TCP in asymmetric networks.
We will dedicate a special emphasis to analyze negative effects to TCP in asymmetric networks,
in which the bandwidth available in one direction is different to the other direction. Among these
types of networks, one of the most popular and promising are those used to provide residential
access to data and Internet services. In particular we will focus on Hybrid Fiber-Coaxial (HFC)
networks, generally those used by the cable TV industry and in the cable modem / headend
system. Those systems are characterized by a downstream transmission of speeds up to 40 Mbps
and a shared upstream channel with speeds up to 5 Mbps. In the downstream channel, all cable
modems hear the same signals, but the access to the shared upstream channel is controlled by the
headend. These kinds of systems have been the subject of numerous research works [4].
The HFC system is a shared medium and therefore, user population and usage will be of great
impact in the performance seen by a user. Under a scenario in which the majority of the traffic is
going to flow from the network to the users, i.e. downstream, the fact that the upstream channel
is shared may not decrease dramatically the performance, since the bandwidth needed upstream
is much smaller than the needed downstream. For example, say we have a downstream channel
of 10 Mbps and an upstream channel of 1 Mbps. The maximum packet size is 1,500 bytes and
the ACK packets are 40 bytes. We assume that the receiver is generating an ACK for each data
packet, although this is not usually the case since most of the TCP implementations use delayed
15
Some adverse effects in TCP
ACK and they generate and ACK every two or more packets. That means that the bandwidth
ratio downstream/upstream is 37.5, i.e. the upstream channel could support a downstream
channel of up to 37.5 Mbps. Therefore, for a downstream channel of 10 Mbps, an upstream
speed of 260 Kbps should be enough to accommodate the ACK stream.
However, if any of the users in a different cable modem on the same headend receiver is trying
to send data upstream, then the ACK stream for the other users that are obtaining data from the
network is likely to be affected. In the previous example, the ACK stream from a user getting
data downstream would typically need some 10-20% of the upstream bandwidth. That seems
small enough to not be adversely affected by the upstream data trying to get on the remaining
80%. But in some cases, this effect is worse than expected because the fact that now we are
sending 1,500 byte packets upstream competing with the 40-byte ACK packets introduces a
larger delay for the ACKs. If that source of upstream data is persistent, then it introduces another
further possible disadvantage for the ACK stream. In that case, the data stream does not need to
ever go to contention because it will use piggybacking (informing the headend of having further
data ready to send with every packet), whereas the ACK stream would eventually need to go to
contention. This translates into further ACK delays that can lead to adverse effects due to the
window size limitation mentioned previously, and it degrades dramatically the speed of
downstream transfers (even though they need very little bandwidth upstream). We will obtain
measurements confirming this effects, but as an example, the roundtrip can go from around 30
ms without cross traffic up to around 140 ms with cross traffic, values at which the window size
limitation may be in effect. This is due to the fact that under cross traffic conditions, an ACK is
likely to arrive with many other ACKs before it and has to wait for this ACKs to be transmitted
upstream before it can be transmitted itself.
Let's recall now that ACKs in the same TCP connection are cumulative, i.e. an ACK with a
higher number has the same information as an ACK with a lower one. Therefore, if we have two
(or more) ACKs for the same connection in a buffer, we can disregard the information of the
lower numbered, since it is contained on the highest numbered ACK. This was first proposed in
16
Some adverse effects in TCP
[4], and it will help solve exactly the problem we have here. Based on this idea, we intend to
demonstrate that its application is beneficial under this particular scenario, and extensible to
many others.
Flow switching in high-speed networks.
As was stated before, TCP is a sliding window protocol and this nature makes in not very
efficient in terms of bandwidth utilization over high latency networks or networks in which the
available bandwidth varies rapidly over time. Ideally, TCP is not able to send more than one
window worth of data every roundtrip time, so having a long delay in a very fast link is a worst
case scenario for TCP.
TCP is also characterized by the coupling between flow control (i.e. the mechanism that allows
to not overflow the ends), congestion control (i.e. the mechanism by which TCP reacts to the
state of the network), and recovery (i.e., the mechanism by which TCP is able to recover from
losses on the network). This coupling may reduce its throughput because a loss can either come
from any of these sources. In addition, the congestion avoidance mechanism can prove to be
excessively conservative, therefore forcing the connection to be not as fast as it could be. All of
these control methods are achieved by means of the ACK packets received from the destination
and this may be a source of problems.
In order to modify TCP, we want to take advantage of two factors: the possibilities of having the
network inform the sources of the available bandwidth (the accuracy and interface of this
information can be discussed later); and the notion of decoupling flow and congestion control
from the recovery mechanism. Using these mechanisms we will be able to improve flow control
under circumstances that make current TCP inefficient. Our proposal is based on the two key
ideas mentioned before: decoupling the flow and congestion control mechanism from the
recovery, and taking advantage of the bandwidth information provided by the network.
17
Some adverse effects in TCP
In order to achieve these goals, small changes are required to the TCP stack at the source (the
receiver stack remains as is). The recovery mechanism is to remain intact (i.e. duplicated ACKs
trigger fast recovery and timeouts cause full retransmissions). The flow and congestion control,
however, are going to be decoupled, and will no longer be dependent on ACK reception. We are
going to introduce the notion of TCP modes. Our modified TCP stack is going to be able to work
in two modes: Regular TCP mode and High Performance (HTCP) mode. The Regular TCP
mode would obviously be the current implementation of traditional TCP stacks. The HTCP mode
will be characterized by the assumption that the network is able to provide bandwidth
information to the source, although how this information is provided is not the object of this
description. When the source has this information, it will go into HTCP mode. In this mode the
timing for packet transmission would not be controlled anymore by the ACKs. We then switch
from window-based operation to rate-based operation, and the TCP source will send packets
according to the rate it has been given by the network. Since now we have information from the
network about the bandwidth available, the congestion avoidance phase is no longer needed. The
practical result of this change to TCP mode will be the overriding of the congestion avoidance
phase, thus permitting TCP transfer at full speed.
The operation of our sender in HTCP mode, however, will still make use of the ACKs received
from the destination, in order to ensure lossless transmission. For this purpose, all the recovery
functionality on regular TCP is kept unchanged. Repeated ACKs still will trigger fast
retransmission of lost packets, and timeouts will result in retransmitting all the outstanding
packets (starting from snduna). Therefore, the recovery function is guaranteed to be
functional. We must also ensure that the amount of outstanding data is less or equal than the
receiver window. Therefore, even tough the packets are now send according to a clock self timed
to the bandwidth given by the network, if the data sent and not yet acknowledged grows up to the
receiver window, we cannot send any further packet until we receive an ACK. This implies that
the receiver window is going to be of great importance and should be set to a fairly large amount.
Let us remember that a basic theoretical limit is that such a protocol cannot send more data that
what it is contained in a full window, before receiving an ACK for any packet on this window.
18
Some adverse effects in TCP
Consider the available bandwidth at our high-speed optical network to be in the orders of 1
Gbps, and with roundtrip delays in the order of tens of milliseconds (say 20 ms.). The buffer
needed in order to allow full speed at the link would be 20 Mbytes, which is not unfeasible. We
should also note that since only one connection at a time may be using the full speed of the link,
this buffer space is needed on a per link basis, not on a per connection basis, which allows for a
much convenient scaling.
19
Some adverse effects in TCP
This page intentionally left blank
20
Preliminary analysis
Preliminary Analysis
We will describe in this section some experiments that helped us understand and analyze further
the adverse effects described in the previous sections, in particular the window size limitation
and the effect of cross traffic in asymmetric networks. We will first describe the test scenario and
we will comment on the different measurements that we obtained to support our interpretation of
the problems.
We will pay special attention here at the type of networks we described before as asymmetric
networks, since it is one of the cases in which the two described phenomena may happen more
evidently. In particular, we are going to obtain measurements in a HFC (Hybrid Fiber-Coaxial)
system, similar to the configuration that can be observed in cable systems, in which a cable
router in the premises of a cable provider serves a number of residential users. Those users have
access to the network through a cable modem, a device hooked to the standard coaxial cable that
provides cable TV service. This Internet access service is already running in some parts of the
U.S. and some countries in Europe, so we consider it a realistic scenario for our purposes.
Test scenario in asymmetric networks
In this section we are going to describe the laboratory test we devised, as it is depicted in Figure
3. As mentioned before, it corresponds to a typical setup one can encounter when analyzing a
cable data system. We use two Cable Modems (CM), connected through separate coaxial cables
to a Cable Modem Termination System (CMTS). On the same transmitter, we have two coaxial
lines with a cable modem each, as if they were two different users served by the same transmitter
at the CMTS. One of the cable modems (CM2) would have an upstream traffic generator that we
will use for certain test to emulate a user with heavy upstream traffic. The other cable modem
(CM1) has a local Ethernet (downstream Ethernet) in which two computers are attached. One of
them will be our test subject, in which we are going to monitor TCP performance. The other PC
(running Linux and tcpdump) will act as a packet sniffer and will allow us to obtain traffic
21
Preliminary analysis
traces. The packet sniffer has also a second network interface (ethl) card that listens to the
Ethernet segment to which the network interface of the CMTS is connected (upstream Ethernet).
This setup with a common time reference will allow us to track packets and obtain statistics
about their delay within the HFC system. We can track the time it takes for a packet when it is
visible in the upstream Ethernet segment until it appears in the downstream Ethernet
(downstream delay) and vice-versa (upstream delay).
The two arrows in Figure 3 represent the different types of connections that we are going to
monitor. They will be from our user PC in the downstream Ethernet to either a machine that is
directly on the upstream Ethernet (to minimize the effects of further network segments), or to a
machine sitting across some network (which may be the Internet itself). This latter type or
WinNTPC
150.36.158.1U
150.36.1. 9
CMTs
Corporate
Network
150.36.158.181
CM1
CM2
150.36.158.180
Upstream
Traffic generator
e th0
< -----------------------
Win95 PC
150.36.158.18
Dual Win95/Linux 6.0 PC
150.36.158.17
150.21.2.23
Ethernet
RF Coax
Figure 3: Test scenario in asymmetric networks
22
HP-UX server(Wc)
Preliminary analysis
connections will be the most interesting given that they are similar to the kind of TCP
connections a residential user will establish.
Our tests will consist of measuring the time elapsed for downloading a file using FTP from a
server located across a corporate network. The roundtrip time from the user's machine to that
server is in the order of 30 milliseconds. We will run the test for different upstream bandwidth,
varying the maximum window value that the receiver advertises, and we will add the effect of
another user sending traffic upstream in other cable modem, so we can see the effects that it
causes in the TCP throughput.
The effect of the receiver window size
For isolating the effects of the window size, we do not use the upstream traffic generator in
800
(I)
700-
-- t35040
32120
__
600
17520
0.
500
E
-
-
- -
40 0
-
- - - - - - - - -
- -- - -- -- - - -- - -
- -
- -
- -
- - -- - ----
- -
300
0
- - -
- - - - -
- - -
- - -
- - -
- - -
- -
- -
- -
-
-
-
-
- -
- - - - - -
-
-
200 -
- - -
-
-
E
E 100
0
- ---
0
-
--
1000
---
-- - - - -
2000
--
- -
3000
-
- -- -
-
4000
-
-
5000
- -
-
-
6000
Upstream bandwidth (Kbits/s)
Figure 4: Effect of Window Size in TCP throughput
23
Preliminary analysis
CM2. As we can see in Figure 4, the throughput that a TCP session can achieve is going to be
limited by the receiver window size settings. The horizontal axis shows the bandwidth available
for the upstream channel (which is entirely available for the FTP session, since there are no other
traffic on the channel). Let us recall that the upstream bandwidth in the most restringing scenario
is 640 Kbps, enough to carry a 24 Mbps stream downstream (considering 40-byte ACK packets,
1,500-byte data packets and no delayed ACK), although it is limited by the 10 Mbps by the
Ethernet segment. Using our formula to calculate the theoretical maximum throughput, for a
window of 8,760 bytes and a roundtrip time of 35 ms we obtain a maximum throughput of 292
Kbytes/s, which is clearly consistent with the values shown in Figure 4. Usually, Microsoft
Windows' TCP stack default receiver window value is 8,760, so this is the most likely scenario
for a residential user browsing the Internet from his home PC. We can see that only by increasing
that default value, the throughput increases accordingly. When the window size is doubled to
17,520 bytes, we observe the maximum throughput to also double, which confirms that the
reason of such a low throughput with a smaller window is indeed due to the window value.
Further increases of the window do not produce such dramatic results because other effects
appear. Therefore we can conclude that an ill-chosen setting for the receiver window size can
create an artificial bottleneck.
The effect of cross traffic
In the same test scenario we want to verify the adverse effects of having other users sending data
upstream. In an ideal scenario for a residential high speed access (as is a cable system), the users
would be primarily browsing the Internet, and therefore the bulk of data transmission would be
done in the downstream direction, i.e. from the network to the residential users. That is why an
asymmetric cable system would be effective, since the larger bandwidth would be offered in the
direction that is needed the most, the downstream path. In that case, the TCP packets that would
be flowing in the upstream direction would be mainly ACK packets with no data, thus needing
much less bandwidth than the downstream channel.
24
Preliminary analysis
A possible adverse effect of having a smaller upstream channel (that is also shared by all users
on the same CMTS transmitter) is when some users have a behavior that does not follow the
patterns described above. In the case when one of the residential users is sending data in the
upstream direction (e.g. running a web server), then we have in the upstream channel 1,500-byte
data packets together with the 40-byte ACK packets from other users. Let us remember that in
this type of cable system, there is the issue of media access to the upstream channel. This means
that any packet experience an access delay, i.e. the time it takes for the cable modem to request a
grant to the cable router until the packet is effectively transmitted. This access delay is not
dependent of the size of the packet, but is affected by the size of other packets. Both kinds of
packets (regardless of its size) would need the same amount of time to get a grant for
transmitting upstream, but the larger other packets are, the more time they have to wait.
Therefore, having larger packets competing for upstream bandwidth increase the delay
experienced by the smaller ACK packets.
800
700 ----------
e.
-----
-----
----
60 0 --
- - -- - - -- - --
- -
-
-
-
- ------------
35040
-
32120
-- - - - - - - - - - - - - - - -
- -
C.
50 0
- - -
400
-
- - -
- -
-
17520
- - - - - - - - - - - - - - - - - - - - - - -- - - - - - - -- - - ---
-
0
E
- - - - -
*0 300 -
-- - - - -
-
-
-
-
- - - - - - - - - -
- -
-
-
-
-
-
- - -
-
-
-
8760
0
20 0
-
- - -
- -
-
-
- - - - - - - - - - - - -- - - - - - - - ---
- - - -
- -
E
cc j
1-
2
-
-
-
-
-
--
- -
-
--
-
- --
-
-
-
- -
--
-
- -
-- -
-
0~
0
1000
2000
3000
4000
5000
6000
Upstream bandwidth (Kbits/s)
Figure 5: Effect of Cross Traffic in TCP throughput
25
Preliminary analysis
In order to prove the effect of cross traffic over the performance of regular TCP sessions, we
introduced a traffic generator connected to CM2 (see Figure 3). This traffic generator sends TCP
data traffic upstream at the highest rate available. As we can see in Figure 5, when the upstream
channel is large, the effect is not very important, but as soon as we use smaller channels, the
effect of cross traffic can prove to be devastating. We also try to characterize the effect of
different window sizes and we can verify that for small upstream channels, there is no gain in
increasing the window size. In particular, for the smallest upstream channel (640Kbps), the
maximum throughput we obtain is not larger than 250 Kbytes/s, as opposed to the nearly
680 Kbytes/s we were obtaining when there was no cross traffic.
We want to find an explanation for such degradation, especially considering that for a
680 Kbytes/s stream (approximately 450 data packets per second), the bandwidth used in the
Delay CMTS-CM (Upstream direction)
Cross Traffic ......... No cross traffic
10
609.7 Kbytes/s
8
-- --- - - - - - 6
-- - - --- -
205,0 Kbytes/s
aL
4
2
-
-
-
-
0
0
20
40
60
80
100
120
140
Delay (ms)
Figure 6: Upstream delay for ACK packets
26
160
180
200
Preliminary analysis
upstream channel is less than 150 Kbps (less than 25% of the available bandwidth). Therefore,
the mere fact that there is more traffic should not be affected, since a fair share of bandwidth
would still allocate the same bandwidth to the regular TCP connection. We proceed to analyze
several traffic traces trying to characterize the delay experienced by ACK packets in their
upstream trip. We will measure the upstream delay in the HFC system, i.e. from when an ACK
packet is seen at the local Ethernet connected to the cable modem until it appears in the Ethernet
segment attached to the cable modem termination system (CMTS, or cable router). In Figure 6,
we represent the probability density function (pdf) of this ACK delay, i.e. the probability that an
ACK packet will experience a given delay in milliseconds. As we can see in the figure, when
there is no cross traffic in CM2, the bulk of ACK packets spend about 25 ms within the CMCMTS system. Considering that the whole roundtrip time for this particular setup is of the order
of 35ms, we can see how this delay is the major contributor, but it does not affect significantly
TCP performance, since the window size limitation is far from occurring. However, when we
witch on the upstream data traffic on CM2, we see how the delay dramatically increases up to
140 ms, thus falling within the window size limitation. Now the roundtrip time is close to 150
ms, which would only allow a theoretical maximum throughput of 233 Kbytes/s with a window
of 35,040 bytes.
Let us examine with more detail this effect and in order to do so, we will try to establish a
breakdown of the delay CM-CMTS in different components:
"
Queuing delay: This refers to the time elapsed between and ACK packet is seen on the
Ethernet segment near the cable modem, until it is located ahead of the upstream waiting
queue, therefore allowing the CM to ask for a new transmission grant.
"
Access delay: This is the time elapsed between the grant request and the actual moment in
which transmission starts.
27
Preliminary analysis
*
Transmission delay: This is the transmission (i.e. depending of the upstream bandwidth)
plus propagation delay on the coaxial segment between the CM and the CMTS.
"
Processing delay: This is the time it takes for the CMTS to process and send the packet to
the appropriate network interface (i.e., when the packet is seen in the Ethernet segment to
which the CMTS is connected).
We can estimate how important each of these contributions can be to the overall delay, and, at a
first glance, we can suggest that the transmission delay is going to be independent of the amount
of traffic in the upstream channel. We also can assume that the processing delay variation in the
CMTS is negligible and therefore it will not be dramatically affected by the difference in traffic
volume. However, the queuing and access delays are going to increase when we have cross
traffic. The access delay is going to increase because now the upstream channel is utilized for
longer periods of time, thus reducing the granularity with which new requests can be
accommodated. As a side effect of this phenomenon, since the time that the packet currently
server spends at the head of the queue increases, a packet coming to the queue is more likely to
encounter more packets, thus also increasing the queuing delay. We do not have a direct way to
separate the effect of both delays, but we can measure the number of packets that are
simultaneously inside the CM-CMTS system to have an idea of how the queue size at a cable
modem increases due to cross traffic.
In Figure 7 we picture the evolution of two TCP connection; one of them is a regular TCP
session with no other traffic and is compared to a second connection under the effect of cross
traffic. In the isolated connection we see how the number of ACK packets within the system has
an average value of approximately 5 packets, but the variation is very fast, thus indicating that
ACKs may be generated in bursts. This assumption is justified by the fact that under a highspeed connection and due to TCP slow start characteristics, it will not be uncommon to have
bursts of data packets, thus leading to bursts in ACK packets.
28
Preiminaty analysis
On the other hand, when we have cross traffic, the number of packets in transit increases
systematically up to 12 packets, with little variation. This indicates that, since the transmission
and processing delay are considered invariant, the queuing and access delay dramatically
increase. Since access time increases due to the bigger data packets present at CM2, the queues
at the cable modem grow bigger.
We can even try to extract more information on how the delay is characterized to definitely
conclude about the causes of such a dramatic increase in delay. In order to do that, we want to
depict the delay that an ACK packet experiences as a function of the number of ACK packets
that still remain within the HFC system. We show such a chart in Figure 8, in which the
horizontal axis is the number of ACK packets present in the system when a given ACK packet
arrives to the CM, and the vertical axis corresponds to delay in milliseconds. We can estimate the
ACK packets on the HFC system
---
Cross Traffic -
No cross traffic
14
12
10
(A
(A
U
(A
0.
8
Ii
6
C)
4
4
2
0
0
2
4
6
8
10
12
14
16
18
20
Time (s)
Figure 7: ACK packets inside the CM-CMTS system
29
Preliminary analysis
different contributions to the delay from the shape of the data point. Each ACK packet will have
a fixed delay component, which will correspond to the transmission and processing delay. This
value is the common offset that we find in both sets of data, and can be estimated at around 1520 ms.
In addition there is the delay part that varies when we have cross traffic, which is the queuing
delay and the access delay. The way we can estimate the access delay is through the slope of the
mean delay per value of ACK packets upon arrival. In the case that there is no cross traffic, when
there is just one packet, the total delay experienced is around 20 milliseconds. When there is 10
ACK packets ahead of a new packet, the delay is around 40 ms, which gives us an estimate of a
delay access of 2 ms per packet. Let us now look at the case in which there is upstream data
traffic on CM2. The delay when there is only one ACK packet is around 30 ms, whereas the
Buffering delay
a
200
No cross traffic * Cross traff c
.-
180
160
----------
140
E
U.
-
-- ----
-
- - - - - ---
------
-- - -
--
---
- --
120
I-
-1
100
80
60
40
-
-
-
- -
- -
-
-
-
- -
-
-
20
0
0
1
2
3
4
5
6
7
8
9
10
11
ACK at HFC upon arrival
Figure 8: Delay of ACK packets as a function of the number
of ACK packets inside the CM-CMTS system
30
12
13
Preliminary analysis
delay when we have 10 more packets in the queue is around 140 ms. This gives us an access time
of around 10 ms per packet. We confirm this estimate noting that the difference between the
delay for just one packet is around 8 ms, as it is shown in the Figure.
This numbers confirm our fear that the effect caused by upstream data traffic are much worse
than simply adding more traffic to the upstream channel. The access delay per packet is
increased four or five times, thus creating a phenomenon in which several ACK packets for the
same TCP connection have to wait in the same queue. This effect suggests an immediate
improvement, which is the use of concatenation. Concatenation is a feature that a cable system
may implement in which grants for upstream transmission are not done in a packet-by-packet
basis, but rather depending on the amount of data available for transmission. In systems where
there is no concatenation, the grants for transmission time in the upstream channel are given in a
packet by packet basis, regardless of the size of the packet. This leads to adverse situations,
especially under the scenario with cross traffic in another cable modem. This effect is mitigated
with the use of a technique called piggybacking, which allows to inform the cable router (the
element that actually does the scheduling) within an upstream data transmission that there is
more data waiting for being transmitted. This mechanism allows persistent sources to spare some
time in contention for upstream channel, but it does not prevent the effect of a larger access time
due to the mismatch in packet sizes. For the measurements presented on this work, the cable
modem was using piggybacking but no concatenation. The fact that the access time increases
with cross traffic and that this leads to an increasing queue size in the cable modem suggests that
concatenation can be useful in mitigating this effect, although it would increase the processing
complexity at the cable modem.
Some possible solutions
We will describe in this subsection some of the solutions that can be thought of in order to
relieve some of the adverse effects we have seen in the previous sections. Then, in the next
31
Preliminary analysis
section we will develop some of them that are of particular interest for us, and we will describe
in detail their functionality and degree of improvement.
ACK Suppression (AS) at CM
This is a method for alleviating the problem cause by cumulated ACKs during cross traffic. It
was proposed on [4], after an idea of P. Karn and is based in the fact that TCP ACK packets are
cumulative, so when we have several of them from a same connection in the same queue, only
the most recent one is relevant. The main characteristics of this solution are:
" No extra buffering required: we only need to have an efficient management of the queue that
would allow for quick removal.
" May create burstiness: When we eliminate intermediate information, the TCP source may
tend to be bursty
*
Maintaining a per flow state would be ideal, but it is not strictly necessary.
Window modification at CMTS or CM
This solution is aimed at solving the window size limitation described in the previous sections.
The main idea is to break down the scope of the window size limitation to a smaller part of the
whole path, by installing somewhere along that path a module that would modify the receiver
window advertised by one end of TCP. By increasing this value, we allow the sender to transmit
data faster and avoid the typical stalling of the TCP connection due to the mismatch between
window size, roundtrip time and link speed. This solution may require some amount of buffering
and it needs to maintain per flow state, so it can a degree of complexity that we have to deal
with. On the other hand, and as opposed to other similar full proxy solutions proposed, this
mechanism would be soft state, i.e. in the event of a failure of the Window Manager software,
the TCP connection would not be damaged and would recover itself from the failure.
ACK arrival estimation at CMTS
Another solution for the ACK compression problem we can explore takes in account that the
32
Preliminary analysis
CM-CMTS segment of the TCP connection is common, and the upstream and downstream path
traverse the same network elements (fact that cannot be guaranteed in the public Internet
segment of the connection). Due to this property, and since the CMTS would be able to monitor
the data packets flowing upstream, it could estimate when the cable modem would have an ACK
ready to be send upstream. With this estimate, the CMTS could issue and unsolicited grant to the
CM, before the CM has to ask for the grant itself, therefore reducing the access delay an ACK
packet would experience.
This solution has a major drawback on its complexity, since we need not only to keep per-flow
state at the CMTS, but also devote processing time to estimate the roundtrip times CMTS-CM.
We also have to alter the scheduling process at the CMTS, therefore introducing other problems
that could reduce the scheduling efficiency.
ACK reconstruction (AR) at CMTS
This method was also proposed on [4]. It basically tries to reconstruct a constant stream of ACKs
in such a way that the TCP sender would transmit data in a non-bursty manner. This method
would be quite efficient for smoothing a stream of ACKs that would cause the TCP sender to
behave in bursts, by delaying the ACKs and releasing the according to an estimated rate.
However, if the problem is the opposite and we do not need only to delay, but occasionally to
generate ACKs, then this mechanism becomes hard state with strong implications in case of
failure.
TCP with high-speed flow switching.
In this section we are going to describe some scenarios in which the use of a high-speed flow
switching does not allow TCP to fully utilize all the optical bandwidth that it has available. As
we have described in the introduction, our objective here is twofold. In one hand, we want to
ensure that the transfer protocol may use all the bandwidth that it has available. On the other
hand, we want to maintain the feature that makes TCP so robust and which helped it to become a
33
Preliminary analysis
de facto standard in networking. In TCP as we now it today, however, the mechanisms that
control the flow of data (i.e. using efficiently the bandwidth) and those that ensure that the
transfer is correct and complete (i.e. robustness as a lossless protocol) are combined. They obtain
their information from a unique source, the ACK packets. These packets not only inform TCP of
which packets have been correctly received, but at the same time (and due to the sliding window
mechanism) control how fast new information is transmitted. In order to accomplish efficiently
our first objective we have to come up with some idea that would allow separating those two
mechanisms. However, in order to do so, we need to have some information about the current
characteristics of the network, and the possession or not of this information will define tow
possible modes of operation. One which is the regular TCP as we know it today, and a second
mode (that we call High-performance TCP or HTCP) in which, although maintaining TCP's
recovery features, we allow the flow control to be governed by the information the network has
provided. In this mode, we no longer use the standard sliding window mechanism, but we send
data at the rate specified by the network, although we are limited by the amount of information
that can be stored in the sender's buffers.
We are especially interested in a scenario in which we have several concurrent TCP transfers
from separate sources over a bottleneck link, as it is shown in Figure 9. This bottleneck link has
actually in parallel a high-speed optical fiber (e.g., OC-12) and a much slower conventional
wired link. Traffic can be routed to the high-speed fiber only in a per incoming link basis, which
source 1
Switch 1
source 2
Switch 2
OC-12 (677 Mbps)
10 Mbps
source n
Figure 9: Scenario for optical flow switching and TCP
34
Preliminary analysis
means that in our scenario only one of the TCP transfers can be routed over a given wavelength
in the fiber. All other transfers are routed to the remaining wire link, in which they have to share
the bandwidth (significantly smaller than the optical link). Under this scenario, in order to
achieve a fair share of the bottleneck link, we should establish some kind of rotation for the set
of TCP connections sharing the link. We use a simple round robin manner in which the access to
the optical link is given alternatively to a single connection (although the way in which this is
scheduled is not the object of this work). We will rather focus in devising mechanisms by which
TCP connection can efficiently be switched from the shared wire link to the high speed optical
link and vice-versa.
We have to take in account that since the bandwidth difference between the two links is fairly
large, TCP will have problems to adapt its rate to the new bandwidth availability. In particular,
when TCP is switched to a faster link, it might take too much time to actually realize that extra
bandwidth is available. As a rule of thumb, a TCP transfer in congestion avoidance mode can
increase its window by one unit every roundtrip time. Therefore, it will need several roundtrip
times for increasing the window enough as to fully utilize the new bandwidth. In addition, if the
time allotted to a TCP connection is not much larger than several roundtrip times, TCP's own
congestion avoidance mechanism may not allow the connection to reach the throughput it could
achieve when using the high-speed optical link. On the contrary, by the time TCP can utilize
such bandwidth, it is not there anymore, clearly causing a waste of resources.
On the other hand, the transition from a fast link to a slower one can be effective in a short
period of time since the TCP stack will realize the eventual loss of some packets and slow down
the transfer. However, if the adaptation is performed without caution, the TCP transfer may end
up sending too many packets, therefore experiencing too many losses and, more importantly,
causing losses to others. Therefore, it is crucial to devise carefully the mechanisms that would
allow an efficient transition between the two modes. In the following subsection we describe in
more detail the peculiarity of each transition.
35
Preliminary analysis
Mode switching
We define mode switching to be the transient phase between the two modes. The transition from
regular mode to HTCP mode is simply done whenever we receive information from the network
about the available bandwidth. The reverse transition (from HTCP back to Regular TCP mode) is
done when the network explicitly tells the sender so, or when the sender cannot trust the received
information anymore. It is not the object of this work to define the mechanisms by which this
information is communicated, but a simple information packet exchange can be thought of. The
second kind of transition, back to regular TCP is, as we have explained before, slightly more
complicated and critical because there will be a larger amount of data on the fly and this may
cause some problems due to the bandwidth mismatch. We describe here the main characteristics
of the two transition phases:
*
Regular TCP -- HTCP: When switching to High Peformance TCP mode, we only need to
keep the last value of sndcwnd for its eventual use when switching back to regular TCP
mode. Depending of the strategy that we follow on the other transition, the value of
sndcwnd will be modified or not during HTCP mode.
" HTCP
->
Regular TCP: This is the most delicate part, since now we have to return to the
regular TCP mode. We have a large amount of data on-the fly, so the frequency of ACKs is
going to be increased, although the link is back to a lower rate. There is a number of
approaches we can take, but they will be focused in two objectives: preserving the own
transfer's efficiency (i.e., avoiding causing some losses to the own TCP connection), and
preserve other transfer's evolution (i.e., avoiding causing extraordinary losses to other
connections). The basic scenario that we will encounter upon this transition is a large
window (i.e. a high number of outstanding packets) that has to be decreased to a much
smaller one. In addition, we have the inconvenient that during the first moments of regular
TCP mode, there will be a great number of packets still unacknowledged that were sent
during the HTCP mode. The timing of those ACK packets has nothing to do with the state of
36
Preliminaty analysis
the newly recovered TCP connection, and they will arrive at a much higher rate that they
would under the newly adopted connection characteristics. This can lead to the source
sending too many packets too quickly, therefore causing overflow in the bottleneck link
buffer, which will translate in losses and the ongoing connection to be stalled.
The recovery phase
We are going to devote this subsection to the most critical part of the mode switching mechanism
in our proposal, the window size recovery in the transition from HTCP to regular TCP. When
this transition occurs, the most likely scenario will have the following characteristics:
*
The number of packets outstanding at this point can be as large as the maximum window
size, since we are overriding the congestion avoidance mode. During the HTCP phase data is
sent at a rate according to the information provided by the network, not according to the
timing provided by the ACK packets. Therefore the number of outstanding packets can grow
as to reach the maximum window size or to fill the bandwidth-delay product, whichever is
smaller.
*
Since there is a number of outstanding packets that have been sent at a high speed, when the
ACKs for those packets arrive to the sender, they will do it at a rate according to which they
were sent. If this rate is much higher than the rate the new regime can accommodate, if we
slide the TCP window according to those ACKs, we are likely to send data at a too fast rate.
*
The value of the window size that will bound the throughput on the new regime is somewhat
unknown, although we can use different methods to estimate it. In any case, it is most likely
that this new window is going to be much smaller than the number of outstanding packets at
the time of the HTCP -+ TCP mode switching. This implies that there are a number of
strategies we can think of in order to bring the number of outstanding packets to the value we
have estimated for the new regime.
37
Preliminary analysis
According to this description, we are going to define some phases during the transition that
would ease the description of our proposed solution. First, we define what we are going to call
the recovery phase. It is the lapse of time between the reception of the information that suspends
HTCP (or the moment in which according to that information, we decide to end that mode) until
the instant in which we deem the connection recovered and we switch back to a full regular TCP.
Within the recovery phase we can also distinguish two separate phases: the window adaptation
phase, and the rate adjustment phase. The transfer is in the window adaptation phase while it is
adjusting the number of outstanding packets we had at the end of the HTCP mode, to the window
size at which we want to bring the transfer in the new regime. As an example, if at the end of the
HTCP mode there were 100 outstanding packets and we wish to bring the connection to a
window of 20 packets, the window adaptation phase will extend for the time in which the
number of outstanding packets is reduced from 100 to 20. However, even though we have
reached the desired window size, the reminding 20 ACKs for packets sent during the HTCP
mode are likely to arrive at a higher rate that is really available on the new slower link (since
those ACKs correspond to data packets sent over the high-speed link). Therefore, we define the
transfer to be in the rate adjustment phase while the ACKs that are being received correspond to
packets sent during the HTCP mode. As soon as we receive an ACK for a packet that was sent
during the newly acquired TCP we end the rate adjustment phase (and by consequence, the
recovery phase).
We have to note that depending on the particular circumstances of the connection, the
breakdown of the recovery phase may differ. In particular, when the number of outstanding
packets at the end of the HTCP mode is equal or less that the new desired window, there will not
be a window adaptation phase. Similarly, when the newly desired window is equal to one packet
(corresponding to the most conservative solution in which the TCP regime starts practically from
scratch) there will not be a rate adjustment phase.
38
Preliminary analysis
There are a number of strategies that we can follow in order to make both window adaptation
and rate adjustment efficient and not prone to losses. Some of them have been proposed in the
literature ([11], [25]), although they are applied in different scenarios that the one we are dealing
with.
In particular, what is going to be one of the critical factors is the desired value of the TCP
window that we want to return at. There are a number of choices that we can use and they will
differ in the degree of aggressiveness. The most conservative will be setting the window to one
packet, which is almost equivalent to restart TCP in the new regime from scratch. If we want to
be more aggressive we can choose to come back at the value at which the window was
previously to the switching to HTCP mode. An even more aggressive mechanism can be to grow
the window as if when HTCP we were in regular TCP mode. Finally, and if we want to be
almost suicidal, we can simply keep set the window immediately to the current number of
outstanding packets, hoping that the new regime could sustain that rate (which is highly
improbable).
After deciding the value of the new window at which we want to reduce the rate, which can be
estimated using some of the propositions in [25], we are faced with the problem of effectively
reducing the current window to the desired value. During the window adaptation phase we can
take the following approaches, depending of the trade off we want to make between safety and
speed in recovering the desired window value:
*
Conservative: In order to not cause any additional loss due to the window mismatch, we will
not send any data packet until the desired window is reached. We will receive ACKs during
this period, but we only incorporate the information they carry about correctly received
packets. They will not trigger the transmission of new packets and only will help close the
window down.
39
Preliminary analysis
Aggressive: In order to avoid the stall cause by the conservative approach, we can think of
sending data packets interspersed between the ACKs. We need to set a parameter
(htcpack_intersp_) that will control every how many ACKs do we send a data packet
(which obviously has to be greater than one if we want to decrease the window). However,
since the timing of the ACKs is completely unrelated to the actual conditions of the slower
link, even a high parameter may lead to an excess of data packets.
There are also some subtleties as to how the initial conditions of the window adaptation phase.
As an example, we can decide that the new window is going to be of w, packets, when the
current number of outstanding packets is much larger, say wh. We need to send at least one
packet more before entering the window adaptation phase, in order to allow the new regime to
provide the first ACK with the delay characteristics of the new situation. However, we can send
more than one packet right before entering this mode. In this case, we would have sent some
fraction of the newly desired window with the new characteristics and this may help the TCP
connection to resume faster its normal behavior. Say that we send n packets (with n
wn) before
entering the window adaptation mode. The number of ACKs for packets out of the new window
that will arrive (wh + n) will do so under the high-speed timing, and therefore, the rate adjustment
phase will be smaller (w,,.- n). In an extreme case, when we send in the new regime as many
packets as the new window allows (n = wn), the rate adjustment phase disappears.
Similarly, during the rate adjustment phase, we may apply some of the same approaches
described above, or a combination of them. If in the instant that we reach the rate adjustment
phase (i.e., when the number of outstanding packets equals the desired window size, but we still
have not received ACKs for packets sent during the new regime) we start "trusting" the timing of
the incoming acknowledgements, we still might experience problems. This is due to the fact that
these ACKs still do not carry any information about the current conditions of the new regime.
We will receive w,.- n such acknowledgements, and when this number is still too large for what
the new regime can accommodate, the TCP transfer may still experience losses. Therefore, for
40
Preliminary analysis
the rate adjustment phase we can apply an interspersing mechanism that would be similar to the
one described above for the window adaptation
41
Preliminary analysis
This page intentionally left blank
42
Implementation of solutions proposed
Implementation of Solutions Proposed
In this section we will describe the implementation of two of the solutions proposed in the
previous section. We will describe in detail the mechanisms involved in each of the solutions and
how they can mitigate the effects of the problems they aim to solve. We will then describe the
practical implications of their implementation. We will finish the work by presenting the results
we collected to prove the benefits of these solutions.
Window size modifier (WM)
The main purpose of the algorithm is to break the limitation of not properly tuned receiver
windows. As it has been explained in the previous sections, because of the sliding window nature
of TCP, we can roughly send only one window worth of data every roundtrip time between the
TCP sender and receiver. The main idea of this modification is splitting the roundtrip time in two
components, Source-CM + CM-Receiver and keeping the limitation of the small receiver
window only in the CM-Receiver system. A number of proposals have been made to use the
receiver window to adapt the TCP behavior to the conditions on the network, but they have been
focused in rate control, i.e. slowing down too aggressive TCP transfers. A proposal described in
[5] implements this idea by reducing the receiver window size and therefore explicitly reducing
the actual TCP window size. Our approach is different in the sense that it is not used to reduce
the TCP throughput, but rather to allow TCP to access more efficiently the bandwidth available.
However, our scheme can also be used as a rate limiter, thus giving the service provider more
control over the quality of service perceived by the users.
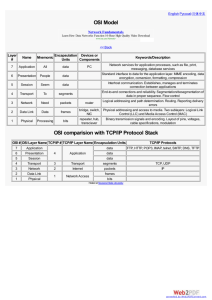
In order to accomplish the window size limitation split, we will install a Window Modifier (WM)
at the CM, which will change the value of the receive window advertised by the CPE by a value
configurable at the CM. In order to preserve TCP end to end semantics and maintain the
consideration of soft state solution, the WM will not generate any spurious ACK nor will
retransmit any packet. It will eavesdrop ongoing TCP connections and will change the value of
the receive window advertised by the receiver. It will monitor the data coming downstream and
43
Implementation of solutions proposed
will hold (buffer) those packets that are out of the true advertised window on the CM-Receiver
system, until a new ACK makes room for them. When a packet is buffered at the CM, it means
that it has not been sent yet to the receiver. As soon as is sent, the CM does no longer have it nor
keeps a copy. Therefore, we are not implementing a proxy or retransmission service at the CM,
but only providing temporary buffering for avoiding receiver window overflows. No spurious
ACK packets are generated and only buffering up to the difference between the true advertised
window and the modified value is needed. However, we need to maintain a per flow state but the
overhead involved is reduced to identifying the flow, modifying the window size value within
the TCP packet and is recalculating the TCP checksum, since the MAC CRC is automatically
recomputed by the hardware.
This approach allows for the WM to be considered soft state. In the event of a WM failure,
TCP's own recovery mechanism will be enough to continue the data flow. A full TCP Proxy is
considered hard state and the implications of a failure are much worse than in the WM case.
In Figure 10 we present an example of operation of the Window Modifier mechanism. In a
system with a receiver window value of 8,760 bytes (the default in most Microsoft Windows
systems) over a roundtrip time of 40 milliseconds, the maximum throughput we can achieve is
219 Kbytes/s (i.e. 8,760 bytes every roundtrip time). In a cable modem system in which the
downstream speeds can be up to 40 Mbps (5 Mbytes/s) this is clearly a waste. If we place a WM
module in the cable modem, with a modified value of 35,040 bytes, then the limitation only takes
place in the segment with minimum theoretical throughput. In the Receiver-CM segment, the
limitation
is
8,760.
/
35,040/
= 1 Mbytes/s. In the CM-Sender segment, the limitation is
,/0.035 '
1.75 Mbytes/s. Therefore, the limiting segment is now the CM-Sender segment,
0.005
*
with a maximum window size of 35,040 bytes, which would allow a maximum throughput of
35,040.04
44
-
876 Kbytes/s, i.e. almost 4 times the previous throughput.
Implementation of solutions proposed
Win95 PC
CM
CMTS
HP-UX server (tci)
Corporate
Network
1 -5
8760
ms
20 - 30 ms
I
-
5- 10 ms
5- 10 ms
-45g
0
Regular TCP
40 ms
219 Kbytes/s
060
219 Kbytes/s
Window Modifier at CM
876 Kbytes/s
8760
1,152 Kbytesls
35040
1, Q11 Kbytests
=.3
Figure 10: Functionality of the Window Modifier
We tested the performance after implementing this feature and it works as expected. We will
show the exact details in the results subsection, but as an example, for a PC with a true receiver
window of 8760 bytes, it speeds up a ftp transfer from around 260Kbytes/s. (without the WM),
to 650 Kbytes/s with a fake window of 35040.
It is clear that the WM feature is based on a misconfiguration of the customer PC, and if the user
was able to set up this value on the Windows registry, under the key
HKEYLOCALMACHINE\System\CurrentControlSet\Services\VxD\MSTCP\DefaultRcvWindow
the WM feature would be of little effect, but for many users this simple setting may be out of
their knowledge. On the other hand, more knowledgeable users may explode this configuration
to get better service than others, and even setting this value to an impractical too large value.
This could create an adverse effect, maybe allowing intermediate buffers to overflow. Therefore,
45
Implementation of solutions proposed
it is interesting to have a mean of controlling this setting in a way transparent for the user. It may
be thought of as a rate limiter, to avoid false expectations of service when there is more users in
the future (this is to be of great importance for the cable companies) and/or to provide an
uniform service to all users. Also, given the way it is implemented it would be relatively easy to
introduce different classes of service: higher windows for some users, smaller for others, no
matter what their actual settings on their PCs are. Everything will be easily controlled at the
cable modem (and consequently, from the CMTS).
This method was first thought to be implemented at the cable router, but it was finally decided to
add it to the cable modem for two reasons:
" since we need to keep per-flow state, having it at the CM makes it much more easily
scalable, since the number of flows at the CM is limited by the number of computers
connected to it (usually one) and the number of simultaneous flows per computer (usually
some tens).
*
Assuming the small window is at the user equipment, the closest to it, the better. Also, most
of the delay is at the CM-CMTS upstream path, so using is at the CM allows to constraint the
small window size to a very low delay (basically, the Ethernet delay between the computer
and the CM).
ACK suppression (AS)
One interesting phenomenon we saw in the analysis of the traces under cross traffic was the
queuing effects on the cable CM-CMTS system. This refers to the time between we see a packet
on the user's Ethernet segment (the one at which the user's computer and the cable modem are
connected) and the headend network interface (the segment at which the headend is attached on
the network side). Without cross traffic, the typical delay is in the order of 20 seconds. But with
cross traffic, this delay can grow up to 120 ms. There is also a correlation between this delay and
46
Implementation of solutions proposed
the number of previous ACKs still in this system when a given ACK arrived to it, i.e. the more
ACKs in the system, the greater the delay. As it is shown in Figure 8, under cross traffic
conditions, an ACK is likely to arrive with around 10 ACKs before it, and has to wait for this
ACKs to be transmitted upstream before it can be transmitted itself.
Let's recall now that ACKs in the same TCP connection are cumulative, i.e. an ACK with a
higher number has the same information as an ACK with a lower one. Therefore, if we have two
(or more) ACKs for the same connection in a buffer, we can disregard the information of the
lower numbered, since it is contained on the highest numbered ACK.
We only drop ACKs with no data associated and we apply a special treatment to ACKs that may
trigger fast retransmission. Repeated ACKs serve as a mean for the sender of knowing whether
there is congestion or an error during the transmission, and although there is no explicit
information within the packet, it is a very important implicit information (just the fact of
receiving a repeated ACK). Therefore, we will not purge any repeated ACK, only those that have
not been repeated and are superseded by a higher numbered ACK. The possible drawback of
applying this algorithm would be the increase of the degree of burstiness on the TCP connection.
Since we would be receiving less ACKs, and those would acknowledge more data, it is more
likely that the source will send bursts of packets, rather than a constant stream as it will be with
an ideal ACK stream. However, the possible adverse effects of this increased burstiness are
outweighed by the performance improvement brought by the reduction on the queuing delay
WM and AS Implementation Details
We will describe here the implementation details of the solutions proposed above. Since both
(and possibly any approach to improve TCP performance) need to operate in a per TCP flow
basis we will create a common set of routines that will allow to characterize and log TCP flows.
On top of these, we will run the two now performance improvement methods. As explained in
47
Implementation of solutions proposed
the introduction, both solutions are independent and mutually exclusive, so they will have little
or no interaction.
As shown in Figure 11, we define the upstream path in the CM to be the set of procedures
applied to a packet in transit from the Ethernet interface to the coaxial interface. Similarly, the
downstream path is defined to be the set of procedures applied to a packet in transit form the
coaxial interface to the Ethernet interface. The operations of the different solutions would also
depend in the path we are considering. The basic operations for both modules are as follows:
Window Modifier Operation
The operation of the window modifier is different depending on the path. On the upstream path
we have to modify the advertised receiver window value, and on the downstream ensure that the
user's machine does not get overflow with packet out of its true window.
To user
To CMTS Mi
Downstream Path
--------------------- .
Et iernet
Int erface
RF
TCP/IP
MAC
..........
4
------
1
I
Coax
Cable Modem ControlP
Interface
-- ---------
MAC
TCP/IP
=J=*
--------------- -----------
RF
Upstream PaV7
Figure 11: Cable Modem Block Diagram
48
I
Implementation of solutions proposed
*
Upstream path: It will extract the value of the window advertised by the CPE on every
packet flowing upstream and it will modify it to the window value specified by the
configuration. This involves recalculating the TCP checksum. If the packet is an ACK it will
compute the new window available at the CPE and if there are packets buffered, it will send
those within the new window.
*
Downstream path: It will check if the packet is within the CPE window. It will buffer the
packet if it is outside that window (overflowing the CPE if forwarded immediately) or simply
forward it if it is within the window
ACK Suppression operation
This module is only applied to ACK packets with no data in the upstream path. Since going
though the entire queue every time is time consuming and difficult to implement (and we don't
want to alter the queue management) this module keeps a pointer to the most recent ACK in the
queue (if any). Upon receipt of an ACK, if there is no pointer associated with this connection,
that means there are no ACKs for this connection in the queue, so we simply update the pointer
and enqueue the ACK packet. If the pointer is not null, we verify that the ACK in queue can be
substituted by the current ACK, we overwrite the contents of the ACK in queue with the current
ACK, and we drop the buffer holding the current packet (since its contents have been copied
ahead in the queue).
This implementation needs a callback in order to null the pointer every time an ACK that is
pointed to leaves the queue.
Interface description
The whole set of routines is self-contained in a TCP enhancement module (tcpenh. c) and the
existing platform will interface with the new module through a small set of routines:
49
Implementation of solutions proposed
"
TCPinit: This routine is the initialization of all variables used by the common set of
routines. It should be called once at boot time.
*
TCPctl: This is the single point of entry to the TCP enhancement module. It is passed a
pointer to the packet and a value indicating the originator of the packet: CMTS (downstream
path) or CPE (upstream path). It will return 0 when the values have been successfully
updated and the packet can keep being processed. It will return -1 when there is no further
processing needed for this packet. In the downstream path, that means the packet has been
buffered and it will be send to the CPE later. In the upstream path, it means that an ACK has
been dropped or its contents have overwritten a previous one, so the buffer containing the
current ACK packet can be freed.
" TCPack2HW: This routine is a callback to warn the AS module that an ACK which was
pointed to has left the queue. This ensures that the pointer to the latest ACK has always a
valid reference.
Operation details
In this subsection, we will explain in detail what and how each component of the TCP
enhancement module works. As explained before, since both solutions need to have information
on a per TCP flow basis, we created a common platform for logging and keeping information
about active TCP connection. The purpose of the common platform is to maintain an accurate
view of the ongoing TCP connections, so WM and AS would operate error free. It will listen to
TCP traffic in both downstream and upstream path and will extract the necessary information for
each flow, namely the advertised window size and the last packet acknowledged, among other
things.
There will be a unified entry point to this information through a variable named TCPstate, a
pointer to a structure with the following fields:
50
Implementation of solutionsproposed
S16
numlogged;
/*
U8
WMenabled;
/* status of WM (TRUE/FALSE) */
U8
ASenabled;
/* status of AS
U8
TCPenabled;
/*
TCP status
U32
ASsuppressed;
/*
# of acks suppressed by AS */
U32
ASprocessed;
/* # of acks processed by the TCP module */
U32
ASunique;
/*
# of unique acks processed by the TCP module */
U32
lasttimeout;
/*
instant of last cleaning timeout */
number of logged connections */
connstate-ptr cstate[TCPMAXCONN];
(TRUE/FALSE) */
(AS 11
WM TRUE/FALSE) */
/* array of per-connection state */
the last field is an array of pointers to connection state records, each of one has the following
fields:
U16
connid;
connection id --
U8
cpe-state;
state of TCP connection (CPE side) */
U8
cmtsstate;
/* state of TCP connection (CMTS side) */
U32
dsaddr;
/* downstream IP address
U32
usaddr;
upstream IP address
U16
ds-port;
downstream port
U16
usport;
upstream port
U16
last_win;
U16
TCP_win;
U32
lastack;
/* last ack # received from CPE side */
U32
lastseq;
/* higher seq # received from CMTS side */
U32
isn;
/* initial seq no for this connection */
S16
data;
/* amount of data buffered
U32
activity;
U8
connstate;
/* status of the TCP connection */
U32
cpe-fin;
/* sequence number of FIN packet sent by CPE */
U32
cmtsfin;
UsDataBuffer
unique */
(CPE side)*/
(CMTS side) */
(CPE side) */
(CMTS side) */
/* last receive window size from CPE side */
window size to be advertised */
instant of last activity */
*queuedACK;
U32
queuedACKnumber;
U8
ASapplied;
(bytes) */
sequence number of FIN packet sent by CMTS */
/*
pointer to the last queued ACK */
/*
value of the last queued ACK */
TRUE/FALSE AS applied to this session */
51
Implementation of solutions proposed
DataBuffer *databuffer;
/*
pointer to the first buffered packet */
DataBuffer *databufferjlast; /* pointer to the last buffered packet */
The field connstate
indicates the status of the connection (under the eyes of the TCP
enhancement module, which can be different of the actual state on each end). It can be in any of
the following states:
*
TCPCLOSED: no info for this session
*
TCP_HALFOPEN: info for just one end
"
TCPALIVE: info for both ends
"
TCPHALFCLOSED: sesion is closing (one end has sent a FIN)
WM and AS will only operate (buffering data or dropping ACKs) when the connection is on the
TCPALIVE state. Similarly, cmts_state and cpe state hold the status information for
the CMTS and CPE side, respectively. It can be:
CPE:
TCPCPEALIVE: there is info from this side.
TCPFIN: this side sent a FIN and awaits the FIN ACK
TCPCLOSED: no info for this side.
CMTS:
TCPCMTSALIVE: there is info from this side.
TCPFIN: this side sent a FIN and awaits the FIN ACK
TCPCLOSED: no info for this side.
lastwin
is the latest receive window size advertised by the CPE. It is updated with every
upstream packet for this particular connection.
52
...
..
...
..
.........
..
Implementation of solutions proposed
~~Ret
0
-4
AS processing
packet?
No
(if applicable)
Ys
WM Processing
Initialize TCP flow:
c
TOPinitcon)
DRet
0
Clear TCP flow:
(if applicable)
Is a SYN
T
last ACK
&Update
?
No
Yes%
Setrepeat
Is a RST
TI
OCPPclearconn()
paket
)
C
Y
Is repeated?
No
De
N
get conn id
Yes
(we started logging in the
middle of an open connection)
I s an ACK
Initialize TCP flow:
TCP initc onn (
SRet 0
GS
conn id == -A ?
&
)No
Initialize TCP flow:
No
upstrea.
Yes -4
Log seq. Number
set this side to TCP_-FIN
set TCPHALFCLOSED
ye
TCP initconin 6
TCPHALFOPEN?
C RED
No (flow is ACTIVE)
Yes
is side is TCP -
No
&& pkt is ACK
ACKs the F.
Yes
Is a FIN packet?
No
Change this side
to TCP_CLOSED
Other end
TP,
CPCLOSED9
No
Yes
Clear TCP 1f,1121,w:jj
TCP
c learconn ( )
Figure 12: TCP flow state flowchart
53
Implementation of solutions proposed
TCPwin is the value that the CM will insert on every upstream packet, and is the value seen by
the end on the CMTS side.
lastack is the latest (and highest) ACK received from the CPE. Together with last_win,
it allow us to tell whether a data packet downstream is within the CPE window or not.
data, *databuffer and *databufferlast
hold the information about the data
packets queued awaiting to be within the CPE window. They form a linked list with FIFO
discipline. *databuf f er points to the head of the queue (the oldest packet, to be dequeued
first) and *databuf ferlast
points to the end, where new incoming packets will be
buffered if necessary.
The algorithm used by this common platform is quite simple. The WM and AS processing
routines will be different for each of the data paths. The algorithm differs from upstream to
downstream in the fact that, upstream, we care about the window size and ACK number of the
packet, whereas downstream we look at the sequence number and size of data packets. However,
the most important task of the common algorithm is ensuring that the per-flow state is efficiently
maintained. In Figure 12 we show the flowchart of the software module that controls and
maintains such information. Basically, we have to ensure that the image the TCP enhancement
module has of the TCP connection is accurate with the true state of the connection, and therefore,
we must keep track of the SYN packets, as well as FIN and RST packets. Since we only perform
modifications for TCP sessions for which we have complete information from both sides of the
connection, before performing any action under the WM or AS mechanisms, we run different
test to identify the previous information we have about that session. Let us remind that a TCP
flow is completely identified by the IP address/TCP port pair (origin/destination).
The routine TCP_ctl is inserted in the TCP/IP block in both upstream and downstream path
(see Figure 11). It either returns 0, meaning that the packet will continue its normal processing
54
Implementation of solutions proposed
on the data path (although its contents may have been modified), or it returns -1, meaning that
there in not further processing pending for that packet.
The flowchart depicted in Figure 12 is followed in both the upstream and downstream paths. The
differences between them are specified within the WM and AS processing. Those two
procedures are depicted in Figures 13 and 14. At this stage, per flow information has been
WM processing
(upstream)
Yes
Is this an
ACK packet?
Update lastUackp
Slid buferIs
there data
buffered?
No
Send TCP data
packet downstream
Yes
Is it within
ceiver window?
No
Modify receiver
window
Update TCP
and MAC CRC
Figure 13: WM processing block diagram (upstream)
55
Implementation of solutions proposed
already recovered and we are accessing the records pertaining only to each TCP session. In
Figure 13, we show the Window Modifier processing block diagram corresponding to the
upstream path. In it we monitor ACK sequence numbers flowing upstream, and we release any
packet previously buffered in the downstream path when the true receiver window slides as to
allow out-of-window packets to be forwarded downstream. The downstream path itself is quite
simple, since we only check whether data packets are out of the true advertised window. This
may occur when the sender has transmitted packets according to the window advertised by the
WM engine, but which are not within the true window of the cable modem. In this case, data
packets are buffered at the cable modem until an ACK that is flowing upstream slides the
receiver window allowing the data packets to be sent without overflowing the receiver.
In Figure 14 we show the AS processing block diagram. AS processing is only applied on the
upstream path and it basically maintains a cache (pointer) to the last ACK seen on this TCP
connection. When a new ACK is received, we verify whether there is another ACK packet
cached for that connection. If it is not a repeated ACK we simply overwrite the contents of the
.... ..
...............
r..................................................................................
Yes
No
s taYes
repeated ACK?
Isthere an
ACK cached?
No
Is it a
repeated ACK?
No
Overwrite old ACK
with new.AC
Clean ACK cache]
Cache ACK
Figure 14: AS processing block diagram (upstream)
56
Implementation of solutions proposed
previous ACK and we interrupt the processing of the buffer containing the packet, since its
contents have been copied to another buffer already in the queue. In all other cases, we simply
update the cache accordingly and continue the processing of the packet.
High Performance TCP
Basic algorithms
We will show here the changes that are needed in order to implement the new proposed
algorithm. Although the operation of TCP changes, the actual modifications to the TCP code
should not be very costly. We will first describe the algorithm for regular TCP, followed by the
new algorithm, showing the changes between the two.
In regular TCP ACK reception triggers transmission of new packets since it may open the
window. The basic idea is to send as many packets as possible, as to exhaust the current sender
window (snd cwnd) or the receiver window (rcv_wnd):
When receiving an ACK
if (ACK sequence number >= snduna)
{
/*
New ACK */
snduna
<-
ACK sequence number
update sndcwnd
while (sndnxt <=
(snduna + min(rcv-wnd, sndcwnd)))
{
send (snd-nxt)
increment sndnxt
}
}
else
{
if
(ACK sequence number == snd una)
Repeated ACK (fast retransmit processing)
else
ACK out of date, ignore.
}
57
Implementation of solutions proposed
During the High-performance TCP (HTCP) ACK reception does not control anymore whether
new packets are transmitted. Only the variable snduna gets updated. The recovery mechanism
remains untouched, and we actually have two separate mechanisms that perform flow control
and packet transmission. The task that will perform the flow control (i.e. ensuring that all packets
are received and scheduling retransmissions if needed) is practically the same as we used in
regular TCP, only removing the transmission of new packets fragment:
When receiving an ACK
if (ACK sequence number >= snduna)
{
/* New ACK */
snduna <- ACK sequence number
/* Do not do anything else */
}
else
{
(ACK sequence number == snduna)
Repeated ACK (fast retransmit processing)
else
ACK out of date, ignore.
if
}
Another task will regularly query for packets to be transmitted. The idea here is, whenever the
channel is free, we check whether we can send another packet. As long as the packet to be sent is
within the window determined solely by the receiver window (rcv wnd), it will be transmitted,
so therefore we ignore the current value of sndcwnd. The algorithm for this routine should be
as follows:
Whenever the optical transmitter is idle
while
(snd-nxt <=
(snd-una + min(rcv-wnd))
{
send (snd-nxt)
increment sndnxt
}
58
Implementation of solutions proposed
Actually, we can simplify the implementation of this second task by scheduling the times at
which new packets are to be sent. When we send a new packet, since we now its size and the rate
of the optical link, we can calculate at what time in the future the next packet has to be sent.
Therefore we can schedule an interruption at that time to check whether there is more data to be
sent.
59
Implementation of solutions proposed
This page intentionally left blank
60
Description of results
Description of Results
In this section we will describe the results we obtained applying the mechanisms described so
far. We used the same test scenario that we used for obtaining measurements (see Figure 3). We
implemented the Window Modifier and the ACK Suppression methods through software in a
prototype cable modem, as described in the previous section. In all results presented here for
these two solutions we had a roundtrip time of approximately 30 milliseconds and we were using
an upstream channel of 1280 Kbps.
Window Modifier
For the window modifier we do not use the traffic generator attached to CM2 (see Figure 3), but
simply monitoring FTP transfers from the PC attached to CM1 to a server across a corporate
TCP transfer evolution
4000000
3500000 -
-
------
----
--
-
-
-
-
-
600 Kbytes/s
-- - -- - - --- - ---------
3000000
2500000 -
-- -- -
- - ------ ------------ - --- --- --280 Kbytes/s
2000000
0)
01
cc
Q0-
-- - -
-- ---
- --
---
--- - - - - -
1500000
-------------1000000
--- - - -
500000
- --
---
35040 (WM) (8760)
- 35040
- -
'
-8760
0
i
0
2
i
!
i
i
i
4
!
i
i
!
i
i
i
6
i
i
i
8
i
i
i
i
i
i
i
i
10
f
#
12
i
i
.
.
14
Time (s)
Figure 15: TCP transfer evolution with Window Modifier
61
Description of results
network. The way we are going to demonstrate the improvements of this mechanism is by
monitoring the TCP sequence number in the data packets and showing its evolution over time.
The relevant parameter in this kind of chart is the slope of the sequence number evolution, which
corresponds to the instantaneous throughput of the TCP transfer. We will show just a sample of
some of the many connections we have observed, in which all of them the behavior is equal to
the samples described here.
In Figure 15, we show such a chart in which we have depicted the evolution of three TCP
transfers. One corresponds to a transfer in which the receiver window size is set to 8,760 bytes.
We can verify how the slope of the sequence number corresponds to a throughput of
280 Kbytes/s (which is consistent with the theoretical limitation to the maximum throughput
posed by the receiver window size). We also show the transfer with a receiver window of 35,040
bytes, in which we see how the throughput increases up to 600 Kbytes/s. As an aside, we see
how this particular transfer experienced a stall for 1.5 seconds due to consecutive losses within
the same window. TCP cannot handle this types of losses (fast recovery can handle isolated loses
as long as they are not within the same window), and a timeout happens to resume the TCP
transfer. However, the point of the figure is not dealing with losses (which is an enormous task in
and on itself), but looking at how the TCP throughput evolves through time with different
schemes. Finally, the third set of data corresponds to a TCP transfer in which the receiver has its
window set to 8,760 bytes (the same as the first trace shown), but we used the window modifier
mechanism in the cable modem (CM1), with a simulated window of 35,040. We can verify how
this transfer achieves a throughput that is comparable to the one obtained with a true window, as
if the actual windows size parameter governing the transfer was the modified 35,040 instead of
the true 8,760.
The first conclusion we can extract from Figure 15 is that the window modifier mechanism
works perfectly fine and for a specific modified window size achieves a throughput comparable
to the one that would be achieved with the same value as the true value in the window. This is
achieved in a manner that is completely transparent to the user, and independent of the value that
62
Description of results
this user has specified in his TCP configuration. This is specially important to provide a uniform
service to many users, since it would help those with a too small window size to achieve higher
throughputs. It would also prevent other users that deliberately set too large values for their
window sizes to interfere and decrease performance of other users.
A possible drawback of this mechanism, as it was described on the previous section, may be the
additional delay introduced by the downstream buffering in the cable modem when a data packet
is momentarily outside the true receiver window. In Figure 16 we evaluate how important is this
effect, and we show the probability density function of the delay that a data packet experiences
in the downstream path within the CMTS-CM system. When we do not use the window modifier
mechanism, the delay is confined between 5 and 10 milliseconds. When we apply the window
Delay CMTS-CM (Downstream direction)
..
With WM ..
Without WM
40
35 30
--- - - -- -
- - - --- --- --
---
--- - -
4
-- -- ---
-0
-
20
- -- - - -
--- ---
------
-
--- -- - --
15
10
----
- - -
- - -- - -
- -- - - --
---- --
5
0
0
5
10
15
20
25
30
Time (ms)
Figure 16: Downstream delay
63
Description of results
modifier, the downstream delay increases, but as we expected, not dramatically. The mean
increase in delay due to the window modifier could be approximated to about 10 milliseconds,
which is a value that can be easily assumed and will not cause any major problem with the
connection.
ACK Suppression
For the ACK Suppression mechanism we use the same setup that we used when obtaining
measurements that confirmed the problem. In figure 17 we show the probability density function
of the delay experienced by an ACK packet on the upstream path. We include the two data sets
Upstream delay CM-CMTS
8
ossC traffic (S)
7
cross traffic
-_No
6 0 Kbytes/T
-
ross ric
6
5
-
0
F
--
1-
-
-
4
a
420 Kbyt s/s
3
-
I
^3-bytes
-
-
2
1
0
A.
0
r. 1 -
A
20
40
'o
iW59-
60
80
o'AA
100
Delay (m s)
Figure 17: Upstream delay with ACK Suppression
64
AA
120
140
Description of results
similar to those we showed in Figure 6, corresponding to the delay with and without cross traffic.
In Figure 17 we also include the delay when we actually apply the ACK Suppression mechanism
to a TCP transfer supporting cross traffic in a different cable modem. We see how the mean
delay is decreased to about half its value when we have cross traffic. This decrement in delay
mitigates the effect of the window size limitation that we were experiencing and increases the
throughput from 310 Kbytes/s to some 420 Kbytes/s.
In Figure 18 we show the evolution over time of the same TCP transfers shown in figure 17.
Again, the important parameter to look at on the figure is the slope of the data set, which gives us
an indication of the throughput. For the connection without cross traffic we see a throughput of
near 600 Kbytes/s, whereas the transfer with cross traffic, this throughput decreases to
TCP transfer evolution
4000000
3500000 -
420 K sytess
3000000
0L
2500000
.0
310 Kbytesls
2000000
- -- - - ---
1500000 -
1000000 -
- --- -
- - - - - ---- - - - - -
---- - -- - - - - -- - ----- -
500000 -
0
W-1
0
t
i
i
i
2
!
i
!
i
1
4
!
i
1
1
1
1
1
1
6
!
------------Cross traffic(AS)
No crosas-traffic
cros traffic
- !
8
i
-
i
i
i
i
i
i
10
i
i
i
12
i
!
i
i
14
Time (s)
Figure 18: TCP transfer evolution with ACK Suppression
65
Description of results
310 Kbytes/s. However, when we introduce the ACK Suppression mechanism, since we decrease
the delay significantly, for the same cross traffic conditions, the throughput increases from
310 Kbytes/s to 420 Kbytes/s. It does not eliminate completely the effect of cross traffic, but we
see how it increases the TCP performance by nearly a 40 %. This results also suggest, as we
expected, that the use of concatenation in a cable modem may be highly beneficial.
High Performance TCP and high speed flow switching
We are going to describe in this section the parameters we used in our simulations and the results
and conclusions we can extract from them. We used the ns simulator package from UC Berkeley
[28] and we performed our measurements over a topology as shown in Figure 9, in which we
have a bottleneck link under study composed by an OC-12 optical link at 677.080 Mbps, and a
traditional electronic link at 10 Mbps. All other links are big enough to accommodate all the
traffic they would ever need to carry. The propagation delay on the bottleneck link is 5 ms and in
the other links (from the sources to the switches and to the switches to the destination is 1 Ms.
This gives a roundtrip time (not counting queuing delay of 14 milliseconds. Given the optical
link speed, the bandwidth-delay product amounts to about 9.5 Mbps of data that can be
outstanding for a given TCP connection. With packet sizes of 1,000 bytes, this corresponds to
1,185 packets, which is the amount of buffering space the endpoints would need in order to
operate at full speed. We selected these values to allow the mentioned full utilization while
maintaining reasonable values for buffering space at both ends. The propagation delay
corresponds to a distance of about 1,000 miles, which can be thought of if we refer to a trunk
link between two major US cities.
During our simulations, we had a variable number of TCP sources that would share the
electronic bottleneck link (at 10 Mbps). Since we want to achieve a relatively fair share of the
bandwidth in the optical link, but we can only route to that link one of the entries to the switch,
we perform some sort of time sharing between all the sources on the fast optical link. The way
we implement this in our simulations is by alternatively switching flows from the slow electronic
66
Description of results
link to the fast optical link and vice-versa. In this way, the bandwidth that a single TCP
connection has available suddenly increases from some Mbps to more than 600 Mbps. It will
have this bandwidth for a period of about one second, and then it will come back to the pool of
connections using the electronic link. Regular TCP will be unable to use all the bandwidth
immediately, and it will take much more than one second to grow its window as to allow that
throughput. On the other hand, with HTCP we should be able to immediately use all the
bandwidth that is available. We want to compare this performance with the one that we would
see on the same scenario when we use regular TCP all along. We will show how the throughput
obtained in the two cases is dramatically different, suggesting that HTCP is a promising idea that
can help achieve a better utilization of such a flow switching mechanism.
In Figure 19 we compare the throughput we obtain when a connection is using HTCP mode with
the performance we would obtain if a regular TCP connection were given the same bandwidth
TCP throughput (loss free link)
700
HTCP
TCP
650
600
550
500
450
400
3 350
300
250
200
150
100
50
0
1
2
3
4
5
Time (s)
6
7
8
9
10
Figure 19: Throughput comparison
67
Description of results
allocation, but without using our HTCP scheme. We can see how the connection using HTCP is
able to utilize the full OC-12 bandwidth during the one second that the TCP transfer is given the
optical link. On the other hand, we see how the connection not using TCP would not use almost
any of the extra bandwidth it could use. This is due to the fact that at the time the connection was
switched over the fast optical link, the current window size was appropriate for the slow link.
Now that it has much more bandwidth available, it takes some time to take advantage of it. TCP
in particular would be able to grow the window size by one packet every roundtrip time, which
means that during the one second that the 677 Mbps are available, the TCP window will be
increased by approximately 70 packets. This increase in the window may allow an increase of 40
Mbps in the maximum bandwidth, which is clearly not enough as to fully utilize the available
bandwidth.
Among the objectives we have when performing the simulations, we want to ensure that the new
TCP transfer evolution
7000-
6000 -
E 5000
C
(D
U
4000
-o
3000
2000
I
5.04
5.05
5.06
5.07
5.08
5.09
Time (s)
I
5.1
I
5.11
Figure 20: Evolution of a TCP transfer under losses
68
5.12
5.13
Description of results
TCP mode we have devised retains the recovery characteristics that TCP had. In particular, we
want to see how our new HTCP mode would behave in case of losses. Let us recall that if while
in HTCP mode, the sender receives three duplicated acknowledgements, it will retransmit the
packet in question, while still sending new packets. When we are in HTCP mode the limitation
for outstanding packets is the maximum value of the TCP window, not the current value
controlled by the congestion avoidance mechanism. Therefore, as long as the maximum window
is not exhausted, we will keep sending further packets, as opposed to regular TCP in which the
congestion window would be halved and new packets would be sent only after the number of
repeated ACKs allows to increase the window up to the previous value.
In Figure 20 we observe the behavior of a TCP transfer during the HTCP mode, the blue points
being the data packets sent by the source, and the red crosses being the ACK packets received
also at the source. The optical link has a low error rate, but enough as to cause the fast retransmit
mechanism to be applied. We can see how at 5.058, after three repeated ACKs, we retransmit
one packet that had been lost before, although we keep sending packets until the maximum
window (2,000 packets) is reached, at which point we stop. A roundtrip time after retransmitting
the packet, we start receiving new ACKs, but they are again repeated because of other loss. A
new retransmission is done but new packets are still being sent. This behavior is repeated several
times, but we see how the connection is never interrupted and does not need a timeout to resume.
In the worst case scenario, the connection may be idle for a roundtrip time. The only way in
which the HTCP would need a timeout to resume is when the retransmitted packet is lost (which
would be also critical for regular TCP), or when two packets are lost and the difference between
then is less than three packets. In this case, after the first retransmission we will not be able to
send enough packets as to generate three repeated ACKs that would trigger the retransmission of
the second lost packet. This behavior does not allow the eventual stall and timeout that regular
TCP may suffer when the window is halved and no more packets can be sent unless new ACKs
are received, while at the same time not the receiver is unable to send more ACKs due to the lack
of incoming data packets. Therefore, our proposal does not perform any worse than current
69
Description of results
versions of TCP, and in some cases is even more robust, being less the chances of the connection
having to resume due to a timeout.
Regarding the amount of buffering needed at the source, If we take a closer look in figure 21 to
the number of outstanding packets (sent but not yet acknowledged) during the connection, we
see how for the most part of the connection that figure is 1,185, which is what we had previously
calculated for completely filling the optical link. During the periods that we are in fastretransmit, the number of outstanding packet increases up to the maximum value that we allow
(2,000 packets). Of course, receiver window has to be increased accordingly, in order to allow
that much outstanding data.
Finally, another area in which we want to have an understanding of which options are best fit is
200 01
1
Outstanding packets
18001600 -
1400 -
Co,
1200-
a
1000E
z 800600400200-
0.4.5
5
5.5
Time (s)
6
Figure 6:Outstanding packets during HTCP
70
6.5
Description of results
in the mode switching, especially during the transition between HTCP and regular TCP. The
options we can play with are basically the window value at which we want the connection to
revert after the transition to regular mode, and the strategy we can choose for interspersing the
sending of data packets while receiving ACKs at fast timing. We basically found out during the
simulation that since the timing of the ACKs for packets send during HTCP mode have no
relation to the current state of the slow link, sending any packet according to that timing can be
devastating. The time during which the connection may be inactive will be a roundtrip time, as
opposed to a much larger stall period in the event of massive losses leading to a timeout.
Therefore, it is preferable to be conservative and for this reason, the best solution is to remain
inactive during the arrival of the ACKs for the packets sent during HTCP. Using techniques like
rate halving [11] may be beneficial to prevent an excessive slowdown, but in our case it can lead
to excessive losses that can cause a timeout on the current connection, and more importantly, to
other connections.
As to which value we should set the TCP window when we come back to regular mode, we have
tried three approaches:
" Outstanding packets during HTCP: Setting the window to the current number of
outstanding packets at the end of the HTCP mode has proven to be devastating. At that time,
that value is very high and the bandwidth in the slow link is much smaller, so the excess of
packets in the slow link leads consistently to buffer overflows that cause the transitioning
connection to stall, as well as other ongoing connections.
" Previous value of TCP window: We can keep the value at which the window was before
switching to HTCP mode and use it as the target window value when returning to regular
TCP mode. However, by the time the connection is switched back to the slow link, the other
ongoing connections would have adapted their rates to the new scenario (without the
switched connection). Therefore the previous window value is relevant, but not truly realistic
to the current conditions on the slow link. For this reason, we see how mode switching to
71
Description of results
regular TCP using this option still leads to losses to the own connection, although it causes
less disruptions to other ongoing connections.
*
Restart window: The third option we tried is to reinitialize the window to the value it would
take at the beginning of a new connection. In some sense, it is actually the case, since the
slow link would be shared among other connections and the connection that is switched back
would need to be introduced as it was a fresh new connection. However, if switching back a
connection to regular HTCP mode implies switching one of the ongoing connections in the
slow link to HTCP, then the option of the previous value of the TCP window would be the
more appropriate, since in this case, the connection that is being switched back does not need
to start fresh, but can supplant the connection that has been brought to HTCP.
72
Conclusions and future work
Conclusions and future work
We have presented in this work different scenarios that lead to inefficiencies in TCP operation..
These are situations to which TCP is confronted in quite simple scenarios and they lead to
different problems that we could consider independently. However, they are not mutually
exclusive, therefore they can be experienced simultaneously, but will have little or no interaction.
We have showed how an incorrect setting of the receiver window size can cause an artificial
limitation to TCP throughput. We have proposed a method that, without introducing any changes
to the current TCP implementation, allows to overcome this problem, while at the same time
offers a tool for optimizing the fair allocation of bandwidth over a shared network. Future work
on this area would include more extensive trials on heavily utilized networks, or analyzing the
best methods to optimize the value at which the receiver window should be set, in order to avoid
additional losses caused by increasing the window.
We have also identified a problem with the compression of ACKs due to the mismatch on data
and ACK packet sizes on shared channels. This problem causes more disruption that the mere
addition of traffic and can significantly degrade TCP performance. We have looked at different
simple methods that could help us relieve this effect and we have adopted a previously proposed
solution and demonstrated how it improves the TCP throughput. Future work on this area may
include optimizing the mechanism by which we identify and maintain the statistics of TCP
connections
Finally, we have presented a modification to TCP that would help optimize its performance over
high latency networks, or in which the available bandwidth varies rapidly over time. Our
proposal would allow to efficiently use the bandwidth that is offered, by using the information
that is provided by the network to send data at an according rate, therefore overriding the need
for TCP to slowly probe the available bandwidth. Probing is a fine solution when the bandwidth
is unknown, but is not very efficient when the available bandwidth is very large and can be
73
Conclusions and future work
specified. We have proven that our scheme preserves the robustness that characterize TCP, and
behaves slightly better in the presence of losses. Future work would include describing the best
methods to efficiently communicate the available bandwidth to the sources, defining the
scheduling policy at the switch and how it would affect performance, and probably establish a
framework for the use of this proposal over high-speed optical networks.
74
References
References
[1] V. Cerf and R. Kahn, A Protocolfor Packet Network Interconnection. IEEE Transactions
on Communications COM-22, pp. 637-641, 1974
[2] V. Jacobson, Congestion Avoidance and Control, In Proc. ACM SIGCOMM '88
[3] D.-M. Chiu and R. Jain, Analysis of the Increase and Decrease Algorithms for
Congestion Avoidance in Computer Networks. Computer Networks and ISDN Systems,
Vol. 17, pp. 1-14, 1989.
[4] H. Balakrishnan, S. Seshan, and R. Katz, Improving Reliable Transport and Handoff
Performance over Wireless Networks, ACM Wireless Networks, Vol. 1, No. 4, pp. 469481, December 1995.
[5] L. Kalampoukas, A. Varma and K. K. Ramakrishnan, Explicit Window Adaptation: A
Method to Enhance TCP Performance, Proc. of Infocom'98.
[6] H. Balakrishnan, V. Padmanabhan and R. Katz. The Effects of Asymmetry on TCP
Performance.ACM Mobile Networks and Applications (MONET), 1999 (to appear).
[7] H. Balakrishnan, V. Padmanabhan, S. Sechan and R. Katz. A Comparisonof Mechanisms
for Improving TCP Performance over Wireless Links. IEEE/ACM Transactions on
Networking, December 1997.
[8] S. Floyd and V. Jacobson. Random Early Detection Gatewaysfor CongestionAvoidance,
IEEE/ACM Transactions on Networking, V. 1 N. 4, August 1993.
[9] W. R. Stevens. TCP Slow Start, Congestion Avoidance, Fast Retransmit, and Fast
Recovery Algorithms, January 1997. RFC 2001.
[10] M. Mathis, J. Mahdavi, ForwardAcknowledgment: Refining TCP Congestion Control,
Proceedings of SIGCOMM'96, August, 1996.
[11] M. Mathis, J. Mahdavi, TCP Rate-Halving Algorithm for TCP Congestion Control,
Draft, June, 1999.
[12] W. R. Stevens, TCP/IPIllustrated, vol. 1. Addison-Wesley Publishing Company, 1994.
[13] V. Jacobson, R. Braden, and D. Borman, TCP extensions for high performance,
RFC 1323, May 1992.
[14] A. Mankin, Random drop congestion control, in Proceedings of ACM SIGCOMM'90,
pp. 1--7, September 1990.
75
References
[15] T. V. Lakshman and U. Madhow, Performance analysis of windowbase flow control
using TCP/IP: The effect of high bandwidthdelayproducts and random loss , in Proc. of
High Performance Networking, V. IFIP TC6/WG6.4 Fifth International Conference, vol.
C, pp. 135--149, June 1994.
[16] L. Zhang, S. Shenker, and D. D. Clark, Observations on the dynamics of a congestion
control algorithm: The effects of twoway traffic , in Proceedings of ACM SIGCOMM'91,
pp. 133--147, September 1991.
[17] S. Floyd, TCP and explicit congestion notification, Computer Communication Review,
vol. 24, no. 5, pp. 8-23, October 1994.
[18] L. S. Brakmo and L. L. Peterson, TCP Vegas: End to end congestion avoidance on a
global Internet, IEEE Journal on Selected Areas in Communications, vol. 13, no. 8, pp.
1465--80, October 1995.
[19] R. Jain, Myths about congestion management in highspeed networks , Internetworking:
Research and Experience, vol. 3, no. 3, pp. 101-- 113, September 1992.
[20] B. Bakshi, P. Krishna, N. Vaidya and D. Pradham, Improving Performance of TCP over
Wireless Networks, 17th International Conference on Distributed Computing Systems
(ICDCS), May 1997
[21] S. Floyd and K. Fall. Promoting the Use of End-to-End Congestion Control in the
Internet. Submitted to IEEE Transactions on Networking.
[22] S. Johnson. Increasing TCP Throughput by Using an Extended Acknowledgment
Interval. Master's Thesis, Ohio University, June 1995.
[23] M. Mathis, J. Semke, J. Mahdavi, T. Ott, The Macroscopic Behavior of the TCP
Congestion Avoidance Algorithm, Computer Communication Review, volume 27,
number3, July 1997
[24] J. Postel. Transmission Control Protocol, RFC 793, September 1981.
[25] V. Visweswaraiah and J. Heidemann. Improving Restart of Idle TCP Connections.
Technical Report 97-661, University of Southern California, 1997.
[26] M. Allman. On the Generation and Use of TCP Acknowledgments. ACM Computer
Communication Review, 28(5), October 1998
[27] Mark Allman, Vern Paxson, W. R, Stevens. TCP Congestion Control, April 1999.
RFC 2581.
76