Learning Classifiers from Medical Data
by
Jeffrey J. Billing
Submitted to the Department of Electrical Engineering and Computer Science
in Partial Fulfillment of the Requirements for the Degrees of
Bachelor of Science in Computer Science and Engineering
and Master of Engineering in Electrical Engineering and Computer Science
at the Massachusetts Institute of Technology
May 24, 2002
Copyright 2002 Jeffrey J. Billing. All rights reserved.
The author hereby grants to M.I.T. permission to reproduce and
distribute publicly paper and electronic copies of this thesis
and to grant others the right to do so.
Author:
Department of 'iLN4tri#
Enkineering and Computer Science
,- Jvay 24, 2002
Certified by:
Kaelblhe
'.Lslie Sqpervisor
'Thesis
Accepted by:
A
ur C. Smith
Chairman, Department Committee on Graduate Theses
MASSACHUSETTS INSTITUTE
OF TECHNOLOGY
JUL 3 1 2002
LIBRARIES
BARKER
Learning Classifiers Networks from Medical Data
by
Jeffrey J. Billing
Submitted to the
Department of Electrical Engineering and Computer Science
May 24, 2002
In Partial Fulfillment of the Requirements for the Degree of
Bachelor of Science in Computer Science and Engineering
and Master of Engineering in Electrical Engineering and Computer Science
ABSTRACT
The goal of this thesis was to use machine-learning techniques to discover classifiers
from a database of medical data. Through the use of two software programs, C5.0 and
SVMLight, we analyzed a database of 150 patients who had been operated on by Dr.
David Rattner of the Massachusetts General Hospital. C5.0 is an algorithm that learns
decision trees from data while SVMLight learns support vector machines from the data.
With both techniques we performed cross-validation analysis and both failed to produce
acceptable error rates. The end result of the research was that no classifiers could be
found which performed well upon cross-validation analysis. Nonetheless, this paper
provides a thorough examination of the different issues that arise during the analysis of
medical data as well as describes the different techniques that were used as well as the
different issues with the data that affected the performance of these techniques.
Thesis Supervisor: Leslie Kaelbling
Title: Professor, MIT Artificial Intelligence Lab
2
Learning Classifiers from Medical Data
1. Introduction
A major trend in current artificial intelligence has been the development of expert
systems. These systems use an expert-level knowledge base to perform a given task or to solve a
particular problem. One of the first implementations of these was a rule-based expert system. A
rule-based expert system is initialized with a small set of variables having values assigned to
them while the rest are not assigned any value. It then uses either forward- or backward-chaining
to propagate through a set of "if-then" rules, attempting to deduce the values of the unknown
variables. The ultimate goal of the system was to deduce the value of a particular "goal" variable.
These systems were applied in many places in industry and proved to be a valuable
resource. When implemented correctly, they began to save companies large amounts of money by
solving problems and tasks more efficiently and without error, as a computer will not overlook
particular details that a human might fail to recognize. These systems, however, had the major
drawback that they relied on extensive manual knowledge-acquisition. To create an "expert"
system, one must have access to an expert and be able to represent all of his knowledge in a
computer program in the form of "if-then" rules. The process of collecting this information was
very tedious, and in addition, because the program was based solely on the knowledge of the
expert, you could never hope to create a system that could make deductions beyond the capacity
of those that the expert could make. Furthermore, the lack of probabilistic inference within these
types of systems, where you could predict probabilities of certain variables based on the values of
other variables, was a major drawback. Thus, while expert systems proved powerful in many
areas, their reliance on manual labor and previous expert knowledge had its inevitable limitations.
Upon the realization of these limitations the evolution of artificial intelligence turned
towards the analysis of raw data. By drawing conclusions directly from the data, these "data
mining" techniques had the power to learn facts from the data that were previously unknown, and
thus were not limited to merely having the same capabilities of experts. Clearly, the capability of
such programs surpassed that of the expert systems, but the algorithms to learn these types of
unknown facts required much more complicated programs than the relatively simple rule-based
systems. Furthermore, while these data mining techniques required no expert knowledge as a
foundation for their algorithms, they do require strict guidelines for formatting the data such that
it is in a form suitable for analysis. As will be shown later on in this paper, this process of
formatting the data in a suitable and appropriate fashion can be quite complicated.
3
While the field of artificial intelligence has evolved from expert systems to data mining,
the medical field has been evolving from paper medical records to electronic medical records. For
many obvious reasons, the medical field, like banks and airlines and every other major industry,
has been in the process of converting all its information management from paper records into
computers. As doctors' notebooks, and all the data therein, have been computerized, an enormous
wealth of data that never before could have been analyzed has been made available. For example,
previously when medical records were kept on paper, the task of cross-checking dozens of
different data points over hundreds of patients in the attempt of finding meaningful correlations
was an enormous task that would require hundreds or thousands of man hours. With the use of
computers and the conversion of these medical records into electronic format, however,
programmers now have the ability to perform searches of this sort in mere seconds.
The simultaneous development of artificial intelligence data mining techniques and
electronic medical records provides the potential to analyze newly available data with the newest
techniques. The potential for bringing to light correlations in medical data that have been long
buried in stacks of papers is thus enormous. If this analysis can elucidate unknown medical
information, from just one small database of patients who have undergone this one particular
surgery, then these types of techniques can be expected to discover gigantic amounts of medical
information from the scores of datasets that are being constructed every day.
This paper will describe an attempt to learn new medical information from one particular
database of patients who have all undergone a similar type of surgery. We applied two different
machine learning/artificial intelligence techniques in attempt to learn classifiers for the data:
learning decision trees from the data by way of an algorithm known as C5.0, and using Support
Vector Machines (SVM's) to discover classifiers for the data. The rest of this paper consists of an
introductory description of these two techniques, a description of the data and the lengthy process
of formatting this data appropriately for analysis, and a description of the results of the analysis
and a look into the future for this project and other similar projects. The results described below,
for an assortment of reasons, did not turn out to be fruitful, as the data itself provided too many
barriers for these different techniques to overcome. Nevertheless, an in-depth description of the
process of preparing the data for these different techniques and a review of the results that were
achieved should prove useful to future researchers who aspire to use these types of techniques to
perform data mining analysis on similar types of datasets.
4
2. Techniques
There exist many discriminative methods for analyzing data and predicting outcomes.
Unfortunately, in many cases the relationships between different variables are not known and so
many of the classical statistical methods are not applicable. Such is the case with this particular
dataset and in fact, one goal of this project was to learn more about the relationships and
interactions between variables.
2.1 Decision Trees
The first machine learning technique we used to attempt to find relationships between the
variables was to learn decision trees from the data. The goal of decision trees is to find a classifier
for a particular attribute - the outcome variable. A decision tree is an acyclic structure consisting
of a root node, many subsequent child nodes and then finally leaf nodes, all of which are
connected by directed arrows. At the top of a decision tree is the "root" node, which corresponds
to an attribute in the database. Then, at the next level of the tree are the root node's children, a set
of nodes connected to the root node by a set of edges (one edge per node), where each edge
represents one of the possible values that the root node's variable could take. In this way, the
parent node and its connection to its children form a decision within the data. The root node
represents a variable, for example, "heartburn" - whether or not the patient suffers from
heartburn. This node would then have two children, one that would be connected to its parent by
a line labeled "yes" and the other that would be connected to its parent by a line labeled "no." In
this way the dataset would be split so that those patients who suffered from heartburn would fall
on the side of the tree under the node with the "yes" edge and those patients who did not suffer
from heartburn would fall on the other side of the tree, under the node with the "no" edge. Thus, a
decision had been made that split the data into two subsets. Then, the tree structure repeats itself
as each of these children nodes become root nodes for their respective subtrees and new attributes
are assigned to these new root nodes that partition the data further. This structure recurses until, at
some point, the decision tree has no more decisions to be made, and the children nodes are
"leaves." A leaf is a node that has no children, and thus marks the end of one branch of the tree.
Leaves are the only nodes in the tree that do not mark a decision to be made. They represent all
the patients in the database that conform to all the decisions made by the branch of the tree that
lead to them from the original root node. So, each leaf represents a unique subset of the data.
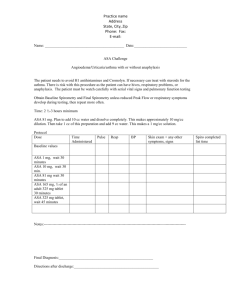
Below is an example of a sample decision tree, which is classifying whether or not the
patient had a "hard surgery." The topmost node, "reflux symptoms" is the root node of this tree.
The edges are each labeled "0" or "1." A label of "0" means that the attribute was not present,
whereas a label of "1" means that the attribute was present. Thus, for patients who did not suffer
5
from reflux symptoms, the next decision that split the data was whether or not the patient suffered
from dysphagia. Similarly, for patients who did suffer from reflux symptoms, the next decision to
classify the data was whether or not the patient suffered from heartburn.
retluxsyrtphtms
0
1_I1 32
1
dysphag~i
hearxuii
090..
021.1
0
ahrynggealsyrptorn'
0
0(
1
1_3_ I
Figure 1 - Sample Decision Tree Classifying "Hard Surgery"
As previously stated, the purpose of a decision tree is to classify the data in terms of an
"outcome" variable. Each leaf is thus represented by one of the possible values for this outcome
variable; this value is the leftmost number in the leaf, as you can see in the sample decision tree
above. You will also note that each leaf contains two more numbers to the right of this one. The
middle number expresses the number of cases in the database that conform with all the decisions
that have led to that particular leaf. The rightmost number expresses the number of these cases
whose value for the "outcome" variable is different from that expressed in the leaf. It should be
obvious that for any dataset there exist many potential decision trees. The goal of the
classification algorithm is to find the decision tree that best fits the data, that is, whose leaves
have the smallest margin of error - this can be calculated by dividing the second number by the
first. Therefore, for the leftmost leaf, which classifies all patients who didn't have reflux
symptoms and didn't have dysphagia as patients who would undergo a difficult surgery. From the
training data there were 2/118 errors, which is less than 2% error.
While the goal of the algorithm is to have the least amount of error, the algorithm also
does not want to over-analyze the data. This can be done if every single case in the database is
given its own leaf. Overfitting the data in this way provides no special insights, however, into the
intricacies of the data. The goal of a classification algorithm is to balance the error rate of the tree
(the number of misclassified cases divided by the total number of cases) with the size of the tree
(the number of nodes in the tree) in hopes of finding a tree that will do a good job of predicting
outcomes of previously unseen patients.
6
2.1.1 Expanding the tree
A decision tree classifier starts at the root node; its first decision is which variable to
represent in the root node. For our research we used a commercially available product called
C5.0. There are many ways a classifier can choose the root node; C5.0 uses a value called "gain
ratio" to make its decision. The gain ratio reflects, upon partitioning the data T by test X, the
proportion of information that is generated that will also help for classification. This quantity is a
modified version of the simpler "gain" which solely measures, upon partitioning the data T by test
X, the information that is generated, not taking into account whether or not this information will
aid in classification. What follows is a mathematical explanation of these terms and other terms
needed for their derivation.
First we will let S be an arbitrary set of cases, we will let C be the set of possible classes
of the outcome variable, and we will let T be specifically the set of training cases. The probability
that a random case S, in S, belongs to a particular class C, which is a distinct member of the set C,
will be called prob(C,S). Information clearly states that with this probability being defined, the
information conveyed by saying that S belongs to class C is, in bits, minus the base two logarithm
of the prob(C,S) (Quinlan 1993). When the set S is replaced by the set T, so that the above
explanation refers to a set of training cases, we can define the average amount of information
needed to identify the class of any particular case in this training set as info(T) (Quinlan 93),
where
info(T) =
probf j,T Jogprob j,T)
bits.
j=1
Once the test X has been applied to the training set T, and T has thus been partitioned into
subsets, the expected information of the data at this point, we will call it xin(T), can be calculated
as a weighted sum of the expected information of each of the subsets, t
xinT
|T)
t | in
0=xifot3
j=
1 TI
From here, the amount of information that was gained by performing test X can be found by
subtracting the expected information of the initial training set by the expected information of the
training set after partitioning it by test X, such that
gain(X) = info(T) - xin(T).
As previously mentioned, this is one possible value that can be used to choose which test should
be at the root node of the tree. Or, in other words, which variable should appear in the root node.
The drawback of this criterion, however, is its tendency to choose a test that has many different
outcomes. For example, in our database every patient has a unique patient ID, performing this test
on the database would lead to many leaves each containing one case representing a single class.
7
As a result, the expected information of each of these leaves would be zero and thus the gain
would be maximized. This would mean that an algorithm that chose its root node solely based on
the gain criterion would choose the patient ID test as its first test, and it should be obvious that
doing so will not provide any interesting classification results as you will receive a tree of depth
two with as many leaves as there are patients.
Using the gain ratio, instead of just the gain, solves this problem. Upon splitting, a certain
amount of information is gained that is not relevant for classification. This value is represented by
what we will call the splitting information, or split(X). In calculating the gain ratio, the gain is
normalized with this splitting information, producing a value that represents the amount of
information which was generated by performing test X and which has the potential to be useful
for classification. The calculation of the splitting information is parallel to the calculation of
info(T),
n
split(X)=
-IT I
x log,
-
ITI
ITlI
( IT I
From here, the calculation of the gain ratio is simple,
gain ratio (X) = gain (X) / split (X).
The C5.0 algorithm loops through all the possible tests that could be performed and
calculates the gain ratio for each of them. It doesn't, however, merely choose the test with the
largest gain ratio. Rather, the algorithm chooses a test which maximizes the gain ratio while also
satisfying the condition that the information gain be greater than or equal to the average
information gain over all the different possible tests. The test with the highest gain ratio that
satisfies this condition then becomes the root node. This procedure then recurses until the tree has
been fully expanded.
2.1.2 Pruning the tree
The fully expanded tree supplied by the above algorithm is not expected to have the
ability to predict outcomes on unseen data. A tree that is fully expanded from the training data
will over-fit this data and not be useful for classifying unseen cases. Developing a classifier,
however, is the goal of learning a decision tree, and so one more step must be included in the
algorithm to develop a program that can learn trees with predictive abilities. This final step is
called pruning and its main goal is to remove the parts of the tree that don't contribute to
classification. It does this by calculating a "predicted error rate" for each branch or leaf of a tree,
and then checking to see if any modifications to the tree will decrease this value.
The predicted error rate is an estimation of the number of misclassifications that would occur,
given a test dataset of equal size to the training dataset. The idea behind using this value to aid in
8
pruning is simple. If, for example, you knew what the error rate on test data was going to be for
all the branches and leaves of a tree, you could modify the tree to minimize this error rate for the
entire tree. Doing so would give you the classifier that had the best performance on unseen data.
So, to attempt to find this ideal classifier, the algorithm estimates this error rate and prunes the
tree based on this estimation.
The underlying idea behind the estimation technique is to find a probability distribution
for this predicted error rate, rather than trying to find an exact number. The designers of C5.0
used a binomial distribution to represent this probability distribution. The theory is that for any
leaf (or branch) we know the number of cases, N, in the training data that fall under that leaf (or
branch) and we also know the number of misclassified cases, E, that fall under that leaf (or
branch). In a probabilistic sense we can view these errors as being E events in N trials, and thus
the probability of a new case being misclassified can be represented by the binomial distribution
of (E,N), which can be summarized by a pair of confidence limits. To attain a number for the
predicted error rate, as opposed to a probability, C5.0 finds the upper limit on this probability
from the confidence limits for the binomial distribution. To calculate this upper limit C5.0 has a
parameter called the confidence level which has a default value of 25%, but which the user can
vary anywhere between zero and a hundred percent. It should be noted that, after explaining the
way C5.0 calculates this predicted error rate, Quinlan does, however, state, "Now, this description
does violence to statistical notions of sampling and confidence limits, so the reasoning should be
taken with a large grain of salt. Like many heuristics with questionable underpinnings, however,
the estimates that it produces seem frequently to yield acceptable results" (Quinlan 93). With this
method of predicting the error rates of leaves and branches, where the error rate for a branch is
just the weighted sum of the error rates of the leaves that make up that branch, C5.0 prunes the
tree by calculating the predicted error rates of the current tree and comparing that to the predicted
error rate of slight modifications to the tree. The pruning procedure has the ability to replace
branches with single leaves as well as the ability to replace sections of a branch with a node from
that branch.
Below is a sample output of C5.0 and the tree that we formed by putting this output
through a program that draws the information into a aesthetically pleasing tree structure.
9
C5.0 Output
Tree Drawing Software Output
refluxsymptoms = 0:
rt'usyptoms
:...dysphagia = 0: 1 (118/2)
dysphagia = 1: 0 (10/1)
refluxsymptoms = 1:
:...heartburn = 0:
...pharyngealsymptoms = 0: 0 (2)
pharyngealsymptoms = 1: 1 (3/1)
heartburn = 1: 0 (21/1)
(ibum
1
I 11_2
(1_I
Q21
0
phngeasymptmn
0
(L2-.0
1
1_3_1
Table 1 - Sample C5.0 Results
The other functionality C5.0 supplies that we used a great deal is the general technique of
evaluating a classifier with cross-validation. This will be described in detail in section 3.3.
2.2 Support Vector Machines
The other method we used to try to find classifiers from this dataset were support vector
machines. SVMs have been found to be successful in classifying data across a wide range of
datasets and according to Christopher Burges, "In most of these cases, SVM generalization
performance (i.e. error rates on test sets) either matches or is significantly better than that of
competing methods" (Burges 98). SVMs are a relatively new technique developed originally by
Vapnik in 1979 and have begun to receive much attention over the past decade. Burges calls the
development of SVMs "one of the shining peaks of the theory of statistical learning" (Burges 98).
The foundation of SVMs lies in the idea that to have the best results on test sets, the proper
balance must be found between having small error rates on particular training sets and "the ability
of the machine to learn any training set without error" (Burges 98). This second part is known as
the "capacity" of the machine. The description below is a summary of the more detailed
description of SVMs found in Burges' tutorial on the subject.
Similarly to decision trees, SVMs attempt to find a classifier for the data. To do this, the
input into the system must include a particular variable designated as the outcome variable, which
must be a binary variable. An algorithm to learn SVMs will then search for "separating
hyperplanes." The general goal of the algorithm is to find hyperplanes that divide up the data so
that all data points lying in the same region have the same value for the outcome variable. The
data points that lie closest (in terms of perpendicular distance) to the hyperplanes are called the
support vectors. These support vectors have an interesting property, "the support vectors are the
critical elements of the training set. They lie closest to the decision boundary; if all other training
points were removed (or moved around, but so as not to cross [any hyperplanes]), and training
10
was repeated, the same separating hyperplane would be found" (Burges 98). With support vectors
defined, we can now further describe the manner in which the support vector machine chooses its
hyperplanes.
Figure 2 - Hyperplane Example
'Ie cled data points amrthe upt vwcts
and the margin is the distare bdwen these.
Mari
1ag
Origin
2
Hyperp lane
2.2.1 Finding the Optimum Hyperplane
To fully describe the method by which an SVM finds the best hyperplanes requires a
Lagrangian formulation of the problem. Doing so is beyond the scope of this thesis, and can be
found in (Burges 1998), but the idea behind what the search method attempts to find can be
explained in general terms. The important value is that of the perpendicular distance from a
hyperplane to its support vector. The "margin" of a separating hyperplane is said to be the sum of
the perpendicular distances from a hyperplane to that hyperplane's support vectors that represent
the different possible outcomes (see diagram below). The goal of the algorithm is to find the
hyperplane with the largest margin (Burges 98). In our case, as with most non-trivial datasets, we
were not going to be able to find completely separable hyperplanes. That is, we were not
expecting to find hyperplanes that divide up the data perfectly, such that all cases on one side of a
hyperplane fall under one class and all cases on the other side fall under another class. Rather, we
are hoping to find the hyperplanes with minimal error. Because we are dealing with "nonseparable data," the algorithm to find the hyperplane with maximal margin must be able to take
into account data points that are on the "wrong" side of the hyperplane; this is done by
introducing "slack" variables. For data that is separable, there exist two constraints on the training
data, X, where x is a particular case in the data, w is a normal to the hyperplane,
Euclidean norm of w,
IbiI/i|wil
liwil
is the perpendicular distance from the hyperplane to the origin and
y is the value (either positive or minus one) of the outcome variable for case x. Then,
xw + b
1
for y = 1
is the
and
xw + b
1
11
for y = -1
are equations that represent the constraints that ensure that the hyperplane completely separates
the data. For non-separable data, however, these constraints have to be modified with the
aforementioned slack variables. We will call the slack variables associated with a particular case
in the data 'e', such that,
xw+b
1 -e
for y = 1
and
xw + b
1 +e
for y = -1.
If a slack variable is greater than one, then an error may occur such that the case 'x' can be found
on the wrong side of the hyperplane. These types of errors need to be accounted for, in addition to
the width of the margin, when deciding which hyperplane best fits the data. By summing up the
values of all the slack variables, SVMs create a penalty that can take away from the score of a
hyperplane. This sum is multiplied by a value, C, that is a parameter that can be modified by the
user, depending on how much the user would like to penalize the classification for training errors.
2.2.2 Kernel Function
Support vector machines have the ability to learn non-linear hyperplanes through the use
of a "kernel" function. To learn a non-linear hyperplane the algorithms first map the data from
their original space to a Euclidean space, H. Call the mapping that does this, f, such that:
f:
Rd
-+ H.
Converting the data to a different space in this manner means that in the equations to find the best
hyperplane the value x must be replaced with the value f(x), where x still represents a single case
of data. This would cause problems because the mapping f could be extremely complicated,
however, in the maximization equations, the cases of data only exist in the form of dot products
with each other. Thus if z was another single case of data, the only places these cases of data
occur in the calculations is in dot products of the form xz. Using this fact, these cases of data,
once converted into the new Euclidean space, only occur in dot products of the form f(x)f(z). The
kernel function is then defined to be
K(x,z)=f(x)f(z).
Now, since the data only appears in the form of dot products, and we have defined a new function
that is equal to the dot product of two cases of data, the new function (the kernel function) can
replace every instance of dot products of data that appear in the maximization equations.
Interestingly, this means that the mapping function f never appears in the calculations, a very
important result because generally f will be very high dimensional, and so not having it in the
equations is very helpful. Basically, what using the kernel function does is that it allows us to still
learn linear hyperplanes; we're just learning these in a different Euclidean space. Furthermore,
12
once we have learned the hyperplanes in this new space, we can also test the support vector
machine by substituting the kernel function in for the dot products of data that appear in the
constraint equations described earlier. In this kernel function, rather then having two cases of data
as the inputs, one of these inputs will be w, then normal to the hyperplane, which also exists in
the new Euclidean space, and thus can be inserted into the Kernel function. This trick, however,
only works for certain choices of f. The different possible functions that we were able to use are
discussed in the next section.
2.2.3 SVMLight
The software that we used to learn our support vector machines is a commercially
available package called SVMlight, version 4.00. In using this software we adjusted two
parameters, which have been discussed in the two previous sections. These parameters are the
kernel function and the cost-factor. The kernel function in SVMlight has 5 different options: a
linear function (default value), a polynomial function, a radial basis function, a sigmoid function,
and the final option is for the user to define their own kernel function. The cost factor, "by which
training errors on positive examples outweigh errors on negative examples" (Burges 98), has a
default value of 1 and can be set to any value between zero and one. A sample input and output
for SVMlight, run off of Athena, are shown below:
Input:
Input:
athena% svmlearn test.dat
athena% svmclassify train.dat model
Output:
Output:
Scanning examples.. .done
Reading examples into memory...
(97 examples read)
Reading model...OK. (53 support vectors read)
Classifying test examples..100..done
Runtime (without 10) in cpu-seconds: 0.00
Accuracy on test set: 38.89% (42 correct, 66
incorrect, 108 total)
Setting default regularization parameter C=0
O ptim izing ............................................................
Optimization finished
(47 misclassified, maxdiff=0.00047).
Runtime in cpu-seconds: 0.40
Number of SV: 95 (including 93 at upper bound)
Norm of weight vector: Iwl=0.00006
Norm of longest example vector: lx=45775.5
Number of kernel evaluations: 3891
Writing model file...done
Table 2 - Sample Input/Output for SVMLight
13
3. Formatting the Data
With this being the beginning of an era of newly found data mining potential, many of
the steps along the way in developing this thesis were made much more complicated as the data
entry techniques currently used in local hospitals do not lend themselves very well to the analysis
of data. While describing the different artificial intelligence techniques that were used and
making some interesting conclusions from the data, this paper will also have a great deal of focus
on the manual data analysis that was undertaken, not in a data mining sense, but in the sense that
to make the database suitable to be run through the different programs that perform the data
mining much work was needed. From debugging errors within the data to resolving ambiguities
within the data to simply deciding the best way to represent the data, much work was done before
the data was ever introduced to the algorithms developed for the purposes of data mining.
Upon receiving the first database, "lapops.mdb," in March of 2001, our first task was to
format the data so that the different machine learning algorithms could use it. The data was
supplied by Dr. David Rattner of the Massachusetts General Hospital in the form of a Microsoft
Access Database. This first database contained 38 attributes for 164 patients that Dr. Rattner had
operated on between November of 1997 and February of 2001. It should be mentioned now that
these numbers would change over the next 15 months as the database was constantly being
modified as seen fit by the researchers and the doctors. The process of formatting the data was a
tedious one, involving a large amount of interaction with Dr. Rattner and his assistant; asking
them questions about what format would best display the data medically, then accounting for
their answers and formatting in a way that would likewise be suitable for the analysis.
The original database had many frustrating details. As is common in such databases, there was a
great deal of missing data (see Appendix A for a detailed description of the data in
"lapops.mdb"). In addition, different assistants had recorded the data for different patients, and
thus no structured terminology existed, so our first task for many of these fields was to determine
a coding that could be used to classify each entry into one of a few different possibilities for each
variable.
3.1 LAPOPS.MDB - March 2001
The first database we received, "lapops.mdb," contained 38 data points for 164 patients.
Of this data, 14 of the 38 variables were immediately deemed inapplicable for analysis. Ten of
these variables were inadequate because less then ten of the 164 patients had data for these
variables. The other four variables that we decided would not be used for analysis were the case
number, the unit number, the operation date, and the name of the referring doctor, all of which
had no effect on the surgery itself or the symptoms and so had no relationship with the other
14
variables in the database. Of the remaining 24 variables, six were continuous variables, three
were binary, one was discrete-valued, and fourteen needed to be coded into discrete values
through interaction with the doctors. A variable-by-variable review will recap the details of these
24 variables (more detailed analysis of the data can be seen in Appendix A).
Continuous Variables
Age
Height
Weight
Operation Time
Flatus Day
Disch Day
Variables requiring Coding
Primary Symptom
Secondary Symptom
Endoscopy
UGI
Peristalsis
Comorbidity
Pre-operative Medications
Operation Comments
Hospital Comments
Hiatal Hernia Size
Single pH Probe
Dual pH Probe
LES Pressure
Binary Variables
Paraesophageal Hernia
Re-operation
Conversion
Discrete Variables
Assistant
Table 2. Variables used in analysis of Lapops.mdb
3.1.1 Continuous Variables
Age contained values between 21 and 90 years, with one value of 740, which upon
review of the paper records was determined to be 40.
Height contained values between 58 and 81 inches as well as having 5 missing values
that could not be obtained upon review of the paper records.
Weight contained values between 90 and 280 pounds while having 2 missing values that
could not be determined upon review of the paper records.
Operation Time ranged between 60 and 270 minutes with no missing values. Note: this
field was actually not continuous, but rather entered in units of fives, but for all intents and
purposes it can be considered as if it was a continuous variable.
Flatus Day ranged between 0 and 5 with an average of .77
Disch Day ranged between 0 and 19 with an average of 1.6.
3.1.2 Binary Variables
Paraesophageal Hernia was a binary variable with 16 "yes" values, meaning that a
paraesophageal hernia was present, and 148 "no" values where the hernia was not present.
Re-operation was a binary variable with 17 "yes" values, meaning that another operation
was necessary, and 147 "no" values where a second operation was not needed.
15
Conversion was the third binary variable and consisted of 6 "yes" values, meaning that
mid-operation the doctor changed from a laparoscopic surgery involving a very small incision to
a much larger open surgery. The other 148 patients had "no" values for this attribute, meaning
that the laparoscopic surgery was sufficient.
3.1.3 Discrete Variables
Assistant was a discretely valued variable containing one of six values (pg0-pg5), each
one representing one of the six assistants. "pg5" assisted in 138 of the 164 operations while the
next most frequent assistant was "pg4" who assisted just 10 times.
3.1.4 Discrete and Binary Variables requiring coding
Primary Symptom contained 34 different entries and upon consultation with Dr. Rattner
these different values were grouped into four different categories: typical symptoms, atypical
symptoms, bleeding symptoms, and paraesophageal symptoms. With this coding "primary
symptom" was converted into a discrete variable with four possible values.
Secondary Symptoms were coded into the same four categories as "primary symptom"
was above. Except instead of being one column made up of a discrete variable with four different
possibilities, this variable was divided into four variables, each one being a binary variable that
represented the presence or void of that particular type of symptom. This way, if the data point in
the original was left blank, i.e., there were no secondary symptoms, then all four of these newly
created variables would reflect that no such secondary symptom was present.
Endoscopy shows the result of a particular test given to a patient and in the database the
records contained 28 different entries. Upon consultation with Dr. Rattner, these values were
clumped into creating a discretely valued variable with five different possibilities. These values
are: endoscopy not performed, endoscopy normal, endoscopy revealed hiatal hernia or
esophageal shortening, endoscopy revealed Barretts syndrome or esophagitis, and endoscopy
revealed other type of problem. This last option was used to combine a bunch of conditions that
were revealed too infrequently to deserve their own possibility.
UGI also shows the result of a particular test given to patients, and also contained many
different entries. In a similar consultation with Dr. Rattner, UGI was converted into a discretelyvalued variable with six different possibilities: UGI not performed, UGI normal, UGI revealed
reflux, UGI revealed hiatal hernia, UGI revealed paraesophageal hernia, and UGI revealed
motility problem.
Peristalsis, a variable that is yet another result of a test given to the patients, was
converted to a discretely valued variable with four different possibilities upon consultation with
16
Dr. Rattner. These values were: peristalsis absent, peristalsis normal, peristalsis disordered, and
peristalsis hyperactive.
Comorbidity was a field that describes the other conditions a patient is suffering from; it
contained almost 50 different values in the database. Upon review by Dr. Rattner, each
comorbidity that occurred in the database was given one of three values: not severe, mildly
severe, or very severe. In this way this variable was converted into a discretely-valued variable
with 3 possible values.
Pre-operative Medications was a field that listed the different medications that a patient
was taking prior to the operation. The list of different medications far exceeded 50, and so Dr.
Rattner went through the list and assigned each medication to one of three different categories.
These categories were: drugs that aided in acid Suppression, Steroids or drugs that aided in
immunosupression, and a category that consisted of all "other" types of drugs. With these three
categories and a value of "none" reserved for the nine patients who were taking no pre-operative
medications, this variable was converted into a discretely valued variable with four possible
values.
Operation Comments was a field that just contained a plethora of different comments
recorded by the doctors during the operation. While each comment was different and hence there
was no way to clump the comments into different groups, Dr. Rattner was able to go through the
list of comments and say whether each one implied that the operation was "easy" or "hard." In
this way, this variable was converted into a binary variable representing these two possibilities. If
this field was left empty the operation was considered to be easy.
Hospital Comments was a similar field to the previous one in that each comment was
unique and so clumping the comments into different groups was not possible. Instead, Dr. Rattner
found it best to make this a binary variable with one value representing that there was no
comments made, and the other value representing that a comment was entered into the database.
This interpretation was appropriate because the comments that were entered all had to do with
problems the patients encountered while being under the care of the hospital, and so that is the
most accurate way to interpret the meaning of this binary variable.
Hiatal Hernia Size contained about 7 different values. These were put into a 0-6 coding
with "0" representing that no hernia existed and with "6" representing a "huge" hernia existing.
Because some of the values only occurred once or twice in the database, this field would soon be
reduced into a discretely-valued variable with 4 possibilities, 0-3, respectively representing:
none, small, medium and large.
17
Single pH Probe contained blank, normal, negative and positive values, as well as some
numbers that were recorded as measurements straight from the probe. After determining what
range represented normal, negative and positive values, this was coded into a discretely valued
variable with 4 possible values: test not performed, negative, normal, and positive. According to
Dr. Rattner, a pH probe is only necessary to document reflux, if it has not been documented
through some other measure. So, in this sense, the lack of a test for pH could imply that the case
was more straightforward, by the reflux being easily recordable, but Dr. Rattner felt this to be a
soft assumption, all the while an interesting one.
Dual pH Probe lends itself to a simple 4-way coding of test not performed, no
correlation, slight correlation, and positive correlation. Only one patient had a value of "no
correlation" and so this variable could easily be reduced into a 3-way discrete variable by
deciding to join that value with that of "slight correlation."
LES Pressure, in a similar way to the single pH probe, had a mix of nominal values such
as "high" and "low" as well as having the actual numerical measurements as some of the data
points. Upon consultation with Dr. Rattner for the nominal values of such numerical
measurements, this variable was converted to a discretely-valued variable with 4 possibilities.
These were: test not performed, low, normal, and high. A blank field under this variable implied
that the test was not performed and a value of "absent" was placed under the categorization of
"low," albeit the lowest possible value.
3.1.5 Results
When preparing this initial database to be run through C5.0, our focus was on getting
simple outputs that could be understood by the doctors to get them excited about the project. As a
result, we chose to use only those variables that reflected information that was attained before the
patient had undergone the surgical procedure. With this in mind, we chose to make the decision
trees a classifier on whether or not the surgery was considered by the doctors to have been a "hard
surgery" - a classification that was determined under the "operation comments" attribute as
explained above. Furthermore, we chose to turn all the multi-valued variables into binary
variables. For those variables that had more than two discrete values we simply split each discrete
possibility into a binary variable of its own. Thus, if variable A had options 1, 2, and 3, we made
three variables: A1, A2, and A3. A l was a "yes" if variable A took the value of 1 and was a "no"
if A took a value of 2 or 3. A2 and A3 were formatted in the same fashion for their respective
values. In recap, for this first set of analyses, in the case of C5.0 we were classifying whether or
not the surgery was considered "hard," and for both techniques, we were only using data that
18
could be collected prior to the surgery and could be put into the form of either a binary variable or
a continuous variable.
The C5.0 results accomplished their goal of grasping the interest of the doctors and
getting them to promise us more data. The tree below is the simplest of those that we presented to
the doctors. The algorithm selected seven (of the almost 40) variables and successfully classified
73.6% of the patients in terms of whether or not they were in fact a hard surgery. This tree was
formed with a pruning confidence level of 25% (see section on C5.0 above for explanation of this
parameter). The right half of the tree did a better job, classifying 25 of 28 cases correctly (89%),
while the higher concentrated left side classified 95 of 136 correctly (70%). When the pruning
confidence level was raised in subsequent trials, the left side of the tree, in particular the two
leaves that have 17 errors in them, was expanded farther, while the right side of the tree pretty
much stayed the same.
Figure 3 - Classifying Hard Surgery
The presentation to the doctors had the intended effect. They were extremely excited about the
trees they had seen and thus put their assistant hard at work to come up with a new database with
more data. The doctors found the decision trees easy to comprehend and thus in our first meeting
with them when we presented our initial results, they encouraged us to move forward with
discovering interesting classifiers from the decision trees. Four weeks after this meeting, we
received a new and improved database, "LNF.mdb," and went back to the task of formatting a
database again.
3.2 LNF.MDB - August 2001
The major change we were expecting from the first database to this one was the addition
of a hundred more patients. Unfortunately, rather than finding the database to now contain 264
records, we found the original 164 patients, each with much more detailed information. The new
19
database was split up into three sets of eight tables. The three sets of tables had to do with the
three different types of surgeries that were considered to be the same type of operation: 'first
operation,' 'paraesophageal', and 'redo.' For each of these three classifications, there were 8
tables to represent the data. These tables were: 'Follow Up,' 'Medications and Comorbidities,'
'PMH, PSH, Other Complaints and Allergies,' 'Preoperative Symptoms,' 'Demographics,'
'Diagnostic Work Up,' 'In Hospital Stay,' and lastly, 'Operative Details.' All in all these tables
combined covered more than 150 fields for each patient, a vast increase from the 24 fields we had
narrowed the first database down to. As a result, the process of formatting the data started again.
The first task was simply to decide what fields should be kept for analysis.
Many of the new fields were very useful. In particular, the 'Follow Up' included data that
represented the patient's responses to a questionnaire that was given months after having
undergone the surgery. These questionnaires allowed us to create some new "outcome" fields that
were meant to reflect the short- and long-term success of the surgery. In addition to these types of
new fields, the doctors worked hard to come up with a field called "ASA" which represented the
patient's general health. Also, many of the new fields were modifications or different
interpretations of fields that had existed in the original database. Many of the new fields were not
very useful. In the end, we narrowed the number of fields down to 38, a workable number much
less than the 150+ we started with, but also a more than 50% increase from the number of fields
in the original database that we did the analysis with. The process of deciding which fields to
keep as well as how best to represent those fields took us a few months and involved a few
evolutions of the database.
The first thing that was decided was that the paraesophageal operations were different
enough from the first operations and re-do's that they were excluded from the subsequent
database. This excluded 25 patients, bringing the size of the database down to 139. Concurrently,
however, the doctor's assistant added 15 more patients to the data so that by the time we were
ready to run the analysis the database consisted of 154 patients. After deciding of the sets of
tables to analyze, the next step was to combine the different fields that we planned to analyze into
one table. Below is an explanation of the 37 fields that were put into this table that we named,
"useable," and an explanation of the way each of them was coded. Interestingly, of these 37
fields, only 6 were identical to fields that were in the original database. These six variables were:
Age, Operation Time, Conversion, LES Pressure, Peristalsis, and HH Size.
Below is a recap of the 31 new variables, in the same form that we reviewed the fields in
the first database. Many of these fields, as previously mentioned, represent direct modifications or
20
alter interpretations of fields that occurred in the previous database, while some of these fields are
completely new.
3.2.1 New Continuous Variables
Body Mass Index (BMI) is a measure of a person's body mass. BMI is calculated by
dividing the persons weight by their height.
Total Deemester Score is the measurement from the pH studies of certain patients. 77 of
the 154 patients in this database had a value recorded for this test. Of those 77, twenty had values
of zero, leaving us with just 57 patients who had a non-zero score recorded for this variable
Number of Medications referred to the number of different medications the patient was
taking prior to having the operation. Value in this field ranged from 0-18 with the majority lying
between one and seven. In the previous database we had developed a coding for the different
types of medications a person had been taking pre-operation. After discussion with the doctors it
was decided that analyzing the number of medications a patient was on was a good way to
analyze the general health of a particular patient.
3.2.2 New Binary Variables
The first seven of these stem from the old discrete variable, "symptoms," which had 7
different values. This multi-valued variable was turned into seven distinct binary variables, each
one representing the presence or absence of that particular symptom. These seven symptoms
were: heartburn, regurgitation, respiratory symptoms, asthma, laryngeal symptoms,
pharyngeal symptoms, and GI Atypical symptoms.
Reflux is one of the variables determined from the UGI test. This new database actually
contained 5 new binary variables relating to the UGI test: 'UGI was performed,' 'UGI was
normal,' 'UGI was abnormal,' 'Poor Motility was evident from UGI', and 'Reflux was evident
from UGI.' However, 78 of the 86 patients who had the test performed had 'UGI was abnormal'
values and only six patients were found to have 'Poor Motility,' whereas 67 patients were found
to experience 'Reflux' and thus the doctors agreed that it was the only one of these variables that
was appropriate for including in the database.
Hiatal Hernia simply expressed whether or not the patient suffered from this type of a
hernia. 101 of the patients did in fact have hiatal hernias.
Barretts is very similar to the discrete value that will be explained later describing the
grade, or severity, of a condition called esophagitis. Barretts is equivalent to having an
esophagitis of grade IV. Thirty-five patients suffered from this severe form of esophagitis.
Esophagitis, related to the above, this expresses whether or not patients suffered from
esophagitis. 93 of the 154 patients did indeed suffer from this condition.
21
Abdominal Operations refers to a patient's past medical history and records whether or
not a patient had undergone an abdominal operation before having this particular surgery. Fortysix of the patients were found to have had previous abdominal operations.
3.2.3 New Binary Variables to be used as Outcome Variables
IntraOperation Complications was originally a text field where the surgeon had entered
written text for 10 of the patients. We decided to use this field as one of the outcome variables, to
attempt to discover what could cause such complications, and so it was changed to a binary
variable where the ten patients about whom doctors had commented all were given values of
"yes" and the rest of the patients received a value of "no."
InHospital Complaints described the patient's complaints while they were visiting the
hospital. This field was analogous to IntraOperation Complications in its conversion from a text
field to a binary field and we similarly decided to use it as an outcome variable. Upon the
conversion to binary form, 16 patients were given a value of "yes."
Longer Term Recovery was a field extracted by the doctor's assistant from the
aforementioned questionnaire. Many, but not all, of the patients had been given this questionnaire
after being released from the hospital. For each patient who returned the questionnaire, the
assistant assigned either a value of "not perfect" or left the field blank. This field was thus
determined to be an outcome variable as well, in an attempt to determine what relationships of
variables could cause the long-term recovery of a patient to be, 'not perfect.'
Dilatation was a field determined from the same questionnaire mentioned above. Ten
patients were found to suffer from this condition and it was determined that this would also be an
outcome variable.
Dysphagia was another field extracted from the questionnaire. Fourteen patients suffered
from dysphagia and again, it was decided that dysphagia would be used as an outcome variable.
Reflux Symptoms refers to patients experiencing reflux after the surgery and was
determined from the questionnaire. It will be used as an outcome variable and was found in 26
patients.
Abnormal Exam refers to the patient's status post-surgery after being reviewed by a
clinician. Thirteen patients had post-surgery abnormal exams and again; this field was used as an
outcome variable.
3.2.4 New Discrete Variables
Primary Symptom had 7 possible values, the seven symptoms described above in
section 3.2.2. Almost 100 of the patients suffered from heartburn as their primary symptom.
22
Correlation with Symptoms refers to those patients who had a pH study and whether or
not the results of the test agreed with what the doctor would have expected based on the patient's
symptoms. Only 60 of the patients had recorded values for this field and 51 of them had values
of "good" or "excellent."
Grade of Esophagitis refers to the previously mentioned severity of esophagitis. While
62 patients had no data entered, i.e. they didn't suffer from esophagitis, 49 patients had grade I, 1
patient had grade II, 3 patients had grade III and 39 patients had grade IV. It was thus decided to
give this field 3 different values - one to represent the blank fields of those patients who didn't
suffer esophagitis, one to represent patients who suffered from esophagitis of grades I, II or III
and a third to represent patients who suffered from grade IV esophagitis, also known as Barrett's
esophagitis.
Number of Sutures recorded the number of sutures that were stitched into the patient
during the surgery. While 39 patients had blank fields, in which case the doctors informed us it
was simply not recorded how many sutures had been used, the majority of patients had 2-4
sutures and the range covered values from 1-7, making this an 8-value field for now, with "0"
meaning that no data was recorded.
ASA was a field that was a result of the doctor's subjective opinion of the general health
of each patient. An ASA of 1 meant the patient had no serious health problems. An ASA of 2
meant that the patient had serious, but non-life threatening health problems. An ASA of 3 meant
that the patient had significant health problems requiring immediate attention. Only 12 patients
had an ASA of 3, while the other 142 patients were split half and half, with 71 having an ASA of
1 and 71 having an ASA of 2.
Total Other Complaints ranged from zero to five and recorded the number of different
complaints of each patient.
3.2.5 New Discrete Variables to be used as Outcome Variables
Ease of Operation was a more detailed variable stemming from the "hard/easy
operation" variable that the doctor had created by reviewing the "operation comments" field in
the original database. At this point, however, the doctors found it appropriate to subdivide this
field into three groups, rather then leaving it as a binary field, so that an operation could either be
"easy", "medium", or "hard."
Post-operation Recovery was a subjective field from the questionnaire where a patient
was asked to rate their recovery months after they had had the surgery. Six patients did not
answer this question on the questionnaire, and the other responses varied across the four options
23
patients were given: excellent, good, fair, and poor, with excellent and good receiving the
majority of the responses.
3.2.6 Results
Below is one of the trees that resulted from running the above database through C5.0. It
classifies "Hard Surgery" and shows the tree in a new format. During the past few months as we
formatted the database there was lots of downtime waiting for the doctors to respond with the
different codings of the variables, and so we wrote a java program to manipulate the text output
from C5.0 so that it was in a form that could be directly input to a commercially available graphdrawing program.
PIT
I 0
HIES
0
180O
I 2_0
I
0
Otthers
0
HES
Ij2L.
Single
1
I
0_2_0
0.39
0
1 6 I
Figure 4 - Classifying Hard Surgery
Unfortunately, while running this newly refined dataset through C5.0 we found some
minor details in the data that needed to be taken care of before we could produce trees that we
could actually analyze and hope to learn things from. For example, one patient had a "no" in the
field for stating whether or not he had a hiatal hernia, but then, in the field for recording the size
of a patient's hiatal hernia, he had a value. In this case it was determined that the first field should
read "yes" as the patient did in fact have such a hernia. Complications of this type made the
analysis inaccurate and so no interpretations of the trees could take place until these small
inconsistencies within the data were resolved.
During this time we also made other changes to the database upon reviewing the different
fields we had chosen and deciding that there existed some redundancies in the data. One such
change we made was to remove the binary fields Esophagitis and Barretts. The information in
these two fields are basically summed up in the Grade field as well, and the only advantage to
having them in the database was to keep the information in binary formats. At this point,
however, we were no longer concerned with having all the fields binary, rather, our focus was on
minimizing the number of variables, and thus we decided to solely keep the Grade field for
24
analysis. We also decided to add a field called Duration of Symptoms. This had two possible
values in addition to an unknown value. So, in the database, a "0" referred to an unknown
duration of symptoms, a "1" referred to a patient having the symptoms for less than 5 years, and a
"2" referred to a patient having the symptoms for more then 5 years. The doctors suggested we
add this field as they thought that the period of time that a patient had suffered from their
symptoms could, in fact, affect the outcomes of the surgery. Furthermore, we decided to leave out
the Deemester field because of the large amount of missing information. Only 57 of the patients
had deemester values and having data on only one third of the population in the database did not
seem like enough to produce results we could have confidence in. The other change that was
made was to offer a recoding for Primary Symptom. The recode reduced the number of possible
values from 7 to 5 by combining some of the more rare symptoms into the same category.
The one other main point that needed to be resolved was what different blank values
actually meant. That is, was there an underlying reason why a doctor would not perform certain
tests (like the UGI, pH Study, endoscopy, and manometry) on certain patients? Our question was
simple: would the doctors choose to not perform a test because they were able to discover
something from the patient that deemed these tests not appropriate or useful, or was it mere
randomness that different patients underwent mildly different diagnoses? This was an important
question because if the doctors were using some sort of medical formula to decide who to give
what tests to, then the fact that patient A was not subjected to test X could, in fact, tell us
something about the patient, and so if there was a missing value for one of these tests in the
database, maybe that shouldn't just be considered a random occurrence that can't really be used
for analysis. Rather, if we could find out what it was about a patient that would cause a doctor to
decide not to perform a certain test on them, then we could use the missing data as actual data.
Dr. Rattner's reply below provided us with some insight into a doctor's train of thought, but did
not give us enough to feel comfortable deriving more data from the missing data points.
"There are no real hard and fast rules to answer your question. Almost everyone has manometry.
The only reason it is not performed is that a patient could not swallow the manometry probe or
refused to have the test performed. PH probe is more complex. In order to have surgery, patients
need to have either a paraesophageal hernia or have proof that their symptoms are caused by acid
reflux. Proof of acid reflux can occur because a patient gets better when given medication
(prilosec, prevacid, etc.), endoscopy shows esophagitis. In the absence of these two preconditions,
a pH probe study is done to document reflux. So the absence of pH probe may imply that the case
was more straightforward in terms of diagnosis and perhaps [the case] has [a] more severe disease,
but this is very, very soft assumption and I would not think it to be particularly important - but
that is just a guess."
25
We ran C5.0 to learn trees on the eight separate outcomes described above: Abnormal
Exam, Dilatation, Dysphagia, Ease of Operation, InHospital Complaints, IntraOperation
Complications, Longer Term Recovery, and Post-operation Recovery.
heartbum
I
0
0_1369
larysyMpts
1
0
50
0
pharsymip'
0
1
M dke
0-7_1
2
0_0
0
1
12_0
3
020
12_0
Figure 5 - Classifying Dysphagia
Some of these trees over-fit the data in ways that reducing the pruning level couldn't
prevent (see Appendix B for all of these trees), but the following trees seemed small enough to
derive useful results from. (Note: these trees were created without the use of the five continuous
variables because our graph-drawing program wasn't ready to handle that type of variable.)
abdormops
0
4
1
symptdur
0
1
2
1
050
3
2
020
11s
0
0_1_0
2
I__0
1
'sthma
0
1
Figure 6 - Classifying IntraOperation Complications
26
The first interesting result can be seen immediately from Figure 6. Less then 4% (4/108)
of the patients who had never had an abdominal operation before experienced complications
during their operation, while about 13% (6/46) of patients who had previously had their abdomen
operated on experienced intraoperation complications. Furthermore, of the 46 patients who had
previously underwent abdominal operations, none of the 17 patients who had been experiencing
their symptoms for less than five years had complications, while five of the 17 patients who had
been experiencing their symptoms for more than five years experienced complications. This tells
us that if you had previously had your abdomen operated on, and the symptoms that caused you
to undergo this operation had been bothering you for more than five years, then your chance of
having complications with this particular operation is almost 30% (5/17), a significant risk when
you consider that only 6.5% (10/154) patients in general experience any type of complications.
From Figure 5 we can see that 6.6% (9/136) of patients who experience heartburn also
suffer from post operation dysphagia, a number similar to the 9.1% (14/154) of patients in general
who experience this. Of the patients who don't experience heartburn, however, almost 28% (5/18)
experience dysphagia.
Initially, we felt these results were of interest. At the least, they validated the use of these
classification trees to find relationships between variables. For example, the value of variable A
may not be highly predictive for the outcome, but when you also have some other variable with a
certain value, then the presence of variable A becomes highly predictive. Learning these types of
relationships from these decision trees demonstrated that a machine learning technique can
discover context-sensitive effects that we believed to be beyond the reach of most linear
regression techniques that are commonly used to analyze medical data.
3.3 Cross-Validation
With these encouraging results, we set to work developing trees with the continuous
variables and also beginning to examine the cross-validation error rates of the trees. Crossvalidation is a method of measuring how well your might expect your classifier to perform on
data that did not contribute to the learning of the classifier. One way to measure how well your
classifier might perform on new data is to simply split up the data set into a training set and a test
set, then learn a classifier from the training set and test its performance on the held out test set of
data. Unfortunately, we were already dealing with a small number of patients, and to decrease
that number even further by partitioning the data was not an attractive idea. Cross-validation
takes in one parameter - a number of folds, 'n'. It then splits the data into 'n' different groups,
trains a classifier on 'n-l' of those groups, and tests that classifier on the one division of the data
that was withheld. It does this 'n' times, each time leaving out a different group. The performance
27
of each section is determined by the percentage of the test cases that are classified correctly. By
adding up the errors from each of the 'n' folds, a number can be found that represents all the
cases that were misclassified during the analysis. Dividing this number by the total number of
cases gives the cross-validation error rate. Say, for example, we have a set of 300 cases and we
split them up into 3 different folds. Then, cross-validation will train on two of the folds and test
the trained classifier on the 100 cases that were left out of the training, and it will do this three
times. Say the first classifier misclassifies 17 cases, the second 27, and the third misclassifies only
7 cases. Thus 51 of the 300 cases were misclassified and the cross-validation error rate would be
17%. From this, we could reasonably expect that if we trained the classifier on the entire 300
cases, and then we were given a new set of data, that our classifier would properly classify around
80% of the new cases.
To use cross-validation, the first decision to be made is the number of folds that you wish
to split the data into. In our analysis, w at first we began running the data with about 10 folds, so
that C5.0 would learn a certain decision tree from all but 1/10 of the data and then test the
remaining part to see how many of those 15 or 16 cases were classified correctly by the decision
tree. It would do this 10 times and then calculate the error rate by adding up all the cases that
were misclassified and dividing by the total number of cases in the database. After realizing that
using this many folds was not ideal, because the test sets were too small, we worked the number
of folds down to just two, so that we would learn a decision tree from half of the data, and then
test that tree on the other half of the data. After determining to use just two folds, another decision
was what level of pruning confidence was appropriate. In general we found that for all the cases,
a pruning confidence that was too low would always produce a naive tree that classified
everything as the most common instance of the outcome variable. That is, for example, Post
Operation Recovery had 88 patients with a value of 'excellent,' and so the naive tree for this
outcome would just say that no matter what a patient's data was, he should be classified as having
an 'excellent' value. This naive tree would have a normal error rate of 66/154, or 43%. As you
increase the pruning confidence, the normal error rate for trees learned from the entire database
decrease, but unfortunately, we were never able to learn trees that would have cross-validation
error rates that could beat the naive rates.
With the Ease of Operation outcome, for example, the naive error rate was 46.8%
(72/154 - 82 patients had an easy operation, 26 had a medium-difficulty operation, and 46
patients had a difficult operation) and C5.0 would produce this tree with a pruning confidence of
<15%. With a pruning confidence of exactly 15% and using 2 folds we ran the program four
times and resulted in the following four cross-validation error rates: 59.7%, 51.9%, 48.7%, and
28
49.4% (average of 52.4%). As you can see, some of these come very close to the naive rate, but
they never surpass them. With the same pruning confidence and using 3 folds we got crossvalidation error rates of 61%, 50%, 49.4%, and 55.2% (average of 53.9%), again never beating
the naive rate, and you can also see that the average error rate was larger for three folds than for
two. Running the same types of analysis on this outcome with a pruning confidence of both 30%
and 60% gave the same results. With two folds the average cross-validation error rate was 55%
and with three folds the average cross-validation error rate was 56%.
The one other parameter within C5.0 that we modified was the minimum number of cases
that are allowed to fall within a leaf of the tree. The default value is two. Adjusting this value to
five caused the naive tree to result from any analysis with pruning confidence of <17%. With
exactly a 17% pruning confidence and running the cross-validation with 2 folds resulted in error
rates of 53.9%, 47.4%, 48.7%, and 59.7%. These demonstrate the same result - never is the naive
error rate of 46.8% ever beaten. Running similar analysis on the other outcome variables provided
us with this same problem over and over again. How could we claim that these decision trees
were producing interesting and useful information when we couldn't show that they could predict
the outcomes of patients that we already had data for? How could we expect these results to be
used to accurately predict outcomes for future patients?
The problem was an inherent one within the data. For all of our binary outcome variables
one of the two possible values occurred significantly more frequently then the other, in most
cases it was about a nine to one ratio. With these ratios, we only had ten to twenty patients who
exhibited this less frequent outcome. This simply is just not a large enough sample to learn
interesting results from. The problem is not the ratio of nine to one in and of itself, but that with
only 154 patients, that ratio leads to too few cases of the rare outcomes. If, for example, we were
provided with a thousand patients complete with data, and still were forced to deal with a nine to
one ratio between the different values of the variables, this would not have been a problem
because we would have had about 150 patients to represent the less-frequent values. As it turns
out, with only ten or twenty patients to analyze the rare outcomes with, the decision trees cannot
grasp the underlying structure and trends within these patients, but rather C5.0 finds a few
patients who coincidentally had similar values in one field and it concludes that this is a factor in
determining what value this patient's outcome variable should take on. The decision tree's
acceptance of these coincidences as actual trends in the data is what causes the cross-validation
rates to never exceed the naive rates. When you build a classification tree on the basis of random
coincidences, those are certainly not going to hold true when you test those hypotheses on the
other half of the population.
29
With this upsetting conclusion all but determined, we turned to one last technique,
Support Vector Machines, to prove or disprove our hypothesis. The results from running the data
through SVMlight confirmed our hypothesis. For none of the outcomes, under no tunings of the
different parameters, did the accuracy of the SVMs ever outperform the accuracy of the naive
classification, although under certain conditions it did equal the naive classification. For example,
Post Operation Reflux, had a naive accuracy of 83%, that is, 83% of the patients in the database
experienced Reflux after the operation. We were training and testing the SVMs in the same way
as we had the decision tree, learning the support vectors on a random half of the data and then
testing those support vectors on the other half. We received the best results from the SVMs using
a polynomial of order two. Running SVMlight under this condition and varying the other
significant parameter, the cost of errors "C", yielded the following results.
C
Accuracy
.9
.5
.1
.05
.01
.001
.0001
79%
79%
81.5%
82.5%
83%
83%
83%
Table 3 - Accuracy of SVMs conditioned on C, the cost factor.
These results confirmed our fears that the data, with its minimal number of rare cases, was simply
not mine-able at this time.
Although we were confident of the techniques that we had used, the one last thing we
thought should be done to show that the data was in fact the reason we were not able to extract
good results, as opposed to the techniques being flawed, was to run C5.0 and SVMLight on a
database found in the UCI repository of databases that were known to be mine-able. We chose to
run the program on a database of Automobiles, which consisted of 205 records that had as an
outcome variable whether the car was considered safe or risky to drive. We chose this database
because it was one of the smallest, and we wanted to show that a database could be mined even
with a small number of cases, like what we were dealing with. For C5.0, using 4 folds and a 45%
pruning confidence level, we got received cross-validation error rates of 23%, 22.5%, 24.5%,
21%, and 28.5%, giving us an average error rate of 23.9%. This is much better than the nafve
error rate that was 46% - as 94 of the 205 cases were considered to be safe cars. Similarly, for
SVMLight, training on one half of the data and then testing the other half resulted in an error rate
of 21.8%.
30
4. Conclusions
When we began working on this project over a year ago, the goals were to take this
medical database and using different machine learning techniques try to understand the structure
of the system that created the data. That is, we were hoping to find an underlying structure in the
way the different variables involved in this particular surgery were related. The goal was that
understanding this structure better would ultimately aid the doctors in understanding the reasons
why things went right and wrong in regards to this surgery, and that through understanding these
different concepts, the doctors would be better suited to treat their patients. Unfortunately, we ran
across many difficulties along the way, most notably a lack of data. Not a lack of information
about each patient, but rather, a lack of patients. Only having about 150 patients on whom we
could search for correlations was simply not enough, especially when most of the particular
outcomes that we were hoping to help the doctors predict are very rare. With this all in mind it's
hard to view this project as a success. After all, we did not accomplish our initial goals.
The issues that we dealt with, however, in preparing this type of data to be analyzed by
these techniques, are issues that future researchers will inevitably come across, and so hopefully
the discussion that lies in this paper will prove useful as a warning to those future researchers, as
well as a guide for how to deal with the inevitable bumps they will run across when dealing with
medical data.
In the hypothetical, had we been provided with more patients' data, and had we found the
types of correlations and structure we were hoping to elucidate, there are some things we were
hoping to do with these results. One thing we thought could be very interesting if we were able to
learn solid predictive rules for determining the values of particular outcome variables was to
present a certain number of cases to the doctor, with all the information that we would supply our
algorithms with, and compare the predictive abilities of these two entities - the doctor and our
program. The hope would of course be that the program would perform near as well as the doctor,
possibly even better, in such a way that it could, in the future, be used as either a decision support
system (where it is like a second opinion, and upon the occasional time that it disagrees with the
doctors intuition it may point out something that the doctor had overlooked), or as a pre-surgery
tool that the doctor could use to give the patients an idea of what their probability of success may
be. The medical field is slowly opening its arms to the idea of computerized techniques to do give
this sort of advice, and a major part of implementing systems of this sort is going to be preparing
the data and dealing with the issues presented in this paper.
31
Works Cited
1. Buntine, Wray. A guide to the literature on learning probabilistic networks from data, IEEE Transactions
on Knowledge and Data Engineering, Berkeley, CA, 1996.
2. Singh, Moninder, Constructionof Bayesian Network Structuresfrom Data: a Brief Survey and an
Efficient Algorithm, University of South Carolina, Columbia, SC, 1995.
3. Friedman, N., The Bayesian Structural EM Algorithm, 1998.
4. Krause, Paul, Learning ProbabilisticNetworks, Philips Research Laboratories, Redhill, United
Kingdom, 1998.
5. Friedman, N., Being Bayesian about Network Structure, 2000.
6. Jensen, Finn V., An Introduction to Bayesian Networks, UCL Press, London, England, 1996.
7. Charniak, Eugene, Bayesian Networks without Tears, Al Magazine, Winter 1991, pp 50-63.
8. Quinlan, Ross J., C4.5 Programsfor Machine Learning, Morgan Kaufmann Publishers, San Mateo,
California, 1993.
9. Nilsson, Nils J., Artificial Intelligence: A New Synthesis, Morgan Kaufmann Publishers, San Francisco,
California, 1998.
10. Burges, Christopher J.C., A Tutorial on Support Vector Machines for Patter Recognition, Data Mining
and Knowledge Discover 2, pp. 121-167, 1998.
11. Heckerman, David. A Tutorial on Learning with Bayesian Networks. Microsoft Research. Redmond,
WA. 1996.
12. DuMouchel, William et al. EmpiricalBayes Screeningfor Multi-Item Associations. AT&T Labs.
Florham Park, NJ.
32
Appendix A - Lapops.mdb 3/19/01
Al. Variable Names, Types, and Numbers of Missing Values
Name
Vairiabhe
VnrinhIPNnmP
1 Age
2 Height
3 Weight
4 Operation Time
5 Flatus Day
6 Disch Day
7 Paraesophageal Hernia
8 Reoperation
9 Conversion
10 Assistant
11 Primary Symptom
12 Secondary Symptoms
13 Endoscopy
14 UGI
15 Peristalsis
16 Comorbidity
17 Preoperation Meds
18 Op Comments
19 Hospital Comments
20 HH Size
21 Single pH Probe
22 Dual pH Probe
23 LES Pressure
24 Op Type
Type of Variable
continuous
continuous
continuous
continuous
continuous
continuous
binary
binary
binary
discrete
text
text
text
text
text
text
text
text
text
nominal&measurements
nominal&measurements
nominal&measurements
nominal&measurements
nominal
# of Missing Values
0
5
2
0
0
0
0
0
0
0
0
71
15
65
21
85
9
19
15
7
79
10
21
A2. Details and Coding (Variable-by-variable)
A2.1 Continuous Variables:
Age - Range: 21-90 years
# of cases
Ages
16
21-30
27
31-40
41-50
51-60
61-70
71-80
81-90
59
36
17
6
3
Height - Rang e: 58-81 inches (5 missing values)
# of cases
Heights
41
58-63
64-69
70-75
76-81
82
34
2
33
Weight - Range: 90-280 pounds (2 missing values)
Weights
# of cases
90-127
128-165
166-203
204-241
242-280
19
56
56
25
6
Operation Time - Range: 60-270 minutes
Times
# of cases
60-94
95-129
130-164
165-199
200-234
14
88
44
13
3
Flatus Day - Range: 1-7 days
Disch Day - Range: 0-4 days
A2.2 Discrete Variables
Assistant
0=pg0
1=pgl
2=pg2
3=pg3
4=pg4
5=pg5
A2.3 Binary Variables
Paraesophageal Hernia
0=no
1=yes
Reoperation
0=no
1=yes
Conversion
O=no
1=yes
A2.4 Coded Variables
Symptoms - 4 possible values - this coding was used both for Primary Symptom and Secondary
symptoms.
1= "Atypical Symptoms" include the following: Hoarseness, Dyspnea, Early stiety, Bloating, Choking,
Choking heartburn, Cough, Asthma, Severe asthma, Back pain, Chest pain, Abdominal pain, Stomach pain,
Laryngeal, Laryngeal inflammation, Sore throat, Spasm, Pulmonary compromise, Ent sx, Voice change,
and Aspiration.
2= "Bleeding Symptoms include the following: Anemia, Bleeding, and GI bleeding.
3= "Typical Symptoms" include the following: Dysphagia, Heartburn,Recumbent reflux, Reflux,
Regurgitation, Substernal pain, Stricture, Nausea, and Vomiting.
4= "Paraesophageal Symptoms" include the following: Gastric volvulus.
34
Endoscopy
Blank = endoscopy not performed
0= "Normal" includes the following: N1, Normal, NI esophagus.
1= "Hiatal Hernia or Esophageal Shortening" includes the following: GEJ @ 32 cm, HH, Small HH, Large
HH, Hernia.
2= "Barretts or Esophagities" includes the following: Esophagitis, Mild Esophagitis,Severe Esophagitis,
Erosive Esophagitis,Ulcerative esophagitis, Schatzke ring, Barretts @ 34cm, Barrets, ? Barrets, Ulcer,
Esophageal ulcers, Linear ulcer, Sever ulceration,Stx.
3= "Other" includes the following: Gaping GEJ, Patulous GEJ, Gaping LES, Patulous LES, Gastritis,
Gastricpolyp, Tortuous stomach, Pyloric Stenosis.
UGI
blank = test not performed
0= "Normal" includes the following: No HH, Nl, Normal, Prominentfolds.
1= "Reflux" includes the following: Small amt reflux, GE reflux, Reflux, Free reflux, Free reflux to
clavicles, Spontaneous reflux.
2= "Hiatal Hernia" includes the following: HH, Small HH, Mod HH, Large HH, Huge HH, 3-4 cm HH2No
fundoplication defect seen.
3= "Paraesophageal Hernia" includes the following: Type III HH, Huge type III HH, ParasophagealHH,
Huge III hernia, Large Paraesophhernia, Paraesophhernia, Recurrent hernia, Gastric Volvulus, Huge
paraesophageal.
4= "Motility Problem" includes the following: Poorcontractions, ? Poormutility, Dealyed gastric
emptying, No peristalsis.
Peristalsis
0= "Absent" includes the following: Absent, None.
1= "Disordered" includes the following: Decreasedby UGI, Low amplitude distally, Low amplitude, Low,
Diminished, Disordered,Mild dysmotility, Some spontaneous, ontractions, Sl dim amplitude in distal, Sl
diminished distally, SL low amplitude, SL dysmotility, SL decreasedamplitude, SL diminished.
2= "Hyperactive" includes the following: Nutcracker,High Amplitude.
3= "Normal" includes the following: Normal, NL.
Comorbidity
0= "Not Severe" includes blank values and the following: Arthritis, brain cyst, ca breast, chronic leg pain,
diverticulosi, none, pe, igraines.
1= "Mildly Severe" includes the following: anemia, anxiety, astma, Back Pain, CAD, COPD; severe
COPD, chollithiasis,crohns, chronicfatigue syndrome, Depression,diabetes, diarrhea,Disabled,Delayed
gastric emptying, DU, elderly, HTN, Hypertension, IBD, IgG deficiency, mult allergies, multiple
complaints, obesity, elderly, pancreatitis,panic disorder,obese body habitus, psych, psychotic, Pulm
embolus, Sarcoidosis,smoker, tram flap, t\vocal cord paralysis.
2= "Very Severe" includes the following: ?scleroderma, Severely debilitated,sever steroid dependent
stham, severe COPD, sever pulm disease, autoimmune disease, Cushigoid,fatty liver, Hearttransplant,
Hepatitis; Chronic Hepatitis C; Hep C, immunosuppression, lupus, lung transplant,Marfans, motility
disorder.
Preoperation Medications
0= "None"
1= "Acid Suppression" includes the following: Aciphex, Carafate, Cimetidine, Gaviscon, Prevacid,
Prilosec, Propulsid,Ranitidine, Zantac.
2= "Steroids or Immunosuppression" includes the following: Vancenase, Singulair,Prednisone,
Prednisone60 mg, Glyburide, Flonase, Immuran, Inhalers, Insulin, Interferon, Many asthma meds, Many
others, Medrol, Microzid, Nasocort.
3= "Other" includes the following: Adalate, Al;buterol, Allegra, Amitryptilline, Antidepressants,Anti-htn,
Asthma meds, Atenolol, Ativan, Azulfidine, buspar, Calan, Clonidine, Combivent inhaler, Coumadin,
35
Cozar, Darvocet, Deepakote, Dilantin,Digoxin, Effexor, Feso4, Klonepin, Lipitor, Lithium, Lotensisn,
MAO inhibitor,Multiple, Multiple antidepressants,Multiple Pulmonary,Narcotics, Norvasc, OCP, Paxil,
Prinivil, Proventil, Psych meds, Psych meds many, Prozac, Ritalin, Slobid, Synthoroid, Tamaze[pam,
Thyroxine, Tube feeds, TPN, Trazadone, Vicodin, Welbutrin, Xanax, Zestril, Zoloft.
Op Type
1=Primary Nissen
2=Redo Nissen
3=Primary Partial
4=Redo Partial
5=Primary Hill
6=Redo Toupet
7= failure
Operation Comments
0= "Easy Operation" includes the following: Smooth, Obese, Easy Op, Large L Hepatic Artery sacrificed,
pg5 did 50% of case, PG5 did case, PG % did all dissection, Pg5 did entire case; hematoma in fundus,
PG5 did entire case, thin tissue, easy op, Also did cholecystx, replaced left hepatic, PG5 did the case,
replaced L hepatic,pg5 did nissen sutures, hiatal closure with pledgets, went well, pledgeted suturesfor
crura, went well, pg5 did entire case, over 60 Fr Bougie and combined with a lap hernia, 60fr bougie,
Previous nissen looked fine, pldegeted hiatal sutures, pg 5 did much of case, pledgeted all sutures, pldegets
on all sutures, pledgets etc, only 1 cruralstitch, smooth, Large hiatus closed with pledgeted sutures,
smooth for a re-do- crural closure hadfailed and wrap appeard short, obese, but doable, pg5 did case, 5
mm trocars.
1= "Hard Operation" includes the following: Obese, Hard operation,.5cm wrap, large hilatus- 7 sutures,
replaced] L Hepatic artery [preserved, bleedfrlom short gastrics,sl obese], thick sac, extremely difficult
due to obesity, woody esophagus,PG% did entire case; Posteriorfixation stitch placed, Large liver, tough
exposure, PG5 did entire case, PG5 did case, Fragiletissue, Huge HH, Pledgeted sutures, difficult fundic
dissection, Very thin weak tissue, pledgeted sutures used, much fat around GEJ-removed it-could not place
posteriorfixation, gastricperffrom harmonic scalp repairedintraop/ Obese!!, Tightend up priorwrap,
Severe adhesions, enterotomy made and repaired,Diffficult hiatal dissection, Bleeding from phrenic art.almost converted, Very difficult, Huge HH, obesity, Difficult anatomy! Huge HH, Some esophageal
shortening, Repair of gastric sserosaltear, Vagal nerves cut led to pyloroplsty, very tough due to scarring,
large L Lobe made difficult esposure, eplaced L hepatic was preserved, left sac] attached to stomach,
large sac L pneumothorax, Pt refused anti-reflux procedure,difficult due to fatty liver and obesity, multiple
adhesions, replaced L hepatic, extremely difficult! pledgeted sutures, Esophagealperffrom Nissen suture
at tend of case, scarring in LUQ and splenic area, scarringinlesser sac, lipoma at GEJ- ? Anterior vagal
inj, weak steroid tissue, used pledgets, pledgeted sutures, large left lobe, pg 5 did most of case, lipoma at
GEJ, Brutal-poor exposure, huge liver, pledgeted 7 sutures in hiatus, largeliver, severe
esophagits,?shortening, bleedingfrom short gastric,friable tissue, friable tissue;pledgetedall sutures,
tough operation,could not reduce stomach inot abd- will need collis belsey, bledfrom aorta!, tough due to
obesity and large L lobe of liver, could not dissect hiatus due to L Lobe of liver and obesity, small fundus,
fragile crura, large HH, poor cruralmusculature, obese,tough exposure, tough op due to scar, looked good
at conclusion, large liver obscuring crura, Slipped Nissen, replced L hepatic preserved,thin tissue,
previous repairherniated?,6 ports, obese, PG5 placed wrap stitches, Hard due to obesity, large liver,
tough posteroirfundic dissection, Fat!, obese and large HH with lipoma x2 at GEJ, fibrotic esophagus?,
difficult due to obesity/scarring,large HH,flimsy tissue, large liver, mod large HH, mult adhesions, Fat,
hard case0pneumothorax?, "4x2"" goretex patch ",sack very stuck andfatty, Tough- see op note.
2= "Converted to open operation" includes the following: Huge Liver with PHT caused conversion,
Frozen abdomen requiredconversion.
Hospital Comments
0= blank
36
1= "any comment" includes the following: aspirationpneumonia, pneumonis/asthma secondary to IgG
defic/ Ptx, postop bronchospasm,post op pneumonia, post op bleed from trocarsite, pain- unclear cause,
shoulder pain. Small pneumo, migraine headache,Aspirationpneumonia, Left Pneumothorax,nausea,
miled ileus, anxiety, post op MI on emegence from anesthesia,Perfd esophagus repairedPOD 1.
HH Size
0=0 or none
1=small
2=mod
3=mod-large
4=large
5=x-large
6=huge
Single pH Probe
0=blank
1=negative
2=normal (15,18)
3=positive (41, 85)
Dual pH Probe
0=blank
1=no correlation (only 1 of these)
2=slight correlation
3=positive correlation
LES Pressure
O=blank, not measured
1=low, absent, <15
2=normal, 15<x<30
3= high, x>35
37
Appendix B
Abnormal exam
heartbum
0
1
0 136_8
asthma
0
totalmnmbcom).
2
)
3
1
4
010
020
03
050
4 ,,seofop
2
l10
0_31
1 1_0
3
1_0
Dilatation
pinsymptl
2
0 (9_3
0
9
6
3
7
8
5_
210_1
5
4
1 2
()_I_
120
Dysphagia
heartburn
1
0- 16_
0
Iarysympts
S5 C
pharsympts
0_7_1
1rade
2
1
0-10
1 2
0
0
1
0_2_0
iz
e aseofopH
3
1 20
38
3
0_30
3
0_0_0
0_4_
0
1
2
1 _20
I~q
pi z;C
1
(C
I
1
I
(R "
10
WILitqv IoMUw
M?41t!
sdtls&,;
'3)
C,
IntraOperation Complication
atxdomops
0
108_4
1
syIptdur
0
0 12_1
1
2
asa
0- 373)
1 3 2
LES
0 -2-_
0
0
0
2
I 9.0
1
aslm
0
1
Longer Term Recovery
40
i-~
i:~
'~
to
~I:I
~
Post Operation Recovery
~
&
V®
9
41
abdoff oll
0_I 7.0
0
0..-72..2
040)
1411Iiunibcolls
2
0-J
3
armymt
T n"I-r.u
4
1) _0 1 0 Perktisi
Ij A
5
Peristais
( 195)
Sympndilt
grade I
J.I..0 02..0
0.1
0
FIi
02
O-A
1 .... i I30
Appendix C
Ease of Operation (with Age included)
Dilatation
Age <= 41: 1 (59/16)
Age > 41:
:...HH Size = 3:
. . Age <= 48: 1 (2)
: Age > 48: 3 (7)
HH Size = 1:
:...Manometry = 0: 3 (3/1)
Manometry = 3: 1 (1)
: Manometry = 4: 1 (6/1)
Prim Sympt = 4: 0 (8/1)
Prim Sympt = 1:
:...Manometry = 0: 0 (13)
Manometry = 1: 0 (10)
Manometry = 2: 0 (47/1)
Manometry = 4: 0 (31)
Manometry = 3:
HH Size
.... = 0: 0 (2)
:
HH Size = 1: 0 (3)
:
HH Size = 2: 1 (1)
:
HH Size = 3: 1 (1)
Prim Sympt = 2:
...Abdominal Ops = 1: 0 (9)
Abdominal Ops = 0:
Sympt ....Duration = 0: 0 (7/1)
Sympt Duration = 1: 1 (1)
:
:
Sympt Duration = 2: 0 (9/1)
Prim Sympt = 3:
...Regurgitation = 1: 0 (7)
Regurgitation = 0:
...Sympt Duration = 0: 0 (2)
Sympt Duration = 1: 1 (1)
Sympt Duration
=
: Manometry = 1:
: ...Regurgitation = 1: 2 (3)
: : Regurgitation = 0:
:
: :
...BMI <= 27: 1 (2)
BMI > 27: 3 (2)
: Manometry = 2:
: :...ASA = 2: 1 (12/4)
ASA=3: 3 (3/1)
* ASA =1:
:
:.Regurgitation = 0: 1 (5)
:
Regurgitation = 1: 2 (3/1)
HH Size = 0:
...Gi Sympts Atyp = 0: 3 (11/3)
Gi Sympts Atyp = 1:
:...Sympt Duration = 0: 2 (3/1)
Sympt Duration = 1: 3 (3/1)
Sympt Duration = 2:
:
:...Resp Sympts = 0: 1 (2/1)
2: 1 (2)
:
:
Resp Sympts = 1:
:...Age <= 50: 2 (2)
:
Age > 50: 1 (4/1)
HH Size = 2:
...Gi Sympts Atyp = 0: 1 (5/1)
Gi Sympts Atyp = 1:
:...PostOp Recov = 0: 3 (1)
PostOp Recov = 2: 3 (6/1)
PostOp Recov = 1:
:...PH = 2: 1 (0)
PH = 0: 1 (5/1)
PH = 1:
:...Resp Sympts = 0: 2 (2)
Resp Sympts = 1: 3 (2)
43
Ease of Operation (without Age
excluded)
PostOp Recov = 2:
:...Resp Sympts = 0: 2 (3/1)
Resp Sympts = 1:
:...Gi Sympts Atyp = 0: 3 (2)
Gi Sympts Atyp = 1:
...BMI <= 26: 1 (2)
BMI > 26: 2 (2/1)
Prim Sympt = 4:
:...Resp Sympts = 0: 2 (5/2)
Resp Sympts = 1: 1 (3)
Prim Sympt = 2:
:...ASA= 1: 1(7/1)
ASA = 3: 3 (8/3)
ASA=2:
Asthma=
.... 0: 1 (6/1)
:
Asthma = 1: 3 (5/2)
Prim Sympt = 3:
:...Age <= 43: 1 (5)
Age > 43:
:...Asthma = 0: 3 (4)
:
Asthma = 1: 1 (3/1)
Prim Sympt = 1:
:...HH Size = 3:
...
PH = 2: 3 (0)
: PH= 0: 1(3)
: PH = 1: 3 (7/1)
HH Size = 2:
:...Sympt Duration = 0: 1 (3)
: Sympt Duration = 1: 3 (3/1)
: Sympt Duration = 2:
: :...Manometry = 0: 1 (1)
:
Manometry = 1: 2 (3/1)
:
Manometry = 2: 3 (5/1)
:
Manometry = 3: 2 (1)
:
Manometry = 4: 3 (1)
HH Size = 1:
:...Resp Sympts = 1:
: :...BMI <= 37.6: 1 (21.9/1)
: : BMI> 37.6: 3 (2.1/0.1)
: Resp Sympts = 0:
: :...Regurgitation = 0: 1 (14/5)
:
Regurgitation = 1:
:
:...PH = 2:2 (0)
SPH
= 0: 2 (8/2)
:
PH = 1: 3 (3/1)
HH Size = 0:
...
PH= 2: 1 (0)
PH = 0:
:...Asthma = 1: 2 (3/1)
Asthma = 0:
:...Resp Sympts = 1: 1 (5)
Resp Sympts = 0:
:...Gi Sympts Atyp = 0: 3 (4/1)
Gi Sympts Atyp = 1: 1 (2)
PH = 1:
:...Phar Sympts = 1: 1 (2)
Phar Sympts = 0:
:...PostOp Recov = 0: 3 (0)
PostOp Recov = 1: 3 (7/2)
44
In Hospital Complications
Heartburn = 0: 0 (18)
Heartburn = 1:
:...Manometry = 0: 0 (15/1)
Manometry = 3: 0 (9)
Manometry = 1:
...Lary Sympts = 1: 1 (2)
: Lary Sympts = 0:
:...Prim Sympt = 2: 1 (1)
Prim Sympt = 3: (2)
* Prim Sympt = 4: 0 (2/1)
*Prim Sympt =1:
:...ASA = 1: 0 (4)
:
:
ASA = 2: 0 (3)
:
ASA = 3: 1 (1)
Intra-Operation Complications
:
Abdominal Ops = 0: 0 (108/4)
Abdominal Ops = 1:
:...Sympt Duration = 0: 0 (12/1)
Sympt Duration = 1: 0 (17)
Sympt Duration = 2:
Manometry = 4:
...
ASA = 1: 0 (5)
ASA = 3: 0 (2)
ASA = 2:
:...Manometry in {1,31: 0 (0)
Manometry = 0: 0 (1)
Manometry = 4: 1 (3)
.... Sympt Duration = 1: 0 (10)
: Sympt Duration = 0:
- :...HH1: 0 (3)
:IH0:
HH
: : :...PH = 2: 0 (0)
S:
PH= 0: 1 (3/1)
: :
PH = 1: 0 (2)
: Sympt Duration = 2:
: ...Regurgitation = 1: 0 (9)
Regurgitation = 0:
:
:...Gi Sympts Atyp = 0: 0 (3)
:
Gi Sympts Atyp = 1:
:
:...Age <= 44: 1 (4/1)
:
Age > 44: 0 (5)
Manometry = 2:
:...Asthma = 0: 0 (3)
Asthma = 1: 1 (3/1)
Manometry = 2:
...Phar Sympts = 1: 0 (16)
Phar Sympts =0:
:...HH = 0: 0 (12)
HH = 1:
:...Asthma = 1:
...Regurgitation = 0: 1 (4/1)
Regurgitation = 1: 0 (4)
Asthma = 0:
:...Gi Sympts Atyp = 1: 0 (11)
Gi Sympts Atyp = 0:
:...Sympt Duration = 0: 1 (1)
Sympt Duration = 1: 0 (5/1)
Sympt Duration = 2: 0 (5)
45
Post Operation Recovery
Post Operation Reflux
ASA = 3: 1 (12/1)
ASA= 1:
:...Lary Sympts = 0:
Abdominal
..
Ops = 0:
Age <=
. . 42: 1 (20/3)
: : : Age>42:
Sympt
.... Duration = 0: 1 (5/1)
: : :
Sympt Duration = 1: 2 (7)
Sympt Duration = 2: 1 (12/5)
: : Abdominal Ops = 1:
Sympt Duration = 1: 0 (42/4)
Sympt Duration = 2:
:...Regurgitation = 1: 0 (32/2)
: Regurgitation = 0:
ASA = 2: 0 (17/1)
ASA=3:1(2)
ASA = 1:
:...BMI <= 20.9: 1 (2.1/0.1)
BMI > 20.9: 0 (20.9/3)
Sympt Duration =0:
:...Lary Sympts = 1: 0 (6)
Lary Sympts = 0:
...Asthma = 1:
:...Phar Sympts = 0: 1 (4)
Phar Sympts = 1: 0 (5/1)
Asthma = 0:
:...HH Size = 1: 0 (12/2)
HH Size = 2: 0 (1)
HH Size = 3: 0 (2/1)
HH Size = 0:
:...Regurgitation = 0: 1 (5/1)
Regurgitation = 1: 0 (3)
HH =. . 0: 2 (3)
S.
:
:
:
:
:
:
:
:
:
:
:
:
HH = 1:
:
:...Manometry = 0: 2 (1)
:
Manometry = 1: 2 (1)
:
Manometry = 2: 2 (4/1)
:
Manometry = 3: 1 (1)
:
Manometry = 4: 1 (4)
Lary Sympts = 1:
Regurgitation
..
= 1:
:...Abdominal Ops = 0: 1 (3)
: Abdominal Ops = 1: 2 (2)
Regurgitation = 0:
:...Phar Sympts = 1: 1 (3)
Phar Sympts = 0:
:...Age <= 39: 1 (2)
Age > 39: 0 (3)
ASA=2:
:...Heartburn = 0: 2 (5)
Heartburn = 1:
:...Manometry = 1: 1 (5/2)
Manometry = 3: 0 (2/1)
Manometry = 0:
:...Asthma= 0: 1 (7/1)
Asthma = 1: 2 (3)
Manometry = 4:
:...DM Score <= 25: 1 (6.3/2)
DM Score > 25:
:...PH = 2: 2 (0)
PH = 0: 1 (4.7/1.3)
PH = 1: 2 (8/1.3)
Manometry = 2:
:...PH = 2: 1 (0)
PH = 0:
:...Sympt Duration = 0: 2 (3)
Sympt Duration = 1: 1 (3/1)
Sympt Duration = 2:
:...Age <= 50: 2 (2)
Age > 50: 1 (2)
PH = 1:
:...Asthma = 0: 1 (12/3)
Asthma = 1:
:...Abdominal Ops = 0: 2 (5/1)
Abdominal Ops = 1: 1 (3)
46
....