Sparse Coding of Zebra Finch Song G. Greene, C. Houghton, Trinity College Dublin
advertisement

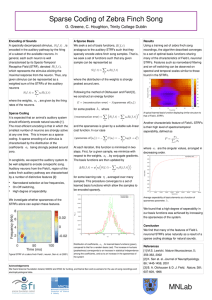
Sparse Coding of Zebra Finch Song G. Greene, C. Houghton, Trinity College Dublin Introduction The calculation of regularised Spectro­Temporal Receptive Fields (STRFs) for auditory neurons have been described by Sen et al., among others. The STRFs of Field L neurons in the zebra finch auditory pathway are characterised by a number of distinctive features [1]: Narrowband selection at low frequencies, On­Off switching, High degree of seperability. We investigate whether these features arise naturally as a result of a sparse coding strategy for natural sounds. Linear STRF Model Given a time varying, spectrally decomposed stimulus, where is the log amplitude of the stimulus in the frequency band , the instantaneous firing rate of a particular neuron is given by the convolution Concantenating the frequency bands, this can be discretised as for The STRF is then given by the least squares solution A Sparse Basis We seek a set of invertible basis functions, such that any given sample can be represented as where the distribution of the weights is strongly peaked around zero. Following the method of Olshausen and Field [3] , we construct an energy function Results Using a training set of zebra finch song recordings, the algorithm described converges to a set of optimal basis functions whose inverses share many of the characteristics of Field L neuronal STRFs. Features such as narrowband filtering and on­off switching can be observed on spectral and temporal scales similar to those found in the calculated neuronal STRFs. for some positive , where and the sparseness is given by a suitable sub­linear cost function. In our case At each iteration, this function is minimised in two steps. First, for a given sample, we minimize with respect to the weights, , by conjugate gradients. The basis functions are then updated by for some learning rate , averaged over many samples. This procedure converges to a set of learned basis functions which allow the samples to be encoded sparsely. Regularisation A regularised, low­noise solution is found by replacing the inverse above with a regularised pseudo­inverse from which low eigenvalue contributions have been removed. A typical predicted STRF for k=20. Predicted STRFs are calculated using a regularization process similar to that used in the calculation of actual neuronal STRFs Another characteristic feature of Field L STRFs is their high level of spectral­temporal seperability, defined as where are the singular values of the STRF, arranged in decreasing order. Where are the eigenvectors and are the eigenvalues of . Sparse Coding It is expected that an animals auditory system should be optimised so as to sparsely encode natural stimuli [2]. In the case of songbirds, we expect the auditory system to be well adapted to encode conspecific song. Given a sample of birdsong, , to be encoded by a set of auditory neurons, we can express the sample as a weighted sum of a set of basis functions corresponding to the neurons In a sparse coding regime, the basis functions would be such that the distribution of the weights should be strongly peaked around zero. If we take the weights to be the instantaeous firing rates of the neurons at time , then we can rearrange to get: i.e., the inverses of the basis functions constitute a set of optimal STRFs for which the firing rates, , are sparse. Distribution of coefficients, , for learned basis functions (green), compared to that for a random basis (red). The increase in kurtosis (peakedness) corresponds to an increase in statistical independence among the coefficients, and so to an increase in the sparseness of the system To ensure that these basis functions are invertible, we preprocess the song by projecting down onto the first eigenvectors of the autocorrelation matrix . This corresponds to the regularization used in the calculation of the actual neuronal STRFs. We can now rewrite where is square, and is a orthonormal matrix of eigenvectors which gives the inverse the columns of which are the predicted sparse STRFs of the set of neurons. Seperability of predicted STRFs as a function of sparseness. We found that the seperability of the predicted STRFs increases with the sparseness of the system. Conclusion We find that many of the features of regularised neuronal STRFs arise naturally as result of a sparse coding strategy for natural sounds References [1] K. Sen et. al. Journal of Neurophysiology, 86; 1445­1458, 2001 [2] M.S. Lewicki. Nature Neuroscience, 5; 356­363, 2002 [3] B. A. Olshausen & D. J. Field. Nature, 381; 607­609, 1996 Acknowledgements We thank Science Foundation Ireland, MACSI and IITAC for funding, and Kamal Sen and co­workers for the use of song recordings and electrophysiological data. MNLab