Spatial analysis of a designed experiment
advertisement

Spatial analysis of a designed experiment
RA Fisher’s 3 principles of experimental design
randomization ⇒ unbiased estimate of treatment effect
replication ⇒ unbiased estimate of error variance
blocking = “local control of variation” ⇒ eliminate unwanted sources
of variation
Any experiment: experimental units (eu’s) are not identical
Lots of sources of variation:
Field experiment: variation is often spatially structured
elevation / moisture / drought; soil type
proximity to field edge
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
1 / 69
Uniformity trials
Uniformity trial
Common in early - mid 20’th century in US and UK
“Experiment without a treatment”
before using an experimental field, plant a crop, harvest in small plots
look at how variation is structured across the field
Usually find that high yielding plots are surrounded by other
high-yielding plots
and similarly for low-yielding plots.
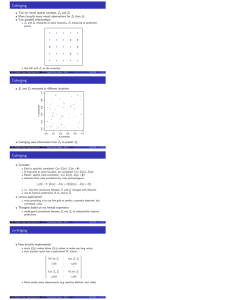
E.g. Mercer and Hall wheat yield data (next slide)
Classic data set (1910 study, 1911 paper)
Experimental field planted in wheat. No treatments - all the same
Harvested in small plots: 3.3m E-W, 2.51m N-S
ca 2-fold variation in yield
Key point: variation is spatially correlated
Spatial Data Analysis - Part 11
Spring 2016
2 / 69
0.0
0.2
0.4
0.6
0.8
1.0
c Philip M. Dixon (Iowa State Univ.)
0.0
c Philip M. Dixon (Iowa State Univ.)
0.2
0.4
0.6
Spatial Data Analysis - Part 11
0.8
1.0
Spring 2016
3 / 69
Blocking
Traditional approach is to control unwanted variability by blocking
Blocks are groups of similar experimental units
human study: group by sex and age-group (e.g. male, age 20-29)
field study: group based on knowledge of field, almost always adjacent
plots
e.g. low part of field = one block, high part = second block
very useful. Typical efficiency = 110% - 120%
i.e. Var CRD = 1.1 Var RCBD - 1.2 Var RCBD
Alternatively, 10 replicates in an RCBD have same precision as 11-12
replicates in a CRD
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
4 / 69
Blocking: practical issues
3 issues/problems:
0.0 0.2 0.4 0.6 0.8 1.0
1) analysis model is constant block effect (same for all plots w/i that
block). But, variation may be smoother
20
40
60
80
100
0
20
40
60
80
100
0.0 0.2 0.4 0.6 0.8 1.0
0
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
5 / 69
Blocking: practical issues
0.0
0.2
0.4
0.6
0.8
1.0
2) often hard to know where to place blocks (e.g. M-H data)
0.0
c Philip M. Dixon (Iowa State Univ.)
0.2
0.4
0.6
Spatial Data Analysis - Part 11
0.8
1.0
Spring 2016
6 / 69
Blocking: practical issues
3) want blocks to be small, but may need to be large to include all
trts
small blocks more likely to be homogeneous
this (in my mind) is why one rep per trt and block is so common
Plant breeders often have very large numbers of treatments
trts = varieties of plant, often 128 or 256.
often use very ingenious incomplete block designs
Complete block: all treatments in each block
Breeders: subset treatments in each block, e.g. 16 trts per incomplete
block
often “resolvable”: collection of small blocks makes a large block that
has all trts
8 incomplete blocks, each with 16 diff trts, includes all 128 trts
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
7 / 69
Consequences of spatial correlation
Nearby plots are clearly similar to each other.
I sometimes see the argument that the usual ANOVA on a field
experiment is wrong because of the spatial correlation
Remember: ANOVA makes three assumptions:
errors are normally distributed
errors have equal variance
errors are independent
Which is most important??
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
8 / 69
Consequences of spatial correlation
A: independence
So, you do an experiment on plots that are spatially correlated
Is ANOVA wrong, because it violates the independence assumption?
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
9 / 69
Consequences of spatial correlation
I say no, at least for a designed experiment:
the independence comes from the random assignment of treatments to
plots.
So there is nothing wrong about ignoring spatial correlation
But accounting for spatial correlation may be a better analysis
increased precision of estimates
increased power of tests
analogous to sampling spatially organized things
a simple random sample, assuming independence, is just fine
OLS estimates (usual estimates) and tests are NOT wrong
GLS estimates that account for spatial correlation will be better
Note: very different from ignoring subsampling or repeated meas.
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
10 / 69
Illustration
Consider a field, spatially correlated plots (details don’t matter)
Design a study to compare 5 treatments, 50 plots
Consider two experimental designs: CRD or blocks (RCBD)
and two analyses: usual or spatial analysis
5
Generate data from “a study” using a design (CRD, RCBD)
Estimate parameters using a model (usual, spatial), repeat 1000 times
Focus on estimated difference between two treatments: µ̂1 − µ̂2
●
Trt 1 − Trt 2
1 2 3
4
●
●
●
●
●
●
●
●
●
●
●
CRD, spatial
RCBD
RCBD, spatial
−1
0
●
●
●
CRD
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
11 / 69
Illustration
Design
CRD
“
RCBD
“
Analysis
–
spatial
–
spatial
Average
2.010
2.003
2.006
2.003
sd=se
0.870
0.282
0.299
0.266
√
Ave est Var
0.875
0.244
0.302
0.254
ratio
1.006
0.868
1.011
0.953
Bias of estimates: Compare ave. estimate to truth (=2.00)
Ignoring spatial correlation still unbiased
Precision of estimates: look at sd of estimates
Blocking substantially increases precision (much more than 10%)
Spatial analysis further increases precision
A lot for CRD, a bit for RCBD
√
Is the precision well estimated (equiv. of se = sd/ n)
Non-spatial analysis: fine (ratios close to 1)
Spatial analyses: tends to underestimate se
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
12 / 69
Papadakis’s method
Old method - original paper in 1937
Concept:
Use neighbors to “predict” what an obs. would be like if no treatment
Use this value as a covariate in model to remove “local” spatial
variation
Details:
Fit preliminary model Yij = µ + τi + εij
Estimate residuals = ε̂ij = Yij − (µ̂ + τ̂i ), i.e. obs. - trt mean
calculate r¯ij = average residual for each obs. by ave. resids of neighbors
do not include residual for self
include r¯ij as a covariate in the model
Yij = µ + τi + β r¯ij + γij
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
13 / 69
Papadakis method
Divides “error” into two components:
a) contribution of neighbors: β r¯ij
b) “intrinsic error”: γij
Consequences:
obs. surrounded by “high” neighbors (relative to their treatment
means) are expected to be high
surrounded by “low” expected to be low
if β̂ ≈ 0, little to no spatial correlation
neither blocking nor Papadakis adjustment very useful
Not easily implemented in modern software
Can exploit relationship between Papadakis and spatial models for areal
data
Modern version: nearest neighbor adjustment
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
14 / 69
Spatial linear model
Notation: i: Treatment, j: Replicate
Yij
= µ + τi + εij
εij
∼ mvN(0, Σ)
Just like the usual linear model (ANOVA or regression or
combination), but errors are correlated
VC matrix, Σ, usually specified as a geostatistical model
VC matrix is for plot errors, not observations
Parameterized in terms of correlation or covariance
Common to assume equal variances and to use one of the usual
variogram models
e.g. Exponential, Spherical, Matern
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
15 / 69
Spatial Linear Model
Notice this is very much like models for repeated measures data
Treatments assigned to subjects,
each subject measured more than once
observations on same subject probably correlated
402 discussed various models for those correlations
correlation depends on time lag between observations
Spatial is similar; now correlation depends on distance, not time lag
Can add additional trend to the fixed effects model
Yij
= µ + τi + βE Eastingij + βN Northingij + εij
εij
∼ mvN(0, Σ)
Or block effects (αj )
c Philip M. Dixon (Iowa State Univ.)
Yij
= µ + τi + αj + εij
εij
∼ mvN(0, Σ)
Spatial Data Analysis - Part 11
Spring 2016
16 / 69
Example: Alliance wheat trial
Variety trial in wheat. 56 varieties, 4 reps of each, blocked
Exploratory analysis:
Fit a model without blocks
(we are interested in the spatial effect, after all)
plot residuals for each location
see next slide
spatial pattern in residuals is obvious
c Philip M. Dixon (Iowa State Univ.)
Spring 2016
17 / 69
Spring 2016
18 / 69
15
10
5
Easting
20
25
Spatial Data Analysis - Part 11
10
20
30
40
Northing
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Calculating GLS estimates
Remember that GLS estimates require a Σ matrix
Two ways to estimate Σ:
Variogram on OLS residuals
Estimate Σ and β together (REML)
1) Estimate a variogram from residuals is an approximation
Why is this an approximation?
A: residuals are negatively correlated
often ignored when error df/n close to 1
not so here! because only 4 reps / entry
error df/n = 0.75
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
50
●
● ● ●
semivariance
40
●
●
●
●
● ●
●
30
●
●
●
●
●●
●
20
19 / 69
●
10
5
10
15
distance
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
20 / 69
Variogram looks linear, even when extend max lag distance to 20
Suggests a spatial trend
Add Northing, Easting, and their product to model
Product because of blob of extreme residuals in one corner of field
Variogram of those residuals looks much nicer
Could use this variogram to estimate Σ, then use GLS to estimate β̂
But, notice the problem:
Σ̂ based on OLS residuals
GLS estimates of β̂ are not the same as the OLS estimates
so residuals are not the same
so Σ̂ will change
And, have the df/n issue
Alternative is to simultaneously estimate Σ and β, using REML to
account for fixed effects (df/n issue)
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
20
semivariance
●
●
Spring 2016
●
● ●
●
21 / 69
●
●
●
●
15
●
●
●
●
10
5
5
10
15
distance
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
22 / 69
REML estimation of variances and related quantities
Maximum likelihood is great, but estimates are often biased
Example: Yi ∼ N(µ, σ 2 )
ML estimate of σ 2 is n1 Σ(Yi − µ̂)2
1
Unbiased estimate is n−1
Σ(Yi − µ̂)2
subtracting 1 “accounts” for using the data to estimate µ̂ before
estimating σ̂ 2
can be a serious issue when n small, or many fixed effect parameters
If estimate k fixed effect parameters, unbiased est. is
1
n−k Σ(Yi
− µ̂)2
Basic idea for a solution known in 1937 (Bartlett), but widely
popularized in early 1970’s (Patterson and Thompson)
Since Patterson and Thompson, known as REML = REstricted ML or
REsidual ML
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
23 / 69
REML
Concept:
Calculate residuals for each obs. using fixed effects model
When the fixed effects have k d.f., the residuals have n − k df.
If you give me n − k residuals, I know the values of the remaining k
residuals
Simple example: Y ∼ N(µ, σ 2 ). Residuals must satisfy Σi (Yi − µ̂) = 0,
so if you give me the first n − 1 residuals, I know the value of the last
residual: Yn − µ = −Σn−1
i=1 (Yi − µ).
So change the data: replace the n obs. by n − k residuals.
no loss of information because the remaining k values are known
Then do ML on the n − k residuals
1
For the simple example: σ̂ 2 = n−1
Σ(Yi − µ̂)2 , which is the unbiased
estimate!
1
In general, σ̂ 2 = n−k
Σ(Yi − µ̂)2 , which is (again) the unbiased
estimate!
REML accounts for the “loss of df due to estimating fixed effects”
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
24 / 69
Alliance: results from spatial linear model
error variance is smaller than in the non-spatial analysis
more precise estimates of treatment differences
parameters of fitted semi-variogram different from empirical sv
Reinforces earlier point about residuals
R (and SAS) use REML to estimate variogram parameters.
REML accounts for the “loss of df from fitting fixed effects”
empirical sv does not
so use empirical sv only to get an idea of starting values
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
25 / 69
More points about REML
REML is an easy way to fit many spatial models
estimates of variances/covariances not always unbiased
but usually less biased than ML estimates
How to choose the best model?
Can calculate an AIC statistic from the REML lnL
AIC = -2 lnL + 2k
Interpret just like usual AIC:
Smaller is better (good fit to data with a simple model)
BUT, REML/AIC only evaluates correlation models!
must use same fixed effects model for all models
That’s because AIC only comparable when models fit to the same data
Changing the fixed effects model changes the residuals, so changes the
data that REML uses
Very common mistake!
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
26 / 69
More points about REML
AIC only compares the specified set of models
Consider the following results for 3 correlation models:
Model
A
B
C
AIC
104.2
100.1
108.4
Tempting to say “B” is the correct correlation model
NO. You only know that B is the best among the set you evaluated
There could easily be a model D with AIC = 75.7 that fits much better
than any you considered.
Use diagnostics to check for anisotropy, outliers, and equal variances
Most models assume isotropy, no outliers, equal variances
Or ignore, because an approximate spatial model is usually good
enough
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
27 / 69
Accounting for spatial correlation
Three common approaches
1) geostatistical model: either point or areal data
2) Simultaneous Autoregressive (SAR) Model for areal data
3) Conditional Autoregressive (CAR) Model for areal data
We’ve just talked about the geostatistical model
More choices for areal data
Choice reflects training / background of the user as much as reality
Statisticians: tend towards geostatistical approaches
use CAR models in Bayesian analysis
Spatial econometricians: almost exclusively SAR/CAR models
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
28 / 69
Concepts behind the three models
Geostatistical model: specify correlation (or covariance)
usually among the errors, could be observations (ordinary kriging)
SAR models: specify connections between errors (or observations)
How ehere depends on eneighbors
CAR models: specify connections in a different way
Distribution of ehere given values of eneighbors
Why the difference matters, using time series models:
10 observations, one per year
Correlation model: all observations are correlated, Cor Yi , Yj = ρ(i−j)
CAR model: Yi only depends on previous obs Yi−i : Yi = ρ Yi−1 + εi
no “connection” between Yi and Yi−2 , but there is still a non-zero
correlation
Correlations must be symmetric: Cor Yi , Yj = Cor Yj , Yi
Connections do not have to be symmetric (see next slides)
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
29 / 69
SAR models: concepts
General regression / ANOVA model
1
1
Y = X β + ε, if X = .. , then Y = µ + ε
.
1
model connections by allowing error values to depend neighboring
regions
ε(si ) = ρΣN
j=1 bij εj + ν(si )
bij are the elements of the spatial dependence matrix expressing
dependence among regions
ρ quantifies strength of dependence
ν(si ) is an independent random disturbance for each region.
Usually assume ν(si ) ∼ N(0, σν2 )
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
30 / 69
SAR model: concepts
Connections do not have to be symmetric.
9 observations on a grid. Each depends on average of its rooks
neighbors
Y1 Y2 Y3
Y4 Y5 Y6
Y7 Y8 Y9
Y1
= ρ(Y2 + Y4 )/2 + ε1 = ρ0.5Y2 + ρ0.5Y4 + ε1
Y4
= ρ(Y1 + Y5 + Y7 )/3 + ε4 = ρ0.333̄Y1 + ρ0.333̄Y5 + ρ0.333̄Y7 + ε4
b14 = 0.5ρ but b41 = 0.333̄ρ
But they could be: bij = 1 if i and j share a boundary, 0 otherwise
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
31 / 69
SAR model: concepts
There are n(n − 1) elements of bij ,
Usually not individually specified but determined by some system, e.g.:
average of rooks (or queens) neighbors
proportion of boundary shared with a neighbor
is there a shared boundary
Can convert the specification of dependence into a model for the data
Y
= X β + (I − B )−1 ν
Which gives you the VC matrix for the vector of Y ’s
Σ = (I − B )−1 Σν (I − B )−1
Pictures of variances and correlations in details section (end of these
notes)
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
32 / 69
SAR model: concepts
SAR models capture important features of the problem
VC matrix has correlations that decline with distance (good)
but variances are not constant (good? not-so-good?)
edges of the study region have huge impacts on a SAR model
My thoughts:
geostatistical model (directly specifying correlation): edges irrelevant
only care about correlations between locations in the data set
SAR model (specifying connections):
no connections with anything outside study area
is that reasonable? depends on specifics of each problem
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
33 / 69
SAR model: estimation and inference
Assume ν’s are normally distributed with mean 0
errors, ε’s, are normally distributed with mean 0, and
observations, Y ’s, are normally distributed with mean
both with VC matrix that depends on ρ, σν2
Xβ
Estimate β and VC parameters (ρ, σν2 ) by likelihood (ML or REML)
Likelihood ratio tests for hypotheses
Z (Wald) inference for individual parameters
(tests and confidence intervals)
AIC or BIC for model selection
Details in details section
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
34 / 69
CAR models: concepts
A different way to specify connections
SAR models all Y values simultaneously
CAR models distrib of a each Y given the values of its neighbors
Yi | Y−i = X i β + ΣN
j=1 cij (Yj − X j β) + νi
RHS same as SAR model
The difference is that Y−i now treated as fixed values when specifying
distrib of Yi
Diff. VC matrix for obs.: Σε = Var Y = (I − C )−1 Σν
Pictures and examples in the details section
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
35 / 69
CAR models: concepts
My opinion:
for normally distributed data,
a different structure for the variance-covariance matrix
which model is more appropriate for the data?
use AIC to evaluate choice of covariance structure (CAR or SAR)
for non-normally distributed data,
probably using Bayesian inference
substantial advantages:
conditional specification REALLY simplifies numeric Bayes (MCMC)
algorithms
Again, study area edges are crucial.
Both CAR and SAR presume no connections with regions outside the
study area
And prediction of new location / area problematic.
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
36 / 69
Final thoughts on spatial ANOVA/regression
1) Everything I’ve said about ANOVA models applies in
straight-forward fashion to regression models
Both are specific choices of
X
in
Y
= Xβ + ε
2) One thing to be aware of:
estimates of β̂ can change whan you change the correlation model
In the usual (independence) ANOVA/regression model:
estimate the trt. means or the β̂’s
use these to estimate the variance σ 2
but, the estimates do not depend on the variance
In spatial (or more generally, most correlated data models), GLS
estimates of β̂ depends on Σ.
e.g. in a plant breeder variety trial, adj. for spatial correlation may
change ranking of varieties (because trt means are different).
If you believe you have a good model for the spatial correlation, GLS
ranking is better
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
37 / 69
Final thoughts on spatial ANOVA/regression
3) calculating d.f. for treatment means or comparisons of trt. means
In simple problems (independent data), d.f. = n − k
not so when obs. are correlated. If + correlation, each obs. is less
than 1 new piece of information
A very difficult problem.
One approach: refuse to compute df (At least one R package)
Current best, but not great, for models with correlated observations
Kenward-Rogers adjustment.
Spilke et al. 2010, Plant Breeding 129: 590-598
ddfm=kr in SAS
pbkrtest package in R. Does not work with nlme models (e.g., with
spatial correlation)
not too big an issue if many error df
KR also adjusts variances to reduce bias
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
38 / 69
Final thoughts on spatial ANOVA/regression
4) When are spatial models likely to work well?
No published guidance (that I know about)
My thoughts:
At least 10 treatments, at least 5 reps per trt
and small scale = patchy spatial variation
May also need to remove blocks from fixed effect part of model
“fights” with the spatial correlation
5) Remember there is a crucial difference between observations and
residuals
Spatial models are for the residuals
Observations may have a very different pattern (next page)
Especially when treatments have large effects
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
39 / 69
Observations or residuals?
●●
●●
●
● ●
● ●●●●
●
● ●
●●
●● ●
●●
●
●●●●
●
●
● ●
●
●
●●
● ●●
●●
●
●
●
6
●
●
−4
Residual
−2
0
2
0
10
20 30
Location
40
0
10
20 30
Location
40
●
●
●
●
●
● ● ●
● ●
●
●
●
●
●
50
●
●
●●●● ● ●
●
●●●●●●
● ●●●
● ●
●
●
●●
●●●
●●●
●
●●●
●
●
●●
●
●
●●●
●●
●
●
●
●
c Philip M. Dixon (Iowa State Univ.)
SV: observations
0
4
8
12
●
5
SV: residuals
4
8
12
●
●
● ●
0
Observation
10 14 18
50 plots along a transect
10
15
Distance
● ●
● ●
● ●
● ●
● ● ●
50
Spatial Data Analysis - Part 11
5
10
15
Distance
20
●
● ● ●
20
Spring 2016
40 / 69
Final thoughts on spatial ANOVA/regression
6, 7) What if the X variable is spatially correlated?
Very common in observational data
Has a couple of consequences
6) Spatial correlation in observations arises because X is correlated
Observations, Y, are spatially correlated
X is spatially correlated
residuals after regressing Y on X have no spatial correlation
No need to adjust for spatial correlation; X has “taken care of it”
Often not completely so
Still some “left over” spatial correlation in the residuals
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
41 / 69
Final thoughts on spatial ANOVA/regression
One view of spatial correlation:
an omitted spatially correlated X variable accounts for that “left over”
correlation
Spatial correlation is a surrogate for all omitted variables
spatial correlation model is equivalent to a model with independent
errors and a “spatial X”
Moran eigenvector maps (Griffith and Peres-Neto 2006, Ecology
87:2603-2613)
takes this idea one step further
construct a small set of new variables that account for the spatial
correlation
i.e., move the spatial correlation from the VC matrix of errors into the
fixed effect part of the model
essentially a principal components analysis
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
42 / 69
Final thoughts on spatial ANOVA/regression
7) Sometimes get bad news when you include a spatial correlation
Independent errors: regression coefficient for “your favorite” X is large
and precise
Spatial correl.: now small, large se. Your favorite effect has vanished!
Just like what happens when 2 X variables are highly correlated
(multicollinearity)
Spatial: “your favorite” X is highly correlated with the “spatial X”
Difficult issues with interpretation
Various approaches, appropriate practice is not settled
Last two points primarily concern regression
Could be an issue for ANOVA, but only if treatments are very poorly
distributed across the study area
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
43 / 69
SAR models: details and examples
General regression / ANOVA model
1
1
Y = X β + ε, if X = .. , then Y = µ + ε
.
1
model spatial correlation by allowing ε to depend on error values in
neighboring regions
ε(si ) = ΣN
j=1 bij εj + ν(si )
bij are the elements of the spatial dependence matrix expressing
dependence among regions
ν(si ) is an inde[pendent random disturbance for each region.
Usually assume ν(si ) ∼ N(0, σν2
What this model “means”. Some examples:
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
44 / 69
SAR models
In all, assume row standardized rook’s neighbors, so {bij } is
0
0.25 0
0.25 0
0.25
0
0.25 0
focus on the center (bij value in bold). That is location s5 .
ε(s5 ) = 10 Is this value large or small?
A: depends on neighbors where bij is not zero
In the next few slides, we consider various values of ε for the neighbors
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
45 / 69
7 8 10
12 10 8
11 10 9
Only the bolded neighbors matter, Σbij ε(sj ) = 9.5, ν(si ) = 0.5
large error similar to neighbors, so independent contribution, ν(si ) is
small
7 16 10
14 10 12
11 16
9
Σbij ε(sj ) = 14.5, ν(si ) = −4.5
large error, but neighbors are larger, so independent contribution, ν(si )
is negative
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
46 / 69
1 1 2
3 10 1
1 2 3
Σbij ε(sj ) = 1.75, ν(si ) = 8.25
much larger than neighbor errors, so independent contribution, ν(si ) is
large
−5 −7 −10
−3 10 −6
−1
2
0
Σbij ε(sj ) = −3.5, ν(si ) = 13.5
neighbors suggest a negative error, so independent contribution, ν(si )
is very large
If part of the variation in errors can be “explained” by neighbors, then
it is removed.
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
47 / 69
SAR models: implied variance-covariance
Reminders:
Can convert the specification of dependence into a model for the data
Y
= X β + (I − B )−1 ν
Which gives you the VC matrix for the vector of Y ’s
Σ = (I − B )−1 Σν (I − bB)−1
What does this model imply about VC matrix of the observations?
Consider ρ = 0.9, W is rook’s neighbors, row standardized, Σν = σ 2 I
Pictures on next few slides
Correlation declines with distance: good!
But Var Y not constant - largest in corners, smallest in middle of region
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
48 / 69
Correlation with [1,1]
1.0
0.8
0.6
0.4
0.2
0.0
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
49 / 69
Correlation with [4,4]
1.0
0.8
0.6
0.4
0.2
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
50 / 69
Variance of Y
7.0
6.5
6.0
5.5
5.0
4.5
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
51 / 69
SAR models
Degree of non-constant variance depends on magnitude of ρ
Similar plots for ρ = 0.5
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
52 / 69
Variance, rho = 0.5
1.40
1.38
1.36
1.34
1.32
1.30
1.28
1.26
1.24
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
53 / 69
Correlation with [1,1], rho = 0.5
1.0
0.8
0.6
0.4
0.2
0.0
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
54 / 69
Correlation with [4,4], rho = 0.5
1.0
0.8
0.6
0.4
0.2
0.0
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
55 / 69
Estimation for SAR models
Reminder: model is Y = X β + (I − B )−1 ν,
where B = ρW
W is the known spatial weight matrix
IF ρ is known, then B is known, only need to estimate β̂
Easy:
1) calculate Σε = (I − B )−1 Σν (I − B )−1 and use GLS, or
2) Note that: (I − B )Y = (I − B )(X β) + ν
transform Y vector and X matrix, and you have an OLS problem.
Usual situation: ρ is unknown, need to estimate
use maximum likelihood
general alternative to LS for any statistical problem
Have already seen the VC matrix for ε: Σε = (I − B )−1 Σν (I − B )−1 ,
where B = ρW
mvNormal lnl is
0
k
1
1
− log 2π − log | Σε | − (y − X β) Σ−1
ε (y − X β)
2
2
2
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
56 / 69
Maximizing the mvN lnL
Iterative algorithm.
Key insight is that given Σε , mle of β is trivial (GLS)
Assume ρ = 0, find OLS estimate of β
Condition on β, use numerical maximization to find ρ̂ | β
find GLS estimate of β for Σε (ρ)
repeat last two steps until convergence.
Traditional frequentist approach is to estimate β and Var β
conditional on ρ̂
Bayesian approach incorporates uncertainty in ρ̂ into uncertainty
about β
Not an issue for simple problems (e.g. Σε = σ 2 I ) because in this
case, β̂ independent of σ 2
Is in issue in these models because ρ̂ and β̂ are not independent.
For sp diversity data, ρ̂ = 0.914.
That is strong positive spatial dependence.
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
57 / 69
Useful things about likelihood
test hypotheses using Likelihood Ratio Test (LRT)
e.g. test Ho : ρ = 0
calculate lnL given ρ = 0 (need to maximize over β): lnL0
calculate lnL at mle’s of all parameters: lnLA
lnLA ≥ lnL0 , because ρ probably not 0
but by how much? ∼ 0 ⇒ data consistent with ρ = 0 ⇒ accept Ho
but how much is “too far” from 0?
General result: When Ho true, −2(lnL0 − lnlA ) ∼ χ2k where k is the
difference in # parameters between the two models
This is an asymptotic result, but surprisinly effective in small samples
Here, k = 1 because testing hypothesis about 1 parameter
lnLA = -112.137
lnL0 = -158.306
∆ = −2(lnL0 − lnLA ) = 92.34
2
χ1,0.95 = 3.84. Here p << 0.0001
LRT only works when one model is a simplification of another
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
58 / 69
Useful things about likelihood
Model selection: e.g. compare different
W
matrices
AIC = -2 lnL + 2 k
k is # of parameters. spdep counts β, σ 2 , and ρ
Can compare models with same number of parameters, or diff. #
parameters
choose model with smallest AIC
Here, 3 parameters (µ, σ 2 , and ρ)
ρ = 0: AIC = 316.61 + 6 = 322.61
ρ = 0.914: AIC = 224.27 + 6 = 230.27
Choose model with ρ = 0.914
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
59 / 69
Useful things about likelihood
confidence interval for ρ by profile likelihood
Concept: Repeat LRT for many values of ρ
include inside 95% ci all values of ρ for which test is p > 0.05
here (0.82, 0.98)
consequences of choice of ρ on inference about β
ρ = 0 (independence): µ̂ = 6.09, se = 0.36
ρ = 0.914: µ̂ = 5.69, se = 1.69
Two points:
just demonstrated non-independence of ρ̂ and β̂ in a SAR model
se given correlation is 4.7 times larger
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
60 / 69
CAR models: details
SAR models all Y values simultaneously
CAR models distrib of a each Y given the values of its neighbors
Yi | Y−i = X i β + ΣN
j=1 cij (Yj − X j β) + νi
RHS same as SAR model
The difference is that Y−i now treated as fixed values when specifying
distrib of Yi
Diff. VC matrix for obs.: Σε = Var Y = (I − C )−1 Σν
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
61 / 69
to be a valid VC matrix, requires some conditions:
ρ can not be too large
Definition depends on the weight matrix,
C must be symmetric, Cij = Cji
so my example now uses binary weights
W
Practical difference: pattern of variance not the same
Pictures on next slide
biggest var in the middle of the area (more connections to other points)
But correlation pattern similar
correl between pairs in middle higher among than between middle and
edge
similar to SAR pattern, but details slightly different
Fitting a CAR model gives: µ̂ = 5.10, se = 0.83, ρ̂ = 0.253.
0.253 doesn’t seem large, but close to maximum possible value
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
62 / 69
Spring 2016
63 / 69
Spring 2016
64 / 69
Variance, CAR
2.8
2.6
2.4
2.2
2.0
1.8
1.6
1.4
1.2
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Correlation with [1,1], CAR
1.0
0.8
0.6
0.4
0.2
0.0
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Correlation with [4,4], CAR
1.0
0.8
0.6
0.4
0.2
0.0
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
65 / 69
Different variance and correlation pattern ⇒ CAR and SAR are not
the same models
Which fits the data better? How will you answer this Q?
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
66 / 69
Different variance and correlation pattern ⇒ CAR and SAR are not
the same models
Which fits the data better? How will you answer this Q?
I would use AIC
model
AIC
SAR
241.54
CAR 262.38
Indep 320.61
Clear dominance of SAR model
Traditional interpretation
AIC w/i 2 of the top: worse model is reasonable competitor
AIC more than 10 from the top: worse model is very unlikely
For Bayesian analysis, CAR models very, very popular
They are easy to use in an MCMC chain, because they are conditional
distributions
Smoothed values for the CAR model on next slide
c Philip M. Dixon (Iowa State Univ.)
div
Spatial Data Analysis - Part 11
CarPred
Spring 2016
67 / 69
12
10
8
6
4
2
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
68 / 69
SarPred
CarPred
10
9
8
7
6
5
4
3
2
1
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 11
Spring 2016
69 / 69