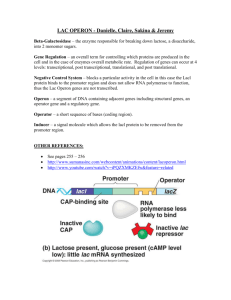
1. Structural genes
advertisement

ZOO 405, Week 3 ZOO405 by Rania Baleela is licensed under a Creative Commons AttributionNonCommercial-ShareAlike 3.0 Unported License This week • • • • • • Genome content Eukaryotic genome constitution Viruses Morphological types of viruses Retroviruses and their genome organization Retroviruses classification Genome content Size measurements in the molecular world • 1 mm (millimeter) = 1/1,000 meter • 1 mm (“micron”) = 1/1,000,000 of a meter (1 x 10-6) • 1 nm (nanometer) = 1 x 10-9 meter •1 bp (base pair) = 1 nt (nucleotide pair) •1,000 bp = 1 kb (kilobase) •1 million bp = 1 Mb (megabase) •5 billion bp DNA ~ 1 meter •5 thousand bp DNA ~ 1.2 mm The C-value enigma/paradox “Although genes are made of DNA, much DNA is not genes” Doolittle, 1989 Species Genome size (Mb) Predicted Gene Number Human 3,200 40,000- 50,000 Mouse 3,200 40,000 Pufferfish 380 38,000 Seq squirt 160 16,000 Fruit fly 180 14,000 Mosquito 280 14,000 Nematode 98 19,000 Mustard weed 125 25,000 Rice 400 35,000 Corn 2,500 40,000 Yeast 12 5,800 Neurospora 40 10,000 The C-value paradox Complexity does not correlate with genome size Dr Richard Horton 3.4 109 bp Homo sapiens 1.5 1010 bp Allium cepa 6.8 1011 bp Amoeba dubia Genome size changes Increase: (1) global increases (i.e. the entire genome or a major part of it is duplicated), (2) regional increases (i.e. a particular sequence is multiplied to generate repetitive DNA). Decreases: Loss of 1 chromosome (Aneuploidy). Mechanisms for global genome size increase 1. Polyploidization = the addition of one or more complete sets of chromosomes to the original set. 2. Repetitive sequences: Ribosomal RNA genes Centromeres Telomeres TEs. Transposable Elements and genome size • Variation in gene numbers cannot explain variation in genome size among eukaryotes • Most of variation in genome size is due to variation in the amount of repetitive DNA (mostly derived from TEs) • TEs accumulate in intergenic regions The amount of TE correlate positively with genome size Mb 3000 Genomic DNA 2500 TE DNA 2000 1500 Protein-coding DNA 1000 500 0 (Feschotte & Pritham 2006) The proportion of protein-coding genes decreases with genome size, while the proportion of TEs increases with genome size TEs Protein-coding genes Gregory, Nat Rev Genet 2005 Contrasted Genome Landscapes Transposable Element Genetic components of the human genome Noncoding DNA the end of the paradox • Today, C-value differences are no longer paradoxical. • In spite of its label, the “paradox” was not the lack of a correlation with complexity, per se, but rather the inability of early researchers to reconcile the constancy of DNA content within species (which occurs because it is the stuff of genes) with the variation in quantity of DNA among species (which does not relate to the number of genes). Excess transposition may provoke rapid changes in genome size e.g. grass genomes Long Terminal Repeat (LTR) retrotransposons • Abundant and can impact gene and genome evolution. • Most are large elements (0.4 kb) and are most often found in heterochromatic (gene poor) regions. • The smallest LTR retrotransposon = 292 bp (Gao et al., 2012): • In rice, maize, sorghum and other grass genomes (indicates presence in the grass ancestor at least 50– 80 MYA). It may still be active in some genomes • The small LTR retrotransposons (SMARTs) => distributed throughout the genomes and are often located within or near genes=> can in a few instances alter both gene structures and gene expression. Rapid changes in genome size in the grasses ~50 myr ~10 myr Genome size: 4800 Mb 430 Mb 750 Mb 2500 Mb Figure adapted from Sue Wessler Variation in TE activity triggers rapid changes in genome size in grasses Genes TEs ~50 myr ~10 myr Genome size: 4800 Mb 430 Mb 750 Mb 2500 Mb Retrotransposon amplification has resulted in the doubling of the maize genome in the last ~6 myr (San Miguel et al. 1998) Variation in TE activity triggers rapid changes in genome size in grasses Genes TEs ~50 myr ~10 myr Genome size: 4800 Mb 430 Mb 750 Mb 2500 Mb 3 super-abundant retrotransposon families in O. australiensis That’s 62% of the genome ! (605/965 Mb) (Piegu et al. , 2006) The solution to the paradox Most eukaryotic DNA does not code for proteins, so there is no reason to expect a complex organism to have a large genome or a simple organism to have a small one. “The C-value paradox vanished the moment geneticists abandoned the concept of the genome consisting of the genes, all the genes, and nothing but the genes” C….G….&…..I values • C -Value :The amount DNA found in haploid genome, measured in million base pairs or in pg. • G- Value: The number of gene found in the haploid genome; the number includes predicted and ORFs. • I- value: The amount of information embedded by the genome. “We’re pretty good at thinking about how individual genes are turned on and off. We’re not as good at thinking about how the whole genome is coordinated.” Quote of Jeanne Lawrence in “The Cell Nucleus Shapes up“ Science 1993, Vol 259, pp 1257-1259 Constitution of eukaryotic genome Eukaryotic genomes composition 1. 2. 3. 4. 5. Structural genes (e.g. operon models). Interrupted genes Conserved exons & unique introns Gene numbers Repetitive DNA (e.g. tandem gene clusters, tandem arrays) 1. Structural genes • Are genes that codes for any RNA or protein product other than a regulatory protein. • The the Lac Operon is a mRNA structural gene • Operon Model = inducible genes=> Genes whose expression is turned on by the presence of some substance – Lactose induces expression of the lac genes – An antibiotic induces the expression of a resistance gene lac operon • Operon = bacterial block of genes encoding enzymes that are all part of a metabolic pathway • Composed of 3 structural genes coding for proteins involved in the uptake and catabolism of lactose • Lac=> Lactose which is a 12 Carbon sugar made of 2 simpler 6 Carbon sugars (i.e. glucose and galactose) • glucose is a very efficient carbon source; it can enter directly into the metabolic paths that provide both energy and substrates for making more complex compounds. • If lactose is provided as the carbon source, it must first be broken down into the 2 component sugars before it can be used Structural genes In E. coli β-galactosidase breaks lactose Lactose Operon • Structural genes – lac z, lac y, & lac a – Promoter – Polycistronic mRNA • Regulatory gene – Repressor • Operator • Operon • Inducer - lactose Regulatory Gene i Operon p o z y a DNA m-RNA Protein Transacetylase -Galactosidase Permease E. coli lac operon • E. coli grown in glucose as the sole carbon source have about 3 copies of the enzyme βgalactosidase/cell. • E. coli grown in lactose as the sole carbon source have about 3,000 copies of the enzyme β-galactosidase/cell. Lac operon functions when only glucose is present 1. The Promoter for the I gene is always "on", but is very weak, so it is transcribed only rare 2. The I mRNA is translated into the repressor protein. A typical cell will have only about 10 copies of this protein. 3. In the absence of lactose, the repressor protein binds to the Operator, preventing transcription form the second promoter. Almost no ZYA mRNA is made. Only lactose is present 1. The Promoter for the I gene is occasionally bound by RNA polymerase to initiate transcription. 2. The I mRNA is translated into the repressor protein (~ 10 copies). 3. Lactose binds to the repressor and converts it into an inactive state, where it can't bind the Operator (reversed when all the lactose is digested). 4. The promoter for making Z-Y-A mRNA is not blocked=> many copies of the mRNA are made. The small amount of lactose that diffuses in is able to initiate induction of transcription of the Z-Y-A mRNA.= the 3 proteins are made. 5. Translation begins at the 5' end of the mRNA and makes β-galactosidase from the Z gene. There is a stop codon, followed immediately by another AUG start, so many, but not all, ribosomes read on through and make permease from the Y gene. The same process allows some A gene product to also be made. Inducer=> lactose Absence Active repressor No expression = Negative control Negative Regulation of transcription Inducible Negative Regulation Repressible Positive Regulation The lac Operon Induction of the lac operon Catabolite Repression (Glucose Effect) = Control of an operon by glucose The lac control region 1. 3 operators (O1, O2, O3); region where regulatory proteins bind 2. RNA polymerase binding site (promoter)i 3. cAMP-CRP complex binding site (CAP) Mechanism of catabolite repression • c-AMP • CAP (CRP) protein • CAP-cAMP complex – Promoter activation • Positive control Absence of glucose Adenyl cyclase c-AMP CAP i p o ATP z y a Active Inactive -GalactosidasePermease Transacetylase Maximum expression Mechanism of catabolite repression • Glucose:cAMP • No CAP-cAMP complex – No Promoter activation Presence of glucose Adenyl cyclase X CAP i p o z ATP y a Inactive -GalactosidasePermease Transacetylase Low level expression Operon model- repressible genes • Repressible genes are those whose expression is turned off by the presence of some substance (co-repressor) – Tryptophan represses the trp genes