AN INVESTIGATION OF VOWEL FORMANT TRACKS PURPOSES by
advertisement

AN INVESTIGATION OF VOWEL FORMANT TRACKS
FOR PURPOSES OF SPEAKER IDENTIFICATION
by
Ursula Gisela Goldstein
S.B., Massachusetts Institute of Technology
(1972)
SUBMITTED IN PARTIAL FULFILLMENT OF THE
REQUIREMENTS FOR THE DEGREE OF
MASTER OF SCIENCE
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
January, 1975
Signature of Author,
.
.
a000.0
00*0
00
000
0
Department of E ecrical,Engine4eing, January 22, 1975
Certified by...
4 esiSupervisor
Accepted by.................
0--....
....
0 000*0
SCV
Chairman, Departmental Committee on Graduate Students
ARCHIVFS
[:MAR
5 1975
is RARI EE
AN INVESTIGATION OF VOWEL FORMANT TRACKS
FOR PURPOSES OF SPEAKER IDENTIFICATION
by
Ursula Gisela Goldstein
Submitted to the Department of Electrical Engineering on
January 22, 1975 in partial fulfillment of the requirements for the Degree of Master of Science.
ABSTRACT
The formant structure of 3 diphthongs, 4 tense vowels,
and 3 retroflex sounds was examined in detail for possible
speaker-identifying features. These sounds were spoken
5 times each in sentence context by 10 speakers of
General American on one day. Six speakers returned on a
second day at least three weeks later to repeat the
recordings.
A formant-tracking system was devised, based on
covariance-type, pitch-asynchronous linear prediction and
a root-finding algorithm that was applied to the
denominator of the resulting transfer function. The
system was evaluated by examining the smoothness and
internal consistency of the computed formant tracks of
the recorded phones. Particular problems encountered
included the apparent disappearance and reappearance of
higher formants for two speakers, and the lack of enough
poles in the linear prediction program to adequately
model the vocal track of a third speaker.
Eighteen different measurements were made on each
repetition of each diphthong and tense vowel, 24 measurements were made on each repetition of [rE] and [ar], and
In
25 measurements were made on each repetition of [3].
order to determine which measurements would be most useful
as speaker-identifying features, F ratios were calculated
for each measurement as well as individual speaker means
and standard deviations. Correlation coefficients were
calculated to test for possible dependence between features.
Features that are potentially most effective in
identifying speakers are the maximum value of Fl for [ar]
and [o], the minimum of F2 for [ar], average F4 for [aU],
minimum F3 for [T], F2 at a point 20 msec. before the
end of [aI], average F3 minus F2 for [rE], F2 at a
point 20 msec. after the beginning of [e], and maximum
F2 for [o] and [aU].
THESIS SUPERVISOR: Kenneth N. Stevens
TITLE: Professor of Electrical and Bioengineering
ACKNOWLEDGEMENT
I would like to express my deepest appreciation to
Professor Kenneth N. Stevens, who made this thesis possible
through his infinite patience, support and advice.
My
thanks also go to the many people, too numerous to mention,
who made the computer work of this thesis possible
by providing me with advice, programs, and some of their
precious time helping me find the errors in my work.
I
would like to thank my recording subjects, who cheerfully
donated their time free of charge.
Special thanks go to
Keith North, whose technical advice and maintenance of the
spectrograph machine, computer, and tape recorders were
invaluable.
This thesis was performed in the Speech Communication
Group of the Research Laboratory of Electronics at the
Massachusetts Institute of Technology.
TABLE OF CONTENTS
Abstract .
.
.
.
Acknowledgement
Table of Contents
List of Figures
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . .2
S . . . .4
. . .
. . .
. . . . .
. . . .
. .
. . .
. . . . .
. .
. . .
. .
. . .
. .
. . .
. . . .5
. . . . .
. . .
. .
. . . . .
. .
9
Chapter I
Introduction . .
. .
. . . . .
. .
10
Chapter II
Literature Review
. . . .
. . . 18
List of Tables . . . .
2.1
Speaker Recognition Using Feature
Extraction . .
2.2
. . . .
. . .
. .
. . .
Formant Tracking . . . . . .
. .
. . . . . . 32
. . .
. . . . . . 32
3.1
Data Base
3.2
Formant-Tracking Procedure .
Chapter IV
. . .
. .
. .
. . .
. . . . 32
. .
. . . . 40
. .
40
. . .
Observations Based on Formant Tracks of
.
The Speaker-Identifying Features . . .
.
. . .
.
69
. .
. .
76
. .
. . • 83
. . .
. .
. .
. . .
46
. .
the Entire Data Base . .
Chapter V
.
Initial Experiments for Determining the
Exact Formant-Tracking Method
4.2
. .
Evaluation of the Formant-Tracking
Procedure
4.1
. . . . . . . 24
. .
Chapter III Experimental Procedure . .
. . . . .
. . . 18
. .
. .
5.1
Introduction . . .
5.2
Diphthongs . . . . . . . . . . .
5.3
Tense Vowels . . .
. .
. . .
. .
.
69
Retroflex Sounds . .
5.4
.
.
Conclusions and Discussion .
Chapter VI
. . .
.
89
........
104
.
. .
. .
The Most Effective Features for Speaker
6.1
Identification . ... . . .
. .
. . .
. .
. .104
Comparison of Best Features with Previous
6.2
Work . . .
. .
. . .
. .
. . .
. .
. . . . .110
Implications for Speaker Identification
6.3
Using Spectrograms ......
.....
.. 113
6.4
The Limitations of this Study
.....
.. 115
6.5
Relations between Dialect and Various
Measurements . . . . . .
. . . . . . ...116
Possibilities for Further Work . .
6.6
Appendix
. .
. . . .
. .
. ...117
.
.. . . . . . ... .118
. . . . . .
References .
. .
. . .
. .
. . .
. .
. . .
. .
.221
LIST OF FIGURES
3.1
Manual Placement of a Beginning-of-Vowel Marker .
3.2
Example of a Formant Track Display
3.3
Example of a Spectrum Plot
3.4
Pole Plot Giving Rise to the Spectrum of Figure
3.3 . .
4.1
. . . .
. .
. . .
. .
. . .
..... .
. .
. .
. .
. . .
. .
.. .37
. .
.38
. .
.39
.
.42
Formant Tracks Computed from a Preemphasized
Signal Using 12 Predictor Coefficients
4.2
. . .
.35
. ....
Formant Tracks Computed from an Unpreemphasized
Signal Using 13 Predictor Coefficients with
. .
Q-Criterion ..........
4.3
. ...... . .43
Formant Tracks Computed from an Unpreemphasized
Signal Using 13 Predictor Coefficients without
Q-Criterion . . . . . . . . . . . . . . . . . . . . 44
4.4
Average Normalized Error versus Number of Predictor
Coefficients for Speaker 1
4.5
Average Normalized Error versus Number of Predictor
Coefficients for Speaker 3
4.6
............
. .
48
Average Normalized Error versus Number of Predictor
Coefficients for Speaker 6
4.7
.47
. ...........
. ...........
.49
Formant Tracks Computed Using 10 Predictor
Coefficients
. .
. . . . . .
. .
. .
. .
. . .
. .50
4.8
Formant Tracks Computed Using 14 Predictor
. ...
Coefficients
4.9
.
.....
........ . 51
.
Speaker 10 Saying "Say bide again."
. . . . . ...
54
4.10 Speaker 10 Saying "Say bode again," Second
Repetition
. ...
...
..
.........
. 55
4.11 Speaker 10 Saying "Say bode again," Third
Repetition
........
............
56
4.12 Speaker 3 Saying "Say bide again," on Day 1 .
.
.
59
4.13 Speaker 3 Saying "Say bide again," on Day 2 .
.
.
60
4.14 Uncorrected Formant Tracks Calculated with 12
Predictor Coefficients
. .
..
..
. .............
61
4.15 Uncorrected Formant Tracks Calculated with 14
Predictor Coefficients
...
. ...
.............
62
4.16 Corrected Formant Tracks Calculated with 12
Predictor Coefficients
. ...
.
. .
. .
. . ....
64
4.17 Corrected Formant Tracks Calculated with 14
Predictor Coefficients
.
. ....
.............
65
4.18 Algorithm for Correcting Discontinuities in
Formant Tracks
. ....
. . .. .................
. .
67
5.1
[rE] with a Steady Fourth Formant . . .
5.2
[re] with Fourth Formant Rising Parallel to Third . 97
5.3
[re] with Fourth Formant Rising after Third has
Leveled Off . . . .
5.4
. . .
. .
. .
. .
. 96
. . .
98
. .
. 100
[re] Showing a Noisy Fourth Formant . .
LIST OF TABLES
.
5.1
Feature Names, Descriptions, and Applications
5.2
Correlation Coefficients for the Features Computed
on [aI]
. . .
. . .
. . .
. .
. .
.
.. .
70
.. .. .. 75
. .
. . . . 77
5.3
F Ratios of F2 Measures for Diphthongs
5.4
F Ratios of Timing Measures for Diphthongs
5.5
F Ratios of Fl Measures for Diphthongs
5.6
F Ratios of Higher Formant Measures for Diphthongs
5.7
F Ratios of F2 Measures for Tense Vowels
. . . . . 86
5.8
F Ratios of Fl Measures for Tense Vowels
.....
5.9
F Ratios of Timing Measures for Tense Vowels
.
. .
. ..
80
. . . . 82
.
84
88
.
90
5.10 F Ratios of Higher Formant Measures for Tense
Vowels
. . . . . . . . . . . . . . . . . . . . . . 90
5.11 F Ratios of Fl Measures for Retroflexes . .
. . . . 92
5.12 F Ratios of F2 Measures for Retroflexes . .
. . .
5.13 F Ratios of F3 Measures for Retroflexes . .
. .
5.14 F Ratios of F4 Measures for Retroflexes . .
102
. . ....
5.15 F Ratios of Timing Measures for Retroflexes . .
. . 95
. .103
6.1
Features Having Average F Ratios Greater than 60
6.2
Selected Correlation Coefficients of Features from
Table 6.1 .
. . .
. . .
. .
. .
107
....
. .
. .108
. .
. . .
. . .
The 10 Most Effective Features
6.4
Comparison of Feature Performance Between this
............
.105
. . .
. . .
6.3
Study and that of Sambur
. 93
.
. .111
CHAPTER I
Introduction
The last decade has seen a great amount of interest
and research in the areas of speaker identification and
speaker verification using the acoustic speech signal.
A reliable system that identifies a person by his voice
has numerous direct applications, such as banking by
telephone, identification for purposes of credit transactions and privileged access to information, or the
controversial practice of using voice evidence for law
enforcement purposes.
A somewhat less direct application
of knowledge about speaker differences is in the area of
automatic speech recognition.
A method of compensating
for individual variations would simplify the recognition
procedure.
A knowledge of these variations and their
relationships to dialect is also of interest to phonetic
research.
The approach to the problem and the difficulty of
achieving speaker recognition depend greatly on the nature
of the task to be performed.
The easiest task is simply
to match an unknown speaker with one of a closed set
of two or more reference speakers.
Unfortunately, this
situation rarely arises in practice, particularly if one
expects the speakers to be cooperative.
A more common
problem is that of matching the unknown to a reference
11
with the possibility of not finding a match, a situation
called "open set."
This is the situation that usually
arises when voiceprint evidence is used in a court case.
One might expect the suspect to be in a different physiological state (possibly resulting in a change in his voice),
or to try and disguise his voice when saying the phrase
that is to serve as his reference.
These two matching
problems, whether open or closed set, are commonly
referred to as speaker identification.
In speaker verifi-
cation, the task is to decide whether the unknown is the
same person as a single reference.
This situation can
occur when a person is required to verify his identity
by saying a certain phrase.
An imposter will probably
try to imitate the voice of the reference speaker.
The earliest work in speaker recognition involved
the visual inspection of spectrograms.
In this procedure,
the observer must perform the separation of the speech
signal's linguistic information from the information
relating to the identity of the speaker.
Complicating
the situation is the fact that a certain amount of information is lost because of mechanical difficulties, such as
the limited dynamic range of the spectrogram paper.
A
fairly comprehensive investigation of speaker recognition using spectrograms involved various experimental
conditions, such as closed sets versus open sets of
12
reference spectrograms, recordings made at least one
month apart as opposed to at the same session, etc.
(Tosi, et. al., 1972).
Error rates varied from 1% to
30%.
The more automated forms of speaker recognition
generally fall into two categories:
and feature extraction.
template matching
The template matching type makes
a decision about the identity of the speaker on the basis
of the mathematical proximity of the sample utterance to
a reference, but does not make a detailed comparison of
certain acoustic events arising from individual speech
sounds.
This approach seems to serve quite well for
speaker verification, where a speaker would not purposely
introduce large variations in the speech sample, as he
might in giving evidence for a court case.
lies in its simplicity.
Its advantage
Most template matching schemes
perform some form of time and amplitude normalization on
the unknown and then calculate the distance of this
unknown from the reference it is supposed to represent.
If the distance is larger than a certain threshold, an
answer of no-match is given (Pruzansky, 1963; Li, et. al.,
1966; Luck, 1969; Das and Mohn, 1971; Lummis, 1973).
The speech theoretic approach examines linguistic
units and tries to extract an optimum set of features.
13
Several criteria have been suggested for selecting these
features (Wolf, 1972).
They should occur frequently
in normal speech, vary widely between speakers but not
for a given speaker, not change over time, not be affected
by background noise or poor transmission, not be affected
by conscious efforts to disguise the voice, and be easily
measurable.
The list of possible identifying features is virtually
endless, and has only been partially examined.
One
technique which has yielded some good features in previous
work but has certainly not been exhausted is that of
vowel formant calculation (Wolf, 1972; Sambur, 1972).
With the exception of one slope measurement, formant
information has generally been taken more or less at one
point in the middle of a steady-state vowel.
The slope
measured was that of the second formant transition of
the diphthong [aI],
computed by fitting a straight line
to the second formant values over the entire duration of
the diphthong.
The results of this fairly simple measure-
ment were so good that it would seem reasonable to do some
further investigation into the fine structure of formant
locations, transitions, and timing.
An indication that formant frequencies of diphthongs
might prove to be particularly useful is given by the large
14
individual variability encountered in previous work with
diphthongs (Holbrook and Fairbanks, 1962).
Diphthongs
have also been found to vary widely between different
dialects.
In their formulation of phonological rules,
Labov, Yaeger and Steiner (1972) mention that two rules
pertaining specifically to diphthongization have been
found not to apply in certain northern United States
cities.
They also state that different English dialects
will require different underlying representations as inputs
to these rules - another indication of the large variability between dialects.
Another motivation for studying formant movements is
that formants figure very prominently in speaker recognition by spectrograms.
For example, in the experiment
on voice identification, (Tosi, et. al.,
1972) the spectro-
gram readers were instructed to look for 6 different
types of speaker-identifying clues:
frequencies of vowel formants,
(a) similar mean
(b) formant bandwidths,
(c) gaps and types of vertical striations, (d) slopes of
formants,
(e) duration, and
(f) characteristic patterns
of fricatives and interformant energies.
Clues (a) and
(d) are directly related to formant frequency tracking,
while (e) and (f) are related to a somewhat lesser extent.
Therefore, an investigation of formant movements might
15
also help a spectrogram reader direct his attention to
the most helfpul details.
The three sounds generally called diphthongs are [31]
as in boy, [aI] as in buy, and [aU] as in loud.
However,
[o] in boat and [e] in bay also often have definite
diphthong-like glides, as do the vowels [i] in beat and
[u] in boot.
The other two tense vowels, [a] and [ael ,
will also sometimes have offglides, but not in the direction of [I] or [U],
as one finds in all of the pre-
viously mentioned tense vowels and diphthongs.
Another potentially interesting group of sounds
centers around the retroflex sounds.
In the word bird,
the retroflex sound is a vowel, but in bread and bard it
is generally considered to be consonantal.
A recent
investigation of the acoustic characteristics of /w,r,l,y/
found that the r-colored sounds differ acoustically from
one another and vary from one speaker to another (Klatt,
1972).
The purpose of this study is to investigate the
formant trajectories of the sounds [I],
[o],
[e],
[aI],
[aU],
[i] and [u] and the three retroflex sounds [r-],
['] and [-r] in order to find and statistically evaluate
features that could be relevant to speaker identification.
Secondary objectives are (1) to develop and evaluate a
method of tracking formants for a variety of sounds produced by different speakers, and
(2) to gain insight
into the acoustic and articulatory attributes of these
classes of sounds, particularly as they are influenced
by the characteristics of the speaker.
Chapter II contains a review of the literature in
two subject areas.
The section on speaker recognition
using feature extraction describes some of the more
successful features of previous work and how they were
chosen.
The formant-tracking section discusses some of
the different issues involved in the use of linear prediction and also briefly mentions a few other techniques
that have been used for formant tracking.
Chapter III describes the recording procedure used
to obtain the data base and the algorithm used for extracting
formant tracks.
Chapter IV first presents the experiments which led
to the choice of the specific formant-tracking method
described in Chapter III.
Next, it discusses some of
the problems encountered in the use of this method for
processing the data of this study and ends by suggesting
an additional algorithm for improving the method.
Chapter V presents the speaker-identifying features
evaluated in this study, giving F ratios for each one and
17
naming their advantages and disadvantages, where appropriate.
Chapter VI states some general conclusions obtained
in this study, including a list of the 12 best features.
It also gives some suggestions for speaker identification
by spectrograms, a discussion of the limitations of this
study, and some recommendations for future work.
The Appendix lists all F ratios and all of the individual speaker means and standard deviations associated
with each feature that was investigated.
CHAPTER II
Literature Review
2.1
Speaker Recognition Using Feature Extraction
As mentioned in chapter one, a template matching pro-
cedure based on gross measures such as average glottal frequency or average spectrum is fairly easy to implement.
It would seem reasonable, however, that a more complicated
procedure that examines in detail the acoustic
character-
istics of different phonetic segments might produce better
accuracy.
In 1967,
a procedure was
suggested that automatically
extracted certain portions of continuous speech for use in
speaker verification
(Meeker, et. al.,
1967).
the slope of the spectrum was measured.
For vowels,
For consonants,
spectral characteristics, duration, and other temporal aspects were used.
Best results were obtained when many in-
dividual measurements were combined.
An experiment reported the following year based its
analysis on the power spectrum of the nasal consonant [n]
(Glenn and Kleiner, 1968).
There are several good reasons
for using nasals in speaker identification.
First,
the
spectrum of a nasal depends almost entirely on the physiology of the speaker and would be very hard to disguise or
imitate.
There is no lack of data, since
nasals comprise
19
Also, the measure-
11% of the phonemic content of English.
ment of a power spectrum is not very complicated or time
consuming; in this experiment it was accomplished with a
The one disadvantage is that this measurement
filter bank.
can be considerably affected by a cold or some other form
of nasal congestion.
With a population of 10 speakers,
With 30 speakers, the
identification accuracy was 97%.
accuracy fell to 93%.
The study by Wolf (1972) evaluated the effectiveness
of a number of different measurements with the help of
analysis of variance.
This technique, which involves cal-
culating an F ratio, was first used in speaker recognition
for determining which attributes of an utterance would be
most useful in identifying the speaker (Pruzansky and
Mathews, 1964).
the matrix
Each attribute, xij, was an element of
formed by playing the utterance into a filter
bank and sampling the output in time.
An F ratio is
defined by:
variance of the talker means
F=
average within-talker variance
with
2
s1
s22
n
m1
m(n-)
m
3=1
( Pj
n jm
i(ij
i=1 j=1
2
)
PJ 2
2
s1
1
s2
20
where m is the number of speakers, n is the number of
repetitions of the utterance,
j is the mean for the Jth
speaker, and 5 is the grand mean over all speakers and
utterances.
The following parameters were examined by Wolf for
possible use as features:
1.
Fundamental frequency at several locations in the re-
corded sentences.
This was estimated from the distance between zero crossings of the low-pass filtered speech wave.
Except for one
of the locations, FO measurements had the highest F ratio
of all parameters tested.
Unfortunately, FO is rather
susceptible to voluntary changes.
Another problem with FO
found by Sambur (1972) was that it tended to vary from one
recording session to another, a condition not tested by
Wolf.
2.
Nasal consonants
Short term spectra obtained by sampling the outputs
of 36 bandpass filters were used as measurements.
Pole
and zero locations could have been used to express the
same information more concisely, but proved very difficult
to measure.
3. Vowels
Formant frequencies were measured using an analysisby-synthesis technique for the vowels [ a] and [a] and by
peak picking on the filter bank output for [A].
Formants
depend on both vocal tract anatomy and the speaker's
acquired habits, and therefore may be somewhat susceptible
to change by mimicking or disguising.
Three other features giving noticeably good results
were the second and third central moments of the spectral
peak in [i] caused by the second, thirdl, and fourth formants and an estimate of the source spectrum shape as defined by the relative amplitudes of the first and third
formants of [u].
Less good results were obtained from the
spectrum of fricatives, the duration of the word "bought,"
and the presence of prevoicing for voiced stops.
A closed
set identification experiment with 21 speakers using 17
features produced no errors.
Two fairly new techniques for working with speaker
identification were used by Sambur
(Sambur, 1972).
in his Ph. D. thesis
The first, predictive coding, had been
used by Atal to measure pitch contours for a speaker identification experiment (Atal, 1968).
This versatile tech-
nique is also useful for finding formants and bandwidths,
estimating the glottal spectrum, building a vocoder, etc.
(Atal and Hanauer, 1971).
The second technique was the use of a probability of
error criterion for choosing features.
The analysis of
variance technique had several drawbacks.
First, the
F ratio tells whether or not there is a difference between
some of the means of the various distributions, but it does
not assure us that all of the means are significantly different.
Therefore, if one of the speakers used in the
evaluation of a feature produces a very large difference
in this feature, then a high F ratio will result, even if
all of the other speakers' data have almost identical
means.
The values of FO used by Wolf which gave the high-
est F ratios showed this tendency, with about 5 speakers
producing most of the variation in a group of 21.
The sec-
ond problem with the F ratio is that it gives no information about any dependence between different features.
The calculation of probability $@ error assumes that
the samples of a given feature form a gaussian distribution
for each speaker.
The overlap of these distributions
gives the probability of error for that feature.
The
total probability of error involving all features is calculated using the union error bound.
N features were or-
dered in terms of maximum effectiveness using the following
procedure:
1)
Calculate probability of error using all combin-
ations of N-1 features.
2)
Select the N-1 features givng the lowest error.
3)
Eliminate the feature that was not part of the
best set, and repeat the procedure until only one
feature is left.
The 10 best features indicated by this analysis included 3 vowel formant frequency measurements, 4 nasal formant
frequency measurements, the voice onset time of [k], one
FO measurement, and a rough estimate of the slope of the
second formant in [aI].
Since the three vowel formant meas-
urements were taken at only one instant in time, and since
the slope measure proved so effective, one might suspect
that a more detailed examination of vowel formant movement
could yield additional speaker information.
This notion is supported by a spectrogram study of
formant tracks and fundamental frequency for speaker identification (Boulogne, Carre, and Charras, 1973).
Two-
dimensional plots were made of F1 vs. F2, F2 vs. F3, Fl
vs. F3, and FO vs. AO, where AO is the amplitude of voicing.
The data base was 2 repetitions each by 10 speakers of a
single phrase.
Test plots were matched to references both
by visual inspection and by the computation of correlation
coefficients.
The F2 vs. F3 plot gave no identification
errors, and the other plots gave very few errors.
The results of this experiment are very encouraging
but somewhat preliminary due to the small data base and
elementary measurement techniques.
The two-dimensional
plots have the advantages of including much more information than a single measurement and also avoid some of the
24
problems of temporal alignment.
On the other hand, this
discarded temporal information might also be useful.
Therefore an extended study of formant tracks using a sophisticated formant tracking scheme and a large data base
with recordings made on more than one occasion could reveal
some potentially effective speaker-identifying features
that have been previously overlooked.
2.2
Formant Tracking
The problem of determining formant frequencies has
been attacked in several different ways.
The two oldest
methods are peak picking on the output of a filter bank and
estimating the center frequency of a high-energy band on
a spectrogram.
Though fairly simple and straightforward,
these methods are not very accurate, and the second one is
not applicable to any sort of automatic system.
A definite inprovement came with the introduction of
an analysis-by-synthesis technique (Bell, et. al., 1961).
The spectrum of real speech obtained by passing it through
a filter bank was compared with the spectrum generated
from information about pole and zero locations.
Pole-zero
locations were varied until a best fit was obtained.
The
main drawback was that an automatic version of this procedure was quite slow.
Sampling the spectrum at 8.3 msec.
intervals, it ran at about 1000 times real time.
25
A different method employing mainly digital analysis
techniques used a peak-picking algorithm on a cepstrally
The
smoothed speech spectrum (Schafer and Rabiner, 1970).
cepstral smoothing yields a more detailed spectral envelope
than a filter bank, but the peak-picking procedure throws
out all information gained from relative amplitudes of
spectral peaks and spectral amplitude between peaks.
This
information sometimes helps to identify two formants that
are so close together that they form a single peak.
To
help resolve spectral peaks suspected of representing more
than one formant, Schafer and Rabiner made use of the chirp
z-transform.
This algorithm enhances peaks by calculating
the spectrum on a contour inside the unit circle and hopefully closer to the pole locations.
Expected frequency
ranges for the first three formants and expected formant
amplitudes were used to detect unresolved spectral peaks.
Olive (1971) introduced a method that combined the
benefits of analysis-by-synthesis with those of cepstral
smoothing.
His system first calculated a cepstrally
smoothed spectrum and then matched it to a theoretical
spectrum with 3 formant frequency variables.
The matching
consisted of deriving 3 nonlinear simultaneous equations
by minimizing the least-squared error between the spectra
and then solving these 3 equations by an iterative method
known as the Newton-Raphson technique.
26
A technique that has been receiving much attention
recently is linear prediction, also known as predictive
coding.
This technique is not new, being Just a special
case of a method developed by Prony in 1795 (Markel, 1972).
It has also been in common use for quite some time by geophysicists (Treitel and Robinson, 1967).
Linear prediction is a generalized analysis-by-synthesis technique which assumes that the signal to be analyzed
can be represented by an all-pole spectrum (Makhoul and
Wolf, 1972).
It has generally been accepted that the vocal
tract transfer function has all poles and no zeros for nonnasal voiced sounds (Fant, 1960, p. 42).
The combined ef-
fect of the glottal source and the radiation load can be
approximated by two poles (Atal and Hanauer, 1971).
The
z-transform of non-nasal voiced sounds can therefore be
represented by
A U(z)
P
1 -
akz
-k
k=l
where U(z) is the z-transform of an impulse train and p is
the number of poles representing the vocal tract, voicing
source, and radiation load.
In the time domain, this
becomes
s
=
k=l
aks
n-k
+ Aun
Linear prediction computes a set of predictor coefficients
{ak
that will minimize the total-squared error between
the original signal sn and an approximation sn that does
not include the impulse train, un
.
The term Aun is allowed
The total-squared error is
to become part of the error.
defined by
E
(s
-s
"
)
2
=
(s
n
n
P
E
aks nk
2
k=l
To minimize this error, the p partial derivatives of E with
respect to ak are all set to zero, giving p equations in p
unknowns.
If the number of samples included in the summation
over n in the computation of E is limited to a finite number N, the procedure is referred to as the covariance
method of linear prediction, which was the method used by
Atal and Hanauer (1971).
If the summation is carried out
over all time samples, but the original signal is windowed
such that only a finite number of samples is non-zero, the
procedure is called the autocorrelation method of linear
prediction.
These two methods can also be implemented
either pitch synchronously or pitch asynchronously.
If the
first sample of the window or of the N samples included in
the total-squared error is always in a fixed position relative to the beginning of the pitch period, the method is
called pitch synchronous.
If the analysis frame is
advanced a fixed amount for each computation of the predictor coefficients regardless of the location of the pitch
periods, the method is pitch asynchronous.
There are various advantages and disadvantages associated with both of these methods.
One might expect the
autocorrelation method to give somewhat less accurate
results, since this method tries to represent a finite duration impulse response (the windowed signal) with an infinite duration impulse response filter (the all-pole model),
a situation which is theoretically impossible.
But in
practice, the two methods of linear prediction give remarkably similar results.
Chandra and Lin (1974) found that
for pitch asynchronous analysis and relatively large segment size (20-25 msec.), the two methods performed about
equally well.
Performance was judged on the basis of total
minimum normalized squared error, accuracy in estimating
the speech spectrum, and accuracy in estimating formant
parameters.
The covariance method performed better with
pitch synchronous analysis than it did with asynchronous
analysis, and also performed better than the autocorrelation
method when both were tried pitch synchronously.
Further
improvement can be gained when using the covariance method
pitch synchronously if analysis is confined to the closedglottis part of the pitch period or if the one sample producing the largest error in the error signal for a given
29
pitch period is eliminated from the analysis segment (Atal,
For these reasons, the covariance method might be
1974).
chosen for situations where accuracy of formant frequencies
is of utmost importance.
By making use of symmetry and other special conditions
that arise during the solution of the p simultaneous equations to obtain the predictor coefficients, the time and
storage required can be greatly reduced for both the autocorrelation and covariance methods.
These savings are
somewhat greater with the autocorrelation method than with
the covariance method (Portnoff, Zue, and Oppenheim, 1972).
The second advantage of the autocorrelation method
is that in theory it guarentees that all poles of the
transfer function will be inside the unit circle of the
z-plane.
In actual practice, an unstable filter may result
from a finite word length computation (Markel and Gray,
1973).
An unstable filter representation can cause prob-
lems if the predictor coefficients are to be used for
speech synthesis.
The determination of the predictor coefficients is
only part of the job of finding formant frequencies, since
all that it provides is a system function in unfactored
form.
To find the formant frequencies, one can either
find the roots of the denominator of this system function
and eliminate those that do not appear to represent
30
formants, or one can perform peak-picking on the spectrum
calculated from this system function.
The root-finding
technique gives excellent resolution of the formant frequencies, but is extremely time-consuming, since the calculation must be performed iteratively.
Besides suffering
from the problem of resolving merged spectral peaks, the
peak-picking method is limited in its frequency resolution
by the number of points used by the FFT to calculate the
spectrum.
For example, McCandless (1974) used a 256 point
FFT, giving 40 Hz spectral resolution.
Her system included
a very sophisticated algorithm for determining which peaks
represented formants and where a formant might have been
missed.
Spectral peaks representing 2 formants were re-
solved by repeatedly recomputing the spectrum on a circle
in the z-plane with radius less than 1, until 2 distinct
peaks were found.
The system of McCandless also preemphasizes the input
signal 6 dB/octave before sampling it.
This 6 dB/octave
preemphasis has various effects, most of them beneficial.
It deemphasizes the first harmonic, which is otherwise
sometimes picked up as a formant (Markel, 1972).
It em-
phasizes the higher formants, thus bringing them closer to
the level of the lower formants and reducing computational
problems such as roundoff error.
The preemphasis, which
Markel simulates by differencing the speech after it has
31
been sampled, acts as an additional zero at z=l.
This zero
approximately cancels one of the glottal poles, such that
the total number of poles in the analysis can be reduced
by 1.
The disadvantage of preemphasis is that it shifts
the formant frequencies somewhat, with the largest effect
occuring with the first formant.
Makhoul and Wolf (1972)
found a raising of the first formant of about 80 Hz when
using peak-picking and about 40 Hz for root-finding when
preemphasis was used in the analysis of one vowel.
CHAPTER III
Experimental Procedure
3.1
Data Base
Recordings were made of the 3 diphthongs [I],
[aI],
and [aU],
3 retroflex sounds [r],
4 tense vowels [i],
[e],
[o],
and [u].
[rC], and [ar], and
In order to facil-
itate comparison of one vowel with another, all vowels
were recorded in the context, "Say b d again."
Ten adult
male speakers of American English with no noticeable accents
or speech defects were chosen to make the recordings.
Each
person spoke 5 repetitions of each of the 10 sentences in
one recording session.
Six of the original 10 speakers
returned at least 3 weeks after the first recording session
to make another set of recordings, again with 5 repetitions
of each of the 10 sentences.
This second set of recordings
was made in order to check on the changes in a speaker's
voice over time.
3.2
Formant Tracking Procedure
Recordings were processed semiautomatically on a
PDP-9 minicomputer specially set up for speech analysis.
The software written for this purpose seeks to minimize
the amount of time needed to compute a highly accurate set
of formant tracks, both in terms of computer time and
operator time.
However, for several reasons, no attempt
was made to fully automate this procedure.
Currently,
there is no automatic formant-tracking program in
existence which gives 4 formants with 100% reliability.
The best systems giving 3 formants generally have very
complicated decision algorithms, and even then cannot
guarantee absolute 100% reliability (McCandless, 1974).
Since an error in formant identification can produce
serious errors in a speaker identification scheme based
on specific formant frequencies, and since the major
emphasis of the study is on the use of formant tracks
rather than on their computation, it was decided that
an interactive system should be constructed.
With
such a system, the operator can observe the results of a
first, automatic stage of tracking and can intervene
manually to correct errors.
Informal observations by the
program user during the process of trying to identify
missing formants or eliminate extraneous ones could be
useful in the construction of a more automatic system at
some later time.
Audio input was preemphasized 6 dB/octave, band-limited
to 5 KHz, and sampled at 10 KHz.
The sampled signal was
displayed on a cathode-ray tube, and then marked by hand
to indicate beginning and end of processing.
The beginning
was defined at 20 msec. after the noise burst indicating
the release of [b].
The end was marked when a sudden drop
in amplitude and an obvious loss of high frequencies
indicated the closure for [d].
On about 5 sentences, these
two points were not obvious, due to unprecise pronunciation
by the subject.
In these cases, analysis was started
well before the expected beginning and stopped after
the expected end.
The two end markers were then readjusted
to the two points where gross discontinuities in the
formants indicated the presence of a consonant.
Figure
3.1 shows an example of the beginning of a vowel that was
marked at the point where the formant tracking program
was able to find a continuous set of formants.
The first main processing loop of the formant tracking program calculates 12 predictor coefficients for
each 10 msec. frame, using the covariance method non pitch
synchronously, and stores these values on disk.
The
second loop calculates pole locations of the transfer
function for each frame and then transforms them to
formants and bandwidths (Jenkins and Traub, 1970).
Formants
with bandwidths greater than 700 Hz are removed from the
general formant array and placed in a temporary location
for extraneous formants.
The last phase of the program
displays the formants and allows corrections to be entered
manually by the operator, according to continuity considerations and his knowledge of acoustic theory.
Formants
can be restored from the temporary locations if they are
FORMANT TRACKS
[u] recorded on day 1
by speaker 2, repetition 1
Formant
Frequency
in
KHz
50
100
150
200
250
300
Time in msec.
Figure 3.1
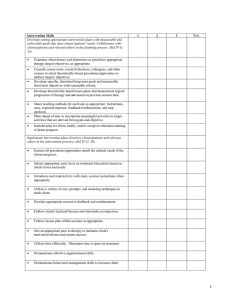
Manual Placement of a Beginning-of-Vowel Marker
Beginning-of-vowel marker was placed at 40 msec., the point
where the formant-tracking program began to find a continuous
set of formants.
judged as not extraneous.
Formants can also be removed
if they seem extraneous but were not automatically
eliminated.
On very rare occasions, the root-finding
subroutine could not find the roots in 10 iterations.
In this case, the formant frequencies were set to zero
by the program and were later filled in by averaging
the formants of the previous and the next frame.
During
the course of the measurements, this situation only
occurred twice.
Corrected formant tracks were appropriately
labeled and stored on DEC-tape.
Occasionally, a situation arose when the user had
trouble deciding which poles to choose as formants.
To
help him make a decision, the program calculated a logmagnitude plot of the spectrum and a pole-plot in the
z-plane for any frame indicated by the user.
are shown in Figures 3.2, 3.3, and 3.4.
Examples
In actual
practice however, these plots rarely gave more insight
than the actual formant frequencies and bandwidths.
37
FORMANT TRACKS
[aU] recorded on day 1
by speaker 8, repetition 4
50
100
150
200
Time in msec.
Figure 3.2
Example of a Formant Track Display
250
300
SPECTRUM - frame 13
[aU] recorded on day 1
by speaker 8, repetition 4
Relative
Energy
in dB
20
10
1
2
3
4
5
Frequency in KHz
Figure 3.3
Example of a Spectrum Plot
Spectrum calculated from predictor coefficients 130 msec.
from beginning of formant tracks in Figure 3.2
Pole Plot - frame 13
Im(z)
[aU]
recorded on day 1
by speaker 8
repetition 4
Re (z)
Figure 3.4
Pole Plot Giving Rise to the Spectrum of Figure 3.3
CHAPTER IV
Evaluation of the Formant-Tracking Procedure
4.1
Initial Experiments for Determining the Exact
Formant-Tracking Method
The problem of maximizing the accuracy of formant
tracking is much less well-defined than the problem of
minimizing computation time, simply because there are
no absolute scales for comparison.
Spectrograms can only
be read to an accuracy of about 50 Hz, and quite often
do not show more than 3 formants reliably.
The analysis
of synthetic speech is not a fair test, because the synthesizer usually generates speech under the same assumptions as those used by the analysis scheme, namely, poles
and zeros, or just poles.
In this study, the accuracy of
the analysis was judged on the basis of the smoothness
of the formant tracks and the degree to which the uncorrected
formant tracks corresponded to those expected on the basis
of spectrograms, continuity, and acoustic theory.
The effects of varying the number of predictor
coefficients and of preemphasizing the signal were
investigated briefly in terms of speed and accuracy of
formant tracking.
Formant tracks of the same vowel seg-
ment were compared for 13 poles without preemphasis and 12
poles with preemphasis.
(A discussion of the number of
poles as related to preemphasis is given in Section 2.2.)
The preemphasis case seemed to produce slightly smoother
formant tracks, especially in the higher formants, as
shown in Figures 4.1 and 4.2.
For the case without pre-
emphasis, an additional condition was added to the formant
and bandwidth calculation subroutine.
Since the first
harmonic of the unpreemphasized spectrum is often strong
enough to be mistaken for a formant, as shown in Figure
4.3, all formants with Q less than 2.0 were labeled as
extraneous, in addition to those rejected because of
bandwidth greater than 700 Hz.
Occasionally this condition
falsely eliminated the first formant, and occasionally
it failed to eliminate a first harmonic peak.
The pre-
emphasis case required less computation time, both in
calculating predictor coefficients and in finding roots,
simply because it deals with one less unknown.
For the
non-preemphasis case, the root-finder failed to converge
within 10 iterations on several occasions, whereas it
performed quite well in these instances when preemphasis
was used.
Since the measurements taken in this study were
to be used mainly on a comparative basis, it was felt
that the above-mentioned advantages of preemphasis justified the disadvantage of the slight formant frequency
shift that it causes.
FORMANT TRACKS
[aUl recorded on day 1
by speaker 8, repetition 4
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.1
Formant tracks. computed from a preemphasized signal using 12
predictor coefficients, before manual corrections were made.
FORMANT TRACKS
[aU] recorded on day 1
by speaker 8, repetition 4
Formant
Frequency
in
KHz
50
100
150
200
250
300
Time in msec.
Figure 4.2
Formant tracks computed from an unpreemphasized signal using
13 predictor coefficients and automatically eliminating
formants having Q less than 2.0. The first formant was
falsely eliminated in 2 frames.
FORMANT
IRACKS
[aU] recorded on day 1
by speaker 8, repetition 4
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.3
Formant tracks computed from an unpreemphasized signal using
13 predictor coefficients without Q criterion. The first
harmonic of the spectrum is sometimes mistaken for the first
formant.
45
Since the number of predictor coefficients, p, also
affects the accuracy of formant tracking, a brief study
was undertaken to determine what number would be most
appropriate for the data under investigation.
If not
enough predictor coefficients are used, there will not
be enough poles to account for all formants present in
the 5 KHz range being considered.
If there are too many
predictor coefficients, poles will be assigned to
extraneous peaks in the spectrum, possibly shifting the
values of other poles, and making it difficult to decide
which poles are the actual formants.
Theoretically, 12 poles should be about right for
the conditions of this formant tracker.
A 5 KHz low-pass
filtered signal should allow for about 5 formants for a
male voice, assuming plane-wave propagation in an acoustic
tube (Makhoul and Wolf, 1972, p. 24).
The glottal source
and the radiation characteristic can be represented by
2 poles, but in order to compensate for aliasing, this
number is best raised to 3 (Makhoul and Wolf, 1972).
Finally, the preemphasis removes one pole.
One method suggested for determining p is to compute
the average normalized error for a sound using a number
of different p's
(Makhoul and Wolf, 1972).
of p, this error is fairly high.
For low values
In theory, the error
46
should decrease substantially with each increase in p
until all formants are matched with poles, at which point
the error curve levels off.
This "knee" in the curve,
therefore, indicates the optimum value for p.
This type of analysis was performed for 3 speakers
with 4 different vowels and p ranging from 9 to 14.
Speech was preemphasized 6 dB/octave in each case.
As
shown in Figures 4.4, 4.5, and 4.6, the error curves
obtained generally had a knee at p=10.
However, as can
be seen by comparing the 10-coefficient formant plot in
Figure 4.7 with the 12-coefficient plot of Figure 3.2,
10 predictor coefficients are not enough to represent
all formants.
for p=10.
Every case tested produced bad results
Values for p of 11, 12, and 13 all produced
good results.
For p=14, there was some evidence of
extraneous formants, as shown in Figure 4.8.
Since 12
is halfway between the two cases that gave trouble, this
seems to be a good value for p.
Also, with a little
imagination, one might discern a second knee for some
error curves at p=12.
4.2
Observations Based on Formant Tracks of the Entire
Data Base
The first formant tracked perfectly on every utterance,
never requiring any correction.
The second formant
.10
.05 1
I
I
10
I
I
12
13
Number of Predictor Coefficients
Figure 4.4
Average Normalized Error versus Number of Predictor
Coefficients of Various Phones for Speaker 1
V
14
48
0
.10
*d
O
0
.05
9
10
11
12
13
Number of Predictor Coefficients
Figure 4.5
Average Normalized Error versus Number of Predictor
Coefficients of Various Phones for Speaker 3
14
.10
.05
I
Number of Predictor Coefficients
Figure 4.6
Average Normalized Error versus Number of Predictor
Coefficients of Various Phones for Speaker 6
FORMANT TRACKS
[aU] recorded on day 1
by speaker 8, repetition 4
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.7
Formant tracks computed using 10 predictor coefficients.
The fourth and fifth formants shown in Figure 4.1 were
generally represented by a single formant track and sometimes missed altogether.
51
FORMANT TRACKS
[aU] recorded on day 1
by speaker 8, repetition 4
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.8
Formant tracks computed using 14 predictor coefficients. An
extraneous pole-pair was recorded as the third formant at 30
msec. from the beginning of the tracks.
presented problems in about 2% of all utterances.
Errors
generally occurred in cases where the second formant was
unusually high or low, such as in [u] and [i],
third formant was low.
or if the
As the second formant dips in
[u] and [I], its level goes down, and the peak blends
into the first formant peak.
The linear prediction
algorithm then assigns a wider bandwidth to the second
formant.
Occasionally, this bandwidth exceeds 700 Hz
for a few analysis frames, so that the formant is labeled
as extraneous.
When the second formant is close to the
third, as in [i] and [], the algorithm sometimes assigns
an extra pole-pair to this combined peak.
With another
pole-pair to raise the spectrum level near the second
and third formants, the bandwidths assigned to the polepairs representing these two formants are larger than
might be expected, occasionally exceeding 700 Hz.
On
other occasions, the bandwidth corresponding to the extra
pole-pair is narrow enough to cause it to be labeled
as a formant.
Third formant errors occurred in about
10% of all utterances.
Most of these occurred in cases
where the second and third formants were very close
together.
Other errors occur when the third formant is
so weak that the bandwidths associated with it sometimes
rise above 700 Hz.
The fourth formant produced errors
in about 25% of all sentences, for reasons similar to those
given for the third formant errors as well as a few
additional complications.
In many cases, it was difficult to decide how and
where to correct third and fourth formant errors, even
with the help of pole plots, spectrum plots, and spectrograms.
With speaker number 10, a resonance of higher
frequency than the third formant seemed to disappear and
reappear.
In all repetitions of [aI],
[DI], and [el],
it appeared at the very end of the diphthong, as can be
seen in the spectrogram of Figure 4.9.
[u],
[o],
and [re],
In the phonemes
it appeared in some repetitions,
but not in others, as shown in Figures 4.10 and 4.11.
When it did appear, its level was lower than that of both
the next higher and the next lower formants.
One possible
explanation of this phenomenon is that the speaker sometimes creates an extra cavity in his vocal tract by raising
the tongue blade, and therefore introduces an additional
pole-zero pair.
This is particularly likely for the
context used in the recording of these vowels.
speaker may be anticipating the final [d],
The
which is a
consonant that requires a raised tongue blade.
The [r]
in bread can also be articulated with a raised tongue blade,
making it very likely that the blade will remain high
throughout the following [C].
.
:
.
. .:
'2
.
_ 7' I
i' ,
-"
:; -'_
° .. . "
. ]'.
_:
6
.
-
5
.
.
. .,.:
'L\
-
I
I
I
I
0.5
I
a
I
I
I
1.0
Time in Seconds
Figure 4.9
Speaker 10 saying "Say bide again." An extra formant appears
between the third and fourth formants at the end of [al].
5
C4
0
0
0.5
1. 0
Time in Seconds
Figure 4.10
Speaker 10 saying "Say bode again," second repetition.
"formants" are present in a 4000 Hz range.
Five
56
L.
1
1
1
i
0.5
1
I
0.5
m
1.0
Time in Seconds
Figure 4.11
Speaker 10 saying "Say bode again," third repetition.
four "formants" are apparent in a 4000 Hz range.
Only
57
Whether or not this resonance should be called the
fourth formant depends on how one chooses to define a
formant.
For purposes of this study, whenever a resonance
was detected with a bandwidth less than 700 Hz for over
50% of the time, it was declared a formant.
Missing
frames were then filled in from the temporary locations
where rejected formants were stored.
By following this
decision rule, those resonances that were rejected were
generally also those that were too weak to be visible on
a spectrogram.
Speaker number 3 presented a similar problem with the
"third" formant, with the difference that his data were
self-consistent on a single day's recordings.
On the
first day, 4 distinct formants were detected in a frequency
range up to 3000 Hz for the diphthong [aI].
On the second
day, only 3 formants were detected in the same range.
Examination of spectrograms revealed that on the recordings
from the second day, there was a very weak concentration
of energy in the frequency region where a third formant
had been detected on the first day's recordings.
However,
the difference between the two day's recordings is not
simply the strength of the resonance that was detected as
the third formant on the first day.
This resonance also
seems to affect the locations of the other formants, since
the average value of the fourth formant of the first day
was consistently 200 Hz higher than the average value of
the apparent third formant of the second day.
One possible
explanation is that for some reason there was nasal
coupling in the production of the vowel on day 2.
This
nasal coupling would have the affect of lowering the
amplitude of the third formant during [a] and lowering
the frequency of the fourth formant (House and Stevens, 1956).
Examples of spectrograms showing the phenomenon are given
in Figures 4.12 and 4.13.
Lower-than-expected formants created major problems
with speaker 7, who appeared to have the lowest average
third and fourth formant frequencies, and therefore, the
largest vocal tract.
An examination of a frequency
listing of formants labeled as extraneous showed that
the formant tracker quite often assigned the 12 available
poles to 6 recognizable formants.
This left no poles
for representing the spectrum of the voicing source.
The
appropriate spectrum was, therefore, approximated by totally
inappropriate formant bandwidths, i.e., very low bandwidths
on the first formant and much larger bandwidths on the
higher formants, which were consequently rejected by the
program.
When 14 predictor coefficients were used to ana-
lyze a few vowels for this speaker, results were much better.
Figures 4.14 and 4.15 show formant tracks for this speaker
i.
-~
er
r
-'
r
3 ~:l:i
ar:"il
'
~ni-: a~
;r7L:~~~t
;rl
n'i-Y;~PT~~I
I!_~
~ljlh~i:;~C'4
" 4:
-" (5~::e.
n .i
i"
~~CFZ~~~i
o
0.5
1.0
Time in Seconds
Figure 4.12
Speaker 3 saying "Say bide again" on day 1, second repetition.
Five distinct formants are visible in [al].
7.
6.
5.
4
3.
2
1
0
1
I-
1
I
5
0.5
Time in Seconds
Figure 4.13
Speaker 3 saying "Say bide again" on day 2, fifth repetition. Only four formants are visible in [al].
1.0
61
FORMANT TRACKS
[aU] recorded on day 2
by speaker 7, repetition 5
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.1 4
Uncorrected formant tracks calculated with 12 predictor
coefficients.
62
FORMANT TRACKS
[aU] recorded on day 2
by speaker 7, repetition 5
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.15
Uncorrected formant tracks calculated with 14 predictor
coefficients.
before manual correction for 12 and 14 predictor coefficients,
respectively.
Figures 4.16 and 4.17 show the same formant
tracks after corrections were made.
One problem associated with changing the number of
predictor coefficients is that this can cause the apparent
formant frequencies to shift considerably.
It is, there-
fore, inadvisable to adjust the number of predictor
coefficients to any sort of "optimum" for a given utterance,
as might well be done in a speech recognition system.
In determining the number of predictors to be used, it
is best to choose the maximum number required by any
speaker, since it is generally easier to eliminate
extraneous pole pairs than to guess at the locations of
non-existent ones.
On the basis of experience with
speaker 7, it would, therefore, have been better to use
14 predictor coefficients for this experiment.
For all of its crudeness, the method of eliminating
all of the pole pairs with bandwidth greater than 700 Hz
worked remarkably well.
A system that simply rejects all
but the five formants with the lowest bandwidths probably
wouldn't work much better, since the number of formants
detected in the 5000 Hz range under consideration varied
from 4 to 6, depending on the specific speaker and sound.
One possible refinement for the formant-tracking
procedure used in this study would be to add a stage for
64
FORMANT TRACKS
[aU] recorded on day 2
by speaker 7, repetition 5
Formant
Frequency
in
KHz
50
100
150
200
250
300
Time in msec.
Figure 4.16
Formant tracks calculated from 12 predictor coefficients
after manual corrections were made.
65
FORMANT TRACKS
[aU] recorded on day 2
by speaker 7, repetition 5
Formant
Frequency
in KHz
50
100
150
200
250
300
Time in msec.
Figure 4.17
Formant tracks calculated from 14 predictor coefficients
after manual corrections were made.
finding discontinuities in the formant tracks and correctThe correction algorithm,
ing them, when necessary.
summarized in Figure 4.18, scans the formant tracks,
looking for discontinuities greater than 300 Hz, beginning
with the first formant.
A first attempt at correcting
discontinuities consists of reinserting formant values
that had previously been rejected.
If no reject is
available of frequency lower than that of the formant
suspected in error, one can try removing the formant at
the lower end of the discontinuity.
If the bandwidth at
this point is relatively large, any type of improvement
in the continuity of the formants would justify the
removal of this pole-pair.
However, if the bandwidth is
narrow, this formant is best left intact unless the
removal of this single frame gives perfect continuity.
An aid in testing the appropriateness of a given
formant configuration is the examination of a formant
higher than the one with the suspected error.
For some
speakers, there is evidence of a narrow-bandwidth, stable
fourth formant but a much less well-defined third formant.
By eliminating or inserting values for the third formant
that force a smooth fourth formant, a good estimate can be
obtained for the third formant.
This correction algorithm is not overly sophisticated
._r ___I_~i__
I
~_
FIGURE 4.18
Algorithm for Correcting Discontinuities in Formant Tracks
;_liL~___1_
_I__
_I~
68
and certainly cannot guarantee perfect formant tracks.
Hopefully it will make some improvement in the crude
tracks obtained by eliminating all pole-pairs of bandwidth greater than 700 Hz.
But in order to obtain any
radical improvements in formant tracking, it may be
necessary to define more carefully what is meant by
the word "formant", for purposes of eliminating ambiguities
such as those encountered with speakers 3 and 10.
69
CHAPTER V
The Speaker-Identifying Features
5.1
Introduction
The formant tracks, as determined by the methods of
the previous chapter, contain a mixture of noise, linguistic information, and personal information.
The next
phase of a speech-theoretic speaker identification system
would be to extract the personal information pertaining
only to the identity of the speaker.
In this study, a
large number of features was measured for each of the
sounds being investigated, and each feature was then
evaluated in terms of its effectiveness in speaker identification.
A list of the names given to these features, a
short description of each one, and a list of which sounds
each was applied to is given in Table 5.1.
A more detailed
description of how some of the features were measured will
be given in the remaining sections of this chapter.
In the measurement process, similar phones were
grouped together so that approximately the same set of
features was tested for each phone of a given class.
three major classes used were
and [aU];
2) tense vowels
3) retroflex sounds [rE],
[e],
[ar],
1) diphthongs [II],
[o],
[i],
and [3].
The
[aI],
and [u]; and
The evaluation
of the features will be organized according to these classes.
Table 5.1
NAME
AVEF3
Feature Names, Descriptions, and Applications
APPLICATION
:I, aI, aU,
e, i, o, u
DESCRIPTION
average third formant not
including last 20 msec of
formant track
average fourth formant not
including last 20 msec of
formant track
average third minus second
formant omitting last 20
msec of formant track
total duration
AVEF4
all
AVE3M2
re, ar, 3"
DUR
all
DUR1
oI, aI, aU
DUR2
3I, aI, aU
FINAL1
rE,
FINAL2
3I, al, aU,
re, ar, e,
i, o, u
FINAL3
re, ar
FINAL4
rE, ar
F1MAX2
DI, aI, aU,
e, i, o, u
F lMAX 3
re, ar
FlMIN2
DI, aI, aU,
e, i, o, u
F1 at point in time when F3
reaches a maximum
Fl at point in time when F2
reaches a minimum
FlMIN3
re, ar,3
F1 at F3 minimum
F2MAX3
rE, ar
F2 at F3 maximum
ar
duration 1 measured from
beginning of formant tracks
to middle of second formant
glide
duration 2 measured from
middle of second formant
glide to end of formant
tracks
Fl measured 20 msec before
end of formant tracks
F2 measured 50 msec before
end of formant track on
[aU], [o], and [u]; 20
msec before end on all other
sounds
F3 measured 20 msec before
end of formant tracks
F4 measured 20 msec before
end of formant tracks
F1 at point in time when F2
reaches a maximum
71
NAME
APPLICATION
DESCRIPTION
F2MIN3
re, ar,3^
F2 at F3 minimum
F4MAX3
re, ar
F4 at F3 maximum
F4MIN3
re, ar,3A
F4 at F3 minimum
INITL1
aI, aI, aU,
re, ar, e,
i, o, u
INITL2
DI, aI, aU,
re, ar, e,
i, 0, u
INITL3
re, ar
initial Fl, measured 20
msec after beginning of
formant track for [re] and
[ar], at beginning of track
for all other sounds
initial F2, measured 20
msec after beginning of
formant track for [re] and
[ar], at beginning of
track for all other sounds
initial F3, taken 20 msec
after beginning
INITL4
rE, ar
initial F4, taken 20 msec
after beginning
LOCALS
aI, aI, aU
MAXF1
all
local slope, measured over
110 msec around point of
maximum slope of F2 for
[aI] and [oI], measured
from beginning to MINF2 for
[au]
maximum first formant
MAXF2
all
maximum second formant
MAXF 3
re, ar
maximum third formant
MAXF 4
maximum fourth formant
MIDFl
e, i, o, u,
MIDF2
e,
MIDF 3
MIDF4
i,
o,
u,
first formant at midpoint
of formant tracks
second formant at midpoint
third formant at midpoint
T
fourth formant at midpoint
72
NAME
APPLICAT ION
MID1AV
e, i, o, u,3'
MID2AV
e, i,
DESCRIPTION
MID4AV
3'
MINF2
all
MIDFI averaged with the
first-formant values on
either side of it
MIDF2 averaged with the
surrounding values
MIDF3 averaged with the
surrounding values
MIDF4 averaged with the
surrounding values
minimum second formant
MINF3
rE, ar, 3
minimum third formant
MINF4
3'
minimum fourth formant
PCTDUR
aI, aI, aU
RANGE 2
DI, aI, aU,
e, i, o, u
MINF3 averaged with the 2
surrounding values
percent duration one =
(DURl/DUR) x 100
range of second formant =
o,
u,3r
MID3AV
MIN3AV
2
2
2
2
MAXF2 - MINF2
RANGE 4
re, ar
SLOPE2
:I, aI, aU,
e, i, o, u
slope of second formant
SLOPE3
rE, ar, 3'
slope of third formant
STDF1
DI, aI, aU,
e, i, o, u
standard deviation of F1
over its entire duration
TOTALS
DI, aI, aU,
e, i, o, u, 5
total slope, measured by
fitting a straight line
to the formant in question
over its total duration
FlMIN3 averaged with the 2
surrounding points
F2MIN3 averaged with the 2
surrounding points
F4MIN3 averaged with the 2
surrounding points
range of fourth formant =
MAXF4 - MINF4
lMIN3A
2MIN3A
4MIN3A
The total data collected can also be divided into
three groups according to when they were recorded.
The
first day of recordings for all ten speakers form one
group, the second day of recordings for six of the ten
speakers form the second group, and both days of recordings
for the six speakers form the third group.
The statistical
evaluation process consisted of computing the mean and
standard deviation of each feature for each speaker.
For
days one and two, these calculations were based on five
repetitions, and for the combined group, they were based
on ten repetitions.
In addition, three F ratios were
calculated for each feature for each of the three timegroupings.
Tables of F ratios will be given in sections
5.2, 5.3, and 5.4 along with the evaluation of the
effectiveness of the features for speaker identification.
The full set of means, standard deviations, and F ratios
is
given in the Appendix.
As mentioned in Chapter II, a higher F ratio indicates
a feature that gives larger interspeaker variation in
relation to the intraspeaker variation, and is therefore
usually more useful for speaker identification than a
feature with a lower F ratio.
Though not as sophisticated
as the probability-of-error method used by Sambur (1972),
the calculation of F ratios has the advantage of being
74
fast and easy to implement--a very desirable advantage
when dealing with a large number of features.
However,
the problems of possible dependence between features
and artificially high F ratios caused by one very different speaker must still be addressed.
Therefore, the
distribution of speaker means was checked visually for
all features with high F ratios.
Possible dependence
between features was tested by computing correlation
coefficients relating all features for a given phone for
each time grouping, first using each individual measurement in the data base, then using the speaker averages.
For a given phone, the correlation matrices associated
with the three time groupings were very similar.
The
correlations based on speaker averages were almost
identical to those based on individual measurements.
An example of one of these correlation matrices is shown
in Table 5.2.
Since the matrix is symmetric, only the
lower triangle is shown.
Except for those features that
were deliberately designed to be redundant, most of the
features appeared to be fairly independent, generally having
correlation coefficients less than .5.
Since the number
of correlation matrices computed was very large, and since
most did not show anything overly new or interesting, the
complete set of correlation matrices will not be given
here.
Individual correlation coefficients will be given
1
MAXF2
1.00
MINF2
0.33
DUR
TABLE 5.2
CORRELATION COEFFICIENTS FOR THE FEATURES COMPUTED ON DAY 1
FOR [AI] USING SPEAKER AVERAGES OF FEATURES AS A DATA BASE
2
4
3
5
6
7
9
10
11
12
13
14
15
16
17
1.00
-0.19
1.00
DUR 1
0,32
-0.30
0.98
1.00
DUR2
0*38
0036
0.58
0.41
1.00
LOCALS
0*59
-0.43
0027
0.36
-0.23
1.00
F1MIN2
0.66
0.58
*0.26
-0.29
-0.01
0.31
FI1MAX2
-0.55
0.07
-0
35
-0.37
-0.08
-0.54
-0.13
1.00
INITL I
0.53
0*64
-0*38
-0.43
0.05
0.13
0.96
0.02
1.00
RANGE2
0.83
-0.25
0.49
0.51
0*17
0.86
0.34
-0.61
0o17
1.00
MAXF 1
0.75
0.49
0.06
-0.02
0.38
0.79 -0o09
0*66
0.48
1.00
PCTDUR
0.19
-0.47
0076
0.87
-0.09
0,52
0.*23
-0.37
-0.42
0.47
0*16
1.00
AVEF4
0*78
0032
0.32
0.30
0.27
0.42
0.50
-0.77
0o35
0.61
0.53
0.24
1.00
STDF1
0.93
0.40
0*20
0.19
0.17
0.59
0.80
-0.61
0*66
0.72
0.78
0.18
0.86
1.00
AVEF3
0.27
0.21
-0*45
-0.43
-0.27
0.32
0.50
-0.10
0.44
0.15
0.41
-0.30
0o41
0.41
1.00
FINAL2
0099
0.40
0o29
0*24
0.37
0*56
0.72
-0.49
0.59
0.78
0.78
0.10
0.76
0.93
0.36
1.00
INITL2
0035
1.00
-0.17
-0.27
0.37
-0.42
0059
0.06
0*64
-0.23
0.51
-0.44
0.33
0.42
0.19
0.41
'1B
1.00
e~~
1.00
in the text whenever they are relevant to the evaluation
of the features.
5.2
Diphthongs
The best speaker-identifying features for diphthongs
were those associated with the two target frequencies of
the second formant.
Highest F ratios, shown in Table
5.3, were obtained from the maximum value of F2 (MAXF2).
For [aU], this maximum of the second formant was constrained
to occur before the minimum in order to insure that it
represented the target of [a] rather than the glide up
to [d].
The one major drawback to using a maximum second-
formant frequency measure in an automatic identifying
scheme is that it requires computing a complete set of
formant tracks, which is a very time-consuming procedure.
One solution to this problem is to guess at the location
of the second formant maximum and then compute formant
frequencies for only one 10-millisecond frame.
and [0I],
For [aI]
this point, called FINAL2, was set at 20
milliseconds before the end of the formant track.
[au],
For
the first frame of the formant track, called INITL2,
was used to represent the maximum of the second formant.
F ratios for these measurements, shown at the right side
of Table 5.3, were almost as large as those for the
original maximum F2 values.
All correlation coefficients
Table 5.3
day 1
F Ratios of F2 Measures for Diphthongs
day 2
both
day 1
day 2
both
aI
aI
57.8
48.4
MAXF2
45.1
78.7
94.6
131.0
30.6
73.9
FINAL2
60.5
36.2
117.2
81.2
aU
84.5
MAXF2
30.2
92.3
81.6
INITL2
36.7
99.2
3I
aI
45.6
54.9
INITL2
7.8
34.5
10.2
47.3
aU
FINAL2
35.3
78.3
0I
aI
aU
MINF2
13.5
37.8
52.4
9.2
35.8
36.9
MINF2
40.5
87.0
35.7
63.7
35.9
24.4
RANGE 2
27.6
51.9
8.3
39.6
76.7
24.5
8.7
relating MAXF2 to FINAL2 for [aI] and [I] or to INITL2
for [au] were greater than 0.9.
The single-frame estimate for MINF2, called FINAL2,
was placed 50 milliseconds before the end of the formant
[o],
tracks for [aU],
MINF2 and the corres-
and [u].
ponding single-frame estimate, FINAL2, had very high
F ratios for [aU], somewhat lower for [aI],
low for [I].
and quite
A possible explanation for the large
intraspeaker standard deviations causing the low F
ratios for [,I] is that the degree of lip-rounding at
the beginning of this diphthong may be much more variable
than the position of the tongue.
The RANGE2, computed by subtracting MINF2 from MAXF2,
produced fairly high F ratios, but not as high as MAXF2.
The intraspeaker variations of MAXF2 are probably not
correlated with the variations of MINF2, so a combination
of these two measures merely serves to increase each
speaker's standard deviation.
Since RANGE2 and MAXF2
are highly correlated, with all correlation coefficients
greater than 0.8, it would be unwise to include RANGE2
in an identification system that already made use of MAXF2.
Another feature that showed some correlation with
MAXF2 was SLOPE2.
Though Sambur (1972) found the slope
of F2 to be one of his better features, this study seems
to indicate that several other features are considerably
better.
Sambur computed the second-formant slope by
fitting a straight line to the second formant over its
entire duration, a measurement which is here referred to
as TOTALS.
A slight improvement was obtained in this
study with LOCALS, which involved fitting the line over
a smaller area around the region of steepest slope.
[au],
For
best results were obtained for a line fit from the
beginning of the vowel to F2MIN.
For [aI] and [I], the
point of steepest slope was assumed to be the point where
the second formant frequency was just higher than the
average of its maximum and minimum.
The slope was then
computed over this point and the 10 frames surrounding
it for a total of 110 milliseconds.
F ratios for slope
measurements and other timing measurements are given
in Table 5.4.
Visual inspection of formant tracks for
several speakers seemed to verify the validity of the
slope measurements for repetitions that caused large
standard deviations.
Therefore, a more sophisticated
method for finding slope would probably not greatly improve
the effectiveness of this feature.
The midpoint of the F2 glide, which was used to
approximate the region of steepest slope, also served as
the basis of three not very successful measurements.
This
Table 5.4
day 1
F Ratios of Timing Measures for Diphthongs
day 2
both
day 1
day 2
both
SLOPE2
LOCALS
TOTALS
DI
aU
aI
aU
20.7
38.7
23.1
35.3
29.2
4.4
44.7
50.8
14.1
16.3
37.2
21.1
23.5
17.2
5.9
19.2
42.9
16.0
aI
aU
19.2
43.6
36.6
DUR
18.6
20.1
21.8
30.4
26.6
43.6
6.6
7.4
12.6
PCTDUR
13.4
2.4
33.8
17.0
6.5
42.7
DI
aI
aU
12.0
43.2
7.2
11.1
23.0
17.8
13.6
3.7
31.8
DUR2
21.1
4.2
34.6
32.6
4.2
58.5
DUR1
9.1
9.7
16.4
midpoint was used to divide the overall duration of the
diphthong into duration 1, the duration of the first
target or steady-state portion, and duration 2, the
duration of the second target.
Percent duration 1 was
calculated as the percentage of the total duration given
by duration 1.
In general, the F ratios of the total
duration were higher than those of any of the other
duration measures.
The maximum of the first formant gave surprisingly
good results.
This measure did not show an overly
wide range between speakers, but within speakers it was
very steady and reliable, making it almost as effective
as the target frequencies of F2.
Considerably less
effective, though related to MAXF1, was the standard
deviation of Fl computed over its total duration.
This
measure had been intended to give an estimate of the
overall variation of Fl.
Another poor measure was
initial Fl, the first formant frequency taken at the
beginning of the sound.
F ratios for Fl measures are
given in Table 5.5.
Since MAXF2 and MINF2 were such good measures, one
might expect them to represent stable targets of the
articulators, indicating that Fl measured at these points
might also be a good feature.
This proved not to be the
case; Fl was extremely unstable at these points, indicating
82
Table 5.5
day 1
F Ratios of Fl Measures for Diphthongs
day 2
both
day 1
day 2
both
22.9
15.6
39.0
MAXF1
59.7
77.9
32.4
30.0
45.0
56.5
18.3
33.8
17.4
STDF1
26.5
26.3
12.6
47.3
38.8
25.4
0I
aI
aU
3.3
13.1
7.5
FlMAX2
27.8
13.7
7.6
18.6
2.8
13.2
18.5
13.2
19.4
FlMIN2
6.4
5.4
12.6
15.1
9.2
36.1
aI
aU
13.6
41.4
19.6
INITL1
3.9
11.2
18.4
8.8
21.3
24.2
that different formants do not necessarily reach targets
at the same time.
This finding may not be unreasonable,
since the first formant is closely associated with tongue
height, while the second formant is associated with forward or backward position of the tongue.
Measurements of the third and fourth formants gave
conflicting results.
Since these formants didn't show
much movement, average values of these formants computed
over all but the last 20 milliseconds of the sound were
used as features.
In many cases, these features gave very
high F ratios, as can be seen from Table 5.6.
However,
for AVEF3 on [aI] measured over both days and AVEF4 on
[,I] measured over both days, the F ratios were very low,
due to a shift in the higher formant frequencies of a
few speakers, as mentioned in Chapter IV.
Because of
the instability of these formants and the difficulty
of measuring them, it may not be worthwhile to include
these features in an identification scheme.
5.2
Tense Vowels
The tense vowels [e],
[o],
[i],
and [u] were examined
using a set of features similar to that used for the
diphthongs.
Generally, these vowels show evidence of an
offglide similar to that found in the diphthongs.
The
magnitude of the formant shift in the offglide is greater
Table 5.6
F Ratios of Higher Formant Measures for Diphthongs
day 1
3I
aI
aU
72.5
52.3
18.6
day 2
AVEF 3
22.4
36.5
80.8
both
day 1
32.1
8.9
32.4
20.9
92.9
49.0
day 2
both
AVEF4
35.3
103.9
182.6
10.7
67.5
59.8
85
in [e] and [o] than in [i] or [u],
as expected, but still
much less than in the diphthongs, making it difficult to
locate the point in time when the maximum slope of F2
occurs.
For this reason, the slopes for the tense vowels
were calculated by fitting a straight line to the second
formant over almost its total duration, eliminating the
last 50 milliseconds for [u] and [o],
and eliminating the
last 20 milliseconds for [i] and [e].
The calculation of
durations one and two and percentage duration one would
then also be meaningless, so these measurements were
dropped and four others were introduced.
First and
second formants were measured at the midpoint of the vowel,
first at one point only, and then averaged over three
frames.
The tense vowels did not yield as many good measures
that were independent of one another as did the diphthongs.
The second formant measures, whose F ratios are given in
Table 5.7, were reasonably effective but not very independent.
For example, the correlation coefficient of MINF2
and MAXF2 averaged about 0.1 for [I] but averaged about
0.6 for [e].
The low correlation of MINF2 and MAXF2
for [I] reflects the large range of possibilities for
pronunciation of the two targets of this diphthong, the
first target being low, back, and rounded, whereas the
second target is high, front, and unrounded.
With [e] the
Table 5.7
day 1
F Ratios of F2 Measures for Tense Vowels
day 2
both
day 1
52.9
55.3
48.9
64.7
FINAL2
53.3
39.6
85.4
58.3
93.5
51.7
8.9
INITL2
23.9
7.9
55.5
4.6
day 2
both
37.7
63.0
MAXF2
25.2
29.0
47.8
9.9
MAXF 2
74.0
23.9
57.1
48.1
MINF2
52.5
110.5
24.4
50.2
62.0
66.5
INITL2
104.2
54.1
42.3
74.0
33.5
26.2
MINF2
22.2
13.9
62.1
22.1
21.8
6.0
FINAL2
18.4
18.1
51.1
12.5
37.3
42.1
37.7
41.5
MIDF2
28.1
45.5
28.8
24.5
56.9
57.6
77.1
43.5
33.6
48.7
35.5
59.0
MID2AV
35.3
67.6
31.9
27.7
59.0
74.7
78.5
50.6
20.9
4.2
14.0
4.8
RANGE2
19.7
3.7
25.9
11.3
44.6
6.0
54.2
12.4
only change that generally occurs is a glide from mid
to front.
Therefore, the correlation between MINF2 and
MAXF2 for [e] is an indication of how much individual
variation is present in the extent and exact direction
of this glide.
The best measures for [i] and [u] were the second
formant frequencies taken at the middle of the vowel and
averaged over three frames.
MAXF2, MINF2, FINAL2, and
INITL2 were generally less effective, and RANGE2 was
totally useless.
For [e] and [o],
the best second formant
measures were those taken at the location of the first
vowel target:
MINF2 for [e],
and MAXF2 for [o].
INITL2
gave a reasonably good approximation to these measures.
An even higher F ratio for [e] and [o] was given by
MAXF1, as shown in Table 5.8.
Unfortunately, most of the
interspeaker variation was due to one speaker, a situation
that did not exist with MAXF1 for the diphthongs.
A
possible rival to MAXF1 is Fl at the midpoint of [o] and
[u],
averaged over three frames (MIDlAV).
F ratios
for these features are somewhat lower than for MAXF1,
but the interspeaker variation is distributed more evenly
over all speakers.
Table 5.9 shows that slope measurements were generally
poor for [i],
[o],
and [u], and mediocre for [e].
The
generally positive slopes of [i] and [e] and the negative
Table 5.8
day 1
F Ratios of Fl Measures for Tense Vowels
day 2
both
day 1
MAXF1
76.3
26.4
153.5
96.1
165.6
43.2
122.1
123.6
27.3
23.0
12.5
18.7
8.5
6.5
8.0
17.4
FlMIN2
76.5
16.8
13.4
26.4
48.7
18.2
15.0
45.7
4.3
9.0
24.5
32.8
16.1
7.5
33.7
21.6
MIDF1
15.2
3.3
63.5
46.7
13.9
7.8
68.8
59.2
17.0
9.3
46.9
25.4
30.9
7.7
11.7
11.1
STDF1
33.2
9.4
32.8
16.6
84.4
7.5
38.5
42.7
80.3
21.5
35.3
39.0
day 2
INITL1
65.4
28.2
42.3
55.1
both
81.4
39.9
32.6
67.9
FlMAX2
15.2
5.4
2.1
5.3
113.9
79.0
59.3
104.2
MIDlAV
18.2
3.6
69.9
61.6
17.6
8.7
72.7
75.6
slopes for [u] and [o] show that these sounds are all
somewhat diphthongized, but apparently this slope is
not steep enough to allow for significant interspeaker
variations.
Duration was not particularly effective, and
the higher formants were subject to the same measurement
problems as found for the diphthongs, as evidenced by
the F ratios given in Tables 5.9 and 5.10.
5.3
Retroflex Sounds
The general American pronunciation of the retroflex
vowel [3] is characterized by a very low third formant.
In the retroflex sounds [rs] and [ar], a vowel target is
placed next to an [3I]-like target, giving a sound quite
similar to a diphthong, but with the largest formant
transition in the third formant instead of the second.
As with the diphthongs, an attempt was made to define the
two target locations of each sound by the time locations
of a maximum and a minimum, this time of the third
formant.
These locations were also approximated by two
points in time, 20 milliseconds in from the ends of the
formant tracks, and indicated by INITL3 and FINAL3.
[rc],
For
INITL3 corresponded to MINF3, and FINAL3 was to
represent MAXF3.
For [ar] the situation is reversed, with
INITL3 approximating MAXF3 and FINAL3 approximating MINF3.
For most measurements taken at the targets and at their
Table 5.9
day 1
Table 5.10
F Ratios of Timing Measures for Tense Vowels
day 2
both
day 1
day 2
both
SLOPE2 (TOTALS)
17.7
32.5
50.6
3.6
3.8
4.0
11.5
4.4
14.7
3.1
11.9
6.8
19.1
14.5
20.7
23.0
DUR
19.6
12.2
28.0
48.2
25.4
18.0
25.6
47.1
F Ratios of Higher Formant Measures for Tense Vowels
24.3
18.3
48.4
79.1
AVEF 3
28.5
38.1
9.4
64.0
62.8
60.5
12.6
70.0
71.4
19.5
16.7
5.8
AVEF4
15.9
37.5
5.0
19.5
41.1
76.0
11.1
17.5
91
approximations, results were less than satisfying.
Target
measurements for [3] were only considered for MINF3 and
were approximated by measurements taken at the midpoint
of the vowel.
Averaging the measures for [3] over
three points generally gave somewhat higher F ratios.
Without doubt, the best measurement for the retroflex
sounds, and possibly for all speech sounds investigated,
was MAXF1 for [ar],
as can be seen by examining the F
ratios of Table 5.11.
Not only did this measure have
consistently high F ratios and low individual standard
deviations, but it varied widely over several speakers,
not just one.
Also quite good was MAXF1 for [rE].
The
interspeaker variation of MAXF1 for [T] was due mainly to
one speaker.
Another good first formant measure was that
taken at the time location of MINF3 in [T].
An excellent
approximation is given by Fl measured at the midpoint of
the vowel and averaged over that point and the two surrounding
points.
Rivaling MAXF1 for effectiveness is MINF2 for [ar],
as shown in Table 5.12.
This measure corresponds closely
to F2MAX3 and probably indicates how strongly a particular
speaker's
[a] is affected by the adjacent retroflex.
INITL2, though not quite as effective or stable as MINF2,
provides an economical alternative, since it does not
require a complete formant track.
MAXF2 for [re] and MIDF2
Table 5.11
F Ratios of Fl Measures for Retroflexes
day 1
day 2
47.5
52.0
53.1
29.4
151.7
71.4
both
day 1
day 2
both
MAXF1
re
ar
57.5
154.1
87.4
ar
10.5
31.8
F1MIN3
9.7
28.4
5.8
42.4
30.3
34.2
F1MAX3
25.1
27.6
37.8
28.3
re
ar
20.1
37.8
INITL1
10.3
48.3
4.3
43.4
23.5
19.2
FINAL1
27.3
7.5
44.1
14.6
35.3
F1MIN3
56.0
63.0
32.7
MIDF1
60.0
68.0
35.8
1MIN3A
62.6
67.9
37.2
MID1AV
65.3
70.7
re
3'
Table 5.12
day 1
F Ratios of F2 Measures for Retroflexes
day 2
both
day 1
day 2
both
ar
6.4
131.2
27.5
MINF2
20.0
58.6
14.7
16.3
101.9
30.7
33.8
28.6
22.1
MAXF2
36.1
21.3
21.0
42.7
49.7
35.7
rE
ar
43.3
41.9
F2MAX 3
32.8
79.6
53.5
76.8
10.7
11.3
F2MIN3
6.7
11.0
7.8
12.9
7.0
61.9
INITL2
8.3
8.5
107.2
81.4
57.7
28.5
FINAL2
50.3
21.6
60.1
49.8
43.5
MIDF2
20.4
13.6
F2MIN3
12.0
24.4
41.4
MID2AV
21.1
18.4
2MIN3A
12.0
28.8
re
re
ar
T%
36.5
44.8
for [T] provided reasonably good measures, though MIDF2
was quite dependent on MIDF3.
The other second formant
measures are probably not worth calculating, as shown by
their F ratios in Table 5.12.
The most effective third formant measure found was
MIN3AV for [T],
as can be seen from the F ratios of Table
5.13. AVE3M2 for [re] produced slightly lower F ratios,
mainly due to the high standard deviations of three
speakers.
Other third formant measures had lower F
ratios simply because the third formant tracks were
rough and noisy.
formant measures.
Similar problems plagued the fourth
The fourth formant measure for [re]
performed particularly badly because of an inconsistency
in the formant tracks of speaker 10.
In the case of
repetition five of [r] for this speaker, a weak resonance
which had been ignored on the four previous repetitions,
was tracked as the fourth formant.
An interesting pattern was noted in the fourth
formant tracks of [re].
was very steady.
For five speakers, this formant
For one speaker it started low and rose
parallel to the third formant.
For the four remaining
speakers it started low but did not begin to rise until
the third formant started to level off.
Examples of
these three cases are shown in Figures 5.1, 5.2, and 5.3.
95
Table 5.13
day 1
r
ar
re
ar
r"
F Ratios of F3 Measures for Retroflexes
day 2
both
day 1
day 2
both
26.5
18.4
MINF3
15.2
34.6
16.6
53.4
19.8
30.8
MAXF3
13.8
10.7
21.7
20.2
21.3
22.5
INITL3
12.7
19.8
13.3
17.7
17.4
29.0
FINAL3
8.3
28.8
13.8
57.0
36.9
MINF3
101.1
93.9
40.4
MIDF3
97.5
82.3
52.9
MIN3AV
119.8
103.8
39.4
MID3AV
102.9
99.7
30.1
17.4
63.6
AVE 3M2
128.7
9.2
33.6
96
FORMANT TRACKS
[rE] recorded on day 2
by speaker 6, repetition 2
Formant
Frequency
in KHz
50
100
150
200
250
Time in msec.
Figure 5.1
[rs] with a Steady Fourth Formant
300
FORMANT TRACKS
[re] recorded on day 1
by speaker 1, repetition 1
Formant
Frequeney
in KHz
50
150
100
200
250
300
Time in msec.
Figure 5.2
Cre] with Fourth Formant Rising Parallel to Third
98
FORMANT TRACKS
[re] recorded on day 2
by speaker 2, repetition 1
Formant
Frequency
in KHz
CC-C~-L'N
50
100
I
150
200
I
250
m
300
Time in msec.
Figure 5.3
[re] with Fourth Formant Rising after Third has Leveled Off
A possible explanation for this phenomenon is that different speakers use different tongue shapes when saying
[r]
(Kurath, 1939, p. 128).
An [r] formed with a lifted
tongue blade might introduce an extra pole in the vicinity
of the second or third formant.
As the tongue blade is
lowered, this pole rapidly rises in frequency and is
labeled by the formant tracker as the third formant, then
the fourth, and then the fifth, before it finally disappears.
This effect can be seen in Figure 5.3.
The
steady fourth formant in Figure 5.1 may be an indication
that the fourth formant of this speaker depends on a
portion of the vocal tract that remains relatively fixed
in shape, regardless of the particular vowel spoken
(Stevens 1972, p. 217).
In the case of Figure 5.2,
creation of a constriction may lower both the fourth and
the third formants.
The removal of this constriction
allows the two formants to rise simultaneously.
Since each speaker was perfectly consistent in
producing his particular fourth formant shape, one might
expect it to be an excellent tool for separating speakers
into three classes.
However, as can be seen from the
irregularity of the fourth formant in Figure 5.4, a
noisy fourth formant track can be a severe limitation in
the pattern recognition necessary for classifying the
fourth formant shape.
A measure of the range of the fourth
100
FORMANT TRACKS
[rE] recorded on day 1
by speaker 7, repetition 5
Formant
Frequency
in KHz
50
100
150
200
250
Time in msec.
Figure 5.4
[re] Showing a Noisy Fourth Formant
300
101
formant gave rather poor results, as can be seen in Table
5.14.
Rather than trying to devise elaborate schemes for
automatically classifying the fourth formant shape, one
might find it better to reserve this procedure for a
subjective task, such as speaker identification by
spectrograms.
Duration and third formant slope measures gave
mediocre results, as shown in Table 5.15.
Slopes for
[re] and [ar] were taken over eleven points at the midpoint
of the F3 transition, in the same way as slopes were
calculated for [aI] and [lI].
taken over the total duration.
For [3] the slope was
102
Table 5.14
re
ar
T
both
day 1
37.7
F4MIN3
10.9
39.8
35.9
58.8
21.6
9.2
F4MAX3
30.5
19.7
35.4
32.2
14.7
86.8
INITL4
10.5
27.0
39.4
70.6
14.3
12.0
FINAL4
25.9
14.6
27.3
13.9
6.9
MIDF4
20.4
19.4
7.7
MID 4AV
45.3
23.6
11.4
ar
day 2
both
day 1
re
F Ratios of F4 Measures for Retroflexes
day 2
7.1
F4MIN3
50.7
8.3
4MIN3A
45.2
21.6
4.9
MINF4
21.3
19.8
16.5
MAXF4
16.9
21.1
AVEF4
21.5
57.9
48.4
51.5
74.7
32.1
22.8
6.0
RANGE 4
33.3
0.7
57.9
1.9
10.1
89.4
13.3
19.4
103
Table 5.15
day 1
rF
ar
r"
13.5
15.6
20.6
F Ratios of Timing Measures for Retroflexes
day 2
SLOPE3
40.9
20.1
5.0
both
day 1
day 2
both
25.3
21.3
11.6
16.7
14.1
18.4
DUR
18.8
28.3
23.7
20.9
34.6
27.0
104
CHAPTER VI
Conclusions and Discussion
6.1
The Most Effective Features for Speake r Identification
After the general discussion of the various advan-
tages and disadvantages of all the features given in
Chapter V, it seems appropriate to prepare a short list
of those features most likely to be effective in a speakeridentification system.
Toward this purpose, Table 6.1
lists the 29 features with average F ratios greater
than 60.
The average F ratios were obtained by averaging
the 3 F ratios associated with the 3 recording times:
day one, day two, and both days.
But these 29 features
are not necessarily an optimum feature set, since some
of them might be correlated or have artificially high
F ratios.
An inspection of the individual speaker averages
for each feature showed that a number of these F ratios
were unduly high because of a large variation by one
speaker.
For this reason, MAXF1 for [e],
FlMAX2 for [o] and [u],
[u],
and [3],
and AVEF3 for [u] were eliminated
from further consideration.
Several sets of features are
obviously redundant, since they represented essentially
the same acoustical property but with slightly different
measurement procedures.
Therefore, it is best to keep
only the one feature in each set with the highest F ratio.
105
Table 6.1 Features having Average F Ratios Greater than 60
Feature
MAXF1
MAXF1
MAXF1
MINF2
AVEF4
MIN3AV
FINAL2
AVEF4
MAXF1
MAXF2
MID3AV
MINF3
AVE3M2
AVEF4
INITL2
MIDF3
MINF2
FlMAX2
MAXF2
AVEF3
MAXF1
MAXF2
MAXF2
F1MAX2
MID2AV
MIDIAV
FINAL2
INITL4
INITL2
Sound
F Ratio
ar
e
o
ar
aU
T
aI
aI
u
aI
119.3
107.4
103.6
97.2
97.1
92.2
90.8
88.1
86.2
86.0
80.7
77.3
74.0
74.0
73.4
73.4
73.4
72.5
71.8
71.0
70.6
69.0
65.8
65.4
63.7
63.2
62.5
61.5
60.9
3
re
ar
e
3
e
o
o
u
T
aU
aI
u
i
o
e
ar
i
Possible Disadvantage
1 speaker very different
correlated with AVEF4 for aU
1 speaker very different
same as FINAL2
same as MIN3AV
same as MIN3AV
correlated with AVEF4 for aU
same as MIN3AV
same as INITL2
1 speaker very different
1 speaker very different
1 speaker very different
correlated with FINAL2 aI
1 speaker very different
correlated with FINAL2 aI
correlated with MAXF1 o
correlated with FINAL2 aI
correlated with AVEF4 aU
correlated with FINAL2 aI
106
This eliminates MAXF2 for [aI], MID3AV for [3i],
[3],
MIDF3 for [3],
and MINF2 for [e].
MINF3 for
In order to further
eliminate redundant features, correlation coefficients
were calculated for the remaining 18 features, as shown
in Table 6.2.
As might be expected, several groups of
features are quite dependent.
The following groups of
features all had relative correlation coefficients greater
than .8 within the group:
1)
for [i],
MAXF2 for [oI], FINAL2 for [aI] and [e],
MIDlAV
and INITL2 for [i]
2)
MAXF1 for [o] and MID1AV for [o]
3)
AVEF4 for [aU],
[aI],
4)
MAXF2 for [aU]
and [o],
and [ar],
and INITL4 for [ar]
and AVEF4 for [ar].
Keeping only the feature with the highest F ratio in
each group of dependent features leaves the 10 features
listed in Table 6.3.
The first formant measures were generally quite
uncorrelated with the second formant measures, indicating
that one or both of these types of measures contain more
information than just the overall length of the vocal
tract.
One feature that was particularly uncorrelated
with any of the others was MINF2 for [ar].
This feature
gives an indication of how strongly a speaker's [a] is
affected by the adjacent [r] and may also depend on the
way he shapes his tongue for [r].
This notion is supported
TABLE
6.2
3
2
I
4
5
7
6
8
9
10
FROA TABLE 6.1
TAKEN ON DAY 1
11
12
13
14
15
16
17
MAXF2
1.00
AVEF4
0,74
1,00
FINAL2
0.95
0076
1.00
MAXF2
0,73
0.51
0 79
1.00
AVEF4
0068
0.80
0.73
0.75
1.00
MIN3AV
0.30
0.25
0.27
0.40
0.37
1.00
INITL4
0.46
0*74
0.50
0.42
0o88
0.14
1.00
06
0.21
0.05
0.17
0.15
0.18
1.00
MAXF 1
0.47
0.22
0.45
0.22
0.24
0.63
-0.01
0.50
1.00
AVEF4
0.52
0
0.59
0.51
0.91
0.09
0.98
0.21
0.03
1.00
AVE3M2
0614
0.26
-0.05
-0.08
0.54
0.15
0.42
-0.21
1.00
FINAL2
0085
0.50
0.84
0.64
0.43
0.41
0.23
0.52
0.30
0.11
1.00
INITL2
0070
0.45
0.79
0.55
0035
0.00
0.24
0.09
0.30
0035
-0.23
0083
1.00
MAXF2
0.48
0.54
0.52
0065
0.71
0.77
0.58
0.32
0.43
0.58
0.20
0.50
0.36
1.00
MAXF 1
0.10
-0.04
-0.04
-0.03
0.03
0074
-0.15
0.30
0.77
-0.20
0.70
0.12
-0.28
0.33
1.00
MIDiAV
-0,13
-0.29
-0.22
-0.28
-0.27
0.56
-0.44
0.36
0. 74
-0.48
0.57
0.04
-0.35
0.04
0.91
1.00
MID2AV
0.88
0 56
0090
0.78
0 55
0.43
0.30
-0.14
0.48
0.38
0.02
0 97
0.82
0.56
0.06
-0.12
1.00
INITL2
0*82
0.51
0.86
0.67
0.47
0.27
0.31
-0.11
0.39
0.39
-0.12
0.96
0092
0.49
-0.10
-0.24
0096
MINF2
_1
CORRELATION COEFFICIENTS RELATING FEATURES
THAT DID NOT HAVE IMMEDIATE DISADVANTAGES,
-0
76
-0015
-0*19
-0.12
-0.14
IIII1IC-
------
108
Table 6.3
The 10 Features of this Study that are Most
Likely to be Useful for Speaker Identification
Feature
Sound
F ratio
MAXF1
ar
119.3
MAXF1
o
103.6
MINF2
ar
97.2
AVEF4
aU
97.1
MIN3AV
92.2
FINAL2
aI
90.8
AVE3M2
re
74.0
INITL2
e
73.4
MAXF2
o
71.8
MAXF2
aU
69.0
109
by the low correlation coefficients between MINF2 for [aI]
and MINF2 for [ar]:
.56 for day 1 and .26 for day 2.
One of the original motivations for studying diphthongs and r-colored sounds was the large dialect variation shown by these sounds (Labov, Yaeger, and Steiner,
1972; Kurath, 1939).
As can be seen by examining Table
6.3, the most effective features for speaker identification
that were found in this study were those that allowed
the most variation according to the speakers' individual
speech habits.
The cardinal vowels [i] and [u] were not
represented in this list, presumably because the personal
information in their formant tracks was based mainly on
vocal-tract size, rather than on individual speaking
habits.
The list of "best" features includes two measures
involving the third formant and one involving the fourth.
Of these three features, the only one that appeared
completely reliable was MIN3AV for [_],
since the third
formant of []1 was strong and easily identifiable for
each speaker.
for [aU].
This was not always the case with AVEF4
The problems encountered in identifying the
fourth formant of [o] for speaker 10, as mentioned in
Chapter IV, might indicate that the fourth formant makes
a rather unreliable feature, and that the high F ratio
associated with AVEF4 for [aU] was purely coincidental.
110
Considering the trouble given by the higher formants
during the formant-tracking procedure, it might be more
reasonable not to even try to measure them.
A system
where the speech waveform was low-pass filtered to 2500 Hz,
then sampled at 5000 Hz would allow at most 3 formants.
The linear-prediction program could then be run with 8
predictor coefficients, and the root finder would have to
solve only an eighth-order polynomial.
With very little
loss of information, this system could be expected to
run about twice as fast as the one used in this study.
6.2
Comparison of Best Features with Previous Work
Since no actual identification experiment was per-
formed in this study, a direct comparison between this
study and the results of previous work is rather difficult.
However, a few simple estimates concerning relative
effectiveness of different features can be made.
The comparison with the work of Sambur (1972) is
facilitated by the fact that this study duplicated five
of his measurements and very nearly duplicated 4 others,
as shown in Table 6.4.
The slope of the second formant
of [al], which was ranked as 10th best in Sambur's work,
showed an intermediate degree of effectiveness in this
work.
Sambur's third best measurement, the third formant
of [u], was measured at a single point in time in the
middle of the vowel.
At the outset of this study, it was
111
Table 6.4
Comparison of Feature Performance
Between this Study and that of Sambur
Sambur's Study
Name
UF3
Ranking
3
Exact
This Study
Name
AVEF 3
F Ratio
u
Duplicate ?
71.0
no
AI
10
TOTALS aI
39.6
yes
UF2
14
MIDF2
u
36.5
yes
EEF2
15
MIDF2
i
48.4
yes
UF1
18
MIDFl
u
42.5
yes
EEF1
23
MIDFl
i
EEF4
24
AVEF4
i
44.3
no
EEF 3
25
AVEF3
i
39.0
no
UF4
31
AVEF4
u
14.3
no
6.2
yes
112
decided that third and fourth formant measures for tense
vowels should consist of the average frequency of these
formants taken over the duration of the vowel, because
there was very little higher formant movement and because
the averaging helped reduce some of the noise of the
measurement process.
Therefore, the closest measure
available to match with Sambur's UF3 was AVEF3 for [u],
which probably had a slightly higher F ratio than a
single measurement of F3 would have given.
Nevertheless,
the average F ratio of 71.0 for AVEF3 of [u] was still
considerably lower than the F ratio of 119.3 for MAXF1
of [ar], which was judged to be the most effective
feature found in this study.
Therefore, the better
features of this study would probably be somewhat more
effective for speaker identification in comparison with
those found by Sambur.
Six of the best measurements found in this study had
higher F ratios than the best feature found by Wolf (1972),
which had an F ratio of 84.9.
Wolf's nine best features
were fundamental frequency measures, which Sambur downrated because of their variability from one recording
session to another.
The feature with the tenth largest
F ratio in Wolf's study was the second formant frequency
of [a] , having an F ratio of 46.6.
This value is consider-
113
ably lower than the F ratios of the better features of
this study.
6.3
Implications for Speaker Identification Using Spectrograms
Some of the features found effective for automatic
speaker identification would not be very useful when
working with spectrograms, simply because spectrograms
do not allow formant frequencies to be measured more
accurately than within about 50 Hz.
This eliminates the
use of the first formant features, which must be accurate
within about 10 Hz in order to be effective.
The second
formant measures allow a somewhat larger margin of error
and therefore may be useful.
As mentioned in Chapter IV,
the experience with speakers 3 and 10 indicates that the
strength of a higher formant is not always a good clue
to the speaker's identity, nor is its frequency.
One of the advantages of a subjective approach to
speaker identification, such as the use of spectrograms,
is that the collection of features used to make the
identification can be tailored to suit the individual
situation.
For example, when a third or fourth formant
is strong enough to show up clearly on the spectrograms
under consideration, its movement may be a good clue to the
unknown speaker's identity, as in the case of the fourth
114
formant of [re].
For this sound, a steady fourth formant
on one spectrogram and a sharply rising fourth formant on
another would virtually eliminate the possibility that
the two samples were spoken by the same person.
Another
interesting identity clue was shown in Figure 4.9.
The
extra "formant" that appears between the third and fourth
formants toward the end of [aI] may make the formanttracking task more difficult, but because it is consistent
for this speaker and did not occur for any other speaker
in this study, it makes a very good clue for identifying
him from a spectrogram.
Other possibly useful features
for spectrographic identification are those in Table 6.1
that were rejected on the grounds that most of the variation was due to one speaker.
If one of these features
gave approximately the same value on two different spectrograms, it might be difficult to judge whether the spectrograms were from the same speaker.
But if the feature gave
two very different values on the two spectrograms, this
could be strong evidence that the two spectrograms did
not represent the same speaker.
Second formant slopes of diphthongs may be somewhat
helpful, because a formant slope can be judged rather
easily by eye.
However, these slopes are not overly stable
from one utterance to the next, since they are strongly
115
affected by the rate of speaking.
The highest average
F ratio obtained for a slope measurement was 40 for
LOCALS of [aI], which is considerably lower than any
of the F ratios given in Table 6.3.
6.4
The Limitations of this Study
The data used for this study may not be representative
of all situations encountered in practice.
The recordings
were made under ideal laboratory conditions with the subjects reading a prearranged set of sentences.
In practice,
one will probably have to cope with background noise,
distortion or band-limiting of transmission equipment,
and different sentence contexts for the sounds under investigation.
Other complications include the possibility
of an alteration in a person's voice due to emotional or
physical stress, or an uncooperative speaker, i.e., a
person who is trying to disguise his voice or mimick
another person.
All of the speakers in the current
study were cooperative and under no particular stress.
On the other hand, the speakers for this study did
not represent a complete cross section of all dialects
of American English.
The speakers that were originally
chosen for the study had no noticeable foreign accents and
no strong regional dialects.
Therefore, the interspeaker
variations of some of the features are probably not as high
as they might have been with a more varied group of subjects.
116
6.5
Relationships Between Dialect and Various Measurements
Despite the effort that had been made to record only
speakers of General American, some dialectal variations
were found.
Speaker 1 grew up in northern Florida,
speakers 2, 4, and 7 were from the Midwest, speaker 3
was from Canada, speaker 5 grew up in New Hampshire, and
the others were from the Middle Atlantic area.
The dia-
lectal variations of these speakers were sometimes confused by the fact that some speakers resided for periods
of time in several different geographic regions.
One noticeable effect of dialect was in the second
formant slopes of [aI].
These slopes were generally
smaller for the three midwestern speakers than for any
of the other speakers.
However, the three midwestern
speakers were not readily identifiable from the data of
MAXF2, MINF2, RANGE2, or DUR, which are all somewhat
related to slope.
The speaker from Florida was characterized by a
high value of AVE3M2 for [re] and by very large variations
in Fl, as evidenced by his large values of MAXF1 and
STDF1 for all vowels.
However, since there was no other
speaker from Florida with whom he could be compared, one
cannot determine whether these characteristics were strictly
individual or due to some dialect.
117
A characteristic that did not appear to follow any
dialect patterns was the fourth formant pattern of [re],
shown in Figures 5.1, 5.2, and 5.3.
Speakers 3, 4, 6, 7,
and 8 had steady fourth formants, while the other five
had strongly varying fourth formants.
6.6
Possibilities for Further Work
Besides extending the work of this study to include
some of the additional variables mentioned in Section 6.4,
it would be useful to test some of the more effective
features in a more rigorous manner.
First, one might
perform a probability-of-error analysis (Sambur, 1972) of
these features together with some of the more successful
features of other studies such as the second formant of
[n],
the voice onset time of [K], the third and fourth
formants of [m] and an FO measurement.
Next, one might
run an identification experiment with this combined feature
set, using speakers who had not been involved in the
original feature evaluation.
Another area of interest might be the study of the
higher formants; why they appear and disappear unexpectedly,
and how to compensate for this problem.
If indeed the
problems with speakers 3 and 10 were caused by zeros in
the spectrum, perhaps one could devise a system to
indicate the presence of a zero, and then determine its
frequency (Tribolet, 1974).
118
APPENDIX
The Appendix lists all F ratios and all of the
individual speaker means and standard deviations associated
with each feature that was investigated.
presented by phone in the following order:
[aU],
[e],
[i],
[o],
[u],
[rE],
[ar],
[T].
The data are
[Il],
[aI],
The data for
each phone are subdivided into time-groupings, as explained
in Section 5.1, and presented in the following order:
day 1, day 2, and both days.
The features are arranged
within each of these time-groupings in the same order in
which the F ratios are presented in Chapter V.
Explain-
ations of the feature abbreviations are given in Table 5.1.
MEANS.
STANDARD
DEVIATIONS
AND
F RATIOS
FOR
tOl1]
ON
TAKEN
DAY
1
SPEAKER
NUMBER
F
MAXF2
MEAN
STD.
1946.0
32o6
MEAN
STD
1926.0
19.4
765*8
21.0
778*6
28.8
RANGE2
MEAN
STD.
1180*2
:
1124*8
40o3
F
8.30
0.33
:
932.9
28*4
46.8
1817.3
21*9
2178.6
37,3
1813*6
84*9
1823*7
37 .1
1896*4
120.9
1610,8
68*6
1726*0
78*4
1687.6
117.5
690*7
19.8
877.6
25.7
826*1
30.6
731.4
35*8
649*4
17*8
74563
813*7
44*0
897.8
31.9
826.5
29.8
802.8
115.1
729*4
30.3
774.5
33*8
1084*4
75.3
839.7
35*5
1076*1
50.3
1174.3
49.6
1433.3
58*4
9*26
0657
7626
0o65
8*16
1.24
8*52
1.19
1692*6
14.8
1815.0
36.3
1962*0
1683.2
20.5
1801*2
36*9
821.1
23.7
882*4
23.2
62o3
1665*9
51.7
3061
1805*7
31.0
2155.5
44.4
45.60
901.1
30.3
F
LOCAL S
MEAN
STD*
1997.8
31.3
F
INITL2
MEAN
STD.
=
F '
MINF2
MEAN
STD*
57.84
2025*8
36*3
F
FINAL2
:
:
9,*35
1.27
748*3
28.8
2591
9.17
790.7
19.4
63974
1069*1
27.5
871.5
28.7
1124*3
26.8
20.75
11,00
0.43
7648
0 35
9,89
0.33
.___
. __ ~__~C__
12669
0.92
~_~__I__
MEANS,
STANDARD
5o39
0.27
282*0
13.0
F
16607
8.5
:
92 2
17.0
115.3
12.3
F
578.3
15.1
:
171*8
24.8
F
MAXF 1
:
6501
4o6
3.1
DUR2
MEAN
STD
264*0
32.1
59*2
DUR 1
MEAN
STD
5.44
1.00
F
PCTDUR
MEAN
STD
F RATIOS
FOR
[nI].
TAKEN
ON
DAY
1
16.28
F :
DUR
MEAN
ST D
=
F
TOTALS
MEAN
STD.
AND
2
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
:
521.6
18.4
4*76
0.67
4.44
0*60
5.43
1.11
4.19
8
0.47
0.54
250*0
10.0
238.0
13.0
208.0
13.0
242*0
31.9
328.0
17.9
236.0
15.2
61.1
4.0
65.1
1.9
71.8
5.0
68.6
3.5
62*1
4.1
67*0
1.4
60*5
151.5
13.3
162.6
5o2
171.0
15.4
142.8
12*2
151.1
28.0
219*6
12*8
142*5
6.3
8704
7*6
67*0
12.4
65.2
7.8
90.9
7*3
108.4
2*0
96.5
9*7
93.5
15.4
513.8
12.7
527.0
14.4
506.4
18.1
502.7
794
492,8
17.0
44504
474.2
20.8
6.46
0.49
4.61
0.21
5.21
0 36
248.0
11.0
09
19,25
202.0
8*4
6.56
68.3
1.7
4.4
12.05
138.0
8*8
13.56
64.0
70~
22o89
20.8
nia
~
574.
33.9
+
q
MEANS,
SPEAKER
NUMBER
F
403.9
12.2
430.3
33o1
MEAN
STD,
MEAN
STD.
:
2325*0
41*4
F :
AVEF4
3015.4
19.7
30.6
3.0
F
RATIOS
FoR
01 1,
TAKEN
ON
DAY
1
3222.3
58.0
43.4
6.3
40.8
12.8
66.6
12.0
28.4
2*5
43.0
4*9
376*9
47.5
373*2
32.*2
347*3
32*3
371.6
10*9
32*6
2.8
4102
5.0
3.32
413*5
17,6
425.8
22.4
408*8
23*4
408.3
475.8
442.8
8.1
419*9
7*9
411.9
3,1
385o6
15.1
376o4
10.2
419.2
20*6
448*8
416*7
8*6
410*7
4,6
38895
38.7
367*4
16.6
396*1
12.7
7.4
18.52
446*4
9*2
13.4
13.56
443*6
8*2
451.1
12*8
1911.9
67o4
2254,1
24.6
2280*2
9*7
2182*6
51,7
2179*3
27.1
2215e4
52*3
1910.3
37.7
2371.3
3591
3018.4
48*6
3039,0
15.1
3089.3
161.3
3085*3
3047.7
124*5
3205*1
48.7
3486.1
104.3
15*0
F
2302*2
40.7
:
454*5
25.7
AVEF3
:
453*4
15*4
F
423.4
:
377.8
56o2
F
INITL 1
MEAN
STD,
AND
1833
46o 1
2*3
63.8
4o9
F1MI N2
MEAN
STD.
:
F
FIMAX2
MEAN
STD.
DEVIATIONS
1
STDF 1
MEAN
STD
STANDARD
11,3
72.53
20.87
2876*2
34*8
5309
MEANS,
STANDARD
MEAN
STD.
FINAL2
MEAN
STD.
MINF2
MEAN
STD.
INITL2
MEAN
STD
RANGE2
MEAN
STD
AND
F RATIOS
FOR
ro0Il
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
45.05
1941.7
46.4
F
:
:
:
F :
MEAN
STD*
7*58
0.51
1602.3
5397
2021.3
108.9
1810e2
19,1
1630.7
25*6
2014.0
107.0
1585.3
55.0
717.1
705.0
30.1
841*0
31.5
88809
41.3
745*0
40.3
7
12.8
885.6
25*3
93003
59*9
77709
4904
1343*0
142.7
1117.0
23.4
79490
29.7
1144.8
118.5
857.4
7507
10*84
0.77
11.10
0*16
7.43
0.80
7.77
791.0
7903
821
27.64
1148.8
63.4
LOCALS
2033.7
107.2
76.9
802.8
28.6
F :
1635.0
27.7
13*46
792*9
26.3
F
1822.0
24.3
36.17
1921 .0
47.8
F
2060.1
8907
35.25
9.68
0.98
6074
0.73
MEANS,
STANDARD
TOTALS
F :
MEAN
STD
4.84
0.33
DUR
F
:
MEAN
STD
57.5
2.8
DUR 1
F :
MEAN
STD,
180.5
15.6
MAXF1
MEAN
STD
FOR
[OI1,
TAKEN
ON
DAY
2
F
=
=
:
556.5
10.5
6.54
0.18
4.50
0.54
5*14
0.79
4o46
258*0
30.3
204.0
8.9
234*0
25. 1
248.0
8.4
224.0
13.4
58.8
2.0
68.8
0.7
61.3
4.5
70.0
4.4
64.6
3.0
151*8
18.9
140.2
5.6
142.7
9.3
173.5
11.8
144.7
10.7
106.2
130
63.8
3.8
91.3
19.3
74'5
11.1
79.3
8.5
493.2
12.1
513.1
10.2
0,35
13.36
9.12
21.12
133.5
12.3
F
6.82
0 45
18.59
314.0
20.7
F
MEAN
STD,
RATIOS
23.48
PCTDUR
DUR2
F
1
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS AND
59.73
530.6
91
522e7
13.5
4416
12.3
MEANS,
STANDARD
STDF 1
F
MEAN
STD.
62.8
4.5
FI MAX2
F =
F1MIN2
MEAN
STD
INITL1
MEAN
STD
AVEF3
MEAN
STD.
AVEF4
MEAN
STD
AND
F RATIOS
FOR
t[OIl
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
=
26.48
=
:
:
3096o7
38*7
34.9
4.3
34368
14.5
38962
21.0
432.8
13.9
414.6
338.8
17.1
442*2
44962
8.7
481*1
10.2
43161
18*6
425.8
21.3
439.0
9,9
456.8
16*5
42467
14.0
397*4
41.5
228667
5568
2055.0
111.0
2206*4
15.0
2256o2
28.7
2015.7
6465
321467
48,6
3012.9
3060
30746 1
6468
3002,1
279060
64.5
61.2
17.1
12.7
406.0
3965
22*38
2317.9
23.3
F
3767
5.2
3.94
429.7
12.2
F
3690
4o1
6.37
448,3
24.5
F
3669
4.2
27.79
39568
10.5
F =
45*0
5.3
35.28
MEANS,
STANDARD
MEAN
STD.
FINAL2
MEAN
STD.
MINF2
MEAN
STD*
INITL2
MEAN
STD
RANGE2
MEAN
STD.
AND
F RATIOS
FoR
t01o.
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
94.62
1943.9
204390
37.9
67*0
1819.7
21.9
1663e8
36,9
199708
90.9
1634.1
5409
2009.6
7605
1808.0
24.4
1656*9
35*3
1955.2
124.2
1598.0
60.2
80901
72606
3509
831 .1
28*3
883.3
33.0
785.5*
5405
861.9
9305
806.2
884.0
22.5
23.0
914.0
48.3
802*2
4602
1233.9
151.7
1093.1
832*7
49e3
1114.6
848.6
98*8
5605
10.09
1.27
11.05
0.31
7,46
0 58
9.47
7.00
0.71
F
=
60.45
192305
3405
F
:
8.69
779.4
111.5
2696
F
=
10.18
790,7
29,9
F
=
39.60
1164.5
55.1
LOCAL S
F
MEAN
STD.
7*94
:
0055
3409
44.71
0079
MEANS,
STANDARD
TOTALS
F
MEAN
STD.
5.11
0.41
DUR
F =
=
F =
MEAN
STD
58.3
2.9
DUR 1
F
DUR2
MEAN
STD
MAXF1
MEAN
STD
F RATIOS
FOR
[OI,
TAKEN
ON
BOTH
DAYS
19.20
:
:
:
567.4
16.8
0639
4.95
0.72
4.45
0 46
261,0
29*6
203.0
8.2
241*0
19.7
2430
11.6
216*0
15.1
62*0
4.7
6805
1,3
61*2
4.0
70.9
4.5
6606
139o 1
7.0
1470 1
11.7
172.2
13.0
143*7
10.9
16.0
63.9
2.9
9369
14.7
70.8
11.8
72.3
10.7
507.4
21*0
513.5
10,9
528.8
11,5
512.7
14.7
467.2
30.4
3.7
11.11
161*8
23.3
32.62
124*4
15.0
F
6.50
0*35
17.01
173.6
13.9
F
455
6.13
1.03
30.36
298,0
23.5
PCTDUR
MEAN
STD*
AND
1
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
9902
29.98
MEANS,
STANDARD DEVIATIONS
STDF 1
F
MEAN
STD
63.3
4.4
F1MAX2
F
F 1 MIN2
MEAN
STD
INITLI
MEAN
STD
AVEF3
MEAN
=
tol,.
TAKEN
ON
BOTH
DAYS
47.32
33.8
4.8
3967
6.3
35.1
4.8
38,0
5S0 1
360.8
42.6
401,3
22.3
429.3
180
411.5
12.9
357e8
39e2
439*3
44708
17.1
478.4
11.6
425.5
11.6
408.9
29.1
44708
8.6
23.0
441 .3
8.9
453*9
14*2
420.7
11.7
404s0
2807
2305.9
50.5
198305
114.8
2230*2
31*6
2219*4
55.3
209765
98*0
3218*5
50.6
294405
78o3
304663
61.5
3045.7
124*6
2937*6
164*9
:
10.85
399.9
11.6
F
F
=
:
15.14
F
:
4406 1
32.14
231001
AVEF4
F
=
3056,1
51.7
266
8.77
426e6
19.2
32.4
STD
FOR
45*5
3.9
STD
MEAN
F RATIOS
1
SPEAKER
NUMBER
MEAN
STD
AND
10.74
r~
~Br
a9
MEANS,
STANDARD
F
MAXF2
1878.7
38.6
1850.7
52.5
1219.0
7*5
1222.3
10.9
659.7
33.3
:
1244.5
4795
5.45
0*57
:
1244.5
47o5
:
7389
63*3
F
LOCALS
MEAN
STD*
1972.9
33*8
F
RANGE2
MEAN
STD
=
F
INITL2
MEAN
STD.
F RATIOS
FOR
[AIl]
TAKEN ON
DAY
1
48.36
1983*4
27s7
F
MINF2
MEAN
STD.
:
F
FINAL2
MEAN
STD*
AND
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
:
4.13
0.45
1777*6
23.0
1827.1
86*7
1798*9
79*5
2134.6
39,1
1660.1
58.7
1793.0
42*3
1723.7
29.1
2129.2
34*6
1129.8
22o2
1206.4
35.4
1141.2
10.9
961e1
1075*8
32.5
1139.5
34.4
1206.4
35.4
1152* 1
17.8
984.2
29,5
540e2
24.4
684*6
897.2
55*1
43*9
462*6
61*2
68599
84*7
837.8
82.8
4.77
5*96
0.71
7.16
0*70
3*27
5,27
0.48
7.01
1.21
1671*5
17.8
1743*3
4595
2027.0
1668*5
20.6
1723o0
61*3
2021*5
31.5
1131.3
27.2
1058.6
13.1
1135.4
23,2
3206
1669.0
55,9
73.94
1771*2
29.9
54*88
1044.5
33.5
1183
24.6
1
18.3
35.83
1051.8
37.7
1189*8
20*8
35.91
733*1
33*2
951.5
44.9
38.71
7.19
0,27
0.22
0.34
Inrp
-- ---
----.
6~
_~__
9*02
0.55
ta
--
--
ee
----------
MEANS,
STANDARD
2.40
0.10
294.0
16.7
4
FOR
IAI],
ON
TAKEN
DAY
1
58*7
3o3
F
205,2
9.6
88,8
17.6
740.2
2107
=
105.5
9.0
F
MAXF 1
=
150.5
17.5
F
2,47
4.67
0.18
2.50
0.13
3.41
0.26
2074
0015
2,42
0028
2.85
0.41
264,0
18*2
238.0
13.0
346.0
5.5
218*0
13*0
254*0
26.1
65.4
3*8
65*8
3.5
7005
0.7
58*7
5,9
68.9
4.7
72e 1
107
172.8
19.5
156.5
9.7
244.0
1.6
127*5
701
175.8
27.6
241.0
12.6
91.2
8*2
81.5
11.1
102.0
90.5
17.8
78.2
8*4
93o0
403
8607
12.4
639*5
10.8
702.8
18.7
726.0
43.2
636*1
24.9
709*6
40.7
616*2
21.7
74808
20.0
0.19
43.60
256*0
20*7
-4
DUR2
MEAN
STD
0.63
69*9
DUR 1
MEAN
STD
4s68
0e46
3.28
F :
PCTDUR
MEAN
STD
F RATIOS
3719
F =
DUR
MEAN
STD
3
F
TOTALS
MEAN
STD
AND
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
:
705.9
20*9
202.0
11.0
334*0
11*4
254*0
11.4
7943
62.7
4.3
66,0
3.6
43.19
126.7
11,0
167.3
6.1
3o72
75*3
905
4.1
15.59
679*2
20.4
Aill
MEANS,
STANDARD
DEVIATIONS
AND
F RATIOS
FOR
TAKEN
[AIl.
ON
DAY
1
SPEAKER
NUMBER
F
STDF 1
MEAN
STD.
94.3
96*8
10.6
11.4
F
F1MAX2
MEAN
STD
486*4
40o0
626*0
36.1
INITL 1
MEAN
STD.
608.7
4.3
MEAN
STD*
22.7
641.3
13.5
=
641*3
13*5
=
2427*7
33.1
3329.2
76.3
3514.9
69.0
91.4
11.8
51.2
6.7
548*7
30.9
460*2
36.2
502.7
9*2
5800
20.4
624.9
25.6
586#8
56*3
562.9
5.1
610*8
17.4
67.5
4.8
64.8
7.1
466*3
17.5
84*5
4.2
68.7
134.0
4*9
15.1
427*3
26*8
412.8
44.3
384.4
568.5
18.5
589.6
57.3
511.8
37.1
719*1
541 8
13.9
568,5
18,5
544*0
487 7
29*0
688*8
13.10
476.3
F :
AVEF4
72.4
5.8
15.5
F
237597
61,2
33.82
469*3
F
AVEF3
MEAN
STD.
=
F :
F1 MIN2
MEAN
STD.
=
25.5
13.16
581*9
10.2
22.7
41*37
559.6
10.2
40*8
16.7
52*28
2680*1
38*4
2504.7
30.9
2308.5
46.2
2403*5
53.5
2251.3
3329.1
58*6
2897*6
62*9
3386.3
11.0
2866*2
88.9
37o3
2363.7
72*2
212404
62.7
2550*4
26.2
92*93
3191.0
31*3
___
3451*7
66.5
___Y __
3237.3
54*6
__ _
3668.5
13.6
_ ____I
_ ___~_L
_U
MEANS,
STANDARD
MEAN
STD
FINAL2
MEAN
STD,
MINF2
MEAN
STD
INITL2
MEAN
STD
RANGE2
MEAN
STD
LOCALS
F
=
F RATIOS
FOR
TAKEN ON
[AI.
DAY
2
78.66
1970.3
56.8
F
=
F
=
=
=
0.66
2023,7
58.2
1652.6
58 1
2046e0
3505
1741,7
23.9
1657*9
35*4
2023.0
59.3
163406
5506
1203*6
31.6
1017.6
28.6
1119.3
30o0
1175.6
28.1
1180.2
20*7
1203.7
31.8
1017.6
28.6
1125,0
1179.4
30.7
1184*6
23.5
848*3
7345
25.4
547.7
2607
848.1
5908
472*4
51.7
6*54
4.87
0,76
7078
3094
0045
34o
1
51*88
75207
57.4
F
1667.0
3709
34.54
1228*7
23.7
F
175201
14.5
37.76
1217.6
20.8
F =
2051*9
33.5
81.21
1945.3
55.0
MEAN
STD.
AND
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
5706
29.19
5.21
0.44
0.19
0076
._ _ I I~_
___1 __ _I__ L~___
__ ~_L_
____~_
~ _________
_
MEANS,
STANDARD
TOTALS
F
MEAN
STD.
2*79
DUR
F
=
:
FOR
[Al,
TAKEN ON
DAY
2
=
MEAN
STD
69.2
DUR1
F
F
=
MEAN
STD
9507
MAXF1
F
751 3
23.1
198.0
16.4
256*0
20.7
268,0
14.8
224.0
60.4
5.9
6409
3.8
71.7
2.4
66.5
6.4
19803
48o6
119.9
17.6
166.6
103.7
18.3
78.1
11.1
89*4
7*8
7509
7.7
75*2
17.1
706*9
11.1
685.7
16.1
652,9
17,8
785.9
19.0
601*8
10.2
302.0
37*0
20.7
9.69
20.4
192o 1
12.0
14808
17.0
4.18
11.5
=
0*11
65* 0
8*6
216.3
19.9
DUR2
3*34
0.13
4.61
0.58
2*42
4*4
=
2.50
0.24
256
3,16
0,74
20.11
312.0
13.0
F
MEAN
STD
F RATIOS
17*23
0.30
PCTDUR
MEAN
STD.
AND
1
SPEAKER
NUMBER
MEAN
STD,
DFVIATIONS
77.92
MEANS,
STANDARD
MEAN
STD
F1MAX2
MEAN
STD.
F 1 MIN2
MEAN
STD,
INITL 1
MEAN
STD.
AVEF3
MEAN
STD*
AVEF4
MEAN
STD
AND
F RATIOS
FOR
JAIl,
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
STDF 1
DEVIATIONS
F
:
26.28
103.2
16.8
71.5
2.8
60*5
9*8
102.7
10,0
55*2
10.3
459.1
403*6
12.9
35o8
476.9
5.4
513.0
20.4
489.3
17.3
434.3
34*8
643*3
17.9
579.2
11.2
609.8
31.9
616.3
36.3
572*2
24.4
640.5
16.7
579.2
11.2
576*5
9*1
604.7
572.4
2483*2
2193,3
42.1
2541.3
49*0
2327.0
38.5
2120.5
124.0
2916.4
50.9
3360*0
3214.2
57.4
2698o1
56,3
114.2
11.3
F
F
=
:
13.67
5.43
659.2
55.9
F =
11.22
603.7
16.2
F
=
18.4
42.9
=
3397.8
61.2
2492
36.49
2445*4
F
21.1
103*87
3504*0
50 *
113.4
MEANS,
STANDARD
MEAN
STD
FINAL2
MEAN
STD
MINF2
MEAN
STD
INITL2
MEAN
STD
RANGE2
MEAN
STD
AND
F RATIOS
FOR
EAI,.
TAKEN
ON
BOTH DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
:
130.97
1924.5
66.6
F =
71.1
:
=
=
:
F
MEAN
STDo
6.05
0986
1660.8
54.5
2009.4
50.5
1756o5
29.9
1663.2
27*9
2022.3
44.7
1647.4
55,5
1224.1
43.7
1031.0
32.6
1125.3
27*7
1152.7
34,0
1193.3
1224.1
43.8
1034.7
36.3
1130*2
28.0
1159.5
37.2
1195.5
30.6
79396
81.1
733.8
27.9
544*0
24*4
872.6
55.8
467.5
53.6
4,67
0.71
6.87
0.41
4.82
0*53
7,47
0.76
3.60
0.51
30.6
76*69
706.2
66.0
LOCALS
2025.3
445
*
47.28
1225.5
17.7
F
1669.3
28.0
52*44
1218.3
14.7
F
1764.9
22.6
117.21
1898*0
F
2017.6
46*3
50.84
MEANS,
STANDARD
=
TOTALS
F
MEAN
STD
2*59
0.30
DUR
F
=
FOR
CAI],
TAKEN
ON
BOTH
DAYS
MEAN
STD
69.6
DUR 1
F
:
F
MEAN
STD
92.3
14.5
MAXF1
F
=
=
745.7
21.9
2053
3.04
2 * 46
0.13
0.33
0025
279.0
3793
200.0
13.3
2600
18.9
307.0
42.4
221o0
16.6
61.9
7.0
61.6
5.0
65*1
71.1
1.8
6206
3.6
174,4
42.7
123.3
14.3
169.7
19.1
218.0
28.5
138*2
16*6
7.1
22*98
210.7
15.9
DUR2
4*64
0.50
6*47
4.1
:
3.22
0065
26.65
17.0
F
MEAN
STD
F RATIOS
42*90
303.0
PCTDUR
MEAN
STD
AND
1
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
4.81
104.6
13.6
76 * 7
9,8
90.3
796
8900
15.0
82*8
18.3
45.01
70694
15.8
682.4
17.6
646*2
15.6
756*0
44*6
619.0
25.5
MEANS,
STANDARD
MEAN
STD
FI1MAX2
MEAN
STD
F1MIN2
MEAN
STD
INITL1
MEAN
STD.
AVEF3
MEAN
STD
AVEF4
MEAN
STD .
9I
AND
F RATIOS
FOR
CAIl
TAKEN ON
BOTH
DAYS
1
SPEAKER
NUMBER
STDF 1
DEVIATIONS
F
:
38.78
720
4.3
64*0
8*1
97.0
11.9
5302
8,5
436*5
43.3
47606
489*6
30.5
474.7
30.8
46805
43.
642.6
642*3
15.0
580,6
10.2
594.9
47o7
2907
601.6
47.3
570.3
20.5
640.9
14.3
569.4
569*7
10.0
573.3
37.2
570,4
20.4
2455e4
38*6
2436.7
259.3
2523.0
43.1
2365.2
59.6
2185.9
110*5
350904
57.1
3053.7
150.1
3344.6
86*7
330003
98*7
2782.2
113*0
104.2
14.7
F
:
100.0
14.0
2.78
472.7
31.5
F =
F :
9*21
21.27
606.2
11.5
F
:
:
3363.5
7405
14.5
8*86
2410.6
61.9
F
15.6
67*54
9
9
9
9
t
9e
MEANS,
STANDARD
1491.5
11.3
INITL2
1476.9
9.3
1051.9
14*5
MEAN
STD,
=
FOR
[AU].
TAKEN
ON
DAY
1
25.1
35*7
F
439*6
15.2
:
:
1233.1
31.9
1548*8
47.6
1458.5
40.2
1359.2
37.2
1348.7
63.8
1698.5
56o2
1177.3
19.3
122695
38.5
1524.8
49*5
1397.1
34.5
1328.9
5197
1283.8
50*0
1689*0
50*8
973*5
990*0
30*4
1229.3
1130.1
36.3
64.4
1079s7
455S
925.1
31*2
1176.0
41.5
976.0
21.2
993.3
31*6
1239.5
25*9
1154.8
75*9
1122*8
4391
955.5
2394
1190.4
37.6
242.0
18*3
24391
35.1
319.5
37.5
328.4
81.6
27994
46*2
423,7
83.7
522*5
29.8
-1.03
-1.24
-1.48
-1.73
-1.33
-1
"299
0.24
36.90
950.9
45.9
18.3
35.70
960.1
53.8
24.35
268.8
31*4
477.4
29.6
F
-1 66
0.08
1192*4
15.0
=
953.3
1215.4
8.9
81.57
949.3
35*6
1067.3
LOCALS
MEAN
STD
=
1394.7
50.7
F
RANGE2
1219.7
22*2
20*4
F
FINAL2
MEAN
STD
F RATIOS
84.45
1426.7
F
MINF2
MEAN
STD
=
F
MAXF2
MEAN
STD*
AND
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
23.11
-1 45
0,20
-2978
0 45
VIR
0.19
0.18
0.34
0.48
47
0,27
0.34
V4"
*a6ikCt'g
MEANS,
STANDARD
-1 65
0,08
340,0
1i0o
=
53*4
4*6
F
15204
19.1
187.6
16*9
729 3
10.1
=
114.4
12.3
F
MAXF 1
=
131*6
18.1
F
DUR2
MEAN
STD*
246.0
19.5
44.8
5*1
DUR 1
MEAN
STD
=
F
PCTDUR
MEAN
STD
F RATIOS
FOR
[AU],
TAKEN
ON
DAY
1
21.14
-2076
0.46
F
DUR
MEAN
STD
:
F
TOTALS
MEAN
STD.
AND
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
:
680.3
22.0
-1.33
0.24
-1.21
0.21
-1.46
-1.61
0 57
-1.29
0.30
-1.50
0.30
-2.96
0.33
8.9
232.0
4.5
278*0
13.0
234,0
16*7
258*0
32*7
346.0
8.9
256.0
16.7
6509
3.0
6209
1.8
35o4
12.3
5204
54.7
9.2
4*0
50.6
493
174.2
1395
145.8
3*3
-1.01
0.17
0,23
36.62
222.0
8.4
26490
12.60
64.5
5o6
61.9
2,*3
7.17
142.9
798
99*4
37.6
144.8
10.2
136.7
37*5
189*3
15.9
129.3
9*5
121*3
17.7
156.7
13.7
126.7
17.0
666*2
13.5
627*4
17.0
701.1
4.7
31.79
79 .1
15.4
89.8
5*8
8602
5 0 si
17896
2809
89.2
9.3
39.01
668.6
13.3
638.8
15.1
685.7
14.2
761
0
13.9
623*3
24.5
MEANS,
STANDARD
DEVIATIONS
AND
F RATIOS
FOR
(AU],
TAKEN ON
DAY
1
SPEAKER
NUMBER
F
STDF 1
MEAN
STD
MEAN
STD
F
639o1
15.1
619.5
22.5
591.0
14*5
MEAN
STD*
2352.9
11*0
AVEF4
MEAN
STD*
4*1
66*7
7.9
73*0
8*3
950
10.1
58.0
11.0
92,6
6*6
64.5
10.0
101.7
8.1
7.48
573.2
31.9
606.8
21.6
61698
60*6
545.0
23,0
622.9
11.6
544o8
520.2
491 *2
29*2
455*0
478.9
525* 1
2707
579.7
10.2
59702
8.0
15.1
65.1
11.2
64608
582*6
580.3
620.8
55605
25*4
9,1
2403
54203
25,0
56705
504
4296
480.4
38.1
619.8
14.4
191907
238*4
2451,7
3203
235607
67e4
2236,4
59,0
213208
28*1
2326.8
31.7
2022*0
82,0
2383*4
4905
3273.9
107,7
2881.6
155*3
3586*8
2935*7
3313.2
132*3
149*1
3266.9
34,3
3685*5
82*5
:
475*2
2906
:
2317*0
50*4
F
3369.5
50*7
580
643*2
40*3
F
AVEF3
17.35
616.2
8*6
F :
INITL 1
MEAN
STD
:
671 0
17*0
F
F1 MI N2
MEAN
STD e
88,5
8.5
689
10.5
F1MAX2
:
:
3339.4
73o2
644,6
30.5
19.39
16*8
19. 35
7*0
18,57
48.99
2694*3
68s4
52*6
MEANS,
STANDARD
1
SPEAKER
NUMBER
MAXF2
MEAN
STD
INI TL2
MEAN
STD.
MINF2
MEAN
STD
FINAL2
MEAN
STD,
RANGE2
MEAN
STD
LOCALS
MEAN
STD
DEVIATIONS
F
F RATIOS
FOR
[AU,
TAKEN
ON
DAY
2
2
:
30.24
1455*2
47.3
F
AND
:
1218.5
14.3
1206.6
16.3
1581 * 2
115.3
1425.7
40*9
1359.6
53.1
1172.7
27,9
1193*1
1509
1559.6
108.3
1355e3
36.69
1435.8
35 7
F :
137393
5500
2605
40.49
1031.7
95464
5560
965.8
31.0
975*8
15.8
38*7
1229,3
21.3
115907
60.2
969*8
586 1
97562
33.0
98460
3565
1239.2
28.5
1169*0
418*8
74*7
252.7
20.9
230*7
351 9
119.5
265*9
61.3
-2.04
-1.14
-1.10
0618
0616
-1.48
0.62
-1.28
0649
F =
35.34
1067.5
28*1
F
:
8.30
42305
3662
F
:
-1.46
0.11
60*6
3504
4*38
0,34
MEANS,
STANDARD
MEAN
STD.
DUR
MEAN
STD
F
=
0.12
F
=
MEAN
STD
52.7
7.6
DUR1
F
MEAN
STD
MAXF 1
MEAN
STD
RATIOS FOR
[AU),
TAKEN ON
DAY 2
=
:
:
:
752.8
20.1
-1.05
0.15
-144
0*55
-1.25
0,34
292.0
42.1
214.0
8.9
24860
4*5
288,0
16.4
246o0
29.7
52.3
4.4
67.0
4.7
62o 1
3.5
26.3
5905
7.3
404
152*2
20.7
143.5
13.8
154* 1
7568
22.3
14695
19.7
139e8
27.9
70.5
8.6
212,2
23.4
9905
16.3
803.6
589.4
28,4
16*36
8.2
34.58
164,6
25.3
F
-1.02
0.13
33.81
183.4
27.7
F
-2,04
0.49
21.80
348,0
4.5
F
DUR2
F
5.88
-1.47
PCTDUR
MEAN
STD
AND
1
SPEAKER
NUMBER
TOTALS
DEVIATIONS
9309
9.5
32*38
686* 1
20.5
641
2
13.2
645o 1
16.9
60,9
MEANS,
STANDARD
STDF I
F
MEAN
STD
62.3
797
F1MAX2
F
F1MIN2
MEAN
STD
INITL1
MEAN
STD.
AVEF3
MEAN
STD*
AVEF4
MEAN
STD.
AND
F
RATIOS
FOR
EAU],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
=
:
12*56
:
=
3377.1
57.1
62306
3407
613*6
14.5
611.9
30 * 1
56407
41.3
487*o
26*9
552.7
26,9
537.6
25.7
57304
48.1
473*8
38*7
637*1
18*3
576 8
16.7
581*6
2292
571.7
20.4
515.3
29*3
2351*7
53o5
2131.4
81.0
2454o0
37*8
2252s0
15.2
1925*3
55,0
3310*7
38*6
2911e6
75.9
347395
60.2
3350,9
29o3
2624*0
56,1
80.83
2412.8
2490
F
664*9
150
18*39
609.4
18.7
F
53*6
4.6
12.63
629*0
4206
F =
51.0
8.4
7*58
641 6
15.4
F :
101.6
18.1
56o6
17*2
81.7
13.2
182*63
__ _llil_
__
MEANS,
STANDARD
MEAN
STD.
INITL2
MEAN
STD*
MINF2
MEAN
STD.
FINAL2
MEAN
STD.
RANGE2
MEAN
STD.
LOCALS
MEAN
STD.
~I
QC
AND
F RATIOS
FoR
[AU],
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F :
92*28
147303
1400.0
1211.0
13.2
1442.1
48*2
1219.1
17.6
1565e0
37.6
8409
42*0
1377*1
52.3
1182.6
23.5
118502
18.7
1542.2
R1a5
1376.2
3604
951.9
95804
37.7
974.7
2806
1229.3
28.0
114409
967,6
42.8
98000
27.9
1239.3
1161.9
25.7
6502
4481
61.8
260,8
26.6
23603
2702
335.7
85.2
29792
7505
-2.41
0.59
-1.29
0*24
-1.06
0,17
-1.48
0.48
-1.51
F
=
99.15
1456.4
32.8
F
=
87.00
1041,8
17.9
F
=
43.8
78.30
1067.4
961.5
25.1
46*3
F
=
24.50
431.5
27.5
F
=
-1 56
0o14
60.8
14.15
0046
MEANS,
STANDARD
AND
F
RATIOS
FOR
TAKEN
[AU]3
ON
BOTH
DAYS
1
SPEAKER
NUMBER
TOTALS
F
MEAN
STD.
:
15.95
-1.56
0.13
DUR
F
:
PCTDUR
F
MEAN
STD*
48,7
7.4
DUR 1
F
:
:
MEAN
STD
16709
27.8
DUR2
F :
MEAN
STD
176.1
23,6
F
MAXF1
:
741 1
19.4
MEAN
STD,
IB
-2.40
0,59
-1.17
0.25
-1
0,15
-1*45
0.43
-1,43
0,48
26990
3993
218.0
9.2
256,0
10.7
283,0
14.9
2400
23.6
5208
4*3
6508
5.0
64,0
30.9
10.7
60.7
3.5
141.9
21*3
143.2
10,6
87.6
31*7
145.6
14*8
127.1
24.4
7408
91.9
7*7
19504
9404
30.5
13.6
68392
20.3
65409
641.9
15.4
782.3
606.4
30.7
03
43,63
344.0
8.4
MEAN
STD.
£-
DEVIATIONS
42*69
3*7
17.84
1640 1
14.9
58.47
12,6
56.54
19.1
4703
MEANS,
STANDARD
STDF 1
F =
MEAN
STD
65.6
9.3
F1MAX2
F
F1MIN2
MEAN
STD
INITL 1
MEAN
STD
AVEF3
MEAN
STD
AVEF4
MEAN
STDo
AND
F
RATIOS
FOR
[AU1,
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
:
25*36
14.4
:
=
3373*3
510
35.6
585e8
38*2
548.8
19.2
528.9
26.8
585.3
36.2
482*5
3396
64290
21,5
57907
12.1
580.9
16.0
557.0
26.5
541.4
34,0
2334.4
52.3
2025,5
201.6
2452.9
33, 1
2244.2
41.4
2029.1
116.9
3325*1
57,2
2802.9
133.3
3373.7
133.6
3468.9
137.3
2779.8
190.2
1505
634.1
32.7
481*5
27o5
32.38
2382.8
36.1
F :
592*6
668*0
9.2
24.23
600.2
18.5
F :
614*9
11,3
6001
36.12
624,2
3205
F
57,3
13.6
54,5
7.2
13.24
64004
F
98,3
14.2
85.1
I1o0
59.85
MEANS,
STANDARD
MAXF2
F
2146.7
22.8
2087*8
29.7
MEAN
STD
1546.1
23.4
INITL2
MEAN
STD.
1546.5
23*5
1973.2
47.0
2025*8
21.7
:
TAKEN ON
DAY
1
1876.2
49,0
2162*8
46.8
2156.5
44*1
1981*8
78*5
2140.3
57*9
197(9 0
82*0
2403*0
1802.5
17*4
2121*6
27*3
2116*4
44*2
1902*4
81*6
2081*6
70s5
1844*2
5396
2367.9
56*2
1516.4
43.0
1766*2
1860.4
172170
98*6
1439*5
2044.4
98*,
1682.2
84*0
41*3
41*8
1517*4
44*7
1766*2
15.4
1867*1
109.8
1682*2
84.0
1750.8
64*4
1439*5
41*3
2044*4
41.8
1770*8
33.6
2036*3
33*4
2105.3
40*4
1936.7
72*8
2021.1
92*3
1867.3
71.1
2323 0
58*7
1772.0
36.1
2022*4
52,1
2100*7
33*0
1925*,
97.1
2024.7
1854*8
77o1
82.1
2309.1
46o1
35.0
57905
:
:
2105.4
19.9
F
MID2AV
MEAN
STD*
[E],
48.90
1989*7
38o5
F
1973.5
52.0
:
2039.4
22*0
1980.9
22.6
F
MIDF2
MEAN
STD
RATIOS FOR
37.70
2117*4
75.1
F
MINF2
=
2163*0
53.0
F
FINAL2
MEAN
STD*
F
2
SPEAKER
NUMBER
MEAN
STD
AND
DEVIATIONS
:
2113.9
27*0
1702*6
25*3
15.4
"
62.04
1702*6
25*3
37.30
1951*9
34*4
33*62
1952*5
31.0
a
ap c
~
m~F
~sC
MEANS,
STANDARD
DEVIATIONS
AND
F
RATIOS
FOR
TAKEN
[E3,
ON
DAY
SPEAKER
NUMBER
RANGE2
MEAN
STD*
F
600.6
3406
MAXF1
MEAN
STD,
558.5
2904
MEAN
STD*
560.6
28.7
MEAN
STD.
387.5
2506
MIDF 1
MEAN
STD*
:
355.2
29*2
F
465.7
16.6
=
420*0
59*8
F
F1MAX2
:
447*8
20*9
F
F 1 MIN2
:
458o3
6*3
F
INITL1
MEAN
STD*
182.1
53o2
F
606*9
1900
:
:
396.8
14*4
20.94
336.8
40.9
359.8
2291
396.7
40.4
296*0
111.9
29996
53.2
413.3
70.3
539.5
65*4
358.6
4802
484*9
11.0
480*4
10.3
475*4
15.3
433.1
14*1
447.8
14. ,
481*8
6*2
46607
9.0
469*5
16.8
460.2
9.1
440.8
12*4
428.o
14.4
429.7
15,1
426*2
20,2
460*6
4*3
466*2
11.1
460*2
9.1
443.6
10*7
428 Ii
14.4
399*1
426*2
77*1
20*2
460*6
4.3
359.1
11.4
366.6
52*3
404*9
22*4
39290
34.3
342e4
29*5
324*6
9*1
35901
4*1
416.3
22.4
443o3
434*3
14*7
413*1
19.8
390*7
347*7
24*8
379*6
8*6
80.32
463*4
3*9
27.27
460*2
5*5
8*49
460*2
55
4.29
387*0
12o3
16*14
437*1
8.4
28*3
C
2494
fAPB
p
kC1
V
MEANS,
STANDARD
F
MID1AV
464 * 1
16.7
TO
90* 1
4.0
MEAN
STD.
F :
270.0
15.8
2668*7
42.0
3404.0
51.1
:
2838.1
69e6
F
AVEF4
MEAN
STD
238.0
19.2
F
AVEF3
MEAN
STD*
:
0 *64
0 35
2.81
0.29
DUR
MEAN
STD*
:
42.8
3.1
F
ALS
:
393*4
1497
F
STDF 1
MEAN
STD.
AND
F RATIOS
FOR
[E],
ON
TAKEN
DAY
1
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
:
3644*0
14.6
16.98
437*5
6*8
355.4
381*9
436*6
409.6
390*1
16.6
441*1
27*9
14.7
15 .1
28 .1
17.8
7*7
51*9
10.3
54*8
10.7
31.0
34 1
6*0
41.7
7.9
636
43o5
3.2
1.85
0.11
2.12
0 28
1.00
0.20
1 58
1.73
0,19
0.24
1.67
0.48
214.0
*5
212.0
19.2
248*0
27.7
188*0
17.9
240*0
30.0
314*0
2390
218.0
13.0
252';.0
66.9
2541.2
53.5
2640*0
22*9
2318.6
65.8
2549.3
80.7
2423*2
107.0
2675*6
28.9
3368.2
3439*5
16,6
3630.0
3134.0
3369.7
337096
3993o9
26,6
128*5
418.0
3091
35*0
8.3
6,7
5*9
17*,7
2.10
0,38
0.45
1.85
19.14
190.0
10.0
24.30
2616*2
71.7
71.44
3208* ,
71.9
23o7
fF
32o6
51*4
112.5
C
~~?~
MEANS,
STANDARD
MEAN
STD
FINAL2
MEAN
STD
MINF2
MEAN
STD
INITL2
MEAN
STD
MIDF2
MEAN
STD.
MID2AV
MEAN
STD,
AND
F
RATIOS FOR
E],.
TAKEN
ON
DAY 2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
:
25.16
2150.7
34.1
F
:
:
:
45o4
1817*6
2157o2
22.6
1894*7
83.1
1839.5
106.8
1690e1
34.7
1512.7
20*7
1708.7
34.7
1512.7
20.7
1839.5
106.8
1696
2139*8
22.3
197909
1829o3
17.1
4203
2127*3
24.3
1869.7
103*0
2143,5
28,9R
1978,5
11.4
1823o6
40,7
2131.7
24,4
1862#7
98.4
24,8
31.9
52.49
1967o5
31*6
1708.7
34.9
54.08
19788
36*3
2
31*9
28.10
60.7
2011 .7
2033.8
31.9
1998,6
F =
1934.9
122.8
2132*8
154304
43.7
F :
2202.4
15.8
53.27
154304
43.7
F
1900.5
43.1
41.1
2104.5
26.2
F
2058.6
15.7
2187*8
35.34
MEANS,
STANDARD
MEAN
STD.
MAXF 1
MEAN
STD,
INITL 1
MEAN
STD,
F1MIN2
MEAN
STD*
F 1 MAX2
MEAN
STD,
MIDF 1
MEAN
STD
AND
F RATIOS
FOR
[E],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
RANGE2
DEVIATIONS
F
:
19.66
607.3
43.2
F
=
=
11.2
:
11.2
:
11.2
=
44262
3403
36209
9763
244*8
101.2
463*9
15.
45464
19.0
499o6
20.3
471.7
190
411*0
12.0
45792
20.9
441.2
471.9
23.2
452.5
9.0
402.6
10.7
456*4
13.3
441 ,2
14.9
471.9
23*2
452.5
9.0
403.7
12*0
352.9
14.0
38262
27.0
381 *2
100
403.5
11.5
32964
7.7
38463
14,4
4127
892
422.7
17.0
429,8
5.3
355.1
16.5
14.9
15.23
361*1
F
44*0
76.47
573.9
F
38768
65.41
573*9
F
350.0
32.1
76.28
596*9
5.6
F
220*3
6662
15.23
----
---r
_I.
~.__._~---------
--
MFANS,
STANDARD
MEAN
STD
F
=
F
MEAN
STD
96.5
TOTALS
F
MEAN
STD,
2.49
DUR
F
AVEF3
MEAN
STD
AVEF4
MEAN
STD.
F
RATIOS
FOR
[El,
TAKEN
ON
DAY
2
18.17
444,0
32.1
STDF 1
MEAN
STD,
AND
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
=
:
=
347408
43.1
355.6
14.3
42.4
7.1
34.3
12,6
53*8
5S6
36,2
15.0
3604
4*4
0.60
0 33
2.10
0.30
2.06
0.10
1.48
0.39
1.20
0,19
298*0
42.7
182.0
8.4
208*0
17.9
254v0
11.4
206.0
31.3
2835*3
51*6
2590.5
43.4
2428*9
8406
2673.6
56.5
2385,8
116.1
3604,0
70.7
3065.5
117.3
337591
3479.0
7907
3094*9
253a3
28.51
267203
3608
F
427e8
8.3
19.58
296.0
20.7
F
426*5
15,1
32.53
0.22
:
412.3
7.6
33.17
5.7
:
384*0
13.6
15.89
27*4
MEANS,
STANDARD
MEAN
STD*
FINAL2
MEAN
STD.
MINF2
MEAN
STD
INI TL2
MEAN
STD.
MIDF2
MEAN
STD
MID2AV
MEAN
STD*
AND
F RATIOS
FOR
[E],
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
52.95
2049.0
20.7
188R 4
4504
2179.4
39*6
1958*4
46*0
2125.1
55,0
2029.8
22.4
1810.1
2136,8
39o5
1898.6
7708
154407
197492
1850,0
97e6
168601
2609
1705.6
28.8
1514*5
33.1
1984*3
35*7
1705.6
2808
1515*0
3209
1853.3
103.2
168902
2122*6
27.0
1965.9
29.5
180001
4704
2116.3
33.5
1903.2
91.2
2128*7
30.6
1965*5
179708
2116.2
31.9
1894.1
2175,4
2148.7
27.4
F :
85*41
2096.2
27.8
F
F
=
31*8
60*8
= 104.19
3391
:
5409
:
199204
48.1
6004
56.94
1986.0
F
25 *,
110.49
154409
F
100.2
59,05
25.9
4503
9709
MEANS,
STANDARD
MEAN
STD.
MAXF 1
MEAN
STD
INITL 1
MEAN
STD
F 1 MIN2
MEAN
STD
F1MAX2
MEAN
STD,
MIDFI1
MEAN
STD
AND
F RATIOS
FOR
[E].
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
RANGE2
DEVIATIONS
F
:
44.59
603.9
37.0
F
:
14.2
:
22,5
:
:
453.9
28.3
329.5
105.0
272*2
81.5
4611
11.5
458.9
13.8
49292
17.2
473,5
16.4
42260
17*0
452*5
20.3
450.7
14.6
470*7
19.1
446o6
11.9
415.7
18.2
438*2
45.1
450,7
14.6
469*0
17.4
448.0
10.4
416.3
18.2
354*0
21.6
384.6
20*0
370.1
15.4
404,2
16.8
360.7
40*5
390.6
15.1
424.9
15.1
419*5
19.3
432.1
384.1
10.7
3560
5.43
374.3
23.3
F
3660
48.69
567.2
21.7
F
373.8
81.38
566.2
F
34364
35.3
165*65
601.9
F
201.2
60o1
13.90
MEANS,
STANDARD
MEAN
STD,
F
:
26.3
=
F
MEAN
STD*
93*3
5.7
TOTALS
F
MEAN
STD*
2,65
0.30
DUR
F =
AVEF3
MEAN
STD
AVEF4
MEAN
STD
F RATIOS
FOR
[El,
TAKEN
ON
DAYS
BOTH
17.57
454,0
STDF 1
MEAN
STD.
AND
1
SPEAKER
NUMBER
MIDI AV
DEVIATIONS
=
=
=
3439. 4
58.1
15,0
422*2
15.6
432,2
12.2
382.6
31,6
42*6
592
34.6
10.1
52.9
7.9
3306
35.3
5.1
0*62
0032
2.10
0*32
1.96
0.15
1.24
268.0
186o0
9.7
211.0
12.9
251 0
20.2
2836.7
57*8
2603.4
57.5
247609
8860
2656.8
3624,0
52*6
3137.1
118.8
3371.6
3554.5
98.1
11.3
50.61
0*39
1 39
0,38
25*38
4464
197,0
25.8
62.79
2670*5
37.3
F
424o9
84.39
283.0
22.1
F
388.7
14.2
4403
235202
95*8
41.11
2404
311404
185.9
MEANS,
SPEAKER
NUMBER
2264.2
20.8
2160.4
STD*
27*3
1952o5
85.1
INITL 2
2212*6
46.2
2217.3
35.3
2122*6
58.7
:
[I],
TAKEN
ON
DAY
1
1998.2
26.6
220?,3
23.
2309.7
2117.5
2225*7
2056*6
17*5
23.2
39*7
58*4
249204
26 *
:
2140*0
38o7
:
2220.6
35o5
:
2219.0
47.0
193296
15.0
2177*8
25*3
2234.8
35.2
2070.6
42*1
2162.2
40*5
1970.8
53.4
2426*1
20.2
177599
18*6
2078*6
15.4
2145o,
41.6
1883.3
107.6
2075*7
46*5
1834.7
37.8
2323 8
40.5
180192
24*4
2093*6
12.9
2181.2
31.4
193096
80.6
2104*7
49,7
1841*8
44*3
2358.0
38.0
1981.4
25*4
2175.1
17.8
2280e2
18A
2094*0
16.0
2197o2
3593
2028*4
66.6
2457*3
24e6
1984.1
31*0
217491
20.1
2283.2
21*5
2092,2
17.4
2198*5
35*2
202296
63.9
2461.2
25.6
48.07
18*6
F
MID2AV
MEAN
STD.
FOR
64.68
209699
F
MIDF2
:
2209.0
44*6
F
1991.2
63.4
2209.2
77*2
3303
F
MINF2
MEAN
STD*
F RATIOS
62.96
2270.2
F
MEAN
MEAN
STD.
:
F
FINAL2
MEAN
STD*
AND
1
MAXF2
MEAN
STD*
DEVIATIONS
STANDARD
1995*7
28* 3
66*52
1999*8
33*2
42,13
2161*1
99*4
48.67
2143*4
85*3
MEANS,
STANDARD
F
RANGE2
311.7
7998
354.5
4*4
MEAN
349*0
STD.
4.8
340*9
14.1
32203
21*4
=
271*8
17*1
=
268.6
14*3
F =
MIDF1
MEAN
STD,
=
301.4
17.8
F
F1MAX2
MEAN
STD*
RATIOS
FOR
[I].
TAKEN
ON
DAY
1
318.0
7.3
222*3
35.7
123*7
19.1
164.2
32e4
234*2
89*0
150.0
50*0
221.9
71.7
168.5
56.2
337.7
7*6
289.6
20.9
308.4
9.3
314.3
9Q
300.3
14.0
321*6
3*9
284.3
7.8
336.1
9*7
270*5
14o4
302.2
10.3
309.4
9.7
289.1
10.7
279*6
108
283.1
8.9
323.6
14.4
273.2
16*3
283*0
14.6
274*8
45.4
289.8
20.4
279.2
10.4
270.5
15 ,
269.5
6.0
253*3
11.2
290.2
8.9
291.6
17.5
274*3
1294
287*
18.4
270*2
8.9
271.7
4.1
250.2
287*8
282.7
275o2
286.8
271*2
12*3
19,5
20e9
21o4
2*2
21.51
304.3
12*4
F
F1MIN2
213*5
78*6
173.2
28*4
F
INITL 1
MEAN
STD.
F
4.17
:
F =
MAXF 1
MEAN
STD.
AND
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
267*5
21.8
350.1
15.6
23.05
29993
12.7
6.54
306*6
23.8
9*03
291s5
15.3
7.49
297.2
13*5
10,4
MEANS,
STANDARD
F =
MIDIAV
317.6
9*1
F
MEAN
STD*
F
252.0
32.7
MEAN
STD
2806s4
12.1
MEAN
STD.
3329.5
9.1
:
3148i
75*8
F
AVEF4
:
210.0
12o2
F
AVEF3
=
0.43
0022
0.81
0.22
DUR
=
11.0
0.8
14.5
493
TOTALS
MEAN
STD
267.4
17.7
F
STDF1
MEAN
STD
AND
F RATIOS
FOR
TAKEN ON
[IJ]
DAY
1
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
:
3749*8
67*6
9*35
297.5
11.2
271.7
5.7
25198
9.5
289.7
6*5
283.9
272*6
18
180
23.9
3.7
12*7
4v3
8*3
1*1
14.5
7*8
0 88
0 19
0.50
0, 07
0.44
0*22
180 0
18.7
200.0
14"1
206.0
23.0
2804.3
2953.0
4796
3455*7
23*6
9
284o3
190 (
271*2
4.7
7.71
20.2
7*5
10.1
3.
16.9
2*9
6o2
0.33
0.26
0152
0,40
0,22
0.23
200*0
244*0
1.0
3*62
1 06
0,61
0
77
0
42
14*48
162* 0
8*4
160.s
8*9
186 0
15.2
12.2
20*0
2837.0
54.3
2517.5
164*9
2825.3
6298
288494
70.4
2937*4
107.3
3546o4
18.2
307090
131.1
3407*0
31,5
3387.5
72.3
3828.
303.0
18*26
2903.5
950
2994
19.54
3251.4
89.8
3357.6
17.3
MEANS,
STANDARD
MEAN
STD
FINAL2
MEAN
STD
MINF2
MEAN
STD
INITL 2
MEAN
STD
MIDF2
MEAN
STD
MID2AV
MEAN
STD
AND
F
RATIOS
FOR
[I],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
28.98
232294
54*0
F
:
:
:
:
:
2267.0
19*4
2107.9
71.9
2194.4
37.1
2104.2
38*8
1979
2296.9
37.3
2003.9
49 9
2098*3
34.2
2017.6
40.2
1796*6
1841.4
19.2
2180.6
70.0
2162o7
550
2039*7
46.0
186508
47*8
2237.8
28.2
1928*3
43.8
2233o4
54*0
2115.1
27,3
2007.4
5905
2314.2
45.4
2047.9
28.2
2234.4
38,1
2116.9
27,7
2013.6
44*2
2305.3
32.6
20480
30.4
440
1
1
122@3
45*47
226902
18.5
F
2334,7
26.1
42.28
2012.7
61.0
F
2048*5
38,4
24.42
2012.7
61.0
F
2131.7
3204
39.57
2222.6
58.3
F
2314*4
75,0
67.60
MEANS,
STANDARD
MEAN
STD
MAXF1
MEAN
STD,
INITL 1
MEAN
STD.
F1MIN2
MEAN
STD.
F1 MAX2
MEAN
STD*
MIDF 1
MEAN
STD
AND
F RATIOS
FOR
[I],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
RANGE2
DEVIATIONS
F
:
3.68
309.7
86.9
F
:
:
=
=
=
302.9
20.2
69.1
125o1
338.5
6.7
330a 1
6.1
312,1
4.5
304.8
10*3
298o2
14*7
309.1
6.6
325.6
6*5
301.5
I1
301.3
9.6
288*6
15.5
311.2
8.2
306*0
19.3
278o3
21.1
287.0
17.7
280.9
16.1
311.8
17.6
292.8
22*2
295.1
12.5
280*8
18.7
283.1
14o0
314,9
13.0
288*1
2795
298.5
14.3
276*3
10.5
2.14
297.4
18,0
F
154.1
16.85
357.9
6.6
F
303.6
17o3
266*5
251.9
49.8
42.7
28.19
357.9
6.6
F
114.1
26.45
367.4
13.4
F
216*1
10695
3o27
MEANS,
STANDARD
MEAN
STD
F
=
F
MEAN
STD.
23.4
4.3
TOTALS
F
MEAN
STD,
0.87
DUR
F
AVEF3
MEAN
STD*
AVEF4
MEAN
STD.
RATIOS
FOR
[I],
TAKEN
ON
DAY
2
3.56
301.6
19.6
STDF 1
MEAN
STD*
AND F
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
=
=
=
3432,8
50.7
275s1
10.2
808
2.1
11.2
3,6
16*5
7.3
9,2
2.6
ll.1
2.?
0.23
0.27
0*53
0 *32
0.45
0*24
0 14
0.31
0.24
274*0
37.8
154,0
8.9
7.1
218.0
13.0
196*0
71.6
3143.1
59.5
2857,0
46.5
2807.5
71*7
2850.5
67,2
2618.2
77*4
3719.4
67.9
3172.1
29.3
3346.9
88.8
3478.4
51.0
3168*2
127.0
0.19
190
0
38.12
2784*0
39 3
F
298.1
13.9
12.21
11.4
:
287*4
20.7
3.84
294s 0
F
313,1
15.1
9*42
0*40
=
284.2
15*2
37.48
MEANS,
STANDARD
MEAN
STD
FINAL2
MEAN
STD
MINF2
MEAN
STD
INITL2
MEAN
STD
MIDF2
MEAN
STD
MID2AV
MEAN
STD,
AND
F RATIOS
FOR
[I]4
TAKEN ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F :
55.29
2293.3
49*2
F
:
=
:
:
2242 1
37T6
2112*7
50*6
2201.7
2113.4
47.9
1955*9
39*6
2265,8
47.3
2037.3
3994
2097*6
2006.6
34.7
1786*2
2163o 1
57.3
1862 * 4
2151*4
46.4
2019.8
2209.5
41.0
1934*0
43.3
1833.5
49*4
2227*0
43*6
2138.1
1994.4
72*9
45*2
2297.2
37.3
2071*0
32.5
2226*7
41,2
2130,2
61.4
1998*8
39*2
2294.3
28.6
2070.5
32 * 7
55.9
20.9
110*8
74.00
61.4
57*56
2240*9
44.6
F
2322.,2
24.7
26*0
2001.9
59.8
F
2023,4
40*9
50.18
1982.6
76.7
F :
2170.4
69o 1
58*29
2191.5
54,0
F
2292o3
59*5
74.70
MEANS,
STANDARD
MEAN
STD
MAXF 1
MEAN
STD
INITL 1
MEAN
STD
F1MIN2
MEAN
STD
F 1 MAX2
MEAN
STD
MIDF1
MEAN
STDe
AND
F RATIOS
FOR
[II,
TAKEN ON
BOTH DAYS
1
SPEAKER
NUMBER
RANGE2
DEVIATIONS
F
=
6.03
310.7
78.7
F
=
11.6
:
=
13.7
:
310.4
16*4
250.3
103.7
304.0
14*2
344o3
333,9
7.6
310.3
7.2
309.5
10.8
299*8
330.9
9e5
301.9
10.1
30503
15e
304.2
10,9
280.2
17.7
308.9
17.0
314.8
18e5
28006
280.9
17.3
33.1
274.7
15.8
301.7
18.9
281*1
19.6
292.7
10.6
286.2
18,0
27593
19.1
306,1
15.6
279*9
293o1
13,8
279*5
1591
12.9
10.1
5.29
309.9
22.8
F
159.1
51.1
18.23
349.4
F :
237.1
43.7
39.91
353.5
7.2
F
163,8
7904
43.17
360.9
F
194.7
76*9
7.78
205
MEANS,
STANDARD
MEAN
STD
F
=
ON
BOTH
DAYS
8.72
305,3
15,0
279*6
16.5
293.9
1II
279.5
15.0
9*9
1.9
15.7
7,3
20.2
6.7
8.7
1.9
12.8
5,7
0*33
0,26
0.80
0*54
0 66
0.29
0.34
0.20
0.54
0.41
242.0
42,9
158.0
9,2
1850
14*3
212.0
18*7
178*0
52,0
3145*9
64.3
2880.3
74.6
2805,9
51.7
2843.7
58.0
2567.8
132.5
3734*6
65 * 9
3211,7
75.6
3352.3
60*6
3512.4
50.8
3119.1
132.2
TOTALS
F
MEAN
0.84
STD*
0.31
DUR
F
MEAN
STD
TAKEN
17.9
19.0
6.2
AVEF4
11],
275,8
MEAN
STD
MEAN
STD
FOR
16.7
F
AVEF3
F RATIOS
309.6
STDF 1
MEAN
STD*
AND
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
=
:
=
7.53
3*97
18.02
273,0
32.0
F
=
60*50
2795.2
29*9
F
=
1
64.4
3381
75.98
MEANS,
STANDARD
F =
MAXF2
1212.1
28.0
1187*2
21.1
938.5
28.6
MEAN
STD.
968.6
43.9
1038.7
46.9
MEAN
STD
1045.9
51*5
:
:
924e4
29.9
F
MID2AV
:
951.3
62.5
F
MIDF2
MEAN
STD,
FOR
[0],
TAKEN ON
DAY
1
1026.2
22*4
997,0
30,1
1111.8
31.6
104797
37.6
1204*8
55*5
946.2
1021.4
31*4
997*0
30e1
1103e6
22*4
1034*9
39.5
1164*2
25o2
926.5
847.9
19.3
784*5
930*9
42*7
1085.5
24*7
880.8
20.6
823o1
68*7
1180,1
28.9
881.1
23.5
853*2
20*6
881.3
856*0
16*9
28o4
1158.0
21,0
51*74
864.5
42*1
F
FINAL2
875*2
26o4
1109.9
54v3
F
MINF2
MEAN
STD
F RATIOS
47.80
1119.6
57,5
F =
INITL2
MEAN
STD
AND
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
:
919.9
34.0
864.8
32.3
34o1
1147.8
25 ,
981*9
72o8
768*,
37*5
961.7
20.2
949*7
46e2
1075*3
100*3
907o1
46*4
1050.u
72.4
1146.3
46.8
963*0
29.8
1059*2
68.7
820*3
60*1
979
22
1145.1
44.5
964*8
36.5
1062.3
46.9
826.0
50*3
97906
16*7
33o48
79294
20#6
50*6
21.79
794*8
22.4
37.72
810*6
17*1
8
1
46.91
812*3
18.3
16.0
MEANS,
STANDARD
RANGE2
F
273*5
42 0
600*3
11.8
MEAN
STD
52907
25.2
449*3
2907
MEAN
STD,
57203
497
:
:
46906
13*1
F :
MIDF1
MEAN
STD
=
406*3
20.9
F
F1 MAX2
:
474 .9
23*4
F
F1MIN2
MEAN
STD.
178.3
15.7
212.5
26.3
481*6
5.8
507.5
8*1
523.9
22.2
475*0
466*1
487.8
[0o],
TAKEN
ON
DAY
1
517.6
19.4
13.99
82.8
28,7
419.4
8.3
116.8
53.6
222.9
79.7
177e4
61*3
196e3
24,6
10.8
460*9
21.2
471*8
22.8
460*3
9.2
480.7
10.8
5000
2507
446*3
12.1
453.4
21.8
451*4
429.8
12*9
46705
11.5
427.3
19*9
437*6
21e0
387.9
27.8
392*9
15*4
369.9
24.5
395e2
11*1
494 1
20.7
500*0
25.7
450.4
1294
453.7
17.7
468.7
23.1
437.5
21.2
473.4
10,9
454.4
12*6
473.0
16*7
436*4
9.9
418.4
796
407*7
11.3
394*4
29.7
399.5
4.7
5309
40*4
35.28
47702
22*5
F
INTTL 1
:
255* 1
24*7
F
MAXF I
MEAN
STD
FOR
2
SPEAKER
NUMBER
MEAN
STD
F RATIOS
DEVIATIONS AND
12.47
9.7
21*8
8.3
7e96
416.1
12.4
4350
6*4
24.51
477.0
6.8
33.75
457*5
10.4
MEANS.
STANDARD
DEVIATIONS
AND
F RATIOS FOR
[01.
TAKEN
ON
DAY
1
SPEAKER
NUMBER
F :
MID1AV
MEAN
STD
521.6
18.4
MEAN
STD.
6602
4.0
MEAN
STD.
-1*34
0.11
MEAN
STD*
2780
13.0
MEAN
STD,
2404*4
11.9
MEAN
STD.
3078.8
46.5
-0,64
0.29
:
:
3175*1
48.3
46o5
5*2
45*8
7o4
-0087
0,49
-0.44
0,28
-1.23
0 39
194,0
23*0
234*0
23*0
296.0
15.2
204*0
11*4
2205e7
26*9
2246*1
49.6
2252*3
19.0
1913*2
25*3
2400*0
45.1
2983.4
123*9
3007*5
3112*6
44*9
3244.1
53*9
3648*6
38_3o2
3407
4.9
65*0
1692
24*4
493
4406
14.3
-1.16
0.21
-1.23
0029
0012
0,31
-0088
0038
2120
222*0
16*4
234.0
15,2
2220.3
12*8
2407.4
17.1
2894.9
3124.2
6593
410*3
11.9
4407
9,9
20.67
1900
14*1
lII0
48.42
2233*0
19*(Q
F
AVEF4
:
398*1
3*4
419.1
9*6
473*3
12s2
11.53
238*0
21*7
F
AVEF3
28@,l
3.5
-1.45
0.29
F
DUR
:
400.6
30.6
436.7
1000
451.9
10.3
11.70
35o6
9.7
F
TOTALS
458.1
10.2
420*6
9*6
F =
STDF1
35*51
1922*2
160*1
16.70
2690.6
25*9
34.0
93*1
MEANS,
STANDARD
MEAN
STD
INI TL2
MEAN
STD*
MINF2
MEAN
STD
FINAL2
MEAN
STD
MIDF2
MEAN
STD,
MID2AV
MEAN
STD,
AND
F RATIOS
FOR
[l1
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F =
74.03
1051.8
4361
893,1
32.0
1022.7
23*2
1173.1
1173e55669
893.1
1021,1
22.8
1167,6
12.3
1038044.8
913.0
88,6
795,0
30.2
860*8
14.2
1079.1
95207
97968
98765
829,4
59*6
29.5
876*4
12*0
1155.0
40.5
103660
39.5
974,3
816.6
33.5
870 0
15.4
1099.6
32.2
961.6
7061
973*2
58,9
812,7
34,7
871*9
17.4
1098.2
34.4
966*4
1218.5
1196e 1
3464
F
=
422
23.94
1162.5
94.3
F
=
24.3
F
=
=
=
1046.5
44o6
19.5
49
1
18.33
119.3
28986
104869
45.2
F
32,0
22.15
925.6
F
6.9
4864
31*91
49.4
MFANS,
STANDARD
SPEAKER
NUMBER
DEVIATIONS
F :
MAXF 1
F
MEAN
=
INITL 1
F
MEAN
STD,
:
MEAN
STD
=
13.
F
=
F
MIDF 1
:
520.4
MEAN
STD,
13.6
a%
2
94.0
21.4
99*1
25.9
513.6
13.0
477.1
9.7
423 3
12*5
456.3
16.6
487*5
468.3
15.5
416.4
386e6
30.7
444 * 1
14,2
4410
10.9
433.2
10.7
36.0
19.5
493*9
15.1
45603
16.6
491.8
15.3
47108
12.5
420.3
13*9
412.9
13.5
441.,7
5.5
450.6
12.5
44504
15.2
37402
17.8
98.0
499*5
13*2
470,0
491.3
56.4
10.1
13.0
17*2
113.87
617.3
10.0
MEAN
STD,
DAY
6
433.9
28.3
F1MAX2
ON
161*9
13.5
28301
59*7
17.6
F
TAKEN
42.33
55409
F 1 MIN2
[0],
153.51
621 7
13,2
STD o
FOR
25.90
292.9
46.0
MEAN
STD*
F RATIOS
2
1
RANGE2
AND
63.48
ir
Ir
MEANS,
STANDARD
MEAN
STD
F
:
14.4
F :
MEAN
STD
8403
TOTALS
F
STD,
DUR
MEAN
STD.
AVEF3
MEAN
STD
AVEF4
MEAN
STD
F RATIOS
FOR
0o],
TAKEN ON
DAY
2
69.86
519.4
STDF 1
MEAN
AND
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
:
=
3146.5
81.4
8.7
373.6
18.0
48.1
9*2
27.4
3.0
36o3
1*7
25.3
9.9
37.5
7,3
-0 *99
0,49
-0.51
0 59
-1.22
0.13
-0.36
0.15
-0044
0 69
322o0
420 1
188.0
14.8
202.0
13.0
232,0
13.0
190 0
33.9
2212.4
182.6
2193.8
22.9
2266.9
17.4
2082*8
84o0
2942.8
3007.4
22*1
3173,6
294.3
2875*6
7507
9*44
2241 *0
2439o2
10.5
F
440 *6
28.02
302.0
14.8
F :
451*5
11.7
4.37
-1*28
0.26
F
4420
5.8
32.51
13.8
:
414 2
14.5
43*2
5*00
3191.8
77*0
17,5
MEANS,
STANDARD
MEAN
STD,
INTTL2
MEAN
STD*
MINF2
MEAN
STD
FINAL2
MEAN
STD
MIDF2
MEAN
STD
MID2AV
MEAN
STD.
AND
F
RATIOS
FOR
[o],
TAKEN
ON
BOTH DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
:
93.49
F
:
:
:
:
1046.2
45.4
1141.7
62*3
878.9
33.8
1021,3
25.9
1135.6
37.8
103608
39.9
888.8
70.2
79307
24.4
854.4
17.4
1082.3
21*3
941*8
48*4
96964
60.6
812.1
30.7
878.6
16.1
1167.6
35.7
992.8
96.7
949o3
5702
813.6
25.3
875.5
19.6
1123.0
45.2
962.3
37*9
946.5
812.5
26.1
876*6
16.5
1121.7
965*6
40.9
77e14
1043*8
43.7
F
1049.7
38*2
51.10
974.2
39.8
F :
1142.4
38.9
62.08
932o 1
25,9
F
1024.5
21.6
55.51
1174.8
6508
F
6294
884.1
29.2
115709
1215.3
29.8
78,50
53*3
4409
MEANS,
STANDARD
MEAN
STD.
MAXF 1
MEAN
STD.
INTTL 1
MEAN
STD.
F1MI N2
MEAN
STD.
F1MAX2
MEAN
STD*
MIDF1
MEAN
STD.
BOTH DAYS
10],
26991
4565
90.4
4209
170*1
16.3
60.1
108.0
46.9
40.8
488.3
21.0
475.8
9,9
510.6
10.7
47660
442.1
9,7
25.7
48361
20.2
461.,2
13.8
487.6
16.9
457.3
17.5
434.9
396.4
26,9
430.1
19.4
438.0
9.0
435.4
15.9
375.4
26.2
481*8
18.5
466e7
16.2
492*9
17.2
461
416.1
11.1
449.6
11.4
45265
12e0
440.9
13.0
AND
F
1
SPEAKER
NUMBER
RANGE2
TAKEN ON
RATIOS FOR
DEVIATIONS
F
=
54.24
283.2
42.8
F =
122.10
611.0
16.4
F
:
32.61
542.3
24.4
F
=
15.02
441,6
28.5
F
:
79.04
594.8
24.8
F
:
519.0
15.9
26.9
43760
1
16.3
23.1
68.82
396.3
26e6
_
-- _ _r
--
-- 41Lw
MEANS.
STANDARD
MEAN
STD*
F
=
F
MEAN
STD.
75.3
13.5
TOTALS
F
DUR
MEAN
STD.
AVEF3
MEAN
STD
AVEF4
MEAN
STD
F RATIOS
FOR
to10,
TAKEN
ON
BOTH
DAYS
72.66
:
:
:
:
3112.6
72s 0
28,1
3.2
35.5
3.6
24.8
7.2
41.1
11*3
-1.22
0 45
-0.57
0,44
-1.19
0 17
"-012
0.34
-0966
0*57
280 0
54*4
189,0
13.7
207.0
12.5
233.0
13.4
192 0
27,4
2237.0
32*0
2067.3
222.7
2207.0
22*4
2236o3
38o7
2164*5
107,9
3183.4
61.2
2816.7
13496
2951 .2
65 * 2
3078o5
235.3
2941.6
106.0
14.69
25.62
12.57
2421.8
21.2
F
438*7
9.1
41.8
11.1
2909 0
18.3
F
451.7
10*4
38.48
-1*31
0 19
F :
396.3
27 * 6
450,0
11.5
417.4
12.0
520e5
15.6
STDF1
MEAN
STD.
AND
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
11.12
MEANS,
STANDARD
F
MAXF2
1271.1
14.7
1209*1
24.7
1048.2
12*9
MEAN
STD*
110093
54*1
1160.6
9.5
1081.7
39.9
:
[U],
TAKEN
ON
DAY
1
1164.2
6*7
1163.8
44.5
1054.7
55.0
1158.3
16.5
1091*3
55.3
1194.2
22.4
894.6
18.2
978*5
63.0
1163.8
44,5
1040*3
32*6
1142.8
7*8
1077.2
53,1
1193* 1
20.4
888*3
25*4
960.8
47o4
925*8
3295
86093
11.2
1106.7
24*5
996.4
69*2
982,3
55.8
708.8
62 * 1
894.4
36*9
980*4
42*0
905.9
28*8
1184*8
32.7
1050*9
66.3
1056*6
107*4
89900
136*5
1031*8
63*9
931.8
31*4
876o3
21,8
1122 * 5
34o5
1007.6
73,1
1074*1
36*1
775*2
63,3
934*8
61.8
945*2
28.7
878*2
22.5
1127.6
29*0
1015.0
63.5
1077o7
27.4
771.4
41*3
932.2
53*6
26.16
:
1211.1
224*5
1168* 1
51*0
F
MID2AV
MEAN
STD*
FOR
8.90
F :
MIDF2
MEAN
STD
=
1030o4
89*7
F
FINAL2
1085.0
37.1
1180*7
227*4
F
MINF2
MEAN
STD*
F RATIOS
9.95
=
1205.3
222.5
F
INITL2
MEAN
STD*
AND
2
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
:
1150.0
43.5
928.6
33.7
5*97
949*8
30,0
41.53
944.7
24,0
58.98
948*1
24*5
MEANS,
STANDARD
RANGE2
F
222*9
6.9
457*0
14.2
MEAN
STD.
418*0
24.7
3690
5*0
MEAN
STD
432,9
8.0
381*9
3,8
:
=
:
310.4
20.7
F
MIDF1
MEAN
STD*
194.5
64*6
51.6
2497
374.0
23.0
331.7
909
371.7
24o9
343.7
TAKEN
ON
DAY
1
:
288.9
1061
94*9
211.9
185.8
84.1
49.6
63.2
56*7
4061
331.3
15.0
332.0
7.5
354,0
16*4
344,6
11.8
300.8
5.0
323.7
7,8
327.9
120
330.6
6.5
350*6
20*7
328*8
21.5
297 * 3
5,3
18.1
291.6
24,9
306.1
16.5
298*3
19.9
303*5
16*2
3188
17.2
27798
5*7
371*7
24.9
328.0
5,9
327,0
12.6
325.4
7.6
350.2
20,0
32994
21.0
294*3
2.6
344.2
20.4
298*4
21.3
304.3
6.9
295.2
23.9
325,9
9*4
324*0
16*5
281 * 1
8*9
3901
282*9
6 1
F
F1MAX2
:
156*4
35.7
317,7
23*0
F
F 1 MIN2
MEAN
STD
238.0
58.3
[U],
4.83
321,1
27.2
F
INITL 1
:
174*9
14599
F
MAXF1
MEAN
STD.
FOR
AND
2
SPEAKER
NUMBER
MEAN
STD*
F RATIOS
DEVIATIONS
341.9
7.4
18*73
3406 1
8.9
17.39
324.8
50
32.76
340, 1
7.3
21.57
323.0
7.9
MEANS,
STANDARD
DEVIATIONS
AND
F RATIOS
[U],
FOR
TAKEN
ON
DAY
1
SPEAKER
NUMBER
MID1AV
MEAN
STD*
F
379.7
5.6
STDF 1
MEAN
STD.
MEAN
STD.
35.1
5.2
MEAN
STD.
-0.90
MEAN
STD.
MEAN
STD.
2926.3
10.6
=
=
2233.6
49*9
F
AVEF4
7.9
18,8
7.8
8.8
3.0
16.6
2*6
15.6
492
8.3
2.5
13.9
2.4
20.7
9o6
-1.21
-1.66
-1.07
0.04
-0.60
0.44
0.31
:
3201.8
235.7
325*2
279.1
12.9
1.9
17.2
8.1
8.9
1.6
-0.32
0.52
0.25
0*50
17660
8.9
196.0
21*9
264*0
8.9
186.0
21.9
223060
22*6
2186.7
23.8
2236*0
17.0
1924*0
66.2
2386.5
40.2
334962
3045,3
157.5
321463
3086*7
158.2
3585*7
500.9
0.71
0.52
0.21
19060
19860
14.8
214.0
21.9
-1.02
0.59
22.98
17460
224*0
21e9
F
2385.7
21.3
22.9
3.12
2.11
F
AVEF3
:
322.0
298.7
298.4
19.7
11.10
0906
0.16
302.0
32.7
=
307*2
343.8
4.8
323o4
13.6
6.8
F
DUR
25.36
288.6
9.7
F
TOTALS
:
11.4
14.1
79.05
2131.5
19.0
229564
3043.8
2981*3
337060
2560
82.7
36*8
2117.2
13.6
30.8
5.76
t
~
21.2
a
32.7
~
*pr
4L~~
MEANS,
STANDARD
MEAN
STD
INITL2
MEAN
STD.
MINF2
MEAN
STD*
FINAL2
MEAN
STD
MIDF2
MEAN
STD
MID2AV
MEAN
STD
AND
F RATIOS
FOR
[U],
TAKEN ON
DAY
2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
:
23.91
1260.5
12.5
F
=
:
:
:
:
1146o 1
26.2
1159*6
48.5
1069.1
39.1
1096*7
47.9
1171.9
21.2
1087,5
39*6
1032*3
37*8
949*3
1098.9
1048.2
50.0
932.6
22.8
34o5
48*0
1096*5
53* 1
970.3
32 .1
967*2
12.3
1236.0
43,0
1201.8
113.4
1080.5
42.0
958,8
40.6
941.8
26*7
1137.8
2398
1068*5
53.9
1079*4
39*5
960.4
41.5
942.8
25.3
1140.5
30.6
1078.9
52*3
24.9
18.12
24.47
1139.8
38.4
F
1095*4
13.86
1062.8
49.6
F
1189.8
34.0
7.91
1033.9
25.9
F
1100.5
51.6
29.9
1192.3
42.0
F
1070.5
37 8
1195*0
27.72
will
e
d
MEANS,
STANDARD
MEAN
STD
MAXF1
MEAN
STD
INITL 1
MEAN
STD.
F1MIN2
MEAN
STD.
F1MAX2
MEAN
STD
MIDF1
MEAN
STD
F :
34,1
=
17.9
=
:
TAKEN
ON
DAY
2
=
381.3
8*4
121.2
50.6
167.9
40.2
90 .9
4798
47*2
30.2
325*3
8*6
342.1
9.7
38602
12.3
333.7
3.6
325.6
10.1
31793
10.9
337.9
12.2
384*4
10.1
328.5
7.0
323.4
11.8
300.4
7*9
322.5
10.6
34803
6,1
322.6
4.8
311.4
12.7
319.7
7.7
339.6
12.4
383*8
11.1
328.4
10.4
321.3
7.2
305.7
13.5
321.0
5.1
350.2
10.3
321 .5
3.6
312.0
11.2
59.34
427.0
21.1
F =
162.7
46*4
26*40
36206
14.9
F
[U],
55.14
42260
19.8
F
FOR
RATIOS
96.06
449.3
F
F
11.27
226.6
F
AND
2
1
SPEAKER
NUMBER
RANGE2
DEVIATIONS
46.69
_1__ _____
_____~____
_
~ _ __ __~_ _
MEANS,
STANDARD
MEAN
STD.
F :
F
MEAN
STD.
33.9
8.7
TOTALS
F
DUR
MEAN
STD
AVEF3
MEAN
STD
AVEF4
MEAN
STD
F RATIOS
FOR
[U],
TAKEN
ON DAY
2
61.63
383.0
7.1
STDF 1
MEAN
STD*
AND
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
:
:
:
3100.6
118,0
11.0
2.1
10.0
2.0
20*7
6.1
320 0
3.7
311.3
10.7
11.7
4*7
11.9
3.8
22
0 37
0 * 07
0,35
0 56
0 79
-1
-0 *54
0 32
-1
296*0
27.9
174o 0
8o9
182*0
13*0
232*0
2182 * 2
49*4
2069.3
2128*6
17.1
2293.8
10.0
3263.8
3049.6
52 * 4
2962*0
29*5
3291
04
0*43
48*22
23,9
0
29.2
170
63.97
2403.2
27.7
F :
351.0
7.0
11.91
322 ,0
16.4
F
322.4
5.5
16.57
-0.81
0.08
F :
304,2
13.1
35,9
2093.3
54*6
19.45
67*9
___
0
127.4
__._ _ .
___llL
2871.3
61.3
_~__
_ __L
MEANS,
STANDARD
MEAN
STD
INITL2
MEAN
STD
MINF2
MEAN
STD.
FINAL2
MEAN
STD
MIDF2
MEAN
STD*
MID2AV
MEAN
STD
AND
F RATIOS
FOR
[U],
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F =
10009
1265.8
14.0
F :
:
=
1155.1
20.4
1093.3
40.5
1170 * 1
155*4
1075.4
37.8
1130.3
56.1
1157.3
21.5
1082.3
44*5
1031.3
64*9
93990
41.6
929*2
26*7
1102.8
28.5
1022.3
62*,4
1153o8
165*2
960,0
31.2
973*8
30 0
1210.4
45.0
1126*3
118.3
1124,3
63.8
951 7
32*3
936*8
28*,0
1130.2
29*1
1038 * 0
68o5
1114.7
54*0
954.2
32 * 8
944*0
25*5
1134.1
28.9
1047 0
64,4
43.52
1150.2
28.6
F
1174o 1
30.2
12.54
1081.6
52s8
F :
1132*2
56*4
22.12
1041 .0
20.7
F =
1077,7
36.1
4.60
1200.7
33.7
F
1200.2
149*8
50.59
I _I___
__ ____1
__Y_
_____
___I__
_L_~_ _~__)___
MEANS,
STANDARD
MEAN
STD
MAXF 1
MEAN
STD
INITL1
MEAN
STD,
F1 MIN2
MEAN
STD
F1MAX2
MEAN
STD
MIDF1
MEAN
STD*
AND
F RATIOS
FOR
CU],
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
RANGE2
DEVIATIONS
F
=
12*42
224.8
23.3
F
=
:
21.2
=
=
:
381.6
6.2
71.0
46.2
323*2
19.1
342.0
8.1
380 1
18.5
332.5
10,4
32808
9.0
317.5
16.9
339.0
10.2
378,0
19.1
328.2
9.3
327,0
9,8
291.7
11.3
32306
3460
7.9
12.9
314.3
14.4
304.9
17.2
315.0
339.9
9e6
377*8
19*3
327*7
10.9
32394
322.0
347*2
15,5
312,9
10.4
30396
19.7
104.20
429.9
15.4
F
71.3
41.4
45.73
365,8
11.0
F
203o0
60.0
67*89
4200
F
138.8
45.2
123.61
453.2
15.7
F
168 B
102.3
15.5
7.3
59.23
297*3
14*3
6.3
a- afi
ir
%
e
MEANS,
STANDARD
MEAN
STD,
F
=
F =
MEAN
STD
3465
TOTALS
F
DUR
MEAN
STD
AVEF3
MEAN
STD*
AVEF4
MEAN
STD
F RATIOS
FOR
[U],
TAKEN
ON
BOTH
DAYS
75.61
381 .3
693
STDF1
MEAN
STD
AND
1
SPEAKER
NUMBER
MID1AV
DEVIATIONS
0013
:
=
250
:
3013.5
121.2
305.0
15.9
12.3
5.0
9.4
2.5
18.6
4.9
10.0
4.0
12*9
3*2
-0.24
1.46
-1.13
0*37
-1.44
0058
0.06
0*27
-0.02
0.86
260 *0
4407
174.0
9.7
186*0
223.0
23.6
173.0
20.6
2207*9
54* 1
2093.3
2130e0
17.1
2261.9
37.5
2140.0
35.9
3232*8
166*7
3046.7
3808
2971.6
59,4
332001
9104
295803
13.5
69.97
239404
F
313.6
89
47.07
312.0
2696
F
347*4
14o5
6.81
-0*86
F
32209
4.9
42.70
6.8
=
29604
13.6
63.2
17.S3
145*2
f9
MEANS,STANDARD
MAXF 1
F
594*6
7.7
390.9
MEAN
STD.
MEAN
445*3
STD.
21.8
FINAL 1
MEAN
STD.
F
RATIOS FOR
[RE],
TAKEN
ON
DAY
1
1202.6
39.7
47.53
504.9
14.0
=
537.8
170
:
1098*6
51.6
548.9
10.8
586*8
10.8
537.0
13.0
481.3
494.7
514,9
8.2
10.7
16.3
546.9
18.1
10.53
434 * 1
13.4
403.4
10.2
436*2
7.9
416*6
12*6
406.6
10.5
364*1
33*4
372*2
9.5
370.5
14.5
538.7
11.2
580 1
11.0
523.4
8*9
457.4
460*7
14.9
471.1
7*3
506.1
20.0
412.9
12.3
460.9
415.8
12.5
427.8
11.8
362*0
27.4
373*7
15.5
369*7
537*2
13*5
556*0
30.2
515.7
7,8
454.7
17.1
453*5
18.7
466*5
5*2
500*4
15.0
1081.8
1210.2
43.9
39*6
1140*6
35.3
1220.7
95.2
1191.8
89*9
988.5
82*7
1190.3
80.0
30.29
499*2
14*2
20.2
20.11
446* 0
8.9
25* 0
F
MINF2
=
424.9
F
549.0
25 * 1
=
555 8
26* 1
F
INITL 1
MEAN
STD.
17.7
F
571.3
32.3
:
420* 1
30.5
FlMAX3
:
571.1
12.5
F
F1MIN3
MEAN
STD.
AND
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
8*3
17.4
23.49
500 7
14.3
6.45
1193.6
61.7
MEANSSTANDARD
1714.5
15.4
1675.6
48.3
1204.8
41.4
1299.3
60.3
ERE].
TAKEN
ON
DAY
1
1647.3
30.4
171896
62.8
1972*4
3706
1679*1
36.4
1528*3
33.4
1963.2
54.9
1220.7
1245.2
27*2
95s2
57*8
1031*5
51.0
1343.6
75*8
1271.5
38o0
1187.2
35*1
1372.1
92*0
1255o7
50e4
1028*0
62o5
1333.2
167.9
1391.6
19.5
1548.3
15.3
174794
112.8
1649*5
30*2
1678o6
1524.9
39e5
39.7
1972*4
37o6
1525.3
31.7
1589.0
21.2
1526.4
50.8
1713*3
72.5
1710.8
33*6
1601.7
1780.2
1664*7
25*8
21*8
32*4
53*2
125.6
35,5
1400.9
20*6
1589.5
6590
1760.0
98.0
165405
1110.7
31.6
1218o6
56*6
1185.1
1186.9
34.4
168296
34.6
43.32
:
1752*7
32*9
1234.8
52*2
:
1218o3
102.9
:
1747*1
1994
F
MINF3
153591
33.7
1522.8
F
FINAL2
MEAN
STD.
FOR
1665*7
F
INITL22
MEAN
STD,
RATIOS
33.79
F :
F2MIN3
MEAN
STD*
F
1784*8
F
F2MAX3
MEAN
STD*
=
F
MAXF2
MEAN
STD
AND
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
:
1563*8
35.6
1644.9
43*0
27,8
10.72
1240*1
48.7
6.98
1294*5
79*1
57.74
1634.4
27*2
26.55
1552.6
30.7
129792
82.8
1778.5
116.9
MEANS,STANDARD DEVIATIONS
F
MAXF3
2609.8
45.0
1808.9
101.6
2597.5
40o2
759*0
32.6
MEAN
STD*
2693*1
48@3
=
=
594*6
14*4
=
2915.0
69*4
F =
F4MAX3
MEAN
STD*
[RE],
TAKEN
ON
DAY
1
3413o8
114.4
2471*6
76.7
2318.8
60*1
2283.9
155.0
2283.3
102.2
2474*6
59*7
2355.2
108.3
2780.7
1552.8
25o3
1622.6
1547*5
25*7
70e4
1757.4
79.5
1758*2
40.2
1327o2
77*8
1812.8
123.9
245296
110*4
2280*8
54*7
2276*4
148*7
2280*4
98.5
2454o5
63.0
2340*2
2730.8
75,0
557.2
15,6
426.9
22.7
467.5
58.8
615*0
538.3
22o9
22*9
3407.2
22.1
2857*1
2194
3612.1
85*6
2825.0
182.8
3087.2
25197
2741*6
8292
3113*3
454.5
3380*4
34.9
3425*3
73*8
3556*1
106.1
3014.1
182,7
3217.1
86.0
3194*5
77.9
3874.8
247*5
43e1
21*28
2609.7
5397
F
F4MIN3
2607.7
4993
1605*4
54.9
F
AVE3M2
MEAN
STD
FOR
19.76
2679.8
117.0
F
FINAL3
MEAN
STD.
:
F =
INITL3
MEAN
STD
F RATIOS
2
SPEAKER
NUMBER
MEAN
STD*
AND
3690*8
83.8
1625.8
61*3
17.36
258195
36.9
122*3
30.12
652o9
52.2
608.9
24.9
585*9
67*2
11.40
3165.8
244.1
21.59
3250*9
6195
DEVIATIONS
MEANSISTANDARD
INTTL4
F
2727.4
57*6
3408.9
96.0
3239*0
23.7
3206*6
10.6
:
954*7
9993
92*3
F
7967
1.35
256*0
8.9
:
10,57
1
F
DUR
MEAN
STD
3686*1
33*2
886e6
SLOPE3
MEAN
STD
:
F
RANGE4
MEAN
STD,
2921.9
56*3
F =
AVEF4
MEAN
STD.
-
F
FINAL4
MEAN
STD*
F RATIOS
FOR
[REI.
TAKEN
ON DAY
1
2
SPEAKER
NUMBER
MEAN
STD,
AND
079
=
214*0
20.7
14.69
317792
120.5
3355*4
44.6
2849*3
27.8
3612.9
89,6
2915.7
63.8
3091.4
202.0
2786.9
3056.5
89.1
413.7
3375.4
35*0
3409.9
22*8
3452*9
198.5
3021.9
18708
3231 .7
6496
3080.3
3855.1
291.3
3341.6
3076.9
3566*5
287B.8
41.4
21*8
114.1
3090.2
4491
3093*2
26.1
728*0
42.8
273*4
151*8
329,1
213,3
416*9
79.2
690*4
112*3
920.4
24996
8.03
0.55
6.12
1.17
5o49
1.91
7.15
0.36
7.42
1a20
9,72
0 o67
196*0
3291
172*0
19.2
180.0
14*1
14.32
3273o7
137.9
171.3
10.13
3225. 1
87o 7
5403
3461*3
412*6
22.82
362o3
71.4
236,9
58.4
13.50
11.78
1.15
8.11
0,74
16.68
168.0
8.4
206,0
11.4
170,0
10.0
258.0
25.9
192o0
14.8
MEANS.STANDARD
MEAN
STD
F 1 MIN3
MEAN
STD*
F1MAX3
MEAN
STD
INITL 1
MEAN
STD
FINAL 1
MEAN
STD
MINF2
MEAN
STD
AND
F RATIOS
FOR
[RE],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF1
DEVIATIONS
F
:
29.39
583o5
10.9
F
:
23.6
:
:
1160.2
30.4
454,9
21.1
410.3
22.6
413.5
4.2
440.6
12.1
435,0
10.4
379.5
17.3
519.5
49405
19.5
16.0
542*0
14*8
515.0
35.1
424.4
1398
19*3
414.9
7,9
441.6
896
42602
9*9
374.8
26,5
522,5
170
501.5
5.5
543.1
16.1
515.0
35.1
424.4
13*8
1002.8
24.2
1207,6
6.7
1060.4
1181.5
38.1
120992
76.0
396* 1
27o32
53602
6.6
F :
567.8
36.5
10*32
443.0
27.8
F
548*2
12.8
25.13
562,1
21.3
F
506.7
8.9
9.73
396.1
F =
550*3
110
20.02
46,7
MEANSSTANDARD
MEAN
STD.
F2MAX3
MEAN
STD.
F2MIN3
MEAN
STD,
INIT L2
MEAN
STD
FINAL2
MEAN
STD
MINF3
MEAN
STD
AND
F RATIOS
FOR
[RE],
TAKEN
ON
DAY 2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
36.10
1739.0
57.7
F :
6502
:
:
1664.9
44*8
1106.3
890 1
1249,6
1286.0
50.7
1306.1
27.7
1172.6
1225.0
43.5
1268.0
34*2
1710.6
21.8
1619.3
30.9
143907
2609
1827,5
53.7
1591.9
1458*6
1550,8
19.8
1545o2
44.5
1645,8
32.5
1652.7
42e0
1702.6
6301
1633,5
9,5
143792
1178*7
56*2
1229.5
30,1
1081*3
9303
2708
56.6
82*2
50.25
1701.0
28.7
F :
1591.9
66.8
27.2
8.51
1227.1
50.8
F :
1827.5
53.7
1511*1
24,7
6.68
1166.0
33.8
F
1592.0
66.7
1659.2
32.81
1732*3
F
1830.1
49.7
179901
33.2
6608
15.22
77*3
___
~_
MEANS.STANDARD DEVIATIONS
MEAN
STD
INITL3
MEAN
STD
FINAL3
MEAN
STD*
AVE3M2
MEAN
STD.
F4MIN3
MEAN
STD
F4MAX3
MEAN
STD*
F RATIOS
FOR
[RE],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF3
AND
F =
13.78
262502
36.6
F
=
:
:
=
=
3430.8
80.9
8307
2217.9
182.5
1515*6
1580,8
20,5
156302
1665.8
41.0
1675*8
33*8
2343.4
225.9
2455*1
48.3
2449o6
83*7
2217.9
182.5
19*3
505.2
18.5
584.7
22.4
426.7
26,8
401.7
38.0
2898o9
119.7
3100.9
65,0
3454o0
77o8
3362o4
365,5
2889*2
214e1
366290
173*6
2993.7
90,1
3309.0
106.5
3311.2
70.5
2799.3
181.6
2657.6
34*5
4207
128.74
641
2
10.90
2783.9
58.2
F
244906
8.29
730,9
20.5
F
2456*8
46.4
54*3
2606.6
35.2
F
2428.7
110.3
12.75
169704
67.8
F
2680.4
48,4
30.51
J--
--- -- ---
---
----- ~
--
------- ~ ---- ~ -~-~----~
Il-----~----
C-- ------
-- 1-
-I------
MEANS,STANDARD
MEAN
STD
FINAL4
MEAN
STD*
AVEF4
MEAN
STD
RANGE4
MEAN
STD
F
F
:
F
:
FOR
[RE].
TAKEN
ON
DAY
2
F =
:
MEAN
STD.
8.27
0.85
DUR
F :
266.0
15.2
3404.9
401,6
2859 1
210.6
3678*6
69,9
2910.9
181.6
3329.5
3311,2
70.5
2799*3
3225o8
87*6
3058.4
44 * 7
3324,0
3423.6
187.0
2799*9
25.88
135.7
181.6
21.51
69*5
132*5
33.25
750*6
85*6
:
3452.4
81*1
146*5
3209.7
23.2
F
3212s 0
29,7
2880.7
3375.2
166.6
F
C
F RATIOS
10.47
2827.2
20.4
SLOPE3
MEAN
STD
AND
1
SPEAKER
NUMBER
INITL4
DEVIATIONS
989.3
67*0
418.1
117,3
326*7
42,3
444*3
105.3
260*0
180.4
12057
0097
8*63
0*62
7089
0 76
6.37
0.19
6962
1.01
282*0
50.7
180,0
12.2
186*0
15.2
214.0
8.9
16890
19.2
40.87
18.78
c
9
MEANS.STANDARD
MEAN
STD
FIMIN3
MEAN
STD.
F1MAX3
MEAN
STD*
INITL 1
MEAN
STD
FINAL 1
MEAN
STD
MINF2
MEAN
STD
F RATIOS
FOR
[RE].
TAKEN ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF1
DEVIATIONS AND
F
:
57.52
589.1
10.7
F
:
:
:
=
468.1
20.5
415.2
19.9
423.8
14.3
422.0
22*3
425.8
14.6
393,0
19.6
53707
29.0
496.9
14.5
540.4
519.2
24.5
440.9
12.5
410.5
26,0
430.5
18.2
427.2
18.1
421.0
11.9
401.3
34,0
530.2
17.9
501 1
10.2
540.2
14.4
515.4
24.0
439*6
21.7
1071o1
44,2
1161.0
40.8
1215.0
81.4
23.8
44.12
542.6
18.6
F :
552.4
30.5
4.33
44402
23.6
F
548-6
11i 1
37.83
56607
26.2
F
505.8
11.1
5.80
393.5
25.8
F
560.7
15,6
16*28
1181.4
1050.7
40.2
63.2
1200.6
42.0
ap
at
MEANSSTANDARD
MEAN
STD
F2MAX3
MEAN
STD,*
F2MIN3
MEAN
STD.
INITL2
MEAN
STD.
FINAL2
MEAN
STD
MINF3
MEAN
STD
AND
F
RATIOS
FOR
[RE].
TAKEN
ON
BOTH DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
42.67
1517.0
28.9
1805,1
93.8
1628*3
63*3
1639.2
29.9
1419*1
30 * 0
1793.8
82 * 5
1623.2
1206.8
59,1
1234.8
38.6
1108.5
63* 1
1217.3
53.9
1253*4
79,7
1149.8
117.4
1300.3
56o2
1179*7
33e2
1206.1
42.2
1320 1
98*9
1674,2
1728*9
1626 * 9
39.7
27.4
1415.6
33*6
1787,5
93.4
1620e7
57*5
1535*3
37*9
1586.1
1683.0
74*7
64*4
1726.7
41.9
F
:
=
65.0
=
F =
1691.8
58*7
58*4
8.31
1263*2
F
1727 * 6
54o3
22.2
7*83
1185.4
41.1
F
1662o4
53.49
1704.0
61.8
F :
1791.9
29o 0
60.14
28.6
16.55
1511.2
79*,3
1551.7
24.4
MEANS,STANDARD
MEAN
STD,
INITL3
MEAN
STD
FINAL3
MEAN
STD.
AVE3M2
MEAN
STD
F4MIN3
MEAN
STD
F4MAX3
MEAN
STD,
AND
F RATIOS
FOR
IRE].
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF3
DEVIATIONS
F
=
21*69
2518.2
124.0
2464.2
60.3
2366*7
146o4
2250*6
143.6
69*9
1603.3
49.2
155800
33.6
1606.6
82.7
1716e6
71.9
2633.6
49*5
2462.5
197,6
245308
8003
2363,0
145.9
2249.1
142*1
617.9
579,0
86.1
59608
25.7
42608
23.4
434.6
29*3
29070
9206
3133.3
171.8
3430*6
3487,3
59*3
28207
190.7
3676*4
129,4
3122*3
153.8
334407
8306
3433.6
154o5
290607
2617.5
2680.1
39.5
8494
F
=
13.32
1560*5
1753.2
100.4
F
=
13.79
2602.1
36.0
F :
63.29
745*0
29o6
F
=
35.91
2738.5
69*5
F
:
3422.3
93.8
58*1
2857
1
35.39
205.7
MEANSSTANDARD
SPEAKER
NUMBER
1
INITL4
F :
MEAN
STD.
FINAL4
MEAN
STD
AVEF4
MEAN
STD
RANGE4
MEAN
STD*
AND
F RATIOS
FOR
RE],. TAKEN
ON
BOTH
DAYS
39.37
2777.3
2901*3
66.5
106.8
319406
84,7
3403*9
80#1
3508.9
29504
2887.4
14907
3682,4
51.8
3092,3
24403
335204
9605
3382.1
2910*6
3216.2
5907
3141.8
3332*8
5003
3495*0
283903
146.4
123.8
972*0
78*2
39002
96.2
281*8
358,8
152.6
294*6
11.57
1.72
10.21
1*87
8.00
0,72
6024
0.80
6.06
1 *56
24890
51.2
174*0
11.7
196*0
205.0
24.2
170o0
18.3
F
:
27.29
3392*0
129 *4
F
:
2609
F
=
:
MEAN
STD*
7.97
DUR
F
261e0
12.9
109.7
6704
189*8
25.30
1.11
=
210.0
57.90
818.6
113.0
F
15900
51.51
3224.3
SLOPE3
MEAN
STD*
DEVIATIONS
20.90
16.5
v
W,
MEANS,
STANDARD
DEVIATIONS
710.4
13.5
677.5
30.8
560.4
25.4
INITL 1
594o6
14.7
ON
DAY
1
534.2
15.6
:
555.4
10.0
578*0
30.3
526.2
8.1
627.8
23.1
9.4
551 .6
10.5
5507
40.8
573.8
18.1
490*1
21.5
425.6
29.8
492.2
19.1
599.0
9*5
583.9
17.6
606.4
19.8
638*3
12*4
589.0
44*5
515.8
16.4
47298
464*2
28*3
21.9
574.6
15.6
593.2
23.0
611.6
19*3
574,6
25*2
520.3
16.5
481.6
29.4
481*3
10*8
568.9
9.6
498*2
491.0
16.7
10*5
500.5
29.0
512*1
14,8
464*2
16*6
419.0
15.9
430.5
20.5
430*7
32*7
965*6
18.7
1067.9
28.6
964.7
14.1
996.3
9.8
850.0
13.2
89503
18.3
569*9
34o17
:
37.82
616*4
9*8
=
:
566.3
9.7
19.18
492.5
16*7
F
1055.0
22*3
656.7
17.2
31.78
626*3
9*1
F
MINF2
MEAN
STD,
TAKEN
654.2
8.9
4901
F
FINAL 1
MEAN
STD*
LAR3,
612.7
20.7
610.8
9.8
561.3
F
F1MAX3
MEAN
STD
638*6
8.2
F :
F 1 MIN3
MEAN
STD
RATIOS FoR
51. 95
F =
MAXF 1
MEAN
STD
F
3
SPEAKER
NUMBER
MEAN
STD
AND
131.20
1142.9
11.1
952.8
32*6
1154.8
12.6
MEANS,
STANDARD
F
MAXF2
1539*3
27.8
1080*1
3698
1259*6
92,3
1077.8
39.1
1539.3
27.8
1944.6
44.8
:
1199.1
26.2
:
1560*2
29*8
F
MINF3
MEAN
STD,
1491*4
48.9
F
FINAL2
MEAN
STD.
1204.0
35.1
F
INITL2
MEAN
STD.
=
F :
F2MIN3
MEAN
STDe
;
1560.2
29.8
F
F2MAX3
MEAN
STD
AND
F RATIOS
FOR
CAR].
TAKEN
ON
DAY
1
2
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
:
1789*2
48o2
28.55
1429.5
219
1453*2
29.5
1441*1
49*7
1500.8
41*0
1321.3
44*0
1470.4
42*1
1355.5
74.3
1656o9
1179o5
10.5
1023.2
58.6
1106.0
31.7
981.8
12.7
1011*7
9,6
928*5
23*2
921.0
24.0
1282*4
38.0
1353.6
24.4
131397
48o0
1244.9
85.9
1454 5
34*3
1140.0
1361.4
97.1
69.1
22,0
41.94
1026*6
50.2
11*27
1130.8
156.0
61*85
980*4
39.0
1165.4
16.4
97492
12.6
1112*2
36.3
985.5
10.7
1019.9
12.5
908.4
45.4
913.1
20.8
1453.2
29.5
1441* 1
4967
1500*4
41*6
1321.3
44.0
1470*4
42,1
1355,5
74.3
1656*9
22#0
1713v4
31.8
1714.8
91.5
1759.8
21*7
1584.6
106.6
17700
6396
1521.3
84*3
1815.8
32.5
28.47
1429*5
21.9
18*39
1607*3
65*1
MEANS,
STANDARD
F
MAXF3
2249.0
54.9
2215.7
60.5
MEAN
STD.
2091*6
42.5
878.0
38.8
3054.6
43*7
[AR],
FoR
TAKEN
ON
DAY
1
3048.6
80.0
2290 .3
43.8
2396*7
51.9
2109.5
47.3
2116.4
42*9
2224.8
57*7
1906*7
48*3
2265.1
55.7
2273,9
44,0
2307*3
38.6
2075e3
34.0
2112.7
44.8
2211*7
46*0
1896*6
53*6
2251*6
68*4
1822.7
51*4
1781.1
83.3
1879*0
1628*3
65*5
1812*1
78*0
1638.3
91.7
2028.7
15.4
723.4
17.7
973.1
44.1
775.8
52.2
780.9
84,0
875.0
62.7
725*4
46.8
86506
48.1
3333.8
38.3
2907.7
64.1
3480.9
94.5
2934*6
121.6
3019.3
132*4
3229.4
78.2
3556.4
101*3
3305.6
44.5
3017.0
89.3
3350.9
96*4
2838.9
71.1
3330.8
366.5
3312*2
89*6
340401
63 3
22.49
1816.6
162.5
:
29o04
=
698.5
71.4
3376*3
47.2
F
F4MAX3
MEAN
STD
:
F =
F4MIN3
MEAN
STD.
2051.9
310
1822.7
59.8
F
AVE3M2
MEAN
STD.
F RATIOS
30.81
2154*3
111.0
F
FINAL3
m
2168.8
9992
F
INI TL3
MEAN
STD*
AND
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
:
331695
37*3
1730*2
30.0
5804
17.37
650.1
44o4
37.70
2703*2
187.7
9*15
2848.0
281.2
rf
rC
p
Ww
MEANS,
STANDARD
F
INI TL4
3089.1
70.8
2838.5
49.2
MEAN
STD
3036.9
35.3
RANGE4
MEAN
STD*
308.6
85.8
:
=
199.3
58*8
F :
-1.33
0.51
-3.19
0.63
F
DUR
MEAN
STD.
:
3335.2
34.3
F
SLOPE3
MEAN
STD,
F RATIOS
[AR),
FOR
TAKEN
ON
DAY
1
86.83
3268*6
53.3
F
AVEF4
:
333098
39*6
F
FINAL4
MEAN
STD*
AND
2
SPEAKER
NUMBER
MEAN
STD*
DEVIATIONS
314.0
11.4
:
254*0
23.0
2662*8
28*5
3367.7
74*0
2824.6
82*5
3431.8
585
3325*5
97*3
3418*4
58*6
2833.7
46*7
3375.4
109.8
3001.8
120.1
3028*2
107*2
3076.0
119.3
3599*0
13908
33180 1
28*4
2952.9
19*8
3411*3
67.6
2864.0
47.0
3342*4
139.0
3248.5
25.5
3490.9
76o0
353o7
104.6
311.9
101.7
2307
97*5
390.2
270.7
692.3
238.2
395*2
120*0
280.5
130.7
-5.24
0,34
-6.23
0.88
-3.18
0.20
-4.70
1.00
-2.61
0,37
-1.94
0.71
-3075
0 79
266.0
20.7
236*0
15.2
256.0
15.2
232.0
14.8
238.0
14*8
296.0
37.8
230.0
10.0
3303.5
63.5
2975*6
3096*5
114.4
4504
11.98
2787*8
433*7
89*41
266205
70*6
6.00
777*1
318*6
15.63
-2.44
1.93
14.13
208.0
110
r
f-
4ppop
r
v
MEANS,
STANDARD
MEAN
STD
F1MIN3
MEAN
STD
F1MAX3
MEAN
STD
IN T TL 1
MEAN
STD.
FINAL
MEAN
STD*
MINF2
MEAN
STD,
AND
F RATIOS
FOR
[AR].
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF1
DEVIATIONS
F
=
151.71
695,8
13.7
F
:
:
19.6
15.4
:
:
1020.9
22.2
538.8
9.9
53608
3903
545.8
22.7
570.9
11.5
581.5
22.3
46801
12.4
600.6
4.7
570.3
14.0
602*3
7.4
626.5
31.4
501 0
20.2
59901
7*3
579.0
3.6
608.2
6.2
601.1
21.4
500.9
14.9
502.4
1909
494.9
6.8
501.4
12.0
517.5
2903
44793
27,2
1090.8
42.9
953,7
16.3
1166.2
12.4
1085.4
21 *
968.7
13*9
7.50
504.6
13.8
F
670.4
7.2
48.31
599.4
F
618.9
9.7
27.61
574.6
F :
618.9
5.8
28.38
631.7
17.0
F
621 7
10*5
58.57
MEANS,
STANDARD
MEAN
STD
F2MAX3
MEAN
STD
F2MIN3
MEAN
STD *
INITL 2
MEAN
STD *
FINAL2
MEAN
STD
MINF3
MEAN
STD,
AND
F
RATIOS
FOR
[AR].
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
:
21*28
1571.3
2507
F
:
:
=
190005
16.9
977.6
14.7
1180*2
18.5
1124.1
998*8
17.8
8.3
1448.0
84*6
1312.3
63.9
1263,3
1350,7
24.9
1208*4
5705
1160.6
986,1
12.5
1180*2
19.5
1111.6
26e6
980.0
19.1
154693
84.6
1395.6
52.2
1436.1
28*0
1490e0
4907
128101
46 1
1791.6
69,9
1667.5
26.3
1743.8
21.9
1750o 1
25.6
1593,3
50.8
30.6
250
21.55
1571 .3
25.7
F
1167o5
4907
81.39
1051.2
22.5
F :
1490o0
10.97
45.9
:
1436.1
28*0
31*2
129804
F
139596
52*2
79.58
1044.1
30.7
F
128207
48.5
1549o0
8495
34.61
MEANS.
STANDARD
MEAN
STD
INITL3
MEAN
STD
FINAL3
MEAN
STD
AVE3M2
MEAN
STD*
F4MIN3
MEAN
STD
F4MAX3
MEAN
STD
AND
F RATIOS
FOR
CAR]o
TAKEN ON
DAY
2
1
SPEAKER
NUMBER
MAXF3
DEVIATIONS
F
:
10.68
2074.9
63.9
2270*1
3260
2175.4
10.6
2042*6
2176*3
55.9
2037.0
2263.4
3768
2154.4
1970.7
I1a4
87o3
1871*1
113o0
1708.4
2565
1825.6
1791 6
17.3
161298
3894
771.3
702,5
52,8
729.9
170
814.8
21.9
72768
2881.5
107,1
3421.4
17,2
3358.9
143.1
284964
78,2
290265
3289*8
3144,6
47.7
106.4
2834.2
56*0
2245.2
2213.8
39.9
4763
F
:
19.84
2183.6
42.2
F
=
:
52,9
3067.6
102.5
6869
39.83
3185o7
71.6
F :
41.6
9.22
862.3
30 1
F
57.3
28.82
1992.9
32.7
F =
122*7
329996
44.6
19.68
330260
113.9
13169
MEANS,
STANDARD
MEAN
STD
FINAL4
MEAN
STD
AVEF4
MEAN
STD
RANGE4
MEAN
STD
SLOPE3
MEAN
STD
DUR
MEAN
STD,*
AND
F RATIOS
FoR
[AR], TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
INITL4
DEVIATIONS
F =
27.03
3100.9
92.1
F =
:
:
:
:
334a0
15.2
2815.0
88*5
3224o1
7908
3054.1
152,0
319568
75* 1
3319.8
85.0
2886.2
133.7
3292*9
45*9
2919*4
55.7
3293*9
3205.2
57.4
2843.6
7403
362o1
156.8
321 6
100.6
485*3
158,3
478.2
240,8
440.6
249,8
-3.12
0*93
"3.70
0.87
-4.89
0057
"4*42
0.28
-3*74
0,68
304*0
36*5
208.0
11.0
248o0
16*4
250,0
18.7
208.0
21.7
66.8
20.12
-1.14
0.27
F
3223.9
108.2
0.72
371 8
98.8
F
3309,2
114.7
57.89
3076,4
25.5
F
288008
58,3
14.58
2925e8
44.3
F
3264.5
56,9
28.27
MEANS,
STANDARD
AND
F RATIOS
FOR
[AR).
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
F :
MAXF 1
154.08
703.1
15.0
MEAN
STD
F :
F 1 MIN3
33.7
F
F 1 MAX3
=
F
INITL 1
:
14.4
F
FINAL 1
=
F
MINF2
MEAN
STD
:
1037,9
27o6
p
663.5
14.4
547.1
12.8
549*1
43.9
557.9
20.7
561*2
14.5
577.7
19.6
479.1
20.2
613*4
15.2
577.1
16.6
604.4
14.3
607.8
41.4
508.4
19.0
607*7
12.2
572,6
9*7
600.7
17&7
587.8
26.1
510.6
18.0
497.4
18.1
496.5
12.2
496.2
12,0
514.8
22.1
45598
23.0
1116.9
40.4
953.3
24.3
1160.5
13.2
1076o7
25.4
966.7
13.4
14.62
519*4
20.9
MEAN
STD
615.8
15.6
43.44
597.0
MEAN
STD
614.8
8.7
28*31
567.5
22.6
MEAN
STD
630.1
12.6
42.43
654.6
MEAN
STD,
w
DEVIATIONS
101*90
MEANS,
STANDARD
MEAN
STD.
F2MAX3
MEAN
STD
F2MIN3
MEAN
STD
INITL2
MEAN
STD
FINAL2
MEAN
STD
MINF3
MEAN
STD
F RATIOS
AND
FOR
[ARl,
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
49.72
1555.3
30.3
F
:
:
1469*7
69,0
1179*8
1302
0
4892
1179.9
14*2
1115.0
26.0
990 * 3
122105
147.6
127209
1332.2
41.0
122607
34.1
983,3
27.5
117208
18.7
1111.9
29.4
98208
1412.6
41.8
1444*6
28,6
149502
1301.2
60.3
43.5
47.5
1790.4
163704
56*6
56,5
172806
3003
1754.9
23.0
1588.9
78*9
43o4
:
3201
13*5
71.6
:
1922.5
39.5
14.8
49.78
1555.3
30.3
F
1002.1
1495,4
43.3
= 107.18
1064.5
33.2
F
1185.8
36 8
1444.6
28 * 6
41.8
12.88
1279.0
71.7
F
1412.6
76.78
1062.1
37.1
F
1554*6
60 * 0
1553*2
53.36
___I_
_
___
__
_~ __~_1___
MEANS,
STANDARD
MEAN
STD
INTL3
MEAN
STD.
FINAL3
MEAN
STD
AVE3M2
MEAN
STDe
F4MIN3
MEAN
STD
F4MAX3
MEAN
STD
AND
F RATIOS
FOR
CAR].
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF3
DEVIATIONS
F
:
20.20
2063.4
48.9
2280*2
37o7
2142.4
47.4
2079.5
95*0
1926.8
163.4
2268.7
39.1
2114.8
48.1
2041.7
1846.9
89.0
1719e3
28.6
1824.1
1835.3
61.4
1620.6
42.8
734*9
70*6
676.3
53.7
726.6
16.7
795,3
43,0
75404
7706
333890
5902
279204
172.0
3377.6
54e0
3419.9
131.2
2892*0
106.3
3309.2
8003
2875,3
3297,7
19203
7704
3247.8
153.9
2836.6
6004
2247.1
2191.3
45.3
77o0
F
:
17.71
2165*3
219906
52. 0
F
=
83.7
57.05
204203
63.1
F
:
33.8
:
58.84
3120.1
8809
F :
3058, 1
87.3
5204
15e51
870.2
F
9904
32*19
__
__
~__I_
MEANS,
STANDARD
MEAN
STD
FINAL4
MEAN
STD.
AVEF4
MEAN
STD*
RANGE4
MEAN
STD.
SLOPE3
MEAN
STD
DUR
MEAN
STD
AND
F RATIOS
FOR
[AR],
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
INI TL4
DEVIATIONS
F
=
70*62
3095.0
77,7
F
2819*8
80.8
3347.6
97.1
2944.0
105.2
3306o0
330802
2853.8
55.5
2771.8
122.8
3306.4
3246*4
680 1
292 1 0
337,0
3146, 1
3314.1
2791 .0
148.1
87,5
13.92
:
2882.2
63*7
F =
134.4
74.67
3056*6
7
35
329508
115.7
3297o 7
5709
F =
4403
54@5
123.7
1.93
35404
280.7
140*8
54903
327,5
419*5
14463
216.8
415.4
247*0
-3.15
0O75
-3.07
1.56
5,.07
0.48
-3*80
0*69
-4.22
0.95
324.0
279*0
39*0
208.0
10.3
257,0
20o0
253,0
16.4
220*0
16.5
340*2
9304
F
=
21*29
-124
0*40
F
:
34.64
21*6
___
_
______1~1_
MEANS,
STANDARD
MAXF 1
F
554.0
10.1
540.2
13.5
1MIN3 A
MEAN
STD
542.1
14.3
538.9
1594
417*3
31.8
540.4
15.0
:
420*3
33*2
F
1287.8
3892
:
419.3
31.3
F
MINF2
MEAN
STD
417*4
31.6
F
MID1AV
MEAN
STD
=
F :
MIDF 1
MEAN
STD.
=
447.5
29.0
F
F 1 MIN3
MEAN
STD*
AND
F RATIOS
FOR
CER1,
TAKEN
ON
DAY
1
2
SPEAKER
NUMBER
MEAN
STD
DEVIATIONS
:
1221*4
23*0
53.06
460.9
6.2
451.4
6.3
475.5
3*7
471.0
10.1
431.6
7*9
407*0
11.3
442.7
10.8
431.6
5.7
432.5
7.7
412.5
16.3
448.2
12*8
411*4
24.0
382o2
9.1
401.9
21.2
397*2
6.4
432.1
8.6
416.9
8.2
449,8
150
411,5
24s7
385*1
6*9
402*.1
22.2
398.3
6.5
424.4
5.2
431 1
18.4
453*2
10.7
414.4
16.0
385*4
80
406.7
29*5
390.7
6.1
426*6
5.5
427*8
17.5
452 0
5,5
416.1
12.9
390.7
7*0
408*3
24*5
392.1
3.0
1175.7
1271.6
150
1260.4
30,5
1228*3
1254*1
1113.2
1293*4
35.32
456*9
6*5
35.83
45 4*5
4*5
32.77
45 4.4
5*3
37.16
454*8
4o4
27.53
1102.3
3098
23.0
26,8
30,9
36.8
31,3
MEANS,
STANDARD
F
MAXF2
1602.1
38.6
1375.8
42.0
MEAN
STD
1377.6
42.0
1398.9
37.1
MEAN
STD*
1399*4
38.5
MEAN
STn
w ,
, .
1896.7
46,1
---
=
:
1388.2
27,5
F
MINF3
:
1408.1
3693
F
MID2AV
:
1339*3
35*2
F
MIDF2
MEAN
STD
F RATIOS
FOR
[ER].
TAKEN ON
DAY
1
22907
1345*9
40.1
F
2MIN3A
=
1557.1
23.3
F
F2MIN3
MEAN
STD
AND
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
=
1489*0
-105.4
-
142098
310
1649.1
1455*1
43*8
1419e5
11.8
1503.1
1436.8
21.0
1468*9
78*0
1429.5
33*7
1238.7
23.6
1315.8
47*3
1302*1
25,5
1305.2
13.5
1325*2
43.2
1182*9
83.3
1341.2
2496
1242.5
17.1
1320.9
35*1
1309.1
22.0
1304.8
132196
17.6
42.1
1204o6
55,3
1343.5
18.7
1251.0
24.5
1294*6
23.9
1322*5
18.1
1297*2
13.1
1310*6
22.8
1204.3
25.2
1370.6
13.5
1253.i
25.9
1296*6
24.8
1318.8
23,4
1297,1
11.9
1310.0
22*2
1198.9
25*4
1367.8
12.4
1526.3
27.7
1571*8
8.0
1608.3
44.6
1542.1
51.1
1699*1
24.5
14455'
23*2
1642.3
44*5
38*3
31,6
13.59
1182.7
18.2
18.39
1182*5
22*3
43.48
1199.8
21.9
41.37
119896
24*2
36.94
1499*3
39.1
MEANS,
F
MIN3AV
1919.2
43.9
1953*7
31.3
MEAN
STD.
1944*3
29o3
MEAN
STD.
579.0
18.4
MEAN
STD*
3113*4
11*9
:
3206.0
176*3
F
4MIN3A
MEAN
STD
:
234.3
4905
F
F4MIN3
:
1593.2
86.4
F
AVE3M2
:
1642*9
89*1
F
MID3AV
:
1532.8
73*0
F
MIDF3
MEAN
STD.
AND F
RATIOS
FOR
[ER].
TAKEN
ON
DAY
1
2
SPEAKER
NUMBER
MEAN
STD.
DEVIATIONS
STANDARD
52.88
1522.0
330
1538.4
2902
1592.7
10.5
1633.6
31*7
1555.4
50,8
1725.8
2360
1478.6
17.9
1650.3
45.4
1540*1
25.7
1608.0
22.1
1661.5
4208
1553.4
41 1
1732*6
23.8
1509.5
43.6
1660.4
50.5
1541.9
1601.8
21*1
1647*2
61.2
1551.4
43.3
1736*2
25*8
1505*2
42*5
1658*3
49*0
286*9
33.5
433*8
20.3
321.9
12.2
33790
40*40
1525.0
54.1
39.38
1530.9
38.5
28.1
63.63
35604
10.1
346*4
21*4
38204
346309
78.3
293907
5507
3542.6
42*7
3000*1
115.1
331501
2942.5
59,8
3539.0
47*4
2970.4
83.5
323.5
14.1
21.0
3405
7.09
3270.3
260.4
172o4
3242*4
283.6
3296.0
3282*9
3207.7
127,9
96*1
289e7
114*3
3186
6
826
8:
3109.7
3211*9
3269.2
3419.4
13,7
141,8
24297
6290
MEANS,
STANDARD
F
MIDF4
3103.8
21.1
3109.5
12,6
MEAN
STD*
2909*1
94.4
MAXF4
MEAN
STD.
AVEF4
MEAN
STD
SLOPE3
MEAN
STD,
:
3130*1
143o2
F
0,44
0,18
:
3307*3
88*4
F
3093.5
18.5
:
2909*5
244o8
F
3169o7
21*1
:
3113*3
21596
F
MINF4
:
3136.8
182.6
F
MID4AV
MEAN
STD,
AND
F RATIOS
FOR
[ER]3
TAKEN
ON
DAY
1
2
SPEAKER
NUMBER
MEAN
STD,
DEVIATIONS
:
0 74
0.47
6.93
3202.7
305,7
3374.9
40.9
2982*2
55*9
3553*0
63.8
2915.1
122.1
3351.4
111.7
3306.5
53.5
3255.6
314.9
3408.5
52.3
2976.9
48,1
3546.2
58.8
2952.7
103.5
335390
3308*2
77.1
3275.3
2822
3246. ~
82,3
2842*8
54.9
3282.0
91.3
2808.9
189.0
2938.5
102*6
3009*5
980
3067.1
299*6
3508.3
93.0
3015.4
629
3583*1
67.9
3093,8
115*4
343690
84*9
3464.6
60*3
3683*8
231.0
3391*1
38.6
2937.8
43.1
3499.5
50.8
2947.8
104.5
3276.5
78*4
330591
61*1
3329.5
217.6
-1.22
0.43
-0.47
0.35
-0*25
0.18
-0.15
0.20
0 65
0*33
7.75
3219*1
262.1
111.1
4.90
3009.8
155.7
16.45
343907
203.2
13*28
3224.8
183*2
20.62
0.40
0.28
0.46
0.15
-0.43
0,34
MEANS,
o
STANDARD
DEVIATIONS AND
F RATIOS
FOR
tER1,
TAKEN
ON
DAY
1
CNI
SPEAKER
NUMBER
1
DUR
MEAN
STD.
F
276.0
29.7
=
212.0
25*9
18.41
170.0
12s2
196*0
15.2
214.0
8*9
232*0
16.4
202.0
19.2
2100
2902
298.0
17.9
218.0
8.4
MEANS,
STANDARD
MEAN
STD
F1MIN3
MEAN
STD
1MIN3A
MEAN
STD.
MIDF 1
MEAN
STD
MID1AV
MEAN
STD
MINF2
MEAN
STD
9p
4
AND
F
RATIOS
FOR
CER].
TAKEN
ON
DAY 2
1
SPEAKER
NUMBER
MAXF I
DEVIATIONS
F
=
71.44
433.3
5.0
456*8
49402
12*7
17. 1
426e6
6.4
44402
19.7
46207
20.7
20.9
37409
20.3
39706
426,5
20.4
7.1
441*5
13.1
463.6
21.2
376*9
22.1
401.7
426.7
6.0
443*2
470,2
20.5
377.3
12.5
427.2
6.2
440.8
13.6
469.1
20.4
377*9
13.9
1151 .7
1197.9
10.8
1280.9
23.4
1200*7
37o0
565,0
44001
12.7
19*4
F
:
56.03
39505
541 .4
11.7
F
=
62.58
542.3
7.0
F
:
60.03
547,2
10.9
F
:
2504
=
20.3
65.31
543o7
9.9
F
410.2
17,0
401 *8
25*2
14*70
1179.7
48*2
1298.5
32*7
c
f
39.0
o
e
t
MEANS,
STANDARD
MEAN
STD*
F2MIN3
MEAN
STD,
2MIN3A
MEAN
STD
MIDF2
MEAN
STD.
MID2AV
MEAN
STD
MINF3
MEAN
STD
AND
F RATIOS
FOR
[ER),
TAKEN
ON
2
DAY
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
=
20.97
166767
35.0
F :
=
31.6
29.8
:
1834.0
36.1
1422.6
82.7
1252*2
6564
1204.7
18,0
1238.3
11.2
1342.2
4962
1295.0
5365
1271.2
6964
1208.4
19.3
1238.2
130
1348,6
51.0
1287*3
43.5
129798
66o8
1196.6
15,1
123962
12.5
1333.1
30.5
1271*8
23.6
1308.2
6861
1195.1
15.7
123864
13.5
1332.4
29.0
1277*8
19.7
1460*9
25.9
1530
4
149968
24.2
10.2
1629.1
44.1
1543.4
28.3
21.15
1396.7
F
1523,6
41.0
20.38
139667
F :
142362
3460
11.96
138068
29.6
F
1391 .9
2665
11*96
1381.6
35.1
F :
1501.3
55*8
101.10
V
C
MEANS,
STANDARD
MEAN
STD
MIDF3
MEAN
STD*
MID3AV
MEAN
STD
AVE3M2
MEAN
STD
F4MIN3
MEAN
STD
4MIN3A
F RATIOS
FOR
EER],
TAKEN
ON
DAY
2
1
SPEAKER
NUMBER
MIN3AV
DEVIATIONS AND
1:03.83
F
1855.4
F
=
:
MEAN
3280.3
STD*
2294
1503*1
12.1
1650 * 5
39.3
1563.8
37.1
1520.9
26*2
153907
1507*.3
11*6
1647.1
35.1
1570.1
34,7
238*6
50.7
356.4
24s0
313.0
5.7
345.1
23.6
337.8
51.0
3054.8
5502
295702
48o3
342795
59,0
3315o4
80.8
2746,0
303507
82.7
3001.4
3420.2
90*2
3307.2
70.5
274490
12509
28,7
50.75
3268.7
29.1
F :
1538.5
30.2
33.62
9.7
=
1518.4
102.86
498.6
F
30*1
30.6
187393
38*7
F =
39.0
1538.5
97.53
1878,5
35.8
F
155696
2603
1507.6
11.5
1636*3
33e4
1474o 1
3407
14990
45,19
72.2
MEANS,
STANDARD
MEAN
STD*
MID4AV
MEAN
STD
MINF4
MEAN
STD*
MAXF4
MEAN
STD
AVEF4
MEAN
STD
AND
F
RATIOS
FOR
[ER].
TAKEN
ON
2
DAY
1
SPEAKER
NUMBER
MIDF4
DEVIATIONS
F :
20.38
3315.0
9697
2755 5
135.2
56.7
3328*0
9509
2753.7
117.5
2813.3
123o3
3263*7
6796
3205.9
90.2
2630.5
158,2
314890
60*6
3293.2
3490*4
3451
2957.6
17594
3062.6
64.9
3046.3
91.0
342103
42o0
3330.6
87.3
2783*1
0*76
0.43
-0928
0,35
0,28
0022
-0.40
0,25
-1.00
329293
3030.0
35.4
68o0
F
:
303101
28.2
5992
:
2917o7
14408
=
F
MEAN
STD*
0.16
0.13
=
132.0
37.3
6
130.8
48.44
326706
13.6
SLOPE3
3440.5
16.94
3351.1
23.9
F
2991.2
114.4
106.2
21.27
3096.8
101.6
F :
34081
45.35
3284.0
F
3025.0
207,8
108.4
4.96
1.35
MEANS,
STANDARD
DEVIATIONS
AND
F RATIOS
FOR
[ER3,
TAKEN ON
DAY
2
SPEAKER
NUMBER
DUR
MEAN
STD.
F :
310.0
15.8
23973
276o0
43.9
172.0
8.4
192 .0
19.2
238,0
23.9
19000
2405
MEANS,
STANDARD
MEAN
STD.
F1MIN3
MEAN
STD
1MIN3A
MEAN
STD
MIDF 1
MEAN
STD
MID1AV
MEAN
STD.
MINF2
MEAN
STD*
AND
F RATIOS
FOR
[ER),
TAKEN ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF 1
DEVIATIONS
F :
87.37
559.5
12*3
F
=
11.9
:
:
:
12.1
1293.1
34.0
482*6
18.0
420.9
16.8
406*4
27.7
441 8
17.1
438.4
15.4
455.5
18.0
393.1
28*4
407,5
27.2
44095
15.8
436*8
11.6
456.7
18.8
394*2
410*5
440.5
15.5
433*8
17.1
461.7
2804
17.8
395.9
23*8
411,1
29*4
441.0
15.4
433.7
12.3
460.6
16.7
397.0
23.7
1200.5
1127.0
41*8
42.1
1186*8
20.6
1270.7
27*8
1214.5
33.7
28.7
70.67
542o 1
F :
454*1
9,9
67.99
543.1
13.3
F
15.5
67.89
542,2
10.6
F
4470
63.01
540.8
F
1
443*8
23*6
30.73
MEANS,
STANDARD
MEAN
STD*
F2MIN3
MEAN
STD.
2MIN3A
MEAN
STD
MIDF2
MEAN
STD
MID2AV
MEAN
STD
MINF3
MEAN
STD
AND
F RATIOS
FOR
[ER).
TAKEN ON
BOTH
DAYS
1
SPEAKER
NUMBER
MAXF2
DEVIATIONS
F
:
35.75
1634.9
49.0
F
:
=
=
=
1865o3
51.1
142997
5704
129961
1
1193.7
20.6
1238o5
17.4
1322.2
42.5
1300.1
37.2
1305.3
63o1
1195.4
2460
1240.3
14.5
1328.9
42.5
1296*0
3206
1353,0
77e2
1198.2
17,8
1245.1
19.4
1327.8
2403
128465
1348*2
1196.8
19.3
1245.9
21.0
1325.6
25.8
1287*5
18*4
1514.8
34o8
1513.1
1618.7
154208
39.0
36.50
22.4
44*83
1398.1
3205
F
1513.3
37.0
28.81
1397.8
32.5
F
1439.1
40*7
71
1379.2
34.3
F =
1406.3
31.2
24.45
137807
36@6
F
1529*2
4909
64,6
93.87
1474.9
73.9
24o 1
4303
MEANS,
STANDARD
MEAN
STD.
MIDF3
MEAN
STD.
MID3AV
MEAN
STD
AVE3M2
MEAN
STD*
F4MIN3
MEAN
STD
4MIN3A
MEAN
STD
AND
F RATIOS
FOR
TAKEN
[ER],
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MIN3AV
DEVIATIONS
F
=
119*77
188703
50.2
F =
:
4905
=
=
:
3195.0
91.6
1556.0
3904
1580.7
90.9
1531 .7
41.9
1521.6
27*2
1656.0
1558.6
37*3
1557.1
1535.3
32o4
1524*6
2793
1647e2
47.0
1560*7
236.4
356,4
47*3
17,4
318.2
11.5
363,8
28.9
312.4
48.7
3445*7
680 1
3429.0
134.3
2873.0
183e6
3419.8
72o9
3423.1
134.7
2857.2
156.1
39*2
383
77.94
19*41
3191.1
84.5
F
1634.9
33,5
71*2
538.8
44.6
F
1523,0
26.5
99.67
1908,8
F
1530.2
29.4
82.26
1916.1
50.8
F
1503.4
61.8
3130.4
146*7
3113.7
3123*8
143,5
3135.3
220.0
241
6
21.59
I
_
____
L__ ___
_
_C__~_L
_ _
_ _ __ __IL~I
MEANS,
STANDARD
MEAN
STD
MID4AV
MEAN
STD,
MINF4
MEAN
STD.
MAXF4
MEAN
STD
AVEF4
MEAN
STD
AND
F
RATIOS FOR
[ER3,
TAKEN
ON
BOTH
DAYS
1
SPEAKER
NUMBER
MIDF4
DEVIATIONS
F =
19.39
319860
103.1
F
:
:
=
:
F
MEAN
STD.
0.30
0.21
:
3072*2
155,3
3105.2
225.3
3424.5
3437.1
137.3
285302
2913*6
189.7
2911,6
168.1
3255.1
71.6
3244,0
2719.7
189*3
3227.6
110*2
3366.4
179.0
3499*3
67o5
3517.3
12003
3025o7
157.3
3096*4
110.7
3135.6
165.7
3406*2
41.2
3415,0
111.6
2865.5
13297
0075
0.42
0.06
0.47
0037
0.20
-0*44
0*29
-0.71
0.98
147.3
2835.3
147 7
54*1
148o0
9405
32.08
3180.5
93.0
SLOPE3
3434o0
21.15
3260.4
97.9
F
3391 *5
77*9
19.76
3003.0
135.4
F
3113.9
263.6
23*55
3196,8
94.2
F
3083.4
141.6
11.59
CL-----~-~L-L~
---~ -~--~Y---
o
MEANS,
STANDARD
SPEAKER
NUMBER
DUR
MEAN
STD*
DEVIATIONS
1
F
=
293.0
28.7
AND
F RATIOS
FOR
[ER],
TAKEN
ON
BOTH
DAYS
2
3
4
6
7
244,0
47.9
171.0
9.9
194.0
16.5
235.0
1996
196*0
21*7
26.96
f9
221
REFERENCES
Atal, B. S., "Automatic Speaker Recognition Based on
Pitch Contours," Ph.D. Thesis, Polytech. Inst. of Brooklyn,
1968.
Atal, B. S., "Influence of Pitch on Formant Frequencies
and Bandwidths Obtained by Linear Prediction Analysis,"
J. Acoust. Soc. Am., vol. 55, supplement, Spring, 1974,
Program of the 87th Meeting, New York, NY, Paper NN2,
April, 1974.
Atal, B. S. and Hanauer, Suzanne L., "Speech Analysis
and Synthesis by Linear Prediction of the Speech Wave,"
J. Acoust. Soc. Am., vol. 50, no. 2 (Part 2), pp. 637655, August, 1971.
Bell, C. G., Fujisaki, H., Heinz, J. M., Stevens, K. N.,
and House, A. S., "Reduction of Speech Spectra by Analysisby-Synthesis Techniques," J. Acoust. Soc. Am., vol. 33,
no. 12, pp. 1725-1736, Dec. 1961.
Boulogne, M., Carr6, R., and Charras, J. P., "La Frequence
Fondamentale, Les Formants, Elements d'Identification
des Locuteurs," Revue d'Acoustique, no. 23, 1973.
Chandra, S., and Lin, W. C., "Experimental Comparison
Between Stationary and Nonstationary Formulations of
Linear Prediction Applied to Voiced Speech Analysis,"
IEEE Trans. on Acoust., Speech, and Signal Proc., vol. 22,
no. 6, pp. 403-415, Dec., 1974.
Das, S. K., and Mohn, W. S., "A Scheme for Speech Processing
in Automatic Speaker Verification," IEEE Trans. on Audio
and Elect., vol. 19, no. 1, pp. 32-43, March, 1971.
Fant, G., Acoustic Theory of Speech Production, Mouton
and Co., 's-Gravenhage, The Netherlands, 1960.
Glenn, J. W., and Kleiner, N., "Speaker Identification
Based on Nasal Phonation," J. Acoust. Soc. Am., vol. 43,
no. 2, pp. 368-372, Feb. 1968.
Holbrook, Anthony, and Fairbanks, Grant, "Diphthong
Formants and their Movements," J. of Speech and Hearing
Research, vol. 5, no. 1, pp. 38-58, March, 1962.
222
House, Arthur S., and Stevens, Kenneth N., "Analog Studies
of the Nasalization of Vowels," J. of Speech and Hearing
Disorders, vol. 21, no. 2, pp. 218-232, June, 1956.
Jenkins, M. A., and Traub, J. F., "A Three-Stage Algorithm
for Real Polynomial Using Quadratic Iteration," SIAM J.
Numer. Anal., vol. 7, no. 4, Dec., 1970.
Klatt, D., "Acoustic Characteristics of /w,r,l,y/ in
Sentence Contexts," J. Acoust. Soc. Am., vol. 55, no.
2, p. 397(A), Feb., 1974.
Kurath, Hans, Handbook of the Linguistic Geography of
New England, The American Council of Learned Societies,
Providence, RI, 1939.
Labov, William, Yaeger, Malcah, and Steiner, Richard,
"A Quantitative Study of Sound Change in Progress,"
Report on National Science Foundation Contract NSF-GS-3287,
University of Pennsylvania, Philadelphia, PA, 1972.
Li, K. P., Dammann, J. E., and Chapman, W. D., "Experimental Studies in Speaker Verification Using an Adaptive
System," J. Acoust. Soc. Am., vol. 40, no. 5, pp. 966978, Nov., 1966.
Luck, J. E., "Automatic Speaker Verification Using Cepstral
Measurements," J. Acoust. Soc. Am., vol. 46, no. 4
(Part 2), pp. 1026-1032, Oct., 1969.
Lummis, Robert C., "Speaker Verification by Computer
Using Speech Intensity for Temporal Registration," IEEE
Trans. on Audio and Elect., vol. 21, no. 2, pp. 80-89,
April, 1973.
Makhoul, John I., and Wolf, Jared J., "Linear Prediction
and the Spectral Analysis of Speech," Bolt, Beranek, and
Newman, Inc., Cambridge, MA., Report 2304, Aug., 1972.
Markel, J. D., "Digital Inverse Filtering, a New Tool for
Formant Trajectory Estimation," IEEE Trans. on Audio and
Elect., vol. 20, no. 2, 129-137, June, 1972.
Markel, J. D. and Gray, Jr., A. H., "On Autocorrelation
Equations as Applied to Speech Analysis," IEEE Trans. on
Audio and Elect., vol. 21, no. 2, pp. 69-79, April, 1973.
223
McCandless, Stephanie S., "An Algorithm for Automatic
Formant Extraction Using Linear Prediction Spectra,"
IEEE Trans. on Acoust., Speech, and Signal Proc., vol.
22, no. 2, pp. 135-141, April, 1974.
Meeker, W. F., Martin, T. B., Herscher, M. B., Phyfe, D.,
and Weinstock, M., "Automatic Speaker Recognition Using
Speech Recognition Techniques," J. Acoust. Soc. Am.,
vol. 42, no. 5, p. 1182(A), Nov., 1967.
Olive, J. P., "Automatic Formant Tracking by a NewtonRaphson Technique," J. Acoust. Soc. Am., vol. 50, no. 2,
(Part 2), pp. 661-670, Aug., 1971.
Portnoff, M., Zue, V., and Oppenheim, A., "Some Considerations in the Use of Linear Prediction for Speech Analysis,"
QPR No. 106, Res. Lab. of Electronics, M.I.T., Cambridge,
Mass., July 15, 1972.
Pruzansky, S., "Pattern-Matching Procedure for Automatic
Talker Recognition," J. Acoust. Soc. Am., vol. 35, pp.
354-358, 1963.
Pruzansky, S., and Mathews, M. V., "Talker-Recognition
Procedure Based on Analysis of Variance," J. Acoust.
Soc. Am., vol. 36, no. 11, pp. 2041-2047, Nov., 1964.
Sambur, Marvin R., "Speaker Recognition and Verification
Using Linear Prediction Analysis," Ph.D. Thesis, M.I.T.,
Sept., 1972.
Schafer, R. W., and Rabiner, L. R., "System for Automatic
Analysis of Voiced Speech," J. Acoust. Soc. Am., vol. 47,
no. 2 (Part 2), pp. 634-648, Feb., 1970.
Stevens, Kenneth N., "Sources of Inter- and Intra-Speaker
Variability in the Acoustic Properties of Speech Sounds,"
in Rigault, Andre and Rene Charbonneau (Eds.), Proceedings
of the Seventh International Congress of Phonetic Sciences,
Mouton, The Hague, pp. 206-232, 1972.
Tosi, Oscar, Oyer, Herbert, Lashbrook, William, Predrey,
Charles, Nicol, Julie, and Nash, Ernest, "Experiment on
Voice Identification," J. Acoust. Soc. Am., vol. 51,
no. 6, (Part 2), pp. 2030-2043, June, 1972.
Treitel, S., and Robinson, E. A., "Introduction, Special
Issue on the M.I.T. Geophysical Analysis Group Reports,"
Geophysics, vol. 32, no. 3, pp. 416-417, June, 1967.
224
Tribolet, Jose Manuel, "Identification of Linear Discrete
Systems with Applications to Speech Processing," S.M. Thesis,
M.I.T., January, 1974.
Wolf, Jared J., "Efficient Acoustic Parameters for Speaker
Recognition," J. Acoust. Soc. Am., vol. 51, no. 6,
(Part 2), pp. 2044-2056, June, 1972.