Bradish
advertisement

PARALLELIZATION OF
ARTIFICIAL NEURAL
NETWORKS
Joe Bradish
CS5802 Fall 2015
BASICS OF ARTIFICIAL NEURAL NETWORKS
What is an Artificial Neural Network (ANN)?
What makes up a neuron?
How is “learning” modelled in ANNs?
A neural network is a collection of interconnected neurons that
compute and generate impulses
Specific parts include neurons, synapses, and activation functions
An artificial neural network is a mathematical model, based on
natural neural networks found in animals’ brains.
STRUCTURE OF A NEURAL NETWORK
BASIC STRUCTURE
OF A NEURON
•
There is an input vector containing {x1, x2, … , xn} and an associated
vector of weights {w1, w2, … , wn}.
•
The input x weight vector summation is calculated and the output is
sent into an activation function.
•
Based on the activation function, the summation is mapped to some
value, generally between {-1, 1}, such as in the shown step activation
function. This value is then considered the output of the neuron.
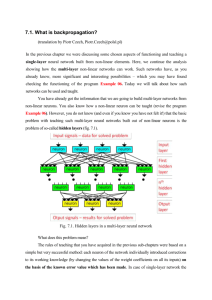
To properly train a neural network, the weights must be “tuned” to model the
goal function as closely as possible.
“Goal” function represents the function that maps input data to output data in our
training set.
Training a neural network is by far the most costly step in the majority of
scenarios.
Google has reported training times <2 days for certain problems and network sizes.
Once trained, new items can be classified very quickly though
Some popular options
Backpropagation (used in the majority of cases).
genetic algorithms with simulated annealing
Hebbian learning
a combination of different methods in a “Committee of Machines”
TRAINING A NEURAL NETWORK
Most popular training method
Works by reducing error on the training set
Uses gradient descent on the error
Requires many training examples to get error low
mean squared error
Partial derivatives are used to determine which neuron/weight to
blame for parts of the error
BACKPROPAGATION
Backward pass is done through backpropagation
• Uses chain rule to calculate partial derivative
Underlying operations are
embarrassingly parallel, but
many problems still remain
Backpropagation, Communication and
Computational issues all must be considered
when scaling neural networks
Requires neurons of one layer to be fully connected to the
neurons of the next layer
Gradient descent is prone to getting stuck in local optima
Lots of communication required
Requires many iterations to reduce error to acceptable rate
Training data set sizes are very large
Rule of thumb for error
Training set size should be roughly the number of weights divided by the
permitted classification error rate
10% error rate = 10x the number of weights, 1% = 100x, etc.
PROBLEMS WITH SCALING
BACKPROPAGATION
Main operation is matrix multiplication
N-node layer requires N2 scalar multiplications and N sums of N
numbers
Requires a good multiply or multiply-and-add function
Activation function
Often sigmoid is used f(x) = 1/(1+e-x)
Has to be approximated efficiently
COMPUTATIONAL ISSUES IN SCALING
ANNS
High degree of connectivity
Large data flows
Structure and bandwidth are very important
Broadcasts and ring topologies are often used because of the
necessary communication requirements
More processors does not mean faster computation in many
cases
COMMUNICATION ISSUES IN SCALING
ANNS
Model dimension
Data Dimension
One model, but multiple workers
train individual parts
Different workers train on completely
different sets of data
High amount of communication
Also high amount of communication
Need to synchronize at the edges
Efficient when the computation is
heavy per neuron
Datasets where each data point
contains many attributes
Need to synchronize parameters,
weights to ensure consistent model
Efficient when each weight needs a
high amount of computation
Large datasets where each data
point only contains a few attributes
TWO KEY METHODOLOGIES
Example of splitting on the data
dimension
Inspired by human brain’s ability to communicate between
groups of neurons without fully connected paths
Focused on parallelizing the model dimension
Uses MPI library
Reduces need for communication between every neuron in
consecutive layers of a neural network
Only boundary values are communicated between “ghost” neurons
SPANN
(SCALABLE PARALLEL ARTIFICIAL NEURAL NETWORK)
Neocortex is the part of the brain most commonly associated with intelligence
Columnar structure with an estimated 6 layers
BIOLOGICAL
INSPIRATION
Recall from Serial Backpropagation
Example comparison of 3 layer network:
• Serial ANN
• 200 input, 48 output, 125 hidden
• (200+48)*125 = 31,000 weights
need to be trained
• Using SPANN in a Parallel ANN
• 200 input, 48 output, 120 hidden
• 6 layers, 8 processors
• 30,280 weights need to be
trained, but only 3785 per
processor
SPANN CONT.
Parallel Backpropagation
• L is the number of layers, including
input/output layers
• Nproc is the number of processors being
used
• As shown by the first box, every input is
sent to every processor
• Each processor only has Nhidden / Nproc
hidden neurons/layers and Nout / Nproc
output layers
• Divide by number of processors to get
weights/processor
• 37890 weights on a serial ANN took 1313 seconds to complete training, compared
to 30,240 weights taking 842 seconds
• There is significant slowdown shown in the serial version
• 8 resolution computes ~36 weights/sec, but 9 resolution falls to only ~28.5
weights/sec
• The time taken per weight grows slower in SPANN, so once the size of the training
data reaches a significant size, it becomes much quicker per weight.
• Speedup factor is related to the training data size
• Larger size, larger speedup
PERFORMANCE COMPARISON
RESULTS CONT.
Developed an architecture that can scale into billions of weights or
synapses
Successful by reducing the communication requirements in between
layers to a few “gatekeeper nodes”
Uses a human biological model as inspiration
SPANN CONCLUSIONS
SCALING ANNS CONCLUSIONS
•
Neural networks are a tool that have provided significant developments
in artificial intelligence and machine learning fields
•
Scaling issues are big, even though calculations are embarrassingly
parallel
•
Communication
•
Computational
•
SPANN showed promising results
•
Research continues today
•
Heavy focus on communication, as training set sizes are growing
faster than the computational requirements in many cases
QUESTIONS?