PairedT-TestNotesNoV..
advertisement

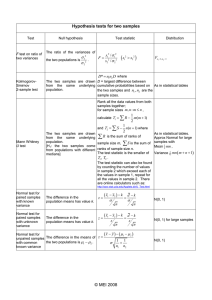
Dependent Samples: Hypothesis Test For Hypothesis tests for dependent samples, we 1. 2. 3. list the pairs of data in 2 columns (or rows), take the difference between each pair of data, analyze the differences xd d n i where di is the difference for the ith pair of data and n is the # of pairs of data. sd is the standard deviation of the differences. x d Then, t d has a t distribution with df = n-1 sd under the usual assumptions. n Dependent Samples: P-value Calculation For Hypothesis tests, we want to find p-values. This requires Minitab. Let the observed test statistic be t* Now, p-value = P(tn-1 > t*), when Ha: d > 0 P(tn-1 < t*), when Ha: d < 0 or, 2P(tn-1 > |t*|), when Ha: d 0 where n = number of pairs in the analysis. Diabetes Knowledge Scores Scores before and after a lecture. Let d = after-before Before 75 62 67 70 55 59 60 64 72 59 After 77 65 68 72 62 61 60 67 75 68 Difference 2 3 1 2 7 2 0 (After-Before) 2 3 1 2 7 2 0 3 3 9 32 xd 10 10 sd = 2.741 (Minitab) = 3.2 3 3 9 Dependent Samples Hypothesis Test Step 1: H0: d = 0 H1: d > 0 xd 0 Step 2: t* = s has a t-distribution with df = 9. d 10 3 .2 0 Step 3: t* = 2.741 = 3.7 (round to tenths place) 10 Step 4: p-value = P(tdf=9 > 3.7) = .00246 (Minitab) Dependent Samples Hypothesis Test Step 5: Since the p-value is less than any reasonable level of significance, we reject the null hypothesis and accept the research hypothesis. Step 6: With a .05 level of significance, we conclude there is enough evidence that the program yields a mean increase in knowledge of diabetes. Dependent Samples Confidence Interval We can also find a formula to estimate the mean difference. The result is s xd t / 2,df n1 d n Diabetes Example: Find a 95% CI. Recall, xd = 3.2 and sd = 2.741. Also, there were n = 10 pairs of data so df = 9. t.025,9 = 2.262 from software. Thus, 3.2 2.262 2.741 = 3.2 1.961 = (1.2, 5.2 ) 10 We are 95% confident the mean increase in knowledge about diabetes from the course is between 1.2 and 5.2 points. Dependent Samples Confidence Interval Travel Times for two routes (Minitab output) Paired T-Test and CI: Route I, Route II Paired T for Route I - Route II N Mean StDev SE Mean Route I 10 26.700 2.406 0.761 Route II 10 25.900 2.183 0.690 Difference 10 0.800 1.317 0.416 95% CI for mean difference: (-0.142, 1.742) T-Test of mean difference = 0 (vs not = 0): T-Value = 1.92 P-Value = 0.087 It is unclear at the 95% level of confidence which route is faster on average (takes less time). If route I is faster, it is by no more than 0.14 minute, on average. If route II is faster on average, it is by no more than 1.74 minutes. Prescription Drug Costs Are Rx drugs from Canada cheaper than drugs in the USA? Because costs of drugs vary considerably, we should consider using a dependent samples design. Otherwise, the large variation is costs among the Rx drugs may hide a difference in typical costs. A sample of 10 drugs were chosen, then using an online pharmacy price checking website, the drugs were priced at a Canadian and a USA pharmacy. Rx Costs - Independent Samples Analysis The output from an independent samples analysis is given on the next slide. What is the research hypothesis? Ha: The mean cost of drugs in Canada is lower than the mean cost of drugs in the USA. What would we conclude from THIS analysis? We will ask whether this is appropriate or not later. Rx Costs - Independent Samples Analysis Two-Sample T-Test and CI: Canada, USA N Mean StDev SE Mean Canada 10 3.16 3.28 1.0 USA 10 4.56 3.58 1.1 Difference = mu (Canada) - mu (USA) Estimate for difference: -1.41 T-Test of difference = 0 (vs <): T-Value = -0.91 P-Value = 0.186 DF = 18 Both use Pooled StDev = 3.4348 Rx Costs - Independent Samples Analysis From this output, we would conclude that there is not enough evidence to convince us that the mean cost of drugs from Canada is lower than the mean cost of drugs in the USA. Do you believe this? Why or why not? Rx Costs - Dependent Samples Analysis Because we priced the same 10 drugs, we should be using a dependent samples (paired) analysis. This also controls for variability among drug costs. The output from a dependent samples analysis is given on the next slide. What is the research hypothesis? Ha: The mean cost of drugs in Canada is lower than in the USA. Rx Costs - Dependent Samples Analysis Paired T-Test and CI: Canada, USA Paired T for Canada - USA N Mean StDev SE Mean Canada 10 3.16 3.28 1.04 USA 10 4.56 3.58 1.13 Difference 10 -1.405 0.763 0.241 95% upper bound for mean difference: -0.962 T-Test of mean difference = 0 (vs < 0): T-Value = -5.82 P-Value = 0.000 Rx Costs - Dependent Samples Analysis Notice that there is now overwhelming evidence to support the research hypothesis. The p-value is listed as 0.000 (< 0.001 is how it would be reported). This implies there is almost no chance of seeing this pattern in a sample of 10 pairs of drug costs if the mean costs are not different between Canada and the USA. (ie: there is no chance of seeing the sample data if the null hypothesis is true). So we would claim the research hypothesis has been proven beyond a reasonable doubt. Rx Costs - Dependent Samples Analysis What about assumptions? In dependent samples analysis, we need to have • a random sample of paired observations • differences must be normally distributed, or we need a large sample (30 or more differences as a rule of thumb) The sample was selected when I looked at names of drugs listed on the website, so it is not truly a random sample. This is one criticism. How would we check the normality assumption? Is Data Normal or not? Stat Basic Statistics Normality Test gives a way to check. (Enter the variable) Your hypotheses are: Ho: The data comes from a normal population of data. Ha: The data comes from a population that is not a normal distribution. Caveat: Statisticians NEVER accept the null hypothesis, yet that is exactly what this test does! Is Data Normal or not? If the p-value is small, we must use another technique (called nonparametrics). If the p-value is large, then researchers assume the ttest is ok to use. The t-test is called robust to this assumption, so only when the original population is very different from a normal distribution does it make a big difference (the p-value is not affect much when the population is slightly non-normal). Is Data Normal or not? Minitab Probability Plot of differences Normal 99 Mean StDev N AD P-Value 95 90 Percent 80 70 60 50 40 30 20 10 5 1 -3.5 -3.0 -2.5 -2.0 -1.5 -1.0 differences -0.5 0.0 0.5 -1.405 0.7634 10 0.265 0.609