The case states no significant harm occurred to
advertisement

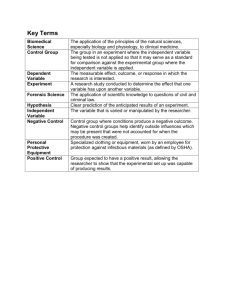
CareGroup Case Study Daniel Runt Med Inf 404 – Health Care Operations Northwestern University February 23, 2014 What process controls were needed to prevent this event from occurring? Any changes to the entire computer system needed to be known to others in the IT department, and approved by supervisors. The specific cause of the issue occurred when a researcher installed and then abandoned an unconfigured file transfer program, which overloaded the network. If the researcher had notified and gotten approval from the IT department, they might have been able to assist with the configuration and optimization of the software, and monitored it while the researcher left to care for his wife. Additionally, routine network stress tests would have helped to identify the network vulnerabilities and out of date hardware. The reason the program was able to overload the network was because the network had fallen out-of-spec. The Spanning Tree Protocol (STP) was unable to manage the network since it had had several unapproved network extensions. Finally, the network expert who was responsible for maintaining the network had left the organization, and an appropriate replacement had not been procured. No single individual should be the only one that understands such a complicated aspect of the business. On top of that, during his tenure he had fallen behind on the latest technologies; technologies that could have prevented the outage event had he known and implemented them. The case states no significant harm occurred to any patient, however what do you believe were the likely relevant impacts to patient care during the event? While “no significant harm” came to any patient, care was most certainly impacted (McFarlan & Austin, 2005). The ED was forced to close for over 13 hours on November 15th, forcing ambulances to divert to other hospitals. While this may have not been out of the ordinary for any area hospital, there is probably a reason that the ED had to divert patients. The reason was most likely that the hospital was already operating at their limits. Staff was falling behind their existing workloads and had to cut off one source of new admissions. Care was most likely similar to when the hospitals were operating normally, only much slower. Clinicians and pharmacists did not have access to medication interaction validation reports, so they had to do medication checks by hand. Since digital imaging software was down, extra time had to be taken to analyze physical X-ray films. Medical histories had to be fully reported from patients, since their computerized histories were inaccessible. All of these can be relied upon in a pinch, but it certainly slows the patient care, and in an industry where time is often of the essence, CareGroup was lucky that no adverse outcomes were reported due to the outage. As an IT leader, how would you evaluate the timeline of the response? Too long/short, too conservative/aggressive in approach to execution? The outage was very long for what initially seemed to be a simple networking problem. The problem lied in the size of the network, which was very large and spanned several sites. A single addition the network – one which the IT department had no knowledge of – was capable of weakening it to the point where the event in question could occur. If the IT team had known about the rogue program or the faulty hardware, the issue may have been resolved in a much quicker time frame. CISCO’s approach, while conservative, was exactly the right way to do it. If people are off on their own, making their own changes, it is impossible to know which change had worked and why. Their philosophy of not allowing the users back on until a 24 hour period passed without issue was also the correct course of action. Forcing users to switch back and forth between paper and computerized systems only wastes time, time that they are already losing due to using non-computerized ways of doing things. Works Cited McFarlan, F. Warren, & Austin, Robert D. (2005). CareGroup. Harvard Business Review, 9-303-097.