A History and Overview of Machine Listening 1. 2.
advertisement

A History and Overview
of Machine Listening
Dan Ellis
Laboratory for Recognition and Organization of Speech and Audio
Dept. Electrical Eng., Columbia Univ., NY USA
dpwe@ee.columbia.edu
http://labrosa.ee.columbia.edu/
1. A Machine Listener
2. Key Tools in Machine Listening
3. Outstanding Problems
COLUMBIA UNIVERSITY
IN THE CITY OF NEW YORK
Machine Listening - Dan Ellis
2010-05-12
1 /28
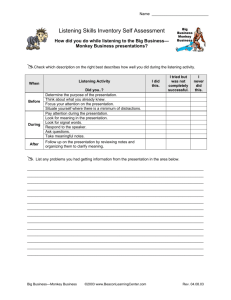
1. Machine Listening
•
“Listening puts us in the world” (Handel, 1989)
Listening
= Getting useful information from sound
signal processing + abstraction
“useful” depends
on what you’re doing
• Machine Listening
= devices that respond
to particular sounds
Machine Listening - Dan Ellis
2010-05-12
2 /28
• 1922
Listening Machines
magnet releases dog
in response to 500 Hz
energy
Machine Listening - Dan Ellis
• 1984
two claps toggle
power outlet on/off
2010-05-12
3 /28
Why is Machine Listening obscure?
• A poor second to Machine Vision:
vision leads to more immediate practical applications
(robotics)?
“machine listening” has been subsumed by
speech recognition?
images are more tangible?
Machine Listening - Dan Ellis
2010-05-12
4 /28
Listening to Mixtures
• The world is cluttered
& sound is transparent
mixtures are a certainty
• Useful information is structured by ‘sources’
specific definition of a ‘source’:
intentional independence
Machine Listening - Dan Ellis
2010-05-12
5 /28
Listening vs. Separation
• Extracting information
freq / Hz
does not require reconstructing waveforms
Query audio
4000
3500
3000
2500
2000
e.g. Shazam
fingerprinting
[Wang ’03]
1500
1000
500
0
Match: 05−Full Circle at 0.032 sec
4000
3500
3000
2500
2000
1500
1000
500
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
time / sec
• But... high-level description permits resynthesis
Machine Listening - Dan Ellis
2010-05-12
6 /28
Listening Machine Parts
Memory /
models
Sound
Front-end
representation
Scene
organization /
separation
Object
recognition
& description
Action
• Representation: what is perceived
• Organization: handling overlap and interference
• Recognition: object classification & description
• Models: stored information about objects
Machine Listening - Dan Ellis
2010-05-12
7 /28
Listening Machines
• What would count
as a machine listener,
... and why would
we want one?
replace people
surpass people
interactive devices
robot musicians
• ASR? yes
• Separation? maybe
Machine Listening - Dan Ellis
2010-05-12
8 /28
Describe
Automatic
Narration
Emotion
Music
Recommendation
Classify
Environment
Awareness
ASR
Music
Transcription
“Sound
Intelligence”
VAD
Speech/Music
Environmental
Sound
Speech
Dectect
Task
Machine Listening Tasks
Machine Listening - Dan Ellis
Music
Domain
2010-05-12
9 /28
1970
rly
ee
sp
ch
re
M
co
oo
gn
Ba re
itio
ke r ’7
n
r ‘7 5
:
5: M
H usi
D
idd c
av
is
en Tra
&
M nsc
M
ar rip
“T
er
ko ti
he
m
v M on
e
C
l
s
te
W lap
od
in
ein p
els
‘
80
M tr er
”
c
:M
Se Aul aub
FC
r a ‘
Cs
Br ra ‘8y/Q 86:
eg 9 ua So
Br ma : SM tie urc
ow n S ri e
G n & ‘90: ‘86: sep
o
A
Sin ara
Be to ‘9 Co ud
ok ito uso tion
l
4
l
:
&
Ell
i
r
is Se Mus e ‘94 y S d m
od
M ‘96 jno ic : C ce
us : P w Sc A ne
els
Le cle re sk en SA A
na
d i
e
Tz & Fish icti ‘95 e A
lys
an Se ‘9 on : IC nal
is
Kl eta ung 8 -dr A ysis
a k
ive
n
D puri is & ‘99:
iar ‘0 C N
C
AS
Kr iza 3: T oo MF
A
ist tio ra k:
j
‘
n
Ell an n sc 02
is sso
rip M
&
n
tio usi
W Le e
n cG
eis e t a
s & ‘06 l. ‘0
en
re
:
6
Ell Se : Ir
g
is’ m oq
10 e u
: E nti ois
ige ng
nv Li
oi feL
ce o
m gs
od
els
Ea
2. Key Tools in Machine Listening
• History: an eclectic timeline:
1980
Machine Listening - Dan Ellis
1990
2000
2010
Applications:
Speech
Music
Environmental
Separation
what worked? what is useful?
2010-05-12 10/28
Early Speech Recognition
Vintsyuk ’68
Ney ’84
Lowest cost to (i,j)
70
60
D(i,j) = d(i,j) + min
50
Local match cost
{
D(i-1,j) + T10
D(i,j-1) + T01
D(i-1,j-1) + T11
}
Best predecessor
(including transition cost)
10
10
20
Test
• Innovations:
template models
Machine Listening - Dan Ellis
30
40
50 time /frames
D(i-1,j)
D(i-1,j)
T01
20
T10
11
30
T
40
Reference frames rj
FOUR
ONE TWO THREE
Reference
FIVE
• DTW template matching
D(i-1,j)
Input frames fi
o time warping
2010-05-12 11/28
MFCCs
Davis & Mermelstein ’80
Logan ’00
• One feature to rule them all?
0.5
Sound
0
FFT X[k]
spectra
−0.5
0.25
0.255
0.26
0.265
0.27 time / s
10
Mel scale
freq. warp
log |X[k]|
audspec
5
0
4
0x 10
1000
2000
3000
freq / Hz
0
5
10
15
freq / Mel
0
5
10
15
freq / Mel
2
1
0
100
50
IFFT
cepstra
0
200
MFCC
resynthesis:
0
Truncate
−200
0
10
20
30
quefrency
MFCCs
just the right amount of blurring
Machine Listening - Dan Ellis
2010-05-12 12/28
Hidden Markov Models
• Recognition as
.8
.8
S
.1
.1
A
inferring
the parameters
of a generative
model
.1
.1
.1
C
p(qn+1|qn)
B
S
A
qn B
C
E
.1
.1
E
.7
0
.1
.8
.1
0
0
.1
.1
.7
0
0
0
0
.1
1
State sequence
q=A
0.8
q=B
q=C
3
0.6
xn
p(x|q)
Machine Listening - Dan Ellis
1
.8
.1
.1
0
AAAAAAAABBBBBBBBBBBCCCCBBBBBBBC
0.4
0
2
0
0.8
q=A
q=B
q=C
3
xn
0.6
0.4
2
1
0.2
0
Observation
sequence
1
0.2
p(x|q)
+ probability
+ training
0
0
0
0
0
SAAAAAAAABBBBBBBBBCCCCBBBBBBCE
Emission distributions
• Time warping
qn+1
S A B C E
Baker ’75
Jelinek ’76
0
1
2
3
4
observation x
0
0
10
20
30
time step n
2010-05-12 13/28
Model Decomposition
• HMMs applied to multiple sources
infer generative states
for many models
combination of observations...
exponential complexity...
Varga & Moore ’90
Gales & Young ’95
Ghahramani & Jordan’97
Kristjansson et al ’06
Herhsey et al ’10
model 2
model 1
Machine Listening - Dan Ellis
observations / time
2010-05-12 14/28
Segmentation & Classification
Chen & Gopalakrishnan ’98
Tzanetakis & Cook ’02
Lee & Ellis ’06
• Label audio at scale of ~ seconds
8
7
6
5
4
3
2
1
0
VTS_04_0001 - Spectrogram
MFCC
Covariance
Matrix
30
20
10
0
-10
MFCC covariance
-20
1
2
3
4
5
6
7
8
9
time / sec
20
18
16
14
12
10
8
6
4
2
1
2
3
4
5
6
7
8
9
time / sec
50
20
level / dB
18
16
20
15
10
5
0
-5
-10
-15
-20
value
MFCC dimension
MFCC bin
freq / kHz
segment when
Video
signal changes
Soundtrack
describe by
MFCC
statistics
features
classify with
existing models (HMMs?)
14
12
0
10
8
6
4
2
5
10
15
MFCC dimension
20
• Many supervised
applications
speaker ID
music genre
environment ID
Machine Listening - Dan Ellis
2010-05-12 15/28
-50
Music Transcription
• Music audio has a very specific structure
Goto ’04
... and an explicit abstract content
Moorer ’75
Goto ’94,’04
Klapuri ’02,’06
pitch + harmonics
rhythm
‘harmonized’ voices
Machine Listening - Dan Ellis
2010-05-12 16/28
Sinusoidal Models
• Stylize a spectrogram
freq / kHz
into discrete components
McAulay & Quatieri ’84
Serra ’89
Maher & Beauchamp ’94
4
3
2
freq / kHz
1
0
4
from
Wang ’95
3
2
1
0
0.5
1
1.5
2
2.5
3
3.5
time / s
discrete pieces → objects
good for modification & resynthesis
Machine Listening - Dan Ellis
2010-05-12 17/28
Comp. Aud. Scene Analysis
Weintraub ’85
Brown & Cooke ’94
Ellis ’96
Roweis ’03
Hu & Wang ’04
• Computer implementations of
principles from [Bregman 1990] etc.
harmonicity,
onset cues
input
mixture
Front end
signal
features
(maps)
Object
formation
discrete
objects
Source
groups
Grouping
rules
freq
onset
time
period
8
Oracle
mask:
6
4
2
0
freq / kHz
time-frequency
masking
for resynthesis
freq / kHz
frq.mod
8
6
4
2
0
Machine Listening - Dan Ellis
0.5
1
1.5
2
2.5
3
time / s
2010-05-12 18/28
Independent Component Analysis
• Can separate “blind” combinations by
Bell & Sejnowski ’95
Smaragdis ’98
maximizing independence of outputs
m1
m2
a11
a21
x
a12
a22
s1
s2
−δ MutInfo
δa
kurt(y) = E
��
y−µ
σ
�4 �
as a measure
of independence?
−3
s2
0.6
0.4
kurtosis
kurtosis
mix 2
Mixture Scatter
0.8
s1
10
8
0.2
6
0
4
-0.2
-0.4
2
-0.6
-0.3
0
s1
-0.2
-0.1
0
0.1
0.2
0.3
0.4
mix 1
Machine Listening - Dan Ellis
Kurtosis vs. e
12
0
0.2
0.4
0.6
s2
0.8
e//
2010-05-12 19/28
1
Nonnegative Matrix Factorization
Lee & Seung ’99
Abdallah & Plumbley ’04
Smaragdis & Brown ’03
Virtanen ’07
• Decomposition of spectrograms
into templates + activation
X=W·H
fast & forgiving gradient descent algorithm
fits neatly with time-frequency masking
100
150
200
1
2
120
100
80
60
40
20
1
2
Bases from all W
t
Machine Listening - Dan Ellis
3
50
100
150
Time (DFT slices)
200
Smaragdis ’04
3
Frequency (DFT index)
Rows of H
50
Virtanen ’03
sounds
2010-05-12 20/28
Summary of Key Ideas
Templates
HMMs
Bases
Spectrogram
MFCCs
Sinusoids
Sound
Front-end
representation
Memory /
models
Scene
organization /
separation
Segmentation
CASA
ICA, NMF
Machine Listening - Dan Ellis
Object
recognition
& description
Action
Direct match
HMMs
Decomposition
Adaptation
SVMs
21
2010-05-12
/28
3. Open Issues
• Where to focus to advance machine listening?
task & evaluation
separation
models & learning
ASA
computational theory
attention & search
spatial vs. source
Machine Listening - Dan Ellis
2010-05-12 22/28
Scene Analysis Tasks
• Real scenes are
complex!
f/Hz City
4000
2000
1000
400
200
1000
400
200
100
50
0
background noise
many objects
prominence
• Is this just scaling,
or is it different?
1
2
3
f/Hz Wefts1ï4
4
5
Weft5
6
7
Wefts6,7
8
Weft8
9
Wefts9ï12
4000
2000
1000
400
200
1000
400
200
100
50
Horn1 (10/10)
Horn2 (5/10)
Horn3 (5/10)
Horn4 (8/10)
Horn5 (10/10)
f/Hz Noise2,Click1
4000
2000
1000
400
200
Crash (10/10)
f/Hz Noise1
• Evaluation?
4000
2000
1000
ï40
400
200
ï50
ï60
Squeal (6/10)
Truck (7/10)
ï70
0
Machine Listening - Dan Ellis
1
2
3
4
5
6
7
8
9
time/s
2010-05-12 23/28
dB
How Important is Separation?
• Separation systems often evaluated by SNR
based on pre-mix components - is this relevant?
• Best machine listening systems have resynthesis
e.g. Iroquois speech recognition “separate then recognize”
mix
separation
t-f masking
+ resynthesis
identify
target energy
ASR
speech
models
words
mix
find best
words model
identify
target energy
words
speech
models
source
knowledge
• Separated signals don’t have to match originals
to be useful
Machine Listening - Dan Ellis
2010-05-12 24/28
/a/
/e/
How Many Models?
speaker adapted models :
base + parameters
/u/
extrapolation beyond normal
VT length ratio
➝ better analysis/o/
• More specific models
need dictionaries for/i/“everything”??
Domain of normal speakers
• Model adaptation and hierarchy
• Time scales of model acquisition
mean
pitch / Hz
Smith, Patterson et al. ’05
innate/evolutionary (hair-cell tuning)
developmental (mother tongue phones)
dynamic - the “Bolero” effect
Machine Listening - Dan Ellis
2010-05-12 25 /28
Auditory Scene Analysis?
• Codebook models learn harmonicity, onset
VQ256 codebook female
... to subsume rules/
representations of
CASA
Frequency (kHz)
8
0
6
20
40
4
60
2
0
80
50
100
150
Codeword
200
250
Level / dB
• Can also capture sequential structure
e.g. consonants follow vowels
use overlapping patches?
• But: computational factors
Machine Listening - Dan Ellis
2010-05-12 26/28
Computational Theory
• Marr’s (1982) perspective on perception
Computational
Theory
Properties of the world
that make the problem
solvable
Algorithm
Specific calculations
& operations
Implementation
Details of
how it’s done
• What is the computational theory
of machine listening?
independence? sources?
Machine Listening - Dan Ellis
2010-05-12 27/28
Summary
• Machine Listening:
Getting useful information from sound
• Techniques for:
representation
separation / organization
recognition / description
memory / models
• Where to go?
separation?
computational theory?
Machine Listening - Dan Ellis
2010-05-12 28/28
References 1/2
S. Abdallah & M. Plumbley (2004) ”Polyphonic transcription by nonnegative sparse coding of power spectra”, Proc. Int. Symp. Music Info.
Retrieval 2004.
J. Baker (1975) “The DRAGON system – an overview,” IEEE Trans.
Acoust. Speech, Sig. Proc. 23, 24–29, 1975.
A. Bell & T. Sejnowski (1995) “An information maximization approach to
blind separation and blind deconvolution,” Neural Computation, 7,
1129-1159, 1995.
A. Bregman (1990) Auditory Scene Analysis, MIT Press.
G. Brown & M. Cooke (1994) “Computational auditory scene analysis,”
Comp. Speech & Lang. 8(4), 297–336, 1994.
S. Chen & P. Gopalakrishnan (1998) “Speaker, environment and channel
change detection and clustering via the Bayesian Information Criterion,”
Proc. DARPA Broadcast News Transcription and Understanding Workshop.
S. Davis & P. Mermelstein (1980) “Comparison of parametric
representations for monosyllabic word recognition in continuously
spoken sentences,” IEEE Trans. Acoust. Speech Sig. Proc. 28, 357–366, 1980.
D. Ellis (1996) Prediction-driven computational auditory scene analysis, Ph.D
thesis, EECS dept., MIT.
D. Ellis & K. Lee (2006) “Accessing minimal impact personal audio
archives,” IEEE Multimedia 13(4), 30-38, Oct-Dec 2006.
M. Gales & S.Young (1995) “Robust speech recognition in additive and
convolutional noise using parallel model combination,” Comput. Speech
Lang. 9, 289–307, 1995.
Z. Ghahramani & M. Jordan (1997) “Factorial hidden Markov models,”
Machine Learning, 29(2-3,) 245–273, 1997.
M. Goto & Y. Muraoka (1994) “A beat tracking system for acoustic
signals of music,” Proc. ACM Intl. Conf. on Multimedia, 365–372, 1994.
Machine Listening - Dan Ellis
M. Goto (2004) “A real-time music scene description system:
Predominant-F0 estimation for detecting melody and bass lines in realworld audio signals,” Speech Comm., 43(4), 311–329, 2004.
S. Handel (1989) Listening, MIT Press.
J. Hershey, S. Rennie, P. Olsen, T. Kristjansson (2006) “Super-human multitalker speech recognition: A graphical modeling approach,” Comp. Speech
& Lang., 24, 45–66.
G. Hu and D.L.Wang (2004) “Monaural speech segregation based on
pitch tracking and amplitude modulation,” IEEE Tr.
Neural
Networks, 15(5), Sep. 2004.
F. Jelinek (1976) “Continuous speech recognition by statistical methods,”
Proc. IEEE 64(4), 532–556.
A. Klapuri (2003) “Multiple fundamental frequency estimation based on
harmonicity and spectral smoothness,” IEEE Trans. Speech & Audio
Proc.,11(6).
A. Klapuri (2006) “Multiple Fundamental Frequency Estimation by
Summing Harmonic Amplitudes,” Proc. Int. Symp. Music Info. Retr.
T. Kristjansson, J. Hershey, P. Olsen, S. Rennie, and R. Gopinath (2006)
“Super-human multi-talker speech recognition: The IBM 2006 speech
separation challenge system,” Proc. Interspeech, 775-1778, 2006.
D. Lee & S. Seung (1999) ”Learning the Parts of Objects by Nonnegative Matrix Factorization”, Nature 401, 788.
B. Logan (2000) “Mel frequency cepstral coefficients for music
modeling,” Proc. Int. Symp. Music Inf. Retrieval, Plymouth, September 2000.
R. Maher & J. Beachamp (1994) “Fundamental frequency estimation of
musical signals using a two-way mismatch procedure,” J. Acoust. Soc. Am.,
95(4), 2254–2263, 1994.
D. Marr (1982) Vision, MIT Press.
2010-05-12 29/28
References 2/2
R. McAulay & T. Quatieri (1986) “Speech analysis/synthesis based on a
sinusoidal representation,” IEEE Trans. Acoust. Speech Sig. Proc. 34, 744–
754, 1986.
A. Moorer (1975) On the segmentation and analysis of continuous musical
sound by computer, Ph.D. thesis, CS dept., Stanford Univ.
H. Ney (1984) “The use of a one stage dynamic programming algorithm
for connected word recognition,” IEEE Trans. Acoust. Speech Sig. Proc. 32,
263–271, 1984.
S. Roweis (2003) ”Factorial Models and Refiltering for Speech
Separation and Denoising”, Proc. Eurospeech, 2003.
X. Serra (1989) A system for sound analysis/transformation/synthesis based
on a deterministic plus stochastic decomposition, Ph.D. thesis, Music dept.,
Stanford Univ.
P. Smaragdis (1998) “Blind separation of convolved mixtures in the
frequency domain,” Intl.Wkshp. on Indep. & Artif. Neural Networks,Tenerife,
Feb. 1998.
P. Smaragdis & J. Brown (2003) ”Non-negative Matrix Factorization for
Polyphonic Music Transcription”, Proc. IEEE WASPAA,177-180, October
2003
P. Smaragdis (2004) “Non-negative Matrix Factor Deconvolution;
Extraction of Multiple Sound Sources from Monophonic Inputs,” Proc.
ICA, LNCS 3195, 494–499.
D. Smith, R. Patterson, R. Turner, H. Kawahara & T. Irino (2005) “The
processing and perception of size information in speech sounds,” J
Acoust Soc Am. 117(1), 305–318.
G. Tzanetakis & P. Cook (2002) “Musical genre classification of audio
signals,” IEEE Tr. Speech & Audio Proc. 10(5).
A.Varga & R. Moore (1990) “Hidden Markov Model decomposition of
speech and noise,” IEEE ICASSP, 845–848, 1990.
Machine Listening - Dan Ellis
T.Vintsyuk (1971) “Element-wise recognition of continuous speech
composed of words from a specified dictionary,” Kibernetika 7, 133–143,
1971.
T.Virtanen (2007) “Monaural sound source separation by nonnegative
matrix factorization with temporal continuity and sparseness criteria,”
IEEE Tr. Audio, Speech, & Lang. Proc. 15(3), 1066–1074, Mar. 2007.
A. Wang (2006) “The Shazam music recognition service,” Comm. ACM 49
(8), 44-48, 2006.
M. Weintraub (1986) A theory and computational model of auditory
monaural sound separation, Ph.D. thesis, EE dept., Stanford Univ.
R. Weiss & D. Ellis (2010) “Speech separation using speaker-adapted
Eigenvoice speech models,” Comp. Speech & Lang., 24(1), 16–29, Jan 2010.
2010-05-12 30/28