LearningLanguageInNeuralNetworks_SS100May312011

Learning in Neural Networks,
with Implications for Representation and
Learning of Language
James L. McClelland
SS 100, May 31, 2011
A Pattern Associator Network
Corresponding output (e.g., smell of a rose)
Matrix of connections
Pattern representing a given input (e.g. sight of a rose)
Summed input
Learning Rule for the Pattern
Associator network
• For each output unit:
– Determine activity of the unit based on its input and activation function.
– If the unit is active when target is not:
• Reduce each weight coming into the unit from each active input unit.
– If the unit is not active when the target is active:
• Increase the weight coming into the unit from each active input unit.
• Each connection weight adjustment is very small
– Learning is gradual and cumulative
• If a set of weights exists that can correctly assign the desired output for each input, the network will gradually home in on it.
• However, in many cases, no solution is actually possible with only one layer of modifiable weights.
Overcoming the Limitations of
Associator Networks
• Without ‘hidden units’, many input-output mappings cannot be captured.
• However, with just one layer of units between input and output, it is possible to capture any deterministic input-output mapping.
• What was missing was a method for training connections on both sides of hidden units.
• In 1986, such a method was developed by David
Rumelhart and others.
• The network uses units whose activation is a continuous, non-linear function of their input.
• The network is trained to produce the corresponding output (target) pattern for each input pattern.
• This is done by adjusting each weight in the network to reduce the sum of squared differences between the network’s output activation and the corresponding target output:
S i (t i
-a i
) 2
• With this algorithm, neural networks can represent and learn any computable function.
• How to ensure networks generalize ‘correctly’ to unseen examples is a hard problem, in part because defining what is the correct generalization is unclear.
Summed input
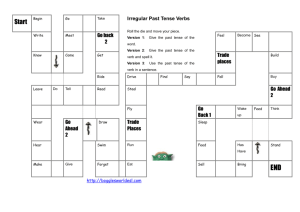
Standard Approach to the Past Tense
(and other Aspects of Language)
• We form the past tense by using a (simple) rule.
– ‘add ‘ed’: played, cooked, raided
• If an item is an exception, the rule is blocked.
– So we say ‘took’ instead of ‘taked’
• If you’ve never seen an item before, you use the rule
• If an item is an exception, but you forget the exceptional past tense, you apply the rule
• Predictions:
– Regular inflection of ‘nonce forms’
• This man is tupping. Yesterday he …
• This girl is blinging. Yesterday she …
– Over-regularization errors:
• Goed, taked, bringed
The Learning-Based, Neural
Networks Approach
• Language (like perception, etc) arises from the interactions of neurons, each of which operates according to a common set of simple principles of processing, representation and learning.
• Units and rules are useful to approximately describe what emerges from these interactions but have no mechanistic or explanatory role in language processing, language change, or language learning.
An Learning-Based, Connectionist Approach to the Past Tense
• Knowledge is in connections
• Experience causes connections to change
• Sensitivity to regularities emerges
– Regular past tense
– Sub-regularities
• Knowledge of exceptions co-exists with knowledge of regular forms in the same connections.
The RM Model
• Learns from verb [root, past tense] pairs
– [Like, liked]; [love, loved]; [carry, carried]; [take, took]
• Present and past are represented as patterns of activation over units that stand for phonological features.
Over-regularization errors in the
RM network
Most frequent past tenses in English:
– Felt
– Had
– Made
– Got
– Gave
– Took
– Came
– Went
– Looked
– Needed
Here’s where 400 more words were introduced
Trained with top ten words only.
Additional characteristics
• The model exploits gangs of related exceptions.
– dig-dug
– cling-clung
– swing-swung
• The ‘regular pattern’ infuses exceptions as well as regulars:
– say-said, do-did
– have-had
– keep-kept, sleep-slept
– Burn-burnt
– Teach-taught
Elman’s Simple Recurrent Network
• Task is to predict the next element of a sequence on the output, given the current element on the input units.
• Each element is represented by a pattern of activation.
• Each box represents a set of units.
• Each dotted arrow represents all-to-all connections.
• The solid arrow indicates that the previous pattern on the hidden units is copied back to provide context for the next prediction.
• Learning occurs through connection weight adjustment using an extended version of the error correcting learning rule.
Hidden Unit Patterns for Elman Net
Trained on Word Sequences
Key Features of the Both Models
• No lexical entries and no rules
• No problem of rule induction or grammar selection
• Note:
– While this approach has been highly contravertial, and has not become dominant in AI or Linguistics, it underlies a large body of work in psycholinguistics and neuropsychology, and remains under active exploration in many laboratories.
Questions from Sections
• What is the bridge between the two perspectives?
– Why should someone who is interested in symbolic systems have to know about both fields? Aren't they fundamentally opposites of each other? If not, where aren't they?
• How has neuroscience (and findings from studying the brain) shaped and assisted research traditionally conducted under the psychology umbrella?
• Has computational linguistics really solved 'the biggest part of the problem of AI'?