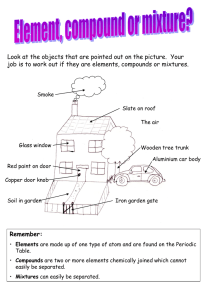
Sound, Mixtures, and Learning: LabROSA overview

Sound, Mixtures, and Learning:
LabROSA overview
1 Sound Content Analysis
2 Recognizing sounds
3 Organizing mixtures
4 Accessing large datasets
5 Music Information Retrieval
Dan Ellis <dpwe@ee.columbia.edu>
Laboratory for Recognition and Organization of Speech and Audio
(Lab ROSA )
Columbia University, New York http://labrosa.ee.columbia.edu/
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 1
1
4000 frq/Hz
3000
2000
1000
0
0
Sound Content Analysis
2 4 6
Analysis
8 10 12
0
-20
-40 time/s
-60 level / dB
Voice (evil)
Stab
Rumble
Voice (pleasant)
Choir
Strings
• Sound understanding : the key challenge
- what listeners do
- understanding = abstraction
• Applications
- indexing/retrieval
- robots
- prostheses
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 2
The problem with recognizing mixtures
“Imagine two narrow channels dug up from the edge of a lake, with handkerchiefs stretched across each one.
Looking only at the motion of the handkerchiefs, you are to answer questions such as: How many boats are there on the lake and where are they?” (after Bregman’90)
• Auditory Scene Analysis : describing a complex sound in terms of high-level sources /events
- ... like listeners do
• Hearing is ecologically grounded
- reflects natural scene properties = constraints
- subjective, not absolute
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 3
Frequency analysis
Auditory Scene Analysis
(Bregman 1990)
• How do people analyze sound mixtures?
- break mixture into small elements (in time-freq)
- elements are grouped in to sources using cues
- sources have aggregate attributes
• Grouping ‘rules’ (Darwin, Carlyon, ...):
- cues: common onset/offset/modulation, harmonicity, spatial location, ...
Dan Ellis
Onset map
Harmonicity map
Position map
Grouping mechanism
Sound, Mixtures & Learning
(after Darwin, 1996)
2003-07-21 - 4
Source properties
Cues to simultaneous grouping
• Elements + attributes
8000
6000
4000
2000
0
0 1 2 3 4 5 6 7 8 9 time / s
• Common onset
- simultaneous energy has common source
• Periodicity
- energy in different bands with same cycle
• Other cues
- spatial (ITD/IID), familiarity, ...
• But: Context ...
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 5
Outline
1 Sound Content Analysis
2 Recognizing sounds
- Clean speech
- Speech-in-noise
- Nonspeech
3 Organizing mixtures
4 Accessing large datasets
5 Music Information Retrieval
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 6
2
Recognizing Sounds: Speech
• Standard speech recognition structure:
Acoustic model parameters
Word models s ah t
Language model p("sat"|"the","cat") p("saw"|"the","cat") sound
Feature calculation
Acoustic classifier feature vectors phone probabilities
HMM decoder phone / word
sequence
Understanding/ application...
• How to handle additive noise ?
- just train on noisy data: ‘multicondition training’
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 7
How ASR Represents Speech
• Markov model structure: states + transitions
M'
1
S
0.9
0.8
0.18
A
0.1
0.8
K 0.9
T
0.2
E
0.02
O
0.1
4
State models (means)
0.9
Model M'
2
3
0.8
0.05
A
0.1
2
S K
0.9
1
0
0.15
O
0.1
State Transition Probabilities
10
0.8
T
20
0.2
30
40
50
E
10 20 30 40 50
• A generative model
- but not a good speech generator!
4
3
2
1
0
0 1 2 3 4 5 time / sec
Dan Ellis
- only meant for inference of p ( X | M )
Sound, Mixtures & Learning 2003-07-21 - 8
General Audio Recognition
(with Manuel Reyes)
• Searching audio databases
- speech .. use ASR
- text annotations .. search them
sound effects library ?
• e.g. Muscle Fish “SoundFisher” browser
- define multiple ‘perceptual’ feature dimensions
- search by proximity in (weighted) feature space
Segment feature analysis
Sound segment database Feature vectors
Seach/ comparison
Segment feature analysis
Query example
- features are global for each soundfile, no attempt to separate mixtures
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 9
Results
Audio Recognition: Results
• Musclefish corpus
- most commonly reported set
• Features
- MFCC, brightness, bandwidth, pitch ...
- no temporal structure
• Results:
- 208 examples, 16 classes
Global features : 41% corr HMM models : 81% corr.
Musical
Mu
59/
46
Speech
Eviron.
Animals
Mechan 1
Sp Env
24
11/ 6 4
7/ 2
2
4
Dan Ellis
An
2
5
Mec
19
1/
1
2
8/ 4 3
Sound, Mixtures & Learning
Mu
136/
6
1
1
Sp Env
2
14/ 2 5
7/
3
An
2003-07-21 - 10
1
3
1
4/
Mec
5
1
1
12/
dogBarks2
What are the HMM states?
• No sub-units defined for nonspeech sounds
• Final states depend structure, initialization
- number of states
- initial clusters / labels / transition matrix
- EM update objective
• Have ideas of what we’d like to get
- investigate features/initialization to get there
8
7
6
5
4
3
2
1 time
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 11
Alarm sound detection
(Ellis 2001)
3
2
1
0
0 s0n6a8+20
4
• Alarm sounds have particular structure
- people ‘know them when they hear them’
- clear even at low SNRs hrn01 bfr02 buz01
5 10 15 20 25
20
0
-20 time / s
-40 level / dB
• Why investigate alarm sounds?
- they’re supposed to be easy
- potential applications...
• Contrast two systems:
- standard, global features , P ( X | M )
- sinusoidal model, fragments , P(M,S|Y)
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 12
Alarms: Results
Restaurant+ alarms (snr 0 ns 6 al 8)
2
1
0
4
3
MLP classifier output
0
2
1
4
3
6 7
Sound object classifier output
8 9
25 30 35 40 45 time/sec
50
• Both systems commit many insertions at 0dB
SNR, but in different circumstances:
Noise
Neural net system Sinusoid model system
Del Ins Tot Del Ins Tot
1 (amb) 7 / 25
2 (bab) 5 / 25
3 (spe) 2 / 25
4 (mus) 8 / 25
2
63
68
37
36%
272%
280%
14 / 25
15 / 25
12 / 25
180% 9 / 25
1 60%
2 68%
9 84%
135 576%
Overall 22 / 100 170 192% 50 / 100 147 197%
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 13
Outline
1 Sound Content Analysis
2 Recognizing sounds
3 Organizing mixtures
- Auditory Scene Analysis
- Parallel model inference
4 Accessing large datasets
5 Music Information Retrieval
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 14
3
Organizing mixtures:
Approaches to handling overlapped sound
• Separate signals , then recognize
- e.g. CASA, ICA
- nice, if you can do it
• Recognize combined signal
- ‘multicondition training’
- combinatorics..
• Recognize with parallel models
- full joint-state space?
- or: divide signal into fragments, then use missing-data recognition
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 15
Computational Auditory Scene Analysis:
The Representational Approach
(Cooke & Brown 1993) input mixture
• Direct implementation of psych. theory
Front end signal features
(maps)
Object formation discrete objects
Grouping rules
Source groups freq onset time period frq.mod
- ‘bottom-up’ processing
- uses common onset & periodicity cues frq/Hz
3000
2000
1500
1000 brn1h.aif
600
400
300
200
150
100
0.2
• Able to extract voiced speech: brn1h.fi.aif
frq/Hz
3000
2000
1500
1000
600
400
300
200
150
100
0.4
0.6
0.8
1.0
time/s 0.2
Dan Ellis Sound, Mixtures & Learning
0.4
0.6
0.8
2003-07-21 - 16
1.0
time/s
Adding top-down constraints
Perception is not direct but a search for plausible hypotheses
• Data-driven (bottom-up)...
input mixture
Front end signal features
Object formation discrete objects
Grouping rules
Source groups
- objects irresistibly appear vs. Prediction-driven (top-down) input mixture
Front end signal features hypotheses
Noise components
Hypothesis management
Periodic components prediction errors
Compare
& reconcile predicted features
Predict
& combine
Dan Ellis
- match observations with parameters of a world-model
- need world-model constraints...
Sound, Mixtures & Learning 2003-07-21 - 17
Prediction-Driven CASA
f/Hz
City
4000
2000
1000
400
200
1000
400
200
100
50
0 f/Hz
Wefts1−4
4000
2000
1000
400
200
1000
400
200
100
50
Horn1 (10/10)
Horn2 (5/10)
Horn3 (5/10)
Horn4 (8/10)
Horn5 (10/10)
1 2 3
Weft5
4 5 6
Wefts6,7
7
Weft8
8 9
Wefts9−12 f/Hz
Noise2,Click1
4000
2000
1000
400
200
Crash (10/10) f/Hz
Noise1
4000
2000
1000
400
200
Squeal (6/10)
Truck (7/10)
Dan Ellis
0 1 2 3 4 5
Sound, Mixtures & Learning
6 7
−40
−50
−60
−70
8 9 time/s
2003-07-21 - 18 dB
Segregation vs. Inference
• Source separation requires attribute separation
- sources are characterized by attributes
(pitch, loudness, timbre + finer details)
- need to identify & gather different attributes for different sources ...
• Need representation that segregates attributes
- spectral decomposition
- periodicity decomposition
• Sometimes values can’t be separated
- e.g. unvoiced speech
- maybe infer factors from probabilistic model?
)
→
( O )
Dan Ellis
- or: just skip those values, infer from higher-level context
- do both: missing-data recognition
Sound, Mixtures & Learning 2003-07-21 - 19
Missing Data Recognition
• Speech models p(x|m) are multidimensional...
- i.e. means, variances for every freq. channel
- need values for all dimensions to get p(•)
• But: can evaluate over a subset of dimensions x k k m )
=
∫
k
, x u m ) d x u x u y
p(x k
,x u
)
• Hence, missing data recognition :
p(x k
| x u
< y )
Present data mask
P(x | q) =
P(x
1
| q)
· P(x
2
| q)
· P(x
3
· P(x
4
| q)
| q)
· P(x
5
· P(x
6
| q)
| q) time →
- hard part is finding the mask ( segregation )
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 20
p(x x k k
)
Comparing different segregations
M
∗
• Standard classification chooses between models M to match source features X
= argmax
M
)
= argmax
M
)
⋅
P M
--------------
( )
)
• Mixtures → observed features Y , segregation S , all related by )
Observation
Y(f )
Source
X(f )
Segregation S freq
spectral features allow clean relationship
• Joint classification of model and segregation:
)
=
P M )
∫
( )
⋅
,
-------------------------
) d X
⋅
P S Y )
- probabilistic relation of models & segregation
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 21
Multi-source decoding
• Search for more than one source
Y(t) S
2
(t) q
2
(t)
S
1
(t)
• Mutually-dependent data masks
• Use e.g. CASA features to propose masks
- locally coherent regions
• Lots of issues in models, representations, matching, inference...
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 22 q
1
(t)
Outline
1 Sound Content Analysis
2 Recognizing sounds
3 Organizing mixtures
4 Accessing large datasets
- Spoken documents
- The Listening Machine
- Music preference modeling
5 Music Information Retrieval
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 23
4
Accessing large datasets:
The Meeting Recorder Project
(with ICSI, UW, IDIAP, SRI, Sheffield)
• Microphones in conventional meetings
- for summarization / retrieval / behavior analysis
- informal, overlapped speech
• Data collection (ICSI, UW, IDIAP, NIST):
- ~100 hours collected & transcribed
• NSF ‘Mapping Meetings’ project
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 24
Meeting IR tool
• IR on (ASR) transcripts from meetings
Dan Ellis
- ASR errors have limited impact on retrieval
Sound, Mixtures & Learning 2003-07-21 - 25
Speaker Turn detection
(Huan Wei Hee, Jerry Liu)
• Acoustic :
Triangulate tabletop mic timing differences
- use normalized peak value for confidence
Example cross coupling response, chan3 to chan0 mr-2000-11-02-1440: PZM xcorr lags
1
4
0
300
250
200
150
100
50
0
0
-1
-2 3
2
50 100 150 time / s
200 250 300
-3
-3
1
-2 -1 0 lag 1-2 / ms
1
10:
9:
8:
7:
5:
3:
2:
1:
0
• Behavioral : Look for patterns of speaker turns mr04: Hand-marked speaker turns vs. time + auto/manual boundaries
5 10 15 20 25 30 35 40 45 50 55 time/min
60
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 26
2 3
Speech/nonspeech detection
(Williams & Ellis 1999)
• ASR run over entire soundtracks?
- for nonspeech, result is nonsense frq/Hz
Spectrogram
4000
2000
0 speech
40
20
0
0 2
Posteriors
• Watch behavior of speech acoustic model:
- average per-frame entropy
- ‘dynamism’ - mean-squared 1st-order difference
3.5
3
Dynamism vs. Entropy for 2.5 second segments of speecn/music
Speech
Music
Speech+Music
4 music
6 8 speech+music
10
2.5
2
1.5
1
12 time/s 0.5
0
0 0.05
0.1
0.15
0.2
Dynamism
0.25
0.3
• 1.3% error on 2.5 second speech-music testset
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 27
The Listening Machine
• Smart PDA records everything
• Only useful if we have index, summaries
- monitor for particular sounds
- real-time description
• Scenarios
- personal listener → summary of your day
- future prosthetic hearing device
- autonomous robots
• Meeting data, ambulatory audio
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 28
Personal Audio
• LifeLog / MyLifeBits /
Remembrance Agent:
Easy to record everything you hear
• Then what?
- prohibitively time consuming to search
- but .. applications if access easier
• Automatic content analysis / indexing...
4
2
0
50 100 150 200 250 time / min
15
10
5
14:30 15:00 15:30 16:00 16:30 17:00 17:30
Dan Ellis Sound, Mixtures & Learning
18:00 18:30 clock time
2003-07-21 - 29
Outline
1 Sound Content Analysis
2 Recognizing sounds
3 Organizing mixtures
4 Accessing large datasets
5 Music Information Retrieval
- Anchor space
- Playola browser
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 30
5
Music Information Retrieval
• Transfer search concepts to music?
- “ musical Google ”
- finding something specific / vague / browsing
- is anything more useful than human annotation?
• Most interesting area: finding new music
- is there anything on mp3.com that I would like?
audio is only information source for new bands
• Basic idea:
Project music into a space where neighbors are “similar”
• Also need models of personal preference
- where in the space is the stuff I like
- relative sensitivity to different dimensions
• Evaluation problems
- requires large, shareable music corpus!
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 31
Artist Classification
(Berenzweig et al. 2001)
• Artists’ oeuvres as similarity-sets
• Train MLP to classify frames among 21 artists
• Using (detected) voice segments :
Song-level accuracy improves 56.7% → 64.9%
Track 117 - Aimee Mann (dynvox=Aimee, unseg=Aimee) true voice
Michael Penn
The Roots
The Moles
Eric Matthews
Arto Lindsay
Oval
Jason Falkner
Built to Spill
Beck
XTC
Wilco
Aimee Mann
The Flaming Lips
Mouse on Mars
Dj Shadow
Richard Davies
Cornelius
Mercury Rev
Belle & Sebastian
Sugarplastic
Boards of Canada
0 true voice
Michael Penn
The Roots
The Moles
Eric Matthews
Arto Lindsay
Oval
Jason Falkner
Built to Spill
Beck
XTC
Wilco
Aimee Mann
The Flaming Lips
Mouse on Mars
Dj Shadow
Richard Davies
Cornelius
Mercury Rev
Belle & Sebastian
Sugarplastic
Boards of Canada
0 10
Dan Ellis
50
20
100 150
Track 4 - Arto Lindsay (dynvox=Arto, unseg=Oval)
200
30 40 50
Sound, Mixtures & Learning
60 70 80
2003-07-21 - 32 time / sec time / sec
Artist Similarity
• Recognizing work from each artist is all very well...
• But: what is similarity between artists ?
- pattern recognition systems give a number...
e toni_braxton jessica_simpson mariah_carey new_ janet_jackson eiffel_65 pet_shop_boys lauryn_hill roxette lara_fabian rs sade sof pr spice_girls
• Need subjective ground truth:
Collected via web site www.musicseer.com
• Results:
- 1,000 users, 22,300 judgments
collected over 6 months
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 33
Audio
Input
(Class i)
Audio
Input
(Class j)
Music similarity from Anchor space
• A classifier trained for one artist (or genre) will respond partially to a similar artist
• Each artist evokes a particular pattern of responses over a set of classifiers
• We can treat these classifier outputs as a new feature space in which to estimate similarity
Anchor n-dimensional vector in "Anchor
Space"
Anchor
Anchor p(a
1
|x) p(a vector in "Anchor
Space" p(a
1
|x) p(a n
|x) p(a
2
|x)
Anchor
Conversion to Anchorspace p(a n
|x)
GMM
Modeling
GMM
Modeling
Similarity
Computation
KL-d, EMD, etc.
Conversion to Anchorspace
• “ Anchor space ” reflects subjective qualities?
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 34
Anchor space visualization
• Comparing 2D projections of per-frame feature points in cepstral and anchor spaces:
Cepstral Features Anchor Space Features
0
0.6
0.4
0.2
0
0.2
0.4
0.6
0.8
1 madonna bowie
0.5
0 third cepstral coef
0.5
5
10
15 madonna bowie
15 10
Country
5
- each artist represented by 5GMM
- greater separation under MFCCs!
- but: relevant information?
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 35
Playola interface ( www.playola.org )
• Browser finds closest matches to single tracks or entire artists in anchor space
• Direct manipulation of anchor space axes
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 36
Evaluation
• Are recommendations good or bad?
• Subjective evaluation is the ground truth
- .. but subjects aren’t familiar with the bands being recommended
- can take a long time to decide if a recommendation is good
80
70
60
50
40
30
20
10
0
• Measure match to other similarity judgments
- e.g. musicseer data:
Top rank agreement
SrvKnw 4789x3.58
SrvAll 6178x8.93
GamKnw 7410x3.96
GamAll 7421x8.92
cei cmb erd e3d opn kn2 rnd ANK
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 37
Summary
• Sound
- .. contains much, valuable information at many levels
- intelligent systems need to use this information
• Mixtures
- .. are an unavoidable complication when using sound
- looking in the right time-frequency place to find points of dominance
• Learning
- need to acquire constraints from the environment
- recognition/classification as the real task
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 38
LabROSA Summary
• Broadcast
• Movies
• Lectures
• Meetings
• Personal recordings
• Location monitoring
ROSA
• Object-based structure discovery & learning
• Speech recognition
• Speech characterization
• Nonspeech recognition
• Scene analysis
• Audio-visual integration
• Music analysis
• Structuring
• Search
• Summarization
• Awareness
• Understanding
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 39
Extra Slides
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 40
Independent Component Analysis (ICA)
(Bell & Sejnowski 1995 et seq.)
• Drive a parameterized separation algorithm to maximize independence of outputs m
1 m
2 x a
11 a
21 a
12 a
22 s
1 s
2
−δ MutInfo
δ a
• Advantages :
- mathematically rigorous, minimal assumptions
- does not rely on prior information from models
• Disadvantages :
- may converge to local optima...
- separation, not recognition
- does not exploit prior information from models
Dan Ellis Sound, Mixtures & Learning 2003-07-21 - 41