Chapter 3 Single-Stage Produce-to-Order c Process job on any one of them
advertisement

Chapter 3
Single-Stage Produce-to-Order
c identical machines
Process job on any one of them
External orders indep. of shop status
1
Assumptions
• No preemption/service interruptions
• Non-idling
• For capacity determination
– Constant mean arrival rate
– Constant mean service time
– Machines always available
2
Questions
• Capacity of the system
– Can it be increased by operating policies?
• Performance measures (WIP, delay in
filling orders)
– Influence of service process, order arrivals
– Operating policies to improve them
• Choice of policy to improve a particular measure
• Information requirements
3
General Performance
• Capacity
• Little’s Formula
• Observations at
– Arrival times
– Departure times
– Arbitrary times
• Basic data
– An is the arrival time point of the nth job; Sn is time
required for its processing (Dn is departure time point)
4
Capacity
A(t ) max{n : An t}
D(t ) max{n : Dn t}
N (t ) N (0) A(t ) D(t ), t 0
limt
A(t )
t
If < c then
=
k
lim k Sn 1/
limt
n 1
limt
D(t )
t
N (t )
0
t
At least one server repeatedly becomes idle
Note: Capacity = c is not the maximum departure rate.
Capacity depends only on the mean service time.
5
Little’s Formula
The nth job to arrive is the K(n)th job to depart. Tn DK ( n ) An
is the time spent in the system by the nth job. Assume these
k
system times are uniformly finite and let T limk 1k n1Tn
be the customer average time spent in the system.
t
1
Also, let N limt t N ( )d
0
be the time average number of jobs in the system.
Then under very general conditions, N T
The mean number of jobs in the system is proportional to the
mean flow time!
6
Heuristic Proof of Little’s Formula
A(t)
B(t) = cum. area
between curves
D(t)
T
Two ways to compute B(T ) n1Tn 0 N (t )dt
Mean time in system in (0,T): W (T ) B(T ) N B(T )
Mean number in system in (0,T): N (T ) B(T ) T
Then
N
T
A(T )
7
Other Little’s Formulae
In queue:
In service:
Expected number of busy servers
Expected number of idle servers
Single server utilization
Single server prob. of empty system
8
Observation Times
N na Number of jobs seen by nth arrival
N nd Number of jobs left behind by nth departure
r a (l ) Proportion of jobs that see l upon arrival
r d (l ) Proportion of jobs that leave l jobs behind
If = (e.g., if < c ) then r a (l ) r d (l )
so that averages seen by arrivals and departures match: N a N d
But in general, observations at arbitrary times do not: N N a
However, if arrivals follow a Poisson process and service
protocols do not use future arrival times then N N a
This is known as PASTA (Poisson Arrivals See Time Averages)
9
Kendall’s Notation for Queuing Systems
A/B/X/Y/Z:
A = interarrival time distribution
B = service time distribution
G = general (i.e., not specified); M = Markovian (exponential);
D = deterministic; PH = phase-type (e.g., Erlang)
X = number of parallel service channels
Y = limit on system pop. (in queue + in service); default is
Z = queue discipline; default is FCFS
Others are LCFS, random, priority. In CS, PS = processor sharing
10
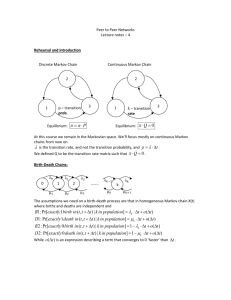
M/M/1 Model
Single machine, Poisson arrivals (rate ), exponential service
times (rate )
CTMC (birth-death) model:
11
M/M/1 Steady-State Probabilities
p(n) limt P{N (t ) n}, n 0,1,...
Level-crossing equations:
p(n) p(n 1), n 0,1,
Solve for p(n) in terms of p(0):
p ( n)
n
p (0), n 1, 2,
Then use the facts that n0 p(n) 1,
and substitute /
to get
n
p(n) (1 ), n 0,1,
n
1
r
(1
r
)
if r 1
n 0
if 1
12
M/M/1 Performance Measures
Steady-state expected number of jobs in the system
E[ N ] n 0 np(n)
Mean flow time
E[T ]
E[ N ]
1
, if 1
1
by Little's Formula
(1 )
Distribution of flow time
FT ( x) P[T x] n 0 p a (n) P[T x | arrival sees n jobs]
n 0 (1 ) n P[T x | T
Erlang n 1 ( )]
n 0 (1 ) n l n 1 e x ( x)l l ! 1 e (1 ) x , x 0
Exponential with parameter (1-)
Departure process is Poisson with rate
13
M/G/1
Best combination of tractability & usefulness
Distributions of number of jobs in the system and flow time
depend on service time distribution
- Available in terms of transforms
Random variables:
S is the length of an arbitrary service time; FS ( s )
is the Laplace transform of its distribution.
T is the flow time; Laplace transform of its distribution is FT ( s)
N is the (random variable) number of jobs in the system with
probability generating function P ( z )
Define = E[S] and assume it is < 1.
14
Transform Equations & Expected Values
(1 )( z 1) FS ( z )
P( z )
z FS ( z )
d
2 E[S 2 ]
E[ N ] lim P( z )
z 1 dz
2(1 )
(1 ) sFS ( s)
FT ( s)
s (1 FS ( s))
2
d
E
[
S
]
E[T ] lim FT ( s)
E[ S ]
s 0
ds
2(1 )
15
M/M/c Model
c identical machines in parallel, Poisson arrivals (rate ),
exponential service times (rate )
CTMC (birth-death) model:
16
M/M/c Steady-State Probabilities
Level-crossing equations:
p(n) n 1 p(n 1), n 0,1,..., c 1
p(n) c p(n 1), n c, c 1,...
Define =/c, solve for p(n) in terms of p(0):
(c )
n! p(0), n 0,1,..., c 1
p ( n) c n
c
c! p(0), n c, c 1,...
p
(
n
)
1,
Then use the facts that n0
n0 r n (1 r)1 if r 1
n
to get
c 1 (c )
(c )
p(0) k 0
k!
(1 )c !
k
c
1
17
M/M/c Performance Measures
Steady-state expected number of jobs in the system
(c ) c
E[ N ] n0 np(n) c
p(0), if 1
2
c ! (1 )
Mean flow time
E[T ]
E[ N ]
1 (c ) c
=
p(0) by Little's Formula
c - c !(1 )
1
Expected waiting time
E[W ] E[T ]
1
Expected number in the queue (c is expected number of busy servers)
E[ L] E[W ] E[ N ] c
18
GI/G/c
(I is for independent times between arrivals)
There are no convenient exact results, and assuming Poisson
arrivals doesn’t help; instead we have some approximations that
use:
E[ S ], E[ ] expected time between arrivals,
CS , Ca coefficients of variation of service and interarrival times
(standard deviation) /mean
(1 CS2 ) (2 )Ca2 2CS2
E[ S ]
E[W ]GI / G /1
,
2
E[ ]
2
C
2
(1
)
S
This is just one of 3 (or more) approximations (see Table 3.1). They work
better if the scv of interarrival times is not too large (<2)
19
GI/G/c
2
If Ca 1
Best approximation is
Ca 2 (1 (1 )Ca 2 ) 2CS 2
E[ S ]
E[W ]GI / G /1
,
E[ ]
2 (1 )
It is exact for M/G/1 and D/D/1 models.
If there is more than one server, adjust the GI/G/1
approximation with factor borrowed from M/M/ system:
E[W ]GI / G / c
E[W ]M / M / c
E[W ]GI / G /1
E[W ]M / M /1
20
Multiple Class M/G/1 with
Nonpreemptive Priority
Suppose there are k classes of jobs; arrival processes are
k
(l )
(l )
independent Poisson processes with rates , l 1 .
Processing starts on a class l job only if there are no class r
jobs, r < l, already in the system. FCFS within each class.
(l )
The expected processing time for a type l job is E[ S ].
r
(l )
(l )
(l )
( j)
E
S
and
( 0 0)
Define
r
j 1
We can use a mean value analysis to find the expected flow
time for each class of job:
(l ) 2
E S
l
1
E S ( l ) , l 1,..., k
E T ( l )
2(1 l )(1 l 1 )
k
(l )
21
Optimal Priority Assignment
Say wl is the cost per unit time that a type l job spends in the
system. To minimize the total cost, priorities should be
assigned so that
w1 E S (1) w2 E S (2) ... wk E S ( k ) .
In particular, if the cost for each type is the same, we want to
minimize total average flow time for all jobs in the system.
We should prioritize the job types by Shortest Expected
Processing Time (SEPT Rule). This result agrees with the
SPT scheduling rule to minimize the average flow time in
a deterministic job shop.
22