Sparse Coding of Zebra Finch Song G. Greene, C. Houghton, Trinity College Dublin
advertisement

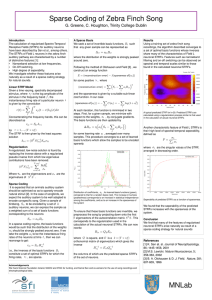
Sparse Coding of Zebra Finch Song G. Greene, C. Houghton, Trinity College Dublin Encoding of Sounds A Sparse Basis Results A spectrally decomposed stimulus, , is encoded in the auditory pathway by the firing of a subset of the available neurons. In general, each such neuron is well characterised by its Specto­Temporal Receptive Field (STRF), denoted , which represents the stimulus eliciting the maximal response from the neuron. Thus, any given stimulus can be represented as a weighted sum of the STRFs of the auditory neurons We seek a set of basis functions, analagous to the auditory STRFs such that they sparsely encode zebra finch song samples. That is, we seek a set of functions such that any given sample can be represented as Using a training set of zebra finch song recordings, the algorithm described converges to a set of optimal basis functions sharing many of the characteristics of Field L neuronal STRFs. Features such as narrowband filtering and on­off switching can be observed on spectral and temporal scales similar to those found in the STRFs. where the distribution of the weights is strongly peaked around zero. Following the method of Olshausen and Field [3] , we construct an energy function where the weights, , are given by the firing rates of the neurons. for some positive , where A typical learned basis function displaying similar structure to that of Field L STRFs Sparse Coding It is expected that an animal's auditory system should efficiently encode natural sounds [1]. The most efficient encoding is that in which the smallest number of neurons are strongly active at any one time. This is known as a sparse coding. A sparse encoding of a stimulus is characterised by the distribution of the coefficients being strongly peaked around zero. In songbirds, we expect the auditory system to be well adapted to encode conspecific song. Auditory neurons from the Field L region of the zebra finch auditory pathway are characterised by a number of distinctive features [2]: Narrowband selection at low frequencies, On­Off switching, High degree of seperability. and the sparseness is given by a suitable sub­linear cost function. In our case At each iteration, this function is minimised in two steps. First, for a given sample, we minimize with respect to the weights, , by conjugate gradients. The basis functions are then updated by Another characteristic feature of Field L STRFs is their high level of spectral­temporal seperability, defined as where are the singular values, arranged in decreasing order. for some learning rate , averaged over many samples. This procedure converges to a set of learned basis functions which allow the samples to be encoded sparsely. Average seperability of basis elements as a function of sparseness parameter, . We investigate whether sparseness of the STRFs alone can explain these features. We found that a high degree of seperability in our basis functions was achieved by increasing the sparseness of the system. Conclusion We find that many of the features of Field L neuronal STRFs arise naturally as a result of a sparse coding strategy for natural sounds. Typical STRF of a zebra finch Field L neuron, Sen et. al (2001) Distribution of coefficients, , for learned basis functions (green), compared to that for a random basis (red). The increase in kurtosis (peakedness) corresponds to an increase in statistical independence among the coefficients, and so to an increase in the sparseness of the system Acknowledgements We thank Science Foundation Ireland, MACSI and IITAC for funding, and Kamal Sen and co­workers for the use of song recordings and electrophysiological data. References [1] M.S. Lewicki. Nature Neuroscience, 5; 356­363, 2002 [2] K. Sen et. al. Journal of Neurophysiology, 86; 1445­1458, 2001 [3] B. A. Olshausen & D. J. Field. Nature, 381; 607­609, 1996 MNLab