Perceptrons Perceptron Convergence Perceptron Learning in Non-separable Case Gradient Descent and Delta Rule
advertisement

Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Introduction to Machine Learning
CSE474/574: Perceptrons
Varun Chandola <chandola@buffalo.edu>
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Outline
1
Perceptrons
Geometric Interpretation
Perceptron Training
2
Perceptron Convergence
3
Perceptron Learning in Non-separable Case
4
Gradient Descent and Delta Rule
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
Outline
1
Perceptrons
Geometric Interpretation
Perceptron Training
2
Perceptron Convergence
3
Perceptron Learning in Non-separable Case
4
Gradient Descent and Delta Rule
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
Artificial Neurons
Figure: Src: http://brainjackimage.blogspot.com/
Figure: Src: Wikipedia
Human brain has 1011 neurons
Each connected to 104 neighbors
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
Perceptron [4, 2]
bias
Θ
x1
w1
x2
w2
..
.
..
.
xd
wd
inputs
weights
P
{-1,+1}
Activation
function
Pd
j=1 wj xj ≥ Θ
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
Geometric Interpretation
x2
w> x
+1
−1
=Θ
n=
Θ
− |w|
w
|w|
x1
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
Eliminating Bias
Add another attribute xd+1 = 1.
wd+1 is −Θ
Desired hyperplane goes through origin in (d + 1) space
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
Hypothesis Space
Assumption: ∃w ∈ <d+1 such that w can strictly classify all
examples correctly.
Hypothesis space: Set of all hyperplanes defined in the
(d + 1)-dimensional space passing through origin
The target hypothesis is also called decision surface or decision
boundary.
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Geometric Interpretation
Perceptron Training
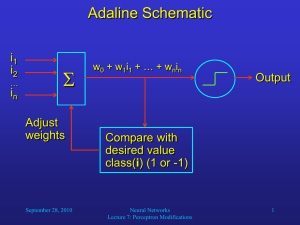
Perceptron Training - Perceptron Learning Rule
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
w ← (0, 0, . . . , 0)d+1
for i=1, 2, . . . do
if w> x(i) > 0 then
c(x(i) ) = +1
else
c(x(i) ) = −1
end if
if c(x(i) ) 6= c∗ (x(i) ) then
w ← w + c∗ (x(i) )x(i)
end if
end for
Varun Chandola
Every mistake tweaks the
hyperplane
Rotation in (d + 1) space
Accomodate the offending
point
Stopping Criterion:
Exhaust all training example,
or
No further updates
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Outline
1
Perceptrons
Geometric Interpretation
Perceptron Training
2
Perceptron Convergence
3
Perceptron Learning in Non-separable Case
4
Gradient Descent and Delta Rule
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Does Perceptron Training Converge?
2 x
2
1
x1
−2
−1
1
2
−1
−2
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Convergence Assumptions
1
Linearly separable examples
2
No errors
3
|x| = 1
A positive δ gap exists that “contains” the target concept
(hyperplane)
4
(∃δ)(∃v) such that (∀x)v> x > c∗ (x)δ.
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Perceptron Convergence Theorem
Theorem
For a set of unit length and linearly separable examples, the perceptron
learning algorithm will converge after a finite number of mistakes (at
most δ12 ).
Proof discussed in Minsky’s book [3].
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Review
Hypothesis Space, H
Conjunctive
Disjunctive
Input Space, x
Input Space, y
d
x ∈ {0, 1}
y ∈ {0, 1}
y ∈ {−1, +1}
d
x∈<
Disjunctions of
k attributes
y ∈<
Linear hyperplanes
c∗ ∈ H
c∗ 6∈ H
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Review
Hypothesis Space, H
Conjunctive
Disjunctive
Input Space, x
Input Space, y
d
x ∈ {0, 1}
y ∈ {0, 1}
y ∈ {−1, +1}
d
x∈<
Disjunctions of
k attributes
y ∈<
Linear hyperplanes
c∗ ∈ H
c∗ 6∈ H
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Outline
1
Perceptrons
Geometric Interpretation
Perceptron Training
2
Perceptron Convergence
3
Perceptron Learning in Non-separable Case
4
Gradient Descent and Delta Rule
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Target concept c∗ 6∈ H
2 x
2
1
Expand H?
Lower
expectations
Principle of
good enough
x1
−2
−1
1
−1
−2
Varun Chandola
Introduction to Machine Learning
2
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Perceptron Learning in Non-separable Case
x2
+1
−1
x1
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Perceptron Learning in Non-separable Case
x2
+1
−1
x1
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Outline
1
Perceptrons
Geometric Interpretation
Perceptron Training
2
Perceptron Convergence
3
Perceptron Learning in Non-separable Case
4
Gradient Descent and Delta Rule
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Gradient Descent and Delta Rule
Which hyperplane to choose?
Gives best performance on training data
Pose as an optimization problem
Objective function?
Optimization procedure?
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Objective Function for Perceptron Learning
An unthresholded perceptron (a linear unit)
Input
layer
Output
layer
x0
Training Examples: hxi , yi i
x1
Weight: w
1X
E (w) =
(yi − w> xi )2
2
x2
Output
x3
i
x4
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Machine Learning as Optimization Problem1
Learning is optimization
Faster optimization methods for faster learning
Let w ∈ <d and S ⊂ <d and f0 (w ), f1 (w ), . . . , fm (w ) be real-valued
functions.
Standard optimization formulation is:
minimize
f0 (w )
subject to
fi (w ) ≤ 0, i = 1, . . . , m.
w
1 Adapted from http://ttic.uchicago.edu/ gregory/courses/ml2012/
~
lectures/tutorial_optimization.pdf. Also see,
http://www.stanford.edu/~boyd/cvxbook/ and
http://scipy-lectures.github.io/advanced/mathematical_optimization/.
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Solving Optimization Problems
Methods for general optimization problems
Simulated annealing, genetic algorithms
Exploiting structure in the optimization problem
Convexity, Lipschitz continuity, smoothness
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Convexity
Convex Sets
Convex Functions
w2
y = x2
w1
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Convex Optimization
Optimality Criterion
minimize
f0 (w )
subject to
fi (w ) ≤ 0, i = 1, . . . , m.
w
where all fi (w ) are convex functions.
w0 is feasible if w0 ∈ Dom f0 and all constraints are satisfied
A feasible w ∗ is optimal if f0 (w ∗ ) ≤ f0 (w ) for all w satisfying the
constraints
Varun Chandola
Introduction to Machine Learning
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Gradient of a Function
∇E (w) =
∂w0
∂E
∂w1
..
.
25
20
15
E[w]
Denotes the direction of
steepest ascent
∂E
10
5
0
2
∂E
∂wd
1
-2
-1
0
0
1
-1
2
3
w0
Varun Chandola
Introduction to Machine Learning
w1
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Finding Extremes of a Single Variable Function
Set derivative to 0
Second derivative for minima or maxima
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Finding Extremes of a Multiple Variable Function Gradient Descent
1
2
Start from any point in variable space
Move along the direction of the steepest descent (or ascent)
By how much?
A learning rate (η)
What is the direction of steepest descent?
Gradient of E at w
Training Rule for Gradient Descent
w = w − η∇E (w)
For each weight component:
wj = wj − η
Varun Chandola
∂E
∂wj
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Convergence Guaranteed?
Error surface contains only one global minimum
Algorithm will converge
Examples need not be linearly separable
η should be small enough
Impact of too large η?
Too small η?
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Issues with Gradient Descent
Slow convergence
Stuck in local minima
Varun Chandola
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
Objective Function for Perceptron Learning
Machine Learning as Optimization
Convex Optimization
Gradient Descent
Issues with Gradient Descent
Stochastic Gradient Descent
Stochastic Gradient Descent [1]
Update weights after every training example.
For sufficiently small η, closely approximates Gradient Descent.
Gradient Descent
Weights updated after summing error over all examples
More computations per weight update step
Risk of local minima
Varun Chandola
Stochastic Gradient Descent
Weights updated after examining
each example
Significantly lesser computations
Avoids local minima
Introduction to Machine Learning
Perceptrons
Perceptron Convergence
Perceptron Learning in Non-separable Case
Gradient Descent and Delta Rule
References
References
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard,
W. Hubbard, and L. D. Jackel.
Backpropagation applied to handwritten zip code recognition.
Neural Comput., 1(4):541–551, Dec. 1989.
W. Mcculloch and W. Pitts.
A logical calculus of ideas immanent in nervous activity.
Bulletin of Mathematical Biophysics, 5:127–147, 1943.
M. L. Minsky and S. Papert.
Perceptrons: An Introduction to Computational Geometry.
MIT Press, 1969.
F. Rosenblatt.
The perceptron: A probabilistic model for information storage and
organization in the brain.
Psychological Review, 65(6):386–408, 1958.
Varun Chandola
Introduction to Machine Learning