18.303 Problem Set 4 Solutions Problem 1: (10+10+10)
advertisement
")
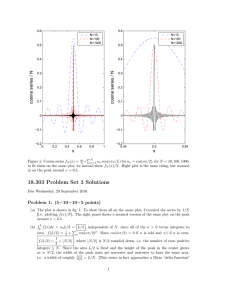
18.303 Problem Set 4 Solutions Problem 1: (10+10+10) (a) Define the translation operator T̂a by T̂a u(x, y, z) = u(x, y, z − a): T̂a shifts functions by a in the z direction. R R∞ (i) We have hu, T̂a vi = Ω dxdy −∞ dz u(x, y, z)v(x, y, z − a), where we have explicitly written the z integral (noting that Ω only affects theRxy integration domain). Now, we do a R∞ change of variables z̃ = z−a, to obtain hu, T̂a vi = Ω dxdy −∞ dz̃ u(x, y, z̃ + a)v(x, y, z̃) = hT̂−a u, vi. Hence T̂a∗ = T̂−a , and obviously T̂−a = T̂a−1 (since translating by −a undoes translation by +a). (ii) This is actually pretty obvious, because translation does not affect w or c, nor does it affect derivatives since d(z − a)/dz = 1, but let’s go through it explicitly. Let’s show that T̂a commutes with the terms in  one by one. That is, we wish to show that i. ∇T̂a u = T̂a ∇u for any u(x, y, z). Proof: *1 ∂(z − a) uz (x, y, z−a) = T̂a ∇u, ∇T̂a u(x, y, z) = ∇u(x, y, z−a) = ux (x, y, z−a)+uy (x, y, z−a)+ ∂z where subscripts denote partial derivatives and the key point is that we can translate either before or after differentiation because the chain rule factor is 1. ii. c(x, y)T̂a v(x, y, z) = T̂a c(x, y)v(x, y, z) for any vector field v(x, y, z). This is obvious because c does not depend on z. iii. ∇ · T̂a v(x, y, z) = T̂a ∇ · v(x, y, z) for any v. Proof: essentially the same as in (i). 1 1 iv. − w(x,y) T̂a u(x, y, z) = T̂a [− w(x,y) u(x, y, z)] for any u. This is obvious because −1/w does not depend on z. Putting (i)–(iv) together, we have: 1 1 1 1 1 ÂT̂a u = − ∇·c∇T̂a u = − ∇·cT̂a ∇u = − ∇·T̂a c∇u = − T̂a ∇·c∇u = T̂a − ∇ · c∇u = T̂a Âu. w w w w w (b) Â(T̂a u) = T̂a (Âu) = T̂a (λu) = λ(T̂a u) using commutation, the eigenequation, and linearity of T̂a . Moreover, if u 6= 0 then T̂a u 6= 0. Therefore, we have just shown that T̂a u is an eigenfunction of  with eigenvalue λ. But we are given that λ has multiplicity 1, which means that the only eigenfunctions are u and scalar multiples of u. Hence T̂a u must be some multiple α of u: T̂a u = αu, hence uis an eigenfunction of T̂a . (c) If u is an eigenfunction of T̂a for all a, that means T̂a u = α(a)u for some eigenvalues α(a). Show that the functions α(a) and u(x) must have the properties: (i) T̂0 u = u by definition, so α(0) = 1 follows. (ii) Let v(x, y) = u(x, y, 0). Then T̂a u = u(x, y, z − a) = α(a)u(x, y, z). Hence, if we evaluate both sizes for z = 0, we obtain u(x, y, −a) = α(a)v(x, y), and then if we let a = −z the result follows. (iii) We have α(a1 )α(a2 )u(x, y, z) = T̂a1 T̂a2 u(x, y, z) = T̂a1 u(x, y, z − a2 ) = u(x, y, z − a1 − a2 ) = T̂a1 +a2 u(x, y, z) = α(a1 + a2 )u(x, y, z)for all u, hence α(a1 + a2 ) = α(a1 )α(a2 ). 1 (iv) Using α(x + h) = α(x)α(h) and α(x) = α(x)α(0) from above, we have α0 (x) = lim h→0 α(x + h) − α(x) α(h) − α(0) = α(x) lim = α(x)α0 (0), h→0 h h which is an ordinary differential equation α0 (x) = βα(x) for β = α0 (0), which has the solution α(x) = α(0)eβx = eβx . If we don’t allow exponential solutions, β must be purely imaginary, hence α(x) = e−ikx for some real k. Problem 2: (10+10+10+5) (a) The boundary conditions give two equations αJm (kR1 ) + βYm (kR1 ) = 0 0 αkJm (kR2 ) + βkYm0 (kR2 ) = 0 (noting the k factors from the chain rule in the second equation). These equations are linear α in α and β, so we can write them as E = 0 for β Jm (kR1 ) Ym (kR1 ) E= . 0 kJm (kR2 ) kYm0 (kR2 ) Hence det E = 0 and we have the equation for 0 0 = det E = Jm (kR1 )kYm0 (kR2 ) − Ym (kR1 )kJm (kR2 ). This has an apparent solution for k = 0, but actually limk→0 det E 6= 0, because the overall k factor multiplying the expression turns out to exactly cancel the divergences in JY 0 and Y J 0 expressions. [This can be seen from the asymptotic analysis in class, where we showed that Jm (x) ∼ xm and Ym (x) ∼ x−m for small x and m > 0, hence Jm (x)Ym0 (x) ∼ 1/x ∼ 0 Jm (x)Ym (x) for small x.] So, we obtain: 0 fm (k) = k[Jm (kR1 )Ym0 (kR2 ) − Ym (kR1 )Jm (kR2 )]. (Of course, we could also multiply fm (k) by any nonzero function if we wanted, since we only care about the zeros of fm .) (b) For this part, it is useful to use the @ syntax in Matlab to first define the derivatives of the Bessel functions using the formulas provided: Jp = @(m,x) 0.5 * (besselj(m-1,x)-besselj(m+1,x)) and Yp = @(m,x) 0.5 * (bessely(m-1,x)-bessely(m+1,x)). Now, setting R1=1 and R2=2, we can define fm (k) via f = @(m,k) besselj(m,k*R1) .* Yp(m,k*R2) - bessely(m,k*R1) .* Jp(m,k*R2). Now, we can plot it for m = 0, 1, 2 (using the hold command to put multiple curves on the same plot) with: fplot(@(k) f(0,k), [0,20], ’r-’); hold on; fplot(@(k) f(1,k), [0,20], ’b–’); fplot(@(k) f(2,k), [0,20], ’k:’); hold off The resulting plot is shown in figure 1; note that fm (k) seems to converge to the same curve, independent of m, for large k. (c) From the graph, the first three zeros of fm are close to k = 1.5, 4.5, and 7.5, so we can use the fzero command to find the precise roots from these starting guesses: 2 Figure 1: Plot of fm (k) for m = 0, 1, 2. Figure 2: Plot of fm (k) for m = 0, 1, 2. k1 = fzero(@(k) f(0,k), 1.5) k2 = fzero(@(k) f(0,k), 4.5) k3 = fzero(@(k) f(0,k), 7.5) which gives k1 ≈ 1.360777385337, k2 ≈ 4.645899896125, and k2 ≈ 7.814162750132. Given k, we can then find α and β by the following procedure. Since the overall scale is arbitrary, set α = 1. Then solve the first equation from (a) above to obtain β = −Jm (kR1 )/Ym (kR1 ). In Matlab: beta1 = -besselj(0,k1*R1)/bessely(0,k1*R1) beta2 = -besselj(0,k2*R1)/bessely(0,k2*R1) beta3 = -besselj(0,k3*R1)/bessely(0,k3*R1) The resulting curves, via fplot(@(r) besselj(0,k1*r)+beta1*bessely(0,k1*r), [R1,R2]) and so on, are shown in figure 2. As desired, they are zero at r = R1 and have zero slope at r = R2 . Also as expected from the min–max theorem, they oscillate as little as possible, with larger k solutions gaining more nodes one at a time in order to stay orthogonal to the previous modes. 3 (d) Running quadl(@(r) r .* (besselj(0,k1*r)+beta1*bessely(0,k1*r)) .* (besselj(0,k2*r)+beta2*be R1, R2, 1e-6) yields ≈ 3.7 × 10−16 , i.e. zero up to roundoff errors! (Even though we only requested 6 digits of accuracy, the numerical integration routine typically gives us much better accuracy, at least when integrating smooth functions.) 4