Lecture 4-04
advertisement

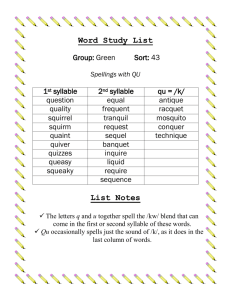
Phonetic Context Effects Major Theories of Speech Perception Motor Theory: Specialized module (later version) represents speech sounds in terms of intended gestures through a model of or knowledge of vocal tracts Direct Realism: Perceptual system recovers (phoneticallyrelevant) gestures by picking up the specifying information in the speech signal. Explanatory level = gesture General Approaches: Speech is processed in the same way as other sounds. Representation is a function of the auditory system and experience with language. Explanatory level = sound Fluent Speech Production The vocal tract is subject to physical constraints... Mass Inertia Radical Context Dependency Also a result of the motor plan Coarticulation = Assimilation adjacent speech becomes more similar An Example Place of Articulation in stops Say /da/ Say /ga/ Anterior Posterior An Example Place of Articulation in stops Say /al/ Say /ar/ Anterior Posterior An Example Place of Articulation in stops Say /al da/ Say /ar da/ Say /al ga/ Say /ar ga/ Place of articulation changes = Coarticulation An Example Place of Articulation in stops Say /al ga/ Say /ar da/ Coarticulation has acoustical consequences /al da/ /al ga/ * How does the listener deal with this? f t /ar da/ * /ar ga/ Speech Perception /ga/ /al/ /da/ /ar/ 100 none 90 al 80 ar 70 60 50 40 30 20 10 0 1 [ga] 2 3 4 5 6 7 [da] Percent “g” Responses Percent “g” Responses Identifying in Context /al/ /ar/ Direction of Effect Production /al/ More /da/-like /ar/ More /ga/-like Perception /al/ More /ga/-like /ar/ More /da/-like Perceptual Compensation For Coarticulation What happens when there is no coarticulation? AT&T Natural Voices Text-To-Speech Engine “ALL DA” “ARE GA” Further Findings 4 ½ month old infants (Fowler et al. 1990) Native Japanese listeners who do not discriminate /al/ from /ar/ (Mann, 1986) Theoretical Interpretations “There may exist a universally shared level where representation of speech sounds more closely corresponds to articulatory gestures that give rise to the speech signal.” (Mann, 1986) Motor Theory “Presumably human listeners possess implicit knowledge of coarticulation.” (Repp, 1982) Major Theories of Speech Perception Motor Theory: “Knowledge” of coarticulation allows perceptual system to compensate for its predicted effects on the speech signal. Direct Realism: Coarticulation is information for the gestures involved. Signal is parsed along the gestural lines. Coart. is assigned to gesture. General Approaches: Those other guys are wrong. Theoretical Interpretations Common Thread: Detailed correspondence between speech production and perception Special Module for Speech Perception Two Predictions: • • Talker-Specific Speech-Specific Testing Hypothesis #1 Talker-specific Should only compensate for the speech coming from a single speaker Testing Hypothesis #1 Talker-specific Male /al/ Male /da/ - /ga/ Male /ar/ Female /al/ Female /ar/ Mean context shift 40 30 20 10 0 Male Female Testing Hypothesis #2 Speech-specific Compensation should only occur for speech sounds SPEECH /al/ TONES SPEECH /ar/ TONES Testing Hypothesis #2 80 /al/ Mean % /ga/ Responses 70 /ar/ 60 50 40 30 20 10 0 Speech Non-Speech Condition Does this rule out motor theory? It may be that the special speech module is broadly tuned. If it acts like speech it went through speech module. If not, not. SPEECH PRECURSORS /al/ /ar/ Training the Quail 1 /ga/ Withheld from training 2 3 4 5 6 7 /da/ CV series varying in F3 onset frequency Withheld from training /al/ /ar/ Context-Dependent Speech Perception by an avian species Conclusions 1 Links to speech production are not necessary Neither speech-specific nor species-specific 2 Learning is not necessary Quail had no experience with covariation 3 General auditory processes play a substantive role in maintaining perceptual compensation for coarticulation Major Theories of Speech Perception Motor Theory: “Knowledge” of coarticulation allows perceptual system to compensate for its predicted effects on the speech signal. Direct Realism: Coarticulation is information for the gestures involved. Signal is parsed along the gestural lines. Coart. is assigned to gesture. General Approaches: General Auditory Processes GAP Effects of Context a familiar example How well does this analogy hold up for context effects in speech? Effects of Context a familiar example /al da/ /al ga/ * f t /ar da/ * /ar ga/ Hypothesis: Spectral Contrast the case of [ar] Production Perception F3 assimilated toward lower frequency F3 is perceived as a higher frequency /ar da/ 100 none 90 al 80 ar 70 60 50 40 30 20 10 0 1 Time 2 3 4 5 F3 Step 6 7 Evidence for General Approach The Empire Strikes Back Fowler, et al. (2000) audio Ambiguous precursor Test syllable: /ga/-/da/ series video Visual cue: face “AL” or “AR” Precursor conditions differed only in visual information Results of Fowler, et al. (2000) • More /ga/ responses when video cued /al/ 100 video /al/ video /ar/ Percent /ga/ responses 90 80 70 60 50 40 30 20 10 0 1 2 3 4 5 6 Test syllable 7 8 9 10 Experiment 1: Results – F(1,8) = 3.2, p = .111 90 Percent /ga/ responses • No context effect on test syllable 100 80 video /al/ video /ar/ 70 60 50 40 30 20 10 0 1 2 3 4 5 6 7 8 9 10 Test syllable %ga responses by condition for 9 participants A closer look… • 2 videos: /alda/ /arda/ • Video information during test syllable presentation • Should be the same in both conditions /alda/ video /arda/ video …more consistent with /ga/? …more consistent with /da/? % GA responses Results 100 90 80 70 60 50 40 30 20 10 0 Video /da/ from /alda/ Video /da/ from /arda/ 1 2 3 4 5 6 7 Test syllable 8 9 10 Comparisons 100 Percent /ga/ responses 80 % GA responses video /al/ video /ar/ 90 70 60 50 40 30 20 10 100 90 80 70 60 50 40 30 20 10 0 Video /da/ from /alda/ Video /da/ from /arda/ 1 0 1 2 3 4 5 6 Test syllable 7 8 9 2 3 4 5 6 7 10 Test syllable 8 9 10 Conclusions 1 No evidence of visually mediated phonetic context effect 2 No evidence that gestural information is required 3 Spectral contrast is best current account But what about backwards effects??? The Stimulus Paradigm Sine-wave Tone Context (High or Low Freq) Noise Burst (/t/ or /k/) Time Low High Frequency (Hz) Target Speech Stimulus /da-ga/ Got Dot Gawk Dock Time (ms) Speaker Normalization CARRIER SENTENCE “Please say what this word is…” Original, F1, F1 + TARGET “bit”, “bet”, “bat”, “but” Ladefoged & Broadbent (1957) • TARGET acoustics were constant • TARGET perception shifted with changes in “speaker” • Spectral characteristics of the preceding sentence predicted perception ‘Talker/Speaker Normalization’ Sensitivity to Accent, Etc. Experiment Model Natural speech F2 & F3 onset edited to create 9-step series Varying perceptually from /ga/ to /da/ 1 Speech Token 589 ms 9 /ga/ /da/ Time No Effect of Adjacent Context with intermediate spectral characteristics Standard Tone 70 ms Silent Interval 50 ms 2300 Hz PILOT TEST: No context effect on speech perception (t(9)=1.35, p=.21) Speech Token 589 ms Time Acoustic Histories Acoustic History 2100 ms Standard Tone 70 ms Silent Interval 50 ms Speech Token 589 ms Time ACOUSTIC HISTORY: The critical context stimulus for these experiments is not a single sound, but a distribution of sounds 21 70-ms tones, sampled from a distribution 30-ms silent interval between tones Acoustic History Distributions 1 Frequency of Presentation Low Mean = 1800 Hz 1 1300 1800 2300 2800 3300 2300 2800 3300 High Mean = 2800 Hz 1300 1800 Tone Frequency (Hz) Frequency (Hz) Example Stimuli A B 2800 Hz Mean 1800 Hz Mean Time (ms) Characteristics of the Context Acoustic History 2100 ms Standard Tone 70 ms Silent Interval 50 ms Speech Token 589 ms Time Context is not local Standard tone immediately precedes each stimulus, independent of condition. On its own, this has no effect of context on /ga/-/da/ stimuli. Context is defined by distribution characteristics Sampling of the distribution varies on each trial Precise acoustic characteristics vary with trial Context unfolds over a broad time course Results Percent GA Responses 100 90 High Mean 80 Low Mean Contrastive 70 60 50 40 30 20 10 0 p<.0001 1 2 3 4 5 6 Stimulus Step 7 8 9 Notched Noise Histories Frequency (Hz) A B Time (ms) 100 Hz BW for each notch Results Tones 90 Low Mean 80 70 60 50 40 30 20 10 100 High Mean p<0.01 Percent "GA" Responses Percent "GA" Responses 100 Notched Noise Low Mean 80 70 60 50 40 30 20 10 0 High Mean 90 p<0.04 0 1 2 3 4 5 6 Stimulus Step 7 8 9 1 2 3 4 5 6 7 8 9 Stimulus Step N=10 Joint Effects? Acoustic History 2100 ms Standard Tone 70 ms Silent Interval 50 ms Speech Token 589 ms Time Acoustic History 2100 ms /al/ or /ar/ 300 ms Silent Interval 50 ms Speech Token 589 ms Time Conflicting e.g., High Mean + /ar/ Cooperating e.g., High Mean + /al/ Interaction of Speech/N.S. 80 80 70 60 50 40 30 20 /al/ 10 /ar/ p<.0001 70 60 50 40 30 20 /al/ 10 /ar/ Percent "ga" Responses p=.007 90 Percent "ga" Responses Percent "ga" Responses 90 0 100 100 100 Conflicting Cooperating Speech Only p=.009 90 80 70 60 50 40 30 20 /al/ 10 /ar/ 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9 Speech Target Speech Target Speech Target Significantly greater Same magnitude as Speech Only, opposite direction than speech alone Follows NS spectra